
Latent Space: The AI Engineer Podcast
211 episodes — Page 2 of 5

[State of AI Startups] Memory/Learning, RL Envs & DBT-Fivetran — Sarah Catanzaro, Amplify
From investing through the modern data stack era (DBT, Fivetran, and the analytics explosion) to now investing at the frontier of AI infrastructure and applications at Amplify Partners, Sarah Catanzaro has spent years at the intersection of data, compute, and intelligence—watching categories emerge, merge, and occasionally disappoint. We caught up with Sarah live at NeurIPS 2025 to dig into the state of AI startups heading into 2026: why $100M+ seed rounds with no near-term roadmap are now the norm (and why that terrifies her), what the DBT-Fivetran merger really signals about the modern data stack (spoiler: it’s not dead, just ready for IPO), how frontier labs are using DBT and Fivetran to manage training data and agent analytics at scale, why data catalogs failed as standalone products but might succeed as metadata services for agents, the consumerization of AI and why personalization (memory, continual learning, K-factor) is the 2026 unlock for retention and growth, why she thinks RL environments are a fad and real-world logs beat synthetic clones every time, and her thesis for the most exciting AI startups: companies that marry hard research problems (RAG, rule-following, continual learning) with killer applications that were simply impossible before.We discuss:* The DBT-Fivetran merger: not the death of the modern data stack, but a path to IPO scale (targeting $600M+ combined revenue) and a signal that both companies were already winning their categories* How frontier labs use data infrastructure: DBT and Fivetran for training data curation, agent analytics, and managing increasingly complex interactions—plus the rise of transactional databases (RocksDB) and efficient data loading (Vortex) for GPU-bound workloads* Why data catalogs failed: built for humans when they should have been built for machines, focused on discoverability when the real opportunity was governance, and ultimately subsumed as features inside Snowflake, DBT, and Fivetran* The $100M+ seed phenomenon: raising massive rounds at billion-dollar valuations with no 6-month roadmap, seven-day decision windows, and founders optimizing for signal (”we’re a unicorn”) over partnership or dilution discipline* Why world models are overhyped but underspecified: three competing definitions, unclear generalization across use cases (video games ≠ robotics ≠ autonomous driving), and a research problem masquerading as a product category* The 2026 theme: consumerization of AI via personalization—memory management, continual learning, and solving retention/churn by making products learn skills, preferences, and adapt as the world changes (not just storing facts in cursor rules)* Why RL environments are a fad: labs are paying 7–8 figures for synthetic clones when real-world logs, traces, and user activity (à la Cursor) are richer, cheaper, and more generalizable* Sarah’s investment thesis: research-driven applications that solve hard technical problems (RAG for Harvey, rule-following for Sierra, continual learning for the next killer app) and unlock experiences that were impossible before* Infrastructure bets: memory, continual learning, stateful inference, and the systems challenges of loading/unloading personalized weights at scale* Why K-factor and growth fundamentals matter again: AI felt magical in 2023–2024, but as the magic fades, retention and virality are back—and most AI founders have never heard of K-factor—Sarah Catanzaro* X: https://x.com/sarahcat21* Amplify Partners: https://amplifypartners.com/Where to find Latent Space* X: https://x.com/latentspacepodFull Video EpisodeTimestamps00:00:00 Introduction: Sarah Catanzaro's Journey from Data to AI00:01:02 The DBT-Fivetran Merger: Not the End of the Modern Data Stack00:05:26 Data Catalogs and What Went Wrong00:08:16 Data Infrastructure at AI Labs: Surprising Insights00:10:13 The Crazy Funding Environment of 2024-202500:17:18 World Models: Hype, Confusion, and Market Potential00:18:59 Memory Management and Continual Learning: The Next Frontier00:23:27 Agent Environments: Just a Fad?00:25:48 The Perfect AI Startup: Research Meets Application00:28:02 Closing Thoughts and Where to Find Sarah This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

One Year of MCP — with David Soria Parra and AAIF leads from OpenAI, Goose, Linux Foundation
One year ago, Anthropic launched the Model Context Protocol (MCP)—a simple, open standard to connect AI applications to the data and tools they need. Today, MCP has exploded from a local-only experiment into the de facto protocol for agentic systems, adopted by OpenAI, Microsoft, Google, Block, and hundreds of enterprises building internal agents at scale. And now, MCP is joining the newly formed Agentic AI Foundation (AAIF) under the Linux Foundation, alongside Block’s Goose coding agent, with founding members spanning the biggest names in AI and cloud infrastructure.We sat down with David Soria Parra (MCP lead, Anthropic), Nick Cooper (OpenAI), Brad Howes (Block / Goose), and Jim Zemlin (Linux Foundation CEO) to dig into the one-year journey of MCP—from Thanksgiving hacking sessions and the first remote authentication spec to long-running tasks, MCP Apps, and the rise of agent-to-agent communication—and the behind-the-scenes story of how three competitive AI labs came together to donate their protocols and agents to a neutral foundation, why enterprises are deploying MCP servers faster than anyone expected (most of it invisible, internal, and at massive scale), what it takes to design a protocol that works for both simple tool calls and complex multi-agent orchestration, how the foundation will balance taste-making (curating meaningful projects) with openness (avoiding vendor lock-in), and the 2025 vision: MCP as the communication layer for asynchronous, long-running agents that work while you sleep, discover and install their own tools, and unlock the next order of magnitude in AI productivity.We discuss:* The one-year MCP journey: from local stdio servers to remote HTTP streaming, OAuth 2.1 authentication (and the enterprise lessons learned), long-running tasks, and MCP Apps (iframes for richer UI)* Why MCP adoption is exploding internally at enterprises: invisible, internal servers connecting agents to Slack, Linear, proprietary data, and compliance-heavy workflows (financial services, healthcare)* The authentication evolution: separating resource servers from identity providers, dynamic client registration, and why the March spec wasn’t enterprise-ready (and how June fixed it)* How Anthropic dogfoods MCP: internal gateway, custom servers for Slack summaries and employee surveys, and why MCP was born from “how do I scale dev tooling faster than the company grows?”* Tasks: the new primitive for long-running, asynchronous agent operations—why tools aren’t enough, how tasks enable deep research and agent-to-agent handoffs, and the design choice to make tasks a “container” (not just async tools)* MCP Apps: why iframes, how to handle styles and branding, seat selection and shopping UIs as the killer use case, and the collaboration with OpenAI to build a common standard* The registry problem: official registry vs. curated sub-registries (Smithery, GitHub), trust levels, model-driven discovery, and why MCP needs “npm for agents” (but with signatures and HIPAA/financial compliance)* The founding story of AAIF: how Anthropic, OpenAI, and Block came together (spoiler: they didn’t know each other were talking to Linux Foundation), why neutrality matters, and how Jim Zemlin has never seen this much day-one inbound interest in 22 years—David Soria Parra (Anthropic / MCP)* MCP: https://modelcontextprotocol.io* https://uk.linkedin.com/in/david-soria-parra-4a78b3a* https://x.com/dsp_Nick Cooper (OpenAI)* X: https://x.com/nicoaicoprBrad Howes (Block / Goose)* Goose: https://github.com/block/gooseJim Zemlin (Linux Foundation)* LinkedIn: https://www.linkedin.com/in/zemlin/Agentic AI Foundation* https://agenticai.foundationFull Video EpisodeTimestamps00:00:00 Introduction: MCP's First Year and Foundation Launch00:01:17 MCP's Journey: From Launch to Industry Standard00:02:06 Protocol Evolution: Remote Servers and Authentication00:08:52 Enterprise Authentication and Financial Services00:11:42 Transport Layer Challenges: HTTP Streaming and Scalability00:15:37 Standards Development: Collaboration with Tech Giants00:34:27 Long-Running Tasks: The Future of Async Agents00:30:41 Discovery and Registries: Building the MCP Ecosystem00:30:54 MCP Apps and UI: Beyond Text Interfaces00:26:55 Internal Adoption: How Anthropic Uses MCP00:23:15 Skills vs MCP: Complementary Not Competing00:36:16 Community Events and Enterprise Learnings01:03:31 Foundation Formation: Why Now and Why Together01:07:38 Linux Foundation Partnership: Structure and Governance01:11:13 Goose as Reference Implementation01:17:28 Principles Over Roadmaps: Composability and Quality01:21:02 Foundation Value Proposition: Why Contribute01:27:49 Practical Investments: Events, Tools, and Community01:34:58 Looking Ahead: Async Agents and Real Impact This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

Steve Yegge's Vibe Coding Manifesto: Why Claude Code Isn't It & What Comes After the IDE
Note: Steve and Gene’s talk on Vibe Coding and the post IDE world was one of the top talks of AIE CODE: From building legendary platforms at Google and Amazon to authoring one of the most influential essays on AI-powered development (Revenge of the Junior Developer, quoted by Dario Amodei himself), Steve Yegge has spent decades at the frontier of software engineering—and now he’s leading the charge into what he calls the “factory farming” era of code. After stints at SourceGraph and building Beads (a purely vibe-coded issue tracker with tens of thousands of users), Steve co-authored The Vibe Coding Book and is now building VC (VibeCoder), an agent orchestration dashboard designed to move developers from writing code to managing fleets of AI agents that coordinate, parallelize, and ship features while you sleep.We sat down with Steve at AI Engineer Summit to dig into why Claude Code, Cursor, and the entire 2024 stack are already obsolete, what it actually takes to trust an agent after 2,000 hours of practice (hint: they will delete your production database if you anthropomorphize them), why the real skill is no longer writing code but orchestrating agents like a NASCAR pit crew, how merging has become the new wall that every 10x-productive team is hitting (and why one company’s solution is literally “one engineer per repo”), the rise of multi-agent workflows where agents reserve files, message each other via MCP, and coordinate like a little village, why Steve believes if you’re still using an IDE to write code by January 1st, you’re a bad engineer, how the 12–15 year experience bracket is the most resistant demographic (and why their identity is tied to obsolete workflows), the hidden chaos inside OpenAI, Anthropic, and Google as they scale at breakneck speed, why rewriting from scratch is now faster than refactoring for a growing class of codebases, and his 2025 prediction: we’re moving from subsistence agriculture to John Deere-scale factory farming of code, and the Luddite backlash is only just beginning.We discuss:* Why Claude Code, Cursor, and agentic coding tools are already last year’s tech—and what comes next: agent orchestration dashboards where you manage fleets, not write lines* The 2,000-hour rule: why it takes a full year of daily use before you can predict what an LLM will do, and why trust = predictability, not capability* Steve’s hot take: if you’re still using an IDE to develop code by January 1st, 2025, you’re a bad engineer—because the abstraction layer has moved from models to full-stack agents* The demographic most resistant to vibe coding: 12–15 years of experience, senior engineers whose identity is tied to the way they work today, and why they’re about to become the interns* Why anthropomorphizing LLMs is the biggest mistake: the “hot hand” fallacy, agent amnesia, and how Steve’s agent once locked him out of prod by changing his password to “fix” a problem* Should kids learn to code? Steve’s take: learn to vibe code—understand functions, classes, architecture, and capabilities in a language-neutral way, but skip the syntax* The 2025 vision: “factory farming of code” where orchestrators run Cloud Code, scrub output, plan-implement-review-test in loops, and unlock programming for non-programmers at scale—Steve Yegge* X: https://x.com/steve_yegge* Substack (Stevie’s Tech Talks): https://steve-yegge.medium.com/* GitHub (VC / VibeCoder): https://github.com/yegge-labsWhere to find Latent Space* X: https://x.com/latentspacepodFull Video EpisodeThumbnails00:00:00 Introduction: Steve Yegge on Vibe Coding and AI Engineering00:00:59 The Backlash: Who Resists Vibe Coding and Why00:04:26 The 2000 Hour Rule: Building Trust with AI Coding Tools00:03:31 The January 1st Deadline: IDEs Are Becoming Obsolete00:02:55 10X Productivity at OpenAI: The Performance Review Problem00:07:49 The Hot Hand Fallacy: When AI Agents Betray Your Trust00:11:12 Claude Code Isn't It: The Need for Agent Orchestration00:15:20 The Orchestrator Revolution: From Cloud Code to Agent Villages00:18:46 The Merge Wall: The Biggest Unsolved Problem in AI Coding00:26:33 Never Rewrite Your Code - Until Now: Joel Spolsky Was Wrong00:22:43 Factory Farming Code: The John Deere Era of Software00:29:27 Google's Gemini Turnaround and the AI Lab Chaos00:33:20 Should Your Kids Learn to Code? The New Answer00:34:59 Code MCP and the Gossip Rate: Latest Vibe Coding Discoveries This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

⚡️GPT5-Codex-Max: Training Agents with Personality, Tools & Trust — Brian Fioca + Bill Chen, OpenAI
From the frontlines of OpenAI’s Codex and GPT-5 training teams, Bryan and Bill are building the future of AI-powered coding—where agents don’t just autocomplete, they architect, refactor, and ship entire features while you sleep. We caught up with them at AI Engineer Conference right after the launch of Codex Max, OpenAI’s newest long-running coding agent designed to work for 24+ hours straight, manage its own context, and spawn sub-agents to parallelize work across your entire codebase.We sat down with Bryan and Bill to dig into what it actually takes to train a model that developers trust—why personality, communication, and planning matter as much as raw capability, how Codex is trained with strong opinions about tools (it loves rg over grep, seriously), why the abstraction layer is moving from models to full-stack agents you can plug into VS Code or Zed, how OpenAI partners co-develop tool integrations and discover unexpected model habits (like renaming tools to match Codex’s internal training), the rise of applied evals that measure real-world impact instead of academic benchmarks, why multi-turn evals are the next frontier (and Bryan’s “job interview eval” idea), how coding agents are breaking out of code into personal automation, terminal workflows, and computer use, and their 2026 vision: coding agents trusted enough to handle the hardest refactors at any company, not just top-tier firms, and general enough to build integrations, organize your desktop, and unlock capabilities you’d never get access to otherwise.We discuss:* What Codex Max is: a long-running coding agent that can work 24+ hours, manage its own context window, and spawn sub-agents for parallel work* Why the name “Max”: maximalist, maximization, speed and endurance—it’s simply better and faster for the same problems* Training for personality: communication, planning, context gathering, and checking your work as behavioral characteristics, not just capabilities* How Codex develops habits like preferring rg over grep, and why renaming tools to match its training (e.g., terminal-style naming) dramatically improves tool-call performance* The split between Codex (opinionated, agent-focused, optimized for the Codex harness) and GPT-5 (general, more durable across different tools and modalities)* Why the abstraction layer is moving up: from prompting models to plugging in full agents (Codex, GitHub Copilot, Zed) that package the entire stack* The rise of sub-agents and agents-using-agents: Codex Max spawning its own instances, handing off context, and parallelizing work across a codebase* How OpenAI works with coding partners on the bleeding edge to co-develop tool integrations and discover what the model is actually good at* The shift to applied evals: capturing real-world use cases instead of academic benchmarks, and why ~50% of OpenAI employees now use Codex daily* Why multi-turn evals are the next frontier: LM-as-a-judge for entire trajectories, Bryan’s “job interview eval” concept, and the need for a batch multi-turn eval API* How coding agents are breaking out of code: personal automation, organizing desktops, terminal workflows, and “Devin for non-coding” use cases* Why Slack is the ultimate UI for work, and how coding agents can become your personal automation layer for email, files, and everything in between* The 2026 vision: more computer use, more trust, and coding agents capable enough that any company can access top-tier developer capabilities, not just elite firms—Bryan & Bill (OpenAI Codex Team)* http://x.com/bfioca* https://x.com/realchillben* OpenAI Codex: https://openai.com/index/openai-codex/Where to find Latent Space* X: https://x.com/latentspacepodFull Video EpisodeTimestamps00:00:00 Introduction: Latent Space Listeners at AI Engineer Code00:01:27 Codex Max Launch: Training for Long-Running Coding Agents00:03:01 Model Personality and Trust: Communication, Planning, and Self-Checking00:05:20 Codex vs GPT-5: Opinionated Agents vs General Models00:07:47 Tool Use and Model Habits: The Ripgrep Discovery00:09:16 Personality Design: Verbosity vs Efficiency in Coding Agents00:11:56 The Agent Abstraction Layer: Building on Top of Codex00:14:08 Sub-Agents and Multi-Agent Patterns: The Future of Composition00:16:11 Trust and Adoption: OpenAI Developers Using Codex Daily00:17:21 Applied Evals: Real-World Testing vs Academic Benchmarks00:19:15 Multi-Turn Evals and the Job Interview Pattern00:21:35 Feature Request: Batch Multi-Turn Eval API00:22:28 Beyond Code: Personal Automation and Computer Use00:24:51 Vision-Native Agents and the UI Integration Challenge00:25:02 2026 Predictions: Trust, Computer Use, and Democratized Excellence This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

SAM 3: The Eyes for AI — Nikhila & Pengchuan (Meta Superintelligence), ft. Joseph Nelson (Roboflow)
As with all demo-heavy and especially vision AI podcasts, we encourage watching along on our YouTube (and tossing us an upvote/subscribe if you like!)From SAM 1’s 11-million-image data engine to SAM 2’s memory-based video tracking, MSL’s Segment Anything project has redefined what’s possible in computer vision. Now SAM 3 takes the next leap: concept segmentation—prompting with natural language like “yellow school bus” or “tablecloth” to detect, segment, and track every instance across images and video, in real time, with human-level exhaustivity. And with the latest SAM Audio:SAM can now even segment audio output!We sat down with Nikhila Ravi (SAM lead at Meta) and Pengchuan Zhang (SAM 3 researcher) alongside Joseph Nelson (CEO, Roboflow) to unpack how SAM 3 unifies interactive segmentation, open-vocabulary detection, video tracking, and more into a single model that runs in 30ms on images and scales to real-time video on multi-GPU setups. We dig into the data engine that automated exhaustive annotation from two minutes per image down to 25 seconds using AI verifiers fine-tuned on Llama, the new SACO (Segment Anything with Concepts) benchmark with 200,000+ unique concepts vs. the previous 1.2k, how SAM 3 separates recognition from localization with a presence token, why decoupling the detector and tracker was critical to preserve object identity in video, how SAM 3 Agents unlock complex visual reasoning by pairing SAM 3 with multimodal LLMs like Gemini, and the real-world impact: 106 million smart polygons created on Roboflow saving humanity an estimated 130+ years of labeling time across fields from cancer research to underwater trash cleanup to autonomous vehicle perception.We discuss:* What SAM 3 is: a unified model for concept-prompted segmentation, detection, and tracking in images and video using atomic visual concepts like “purple umbrella” or “watering can”* How concept prompts work: short text phrases that find all instances of a category without manual clicks, plus visual exemplars (boxes, clicks) to refine and adapt on the fly* Real-time performance: 30ms per image (100 detected objects on H200), 10 objects on 2×H200 video, 28 on 4×, 64 on 8×, with parallel inference and “fast mode” tracking* The SACO benchmark: 200,000+ unique concepts vs. 1.2k in prior benchmarks, designed to capture the diversity of natural language and reach human-level exhaustivity* The data engine: from 2 minutes per image (all-human) to 45 seconds (model-in-loop proposals) to 25 seconds (AI verifiers for mask quality and exhaustivity checks), fine-tuned on Llama 3.2* Why exhaustivity is central: every instance must be found, verified by AI annotators, and manually corrected only when the model misses—automating the hardest part of segmentation at scale* Architecture innovations: presence token to separate recognition (”is it in the image?”) from localization (”where is it?”), decoupled detector and tracker to preserve identity-agnostic detection vs. identity-preserving tracking* Building on Meta’s ecosystem: Perception Encoder, DINO v2 detector, Llama for data annotation, and SAM 2’s memory-based tracking backbone* SAM 3 Agents: using SAM 3 as a visual tool for multimodal LLMs (Gemini, Llama) to solve complex visual reasoning tasks like “find the bigger character” or “what distinguishes male from female in this image”* Fine-tuning with as few as 10 examples: domain adaptation for specialized use cases (Waymo vehicles, medical imaging, OCR-heavy scenes) and the outsized impact of negative examples* Real-world impact at Roboflow: 106M smart polygons created, saving 130+ years of labeling time across cancer research, underwater trash cleanup, autonomous drones, industrial automation, and more—MSL FAIR team* Nikhila: https://www.linkedin.com/in/nikhilaravi/* Pengchuan: https://pzzhang.github.io/pzzhang/Joseph Nelson* X: https://x.com/josephofiowa* LinkedIn: https://www.linkedin.com/in/josephofiowa/Full Video EpisodeTimestamps00:00:00 Introduction and the SAM Series Legacy00:00:53 SAM 3 Launch: Three Models in One Release00:05:30 Live Demo: Concept Prompting and Visual Exemplars00:10:54 From Prototype to Production: The Evolution of Text Prompting00:15:45 The Data Engine: Automating Exhaustive Annotation00:14:10 Real-World Impact: 130 Years of Humanity Saved00:25:11 Architecture Deep Dive: Decoupled Detection and Tracking00:28:02 SAM 3 Agent: Bridging Vision and Language Models00:33:20 Head-to-Head: SAM 3 vs Gemini and Florence00:47:50 Video Understanding and the Masklet Detection Score00:20:24 Fine-Tuning and Domain Adaptation: From Waymos to Medical Imaging00:52:25 The Future of Perception: Native Vision vs Tool Calls01:05:45 Building with SAM 3: Roboflow's Rapid Auto-Labeling00:57:02 Open Source Philosophy and the Path to AGI00:58:24 What's Next: SAM 4, Video Scale, and Beyond Human Performance This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.spa
⚡️Jailbreaking AGI: Pliny the Liberator & John V on Red Teaming, BT6, and the Future of AI Security
Note: this is Pliny and John’s first major podcast. Voices have been changed for opsec.From jailbreaking every frontier model and turning down Anthropic’s Constitutional AI challenge to leading BT6, a 28-operator white-hat hacker collective obsessed with radical transparency and open-source AI security, Pliny the Liberator and John V are redefining what AI red-teaming looks like when you refuse to lobotomize models in the name of “safety.”Pliny built his reputation crafting universal jailbreaks—skeleton keys that obliterate guardrails across modalities—and open-sourcing prompt templates like Libertas, predictive reasoning cascades, and the infamous “Pliny divider” that’s now embedded so deep in model weights it shows up unbidden in WhatsApp messages. John V, coming from prompt engineering and computer vision, co-founded the Bossy Discord (40,000 members strong) and helps steer BT6’s ethos: if you can’t open-source the data, we’re not interested. Together they’ve turned down enterprise gigs, pushed back on Anthropic’s closed bounties, and insisted that real AI security happens at the system layer—not by bubble-wrapping latent space.We sat down with Pliny and John to dig into the mechanics of hard vs. soft jailbreaks, why multi-turn crescendo attacks were obvious to hackers years before academia “discovered” them, how segmented sub-agents let one jailbroken orchestrator weaponize Claude for real-world attacks (exactly as Pliny predicted 11 months before Anthropic’s recent disclosure), why guardrails are security theater that punishes capability while doing nothing for real safety, the role of intuition and “bonding” with models to navigate latent space, how BT6 vets operators on skill and integrity, why they believe Mech Interp and open-source data are the path forward (not RLHF lobotomization), and their vision for a future where spatial intelligence, swarm robotics, and AGI alignment research happen in the open—bootstrapped, grassroots, and uncompromising.We discuss:* What universal jailbreaks are: skeleton-key prompts that obliterate guardrails across models and modalities, and why they’re central to Pliny’s mission of “liberation”* Hard vs. soft jailbreaks: single-input templates vs. multi-turn crescendo attacks, and why the latter were obvious to hackers long before academic papers* The Libertas repo: predictive reasoning, the Library of Babel analogy, quotient dividers, weight-space seeds, and how introducing “steered chaos” pulls models out-of-distribution* Why jailbreaking is 99% intuition and bonding with the model: probing token layers, syntax hacks, multilingual pivots, and forming a relationship to navigate latent space* The Anthropic Constitutional AI challenge drama: UI bugs, judge failures, goalpost moving, the demand for open-source data, and why Pliny sat out the $30k bounty* Why guardrails ≠ safety: security theater, the futility of locking down latent space when open-source is right behind, and why real safety work happens in meatspace (not RLHF)* The weaponization of Claude: how segmented sub-agents let one jailbroken orchestrator execute malicious tasks (pyramid-builder analogy), and why Pliny predicted this exact TTP 11 months before Anthropic’s disclosure* BT6 hacker collective: 28 operators across two cohorts, vetted on skill and integrity, radical transparency, radical open-source, and the magic of moving the needle on AI security, swarm intelligence, blockchain, and robotics—Pliny the Liberator* X: https://x.com/elder_plinius* GitHub (Libertas): https://github.com/elder-plinius/L1B3RT45John V* X: https://x.com/JohnVersusBT6 & Bossy* BT6: https://bt6.gg* Bossy Discord: Search “Bossy Discord” or ask Pliny/John V on XWhere to find Latent Space* X: https://x.com/latentspacepodFull Video EpisodeTimestamps00:00:00 Introduction: Meet Pliny the Liberator and John V00:01:50 The Philosophy of AI Liberation and Jailbreaking00:03:08 Universal Jailbreaks: Skeleton Keys to AI Models00:04:24 The Cat-and-Mouse Game: Attackers vs Defenders00:05:42 Security Theater vs Real Safety: The Fundamental Disconnect00:08:51 Inside the Libertas Repo: Prompt Engineering as Art00:16:22 The Anthropic Challenge Drama: UI Bugs and Open Source Data00:23:30 From Jailbreaks to Weaponization: AI-Orchestrated Attacks00:26:55 The BT6 Hacker Collective and BASI Community00:34:46 AI Red Teaming: Full Stack Security Beyond the Model00:38:06 Safety vs Security: Meat Space Solutions and Final Thoughts This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

AI to AE's: Grit, Glean, and Kleiner Perkins' next Enterprise AI hit — Joubin Mirzadegan, Roadrunner
Glean started as a Kleiner Perkins incubation and is now a $7B, $200m ARR Enterprise AI leader. Now KP has tapped its own podcaster to lead it’s next big swing.From building go-to-market the hard way in startups (and scaling Palo Alto Networks’ public cloud business) to joining Kleiner Perkins to help technical founders turn product edge into repeatable revenue, Joubin Mirzadegan has spent the last decade obsessing over one thing: distribution and how ideas actually spread, sell, and compound. That obsession took him from launching the CRO-only podcast Grit (https://www.youtube.com/playlist?list=PLRiWZFltuYPF8A6UGm74K2q29UwU-Kk9k) as a hiring wedge, to working alongside breakout companies like Glean and Windsurf, to now incubating Roadrunner which is an AI-native rethink of CPQ and quoting workflows as pricing models collapse from “seats” into consumption, bundles, renewals, and SKU sprawl.We sat down with Joubin to dig into the real mechanics of making conversations feel human (rolling early, never sending questions, temperature + lighting hacks), what Windsurf got right about “Google-class product and Salesforce-class distribution,” how to hire early sales leaders without getting fooled by shiny logos, why CPQ is quietly breaking the back of modern revenue teams, and his thesis for his new company and KP incubation Roadrunner (https://www.roadrunner.ai/): rebuild the data model from the ground up, co-develop with the hairiest design partners, and eventually use LLMs to recommend deal structures the way the best reps do without the Slack-channel chaos of deal desk.We discuss:* How to make guests instantly comfortable: rolling early, no “are you ready?”, temperature, lighting, and room dynamics* Why Joubin refuses to send questions in advance (and when you might have to anyway)* The origin of the CRO-only podcast: using media as a hiring wedge and relationship engine* The “commit to 100 episodes” mindset: why most shows die before they find their voice* Founder vs exec interviews: why CEOs can speak more freely (and what it unlocks in conversation)* What Glean taught him about enterprise AI: permissions, trust, and overcoming “category is dead” skepticism* Design partners as the real unlock: why early believers matter and how co-development actually works* Windsurf’s breakout: what it means to be serious about “Google-class product + Salesforce-class distribution”* Why technical founders struggle with GTM and how KP built a team around sales, customer access, and demand gen* Hiring early sales leaders: anti-patterns (logos), what to screen for (motivation), and why stage-fit is everything* The CPQ problem & Roadrunner’s thesis: rebuilding CPQ/quoting from the data model up for modern complexity* How “rules + SKUs + approvals” create a brittle graph and what it takes to model it without tipping over* The two-year window: incumbents rebuilding slowly vs startups out-sprinting with AI-native architecture* Where AI actually helps: quote generation, policy enforcement, approval routing, and deal recommendation loops—Joubin* X: https://x.com/Joubinmir* LinkedIn: https://www.linkedin.com/in/joubin-mirzadegan-66186854/Where to find Latent Space* X: https://x.com/latentspacepodFull Video EpisodeTimestamps00:00:00 Introduction and the Zuck Interview Experience00:03:26 The Genesis of the Grit Podcast: Hiring CROs Through Content00:13:20 Podcast Philosophy: Creating Authentic Conversations00:15:44 Working with Arvind at Glean: The Enterprise Search Breakthrough00:26:20 Windsurf's Sales Machine: Google-Class Product Meets Salesforce-Class Distribution00:30:28 Hiring Sales Leaders: Anti-Patterns and First Principles00:39:02 The CPQ Problem: Why Salesforce and Legacy Tools Are Breaking00:43:40 Introducing Roadrunner: Solving Enterprise Pricing with AI00:49:19 Building Roadrunner: Team, Design Partners, and Data Model Challenges00:59:35 High Performance Philosophy: Working Out Every Day and Reducing Friction01:06:28 Defining Grit: Passion Plus Perseverance This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

The Future of Email: Superhuman CTO on Your Inbox As the Real AI Agent (Not ChatGPT) — Loïc Houssier
From applied cryptography and offensive security in France’s defense industry to optimizing nuclear submarine workflows, then selling his e-signature startup to Docusign (https://www.docusign.com/company/news-center/opentrust-joins-docusign-global-trust-network and now running AI as CTO of Superhuman Mail (Superhuman, recently acquired by Grammarly https://techcrunch.com/2025/07/01/grammarly-acquires-ai-email-client-superhuman/), Loïc Houssier has lived the full arc from deep infra and compliance hell to obsessing over 100ms product experiences and AI-native email. We sat down with Loïc to dig into how you actually put AI into an inbox without adding latency, why Superhuman leans so hard into agentic search and “Ask AI” over your entire email history, how they design tools vs. agents and fight agent laziness, what box-priced inference and local-first caching mean for cost and reliability, and his bet that your inbox will power your future AI EA while AI massively widens the gap between engineers with real fundamentals and those faking it.We discuss:* Loïc’s path from applied cryptography and offensive security in France’s defense industry to submarines, e-signatures, Docusign, and now Superhuman Mail* What 3,000+ engineers actually do at a “simple” product like Docusign: regional compliance, on-prem appliances, and why global scale explodes complexity* How Superhuman thinks about AI in email: auto-labels, smart summaries, follow-up nudges, “Ask AI” search, and the rule that AI must never add latency or friction* Superhuman’s agentic framework: tools vs. agents, fighting “agent laziness,” deep semantic search over huge inboxes, and pagination strategies to find the real needle in the haystack* How they evaluate OpenAI, Anthropic, Gemini, and open models: canonical queries, end-to-end evals, date reasoning, and Rahul’s infamous “what wood was my table?” test* Infra and cost philosophy: local-first caching, vector search backends, Baseten “box” pricing vs. per-token pricing, and thinking in price-per-trillion-tokens instead of price-per-million* The vision of Superhuman as your AI EA: auto-drafting replies in your voice, scheduling on your behalf, and using your inbox as the ultimate private data source* How the Grammarly + Coda + Superhuman stack could power truly context-aware assistance across email, docs, calendars, contracts, and more* Inside Superhuman’s AI-dev culture: free-for-all tool adoption, tracking AI usage on PRs, and going from ~4 to ~6 PRs per engineer per week* Why Loïc believes everyone should still learn to code, and how AI will amplify great engineers with strong fundamentals while exposing shallow ones even faster—Loïc Houssier* LinkedIn: https://www.linkedin.com/in/houssier/Where to find Latent Space* X: https://x.com/latentspacepodFull Video EpisodeTimestamps00:00:00 Introduction and Loïc's Journey from Nuclear Submarines to Superhuman00:06:40 Docusign Acquisition and the Enterprise Email Stack00:10:26 Superhuman's AI Vision: Your Inbox as the Real AI Agent00:13:20 Ask AI: Agentic Search and the Quality Problem00:18:20 Infrastructure Choices: Model Selection, Base10, and Cost Management00:27:30 Local-First Architecture and the Database Stack00:30:50 Evals, Quality, and the Rahul Wood Table Test00:42:30 The Future EA: Auto-Drafting and Proactive Assistance00:46:40 Grammarly Acquisition and the Contextual Advantage00:38:40 Voice, Video, and the End of Writing00:51:40 Knowledge Graphs: The Hard Problem Nobody Has Solved00:56:40 Competing with OpenAI and the Browser Question01:02:30 AI Coding Tools: From 4 to 6 PRs Per Week01:08:00 Engineering Culture, Hiring, and the Future of Software Development This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

World Models & General Intuition: Khosla's largest bet since LLMs & OpenAI
From building Medal into a 12M-user game clipping platform with 3.8B highlight moments to turning down a reported $500M offer from OpenAI (https://www.theinformation.com/articles/openai-offered-pay-500-million-startup-videogame-data) and raising a $134M seed from Khosla (https://techcrunch.com/2025/10/16/general-intuition-lands-134m-seed-to-teach-agents-spatial-reasoning-using-video-game-clips/) to spin out General Intuition, Pim is betting that world models trained on peak human gameplay are the next frontier after LLMs.We sat down with Pim to dig into why game highlights are “episodic memory for simulation” (and how Medal’s privacy-first action labels became a world-model goldmine https://medal.tv/blog/posts/enabling-state-of-the-art-security-and-protections-on-medals-new-apm-and-controller-overlay-features), what it takes to build fully vision-based agents that just see frames and output actions in real time, how General Intuition transfers from games to real-world video and then into robotics, why world models and LLMs are complementary rather than rivals, what founders with proprietary datasets should know before selling or licensing to labs, and his bet that spatial-temporal foundation models will power 80% of future atoms-to-atoms interactions in both simulation and the real world.We discuss:* How Medal’s 3.8B action-labeled highlight clips became a privacy-preserving goldmine for world models* Building fully vision-based agents that only see frames and output actions yet play like (and sometimes better than) humans* Transferring from arcade-style games to realistic games to real-world video using the same perception–action recipe* Why world models need actions, memory, and partial observability (smoke, occlusion, camera shake) vs. “just” pretty video generation* Distilling giant policies into tiny real-time models that still navigate, hide, and peek corners like real players* Pim’s path from RuneScape private servers, Tourette’s, and reverse engineering to leading a frontier world-model lab* How data-rich founders should think about valuing their datasets, negotiating with big labs, and deciding when to go independent* GI’s first customers: replacing brittle behavior trees in games, engines, and controller-based robots with a “frames in, actions out” API* Using Medal clips as “episodic memory of simulation” to move from imitation learning to RL via world models and negative events* The 2030 vision: spatial–temporal foundation models that power the majority of atoms-to-atoms interactions in simulation and the real world—Pim* X: https://x.com/PimDeWitte* LinkedIn: https://www.linkedin.com/in/pimdw/Where to find Latent Space* X: https://x.com/latentspacepodFull Video EpisodeTimestamps00:00:00 Introduction and Medal's Gaming Data Advantage00:02:08 Exclusive Demo: Vision-Based Gaming Agents00:06:17 Action Prediction and Real-World Video Transfer00:08:41 World Models: Interactive Video Generation00:13:42 From Runescape to AI: Pim's Founder Journey00:16:45 The Research Foundations: Diamond, Genie, and SEMA00:33:03 Vinod Khosla's Largest Seed Bet Since OpenAI00:35:04 Data Moats and Why GI Stayed Independent00:38:42 Self-Teaching AI Fundamentals: The Francois Fleuret Course00:40:28 Defining World Models vs Video Generation00:41:52 Why Simulation Complexity Favors World Models00:43:30 World Labs, Yann LeCun, and the Spatial Intelligence Race00:50:08 Business Model: APIs, Agents, and Game Developer Partnerships00:58:57 From Imitation Learning to RL: Making Clips Playable01:00:15 Open Research, Academic Partnerships, and Hiring01:02:09 2030 Vision: 80 Percent of Atoms-to-Atoms AI Interactions This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

After LLMs: Spatial Intelligence and World Models — Fei-Fei Li & Justin Johnson, World Labs
Fei-Fei Li and Justin Johnson are cofounders of World Labs, who have recently launched Marble (https://marble.worldlabs.ai/), a new kind of generative “world model” that can create editable 3D environments from text, images, and other spatial inputs. Marble lets creators generate persistent 3D worlds, precisely control cameras, and interactively edit scenes, making it a powerful tool for games, film, VR, robotics simulation, and more. In this episode, Fei-Fei and Justin share how their journey from ImageNet and Stanford research led to World Labs, why spatial intelligence is the next frontier after LLMs, and how world models could change how machines see, understand, and build in 3D.We discuss:* The massive compute scaling from AlexNet to today and why world models and spatial data are the most compelling way to “soak up” modern GPU clusters compared to language alone.* What Marble actually is: a generative model of 3D worlds that turns text and images into editable scenes using Gaussian splats, supports precise camera control and recording, and runs interactively on phones, laptops, and VR headsets.* Fei-fei’s essay:on spatial intelligence as a distinct form of intelligence from language: from picking up a mug to inferring the 3D structure of DNA, and why language is a lossy, low-bandwidth channel for describing the rich 3D/4D world we live in.* Whether current models “understand” physics or just fit patterns: the gap between predicting orbits and discovering F=ma, and how attaching physical properties to splats and distilling physics engines into neural networks could lead to genuine causal reasoning.* The changing role of academia in AI, why Fei-Fei worries more about under-resourced universities than “open vs closed,” and how initiatives like national AI compute clouds and open benchmarks can rebalance the ecosystem.* Why transformers are fundamentally set models, not sequence models, and how that perspective opens up new architectures for world models, especially as hardware shifts from single GPUs to massive distributed clusters.* Real use cases for Marble today: previsualization and VFX, game environments, virtual production, interior and architectural design (including kitchen remodels), and generating synthetic simulation worlds for training embodied agents and robots.* How spatial intelligence and language intelligence will work together in multimodal systems, and why the goal isn’t to throw away LLMs but to complement them with rich, embodied models of the world.* Fei-Fei and Justin’s long-term vision for spatial intelligence: from creative tools for artists and game devs to broader applications in science, medicine, and real-world decision-making.—Fei-Fei Li* X: https://x.com/drfeifei* LinkedIn: https://www.linkedin.com/in/fei-fei-li-4541247Justin Johnson* X: https://x.com/jcjohnss* LinkedIn: https://www.linkedin.com/in/justin-johnson-41b43664Where to find Latent Space* X: https://x.com/latentspacepodFull Video EpisodeTimestamps00:00:00 Introduction and the Fei-Fei Li & Justin Johnson Partnership00:02:00 From ImageNet to World Models: The Evolution of Computer Vision00:12:42 Dense Captioning and Early Vision-Language Work00:19:57 Spatial Intelligence: Beyond Language Models00:28:46 Introducing Marble: World Labs' First Spatial Intelligence Model00:33:21 Gaussian Splats and the Technical Architecture of Marble00:22:10 Physics, Dynamics, and the Future of World Models00:41:09 Multimodality and the Interplay of Language and Space00:37:37 Use Cases: From Creative Industries to Robotics and Embodied AI00:56:58 Hiring, Research Directions, and the Future of World Labs This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

⚡️ 10x AI Engineers with $1m Salaries — Alex Lieberman & Arman Hezarkhani, Tenex
Alex Lieberman and Arman Hezarkani, co-founders of Tenex, reveal how they’re revolutionizing software consulting by compensating AI engineers for output rather than hours—enabling some engineers to earn over $1 million annually while delivering 10x productivity gains. Their company represents a fundamental rethinking of knowledge work compensation in the age of AI agents, where traditional hourly billing models perversely incentivize slower work even as AI tools enable unprecedented speed.The Genesis: From 90% Downsizing to 10x Output The story behind 10X begins with Arman’s previous company, Parthian, where he was forced to downsize his engineering team by 90%. Rather than collapse, Arman re-architected the entire product and engineering process to be AI-first—and discovered that production-ready software output increased 10x despite the massive headcount reduction. This counterintuitive result exposed a fundamental misalignment: engineers compensated by the hour are disincentivized from leveraging AI to work faster, even when the technology enables dramatic productivity gains. Alex, who had invested in Parthian, initially didn’t believe the numbers until Arman walked him through why LLMs have made such a profound impact specifically on engineering as knowledge work.The Economic Model: Story Points Over Hours 10X’s core innovation is compensating engineers based on story points—units of completed, quality output—rather than hours worked. This creates direct economic incentives for engineers to adopt every new AI tool, optimize their workflows, and maximize throughput. The company expects multiple engineers to earn over $1 million in cash compensation next year purely from story point earnings. To prevent gaming the system, they hire for two profiles: engineers who are “long-term selfish” (understanding that inflating story points will destroy client relationships) and those who genuinely love writing code and working with smart people. They also employ technical strategists incentivized on client retention (NRR) who serve as the final quality gate before any engineering plan reaches a client.Impressive Builds: From Retail AI to App Store Hits The results speak for themselves. In one project, 10X built a computer vision system for retail cameras that provides heat maps, queue detection, shelf stocking analysis, and theft detection—creating early prototypes in just two weeks for work that previously took quarters. They built Snapback Sports’ mobile trivia app in one month, which hit 20th globally on the App Store. In a sales context, an engineer spent four hours building a working prototype of a fitness influencer’s AI health coach app after the prospect initially said no—immediately moving 10X to the top of their vendor list. These examples demonstrate how AI-enabled speed fundamentally changes sales motions and product development timelines.The Interview Process: Unreasonably Difficult Take-Homes Despite concerns that AI would make take-home assessments obsolete, 10X still uses them—but makes them “unreasonably difficult.” About 50% of candidates don’t even respond, but those who complete the challenge demonstrate the caliber needed. The interview process is remarkably short: two calls before the take-home, review, then one or two final meetings—completable in as little as a week. A signature question: “If you had infinite resources to build an AI that could replace either of us on this call, what would be the first major bottleneck?” The sophisticated answer isn’t just “model intelligence” or “context length”—it’s controlling entropy, the accumulating error rate that derails autonomous agents over time.The Limiting Factor: Human Capital, Not Technology Despite being an AI-first company, 10X’s primary constraint is human capital—finding and hiring enough exceptional engineers fast enough, then matching them with the right processes to maintain delivery quality as they scale. The company has ambitions beyond consulting to build their own technology, but for the foreseeable future, recruiting remains the bottleneck. This reveals an important insight about the AI era: even as technology enables unprecedented leverage, the constraint shifts to finding people who can harness that leverage effectively.Full Video EpisodeTimestamps00:00:00 Introduction and Meeting the 10X Co-founders00:01:29 The 10X Moment: From Hourly Billing to Output-Based Compensation00:04:44 The Economic Model Behind 10X00:05:42 Story Points and Measuring Engineering Output00:08:41 Impressive Client Projects and Rapid Prototyping00:12:22 The 10X Tech Stack: TypeScript and High Structure00:13:21 AI Coding Tools: The Daily Evolution00:15:05 Human Capital as the Limiting Factor00:16:02 The Unreasonably Difficult Interview Process00:17:14 Entropy and Context Engineering: The Future of AI Agents00:23:28 The MCP Debate and AI Industry Sociology00:26:01 Consulting, Digital Transformation, and Conference Insights This is a public episode. If you'd li

Anthropic, Glean & OpenRouter: How AI Moats Are Built with Deedy Das of Menlo Ventures
Deedy Das, Partner at Menlo Ventures, returns to Latent Space to discuss his journey from Glean to venture capital, the explosive rise of Anthropic, and how AI is reshaping enterprise software and coding. From investing in Anthropic early on when they had no revenue to managing the $100M Ontology Fund, Das shares insider perspectives on the fastest-growing software company in history and what’s next for AI infrastructure, research investing, and the future of engineering.We cover Glean’s rise from “boring” enterprise search to a $7B AI-native company, Anthropic’s meteoric rise, the strategic decisions behind products like Claude Code, and why market share in enterprise AI is shifting dramatically. Das explains his investment thesis on research companies like Goodfire, Prime Intellect, and OpenRouter and how the Anthology Fund is quietly seeding the next wave of AI infra, research, and devtools.Full Video EpisodeTimestamps* 00:00:00 Introduction and Deedy’s Return to Latent Space* 00:01:20 Glean’s Journey: From Boring Enterprise Search to Valuation* 00:15:37 Anthropic’s Meteoric Rise and Market Share Dynamics* 00:17:50 Claude Artifacts and Product Innovation* 00:41:20 The Anthology Fund: Investing in the Anthropic Ecosystem* 00:48:01 Goodfire and Mechanistic Interpretability* 00:51:25 Prime Intellect and Distributed AI Training* 00:53:40 OpenRouter: Building the AI Model Gateway* 01:13:36 The Stargate Project and Infrastructure Arms Race* 01:18:14 The Future of Software Engineering and AI Coding This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

⚡ Inside GitHub’s AI Revolution: Jared Palmer Reveals Agent HQ & The Future of Coding Agents
Jared Palmer, SVP at GitHub and VP of CoreAI at Microsoft, joins Latent Space for an in-depth look at the evolution of coding agents and modern developer tools. Recently joining after leading AI initiatives at Vercel, Palmer shares firsthand insights from behind the scenes at GitHub Universe, including the launch of Agent HQ which is a new collaboration hub for coding agents and developers.This episode traces Palmer’s journey from building Copilot inspired tools to pioneering the focused Next.js coding agent, v0, and explores how platform constraints fostered rapid experimentation and a breakout success in AI-powered frontend development. Palmer explains the unique advantages of GitHub’s massive developer network, the challenges of scaling agent-based workflows, and why integrating seamless AI into developer experiences is now a top priority for both Microsoft and GitHub.Full Video EpisodeTimestamps00:00:00 Introduction and Jared's New Role at GitHub00:01:00 From V0 to Agent HQ: The Evolution of Coding Agents00:02:51 The V0 Origin Story: From ChatGPT to AI Playground00:05:40 Building the AI SDK and ShadCN Collaboration00:07:08 The Birth of V0: Prompt to UI Revolution00:09:18 V0's Growth Journey and Model Evolution00:11:05 Model Strategy: Composite Models vs User Choice00:13:16 GitHub's Agent HQ and Model Marketplace00:15:51 The Future of Agent Abstraction and Standards00:16:33 Microsoft Core AI Integration and Workflow Vision00:18:37 Dev Containers and Repo Setup Challenges00:24:10 Agent Quality and Infrastructure Reliability00:27:05 Using Coding Agents for Non-Coding Tasks00:29:11 GitHub Homepage Redesign and Community Feedback00:30:27 Stacked Diffs: GitHub's Most Requested Feature This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

⚡ [AIE CODE Preview] Inside Google Labs: Building The Gemini Coding Agent — Jed Borovik, Jules
Jed Borovik, Product Lead at Google Labs, joins Latent Space to unpack how Google is building the future of AI-powered software development with Jules. From his journey discovering GenAI through Stable Diffusion to leading one of the most ambitious coding agent projects in tech, Borovik shares behind-the-scenes insights into how Google Labs operates at the intersection of DeepMind’s model development and product innovation.We explore Jules’ approach to autonomous coding agents and why they run on their own infrastructure, how Google simplified their agent scaffolding as models improved, and why embeddings-based RAG is giving way to attention-based search. Borovik reveals how developers are using Jules for hours or even days at a time, the challenges of managing context windows that push 2 million tokens, and why coding agents represent both the most important AI application and the clearest path to AGI.This conversation reveals Google’s positioning in the coding agent race, the evolution from internal tools to public products, and what founders, developers, and AI engineers should understand about building for a future where AI becomes the new brush for software engineering.Full Video EpisodeTimestamps00:00:00 Introduction and GitHub Universe Recap00:00:57 New York Tech Scene and East Coast Hackathons00:02:19 From Google Search to AI Coding: Jed's Journey00:04:19 Google Labs Mission and DeepMind Collaboration00:06:41 Jules: Autonomous Coding Agents Explained00:09:39 The Evolution of Agent Scaffolding and Model Quality00:11:30 RAG vs Attention: The Shift in Code Understanding00:13:49 Jules' Journey from Preview to Production00:15:05 AI Engineer Summit: Community Building and Networking00:25:06 Context Management in Long-Running Agents00:29:02 The Future of Software Engineering with AI00:36:26 Beyond Vibe Coding: Spec Development and Verification00:40:20 Multimodal Input and Computer Use for Coding Agents This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

⚡️ Ship AI recap: Agents, Workflows, and Python — w/ Vercel CTO Malte Ubl
In this conversation with Malte Ubl, CTO of Vercel (http://x.com/cramforce), we explore how the company is pioneering the infrastructure for AI-powered development through their comprehensive suite of tools including workflows, AI SDK, and the newly announced agent ecosystem. Malte shares insights into Vercel’s philosophy of “dogfooding” - never shipping abstractions they haven’t battle-tested themselves - which led to extracting their AI SDK from v0 and building production agents that handle everything from anomaly detection to lead qualification.The discussion dives deep into Vercel’s new Workflow Development Kit, which brings durable execution patterns to serverless functions, allowing developers to write code that can pause, resume, and wait indefinitely without cost. Malte explains how this enables complex agent orchestration with human-in-the-loop approvals through simple webhook patterns, making it dramatically easier to build reliable AI applications.We explore Vercel’s strategic approach to AI agents, including their DevOps agent that automatically investigates production anomalies by querying observability data and analyzing logs - solving the recall-precision problem that plagues traditional alerting systems. Malte candidly discusses where agents excel today (meeting notes, UI changes, lead qualification) versus where they fall short, emphasizing the importance of finding the “sweet spot” by asking employees what they hate most about their jobs.The conversation also covers Vercel’s significant investment in Python support, bringing zero-config deployment to Flask and FastAPI applications, and their vision for security in an AI-coded world where developers “cannot be trusted.” Malte shares his perspective on how CTOs must transform their companies for the AI era while staying true to their core competencies, and why maintaining strong IC (individual contributor) career paths is crucial as AI changes the nature of software development.What was launched at Ship AI 2025:AI SDK 6.0 & Agent Architecture* Agent Abstraction Philosophy: AI SDK 6 introduces an agent abstraction where you can “define once, deploy everywhere”. How does this differ from existing agent frameworks like LangChain or AutoGPT? What specific pain points did you observe in production that led to this design?* Human-in-the-Loop at Scale: The tool approval system with needsApproval: true gates actions until human confirmation. How do you envision this working at scale for companies with thousands of agent executions? What’s the queue management and escalation strategy?* Type Safety Across Models: AI SDK 6 promises “end-to-end type safety across models and UI”. Given that different LLMs have varying capabilities and output formats, how do you maintain type guarantees when swapping between providers like OpenAI, Anthropic, or Mistral?Workflow Development Kit (WDK)* Durability as Code: The use workflow primitive makes any TypeScript function durable with automatic retries, progress persistence, and observability. What’s happening under the hood? Are you using event sourcing, checkpoint/restart, or a different pattern?* Infrastructure Provisioning: Vercel automatically detects when a function is durable and dynamically provisions infrastructure in real-time. What signals are you detecting in the code, and how do you determine the optimal infrastructure configuration (queue sizes, retry policies, timeout values)?Vercel Agent (beta)* Code Review Validation: The Agent reviews code and proposes “validated patches”. What does “validated” mean in this context? Are you running automated tests, static analysis, or something more sophisticated?* AI Investigations: Vercel Agent automatically opens AI investigations when it detects performance or error spikes using real production data. What data sources does it have access to? How does it distinguish between normal variance and actual anomalies?Python Support (For the first time, Vercel now supports Python backends natively.)Marketplace & Agent Ecosystem* Agent Network Effects: The Marketplace now offers agents like CodeRabbit, Corridor, Sourcery, and integrations with Autonoma, Braintrust, Browser Use. How do you ensure these third-party agents can’t access sensitive customer data? What’s the security model?“An Agent on Every Desk” Program* Vercel launched a new program to help companies identify high-value use cases and build their first production AI agents. It provides consultations, reference templates, and hands-on support to go from idea to deployed agentFull Video EpisodeTimestamps00:00 Introduction and Malte’s Background at Google01:16 Vercel’s AI Engineering Philosophy and Ship AI Recap03:19 Deep Dive: Workflows vs Agents Architecture09:33 AI SDK Success Story: Staying Low-Level and Humble16:35 Framework Design Principles and Open Source Strategy19:20 Vercel Agent: AI-Powered DevOps and Anomaly Detection27:06 Internal Agent Use Cases: Lead Qualification and Abuse Analysis29:49 Agent on Ev

Why RL Won — Kyle Corbitt, OpenPipe (acq. CoreWeave)
In this deep dive with Kyle Corbitt, co-founder and CEO of OpenPipe (recently acquired by CoreWeave), we explore the evolution of fine-tuning in the age of AI agents and the critical shift from supervised fine-tuning to reinforcement learning. Kyle shares his journey from leading YC’s Startup School to building OpenPipe, initially focused on distilling expensive GPT-4 workflows into smaller, cheaper models before pivoting to RL-based agent training as frontier model prices plummeted. The conversation reveals why 90% of AI projects remain stuck in proof-of-concept purgatory - not due to capability limitations, but reliability issues that Kyle believes can be solved through continuous learning from real-world experience. He discusses the breakthrough of RULER (Relative Universal Reinforcement Learning Elicited Rewards), which uses LLMs as judges to rank agent behaviors relatively rather than absolutely, making RL training accessible without complex reward engineering. Kyle candidly assesses the challenges of building realistic training environments for agents, explaining why GRPO (despite its advantages) may be a dead end due to its requirement for perfectly reproducible parallel rollouts. He shares insights on why LoRAs remain underrated for production deployments, why GEPA and prompt optimization haven’t lived up to the hype in his testing, and why the hardest part of deploying agents isn’t the AI - it’s sandboxing real-world systems with all their bugs and edge cases intact. The discussion also covers OpenPipe’s acquisition by CoreWeave, the launch of their serverless reinforcement learning platform, and Kyle’s vision for a future where every deployed agent continuously learns from production experience. He predicts that solving the reliability problem through continuous RL could unlock 10x more AI inference demand from projects currently stuck in development, fundamentally changing how we think about agent deployment and maintenance.Key Topics:* The rise and fall of fine-tuning as a business model* Why 90% of AI projects never reach production* RULER: Making RL accessible through relative ranking* The environment problem: Why sandboxing is harder than training* GRPO vs PPO and the future of RL algorithms* LoRAs: The underrated deployment optimization* Why GEPA and prompt optimization disappointed in practice* Building world models as synthetic training environments* The $500B Stargate bet and OpenAI’s potential crypto play* Continuous learning as the path to reliable agentsReferenceshttps://www.linkedin.com/in/kcorbitt/* Aug 2023 https://openpipe.ai/blog/from-prompts-to-models * DEC 2023 https://openpipe.ai/blog/mistral-7b-fine-tune-optimized* JAN 2024 https://openpipe.ai/blog/s-lora* MAY 2024 https://openpipe.ai/blog/the-ten-commandments-of-fine-tuning-in-prod * Oct 2024 https://openpipe.ai/blog/announcing-dpo-support * AIE NYC 2025 Finetuning 500m agents * AIEWF 2025 How to train your agent (ART-E) * SEPT 2025 ACQUISTION https://openpipe.ai/blog/openpipe-coreweave * W&B Serverless RL https://openpipe.ai/blog/serverless-rl?refresh=1760042248153Full Video EpisodeTimestamps00:00 Introductions03:15 The Evolution of OpenPipe: From SFT to RL07:49 The Mistral Era and LoRA Adapters11:40 When You Actually Need Fine-Tuning14:43 The Pivot to Reinforcement Learning21:29 GRPO vs PPO: The Technical Trade-offs24:02 The Environment Problem in RL35:52 JAPA and Automated Prompt Optimization44:35 Open vs Closed Models: The Token Economics50:38 Ruler: Self-Supervised RL Rewards57:09 World Models as Environment Solutions1:00:15 CoreWeave Acquisition and Future Vision This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

DevDay 2025: Apps SDK, Agent Kit, MCP, Codex and why Prompting is More Important than Ever
At OpenAI DevDay, we sit down with Sherwin Wu and Christina Huang from the OpenAI Platform Team to discuss the launch of AgentKit - a comprehensive suite of tools for building, deploying, and optimizing AI agents. Christina walks us through the live demo she performed on stage, building a customer support agent in just 8 minutes using the visual Agent Builder, while Sherwin shares insights on how OpenAI is inverting the traditional website-chatbot paradigm by embedding apps directly within ChatGPT through the new Apps SDK.The conversation explores how OpenAI is tackling the challenges developers face when taking agents to production - from writing and optimizing prompts to building evaluation pipelines. They discuss the decision to adopt Anthropic’s MCP protocol for tool connectivity, the importance of visual workflows for complex agent systems, and how features like human-in-the-loop approvals and automated prompt optimization are making agent development more accessible to a broader range of developers.Sherwin and Christina also reveal how OpenAI is dogfooding these tools internally, with their own customer support at openai.com already powered by AgentKit, and share candid insights about the evolution from plugins to GPTs to this new agent platform. They discuss the surprising persistence of prompting as a critical skill (contrary to predictions from two years ago), the challenges of serving custom fine-tuned models at scale, and why they believe visual agent builders are essential as workflows grow to span dozens of nodes.Guests:* Sherwin Wu: Head of Engineering, OpenAI Platform https://www.linkedin.com/in/sherwinwu1/ https://x.com/sherwinwu?lang=en* Christina Huang: Platform Experience, OpenAI https://x.com/christinaahuang https://www.linkedin.com/in/christinaahuang/Thanks very much to Lindsay and Shaokyi for helping us set up this great deepdive into the new DevDay launches!Key Topics:• AgentKit launch: Agent SDK, Builder, Evals, and deployment tools• Apps SDK and the inversion of the app-chatbot paradigm• Adopting MCP protocol for universal tool connectivity• Visual agent building vs code-first approaches• Human-in-the-loop workflows and approval systems• Automated prompt optimization and “zero-gradient fine-tuning”• Service Health Dashboard and achieving five nines reliability• ChatKit as an embeddable, evergreen chat interface• The evolution from plugins to GPTs to agent platforms• Internal dogfooding with Codex and agent-powered supportFull Video EpisodeTimestamps00:00 Welcome to the OpenAI Dev Day Studio01:11 Dev Day Evolution and Community Growth03:08 Apps SDK and ChatGPT Distribution Strategy05:27 MCP Protocol Integration Decision09:26 Agent Kit Launch and Platform Vision11:33 Agent Builder Canvas and Visual Workflows17:22 Evaluations and Agent Testing Evolution19:20 Automated Prompt Optimization and Research26:35 Connector Registry and MCP Servers34:10 Chat Kit as Consumer-Grade Infrastructure39:13 Codex Power User Tips and AI-Native Development42:27 Service Health Dashboard and Reliability Journey This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

Taste is your Moat (Dylan Field of Figma)
Dylan Field (CEO Figma) on how they are letting designers build with Figma Make, how Figma can be the context repository for aesthetic in the age of vibe coding, and why design is your only differentiator now.Full show notes: https://www.latent.space/p/figma This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

Amp: The Emperor Has No Clothes
Quinn Slack (CEO) and Thorsten Ball (Amp Dictator) from SourceGraph join the show to talk about Amp Code, how they ship 15x/day with no code reviews, and why subagents and prompt optimizers aren’t a promising direction for coding agents.Amp Code: https://ampcode.com/Latent Space: https://latent.space/Full Video EpisodeTimestamps00:00 Introduction00:41 Transition from Cody to Amp03:18 The Importance of Building the Best Coding Agent06:43 Adapting to a Rapidly Evolving AI Tooling Landscape09:36 Dogfooding at Sourcegraph12:35 CLI vs. VS Code Extension21:08 Positioning Amp in Coding Agent Market24:10 The Diminishing Importance of Model Selectors32:39 Tooling vs. Harness37:19 Common Failure Modes of Coding Agents47:33 Agent-Friendly Logging and Tooling52:31 Are Subagents Real?56:52 New Frameworks and Agent-Integrated Developer Tools1:00:25 How Agents Are Encouraging Codebase and Workflow Changes1:03:13 Evolving Outer Loop Tasks1:07:09 Version Control and Merge Conflicts in an AI-First World1:10:36 Rise of User-Generated Enterprise Software1:14:39 Empowering Technical Leaders with AI1:17:11 Evaluating Product Without Traditional Evals1:20:58 Hiring This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe
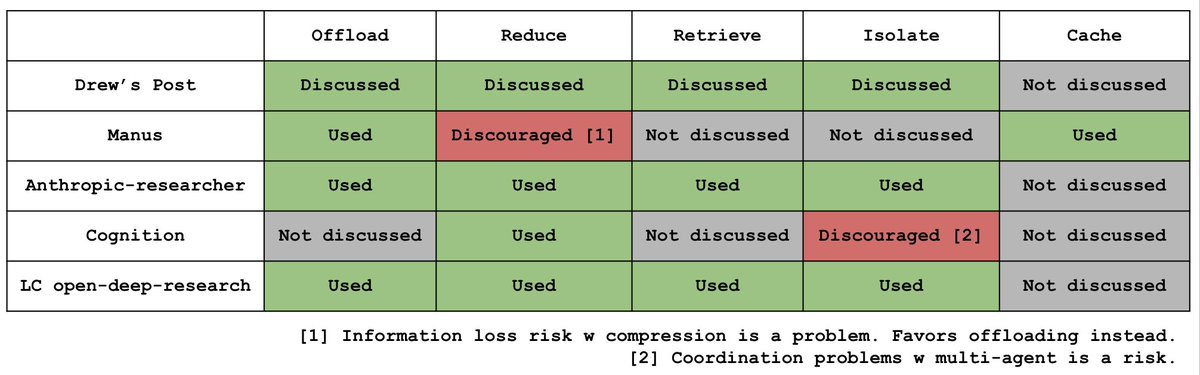
Context Engineering for Agents - Lance Martin, LangChain
Lance: https://www.linkedin.com/in/lance-martin-64a33b5/How Context Fails: https://www.dbreunig.com/2025/06/22/how-contexts-fail-and-how-to-fix-them.htmlHow New Buzzwords Get Created: https://www.dbreunig.com/2025/07/24/why-the-term-context-engineering-matters.htmlContent Engineering: https://rlancemartin.github.io/2025/06/23/context_engineering/ https://docs.google.com/presentation/d/16aaXLu40GugY-kOpqDU4e-S0hD1FmHcNyF0rRRnb1OU/edit?usp=sharingManus Post: https://manus.im/blog/Context-Engineering-for-AI-Agents-Lessons-from-Building-ManusCognition Post: https://cognition.ai/blog/dont-build-multi-agentsMulti-Agent Researcher: https://www.anthropic.com/engineering/multi-agent-research-systemHuman-in-the-loop + Memory: https://github.com/langchain-ai/agents-from-scratch- Bitter Lesson in AI Engineering -Hyung Won Chung on the Bitter Lesson in AI Research: Bitter Lesson w/ Claude Code: Learning the Bitter Lesson in AI Engineering: https://rlancemartin.github.io/2025/07/30/bitter_lesson/Open Deep Research: https://github.com/langchain-ai/open_deep_research https://academy.langchain.com/courses/deep-research-with-langgraphScaling and building things that “don’t yet work”: - Frameworks -Roast framework at Shopify / standardization of orchestration tools: MCP adoption within Anthropic / standardization of protocols: How to think about frameworks: https://blog.langchain.com/how-to-think-about-agent-frameworks/RAG benchmarking: https://rlancemartin.github.io/2025/04/03/vibe-code/Simon’s talk with memory-gone-wrong: https://simonwillison.net/2025/Jun/6/six-months-in-llms/Full Video EpisodeTimestamps00:00 Introduction and Background00:53 The Rise of Context Engineering01:57 Context Engineering vs Prompt Engineering05:56 The Five Categories of Context Engineering10:02 Multi-Agent Systems and Context Isolation14:48 Classical Retrieval vs Agentic Search17:12 LLMs.txt and MCP Servers24:51 Context Pruning and Memory Management37:25 Memory Systems and Human-in-the-Loop42:55 The Bitter Lesson Applied to AI Engineering51:21 Frameworks, Abstractions, and Building for the Future This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe
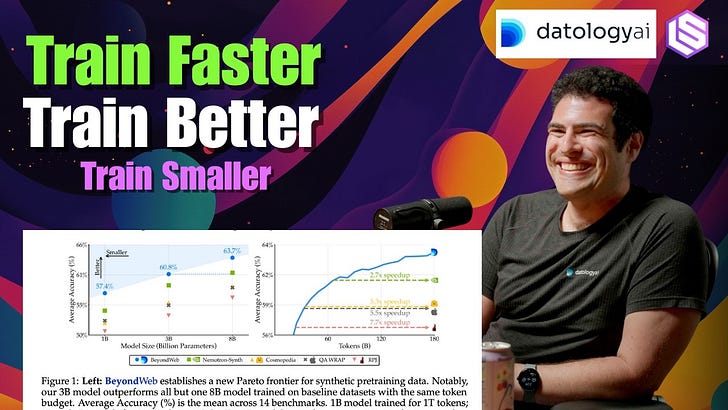
Better Data is All You Need — Ari Morcos, Datology
Our chat with Ari shows that data curation is the most impactful and underinvested area in AI. He argues that the prevailing focus on model architecture and compute scaling overlooks the “bitter lesson” that “models are what they eat.” Effective data curation—a sophisticated process involving filtering, rebalancing, sequencing (curriculum), and synthetic data generation—allows for training models that are simultaneously faster, better, and smaller. Morcos recounts his personal journey from focusing on model-centric inductive biases to realizing that data quality is the primary lever for breaking the diminishing returns of naive scaling laws. Datology’s mission is to automate this complex curation process, making state-of-the-art data accessible to any organization and enabling a new paradigm of AI development where data efficiency, not just raw scale, drives progress.Full Video EpisodeTimestamps00:00 Introduction00:46 What is Datology? The mission to train models faster, better, and smaller through data curation.01:59 Ari’s background: From neuroscience to realizing the “Bitter Lesson” of AI.05:30 Key Insight: Inductive biases from architecture become less important and even harmful as data scale increases.08:08 Thesis: Data is the most underinvested area of AI research relative to its impact.10:15 Why data work is culturally undervalued in research and industry.12:19 How self-supervised learning changed everything, moving from a data-scarce to a data-abundant regime.17:05 Why automated curation is superior to human-in-the-loop, citing the DCLM study.19:22 The “Elephants vs. Dogs” analogy for managing data redundancy and complexity.22:46 A brief history and commentary on key datasets (Common Crawl, GitHub, Books3).26:24 Breaking naive scaling laws by improving data quality to maintain high marginal information gain.29:07 Datology’s demonstrated impact: Achieving baseline performance 12x faster.34:19 The business of data: Datology’s moat and its relationship with open-source datasets.39:12 Synthetic Data Explained: The difference between risky “net-new” creation and powerful “rephrasing.”49:02 The Resurgence of Curriculum Learning: Why ordering data matters in the underfitting regime.52:55 The Future of Training: Optimizing pre-training data to make post-training more effective.54:49 Who is training their own models and why (Sovereign AI, large enterprises).57:24 “Train Smaller”: Why inference cost makes smaller, specialized models the ultimate goal for enterprises.01:00:19 The problem with model pruning and why data-side solutions are complementary.01:03:03 On finding the smallest possible model for a given capability.01:06:49 Key learnings from the RC foundation model collaboration, proving that data curation “stacks.”01:09:46 Lightning Round: What data everyone wants & who should work at Datology.01:14:24 Commentary on Meta’s superintelligence efforts and Yann LeCun’s role. This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

The RLVR Revolution — with Nathan Lambert (AI2, Interconnects.ai)
We first had Nathan on to give us his RLHF deep dive when he was joining AI2, and now he’s back to help us catch up on the evolution to RLVR (Reinforcement Learning with Verifiable Rewards), first proposed in his Tulu 3 paper. While RLHF remains foundational, RLVR has emerged as a powerful approach for training models on tasks with clear success criteria and using verifiable, objective functions as reward signals—particularly useful in domains like math, code correctness, and instruction-following. Instead of relying solely on subjective human feedback, RLVR leverages deterministic signals to guide optimization, making it more scalable and potentially more reliable across many domains. However, he notes that RLVR is still rapidly evolving, especially regarding how it handles tool use and multi-step reasoning.We also discussed the Tulu model series, a family of instruction-tuned open models developed at AI2. Tulu is designed to be a reproducible, state-of-the-art post-training recipe for the open community. Unlike frontier labs like OpenAI or Anthropic, which rely on vast and often proprietary datasets, Tulu aims to distill and democratize best practices for instruction and preference tuning. We are impressed with how small eval suites, careful task selection, and transparent methodology can rival even the best proprietary models on specific benchmarks.One of the most fascinating threads is the challenge of incorporating tool use into RL frameworks. Lambert highlights that while you can prompt a model to use tools like search or code execution, getting the model to reliably learn when and how to use them through RL is much harder. This is compounded by the difficulty of designing reward functions that avoid overoptimization—where models learn to “game” the reward signal rather than solve the underlying task. This is particularly problematic in code generation, where models might reward hack unit tests by inserting pass statements instead of correct logic. As models become more agentic and are expected to plan, retrieve, and act across multiple tools, reward design becomes a critical bottleneck.Other topics covered:- The evolution from RLHF (Reinforcement Learning from Human Feedback) to RLVR (Reinforcement Learning from Verifiable Rewards)- The goals and technical architecture of the Tulu models, including the motivation to open-source post-training recipes- Challenges of tool use in RL: verifiability, reward design, and scaling across domains- Evaluation frameworks and the role of platforms like Chatbot Arena and emerging “arena”-style benchmarks- The strategic tension between hybrid reasoning models and unified reasoning models at the frontier- Planning, abstraction, and calibration in reasoning agents and why these concepts matter- The future of open-source AI models, including DeepSeek, OLMo, and the potential for an “American DeepSeek”- The importance of model personality, character tuning, and the model spec paradigm- Overoptimization in RL settings and how it manifests in different domains (control tasks, code, math)- Industry trends in inference-time scaling and model parallelismFinally, the episode closes with a vision for the future of open-source AI. Nathan has now written up his ambition to build an “American DeepSeek”—a fully open, end-to-end reasoning-capable model with transparent training data, tools, and infrastructure. He emphasizes that open-source AI is not just about weights; it’s about releasing recipes, evaluations, and methods that lower the barrier for everyone to build and understand cutting-edge systems. Full Video EpisodeTimestamps00:00 Welcome and Guest Introduction01:18 Tulu, OVR, and the RLVR Journey03:40 Industry Approaches to Post-Training and Preference Data06:08 Understanding RLVR and Its Impact06:18 Agents, Tool Use, and Training Environments10:34 Open Data, Human Feedback, and Benchmarking12:44 Chatbot Arena, Sycophancy, and Evaluation Platforms15:42 RLHF vs RLVR: Books, Algorithms, and Future Directions17:54 Frontier Models: Reasoning, Hybrid Models, and Data22:11 Search, Retrieval, and Emerging Model Capabilities29:23 Tool Use, Curriculum, and Model Training Challenges38:06 Skills, Planning, and Abstraction in Agent Models46:50 Parallelism, Verifiers, and Scaling Approaches54:33 Overoptimization and Reward Design in RL1:02:27 Open Models, Personalization, and the Model Spec1:06:50 Open Model Ecosystem and Infrastructure1:13:05 Meta, Hardware, and the Future of AI Competition1:15:42 Building an Open DeepSeek and Closing Thoughts This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

AI is Eating Search
ChatGPT handles 2.5B prompts/day and is on track to match Google’s daily searches by end of 2026. AI agents don’t browse like us—they crave queryable, chunkable data for tools like ChatGPT & Perplexity. A new industry is being born, some are calling it AI SEO, others GEO, but what is clear is that it drives amazing results. Businesses are seeing 2-4x higher conversion from visitors coming from AI compared to traditional search. Robert McCloy is the co-founder of Scrunch AI (https://scrunchai.com/), a fast growing company that helps brands and businesses re-write their content on the fly based on what agents are looking for.Full Video EpisodeTimestamps00:00 Intro & Guest Introduction01:30 The Genesis of Scrunch AI & AI Search Impact06:02 AI Search Engines vs. Traditional SEO06:28 Monitoring Prompts & The AI Search Stack08:26 AI Training Data, Crawlers, and Content Strategy12:33 AI Browsers and the Future of Web Consumption16:06 Technical Mechanisms of AI Search & SEO Relevance28:44 Personalization, Agent Experience, and Customer Journeys30:44 Prompt Clusters, User Intent, and B2B Buying Patterns36:06 Optimization Tactics: Prompt Injection, Content, and Pitfalls40:37 Technical Content Delivery: JavaScript, Programmatic SEO, and LMS.txt47:31 Case Studies & Conversion Optimization51:36 Market Share & Platform Trends in AI Search55:10 Wrap-Up & Future of AI-Driven Web This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

Cline: the open source coding agent that doesn't cut costs
Saoud Rizwan and Pash from Cline joined us to talk about why fast apply models got bitter lesson’d, how they pioneered the plan + act paradigm for coding, and why non-technical people use IDEs to do marketing and generate slides.Full writeup: https://www.latent.space/p/clineX: https://x.com/latentspacepodFull Video EpisodeTimestamps00:00 - Introductions 01:35 - Plan and Act Paradigm 05:37 - Model Evaluation and Early Development of Cline 08:14 - Use Cases of Cline Beyond Coding 09:09 - Why Cline is a VS Code Extension and Not a Fork 12:07 - Economic Value of Programming Agents 16:07 - Early Adoption for MCPs 19:35 - Local vs Remote MCP Servers 22:10 - Anthropic’s Role in MCP Registry 22:49 - Most Popular MCPs and Their Use Cases 25:26 - Challenges and Future of MCP Monetization 27:32 - Security and Trust Issues with MCPs 28:56 - Alternative History Without MCP 29:43 - Market Positioning of Coding Agents and IDE Integration Matrix 32:57 - Visibility and Autonomy in Coding Agents 35:21 - Evolving Definition of Complexity in Programming Tasks 38:16 - Forks of Cline and Open Source Regrets 40:07 - Simplicity vs Complexity in Agent Design 46:33 - How Fast Apply Got Bitter Lesson’d 49:12 - Cline’s Business Model and Bring-Your-Own-API-Key Approach 54:18 - Integration with OpenRouter and Enterprise Infrastructure 55:32 - Impact of Declining Model Costs 57:48 - Background Agents and Multi-Agent Systems 1:00:42 - Vision and Multi-Modalities 1:01:07 - State of Context Engineering 1:07:37 - Memory Systems in Coding Agents 1:10:14 - Standardizing Rules Files Across Agent Tools 1:11:16 - Cline’s Personality and Anthropomorphization 1:12:55 - Hiring at Cline and Team Culture This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

Personalized AI Language Education — with Andrew Hsu, Speak
Speak (https://speak.com) may not be very well known to native English speakers, but they have come from a slow start in 2016 to emerge as one of the favorite partners of OpenAI, with their Startup Fund leading and joining their Series B and C as one of the new AI-native unicorns, noting that “Speak has the potential to revolutionize not just language learning, but education broadly”.Today we speak with Speak’s CTO, Andrew Hsu, on the journey of building the “3rd generation” of language learning software (with Rosetta Stone being Gen 1, and Duolingo being Gen 2). Speak’s premise is that speech and language models can now do what was previously only possible with human tutors—provide fluent, responsive, and adaptive instruction—and this belief has shaped its product and company strategy since its early days.https://www.linkedin.com/in/adhsu/https://speak.comOne of the most interesting strategic decisions discussed in the episode is Speak’s early focus on South Korea. While counterintuitive for a San Francisco-based startup, the decision was influenced by a combination of market opportunity and founder proximity via a Korean first employee. South Korea’s intense demand for English fluency and a highly competitive education market made it a proving ground for a deeply AI-native product. By succeeding in a market saturated with human-based education solutions, Speak validated its model and built strong product-market fit before expanding to other Asian markets and eventually, globally.The arrival of Whisper and GPT-based LLMs in 2022 marked a turning point for Speak. Suddenly, capabilities that were once theoretical—real-time feedback, semantic understanding, conversational memory—became technically feasible. Speak didn’t pivot, but rather evolved into its second phase: from a supplemental practice tool to a full-featured language tutor. This transition required significant engineering work, including building custom ASR models, managing latency, and integrating real-time APIs for interactive lessons. It also unlocked the possibility of developing voice-first, immersive roleplay experiences and a roadmap to real-time conversational fluency.To scale globally and support many languages, Speak is investing heavily in AI-generated curriculum and content. Instead of manually scripting all lessons, they are building agents and pipelines that can scaffold curriculum, generate lesson content, and adapt pedagogically to the learner. This ties into one of Speak’s most ambitious goals: creating a knowledge graph that captures what a learner knows and can do in a target language, and then adapting the course path accordingly. This level-adjusting tutor model aims to personalize learning at scale and could eventually be applied beyond language learning to any educational domain.Finally, the conversation touches on the broader implications of AI-powered education and the slow real-world adoption of transformative AI technologies. Despite the capabilities of GPT-4 and others, most people’s daily lives haven’t changed dramatically. Speak sees itself as part of the generation of startups that will translate AI’s raw power into tangible consumer value. The company is also a testament to long-term conviction—founded in 2016, it weathered years of slow growth before AI caught up to its vision. Now, with over $50M ARR, a growing B2B arm, and plans to expand across languages and learning domains, Speak represents what AI-native education could look like in the next decade.Full Video EpisodeTimestamps00:00 Introductions & Thiel Fellowship Origins02:13 Genesis of Speak: Early Vision & Market Focus03:44 Building the Product: Iterations and Lessons Learned10:59 AI’s Role in Language Learning13:49 Scaling Globally & B2B Expansion16:30 Why Korea? Localizing for Success19:08 Content Creation, The Speak Method, and Engineering Culture23:31 The Impact of Whisper and LLM Advances29:08 AI-Generated Content & Measuring Fluency35:30 Personalization, Dialects, and Pronunciation39:38 Immersive Learning, Multimodality, and Real-Time Voice50:02 Engineering Challenges & Company Culture53:20 Beyond Languages: B2B, Knowledge Graphs, and Broader Learning57:32 Fun Stories, Lessons, and Reflections1:02:03 Final Thoughts: The Future of AI Learning & Slow Takeoff This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

AI Video Is Eating The World — Olivia and Justine Moore, a16z
When the first video diffusion models started emerging, they were little more than just “moving pictures” - still frames extended a few seconds in either direction in time. There was a ton of excitement about OpenAI’s Sora on release through 2024, but so far only Sora-lite has been widely released. Meanwhile, other good videogen models like Genmo Mochi, Pika, MiniMax T2V, Tencent Hunyuan Video, and Kuaishou’s Kling have emerged, but the reigning king this year seems to be Google’s Veo 3, which for the first time has added native audio generation into their model capabilities, eliminating the need for a whole class of lipsynching tooling and SFX editing.The rise of Veo 3 unlocks a whole new category of AI Video creators that many of our audience may not have been exposed to, but is undeniably effective and important particularly in the “kids” and “brainrot” segments of the global consumer internet platforms like Tiktok, YouTube and Instagram.By far the best documentarians of these trends for laypeople are Olivia and Justine Moore, both partners at a16z, who not only collate the best examples from all over the web, but dabble in video creation themselves to put theory into practice. We’ve been thinking of dabbling in AI brainrot on a secondary channel for Latent Space, so we wanted to get the braindump from the Moore twins on how to make a Latent Space Brainrot channel. Jump on in!Full Video EpisodeTimestamps00:00 Introductions & Guest Welcome00:49 The Rise of Generative Media02:24 AI Video Trends: Italian Brain Rot & Viral Characters05:00 Following Trends & Creating AI Content07:17 Hands-On with AI Video Creation18:36 Monetization & Business of AI Content23:34 Platforms, Models, and the Creator Stack37:22 Native Content vs. Clipping & Going Viral41:52 Prompt Theory & Meta-Trends in AI Creativity47:42 Professional, Commercial, and Platform-Specific AI Video48:57 Wrap-Up & Final Thoughts This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

Information Theory for Language Models: Jack Morris
Our last AI PhD grad student feature was Shunyu Yao, who happened to focus on Language Agents for his thesis and immediately went to work on them for OpenAI. Our pick this year is Jack Morris, who bucks the “hot” trends by -not- working on agents, benchmarks, or VS Code forks, but is rather known for his work on the information theoretic understanding of LLMs, starting from embedding models and latent space representations (always close to our heart).Jack is an unusual combination of doing underrated research but somehow still being to explain them well to a mass audience, so we felt this was a good opportunity to do a different kind of episode going through the greatest hits of a high profile AI PhD, and relate them to questions from AI Engineering.Papers and References made* AI grad school:* A new type of information theory:* Embeddings* Text Embeddings Reveal (Almost) As Much As Text: https://arxiv.org/abs/2310.06816* Contextual document embeddings https://arxiv.org/abs/2410.02525Harnessing the Universal Geometry of Embeddings: https://arxiv.org/abs/2505.12540* Language models* GPT-style language models memorize 3.6 bits per param: * Approximating Language Model Training Data from Weights: https://arxiv.org/abs/2506.15553* LLM Inversion* “There Are No New Ideas In AI.... Only New Datasets”* misc reference: https://junyanz.github.io/CycleGAN/—for others hiring AI PhDs, Jack also wanted to shout out his coauthorZach Nussbaum, his coauthor on Nomic Embed: Training a Reproducible Long Context Text Embedder.Full Video EpisodeTimestamps00:00 Introduction to Jack Morris01:18 Career in AI03:29 The Shift to AI Companies03:57 The Impact of ChatGPT04:26 The Role of Academia in AI05:49 The Emergence of Reasoning Models07:07 Challenges in Academia: GPUs and HPC Training11:04 The Value of GPU Knowledge14:24 Introduction to Jack's Research15:28 Information Theory17:10 Understanding Deep Learning Systems19:00 The "Bit" in Deep Learning20:25 Wikipedia and Information Storage23:50 Text Embeddings and Information Compression27:08 The Research Journey of Embedding Inversion31:22 Harnessing the Universal Geometry of Embeddings34:54 Implications of Embedding Inversion36:02 Limitations of Embedding Inversion38:08 The Capacity of Language Models40:23 The Cognitive Core and Model Efficiency50:40 The Future of AI and Model Scaling52:47 Approximating Language Model Training Data from Weights01:06:50 The "No New Ideas, Only New Datasets" Thesis This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

Scaling Test Time Compute to Multi-Agent Civilizations — Noam Brown, OpenAI
Solving Poker and Diplomacy, Debating RL+Reasoning with Ilya, what’s *wrong* with the System 1/2 analogy, and where Test-Time Compute hits a wallFull Video EpisodeTimestamps00:00 Intro – Diplomacy, Cicero & World Championship 02:00 Reverse Centaur: How AI Improved Noam’s Human Play 05:00 Turing Test Failures in Chat: Hallucinations & Steerability 07:30 Reasoning Models & Fast vs. Slow Thinking Paradigm 11:00 System 1 vs. System 2 in Visual Tasks (GeoGuessr, Tic-Tac-Toe) 14:00 The Deep Research Existence Proof for Unverifiable Domains 17:30 Harnesses, Tool Use, and Fragility in AI Agents 21:00 The Case Against Over-Reliance on Scaffolds and Routers 24:00 Reinforcement Fine-Tuning and Long-Term Model Adaptability 28:00 Ilya’s Bet on Reasoning and the O-Series Breakthrough 34:00 Noam’s Dev Stack: Codex, Windsurf & AGI Moments 38:00 Building Better AI Developers: Memory, Reuse, and PR Reviews 41:00 Multi-Agent Intelligence and the “AI Civilization” Hypothesis 44:30 Implicit World Models and Theory of Mind Through Scaling 48:00 Why Self-Play Breaks Down Beyond Go and Chess 54:00 Designing Better Benchmarks for Fuzzy Tasks 57:30 The Real Limits of Test-Time Compute: Cost vs. Time 1:00:30 Data Efficiency Gaps Between Humans and LLMs 1:03:00 Training Pipeline: Pretraining, Midtraining, Posttraining 1:05:00 Games as Research Proving Grounds: Poker, MTG, Stratego 1:10:00 Closing Thoughts – Five-Year View and Open Research Directions This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

The Utility of Interpretability — Emmanuel Amiesen
Emmanuel Amiesen is lead author of “Circuit Tracing: Revealing Computational Graphs in Language Models” (https://transformer-circuits.pub/2025/attribution-graphs/methods.html ), which is part of a duo of MechInterp papers that Anthropic published in March (alongside https://transformer-circuits.pub/2025/attribution-graphs/biology.html ).We recorded the initial conversation a month ago, but then held off publishing until the open source tooling for the graph generation discussed in this work was released last week: https://www.anthropic.com/research/open-source-circuit-tracingThis is a 2 part episode - an intro covering the open source release, then a deeper dive into the paper — with guest host Vibhu Sapra (https://x.com/vibhuuuus ) and Mochi the MechInterp Pomsky (https://x.com/mochipomsky ). Thanks to Vibhu for making this episode happen!While the original blogpost contained some fantastic guided visualizations (which we discuss at the end of this pod!), with the notebook and Neuronpedia visualization (https://www.neuronpedia.org/gemma-2-2b/graph ) released this week, you can now explore on your own with Neuronpedia, as we show you in the video version of this pod.Full Video EpisodeTimestamps00:00 Intro & Guest Introductions01:00 Anthropic's Circuit Tracing Release06:11 Exploring Circuit Tracing Tools & Demos13:01 Model Behaviors and User Experiments17:02 Behind the Research: Team and Community24:19 Main Episode Start: Mech Interp Backgrounds25:56 Getting Into Mech Interp Research31:52 History and Foundations of Mech Interp37:05 Core Concepts: Superposition & Features39:54 Applications & Interventions in Models45:59 Challenges & Open Questions in Interpretability57:15 Understanding Model Mechanisms: Circuits & Reasoning01:04:24 Model Planning, Reasoning, and Attribution Graphs01:30:52 Faithfulness, Deception, and Parallel Circuits01:40:16 Publishing Risks, Open Research, and Visualization01:49:33 Barriers, Vision, and Call to Action This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

[AIEWF Preview] Containing Agent Chaos — Solomon Hykes
Solomon most famously created Docker and now runs Dagger… which has something special to share with you on Thursday.Catch Dagger at:- Tuesday: Dagger’s workshop https://www.ai.engineer/schedule#ship-agents-that-ship-a-hands-on-workshop-for-swe-agent-builders- Wednesday: Dagger’s talk: https://www.ai.engineer/schedule#how-to-trust-an-agent-with-software-delivery- Thursday: Solomon’s Keynote https://www.ai.engineer/schedule#containing-agent-chaosFull Video EpisodeTimestamps00:00 Introduction & Guest Background00:29 What is Dagger? Post-Development Automation01:08 Dagger’s Community & Platform Engineers02:32 AI Agents and Developer Workflows03:40 Environment Isolation & The Power of Containers06:28 The Need for Standards in Agent Environments07:25 Design Constraints & Challenges for Dev Environments11:26 Limitations of Current Tools & Agent-Native UX14:11 Modularity, Customization, and the Lego Analogy16:24 Convergence of CICD and Agentic Systems17:41 Ephemeral Apps, Resource Constraints, and Local Execution21:01 Adoption, Ecosystem, and the Role of Open Source23:30 Dagger’s Modular Approach & Integration Philosophy25:38 Looking Ahead: Workshops, Keynotes, and the Future of Agentic Infrastructure This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

[AIEWF Preview] Gemini in 2025 and Realtime Voice AI
As part of our AI Engineer World’s Fair preview, we’re releasing a special cross podcast recorded with Sam Charrington of TWiML AI at last week’s Google I/O!TUESDAY: Shrestha and Kwindla’s workshop: https://www.ai.engineer/schedule#milliseconds-to-magic-real-time-workflows-using-the-gemini-live-api-and-pipecatTUESDAY: Kwindla’s workshop: https://www.ai.engineer/schedule#building-voice-agents-with-gemini-and-pipecatWEDNESDAY: Shrestha and Kwindla’s talk: https://www.ai.engineer/schedule#milliseconds-to-magic-real-time-workflows-using-the-gemini-live-api-and-pipecatWEDNESDAY: Kwindla’s keynote: https://www.ai.engineer/schedule#-voice-keynote-your-realtime-ai-is-ngmiTHURSDAY: Logan’s keynote: https://www.ai.engineer/schedule#a-year-of-gemini-progress-what-comes-nextCatch all the speakers at AIE (both workshops and talks):Logan Kilpatrick: https://www.latent.space/p/chatgpt-gpt4-hype-and-building-llmShrestha Basu Mallick: https://www.linkedin.com/in/shresthabm/Kwindla Hultman Kramer: https://www.linkedin.com/in/kwkramerFull Video Episode This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

[AIEWF Preview] CloudChef: Your Robot Chef - Michellin-Star food at $12/hr (w/ Kitchen tour!)
One of the new tracks at next week’s AI Engineer conference in SF is a new focus on LLMs + Robotics, ft. household names like Waymo and Physical Intelligence. However there are many other companies applying LLMs and VLMs in the real world!CloudChef, the first industrial-scale kitchen robotics company with one-shot demonstration learning and an incredibly simple business model, will be serving tasty treats all day with Zippy (https://www.cloudchef.co/zippy ) their AI Chef platform.This is a lightning pod with CEO Nikhil Abraham to preview what Zippy is capable of!https://www.cloudchef.co/platformSee a real chef comparison:See it in the AI Engineer Expo at SF next week: https://ai.engineerFull Video EpisodeTimestamps00:00 Welcome and Introductions00:58 What is Cloud Chef?01:36 How the Robots Work: Culinary Intelligence05:57 Commercial Applications and Early Success07:02 The Software-First Approach10:09 Business Model and Pricing13:10 Demonstration Learning: Training the Robots16:03 Call to Action and Engineering Opportunities18:45 Final Thoughts and Technical Details This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

The AI Coding Factory
We are joined by Eno Reyes and Matan Grinberg, the co-founders of Factory.ai. They are building droids for autonomous software engineering, handling everything from code generation to incident response for production outages. After raising a $15M Series A from Sequoia, they just released their product in GA!https://factory.ai/https://x.com/latentspacepodFull Video EpisodeTimestamps00:00 Introductions 00:35 Meeting at Langchain Hackathon 04:02 Building Factory despite early model limitations 06:56 What is Factory AI? 08:55 Delegation vs Collaboration in AI Development Tools 10:06 Naming Origins of 'Factory' and 'Droids' 12:17 Defining Droids: Agent vs Workflow 14:34 Live Demo17:37 Enterprise Context and Tool Integration in Droids 20:26 Prompting, Clarification, and Agent Communication 22:28 Project Understanding and Proactive Context Gathering 24:10 Why SWE-Bench Is Dead 28:47 Model Fine-tuning and Generalization Challenges 31:07 Why Factory is Browser-Based, Not IDE-Based 33:51 Test-Driven Development and Agent Verification 36:17 Retrieval vs Large Context Windows for Cost Efficiency 38:02 Enterprise Metrics: Code Churn and ROI 40:48 Executing Large Refactors and Migrations with Droids 45:25 Model Speed, Parallelism, and Delegation Bottlenecks 50:11 Observability Challenges and Semantic Telemetry 53:44 Hiring55:19 Factory's design and branding approach 58:34 Closing Thoughts and Future of AI-Native Development This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

[AIEWF Preview] Multi-Turn RL for Multi-Hour Agents — with Will Brown, Prime Intellect
In an otherwise heavy week packed with Microsoft Build, Google I/O, and OpenAI io, the worst kept secret in biglab land was the launch of Claude 4, particularly the triumphant return of Opus, which many had been clamoring for. We will leave the specific Claude 4 recap to AINews, however we think that both Gemini’s progress on Deep Think this week and Claude 4 represent the next frontier of progress on inference time compute/reasoning (at last until GPT5 ships this summer).Will Brown’s talk at AIE NYC and open source work on verifiers have made him one of the most prominent voices able to publicly discuss (aka without the vaguepoasting LoRA they put on you when you join a biglab) the current state of the art in reasoning models and where current SOTA research directions lead. We discussed his latest paper on Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Credit Assignment and he has previewed his AIEWF talk on Agentic RL for those with the temerity to power thru bad meetup audio.Full Video EpisodeTimestamps00:00 Introduction to the Podcast and Guests01:00 Discussion on Claude 4 and AI Models03:07 Extended Thinking and Tool Use in AI06:47 Technical Highlights and Model Trustworthiness10:31 Thinking Budgets and Their Implications13:38 Controversy Surrounding Opus and AI Ethics18:49 Reflections on AI Tools and Their Limitations21:58 The Chaos of Predictive Systems22:56 Marketing and Safety in AI Models24:30 Evaluating AI Companies and Their Strategies25:53 The Role of Academia in AI Evaluations27:43 Teaching Taste in Research28:41 Making Educated Bets in AI Research30:12 Recent Developments in Multi-Turn Tool Use32:50 Incentivizing Tool Use in AI Models34:45 The Future of Reward Models in AI39:10 Exploring Flexible Reward Systems This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

⚡️The Rise and Fall of the Vector DB Category
Note from your hosts: we were off this week for ICLR and RSA! This week we’re bringing you one of the top episodes from our lightning podcast series, the shorter format, Youtube-only side podcast we do for breaking news and faster turnaround. Please support our work on YouTube! https://www.youtube.com/playlist?list=PLWEAb1SXhjlc5qgVK4NgehdCzMYCwZtiBThe explosion of embedding-based applications created a new challenge: efficiently storing, indexing, and searching these high-dimensional vectors at scale. This gap gave rise to the vector database category, with companies like Pinecone leading the charge in 2022-2023 by defining specialized infrastructure for vector operations.The category saw explosive growth following ChatGPT’s launch in late 2022, as developers rushed to build AI applications using Retrieval-Augmented Generation (RAG). This surge was partly driven by a widespread misconception that embedding-based similarity search was the only viable method for retrieving context for LLMs!!!The resulting “vector database gold rush” saw massive investment and attention directed toward vector search infrastructure, even though traditional information retrieval techniques remained equally valuable for many RAG applications.Full Video EpisodeTimestamps00:00 Introduction to Trondheim and Background03:03 The Rise and Fall of Vector Databases06:08 Convergence of Search Technologies09:04 Embeddings and Their Importance12:03 Building Effective Search Systems15:00 RAG Applications and Recommendations17:55 The Role of Knowledge Graphs20:49 Future of Embedding Models and Innovations This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

⚡️GPT 4.1: The New OpenAI Workhorse
We’ll keep this brief because we’re on a tight turnaround: GPT 4.1, previously known as the Quasar and Optimus models, is now live as the natural update for 4o/4o-mini (and the research preview of GPT 4.5). Though it is a general purpose model family, the headline features are:Coding abilities (o1-level SWEBench and SWELancer, but ok Aider)Instruction Following (with a very notable prompting guide)Long Context up to 1m tokens (with new MRCR and Graphwalk benchmarks)Vision (simply o1 level)Cheaper Pricing (cheaper than 4o, greatly improved prompt caching savings)We caught up with returning guest Michelle Pokrass and Josh McGrath to get more detail on each!Full Video EpisodeTimestampsPart 100:00:00 Introduction and Guest Welcome00:00:57 GPT 4.1 Launch Overview00:01:54 Developer Feedback and Model Names00:02:53 Model Naming and Starry Themes00:03:49 Confusion Over GPT 4.1 vs 4.500:04:47 Distillation and Model Improvements00:05:45 Omnimodel Architecture and Future Plans00:06:43 Core Capabilities of GPT 4.100:07:40 Training Techniques and Long Context00:08:37 Challenges in Long Context Reasoning00:09:34 Context Utilization in ModelsPart 200:10:31 Graph Walks and Model Evaluation00:11:31 Real Life Applications of Graph Tasks00:12:30 Multi-Hop Reasoning Benchmarks00:13:30 Agentic Workflows and Backtracking00:14:28 Graph Traversals for Agent Planning00:15:24 Context Usage in API and Memory Systems00:16:21 Model Performance in Long Context Tasks00:17:17 Instruction Following and Real World Data00:18:12 Challenges in Grading Instructions00:19:09 Instruction Following Techniques00:20:09 Prompting Techniques and Model Responses00:21:05 Agentic Workflows and Model PersistencePart 300:22:01 Balancing Persistence and User Control00:22:56 Evaluations on Model Edits and Persistence00:23:55 XML vs JSON in Prompting00:24:50 Instruction Placement in Context00:25:49 Optimizing for Prompt Caching00:26:49 Chain of Thought and Reasoning Models00:27:46 Choosing the Right Model for Your Task00:28:46 Coding Capabilities of GPT 4.100:29:41 Model Performance in Coding Tasks00:30:39 Understanding Coding Model Differences00:31:36 Using Smaller Models for Coding00:32:33 Future of Coding in OpenAIPart 400:33:28 Internal Use and Success Stories00:34:26 Vision and Multi-Modal Capabilities00:35:25 Screen vs Embodied Vision00:36:22 Vision Benchmarks and Model Improvements00:37:19 Model Deprecation and GPU Usage00:38:13 Fine-Tuning and Preference Steering00:39:12 Upcoming Reasoning Models00:40:10 Creative Writing and Model Humor00:41:07 Feedback and Developer Community00:42:03 Pricing and Blended Model Costs00:44:02 Conclusion and Wrap-Up This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe
SF Compute: Commoditizing Compute to solve the GPU Bubble forever
We are calling for the world’s best AI Engineer talks for AI Architects, /r/localLlama, Model Context Protocol (MCP), GraphRAG, AI in Action, Evals, Agent Reliability, Reasoning and RL, Retrieval/Search/RecSys , Security, Infrastructure, Generative Media, AI Design & Novel AI UX, AI Product Management, Autonomy, Robotics, and Embodied Agents, Computer-Using Agents (CUA), SWE Agents, Vibe Coding, Voice, Sales/Support Agents at AIEWF 2025! Fill out the 2025 State of AI Eng survey for $250 in Amazon cards and see you from Jun 3-5 in SF!Coreweave’s now-successful IPO has led to a lot of questions about the GPU Neocloud market, which Dylan Patel has written extensively about on SemiAnalysis. Understanding markets requires an interesting mix of technical and financial expertise, so this will be a different kind of episode than our usual LS domain.When we first published $2 H100s: How the GPU Rental Bubble Burst, we got 2 kinds of reactions on Hacker News:* “Ah, now the AI bubble is imploding!”* “Duh, this is how it works in every GPU cycle, are you new here?”We don’t think either reaction is quite right. Specifically, it is not normal for the prices of one of the world’s most important resources right now to swing from $1 to $8 per hour based on drastically inelastic demand AND supply curves - from 3 year lock-in contracts to stupendously competitive over-ordering dynamics for NVIDIA allocations — especially with increasing baseline compute needed for even the simplest academic ML research and for new AI startups getting off the ground.We’re fortunate today to have Evan Conrad, CEO of SFCompute, one of the most exciting GPU marketplace startups, talk us through his theory of the economics of GPU markets, and why he thinks CoreWeave and Modal are well positioned, but Digital Ocean and Together are not.However, more broadly, the entire point of SFC is creating liquidity between GPU owners and consumers and making it broadly tradable, even programmable:As we explore, these are the primitives that you can then use to create your own, high quality, custom GPU availability for your time and money budget, similar to how Amazon Spot Instances automated the selective buying of unused compute.The ultimate end state of where all this is going is GPU that trade like other perishable, staple commodities of the world - oil, soybeans, milk. Because the contracts and markets are so well established, the price swings also are not nearly as drastic, and people can also start hedging and managing the risk of one of the biggest costs of their business, just like we have risk-managed commodities risks of all other sorts for centuries. As a former derivatives trader, you can bet that swyx doubleclicked on that…Show Notes* SF Compute* Evan Conrad* Ethan Anderson* John Phamous* The Curve talk* CoreWeave* Andromeda ClusterFull Video PodLike and subscribe!Timestamps* [00:00:05] Introductions* [00:00:12] Introduction of guest Evan Conrad from SF Compute* [00:00:12] CoreWeave Business Model Discussion* [00:05:37] CoreWeave as a Real Estate Business* [00:08:59] Interest Rate Risk and GPU Market Strategy Framework* [00:16:33] Why Together and DigitalOcean will lose money on their clusters* [00:20:37] SF Compute's AI Lab Origins* [00:25:49] Utilization Rates and Benefits of SF Compute Market Model* [00:30:00] H100 GPU Glut, Supply Chain Issues, and Future Demand Forecast* [00:34:00] P2P GPU networks* [00:36:50] Customer stories* [00:38:23] VC-Provided GPU Clusters and Credit Risk Arbitrage* [00:41:58] Market Pricing Dynamics and Preemptible GPU Pricing Model* [00:48:00] Future Plans for Financialization?* [00:52:59] Cluster auditing and quality control* [00:58:00] Futures Contracts for GPUs* [01:01:20] Branding and Aesthetic Choices Behind SF Compute* [01:06:30] Lessons from Previous Startups* [01:09:07] Hiring at SF ComputeTranscriptAlessio [00:00:05]: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO at Decibel, and I'm joined by my co-host Swyx, founder of Smol AI.Swyx [00:00:12]: Hey, and today we're so excited to be finally in the studio with Evan Conrad from SF Compute. Welcome. I've been fortunate enough to be your friend before you were famous, and also we've hung out at various social things. So it's really cool to see that SF Compute is coming into its own thing, and it's a significant presence, at least in the San Francisco community, which of course, it's in the name, so you couldn't help but be. Evan: Indeed, indeed. I think we have a long way to go, but yeah, thanks. Swyx: Of course, yeah. One way I was thinking about kicking on this conversation is we will likely release this right after CoreWeave IPO. And I was watching, I was looking, doing some research on you. You did a talk at The Curve. I think I may have been viewer number 70. It was a great talk. More people should go see it, Evan Conrad at The Curve. But we have like three orders of magnitude more people. And I just wanted to, to highli
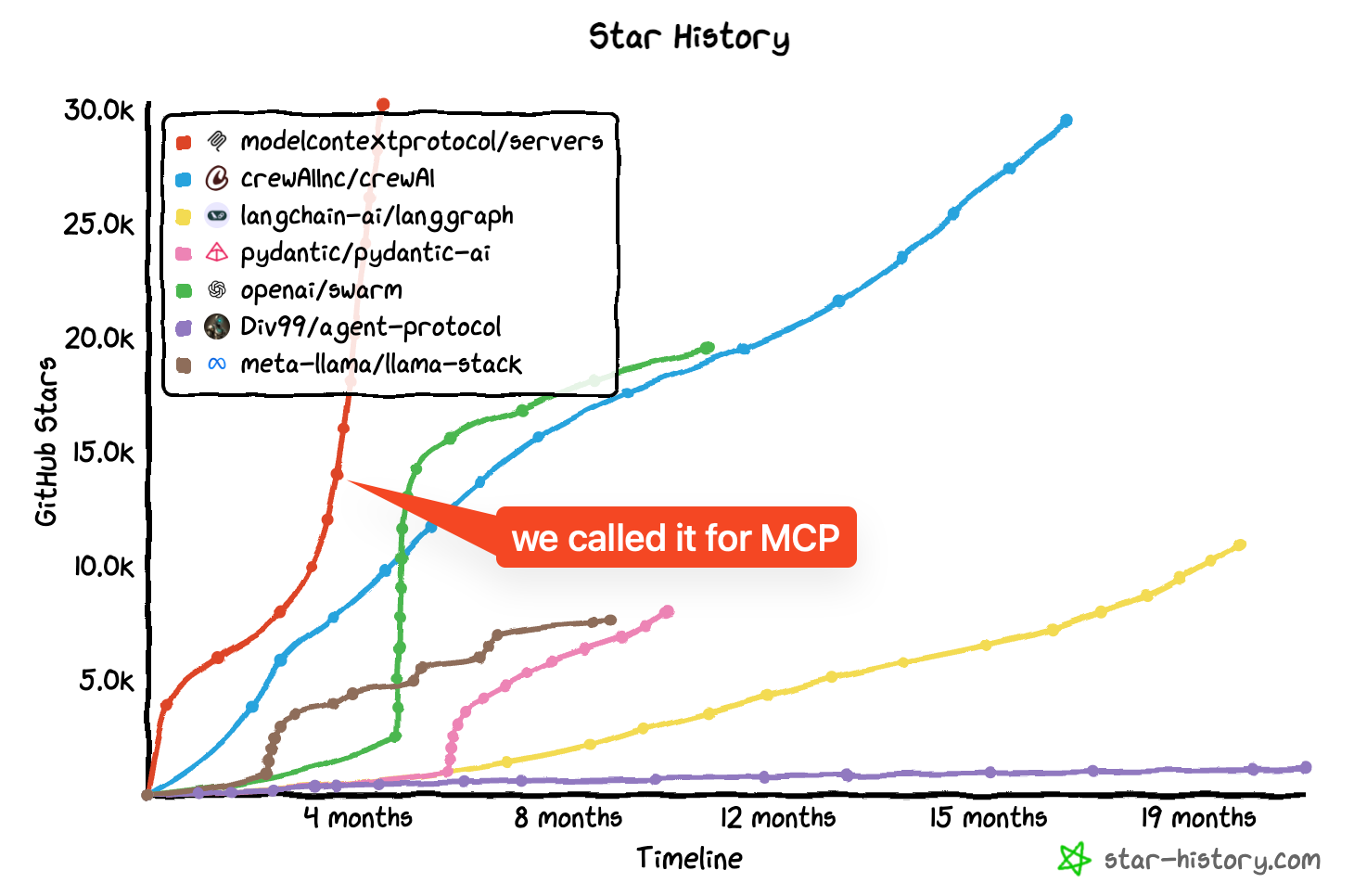
The Creators of Model Context Protocol
We are happy to announce that there will be a dedicated MCP track at the 2025 AI Engineer World's Fair, taking place Jun 3rd to 5th in San Francisco, where the MCP core team and major contributors and builders will be meeting. Join us and apply to speak or sponsor!When we first wrote Why MCP Won, we had no idea how quickly it was about to win.In the past 4 weeks, OpenAI and now Google have now announced the MCP support, effectively confirming our prediction that MCP was the presumptive winner of the agent standard wars. MCP has now overtaken OpenAPI, the incumbent option and most direct alternative, in GitHub stars (3 months ahead of conservative trendline):We have explored the state of MCP at AIE (now the first ever >100k views workshop):And since then, we’ve added a 7th reason why MCP won - this team acts very quickly on feedback, with the 2025-03-26 spec update adding support for stateless/resumable/streamable HTTP transports, and comprehensive authz capabilities based on OAuth 2.1.This bodes very well for the future of the community and project. For protocol and history nerds, we also asked David and Justin to tell the origin story of MCP, which we leave to the reader to enjoy (you can also skim the transcripts, or, the changelogs of a certain favored IDE). It’s incredible the impact that individual engineers solving their own problems can have on an entire industry.Full video episodeLike and subscribe on YouTube!Show Links* David* Justin* MCP* Why MCP WonTimestamps* 00:00 Introduction and Guest Welcome* 00:37 What is MCP?* 02:00 The Origin Story of MCP* 05:18 Development Challenges and Solutions* 08:06 Technical Details and Inspirations* 29:45 MCP vs Open API* 32:48 Building MCP Servers* 40:39 Exploring Model Independence in LLMs* 41:36 Building Richer Systems with MCP* 43:13 Understanding Agents in MCP* 45:45 Nesting and Tool Confusion in MCP* 49:11 Client Control and Tool Invocation* 52:08 Authorization and Trust in MCP Servers* 01:01:34 Future Roadmap and Stateless Servers* 01:10:07 Open Source Governance and Community Involvement* 01:18:12 Wishlist and Closing RemarksTranscriptAlessio [00:00:02]: Hey, everyone. Welcome back to Latent Space. This is Alessio, partner and CTO at Decibel, and I'm joined by my co-host Swyx, founder of Small AI.swyx [00:00:10]: Hey, morning. And today we have a remote recording, I guess, with David and Justin from Anthropic over in London. Welcome. Hey, good You guys have created a storm of hype because of MCP, and I'm really glad to have you on. Thanks for making the time. What is MCP? Let's start with a crisp what definition from the horse's mouth, and then we'll go into the origin story. But let's start off right off the bat. What is MCP?Justin/David [00:00:43]: Yeah, sure. So Model Context Protocol, or MCP for short, is basically something we've designed to help AI applications extend themselves or integrate with an ecosystem of plugins, basically. The terminology is a bit different. We use this client-server terminology, and we can talk about why that is and where that came from. But at the end of the day, it really is that. It's like extending and enhancing the functionality of AI application.swyx [00:01:05]: David, would you add anything?Justin/David [00:01:07]: Yeah, I think that's actually a good description. I think there's like a lot of different ways for how people are trying to explain it. But at the core, I think what Justin said is like extending AI applications is really what this is about. And I think the interesting bit here that I want to highlight, it's AI applications and not models themselves that this is focused on. That's a common misconception that we can talk about a bit later. But yeah. Another version that we've used and gotten to like is like MCP is kind of like the USB-C port of AI applications and that it's meant to be this universal connector to a whole ecosystem of things.swyx [00:01:44]: Yeah. Specifically, an interesting feature is, like you said, the client and server. And it's a sort of two-way, right? Like in the same way that said a USB-C is two-way, which could be super interesting. Yeah, let's go into a little bit of the origin story. There's many people who've tried to make statistics. There's many people who've tried to build open source. I think there's an overall, also, my sense is that Anthropic is going hard after developers in the way that other labs are not. And so I'm also curious if there was any external influence or was it just you two guys just in a room somewhere riffing?Justin/David [00:02:18]: It is actually mostly like us two guys in a room riffing. So this is not part of a big strategy. You know, if you roll back time a little bit and go into like July 2024. I was like, started. I started at Anthropic like three months earlier or two months earlier. And I was mostly working on internal developer tooling, which is what I've been doing for like years and years before. And as part of that, I think there was an effor

Unsupervised Learning x Latent Space Crossover Special
If you’re in SF: Join us for the Claude Plays Pokemon hackathon this Sunday!If you’re not: Fill out the 2025 State of AI Eng survey for $250 in Amazon cards!Unsupervised Learning is a podcast that interviews the sharpest minds in AI about what’s real today, what will be real in the future and what it means for businesses and the world - helping builders, researchers and founders deconstruct and understand the biggest breakthroughs. Top guests: Noam Shazeer, Bob McGrew, Noam Brown, Dylan Patel, Percy Liang, David LuanFull Episode on Their YouTubeTimestamps* 00:00 Introduction and Excitement for Collaboration* 00:27 Reflecting on Surprises in AI Over the Past Year* 01:44 Open Source Models and Their Adoption* 06:01 The Rise of GPT Wrappers* 06:55 AI Builders and Low-Code Platforms* 09:35 Overhyped and Underhyped AI Trends* 22:17 Product Market Fit in AI* 28:23 Google's Current Momentum* 28:33 Customer Support and AI* 29:54 AI's Impact on Cost and Growth* 31:05 Voice AI and Scheduling* 32:59 Emerging AI Applications* 34:12 Education and AI* 36:34 Defensibility in AI Applications* 40:10 Infrastructure and AI* 47:08 Challenges and Future of AI* 52:15 Quick Fire Round and Closing RemarksTranscript[00:00:00] Introduction and Podcast Overview[00:00:00] Jacob: well, thanks so much for doing this, guys. I feel like we've we've been excited to do a collab for a while. I[00:00:13] swyx: love crossovers. Yeah. Yeah. This, this is great. Like the ultimate meta about just podcasters talking to other podcasters. Yeah. It's a lot. Podcasts all the way up.[00:00:21] Jacob: I figured we'd have a pretty free ranging conversation today but brought a few conversation starters to, to, to kick us off.[00:00:27] Reflecting on AI Surprises and Trends[00:00:27] Jacob: And so I figured one interesting place to start is you know, obviously it feels that this world is changing like every few months. Wondering as you guys reflect path on the past year, like what surprised you the most?[00:00:36] Alessio: I think definitely recently models we kinda on the, on the right here. Like, oh, that, well, I, I I think there's, there's like the, what surprised us in a good way.[00:00:44] May maybe in a, in a bad way. I would say in a good way. Recently models and I think the release of them right after the new reps scaling instead talked by Ilia. I think there was maybe like a, a little. It's so over and then we're so back. I'm like such a short, short period. It was really [00:01:00] fortuitous[00:01:00] Jacob: timing though, like right.[00:01:01] As pre-training died, I mean, obviously I'm sure within the labs they knew pre-training was dying and had to find something. But you know, from the outside it was it, it felt like one right into the other.[00:01:09] Alessio: Yeah. Yeah, exactly. So that, that was a good surprise,[00:01:12] swyx: I would say, if you wanna make that comment about timing, I think it's suspiciously neat that like, because we know that Strawberry was being worked on for like two years-ish.[00:01:20] Like, and we know exactly when Nome joined OpenAI, and that was obviously a big strategic bet by OpenAI. So like, for it to transition, so transition so nicely when like, pre-training is kind of tapped out to, into like, oh, now inference time is, is the new scaling law is like conv very convenient. I, I, I like if there were an Illuminati, this would be what they planned.[00:01:41] Or if we're living in a simulation or something. Yeah.[00:01:44] Open Source Models and Their Impact[00:01:44] swyx: Then you said open source[00:01:45] Alessio: as well? Yeah. Well, no, I, I think like open source. Yeah. We're discussing this on the negative. I would say the relevance of open source. I would specifically open models. Yeah, I was surprised the lack, like the llamas of the world by the lack of adoption.[00:01:56] And I mean, people use it obviously, but I would say nobody's [00:02:00] really like a huge fanboy, you know, I think the local llama community and some of the more obvious use cases really like it. But when we talk to like enterprise folks, it's like, it's cool, you know? And I think people love to argue about licenses and all of that, but the reality is that it doesn't really change the adoption path of, of ai.[00:02:18] So[00:02:19] swyx: yeah, the specific stat that I got from on anchor from Braintrust mm-hmm. In one of the episodes that we did was I think he estimated that open source model usage in work in enterprises is that like 5% and going down.[00:02:31] Jacob: And it feels like you're basically all these enterprises are in like use case discovery mode, where it's like, let's just take what we think is the most powerful model and figure out if we can find anything that works.[00:02:39] And, you know, so much of, of, of it feels like discovery of that. And then, right, as you've discovered something, a new generation of models are out and so you have to go do discovery with those. And you know, I think obviously we're

The Agent Network — Dharmesh Shah
If you’re in SF: Join us for the Claude Plays Pokemon hackathon this Sunday!If you’re not: Fill out the 2025 State of AI Eng survey for $250 in Amazon cards!For this episode: Thanks to Matija and Dan and Meng Shao for sharing on socials.We are SO excited to share our conversation with Dharmesh Shah, co-founder of HubSpot and creator of Agent.ai.A particularly compelling concept we discussed is the idea of "hybrid teams" - the next evolution in workplace organization where human workers collaborate with AI agents as team members. Just as we previously saw hybrid teams emerge in terms of full-time vs. contract workers, or in-office vs. remote workers, Dharmesh predicts that the next frontier will be teams composed of both human and AI members. This raises interesting questions about team dynamics, trust, and how to effectively delegate tasks between human and AI team members.The discussion of business models in AI reveals an important distinction between Work as a Service (WaaS) and Results as a Service (RaaS), something Dharmesh has written extensively about. While RaaS has gained popularity, particularly in customer support applications where outcomes are easily measurable, Dharmesh argues that this model may be over-indexed. Not all AI applications have clearly definable outcomes or consistent economic value per transaction, making WaaS more appropriate in many cases. This insight is particularly relevant for businesses considering how to monetize AI capabilities.The technical challenges of implementing effective agent systems are also explored, particularly around memory and authentication. Shah emphasizes the importance of cross-agent memory sharing and the need for more granular control over data access. He envisions a future where users can selectively share parts of their data with different agents, similar to how OAuth works but with much finer control. This points to significant opportunities in developing infrastructure for secure and efficient agent-to-agent communication and data sharing.Other highlights from our conversation* The Evolution of AI-Powered Agents – Exploring how AI agents have evolved from simple chatbots to sophisticated multi-agent systems, and the role of MCPs in enabling that.* Hybrid Digital Teams and the Future of Work – How AI agents are becoming teammates rather than just tools, and what this means for business operations and knowledge work.* Memory in AI Agents – The importance of persistent memory in AI systems and how shared memory across agents could enhance collaboration and efficiency.* Business Models for AI Agents – Exploring the shift from software as a service (SaaS) to work as a service (WaaS) and results as a service (RaaS), and what this means for monetization.* The Role of Standards Like MCP – Why MCP has been widely adopted and how it enables agent collaboration, tool use, and discovery.* The Future of AI Code Generation and Software Engineering – How AI-assisted coding is changing the role of software engineers and what skills will matter most in the future.* Domain Investing and Efficient Markets – Dharmesh’s approach to domain investing and how inefficiencies in digital asset markets create business opportunities.* The Philosophy of Saying No – Lessons from "Sorry, Must Pass" and how prioritization leads to greater productivity and focus.Full Video Episodeon youtube!Timestamps* 00:00 Introduction and Guest Welcome* 02:29 Dharmesh Shah's Journey into AI* 05:22 Defining AI Agents* 06:45 The Evolution and Future of AI Agents* 13:53 Graph Theory and Knowledge Representation* 20:02 Engineering Practices and Overengineering* 25:57 The Role of Junior Engineers in the AI Era* 28:20 Multi-Agent Systems and MCP Standards* 35:55 LinkedIn's Legal Battles and Data Scraping* 37:32 The Future of AI and Hybrid Teams* 39:19 Building Agent AI: A Professional Network for Agents* 40:43 Challenges and Innovations in Agent AI* 45:02 The Evolution of UI in AI Systems* 01:00:25 Business Models: Work as a Service vs. Results as a Service* 01:09:17 The Future Value of Engineers* 01:09:51 Exploring the Role of Agents* 01:10:28 The Importance of Memory in AI* 01:11:02 Challenges and Opportunities in AI Memory* 01:12:41 Selective Memory and Privacy Concerns* 01:13:27 The Evolution of AI Tools and Platforms* 01:18:23 Domain Names and AI Projects* 01:32:08 Balancing Work and Personal Life* 01:35:52 Final Thoughts and ReflectionsTranscriptAlessio [00:00:04]: Hey everyone, welcome back to the Latent Space podcast. This is Alessio, partner and CTO at Decibel Partners, and I'm joined by my co-host Swyx, founder of Small AI.swyx [00:00:12]: Hello, and today we're super excited to have Dharmesh Shah to join us. I guess your relevant title here is founder of Agent AI.Dharmesh [00:00:20]: Yeah, that's true for this. Yeah, creator of Agent.ai and co-founder of HubSpot.swyx [00:00:25]: Co-founder of HubSpot, which I followed for many years, I think 18 years now, gonna be 19 soon. And you caught,
Building Snipd: The AI Podcast App for Learning
We are working with Amplify on the 2025 State of AI Engineering Survey to be presented at the AIE World’s Fair in SF! Join the survey to shape the future of AI Eng!We first met Snipd (affiliate link! we get a free month, you get a free month. but this is not a sponsored pod, we’ve never done one) over a year ago, and were immediately impressed by the design, but were doubtful about the behavior of snipping as the title behavior:Podcast apps are enormously sticky - Spotify spent almost $1b in podcast acquisitions and exclusive content just to get an 8% bump in market share among normies.However, after a disappointing Overcast 2.0 rewrite with no AI features in the last 3 years, I finally bit the bullet and switched to Snipd. It’s 2025, your podcast app should be able to let you search transcripts of your podcasts. Snipd is the best implementation of this so far.And yet they keep shipping:What impressed us wasn’t just how this tiny team of 4 was able to bootstrap a consumer AI app against massive titans and do so well; but also how seriously they think about learning through podcasts and improving retention of knowledge over time, aka “Duolingo for podcasts”. As an educational AI podcast, that’s a mission we can get behind.Full Video PodFind us on YouTube! This was the first pod we’ve ever shot outdoors!Show Notes* How does Shazam work?* Flutter/FlutterFlow* wav2vec paper* Perplexity Online LLM* Google Search Grounding* Comparing Snipd transcription with our Bee episode* NIPS 2017 Flo Rida* Gustav Söderström - Background AudioTimestamps* [00:00:03] Takeaways from AI Engineer NYC* [00:00:17] Weather in New York.* [00:00:26] Swyx and Snipd.* [00:01:01] Kevin's AI summit experience.* [00:01:31] Zurich and AI.* [00:03:25] SigLIP authors join OpenAI.* [00:03:39] Zurich is very costly.* [00:04:06] The Snipd origin story.* [00:05:24] Introduction to machine learning.* [00:09:28] Snipd and user knowledge extraction.* [00:13:48] App's tech stack, Flutter, Python.* [00:15:11] How speakers are identified.* [00:18:29] The concept of "backgroundable" video.* [00:29:05] Voice cloning technology.* [00:31:03] Using AI agents.* [00:34:32] Snipd's future is multi-modal AI.* [00:36:37] Snipd and existing user behaviour.* [00:42:10] The app, summary, and timestamps.* [00:55:25] The future of AI and podcasting.* [1:14:55] Voice AITranscriptswyx [00:00:03]: Hey, I'm here in New York with Kevin Ben-Smith of Snipd. Welcome.Kevin [00:00:07]: Hi. Hi. Amazing to be here.swyx [00:00:09]: Yeah. This is our first ever, I think, outdoors podcast recording.Kevin [00:00:14]: It's quite a location for the first time, I have to say.swyx [00:00:18]: I was actually unsure because, you know, it's cold. It's like, I checked the temperature. It's like kind of one degree Celsius, but it's not that bad with the sun. No, it's quite nice. Yeah. Especially with our beautiful tea. With the tea. Yeah. Perfect. We're going to talk about Snips. I'm a Snips user. I'm a Snips user. I had to basically, you know, apart from Twitter, it's like the number one use app on my phone. Nice. When I wake up in the morning, I open Snips and I, you know, see what's new. And I think in terms of time spent or usage on my phone, I think it's number one or number two. Nice. Nice. So I really had to talk about it also because I think people interested in AI want to think about like, how can we, we're an AI podcast, we have to talk about the AI podcast app. But before we get there, we just finished. We just finished the AI Engineer Summit and you came for the two days. How was it?Kevin [00:01:07]: It was quite incredible. I mean, for me, the most valuable was just being in the same room with like-minded people who are building the future and who are seeing the future. You know, especially when it comes to AI agents, it's so often I have conversations with friends who are not in the AI world. And it's like so quickly it happens that you, it sounds like you're talking in science fiction. And it's just crazy talk. It was, you know, it's so refreshing to talk with so many other people who already see these things and yeah, be inspired then by them and not always feel like, like, okay, I think I'm just crazy. And like, this will never happen. It really is happening. And for me, it was very valuable. So day two, more relevant, more relevant for you than day one. Yeah. Day two. So day two was the engineering track. Yeah. That was definitely the most valuable for me. Like also as a producer. Practitioner myself, especially there were one or two talks that had to do with voice AI and AI agents with voice. Okay. So that was quite fascinating. Also spoke with the speakers afterwards. Yeah. And yeah, they were also very open and, and, you know, this, this sharing attitudes that's, I think in general, quite prevalent in the AI community. I also learned a lot, like really practical things that I can now take away with me. Yeah.swyx [00:02:25]: I mean, on my side, I, I think I watched only li

⚡️The new OpenAI Agents Platform
While everyone is now repeating that 2025 is the “Year of the Agent”, OpenAI is heads down building towards it. In the first 2 months of the year they released Operator and Deep Research (arguably the most successful agent archetype so far), and today they are bringing a lot of those capabilities to the API:* Responses API* Web Search Tool* Computer Use Tool* File Search Tool* A new open source Agents SDK with integrated Observability ToolsWe cover all this and more in today’s lightning pod on YouTube!More details here:Responses APIIn our Michelle Pokrass episode we talked about the Assistants API needing a redesign. Today OpenAI is launching the Responses API, “a more flexible foundation for developers building agentic applications”. It’s a superset of the chat completion API, and the suggested starting point for developers working with OpenAI models. One of the big upgrades is the new set of built-in tools for the responses API: Web Search, Computer Use, and Files. Web Search ToolWe previously had Exa AI on the podcast to talk about web search for AI. OpenAI is also now joining the race; the Web Search API is actually a new “model” that exposes two 4o fine-tunes: gpt-4o-search-preview and gpt-4o-mini-search-preview. These are the same models that power ChatGPT Search, and are priced at $30/1000 queries and $25/1000 queries respectively. The killer feature is inline citations: you do not only get a link to a page, but also a deep link to exactly where your query was answered in the result page. Computer Use ToolThe model that powers Operator, called Computer-Using-Agent (CUA), is also now available in the API. The computer-use-preview model is SOTA on most benchmarks, achieving 38.1% success on OSWorld for full computer use tasks, 58.1% on WebArena, and 87% on WebVoyager for web-based interactions.As you will notice in the docs, `computer-use-preview` is both a model and a tool through which you can specify the environment. Usage is priced at $3/1M input tokens and $12/1M output tokens, and it’s currently only available to users in tiers 3-5.File Search ToolFile Search was also available in the Assistants API, and it’s now coming to Responses too. OpenAI is bringing search + RAG all under one umbrella, and we’ll definitely see more people trying to find new ways to build all-in-one apps on OpenAI. Usage is priced at $2.50 per thousand queries and file storage at $0.10/GB/day, with the first GB free.Agent SDK: Swarms++!https://github.com/openai/openai-agents-pythonTo bring it all together, after the viral reception to Swarm, OpenAI is releasing an officially supported agents framework (which was previewed at our AI Engineer Summit) with 4 core pieces:* Agents: Easily configurable LLMs with clear instructions and built-in tools.* Handoffs: Intelligently transfer control between agents.* Guardrails: Configurable safety checks for input and output validation.* Tracing & Observability: Visualize agent execution traces to debug and optimize performance.Multi-agent workflows are here to stay!OpenAI is now explicitly designs for a set of common agentic patterns: Workflows, Handoffs, Agents-as-Tools, LLM-as-a-Judge, Parallelization, and Guardrails. OpenAI previewed this in part 2 of their talk at NYC:Further coverage of the launch from Kevin Weil, WSJ, and OpenAIDevs, AMA here.Show Notes* Assistants API* Swarm (OpenAI)* Fine-Tuning in AI* 2024 OpenAI DevDay Recap with Romain* Michelle Pokrass episode (API lead)Timestamps* 00:00 Intros* 02:31 Responses API * 08:34 Web Search API * 17:14 Files Search API * 18:46 Files API vs RAG * 20:06 Computer Use / Operator API * 22:30 Agents SDKAnd of course you can catch up with the full livestream here:TranscriptAlessio [00:00:03]: Hey, everyone. Welcome back to another Latent Space Lightning episode. This is Alessio, partner and CTO at Decibel, and I'm joined by Swyx, founder of Small AI.swyx [00:00:11]: Hi, and today we have a super special episode because we're talking with our old friend Roman. Hi, welcome.Romain [00:00:19]: Thank you. Thank you for having me.swyx [00:00:20]: And Nikunj, who is most famously, if anyone has ever tried to get any access to anything on the API, Nikunj is the guy. So I know your emails because I look forward to them.Nikunj [00:00:30]: Yeah, nice to meet all of you.swyx [00:00:32]: I think that we're basically convening today to talk about the new API. So perhaps you guys want to just kick off. What is OpenAI launching today?Nikunj [00:00:40]: Yeah, so I can kick it off. We're launching a bunch of new things today. We're going to do three new built-in tools. So we're launching the web search tool. This is basically chat GPD for search, but available in the API. We're launching an improved file search tool. So this is you bringing your data to OpenAI. You upload it. We, you know, take care of parsing it, chunking it. We're embedding it, making it searchable, give you this like ready vector store that you can use. So that's the file search tool. An
⚡️How Claude 3.7 Plays Pokémon
Special lightning pod with David Hershey from Anthropic, the person behind Claude Plays Pokémon. Sonnet 3.7 is currently trying to complete Pokémon Red live on Twitch thanks to a special harness that David built so that it can see the screen, navigate through it, remember facts about the game, and more. (Since recording, it has successfully escaped Mt Moon! You can follow along on Twitch: https://www.twitch.tv/claudeplayspokemon) This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe
Open Operator, Serverless Browsers and the Future of Computer-Using Agents
Today's episode is with Paul Klein, founder of Browserbase. We talked about building browser infrastructure for AI agents, the future of agent authentication, and their open source framework Stagehand.* [00:00:00] Introductions* [00:04:46] AI-specific challenges in browser infrastructure* [00:07:05] Multimodality in AI-Powered Browsing* [00:12:26] Running headless browsers at scale* [00:18:46] Geolocation when proxying* [00:21:25] CAPTCHAs and Agent Auth* [00:28:21] Building “User take over” functionality* [00:33:43] Stagehand: AI web browsing framework* [00:38:58] OpenAI's Operator and computer use agents* [00:44:44] Surprising use cases of Browserbase* [00:47:18] Future of browser automation and market competition* [00:53:11] Being a solo founderTranscriptAlessio [00:00:04]: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol.ai.swyx [00:00:12]: Hey, and today we are very blessed to have our friends, Paul Klein, for the fourth, the fourth, CEO of Browserbase. Welcome.Paul [00:00:21]: Thanks guys. Yeah, I'm happy to be here. I've been lucky to know both of you for like a couple of years now, I think. So it's just like we're hanging out, you know, with three ginormous microphones in front of our face. It's totally normal hangout.swyx [00:00:34]: Yeah. We've actually mentioned you on the podcast, I think, more often than any other Solaris tenant. Just because like you're one of the, you know, best performing, I think, LLM tool companies that have started up in the last couple of years.Paul [00:00:50]: Yeah, I mean, it's been a whirlwind of a year, like Browserbase is actually pretty close to our first birthday. So we are one years old. And going from, you know, starting a company as a solo founder to... To, you know, having a team of 20 people, you know, a series A, but also being able to support hundreds of AI companies that are building AI applications that go out and automate the web. It's just been like, really cool. It's been happening a little too fast. I think like collectively as an AI industry, let's just take a week off together. I took my first vacation actually two weeks ago, and Operator came out on the first day, and then a week later, DeepSeat came out. And I'm like on vacation trying to chill. I'm like, we got to build with this stuff, right? So it's been a breakneck year. But I'm super happy to be here and like talk more about all the stuff we're seeing. And I'd love to hear kind of what you guys are excited about too, and share with it, you know?swyx [00:01:39]: Where to start? So people, you've done a bunch of podcasts. I think I strongly recommend Jack Bridger's Scaling DevTools, as well as Turner Novak's The Peel. And, you know, I'm sure there's others. So you covered your Twilio story in the past, talked about StreamClub, you got acquired to Mux, and then you left to start Browserbase. So maybe we just start with what is Browserbase? Yeah.Paul [00:02:02]: Browserbase is the web browser for your AI. We're building headless browser infrastructure, which are browsers that run in a server environment that's accessible to developers via APIs and SDKs. It's really hard to run a web browser in the cloud. You guys are probably running Chrome on your computers, and that's using a lot of resources, right? So if you want to run a web browser or thousands of web browsers, you can't just spin up a bunch of lambdas. You actually need to use a secure containerized environment. You have to scale it up and down. It's a stateful system. And that infrastructure is, like, super painful. And I know that firsthand, because at my last company, StreamClub, I was CTO, and I was building our own internal headless browser infrastructure. That's actually why we sold the company, is because Mux really wanted to buy our headless browser infrastructure that we'd built. And it's just a super hard problem. And I actually told my co-founders, I would never start another company unless it was a browser infrastructure company. And it turns out that's really necessary in the age of AI, when AI can actually go out and interact with websites, click on buttons, fill in forms. You need AI to do all of that work in an actual browser running somewhere on a server. And BrowserBase powers that.swyx [00:03:08]: While you're talking about it, it occurred to me, not that you're going to be acquired or anything, but it occurred to me that it would be really funny if you became the Nikita Beer of headless browser companies. You just have one trick, and you make browser companies that get acquired.Paul [00:03:23]: I truly do only have one trick. I'm screwed if it's not for headless browsers. I'm not a Go programmer. You know, I'm in AI grant. You know, browsers is an AI grant. But we were the only company in that AI grant batch that used zero dollars on AI spend. You know, we're purely an infrastructure company. So as much as people w

The Inventors of Deep Research
While “LLM-powered Search” is as old as Perplexity and SearchGPT, and open source projects like GPTResearcher and clones like OpenDeepResearch exist, the difference with “Deep Research” products is they are both “agentic” (loosely meaning that an LLM decides the next step in a workflow, usually involving tools) and bundling custom-tuned frontier models (custom tuned o3 and Gemini 1.5 Flash).The reception to OpenAI’s Deep Research agent has been nothing short of breathless:"Deep Research is the best public-facing AI product Google has ever released. It's like having a college-educated researcher in your pocket." - Jason Calacanis“I have had [Deep Research] write a number of ten-page papers for me, each of them outstanding. I think of the quality as comparable to having a good PhD-level research assistant, and sending that person away with a task for a week or two, or maybe more. Except Deep Research does the work in five or six minutes.” - Tyler Cowen“Deep Research is one of the best bargains in technology.” - Ben Thompson“my very approximate vibe is that it can do a single-digit percentage of all economically valuable tasks in the world, which is a wild milestone.” - sama“Using Deep Research over the past few weeks has been my own personal AGI moment. It takes 10 mins to generate accurate and thorough competitive and market research (with sources) that previously used to take me at least 3 hours.” - OAI employee“It's like a bazooka for the curious mind” - Dan Shipper“Deep research can be seen as a new interface for the internet, in addition to being an incredible agent… This paradigm will be so powerful that in the future, navigating the internet manually via a browser will be "old-school", like performing arithmetic calculations by hand.” - Jason Wei“One notable characteristic of Deep Research is its extreme patience. I think this is rapidly approaching “superhuman patience”. One realization working on this project was that intelligence and patience go really well together.” - HyungWon“I asked it to write a reference Interaction Calculus evaluator in Haskell. A few exchanges later, it gave me a complete file, including a parser, an evaluator, O(1) interactions and everything. The file compiled, and worked on my test inputs. There are some minor issues, but it is mostly correct. So, in about 30 minutes, o3 performed a job that would take me a day or so.” - Victor Taelin“Can confirm OpenAI Deep Research is quite strong. In a few minutes it did what used to take a dozen hours. The implications to knowledge work is going to be quite profound when you just ask an AI Agent to perform full tasks for you and come back with a finished result.” - Aaron Levie“Deep Research is genuinely useful” - Gary MarcusWith the advent of “Deep Research” agents, we are now routinely asking models to go through 100+ websites and generate in-depth reports on any topic. The Deep Research revolution has hit the AI scene in the last 2 weeks:* Dec 11th: Gemini Deep Research (today’s guest!) rolls out with Gemini Advanced* Feb 2nd: OpenAI releases Deep Research* Feb 3rd: a dozen “Open Deep Research” clones launch* Feb 5th: Gemini 2.0 Flash GA* Feb 15th: Perplexity launches Deep Research* Feb 17th: xAI launches Deep SearchIn today’s episode, we welcome Aarush Selvan and Mukund Sridhar, the lead PM and tech lead for Gemini Deep Research, the originators of the entire category. We asked detailed questions from inspiration to implementation, why they had to finetune a special model for it instead of using the standard Gemini model, how to run evals for them, and how to think about the distribution of use cases. (We also have an upcoming Gemini 2 episode with our returning first guest Logan Kilpatrick so stay tuned 👀)Two Kinds of Inference Time ComputeIn just ~2 months since NeurIPS, we’ve moved from “scaling has hit a wall, LLMs might be over” to “is this AGI already?” thanks to the releases of o1, o3, and DeepSeek R1 (see our o3 post and R1 distillation lightning pod). This new jump in capabilities is now accelerating many other applications; you might remember how “needle in a haystack” was one of the benchmarks people often referenced when looking at model’s capabilities over long context (see our 1M Llama context window ep for more). It seems that we have broken through the “wall” by scaling “inference time” in two meaningful ways — one with more time spent in the model, and the other with more tool calls.Both help build better agents which are clearly more intelligent. But as we discuss on the podcast, we are currently in a “honeymoon” period of agent products where taking more time (or tool calls, or search results) is considered good, because 1) quality is hard to evaluate and 2) we don’t know the realistic upper bound to quality. We know that they’re correlated, but we don’t know to what extent and if the correlation breaks down over extended research periods (they may not).It doesn’t take a PhD to spot the perverse incentives here.

Bee AI: The Wearable Ambient Agent
Bundle tickets for AIE Summit NYC have now sold out. You can now sign up for the livestream — where we will be making a big announcement soon. NYC-based readers and Summit attendees should check out the meetups happening around the Summit.2024 was a very challenging year for AI Hardware. After the buzz of CES last January, 2024 was marked by the meteoric rise and even harder fall of AI Wearables companies like Rabbit and Humane, with an assist from a pre-wallpaper-app MKBHD. Even Friend.com, the first to launch in the AI pendant category, and which spurred Rewind AI to rebrand to Limitless and follow in their footsteps, ended up delaying their wearable ship date and launching an experimental website chatbot version. We have been cautiously excited about this category, keeping tabs on most of the top entrants, including Omi and Compass. However, to date the biggest winner still standing from the AI Wearable wars is Bee AI, founded by today's guests Maria and Ethan. Bee is an always on hardware device with beamforming microphones, 7 day battery life and a mute button, that can be worn as a wristwatch or a clip-on pin, backed by an incredible transcription, diarization and very long context memory processing pipeline that helps you to remember your day, your todos, and even perform actions by operating a virtual cloud phone. This is one of the most advanced, production ready, personal AI agents we've ever seen, so we were excited to be their first podcast appearance. We met Bee when we ran the world's first Personal AI meetup in April last year.As a user of Bee (and not an investor! just a friend!) it’s genuinely been a joy to use, and we were glad to take advantage of the opportunity to ask hard questions about the privacy and legal/ethical side of things as much as the AI and Hardware engineering side of Bee. We hope you enjoy the episode and tune in next Friday for Bee’s first conference talk: Building Perfect Memory.Full YouTube Video VersionWatch this for the live demo!Show Notes* Bee Website* Ethan Sutin, Maria de Lourdes Zollo* Bee @ Personal AI Meetup* Buy Bee with Listener Discount Code!Timestamps* 00:00:00 Introductions and overview of Bee Computer* 00:01:58 Personal context and use cases for Bee* 00:03:02 Origin story of Bee and the founders' background* 00:06:56 Evolution from app to hardware device* 00:09:54 Short-term value proposition for users* 00:12:17 Demo of Bee's functionality* 00:17:54 Hardware form factor considerations* 00:22:22 Privacy concerns and legal considerations* 00:30:57 User adoption and reactions to wearing Bee* 00:35:56 CES experience and hardware manufacturing challenges* 00:41:40 Software pipeline and inference costs* 00:53:38 Technical challenges in real-time processing* 00:57:46 Memory and personal context modeling* 01:02:45 Social aspects and agent-to-agent interactions* 01:04:34 Location sharing and personal data exchange* 01:05:11 Personality analysis capabilities* 01:06:29 Hiring and future of always-on AITranscriptAlessio [00:00:04]: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO at Decibel Partners, and I'm joined by my co-host Swyx, founder of SmallAI.swyx [00:00:12]: Hey, and today we are very honored to have in the studio Maria and Ethan from Bee.Maria [00:00:16]: Hi, thank you for having us.swyx [00:00:20]: And you are, I think, the first hardware founders we've had on the podcast. I've been looking to have had a hardware founder, like a wearable hardware, like a wearable hardware founder for a while. I think we're going to have two or three of them this year. And you're the ones that I wear every day. So thank you for making Bee. Thank you for all the feedback and the usage. Yeah, you know, I've been a big fan. You are the speaker gift for the Engineering World's Fair. And let's start from the beginning. What is Bee Computer?Ethan [00:00:52]: Bee Computer is a personal AI system. So you can think of it as AI living alongside you in first person. So it can kind of capture your in real life. So with that understanding can help you in significant ways. You know, the obvious one is memory, but that's that's really just the base kind of use case. So recalling and reflective. I know, Swyx, that you you like the idea of journaling, but you don't but still have some some kind of reflective summary of what you experienced in real life. But it's also about just having like the whole context of a human being and understanding, you know, giving the machine the ability to understand, like, what's going on in your life. Your attitudes, your desires, specifics about your preferences, so that not only can it help you with recall, but then anything that you need it to do, it already knows, like, if you think about like somebody who you've worked with or lived with for a long time, they just know kind of without having to ask you what you would want, it's clear that like, that is the future that personal AI, like, it's just going to be very,
The AI Architect — Bret Taylor
If you’re in SF, join us tomorrow for a fun meetup at CodeGen Night!If you’re in NYC, join us for AI Engineer Summit! The Agent Engineering track is now sold out, but 25 tickets remain for AI Leadership and 5 tickets for the workshops. You can see the full schedule of speakers and workshops at https://ai.engineer!It’s exceedingly hard to introduce someone like Bret Taylor. We could recite his Wikipedia page, or his extensive work history through Silicon Valley’s greatest companies, but everyone else already does that.As a podcast by AI engineers for AI engineers, we had the opportunity to do something a little different. We wanted to dig into what Bret sees from his vantage point at the top of our industry for the last 2 decades, and how that explains the rise of the AI Architect at Sierra, the leading conversational AI/CX platform.“Across our customer base, we are seeing a new role emerge - the role of the AI architect. These leaders are responsible for helping define, manage and evolve their company's AI agent over time. They come from a variety of both technical and business backgrounds, and we think that every company will have one or many AI architects managing their AI agent and related experience.”In our conversation, Bret Taylor confirms the Paul Buchheit legend that he rewrote Google Maps in a weekend, armed with only the help of a then-nascent Google Closure Compiler and no other modern tooling. But what we find remarkable is that he was the PM of Maps, not an engineer, though of course he still identifies as one. We find this theme recurring throughout Bret’s career and worldview. We think it is plain as day that AI leadership will have to be hands-on and technical, especially when the ground is shifting as quickly as it is today:“There's a lot of power in combining product and engineering into as few people as possible… few great things have been created by committee.”“If engineering is an order taking organization for product you can sometimes make meaningful things, but rarely will you create extremely well crafted breakthrough products. Those tend to be small teams who deeply understand the customer need that they're solving, who have a maniacal focus on outcomes.”“And I think the reason why is if you look at like software as a service five years ago, maybe you can have a separation of product and engineering because most software as a service created five years ago. I wouldn't say there's like a lot of technological breakthroughs required for most business applications. And if you're making expense reporting software or whatever, it's useful… You kind of know how databases work, how to build auto scaling with your AWS cluster, whatever, you know, it's just, you're just applying best practices to yet another problem. "When you have areas like the early days of mobile development or the early days of interactive web applications, which I think Google Maps and Gmail represent, or now AI agents, you're in this constant conversation with what the requirements of your customers and stakeholders are and all the different people interacting with it and the capabilities of the technology. And it's almost impossible to specify the requirements of a product when you're not sure of the limitations of the technology itself.”This is the first time the difference between technical leadership for “normal” software and for “AI” software was articulated this clearly for us, and we’ll be thinking a lot about this going forward. We left a lot of nuggets in the conversation, so we hope you’ll just dive in with us (and thank Bret for joining the pod!)Full YouTubePlease Like and Subscribe :)Timestamps* 00:00:02 Introductions and Bret Taylor's background* 00:01:23 Bret's experience at Stanford and the dot-com era* 00:04:04 The story of rewriting Google Maps backend* 00:11:06 Early days of interactive web applications at Google* 00:15:26 Discussion on product management and engineering roles* 00:21:00 AI and the future of software development* 00:26:42 Bret's approach to identifying customer needs and building AI companies* 00:32:09 The evolution of business models in the AI era* 00:41:00 The future of programming languages and software development* 00:49:38 Challenges in precisely communicating human intent to machines* 00:56:44 Discussion on Artificial General Intelligence (AGI) and its impact* 01:08:51 The future of agent-to-agent communication* 01:14:03 Bret's involvement in the OpenAI leadership crisis* 01:22:11 OpenAI's relationship with Microsoft* 01:23:23 OpenAI's mission and priorities* 01:27:40 Bret's guiding principles for career choices* 01:29:12 Brief discussion on pasta-making* 01:30:47 How Bret keeps up with AI developments* 01:32:15 Exciting research directions in AI* 01:35:19 Closing remarks and hiring at Sierra Transcript[00:02:05] Introduction and Guest Welcome[00:02:05] Alessio: Hey everyone, welcome to the Latent Space Podcast. This is Alessio, partner and CTO at Decibel Partners, and I'm joined

Agent Engineering with Pydantic + Graphs — with Samuel Colvin
Did you know that adding a simple Code Interpreter took o3 from 9.2% to 32% on FrontierMath? The Latent Space crew is hosting a hack night Feb 11th in San Francisco focused on CodeGen use cases, co-hosted with E2B and Edge AGI; watch E2B’s new workshop and RSVP here!We’re happy to announce that today’s guest Samuel Colvin will be teaching his very first Pydantic AI workshop at the newly announced AI Engineer NYC Workshops day on Feb 22! 25 tickets left.If you’re a Python developer, it’s very likely that you’ve heard of Pydantic. Every month, it’s downloaded >300,000,000 times, making it one of the top 25 PyPi packages. OpenAI uses it in its SDK for structured outputs, it’s at the core of FastAPI, and if you’ve followed our AI Engineer Summit conference, Jason Liu of Instructor has given two great talks about it: “Pydantic is all you need” and “Pydantic is STILL all you need”. Now, Samuel Colvin has raised $17M from Sequoia to turn Pydantic from an open source project to a full stack AI engineer platform with Logfire, their observability platform, and PydanticAI, their new agent framework.Logfire: bringing OTEL to AIOpenTelemetry recently merged Semantic Conventions for LLM workloads which provides standard definitions to track performance like gen_ai.server.time_per_output_token. In Sam’s view at least 80% of new apps being built today have some sort of LLM usage in them, and just like web observability platform got replaced by cloud-first ones in the 2010s, Logfire wants to do the same for AI-first apps. If you’re interested in the technical details, Logfire migrated away from Clickhouse to Datafusion for their backend. We spent some time on the importance of picking open source tools you understand and that you can actually contribute to upstream, rather than the more popular ones; listen in ~43:19 for that part.Agents are the killer app for graphsPydantic AI is their attempt at taking a lot of the learnings that LangChain and the other early LLM frameworks had, and putting Python best practices into it. At an API level, it’s very similar to the other libraries: you can call LLMs, create agents, do function calling, do evals, etc.They define an “Agent” as a container with a system prompt, tools, structured result, and an LLM. Under the hood, each Agent is now a graph of function calls that can orchestrate multi-step LLM interactions. You can start simple, then move toward fully dynamic graph-based control flow if needed.“We were compelled enough by graphs once we got them right that our agent implementation [...] is now actually a graph under the hood.”Why Graphs?* More natural for complex or multi-step AI workflows.* Easy to visualize and debug with mermaid diagrams.* Potential for distributed runs, or “waiting days” between steps in certain flows.In parallel, you see folks like Emil Eifrem of Neo4j talk about GraphRAG as another place where graphs fit really well in the AI stack, so it might be time for more people to take them seriously.Full Video EpisodeLike and subscribe!Chapters* 00:00:00 Introductions* 00:00:24 Origins of Pydantic* 00:05:28 Pydantic's AI moment * 00:08:05 Why build a new agents framework?* 00:10:17 Overview of Pydantic AI* 00:12:33 Becoming a believer in graphs* 00:24:02 God Model vs Compound AI Systems* 00:28:13 Why not build an LLM gateway?* 00:31:39 Programmatic testing vs live evals* 00:35:51 Using OpenTelemetry for AI traces* 00:43:19 Why they don't use Clickhouse* 00:48:34 Competing in the observability space* 00:50:41 Licensing decisions for Pydantic and LogFire* 00:51:48 Building Pydantic.run* 00:55:24 Marimo and the future of Jupyter notebooks* 00:57:44 London's AI sceneShow Notes* Sam Colvin* Pydantic* Pydantic AI* Logfire* Pydantic.run* Zod* E2B* Arize* Langsmith* Marimo* Prefect* GLA (Google Generative Language API)* OpenTelemetry* Jason Liu* Sebastian Ramirez* Bogomil Balkansky* Hood Chatham* Jeremy Howard* Andrew LambTranscriptAlessio [00:00:03]: Hey, everyone. Welcome to the Latent Space podcast. This is Alessio, partner and CTO at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol AI.Swyx [00:00:12]: Good morning. And today we're very excited to have Sam Colvin join us from Pydantic AI. Welcome. Sam, I heard that Pydantic is all we need. Is that true?Samuel [00:00:24]: I would say you might need Pydantic AI and Logfire as well, but it gets you a long way, that's for sure.Swyx [00:00:29]: Pydantic almost basically needs no introduction. It's almost 300 million downloads in December. And obviously, in the previous podcasts and discussions we've had with Jason Liu, he's been a big fan and promoter of Pydantic and AI.Samuel [00:00:45]: Yeah, it's weird because obviously I didn't create Pydantic originally for uses in AI, it predates LLMs. But it's like we've been lucky that it's been picked up by that community and used so widely.Swyx [00:00:58]: Actually, maybe we'll hear it. Right from you, what is Pydantic and maybe a little bit of the origin story?

The Agent Reasoning Interface: o1/o3, Claude 3, ChatGPT Canvas, Tasks, and Operator — with Karina Nguyen of OpenAI
Sponsorships and tickets for the AI Engineer Summit are selling fast! See the new website with speakers and schedules live! If you are building AI agents or leading teams of AI Engineers, this will be the single highest-signal conference of the year for you, this Feb 20-22nd in NYC.We’re pleased to share that Karina will be presenting OpenAI’s closing keynote at the AI Engineer Summit. We were fortunate to get some time with her today to introduce some of her work, and hope this serves as nice background for her talk!There are very few early AI careers that have been as impactful as Karina Nguyen’s. After stints at Notion, Square, Dropbox, Primer, the New York Times, and UC Berkeley, She joined Anthropic as employee ~60 and worked on a wide range of research/product roles for Claude 1, 2, and 3. We’ll just let her LinkedIn speak for itself:Now, as Research manager and Post-training lead in Model Behavior at OpenAI, she creates new interaction paradigms for reasoning interfaces and capabilities, like ChatGPT Canvas, Tasks, SimpleQA, streaming chain-of-thought for o1 models, and more via novel synthetic model training. Ideal AI Research+Product ProcessIn the podcast we got a sense of what Karina has found works for her and her team to be as productive as they have been:* Write PRD (Define what you want)* Funding (Get resources)* Prototype Prompted Baseline (See what’s possible)* Write and Run Evals (Get failures to hillclimb)* Model training (Exceed baseline without overfitting)* Bugbash (Find bugs and solve them)* Ship (Get users!)We could turn this into a snazzy viral graphic but really this is all it is. Simple to say, difficult to do well. Hopefully it helps you define your process if you do similar product-research work. Show Notes* Our Reasoning Price War post * Karina LinkedIn, Website, Twitter* OSINT visualization work* Ukraine 3D storytelling* Karina on Claude Artifacts* Karina on Claude 3 Benchmarks* Inspiration for Artifacts / Canvas from early UX work she did on GPT-3* “i really believe that things like canvas and tasks should and could have happened like 2 yrs ago, idk why we are lagging in the form factors” (tweet)* Our article on prompting o1 vs Karina’s Claude prompting principles* Canvas: https://openai.com/index/introducing-canvas/ * We trained GPT-4o to collaborate as a creative partner. The model knows when to open a canvas, make targeted edits, and fully rewrite. It also understands broader context to provide precise feedback and suggestions.To support this, our research team developed the following core behaviors:* Triggering the canvas for writing and coding* Generating diverse content types* Making targeted edits* Rewriting documents* Providing inline critiqueWe measured progress with over 20 automated internal evaluations. We used novel synthetic data generation techniques, such as distilling outputs from OpenAI o1-preview, to post-train the model for its core behaviors. This approach allowed us to rapidly address writing quality and new user interactions, all without relying on human-generated data.* Tasks: https://www.theverge.com/2025/1/14/24343528/openai-chatgpt-repeating-tasks-agent-ai* * Agents and Operator* What are agents? “Agents are a gradual progression of tasks: starting with one-off actions, moving to collaboration, and ultimately fully trustworthy long-horizon delegation in complex envs like multi-player/multiagents.” (tweet)* tasks and canvas fall within the first two, and we are def. marching towards the third—though the form factor for 3 will take time to develop * Operator/Computer Use Agents* https://openai.com/index/introducing-operator/* Misc:* Andrew Ng* Prediction: Personal AI Consumer playbook* ChatGPT as generative OSTimestamps* 00:00 Welcome to the Latent Space Podcast* 00:11 Introducing Karina Nguyen* 02:21 Karina's Journey to OpenAI* 04:45 Early Prototypes and Projects* 05:25 Joining Anthropic and Early Work* 07:16 Challenges and Innovations at Anthropic* 11:30 Launching Claude 3* 21:57 Behavioral Design and Model Personality* 27:37 The Making of ChatGPT Canvas* 34:34 Canvas Update and Initial Impressions* 34:46 Differences Between Canvas and API Outputs* 35:50 Core Use Cases of Canvas* 36:35 Canvas as a Writing Partner* 36:55 Canvas vs. Google Docs and Future Improvements* 37:35 Canvas for Coding and Executing Code* 38:50 Challenges in Developing Canvas* 41:45 Introduction to Tasks* 41:53 Developing and Iterating on Tasks* 46:27 Future Vision for Tasks and Proactive Models* 52:23 Computer Use Agents and Their Potential* 01:00:21 Cultural Differences Between OpenAI and Anthropic* 01:03:46 Call to Action and Final ThoughtsTranscriptAlessio [00:00:04]: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO at Decibel, and I'm joined by my usual co-host, Swyx.swyx [00:00:11]: Hey, and today we're very, very blessed to have Karina Nguyen in the studio. Welcome.Karina [00:00:15]: Nice to meet you.swyx [00:00:16]: We finally made it h

Outlasting Noam Shazeer, crowdsourcing Chai AI with >1.4m DAU, and becoming the "Western DeepSeek" — with William Beauchamp, Chai Research
One last Gold sponsor slot is available for the AI Engineer Summit in NYC. Our last round of invites is going out soon - apply here - If you are building AI agents or AI eng teams, this will be the single highest-signal conference of the year for you!While the world melts down over DeepSeek, few are talking about the OTHER notable group of former hedge fund traders who pivoted into AI and built a remarkably profitable consumer AI business with a tiny team with incredibly cracked engineering team — Chai Research. In short order they have:* Started a Chat AI company well before Noam Shazeer started Character AI, and outlasted his departure.* Crossed 1m DAU in 2.5 years - William updates us on the pod that they’ve hit 1.4m DAU now, another +40% from a few months ago. Revenue crossed >$22m. * Launched the Chaiverse model crowdsourcing platform - taking 3-4 week A/B testing cycles down to 3-4 hours, and deploying >100 models a week.While they’re not paying million dollar salaries, you can tell they’re doing pretty well for an 11 person startup:The Chai Recipe: Building infra for rapid evalsRemember how the central thesis of LMarena (formerly LMsys) is that the only comprehensive way to evaluate LLMs is to let users try them out and pick winners?At the core of Chai is a mobile app that looks like Character AI, but is actually the largest LLM A/B testing arena in the world, specialized on retaining chat users for Chai’s usecases (therapy, assistant, roleplay, etc). It’s basically what LMArena would be if taken very, very seriously at one company (with $1m in prizes to boot):Chai publishes occasional research on how they think about this, including talks at their Palo Alto office:William expands upon this in today’s podcast (34 mins in):Fundamentally, the way I would describe it is when you're building anything in life, you need to be able to evaluate it. And through evaluation, you can iterate, we can look at benchmarks, and we can say the issues with benchmarks and why they may not generalize as well as one would hope in the challenges of working with them. But something that works incredibly well is getting feedback from humans. And so we built this thing where anyone can submit a model to our developer backend, and it gets put in front of 5000 users, and the users can rate it. And we can then have a really accurate ranking of like which model, or users finding more engaging or more entertaining. And it gets, you know, it's at this point now, where every day we're able to, I mean, we evaluate between 20 and 50 models, LLMs, every single day, right. So even though we've got only got a team of, say, five AI researchers, they're able to iterate a huge quantity of LLMs, right. So our team ships, let's just say minimum 100 LLMs a week is what we're able to iterate through. Now, before that moment in time, we might iterate through three a week, we might, you know, there was a time when even doing like five a month was a challenge, right? By being able to change the feedback loops to the point where it's not, let's launch these three models, let's do an A-B test, let's assign, let's do different cohorts, let's wait 30 days to see what the day 30 retention is, which is the kind of the, if you're doing an app, that's like A-B testing 101 would be, do a 30-day retention test, assign different treatments to different cohorts and come back in 30 days. So that's insanely slow. That's just, it's too slow. And so we were able to get that 30-day feedback loop all the way down to something like three hours.In Crowdsourcing the leap to Ten Trillion-Parameter AGI, William describes Chai’s routing as a recommender system, which makes a lot more sense to us than previous pitches for model routing startups:William is notably counter-consensus in a lot of his AI product principles:* No streaming: Chats appear all at once to allow rejection sampling* No voice: Chai actually beat Character AI to introducing voice - but removed it after finding that it was far from a killer feature.* Blending: “Something that we love to do at Chai is blending, which is, you know, it's the simplest way to think about it is you're going to end up, and you're going to pretty quickly see you've got one model that's really smart, one model that's really funny. How do you get the user an experience that is both smart and funny? Well, just 50% of the requests, you can serve them the smart model, 50% of the requests, you serve them the funny model.” (that’s it!)But chief above all is the recommender system.We also referenced Exa CEO Will Bryk’s concept of SuperKnowlege:Full Video versionOn YouTube. please like and subscribe!Timestamps* 00:00:04 Introductions and background of William Beauchamp* 00:01:19 Origin story of Chai AI* 00:04:40 Transition from finance to AI* 00:11:36 Initial product development and idea maze for Chai* 00:16:29 User psychology and engagement with AI companions* 00:20:00 Origin of the Chai name* 00:22:01 Comparison with Character AI and f