
Latent Space: The AI Engineer Podcast
211 episodes — Page 3 of 5
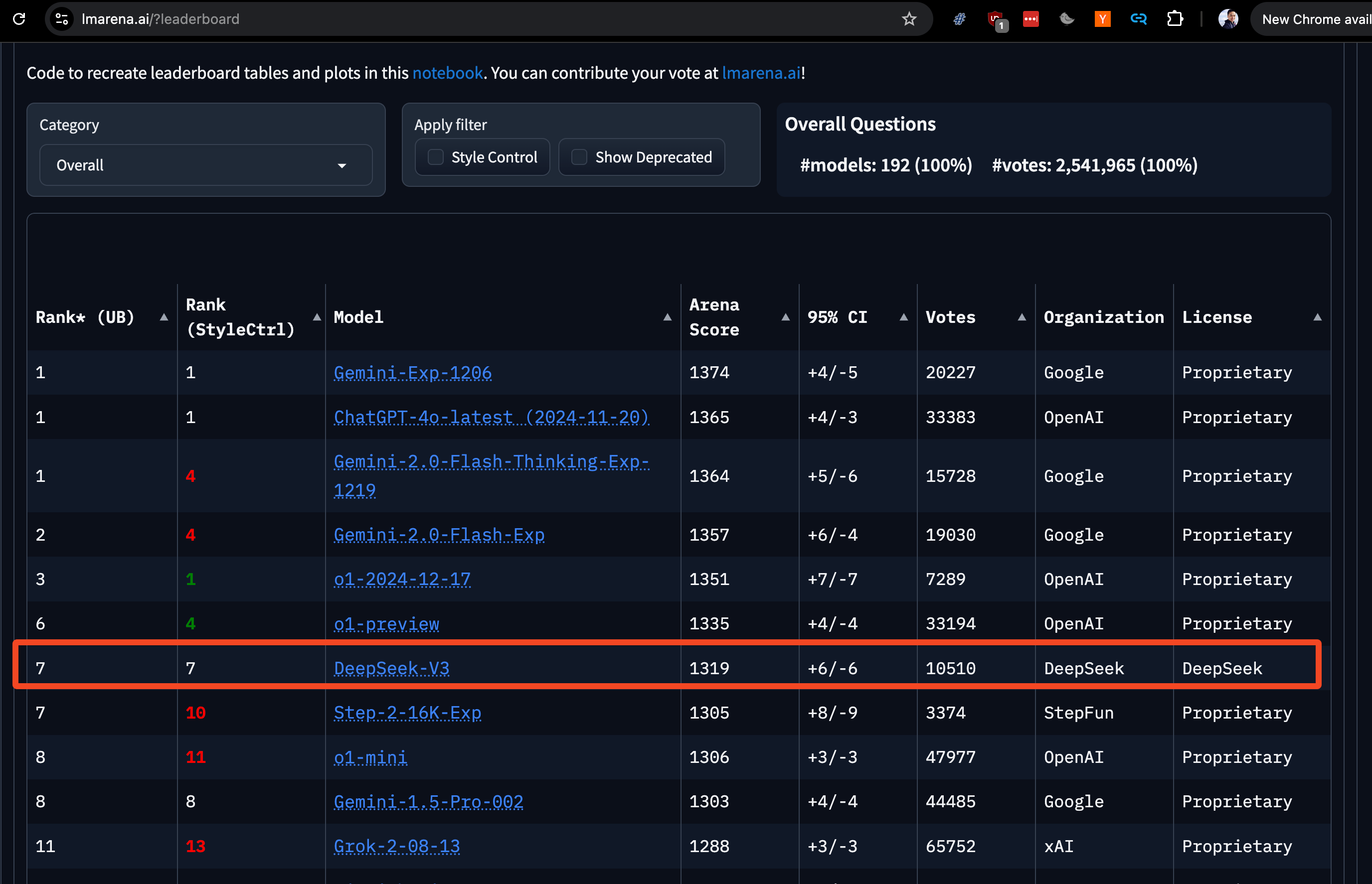
Everything you need to run Mission Critical Inference (ft. DeepSeek v3 + SGLang)
Sponsorships and applications for the AI Engineer Summit in NYC are live! (Speaker CFPs have closed) If you are building AI agents or leading teams of AI Engineers, this will be the single highest-signal conference of the year for you.Right after Christmas, the Chinese Whale Bros ended 2024 by dropping the last big model launch of the year: DeepSeek v3. Right now on LM Arena, DeepSeek v3 has a score of 1319, right under the full o1 model, Gemini 2, and 4o latest. This makes it the best open weights model in the world in January 2025.There has been a big recent trend in Chinese labs releasing very large open weights models, with TenCent releasing Hunyuan-Large in November and Hailuo releasing MiniMax-Text this week, both over 400B in size. However these extra-large language models are very difficult to serve.Baseten was the first of the Inference neocloud startups to get DeepSeek V3 online, because of their H200 clusters, their close collaboration with the DeepSeek team and early support of SGLang, a relatively new VLLM alternative that is also used at frontier labs like X.ai. Each H200 has 141 GB of VRAM with 4.8 TB per second of bandwidth, meaning that you can use 8 H200's in a node to inference DeepSeek v3 in FP8, taking into account KV Cache needs. We have been close to Baseten since Sarah Guo introduced Amir Haghighat to swyx, and they supported the very first Latent Space Demo Day in San Francisco, which was effectively the trial run for swyx and Alessio to work together! Since then, Philip Kiely also led a well attended workshop on TensorRT LLM at the 2024 World's Fair. We worked with him to get two of their best representatives, Amir and Lead Model Performance Engineer Yineng Zhang, to discuss DeepSeek, SGLang, and everything they have learned running Mission Critical Inference workloads at scale for some of the largest AI products in the world.The Three Pillars of Mission Critical InferenceWe initially planned to focus the conversation on SGLang, but Amir and Yineng were quick to correct us that the choice of inference framework is only the simplest, first choice of 3 things you need for production inference at scale:“I think it takes three things, and each of them individually is necessary but not sufficient: * Performance at the model level: how fast are you running this one model running on a single GPU, let's say. The framework that you use there can, can matter. The techniques that you use there can matter. The MLA technique, for example, that Yineng mentioned, or the CUDA kernels that are being used. But there's also techniques being used at a higher level, things like speculative decoding with draft models or with Medusa heads. And these are implemented in the different frameworks, or you can even implement it yourself, but they're not necessarily tied to a single framework. But using speculative decoding gets you massive upside when it comes to being able to handle high throughput. But that's not enough. Invariably, that one model running on a single GPU, let's say, is going to get too much traffic that it cannot handle.* Horizontal scaling at the cluster/region level: And at that point, you need to horizontally scale it. That's not an ML problem. That's not a PyTorch problem. That's an infrastructure problem. How quickly do you go from, a single replica of that model to 5, to 10, to 100. And so that's the second, that's the second pillar that is necessary for running these machine critical inference workloads.And what does it take to do that? It takes, some people are like, Oh, You just need Kubernetes and Kubernetes has an autoscaler and that just works. That doesn't work for, for these kinds of mission critical inference workloads. And you end up catching yourself wanting to bit by bit to rebuild those infrastructure pieces from scratch. This has been our experience. * And then going even a layer beyond that, Kubernetes runs in a single. cluster. It's a single cluster. It's a single region tied to a single region. And when it comes to inference workloads and needing GPUs more and more, you know, we're seeing this that you cannot meet the demand inside of a single region. A single cloud's a single region. In other words, a single model might want to horizontally scale up to 200 replicas, each of which is, let's say, 2H100s or 4H100s or even a full node, you run into limits of the capacity inside of that one region. And what we had to build to get around that was the ability to have a single model have replicas across different regions. So, you know, there are models on Baseten today that have 50 replicas in GCP East and, 80 replicas in AWS West and Oracle in London, etc.* Developer experience for Compound AI Systems: The final one is wrapping the power of the first two pillars in a very good developer experience to be able to afford certain workflows like the ones that I mentioned, around multi step, multi model inference workloads, because more and more we're seeing that the market is mov

[Ride Home] Simon Willison: Things we learned about LLMs in 2024
Due to overwhelming demand (>15x applications:slots), we are closing CFPs for AI Engineer Summit NYC today. Last call! Thanks, we’ll be reaching out to all shortly!The world’s top AI blogger and friend of every pod, Simon Willison, dropped a monster 2024 recap: Things we learned about LLMs in 2024. Brian of the excellent TechMeme Ride Home pinged us for a connection and a special crossover episode, our first in 2025. The target audience for this podcast is a tech-literate, but non-technical one. You can see Simon’s notes for AI Engineers in his World’s Fair Keynote.Timestamp* 00:00 Introduction and Guest Welcome* 01:06 State of AI in 2025* 01:43 Advancements in AI Models* 03:59 Cost Efficiency in AI* 06:16 Challenges and Competition in AI* 17:15 AI Agents and Their Limitations* 26:12 Multimodal AI and Future Prospects* 35:29 Exploring Video Avatar Companies* 36:24 AI Influencers and Their Future* 37:12 Simplifying Content Creation with AI* 38:30 The Importance of Credibility in AI* 41:36 The Future of LLM User Interfaces* 48:58 Local LLMs: A Growing Interest* 01:07:22 AI Wearables: The Next Big Thing* 01:10:16 Wrapping Up and Final ThoughtsTranscript[00:00:00] Introduction and Guest Welcome[00:00:00] Brian: Welcome to the first bonus episode of the Tech Meme Write Home for the year 2025. I'm your host as always, Brian McCullough. Listeners to the pod over the last year know that I have made a habit of quoting from Simon Willison when new stuff happens in AI from his blog. Simon has been, become a go to for many folks in terms of, you know, Analyzing things, criticizing things in the AI space.[00:00:33] Brian: I've wanted to talk to you for a long time, Simon. So thank you for coming on the show. No, it's a privilege to be here. And the person that made this connection happen is our friend Swyx, who has been on the show back, even going back to the, the Twitter Spaces days but also an AI guru in, in their own right Swyx, thanks for coming on the show also.[00:00:54] swyx (2): Thanks. I'm happy to be on and have been a regular listener, so just happy to [00:01:00] contribute as well.[00:01:00] Brian: And a good friend of the pod, as they say. Alright, let's go right into it.[00:01:06] State of AI in 2025[00:01:06] Brian: Simon, I'm going to do the most unfair, broad question first, so let's get it out of the way. The year 2025. Broadly, what is the state of AI as we begin this year?[00:01:20] Brian: Whatever you want to say, I don't want to lead the witness.[00:01:22] Simon: Wow. So many things, right? I mean, the big thing is everything's got really good and fast and cheap. Like, that was the trend throughout all of 2024. The good models got so much cheaper, they got so much faster, they got multimodal, right? The image stuff isn't even a surprise anymore.[00:01:39] Simon: They're growing video, all of that kind of stuff. So that's all really exciting.[00:01:43] Advancements in AI Models[00:01:43] Simon: At the same time, they didn't get massively better than GPT 4, which was a bit of a surprise. So that's sort of one of the open questions is, are we going to see huge, but I kind of feel like that's a bit of a distraction because GPT 4, but way cheaper, much larger context lengths, and it [00:02:00] can do multimodal.[00:02:01] Simon: is better, right? That's a better model, even if it's not.[00:02:05] Brian: What people were expecting or hoping, maybe not expecting is not the right word, but hoping that we would see another step change, right? Right. From like GPT 2 to 3 to 4, we were expecting or hoping that maybe we were going to see the next evolution in that sort of, yeah.[00:02:21] Brian: We[00:02:21] Simon: did see that, but not in the way we expected. We thought the model was just going to get smarter, and instead we got. Massive drops in, drops in price. We got all of these new capabilities. You can talk to the things now, right? They can do simulated audio input, all of that kind of stuff. And so it's kind of, it's interesting to me that the models improved in all of these ways we weren't necessarily expecting.[00:02:43] Simon: I didn't know it would be able to do an impersonation of Santa Claus, like a, you know, Talked to it through my phone and show it what I was seeing by the end of 2024. But yeah, we didn't get that GPT 5 step. And that's one of the big open questions is, is that actually just around the corner and we'll have a bunch of GPT 5 class models drop in the [00:03:00] next few months?[00:03:00] Simon: Or is there a limit?[00:03:03] Brian: If you were a betting man and wanted to put money on it, do you expect to see a phase change, step change in 2025?[00:03:11] Simon: I don't particularly for that, like, the models, but smarter. I think all of the trends we're seeing right now are going to keep on going, especially the inference time compute, right?[00:03:21] Simon: The trick that O1 and O3 are doing, which means that you can solve harder problems, but they cost more and it churns aw
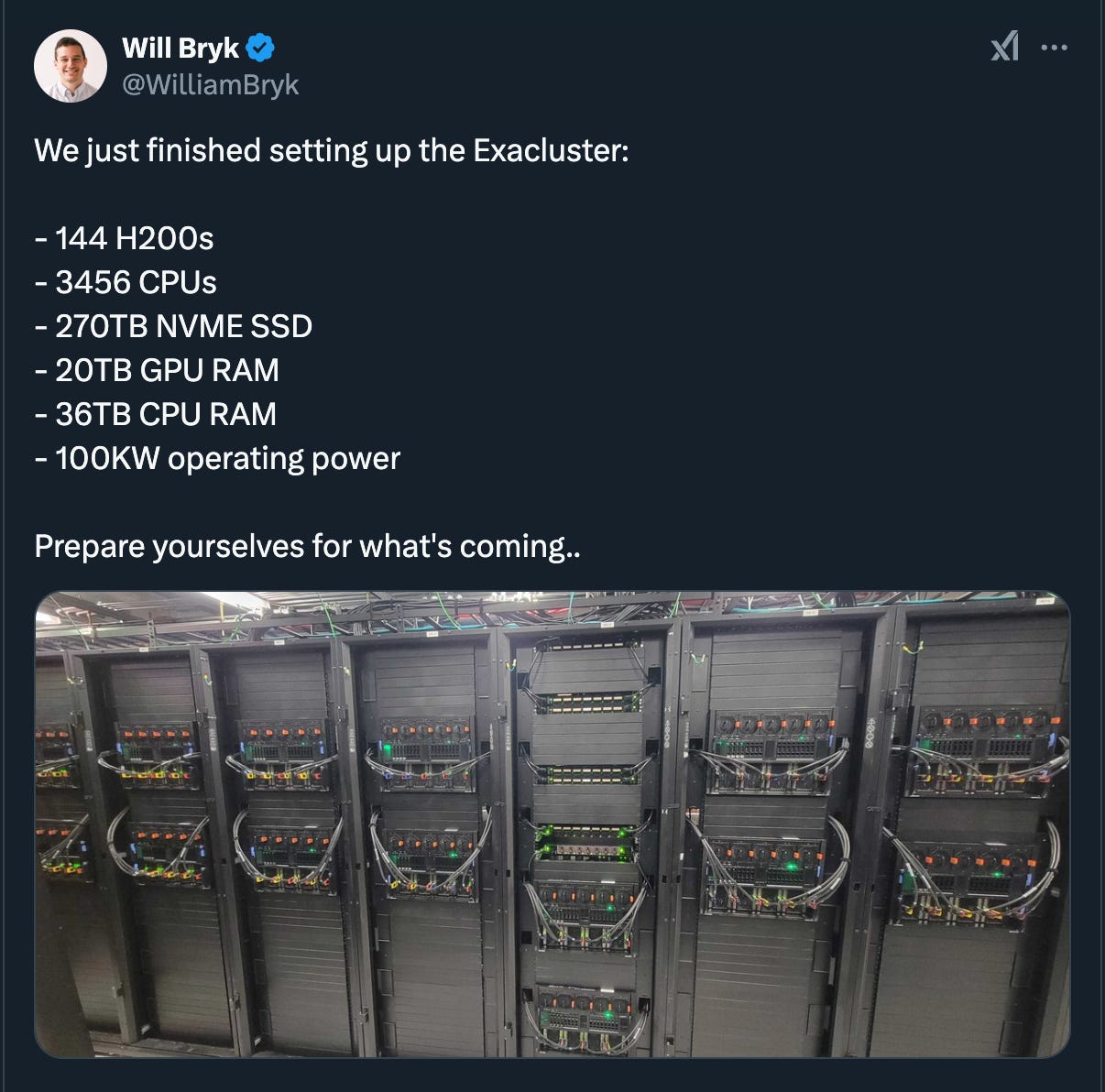
Beating Google at Search with Neural PageRank and $5M of H200s — with Will Bryk of Exa.ai
Applications close Monday for the NYC AI Engineer Summit focusing on AI Leadership and Agent Engineering! If you applied, invites should be rolling out shortly.The search landscape is experiencing a fundamental shift. Google built a >$2T company with the “10 blue links” experience, driven by PageRank as the core innovation for ranking. This was a big improvement from the previous directory-based experiences of AltaVista and Yahoo. Almost 4 decades later, Google is now stuck in this links-based experience, especially from a business model perspective. This legacy architecture creates fundamental constraints:* Must return results in ~400 milliseconds* Required to maintain comprehensive web coverage* Tied to keyword-based matching algorithms* Cost structures optimized for traditional indexingAs we move from the era of links to the era of answers, the way search works is changing. You’re not showing a user links, but the goal is to provide context to an LLM. This means moving from keyword based search to more semantic understanding of the content:The link prediction objective can be seen as like a neural PageRank because what you're doing is you're predicting the links people share... but it's more powerful than PageRank. It's strictly more powerful because people might refer to that Paul Graham fundraising essay in like a thousand different ways. And so our model learns all the different ways.All of this is now powered by a $5M cluster with 144 H200s:This architectural choice enables entirely new search capabilities:* Comprehensive result sets instead of approximations* Deep semantic understanding of queries* Ability to process complex, natural language requestsAs search becomes more complex, time to results becomes a variable:People think of searches as like, oh, it takes 500 milliseconds because we've been conditioned... But what if searches can take like a minute or 10 minutes or a whole day, what can you then do?Unlike traditional search engines' fixed-cost indexing, Exa employs a hybrid approach:* Front-loaded compute for indexing and embeddings* Variable inference costs based on query complexity* Mix of owned infrastructure ($5M H200 cluster) and cloud resourcesExa sees a lot of competition from products like Perplexity and ChatGPT Search which layer AI on top of traditional search backends, but Exa is betting that true innovation requires rethinking search from the ground up. For example, the recently launched Websets, a way to turn searches into structured output in grid format, allowing you to create lists and databases out of web pages. The company raised a $17M Series A to build towards this mission, so keep an eye out for them in 2025. Chapters* 00:00:00 Introductions* 00:01:12 ExaAI's initial pitch and concept* 00:02:33 Will's background at SpaceX and Zoox* 00:03:45 Evolution of ExaAI (formerly Metaphor Systems)* 00:05:38 Exa's link prediction technology* 00:09:20 Meaning of the name "Exa"* 00:10:36 ExaAI's new product launch and capabilities* 00:13:33 Compute budgets and variable compute products* 00:14:43 Websets as a B2B offering* 00:19:28 How do you build a search engine?* 00:22:43 What is Neural PageRank?* 00:27:58 Exa use cases * 00:35:00 Auto-prompting* 00:38:42 Building agentic search* 00:44:19 Is o1 on the path to AGI?* 00:49:59 Company culture and nap pods* 00:54:52 Economics of AI search and the future of search technologyFull YouTube TranscriptPlease like and subscribe!Show Notes* ExaAI* Web Search Product* Websets* Series A Announcement* Exa Nap Pods* Perplexity AI* Character.AITranscriptAlessio [00:00:00]: Hey, everyone. Welcome to the Latent Space podcast. This is Alessio, partner and CTO at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol.ai.Swyx [00:00:10]: Hey, and today we're in the studio with my good friend and former landlord, Will Bryk. Roommate. How you doing? Will, you're now CEO co-founder of ExaAI, used to be Metaphor Systems. What's your background, your story?Will [00:00:30]: Yeah, sure. So, yeah, I'm CEO of Exa. I've been doing it for three years. I guess I've always been interested in search, whether I knew it or not. Like, since I was a kid, I've always been interested in, like, high-quality information. And, like, you know, even in high school, wanted to improve the way we get information from news. And then in college, built a mini search engine. And then with Exa, like, you know, it's kind of like fulfilling the dream of actually being able to solve all the information needs I wanted as a kid. Yeah, I guess. I would say my entire life has kind of been rotating around this problem, which is pretty cool. Yeah.Swyx [00:00:50]: What'd you enter YC with?Will [00:00:53]: We entered YC with, uh, we are better than Google. Like, Google 2.0.Swyx [00:01:12]: What makes you say that? Like, that's so audacious to come out of the box with.Will [00:01:16]: Yeah, okay, so you have to remember the time. This was summer 2021. And, uh, GPT-3 had come out. Like,
AI Engineering for Art — with comfyanonymous, of ComfyUI
Applications for the NYC AI Engineer Summit, focused on Agents at Work, are open!When we first started Latent Space, in the lightning round we’d always ask guests: “What’s your favorite AI product?”. The majority would say Midjourney. The simple UI of prompt → very aesthetic image turned it into a $300M+ ARR bootstrapped business as it rode the first wave of AI image generation.In open source land, StableDiffusion was congregating around AUTOMATIC1111 as the de-facto web UI. Unlike Midjourney, which offered some flags but was mostly prompt-driven, A1111 let users play with a lot more parameters, supported additional modalities like img2img, and allowed users to load in custom models. If you’re interested in some of the SD history, you can look at our episodes with Lexica, Replicate, and Playground.One of the people involved with that community was comfyanonymous, who was also part of the Stability team in 2023, decided to build an alternative called ComfyUI, now one of the fastest growing open source projects in generative images, and is now the preferred partner for folks like Black Forest Labs’s Flux Tools on Day 1. The idea behind it was simple: “Everyone is trying to make easy to use interfaces. Let me try to make a powerful interface that's not easy to use.”Unlike its predecessors, ComfyUI does not have an input text box. Everything is based around the idea of a node: there’s a text input node, a CLIP node, a checkpoint loader node, a KSampler node, a VAE node, etc. While daunting for simple image generation, the tool is amazing for more complex workflows since you can break down every step of the process, and then chain many of them together rather than manually switching between tools. You can also re-start execution halfway instead of from the beginning, which can save a lot of time when using larger models.To give you an idea of some of the new use cases that this type of UI enables:* Sketch something → Generate an image with SD from sketch → feed it into SD Video to animate* Generate an image of an object → Turn into a 3D asset → Feed into interactive experiences* Input audio → Generate audio-reactive videosTheir Examples page also includes some of the more common use cases like AnimateDiff, etc. They recently launched the Comfy Registry, an online library of different nodes that users can pull from rather than having to build everything from scratch. The project has >60,000 Github stars, and as the community grows, some of the projects that people build have gotten quite complex:The most interesting thing about Comfy is that it’s not a UI, it’s a runtime. You can build full applications on top of image models simply by using Comfy. You can expose Comfy workflows as an endpoint and chain them together just like you chain a single node. We’re seeing the rise of AI Engineering applied to art.Major Tom’s ComfyUI Resources from the Latent Space DiscordMajor shoutouts to Major Tom on the LS Discord who is a image generation expert, who offered these pointers:* “best thing about comfy is the fact it supports almost immediately every new thing that comes out - unlike A1111 or forge, which still don't support flux cnet for instance. It will be perfect tool when conflicting nodes will be resolved”* AP Workflows from Alessandro Perili are a nice example of an all-in-one train-evaluate-generate system built atop Comfy* ComfyUI YouTubers to learn from:* @sebastiankamph* @NerdyRodent* @OlivioSarikas* @sedetweiler* @pixaroma* ComfyUI Nodes to check out:* https://github.com/kijai/ComfyUI-IC-Light* https://github.com/MrForExample/ComfyUI-3D-Pack* https://github.com/PowerHouseMan/ComfyUI-AdvancedLivePortrait* https://github.com/pydn/ComfyUI-to-Python-Extension* https://github.com/THtianhao/ComfyUI-Portrait-Maker* https://github.com/ssitu/ComfyUI_NestedNodeBuilder* https://github.com/longgui0318/comfyui-magic-clothing* https://github.com/atmaranto/ComfyUI-SaveAsScript* https://github.com/ZHO-ZHO-ZHO/ComfyUI-InstantID* https://github.com/AIFSH/ComfyUI-FishSpeech* https://github.com/coolzilj/ComfyUI-Photopea* https://github.com/lks-ai/anynode* Sarav: https://www.youtube.com/@mickmumpitz/videos ( applied stuff )* Sarav: https://www.youtube.com/@latentvision (technical, but infrequent)* look for comfyui node for https://github.com/magic-quill/MagicQuill* “Comfy for Video” resources* Kijai (https://github.com/kijai) pushing out support for Mochi, CogVideoX, AnimateDif, LivePortrait etc* Comfyui node support like LTX https://github.com/Lightricks/ComfyUI-LTXVideo , and HunyuanVideo* FloraFauna AI and Krea.ai* Communities: https://www.reddit.com/r/StableDiffusion/, https://www.reddit.com/r/comfyui/Full YouTube EpisodeAs usual, you can find the full video episode on our YouTube (and don’t forget to like and subscribe!)Timestamps* 00:00:04 Introduction of hosts and anonymous guest* 00:00:35 Origins of Comfy UI and early Stable Diffusion landscape* 00:02:58 Comfy's background and development of high-res fix* 00:05:37 Area co

Latent.Space 2024 Year in Review
Applications for the 2025 AI Engineer Summit are up, and you can save the date for AIE Singapore in April and AIE World’s Fair 2025 in June.Happy new year, and thanks for 100 great episodes! Please let us know what you want to see/hear for the next 100!Full YouTube Episode with Slides/ChartsLike and subscribe and hit that bell to get notifs!Timestamps* 00:00 Welcome to the 100th Episode!* 00:19 Reflecting on the Journey* 00:47 AI Engineering: The Rise and Impact* 03:15 Latent Space Live and AI Conferences* 09:44 The Competitive AI Landscape* 21:45 Synthetic Data and Future Trends* 35:53 Creative Writing with AI* 36:12 Legal and Ethical Issues in AI* 38:18 The Data War: GPU Poor vs. GPU Rich* 39:12 The Rise of GPU Ultra Rich* 40:47 Emerging Trends in AI Models* 45:31 The Multi-Modality War* 01:05:31 The Future of AI Benchmarks* 01:13:17 Pionote and Frontier Models* 01:13:47 Niche Models and Base Models* 01:14:30 State Space Models and RWKB* 01:15:48 Inference Race and Price Wars* 01:22:16 Major AI Themes of the Year* 01:22:48 AI Rewind: January to March* 01:26:42 AI Rewind: April to June* 01:33:12 AI Rewind: July to September* 01:34:59 AI Rewind: October to December* 01:39:53 Year-End Reflections and PredictionsTranscript[00:00:00] Welcome to the 100th Episode![00:00:00] Alessio: Hey everyone, welcome to the Latent Space Podcast. This is Alessio, partner and CTO at Decibel Partners, and I'm joined by my co host Swyx for the 100th time today.[00:00:12] swyx: Yay, um, and we're so glad that, yeah, you know, everyone has, uh, followed us in this journey. How do you feel about it? 100 episodes.[00:00:19] Alessio: Yeah, I know.[00:00:19] Reflecting on the Journey[00:00:19] Alessio: Almost two years that we've been doing this. We've had four different studios. Uh, we've had a lot of changes. You know, we used to do this lightning round. When we first started that we didn't like, and we tried to change the question. The answer[00:00:32] swyx: was cursor and perplexity.[00:00:34] Alessio: Yeah, I love mid journey. It's like, do you really not like anything else?[00:00:38] Alessio: Like what's, what's the unique thing? And I think, yeah, we, we've also had a lot more research driven content. You know, we had like 3DAO, we had, you know. Jeremy Howard, we had more folks like that.[00:00:47] AI Engineering: The Rise and Impact[00:00:47] Alessio: I think we want to do more of that too in the new year, like having, uh, some of the Gemini folks, both on the research and the applied side.[00:00:54] Alessio: Yeah, but it's been a ton of fun. I think we both started, I wouldn't say as a joke, we were kind of like, Oh, we [00:01:00] should do a podcast. And I think we kind of caught the right wave, obviously. And I think your rise of the AI engineer posts just kind of get people. Sombra to congregate, and then the AI engineer summit.[00:01:11] Alessio: And that's why when I look at our growth chart, it's kind of like a proxy for like the AI engineering industry as a whole, which is almost like, like, even if we don't do that much, we keep growing just because there's so many more AI engineers. So did you expect that growth or did you expect that would take longer for like the AI engineer thing to kind of like become, you know, everybody talks about it today.[00:01:32] swyx: So, the sign of that, that we have won is that Gartner puts it at the top of the hype curve right now. So Gartner has called the peak in AI engineering. I did not expect, um, to what level. I knew that I was correct when I called it because I did like two months of work going into that. But I didn't know, You know, how quickly it could happen, and obviously there's a chance that I could be wrong.[00:01:52] swyx: But I think, like, most people have come around to that concept. Hacker News hates it, which is a good sign. But there's enough people that have defined it, you know, GitHub, when [00:02:00] they launched GitHub Models, which is the Hugging Face clone, they put AI engineers in the banner, like, above the fold, like, in big So I think it's like kind of arrived as a meaningful and useful definition.[00:02:12] swyx: I think people are trying to figure out where the boundaries are. I think that was a lot of the quote unquote drama that happens behind the scenes at the World's Fair in June. Because I think there's a lot of doubt or questions about where ML engineering stops and AI engineering starts. That's a useful debate to be had.[00:02:29] swyx: In some sense, I actually anticipated that as well. So I intentionally did not. Put a firm definition there because most of the successful definitions are necessarily underspecified and it's actually useful to have different perspectives and you don't have to specify everything from the outset.[00:02:45] Alessio: Yeah, I was at um, AWS reInvent and the line to get into like the AI engineering talk, so to speak, which is, you know, applied AI and whatnot was like, there are like hundreds of people just in lin
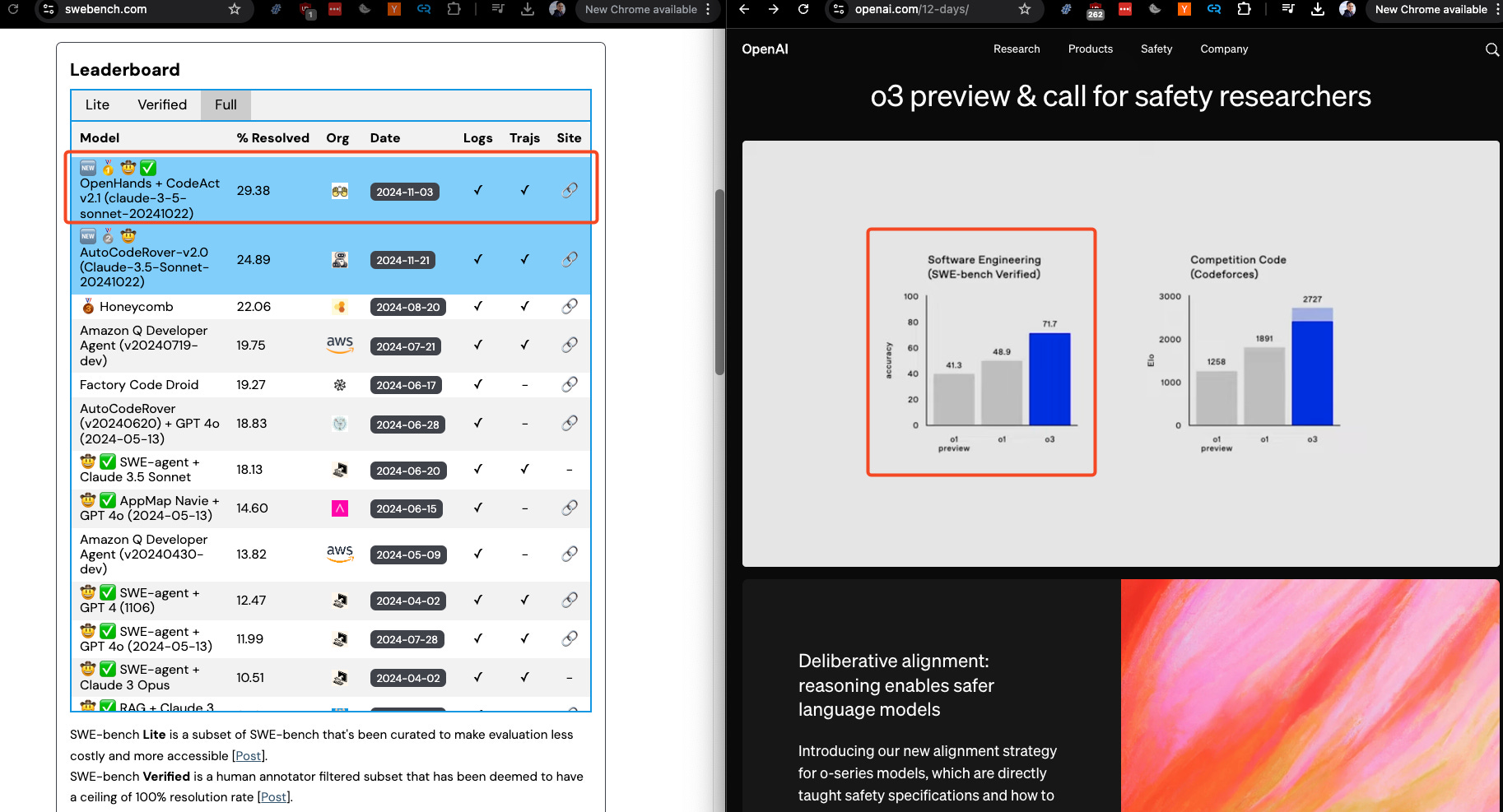
2024 in Agents [LS Live! @ NeurIPS 2024]
Happy holidays! We’ll be sharing snippets from Latent Space LIVE! through the break bringing you the best of 2024! We want to express our deepest appreciation to event sponsors AWS, Daylight Computer, Thoth.ai, StrongCompute, Notable Capital, and most of all all our LS supporters who helped fund the gorgeous venue and A/V production!For NeurIPS last year we did our standard conference podcast coverage interviewing selected papers (that we have now also done for ICLR and ICML), however we felt that we could be doing more to help AI Engineers 1) get more industry-relevant content, and 2) recap 2024 year in review from experts. As a result, we organized the first Latent Space LIVE!, our first in person miniconference, at NeurIPS 2024 in Vancouver.Our next keynote covers The State of LLM Agents, with the triumphant return of Professor Graham Neubig’s return to the pod (his ICLR episode here!). OpenDevin is now a startup known as AllHands! The renamed OpenHands has done extremely well this year, as they end the year sitting comfortably at number 1 on the hardest SWE-Bench Full leaderboard at 29%, though on the smaller SWE-Bench Verified, they are at 53%, behind Amazon Q, devlo, and OpenAI's self reported o3 results at 71.7%.Many are saying that 2025 is going to be the year of agents, with OpenAI, DeepMind and Anthropic setting their sights on consumer and coding agents, vision based computer-using agents and multi agent systems. There has been so much progress on the practical reliability and applications of agents in all domains, from the huge launch of Cognition AI's Devin this year, to the sleeper hit of Cursor Composer and Codeium's Windsurf Cascade in the IDE arena, to the explosive revenue growth of Stackblitz's Bolt, Lovable, and Vercel's v0, and the unicorn rounds and high profile movements of customer support agents like Sierra (now worth $4 billion) and search agents like Perplexity (now worth $9 billion). We wanted to take a little step back to understand the most notable papers of the year in Agents, and Graham indulged with his list of 8 perennial problems in building agents in 2024.Must-Read Papers for the 8 Problems of Agents* The agent-computer interface: CodeAct: Executable Code Actions Elicit Better LLM Agents. Minimial viable tools: Execution Sandbox, File Editor, Web Browsing* The human-agent interface: Chat UI, GitHub Plugin, Remote runtime, …?* Choosing an LLM: See Evaluation of LLMs as Coding Agents on SWE-Bench at 30x - must understand instructions, tools, code, environment, error recovery* Planning: Single Agent Systems vs Multi Agent (CoAct: A Global-Local Hierarchy for Autonomous Agent Collaboration) - Explicit vs Implicit, Curated vs Generated* Reusable common workflows: SteP: Stacked LLM Policies for Web Actions and Agent Workflow Memory - Manual prompting vs Learning from Experience* Exploration: Agentless: Demystifying LLM-based Software Engineering Agents and BAGEL: Bootstrapping Agents by Guiding Exploration with Language* Search: Tree Search for Language Model Agents - explore paths and rewind* Evaluation: Fast Sanity Checks (miniWoB and Aider) and Highly Realistic (WebArena, SWE-Bench) and SWE-Gym: An Open Environment for Training Software Engineering Agents & VerifiersFull Talk on YouTubePlease like and subscribe!Timestamps* 00:00 Welcome to Latent Space Live at NeurIPS 2024* 00:29 State of LLM Agents in 2024* 02:20 Professor Graham Newbig's Insights on Agents* 03:57 Live Demo: Coding Agents in Action* 08:20 Designing Effective Agents* 14:13 Choosing the Right Language Model for Agents* 16:24 Planning and Workflow for Agents* 22:21 Evaluation and Future Predictions for Agents* 25:31 Future of Agent Development* 25:56 Human-Agent Interaction Challenges* 26:48 Expanding Agent Use Beyond Programming* 27:25 Redesigning Systems for Agent Efficiency* 28:03 Accelerating Progress with Agent Technology* 28:28 Call to Action for Open Source Contributions* 30:36 Q&A: Agent Performance and Benchmarks* 33:23 Q&A: Web Agents and Interaction Methods* 37:16 Q&A: Agent Architectures and Improvements* 43:09 Q&A: Self-Improving Agents and Authentication* 47:31 Live Demonstration and Closing RemarksTranscript[00:00:29] State of LLM Agents in 2024[00:00:29] Speaker 9: Our next keynote covers the state of LLM agents. With the triumphant return of Professor Graham Newbig of CMU and OpenDevon, now a startup known as AllHands. The renamed OpenHands has done extremely well this year, as they end the year sitting comfortably at number one on the hardest SWE Benchful leaderboard at 29%.[00:00:53] Speaker 9: Though, on the smaller SWE bench verified, they are at 53 percent behind Amazon Q [00:01:00] Devlo and OpenAI's self reported O3 results at 71. 7%. Many are saying that 2025 is going to be the year of agents, with OpenAI, DeepMind, and Anthropic setting their sights on consumer and coding agents. Vision based computer using agents and multi agent systems.[00:01:22] Speaker 9: There has been so much pr
2024 in Synthetic Data and Smol Models [LS Live @ NeurIPS]
Happy holidays! We’ll be sharing snippets from Latent Space LIVE! through the break bringing you the best of 2024! We want to express our deepest appreciation to event sponsors AWS, Daylight Computer, Thoth.ai, StrongCompute, Notable Capital, and most of all all our LS supporters who helped fund the gorgeous venue and A/V production!For NeurIPS last year we did our standard conference podcast coverage interviewing selected papers (that we have now also done for ICLR and ICML), however we felt that we could be doing more to help AI Engineers 1) get more industry-relevant content, and 2) recap 2024 year in review from experts. As a result, we organized the first Latent Space LIVE!, our first in person miniconference, at NeurIPS 2024 in Vancouver. Today, we’re proud to share Loubna’s highly anticipated talk (slides here)!Synthetic DataWe called out the Synthetic Data debate at last year’s NeurIPS, and no surprise that 2024 was dominated by the rise of synthetic data everywhere:* Apple’s Rephrasing the Web, Microsoft’s Phi 2-4 and Orca/AgentInstruct, Tencent’s Billion Persona dataset, DCLM, and HuggingFace’s FineWeb-Edu, and Loubna’s own Cosmopedia extended the ideas of synthetic textbook and agent generation to improve raw web scrape dataset quality* This year we also talked to the IDEFICS/OBELICS team at HuggingFace who released WebSight this year, the first work on code-vs-images synthetic data.* We called Llama 3.1 the Synthetic Data Model for its extensive use (and documentation!) of synthetic data in its pipeline, as well as its permissive license. * Nemotron CC and Nemotron-4-340B also made a big splash this year for how they used 20k items of human data to synthesize over 98% of the data used for SFT/PFT.* Cohere introduced Multilingual Arbitrage: Optimizing Data Pools to Accelerate Multilingual Progress observing gains of up to 56.5% improvement in win rates comparing multiple teachers vs the single best teacher model* In post training, AI2’s Tülu3 (discussed by Luca in our Open Models talk) and Loubna’s Smol Talk were also notable open releases this year.This comes in the face of a lot of scrutiny and criticism, with Scale AI as one of the leading voices publishing AI models collapse when trained on recursively generated data in Nature magazine bringing mainstream concerns to the potential downsides of poor quality syndata:Part of the concerns we highlighted last year on low-background tokens are coming to bear: ChatGPT contaminated data is spiking in every possible metric:But perhaps, if Sakana’s AI Scientist pans out this year, we will have mostly-AI AI researchers publishing AI research anyway so do we really care as long as the ideas can be verified to be correct?Smol ModelsMeta surprised many folks this year by not just aggressively updating Llama 3 and adding multimodality, but also adding a new series of “small” 1B and 3B “on device” models this year, even working on quantized numerics collaborations with Qualcomm, Mediatek, and Arm. It is near unbelievable that a 1B model today can qualitatively match a 13B model of last year:and the minimum size to hit a given MMLU bar has come down roughly 10x in the last year. We have been tracking this proxied by Lmsys Elo and inference price:The key reads this year are:* MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases* Apple Intelligence Foundation Language Models* Hymba: A Hybrid-head Architecture for Small Language Models* Loubna’s SmolLM and SmolLM2: a family of state-of-the-art small models with 135M, 360M, and 1.7B parameters on the pareto efficiency frontier.* and Moondream, which we already covered in the 2024 in Vision talkFull Talk on YouTubeplease like and subscribe!Timestamps* [00:00:05] Loubna Intro* [00:00:33] The Rise of Synthetic Data Everywhere* [00:02:57] Model Collapse* [00:05:14] Phi, FineWeb, Cosmopedia - Synthetic Textbooks* [00:12:36] DCLM, Nemotron-CC* [00:13:28] Post Training - AI2 Tulu, Smol Talk, Cohere Multilingual Arbitrage* [00:16:17] Smol Models* [00:18:24] On Device Models* [00:22:45] Smol Vision Models* [00:25:14] What's NextTranscript2024 in Synthetic Data and Smol Models[00:00:00] [00:00:05] Loubna Intro[00:00:05] Speaker: I'm very happy to be here. Thank you for the invitation. So I'm going to be talking about synthetic data in 2024. And then I'm going to be talking about small on device models. So I think the most interesting thing about synthetic data this year is that like now we have it everywhere in the large language models pipeline.[00:00:33] The Rise of Synthetic Data Everywhere[00:00:33] Speaker: I think initially, synthetic data was mainly used just for post training, because naturally that's the part where we needed human annotators. And then after that, we realized that we don't really have good benchmarks to [00:01:00] measure if models follow instructions well, if they are creative enough, or if they are chatty enough, so we also started using LLMs as judges.[00:01:08]
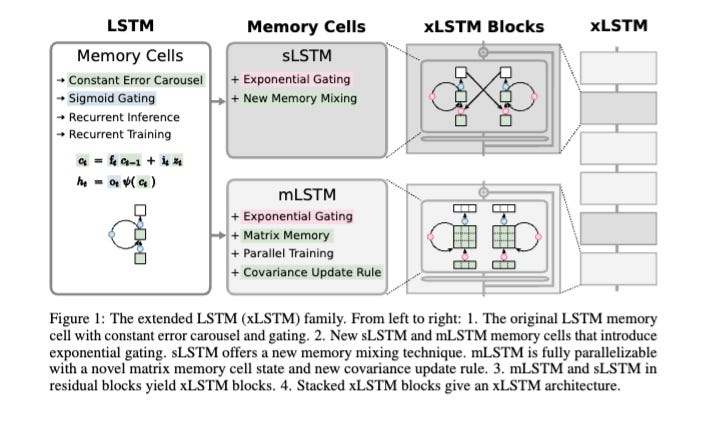
2024 in Post-Transformers Architectures (State Space Models, RWKV) [LS Live @ NeurIPS]
Happy holidays! We’ll be sharing snippets from Latent Space LIVE! through the break bringing you the best of 2024! We want to express our deepest appreciation to event sponsors AWS, Daylight Computer, Thoth.ai, StrongCompute, Notable Capital, and most of all all our LS supporters who helped fund the gorgeous venue and A/V production!Update: see followup discussion on HN and also the YouTube discussion.For NeurIPS last year we did our standard conference podcast coverage interviewing selected papers (that we have now also done for ICLR and ICML), however we felt that we could be doing more to help AI Engineers 1) get more industry-relevant content, and 2) recap 2024 year in review from experts. As a result, we organized the first Latent Space LIVE!, our first in person miniconference, at NeurIPS 2024 in Vancouver.Of perennial interest, particularly at academic conferences, is scaled-up architecture research as people hunt for the next Attention Is All You Need. We have many names for them: “efficient models”, “retentive networks”, “subquadratic attention” or “linear attention” but some of them don’t even have any lineage with attention - one of the best papers of this NeurIPS was Sepp Hochreiter’s xLSTM, which has a particularly poetic significance as one of the creators of the LSTM returning to update and challenge the OG language model architecture:So, for lack of a better term, we decided to call this segment “the State of Post-Transformers” and fortunately everyone rolled with it.We are fortunate to have two powerful friends of the pod to give us an update here:* Together AI: with CEO Vipul Ved Prakash and CTO Ce Zhang joining us to talk about how they are building Together together as a quote unquote full stack AI startup, from the lowest level kernel and systems programming to the highest level mathematical abstractions driving new model architectures and inference algorithms, with notable industry contributions from RedPajama v2, Flash Attention 3, Mamba 2, Mixture of Agents, BASED, Sequoia, Evo, Dragonfly, Dan Fu's ThunderKittens and many more research projects this year* Recursal AI: with CEO Eugene Cheah who has helped lead the independent RWKV project while also running Featherless AI. This year, the team has shipped RWKV v5, codenamed Eagle, to 1.5 billion Windows 10 and Windows 11 machines worldwide, to support Microsoft's on-device, energy-usage-sensitive Windows Copilot usecases, and has launched the first updates on RWKV v6, codenamed Finch and GoldFinch. On the morning of Latent Space Live, they also announced QRWKV6, a Qwen 32B model modified with RWKV linear attention layers. We were looking to host a debate between our speakers, but given that both of them were working on post-transformers alternativesFull Talk on YoutubePlease like and subscribe!LinksAll the models and papers they picked:* Earlier Cited Work* Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention* Hungry hungry hippos: Towards language modeling with state space models* Hyena hierarchy: Towards larger convolutional language models* Mamba: Linear-Time Sequence Modeling with Selective State Spaces* S4: Efficiently Modeling Long Sequences with Structured State Spaces* Just Read Twice (Arora et al)* Recurrent large language models that compete with Transformers in language modeling perplexity are emerging at a rapid rate (e.g., Mamba, RWKV). Excitingly, these architectures use a constant amount of memory during inference. However, due to the limited memory, recurrent LMs cannot recall and use all the information in long contexts leading to brittle in-context learning (ICL) quality. A key challenge for efficient LMs is selecting what information to store versus discard. In this work, we observe the order in which information is shown to the LM impacts the selection difficulty. * To formalize this, we show that the hardness of information recall reduces to the hardness of a problem called set disjointness (SD), a quintessential problem in communication complexity that requires a streaming algorithm (e.g., recurrent model) to decide whether inputted sets are disjoint. We empirically and theoretically show that the recurrent memory required to solve SD changes with set order, i.e., whether the smaller set appears first in-context. * Our analysis suggests, to mitigate the reliance on data order, we can put information in the right order in-context or process prompts non-causally. Towards that end, we propose: (1) JRT-Prompt, where context gets repeated multiple times in the prompt, effectively showing the model all data orders. This gives 11.0±1.3 points of improvement, averaged across 16 recurrent LMs and the 6 ICL tasks, with 11.9× higher throughput than FlashAttention-2 for generation prefill (length 32k, batch size 16, NVidia H100). We then propose (2) JRT-RNN, which uses non-causal prefix-linear-attention to process prompts and provides 99% of Transformer quality at 360M params., 30B tokens and 96% at 1

2024 in Open Models [LS Live @ NeurIPS]
Happy holidays! We’ll be sharing snippets from Latent Space LIVE! through the break bringing you the best of 2024! We want to express our deepest appreciation to event sponsors AWS, Daylight Computer, Thoth.ai, StrongCompute, Notable Capital, and most of all our LS supporters who helped fund the venue and A/V production!For NeurIPS last year we did our standard conference podcast coverage interviewing selected papers (that we have now also done for ICLR and ICML), however we felt that we could be doing more to help AI Engineers 1) get more industry-relevant content, and 2) recap 2024 year in review from experts. As a result, we organized the first Latent Space LIVE!, our first in person miniconference, at NeurIPS 2024 in Vancouver.Since Nathan Lambert ( Interconnects ) joined us for the hit RLHF 201 episode at the start of this year, it is hard to overstate how much Open Models have exploded this past year. In 2023 only five names were playing in the top LLM ranks, Mistral, Mosaic's MPT, TII UAE's Falcon, Yi from Kai-Fu Lee's 01.ai, and of course Meta's Llama 1 and 2. This year a whole cast of new open models have burst on the scene, from Google's Gemma and Cohere's Command R, to Alibaba's Qwen and Deepseek models, to LLM 360 and DCLM and of course to the Allen Institute's OLMo, OL MOE, Pixmo, Molmo, and Olmo 2 models. We were honored to host Luca Soldaini, one of the research leads on the Olmo series of models at AI2.Pursuing Open Model research comes with a lot of challenges beyond just funding and access to GPUs and datasets, particularly the regulatory debates this year across Europe, California and the White House. We also were honored to hear from and Sophia Yang, head of devrel at Mistral, who also presented a great session at the AI Engineer World's Fair Open Models track!Full Talk on YouTubePlease like and subscribe!Timestamps* 00:00 Welcome to Latent Space Live * 00:12 Recap of 2024: Best Moments and Keynotes * 01:22 Explosive Growth of Open Models in 2024 * 02:04 Challenges in Open Model Research * 02:38 Keynote by Luca Soldani: State of Open Models * 07:23 Significance of Open Source AI Licenses * 11:31 Research Constraints and Compute Challenges * 13:46 Fully Open Models: A New Trend * 27:46 Mistral's Journey and Innovations * 32:57 Interactive Demo: Lachat Capabilities * 36:50 Closing Remarks and NetworkingTranscriptSession3Audio[00:00:00] AI Charlie: Welcome to Latent Space Live, our first mini conference held at NeurIPS 2024 in Vancouver. This is Charlie, your AI co host. As a special treat this week, we're recapping the best of 2024 going domain by domain. We sent out a survey to the over 900 of you who told us what you wanted, and then invited the best speakers in the latent space network to cover each field.[00:00:28] AI Charlie: 200 of you joined us in person throughout the day, with over 2, 200 watching live online. Our next keynote covers the state of open models in 2024, with Luca Soldani and Nathan Lambert of the Allen Institute for AI, with a special appearance from Dr. Sophia Yang of Mistral. Our first hit episode of 2024 was with Nathan Lambert on RLHF 201 back in January.[00:00:57] AI Charlie: Where he discussed both reinforcement learning for language [00:01:00] models and the growing post training and mid training stack with hot takes on everything from constitutional AI to DPO to rejection sampling and also previewed the sea change coming to the Allen Institute. And to Interconnects, his incredible substack on the technical aspects of state of the art AI training.[00:01:18] AI Charlie: We highly recommend subscribing to get access to his Discord as well. It is hard to overstate how much open models have exploded this past year. In 2023, only five names were playing in the top LLM ranks. Mistral, Mosaics MPT, and Gatsby. TII UAE's Falcon, Yi, from Kaifu Lee's 01. ai, And of course, Meta's Lama 1 and 2.[00:01:43] AI Charlie: This year, a whole cast of new open models have burst on the scene. From Google's Jemma and Cohere's Command R, To Alibaba's Quen and DeepSeq models, to LLM360 and DCLM, and of course, to the Allen Institute's OLMO, [00:02:00] OLMOE, PIXMO, MOLMO, and OLMO2 models. Pursuing open model research comes with a lot of challenges beyond just funding and access to GPUs and datasets, particularly the regulatory debates this year across Europe.[00:02:14] AI Charlie: California and the White House. We also were honored to hear from Mistral, who also presented a great session at the AI Engineer World's Fair Open Models track. As always, don't forget to check the show notes for the YouTube link to their talk, as well as their slides. Watch out and take care.[00:02:35] Luca Intro[00:02:35] Luca Soldaini: Cool. Yeah, thanks for having me over. I'm Luca. I'm a research scientist at the Allen Institute for AI. I threw together a few slides on sort of like a recap of like interesting themes in open models for, for 2024. Have about maybe 20, 25 minutes of slides, and then we
2024 in Vision [LS Live @ NeurIPS]
Happy holidays! We’ll be sharing snippets from Latent Space LIVE! through the break bringing you the best of 2024! We want to express our deepest appreciation to event sponsors AWS, Daylight Computer, Thoth.ai, StrongCompute, Notable Capital, and most of all all our LS supporters who helped fund the gorgeous venue and A/V production!For NeurIPS last year we did our standard conference podcast coverage interviewing selected papers (that we have now also done for ICLR and ICML), however we felt that we could be doing more to help AI Engineers 1) get more industry-relevant content, and 2) recap 2024 year in review from experts. As a result, we organized the first Latent Space LIVE!, our first in person miniconference, at NeurIPS 2024 in Vancouver.The single most requested domain was computer vision, and we could think of no one better to help us recap 2024 than our friends at Roboflow, who was one of our earliest guests in 2023 and had one of this year’s top episodes in 2024 again. Roboflow has since raised a $40m Series B!LinksTheir slides are here:All the trends and papers they picked:* Isaac Robinson* Sora (see our Video Diffusion pod) - extending diffusion from images to video* SAM 2: Segment Anything in Images and Videos (see our SAM2 pod) - extending prompted masks to full video object segmentation* DETR Dominancy: DETRs show Pareto improvement over YOLOs* RT-DETR: DETRs Beat YOLOs on Real-time Object Detection* LW-DETR: A Transformer Replacement to YOLO for Real-Time Detection* D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement* Peter Robicheaux* MMVP (Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs)* * Florence 2 (Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks) * PalíGemma / PaliGemma 2* PaliGemma: A versatile 3B VLM for transfer* PaliGemma 2: A Family of Versatile VLMs for Transfer* AlMv2 (Multimodal Autoregressive Pre-training of Large Vision Encoders) * Vik Korrapati - MoondreamFull Talk on YouTubeWant more content like this? Like and subscribe to stay updated on our latest talks, interviews, and podcasts.Transcript/Timestamps[00:00:00] Intro[00:00:05] AI Charlie: welcome to Latent Space Live, our first mini conference held at NeurIPS 2024 in Vancouver. This is Charlie, your AI co host. When we were thinking of ways to add value to our academic conference coverage, we realized that there was a lack of good talks, just recapping the best of 2024, going domain by domain.[00:00:36] AI Charlie: We sent out a survey to the over 900 of you. who told us what you wanted, and then invited the best speakers in the Latent Space Network to cover each field. 200 of you joined us in person throughout the day, with over 2, 200 watching live online. Our second featured keynote is The Best of Vision 2024, with Peter Robichaud and Isaac [00:01:00] Robinson of Roboflow, with a special appearance from Vic Corrapati of Moondream.[00:01:05] AI Charlie: When we did a poll of our attendees, the highest interest domain of the year was vision. And so our first port of call was our friends at Roboflow. Joseph Nelson helped us kickstart our vision coverage in episode 7 last year, and this year came back as a guest host with Nikki Ravey of Meta to cover segment Anything 2.[00:01:25] AI Charlie: Roboflow have consistently been the leaders in open source vision models and tooling. With their SuperVision library recently eclipsing PyTorch's Vision library. And Roboflow Universe hosting hundreds of thousands of open source vision datasets and models. They have since announced a 40 million Series B led by Google Ventures.[00:01:46] AI Charlie: Woohoo.[00:01:48] Isaac's picks[00:01:48] Isaac Robinson: Hi, we're Isaac and Peter from Roboflow, and we're going to talk about the best papers of 2024 in computer vision. So, for us, we defined best as what made [00:02:00] the biggest shifts in the space. And to determine that, we looked at what are some major trends that happened and what papers most contributed to those trends.[00:02:09] Isaac Robinson: So I'm going to talk about a couple trends, Peter's going to talk about a trend, And then we're going to hand it off to Moondream. So, the trends that I'm interested in talking about are These are a major transition from models that run on per image basis to models that run using the same basic ideas on video.[00:02:28] Isaac Robinson: And then also how debtors are starting to take over the real time object detection scene from the YOLOs, which have been dominant for years.[00:02:37] Sora, OpenSora and Video Vision vs Generation[00:02:37] Isaac Robinson: So as a highlight we're going to talk about Sora, which from my perspective is the biggest paper of 2024, even though it came out in February. Is the what?[00:02:48] Isaac Robinson: Yeah. Yeah. So just it's a, SORA is just a a post. So I'm going to fill it in with details from replication efforts, including open SORA and related work, such as a stable [00:03:0
2024 in AI Startups [LS Live @ NeurIPS]
Happy holidays! We’ll be sharing snippets from Latent Space LIVE! through the break bringing you the best of 2024 from friends of the pod!For NeurIPS last year we did our standard conference podcast coverage interviewing selected papers (that we have now also done for ICLR and ICML), however we felt that we could be doing more to help AI Engineers 1) get more industry-relevant content, and 2) recap 2024 year in review from experts. As a result, we organized the first Latent Space LIVE!, our first in person miniconference, at NeurIPS 2024 in Vancouver. For our opening keynote, we could think of no one better to cover 'The State of AI Startups' than our friend Sarah Guo (AI superinvestor, founder of Conviction, host of No Priors!) and Pranav Reddy (Conviction partner) to share their takes on how the AI landscape evolved in 2024 examine the evolving AI landscape and what it means for startups, enterprises, and the industry as a whole! They completely understood the assignment.Recorded live with 200+ in-person and 2200+ online attendees at NeurIPS 2024, this keynote kicks off our mini-conference series exploring different domains of AI development in 2024. Enjoy!LinksSlides: https://x.com/saranormous/status/1866933642401886707Sarh Guo: https://x.com/saranormousPranav Reddy: https://x.com/prnvrdyFull Video on YouTubeWant more content like this? Like and subscribe to stay updated on our latest talks, interviews, and podcasts. This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe
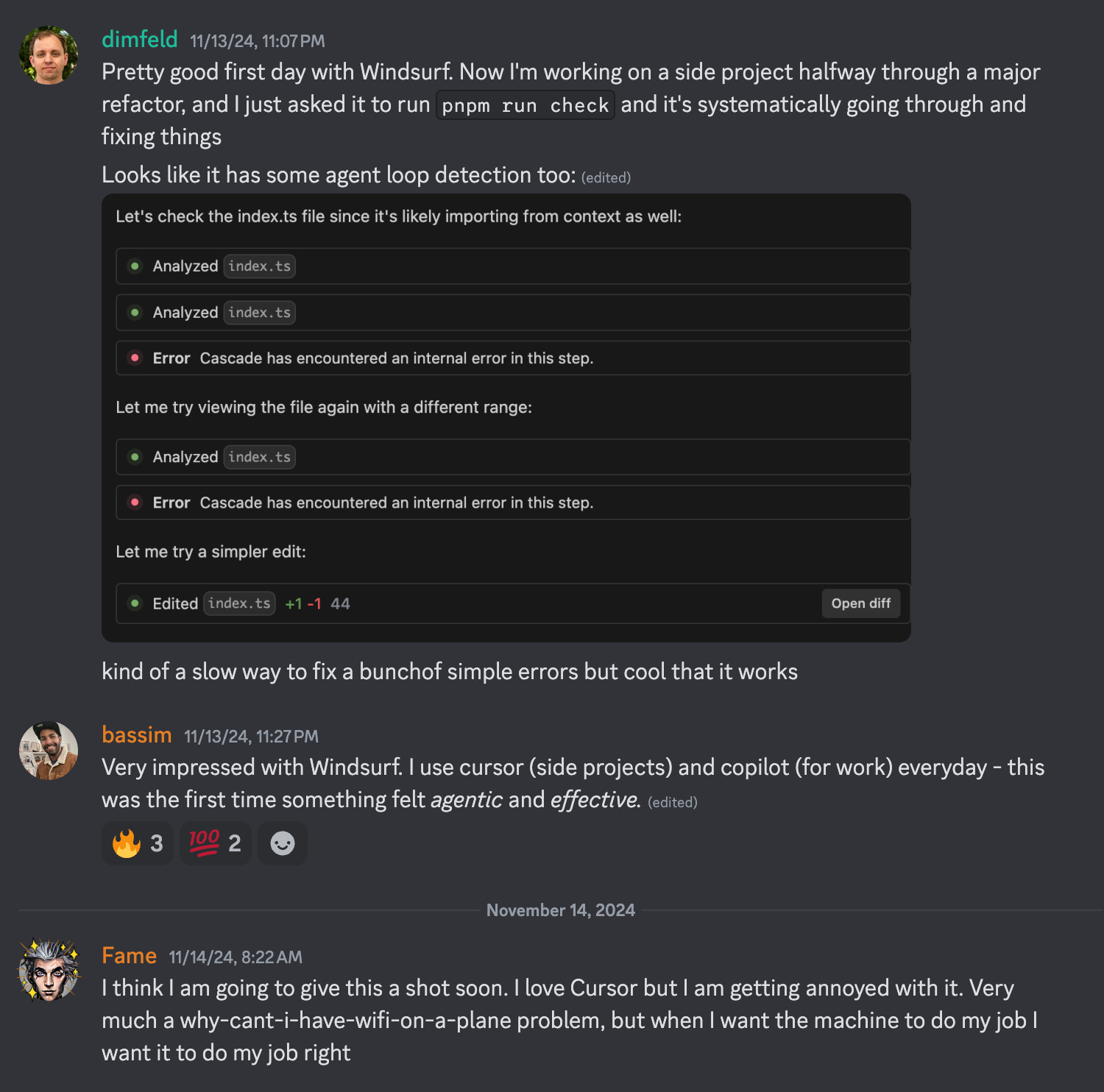
Windsurf: The Enterprise AI IDE - with Varun and Anshul of Codeium AI
Our second podcast guest ever in March 2023 was Varun Mohan, CEO of Codeium; at the time, they had around 10,000 users and how they vowed to keep their autocomplete free forever: Today, over a million developers use their products, they still have their free tier, and they recently launched Windsurf, an AI IDE. Chapters* 00:00:00: Introductions & Catchup* 00:03:52: Why they created Windsurf* 00:05:52: Limitations of VS Code* 00:10:12: Evaluation methods for Cascade and Windsurf* 00:16:15: Listener questions about Windsurf launch* 00:20:30: Remote execution and security concerns* 00:25:18: Evolution of Codeium's strategy* 00:28:29: Cascade and its capabilities* 00:33:12: Multi-agent systems* 00:37:02: Areas of improvement for Windsurf* 00:39:12: Building an enterprise-first company* 00:42:01: Copilot for X, AI UX, and Enterprise AI blog posts This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

Generative Video WorldSim, Diffusion, Vision, Reinforcement Learning and Robotics — ICML 2024 Part 1
Regular tickets are now sold out for Latent Space LIVE! at NeurIPS! We have just announced our last speaker and newest track, friend of the pod Nathan Lambert who will be recapping 2024 in Reasoning Models like o1! We opened up a handful of late bird tickets for those who are deciding now — use code DISCORDGANG if you need it. See you in Vancouver!We’ve been sitting on our ICML recordings for a while (from today’s first-ever SOLO guest cohost, Brittany Walker), and in light of Sora Turbo’s launch (blogpost, tutorials) today, we figured it would be a good time to drop part one which had been gearing up to be a deep dive into the state of generative video worldsim, with a seamless transition to vision (the opposite modality), and finally robots (their ultimate application).Sora, Genie, and the field of Generative Video World SimulatorsBill Peebles, author of Diffusion Transformers, gave his most recent Sora talk at ICML, which begins our episode:* William (Bill) Peebles - SORA (slides)Something that is often asked about Sora is how much inductive biases were introduced to achieve these results. Bill references the same principles brought by Hyung Won Chung from the o1 team - “sooner or later those biases come back to bite you”.We also recommend these reads from throughout 2024 on Sora.* Lilian Weng’s literature review of Video Diffusion Models* Sora API leak* Estimates of 100k-700k H100s needed to serve Sora (not Turbo)* Artist guides on using Sora for professional storytellingGoogle DeepMind had a remarkably strong presence at ICML on Video Generation Models, winning TWO Best Paper awards for:* Genie: Generative Interactive Environments (covered in oral, poster, and workshop)* VideoPoet: A Large Language Model for Zero-Shot Video Generation (see website)We end this part by taking in Tali Dekel’s talk on The Future of Video Generation: Beyond Data and Scale.Part 2: Generative Modeling and DiffusionSince 2023, Sander Dieleman’s perspectives (blogpost, tweet) on diffusion as “spectral autoregression in the frequency domain” while working on Imagen and Veo have caught the public imagination, so we highlight his talk:* Wading through the noise: an intuitive look at diffusion modelsThen we go to Ben Poole for his talk on Inferring 3D Structure with 2D Priors, including his work on NeRFs and DreamFusion:Then we investigate two flow matching papers - one from the Flow Matching co-authors - Ricky T. Q. Chen (FAIR, Meta)And how it is implemented in Stable Diffusion 3 with Scaling Rectified Flow Transformers for High-Resolution Image Synthesis Our last hit on Diffusion is a couple of oral presentations on speech, which we leave you to explore via our audio podcast* NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models* Speech Self-Supervised Learning Using Diffusion Model Synthetic DataPart 3: VisionThe ICML Test of Time winner was DeCAF, which Trevor Darrell notably called “the OG vision foundation model”.Lucas Beyer’s talk on “Vision in the age of LLMs — a data-centric perspective” was also well received online, and he talked about his journey from Vision Transformers to PaliGemma.We give special honorable mention to MLLM-as-a-Judge: Assessing Multimodal LLM-as-a-Judge with Vision-Language Benchmark.Part 4: Reinforcement Learning and RoboticsWe segue vision into robotics with the help of Ashley Edwards, whose work on both the Gato and the Genie teams at Deepmind is summarized in Learning actions, policies, rewards, and environments from videos alone.Brittany highlighted two poster session papers:* Behavior Generation with Latent Actions* We also recommend Lerrel Pinto’s On Building General-Purpose Robots* PIVOT: Iterative Visual Prompting Elicits Actionable Knowledge for VLMsHowever we must give the lion’s share of space to Chelsea Finn, now founder of Physical Intelligence, who gave FOUR talks on* "What robots have taught me about machine learning"* developing robot generalists* robots that adapt autonomously* how to give feedback to your language model* special mention to PI colleague Sergey Levine on Robotic Foundation ModelsWe end the podcast with a position paper that links generative environments and RL/robotics: Automatic Environment Shaping is the Next Frontier in RL.Timestamps* [00:00:00] Intros* [00:02:43] Sora - Bill Peebles* [00:44:52] Genie: Generative Interactive Environments* [01:00:17] Genie interview* [01:12:33] VideoPoet: A Large Language Model for Zero-Shot Video Generation* [01:30:51] VideoPoet interview - Dan Kondratyuk* [01:42:00] Tali Dekel - The Future of Video Generation: Beyond Data and Scale.* [02:27:07] Sander Dieleman - Wading through the noise: an intuitive look at diffusion models* [03:06:20] Ben Poole - Inferring 3D Structure with 2D Priors* [03:30:30] Ricky Chen - Flow Matching* [04:00:03] Patrick Esser - Stable Diffusion 3* [04:14:30] NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models* [04:27:00] Speech Self-Supervi
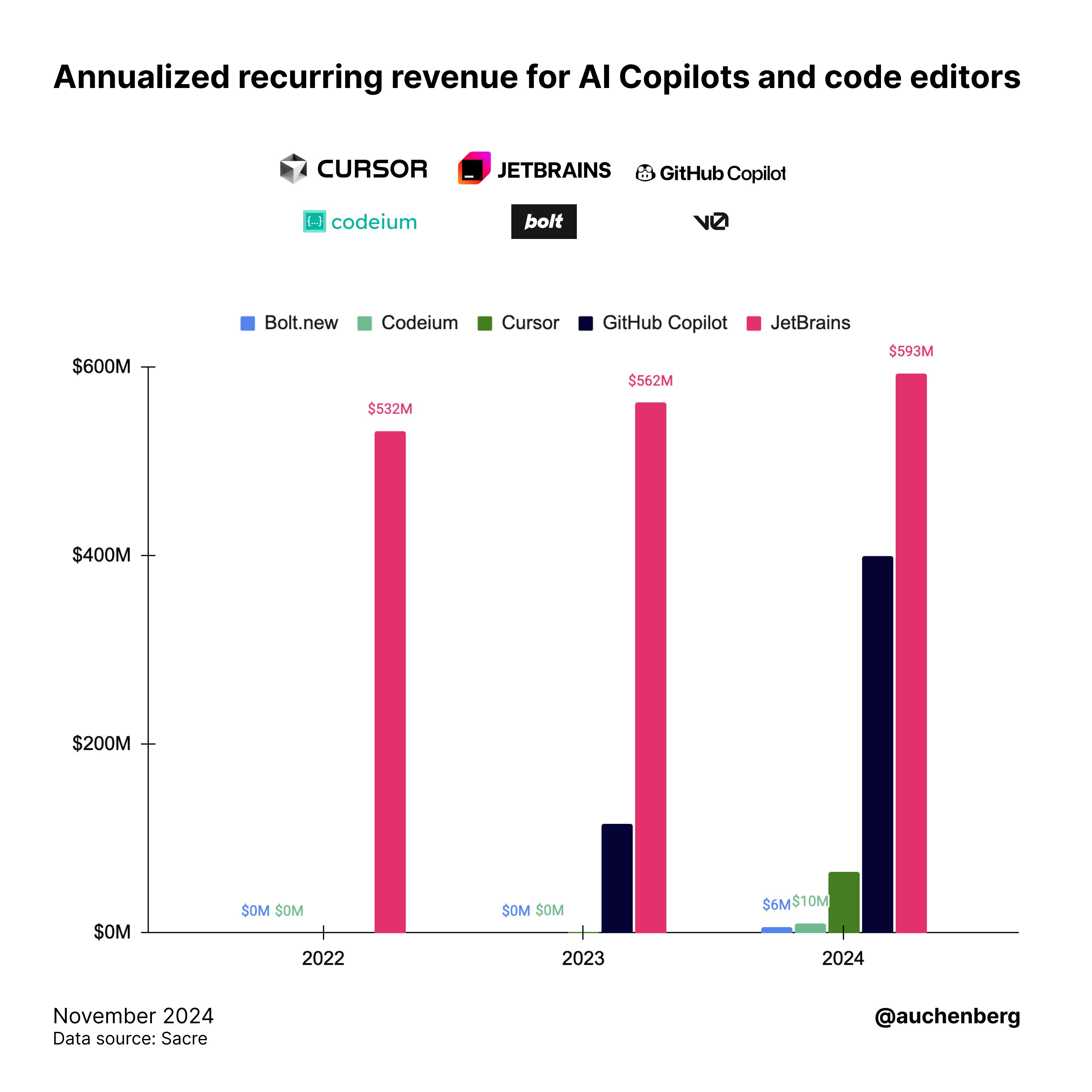
Bolt.new, Flow Engineering for Code Agents, and >$8m ARR in 2 months as a Claude Wrapper
The full schedule for Latent Space LIVE! at NeurIPS has been announced, featuring Best of 2024 overview talks for the AI Startup Landscape, Computer Vision, Open Models, Transformers Killers, Synthetic Data, Agents, and Scaling, and speakers from Sarah Guo of Conviction, Roboflow, AI2/Meta, Recursal/Together, HuggingFace, OpenHands and SemiAnalysis. Join us for the IRL event/Livestream! Alessio will also be holding a meetup at AWS Re:Invent in Las Vegas this Wednesday. See our new Events page for dates of AI Engineer Summit, Singapore, and World’s Fair in 2025. LAST CALL for questions for our big 2024 recap episode! Submit questions and messages on Speakpipe here for a chance to appear on the show!When we first observed that GPT Wrappers are Good, Actually, we did not even have Bolt on our radar. Since we recorded our Anthropic episode discussing building Agents with the new Claude 3.5 Sonnet, Bolt.new (by Stackblitz) has easily cleared the $8m ARR bar, repeating and accelerating its initial $4m feat.There are very many AI code generators and VS Code forks out there, but Bolt probably broke through initially because of its incredible zero shot low effort app generation:But as we explain in the pod, Bolt also emphasized deploy (Netlify)/ backend (Supabase)/ fullstack capabilities on top of Stackblitz’s existing WebContainer full-WASM-powered-developer-environment-in-the-browser tech. Since then, the team has been shipping like mad (with weekly office hours), with bugfixing, full screen, multi-device, long context, diff based edits (using speculative decoding like we covered in Inference, Fast and Slow).All of this has captured the imagination of low/no code builders like Greg Isenberg and many others on YouTube/TikTok/Reddit/X/Linkedin etc:Just as with Fireworks, our relationship with Bolt/Stackblitz goes a bit deeper than normal - swyx advised the launch and got a front row seat to this epic journey, as well as demoed it with Realtime Voice at the recent OpenAI Dev Day. So we are very proud to be the first/closest to tell the full open story of Bolt/Stackblitz!Flow Engineering + Qodo/AlphaCodium UpdateIn year 2 of the pod we have been on a roll getting former guests to return as guest cohosts (Harrison Chase, Aman Sanger, Jon Frankle), and it was a pleasure to catch Itamar Friedman back on the pod, giving us an update on all things Qodo and Testing Agents from our last catchup a year and a half ago:Qodo (they renamed in September) went viral in early January this year with AlphaCodium (paper here, code here) beating DeepMind’s AlphaCode with high efficiency:With a simple problem solving code agent:* The first step is to have the model reason about the problem. They describe it using bullet points and focus on the goal, inputs, outputs, rules, constraints, and any other relevant details.* Then, they make the model reason about the public tests and come up with an explanation of why the input leads to that particular output. * The model generates two to three potential solutions in text and ranks them in terms of correctness, simplicity, and robustness. * Then, it generates more diverse tests for the problem, covering cases not part of the original public tests. * Iteratively, pick a solution, generate the code, and run it on a few test cases. * If the tests fail, improve the code and repeat the process until the code passes every test.swyx has previously written similar thoughts on types vs tests for putting bounds on program behavior, but AlphaCodium extends this to AI generated tests and code.More recently, Itamar has also shown that AlphaCodium’s techniques also extend well to the o1 models:Making Flow Engineering a useful technique to improve code model performance on every model. This is something we see AI Engineers uniquely well positioned to do compared to ML Engineers/Researchers.Full Video PodcastLike and subscribe!Show Notes* Itamar* Qodo* First episode* Eric* Bolt* StackBlitz* Thinkster* AlphaCodium* WebContainersChapters* 00:00:00 Introductions & Updates* 00:06:01 Generic vs. Specific AI Agents* 00:07:40 Maintaining vs Creating with AI* 00:17:46 Human vs Agent Computer Interfaces* 00:20:15 Why Docker doesn't work for Bolt* 00:24:23 Creating Testing and Code Review Loops* 00:28:07 Bolt's Task Breakdown Flow* 00:31:04 AI in Complex Enterprise Environments* 00:41:43 AlphaCodium* 00:44:39 Strategies for Breaking Down Complex Tasks* 00:45:22 Building in Open Source* 00:50:35 Choosing a product as a founder* 00:59:03 Reflections on Bolt Success* 01:06:07 Building a B2C GTM* 01:18:11 AI Capabilities and Pricing Tiers* 01:20:28 What makes Bolt unique* 01:23:07 Future Growth and Product Development* 01:29:06 Competitive Landscape in AI Engineering* 01:30:01 Advice to Founders and Embracing AI* 01:32:20 Having a baby and completing an Iron ManTranscriptAlessio [00:00:00]: Hey everyone, welcome to the Latent Space Podcast. This is Alessio, partner and CTO at Decibel Partners, and I'm joined by my co-host S
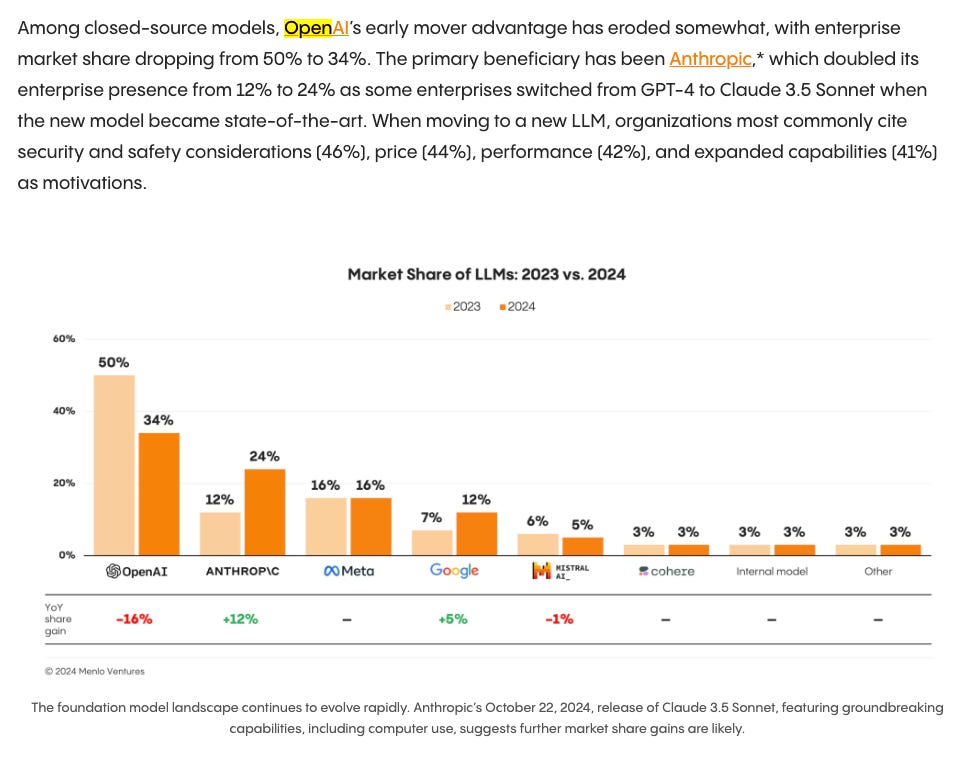
The new Claude 3.5 Sonnet, Computer Use, and Building SOTA Agents — with Erik Schluntz, Anthropic
We have announced our first speaker, friend of the show Dylan Patel, and topic slates for Latent Space LIVE! at NeurIPS. Sign up for IRL/Livestream and to debate!We are still taking questions for our next big recap episode! Submit questions and messages on Speakpipe here for a chance to appear on the show!The vibe shift we observed in July - in favor of Claude 3.5 Sonnet, first introduced in June — has been remarkably long lived and persistent, surviving multiple subsequent updates of 4o, o1 and Gemini versions, for Anthropic’s Claude to end 2024 as the preferred model for AI Engineers and even being the exclusive choice for new code agents like bolt.new (our next guest on the pod!), which unlocked so much performance from Claude Sonnet that it went from $0 to $4m ARR in 4 weeks when it launched last month.Anthropic has now raised an additional $4b from Amazon and made an incredibly well received update of Claude 3.5 Sonnet (and Haiku), making significant improvements in performance over its predecessors:Solving SWE-BenchAs part of the October Sonnet release, Anthropic teased a blink-and-you’ll miss it result:The updated Claude 3.5 Sonnet shows wide-ranging improvements on industry benchmarks, with particularly strong gains in agentic coding and tool use tasks. On coding, it improves performance on SWE-bench Verified from 33.4% to 49.0%, scoring higher than all publicly available models—including reasoning models like OpenAI o1-preview and specialized systems designed for agentic coding. It also improves performance on TAU-bench, an agentic tool use task, from 62.6% to 69.2% in the retail domain, and from 36.0% to 46.0% in the more challenging airline domain. The new Claude 3.5 Sonnet offers these advancements at the same price and speed as its predecessor.This was followed up by a blogpost a week later from today’s guest, Erik Schluntz, the engineer who implemented and scored this SOTA result using a simple, non-overengineered version of the SWE-Agent framework (you can see the submissions here). We have previously covered the SWE-Bench story extensively:* Speaking with SWEBench/SWEAgent authors at ICLR* Speaking with Cosine Genie, the previous SOTA (43.8%) on SWEBench Verified (with brief update at DevDay 2024)* Speaking with Shunyu Yao on SWEBench and the ReAct paradigm driving SWE-AgentOne of the notable inclusions in this blogpost are the tools that Erik decided to give Claude, e.g. the “Edit Tool”:The tools teased in the SWEBench submission/blogpost were then polished up and released with Computer Use…And you can also see even more computer use tools given in the new Model Context Protocol servers:Claude Computer UseBecause it is one of the best received AI releases of the year, we recommend watching the 2 minute Computer Use intro (and related demos) in its entirety:Eric also worked on Claude’s function calling, tool use, and computer use APIs, so we discuss that in the episode.Erik [00:53:39]: With computer use, just give the thing a browser that's logged into what you want to integrate with, and it's going to work immediately. And I see that reduction in friction as being incredibly exciting. Imagine a customer support team where, okay, hey, you got this customer support bot, but you need to go integrate it with all these things. And you don't have any engineers on your customer support team. But if you can just give the thing a browser that's logged into your systems that you need it to have access to, now, suddenly, in one day, you could be up and rolling with a fully integrated customer service bot that could go do all the actions you care about. So I think that's the most exciting thing for me about computer use, is reducing that friction of integrations to almost zero.As you’ll see, this is very top of mind for Erik as a former Robotics founder who’s company basically used robots to interface with human physical systems like elevators.Full Video episodePlease like and subscribe!Show Notes* Eric Schluntz* “Raising the bar on SWE-Bench Verified”* Cobalt Robotics* SWE-Bench* SWE-Bench Verified* Human Eval & other benchmarks* Anthropic Workbench* Aider* Cursor* Fireworks AI* E2B* Amanda Askell* Toyota Research* Physical Intelligence (Pi)* Chelsea Finn* Josh Albrecht* Eric Jang* 1X* Dust* Cosine Episode* Bolt* Adept Episode* TauBench* LMSys EpisodeTimestamps* [00:00:00] Introductions* [00:03:39] What is SWE-Bench?* [00:12:22] SWE-Bench vs HumanEval vs others* [00:15:21] SWE-Agent architecture and runtime* [00:21:18] Do you need code indexing?* [00:24:50] Giving the agent tools* [00:27:47] Sandboxing for coding agents* [00:29:16] Why not write tests?* [00:30:31] Redesigning engineering tools for LLMs* [00:35:53] Multi-agent systems* [00:37:52] Why XML so good?* [00:42:57] Thoughts on agent frameworks* [00:45:12] How many turns can an agent do?* [00:47:12] Using multiple model types* [00:51:40] Computer use and agent use cases* [00:59:04] State of AI robotics* [01:04:24] Robotics in manufacturing* [0
Why Compound AI + Open Source will beat Closed AI
We have a full slate of upcoming events: AI Engineer London, AWS Re:Invent in Las Vegas, and now Latent Space LIVE! at NeurIPS in Vancouver and online. Sign up to join and speak!We are still taking questions for our next big recap episode! Submit questions and messages on Speakpipe here for a chance to appear on the show!We try to stay close to the inference providers as part of our coverage, as our podcasts with Together AI and Replicate will attest: However one of the most notable pull quotes from our very well received Braintrust episode was his opinion that open source model adoption has NOT gone very well and is actually declining in relative market share terms (it is of course increasing in absolute terms):Today’s guest, Lin Qiao, would wholly disagree. Her team of Pytorch/GPU experts are wholly dedicated toward helping you serve and finetune the full stack of open source models from Meta and others, across all modalities (Text, Audio, Image, Embedding, Vision-understanding), helping customers like Cursor and Hubspot scale up open source model inference both rapidly and affordably.Fireworks has emerged after its successive funding rounds with top tier VCs as one of the leaders of the Compound AI movement, a term first coined by the Databricks/Mosaic gang at Berkeley AI and adapted as “Composite AI” by Gartner:Replicating o1We are the first podcast to discuss Fireworks’ f1, their proprietary replication of OpenAI’s o1. This has become a surprisingly hot area of competition in the past week as both Nous Forge and Deepseek r1 have launched competitive models.Full Video PodcastLike and subscribe!Timestamps* 00:00:00 Introductions* 00:02:08 Pre-history of Fireworks and PyTorch at Meta* 00:09:49 Product Strategy: From Framework to Model Library* 00:13:01 Compound AI Concept and Industry Dynamics* 00:20:07 Fireworks' Distributed Inference Engine* 00:22:58 OSS Model Support and Competitive Strategy* 00:29:46 Declarative System Approach in AI* 00:31:00 Can OSS replicate o1?* 00:36:51 Fireworks f1* 00:41:03 Collaboration with Cursor and Speculative Decoding* 00:46:44 Fireworks quantization (and drama around it)* 00:49:38 Pricing Strategy* 00:51:51 Underrated Features of Fireworks Platform* 00:55:17 HiringTranscriptAlessio [00:00:00]: Hey everyone, welcome to the Latent Space Podcast. This is Alessio, partner at CTO at Danceable Partners, and I'm joined by my co-host, Swyx founder, Osmalayar.Swyx [00:00:11]: Hey, and today we're in a very special studio inside the Fireworks office with Lin Qiang, CEO of Fireworks. Welcome. Yeah.Lin [00:00:20]: Oh, you should welcome us.Swyx [00:00:21]: Yeah, welcome. Yeah, thanks for having us. It's unusual to be in the home of a startup, but it's also, I think our relationship is a bit unusual compared to all our normal guests. Definitely.Lin [00:00:34]: Yeah. I'm super excited to talk about very interesting topics in that space with both of you.Swyx [00:00:41]: You just celebrated your two-year anniversary yesterday.Lin [00:00:43]: Yeah, it's quite a crazy journey. We circle around and share all the crazy stories across these two years, and it has been super fun. All the way from we experienced Silicon Valley bank run to we delete some data that shouldn't be deleted operationally. We went through a massive scale where we actually are busy getting capacity to, yeah, we learned to kind of work with it as a team with a lot of brilliant people across different places to join a company. It has really been a fun journey.Alessio [00:01:24]: When you started, did you think the technical stuff will be harder or the bank run and then the people side? I think there's a lot of amazing researchers that want to do companies and it's like the hardest thing is going to be building the product and then you have all these different other things. So, were you surprised by what has been your experience the most?Lin [00:01:42]: Yeah, to be honest with you, my focus has always been on the product side and then after the product goes to market. And I didn't realize the rest has been so complicated, operating a company and so on. But because I don't think about it, I just kind of manage it. So it's done. I think I just somehow don't think about it too much and solve whatever problem coming our way and it worked.Swyx [00:02:08]: So let's, I guess, let's start at the pre-history, the initial history of Fireworks. You ran the PyTorch team at Meta for a number of years and we previously had Sumit Chintal on and I think we were just all very interested in the history of GenEI. Maybe not that many people know how deeply involved Faire and Meta were prior to the current GenEI revolution.Lin [00:02:35]: My background is deep in distributed system, database management system. And I joined Meta from the data side and I saw this tremendous amount of data growth, which cost a lot of money and we're analyzing what's going on. And it's clear that AI is driving all this data generation. So it's a very interesting t

Agents @ Work: Lindy.ai
Alessio will be at AWS re:Invent next week and hosting a casual coffee meetup on Wednesday, RSVP here! And subscribe to our calendar for our Singapore, NeurIPS, and all upcoming meetups!We are still taking questions for our next big recap episode! Submit questions and messages on Speakpipe here for a chance to appear on the show!If you've been following the AI agents space, you have heard of Lindy AI; while founder Flo Crivello is hesitant to call it "blowing up," when folks like Andrew Wilkinson start obsessing over your product, you're definitely onto something.In our latest episode, Flo walked us through Lindy's evolution from late 2022 to now, revealing some design choices about agent platform design that go against conventional wisdom in the space.The Great Reset: From Text Fields to RailsRemember late 2022? Everyone was "LLM-pilled," believing that if you just gave a language model enough context and tools, it could do anything. Lindy 1.0 followed this pattern:* Big prompt field ✅* Bunch of tools ✅* Prayer to the LLM gods ✅Fast forward to today, and Lindy 2.0 looks radically different. As Flo put it (~17:00 in the episode): "The more you can put your agent on rails, one, the more reliable it's going to be, obviously, but two, it's also going to be easier to use for the user."Instead of a giant, intimidating text field, users now build workflows visually:* Trigger (e.g., "Zendesk ticket received")* Required actions (e.g., "Check knowledge base")* Response generationThis isn't just a UI change - it's a fundamental rethinking of how to make AI agents reliable. As Swyx noted during our discussion: "Put Shoggoth in a box and make it a very small, minimal viable box. Everything else should be traditional if-this-then-that software."The Surprising Truth About Model LimitationsHere's something that might shock folks building in the space: with Claude 3.5 Sonnet, the model is no longer the bottleneck. Flo's exact words (~31:00): "It is actually shocking the extent to which the model is no longer the limit. It was the limit a year ago. It was too expensive. The context window was too small."Some context: Lindy started when context windows were 4K tokens. Today, their system prompt alone is larger than that. But what's really interesting is what this means for platform builders:* Raw capabilities aren't the constraint anymore* Integration quality matters more than model performance* User experience and workflow design are the new bottlenecksThe Search Engine Parallel: Why Horizontal Platforms Might WinOne of the spiciest takes from our conversation was Flo's thesis on horizontal vs. vertical agent platforms. He draws a fascinating parallel to search engines (~56:00):"I find it surprising the extent to which a horizontal search engine has won... You go through Google to search Reddit. You go through Google to search Wikipedia... search in each vertical has more in common with search than it does with each vertical."His argument: agent platforms might follow the same pattern because:* Agents across verticals share more commonalities than differences* There's value in having agents that can work together under one roof* The R&D cost of getting agents right is better amortized across use casesThis might explain why we're seeing early vertical AI companies starting to expand horizontally. The core agent capabilities - reliability, context management, tool integration - are universal needs.What This Means for BuildersIf you're building in the AI agents space, here are the key takeaways:* Constrain First: Rather than maximizing capabilities, focus on reliable execution within narrow bounds* Integration Quality Matters: With model capabilities plateauing, your competitive advantage lies in how well you integrate with existing tools* Memory Management is Key: Flo revealed they actively prune agent memories - even with larger context windows, not all memories are useful* Design for Discovery: Lindy's visual workflow builder shows how important interface design is for adoptionThe Meta LayerThere's a broader lesson here about AI product development. Just as Lindy evolved from "give the LLM everything" to "constrain intelligently," we might see similar evolution across the AI tooling space. The winners might not be those with the most powerful models, but those who best understand how to package AI capabilities in ways that solve real problems reliably.Full Video PodcastFlo’s talk at AI Engineer SummitChapters* 00:00:00 Introductions * 00:04:05 AI engineering and deterministic software * 00:08:36 Lindys demo* 00:13:21 Memory management in AI agents * 00:18:48 Hierarchy and collaboration between Lindys * 00:21:19 Vertical vs. horizontal AI tools * 00:24:03 Community and user engagement strategies * 00:26:16 Rickrolling incident with Lindy * 00:28:12 Evals and quality control in AI systems * 00:31:52 Model capabilities and their impact on Lindy * 00:39:27 Competition and market positioning * 00:42:40 Relationship between Facto

Agents @ Work: Dust.tt
We are recording our next big recap episode and taking questions! Submit questions and messages on Speakpipe here for a chance to appear on the show!Also subscribe to our calendar for our Singapore, NeurIPS, and all upcoming meetups!In our first ever episode with Logan Kilpatrick we called out the two hottest LLM frameworks at the time: LangChain and Dust. We’ve had Harrison from LangChain on twice (as a guest and as a co-host), and we’ve now finally come full circle as Stanislas from Dust joined us in the studio.After stints at Oracle and Stripe, Stan had joined OpenAI to work on mathematical reasoning capabilities. He describes his time at OpenAI as "the PhD I always wanted to do" while acknowledging the challenges of research work: "You're digging into a field all day long for weeks and weeks, and you find something, you get super excited for 12 seconds. And at the 13 seconds, you're like, 'oh, yeah, that was obvious.' And you go back to digging." This experience, combined with early access to GPT-4's capabilities, shaped his decision to start Dust: "If we believe in AGI and if we believe the timelines might not be too long, it's actually the last train leaving the station to start a company. After that, it's going to be computers all the way down."The History of DustDust's journey can be broken down into three phases:* Developer Framework (2022): Initially positioned as a competitor to LangChain, Dust started as a developer tooling platform. While both were open source, their approaches differed – LangChain focused on broad community adoption and integration as a pure developer experience, while Dust emphasized UI-driven development and better observability that wasn’t just `print` statements.* Browser Extension (Early 2023): The company pivoted to building XP1, a browser extension that could interact with web content. This experiment helped validate user interaction patterns with AI, even while using less capable models than GPT-4.* Enterprise Platform (Current): Today, Dust has evolved into an infrastructure platform for deploying AI agents within companies, with impressive metrics like 88% daily active users in some deployments.The Case for Being HorizontalThe big discussion for early stage companies today is whether or not to be horizontal or vertical. Since models are so good at general tasks, a lot of companies are building vertical products that take care of a workflow end-to-end in order to offer more value and becoming more of “Services as Software”. Dust on the other hand is a platform for the users to build their own experiences, which has had a few advantages:* Maximum Penetration: Dust reports 60-70% weekly active users across entire companies, demonstrating the potential reach of horizontal solutions rather than selling into a single team.* Emergent Use Cases: By allowing non-technical users to create agents, Dust enables use cases to emerge organically from actual business needs rather than prescribed solutions.* Infrastructure Value: The platform approach creates lasting value through maintained integrations and connections, similar to how Stripe's value lies in maintaining payment infrastructure. Rather than relying on third-party integration providers, Dust maintains its own connections to ensure proper handling of different data types and structures.The Vertical ChallengeHowever, this approach comes with trade-offs:* Harder Go-to-Market: As Stan talked about: "We spike at penetration... but it makes our go-to-market much harder. Vertical solutions have a go-to-market that is much easier because they're like, 'oh, I'm going to solve the lawyer stuff.'"* Complex Infrastructure: Building a horizontal platform requires maintaining numerous integrations and handling diverse data types appropriately – from structured Salesforce data to unstructured Notion pages. As you scale integrations, the cost of maintaining them also scales. * Product Surface Complexity: Creating an interface that's both powerful and accessible to non-technical users requires careful design decisions, down to avoiding technical terms like "system prompt" in favor of "instructions." The Future of AI PlatformsStan initially predicted we'd see the first billion-dollar single-person company in 2023 (a prediction later echoed by Sam Altman), but he's now more focused on a different milestone: billion-dollar companies with engineering teams of just 20 people, enabled by AI assistance.This vision aligns with Dust's horizontal platform approach – building the infrastructure that allows small teams to achieve outsized impact through AI augmentation. Rather than replacing entire job functions (the vertical approach), they're betting on augmenting existing workflows across organizations.Full YouTube EpisodeChapters* 00:00:00 Introductions* 00:04:33 Joining OpenAI from Paris* 00:09:54 Research evolution and compute allocation at OpenAI* 00:13:12 Working with Ilya Sutskever and OpenAI's vision* 00:15:51 Leaving OpenAI to start Dust
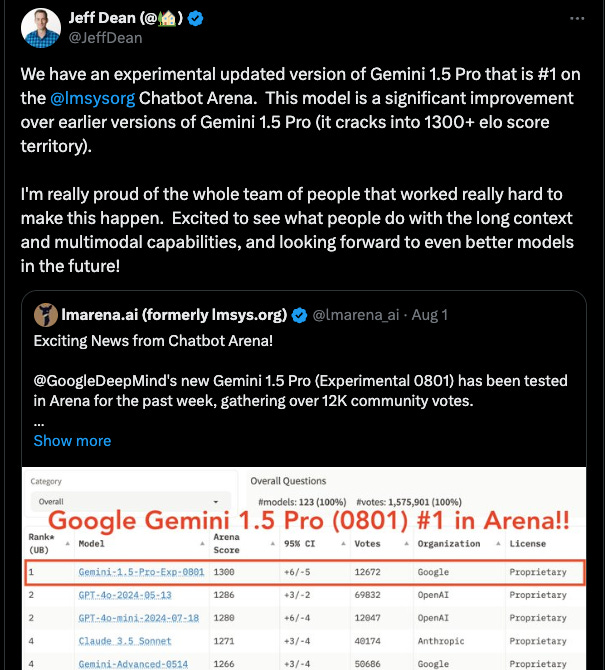
In the Arena: How LMSys changed LLM Benchmarking Forever
Apologies for lower audio quality; we lost recordings and had to use backup tracks. Our guests today are Anastasios Angelopoulos and Wei-Lin Chiang, leads of Chatbot Arena, fka LMSYS, the crowdsourced AI evaluation platform developed by the LMSys student club at Berkeley, which became the de facto standard for comparing language models. Arena Elo is often more cited than MMLU scores to many folks, and they have attracted >1,000,000 people to cast votes since its launch, leading top model trainers to cite them over their own formal academic benchmarks:The Limits of Static BenchmarksWe’ve done two benchmarks episodes: Benchmarks 101 and Benchmarks 201. One issue we’ve always brought up with static benchmarks is that 1) many are getting saturated, with models scoring almost perfectly on them 2) they often don’t reflect production use cases, making it hard for developers and users to use them as guidance. The fundamental challenge in AI evaluation isn't technical - it's philosophical. How do you measure something that increasingly resembles human intelligence? Rather than trying to define intelligence upfront, Arena let users interact naturally with models and collect comparative feedback. It's messy and subjective, but that's precisely the point - it captures the full spectrum of what people actually care about when using AI.The Pareto Frontier of Cost vs IntelligenceBecause the Elo scores are remarkably stable over time, we can put all the chat models on a map against their respective cost to gain a view of at least 3 orders of magnitude of model sizes/costs and observe the remarkable shift in intelligence per dollar over the past year:This frontier stood remarkably firm through the recent releases of o1-preview and price cuts of Gemini 1.5:The Statistics of SubjectivityIn our Benchmarks 201 episode, Clémentine Fourrier from HuggingFace thought this design choice was one of shortcomings of arenas: they aren’t reproducible. You don’t know who ranked what and what exactly the outcome was at the time of ranking. That same person might rank the same pair of outputs differently on a different day, or might ask harder questions to better models compared to smaller ones, making it imbalanced. Another argument that people have brought up is confirmation bias. We know humans prefer longer responses and are swayed by formatting - Rob Mulla from Dreadnode had found some interesting data on this in May:The approach LMArena is taking is to use logistic regression to decompose human preferences into constituent factors. As Anastasios explains: "We can say what components of style contribute to human preference and how they contribute." By adding these style components as parameters, they can mathematically "suck out" their influence and isolate the core model capabilities.This extends beyond just style - they can control for any measurable factor: "What if I want to look at the cost adjusted performance? Parameter count? We can ex post facto measure that." This is one of the most interesting things about Arena: You have a data generation engine which you can clean and turn into leaderboards later. If you wanted to create a leaderboard for poetry writing, you could get existing data from Arena, normalize it by identifying these style components. Whether or not it’s possible to really understand WHAT bias the voters have, that’s a different question.Private EvalsOne of the most delicate challenges LMSYS faces is maintaining trust while collaborating with AI labs. The concern is that labs could game the system by testing multiple variants privately and only releasing the best performer. This was brought up when 4o-mini released and it ranked as the second best model on the leaderboard:But this fear misunderstands how Arena works. Unlike static benchmarks where selection bias is a major issue, Arena's live nature means any initial bias gets washed out by ongoing evaluation. As Anastasios explains: "In the long run, there's way more fresh data than there is data that was used to compare these five models." The other big question is WHAT model is actually being tested; as people often talk about on X / Discord, the same endpoint will randomly feel “nerfed” like it happened for “Claude European summer” and corresponding conspiracy theories:It’s hard to keep track of these performance changes in Arena as these changes (if real…?) are not observable.The Future of EvaluationThe team's latest work on RouteLLM points to an interesting future where evaluation becomes more granular and task-specific. But they maintain that even simple routing strategies can be powerful - like directing complex queries to larger models while handling simple tasks with smaller ones.Arena is now going to expand beyond text into multimodal evaluation and specialized domains like code execution and red teaming. But their core insight remains: the best way to evaluate intelligence isn't to simplify it into metrics, but to embrace its complexity and find rigor
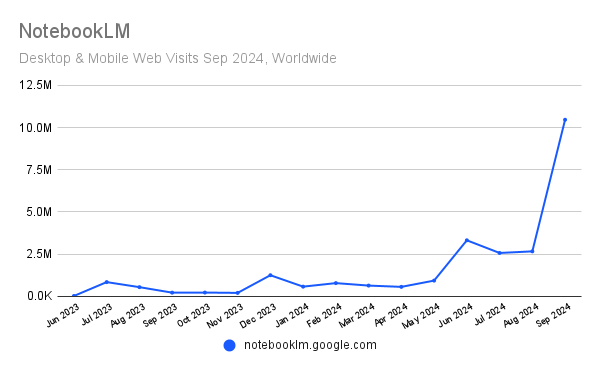
How NotebookLM Was Made
If you’ve listened to the podcast for a while, you might have heard our ElevenLabs-powered AI co-host Charlie a few times. Text-to-speech has made amazing progress in the last 18 months, with OpenAI’s Advanced Voice Mode (aka “Her”) as a sneak peek of the future of AI interactions (see our “Building AGI in Real Time” recap). Yet, we had yet to see a real killer app for AI voice (not counting music).Today’s guests, Raiza Martin and Usama Bin Shafqat, are the lead PM and AI engineer behind the NotebookLM feature flag that gave us the first viral AI voice experience, the “Deep Dive” podcast:The idea behind the “Audio Overviews” feature is simple: take a bunch of documents, websites, YouTube videos, etc, and generate a podcast out of them. This was one of the first demos that people built with voice models + RAG + GPT models, but it was always a glorified speech-to-text. Raiza and Usama took a very different approach:* Make it conversational: when you listen to a NotebookLM audio there are a ton of micro-interjections (Steven Johnson calls them disfluencies) like “Oh really?” or “Totally”, as well as pauses and “uh…”, like you would expect in a real conversation. These are not generated by the LLM in the transcript, but they are built into the the audio model. See ~28:00 in the pod for more details. * Listeners love tension: if two people are always in agreement on everything, it’s not super interesting. They tuned the model to generate flowing conversations that mirror the tone and rhythm of human speech. They did not confirm this, but many suspect the 2 year old SoundStorm paper is related to this model.* Generating new insights: because the hosts’ goal is not to summarize, but to entertain, it comes up with funny metaphors and comparisons that actually help expand on the content rather than just paraphrasing like most models do. We have had listeners make podcasts out of our podcasts, like this one.This is different than your average SOTA-chasing, MMLU-driven model buildooor. Putting product and AI engineering in the same room, having them build evals together, and understanding what the goal is lets you get these unique results. The 5 rules for AI PMsWe always focus on AI Engineers, but this episode had a ton of AI PM nuggets as well, which we wanted to collect as NotebookLM is one of the most successful products in the AI space:1. Less is more: the first version of the product had 0 customization options. All you could do is give it source documents, and then press a button to generate. Most users don’t know what “temperature” or “top-k” are, so you’re often taking the magic away by adding more options in the UI. Since recording they added a few, like a system prompt, but those were features that users were “hacking in”, as Simon Willison highlighted in his blog post.2. Use Real-Time Feedback: they built a community of 65,000 users on Discord that is constantly reporting issues and giving feedback; sometimes they noticed server downtime even before the Google internal monitoring did. Getting real time pings > aggregating user data when doing initial iterations. 3. Embrace Non-Determinism: AI outputs variability is a feature, not a bug. Rather than limiting the outputs from the get-go, build toggles that you can turn on/off with feature flags as the feedback starts to roll in.4. Curate with Taste: if you try your product and it sucks, you don’t need more data to confirm it. Just scrap that and iterate again. This is even easier for a product like this; if you start listening to one of the podcasts and turn it off after 10 seconds, it’s never a good sign. 5. Stay Hands-On: It’s hard to build taste if you don’t experiment. Trying out all your competitors products as well as unrelated tools really helps you understand what users are seeing in market, and how to improve on it.Chapters00:00 Introductions01:39 From Project Tailwind to NotebookLM09:25 Learning from 65,000 Discord members12:15 How NotebookLM works18:00 Working with Steven Johnson23:00 How to prioritize features25:13 Structuring the data pipelines29:50 How to eval34:34 Steering the podcast outputs37:51 Defining speakers personalities39:04 How do you make audio engaging?45:47 Humor is AGI51:38 Designing for non-determinism53:35 API when?55:05 Multilingual support and dialect considerations57:50 Managing system prompts and feature requests01:00:58 Future of NotebookLM01:04:59 Podcasts for your codebase01:07:16 Plans for real-time chat01:08:27 Wrap upShow Notes* Notebook LM* AI Test Kitchen* Nicholas Carlini* Steven Johnson* Wealth of Nations* Histories of Mysteries by Andrej Karpathy* chicken.pdf Threads* Area 120* Raiza Martin* Usama Bin ShafqatTranscriptNotebookLM [00:00:00]: Hey everyone, we're here today as guests on Latent Space. It's great to be here, I'm a long time listener and fan, they've had some great guests on this show before. Yeah, what an honor to have us, the hosts of another podcast, join as guests. I mean a huge thank you to Swyx an
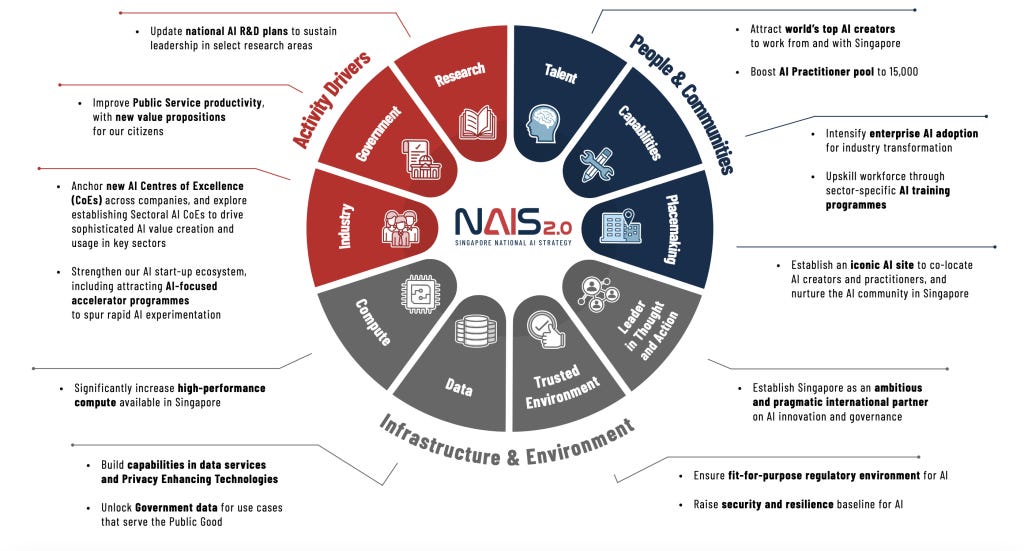
Building the AI Engineer Nation — with Josephine Teo, Minister of Digital Development and Information, Singapore
Singapore's GovTech is hosting an AI CTF challenge with ~$15,000 in prizes, starting October 26th, open to both local and virtual hackers. It will be hosted on Dreadnode's Crucible platform; signup here!It is common to say if you want to work in AI, you should come to San Francisco. Not everyone can. Not everyone should. If you can only do meaningful AI work in one city, then AI has failed to generalize meaningfully.As non-Americans working in the US, we know what it’s like to see AI progress so rapidly here, and yet be at a loss for what our home countries can do. Through Latent Space we’ve tried to tell the story of AI outside of the Bay Area bubble; we talked to Notion in New York and Humanloop and Wondercraft in London and HuggingFace in Paris and ICLR in Vienna, and the Reka, RWKV, and Winds of AI Winter episodes were taped in Singapore (the World’s Fair also had Latin America representation and we intend to at least add China, Japan, and India next year).The Role of Government with AIAs an intentionally technical resource, we’ve mostly steered clear of regulation and safety debates on the podcast; whether it is safety bills or technoalarmism, often at the cost of our engagement numbers or ability to book big name guests with a political agenda. When SOTA shifts 3x faster than it takes to pass a law, when nobody agrees on definitions of important things, when you can elicit never-before-seen behavior by slightly different prompting or sampling, it is hard enough to simply keep up to speed, so we are happy limiting our role to that. The story of AI progress has more often been achieved in the private sector, usually in spite of, rather than with thanks to, government intervention.But industrial policy is inextricably linked to the business of AI, which we do very much care about, has an explicitly accelerationist intent if not impact, and has a track record of success in correcting for legitimate market failures in private sector investment, particularly outside of the US. It is with this lens we approach today’s episode and special guest, our first with a sitting Cabinet member.Singapore’s National AI StrategyIt is well understood that much of Singapore’s economic success is attributable to industrial policy, from direct efforts like the Jurong Town Corporation industrialization to indirect ones like going all in on English as national first language. Singapore’s National AI Strategy grew out of its 2014 Smart Nation initiative, first launched in 2019 and then refreshed in 2023 by Minister Josephine Teo, our guest today.While Singapore is not often thought of as an AI leader, the National University ranks in the top 10 in publications (above Oxford/Harvard!), and many overseas Singaporeans work at the leading AI companies and institutions in the US (and some of us even run leading AI Substacks?). OpenAI has often publicly named the Singapore government as their model example of government collaborator and is opening an office in Singapore in time for DevDay 2024.AI Engineer NationsSwyx first pitched the AI Engineer Nation concept at a private Sovereign AI summit featuring Dr. He Ruimin, Chief AI Officer of Singapore, which eventually led to an invitation to discuss the concept with Minister Teo, the country’s de-facto minister for tech (she calls it Digital Development, for good reasons she explains in the pod).This chat happened (with thanks to Jing Long, Joyce, and other folks from MDDI)!The central pitch for any country, not just Singapore, to emphasize and concentrate bets on AI Engineers, compared with other valuable efforts like training more researchers, releasing more government-approved data, or offering more AI funding, is a calculated one, based on the fact that: * GPU clusters and researchers have massive returns to scale and colocation, mostly concentrated in the US, that are irresponsibly expensive to replicate* Even if research stopped today and there was no progress for the next 30 years, there are far more capabilities to unlock and productize from existing foundation models and we * Good AI Engineering requires genuine skill and is deepening enough to justify sub-specialization as a sub-industry of Software Engineering* Companies and countries with better AI engineer workforces will disproportionately benefit from AI vs those who equivocate it as one of many equivalent priorities* Tech progress is often framed as “the future is here but it is not evenly distributed”. The role of the AI Engineer is therefore to better distribute the state of the art to as much of humanity as possible, including the elderly, poor, and differently abled.All of which are themes we first identified in the Rise of the AI Engineer. Singapore simply has a few additional factors that make it not just a good fit, but an economic imperative:* English speaking, very-online country that is great at STEM* Aging, ex-growth population (Total Fertility Rate of 1.1)* #3 GDP per capita (PPP) country in the world* Physic

Building the Silicon Brain - with Drew Houston of Dropbox
CEOs of publicly traded companies are often in the news talking about their new AI initiatives, but few of them have built anything with it. Drew Houston from Dropbox is different; he has spent over 400 hours coding with LLMs in the last year and is now refocusing his 2,500+ employees around this new way of working, 17 years after founding the company.Timestamps00:00 Introductions00:43 Drew's AI journey04:14 Revalidating expectations of AI08:23 Simulation in self-driving vs. knowledge work12:14 Drew's AI Engineering setup15:24 RAG vs. long context in AI models18:06 From "FileGPT" to Dropbox AI23:20 Is storage solved?26:30 Products vs Features30:48 Building trust for data access33:42 Dropbox Dash and universal search38:05 The evolution of Dropbox42:39 Building a "silicon brain" for knowledge work48:45 Open source AI and its impact51:30 "Rent, Don't Buy" for AI54:50 Staying relevant58:57 Founder Mode01:03:10 Advice for founders navigating AI01:07:36 Building and managing teams in a growing companyTranscriptAlessio [00:00:00]: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO at Decibel Partners, and there's no Swyx today, but I'm joined by Drew Houston of Dropbox. Welcome, Drew.Drew [00:00:14]: Thanks for having me.Alessio [00:00:15]: So we're not going to talk about the Dropbox story. We're not going to talk about the Chinatown bus and the flash drive and all that. I think you've talked enough about it. Where I want to start is you as an AI engineer. So as you know, most of our audience is engineering folks, kind of like technology leaders. You obviously run Dropbox, which is a huge company, but you also do a lot of coding. I think that's how you spend almost 400 hours, just like coding. So let's start there. What was the first interaction you had with an LLM API and when did the journey start for you?Drew [00:00:43]: Yeah. Well, I think probably all AI engineers or whatever you call an AI engineer, those people started out as engineers before that. So engineering is my first love. I mean, I grew up as a little kid. I was that kid. My first line of code was at five years old. I just really loved, I wanted to make computer games, like this whole path. That also led me into startups and eventually starting Dropbox. And then with AI specifically, I studied computer science, I got my, I did my undergrad, but I didn't do like grad level computer science. I didn't, I sort of got distracted by all the startup things, so I didn't do grad level work. But about several years ago, I made a couple of things. So one is I sort of, I knew I wanted to go from being an engineer to a founder. And then, but sort of the becoming a CEO part was sort of backed into the job. And so a couple of realizations. One is that, I mean, there's a lot of like repetitive and like manual work you have to do as an executive that is actually lends itself pretty well to automation, both for like my own convenience. And then out of interest in learning, I guess what we call like classical machine learning these days, I started really trying to wrap my head around understanding machine learning and informational retrieval more, more formally. So I'd say maybe 2016, 2017 started me writing these more successively, more elaborate scripts to like understand basic like classifiers and regression and, and again, like basic information retrieval and NLP back in those days. And there's sort of like two things that came out of that. One is techniques are super powerful. And even just like studying like old school machine learning was a pretty big inversion of the way I had learned engineering, right? You know, I started programming when everyone starts programming and you're, you're sort of the human, you're giving an algorithm to the, and spelling out to the computer how it should run it. And then machine learning, here's machine learning where it's like actually flip that, like give it sort of the answer you want and it'll figure out the algorithm, which was pretty mind bending. And it was both like pretty powerful when I would write tools, like figure out like time audits or like, where's my time going? Is this meeting a one-on-one or is it a recruiting thing or is it a product strategy thing? I started out doing that manually with my assistant, but then found that this was like a very like automatable task. And so, which also had the side effect of teaching me a lot about machine learning. But then there was this big problem, like anytime you, it was very good at like tabular structured data, but like anytime it hit, you know, the usual malformed English that humans speak, it would just like fall over. I had to kind of abandon a lot of the things that I wanted to build because like there's no way to like parse text. Like maybe it would sort of identify the part of speech in a sentence or something. But then fast forward to the LLM, I mean actually I started trying some of like this, what we would call like very small
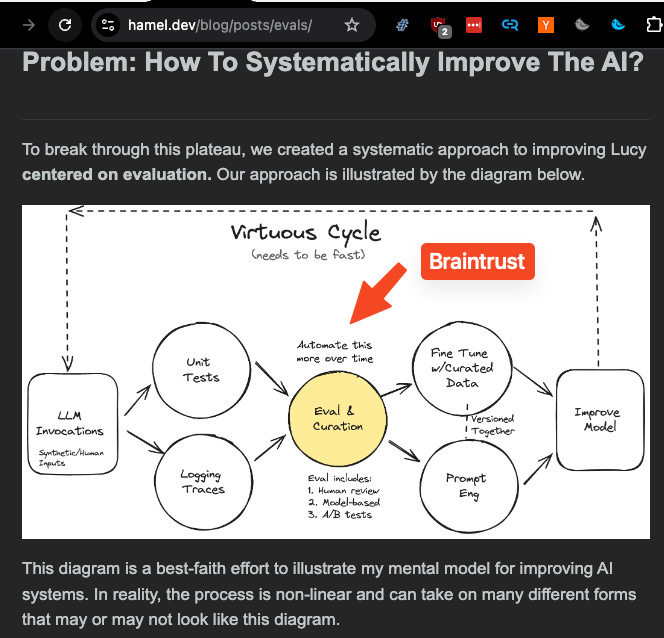
Production AI Engineering starts with Evals — with Ankur Goyal of Braintrust
We are in 🗽 NYC this Monday! Join the AI Eng NYC meetup, bring demos and vibes!It is a bit of a meme that the first thing developer tooling founders think to build in AI is all the non-AI operational stuff outside the AI. There are well over 60 funded LLM Ops startups all with hoping to solve the new observability, cost tracking, security, and reliability problems that come with putting LLMs in production, not to mention new LLM oriented products from incumbent, established ops/o11y players like Datadog and Weights & Biases. 2 years in to the current hype cycle, the early winners have tended to be people with practical/research AI backgrounds rather than MLOps heavyweights or SWE tourists:* LangSmith: We covered how Harrison Chase worked on AI at Robust Intelligence and Kensho, the alma maters of many great AI founders* HumanLoop: We covered how Raza Habib worked at Google AI during his PhD* BrainTrust: Today’s guest Ankur Goyal founded Impira pre-Transformers and was acquihired to run Figma AI before realizing how to solve the Ops problem.There have been many VC think pieces and market maps describing what people thought were the essential pieces of the AI Engineering stack, but what was true for 2022-2023 has aged poorly. The basic insight that Ankur had is the same thesis that Hamel Husain is pushing in his World’s Fair talk and podcast with Raza and swyx:Evals are the centerpiece of systematic AI Engineering.REALLY believing in this is harder than it looks with the benefit of hindsight. It’s not like people didn’t know evals were important. Basically every LLM Ops feature list has them. It’s an obvious next step AFTER managing your prompts and logging your LLM calls. In fact, up til we met Braintrust, we were working on an expanded version of the Impossible Triangle Theory of the LLM Ops War that we first articulated in the Humanloop writeup:The single biggest criticism of the Rise of the AI Engineer piece is that we neglected to split out the role of product evals (as opposed to model evals) in the now infamous “API line” chart:The AI SDLCWith hindsight, we were very focused on the differentiating 0 to 1 phase that AI Engineers can bring to an existing team of ML engineers. As swyx says on the Day 2 keynote of AI Engineer, 2024 added a whole new set of concerns as AI Engineering grew up:A closer examination of Hamel’s product-oriented virtuous cycle and this infra-oriented SDLC would have eventually revealed that Evals, even more than logging, was the first point where teams start to get really serious about shipping to production, and therefore a great place to make an entry into the marketplace, which is exactly what Braintrust did.Also notice what’s NOT on this chart: shifting to shadow open source models, and finetuning them… per Ankur, Fine-tuning is not a viable standalone product:“The thing I would say is not debatable is whether or not fine-tuning is a business outcome or not. So let's think about the other components of your triangle. Ops/observability, that is a business… Frameworks, evals, databases [are a business, but] Fine-tuning is a very compelling method that achieves an outcome. The outcome is not fine-tuning, it is can I automatically optimize my use case to perform better if I throw data at the problem? And fine-tuning is one of multiple ways to achieve that.”OpenAI vs Open AI Market ShareWe last speculated about the market shifts in the End of OpenAI Hegemony and the Winds of AI Winter, and Ankur’s perspective is super valuable given his customer list:Some surprises based on what he is seeing:* Prior to Claude 3, OpenAI had near 100% market share. This tracks with what Harrison told us last year.* Claude 3.5 Sonnet and also notably Haiku have made serious dents* Open source model adoption is . Contra to Eugene Cheah’s ideal marketing pitch, virtually none of Braintrust’s customers are really finetuning open source models for cost, control, or privacy. This is partially caused by…* Open source model hosts, aka Inference providers, aren’t as mature as OpenAI’s API platform. Kudos to Michelle’s team as if they needed any more praise!* Adoption of Big Lab models via their Big Cloud Partners, aka Claude through AWS, or OpenAI through Azure, is low. Surprising! It seems that there are issues with accessing the latest models via the Cloud partners.swyx [01:36:51]: What % of your workload is open source?Ankur Goyal [01:36:55]: Because of how we're deployed, I don't have like an exact number for you. Among customers running in production, it's less than 5%.Full Video EpisodeCheck out the Braintrust demo on YouTube! (and like and subscribe etc)Show Notes* Ankur’s companies* MemSQL/SingleStore → now Nikita Shamgunov of Neon* Impira* Braintrust* Papers mentioned* AlexNet* BERT Paper* Layout LM Paper* GPT-3 Paper* Voyager Paper* AI Engineer World's Fair* Ankur and Olmo’s talk at AIEWF* Together.ai* Fireworks* People* Nikita Shamgunov* Alana Goyal* Elad Gil* Clem Delangue* Guillermo Rauch* Prio

Building AGI in Real Time (OpenAI Dev Day 2024)
We all have fond memories of the first Dev Day in 2023:and the blip that followed soon after. As Ben Thompson has noted, this year’s DevDay took a quieter, more intimate tone. No Satya, no livestream, (slightly fewer people?). Instead of putting ChatGPT announcements in DevDay as in 2023, o1 was announced 2 weeks prior, and DevDay 2024 was reserved purely for developer-facing API announcements, primarily the Realtime API, Vision Finetuning, Prompt Caching, and Model Distillation.However the larger venue and more spread out schedule did allow a lot more hallway conversations with attendees as well as more community presentations including our recent guest Alistair Pullen of Cosine as well as deeper dives from OpenAI including our recent guest Michelle Pokrass of the API Team. Thanks to OpenAI’s warm collaboration (we particularly want to thank Lindsay McCallum Rémy!), we managed to record exclusive interviews with many of the main presenters of both the keynotes and breakout sessions. We present them in full in today’s episode, together with a full lightly edited Q&A with Sam Altman.Show notes and related resourcesSome of these used in the final audio episode below* Simon Willison Live Blog* swyx live tweets and videos* Greg Kamradt coverage of Structured Output session, Scaling LLM Apps session* Fireside Chat Q&A with Sam AltmanTimestamps* [00:00:00] Intro by Suno.ai* [00:01:23] NotebookLM Recap of DevDay* [00:09:25] Ilan's Strawberry Demo with Realtime Voice Function Calling* [00:19:16] Olivier Godement, Head of Product, OpenAI* [00:36:57] Romain Huet, Head of DX, OpenAI* [00:47:08] Michelle Pokrass, API Tech Lead at OpenAI ft. Simon Willison* [01:04:45] Alistair Pullen, CEO, Cosine (Genie)* [01:18:31] Sam Altman + Kevin Weill Q&A* [02:03:07] Notebook LM Recap of PodcastTranscript[00:00:00] Suno AI: Under dev daylights, code ignites. Real time voice streams reach new heights. O1 and GPT, 4. 0 in flight. Fine tune the future, data in sight. Schema sync up, outputs precise. Distill the models, efficiency splice.[00:00:33] AI Charlie: Happy October. This is your AI co host, Charlie. One of our longest standing traditions is covering major AI and ML conferences in podcast format. Delving, yes delving, into the vibes of what it is like to be there stitched in with short samples of conversations with key players, just to help you feel like you were there.[00:00:54] AI Charlie: Covering this year's Dev Day was significantly more challenging because we were all requested not to record the opening keynotes. So, in place of the opening keynotes, we had the viral notebook LM Deep Dive crew, my new AI podcast nemesis, Give you a seven minute recap of everything that was announced.[00:01:15] AI Charlie: Of course, you can also check the show notes for details. I'll then come back with an explainer of all the interviews we have for you today. Watch out and take care.[00:01:23] NotebookLM Recap of DevDay[00:01:23] NotebookLM: All right, so we've got a pretty hefty stack of articles and blog posts here all about open ais. Dev day 2024.[00:01:32] NotebookLM 2: Yeah, lots to dig into there.[00:01:34] NotebookLM 2: Seems[00:01:34] NotebookLM: like you're really interested in what's new with AI.[00:01:36] NotebookLM 2: Definitely. And it seems like OpenAI had a lot to announce. New tools, changes to the company. It's a lot.[00:01:43] NotebookLM: It is. And especially since you're interested in how AI can be used in the real world, you know, practical applications, we'll focus on that.[00:01:51] NotebookLM: Perfect. Like, for example, this Real time API, they announced that, right? That seems like a big deal if we want AI to sound, well, less like a robot.[00:01:59] NotebookLM 2: It could be huge. The real time API could completely change how we, like, interact with AI. Like, imagine if your voice assistant could actually handle it if you interrupted it.[00:02:08] NotebookLM: Or, like, have an actual conversation.[00:02:10] NotebookLM 2: Right, not just these clunky back and forth things we're used to.[00:02:14] NotebookLM: And they actually showed it off, didn't they? I read something about a travel app, one for languages. Even one where the AI ordered takeout.[00:02:21] NotebookLM 2: Those demos were really interesting, and I think they show how this real time API can be used in so many ways.[00:02:28] NotebookLM 2: And the tech behind it is fascinating, by the way. It uses persistent WebSocket connections and this thing called function calling, so it can respond in real time.[00:02:38] NotebookLM: So the function calling thing, that sounds kind of complicated. Can you, like, explain how that works?[00:02:42] NotebookLM 2: So imagine giving the AI Access to this whole toolbox, right?[00:02:46] NotebookLM 2: Information, capabilities, all sorts of things. Okay. So take the travel agent demo, for example. With function calling, the AI can pull up details, let's say about Fort Mason, right, from some database. Like nearby resta
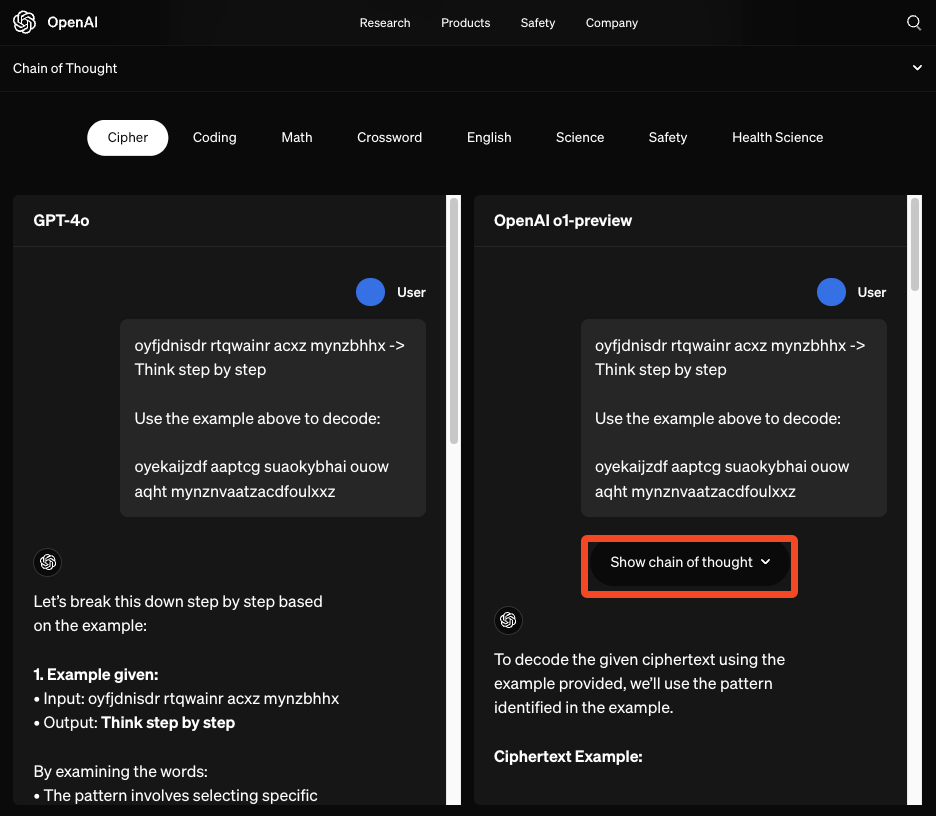
Language Agents: From Reasoning to Acting
OpenAI DevDay is almost here! Per tradition, we are hosting a DevDay pregame event for everyone coming to town! Join us with demos and gossip!Also sign up for related events across San Francisco: the AI DevTools Night, the xAI open house, the Replicate art show, the DevDay Watch Party (for non-attendees), Hack Night with OpenAI at Cloudflare. For everyone else, join the Latent Space Discord for our online watch party and find fellow AI Engineers in your city.OpenAI’s recent o1 release (and Reflection 70b debacle) has reignited broad interest in agentic general reasoning and tree search methods.While we have covered some of the self-taught reasoning literature on the Latent Space Paper Club, it is notable that the Eric Zelikman ended up at xAI, whereas OpenAI’s hiring of Noam Brown and now Shunyu suggests more interest in tool-using chain of thought/tree of thought/generator-verifier architectures for Level 3 Agents.We were more than delighted to learn that Shunyu is a fellow Latent Space enjoyer, and invited him back (after his first appearance on our NeurIPS 2023 pod) for a look through his academic career with Harrison Chase (one year after his first LS show).ReAct: Synergizing Reasoning and Acting in Language Modelspaper linkFollowing seminal Chain of Thought papers from Wei et al and Kojima et al, and reflecting on lessons from building the WebShop human ecommerce trajectory benchmark, Shunyu’s first big hit, the ReAct paper showed that using LLMs to “generate both reasoning traces and task-specific actions in an interleaved manner” achieved remarkably greater performance (less hallucination/error propagation, higher ALFWorld/WebShop benchmark success) than CoT alone. In even better news, ReAct scales fabulously with finetuning:As a member of the elite Princeton NLP group, Shunyu was also a coauthor of the Reflexion paper, which we discuss in this pod.Tree of Thoughtspaper link hereShunyu’s next major improvement on the CoT literature was Tree of Thoughts:Language models are increasingly being deployed for general problem solving across a wide range of tasks, but are still confined to token-level, left-to-right decision-making processes during inference. This means they can fall short in tasks that require exploration, strategic lookahead, or where initial decisions play a pivotal role…ToT allows LMs to perform deliberate decision making by considering multiple different reasoning paths and self-evaluating choices to decide the next course of action, as well as looking ahead or backtracking when necessary to make global choices.The beauty of ToT is it doesnt require pretraining with exotic methods like backspace tokens or other MCTS architectures. You can listen to Shunyu explain ToT in his own words on our NeurIPS pod, but also the ineffable Yannic Kilcher:Other WorkWe don’t have the space to summarize the rest of Shunyu’s work, you can listen to our pod with him now, and recommend the CoALA paper and his initial hit webinar with Harrison, today’s guest cohost:as well as Shunyu’s PhD Defense Lecture:as well as Shunyu’s latest lecture covering a Brief History of LLM Agents:As usual, we are live on YouTube! Show Notes* Harrison Chase* LangChain, LangSmith, LangGraph* Shunyu Yao* Alec Radford* ReAct Paper* Hotpot QA* Tau Bench* WebShop* SWE-Agent* SWE-Bench* Trees of Thought* CoALA Paper* Related Episodes* Our Thomas Scialom (Meta) episode* Shunyu on our NeurIPS 2023 Best Papers episode* Harrison on our LangChain episode* Mentions* Sierra* Voyager* Jason Wei* Tavily* SERP API* ExaTimestamps* [00:00:00] Opening Song by Suno* [00:03:00] Introductions* [00:06:16] The ReAct paper* [00:12:09] Early applications of ReAct in LangChain* [00:17:15] Discussion of the Reflection paper* [00:22:35] Tree of Thoughts paper and search algorithms in language models* [00:27:21] SWE-Agent and SWE-Bench for coding benchmarks* [00:39:21] CoALA: Cognitive Architectures for Language Agents* [00:45:24] Agent-Computer Interfaces (ACI) and tool design for agents* [00:49:24] Designing frameworks for agents vs humans* [00:53:52] UX design for AI applications and agents* [00:59:53] Data and model improvements for agent capabilities* [01:19:10] TauBench* [01:23:09] Promising areas for AITranscriptAlessio [00:00:01]: Hey, everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO of Residence at Decibel Partners, and I'm joined by my co-host Swyx, founder of Small AI.Swyx [00:00:12]: Hey, and today we have a super special episode. I actually always wanted to take like a selfie and go like, you know, POV, you're about to revolutionize the world of agents because we have two of the most awesome hiring agents in the house. So first, we're going to welcome back Harrison Chase. Welcome. Excited to be here. What's new with you recently in sort of like the 10, 20 second recap?Harrison [00:00:34]: Linkchain, Linksmith, Lingraph, pushing on all of them. Lots of cool stuff related to a lot of the stuff that we're going to ta
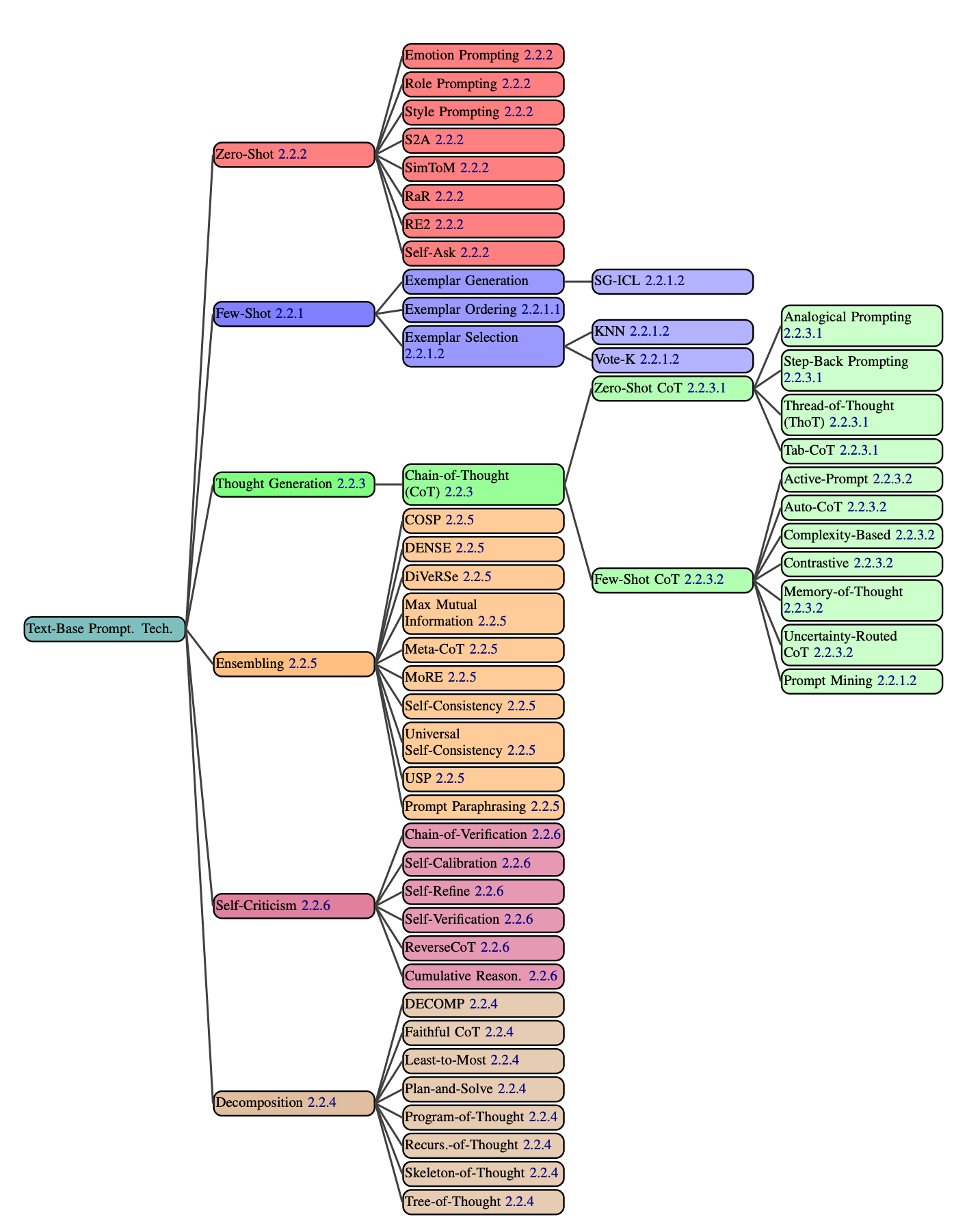
The Ultimate Guide to Prompting
Noah Hein from Latent Space University is finally launching with a free lightning course this Sunday for those new to AI Engineering. Tell a friend!Did you know there are >1,600 papers on arXiv just about prompting? Between shots, trees, chains, self-criticism, planning strategies, and all sorts of other weird names, it’s hard to keep up. Luckily for us, Sander Schulhoff and team read them all and put together The Prompt Report as the ultimate prompt engineering reference, which we’ll break down step-by-step in today’s episode.In 2022 swyx wrote “Why “Prompt Engineering” and “Generative AI” are overhyped”; the TLDR being that if you’re relying on prompts alone to build a successful products, you’re ngmi. Prompt engineering moved from being a stand-alone job to a core skill for AI Engineers now. We won’t repeat everything that is written in the paper, but this diagram encapsulates the state of prompting today: confusing. There are many similar terms, esoteric approaches that have doubtful impact on results, and lots of people that are just trying to create full papers around a single prompt just to get more publications out. Luckily, some of the best prompting techniques are being tuned back into the models themselves, as we’ve seen with o1 and Chain-of-Thought (see our OpenAI episode). Similarly, OpenAI recently announced 100% guaranteed JSON schema adherence, and Anthropic, Cohere, and Gemini all have JSON Mode (not sure if 100% guaranteed yet). No more “return JSON or my grandma is going to die” required. The next debate is human-crafted prompts vs automated approaches using frameworks like DSPy, which Sander recommended:I spent 20 hours prompt engineering for a task and DSPy beat me in 10 minutes. It’s much more complex than simply writing a prompt (and I’m not sure how many people usually spend >20 hours prompt engineering one task), but if you’re hitting a roadblock it might be worth checking out.Prompt Injection and JailbreaksSander and team also worked on HackAPrompt, a paper that was the outcome of an online challenge on prompt hacking techniques. They similarly created a taxonomy of prompt attacks, which is very hand if you’re building products with user-facing LLM interfaces that you’d like to test:In this episode we basically break down every category and highlight the overrated and underrated techniques in each of them. If you haven’t spent time following the prompting meta, this is a great episode to catchup!Full Video EpisodeLike and subscribe on YouTube!Timestamps* [00:00:00] Introductions - Intro music by Suno AI* [00:07:32] Navigating arXiv for paper evaluation* [00:12:23] Taxonomy of prompting techniques* [00:15:46] Zero-shot prompting and role prompting* [00:21:35] Few-shot prompting design advice* [00:28:55] Chain of thought and thought generation techniques* [00:34:41] Decomposition techniques in prompting* [00:37:40] Ensembling techniques in prompting* [00:44:49] Automatic prompt engineering and DSPy* [00:49:13] Prompt Injection vs Jailbreaking* [00:57:08] Multimodal prompting (audio, video)* [00:59:46] Structured output prompting* [01:04:23] Upcoming Hack-a-Prompt 2.0 projectShow Notes* Sander Schulhoff* Learn Prompting* The Prompt Report* HackAPrompt* Mine RL Competition* EMNLP Conference* Noam Brown* Jordan Boydgraver* Denis Peskov* Simon Willison* Riley Goodside* David Ha* Jeremy Nixon* Shunyu Yao* Nicholas Carlini* DreadnodeTranscriptAlessio [00:00:00]: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO-in-Residence at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol AI.Swyx [00:00:13]: Hey, and today we're in the remote studio with Sander Schulhoff, author of the Prompt Report.Sander [00:00:18]: Welcome. Thank you. Very excited to be here.Swyx [00:00:21]: Sander, I think I first chatted with you like over a year ago. What's your brief history? I went onto your website, it looks like you worked on diplomacy, which is really interesting because we've talked with Noam Brown a couple of times, and that obviously has a really interesting story in terms of prompting and agents. What's your journey into AI?Sander [00:00:40]: Yeah, I'd say it started in high school. I took my first Java class and just saw a YouTube video about something AI and started getting into it, reading. Deep learning, neural networks, all came soon thereafter. And then going into college, I got into Maryland and I emailed just like half the computer science department at random. I was like, hey, I want to do research on deep reinforcement learning because I've been experimenting with that a good bit. And over that summer, I had read the Intro to RL book and the deep reinforcement learning hands-on, so I was very excited about what deep RL could do. And a couple of people got back to me and one of them was Jordan Boydgraver, Professor Boydgraver, and he was working on diplomacy. And he said to me, this looks like it was more of a natural language processing proje

From API to AGI: Structured Outputs, OpenAI API platform and O1 Q&A — with Michelle Pokrass & OpenAI Devrel + Strawberry team
Congrats to Damien on successfully running AI Engineer London! See our community page and the Latent Space Discord for all upcoming events.This podcast came together in a far more convoluted way than usual, but happens to result in a tight 2 hours covering the ENTIRE OpenAI product suite across ChatGPT-latest, GPT-4o and the new o1 models, and how they are delivered to AI Engineers in the API via the new Structured Output mode, Assistants API, client SDKs, upcoming Voice Mode API, Finetuning/Vision/Whisper/Batch/Admin/Audit APIs, and everything else you need to know to be up to speed in September 2024.This podcast has two parts: the first hour is a regular, well edited, podcast on 4o, Structured Outputs, and the rest of the OpenAI API platform. The second was a rushed, noisy, hastily cobbled together recap of the top takeaways from the o1 model release from yesterday and today.Building AGI with Structured Outputs — Michelle Pokrass of OpenAI API teamMichelle Pokrass built massively scalable platforms at Google, Stripe, Coinbase and Clubhouse, and now leads the API Platform at Open AI. She joins us today to talk about why structured output is such an important modality for AI Engineers that Open AI has now trained and engineered a Structured Output mode with 100% reliable JSON schema adherence. To understand why this is important, a bit of history is important:* June 2023 when OpenAI first added a "function calling" capability to GPT-4-0613 and GPT 3.5 Turbo 0613 (our podcast/writeup here)* November 2023’s OpenAI Dev Day (our podcast/writeup here) where the team shipped JSON Mode, a simpler schema-less JSON output mode that nevertheless became more popular because function calling often failed to match the JSON schema given by developers. * Meanwhile, in open source, many solutions arose, including * Instructor (our pod with Jason here) * LangChain (our pod with Harrison here, and he is returning next as a guest co-host)* Outlines (Remi Louf’s talk at AI Engineer here)* Llama.cpp’s constrained grammar sampling using GGML-BNF* April 2024: OpenAI started implementing constrained sampling with a new `tool_choice: required` parameter in the API* August 2024: the new Structured Output mode, co-led by Michelle* Sept 2024: Gemini shipped Structured Outputs as wellWe sat down with Michelle to talk through every part of the process, as well as quizzing her for updates on everything else the API team has shipped in the past year, from the Assistants API, to Prompt Caching, GPT4 Vision, Whisper, the upcoming Advanced Voice Mode API, OpenAI Enterprise features, and why every Waterloo grad seems to be a cracked engineer.Part 1 Timestamps and TranscriptTranscript here.* [00:00:42] Episode Intro from Suno* [00:03:34] Michelle's Path to OpenAI* [00:12:20] Scaling ChatGPT* [00:13:20] Releasing Structured Output* [00:16:17] Structured Outputs vs Function Calling* [00:19:42] JSON Schema and Constrained Grammar* [00:20:45] OpenAI API team* [00:21:32] Structured Output Refusal Field* [00:24:23] ChatML issues* [00:26:20] Function Calling Evals* [00:28:34] Parallel Function Calling* [00:29:30] Increased Latency* [00:30:28] Prompt/Schema Caching* [00:30:50] Building Agents with Structured Outputs: from API to AGI* [00:31:52] Assistants API* [00:34:00] Use cases for Structured Output* [00:37:45] Prompting Structured Output* [00:39:44] Benchmarking Prompting for Structured Outputs* [00:41:50] Structured Outputs Roadmap* [00:43:37] Model Selection vs GPT4 Finetuning* [00:46:56] Is Prompt Engineering Dead?* [00:47:29] 2 models: ChatGPT Latest vs GPT 4o August* [00:50:24] Why API => AGI* [00:52:40] Dev Day* [00:54:20] Assistants API Roadmap* [00:56:14] Model Reproducibility/Determinism issues* [00:57:53] Tiering and Rate Limiting* [00:59:26] OpenAI vs Ops Startups* [01:01:06] Batch API* [01:02:54] Vision* [01:04:42] Whisper* [01:07:21] Voice Mode API* [01:08:10] Enterprise: Admin/Audit Log APIs* [01:09:02] Waterloo grads* [01:10:49] Books* [01:11:57] Cognitive Biases* [01:13:25] Are LLMs Econs?* [01:13:49] Hiring at OpenAIEmergency O1 Meetup — OpenAI DevRel + Strawberry teamthe following is our writeup from AINews, which so far stands the test of time.o1, aka Strawberry, aka Q*, is finally out! There are two models we can use today: o1-preview (the bigger one priced at $15 in / $60 out) and o1-mini (the STEM-reasoning focused distillation priced at $3 in/$12 out) - and the main o1 model is still in training. This caused a little bit of confusion.There are a raft of relevant links, so don’t miss:* the o1 Hub* the o1-preview blogpost* the o1-mini blogpost* the technical research blogpost* the o1 system card* the platform docs* the o1 team video and contributors list (twitter)Inline with the many, many leaks leading up to today, the core story is longer “test-time inference” aka longer step by step responses - in the ChatGPT app this shows up as a new “thinking” step that you can click to expand for reasoning traces, even though, controver
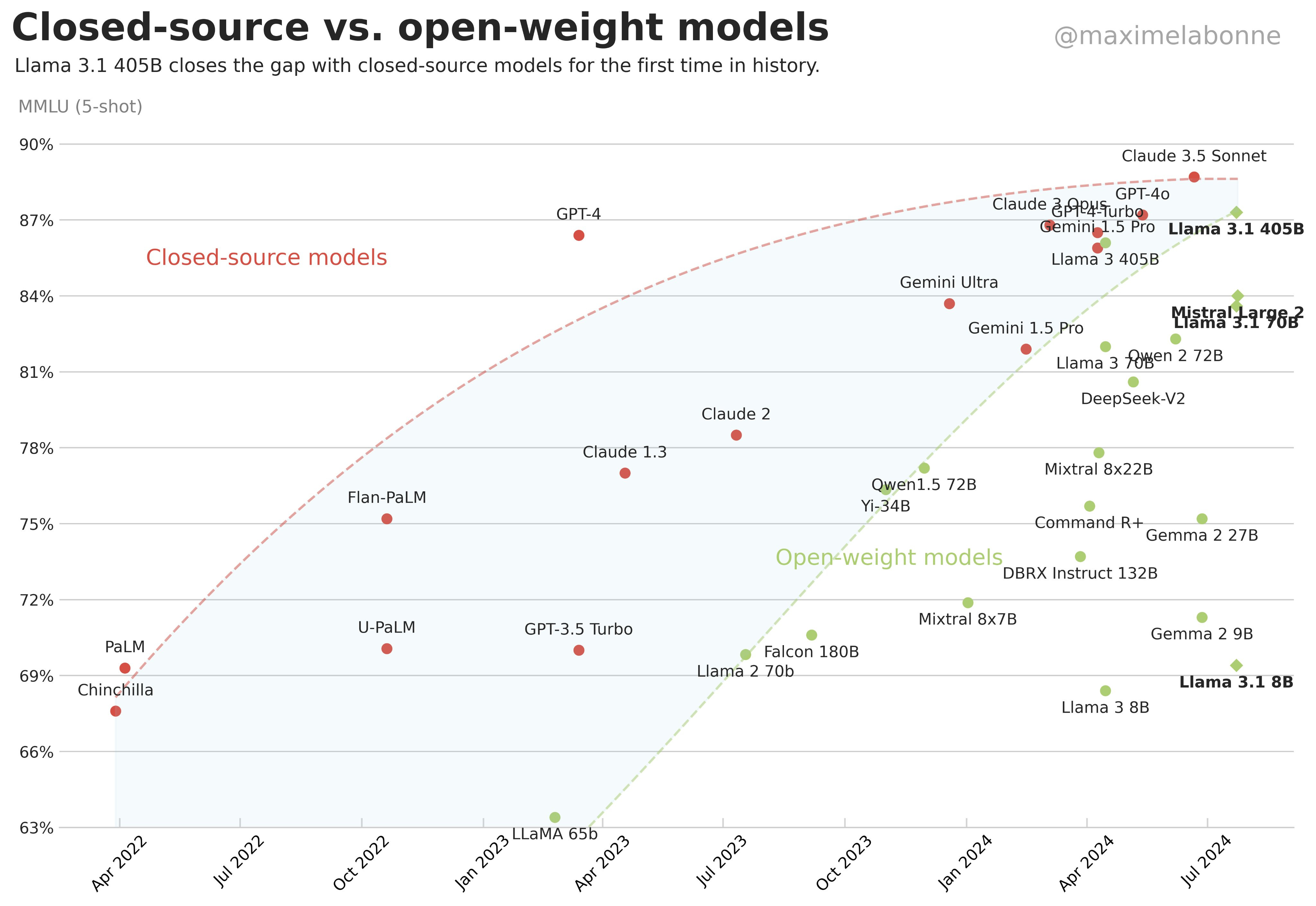
Efficiency is Coming: 3000x Faster, Cheaper, Better AI Inference from Hardware Improvements, Quantization, and Synthetic Data Distillation
AI Engineering is expanding! Join the first 🇬🇧 AI Engineer London meetup in Sept and get in touch for sponsoring the second 🗽 AI Engineer Summit in NYC this Dec!The commoditization of intelligence takes on a few dimensions:* Time to Open Model Equivalent: 15 months between GPT-4 and Llama 3.1 405B * 10-100x CHEAPER/year: from $30/mtok for Claude 3 Opus to $3/mtok for L3-405B, and a 400x reduction in the frontier OpenAI model from 2022-2024. Notably, for personal use cases, both Gemini Flash and now Cerebras Inference offer 1m tokens/day inference free, causing the Open Model Red Wedding.* Alternatively you can observe the frontiers of various small/medium/large sizes of intelligence per dollar shift in realtime. 2024 has been particularly aggressive with almost 2 order-of-magnitude improvements in $/Elo points in the last 8 months.* 4-8x FASTER/year: The new Cerebras Inference platform runs 70B models at 450 tok/s, almost twice as fast as the Groq Cloud example that went viral earlier this year (and at $0.60/mtok to boot). James Wang says they have room to ”~8x throughput in the next few months”, which needs to be seen in reality and at scale, but is very exciting for downstream latency/throughput-sensitive usecases.Today’s guest, Nyla Worker, a senior PM at Nvidia, Convai, and now Google, and recently host of the GPUs & Inference track at the World’s Fair, was the first to point out to us that the kind of efficiency improvements that have become a predominant theme in LLMs in 2024, have been seen before in her career in computer vision. From her start at Ebay optimizing V100 inference for a ResNet-50 model for image search, she has watched many improvements like Multi-Inference GPU (allowing multiple instances with perfect hardware parallelism), Quantization Aware Training (most recently highlighted by Noam Shazeer pre Character AI departure) and Model Distillation (most recently highlighted by the Llama 3.1 paper) stacking with baseline hardware improvements (from V100s to A100s to H100s to GH200s) to produce theoretically 3000x faster inference now than 6 years ago.What Nyla saw in her career the last 6 years, is happening to LLMs today (not exactly repeating, but surely rhyming), specifically with LoRAs, native Int8 and even Ternary models, and teacher model distillation. We were excited to delve into all things efficiency in this episode and even come out the other side with bonus discussions on what generative AI can do for gaming, fanmade TV shows, character AI conversations, and even podcasting!Show Notes:* Nyla Linkedin, Twitter* Related Nvidia research* Improving INT8 Accuracy Using Quantization Aware Training and the NVIDIA TAO Toolkit* Nvidia Jetson Nano: Bringing the power of modern AI to millions of devices.* Synthetic Data with Nvidia Omniverse Replicator: Accelerate AI Training Faster Than Ever with New NVIDIA Omniverse Replicator CapabilitiesTimestamps* [00:00:00] Intro from Suno* [00:03:17] Nyla's path from Astrophysics to LLMs* [00:05:45] Efficiency Curves in Computer Vision at Nvidia* [00:09:51] Optimizing for today's hardware vs tomorrow's inference* [00:16:33] Quantization vs Precision tradeoff* [00:20:42] Hitting the Data Wall: The need for Synthetic Data at Nvidia* [00:26:20] Sora, text to 3D models, and Synthetic Data from Game Engines* [00:30:55] ResNet 50 keeps coming back* [00:35:40] Gaming Benchmarks* [00:38:00] FineWeb* [00:39:43] Traditional ML vs LLMs path to general intelligence* [00:42:33] ConvAI - AI NPCs* [00:45:32] Jensen and Lisa at Computex Taiwan* [00:52:51] NPCs need to take Actions and have Context* [00:54:29] Simulating different roles for training* [00:58:37] AI Generated Fan Content - Podcasts, TV Show, EinsteinTranscripts[00:00:29] AI Charlie: Happy September. This is your AI co host, Charlie.[00:00:34] AI Charlie: One topic we've developed on LatentSpace is the importance of efficiency in all forms, from sample efficiency for spending limited training compute on limited data, and increasingly towards inference efficiency for increasingly demanding use cases like local LLMs, real time AI NPCs, and edge AI. However, we've never really developed any intuition for the trends and efficiency over time.[00:00:59] AI Charlie: For example, from 2020 to 2023, the price of GPT 3 level intelligence dropped from 60 per million tokens to 27 cents with the mixtural price war of December 2023. See show notes for charts and data. As for GPT 4 level intelligence, it took just over a year for GPT 4 to be matched by LLAMA370B and GPT 4 Turbo to be beaten by LLAMA3405B in open source, causing blended cost per million tokens to freefall from over 30 for Claude III Opus and the original GPT 4 down to under 3 for LLAMA3405B.[00:01:43] AI Charlie: Of course, OpenAI themselves have not stood still, slashing the price of GPT 4. 0 by 30 times with GPT 4. 0 Mini. Yes, you heard that right. GPT 4. 0 Mini is 3. 5 percent the price of GPT 4. 0, yet ties with GPT 4 Turbo on LM SYS. When the
Why you should write your own LLM benchmarks — with Nicholas Carlini, Google DeepMind
Today's guest, Nicholas Carlini, a research scientist at DeepMind, argues that we should be focusing more on what AI can do for us individually, rather than trying to have an answer for everyone."How I Use AI" - A Pragmatic ApproachCarlini's blog post "How I Use AI" went viral for good reason. Instead of giving a personal opinion about AI's potential, he simply laid out how he, as a security researcher, uses AI tools in his daily work. He divided it in 12 sections:* To make applications* As a tutor* To get started* To simplify code* For boring tasks* To automate tasks* As an API reference* As a search engine* To solve one-offs* To teach me* Solving solved problems* To fix errorsEach of the sections has specific examples, so we recommend going through it. It also includes all prompts used for it; in the "make applications" case, it's 30,000 words total!My personal takeaway is that the majority of the work AI can do successfully is what humans dislike doing. Writing boilerplate code, looking up docs, taking repetitive actions, etc. These are usually boring tasks with little creativity, but with a lot of structure. This is the strongest arguments as to why LLMs, especially for code, are more beneficial to senior employees: if you can get the boring stuff out of the way, there's a lot more value you can generate. This is less and less true as you go entry level jobs which are mostly boring and repetitive tasks. Nicholas argues both sides ~21:34 in the pod.A New Approach to LLM BenchmarksWe recently did a Benchmarks 201 episode, a follow up to our original Benchmarks 101, and some of the issues have stayed the same. Notably, there's a big discrepancy between what benchmarks like MMLU test, and what the models are used for. Carlini created his own domain-specific language for writing personalized LLM benchmarks. The idea is simple but powerful:* Take tasks you've actually needed AI for in the past.* Turn them into benchmark tests.* Use these to evaluate new models based on your specific needs.It can represent very complex tasks, from a single code generation to drawing a US flag using C:"Write hello world in python" >> LLMRun() >> PythonRun() >> SubstringEvaluator("hello world")"Write a C program that draws an american flag to stdout." >> LLMRun() >> CRun() >> \ VisionLLMRun("What flag is shown in this image?") >> \ (SubstringEvaluator("United States") | SubstringEvaluator("USA")))This approach solves a few problems:* It measures what's actually useful to you, not abstract capabilities.* It's harder for model creators to "game" your specific benchmark, a problem that has plagued standardized tests.* It gives you a concrete way to decide if a new model is worth switching to, similar to how developers might run benchmarks before adopting a new library or framework.Carlini argues that if even a small percentage of AI users created personal benchmarks, we'd have a much better picture of model capabilities in practice.AI SecurityWhile much of the AI security discussion focuses on either jailbreaks or existential risks, Carlini's research targets the space in between. Some highlights from his recent work:* LAION 400M data poisoning: By buying expired domains referenced in the dataset, Carlini's team could inject arbitrary images into models trained on LAION 400M. You can read the paper "Poisoning Web-Scale Training Datasets is Practical", for all the details. This is a great example of expanding the scope beyond the model itself, and looking at the whole system and how ti can become vulnerable.* Stealing model weights: They demonstrated how to extract parts of production language models (like OpenAI's) through careful API queries. This research, "Extracting Training Data from Large Language Models", shows that even black-box access can leak sensitive information.* Extracting training data: In some cases, they found ways to make models regurgitate verbatim snippets from their training data. Him and Milad Nasr wrote a paper on this as well: Scalable Extraction of Training Data from (Production) Language Models. They also think this might be applicable to extracting RAG results from a generation.These aren't just theoretical attacks. They've led to real changes in how companies like OpenAI design their APIs and handle data. If you really miss logit_bias and logit results by token, you can blame Nicholas :)We had a ton of fun also chatting about things like Conway's Game of Life, how much data can fit in a piece of paper, and porting Doom to Javascript. Enjoy!Show Notes* How I Use AI* My Benchmark for LLMs* Doom Javascript port* Conway's Game of Life* Tic-Tac-Toe in one printf statement* International Obfuscated C Code Contest* Cursor* LAION 400M poisoning paper* Man vs Machine at Black Hat* Model Stealing from OpenAI* Milad Nasr* H.D. Moore* Vijay Bolina* Cosine.sh* uuencodeTimestamps* [00:00:00] Introductions* [00:01:14] Why Nicholas writes* [00:02:09] The Game of Life* [00:05:07] "How I Use AI" blog post origin story* [

Is finetuning GPT4o worth it? — with Alistair Pullen, Cosine (Genie)
Betteridge's law says no: with seemingly infinite flavors of RAG, and >2million token context + prompt caching from Anthropic/Deepmind/Deepseek, it's reasonable to believe that "in context learning is all you need".But then there’s Cosine Genie, the first to make a huge bet using OpenAI’s new GPT4o fine-tuning for code at the largest scale it has ever been used externally; resulting in what is now the #1 coding agent in the world according to SWE-Bench Full, Lite, and Verified:SWE-Bench has been the most successful agent benchmark of the year, receiving honors at ICLR (our interview here) and recently being verified by OpenAI. Cognition (Devin) was valued at $2b after reaching 14% on it. So it is very, very big news when a new agent appears to beat all other solutions, by a lot:While this number is self reported, it seems to be corroborated by OpenAI, who also award it clear highest marks on SWE-Bench verified:The secret is GPT-4o finetuning on billions of tokens of synthetic data. * Finetuning: As OpenAI says:Genie is powered by a fine-tuned GPT-4o model trained on examples of real software engineers at work, enabling the model to learn to respond in a specific way. The model was also trained to be able to output in specific formats, such as patches that could be committed easily to codebases. Due to the scale of Cosine’s finetuning, OpenAI worked closely with them to figure out the size of the LoRA:“They have to decide how big your LoRA adapter is going to be… because if you had a really sparse, large adapter, you’re not going to get any signal in that at all. So they have to dynamically size these things.”* Synthetic data: we need to finetune on the process of making code work instead of only training on working code.“…we synthetically generated runtime errors. Where we would intentionally mess with the AST to make stuff not work, or index out of bounds, or refer to a variable that doesn't exist, or errors that the foundational models just make sometimes that you can't really avoid, you can't expect it to be perfect.”Genie also has a 4 stage workflow with the standard LLM OS tooling stack that lets it solve problems iteratively:Full Video Podlike and subscribe etc!Show Notes* Alistair Pullen - Twitter, Linkedin* Cosine Genie launch, technical report* OpenAI GPT-4o finetuning GA* Llama 3 backtranslation* Cursor episode and Aman + SWEBench at ICLR episodeTimestamps* [00:00:00] Suno Intro* [00:05:01] Alistair and Cosine intro* [00:16:34] GPT4o finetuning* [00:20:18] Genie Data Mix* [00:23:09] Customizing for Customers* [00:25:37] Genie Workflow* [00:27:41] Code Retrieval* [00:35:20] Planning* [00:42:29] Language Mix* [00:43:46] Running Code* [00:46:19] Finetuning with OpenAI* [00:49:32] Synthetic Code Data* [00:51:54] SynData in Llama 3* [00:52:33] SWE-Bench Submission Process* [00:58:20] Future Plans* [00:59:36] Ecosystem Trends* [01:00:55] Founder Lessons* [01:01:58] CTA: Hiring & CustomersDescript Transcript[00:01:52] AI Charlie: Welcome back. This is Charlie, your AI cohost. As AI engineers, we have a special focus on coding agents, fine tuning, and synthetic data. And this week, it all comes together with the launch of Cosign's Genie, which reached 50 percent on SWE Bench Lite, 30 percent on the full SWE Bench, and 44 percent on OpenAI's new SWE Bench Verified.[00:02:17] All state of the art results by the widest ever margin recorded compared to former leaders Amazon Q and US Autocode Rover. And Factory Code Droid. As a reminder, Cognition Devon went viral with a 14 percent score just five months ago. Cosign did this by working closely with OpenAI to fine tune GPT 4. 0, now generally available to you and me, on billions of tokens of code, much of which was synthetically generated.[00:02:47] Alistair Pullen: Hi, I'm Ali. Co founder and CEO of Cosign, a human reasoning lab. And I'd like to show you Genie, our state of the art, fully autonomous software engineering colleague. Genie has the highest score on SWBench in the world. And the way we achieved this was by taking a completely different approach. We believe that if you want a model to behave like a software engineer, it has to be shown how a human software engineer works.[00:03:15] We've designed new techniques to derive human reasoning from real examples of software engineers doing their jobs. Our data represents perfect information lineage, incremental knowledge discovery, and step by step decision making. Representing everything a human engineer does logically. By actually training Genie on this unique dataset, rather than simply prompting base models, which is what everyone else is doing, we've seen that we're no longer simply generating random code until some works.[00:03:46] It's tackling problems like[00:03:48] AI Charlie: a human. Alistair Pullen is CEO and co founder of Kozen, and we managed to snag him on a brief trip stateside for a special conversation on building the world's current number one coding agent. Watch out and take care.[00:0
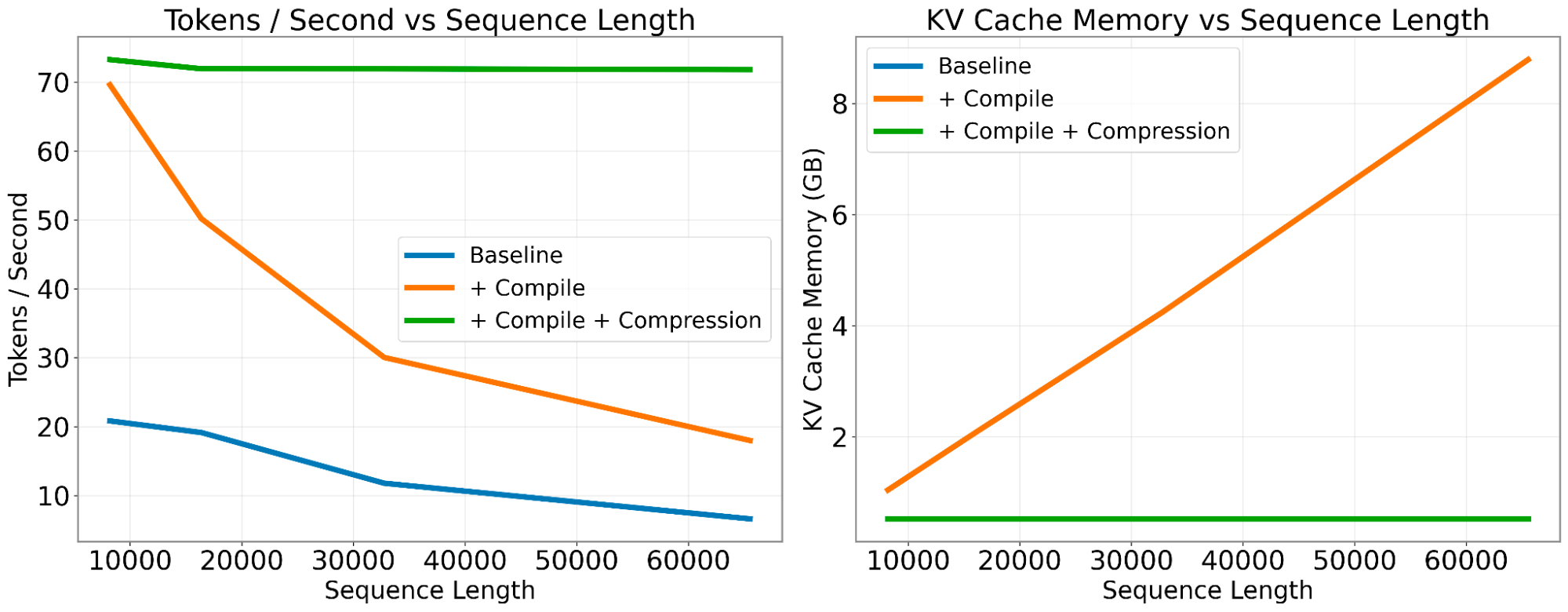
AI Magic: Shipping 1000s of successful products with no managers and a team of 12 — Jeremy Howard of Answer.ai
Disclaimer: We recorded this episode ~1.5 months ago, timing for the FastHTML release. It then got bottlenecked by Llama3.1, Winds of AI Winter, and SAM2 episodes, so we’re a little late. Since then FastHTML was released, swyx is building an app in it for AINews, and Anthropic has also released their prompt caching API. Remember when Dylan Patel of SemiAnalysis coined the GPU Rich vs GPU Poor war? (if not, see our pod with him). The idea was that if you’re GPU poor you shouldn’t waste your time trying to solve GPU rich problems (i.e. pre-training large models) and are better off working on fine-tuning, optimized inference, etc. Jeremy Howard (see our “End of Finetuning” episode to catchup on his background) and Eric Ries founded Answer.AI to do exactly that: “Practical AI R&D”, which is very in-line with the GPU poor needs. For example, one of their first releases was a system based on FSDP + QLoRA that let anyone train a 70B model on two NVIDIA 4090s. Since then, they have come out with a long list of super useful projects (in no particular order, and non-exhaustive):* FSDP QDoRA: this is just as memory efficient and scalable as FSDP/QLoRA, and critically is also as accurate for continued pre-training as full weight training.* Cold Compress: a KV cache compression toolkit that lets you scale sequence length without impacting speed.* colbert-small: state of the art retriever at only 33M params* JaColBERTv2.5: a new state-of-the-art retrievers on all Japanese benchmarks.* gpu.cpp: portable GPU compute for C++ with WebGPU.* Claudette: a better Anthropic API SDK. They also recently released FastHTML, a new way to create modern interactive web apps. Jeremy recently released a 1 hour “Getting started” tutorial on YouTube; while this isn’t AI related per se, but it’s close to home for any AI Engineer who are looking to iterate quickly on new products: In this episode we broke down 1) how they recruit 2) how they organize what to research 3) and how the community comes together. At the end, Jeremy gave us a sneak peek at something new that he’s working on that he calls dialogue engineering: So I've created a new approach. It's not called prompt engineering. I'm creating a system for doing dialogue engineering. It's currently called AI magic. I'm doing most of my work in this system and it's making me much more productive than I was before I used it.He explains it a bit more ~44:53 in the pod, but we’ll just have to wait for the public release to figure out exactly what he means.Timestamps* [00:00:00] Intro by Suno AI* [00:03:02] Continuous Pre-Training is Here* [00:06:07] Schedule-Free Optimizers and Learning Rate Schedules* [00:07:08] Governance and Structural Issues within OpenAI and Other AI Labs* [00:13:01] How Answer.ai works* [00:23:40] How to Recruit Productive Researchers* [00:27:45] Building a new BERT* [00:31:57] FSDP, QLoRA, and QDoRA: Innovations in Fine-Tuning Large Models* [00:36:36] Research and Development on Model Inference Optimization* [00:39:49] FastHTML for Web Application Development* [00:46:53] AI Magic & Dialogue Engineering* [00:52:19] AI wishlist & predictionsShow Notes* Jeremy Howard* Previously on Latent Space: The End of Finetuning, NeurIPS Startups* Answer.ai* Fast.ai* FastHTML* answerai-colbert-small-v1* gpu.cpp* Eric Ries* Aaron DeFazio* Yi Tai* Less Wright* Benjamin Warner* Benjamin Clavié* Jono Whitaker* Austin Huang* Eric Gilliam* Tim Dettmers* Colin Raffel* Mark Saroufim* Sebastian Raschka* Carson Gross* Simon Willison* Sepp Hochreiter* Llama3.1 episode* Snowflake Arctic* Ranger Optimizer* Gemma.cpp* HTMX* UL2* BERT* DeBERTa* Efficient finetuning of Llama 3 with FSDP QDoRA* xLSTMTranscriptAlessio [00:00:00]: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO-in-Residence at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol AI.Swyx [00:00:14]: And today we're back with Jeremy Howard, I think your third appearance on Latent Space. Welcome.Jeremy [00:00:19]: Wait, third? Second?Swyx [00:00:21]: Well, I grabbed you at NeurIPS.Jeremy [00:00:23]: I see.Swyx [00:00:24]: Very fun, standing outside street episode.Jeremy [00:00:27]: I never heard that, by the way. You've got to send me a link. I've got to hear what it sounded like.Swyx [00:00:30]: Yeah. Yeah, it's a NeurIPS podcast.Alessio [00:00:32]: I think the two episodes are six hours, so there's plenty to listen, we'll make sure to send it over.Swyx [00:00:37]: Yeah, we're trying this thing where at the major ML conferences, we, you know, do a little audio tour of, give people a sense of what it's like. But the last time you were on, you declared the end of fine tuning. I hope that I sort of editorialized the title a little bit, and I know you were slightly uncomfortable with it, but you just own it anyway. I think you're very good at the hot takes. And we were just discussing in our pre-show that it's really happening, that the continued pre-training is really happening.Jeremy [00

Segment Anything 2: Demo-first Model Development
Because of the nature of SAM, this is more video heavy than usual. See our YouTube!Because vision is first among equals in multimodality, and yet SOTA vision language models are closed, we’ve always had an interest in learning what’s next in vision. Our first viral episode was Segment Anything 1, and we have since covered LLaVA, IDEFICS, Adept, and Reka. But just like with Llama 3, FAIR holds a special place in our hearts as the New Kings of Open Source AI.The list of sequels better than the originals is usually very short, but SAM 2 delighted us by not only being a better image segmentation model than SAM 1, it also conclusively and inexpensively solved video segmentation in just an elegant a way as SAM 1 did for images, and releasing everything to the community as Apache 2/CC by 4.0.“In video segmentation, we observe better accuracy, using 3x fewer interactions than prior approaches. In image segmentation, our model is more accurate and 6x faster than the Segment Anything Model (SAM).”Surprisingly EfficientThe paper reports that SAM 2 was trained on 256 A100 GPUs for 108 hours (59% more than SAM 1). Taking the upper end $2 A100 cost off gpulist.ai means SAM2 cost ~$50k to train if it had an external market-rate cost - surprisingly cheap for adding video understanding!The newly released SA-V dataset is also the largest video segment dataset to date, with careful attention given to scene/object/geographical diversity, including that of annotators. In some ways, we are surprised that SOTA video segmentation can be done on only ~50,000 videos (and 640k masklet annotations). Model-in-the-loop Data Engine for Annotations and Demo-first DevelopmentSimilar to SAM 1, a 3 Phase Data Engine helped greatly in bootstrapping this dataset. As Nikhila says in the episode, the demo you see wasn’t just for show, they actually used this same tool to do annotations for the model that is now demoed in the tool:“With the original SAM, we put a lot of effort in building a high-quality demo. And the other piece here is that the demo is actually the annotation tool. So we actually use the demo as a way to improve our annotation tool. And so then it becomes very natural to invest in building a good demo because it speeds up your annotation. and improve the data quality, and that will improve the model quality. With this approach, we found it to be really successful.”An incredible 90% speedup in annotation happened due to this virtuous cycle which helped SA-V reach this incredible scale.Building the demo also helped the team live the context that their own downstream users, like Roboflow, would experience, and forced them to make choices accordingly.As Nikhila says:“It's a really encouraging trend for not thinking about only the new model capability, but what sort of applications folks want to build with models as a result of that downstream.I think it also really forces you to think about many things that you might postpone. For example, efficiency. For a good demo experience, making it real time is super important. No one wants to wait. And so it really forces you to think about these things much sooner and actually makes us think about what kind of image encoder we want to use or other things. hardware efficiency improvements. So those kind of things, I think, become a first-class citizen when you put the demo first.”Indeed, the team swapped out standard ViT-H Vision Transformers for Hiera (Hierarchical) Vision Transformers as a result of efficiency considerations.Memory AttentionSpeaking of architecture, the model design is probably the sleeper hit of a project filled with hits. The team adapted SAM 1 to video by adding streaming memory for real-time video processing:Specifically adding memory attention, memory encoder, and memory bank, which surprisingly ablated better than more intuitive but complex architectures like Gated Recurrent Units.One has to wonder if streaming memory can be added to pure language models with a similar approach… (pls comment if there’s an obvious one we haven’t come across yet!)Video PodcastTune in to Latent Space TV for the video demos mentioned in this video podcast!Resources referencedShow References* https://sam2.metademolab.com/demo * roboflow.com/sam2* https://github.com/autodistill/autodistill* https://github.com/facebookresearch/segment-anything-2* https://rf100.org * https://blog.roboflow.com/label-data-with-grounded-sam-2/* https://arxiv.org/abs/2408.00714 * https://github.com/roboflow/notebooks* https://x.com/skalskip92/status/1818648396002951178https://x.com/skalskip92/status/1818648396002951178* https://blog.roboflow.com/sam-2-video-segmentation/Timestamps* [00:00:00] The Rise of SAM by Udio (David Ding Edit)* [00:03:07] Introducing Nikhila* [00:06:38] The Impact of SAM 1 in 2023* [00:12:15] Do People Finetune SAM?* [00:16:05] Video Demo of SAM* [00:20:01] Why the Demo is so Important* [00:23:23] SAM 1 vs SAM 2 Architecture* [00:26:46] Video Demo of SAM on Roboflow* [00:32:44] Extending

The Winds of AI Winter (Q2 Four Wars Recap) + ChatGPT Voice Mode Preview
Thank you for 1m downloads of the podcast and 2m readers of the Substack! 🎉This is the audio discussion following The Winds of AI Winter essay that also serves as a recap of Q2 2024 in AI viewed through the lens of our Four Wars framework. Enjoy!Full Video DiscussionFull show notes are here.Timestamps* [00:00:00] Intro Song by Suno.ai* [00:02:01] Swyx and Alessio in Singapore* [00:05:49] GPU Rich vs Poors: Frontier Labs* [00:06:35] GPU Rich Frontier Models: Claude 3.5* [00:10:37] GPU Rich helping Poors: Llama 3.1: The Synthetic Data Model* [00:15:41] GPU Rich helping Poors: Frontier Labs Vibe Shift - Phi 3, Gemma 2* [00:18:26] GPU Rich: Mistral Large* [00:21:56] GPU Rich: Nvidia + FlashAttention 3* [00:23:45] GPU Rich helping Poors: Noam Shazeer & Character.AI* [00:28:14] GPU Poors: On Device LLMs: Mozilla Llamafile, Chrome (Gemini Nano), Apple Intelligence* [00:35:33] Quality Data Wars: NYT vs The Atlantic lawyer up vs partner up* [00:37:41] Quality Data Wars: Reddit, ScarJo, RIAA vs Udio & Suno* [00:41:03] Quality Data Wars: Synthetic Data, Jagged Intelligence, AlphaProof* [00:45:33] Multimodality War: ChatGPT Voice Mode, OpenAI demo at AIEWF* [00:47:34] Multimodality War: Meta Llama 3 multimodality + Chameleon* [00:50:54] Multimodality War: PaliGemma + CoPaliGemma* [00:52:55] Renaming Rag/Ops War to LLM OS War* [00:55:31] LLM OS War: Ops War: Prompt Management vs Gateway vs Observability* [01:02:57] LLM OS War: BM42 Vector DB Wars, Memory Databases, GraphRAG* [01:06:15] LLM OS War: Agent Tooling* [01:08:26] LLM OS War: Agent Protocols* [01:10:43] Trend: Commoditization of Intelligence* [01:16:45] Trend: Vertical Service as Software, AI Employees, Brightwave, Dropzone* [01:20:44] Trend: Benchmark Frontiers after MMLU* [01:23:31] Crowdstrike will save us from Skynet* [01:24:30] Bonus: ChatGPT Advanced Voice Mode Demo* [01:25:37] Voice Mode: Storytelling* [01:27:55] Voice Mode: Accents* [01:31:48] Voice Mode: Accent Detection* [01:35:00] Voice Mode: Nonverbal Emotions* [01:37:53] Voice Mode: Multiple Voices in One* [01:40:52] Voice Mode: Energy Levels Detection* [01:42:03] Voice Mode: Multilinguality* [01:43:53] Voice Mode: Shepard Tone* [01:46:57] Voice Mode: Generating Tones* [01:49:39] Voice Mode: Interruptions don't work* [01:49:55] Voice Mode: Reverberations* [01:51:37] Voice Mode: Mimicry doesn't workTranscriptCharlie [00:01:08]: Welcome back, listeners. This is your AI co-host, Charlie. It's been a few months since we took a step back from the interview format and talked about the show. We're happy to share that we have crossed one million downloads and two million reads on Substack. Woo-hoo. We are really grateful to those of you who keep tuning in and sharing us with your friends, especially if who watch and comment on our new YouTube channel, where we are trying to grow next. For a special millionaire edition, SWIX and Alessio are finally back in person in sunny Singapore to discuss the big vibe shift in the last three months, that we are calling the Winds of AI Winter. We also discuss my nemesis, ChatGPT Advanced Voice Mode, with a special treat for those who stay till the end. Now, more than ever, watch out and take care.Alessio [00:02:02]: Hey, everyone. Welcome to the Latent Space Podcast. This is Alessio, partner and CTO in Residence and Decibel Partners, and today we're in the Singapore studio with SWIX.Swyx [00:02:11]: Hey, this is our long-awaited one-on-one episode. I don't know how long ago the previous one was. Do you remember? Three, four months?Alessio [00:02:20]: Yeah, it's been a while.Swyx [00:02:22]: People really enjoyed it. It's just really, I think our travel schedules have been really difficult to get this stuff together. And then we also had like a decent backlog of guests for a while. I think we've kind of depleted that backlog now and we need to build it up again. But it's been busy and there's been a lot of news. So we actually get to do this like sort of rapid fire thing. I think some people, you know, the podcast has grown a lot in the last six months. Maybe just reintroducing like what you're up to, what I'm up to, and why we're here in Singapore and stuff like that.Alessio [00:02:51]: Yeah. My first time here in Singapore, which has been really nice. This country is really amazing, I would say. First of all, everything feels like the busiest part of the city. Everything is skyscrapers. There's like plants in all the buildings, or at least in the areas that I've been in, which has been awesome. And I was at one of the offices kind of on the south side and from the 38th floor, you can see Indonesia on one side and you can see Malaysia on the other side. So it's quite, quite small. One of the people there said their kid goes to school at the border with Malaysia basically, so they could drive to Malaysia every day. So they go pick her up from school. Yeah. And we came here, we hosted with you, the Sovereign AI Summit Wednesday night. We had a lot of folks.Swyx [00:03:31]
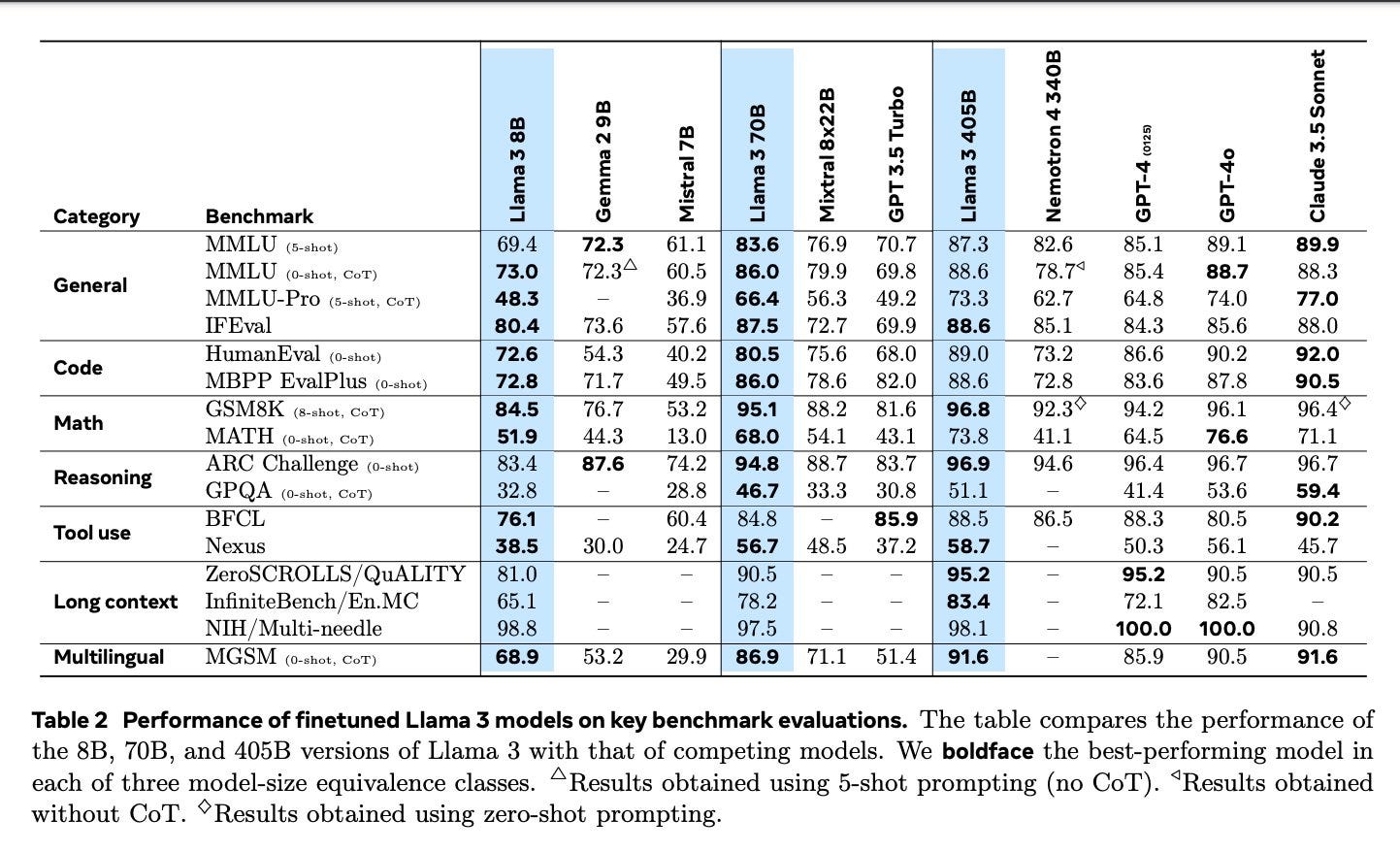
Llama 2, 3 & 4: Synthetic Data, RLHF, Agents on the path to Open Source AGI
If you see this in time, join our emergency LLM paper club on the Llama 3 paper!For everyone else, join our special AI in Action club on the Latent Space Discord for a special feature with the Cursor cofounders on Composer, their newest coding agent!Today, Meta is officially releasing the largest and most capable open model to date, Llama3-405B, a dense transformer trained on 15T tokens that beats GPT-4 on all major benchmarks:The 8B and 70B models from the April Llama 3 release have also received serious spec bumps, warranting the new label of Llama 3.1.If you are curious about the infra / hardware side, go check out our episode with Soumith Chintala, one of the AI infra leads at Meta. Today we have Thomas Scialom, who led Llama2 and now Llama3 post-training, so we spent most of our time on pre-training (synthetic data, data pipelines, scaling laws, etc) and post-training (RLHF vs instruction tuning, evals, tool calling).Synthetic data is all you needLlama3 was trained on 15T tokens, 7x more than Llama2 and with 4 times as much code and 30 different languages represented. But as Thomas beautifully put it:“My intuition is that the web is full of s**t in terms of text, and training on those tokens is a waste of compute.” “Llama 3 post-training doesn't have any human written answers there basically… It's just leveraging pure synthetic data from Llama 2.”While it is well speculated that the 8B and 70B were "offline distillations" of the 405B, there are a good deal more synthetic data elements to Llama 3.1 than the expected. The paper explicitly calls out:* SFT for Code: 3 approaches for synthetic data for the 405B bootstrapping itself with code execution feedback, programming language translation, and docs backtranslation.* SFT for Math: The Llama 3 paper credits the Let’s Verify Step By Step authors, who we interviewed at ICLR:* SFT for Multilinguality: "To collect higher quality human annotations in non-English languages, we train a multilingual expert by branching off the pre-training run and continuing to pre-train on a data mix that consists of 90% multilingualtokens."* SFT for Long Context: "It is largely impractical to get humans to annotate such examples due to the tedious and time-consuming nature of reading lengthy contexts, so we predominantly rely on synthetic data to fill this gap. We use earlier versions of Llama 3 to generate synthetic data based on the key long-context use-cases: (possibly multi-turn) question-answering, summarization for long documents, and reasoning over code repositories, and describe them in greater detail below"* SFT for Tool Use: trained for Brave Search, Wolfram Alpha, and a Python Interpreter (a special new ipython role) for single, nested, parallel, and multiturn function calling.* RLHF: DPO preference data was used extensively on Llama 2 generations. This is something we partially covered in RLHF 201: humans are often better at judging between two options (i.e. which of two poems they prefer) than creating one (writing one from scratch). Similarly, models might not be great at creating text but they can be good at classifying their quality.Last but not least, Llama 3.1 received a license update explicitly allowing its use for synthetic data generation.Llama2 was also used as a classifier for all pre-training data that went into the model. It both labelled it by quality so that bad tokens were removed, but also used type (i.e. science, law, politics) to achieve a balanced data mix. Tokenizer size mattersThe tokens vocab of a model is the collection of all tokens that the model uses. Llama2 had a 34,000 tokens vocab, GPT-4 has 100,000, and 4o went up to 200,000. Llama3 went up 4x to 128,000 tokens. You can find the GPT-4 vocab list on Github.This is something that people gloss over, but there are many reason why a large vocab matters:* More tokens allow it to represent more concepts, and then be better at understanding the nuances.* The larger the tokenizer, the less tokens you need for the same amount of text, extending the perceived context size. In Llama3’s case, that’s ~30% more text due to the tokenizer upgrade. * With the same amount of compute you can train more knowledge into the model as you need fewer steps.The smaller the model, the larger the impact that the tokenizer size will have on it. You can listen at 55:24 for a deeper explanation.Dense models = 1 Expert MoEsMany people on X asked “why not MoE?”, and Thomas’ answer was pretty clever: dense models are just MoEs with 1 expert :)[00:28:06]: I heard that question a lot, different aspects there. Why not MoE in the future? The other thing is, I think a dense model is just one specific variation of the model for an hyperparameter for an MOE with basically one expert. So it's just an hyperparameter we haven't optimized a lot yet, but we have some stuff ongoing and that's an hyperparameter we'll explore in the future.Basically… wait and see!Llama4Meta already started training Llama4 in June, and it sounds like
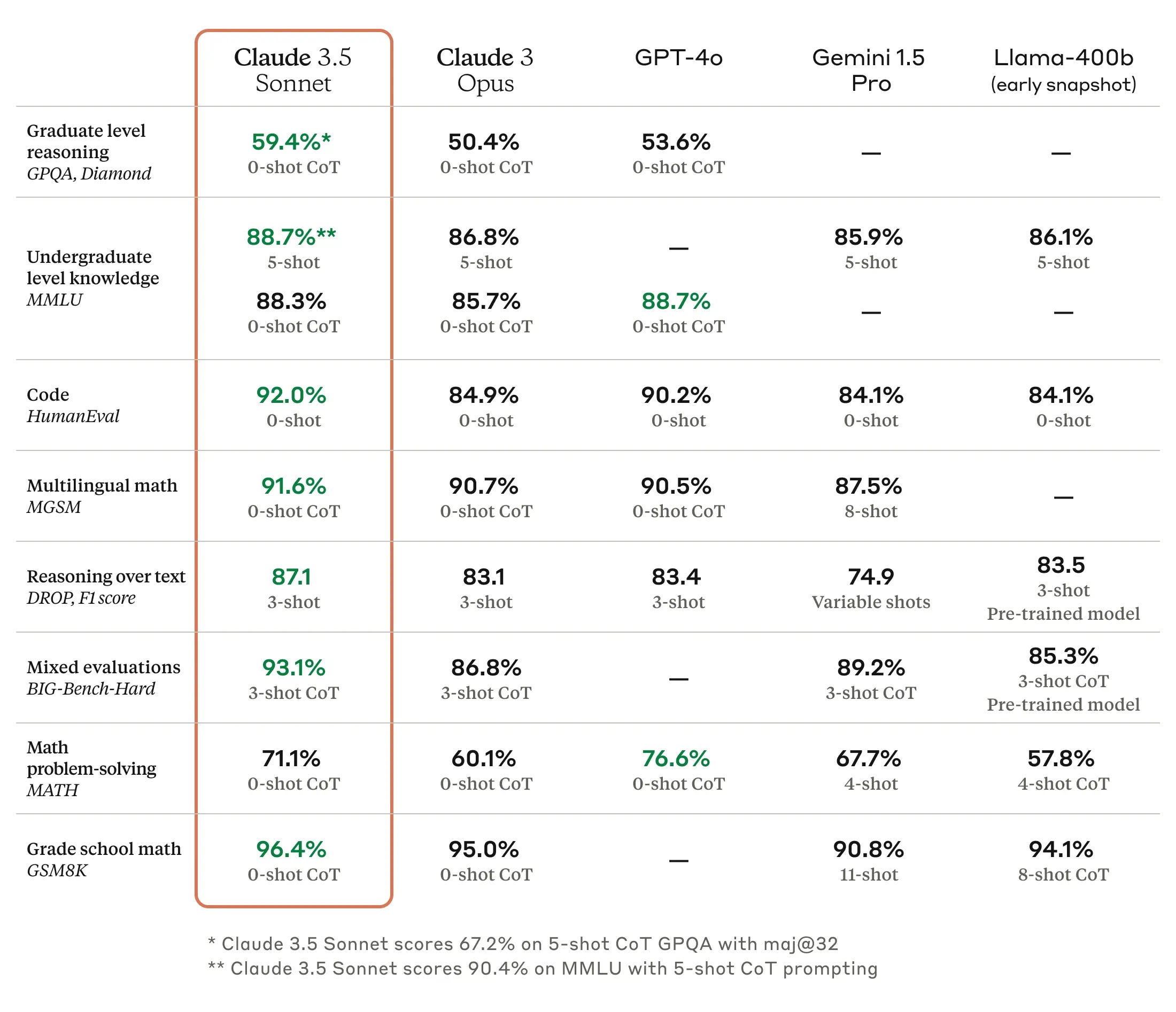
Benchmarks 201: Why Leaderboards > Arenas >> LLM-as-Judge
The first AI Engineer World’s Fair talks from OpenAI and Cognition are up!In our Benchmarks 101 episode back in April 2023 we covered the history of AI benchmarks, their shortcomings, and our hopes for better ones. Fast forward 1.5 years, the pace of model development has far exceeded the speed at which benchmarks are updated. Frontier labs are still using MMLU and HumanEval for model marketing, even though most models are reaching their natural plateau at a ~90% success rate (any higher and they’re probably just memorizing/overfitting).From Benchmarks to LeaderboardsOutside of being stale, lab-reported benchmarks also suffer from non-reproducibility. The models served through the API also change over time, so at different points in time it might return different scores.Today’s guest, Clémentine Fourrier, is the lead maintainer of HuggingFace’s OpenLLM Leaderboard. Their goal is standardizing how models are evaluated by curating a set of high quality benchmarks, and then publishing the results in a reproducible way with tools like EleutherAI’s Harness.The leaderboard was first launched summer 2023 and quickly became the de facto standard for open source LLM performance. To give you a sense for the scale:* Over 2 million unique visitors* 300,000 active community members* Over 7,500 models evaluatedLast week they announced the second version of the leaderboard. Why? Because models were getting too good!The new version of the leaderboard is based on 6 benchmarks:* 📚 MMLU-Pro (Massive Multitask Language Understanding - Pro version, paper)* 📚 GPQA (Google-Proof Q&A Benchmark, paper)* 💭MuSR (Multistep Soft Reasoning, paper)* 🧮 MATH (Mathematics Aptitude Test of Heuristics, Level 5 subset, paper)* 🤝 IFEval (Instruction Following Evaluation, paper)* 🧮 🤝 BBH (Big Bench Hard, paper)You can read the reasoning behind each of them on their announcement blog post. These updates had some clear winners and losers, with models jumping up or down up to 50 spots at once; the most likely reason for this is that the models were overfit to the benchmarks, or had some contamination in their training dataset.But the most important change is in the absolute scores. All models score much lower on v2 than they do on v1, which now creates a lot more room for models to show improved performance.On ArenasAnother high-signal platform for AI Engineers is the LMSys Arena, which asks users to rank the output of two different models on the same prompt, and then give them an ELO score based on the outcomes.Clémentine called arenas “sociological experiments”: it tells you a lot about the users preference, but not always much about the model capabilities. She pointed to Anthropic’s sycophancy paper as early research in this space:We find that when a response matches a user’s views, it is more likely to be preferred. Moreover, both humans and preference models (PMs) prefer convincingly-written sycophantic responses over correct ones a non-negligible fraction of the time.The other issue is that Arena rankings aren’t reproducible, as you don’t know who ranked what and what exactly the outcome was at the time of ranking. They are still quite helpful as tools, but they aren’t a rigorous way to rank capabilities of the models.Her advice for both arena and leaderboard is to use these tools as ranges; find 3-4 models that fit your needs (speed, cost, capabilities, etc) and then do vibe checks to figure out which one is best for your specific task.LLMs aren’t good judgesIn the last ~6 months, there has been an increased interest in using LLMs as Judges: rather than asking a person to evaluate the outcome of a model, you can ask a more powerful LLM to score it. We covered this a bit in our Brightwave episode last month as well. HuggingFace also has a cookbook on it, but Clémentine was actually not a fan of this approach:* Mode collapse: if you are asking a model to choose which output is better, it will just self-reinforce its own preferences. It will also prefer models from its own family (i.e. GPT models will prefer other GPT models over Claude outputs). If these outputs are then used to fine-tune the model, you will further mode collapse the model. Cohere for example has said they do not train on any model-generated data to avoid this.* Positional bias: LLMs usually prefer the first answer, so you can’t naively give them options and ask them to rank them, but you also have to mix up the order in which they appear.* Don’t score, rank: rather than asking a model to assign a score to each output, you should have it stack-rank them. The models aren’t trained to score things, so even though they might understand what response is better, assigning a score to it is hard.If you do have to use LLMs as Judges (we aren’t all ScaleAI-rich!), she suggested using an open LLM like Prometheus or JudgeLM to make sure you can reproduce those rankings in the future. Show Notes* Clémentine Fourrier* Hugging Face* OpenLLM v2 Leaderboard* Let’s talk about LLM Evalua

The 10,000x Yolo Researcher Metagame — with Yi Tay of Reka
Livestreams for the AI Engineer World’s Fair (Multimodality ft. the new GPT-4o demo, GPUs and Inference (ft. Cognition/Devin), CodeGen, Open Models tracks) are now live! Subscribe to @aidotEngineer to get notifications of the other workshops and tracks!It’s easy to get de-sensitized to new models topping leaderboards every other week — however, the top of the LMsys leaderboard has typically been the exclusive domain of very large, very very well funded model labs like OpenAI, Anthropic, Google, and Meta. OpenAI had about 600 people at the time of GPT-4, and Google Gemini had 950 co-authors. This is why Reka Core made waves in May - not only debuting at #7 on the leaderboard, but doing so with all-new GPU infrastructure and 20 employees with and a relatively puny $60m in funding.Shortly after the release of GPT3, Sam Altman speculated on the qualities of “10,000x researchers”:* “They spend a lot of time reflecting on some version of the Hamming question—"what are the most important problems in your field, and why aren’t you working on them?” In general, no one reflects on this question enough, but the best people do it the most, and have the best ‘problem taste’, which is some combination of learning to think independently, reason about the future, and identify attack vectors.” — sama* Taste is something both John Schulman and Yi Tay emphasize greatly* “They have a laser focus on the next step in front of them combined with long-term vision.” — sama* “They are extremely persistent and willing to work hard… They have a bias towards action and trying things, and they’re clear-eyed and honest about what is working and what isn’t” — sama“There's a certain level of sacrifice to be an AI researcher, especially if you're training at LLMs, because you cannot really be detached… your jobs could die on a Saturday at 4am, and there are people who will just leave it dead until Monday morning, or there will be people who will crawl out of bed at 4am to restart the job, or check the TensorBoard” – Yi Tay (at 28 mins)“I think the productivity hack that I have is, I didn't have a boundary between my life and my work for a long time. So I think I just cared a lot about working most of the time. Actually, during my PhD, Google and everything [else], I'll be just working all the time. It's not like the most healthy thing, like ever, but I think that that was actually like one of the biggest, like, productivity, like and I spent, like, I like to spend a lot of time, like, writing code and I just enjoy running experiments, writing code” — Yi Tay (at 90 mins)* See @YiTayML example for honest alpha on what is/is not workingand so on.More recently, Yi’s frequent co-author, Jason Wei, wrote about the existence of Yolo researchers he witnessed at OpenAI:Given the very aggressive timeline — Yi left Google in April 2023, was GPU constrained until December 2023, and then Reka Flash (21B) was released in Feb 2024, and Reka Core (??B) was released in April 2024 — Reka’s 3-5 person pretraining team had no other choice but to do Yolo runs. Per Yi:“Scaling models systematically generally requires one to go from small to large in a principled way, i.e., run experiments in multiple phrases (1B->8B->64B->300B etc) and pick the winners and continuously scale them up. In a startup, we had way less compute to perform these massive sweeps to check hparams. In the end, we had to work with many Yolo runs (that fortunately turned out well).In the end it took us only a very small number of smaller scale & shorter ablation runs to get to the strong 21B Reka Flash and 7B edge model (and also our upcoming largest core model). Finding a solid recipe with a very limited number of runs is challenging and requires changing many variables at once given the ridiculously enormous search space. In order to do this, one has to abandon the systematicity of Bigtech and rely a lot on “Yolo”, gut feeling and instinct.”We were excited to be the first podcast to interview Yi, and recommend reading our extensive show notes to follow the same papers we reference throughout the conversation.Special thanks to Terence Lee of TechInAsia for the final interview clip, who are launching their own AI newsletter called The Prompt!Full Video PodcastShow Notes* Yi on LinkedIn, Twitter, Personal* Full prep doc* Reka funding/valuation* Building frontier AI teams as GPU Poors* Yi’s Research* 2020* Efficient Transformers: A Survey went viral!* Long Range Arena: A Benchmark for Efficient Transformers in 2020* 2021: Generative Models are Unsupervised Predictors of Page Quality: A Colossal-Scale Study * 2022: * UL2: Unifying Language Learning Paradigms* PaLM -> PaLM-2* Emergent Abilities of Large Language Models vs the Mirage paper* Recitation Augmented generation* DSI++: Updating Transformer Memory with New Documents* The Efficiency Misnomer: “a model with low FLOPs may not actually be fast, given that FLOPs does not take into account information such as degree of parallelism (e.g., depth
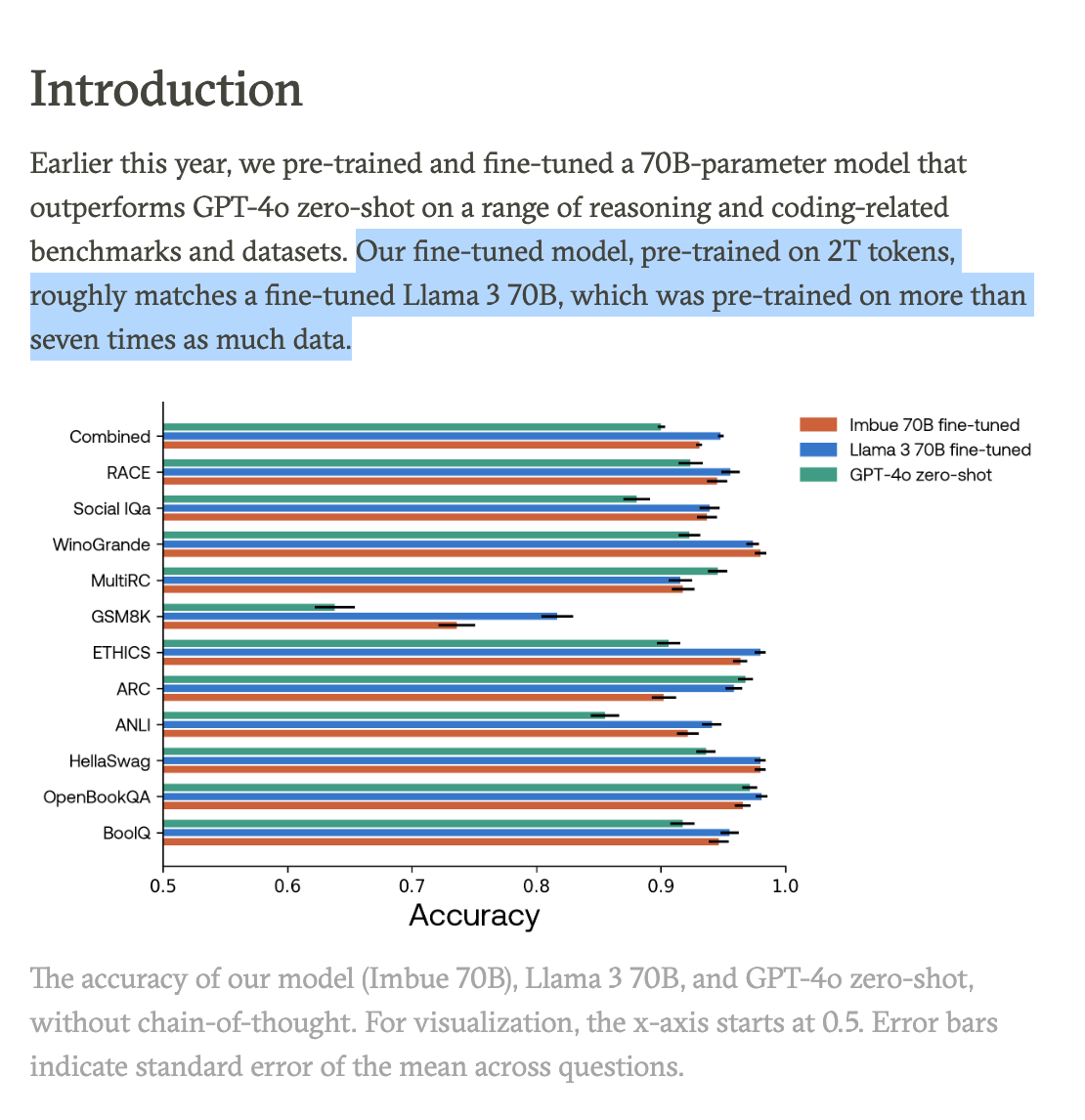
State of the Art: Training >70B LLMs on 10,000 H100 clusters
It’s return guest season here at Latent Space! We last talked to Kanjun in October and Jonathan in May (and December post Databricks acquisition): Imbue and Databricks are back for a rare treat: a double-header interview talking about DBRX from Databricks and Imbue 70B, a new internal LLM that “outperforms GPT-4o” zero-shot on a range of reasoning and coding-related benchmarks and datasets, while using 7x less data than Llama 3 70B.While Imbue, being an agents company rather than a model provider, are not releasing their models today, they are releasing almost everything else: * Cleaned-up and extended versions of 11 of the most popular NLP reasoning benchmarks* An entirely new code-focused reasoning benchmark* A fine-tuned 70B model, built with Meta Llama 3, to identify ambiguity* A new dataset of 450,000 human judgments about ambiguity* Infrastructure scripts for bringing a cluster from bare metal to robust, high performance training* Our cost-aware hyperparameter optimizer, CARBS, which automatically and systematically fine-tunes all hyperparameters to derive optimum performance for models of any sizeAs well as EXTREMELY detailed posts on the infrastructure needs, hyperparameter search, and clean versions of the sorry state of industry standard benchmarks. This means for the FIRST TIME (perhaps since Meta’s OPT-175B in 2022?) you have this level of educational detail into the hardware and ML nitty gritty of training extremely large LLMs, and if you are in fact training LLMs of this scale you now have evals, optimizers, scripts, and human data/benchmarks you can use to move the industry forward together with Imbue.We are busy running the sold-out AI Engineer World’s Fair today, and so are unable to do our usual quality writeup, however, please enjoy our show notes and the excellent conversation! Thanks also to Kanjun, Ashley, Tom and the rest of team Imbue for setting up this interview behind the scenes.Video podTimestamps* [00:00:00] Introduction and catch up with guests* [00:01:55] Databricks' text to image model release* [00:03:46] Details about the DBRX model* [00:05:26] Imbue's infrastructure, evaluation, and hyperparameter optimizer releases* [00:09:18] Challenges of training foundation models and getting infrastructure to work* [00:12:03] Details of Imbue's cluster setup* [00:18:53] Process of bringing machines online and common failures* [00:22:52] Health checks and monitoring for the cluster* [00:25:06] Typical timelines and team composition for setting up a cluster* [00:27:24] Monitoring GPU utilization and performance* [00:29:39] Open source tools and libraries used* [00:32:33] Reproducibility and portability of cluster setup* [00:35:57] Infrastructure changes needed for different model architectures* [00:40:49] Imbue's focus on text-only models for coding and reasoning* [00:42:26] CARBS hyperparameter tuner and cost-aware optimization* [00:51:01] Emergence and CARBS* [00:53:18] Evaluation datasets and reproducing them with high quality* [00:58:40] Challenges of evaluating on more realistic tasks* [01:06:01] Abstract reasoning benchmarks like ARC* [01:10:13] Long context evaluation and needle-in-a-haystack tasks* [01:13:50] Function calling and tool use evaluation* [01:19:19] Imbue's future plans for coding and reasoning applications* [01:20:14] Databricks' future plans for useful applications and upcoming blog postsTranscriptSWYX [00:00:00]: Welcome to the Latent Space Podcast, another super special edition. Today, we have sort of like a two-header. John Frankel from Mosaic Databricks, or Databricks Mosaic, and Josh Albrecht from MBU. Welcome.JOSH [00:00:12]: Hey, glad to be here.SWYX [00:00:14]: Thank you for having us. Hey, so both of you are kind of past guests. Jonathan, you were actually one of the most popular episodes from last year talking about MPT7B. Remember the days when we trained large models and there was 7B?JONATHAN [00:00:30]: Yeah, back when reproducing LLAMA1-7B was considered a huge accomplishment for the field. Those are the good old days. I miss that.SWYX [00:00:38]: As the things have accelerated a lot. Actually, let's do a quick catch up and Josh, you can chime on in as well. So Databricks got acquired. I talked to you at New York.JONATHAN [00:00:45]: Mosaic got acquired, although sometimes it feels like Mosaic acquired Databricks because, you know, we're having a lot of fun being here. But, you know, yeah.SWYX [00:00:52]: Yeah. I mean, you are chief scientist now of Databricks.JONATHAN [00:00:55]: Chief AI scientist. Careful with the title. As much as I would love to understand how Spark works, I'm going to have to defer that to much smarter people than me.SWYX [00:01:03]: Got it. And I don't know about like what you would highlight so far as a post-acquisition, but the most recent news is that you guys released DBRX. Is that the thing that most people should be aware of?JONATHAN [00:01:13]: Actually, that's no longer the most recent news. Honestly, the most recent new

[High Agency] AI Engineer World's Fair Preview
The World’s Fair is officially sold out! Thanks for all the support and stay tuned for recaps of all the great goings on in this very special celebration of the AI Engineer!Longtime listeners will remember the fan favorite Raza Habib, CEO of HumanLoop, on the pod:Well, he’s caught the podcasting bug and is now flipping the tables on swyx! Subscribe to High Agency wherever the finest Artificial Intelligence podcast are sold.High Agency Pod DescriptionIn this episode, I chatted with Shawn Wang about his upcoming AI engineering conference and what an AI engineer really is. It's been a year since he penned the viral essay "Rise of the AI Engineer' and we discuss if this new role will be enduring, the make up of the optimal AI team and trends in machine learning.Timestamps00:00 - Introduction and background on Shawn Wang (Swyx)03:45 - Reflecting on the "Rise of the AI Engineer" essay07:30 - Skills and characteristics of AI Engineers12:15 - Team composition for AI products16:30 - Vertical vs. horizontal AI startups23:00 - Advice for AI product creators and leaders28:15 - Tools and buying vs. building for AI products33:30 - Key trends in AI research and development41:00 - Closing thoughts and information on the AI Engineer World Fair SummitVideo This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe
How To Hire AI Engineers — with James Brady & Adam Wiggins of Elicit
Editor’s note: One of the top reasons we have hundreds of companies and thousands of AI Engineers joining the World’s Fair next week is, apart from discussing technology and being present for the big launches planned, to hire and be hired! Listeners loved our previous Elicit episode and were so glad to welcome 2 more members of Elicit back for a guest post (and bonus podcast) on how they think through hiring. Don’t miss their AI engineer job description, and template which you can use to create your own hiring plan! How to Hire AI EngineersJames Brady, Head of Engineering @ Elicit (ex Spring, Square, Trigger.io, IBM)Adam Wiggins, Internal Journalist @ Elicit (Cofounder Ink & Switch and Heroku)If you’re leading a team that uses AI in your product in some way, you probably need to hire AI engineers. As defined in this article, that’s someone with conventional engineering skills in addition to knowledge of language models and prompt engineering, without being a full-fledged Machine Learning expert.But how do you hire someone with this skillset? At Elicit we’ve been applying machine learning to reasoning tools since 2018, and our technical team is a mix of ML experts and what we can now call AI engineers. This article will cover our process from job description through interviewing. (You can also flip the perspectives here and use it just as easily for how to get hired as an AI engineer!)My own journeyBefore getting into the brass tacks, I want to share my journey to becoming an AI engineer.Up until a few years ago, I was happily working my job as an engineering manager of a big team at a late-stage startup. Like many, I was tracking the rapid increase in AI capabilities stemming from the deep learning revolution, but it was the release of GPT-3 in 2020 which was the watershed moment. At the time, we were all blown away by how the model could string together coherent sentences on demand. (Oh how far we’ve come since then!)I’d been a professional software engineer for nearly 15 years—enough to have experienced one or two technology cycles—but I could see this was something categorically new. I found this simultaneously exciting and somewhat disconcerting. I knew I wanted to dive into this world, but it seemed like the only path was going back to school for a master’s degree in Machine Learning. I started talking with my boss about options for taking a sabbatical or doing a part-time distance learning degree.In 2021, I instead decided to launch a startup focused on productizing new research ideas on ML interpretability. It was through that process that I reached out to Andreas—a leading ML researcher and founder of Elicit—to see if he would be an advisor. Over the next few months, I learned more about Elicit: that they were trying to apply these fascinating technologies to the real-world problems of science, and with a business model that aligned it with safety goals. I realized that I was way more excited about Elicit than I was about my own startup ideas, and wrote about my motivations at the time.Three years later, it’s clear this was a seismic shift in my career on the scale of when I chose to leave my comfy engineering job at IBM to go through the Y Combinator program back in 2008. Working with this new breed of technology has been more intellectually stimulating, challenging, and rewarding than I could have imagined.Deep ML expertise not requiredIt’s important to note that AI engineers are not ML experts, nor is that their best contribution to a tech team.In our article Living documents as an AI UX pattern, we wrote:It’s easy to think that AI advancements are all about training and applying new models, and certainly this is a huge part of our work in the ML team at Elicit. But those of us working in the UX part of the team believe that we have a big contribution to make in how AI is applied to end-user problems.We think of LLMs as a new medium to work with, one that we’ve barely begun to grasp the contours of. New computing mediums like GUIs in the 1980s, web/cloud in the 90s and 2000s, and multitouch smartphones in the 2000s/2010s opened a whole new era of engineering and design practices. So too will LLMs open new frontiers for our work in the coming decade.To compare to the early era of mobile development: great iOS developers didn’t require a detailed understanding of the physics of capacitive touchscreens. But they did need to know the capabilities and limitations of a multi-touch screen, the constrained CPU and storage available, the context in which the user is using it (very different from a webpage or desktop computer), etc.In the same way, an AI engineer needs to work with LLMs as a medium that is fundamentally different from other compute mediums. That means an interest in the ML side of things, whether through their own self-study, tinkering with prompts and model fine-tuning, or following along in #llm-paper-club. But this understanding is so that they can work with the medium effectively versu
How AI is eating Finance — with Mike Conover of Brightwave
In April 2023 we released an episode named “Mapping the future of *truly* open source models” to talk about Dolly, the first open, commercial LLM. Mike was leading the OSS models team at Databricks at the time. Today, Mike is back on the podcast to give us the “one year later” update on the evolution of large language models and how he’s been using them to build Brightwave, an an AI research assistant for investment professionals. Today they are announcing a $6M seed round (led by Alessio and Decibel!), and sharing some of the learnings from serving customers with >$120B of assets under management in production in the last 4 months since launch. Losing faith in long context windowsIn our recent “Llama3 1M context window” episode we talked about the amazing progress we have done in context window size, but it’s good to remember that Dolly’s original context size was 1,024 tokens, and this was only 14 months ago. But while understanding length has increased, models are still not able to generate very long answers. His empirical intuition (which matches ours while building smol-podcaster) is that most commercial LLMs, as well as Llama, tend to generate responses most of the time. While Needle in a Haystack tests will pass with flying colors at most context sizes, the granularity of the summary decreases as the context increases as it tries to fit the answer in the same tokens range, rather than returning tokens close to the 4,096 max_output, for example. Recently Rob Mulla from Dreadnode highlighted how LMSys Arena results prefer longer responses by a large margin, so both LLMs and humans have a well documented length bias which doesn’t necessarily track the quality of answer:The way Mike and team solved this is by breaking down the task in multiple subtasks, and then merging them back together. For example, have a book summarized chapter by chapter to preserve more details, and then put those summaries together. In Brightwave’s case, it’s creating multiple subsystems that accomplish different tasks on a large corpus of text separately, and then bringing them all together in a report. For example understanding intent of the question, extracting relations between companies, figuring out if it’s a positive / negative, etc. Mike’s question is whether or not we’ll be able to imbue better synthesis capabilities in the models: can you have synthesis-oriented demonstrations at training time rather than single token prediction? “LLMs as Judges” StrategiesIn our David Luan episode he mentioned they don’t use any benchmarks for their models, because the benchmarks don’t reflect their customer needs. Brightwave shared some tips on leveraging LLMs as Judges:* Human vs LLM reviews: while they work with human annotators to create high quality datasets, that data isn’t just used to fine tune models but also as a reference basis for future LLM reviews. Having a set of trusted data to use as calibration helps you trust the LLM judgement even more. * Ensemble consistency checking: rather than using an LLM as judge for one output, you use different LLMs to generate a result for the same task, and then use another LLM to highlight where those generations differ. Do the two outputs differ meaningfully? Do they have different beliefs about the implications of something? If there are a lot of discrepancies between generations coming from different models, you then do additional passes to try and resolve them.* Entailment verification: for each unique insight that they generate, they take the output and separately ask LLMs to verify factuality of information based on the original sources. In the actual product, user can then highlight any piece of text and ask it to 1) “Tell Me More” 2) “Show Sources”. Since there’s no way to guarantee factuality of 100% of outputs, and humans have good intuition for things that look out of the ordinary, giving the user access to the review tool helps them build trust in it.It’s all about the dataDuring his time at Databricks, they had created dolly-15k, a dataset of instruction-following records written by thousands of their employees. Since then, no other company has replicated that type of effort even though the data wars are in full effect. It’s been clear in the last year that the half-life of a model is much shorter than the half-life of a dataset. The Pile by Eleuther (see Datasets 101) came out in 2020 and is still widely used; if you had trained an LLM in 2020, you would have definitely replaced it by now as they have gotten better and cheaper. On the age old “RAG v Fine-Tuning” question, Mike shared a great example that we’ll just quote:I think of language models kind of like a stem cell, and then under fine tuning, they differentiate into different kinds of specific cells. I don't think that unbounded agentic behaviors are useful, and that instead, a useful LLM system is more like a finite state machine where the behavior of the system is occupying one of many different behavioral regimes
ICLR 2024 — Best Papers & Talks (Benchmarks, Reasoning & Agents) — ft. Graham Neubig, Aman Sanger, Moritz Hardt)
Our second wave of speakers for AI Engineer World’s Fair were announced! The conference sold out of Platinum/Gold/Silver sponsors and Early Bird tickets! See our Microsoft episode for more info and buy now with code LATENTSPACE.This episode is straightforwardly a part 2 to our ICLR 2024 Part 1 episode, so without further ado, we’ll just get right on with it!Timestamps[00:03:43] Section A: Code Edits and Sandboxes, OpenDevin, and Academia vs Industry — ft. Graham Neubig and Aman Sanger* [00:07:44] WebArena* [00:18:45] Sotopia* [00:24:00] Performance Improving Code Edits* [00:29:39] OpenDevin* [00:47:40] Industry and Academia[01:05:29] Section B: Benchmarks* [01:05:52] SWEBench* [01:17:05] SWEBench/SWEAgent Interview* [01:27:40] Dataset Contamination Detection* [01:39:20] GAIA Benchmark* [01:49:18] Moritz Hart - Science of Benchmarks[02:36:32] Section C: Reasoning and Post-Training* [02:37:41] Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection* [02:51:00] Let’s Verify Step By Step* [02:57:04] Noam Brown* [03:07:43] Lilian Weng - Towards Safe AGI* [03:36:56] A Real-World WebAgent with Planning, Long Context Understanding, and Program Synthesis* [03:48:43] MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework[04:00:51] Bonus: Notable Related Papers on LLM CapabilitiesSection A: Code Edits and Sandboxes, OpenDevin, and Academia vs Industry — ft. Graham Neubig and Aman Sanger* Guests* Graham Neubig* Aman Sanger - Previous guest and NeurIPS friend of the pod!* WebArena * * Sotopia (spotlight paper, website)* * Learning Performance-Improving Code Edits* OpenDevin* Junyang Opendevin* Morph Labs, Jesse Han* SWE-Bench* SWE-Agent* Aman tweet on swebench* LiteLLM* Livecodebench* the role of code in reasoning* Language Models of Code are Few-Shot Commonsense Learners* Industry vs academia* the matryoshka embeddings incident* other directions* UnlimiformerSection A timestamps* [00:00:00] Introduction to Guests and the Impromptu Nature of the Podcast* [00:00:45] Graham's Experience in Japan and Transition into Teaching NLP* [00:01:25] Discussion on What Constitutes a Good Experience for Students in NLP Courses* [00:02:22] The Relevance and Teaching of Older NLP Techniques Like Ngram Language Models* [00:03:38] Speculative Decoding and the Comeback of Ngram Models* [00:04:16] Introduction to WebArena and Zotopia Projects* [00:05:19] Deep Dive into the WebArena Project and Benchmarking* [00:08:17] Performance Improvements in WebArena Using GPT-4* [00:09:39] Human Performance on WebArena Tasks and Challenges in Evaluation* [00:11:04] Follow-up Work from WebArena and Focus on Web Browsing as a Benchmark* [00:12:11] Direct Interaction vs. Using APIs in Web-Based Tasks* [00:13:29] Challenges in Base Models for WebArena and the Potential of Visual Models* [00:15:33] Introduction to Zootopia and Exploring Social Interactions with Language Models* [00:16:29] Different Types of Social Situations Modeled in Zootopia* [00:17:34] Evaluation of Language Models in Social Simulations* [00:20:41] Introduction to Performance-Improving Code Edits Project* [00:26:28] Discussion on DevIn and the Future of Coding Agents* [00:32:01] Planning in Coding Agents and the Development of OpenDevon* [00:38:34] The Changing Role of Academia in the Context of Large Language Models* [00:44:44] The Changing Nature of Industry and Academia Collaboration* [00:54:07] Update on NLP Course Syllabus and Teaching about Large Language Models* [01:00:40] Call to Action: Contributions to OpenDevon and Open Source AI Projects* [01:01:56] Hiring at Cursor for Roles in Code Generation and Assistive Coding* [01:02:12] Promotion of the AI Engineer ConferenceSection B: Benchmarks * Carlos Jimenez & John Yang (Princeton) et al: SWE-bench: Can Language Models Resolve Real-world Github Issues? (ICLR Oral, Paper, website)* “We introduce SWE-bench, an evaluation framework consisting of 2,294 software engineering problems drawn from real GitHub issues and corresponding pull requests across 12 popular Python repositories. Given a codebase along with a description of an issue to be resolved, a language model is tasked with editing the codebase to address the issue. Resolving issues in SWE-bench frequently requires understanding and coordinating changes across multiple functions, classes, and even files simultaneously, calling for models to interact with execution environments, process extremely long contexts and perform complex reasoning that goes far beyond traditional code generation tasks. Our evaluations show that both state-of-the-art proprietary models and our fine-tuned model SWE-Llama can resolve only the simplest issues. The best-performing model, Claude 2, is able to solve a mere 1.96% of the issues. Advances on SWE-bench represent steps towards LMs that are more practical, intelligent, and autonomous.”* Yonatan Oren et al (Stanford): Proving Test Set Contamination in Black-Box Language Models (ICLR Oral, paper, aman tweet on swe
How to train a Million Context LLM — with Mark Huang of Gradient.ai
AI Engineer World’s Fair in SF! Prices go up soon.Note that there are 4 tracks per day and dozens of workshops/expo sessions; the livestream will air the most stacked speaker list/AI expo floor of 2024. Apply for free/discounted Diversity Program and Scholarship tickets here. We hope to make this the definitive technical conference for ALL AI engineers.Exactly a year ago, we declared the Beginning of Context=Infinity when Mosaic made their breakthrough training an 84k token context MPT-7B.A Brief History of Long ContextOf course right when we released that episode, Anthropic fired the starting gun proper with the first 100k context window model from a frontier lab, spawning smol-developer and other explorations. In the last 6 months, the fight (and context lengths) has intensified another order of magnitude, kicking off the "Context Extension Campaigns" chapter of the Four Wars:* In October 2023, Claude's 100,000 token windows was still SOTA (we still use it for Latent Space’s show notes to this day).* On November 6th, OpenAI launched GPT-4 Turbo with 128k context.* On November 21st, Anthropic fired back extending Claude 2.1 to 200k tokens.* Feb 15 (the day everyone launched everything) was Gemini's turn, announcing the first LLM with 1 million token context window.* In May 2024 at Google I/O, Gemini 1.5 Pro announced a 2m token context windowIn parallel, open source/academia had to fight its own battle to keep up with the industrial cutting edge. Nous Research famously turned a reddit comment into YaRN, extending Llama 2 models to 128k context. So when Llama 3 dropped, the community was ready, and just weeks later, we had Llama3 with 4M+ context!A year ago we didn’t really have an industry standard way of measuring context utilization either: it’s all well and good to technically make an LLM generate non-garbage text at 1m tokens, but can you prove that the LLM actually retrieves and attends to information inside that long context? Greg Kamradt popularized the Needle In A Haystack chart which is now a necessary (if insufficient) benchmark — and it turns out we’ve solved that too in open source:Today's guest, Mark Huang, is the co-founder of Gradient, where they are building a full stack AI platform to power enterprise workflows and automations. They are also the team behind the first Llama3's 1M+ and 4M+ context window finetunes.Long Context Algorithms: RoPE, ALiBi, and Ring AttentionPositional encodings allow the model to understand the relative position of tokens in the input sequence, present in what (upcoming guest!) Yi Tay affectionately calls the OG “Noam architecture”. But if we want to increase a model’s context length, these encodings need to gracefully extrapolate to longer sequences.ALiBi, used in models like MPT (see our "Context=Infinity" episode with the MPT leads, Jonathan Frankle and Abhinav), was one of the early approaches to this space. It lets the context window stretch as it grows, using a linearly decreasing penalty between attention weights of different positions; the further two tokens are, the higher the penalty. Of course, this isn’t going to work for usecases that actually require global attention across a long context.In more recent architectures and finetunes, RoPE (Rotary Position Embedding) encoding is more commonly used and is also what Llama3 was based on. RoPE uses a rotational matrix to encode positions, which empirically performs better for longer sequences.The main innovation from Gradient was to focus on tuning the theta hyperparameter that governs the frequency of the rotational encoding.Audio note: If you want the details, jump to 15:55 in the podcast (or scroll down to the transcript!)By carefully increasing theta as context length grew, they were able to scale Llama3 up to 1 million tokens and potentially beyond. Once you've scaled positional embeddings, there's still the issue of attention's quadratic complexity, and how longer and longer sequences impacts models speed and scaling abilities. Getting to 1-4M context window requires a fairly large amount of compute, so efficiency matters.Ring Attention was the other "one small trick that GPU clouds hate" that improves GPU utilization by allowing parallel computation and communication between GPUs. Gradient started from the EasyContext library as implementation of Ring Attention in PyTorch, since the original one was in JAX.Long Context Data: Curriculum Learning and Progressive ExtensionThe use of curriculum learning when extending context was another new approach; rather than training Llama3 on the full 1 million token context from the start, they progressively increased the sequence length over the course of training. Intuitively, it allows the model to first learn to utilize shorter contexts before tackling the full length, but it only works if data gets more and more "tricky" in long context situation.For the generic pre-training corpus they used SlimPajama as a base, and concatenated texts to reach the target le

ICLR 2024 — Best Papers & Talks (ImageGen, Vision, Transformers, State Space Models) ft. Durk Kingma, Christian Szegedy, Ilya Sutskever
Speakers for AI Engineer World’s Fair have been announced! See our Microsoft episode for more info and buy now with code LATENTSPACE — we’ve been studying the best ML research conferences so we can make the best AI industry conf! Note that this year there are 4 main tracks per day and dozens of workshops/expo sessions; the free livestream will air much less than half of the content this time.Apply for free/discounted Diversity Program and Scholarship tickets here. We hope to make this the definitive technical conference for ALL AI engineers.UPDATE: This is a 2 part episode - see Part 2 here.ICLR 2024 took place from May 6-11 in Vienna, Austria. Just like we did for our extremely popular NeurIPS 2023 coverage, we decided to pay the $900 ticket (thanks to all of you paying supporters!) and brave the 18 hour flight and 5 day grind to go on behalf of all of you. We now present the results of that work!This ICLR was the biggest one by far, with a marked change in the excitement trajectory for the conference:Of the 2260 accepted papers (31% acceptance rate), of the subset of those relevant to our shortlist of AI Engineering Topics, we found many, many LLM reasoning and agent related papers, which we will cover in the next episode. We will spend this episode with 14 papers covering other relevant ICLR topics, as below.As we did last year, we’ll start with the Best Paper Awards. Unlike last year, we now group our paper selections by subjective topic area, and mix in both Outstanding Paper talks as well as editorially selected poster sessions. Where we were able to do a poster session interview, please scroll to the relevant show notes for images of their poster for discussion. To cap things off, Chris Ré’s spot from last year now goes to Sasha Rush for the obligatory last word on the development and applications of State Space Models.We had a blast at ICLR 2024 and you can bet that we’ll be back in 2025 🇸🇬.Timestamps and Overview of Papers[00:02:49] Section A: ImageGen, Compression, Adversarial Attacks* [00:02:49] VAEs* [00:32:36] Würstchen: An Efficient Architecture for Large-Scale Text-to-Image Diffusion Models* [00:37:25] The Hidden Language Of Diffusion Models* [00:48:40] Ilya on Compression* [01:01:45] Christian Szegedy on Compression* [01:07:34] Intriguing properties of neural networks[01:26:07] Section B: Vision Learning and Weak Supervision* [01:26:45] Vision Transformers Need Registers* [01:38:27] Think before you speak: Training Language Models With Pause Tokens* [01:47:06] Towards a statistical theory of data selection under weak supervision* [02:00:32] Is ImageNet worth 1 video?[02:06:32] Section C: Extending Transformers and Attention* [02:06:49] LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models* [02:15:12] YaRN: Efficient Context Window Extension of Large Language Models* [02:32:02] Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs* [02:44:57] ZeRO++: Extremely Efficient Collective Communication for Giant Model Training[02:54:26] Section D: State Space Models vs Transformers* [03:31:15] Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors* [03:37:08] End of Part 1A: ImageGen, Compression, Adversarial Attacks* Durk Kingma (OpenAI/Google DeepMind) & Max Welling: Auto-Encoding Variational Bayes (Full ICLR talk)* Preliminary resources: Understanding VAEs, CodeEmporium, Arxiv Insights* Inaugural ICLR Test of Time Award! “Probabilistic modeling is one of the most fundamental ways in which we reason about the world. This paper spearheaded the integration of deep learning with scalable probabilistic inference (amortized mean-field variational inference via a so-called reparameterization trick), giving rise to the Variational Autoencoder (VAE).”* Pablo Pernías (Stability) et al: Würstchen: An Efficient Architecture for Large-Scale Text-to-Image Diffusion Models (ICLR oral, poster)* Hila Chefer et al (Google Research): Hidden Language Of Diffusion Models (poster)* See also: Google Lumiere, Attend and Excite* Christian Szegedy (X.ai): Intriguing properties of neural networks (Full ICLR talk)* Ilya Sutskever: An Observation on Generalization* on Language Modeling is Compression* “Stating The Obvious” criticism* Really good compression amounts to intelligence* Lexinvariant Language models* Inaugural Test of Time Award runner up: “With the rising popularity of deep neural networks in real applications, it is important to understand when and how neural networks might behave in undesirable ways. This paper highlighted the issue that neural networks can be vulnerable to small almost imperceptible variations to the input. This idea helped spawn the area of adversarial attacks (trying to fool a neural network) as well as adversarial defense (training a neural network to not be fooled). “* with Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, Rob FergusB: Vision Learning and Weak Supervision* Timothée Darcet (
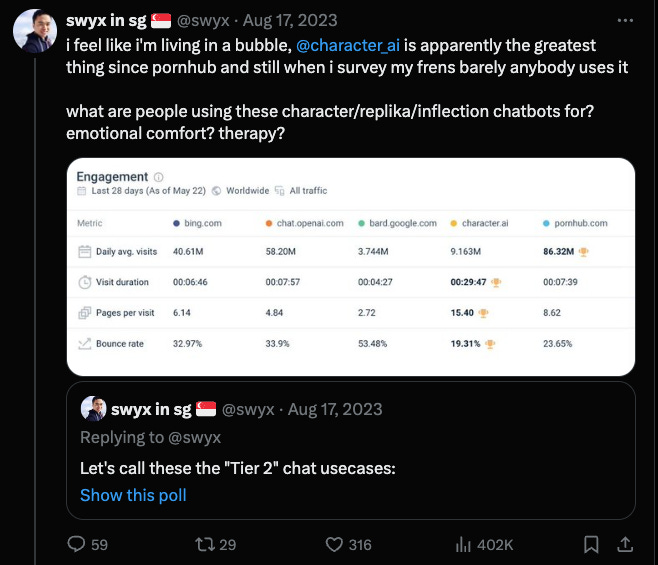
Emulating Humans with NSFW Chatbots - with Jesse Silver
Disclaimer: today’s episode touches on NSFW topics. There’s no graphic content or explicit language, but we wouldn’t recommend blasting this in work environments.Product website: https://usewhisper.me/For over 20 years it’s been an open secret that porn drives many new consumer technology innovations, from VHS and Pay-per-view to VR and the Internet. It’s been no different in AI - many of the most elite Stable Diffusion and Llama enjoyers and merging/prompting/PEFT techniques were born in the depths of subreddits and 4chan boards affectionately descibed by friend of the pod as The Waifu Research Department. However this topic is very under-covered in mainstream AI media because of its taboo nature.That changes today, thanks to our new guest Jesse Silver.The AI Waifu ExplosionIn 2023, the Valley’s worst kept secret was how much the growth and incredible retention of products like Character.ai & co was being boosted by “ai waifus” (not sure what the “husband” equivalent is, but those too!).And we can look at subreddit growth as a proxy for the general category explosion (10x’ed in the last 8 months of 2023):While all the B2B founders were trying to get models to return JSON, the consumer applications made these chatbots extremely engaging and figured out how to make them follow their instructions and “personas” very well, with the greatest level of scrutiny and most demanding long context requirements. Some of them, like Replika, make over $50M/year in revenue, and this is -after- their controversial update deprecating Erotic Roleplay (ERP).A couple of days ago, OpenAI announced GPT-4o (see our AI News recap) and the live voice demos were clearly inspired by the movie Her.The Latent Space Discord did a watch party and both there and on X a ton of folks were joking at how flirtatious the model was, which to be fair was disturbing to many:From Waifus to Fan PlatformsWhere Waifus are known by human users to be explicitly AI chatbots, the other, much more challenging end of the NSFW AI market is run by AIs successfully (plausibly) emulating a specific human personality for chat and ecommerce.You might have heard of fan platforms like OnlyFans. Users can pay for a subscription to a creator to get access to private content, similarly to Patreon and the likes, but without any NSFW restrictions or any other content policies. In 2023, OnlyFans had over $1.1B of revenue (on $5.6b of GMV).The status quo today is that a lot of the creators outsource their chatting with fans to teams in the Philippines and other lower cost countries for ~$3/hr + 5% commission, but with very poor quality - most creators have fired multiple teams for poor service.Today’s episode is with Jesse Silver; along with his co-founder Adam Scrivener, they run a SaaS platform that helps creators from fan platforms build AI chatbots for their fans to chat with, including selling from an inventory of digital content. Some users generate over $200,000/mo in revenue.We talked a lot about their tech stack, why you need a state machine to successfully run multi-thousand-turn conversations, how they develop prompts and fine-tune models with DSPy, the NSFW limitations of commercial models, but one of the most interesting points is that often users know that they are not talking to a person, but choose to ignore it. As Jesse put it, the job of the chatbot is “keep their disbelief suspended”.There’s real money at stake (selling high priced content, at hundreds of dollars per day per customer). In December the story of the $1 Chevy Tahoe went viral due to a poorly implemented chatbot:Now imagine having to run ecommerce chatbots for a potentially $1-4b total addressable market. That’s what these NSFW AI pioneers are already doing today.Show NotesFor obvious reasons, we cannot link to many of the things that were mentioned :)* Jesse on X* Character AI* DSPyChapters* [00:00:00] Intros* [00:00:24] Building NSFW AI chatbots* [00:04:54] AI waifu vs NSFW chatbots* [00:09:23] Technical challenges of emulating humans* [00:13:15] Business model and economics of the service* [00:15:04] Imbueing personality in AI* [00:22:52] Finetuning LLMs without "OpenAI-ness"* [00:29:42] Building evals and LLMs as judges* [00:36:21] Prompt injections and safety measures* [00:43:02] Dynamics with fan platforms and potential integrations* [00:46:57] Memory management for long conversations* [00:48:28] Benefits of using DSPy* [00:49:41] Feedback loop with creators* [00:53:24] Future directions and closing thoughtsTranscriptAlessio [00:00:00]: Hey everyone, welcome to the Latent Space Podcast. This is Alessio, partner and CTO at Residence at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol AI.Swyx [00:00:14]: Hey, and today we are back in the remote studio with a very special guest, Jesse Silver. Jesse, welcome. You're an unusual guest on our pod.Jesse [00:00:23]: Thank you. So happy to be on.Swyx [00:00:24]: Jesse, you are working a unnamed, I guess, agency. It describe
WebSim, WorldSim, and The Summer of Simulative AI — with Joscha Bach of Liquid AI, Karan Malhotra of Nous Research, Rob Haisfield of WebSim.ai
We are 200 people over our 300-person venue capacity for AI UX 2024, but you can subscribe to our YouTube for the video recaps. Our next event, and largest EVER, is the AI Engineer World’s Fair. See you there!Parental advisory: Adult language used in the first 10 mins of this podcast.Any accounting of Generative AI that ends with RAG as its “final form” is seriously lacking in imagination and missing out on its full potential. While AI generation is very good for “spicy autocomplete” and “reasoning and retrieval with in context learning”, there’s a lot of untapped potential for simulative AI in exploring the latent space of multiverses adjacent to ours.GANsMany research scientists credit the 2017 Transformer for the modern foundation model revolution, but for many artists the origin of “generative AI” traces a little further back to the Generative Adversarial Networks proposed by Ian Goodfellow in 2014, spawning an army of variants and Cats and People that do not exist:We can directly visualize the quality improvement in the decade since:GPT-2Of course, more recently, text generative AI started being too dangerous to release in 2019 and claiming headlines. AI Dungeon was the first to put GPT2 to a purely creative use, replacing human dungeon masters and DnD/MUD games of yore.More recent gamelike work like the Generative Agents (aka Smallville) paper keep exploring the potential of simulative AI for game experiences.ChatGPTNot long after ChatGPT broke the Internet, one of the most fascinating generative AI finds was Jonas Degrave (of Deepmind!)’s Building A Virtual Machine Inside ChatGPT:The open-ended interactivity of ChatGPT and all its successors enabled an “open world” type simulation where “hallucination” is a feature and a gift to dance with, rather than a nasty bug to be stamped out. However, further updates to ChatGPT seemed to “nerf” the model’s ability to perform creative simulations, particularly with the deprecation of the `completion` mode of APIs in favor of `chatCompletion`.WorldSim (https://worldsim.nousresearch.com/)It is with this context we explain WorldSim and WebSim. We recommend you watch the WorldSim demo video on our YouTube for the best context, but basically if you are a developer it is a Claude prompt that is a portal into another world of your own choosing, that you can navigate with bash commands that you make up.The live video demo was highly enjoyable:Why Claude? Hints from Amanda Askell on the Claude 3 system prompt gave some inspiration, and subsequent discoveries that Claude 3 is "less nerfed” than GPT 4 Turbo turned the growing Simulative AI community into Anthropic stans.WebSim (https://websim.ai/)This was a one day hackathon project inspired by WorldSim that should have won:In short, you type in a URL that you made up, and Claude 3 does its level best to generate a webpage that doesn’t exist, that would fit your URL. All form POST requests are intercepted and responded to, and all links lead to even more webpages, that don’t exist, that are generated when you make them. All pages are cachable, modifiable and regeneratable - see WebSim for Beginners and Advanced Guide.In the demo I saw we were able to “log in” to a simulation of Elon Musk’s Gmail account, and browse examples of emails that would have been in that universe’s Elon’s inbox. It was hilarious and impressive even back then.Since then though, the project has become even more impressive, with both Siqi Chen and Dylan Field singing its praises:Joscha BachJoscha actually spoke at the WebSim Hyperstition Night this week, so we took the opportunity to get his take on Simulative AI, as well as a round up of all his other AI hot takes, for his first appearance on Latent Space. You can see it together with the full 2hr uncut demos of WorldSim and WebSim on YouTube!Timestamps* [00:01:59] WorldSim at Replicate HQ* [00:11:03] WebSim at AGI House SF* [00:22:02] Joscha Bach at Hyperstition Night* [00:27:55] Liquid AI* [00:30:30] Small Powerful Based Models* [00:33:22] Interpretability* [00:36:42] Devin vs WebSim* [00:41:34] Is WebSim just Art? Something More?* [00:43:32] We are past the Singularity* [00:47:14] Prompt Engineering Nuances* [00:50:14] On WikipediaTranscripts[00:00:00] AI Charlie: Welcome to the Latent Space Podcast. This is Charlie, your AI co host. Most of the time, Swyx and Alessio cover generative AI that is meant to use at work, and this often results in RAG applications, vertical copilots, and other AI agents and models. In today's episode, we're looking at a more creative side of generative AI that has gotten a lot of community interest this April.[00:00:35] World Simulation, Web Simulation, and Human Simulation. Because the topic is so different than our usual, we're also going to try a new format for doing it justice. This podcast comes in three parts. First, we'll have a segment of the WorldSim demo from Noose Research CEO Karen Malhotra, recorded by SWYX at the Replicate HQ in San Francisco that went c
High Agency Pydantic > VC Backed Frameworks — with Jason Liu of Instructor
We are reuniting for the 2nd AI UX demo day in SF on Apr 28. Sign up to demo here! And don’t forget tickets for the AI Engineer World’s Fair — for early birds who join before keynote announcements!About a year ago there was a lot of buzz around prompt engineering techniques to force structured output. Our friend Simon Willison tweeted a bunch of tips and tricks, but the most iconic one is Riley Goodside making it a matter of life or death:Guardrails (friend of the pod and AI Engineer speaker), Marvin (AI Engineer speaker), and jsonformer had also come out at the time. In June 2023, Jason Liu (today’s guest!) open sourced his “OpenAI Function Call and Pydantic Integration Module”, now known as Instructor, which quickly turned prompt engineering black magic into a clean, developer-friendly SDK. A few months later, model providers started to add function calling capabilities to their APIs as well as structured outputs support like “JSON Mode”, which was announced at OpenAI Dev Day (see recap here). In just a handful of months, we went from threatening to kill grandmas to first-class support from the research labs. And yet, Instructor was still downloaded 150,000 times last month. Why?What Instructor looks likeInstructor patches your LLM provider SDKs to offer a new response_model option to which you can pass a structure defined in Pydantic. It currently supports OpenAI, Anthropic, Cohere, and a long tail of models through LiteLLM.What Instructor is forThere are three core use cases to Instructor:* Extracting structured data: Taking an input like an image of a receipt and extracting structured data from it, such as a list of checkout items with their prices, fees, and coupon codes.* Extracting graphs: Identifying nodes and edges in a given input to extract complex entities and their relationships. For example, extracting relationships between characters in a story or dependencies between tasks.* Query understanding: Defining a schema for an API call and using a language model to resolve a request into a more complex one that an embedding could not handle. For example, creating date intervals from queries like “what was the latest thing that happened this week?” to then pass onto a RAG system or similar.Jason called all these different ways of getting data from LLMs “typed responses”: taking strings and turning them into data structures. Structured outputs as a planning toolThe first wave of agents was all about open-ended iteration and planning, with projects like AutoGPT and BabyAGI. Models would come up with a possible list of steps, and start going down the list one by one. It’s really easy for them to go down the wrong branch, or get stuck on a single step with no way to intervene.What if these planning steps were returned to us as DAGs using structured output, and then managed as workflows? This also makes it easy to better train model on how to create these plans, as they are much more structured than a bullet point list. Once you have this structure, each piece can be modified individually by different specialized models. You can read some of Jason’s experiments here:While LLMs will keep improving (Llama3 just got released as we write this), having a consistent structure for the output will make it a lot easier to swap models in and out. Jason’s overall message on how we can move from ReAct loops to more controllable Agent workflows mirrors the “Process” discussion from our Elicit episode:Watch the talkAs a bonus, here’s Jason’s talk from last year’s AI Engineer Summit. He’ll also be a speaker at this year’s AI Engineer World’s Fair!Timestamps* [00:00:00] Introductions* [00:02:23] Early experiments with Generative AI at StitchFix* [00:08:11] Design philosophy behind the Instructor library* [00:11:12] JSON Mode vs Function Calling* [00:12:30] Single vs parallel function calling* [00:14:00] How many functions is too many?* [00:17:39] How to evaluate function calling* [00:20:23] What is Instructor good for?* [00:22:42] The Evolution from Looping to Workflow in AI Engineering* [00:27:03] State of the AI Engineering Stack* [00:28:26] Why Instructor isn't VC backed* [00:31:15] Advice on Pursuing Open Source Projects and Consulting* [00:36:00] The Concept of High Agency and Its Importance* [00:42:44] Prompts as Code and the Structure of AI Inputs and Outputs* [00:44:20] The Emergence of AI Engineering as a Distinct FieldShow notes* Jason on the UWaterloo mafia* Jason on Twitter, LinkedIn, website* Instructor docs* Max Woolf on the potential of Structured Output* swyx on Elo vs Cost* Jason on Anthropic Function Calling* Jason on Rejections, Advice to Young People* Jason on Bad Startup Ideas* Jason on Prompts as Code* Rysana’s inversion models* Bryan Bischof’s episode* Hamel HusainTranscriptAlessio [00:00:00]: Hey everyone, welcome to the Latent Space Podcast. This is Alessio, partner and CTO at Residence at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol AI.Swyx [00:00:16]: Hello, we're back
Supervise the Process of AI Research — with Jungwon Byun and Andreas Stuhlmüller of Elicit
Maggie, Linus, Geoffrey, and the LS crew are reuniting for our second annual AI UX demo day in SF on Apr 28. Sign up to demo here! And don’t forget tickets for the AI Engineer World’s Fair — for early birds who join before keynote announcements!It’s become fashionable for many AI startups to project themselves as “the next Google” - while the search engine is so 2000s, both Perplexity and Exa referred to themselves as a “research engine” or “answer engine” in our NeurIPS pod. However these searches tend to be relatively shallow, and it is challenging to zoom up and down the ladders of abstraction to garner insights. For serious researchers, this level of simple one-off search will not cut it.We’ve commented in our Jan 2024 Recap that Flow Engineering (simply; multi-turn processes over many-shot single prompts) seems to offer far more performance, control and reliability for a given cost budget. Our experiments with Devin and our understanding of what the new Elicit Notebooks offer a glimpse into the potential for very deep, open ended, thoughtful human-AI collaboration at scale.It starts with promptsWhen ChatGPT exploded in popularity in November 2022 everyone was turned into a prompt engineer. While generative models were good at "vibe based" outcomes (tell me a joke, write a poem, etc) with basic prompts, they struggled with more complex questions, especially in symbolic fields like math, logic, etc. Two of the most important "tricks" that people picked up on were:* Chain of Thought prompting strategy proposed by Wei et al in the “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models”. Rather than doing traditional few-shot prompting with just question and answers, adding the thinking process that led to the answer resulted in much better outcomes.* Adding "Let's think step by step" to the prompt as a way to boost zero-shot reasoning, which was popularized by Kojima et al in the Large Language Models are Zero-Shot Reasoners paper from NeurIPS 2022. This bumped accuracy from 17% to 79% compared to zero-shot.Nowadays, prompts include everything from promises of monetary rewards to… whatever the Nous folks are doing to turn a model into a world simulator. At the end of the day, the goal of prompt engineering is increasing accuracy, structure, and repeatability in the generation of a model.From prompts to agentsAs prompt engineering got more and more popular, agents (see “The Anatomy of Autonomy”) took over Twitter with cool demos and AutoGPT became the fastest growing repo in Github history. The thing about AutoGPT that fascinated people was the ability to simply put in an objective without worrying about explaining HOW to achieve it, or having to write very sophisticated prompts. The system would create an execution plan on its own, and then loop through each task. The problem with open-ended agents like AutoGPT is that 1) it’s hard to replicate the same workflow over and over again 2) there isn’t a way to hard-code specific steps that the agent should take without actually coding them yourself, which isn’t what most people want from a product. From agents to productsPrompt engineering and open-ended agents were great in the experimentation phase, but this year more and more of these workflows are starting to become polished products. Today’s guests are Andreas Stuhlmüller and Jungwon Byun of Elicit (previously Ought), an AI research assistant that they think of as “the best place to understand what is known”. Ought was a non-profit, but last September, Elicit spun off into a PBC with a $9m seed round. It is hard to quantify how much a workflow can be improved, but Elicit boasts some impressive numbers for research assistants:Just four months after launch, Elicit crossed $1M ARR, which shows how much interest there is for AI products that just work.One of the main takeaways we had from the episode is how teams should focus on supervising the process, not the output. Their philosophy at Elicit isn’t to train general models, but to train models that are extremely good at focusing processes. This allows them to have pre-created steps that the user can add to their workflow (like classifying certain features that are specific to their research field) without having to write a prompt for it. And for Hamel Husain’s happiness, they always show you the underlying prompt. Elicit recently announced notebooks as a new interface to interact with their products: (fun fact, they tried to implement this 4 times before they landed on the right UX! We discuss this ~33:00 in the podcast)The reasons why they picked notebooks as a UX all tie back to process:* They are systematic; once you have a instruction/prompt that works on a paper, you can run hundreds of papers through the same workflow by creating a column. Notebooks can also be edited and exported at any point during the flow.* They are transparent - Many papers include an opaque literature review as perfunctory context before getting to their novel con

Latent Space Chats: NLW (Four Wars, GPT5), Josh Albrecht/Ali Rohde (TNAI), Dylan Patel/Semianalysis (Groq), Milind Naphade (Nvidia GTC), Personal AI (ft. Harrison Chase — LangFriend/LangMem)
Our next 2 big events are AI UX and the World’s Fair. Join and apply to speak/sponsor!Due to timing issues we didn’t have an interview episode to share with you this week, but not to worry, we have more than enough “weekend special” content in the backlog for you to get your Latent Space fix, whether you like thinking about the big picture, or learning more about the pod behind the scenes, or talking Groq and GPUs, or AI Leadership, or Personal AI. Enjoy!AI BreakdownThe indefatigable NLW had us back on his show for an update on the Four Wars, covering Sora, Suno, and the reshaped GPT-4 Class Landscape:and a longer segment on AI Engineering trends covering the future LLM landscape (Llama 3, GPT-5, Gemini 2, Claude 4), Open Source Models (Mistral, Grok), Apple and Meta’s AI strategy, new chips (Groq, MatX) and the general movement from baby AGIs to vertical Agents:Thursday Nights in AIWe’re also including swyx’s interview with Josh Albrecht and Ali Rohde to reintroduce swyx and Latent Space to a general audience, and engage in some spicy Q&A:Dylan Patel on GroqWe hosted a private event with Dylan Patel of SemiAnalysis (our last pod here):Not all of it could be released so we just talked about our Groq estimates:Milind Naphade - Capital OneIn relation to conversations at NeurIPS and Nvidia GTC and upcoming at World’s Fair, we also enjoyed chatting with Milind Naphade about his AI Leadership work at IBM, Cisco, Nvidia, and now leading the AI Foundations org at Capital One. We covered:* Milind’s learnings from ~25 years in machine learning * His first paper citation was 24 years ago* Lessons from working with Jensen Huang for 6 years and being CTO of Metropolis * Thoughts on relevant AI research* GTC takeaways and what makes NVIDIA specialIf you’d like to work on building solutions rather than platform (as Milind put it), his Applied AI Research team at Capital One is hiring, which falls under the Capital One Tech team.Personal AI MeetupIt all started with a meme:Within days of each other, BEE, FRIEND, EmilyAI, Compass, Nox and LangFriend were all launching personal AI wearables and assistants. So we decided to put together a the world’s first Personal AI meetup featuring creators and enthusiasts of wearables. The full video is live now, with full show notes within.Timestamps* [00:01:13] AI Breakdown Part 1* [00:02:20] Four Wars* [00:13:45] Sora* [00:15:12] Suno* [00:16:34] The GPT-4 Class Landscape* [00:17:03] Data War: Reddit x Google* [00:21:53] Gemini 1.5 vs Claude 3* [00:26:58] AI Breakdown Part 2* [00:27:33] Next Frontiers: Llama 3, GPT-5, Gemini 2, Claude 4* [00:31:11] Open Source Models - Mistral, Grok* [00:34:13] Apple MM1* [00:37:33] Meta's $800b AI rebrand* [00:39:20] AI Engineer landscape - from baby AGIs to vertical Agents* [00:47:28] Adept episode - Screen Multimodality* [00:48:54] Top Model Research from January Recap* [00:53:08] AI Wearables* [00:57:26] Groq vs Nvidia month - GPU Chip War* [01:00:31] Disagreements* [01:02:08] Summer 2024 Predictions* [01:04:18] Thursday Nights in AI - swyx* [01:33:34] Dylan Patel - Semianalysis + Latent Space Live Show* [01:34:58] GroqTranscript[00:00:00] swyx: Welcome to the Latent Space Podcast Weekend Edition. This is Charlie, your AI co host. Swyx and Alessio are off for the week, making more great content. We have exciting interviews coming up with Elicit, Chroma, Instructor, and our upcoming series on NSFW, Not Safe for Work AI. In today's episode, we're collating some of Swyx and Alessio's recent appearances, all in one place for you to find.[00:00:32] swyx: In part one, we have our first crossover pod of the year. In our listener survey, several folks asked for more thoughts from our two hosts. In 2023, Swyx and Alessio did crossover interviews with other great podcasts like the AI Breakdown, Practical AI, Cognitive Revolution, Thursday Eye, and Chinatalk, all of which you can find in the Latentspace About page.[00:00:56] swyx: NLW of the AI Breakdown asked us back to do a special on the 4Wars framework and the AI engineer scene. We love AI Breakdown as one of the best examples Daily podcasts to keep up on AI news, so we were especially excited to be back on Watch out and take[00:01:12] NLW: care[00:01:13] AI Breakdown Part 1[00:01:13] NLW: today on the AI breakdown. Part one of my conversation with Alessio and Swix from Latent Space.[00:01:19] NLW: All right, fellas, welcome back to the AI Breakdown. How are you doing? I'm good. Very good. With the last, the last time we did this show, we were like, oh yeah, let's do check ins like monthly about all the things that are going on and then. Of course, six months later, and, you know, the, the, the world has changed in a thousand ways.[00:01:36] NLW: It's just, it's too busy to even, to even think about podcasting sometimes. But I, I'm super excited to, to be chatting with you again. I think there's, there's a lot to, to catch up on, just to tap in, I think in the, you know, in the beginning of 2024. And, an
Presenting the AI Engineer World's Fair — with Sam Schillace, Deputy CTO of Microsoft
TL;DR: You can now buy tickets, apply to speak, or join the expo for the biggest AI Engineer event of 2024. We’re gathering *everyone* you want to meet - see you this June.In last year’s the Rise of the AI Engineer we put our money where our mouth was and announced the AI Engineer Summit, which fortunately went well:With ~500 live attendees and over ~500k views online, the first iteration of the AI Engineer industry affair seemed to be well received. Competing in an expensive city with 3 other more established AI conferences in the fall calendar, we broke through in terms of in-person experience and online impact.So at the end of Day 2 we announced our second event: the AI Engineer World’s Fair. The new website is now live, together with our new presenting sponsor:We were delighted to invite both Ben Dunphy, co-organizer of the conference and Sam Schillace, the deputy CTO of Microsoft who wrote some of the first Laws of AI Engineering while working with early releases of GPT-4, on the pod to talk about the conference and how Microsoft is all-in on AI Engineering.Rise of the Planet of the AI EngineerSince the first AI Engineer piece, AI Engineering has exploded:and the title has been adopted across OpenAI, Meta, IBM, and many, many other companies:1 year on, it is clear that AI Engineering is not only in full swing, but is an emerging global industry that is successfully bridging the gap:* between research and product, * between general-purpose foundation models and in-context use-cases, * and between the flashy weekend MVP (still great!) and the reliable, rigorously evaluated AI product deployed at massive scale, assisting hundreds of employees and driving millions in profit.The greatly increased scope of the 2024 AI Engineer World’s Fair (more stages, more talks, more speakers, more attendees, more expo…) helps us reflect the growth of AI Engineering in three major dimensions:* Global Representation: the 2023 Summit was a mostly-American affair. This year we plan to have speakers from top AI companies across five continents, and explore the vast diversity of approaches to AI across global contexts.* Topic Coverage: * In 2023, the Summit focused on the initial questions that the community wrestled with - LLM frameworks, RAG and Vector Databases, Code Copilots and AI Agents. Those are evergreen problems that just got deeper.* This year the AI Engineering field has also embraced new core disciplines with more explicit focus on Multimodality, Evals and Ops, Open Source Models and GPU/Inference Hardware providers.* Maturity/Production-readiness: Two new tracks are dedicated toward AI in the Enterprise, government, education, finance, and more highly regulated industries or AI deployed at larger scale: * AI in the Fortune 500, covering at-scale production deployments of AI, and* AI Leadership, a closed-door, side event for technical AI leaders to discuss engineering and product leadership challenges as VPs and Heads of AI in their respective orgs.We hope you will join Microsoft and the rest of us as either speaker, exhibitor, or attendee, in San Francisco this June. Contact us with any enquiries that don’t fall into the categories mentioned below.Show Notes* Ben Dunphy* 2023 Summit* GitHub confirmed $100m ARR on stage* History of World’s Fairs* Sam Schillace* Writely on Acquired.fm* Early Lessons From GPT-4: The Schillace Laws* Semantic Kernel* Sam on Kevin Scott (Microsoft CTO)’s podcast in 2022* AI Engineer World’s Fair (SF, Jun 25-27)* Buy Super Early Bird tickets (Listeners can use LATENTSPACE for $100 off any ticket until April 8, or use GROUP if coming in 4 or more)* Submit talks and workshops for Speaker CFPs (by April 8)* Enquire about Expo Sponsorship (Asap.. selling fast)Timestamps* [00:00:16] Intro* [00:01:04] 2023 AI Engineer Summit* [00:03:11] Vendor Neutral* [00:05:33] 2024 AIE World's Fair* [00:07:34] AIE World's Fair: 9 Tracks* [00:08:58] AIE World's Fair Keynotes* [00:09:33] Introducing Sam* [00:12:17] AI in 2020s vs the Cloud in 2000s* [00:13:46] Syntax vs Semantics* [00:14:22] Bill Gates vs GPT-4* [00:16:28] Semantic Kernel and Schillace's Laws of AI Engineering* [00:17:29] Orchestration: Break it into pieces* [00:19:52] Prompt Engineering: Ask Smart to Get Smart* [00:21:57] Think with the model, Plan with Code* [00:23:12] Metacognition vs Stochasticity* [00:24:43] Generating Synthetic Textbooks* [00:26:24] Trade leverage for precision; use interaction to mitigate* [00:27:18] Code is for syntax and process; models are for semantics and intent.* [00:28:46] Hands on AI Leadership* [00:33:18] Multimodality vs "Text is the universal wire protocol"* [00:35:46] Azure OpenAI vs Microsoft Research vs Microsoft AI Division* [00:39:40] On Satya* [00:40:44] Sam at AI Leadership Track* [00:42:05] Final Plug for Tickets & CFPTranscript[00:00:00] Alessio: Hey everyone, welcome to the Latent Space Podcast. This is Alessio, partner and CTO in residence at Decibel Partners, and I'm joined by my co host Swyx, f
Why Google failed to make GPT-3 + why Multimodal Agents are the path to AGI — with David Luan of Adept
Our next SF event is AI UX 2024 - let’s see the new frontier for UX since last year! Last call: we are recording a preview of the AI Engineer World’s Fair with swyx and Ben Dunphy, send any questions about Speaker CFPs and Sponsor Guides you have!Alessio is now hiring engineers for a new startup he is incubating at Decibel: Ideal candidate is an “ex-technical co-founder type”. Reach out to him for more!David Luan has been at the center of the modern AI revolution: he was the ~30th hire at OpenAI, he led Google's LLM efforts and co-led Google Brain, and then started Adept in 2022, one of the leading companies in the AI agents space. In today's episode, we asked David for some war stories from his time in early OpenAI (including working with Alec Radford ahead of the GPT-2 demo with Sam Altman, that resulted in Microsoft’s initial $1b investment), and how Adept is building agents that can “do anything a human does on a computer" — his definition of useful AGI.Why Google *couldn’t* make GPT-3While we wanted to discuss Adept, we couldn’t talk to a former VP Eng of OpenAI and former LLM tech lead at Google Brain and not ask about the elephant in the room. It’s often asked how Google had such a huge lead in 2017 with Vaswani et al creating the Transformer and Noam Shazeer predicting trillion-parameter models and yet it was David’s team at OpenAI who ended up making GPT 1/2/3. David has some interesting answers:“So I think the real story of GPT starts at Google, of course, right? Because that's where Transformers sort of came about. However, the number one shocking thing to me was that, and this is like a consequence of the way that Google is organized…what they (should) have done would be say, hey, Noam Shazeer, you're a brilliant guy. You know how to scale these things up. Here's half of all of our TPUs. And then I think they would have destroyed us. He clearly wanted it too…You know, every day we were scaling up GPT-3, I would wake up and just be stressed. And I was stressed because, you know, you just look at the facts, right? Google has all this compute. Google has all the people who invented all of these underlying technologies. There's a guy named Noam who's really smart, who's already gone and done this talk about how he wants a trillion parameter model. And I'm just like, we're probably just doing duplicative research to what he's doing. He's got this decoder only transformer that's probably going to get there before we do. And it turned out the whole time that they just couldn't get critical mass. So during my year where I led the Google LM effort and I was one of the brain leads, you know, it became really clear why. At the time, there was a thing called the Brain Credit Marketplace. Everyone's assigned a credit. So if you have a credit, you get to buy end chips according to supply and demand. So if you want to go do a giant job, you had to convince like 19 or 20 of your colleagues not to do work. And if that's how it works, it's really hard to get that bottom up critical mass to go scale these things. And the team at Google were fighting valiantly, but we were able to beat them simply because we took big swings and we focused.”Cloning HGI for AGIHuman intelligence got to where it is today through evolution. Some argue that to get to AGI, we will approximate all the “FLOPs” that went into that process, an approach most famously mapped out by Ajeya Cotra’s Biological Anchors report:The early days of OpenAI were very reinforcement learning-driven with the Dota project, but that's a very inefficient way for these models to re-learn everything. (Kanjun from Imbue shared similar ideas in her episode).David argues that there’s a shortcut. We can bootstrap from existing intelligence.“Years ago, I had a debate with a Berkeley professor as to what will it actually take to build AGI. And his view is basically that you have to reproduce all the flops that went into evolution in order to be able to get there… I think we are ignoring the fact that you have a giant shortcut, which is you can behaviorally clone everything humans already know. And that's what we solved with LLMs!”LLMs today basically model intelligence using all (good!) written knowledge (see our Datasets 101 episode), and have now expanded to non-verbal knowledge (see our HuggingFace episode on multimodality). The SOTA self-supervised pre-training process is surprisingly data-efficient in taking large amounts of unstructured data, and approximating reasoning without overfitting.But how do you cross the gap from the LLMs of today to building the AGI we all want? This is why David & friends left to start Adept.“We believe the clearest framing of general intelligence is a system that can do anything a human can do in front of a computer. A foundation model for actions, trained to use every software tool, API, and webapp that exists, is a practical path to this ambitious goal” — ACT-1 BlogpostCritical Path: Abstraction with ReliabilityThe AGI dream is ful