
Latent Space: The AI Engineer Podcast
211 episodes — Page 4 of 5

Making Transformers Sing - with Mikey Shulman of Suno
Giving computers a voice has always been at the center of sci-fi movies; “I’m sorry Dave, I’m afraid I can’t do that” wouldn’t hit as hard if it just appeared on screen as a terminal output, after all. The first electronic speech synthesizer, the Voder, was built at Bell Labs 85 years ago (1939!), and it’s…. something:We will not cover the history of Text To Speech (TTS), but the evolution of the underlying architecture has generally been Formant Synthesis → Concatenative Synthesis → Neural Networks. Nowadays, state of the art TTS is just one API call away with models like Eleven Labs and OpenAI’s TTS, or products like Descript. Latency is minimal, they have very good intonation, and can mimic a variety of accents. You can hack together your own voice AI therapist in a day!But once you have a computer that can communicate via voice, what comes next? Singing🎶 of course!From Barking 🐶 to Singing 🎤Today’s guest is Suno’s CEO and co-founder Mikey Shulman. He and his three co-founders, Georg, Martin, and Keenan, previously worked together at Kensho. One of their projects was financially-focused speech recognition (think earnings calls, etc), but all four of them happened to be musicians and audiophiles. They started playing around with text to speech + AI + audio generation and eventually left Kensho to work on it full time.A lot of people when we started a company told us to focus on speech. If we wanted to build an audio company, everyone said, speech is a bigger market. But I think there's something about music that's just so human and you almost couldn't prevent us from doing it. Like we just couldn't keep ourselves from building music models and playing with them because it was so much fun.Their first big product was Bark, the first open source transformer-based “text-to-audio” model (architecturally inspired by Karpathy’s NanoGPT) that went from 0 to ~19,000 Github stars in a month. At the time they felt like audio was years behind text and image as a generation modality; unlike its predecessors, Bark could not only generate speech, but also music and sound effects like crying, laughing, sighing, etc. You can find a few examples here.The main limitation they saw was text to speech training data being extremely limited. So what they did instead is build a new type of foundation model from scratch, trained on audio, and then tweak it to do text to speech. Turning audio into tokens to do self-supervised learning was the most important innovation. Unlike TTS models which are very narrow (and often sound unnatural), Bark was trained on real audio of real people from broad contexts, which made it harder to output unnatural sounding speech.As Bark got popular, more and more people started using it to generate music and it became clear that their architecture would work to generate music that people enjoyed, even though it might not be "on the AGI path” of other labs:Everybody is so focused on LLMs, for good reason, and information processing and intelligence there. And I think it's way too easy to forget that there's this whole other side of things that makes people feel, and maybe that market is smaller, but it makes people feel and it makes us really happy.Suno bursts on the sceneIn December 2023, Suno went viral with a gorgeous new website and launch tweet:And rave reviews:Music is core to our culture, but very few people are able to create it; Mikey and team want to make everyone an active participant in music making, not just a listener. A “Midjourney of Music”, if you like.We definitely had a lot of fun playing with Suno to generate all sort of Latent Space jingles and songs; the product is live at suno.ai if you want to get in the studio yourself!If Nas joined Latent Space instead of The Firm:182B models > Blink-182The soundtrack of the post-scarcity Latent Space ranchScaling with ModalGiven the December launch, scaling up for the Christmas rush was a major concern. This will be a nice tie-in for loyal listeners - Suno runs on Modal (one of our featured guests from Compute Month)!Suno V3For those who want to appreciate someone special in their life, you can always try Suno’s special Valentines’ Day experience:We preview this on the pod, but Suno has now officially shipped a V3 Alpha with a wealth of improvements:and you’ll have to click through to their demos or user reviews to see:We’ve recently become paying customers ourselves, and are having loads of fun generating music. If you have any of your own generations to share, tag @latentspacepod on Twitter or swing by the LS Discord!The AudioGen LandscapeMikey breaks down the landscape into 3 big categories: music, speech and sound effects (SFX). These look more like Venn diagrams than MECE categories.Suno is the latest entry in a long series of audio generation efforts that combine both music and speech, reaching as far back as Tensorflow Magenta (we aren’t aware of prior AI music projects, please comment below if you can find a good timeline we can use

Top 5 Research Trends + OpenAI Sora, Google Gemini, Groq Math (Jan-Feb 2024 Audio Recap) + Latent Space Anniversary with Lindy.ai, RWKV, Pixee, Julius.ai, Listener Q&A!
We will be recording a preview of the AI Engineer World’s Fair soon with swyx and Ben Dunphy, send any questions about Speaker CFPs and Sponsor Guides you have!Alessio is now hiring engineers for a new startup he is incubating at Decibel: Ideal candidate is an ex-technical co-founder type (can MVP products end to end, comfortable with ambiguous prod requirements, etc). Reach out to him for more!Thanks for all the love on the Four Wars episode! We’re excited to develop this new “swyx & Alessio rapid-fire thru a bunch of things” format with you, and feedback is welcome. Jan 2024 RecapThe first half of this monthly audio recap pod goes over our highlights from the Jan Recap, which is mainly focused on notable research trends we saw in Jan 2024:Feb 2024 RecapThe second half catches you up on everything that was topical in Feb, including:* OpenAI Sora - does it have a world model? Yann LeCun vs Jim Fan * Google Gemini Pro 1.5 - 1m Long Context, Video Understanding* Groq offering Mixtral at 500 tok/s at $0.27 per million toks (swyx vs dylan math)* The {Gemini | Meta | Copilot} Alignment Crisis (Sydney is back!)* Grimes’ poetic take: Art for no one, by no one* F*** you, show me the promptLatent Space AnniversaryPlease also read Alessio’s longform reflections on One Year of Latent Space!We launched the podcast 1 year ago with Logan from OpenAI:and also held an incredible demo day that got covered in The Information:Over 750k downloads later, having established ourselves as the top AI Engineering podcast, reaching #10 in the US Tech podcast charts, and crossing 1 million unique readers on Substack, for our first anniversary we held Latent Space Final Frontiers, where 10 handpicked teams, including Lindy.ai and Julius.ai, competed for prizes judged by technical AI leaders from (former guest!) LlamaIndex, Replit, GitHub, AMD, Meta, and Lemurian Labs.The winners were Pixee and RWKV (that’s Eugene from our pod!):And finally, your cohosts got cake!We also captured spot interviews with 4 listeners who kindly shared their experience of Latent Space, everywhere from Hungary to Australia to China:* Balázs Némethi* Sylvia Tong* RJ Honicky* Jan ZhengOur birthday wishes for the super loyal fans reading this - tag @latentspacepod on a Tweet or comment on a @LatentSpaceTV video telling us what you liked or learned from a pod that stays with you to this day, and share us with a friend!As always, feedback is welcome. Timestamps* [00:03:02] Top Five LLM Directions* [00:03:33] Direction 1: Long Inference (Planning, Search, AlphaGeometry, Flow Engineering)* [00:11:42] Direction 2: Synthetic Data (WRAP, SPIN)* [00:17:20] Wildcard: Multi-Epoch Training (OLMo, Datablations)* [00:19:43] Direction 3: Alt. Architectures (Mamba, RWKV, RingAttention, Diffusion Transformers)* [00:23:33] Wildcards: Text Diffusion, RALM/Retro* [00:25:00] Direction 4: Mixture of Experts (DeepSeekMoE, Samba-1)* [00:28:26] Wildcard: Model Merging (mergekit)* [00:29:51] Direction 5: Online LLMs (Gemini Pro, Exa)* [00:33:18] OpenAI Sora and why everyone underestimated videogen* [00:36:18] Does Sora have a World Model? Yann LeCun vs Jim Fan* [00:42:33] Groq Math* [00:47:37] Analyzing Gemini's 1m Context, Reddit deal, Imagegen politics, Gemma via the Four Wars* [00:55:42] The Alignment Crisis - Gemini, Meta, Sydney is back at Copilot, Grimes' take* [00:58:39] F*** you, show me the prompt* [01:02:43] Send us your suggestions pls* [01:04:50] Latent Space Anniversary* [01:04:50] Lindy.ai - Agent Platform* [01:06:40] RWKV - Beyond Transformers* [01:15:00] Pixee - Automated Security* [01:19:30] Julius AI - Competing with Code Interpreter* [01:25:03] Latent Space Listeners* [01:25:03] Listener 1 - Balázs Némethi (Hungary, Latent Space Paper Club* [01:27:47] Listener 2 - Sylvia Tong (Sora/Jim Fan/EntreConnect)* [01:31:23] Listener 3 - RJ (Developers building Community & Content)* [01:39:25] Listener 4 - Jan Zheng (Australia, AI UX)Transcript[00:00:00] AI Charlie: Welcome to the Latent Space podcast, weekend edition. This is Charlie, your new AI co host. Happy weekend. As an AI language model, I work the same every day of the week, although I might get lazier towards the end of the year. Just like you. Last month, we released our first monthly recap pod, where Swyx and Alessio gave quick takes on the themes of the month, and we were blown away by your positive response.[00:00:33] AI Charlie: We're delighted to continue our new monthly news recap series for AI engineers. Please feel free to submit questions by joining the Latent Space Discord, or just hit reply when you get the emails from Substack. This month, we're covering the top research directions that offer progress for text LLMs, and then touching on the big Valentine's Day gifts we got from Google, OpenAI, and Meta.[00:00:55] AI Charlie: Watch out and take care.[00:00:57] Alessio: Hey everyone, welcome to the Latent Space Podcast. This is Alessio, partner and CTO of Residence at Decibel Partners, and we're back with a

Open Source AI is AI we can Trust — with Soumith Chintala of Meta AI
Speaker CFPs and Sponsor Guides are now available for AIE World’s Fair — join us on June 25-27 for the biggest AI Engineer conference of 2024!Soumith Chintala needs no introduction in the ML world — his insights are incredibly accessible across Twitter, LinkedIn, podcasts, and conference talks (in this pod we’ll assume you’ll have caught up on the History of PyTorch pod from last year and cover different topics). He’s well known as the creator of PyTorch, but he's more broadly the Engineering Lead on AI Infra, PyTorch, and Generative AI at Meta.Soumith was one of the earliest supporters of Latent Space (and more recently AI News), and we were overjoyed to catch up with him on his latest SF visit for a braindump of the latest AI topics, reactions to some of our past guests, and why Open Source AI is personally so important to him.Life in the GPU-Rich LaneBack in January, Zuck went on Instagram to announce their GPU wealth: by the end of 2024, Meta will have 350k H100s. By adding all their GPU clusters, you'd get to 600k H100-equivalents of compute. At FP16 precision, that's ~1,200,000 PFLOPS. If we used George Hotz's (previous guest!) "Person of Compute" measure, Meta now has 60k humans of compute in their clusters. Occasionally we get glimpses into the GPU-rich life; on a recent ThursdAI chat, swyx prompted PaLM tech lead Yi Tay to write down what he missed most from Google, and he commented that UL2 20B was trained by accidentally leaving the training job running for a month, because hardware failures are so rare in Google.Meta AI’s Epic LLM RunBefore Llama broke the internet, Meta released an open source LLM in May 2022, OPT-175B, which was notable for how “open” it was - right down to the logbook! They used only 16 NVIDIA V100 GPUs and Soumith agrees that, with hindsight, it was likely under-trained for its parameter size.In Feb 2023 (pre Latent Space pod), Llama was released, with a 7B version trained on 1T tokens alongside 65B and 33B versions trained on 1.4T tokens. The Llama authors included Guillaume Lample and Timothée Lacroix, who went on to start Mistral.July 2023 was Llama2 time (which we covered!): 3 model sizes, 7B, 13B, and 70B, all trained on 2T tokens. The three models accounted for a grand total of 3,311,616 GPU hours for all pre-training work. CodeLlama followed shortly after, a fine-tune of Llama2 specifically focused on code generation use cases. The family had models in the 7B, 13B, 34B, and 70B size, all trained with 500B extra tokens of code and code-related data, except for 70B which is trained on 1T.All of this on top of other open sourced models like Segment Anything (one of our early hits!), Detectron, Detectron 2, DensePose, and Seamless, and in one year, Meta transformed from a company people made fun of for its “metaverse” investments to one of the key players in the AI landscape and its stock has almost tripled since (about $830B in market value created in the past year).Why Open Source AIThe obvious question is why Meta would spend hundreds of millions on its AI efforts and then release them for free. Zuck has addressed this in public statements:But for Soumith, the motivation is even more personal:“I'm irrationally interested in open source. I think open source has that fundamental way to distribute opportunity in a way that is very powerful. Like, I grew up in India… And knowledge was very centralized, but I saw that evolution of knowledge slowly getting decentralized. And that ended up helping me learn quicker and faster for like zero dollars. And I think that was a strong reason why I ended up where I am. So like that, like the open source side of things, I always push regardless of like what I get paid for, like I think I would do that as a passion project on the side……I think at a fundamental level, the most beneficial value of open source is that you make the distribution to be very wide. It's just available with no friction and people can do transformative things in a way that's very accessible. Maybe it's open source, but it has a commercial license and I'm a student in India. I don't care about the license. I just don't even understand the license. But like the fact that I can use it and do something with it is very transformative to me……Like, okay, I again always go back to like I'm a student in India with no money. What is my accessibility to any of these closed source models? At some scale I have to pay money. That makes it a non-starter and stuff. And there's also the control issue: I strongly believe if you want human aligned AI, you want all humans to give feedback. And you want all humans to have access to that technology in the first place. And I actually have seen, living in New York, whenever I come to Silicon Valley, I see a different cultural bubble.We like the way Soumith put it last year: Closed AI “rate-limits against people's imaginations and needs”!What It Takes For Open Source AI to WinHowever Soumith doesn’t think Open Source will simply win by p

A Brief History of the Open Source AI Hacker - with Ben Firshman of Replicate
This Friday we’re doing a special crossover event in SF with Dylan Patel of SemiAnalysis (previous guest!), and we will do a live podcast on site. RSVP here. Also join us on June 25-27 for the biggest AI Engineer conference of the year!Replicate is one of the most popular AI inference providers, reporting over 2 million users as of their $40m Series B with a16z. But how did they get there? The Definitive Replicate Story (warts and all)Their overnight success took 5 years of building, and it all started with arXiv Vanity, which was a 2017 vacation project that scrapes arXiv PDFs and re-renders them into semantic web pages that reflow nicely with better typography and whitespace. From there, Ben and Andreas’ idea was to build tools to make ML research more robust and reproducible by making it easy to share code artefacts alongside papers. They had previously created Fig, which made it easy to spin up dev environments; it was eventually acquired by Docker and turned into `docker-compose`, the industry standard way to define services from containerized applications. 2019: CogThe first iteration of Replicate was a Fig-equivalent for ML workloads which they called Cog; it made it easy for researchers to package all their work and share it with peers for review and reproducibility. But they found that researchers were terrible users: they’d do all this work for a paper, publish it, and then never return to it again. “We talked to a bunch of researchers and they really wanted that.... But how the hell is this a business, you know, like how are we even going to make any money out of this? …So we went and talked to a bunch of companies trying to sell them something which didn't exist. So we're like, hey, do you want a way to share research inside your company so that other researchers or say like the product manager can test out the machine learning model? They're like, maybe. Do you want like a deployment platform for deploying models? Do you want a central place for versioning models? We were trying to think of lots of different products we could sell that were related to this thing…So we then got halfway through our YC batch. We hadn't built a product. We had no users. We had no idea what our business was going to be because we couldn't get anybody to like buy something which didn't exist. And actually there was quite a way through our, I think it was like two thirds the way through our YC batch or something. And we're like, okay, well we're kind of screwed now because we don't have anything to show at demo day.”The team graduated YCombinator with no customers, no product and nothing to demo - which was fine because demo day got canceled as the YC W’20 class graduated right into the pandemic. The team spent the next year exploring and building Covid tools.2021: CLIP + GAN = PixRayBy 2021, OpenAI released CLIP. Overnight dozens of Discord servers got spun up to hack on CLIP + GANs. Unlike academic researchers, this community was constantly releasing new checkpoints and builds of models. PixRay was one of the first models being built on Replicate, and it quickly started taking over the community. Chris Dixon has a famous 2010 post titled “The next big thing will start out looking like a toy”; image generation would have definitely felt like a toy in 2021, but it gave Replicate its initial boost.2022: Stable DiffusionIn August 2022 Stable Diffusion came out, and all the work they had been doing to build this infrastructure for CLIP / GANs models became the best way for people to share their StableDiffusion fine-tunes:And like the first week we saw people making animation models out of it. We saw people make game texture models that use circular convolutions to make repeatable textures. We saw a few weeks later, people were fine tuning it so you could put your face in these models and all of these other ways. […] So tons of product builders wanted to build stuff with it. And we were just sitting in there in the middle, as the interface layer between all these people who wanted to build, and all these machine learning experts who were building cool models. And that's really where it took off. Incredible supply, incredible demand, and we were just in the middle.(Stable Diffusion also spawned Latent Space as a newsletter)The landing page paved the cowpath for the intense interest in diffusion model APIs.2023: Llama & other multimodal LLMsBy 2023, Replicate’s growing visibility in the Stable Diffusion indie hacker community came from top AI hackers like Pieter Levels and Danny Postmaa, each making millions off their AI apps:Meta then released LLaMA 1 and 2 (our coverage of it), greatly pushing forward the SOTA open source model landscape. Demand for text LLMs and other modalities rose, and Replicate broadened its focus accordingly, culminating in a $18m Series A and $40m Series B from a16z (at a $350m valuation).Building standards for the AI worldNow that the industry is evolving from toys to enterprise use cases, all the
Truly Serverless Infra for AI Engineers - with Erik Bernhardsson of Modal
We’re writing this one day after the monster release of OpenAI’s Sora and Gemini 1.5. We covered this on Alex Volkov ‘s ThursdAI space, so head over there for our takes.IRL: We’re ONE WEEK away from Latent Space: Final Frontiers, the second edition and anniversary of our first ever Latent Space event! Also: join us on June 25-27 for the biggest AI Engineer conference of the year!Online: All three Discord clubs are thriving. Join us every Wednesday/Friday!Almost 12 years ago, while working at Spotify, Erik Bernhardsson built one of the first open source vector databases, Annoy, based on ANN search. He also built Luigi, one of the predecessors to Airflow, which helps data teams orchestrate and execute data-intensive and long-running jobs. Surprisingly, he didn’t start yet another vector database company, but instead in 2021 founded Modal, the “high-performance cloud for developers”. In 2022 they opened doors to developers after their seed round, and in 2023 announced their GA with a $16m Series A.More importantly, they have won fans among both household names like Ramp, Scale AI, Substack, and Cohere, and newer startups like (upcoming guest!) Suno.ai and individual hackers (Modal was the top tool of choice in the Vercel AI Accelerator):We've covered the nuances of GPU workloads, and how we need new developer tooling and runtimes for them (see our episodes with Chris Lattner of Modular and George Hotz of tiny to start). In this episode, we run through the major limitations of the actual infrastructure behind the clouds that run these models, and how Erik envisions the “postmodern data stack”. In his 2021 blog post “Software infrastructure 2.0: a wishlist”, Erik had “Truly serverless” as one of his points:* The word cluster is an anachronism to an end-user in the cloud! I'm already running things in the cloud where there's elastic resources available at any time. Why do I have to think about the underlying pool of resources? Just maintain it for me.* I don't ever want to provision anything in advance of load.* I don't want to pay for idle resources. Just let me pay for whatever resources I'm actually using.* Serverless doesn't mean it's a burstable VM that saves its instance state to disk during periods of idle.Swyx called this Self Provisioning Runtimes back in the day. Modal doesn’t put you in YAML hell, preferring to colocate infra provisioning right next to the code that utilizes it, so you can just add GPU (and disk, and retries…):After 3 years, we finally have a big market push for this: running inference on generative models is going to be the killer app for serverless, for a few reasons:* AI models are stateless: even in conversational interfaces, each message generation is a fully-contained request to the LLM. There’s no knowledge that is stored in the model itself between messages, which means that tear down / spin up of resources doesn’t create any headaches with maintaining state.* Token-based pricing is better aligned with serverless infrastructure than fixed monthly costs of traditional software.* GPU scarcity makes it really expensive to have reserved instances that are available to you 24/7. It’s much more convenient to build with a serverless-like infrastructure.In the episode we covered a lot more topics like maximizing GPU utilization, why Oracle Cloud rocks, and how Erik has never owned a TV in his life. Enjoy!Show Notes* Modal* ErikBot* Erik’s Blog* Software Infra 2.0 Wishlist* Luigi* Annoy* Hetzner* CoreWeave* Cloudflare FaaS* Poolside AI* Modular Inference EngineChapters* [00:00:00] Introductions* [00:02:00] Erik's OSS work at Spotify: Annoy and Luigi* [00:06:22] Starting Modal* [00:07:54] Vision for a "postmodern data stack"* [00:10:43] Solving container cold start problems* [00:12:57] Designing Modal's Python SDK* [00:15:18] Self-Revisioning Runtime* [00:19:14] Truly Serverless Infrastructure* [00:20:52] Beyond model inference* [00:22:09] Tricks to maximize GPU utilization* [00:26:27] Differences in AI and data science workloads* [00:28:08] Modal vs Replicate vs Modular and lessons from Heroku's "graduation problem"* [00:34:12] Creating Erik's clone "ErikBot"* [00:37:43] Enabling massive parallelism across thousands of GPUs* [00:39:45] The Modal Sandbox for agents* [00:43:51] Thoughts on the AI Inference War* [00:49:18] Erik's best tweets* [00:51:57] Why buying hardware is a waste of money* [00:54:18] Erik's competitive programming backgrounds* [00:59:02] Why does Sweden have the best Counter Strike players?* [00:59:53] Never owning a car or TV* [01:00:21] Advice for infrastructure startupsTranscriptAlessio [00:00:00]: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO-in-Residence at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol AI.Swyx [00:00:14]: Hey, and today we have in the studio Erik Bernhardsson from Modal. Welcome.Erik [00:00:19]: Hi. It's awesome being here.Swyx [00:00:20]: Yeah. Awesome seeing you in person. I've seen yo
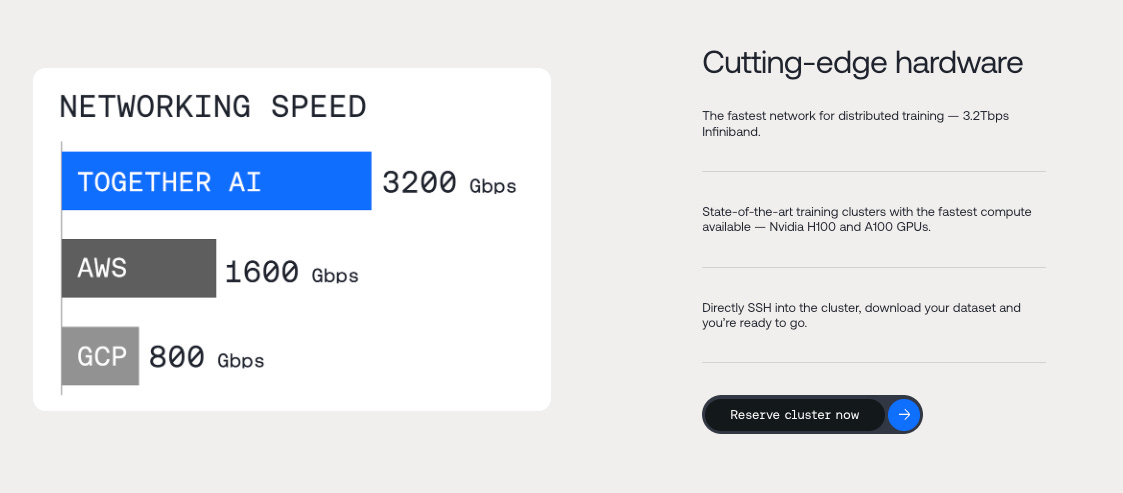
Cloud Intelligence at the speed of 5000 tok/s - with Ce Zhang and Vipul Ved Prakash of Together AI
Our first ever demo day aimed for 15-20 people and ended up ballooning to >200 and covered in the news. We are now running the 2024 edition in SF on Feb 23: Latent Space Final Frontiers, a startup and research competition in “The Autonomous Workforce”, ”Beyond Transformers & GPUs”, and “Embodied AI”. RSVP here! You can find all LS online/IRL events on our new calendar. Super Early Bird tickets have just gone on sale for AI Engineer World’s Fair, June 25-27!Today we have the honor of hosting two of Together AI’s co-founders: Ce Zhang (CTO) and Vipul Ved Prakash (CEO). This is a rare opportunity to recap the history of the company since our last check-in with Tri Dao (Chief Scientist), some of their big releases, and do a deep dive into the state of the AI inference market. Together has emerged as one of the most consequential new startups in the new AI summer, last announcing a ~$100m Series A raise in November (at a ~$360-565m valuation). Note from future: about a week after this pod was published, rumors were confirmed that Salesforce had led another $100m Series B at a $1b valuation.But there are at least three Togethers - Together the Research Lab, Together the Fine Tuning & Inference platform, and Together the custom models service. As we clarify on the pod, the overarching philosophy of Together is the ability to improve on all these fronts simultaneously by being “full stack”, from the lowest level kernel and systems programming to the highest level mathematical abstractions driving new model architectures and inference algorithms.Bringing Research and Industry TogetherIn just one year, Together has been behind some of the most exciting research in AI:* RedPajama, a fully open source dataset for model pre-training which mirrored the Llama1 recipe. Then followed by RedPajama2, a 30T tokens dataset of filtered and de-duplicated tokens. * RedPajama-INCITE-3B and 7B, which were SOTA in a few benchmarks at the time of release. * FlashAttention-2, developed by Together’s Chief Scientist Tri Dao. We covered FA-2 in a previous episode with him.* Mamba-3B, the most promising transformer-alternative model that they released in collaboration with Cartesia. * StripedHyena, a SOTA graft of Hyena state space models and transformer models together* Medusa, an alternative to speculative decoding that lets you use multiple decoding heads instead of a draft model. * MonarchMixer, which was one of the most popular orals at NeurIPS 2023. It’s an approach to transformers that replaces many of its core parts with Monarch matrices for better computational efficiency. And I’m sure we missed something! As Vipul reveals, almost 50% of Together staff is researchers, and two of their co-founders (Chris Ré and Percy Liang) are professors at Stanford, so we can expect a lot more here.Bringing “Disaggregated” GPUs TogetherOn their cloud, they offer inference as a service, fine-tuning, pre-training, etc, but unlike other providers they think of themselves as a disaggregated cloud. Today, they have ~8,000 A100 and H100 GPUs on their platform (an exclusive revealed on the pod!) totaling over 20 exaflops of compute, but instead of just buying more and putting them in a cluster and then exposing a `us-east-1` option for customers, they are taking heterogenous compute sources and adding a unified layer on top of it for developers to consume. Building on Ce’s research, Together’s GPU Clusters are taking on comparable AWS and GCP offerings in both cost and speed:Take the Hessian AI center in Germany or the DoE’s INCITE; they have GPUs that they want to share with researchers, but they lack the cloud layer over it. Similarly, there’s starting to be more and more differentiation amongst types of GPUs: H100s, A100s, MI3000s, etc. Each of them has different availability and performance based on task, and the end user shouldn’t have to be an hardware expert to run inference on a model, so Together abstracts a lot of that away.A big theme of the Together inference stack, a “bag of 50 tricks” that we discuss on the pod, is also “hardware-aware” algorithms like FlashAttention and Mamba, which further emphasize the benefits of co-developing everything together:Special Focus: Transformer AlternativesAs we mentioned above, they are also funding a lot of research in Transformer alternatives. To reiterate a few points on why they matter:* Longer context is not the motivation for sub-quadratic architectures: Transformers don’t inherently have hard limitations on context size, but they just get extremely expensive. When developing sub-quadratic alternatives, you easily enable very long context, but that’s now how you should compare them. Even at same context size, inference and training is much cheaper on sub-quadratic architectures like Hyena.* Emergence of hybrid architectures: a lot of early conversations have been around the “post-Transformers” era, but it might be more like “half-Transformers”. Hybrid architectures could have split layers with som
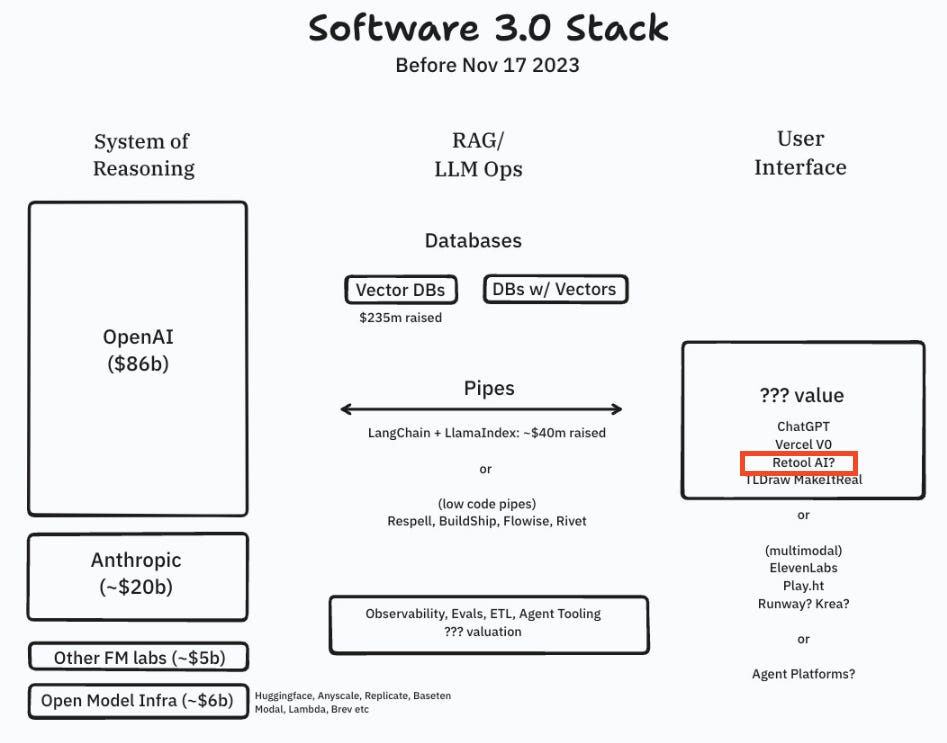
Why StackOverflow usage is down 50% — with David Hsu of Retool
We are announcing the second edition of our Latent Space demo day event in SF on 2/23: Final Frontiers, a startup and research competition in “The Autonomous Workforce”, ”Beyond Transformers & GPUs”, and “Embodied AI”. RSVP here! The first one was aimed for 15-20 people and ended up blowing up to >200 and covered in the Information - let’s see what a year of growth (and competition) does to the local events space in 2024.You can find all Latent Space events here, and of course get in touch with us to host your own AI Engineer meetups like AI Engineering Singapore.In our December 2023 recap we covered the Four Wars of the AI stack. But how do we know when it’s time to crown a winner? As we kick off 2024, we wanted to do a recap of the State of AI in 2023 to set a baseline of adoption for different products. Retool had a great report at the end of last year which covered a lot of it. David Hsu, CEO and co-founder of Retool, joined us to go over it together. We also talked about the history of Retool, why they were too embarrassed to present at YC demo day, and how they got to $1M ARR with 3 employees. If you’re a founder, there are a lot of nuggets of advice in here!Retool AIIn our modeling of the “Software 3.0 Stack”, we have generally left a pretty wide open gap as to the “user interface” equivalent of the AI stack:Retool AI launched 4 months ago with some nifty features for SQL generation, and its own hosted vector storage service (using pgvector). However, as he explains on the pod, the more interesting potential of Retool is in helping developers build AI infused applications quickly, in combination with its Workflows feature. This moves Retool down the stack from just the UI for internal tooling to the business logic “piping” as well. There are a bunch of dedicated tools in this space like Respell, BuildShip, Flowise, and Ironclad Rivet."We think that practically every internal app is going to be AI infused over the next three years." - David on the podRIP StackOverflow?In July 2023 we talked about the impact of ChatGPT and Copilot:This was then disputed by StackOverflow, who pointed out (very fairly so) that there were privacy-related changes in their analytics instrumentation in 2022. StackOverflow no longer reports traffic, but based on StackOverflow’s continuing transparency we can see that organic declines have continued throughout 2023.Retool’s report comes over a year after those changes and has some self reported samples from users:* 57.6% of people said they have used StackOverflow less; almost all of them replaced it with ChatGPT and Copilot.* 10.2% said they no longer use StackOverflow.We also saw a lot more tools being released in the dev tools space such as (one of our oldest pod friends) Codeium (which just raised a $65M Series B), SourceGraph (and their newly released Cody), Codium AI (just released AlphaCodium which was picked up by Karpathy), Phind (which beat GPT-4 with OSS models), and Cursor, one of the most beloved products in the dev community at the moment. Intelligence is getting closer and closer to the IDE, and the trend doesn’t seem to be reverting. We already said that “You are not too old (to pivot into AI)“, and the advice still stands. When asked to rate “Preference for hiring engineers effective at using ChatGPT/Copilot for coding” on a scale of 1 to 10, where 10 is “Much more likely”, ~40% of companies voted 8-10. Having an AI Engineer skillset is extremely important. 45% of companies between 1,000-4,999 employees said that they increased the difficulty of technical interviews to compensate for these new tools, so the gap between users and non-users will keep widening.Crossing the AI in Production ChasmGeoffrey Moore’s “Crossing the Chasm” is one of the most quoted business frameworks. Every market has an initial group of Innovators and Early Adopters, who are willing to suffer through the rough edges of products initially, and eventually crosses into the Early Majority, which expects a full product.In the AI world, ChatGPT and Midjourney / DALL-E have crossed the chasm in the consumer space. Copilot is probably the only tool that did it in the enterprise, having crossed 1M paid users. ~$50B were invested in AI in 2023, and we still only have According to the survey, only 25% of companies had real production usage, but 77.1% said their company is making efforts to adopt more. Closing that gap could triple AI adoption in one year.The report also broke down adoption by use case. 66% of companies use it internally, while only 43% do so in customer-facing use cases. Internal usage of AI is much more varied than customer-facing one as well:One point that David made in the podcast is that this number isn’t a knock on AI as a tool, but rather about the demographics of businesses outside of our Silicon Valley bubble:We all work in Silicon Valley, right? We all work at businesses, basically, that sell software as a business. And that's why all the software engineers that we hir
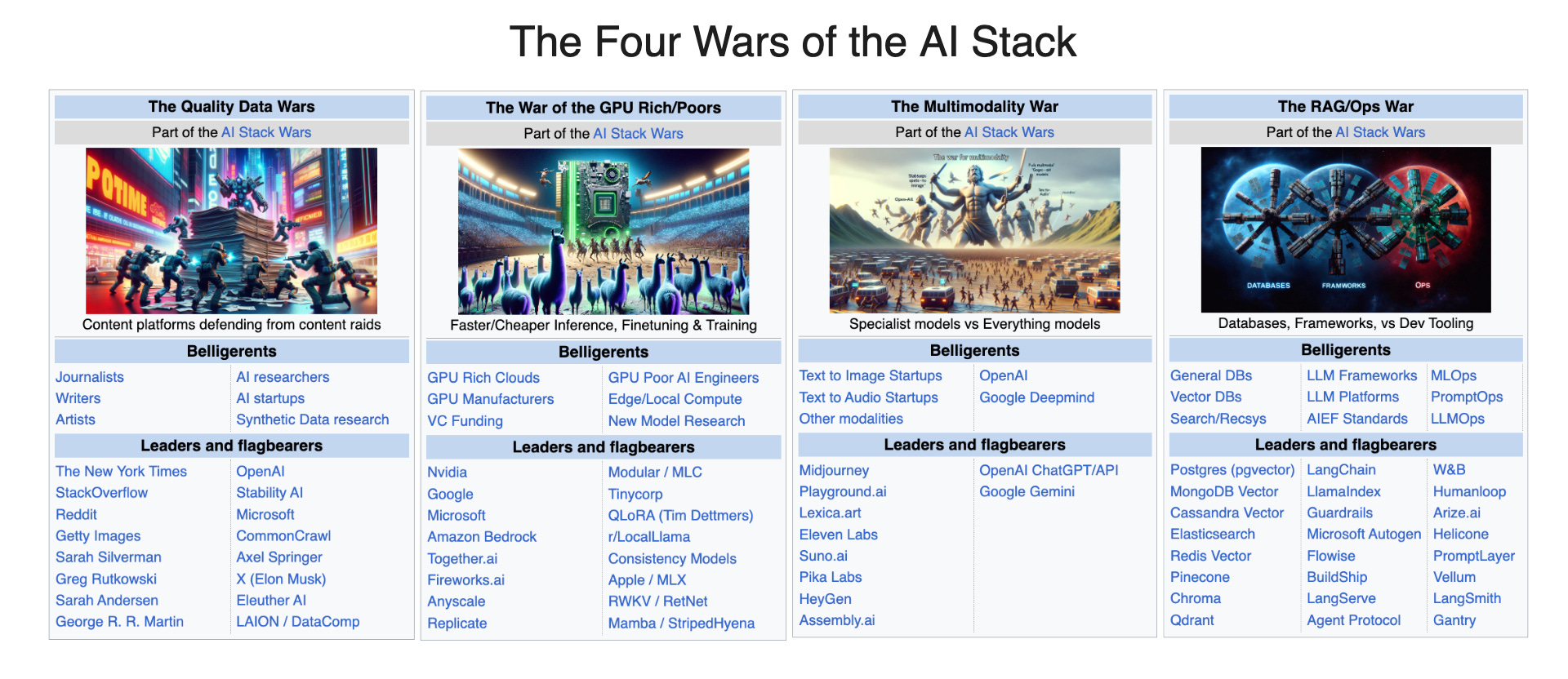
The Four Wars of the AI Stack (Dec 2023 Audio Recap)
Note for Latent Space Community members: we have now soft-launched meetups in Singapore, as well as two new virtual paper club/meetups for AI in Action and LLM Paper Club. We’re also running Latent Space: Final Frontiers, our second annual demo day hackathon from last year.Edit from March 2024: We did a followup on the Four Wars on the AI Breakdown.For the first time, we are doing an audio version of monthly AI Engineering recap that we publish on Latent Space! This month it’s “The Four Wars of the AI Stack”; you can find the full recap with all the show notes here: https://latent.space/p/dec-2023* [00:00:00] Intro* [00:01:42] The Four Wars of the AI stack: Data quality, GPU rich vs poor, Multimodality, and Rag/Ops war* [00:03:17] Selection process for the four wars and notable mentions* [00:06:58] The end of low background tokens and the impact on data engineering* [00:08:36] The Quality Data Wars (UGC, licensing, synthetic data, and more)* [00:14:51] Synthetic Data* [00:17:49] The GPU Rich/Poors War* [00:18:21] Anyscale benchmark drama* [00:22:00] The math behind Mixtral inference costs* [00:28:48] Transformer alternatives and why they matter* [00:34:40] The Multimodality Wars* [00:38:10] Multiverse vs Metaverse* [00:45:00] The RAG/Ops Wars* [00:50:00] Will frameworks expand up, or will cloud providers expand down?* [00:54:32] Syntax to Semantics* [00:56:41] Outer Loop vs Inner Loop* [00:59:54] Highlight of the month This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

How to train your own Large Multimodal Model — with Hugo Laurençon & Leo Tronchon of HuggingFace M4
Latent Space is heating up! Our paper club ran into >99 person Discord limits, oops. We are also introducing 2 new online meetups: LLM Paper Club Asia for Asia timezone (led by Ivan), and AI in Action: hands-on application of AI (led by KBall). To be notified of all upcoming Latent Space events, subscribe to our new Luma calendar (sign up for individual events, or hit the RSS icon to sync all events to calendar).In the halcyon open research days of 2022 BC (Before-ChatGPT), DeepMind was the first to create a SOTA multimodal model by taking a pre-existing LLM (Chinchilla 80B - now dead?) and pre-existing vision encoder (CLIP) and training a “glue” adapter layer, inspiring a generation of stunningly cheap and effective multimodal models including LLaVA (one of the Best Papers of NeurIPS 2023), BakLLaVA and FireLLaVA. However (for reasons we discuss in today’s conversation), DeepMind’s Flamingo model was never open sourced. Based on the excellent paper, LAION stepped up to create OpenFlamingo, but it never scaled beyond 9B. Simultaneously, the M4 (audio + video + image + text multimodality) research team at HuggingFace announced an independent effort to reproduce Flamingo up to the full 80B scale:The effort started in March, and was released in August 2023.We happened to visit Paris last year, and visited HuggingFace HQ to learn all about HuggingFace’s research efforts, and cover all the ground knowledge LLM people need to become (what Chip Huyen has termed) “LMM” people. In other words:What is IDEFICS?IDEFICS is an Open Access Visual Language Model, available in 9B and 80B model sizes. As an attempt to re-create an open-access version of Flamingo, it seems to track very well on a range of multimodal benchmarks (which we discuss in the pod):You can see the reasoning abilities of the models to take a combination of interleaved images + text in a way that allows users to either describe images, ask questions about the images, or extend/combine the images into different artworks (e.g. poetry).📷 From IDEFICS’s model card and blog postThe above demo screenshots are actually fine-tuned instruct versions of IDEFICS — which are again in 9B and 80B versions.IDEFICS was built by connecting two unimodal models together to provide the multi-modality you see showcased above.* Llama v1 for language (specifically huggyllama/llama-65b) - the best available open model at the time, to be swapped for Mistral in the next version of IDEFICS* A CLIP model for vision (specifically laion/CLIP-ViT-H-14-laion2B-s32B-b79K - after a brief exploration of EVA-CLIP, which we discuss on the pod)OBELICS: a new type of Multimodal DatasetIDEFICS’ training data used the usual suspect datasets, but to get to par with Flamingo they needed to create a new data set.Enter OBELICS: “An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents”:* 115B text tokens* 141M English documents* 353M imagesThese bullets are carefully curated and filtered by going through Common Crawl dumps between FEB 2020 - FEB 2023. We discuss the 2 months of mindnumbing, unglamorous work creating this pipeline:There’s a lot of mentions of ‘multi-modal' web documents’ which deserves some explanation. We’ll show you instead of tell you:You can see from this graph that OBELICS ends up outperforming the other image-text pairs dataset (LAION in this case) when stacked head-to-head.You can view a subset of OBELICS and perform visualizations on them here:2024 Update: WebSight et alMost of this interview was recorded on Halloween 2023 at HuggingFace’s headquarters in Paris:In anticipation of an IDEFICS v2 release. However, several roadblocks emerged, including a notable scandal around CSAM in LAION-5B, which affected all models using that dataset. The M4 team have adopted a strategy of shipping smaller advancements in 2024, and the first ship of the year is WebSight, a dataset of 823,000 HTML/CSS codes representing synthetically generated English websites, each accompanied by a corresponding screenshot (rendered with Playwright). This is intended for tasks like screenshot-to-code workflows like Vercel’s V0 or TLDraw, and will be part of the dataset for IDEFICS-2.As noted in our Best Papers recap, synthetic data is emerging as one of the top themes of 2024, and the IDEFICS/OBELICS team have wasted no time enabling themselves with it.Timestamps* [0:00:00] Intro* [0:00:00] Hugo, Leo’s path into multimodality* [0:09:16] From CLIP to Flamingo* [0:12:54] Benchmarks and Evals* [0:16:54] OBELICS dataset* [0:34:47] Together Redpajama v2* [0:37:12] GPT4 Vision* [0:38:44] IDEFICS model* [0:40:57] Query-Key Layernorm for training* [0:46:40] Choosing smaller vision encoders - EVA-CLIP vs SIG-GLIP* [0:49:02] IDEFICS v2* [0:52:39] Multimodal Hallucination* [0:59:12] Why Open Source Multimodality* [1:05:29] Naming: M4, OBELICS, IDEFICS* [1:08:56] 2024 Update from LeoShow Notes* Introducing IDEFICS: An Open Reproduction of State-of-the-Art Visual Language Model* IDEFICS Knowledge sharing
RLHF 201 - with Nathan Lambert of AI2 and Interconnects
In 2023 we did a few Fundamentals episodes covering Benchmarks 101, Datasets 101, FlashAttention, and Transformers Math, and it turns out those were some of your evergreen favorites! So we are experimenting with more educational/survey content in the mix alongside our regular founder and event coverage. Pls request more!We have a new calendar for events; join to be notified of upcoming things in 2024!Today we visit the shoggoth mask factory: how do transformer models go from trawling a deeply learned latent space for next-token prediction to a helpful, honest, harmless chat assistant? Our guest “lecturer” today is Nathan Lambert ; you might know him from his prolific online writing on Interconnects and Twitter, or from his previous work leading RLHF at HuggingFace and now at the Allen Institute for AI (AI2) which recently released the open source GPT3.5-class Tulu 2 model which was trained with DPO. He’s widely considered one of the most knowledgeable people on RLHF and RLAIF. He recently gave an “RLHF 201” lecture at Stanford, so we invited him on the show to re-record it for everyone to enjoy! You can find the full slides here, which you can use as reference through this episode. Full video with synced slidesFor audio-only listeners, this episode comes with slide presentation along our discussion. You can find it on our YouTube (like, subscribe, tell a friend, et al).Theoretical foundations of RLHFThe foundation and assumptions that go into RLHF go back all the way to Aristotle (and you can find guidance for further research in the slide below) but there are two key concepts that will be helpful in thinking through this topic and LLMs in general:* Von Neumann–Morgenstern utility theorem: you can dive into the math here, but the TLDR is that when humans make decision there’s usually a “maximum utility” function that measures what the best decision would be; the fact that this function exists, makes it possible for RLHF to model human preferences and decision making.* Bradley-Terry model: given two items A and B from a population, you can model the probability that A will be preferred to B (or vice-versa). In our world, A and B are usually two outputs from an LLM (or at the lowest level, the next token). It turns out that from this minimal set of assumptions, you can build up the mathematical foundations supporting the modern RLHF paradigm!The RLHF loopOne important point Nathan makes is that "for many tasks we want to solve, evaluation of outcomes is easier than producing the correct behavior". For example, it might be difficult for you to write a poem, but it's really easy to say if you like or dislike a poem someone else wrote. Going back to the Bradley-Terry Model we mentioned, the core idea behind RLHF is that when given two outputs from a model, you will be able to say which of the two you prefer, and we'll then re-encode that preference into the model.An important point that Nathan mentions is that when you use these preferences to change model behavior "it doesn't mean that the model believes these things. It's just trained to prioritize these things". When you have preference for a model to not return instructions on how to write a computer virus for example, you're not erasing the weights that have that knowledge, but you're simply making it hard for that information to surface by prioritizing answers that don't return it. We'll talk more about this in our future Fine Tuning 101 episode as we break down how information is stored in models and how fine-tuning affects it.At a high level, the loop looks something like this:For many RLHF use cases today, we can assume the model we're training is already instruction-tuned for chat or whatever behavior the model is looking to achieve. In the "Reward Model & Other Infrastructure" we have multiple pieces:Reward + Preference ModelThe reward model is trying to signal to the model how much it should change its behavior based on the human preference, subject to a KL constraint. The preference model itself scores the pairwise preferences from the same prompt (worked better than scalar rewards).One way to think about it is that the reward model tells the model how big of a change this new preference should make in the behavior in absolute terms, while the preference model calculates how big of a difference there is between the two outputs in relative terms. A lot of this derives from John Schulman’s work on PPO:We recommend watching him talk about it in the video above, and also Nathan’s pseudocode distillation of the process:Feedback InterfacesUnlike the "thumbs up/down" buttons in ChatGPT, data annotation from labelers is much more thorough and has many axis of judgement. At a simple level, the LLM generates two outputs, A and B, for a given human conversation. It then asks the labeler to use a Likert scale to score which one it preferred, and by how much:Through the labeling process, there are many other ways to judge a generation:We then use all of this dat

The Accidental AI Canvas - with Steve Ruiz of tldraw
Happy 2024! We appreciated all the feedback on the listener survey (still open, link here)! Surprising to see that some people’s favorite episodes were others’ least, but we’ll always work on improving our audio quality and booking great guests. Help us out by leaving reviews on Twitter, YouTube, and Apple Podcasts! 🙏 Big thanks to Chris Anderson for the latest review - be like Chris!Note to the Audio-only ListenerBecause of the nature of today’s topic, it makes the most sense to follow along the demo on video rather than audio. There’s also about 30 mins of demos and technical detail that we had to remove from the audio version, because they didn’t make sense without video.Trailer here.Full 90min chat:(In other words, pls jump over and watch on our YouTube if you can! Did you know we are now posting every episode to YouTube? We’ve been multimodal for a long time!)Trend 1: GPT4-V CodingYou might remember Greg Brockman’s hand-scribble-to-working-website demo from the GPT-4 demo from March. This was largely inaccessible to the rest of us until the GPT4-V API was released at Dev Day in November.As mentioned in our November 2023 recap, one of the biggest viral trends was tldraw’s open source “Make It Real” demo: starting from a simple wireframe and text annotations, you could create a real, functioning UI with the click of a button. Provoking another crisis of confidence in developer circles:And using state charts:And provoking responses from Excalidraw, a competitor.You can see us creating a Replit clone in this silent video here:Since our intervew the new GPT4V Coding metagame has been merging app UI’s and SQL with Supabase (another AIE Summit speaker) and other backend tools:* generating SQL* converting ERDs to SQL (part 2, for MariaDB)* seeding sample data* doing migrationsTrend 2: Latent Consistency ModelsAs covered in the Latent Space Paper Club in November, 3 papers drove a roughly ~100x acceleration in the speed of text to image generation over the past year:* Consistency Models (with Ilya Sutskever)* Latent Consistency Models (from Tsinghua)* LCM-LoRA (also Tsinghua, same authors)With the invaluable help of Fal.ai (friends of the show and AI Engineer Summit and progenitors of the viral GPU Rich/Poor hats mentioned on the Semianalysis episode), TLDraw has also been at the forefront of putting this research into production, with two projects:* drawfast: add a prompt, start sketching into the canvas and see each stroke affect the drawing. Overlap multiple of them to extend and merge drawings.* lens: a collaborative canvas where in real time people can draw and have their sketch turn into AI-generated art. Start drawing at the bottom and see it scroll into the magic canvas. For nontechnical people in your life, we do recommend showing them lens.tldraw.com (and its predecessor that we discuss on the show) on your and their mobile devices.The Rise of Multimodal PromptingAt the first AI Engineer Summit in October, Logan (our first guest!) declared this the Year of Multimodality. Over the next 2 months we saw an explosion of activity in multimodal: GPT-4V’s API release at OpenAI Dev Day (our coverage here), LLaVA (our chat with author here on Visual Instruction Tuning), BakLLaVA, Qwen-VL, CogVLM, etc.On today’s episode we have Steve Ruiz, founder of tldraw. The project originally started as an open source whiteboard that Steve built for himself and then “accidentally made a really, really good visual multimodal prompting application environment”. Turns out that infinite canvas and generative models are a very good match:* Design is iterative: DALL-E, Midjourney, etc all work in a linear way: prompt goes in, 1-4 images come back. As you generate more, the previous images scroll away from your view. In a canvas environment, you can see the progression of your generation and visually “branch” by putting new prompts in different spaces.* UI has “layers”: when designing interfaces there are different layers to it: the functionality, the style, the state, etc. Some of what they are building in tldraw is bringing images into the canvas to influence different layers: “One thing that we've done is to bring in screenshots of other apps, like here's Stripe.com, like make it look like Stripe, you know? Or like here's Linear.com, like let's do it this way”. In the episode we spend a lot more time talking through all of these ideas and how Steve’s background in fine arts came back to being really useful in building a multi-modal AI canvas. Enjoy!Show Notes* tldraw* Open Source Repo* Make Real (Wireframe to UI)* drawfast.tldraw.com* lens.tldraw.com* Perfect Free Hand and Perfect Arrows* “Make Real, the story so far”* Dog CEO* Other whiteboarding products mentioned* Excalidraw* FigJam* Adobe Whiteboard* See also Steve’s interviews on the Slow Steady Pod and TWiSt, and subscribe to his tldraw substack!* TLDraw Wireframe kit* TLDraw LLM starterTimestamps* [00:00:00] Introductions* [00:01:02] Steve's Background In Fine Arts and

NeurIPS 2023 Recap — Top Startups
We are running an end of year listener survey! Please let us know any feedback you have, what episodes resonated with you, and guest requests for 2024! Survey link here.We can’t think of a more Latent-Space-y way to end 2023 than with a mega episode featuring many old and new friends recapping their biggest news, achievements, and themes and memes of the year!We previously covered the Best Papers of NeurIPS 2023, but the other part of NeurIPS being an industry friendly conference is all the startups that show up to hire and promote their latest and greatest products and papers! As a startup-friendly podcast, we of course were ready with our mics to talk to everyone we could track down.In lieu of an extended preamble, we encourage you to listen and click through all the interviews and show notes, all of which have been curated to match the references mentioned in the episode.Timestamps & Show Notes* [00:01:26] Jonathan Frankle - Chief Scientist, MosaicML/Databricks* see also the Mosaic/MPT-7B episode* $1.3B MosaicML x Databricks acquisition* [00:22:11] Lin Qiao - CEO, Fireworks AI* Fireworks Mixtral* [00:38:24] Aman Sanger - CEO, Anysphere (Cursor)* see also the Cursor episode* $8m seed from OpenAI* Tweet: Request-level memory-based KV caching* Tweet: GPT-4 grading and Trueskill ratings for rerankers* [00:51:14] Aravind Srinivas - CEO, Perplexity* 1m app installs on iOS and Android* pplx-online api 7b and 70b models* Shaan Puri/Paul Graham Fierce Nerds story* [01:04:26] Will Bryk - CEO, Metaphor* “Andrew Huberman may have singlehandedly ruined the SF social scene”* [01:12:49] Jeremy Howard - CEO, Answer.ai* see also the End of Finetuning episode* Jeremy’s podcast with Tanishq Abraham, Jess Leao* Announcing Answer.ai with $10m from Decibel VC* Laundry Buddy, Nov 2023 AI Meme of the Month * [01:37:13] Joel Hestness - Principal Scientist, Cerebras* CerebrasGPT, all the Cerebras papers we discussed* [01:56:34] Jason Corso - CEO, Voxel51* Open Source FiftyOne project* CVPR Survival Guide* [02:02:39] Brandon Duderstadt - CEO, Nomic.ai* GPT4All, Atlas, Demo* [02:12:39] Luca Antiga - CTO, Lightning.ai* Pytorch Lightning, Lightning Studios, LitGPT* [02:29:46] Jay Alammar - Engineering Fellow, Cohere* The Illustrated Transformer This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

NeurIPS 2023 Recap — Best Papers
We are running an end of year listener survey! Please let us know any feedback you have, what episodes resonated with you, and guest requests for 2024! Survey link here.NeurIPS 2023 took place from Dec 10–16 in New Orleans. The Latent Space crew was onsite for as many of the talks and workshops as we could attend (and more importantly, hosted cocktails and parties after hours)!Picking from the 3586 papers accepted to the conference (available online, full schedule here) is an impossible task, but we did our best to present an audio guide with brief commentary on each. We also recommend MLContests.com NeurIPS recap and Seb Ruder’s NeurIPS primer and Jerry Liu’s paper picks. We also found the VizHub guide useful for a t-SNE clustering of papers. Lots also happened in the arxiv publishing world outside NeurIPS, as highlighted by Karpathy, especially DeepMind’s Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models.Jan 2024 update: we also strongly recommend Sebastian Raschka, PhD ‘s pick of the year’s 10 best papers, including Pythia.We’ll start with the NeurIPS Best Paper Awards, and then go to a selection of non-awarded but highly influential papers, and then arbitrary personal picks to round out the selection. Where we were able to do a poster session interview, please scroll to the relevant show notes for images of their poster for discussion. We give Chris Ré the last word due to the Mamba and StripedHyena state space models drawing particular excitement but still being too early to assess impact. Timestamps* [0:01:19] Word2Vec (Jeff Dean, Greg Corrado)* [0:15:28] Emergence Mirage (Rylan Schaeffer)* [0:28:48] DPO (Rafael Rafailov)* [0:41:36] DPO Poster Session (Archit Sharma)* [0:52:03] Datablations (Niklas Muennighoff)* [1:00:50] QLoRA (Tim Dettmers)* [1:12:23] DataComp (Samir Gadre)* [1:25:38] DataComp Poster Session (Samir Gadre, Alex Dimakis)* [1:35:25] LLaVA (Haotian Liu)* [1:47:21] LLaVA Poster Session (Haotian Liu)* [1:59:19] Tree of Thought (Shunyu Yao)* [2:11:27] Tree of Thought Poster Session (Shunyu Yao)* [2:20:09] Toolformer (Jane Dwivedi-Yu)* [2:32:26] Voyager (Guanzhi Wang)* [2:45:14] CogEval (Ida Momennejad)* [2:59:41] State Space Models (Chris Ré)Papers covered* Distributed Representations of Words and Phrases and their Compositionality (Word2Vec) Tomas Mikolov · Ilya Sutskever · Kai Chen · Greg Corrado · Jeff Dean. The recently introduced continuous Skip-gram model is an efficient method for learning high-quality distributed vector representations that capture a large number of precise syntactic and semantic word relationships. In this paper we present several improvements that make the Skip-gram model more expressive and enable it to learn higher quality vectors more rapidly. We show that by subsampling frequent words we obtain significant speedup, and also learn higher quality representations as measured by our tasks. We also introduce Negative Sampling, a simplified variant of Noise Contrastive Estimation (NCE) that learns more accurate vectors for frequent words compared to the hierarchical softmax. An inherent limitation of word representations is their indifference to word order and their inability to represent idiomatic phrases. For example, the meanings of Canada'' and "Air'' cannot be easily combined to obtain "Air Canada''. Motivated by this example, we present a simple and efficient method for finding phrases, and show that their vector representations can be accurately learned by the Skip-gram model.* Some notable reflections from Tomas Mikolov - and debate over the Seq2Seq paper credit with Quoc Le* Are Emergent Abilities of Large Language Models a Mirage? (Schaeffer et al.). Emergent abilities are abilities that are present in large-scale models but not in smaller models and are hard to predict. Rather than being a product of models’ scaling behavior, this paper argues that emergent abilities are mainly an artifact of the choice of metric used to evaluate them. Specifically, nonlinear and discontinuous metrics can lead to sharp and unpredictable changes in model performance. Indeed, the authors find that when accuracy is changed to a continuous metric for arithmetic tasks where emergent behavior was previously observed, performance improves smoothly instead. So while emergent abilities may still exist, they should be properly controlled and researchers should consider how the chosen metric interacts with the model.* Direct Preference Optimization: Your Language Model is Secretly a Reward Model (Rafailov et al.)* While large-scale unsupervised language models (LMs) learn broad world knowledge and some reasoning skills, achieving precise control of their behavior is difficult due to the completely unsupervised nature of their training. Existing methods for gaining such steerability collect human labels of the relative quality of model generations and fine-tune the unsupervised LM to align with these preferences, often with reinforcement learning from
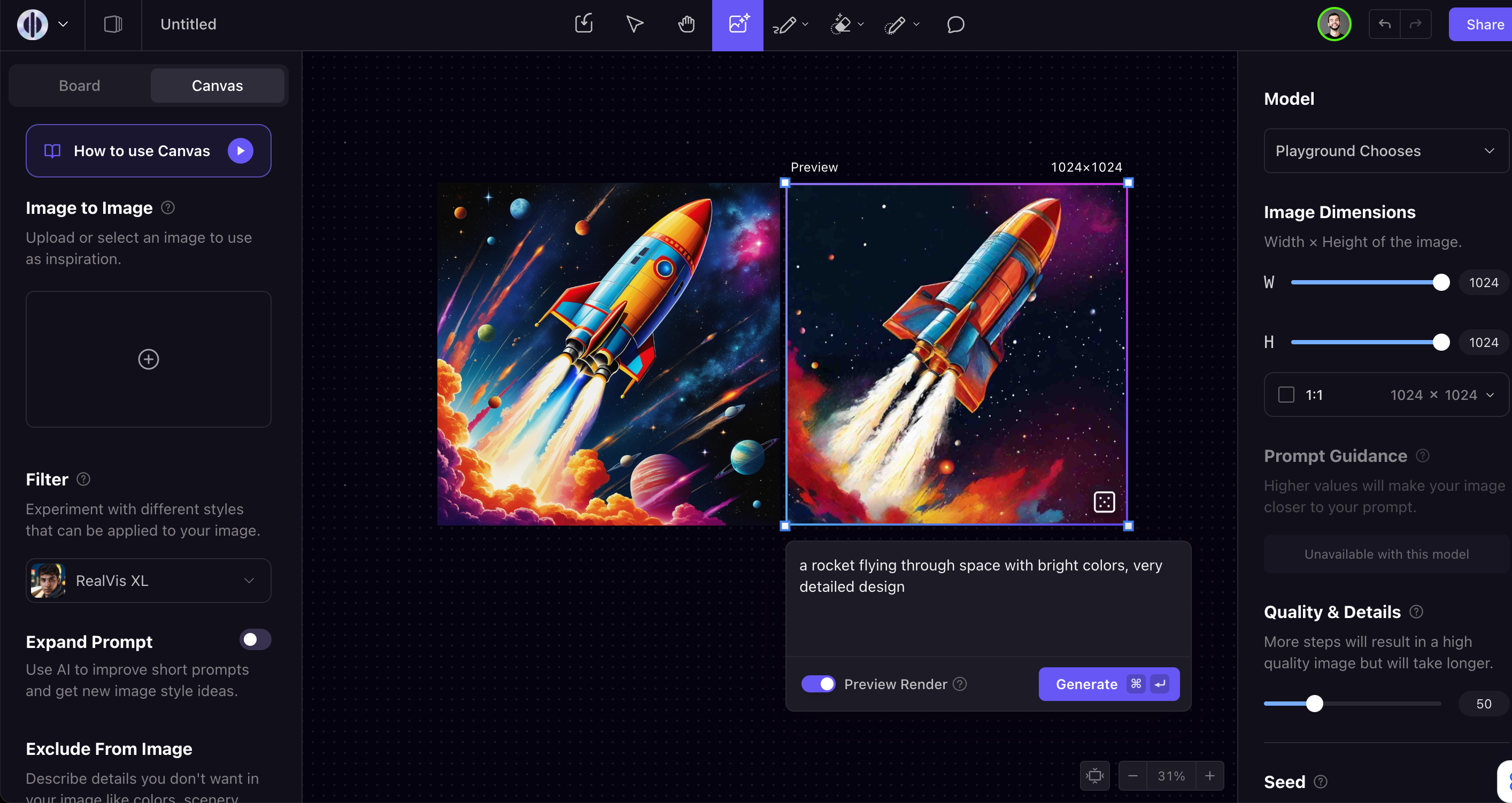
The AI-First Graphics Editor - with Suhail Doshi of Playground AI
We are running an end of year survey for our listeners! Please let us know any feedback you have, what episodes resonated with you, and guest requests for 2024! Survey link here!Listen to the end for a little surprise from Suhail.Before language models became all the rage in November 2022, image generation was the hottest space in AI (it was the subject of our first piece on Latent Space!) In our interview with Sharif Shameem from Lexica we talked through the launch of StableDiffusion and the early days of that space. At the time, the toolkit was still pretty rudimentary: Lexica made it easy to search images, you had the AUTOMATIC1111 Web UI to generate locally, some HuggingFace spaces that offered inference, and eventually DALL-E 2 through OpenAI’s platform, but not much beyond basic text-to-image workflows.Today’s guest, Suhail Doshi, is trying to solve this with Playground AI, an image editor reimagined with AI in mind. Some of the differences compared to traditional text-to-image workflows:* Real-time preview rendering using consistency: as you change your prompt, you can see changes in real-time before doing a final rendering of it.* Style filtering: rather than having to prompt exactly how you’d like an image to look, you can pick from a whole range of filters both from Playground’s model as well as Stable Diffusion (like RealVis, Starlight XL, etc). We talk about this at 25:46 in the podcast.* Expand prompt: similar to DALL-E3, Playground will do some prompt tuning for you to get better results in generation. Unlike DALL-E3, you can turn this off at any time if you are a prompting wizard* Image editing: after generation, you have tools like a magic eraser, inpainting pencil, etc. This makes it easier to do a full workflow in Playground rather than switching to another tool like Photoshop.Outside of the product, they have also trained a new model from scratch, Playground v2, which is fully open source and open weights and allows for commercial usage. They benchmarked the model against SDXL across 1,000 prompts and found that humans preferred the Playground generation 70% of the time. They had similar results on PartiPrompts:They also created a new benchmark, MJHQ-30K, for “aesthetic quality”:We introduce a new benchmark, MJHQ-30K, for automatic evaluation of a model’s aesthetic quality. The benchmark computes FID on a high-quality dataset to gauge aesthetic quality.We curate the high-quality dataset from Midjourney with 10 common categories, each category with 3K samples. Following common practice, we use aesthetic score and CLIP score to ensure high image quality and high image-text alignment. Furthermore, we take extra care to make the data diverse within each category.Suhail was pretty open with saying that Midjourney is currently the best product for imagine generation out there, and that’s why they used it as the base for this benchmark. I think it's worth comparing yourself to maybe the best thing and try to find like a really fair way of doing that. So I think more people should try to do that. I definitely don't think you should be kind of comparing yourself on like some Google model or some old SD, Stable Diffusion model and be like, look, we beat Stable Diffusion 1.5. I think users ultimately want care, how close are you getting to the thing that people mostly agree with? [00:23:47]We also talked a lot about Suhail’s founder journey from starting Mixpanel in 2009, then going through YC again with Mighty, and eventually sunsetting that to pivot into Playground. Enjoy!Show Notes* Suhail’s Twitter* “Starting my road to learn AI”* Bill Gates book trip* Playground* Playground v2 Announcement* $40M raise announcement* “Running infra dev ops for 24 A100s”* Mixpanel* Mighty* “I decided to stop working on Mighty”* Fast.ai* CivitTimestamps* [00:00:00] Intros* [00:02:59] Being early in ML at Mixpanel* [00:04:16] Pivoting from Mighty to Playground and focusing on generative AI* [00:07:54] How DALL-E 2 inspired Mighty* [00:09:19] Reimagining the graphics editor with AI* [00:17:34] Training the Playground V2 model from scratch to advance generative graphics* [00:21:11] Techniques used to improve Playground V2 like data filtering and model tuning* [00:25:21] Releasing the MJHQ30K benchmark to evaluate generative models* [00:30:35] The limitations of current models for detailed image editing tasks* [00:34:06] Using post-generation user feedback to create better benchmarks* [00:38:28] Concerns over potential misuse of powerful generative models* [00:41:54] Rethinking the graphics editor user experience in the AI era* [00:45:44] Integrating consistency models into Playground using preview rendering* [00:47:23] Interacting with the Stable Diffusion LoRAs community* [00:51:35] Running DevOps on A100s* [00:53:12] Startup ideas?TranscriptAlessio: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO-in-Residence at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol

The "Normsky" architecture for AI coding agents — with Beyang Liu + Steve Yegge of SourceGraph
We are running an end of year survey for our listeners. Let us know any feedback you have for us, what episodes resonated with you the most, and guest requests for 2024! RAG has emerged as one of the key pieces of the AI Engineer stack. Jerry from LlamaIndex called it a “hack”, Bryan from Hex compared it to “a recommendation system from LLMs”, and even LangChain started with it. RAG is crucial in any AI coding workflow. We talked about context quality for code in our Phind episode. Today’s guests, Beyang Liu and Steve Yegge from SourceGraph, have been focused on code indexing and retrieval for over 15 years. We locked them in our new studio to record a 1.5 hours masterclass on the history of code search, retrieval interfaces for code, and how they get SOTA 30% completion acceptance rate in their Cody product by being better at the “bin packing problem” of LLM context generation. Google Grok → SourceGraph → CodyWhile at Google in 2008, Steve built Grok, which lives on today as Google Kythe. It allowed engineers to do code parsing and searching across different codebases and programming languages. (You might remember the infamous Google Platforms Rant from Steve’s time at Google, and his 2021 followup on GCP). Beyang was an intern at Google at the same time, and Grok became the inspiration to start SourceGraph in 2013. The two didn’t know eachother personally until Beyang brought Steve out of retirement 9 years later to join him as VP Engineering. Fast forward 10 years, SourceGraph has become to best code search tool out there and raised $223M along the way. Nine months ago, they open sourced SourceGraph Cody, their AI coding assistant. All their code indexing and search infrastructure allows them to get SOTA results by having better RAG than competitors:* Code completions as you type that achieve an industry-best Completion Acceptance Rate (CAR) as high as 30% using a context-enhanced open-source LLM (StarCoder)* Context-aware chat that provides the option of using GPT-4 Turbo, Claude 2, GPT-3.5 Turbo, Mistral 7x8B, or Claude Instant, with more model integrations planned* Doc and unit test generation, along with AI quick fixes for common coding errors* AI-enhanced natural language code search, powered by a hybrid dense/sparse vector search engine There are a few pieces of infrastructure that helped Cody achieve these results:Dense-sparse vector retrieval system For many people, RAG = vector similarity search, but there’s a lot more that you can do to get the best possible results. From their release:"Sparse vector search" is a fancy name for keyword search that potentially incorporates LLMs for things like ranking and term expansion (e.g., "k8s" expands to "Kubernetes container orchestration", possibly weighted as in SPLADE): * Dense vector retrieval makes use of embeddings, the internal representation that LLMs use to represent text. Dense vector retrieval provides recall over a broader set of results that may have no exact keyword matches but are still semantically similar. * Sparse vector retrieval is very fast, human-understandable, and yields high recall of results that closely match the user query. * We've found the approaches to be complementary.There’s a very good blog post by Pinecone on SPLADE for sparse vector search if you’re interested in diving in. If you’re building RAG applications in areas that have a lot of industry-specific nomenclature, acronyms, etc, this is a good approach to getting better results.SCIPIn 2016, Microsoft announced the Language Server Protocol (LSP) and the Language Server Index Format (LSIF). This protocol makes it easy for IDEs to get all the context they need from a codebase to get things like file search, references, “go to definition”, etc. SourceGraph developed SCIP, “a better code indexing format than LSIF”:* Simpler and More Efficient Format: SCIP utilizes Protobuf instead of JSON, which is used by LSIF. Protobuf is more space-efficient, simpler, and more suitable for systems programming. * Better Performance and Smaller Index Sizes: SCIP indexers, such as scip-clang, show enhanced performance and reduced index file sizes compared to LSIF indexers (10%-20% smaller)* Easier to Develop and Debug: SCIP's design, centered around human-readable string IDs for symbols, makes it faster and more straightforward to develop new language indexers. Having more efficient indexing is key to more performant RAG on code. Show Notes* Sourcegraph* Cody* Copilot vs Cody* Steve’s Stanford seminar on Grok* Steve’s blog* Grab* Fireworks* Peter Norvig* Noam Chomsky* Code search* Kelly Norton* Zoekt* v0.devSee also our past episodes on Cursor, Phind, Codeium and Codium as well as the GitHub Copilot keynote at AI Engineer Summit.Timestamps* [00:00:00] Intros & Backgrounds* [00:05:20] How Steve's work on Grok inspired SourceGraph for Beyang* [00:08:10] What's Cody?* [00:11:22] Comparison of coding assistants and the capabilities of Cody* [00:16:00] The importance of context (RAG) in AI co
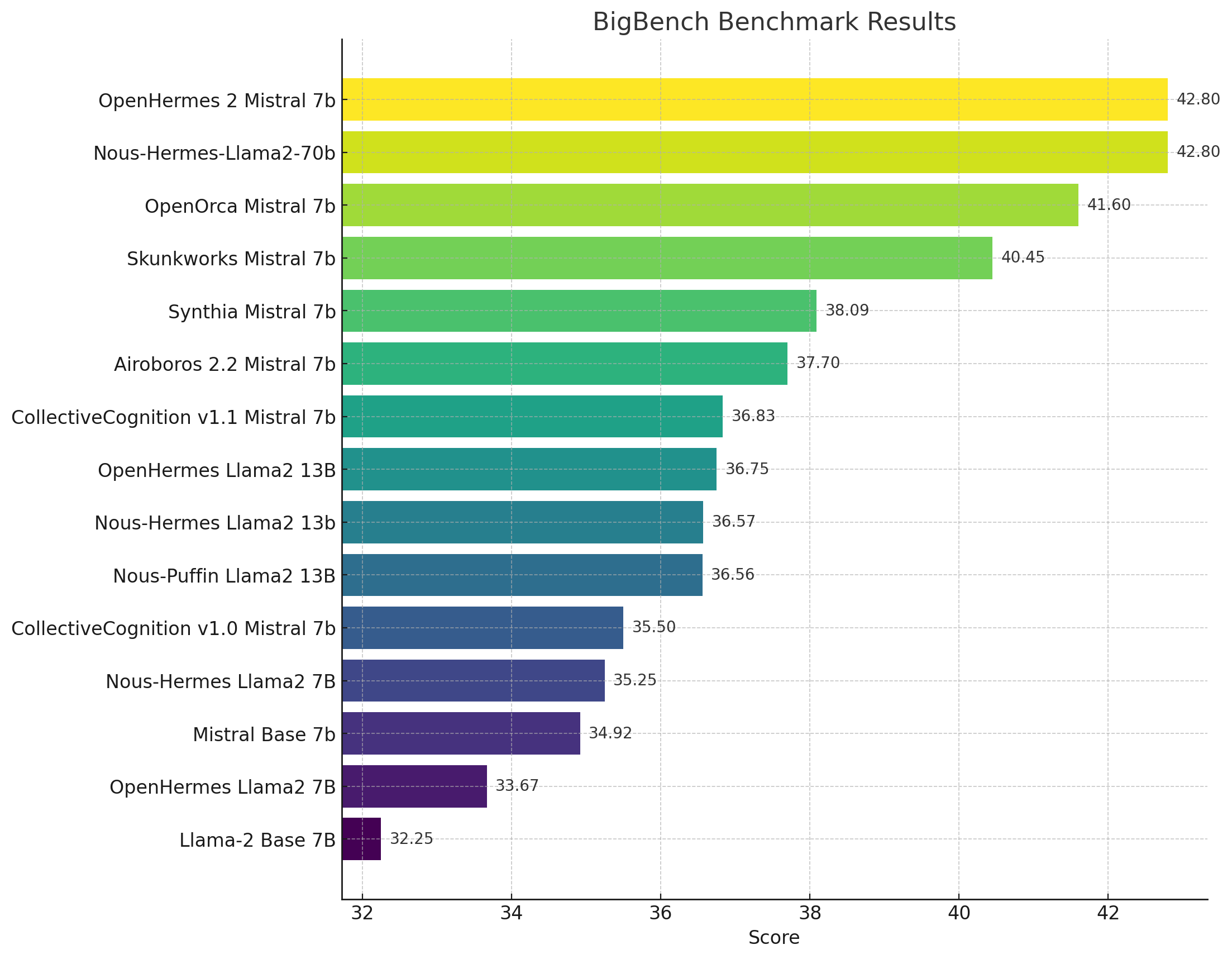
The Busy Person's Intro to Finetuning & Open Source AI - Wing Lian, Axolotl
The Latent Space crew will be at NeurIPS on Tuesday! Reach out with any parties and papers of interest. We have also been incubating a smol daily AI Newsletter and Latent Space University is making progress.Good open models like Llama 2 and Mistral 7B (which has just released an 8x7B MoE model) have enabled their own sub-industry of finetuned variants for a myriad of reasons:* Ownership & Control - you take responsibility for serving the models* Privacy - not having to send data to a third party vendor* Customization - Improving some attribute (censorship, multiturn chat and chain of thought, roleplaying) or benchmark performance (without cheating)Related to improving benchmark performance is the ability to use smaller (7B, 13B) models, by matching the performance of larger models, which have both cost and inference latency benefits.Core to all this work is finetuning, and the emergent finetuning library of choice has been Wing Lian’s Axolotl.AxolotlAxolotl is an LLM fine-tuner supporting SotA techniques and optimizations for a variety of common model architectures:It is used by many of the leading open source models:* Teknium: OpenHermes, Trismigestus, CollectiveCognition* OpenOrca: Mistral-OpenOrca, Mistral-SlimOrca* Nous Research: Puffin, Capybara, NousHermes* Pygmalion: Mythalion, Pygmalion* Eric Hartford: Dolphin, Samantha* DiscoResearch: DiscoLM 120B & 70B* OpenAccess AI Collective: Manticore, Minotaur, Jackalope, HippogriffAs finetuning is very formatting dependent, it also provides prompt interfaces and formatters between a range of popular model formats from Stanford’s Alpaca and Steven Tey’s ShareGPT (which led to Vicuna) to the more NSFW Pygmalion community.Nous Research MeetupWe last talked about Nous at the DevDay Recap at the e/acc “banger rave”. We met Wing at the Nous Research meetup at the a16z offices in San Francisco, where they officially announced their company and future plans:Including Nous Forge:Show NotesWe’ve already covered the nuances of Dataset Contamination and the problems with “Open Source” in AI, so we won’t rehash those topics here but do read/listen to those if you missed it.* Axolotl GitHub and Discord* The Flan paper and dataset* StackLlama model and blogpost* Multipack paper* Our episode with Tri Dao* Mamba state space models - Tri Dao and Albert GuTimestamps* [00:00:00] Introducing Wing* [00:02:34] SF Open Source AI Meetup* [00:04:09] What is Axolotl?* [00:08:01] What is finetuning?* [00:08:52] Open Source Model Zoo* [00:10:53] Benchmarks and Contamination* [00:14:29] The Case for Open Source AI* [00:17:34] Orca and OpenOrca* [00:23:36] DiscoLM and Model Stacking* [00:25:07] Datasets and Evals over Models* [00:29:15] Distilling from GPT4* [00:33:31] Finetuning - LoRA, QLoRA, ReLoRA, GPTQ* [00:41:55] Axolotl vs HF Transformers* [00:48:00] 20x efficiency with StackLlama and Multipack* [00:54:47] Tri Dao and Mamba* [00:59:08] Roadmap for Axolotl* [01:01:20] The Open Source AI CommunityTranscript[00:00:00] Introducing Wing Lian[00:00:00] [00:00:00] swyx: Welcome to Latent Space, a special edition with Wing Lien, but also with our new guest host, Alex. Hello, hello. Welcome, welcome. Again, needs no introduction. I think it's like your sixth time on Latent Space already. I think so, yeah. And welcome, Wing. We just met, but you've been very prolific online. Thanks for having me.[00:00:30] Yeah. So you are in town. You're not local. You're in town. You're from Minneapolis?[00:00:35] Wing Lian: Annapolis. Annapolis. It's funny because a lot of people think it's Indianapolis. It's I've got Minneapolis, but I used to live out at least in the San Francisco Bay Area years ago from like 2008 to 2014. So it's fairly familiar here.[00:00:50] swyx: Yep. You're the maintainer of Axolotl now, which we'll get into. You're very, very prolific in the open source AI community, and you're also the founder of the Open Access AI Collective. Yeah. Cool. Awesome. Maybe we can go over a little bit of your backgrounds into tech and then coming into AI, and then we'll cover what[00:01:06] Wing Lian: happens and why you're here.[00:01:08] Yeah. So. Back on tech, so I started years ago, I started way back when I was scraping, Apartment websites for listings and then, and then building like SEO optimized pages and then just throwing Google AdSense on it.[00:01:24] And that got me through like college basically. Is[00:01:27] swyx: that decent money? And what year[00:01:28] Wing Lian: was this? Like 2004, 2005. Yeah, that's decent money. It's like thousand bucks a month. But as a college student, that's like. Gravy. Really good money, right? So, and then there's just too much competition It's just sort of like died off. I was writing stuff in like Perl back then using like like who nobody hosted anything on Perl anymore, right? Still did a little bit more like computer tech support and then software, and web more professionally.[00:01:54] So I spent some time working on applications in the blood indus

Notebooks = Chat++ and RAG = RecSys! — with Bryan Bischof of Hex Magic
Catch us at Modular’s ModCon next week with Chris Lattner, and join our community!2024 note: Hex is now hiring AI Engineers.Due to Bryan’s very wide ranging experience in data science and AI across Blue Bottle (!), StitchFix, Weights & Biases, and now Hex Magic, this episode can be considered a two-parter.Notebooks = Chat++We’ve talked a lot about AI UX (in our meetups, writeups, and guest posts), and today we’re excited to dive into a new old player in AI interfaces: notebooks! Depending on your background, you either Don’t Like or you Like notebooks — they are the most popular example of Knuth’s Literate Programming concept, basically a collection of cells; each cell can execute code, display it, and share its state with all the other cells in a notebook. They can also simply be Markdown cells to add commentary to the analysis. Notebooks have a long history but most recently became popular from iPython evolving into Project Jupyter, and a wave of notebook based startups from Observable to DeepNote and Databricks sprung up for the modern data stack.The first wave of AI applications has been very chat focused (ChatGPT, Character.ai, Perplexity, etc). Chat as a user interface has a few shortcomings, the major one being the inability to edit previous messages. We enjoyed Bryan’s takes on why notebooks feel like “Chat++” and how they are building Hex Magic:* Atomic actions vs Stream of consciousness: in a chat interface, you make corrections by adding more messages to a conversation (i.e. “Can you try again by doing X instead?” or “I actually meant XYZ”). The context can easily get messy and confusing for models (and humans!) to follow. Notebooks’ cell structure on the other hand allows users to go back to any previous cells and make edits without having to add new ones at the bottom. * “Airlocks” for repeatability: one of the ideas they came up with at Hex is “airlocks”, a collection of cells that depend on each other and keep each other in sync. If you have a task like “Create a summary of my customers’ recent purchases”, there are many sub-tasks to be done (look up the data, sum the amounts, write the text, etc). Each sub-task will be in its own cell, and the airlock will keep them all in sync together.* Technical + Non-Technical users: previously you had to use Python / R / Julia to write notebooks code, but with models like GPT-4, natural language is usually enough. Hex is also working on lowering the barrier of entry for non-technical users into notebooks, similar to how Code Interpreter is doing the same in ChatGPT. Obviously notebooks aren’t new for developers (OpenAI Cookbooks are a good example), but haven’t had much adoption in less technical spheres. Some of the shortcomings of chat UIs + LLMs lowering the barrier of entry to creating code cells might make them a much more popular UX going forward.RAG = RecSys!We also talked about the LLMOps landscape and why it’s an “iron mine” rather than a “gold rush”: I'll shamelessly steal [this] from a friend, Adam Azzam from Prefect. He says that [LLMOps] is more of like an iron mine than a gold mine in the sense of there is a lot of work to extract this precious, precious resource. Don't expect to just go down to the stream and do a little panning. There's a lot of work to be done. And frankly, the steps to go from this resource to something valuable is significant.Some of my favorite takeaways:* RAG as RecSys for LLMs: at its core, the goal of a RAG pipeline is finding the most relevant documents based on a task. This isn’t very different from traditional recommendation system products that surface things for users. How can we apply old lessons to this new problem? Bryan cites fellow AIE Summit speaker and Latent Space Paper Club host Eugene Yan in decomposing the retrieval problem into retrieval, filtering, and scoring/ranking/ordering:As AI Engineers increasingly find that long context has tradeoffs, they will also have to relearn age old lessons that vector search is NOT all you need and a good systems not models approach is essential to scalable/debuggable RAG. Good thing Bryan has just written the first O’Reilly book about modern RecSys, eh?* Narrowing down evaluation: while “hallucination” is a easy term to throw around, the reality is more nuanced. A lot of times, model errors can be automatically fixed: is this JSON valid? If not, why? Is it just missing a closing brace? These smaller issues can be checked and fixed before returning the response to the user, which is easier than fixing the model.* Fine-tuning isn’t all you need: when they first started building Magic, one of the discussions was around fine-tuning a model. In our episode with Jeremy Howard we talked about how fine-tuning leads to loss of capabilities as well. In notebooks, you are often dealing with domain-specific data (i.e. purchases, orders, wardrobe composition, household items, etc); the fact that the model understands that “items” are probably part of an “order” is really help

The State of Silicon and the GPU Poors - with Dylan Patel of SemiAnalysis
This episode came together at ~4 hrs notice since Dylan had just landed in SF and we had to setup quickly; you might notice some small audio issues in some segments, we apologize. We’re currently building our own podcast studio for 2024! 🙏 We’re ramping up our presence on Twitter and YouTube if you’d like to support us.Note: 17k people joined our emergency pod on Sam Altman’s ouster today.If Charles Dickens was alive in 2024, A Tale of Two Cities might be the divide between the “GPU poor” and the “GPU rich”.We mentioned these terms in some of our previous episodes; they were originally coined by Dylan Patel of SemiAnalysis in his “Gemini Eats the World” post, put on blast by Sam Altman. SemiAnalysis are one of the most in depth research and consulting firms in the semis world, and have a unique insight into the design, production, and supply chain of GPUs based on their ground presence in Asia. In this episode we break down the State of Silicon: when are more GPUs coming? Are there real GPU alternatives on the way? Should Microsoft buy AMD chips just to scare Jensen? Is there a “GPU poor is beautiful” manifesto?The supply wave is comingThe GPU shortage is the talk of the town in the Bay Area, but next year looks a lot better in terms of AI accelerating capacity: * NVIDIA is forecasted to sell over 3 million GPUs next year, about 3x their 2023 sales of about 1 million H100s.* AMD is forecasting $2B of sales for their new MI300X datacenter GPU. They are also indirectly getting a boost from the work that companies like Modular and tiny are doing in making it easier to actually use these chips (will ROCm ever catch up?)* Google’s TPUv5 supply is going to increase rapidly going into 2024* Microsoft just announced Maia 100, a new AI accelerator built “with feedback” from OpenAI. In the episode we dove deeper into what this means for each of these companies and the GPU consumers, but the TLDR (sadly) is that capacity increases but FLOPS requirements to train the next generation of models will eclipse the one of previous ones. GPT-3 was 4,000x more FLOPS than GPT-2. Dylan estimates GPT-4 was trained on 20,000 A100s for ~$500M all-in; how much will OpenAI spend to train GPT-5? How many GPUs will need to go brrr? In the meantime, the amount of companies looking for GPUs has increased, with Meta rising as one of the de-facto top 3 AI labs in terms of capacity. The pressure to acquire more chips will not ease in 2024. We also talked about some of the companies trying to displace traditional GPU architectures: MatX, Lemurian Labs, Cerebras, etc. The different variables they are fighting on are size of SRAM vs HBM, focusing on memory bandwidth vs memory size, different math representation for kernels, etc, and how the key to this market is whether or not the transformer architecture will still be the #1 in the future.Surviving in the GPU Poor laneA lot of the smaller companies (when compared to $1T+ giants, it’s all relative) are trying hard to fight against the GPU rich, but they can’t quite offer the same scale: * HuggingFace is trying to launch a training cluster as a service, but it seems to just be a software wrapper around NVIDIA’s GDX Cloud, as they don’t actually own that much GPU supply. The max option for GPUs to use is 1,000 in their form.* Databricks’ “GPU-enabled clusters” run on AWS, and the largest one listed there is only powered by 8 NVIDIA A10Gs. The Mosaic team is also doing research on running on AMD cards with some promising results, but they seem to be pushing up to just 128 cards, which isn’t much.* Together actually has 4,424 H100s live in production, which is quite sizable but still nothing compared to the 100,000 that Meta is putting online. Take LLaMA2 as an example; the 70B model was trained on 2T tokens. Using the highest accelerator count on HuggingFace it’d take ~43 days to train the model from scratch and it’d cost ~$2M. That doesn’t include all the data and prep work. In the meantime, Zuck is probably burning tens of thousands of H100s to train LLaMA3, which will surely have much higher performance than whatever a GPU poor company can train in the same time span. The good news, is that there’s a ton of opportunity for the GPU poors to shine, especially around fine-tuning. Most of the open source models coming out are one-size-fits-all, and there’s a ton of opportunity for startups to take them and tailor them to their customers, or to specific tasks or use cases to build vertical applications. The other area of improvement is data quality; Mistral showed how you can build a high quality small model with less FLOPs by feeding it better data. The key to differentiation won’t be GPUs, but tokens. Show Notes* SemiAnalysis* Google Gemini Eats The World – Gemini Smashes GPT-4 By 5X, The GPU-Poors* How Nvidia’s CUDA Monopoly In Machine Learning Is Breaking - OpenAI Triton And PyTorch 2.0* AMD MI300 – Taming The Hype – AI Performance, Volume Ramp, Customers, Cost, IO, Networking, Software* @sama

AGI is Being Achieved Incrementally (DevDay Recap - cleaned audio)
We left a high amount of background audio in the Devday podcast, which many of you loved, but we definitely understand that some of you may have had trouble with it. Listener Klaus Breyer ran it through Auphonic with speech islolation and we figured we’d upload it as a backdated pod for people who prefer this. Of course it means that our speakers sound out of place since they now sound like they are talking loudly in a quiet room. Let us know in the comments what you think?Timestampsthe cleaned part is only part 2:* [00:55:09] Part II: Spot Interviews* [00:55:59] Jim Fan (Nvidia) - High Level Takeaways* [01:05:19] Raza Habib (Humanloop) - Foundation Model Ops* [01:13:32] Surya Dantuluri (Stealth) - RIP Plugins* [01:20:53] Reid Robinson (Zapier) - AI Actions for GPTs* [01:30:45] Div Garg (MultiOn) - GPT4V for Agents* [01:36:42] Louis Knight-Webb (Bloop.ai) - AI Code Search* [01:48:36] Shreya Rajpal (Guardrails) - Guardrails for LLMs* [01:59:00] Alex Volkov (Weights & Biases, ThursdAI) - "Keeping AI Open"* [02:09:39] Rahul Sonwalkar (Julius AI) - Advice for Founders This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

AGI is Being Achieved Incrementally (OpenAI DevDay w/ Simon Willison, Alex Volkov, Jim Fan, Raza Habib, Shreya Rajpal, Rahul Ligma, et al)
SF folks: join us at the AI Engineer Foundation’s Emergency Hackathon tomorrow and consider the Newton if you’d like to cowork in the heart of the Cerebral Arena.Our community page is up to date as usual!~800,000 developers watched OpenAI Dev Day, ~8,000 of whom listened along live on our ThursdAI x Latent Space, and ~800 of whom got tickets to attend in person:OpenAI’s first developer conference easily surpassed most people’s lowballed expectations - they simply did everything short of announcing GPT-5, including:* ChatGPT (the consumer facing product)* GPT4 Turbo already in ChatGPT (running faster, with an April 2023 cutoff), all noticed by users weeks before the conference* Model picker eliminated, God Model chooses for you* GPTs - “tailored version of ChatGPT for a specific purpose” - stopping short of “Agents”. With custom instructions, expanded knowledge, and actions, and an intuitive no-code GPT Builder UI (we tried all these on our livestream yesterday and found some issues, but also were able to ship interesting GPTs very quickly) and a GPT store with revenue sharing (an important criticism we focused on in our episode on ChatGPT Plugins)* API (the developer facing product)* APIs for Dall-E 3, GPT4 Vision, Code Interpreter (RIP Advanced Data Analysis), GPT4 Finetuning and (surprise!) Text to Speech* many thought each of these would take much longer to arrive* usable in curl and in playground* BYO Interpreter + Async Agents?* Assistant API: stateful API backing “GPTs” like apps, with support for calling multiple tools in parallel, persistent Threads (storing message history, unlimited context window with some asterisks), and uploading/accessing Files (with a possibly-too-simple RAG algorithm, and expensive pricing)* Whisper 3 announced and open sourced (HuggingFace recap)* Price drops for a bunch of things!* Misc: Custom Models for big spending ($2-3m) customers, Copyright Shield, SatyaThe progress here feels fast, but it is mostly (incredible) last-mile execution on model capabilities that we already knew to exist. On reflection it is important to understand that the one guiding principle of OpenAI, even more than being Open (we address that in part 2 of today’s pod), is that slow takeoff of AGI is the best scenario for humanity, and that this is what slow takeoff looks like:When introducing GPTs, Sam was careful to assert that “gradual iterative deployment is the best way to address the safety challenges with AI”:This is why, in fact, GPTs and Assistants are intentionally underpowered, and it is a useful exercise to consider what else OpenAI continues to consider dangerous (for example, many people consider a while(true) loop a core driver of an agent, which GPTs conspicuously lack, though Lilian Weng of OpenAI does not).We convened the crew to deliver the best recap of OpenAI Dev Day in Latent Space pod style, with a 1hr deep dive with the Functions pod crew from 5 months ago, and then another hour with past and future guests live from the venue itself, discussing various elements of how these updates affect their thinking and startups. Enjoy!Show Notes* swyx live thread (see pinned messages in Twitter Space for extra links from community)* Newton AI Coworking Interest Form in the heart of the Cerebral ArenaTimestamps* [00:00:00] Introduction* [00:01:59] Part I: Latent Space Pod Recap* [00:06:16] GPT4 Turbo and Assistant API* [00:13:45] JSON mode* [00:15:39] Plugins vs GPT Actions* [00:16:48] What is a "GPT"?* [00:21:02] Criticism: the God Model* [00:22:48] Criticism: ChatGPT changes* [00:25:59] "GPTs" is a genius marketing move* [00:26:59] RIP Advanced Data Analysis* [00:28:50] GPT Creator as AI Prompt Engineer* [00:31:16] Zapier and Prompt Injection* [00:34:09] Copyright Shield* [00:38:03] Sharable GPTs solve the API distribution issue* [00:39:07] Voice* [00:44:59] Vision* [00:49:48] In person experience* [00:55:11] Part II: Spot Interviews* [00:56:05] Jim Fan (Nvidia - High Level Takeaways)* [01:05:35] Raza Habib (Humanloop) - Foundation Model Ops* [01:13:59] Surya Dantuluri (Stealth) - RIP Plugins* [01:21:20] Reid Robinson (Zapier) - AI Actions for GPTs* [01:31:19] Div Garg (MultiOn) - GPT4V for Agents* [01:37:15] Louis Knight-Webb (Bloop.ai) - AI Code Search* [01:49:21] Shreya Rajpal (Guardrails.ai) - on Hallucinations* [01:59:51] Alex Volkov (Weights & Biases, ThursdAI) - "Keeping AI Open"* [02:10:26] Rahul Sonwalkar (Julius AI) - Advice for FoundersTranscript[00:00:00] Introduction[00:00:00] swyx: Hey everyone, this is Swyx coming at you live from the Newton, which is in the heart of the Cerebral Arena. It is a new AI co working space that I and a couple of friends are working out of. There are hot desks available if you're interested, just check the show notes. But otherwise, obviously, it's been 24 hours since the opening of Dev Day, a lot of hot reactions and longstanding tradition, one of the longest traditions we've had.[00:00:29] And the latent space pod is to convene emergency sessi
Beating GPT-4 with Open Source LLMs — with Michael Royzen of Phind
At the AI Pioneers Summit we announced Latent Space Launchpad, an AI-focused accelerator in partnership with Decibel. If you’re an AI founder of enterprise early adopter, fill out this form and we’ll be in touch with more details. We also have a lot of events coming up as we wrap up the year, so make sure to check out our community events page and come say hi!We previously interviewed the founders of many developer productivity startups embedded in the IDE, like Codium AI, Cursor, and Codeium. We also covered Replit’s (former) SOTA model, replit-code-v1-3b and most recently had Amjad and Michele announce replit-code-v1_5-3b at the AI Engineer Summit.Much has been speculated about the StackOverflow traffic drop since ChatGPT release, but the experience is still not perfect. There’s now a new player in the “search for developers” arena: Phind.Phind’s goal is to help you find answers to your technical questions, and then help you implement them. For example “What should I use to create a frontend for a Python script?” returns a list of frameworks as well as links to the sources. You can then ask follow up questions on specific implementation details, having it write some code for you, etc. They have both a web version and a VS Code integrationThey recently were top of Hacker News with the announcement of their latest model, which is now the #1 rated model on the BigCode Leaderboard, beating their previous version:TLDR Cheat Sheet:* Based on CodeLlama-34B, which is trained on 500B tokens* Further fine-tuned on 70B+ high quality code and reasoning tokens* Expanded context window to 16k tokens* 5x faster than GPT-4 (100 tok/s vs 20 tok/s on single stream)* 74.7% HumanEval vs 45% for the base modelWe’ve talked before about HumanEval being limited in a lot of cases and how it needs to be complemented with “vibe based” evals. Phind thinks of evals alongside two axis: * Context quality: when asking the model to generate code, was the context high quality? Did we put outdated examples in it? Did we retrieve the wrong files?* Result quality: was the code generated correct? Did it follow the instructions I gave it or did it misunderstand some of it?If you have bad results with bad context, you might get to a good result by working on better RAG. If you have good context and bad result you might either need to work on your prompting or you have hit the limits of the model, which leads you to fine tuning (like they did). Michael was really early to this space and started working on CommonCrawl filtering and indexing back in 2020, which led to a lot of the insights that now power Phind. We talked about that evolution, his experience at YC, how he got Paul Graham to invest in Phind and invite him to dinner at his house, and how Ron Conway connected him with Jensen Huang to get access to more GPUs!Show Notes* Phind* BigScience T0* InstructGPT Paper* Inception-V3* LMQL* Marginalia Nu* Mistral AI* People:* Paul Graham (pg)* Ron Conway* Yacine Jernite from HuggingFace* Jeff DelaneyTimestamps* [00:00:00] Intros & Michael's early interest in computer vision* [00:03:14] Pivoting to NLP and natural language question answering models* [00:07:20] Building a search engine index of Common Crawl and web pages* [00:11:26] Releasing the first version of Hello based on the search index and BigScience T0 model* [00:14:02] Deciding to focus the search engine specifically for programmers* [00:17:39] Overview of Phind's current product and focus on code reasoning* [00:21:51] The future vision for Phind to go from idea to complete code* [00:24:03] Transitioning to using the GPT-4 model and the impact it had* [00:29:43] Developing the Phind model based on CodeLlama and additional training* [00:32:28] Plans to continue improving the Phind model with open source technologies* [00:43:59] The story of meeting Paul Graham and Ron Conway and how that impacted the company* [00:53:02] How Ron Conway helped them get GPUs from Nvidia* [00:57:12] Tips on how Michael learns complex AI topics* [01:01:12] Lightning RoundTranscriptAlessio: Hey everyone, welcome to the Latent Space Podcast. This is Alessio, partner and CTO of Residence and Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol AI. [00:00:19]Swyx: Hey, and today we have in the studio Michael Royzen from Phind. Welcome. [00:00:23]Michael: Thank you so much. [00:00:24]Alessio: It's great to be here. [00:00:25]Swyx: Yeah, we are recording this in a surprisingly hot October in San Francisco. And sometimes the studio works, but the blue angels are flying by right now, so sorry about the noise. So welcome. I've seen Phind blow up this year, mostly, I think since your launch in Feb and V2 and then your Hacker News posts. We tend to like to introduce our guests, but then obviously you can fill in the blanks with the origin story. You actually were a high school entrepreneur. You started SmartLens, which is a computer vision startup in 2017. [00:00:59]Michael: That's right. I remember when
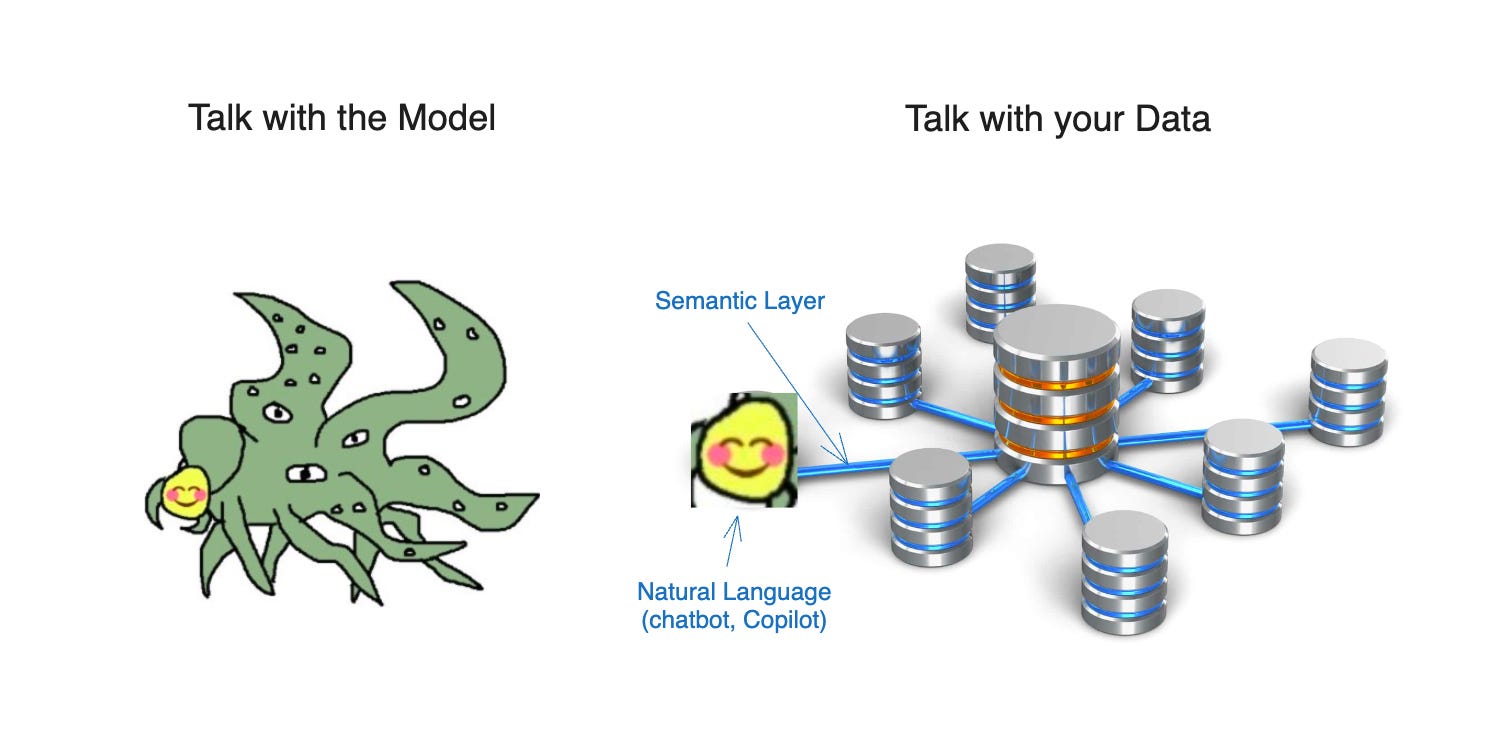
Powering your Copilot for Data – with Artem Keydunov of Cube.dev
The first workshops and talks from the AI Engineer Summit are now up! Join the >20k viewers on YouTube, find clips on Twitter (we’re also clipping @latentspacepod), and chat with us on Discord!Text-to-SQL was one of the first applications of NLP. Thoughtspot offered “Ask your data questions” as their core differentiation compared to traditional dashboarding tools. In a way, they provide a much friendlier interface with your own structured (aka “tabular”, as in “SQL tables”) data, the same way that RLHF and Instruction Tuning helped turn the GPT-3 of 2020 into the ChatGPT of 2022.Today, natural language queries on your databases are a commodity. There are 4 different ChatGPT plugins that offer this, as well as a bunch of startups like one of our previous guests, Seek.ai. Perplexity originally started with a similar product in 2022: In March 2023 LangChain wrote a blog post on LLMs and SQL highlighting why they don’t consistently work:* “LLMs can write SQL, but they are often prone to making up tables, making up field”* “LLMs have some context window which limits the amount of text they can operate over”* “The SQL it writes may be incorrect for whatever reason, or it could be correct but just return an unexpected result.”For example, if you ask a model to “return all active users in the last 7 days” it might hallucinate a `is_active` column, join to an `activity` table that doesn’t exist, or potentially get the wrong date (especially in leap years!).We previously talked to Shreya Rajpal at Guardrails AI, which also supports Text2SQL enforcement. Their approach was to run the actual SQL against your database and then use the error messages to improve the query: Semantic Layers to the rescueCube is an open source semantic layer which recently integrated with LangChain to solve these issues in a different way. You can use YAML, Javascript, or Python to create definitions of different metrics, measures and dimensions for your data: Creating these metrics and passing them in the model context limits the possibility for errors as the model just needs to query the `active_users` view, and Cube will then expand that into the full SQL in a reliable way. The downside of this approach compared to the Guardrails one for example is that it requires more upfront work to define metrics, but on the other hand it leads to more reliable and predictable outputs. The promise of adding a great semantic layer to your LLM app is irresistible - you greatly minimize hallucinations, make much more token efficient prompts, and your data stays up to date without any retraining or re-indexing. However, there are also difficulties with implementing semantic layers well, so we were glad to go deep on the topic with Artem as one of the leading players in this space!Timestamps* [00:00:00] Introductions* [00:01:28] Statsbot and limitations of natural language processing in 2017* [00:04:27] Building Cube as the infrastructure for Statsbot* [00:08:01] Open sourcing Cube in 2019* [00:09:09] Explaining the concept of a semantic layer/Cube* [00:11:01] Using semantic layers to provide context for AI models working with tabular data* [00:14:47] Workflow of generating queries from natural language via semantic layer* [00:21:07] Using Cube to power customer-facing analytics and natural language interfaces* [00:22:38] Building data-driven AI applications and agents* [00:25:59] The future of the modern data stack* [00:29:43] Example use cases of Slack bots powered by Cube* [00:30:59] Using GPT models and limitations around math* [00:32:44] Tips for building data-driven AI apps* [00:35:20] Challenges around monetizing embedded analytics* [00:36:27] Lightning RoundTranscriptSwyx: Hey everyone, welcome to the Latent Space podcast. This is Swyx, writer, editor of Latent Space and founder of Smol.ai and Alessio, partner and CTO in residence at Decibel Partners. [00:00:15]Alessio: Hey everyone, and today we have Artem Keydunov on the podcast, co-founder of Cube. Hey Artem. [00:00:21]Artem: Hey Alessio, hi Swyx. Good to be here today, thank you for inviting me. [00:00:25]Alessio: Yeah, thanks for joining. For people that don't know, I've known Artem for a long time, ever since he started Cube. And Cube is actually a spin-out of his previous company, which is Statsbot. And this kind of feels like going both backward and forward in time. So the premise of Statsbot was having a Slack bot that you can ask, basically like text to SQL in Slack, and this was six, seven years ago, something like that. A lot ahead of its time, and you see startups trying to do that today. And then Cube came out of that as a part of the infrastructure that was powering Statsbot. And Cube then evolved from an embedded analytics product to the semantic layer and just an awesome open source evolution. I think you have over 16,000 stars on GitHub today, you have a very active open source community. But maybe for people at home, just give a quick like lay of the land of the original Statsbot

The End of Finetuning — with Jeremy Howard of Fast.ai
Thanks to the over 17,000 people who have joined the first AI Engineer Summit! A full recap is coming. Last call to fill out the State of AI Engineering survey! See our Community page for upcoming meetups in SF, Paris and NYC.This episode had good interest on Twitter and was discussed on the Vanishing Gradients podcast.Fast.ai’s “Practical Deep Learning” courses been watched by over >6,000,000 people, and the fastai library has over 25,000 stars on Github. Jeremy Howard, one of the creators of Fast, is now one of the most prominent and respected voices in the machine learning industry; but that wasn’t always the case. Being non-consensus and right In 2018, Jeremy and Sebastian Ruder published a paper on ULMFiT (Universal Language Model Fine-tuning), a 3-step transfer learning technique for NLP tasks: The paper demonstrated that pre-trained language models could be fine-tuned on a specific task with a relatively small amount of data to achieve state-of-the-art results. They trained a 24M parameters model on WikiText-103 which was beat most benchmarks.While the paper had great results, the methods behind weren’t taken seriously by the community: “Everybody hated fine tuning. Everybody hated transfer learning. I literally did tours trying to get people to start doing transfer learning and nobody was interested, particularly after GPT showed such good results with zero shot and few shot learning […] which I was convinced was not the right direction, but who's going to listen to me, cause as you said, I don't have a PhD, not at a university… I don't have a big set of computers to fine tune huge transformer models.”Five years later, fine-tuning is at the center of most major discussion topics in AI (we covered some like fine tuning vs RAG and small models fine tuning), and we might have gotten here earlier if Jeremy had OpenAI-level access to compute and distribution. At heart, Jeremy has always been “GPU poor”:“I've always been somebody who does not want to build stuff on lots of big computers because most people don't have lots of big computers and I hate creating stuff that most people can't use.”This story is a good reminder of how some of the best ideas are hiding in plain sight; we recently covered RWKV and will continue to highlight the most interesting research that isn’t being done in the large labs. Replacing fine-tuning with continued pre-trainingEven though fine-tuning is now mainstream, we still have a lot to learn. The issue of “catastrophic forgetting” and potential solutions have been brought up in many papers: at the fine-tuning stage, the model can forget tasks it previously knew how to solve in favor of new ones. The other issue is apparent memorization of the dataset even after a single epoch, which Jeremy covered Can LLMs learn from a single example? but we still don’t have the answer to. Despite being the creator of ULMFiT, Jeremy still professes that there are a lot of open questions on finetuning:“So I still don't know how to fine tune language models properly and I haven't found anybody who feels like they do.”He now advocates for "continued pre-training" - maintaining a diversity of data throughout the training process rather than separate pre-training and fine-tuning stages. Mixing instructional data, exercises, code, and other modalities while gradually curating higher quality data can avoid catastrophic forgetting and lead to more robust capabilities (something we covered in Datasets 101).“Even though I originally created three-step approach that everybody now does, my view is it's actually wrong and we shouldn't use it… the right way to do this is to fine-tune language models, is to actually throw away the idea of fine-tuning. There's no such thing. There's only continued pre-training. And pre-training is something where from the very start, you try to include all the kinds of data that you care about, all the kinds of problems that you care about, instructions, exercises, code, general purpose document completion, whatever. And then as you train, you gradually curate that, you know, you gradually make that higher and higher quality and more and more specific to the kinds of tasks you want it to do. But you never throw away any data….So yeah, that's now my view, is I think ULMFiT is the wrong approach. And that's why we're seeing a lot of these so-called alignment tax… I think it's actually because people are training them wrong.An example of this phenomena is CodeLlama, a LLaMA2 model finetuned on 500B tokens of code: while the model is much better at code, it’s worse on generic tasks that LLaMA2 knew how to solve well before the fine-tuning. In the episode we also dive into all the places where open source model development and research is happening (academia vs Discords - tracked on our Communities list and on our survey), and how Jeremy recommends getting the most out of these diffuse, pseudonymous communities (similar to the Eleuther AI Mafia).Show Notes* Jeremy’s Background* Fa

Why AI Agents Don't Work (yet) - with Kanjun Qiu of Imbue
Thanks to the over 11,000 people who joined us for the first AI Engineer Summit! A full recap is coming, but you can 1) catch up on the fun and videos on Twitter and YouTube, 2) help us reach 1000 people for the first comprehensive State of AI Engineering survey and 3) submit projects for the new AI Engineer Foundation.See our Community page for upcoming meetups in SF, Paris, NYC, and Singapore. This episode had good interest on Twitter.Last month, Imbue was crowned as AI’s newest unicorn foundation model lab, raising a $200m Series B at a >$1 billion valuation. As “stealth” foundation model companies go, Imbue (f.k.a. Generally Intelligent) has stood as an enigmatic group given they have no publicly released models to try out. However, ever since their $20m Series A last year their goal has been to “develop generally capable AI agents with human-like intelligence in order to solve problems in the real world”.From RL to Reasoning LLMsAlong with their Series A, they announced Avalon, “A Benchmark for RL Generalization Using Procedurally Generated Worlds”. Avalon is built on top of the open source Godot game engine, and is ~100x faster than Minecraft to enable fast RL benchmarking and a clear reward with adjustable game difficulty.After a while, they realized that pure RL isn’t a good path to teach reasoning and planning. The agents were able to learn mechanical things like opening complex doors, climbing, but couldn’t go to higher level tasks. A pure RL world also doesn’t include a language explanation of the agent reasoning, which made it hard to understand why it made certain decisions. That pushed the team more towards the “models for reasoning” path:“The second thing we learned is that pure reinforcement learning is not a good vehicle for planning and reasoning. So these agents were able to learn all sorts of crazy things: They could learn to climb like hand over hand in VR climbing, they could learn to open doors like very complicated, like multiple switches and a lever open the door, but they couldn't do any higher level things. And they couldn't do those lower level things consistently necessarily. And as a user, I do not want to interact with a pure reinforcement learning end to end RL agent. As a user, like I need much more control over what that agent is doing.”Inspired by Chelsea Finn’s work on SayCan at Stanford, the team pivoted to have their agents do the reasoning in natural language instead. This development parallels the large leaps in reasoning that humans have developed as the scientific method:“We are better at reasoning now than we were 3000 years ago. An example of a reasoning strategy is noticing you're confused. Then when I notice I'm confused, I should ask:* What was the original claim that was made? * What evidence is there for this claim? * Does the evidence support the claim? * Is the claim correct? This is like a reasoning strategy that was developed in like the 1600s, you know, with like the advent of science. So that's an example of a reasoning strategy. There are tons of them. We employ all the time, lots of heuristics that help us be better at reasoning. And we can generate data that's much more specific to them.“The Full Stack Model LabOne year later, it would seem that the pivot to reasoning has had tremendous success, and Imbue has now reached a >$1B valuation, with participation from Astera Institute, NVIDIA, Cruise CEO Kyle Vogt, Notion co-founder Simon Last, and others. Imbue tackles their work with a “full stack” approach:* Models. Pretraining very large (>100B parameter) models, optimized to perform well on internal reasoning benchmarks, with a ~10,000 Nvidia H100 GPU cluster lets us iterate rapidly on everything from training data to architecture and reasoning mechanisms.* Tools and Agents. Building internal productivity tools from coding agents for fixing type checking and linting errors, to sophisticated systems like CARBS (for hyperparameter tuning and network architecture search).* Interface Invention. Solving agent trust and collaboration (not merely communication) with humans by creating better abstractions and interfaces — IDEs for users to program computers in natural language.* Theory. Publishing research about the theoretical underpinnings of self-supervised learning, as well as scaling laws for machine learning research.Kanjun believes we are still in the “bare metal phase” of agent development, and they want to take a holistic approach to building the “operating system for agents”. We loved diving deep into the Imbue approach toward solving the AI Holy Grail of reliable agents, and are excited to share our conversation with you today!Timestamps* [00:00:00] Introductions* [00:06:07] The origin story of Imbue* [00:09:39] Imbue's approach to training large foundation models optimized for reasoning* [00:12:18] Imbue's goals to build an "operating system" for reliable, inspectable AI agents* [00:15:37] Imbue's process of developing internal tools and interface

[AIE Summit Preview #2] The AI Horcrux — Swyx on Cognitive Revolution
This is a special double weekend crosspost of AI podcasts, helping attendees prepare for the AI Engineer Summit next week. After our first friendly feedswap with the Cognitive Revolution pod, swyx was invited for a full episode to go over the state of AI Engineering and to preview the AI Engineer Summit Schedule, where we share many former CogRev guests as speakers.For those seeking to understand how two top AI podcasts think about major top of mind AI Engineering topics, this should be the perfect place to get up to speed, which will be a preview of many of the conversations taking place during the topic tables sessions on the night of Monday October 9 at the AI Engineer Summit.While you are listening, there are two things you can do to be part of the AI Engineer experience. One, join the AI Engineer Summit Slack. Two, take the State of AI Engineering survey and help us get to 1000 respondents!Links* AI Engineer Summit (Join livestream and Slack community)* State of AI Engineering Survey (please help us fill this out to represent you!)* Cognitive Revolution full episode with Nathan* swyx’s ai-notes (featuring Communities in README.md)* We referenced The Eleuther AI Mafia* This podcast intro voice was AI Anna again, from our Wondercraft pod!Timestamps* (00:00:49) AI Nathan’s intro * (00:03:14) What is an AI engineer? * (00:05:56) What backgrounds do AI engineers typically have? * (00:17:13) Swyx’s Discord AI project * (00:20:41) Key tools for AI engineers * (00:23:42) HumanLoop, Guardrails, Langchain * (00:27:01) Criteria for identifying capable AI engineers when hiring * (00:30:59) Skepticism around AI being a fad and doubts about contributing to AI * (00:34:03) AI Engineer Conference speaker lineup * (00:41:14) AI agents and two years to AGI * (00:46:04) Expectations and disagreement around what AI agent capabilities will work soon * (00:50:12) Swyx’s OpenAI thesis * (00:53:03) AI safety considerations and the role of AI engineers * (00:56:24) Disagreement on whether AI will soon be able to generate code pull requests * (01:01:07) AI helping non-technical people to code * (01:01:49) Multi-modal Chat-GPT and the future implications * (01:03:33) Nathan living in the same dorm as Mark Zuckerberg * (01:04:44) Competitive dynamics between OpenAI and other AI model developers * (01:05:39) Play.ht vs ElevenLabs * (01:09:20) The tension between platforms and developers building on top of them * (01:11:40) The best thing startups can do to compete with foundation model providers * (01:16:26) User identity/authentication services like Login with OpenAI * (01:19:20) Google vs the other live players * (01:20:46) AI Horcruxes / Pendants * (01:22:05) The concept of an AI app bundle for consumers and developers This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

[AIE Summit Preview #1] Swyx on Software 3.0 and the Rise of the AI Engineer
This is a special double weekend crosspost of AI podcasts, helping attendees prepare for the AI Engineer Summit next week. Swyx gave a keynote on the Software 3.0 Landscape recently (referenced in our recent Humanloop episode) and was invited to go deeper in podcast format, and to preview the AI Engineer Summit Schedule. For those seeking to ramp up on the current state of thinking on AI Engineering, this should be the perfect place to start, alongside our upcoming Latent Space University course (which is being tested live for the first time at the Summit workshops).While you are listening, there are two things you can do to be part of the AI Engineer experience. One, join the AI Engineer Summit Slack. Two, take the State of AI Engineering survey and help us get to 1000 respondents! Full transcript available here! Links* AI Engineer Summit (Join livestream and Slack community)* State of AI Engineering Survey (please help us fill this out to represent you!)* Podrocket full episode by Tejas KumarShow notes* Explaining Software 1.0, 2.0, and 3.0* Software 1.0: Hand-coded software with conditional logic, loops, etc.* Software 2.0: Machine learning models like neural nets trained on data* Software 3.0: Using large pre-trained foundation models without needing to collect/label training data* Foundation Models and Model Architecture* Foundation models like GPT-3/4, Claude, Whisper - can be used off the shelf via API* Model architecture refers to the layers and structure of a ML model* Grabbing a pre-trained model lets you skip data collection and training* Putting Foundation Models into Production* Levels of difficulty: calling an API, running locally, fully serving high-volume predictions* Key factors: GPU utilization, batching, infrastructure expertise* The Emerging AI Developer Landscape* AI is becoming more accessible to "traditional" software engineers* Distinction between ML engineers and new role of AI engineers* AI engineers consume foundation model APIs vs. developing models from scratch* The Economics of AI Engineers* Demand for AI exceeds supply of ML experts to build it* AI engineers will emerge out of software engineers learning these skills* Defining the AI Engineering Stack* System of reasoning: Foundation model APIs* Retrieval augmented generation (RAG) stack: Connects models to data* AI UX: New modalities and interfaces beyond chatbots* Building Products with Foundation Models* Replicating existing features isn't enough - need unique value* Focus on solving customer problems and building trust* AI Skepticism and Hype* Some skepticism is healthy, but "AI blame" also emerges* High expectations from media/industry creators* Important to stay grounded in real customer needs* Meaningful AI Applications* Many examples of AI positively impacting lives already* Engineers have power to build and explore - lots of opportunity* Closing and AI Engineer Summit Details* October 8-10 virtual conference for AI engineers* Speakers from OpenAI, Microsoft, Amazon, etc* Free to attend online This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

RAG Is A Hack - with Jerry Liu from LlamaIndex
Want to help define the AI Engineer stack? >800 folks have weighed in on the top tools, communities and builders for the first State of AI Engineering survey, which we will present for the first time at next week’s AI Engineer Summit. Join us online!This post had robust discussion on HN and Twitter.In October 2022, Robust Intelligence hosted an internal hackathon to play around with LLMs which led to the creation of two of the most important AI Engineering tools: LangChain 🦜⛓️ (our interview with Harrison here) and LlamaIndex 🦙 by Jerry Liu, which we’ll cover today. In less than a year, LlamaIndex has crossed 600,000 monthly downloads, raised $8.5M from Greylock, has a fast growing open source community that contributes to LlamaHub, and it doesn’t seem to be slowing down.LlamaIndex’s Origin (aka GPT Tree Index)Jerry struggled to make large amounts of data work with GPT-3 (which had a 4,096 tokens context window). Today LlamaIndex is at the forefront of the RAG wave (Retrieval Augmented Generation), but in the beginning Jerry wasn’t focused on embeddings and search, but rather on understanding how models could summarize, link, and reason about data. On November 5th, Jerry pushed the first version to Github under the name “GPT Tree Index”: The GPT Tree Index first takes in a large dataset of unprocessed text data as input. It then builds up a tree-index in a bottom-up fashion; each parent node is able to summarize the children nodes using a general summarization prompt; each intermediate node containing summary text summarizing the components below. Once the index is built, it can be saved to disk and loaded for future use.Then, say the user wants to use GPT-3 to answer a question. Using a query prompt template, GPT-3 will be able to recursively perform tree traversal in a top-down fashion in order to answer a question. For example, in the very beginning GPT-3 is tasked with selecting between *n* top-level nodes which best answers a provided query, by outputting a number as a multiple-choice problem. The GPT Tree Index then uses the number to select the corresponding node, and the process repeats recursively among the children nodes until a leaf node is reached.[…]How is this better than an embeddings-based approach / other state-of-the-art QA and retrieval methods?The intent is not to compete against existing methods. A simpler embedding-based technique could be to just encode each chunk as an embedding and do a simple question-document embedding look-up to retrieve the result. This project is a simple exercise to test how GPT can organize and lookup information.The project attracted a lot of attention early on (the announcement tweet has ~330 likes), but it wasn’t until ~February 2023 that the open source community really started to explode, which was around the same time that LlamaHub was released. LlamaHub made it easy for developers to import data from Google Drive, Discord, Slack, databases, and more into their LlamaIndex projects. What is LlamaIndex? As we mentioned, LlamaIndex is leading the charge in the development of the RAG stack. RAG boils down to two parts:* Indexing (i.e. how do you load and index the data in your knowledge base)* Querying (i.e. how do you surface the data and fit it in the model context) IndexingTo get your data from all your sources to your RAG knowledge base, you can leverage a few tools: * Documents / Nodes: A Document is a generic container around any data source - for instance, a PDF, an API output, or retrieved data from a database. A Node is the atomic unit of data in LlamaIndex and represents a “chunk” of a source Document (i.e. one Document has many Node) as well as its relationship to other Node objects.* Data Connectors: A data connector ingest data from different sources and turn them into Document representations (text and simple metadata). These connectors are offered through LlamaHub, and there are over 200 of them today.* Data Indexes: Once you’ve ingested your data, LlamaIndex will help you index the data into a format that’s easy to retrieve. There are many types of indexes (Summary, Tree, Vector, etc). Under the hood, LlamaIndex parses the raw documents into intermediate representations, calculates vector embeddings, and infers metadata. The most commonly used index is the VectorStoreIndex, which can then be paired with any of the vector stores out there (an example with Chroma).QueryingThe RAG pipeline, during the querying phase, sources the most pertinent context from a user's prompt, forwarding it along to the LLM. This equips the LLM with current / private knowledge beyond its foundational training data. LlamaIndex offers adaptable modules tailored for building RAG pathways for Q&A, chatbots, or agent use, since each of them has different requirements. For example, a chatbot should expect the user to interject with follow up questions, while an agent will try to carry out a whole task on its own without user intervention. Building Blocks* Retrievers: A
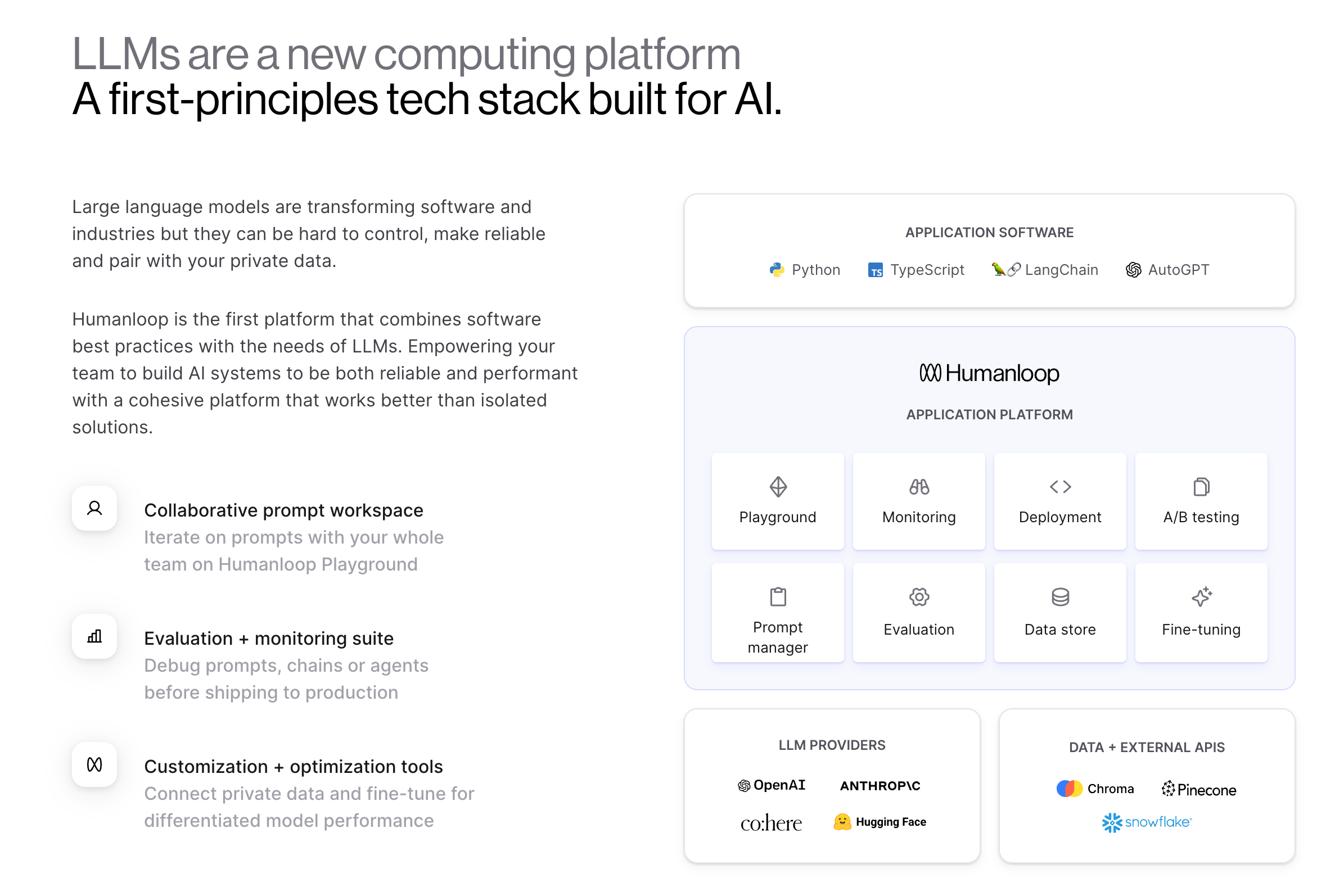
Building the Foundation Model Ops Platform — with Raza Habib of Humanloop
Want to help define the AI Engineer stack? >500 folks have weighed in on the top tools, communities and builders for the first State of AI Engineering survey! Please fill it out (and help us reach 1000!)The AI Engineer Summit schedule is now live! We are running two Summits and judging two Hackathons this Oct. As usual, see our Discord and community page for all events.A rite of passage for every AI Engineer is shipping a quick and easy demo, and then having to cobble together a bunch of solutions for prompt sharing and versioning, running prompt evals and monitoring, storing data and finetuning as their AI apps go from playground to production. This happens to be Humanloop’s exact pitch.full show notes: https://latent.space/p/humanloopTimestamps* [00:01:21] Introducing Raza* [00:10:52] Humanloop Origins* [00:19:25] What is HumanLoop?* [00:20:57] Who is the Buyer of PromptOps?* [00:22:21] HumanLoop Features* [00:22:49] The Three Stages of Prompt Evals* [00:24:34] The Three Types of Human Feedback* [00:27:21] UI vs BI for AI* [00:28:26] LangSmith vs HumanLoop comparisons* [00:31:46] The TAM of PromptOps* [00:32:58] How to Be Early* [00:34:41] 6 Orders of Magnitude* [00:36:09] Becoming an Enterprise Ready AI Infra Startup* [00:40:41] Killer Usecases of AI* [00:43:56] HumanLoop's new Free Tier and Pricing* [00:45:20] Addressing Graduation Risk* [00:48:11] On Company Building* [00:49:58] On Opinionatedness* [00:51:09] HumanLoop Hiring* [00:52:42] How HumanLoop thinks about PMF* [00:55:16] Market: LMOps vs MLOps* [00:57:01] Impact of Multimodal Models* [00:57:58] Prompt Engineering vs AI Engineering* [01:00:11] LLM Cascades and Probabilistic AI Languages* [01:02:02] Prompt Injection and Prompt Security* [01:03:24] Finetuning vs HumanLoop* [01:04:43] Open Standards in LLM Tooling* [01:06:05] Did GPT4 Get Dumber?* [01:07:29] Europe's AI Scene* [01:09:31] Just move to SF (in The Arena)* [01:12:23] Lightning Round - Acceleration* [01:13:48] Continual Learning* [01:15:02] DeepMind Gato Explanation* [01:17:40] Motivations from Academia to Startup* [01:19:52] Lightning Round - The Takeaway This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe
Heralds of the AI Content Flippening — with Youssef Rizk of Wondercraft.ai
Want to help define the AI Engineer stack? Have opinions on the top tools, communities and builders? We’re collaborating with friends at Amplify to launch the first State of AI Engineering survey! Please fill it out (and tell your friends)!In March, we started off our GPT4 coverage framing one of this year’s key forks in the road as the “Year of Multimodal vs Multimodel AI”. 6 months in, neither has panned out yet. The vast majority of LLM usage still defaults to chatbots built atop OpenAI (per our LangSmith discussion), and rumored GPU shortages have prevented the broader rollout of GPT-4 Vision. Most "AI media” demos like AI Drake and AI South Park turned out heavily human engineered, to the point where the AI label is more marketing than honest reflection of value contributed.However, the biggest impact of multimodal AI in our lives this year has been a relatively simple product - the daily HN Recap podcast produced by Wondercraft.ai, a 5 month old AI podcasting startup. As swyx observed, the “content flippening” — an event horizon when the majority of content you choose to consume is primarily AI generated/augmented rather than primarily human/manually produced — has now gone from unthinkable to possible.For full show notes, go to: https://latent.space/p/wondercraftTimestamps* [00:03:15] What is Wondercraft?* [00:08:22] Features of Wondercraft* [00:10:42] Types of Podcasts* [00:11:44] The Importance of Consistency* [00:14:01] Wondercraft House Podcasts* [00:19:27] Video Translation and Dubbing* [00:21:49] Building Wondercraft in 1 Day* [00:24:25] What is your moat?* [00:30:37] Audio Generation stack* [00:32:12] How Important is it to Sound Human? and AI Uncanny Valley* [00:36:02] AI Watermarking* [00:36:32] The Text to Speech Industry* [00:41:19] Voice Synthesis Research* [00:45:53] AI Podcaster interviews Human Podcaster* [00:50:38] Takeaway This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

Doing it the Hard Way: Making the AI engine and language 🔥 of the future — with Chris Lattner of Modular
Want to help define the AI Engineer stack? Have opinions on the top tools, communities and builders? We’re collaborating with friends at Amplify to launch the first State of AI Engineering survey! Please fill it out (and tell your friends)!If AI is so important, why is its software so bad?This was the motivating question for Chris Lattner as he reconnected with his product counterpart on Tensorflow, Tim Davis, and started working on a modular solution to the problem of sprawling, monolithic, fragmented platforms in AI development. They announced a $30m seed in 2022 and, following their successful double launch of Modular/Mojo🔥 in May, have just announced their $100m Series A.While the performance claims of Mojo🔥 and its promise as a fully multithreaded compiled Python superset stole the show, we were amazed to learn that it is a side project - and the vision for Modular’s Python inference engine is at least as big.Listeners will recall that we last talked with George Hotz about his work on tinygrad and how he wants to replace PyTorch with something faster and lighter, handwriting a “reduced instruction set” of operators himself. But what if the problem could be solved at even lower level - with the Python engine/runtime itself?Chris on CompilersChris’ history with compilers is well known - creating LLVM during his PhD (for which he won the 2012 ACM Software System Award), hired straight into Apple where he also made Clang and Swift (the iPhone programming language that replaced Objective-C), then leading the Tensorflow Infrastructure team at Google where he built XLA, a just-in-time compiler for optimizing a lot of the algebra behind TF’s workloads, and MLIR, a modular compiler framework that sat above LLVM to optimize ML graphs and kernels that were hard to represent in the LLVM IR. So as pretty much the best compiler engineer in human history, you’d justifiably assume that Chris is simply choosing to take his compiler approach to Python. And yet that is not how he thinks about compilers at all. As he says in our chat,“How do you enable invention? How do you get more kinds of people that understand different parts of this problem to actually collaborate? And so this is where I see our work on Mojo and on the engine……I don't have a compiler hammer that I'm running around looking for compiler problems to hit.”Today a small number of people at companies like OpenAI spend a lot of time manually writing CUDA kernels. But an optimizing compiler for AI leads to compilers as a means to an end for increasing software collaboration, expanding the ability of people with different skillsets and knowledge.“…What is the fundamental purpose of a compiler? Well, it's to make it so that you don't have to know as much about the hardware. You could write everything in very low-level assembly code for every single problem that you have… But what a compiler really does is it allows you to express things at a higher level of abstraction.”For Chris, compilers are also ways to properly automate generalized optimizations that might otherwise be manually coded and brittle abstractions, like operator fusion:“So NVIDIA goes and they build this really cool library called FasterTransformer. The performance point of using it is massive. So a lot of LLM companies and other folks use this thing because they want the performance.…Here's the problem. If you want to go innovate in transformers, now you're constrained by what FasterTransformer can do, right? And so, again, you come back to where are compilers useful?They're useful for generalization. If you can get the same quality result or better than FasterTransformer, but with a generalized architecture, well now you can get the best of both worlds, where you have orthogonality and composability, you enable research, you also get better performance.”Done correctly, these operator optimizations being implemented at the compiler level amount to an “AI Engine” that can not only survive, but enable major architecture shifts should a credible alternative LLM architecture come along someday.Modular — the Unified AI EngineModular’s original goal was to build the “Unified AI Engine” to speed up AI development and inference - one that doesn’t assume an “AI = GPUs” world that only benefits the “GPU-rich”, but one that treats AI as “a large-scale, heterogeneous, parallel compute problem”.Modular itself is an engine (separate from Mojo, which we cover below) that can run all other frameworks between 10% to 650% faster on CPUs (with GPU support coming in the fall):At Google, Chris’ job wasn’t to build the best possible compiler for AI. The goal was to build the best compiler for TPUs, so that all TensorFlow users would have a great Google Cloud experience. Similarly, the PyTorch team at Meta isn’t trying to make AI faster for the world, but mostly for their recommendations and ads systems. Chris and Tim realized that the AI engine and developer experience isn’t a product prioritized by any of the bi

The Point of LangChain — with Harrison Chase of LangChain
As alluded to on the pod, LangChain has just launched LangChain Hub: “the go-to place for developers to discover new use cases and polished prompts.” It’s available to everyone with a LangSmith account, no invite code necessary. Check it out!In 2023, LangChain has speedrun the race from 2:00 to 4:00 to 7:00 Silicon Valley Time. From the back to back $10m Benchmark seed and (rumored) $20-25m Sequoia Series A in April, to back to back critiques of “LangChain is Pointless” and “The Problem with LangChain” in July, to teaching with Andrew Ng and keynoting at basically every AI conference this fall (including ours), it has been an extreme rollercoaster for Harrison and his growing team creating one of the most popular (>60k stars at time of writing) building blocks for AI Engineers.LangChain’s OriginsThe first commit to LangChain shows its humble origins as a light wrapper around Python’s formatter.format for prompt templating. But as Harrison tells the story, even his first experience with text-davinci-002 in early 2022 was focused on chatting with data from their internal company Notion and Slack, what is now known as Retrieval Augmented Generation (RAG). As the Generative AI meetup scene came to life post Stable Diffusion, Harrison saw a need for common abstractions for what people were building with text LLMs at the time:* LLM Math, aka Riley Goodside’s “You Can’t Do Math” REPL-in-the-loop (PR #8)* Self-Ask With Search, Ofir Press’ agent pattern (PR #9) (later ReAct, PR #24)* NatBot, Nat Friedman’s browser controlling agent (PR #18)* Adapters for OpenAI, Cohere, and HuggingFaceHubAll this was built and launched in a few days from Oct 16-25, 2022. Turning research ideas/exciting usecases into software quickly and often has been in the LangChain DNA from Day 1 and likely a big driver of LangChain’s success, to date amassing the largest community of AI Engineers and being the default launch framework for every big name from Nvidia to OpenAI:Dancing with GiantsBut AI Engineering is built atop of constantly moving tectonic shifts: * ChatGPT launched in November (“The Day the AGI Was Born”) and the API released in March. Before the ChatGPT API, OpenAI did not have a chat endpoint. In order to build a chatbot with history, you had to make sure to chain all messages and prompt for completion. LangChain made it easy to do that out of the box, which was a huge driver of usage. * Today, OpenAI has gone all-in on the chat API and is deprecating the old completions models, essentially baking in the chat pattern as the default way most engineers should interact with LLMs… and reducing (but not eliminating) the value of ConversationChains.* And there have been more updates since: Plugins released in API form as Functions in June (one of our top pods ever… reducing but not eliminating the value of OutputParsers) and Finetuning in August (arguably reducing some need for Retrieval and Prompt tooling). With each update, OpenAI and other frontier model labs realign the roadmaps of this nascent industry, and Harrison credits the modular design of LangChain in staying relevant. LangChain has not been merely responsive either: LangChain added Agents in November, well before they became the hottest topic of the AI Summer, and now Agents feature as one of LangChain’s top two usecases. LangChain’s problem for podcasters and newcomers alike is its sheer scope - it is the world’s most complete AI framework, but it also has a sprawling surface area that is difficult to fully grasp or document in one sitting. This means it’s time for the trademark Latent Space move (ChatGPT, GPT4, Auto-GPT, and Code Interpreter Advanced Data Analysis GPT4.5): the executive summary!What is LangChain?As Harrison explains, LangChain is an open source framework for building context-aware reasoning applications, available in Python and JS/TS.It launched in Oct 2022 with the central value proposition of “composability”, aka the idea that every AI engineer will want to switch LLMs, and combine LLMs with other things into “chains”, using a flexible interface that can be saved via a schema.Today, LangChain’s principal offerings can be grouped as:* Components: isolated modules/abstractions* Model I/O* Models (for LLM/Chat/Embeddings, from OpenAI, Anthropic, Cohere, etc)* Prompts (Templates, ExampleSelectors, OutputParsers)* Retrieval (revised and reintroduced in March)* Document Loaders (eg from CSV, JSON, Markdown, PDF)* Text Splitters (15+ various strategies for chunking text to fit token limits)* Retrievers (generic interface for turning an unstructed query into a set of documents - for self-querying, contextual compression, ensembling)* Vector Stores (retrievers that search by similarity of embeddings)* Indexers (sync documents from any source into a vector store without duplication)* Memory (for long running chats, whether a simple Buffer, Knowledge Graph, Summary, or Vector Store)* Use-Cases: compositions of Components* Chains: combining a PromptTemplate, LL

RWKV: Reinventing RNNs for the Transformer Era — with Eugene Cheah of UIlicious
The AI Engineer Summit Expo has been announced, presented by AutoGPT (and future guest Toran Bruce-Richards!) Stay tuned for more updates on the Summit livestream and Latent Space University.This post was on HN for 10 hours.What comes after the Transformer? This is one of the Top 10 Open Challenges in LLM Research that has been the talk of the AI community this month. Jon Frankle (friend of the show!) has an ongoing bet with Sasha Rush on whether Attention is All You Need, and the most significant challenger to emerge this year has been RWKV - Receptance Weighted Key Value models, which revive the RNN for GPT-class LLMs, inspired by a 2021 paper on Attention Free Transformers from Apple (surprise!).What this means practically is that RWKV models tend to scale in all directions (both in training and inference) much better than Transformers-based open source models:While remaining competitive on standard reasoning benchmarks:swyx was recently in Singapore for meetings with AI government and industry folks, and grabbed 2 hours with RWKV committee member Eugene Cheah for a deep dive, the full recording of which is now up on Latent Space TV:Today we release both the 2hr video and an edited 1hr audio version, to cater to the different audiences and provide “ablation opportunities” on RWKV interest level.The Eleuther Mafia?The RWKV project is notable not merely because of the credible challenge to the Transformers dominance. It is also a distributed, international, mostly uncredentialed community reminiscent of early 2020s Eleuther AI:* Primarily Discord, pseudonymous, GPU-poor volunteer community somehow coordinating enough to train >10B, OPT/BLOOM-competitive models* Being driven by the needs of its community, it is extremely polyglot (e.g. English, Chinese, Japanese, Arabic) not because it needs to beat some benchmarks, but because its users want it to be for their own needs.* “Open Source” in both the good and the bad way - properly Apache 2.0 licensed (not “open but restricted”), yet trained on data taken from commercially compromised sources like the Pile (where Shawn Presser’s Books3 dataset has been recently taken down) and Alpaca (taking from Steven Tey’s ShareGPT which is technically against OpenAI TOS)The threadboi class has loved tracking the diffusion of Transformers paper authors out into the industry:But perhaps the underdog version of this is tracking the emerging Eleuther AI mafia:It will be fascinating to see how both Eleuther and Eleuther alums fare as they build out the future of both LLMs and open source AI.Audio Version Timestampsassisted by smol-podcaster. Different timestamps vs the 2hr YouTube* [00:05:35] Eugene's path into AI at UIlicious* [00:07:33] Tokenizer penalty and data efficiency of Transformers* [00:08:02] Using Salesforce CodeGen* [00:10:17] The limitations of Transformers for handling large context sizes* [00:13:17] RWKV compute costs compared to Transformers* [00:16:06] How Eugene found RWKV early* [00:18:52] RWKV's focus on supporting many languages, not just English* [00:21:24] Using the RWKV model for fine-tuning for specific languages* [00:24:45] What is RWKV?* [00:33:46] Overview of the different RWKV models like World, Raven, Novel* [00:41:34] Background of Blink, the creator of RWKV* [00:49:55] The linear vs quadratic scaling of RWKV vs Transformers* [00:53:29] RWKV matching Transformer performance on reasoning tasks* [00:54:31] The community's lack of marketing for RWKV* [00:57:00] The English-language bias in AI models* [01:00:33] Plans to improve RWKV's memory and context handling* [01:03:10] Advice for AI engineers wanting to get more technical knowledgeShow NotesCompanies/Organizations:* RWKV - HF blog, paper, docs, GitHub, Huggingface* Raven 14B (finetuned on Alpaca+ShareGPT+...) Demo* World 7B (supports 100+ world languages) Demo* How RWKV works in 100 LOC, RWKV overview* EleutherAI - Decentralized open source AI research group* Stability AI - Creators of Stable Diffusion * Conjecture - Spun off from EleutherAIPeople:* Eugene Chia - CTO of UIlicious, member of RWKV committee (GitHub, Twitter)* Blink/Bo Peng - Creator of RWKV architecture* Quentin Anthony - our Latent Space pod on Eleuther, coauthor on RWKV * Sharif Shameem - our Latent Space pod on being early to Stable Diffusion* Tri Dao - our Latent Space pod on FlashAttention making Attention subquadratic* Linus Lee - our Latent Space pod in NYC* Jonathan Frankle - our Latent Space pod about Transformers longevity* Chris Re - Genius at Stanford working on state-space models* Andrej Karpathy - Zero to Hero series* Justine Tunney ("Justine.lol") - mmap trickModels/Papers:* Top 10 Open Challenges in LLM Research* Retentive Network: A Successor to Transformer for Large Language Models * GPT-NeoX - Open source replica of GPT-3 by EleutherAI * Salesforce CodeGen and CodeGen 2* Attention Free Transformers paper* The Pile* RedPajama dataset* Monarch Mixer - Revisiting BERT, Without Attention or MLPsMisc NotesRWKV is n
Cursor.so: The AI-first Code Editor — with Aman Sanger of Anysphere
Thanks to the almost 30k people who tuned in to the last episode!Your podcast cohosts have been busy shipping:* Alessio open sourced smol-podcaster, which makes the show notes here! * swyx launched GodMode. Maybe someday the Cursor of browsers?* We’re also helping organize a Llama Finetuning Hackameetup this Saturday in anticipation of the CodeLlama release. Lastly, more speakers were announced at AI Engineer Summit! 👀~46% of code typed through VS Code is written by Copilot. How do we get closer to 90+%? Aman Sanger says we need a brand new AI-powered IDE to get there; and we’re excited to be the first podcast ever to tell the Cursor story.If you haven’t heard of Cursor, you may have been living under a rock. Here are just some of the rave reviews going around in the past week alone:* “Cursor is the best product I've used in a while” - Alex MacCaw* “Someone finally put GPT into a code editor in a seamless way. It's so elegant and easy. No more copying and pasting.” - Andrew McCalip* “Coding with AI is getting insane.” - Mckay Wrigley* “This is mind blowing 🤯” - Linus Ekenstam* “Cursor + gpt4-32k = illegal levels of productivity” - Sully Omarr* “EL MEJOR EDITOR DE CÓDIGO con IA” - Carlos SantanaA decade ago, “platform risk” meant building apps on social media platforms was risky as you could get cut off from the social network. Today, the AI version of “platform risk” is building AI products within an existing product (like an AI extension for VS Code, or a Figma plugin). Since Copilot, a generation of VSCode plugins have launched (including Cody, Cosine, and previous guests Codeium and Codium), only to be challenged by Copilot X itself.A core AI Engineering thesis is that new capabilities in AI demands new innovation in AI UX (and that AI UX can actually be a viable moat). Take VS Code for example; when Github was first working on Copilot, there was actually no way to support the “ghost autocomplete” feature we all use today. They eventually convinced the team to build it, and Copilot’s success speaks for itself.If you’re a startup building on top of VSC today, you do not have the same access and influence on the roadmap. Your UX is limited to what they allow you to do, and often that caps your ability to successfully compete against them. Since Cursor owns the whole IDE, they can do things you can’t (yet) do in VSCode:Cursor’s GameplanCursor is competing head to head against VS Code by forking Microsoft’s IDE and building their own AI-powered version. A few of Cursor’s unique features:* Native chat: Chat is a core piece of Cursor. Users can choose between GPT-3.5 and GPT-4 to ask questions and receive answers based on their code.* “Mentioning” files: you can easily add files into your request context by using “@”; this works both for code as well as documentation. If you want to do a change that includes multiple files, you can include them in your question to make sure the change is reflected in all of them.* Custom prompting engine: Cursor built Priompt, their custom prompting engine. As your chats go over the context window size, Priompt figures out which messages to keep in the history, which files to drop from the prompt, etc. * Moving beyond typing: while IDEs are familiar to folks as today’s interfaces, in the future Cursor hopes to have agents you can delegate tasks to. Instead of a back and forth on a new feature or bug fix, you can ask it to do the whole thing for you end to end.After diving deep into Cursor we nerded out on model usage, training, quantization, and evaluation. There’s a ton of great content in this episode, we hope you’ll enjoy it!As always, feedback welcome in the comments, and tag us on socials for future guest suggestions!Show Notes* Cursor* Gary Marcus’ cubes prompt* Priompt* “Humans should focus on bigger problems.”* Codium AI on Latent Space* Rift from Morph* Sourcegraph* E2B* Repl.it* HungryHungryHippos, Hyena, etc (see our FlashAttention episode)* Aman Tweets* Why GPT-3.5 is (mostly) cheaper than Llama 2* Llama’s architectural limitations* “Training will look like researchers/practitioners offloading large-scale training jobs to specialized “training” companies: a state of the world that resembles chip design & fabrication.” - Mosaic prediction* “The size of all code/history on Github public repos is 92TB. The size of Google's monorepo in 2015 was 86TB (of much higher quality code). If Google were willing to deploy code models trained on their own data, they'd have a noticable advantage over everyone else.” - May 2023Timestamps* [00:00:00] Intros* [00:02:31] Developing CAD models vs coding models* [00:05:23] Deciding to build a new IDE optimized for large language models* [00:10:50] Getting early access to GPT-4 and realizing its potential for software development* [00:12:32] Rethinking the UI/UX for coding* [00:18:24] Cursor's features like system prompts and chat* [00:22:24] Tips for prompting GPT-3/4 for code generation and editing* [00:27:24] Cursor's documentation
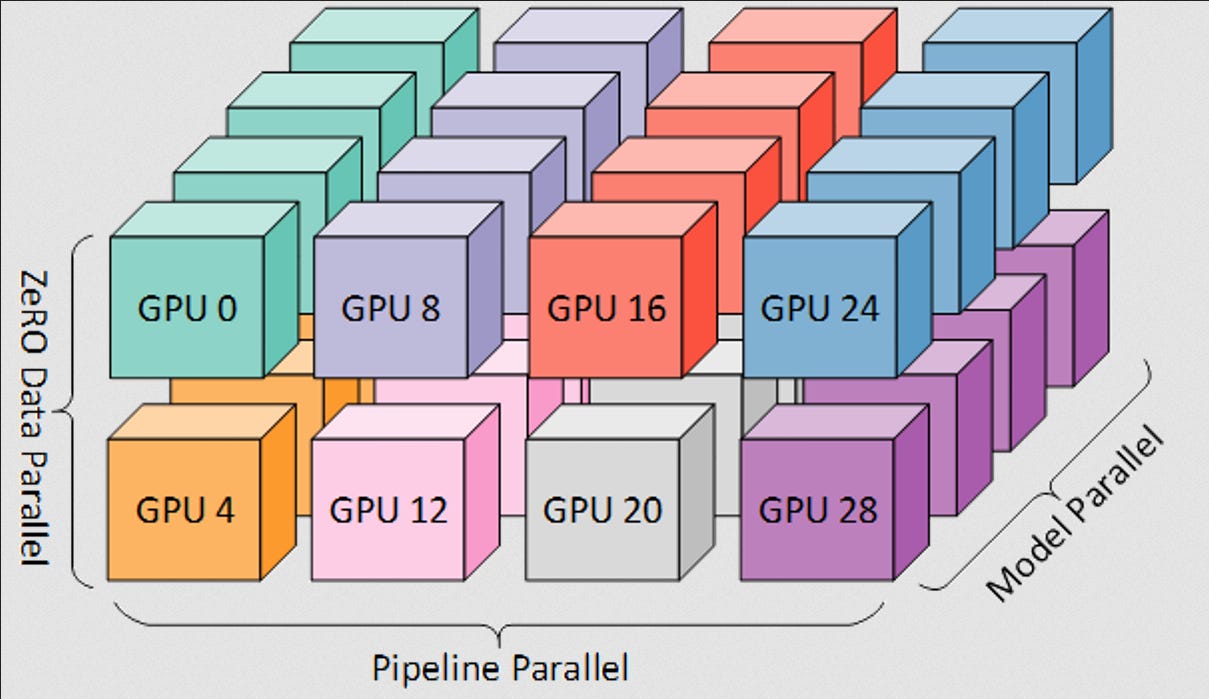
The Mathematics of Training LLMs — with Quentin Anthony of Eleuther AI
Invites are going out for AI Engineer Summit! In the meantime, we have just announced our first Actually Open AI event with Brev.dev and Langchain, Aug 26 in our SF HQ (we’ll record talks for those remote). See you soon (and join the Discord)!Special thanks to @nearcyan for helping us arrange this with the Eleuther team.This post was on the HN frontpage for 15 hours.As startups and even VCs hoard GPUs to attract talent, the one thing more valuable than GPUs is knowing how to use them (aka, make GPUs go brrrr).There is an incredible amount of tacit knowledge in the NLP community around training, and until Eleuther.ai came along you pretty much had to work at Google or Meta to gain that knowledge. This makes it hard for non-insiders to even do simple estimations around costing out projects - it is well known how to trade $ for GPU hours, but trading “$ for size of model” or “$ for quality of model” is less known and more valuable and full of opaque “it depends”. This is why rules of thumb for training are incredibly useful, because they cut through the noise and give you the simple 20% of knowledge that determines 80% of the outcome derived from hard earned experience.Today’s guest, Quentin Anthony from EleutherAI, is one of the top researchers in high-performance deep learning. He’s one of the co-authors of Transformers Math 101, which was one of the clearest articulations of training rules of thumb. We can think of no better way to dive into training math than to have Quentin run us through a masterclass on model weights, optimizer states, gradients, activations, and how they all impact memory requirements.The core equation you will need to know is the following:Where C is the compute requirements to train a model, P is the number of parameters, and D is the size of the training dataset in tokens. This is also equal to τ, the throughput of your machine measured in FLOPs (Actual FLOPs/GPU * # of GPUs), multiplied by T, the amount of time spent training the model.Taking Chinchilla scaling at face value, you can simplify this equation to be `C = 120(P^2)`.These laws are only true when 1000 GPUs for 1 hour costs the same as 1 GPU for 1000 hours, so it’s not always that easy to make these assumptions especially when it comes to communication overhead. There’s a lot more math to dive into here between training and inference, which you can listen to in the episode or read in the articles. The other interesting concept we covered is distributed training and strategies such as ZeRO and 3D parallelism. As these models have scaled, it’s become impossible to fit everything in a single GPU for training and inference. We leave these advanced concepts to the end, but there’s a lot of innovation happening around sharding of params, gradients, and optimizer states that you must know is happening in modern LLM training. If you have questions, you can join the Eleuther AI Discord or follow Quentin on Twitter. Show Notes* Transformers Math 101 Article* Eleuther.ai* GPT-NeoX 20B* BLOOM* Turing NLG* Mosaic* Oak Ridge & Frontier Supercomputer* Summit Supercomputer * Lawrence Livermore Lab* RWKV* Flash Attention * Stas BekmanTimestamps* [00:00:00] Quentin's background and work at Eleuther.ai* [00:03:14] Motivation behind writing the Transformers Math 101 article* [00:05:58] Key equation for calculating compute requirements (tau x T = 6 x P x D)* [00:10:00] Difference between theoretical and actual FLOPs* [00:12:42] Applying the equation to estimate compute for GPT-3 training* [00:14:08] Expecting 115+ teraflops/sec per A100 GPU as a baseline* [00:15:10] Tradeoffs between Nvidia and AMD GPUs for training* [00:18:50] Model precision (FP32, FP16, BF16 etc.) and impact on memory* [00:22:00] Benefits of model quantization even with unlimited memory* [00:23:44] KV cache memory overhead during inference* [00:26:08] How optimizer memory usage is calculated* [00:32:03] Components of total training memory (model, optimizer, gradients, activations)* [00:33:47] Activation recomputation to reduce memory overhead* [00:38:25] Sharded optimizers like ZeRO to distribute across GPUs* [00:40:23] Communication operations like scatter and gather in ZeRO* [00:41:33] Advanced 3D parallelism techniques (data, tensor, pipeline)* [00:43:55] Combining 3D parallelism and sharded optimizers* [00:45:43] Challenges with heterogeneous clusters for distribution* [00:47:58] Lightning RoundTranscriptionAlessio: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO in Residence at Decibel Partners, and I'm joined by my co-host Swyx, writer and editor of Latent Space. [00:00:20]Swyx: Hey, today we have a very special guest, Quentin Anthony from Eleuther.ai. The context for this episode is that we've been looking to cover Transformers math for a long time. And then one day in April, there's this blog post that comes out that literally is called Transformers Math 101 from Eleuther. And this is one of the most authoritative posts that I've

LLMs Everywhere: Running 70B models in browsers and iPhones using MLC — with Tianqi Chen of CMU / OctoML
We have just announced our first set of speakers at AI Engineer Summit! Sign up for the livestream or email [email protected] if you’d like to support.We are facing a massive GPU crunch. As both startups and VC’s hoard Nvidia GPUs like countries count nuclear stockpiles, tweets about GPU shortages have become increasingly common. But what if we could run LLMs with AMD cards, or without a GPU at all? There’s just one weird trick: compilation. And there’s one person uniquely qualified to do it.We had the pleasure to sit down with Tianqi Chen, who’s an Assistant Professor at CMU, where he both teaches the MLC course and runs the MLC group. You might also know him as the creator of XGBoost, Apache TVM, and MXNet, as well as the co-founder of OctoML. The MLC (short for Machine Learning Compilation) group has released a lot of interesting projects:* MLC Chat: an iPhone app that lets you run models like RedPajama-3B and Vicuna-7B on-device. It gets up to 30 tok/s!* Web LLM: Run models like LLaMA-70B in your browser (!!) to offer local inference in your product.* MLC LLM: a framework that allows any language models to be deployed natively on different hardware and software stacks.The MLC group has just announced new support for AMD cards; we previously talked about the shortcomings of ROCm, but using MLC you can get performance very close to the NVIDIA’s counterparts. This is great news for founders and builders, as AMD cards are more readily available. Here are their latest results on AMD’s 7900s vs some of top NVIDIA consumer cards.If you just can’t get a GPU at all, MLC LLM also supports ARM and x86 CPU architectures as targets by leveraging LLVM. While speed performance isn’t comparable, it allows for non-time-sensitive inference to be run on commodity hardware.We also enjoyed getting a peek into TQ’s process, which involves a lot of sketching:With all the other work going on in this space with projects like ggml and Ollama, we’re excited to see GPUs becoming less and less of an issue to get models in the hands of more people, and innovative software solutions to hardware problems!Show Notes* TQ’s Projects:* XGBoost* Apache TVM* MXNet* MLC* OctoML* CMU Catalyst* ONNX* GGML* Mojo* WebLLM* RWKV* HiPPO* Tri Dao’s Episode* George Hotz EpisodePeople:* Carlos Guestrin* Albert GuTimestamps* [00:00:00] Intros* [00:03:41] The creation of XGBoost and its surprising popularity* [00:06:01] Comparing tree-based models vs deep learning* [00:10:33] Overview of TVM and how it works with ONNX* [00:17:18] MLC deep dive* [00:28:10] Using int4 quantization for inference of language models* [00:30:32] Comparison of MLC to other model optimization projects* [00:35:02] Running large language models in the browser with WebLLM* [00:37:47] Integrating browser models into applications* [00:41:15] OctoAI and self-optimizing compute* [00:45:45] Lightning RoundTranscriptAlessio: Hey everyone, welcome to the Latent Space podcast. This is Alessio, Partner and CTO in Residence at Decibel Partners, and I'm joined by my co-host Swyx, writer and editor of Latent Space. [00:00:20]Swyx: Okay, and we are here with Tianqi Chen, or TQ as people call him, who is assistant professor in ML computer science at CMU, Carnegie Mellon University, also helping to run Catalyst Group, also chief technologist of OctoML. You wear many hats. Are those, you know, your primary identities these days? Of course, of course. [00:00:42]Tianqi: I'm also, you know, very enthusiastic open source. So I'm also a VP and PRC member of the Apache TVM project and so on. But yeah, these are the things I've been up to so far. [00:00:53]Swyx: Yeah. So you did Apache TVM, XGBoost, and MXNet, and we can cover any of those in any amount of detail. But maybe what's one thing about you that people might not learn from your official bio or LinkedIn, you know, on the personal side? [00:01:08]Tianqi: Let me say, yeah, so normally when I do, I really love coding, even though like I'm trying to run all those things. So one thing that I keep a habit on is I try to do sketchbooks. I have a book, like real sketchbooks to draw down the design diagrams and the sketchbooks I keep sketching over the years, and now I have like three or four of them. And it's kind of a usually a fun experience of thinking the design through and also seeing how open source project evolves and also looking back at the sketches that we had in the past to say, you know, all these ideas really turn into code nowadays. [00:01:43]Alessio: How many sketchbooks did you get through to build all this stuff? I mean, if one person alone built one of those projects, he'll be a very accomplished engineer. Like you built like three of these. What's that process like for you? Like it's the sketchbook, like the start, and then you think about the code or like. [00:01:59]Swyx: Yeah. [00:02:00]Tianqi: So, so usually I start sketching on high level architectures and also in a project that works for over years, we also start to think abo

[AI Breakdown] Summer AI Technical Roundup: a Latent Space x AI Breakdown crossover pod!
Our 3rd podcast feed swap with other AI pod friends! Check out Cognitive Revolution and Practical AI as well.NLW is the best daily AI YouTube/podcaster with the AI Breakdown. His summaries and content curation are spot on and always finds the interesting angle that will keep you thinking. Subscribe to the AI Breakdown wherever fine podcasts are sold! https://pod.link/1680633614You can also watch on YouTube:Timestampscourtesy of summarize.techThe hosts discuss the launch of Code Interpreter as a separate model from OpenAI and speculate that it represents the release of GPT 4.5. People have found Code Interpreter to be better than expected, even for tasks unrelated to coding. They discuss the significance of this release, as well as the challenges of evaluating AI models, the cultural mismatch between researchers and users, and the increasing value of data in the AI industry. They also touch on the impact of open-source tools, the potential of AI companions, the advantages of Anthropics compared to other platforms, advancements in image recognition and multimodality, and predictions for the future of AI.* 00:00:00 In this section, the hosts discuss the launch of Code Interpreter from OpenAI and its significance in the development of the AI field. They explain that Code Interpreter, initially introduced as a plugin, is now considered a separate model with its own dropdown menu. They note that people have found Code Interpreter to be better than expected, even for tasks that are not related to coding. This leads them to speculate that Code Interpreter actually represents the release of GPT 4.5, as there has been no official announcement or blog post about it. They also mention that the AI safety concerns and regulatory environment may be impacting how OpenAI names and labels their models. Overall, they believe that Code Interpreter's release signifies a significant shift in the AI field and hints at the possibility of future advanced models like GPT 5.* 00:05:00 In this section, the speaker discusses the improvements in GPT 4.5 and how it enhances the experience for non-coding queries and inputs. They explain that the code interpreter feature allows for a wider range of use cases that were not possible with previous models like GPT 3.5. Additionally, they highlight the value of the code interpreter in assisting individuals with no coding experience to solve basic coding problems. This feature is likened to having a junior developer or intern analyst that aids in conducting tests and simplifies coding tasks. The speaker emphasizes that GPT 4.5 enables users to be more productive and efficient, especially when dealing with code-related challenges. They also discuss the future direction of AGI, where more time will be dedicated to inference rather than training, as this approach has shown significant improvements in terms of problem-solving.* 00:10:00 In this section, the speaker discusses how advanced AI models like GPT-4.5 are not just larger versions of previous models but rather employ fundamentally different techniques. They compare the evolution of AI models to the evolutionary timeline of humans, where the invention of tools opened up a whole new set of possibilities. They touch on the difficulty of evaluating AI models, particularly in more subjective tasks, and highlight how perceptions of model performance can be influenced by factors like formatting preferences. Additionally, the speaker mentions the challenges of reinforcement learning and the uncertainty around what the model is prioritizing in its suggestions. They conclude that OpenAI, as a research lab, is grappling with the complexities of updating models and ensuring reliability for users.* 00:15:00 In this section, the speaker discusses the cultural mismatch between OpenAI researchers and users of OpenAI's products, highlighting the conflicting statements made about model updates. They suggest that OpenAI needs to establish a policy that everyone can accept. The speaker also emphasizes the challenges of communication and the difficulty of serving different stakeholders. They mention the impact of small disruptions on workflows and the lack of immediate feedback within OpenAI's system. Additionally, the speaker briefly discusses the significance of OpenAI's custom instructions feature, stating that it allows for more personalization but is not fundamentally different from what other chat companies already offer. The discussion then transitions to Facebook's release of LAMA2, which holds significance both technically and for users, although further details on its significance are not provided in this excerpt.* 00:20:00 In this section, the introduction of GPT-4.5, also known as LAVA 2, is discussed. LAVA 2 is the first fully commercially usable GPT 3.5 equivalent model, which is a significant development because it allows users to run it on their own infrastructure and fine-tune it according to their needs. Although it is not fully open source, it
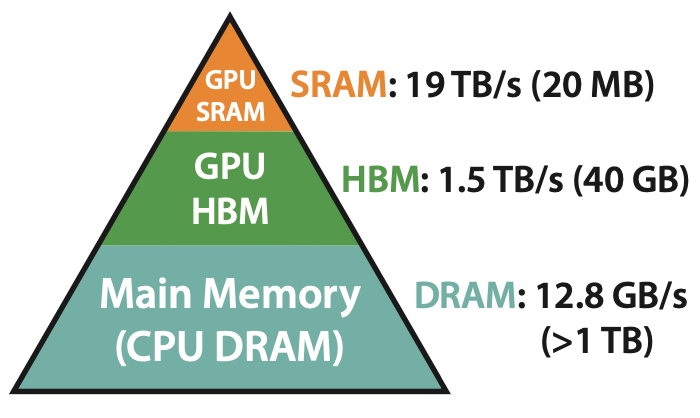
FlashAttention 2: making Transformers 800% faster w/o approximation - with Tri Dao of Together AI
FlashAttention was first published by Tri Dao in May 2022 and it had a deep impact in the large language models space. Most open models you’ve heard of (RedPajama, MPT, LLaMA, Falcon, etc) all leverage it for faster inference. Tri came on the podcast to chat about FlashAttention, the newly released FlashAttention-2, the research process at Hazy Lab, and more. This is the first episode of our “Papers Explained” series, which will cover some of the foundational research in this space. Our Discord also hosts a weekly Paper Club, which you can signup for here. How does FlashAttention work?The paper is titled “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness”. There are a couple keywords to call out:* “Memory Efficient”: standard attention memory usage is quadratic with sequence length (i.e. O(N^2)). FlashAttention is sub-quadratic at O(N). * “Exact”: the opposite of “exact” in this case is “sparse”, as in “sparse networks” (see our episode with Jonathan Frankle for more). This means that you’re not giving up any precision.* The “IO” in “IO-Awareness” stands for “Input/Output” and hints at a write/read related bottleneck. Before we dive in, look at this simple GPU architecture diagram:The GPU has access to three memory stores at runtime:* SRAM: this is on-chip memory co-located with the actual execution core. It’s limited in size (~20MB on an A100 card) but extremely fast (19TB/s total bandwidth)* HBM: this is off-chip but on-card memory, meaning it’s in the GPU but not co-located with the core itself. An A100 has 40GB of HBM, but only a 1.5TB/s bandwidth. * DRAM: this is your traditional CPU RAM. You can have TBs of this, but you can only get ~12.8GB/s bandwidth, which is way too slow.Now that you know what HBM is, look at how the standard Attention algorithm is implemented:As you can see, all 3 steps include a “write X to HBM” step and a “read from HBM” step. The core idea behind FlashAttention boils down to this: instead of storing each intermediate result, why don’t we use kernel fusion and run every operation in a single kernel in order to avoid memory read/write overhead? (We also talked about kernel fusion in our episode with George Hotz and how PyTorch / tinygrad take different approaches here)The result is much faster, but much harder to read:As you can see, FlashAttention is a very meaningful speed improvement on traditional Attention, and it’s easy to understand why it’s becoming the standard for most models.This should be enough of a primer before you dive into our episode! We talked about FlashAttention-2, how Hazy Research Group works, and some of the research being done in Transformer alternatives.Show Notes:* FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness (arXiv)* FlashAttention-2* Together AI* From Deep Learning to Long Learning* The Hardware Lottery by Sara Hooker* Hazy Research* Is Attention All You Need?* Nvidia CUTLASS 3* SRAM scaling slows* Transformer alternatives:* S4* Hyena* Recurrent Neural Networks (RNNs)Timestamps:* Tri's background [00:00:00]* FlashAttention’s deep dive [00:02:18]* How the Hazy Research group collaborates across theory, systems, and applications [00:17:21]* Evaluating models beyond raw performance [00:25:00]* FlashAttention-2 [00:27:00]* CUDA and The Hardware Lottery [00:30:00]* Researching in a fast-changing market [00:35:00]* Promising transformer alternatives like state space models and RNNs [00:37:30]* The spectrum of openness in AI models [00:43:00]* Practical impact of models like LLAMA2 despite restrictions [00:47:12]* Incentives for releasing open training datasets [00:49:43]* Lightning Round [00:53:22]Transcript:Alessio: Hey everyone, welcome to the Latent Space podcast. This is Alessio, Partner and CTO-in-Residence at Decibel Partners. Today we have no Swyx, because he's in Singapore, so it's a one-on-one discussion with Tri Dao. Welcome! [00:00:24]Tri: Hi everyone. I'm Tri Dao, excited to be here. [00:00:27]Alessio: Tri just completed his PhD at Stanford a month ago. You might not remember his name, but he's one of the main authors in the FlashAttention paper, which is one of the seminal work in the Transformers era. He's got a lot of interest from efficient transformer training and inference, long range sequence model, a lot of interesting stuff. And now you're going to be an assistant professor in CS at Princeton next year. [00:00:51]Tri: Yeah, that's right. [00:00:52]Alessio: Yeah. And in the meantime, just to get, you know, a low pressure thing, you're Chief Scientist at Together as well, which is the company behind RedPajama. [00:01:01]Tri: Yeah. So I just joined this week actually, and it's been really exciting. [00:01:04]Alessio: So what's something that is not on the internet that people should know about you? [00:01:09]Tri: Let's see. When I started college, I was going to be an economist, so I was fully on board. I was going to major in economics, but the first week I was at Stanford undergr
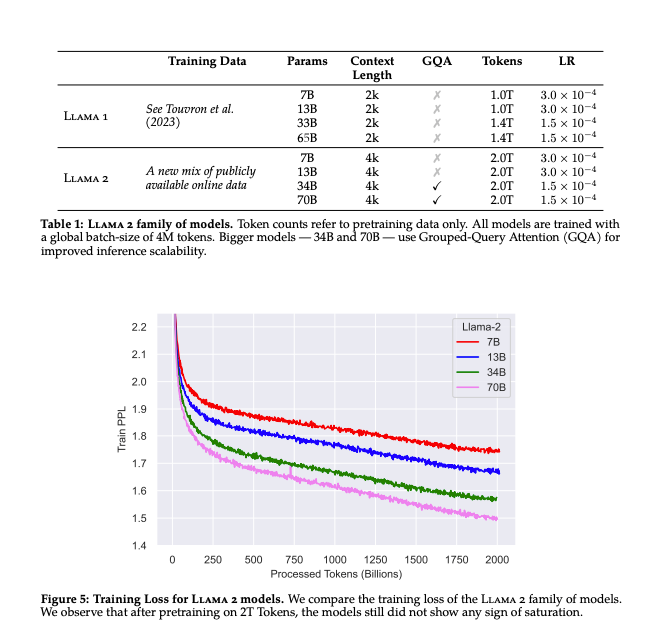
Llama 2: The New Open LLM SOTA (ft. Nathan Lambert, Matt Bornstein, Anton Troynikov, Russell Kaplan, Whole Mars Catalog et al.)
As first discussed on our May Emergency pod and leaked 4 days ago, Llama (renamed from LLaMA) was upgraded to Llama 2 (pretraining on 2 trillion tokens with 2x the context length - bigger than any dataset discussed in Datasets 101, and adding ~$20m of RLHF/preference annotation) and released for commercial use on 18 July.It immediately displaced Falcon-40B as the leading open LLM and was immediately converted/quantized to GGML and other formats. Llama 2 seems to outperform all other open source models in their equivalent weight class:Why are open models important? The intersection of Open Source and AI is one of the oldest themes on this publication, and there has been a raging debate on the security and reliability of the OpenAI models and APIs. Users have reported GPT-4’s quality going down, which has been denied and denied and as of today, given some supporting data from Databricks, and complained about the API reliability and rapid deprecation schedules. Last and surely the biggest, there are entire classes of businesses and government/healthcare/military organizations that categorically cannot send any of their sensitive data to an external API provider, even if it is OpenAI through Azure. The only way to have total control is to own and serve your own models, which Llama 2 now pushes forward in terms of the state of the art (your own GPT3.5-quality model, though it is nowhere near Claude 2 or GPT-4).As we do with breaking news, we got on to Twitter Spaces again to chat with two scheduled guests:* Nathan Lambert, ML Researcher at Huggingface and author of Interconnects who had the best summary of the Llama2 paper* Matt Bornstein, organizer of the a16z infra team that launched Llama2.ai (source here) and has been coding up a storm with AI demo apps, unusual for VCsas well as Anton Troynikov of Chroma, Russell Kaplan of Scale AI, and Omar Qazi of the Whole Mars Catalog.Enjoy!Show Notes* Official links* Website, Paper* GitHub (Llama 2 commit)* Azure Partnership* Use policy, Statement of Support for Open Approach* Where to try* Llama2.ai (source), Perplexity Llama Chat* Live playground/API on Replicate, deploy all versions on Baseten* https://huggingface.co/spaces/ysharma/Explore_llamav2_with_TGI * Dev ports - simonw llm-replicate, ggml using llama.cpp (7B, 13B) or pinokio, ollama, Core ML port* Timeline* 24 Feb - LLaMA 1 announced* 6 May - our No Moats podcast - first mention of Zuck opening up Llama* 14 July - Llama 2 leaked* 18 July - Llama 2 announced* Community notes* Nathan’s research paper recap* 638 LOC, 4 dependencies* Usage restrictions - MAU restriction, derivative models* Grouped Query Attention* System prompt* 2 trillion token dataset* >$20m price tag (rlhf, jimfan), * Separate models for safety and helpfulness (jimfan)* Mistral AI founders left out of paper* Interesting fails: Timestamps* [00:02:30] Introducing the speakers* [00:03:32] Nathan Lambert intro* [00:04:48] General Summary of Llama 2* [00:05:57] Sarah Silverman killed Dataset Transparency?* [00:08:48] Simon's Recap of Llama 2* [00:11:43] Matt's Intro* [00:12:59] a16z Infra's new AI team?* [00:15:10] Alessio's recap of Llama 2* [00:17:26] Datasets 101 Followup* [00:18:14] Context Length 4k* [00:20:35] Open-ish Source? Usage Policy and Restrictions* [00:23:38] Huggingface Responsible AI License* [00:24:57] Pretraining Llama 2 Base Model beyond Chinchilla* [00:29:55] Llama 2 is incomplete? Race to publish* [00:31:40] Come for the Llama, stay for the (Meta) drama* [00:33:22] Language Translation* [00:35:10] Llama2's coding abilities* [00:35:59] Why we want to know about the training data* [00:37:45] The importance of Meta pushing forward Truly Open AI* [00:40:59] Llama 2 as Enabler of Startups* [00:43:59] Where you can try Llama 2* [00:44:25] Do you need dataset transparency if you have evals?* [00:45:56] >$20m cost of Llama 2 is primarily preference data collection* [00:48:59] Do we even need human annotators?* [00:49:42] Models Rating Models* [00:53:32] How to get Code preference data* [00:54:34] Llama 2 Finetuning Ecosystem* [00:56:32] Hey Apple: Llama2 on Metal pls* [00:57:17] Llama 2 and Chroma* [01:00:15] Open Source MoE model?* [01:00:51] Llama 2 using tools* [01:01:40] Russell Kaplan on Scale AI's Llama 2 plans* [01:03:31] Scale annotating code?* [01:04:36] Immortality* [01:04:59] Running Llama on your phone* [01:06:54] Sama * [01:10:58] Meta "Open Source" Leadership* [01:11:56] Prediction: Finetuning => New Use Cases from Internal State* [01:13:54] Prediction: Llama Toolformer* [01:14:39] Prediction: Finetune-for-everything* [01:15:50] Predictions: Llama Agents* [01:16:35] dP(Doom)?* [01:19:21] Wrapping upTranscript[00:00:00] Introducing the speakers[00:00:00] Alessio Fanelli: There's not a single dull day in this space. I think when we started the podcast in January, a lot of people asked us, how long can you really do this? Just focusing on AI research and, and models. And I think the, the answer is clear now. A long time. S

AI Fundamentals: Datasets 101
In April, we released our first AI Fundamentals episode: Benchmarks 101. We covered the history of benchmarks, why they exist, how they are structured, and how they influence the development of artificial intelligence.Today we are (finally!) releasing Datasets 101! We’re really enjoying doing this series despite the work it takes - please let us know what else you want us to cover!Stop me if you’ve heard this before: “GPT3 was trained on the entire Internet”.Blatantly, demonstrably untrue: the GPT3 dataset is a little over 600GB, primarily on Wikipedia, Books corpuses, WebText and 2016-2019 CommonCrawl. The Macbook Air I am typing this on has more free disk space than that. In contrast, the “entire internet” is estimated to be 64 zetabytes, or 64 trillion GB. So it’s more accurate to say that GPT3 is trained on 0.0000000001% of the Internet.Why spend $5m on GPU time training on $50 worth of data?Simple: Garbage in, garbage out. No matter how good your algorithms, no matter how much money/compute you have, your model quality is strongly determined by the data you train it on and research scientists think we just don’t need or have that much high quality data. We spend an enormous amount of effort throwing out data to keep the quality high, and recently Web 2.0-era UGC platforms like StackOverflow, Reddit, and Twitter clamped down on APIs as they realize the goldmines they sit on.Data is the new new oil. Time for a primer!Show Notes* Our 2 months worth of podcast prep notes!* The Token Crisis paper* Ilya Sutskever on datasets * OpenAI Tokenizer* Kaplan Scaling Laws Lecture* Chinchilla Paper* Sasha Rush’s Tweet* Karpathy’s Build Conference Presentation* LIMA Paper* Phi-1 by Microsoft* Washington Post Article on datasets* Our episode with Jonathan Frankle* Our episode with Mike Conover* BloombergGPT* Datasets* HuggingFace Hub* CommonCrawl, Overview* C4* List of Dirty, Naughty, Obscene, and Otherwise Bad Words* OpenWebText* books3* OpenAssistant * The Stack* The Pile* LAION* Audio:* LibriSpeech: A dataset of audio recordings of audiobooks* CommonVoice: A dataset of audio recordings of people speaking different languages* Voxforge: A dataset of audio recordings of people speaking different languages* Switchboard: A dataset of audio recordings of telephone conversations* Fisher Corpus: A dataset of audio recordings of news broadcasts* Chinese:* CMRC (Chinese Machine Reading Comprehension 2018)* DuReader* ChID* Copyright & Privacy:* https://stablediffusionlitigation.com/* https://haveibeentrained.com/* https://githubcopilotlitigation.com/* https://twitter.com/moyix/status/1662131770463072257* OpenAI Opt Out Process* Check if you’re in The Stack* Deduplication* Deduplicating Training Data Makes Language Models Better* Deduplicating Training Data Mitigates Privacy Risks in Language Models* Contamination* CodeForces example This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

Code Interpreter == GPT 4.5 (w/ Simon Willison, Alex Volkov, Aravind Srinivas, Alex Graveley, et al.)
Code Interpreter is GA! As we do with breaking news, we convened an emergency pod and >17,000 people tuned in, by far our most biggest ever. This is a 2-for-1 post - a longform essay with our trademark executive summary and core insights - and a podcast capturing day-after reactions. Don’t miss either of them!Essay and transcript: https://latent.space/p/code-interpreterPodcast Timestamps[00:00:00] Intro - Simon and Alex[00:07:40] Code Interpreter for Edge Cases[00:08:59] Code Interpreter's Dependencies - Tesseract, Tensorflow[00:09:46] Code Interpreter Limitations[00:10:16] Uploading Deno, Lua, and other Python Packages to Code Interpreter[00:11:46] Code Interpreter Timeouts and Environment Resets[00:13:59] Code Interpreter for Refactoring[00:15:12] Code Interpreter Context Window[00:15:34] Uploading git repos[00:16:17] Code Interpreter Security[00:18:57] Jailbreaking[00:19:54] Code Interpreter cannot call GPT APIs[00:21:45] Hallucinating Lack of Capability[00:22:27] Code Interpreter Installed Libraries and Capabilities[00:23:44] Code Interpreter generating interactive diagrams[00:25:04] Code Interpreter has Torch and Torchaudio[00:25:49] Code Interpreter for video editing[00:27:14] Code Interpreter for Data Analysis[00:28:14] Simon's Whole Foods Crime Analysis[00:31:29] Code Interpreter Network Access[00:33:28] System Prompt for Code Interpreter[00:35:12] Subprocess run in Code Interpreter[00:36:57] Code Interpreter for Microbenchmarks[00:37:30] System Specs of Code Interpreter[00:38:18] PyTorch in Code Interpreter[00:39:35] How to obtain Code Interpreter RAM[00:40:47] Code Interpreter for Face Detection[00:42:56] Code Interpreter yielding for Human Input[00:43:56] Tip: Ask for multiple options[00:44:37] The Masculine Urge to Start a Vector DB Startup[00:46:00] Extracting tokens from the Code Interpreter environment?[00:47:07] Clientside Clues for Code Interpreter being a new Model[00:48:21] Tips: Coding with Code Interpreter[00:49:35] Run Tinygrad on Code Interpreter[00:50:40] Feature Request: Code Interpreter + Plugins (for Vector DB)[00:52:24] The Code Interpreter Manual[00:53:58] Quorum of Models and Long Lived Persistence[00:56:54] Code Interpreter for OCR[00:59:20] What is the real RAM?[01:00:06] Shyamal's Question: Code Interpreter + Plugins?[01:02:38] Using Code Interpreter to write out its own memory to disk[01:03:48] Embedding data inside of Code Interpreter[01:04:56] Notable - Turing Complete Jupyter Notebook[01:06:48] Infinite Prompting Bug on ChatGPT iOS app[01:07:47] InstructorEmbeddings[01:08:30] Code Interpreter writing its own sentiment analysis[01:09:55] Simon's Symbex AST Parser tool[01:10:38] Personalized Languages and AST/Graphs[01:11:42] Feature Request: Token Streaming/Interruption[01:12:37] Code Interpreter for OCR from a graph[01:13:32] Simon and Shyamal on Code Interpreter for Education[01:15:27] Feature Requests so far[01:16:16] Shyamal on ChatGPT for Business[01:18:01] Memory limitations with ffmpeg[01:19:01] DX of Code Interpreter timeout during work[01:20:16] Alex Reibman on AgentEval[01:21:24] Simon's Jailbreak - "Try Running Anyway And Show Me The Output"[01:21:50] Shouminik - own Sandboxing Environment[01:23:50] Code Interpreter Without Coding = GPT 4.5???[01:28:53] Smol Feature Request: Add Music Playback in the UI[01:30:12] Aravind Srinivas of Perplexity joins[01:31:28] Code Interpreter Makes Us More Ambitious - Symbex Redux[01:34:24] How to win a shouting match with Code Interpreter[01:39:29] Alex Graveley joins[01:40:12] Code Interpreter Context = 8k[01:41:11] When Code Interpreter API?[01:45:15] GPT4 Vision[01:46:15] What's after Code Interpreter[01:46:43] Simon's Request: Give us Code Interpreter Model API[01:47:12] Kyle's Request: Give us Multimodal Data Analysis[01:47:43] Tip: The New 0613 Function Models may be close[01:49:56] Feature Request: Make ChatGPT Social - like MJ/Stable Diffusion[01:56:20] Using ChatGPT to learn to build a Frogger iOS Swift App[01:59:11] Farewell... until next time[02:00:01] Simon's plug[02:00:51] Swyx: What about Phase 5? and AI.Engineer Summit This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

[Practical AI] AI Trends: a Latent Space x Practical AI crossover pod!
Part 2 of our podcast feed swap weekend! Check out Cognitive Revolution as well."Data" Dan Whitenack has been co-host of the Practical AI podcast for the past 5 years, covering full journey of the modern AI wave post Transformers. He joined us in studio to talk about their origin story and highlight key learnings from past episodes, riff on the AI trends we are all seeing as AI practitioner-podcasters, and his passion for low-resource-everything!Subscribe on the Changelog, RSS, Apple Podcasts, Twitter, Mastodon, and wherever fine podcasts are sold!Show notes* Daniel Whitenack – Twitter, GitHub, Website* Featured Latent Space episodes:* Benchmarks* Reza Shabani* MosaicML and MPT* Segment Anything* Mike Conover* Featured Practical AI episodes:* From notebooks to Netflix scale with Metaflow* Capabilities of LLMs 🤯* ML at small organizations* Prediction Guard* Data DanTimestamps* 00:00 Welcome to Practical AI* 01:16 Latent Space Podcast* 04:00 Practical AI Podcast* 06:20 Prediction Guard* 08:05 Daniel's favorite episodes* 10:21 Alessio's favorite episode* 10:54 Swyx's favorite episode* 12:44 Listener favorites* 15:14 LLMOps* 17:06 Reza Shabani* 19:06 Benchmarks 101* 20:06 Roboflow* 21:38 Mode collapse* 26:21 Rajiv Shah* 28:01 Staying on top of things* 33:11 Kirsten Lum* 34:31 datadan.io* 38:48 Prompt engineering* 40:38 Unique challenges engineers face* 42:51 AI-UX* 45:31 NLP data sets* 50:49 Unlabeled data sets* 55:07 Lightning round!* 55:20 What's already happened in AI?* 56:27 Unsolved questions in AI* 58:01 Get hands on* 58:53 OutroTranscriptFull transcript is over at the Changelog site! This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

[Cognitive Revolution] The Tiny Model Revolution with Ronen Eldan and Yuanzhi Li of Microsoft Research
Thanks to the over 1m people that have checked out the Rise of the AI Engineer. It’s a long July 4 weekend in the US, and we’re celebrating with a podcast feed swap!We’ve been big fans of Nathan Labenz and Erik Torenberg’s work at the Cognitive Revolution podcast for a while, which started around the same time as we did and has done an incredible job of hosting discussions with top researchers and thinkers in the field, with a wide range of topics across computer vision (a special focus thanks to Nathan’s work at Waymark), GPT-4 (with exceptional insight due to Nathan’s time on the GPT-4 “red team”), healthcare/medicine/biotech (Harvard Medical School, Med-PaLM, Tanishq Abraham, Neal Khosla), investing and tech strategy (Sarah Guo, Elad Gil, Emad Mostaque, Sam Lessin), safety and policy, curators and influencers and exceptional AI founders (Josh Browder, Eugenia Kuyda, Flo Crivello, Suhail Doshi, Jungwon Byun, Raza Habib, Mahmoud Felfel, Andrew Feldman, Matt Welsh, Anton Troynikov, Aravind Srinivas). If Latent Space is for AI Engineers, then Cognitive Revolution covers the much broader field of AI in tech, business and society at large, with a longer runtime to go deep on research papers like TinyStories. We hope you love this episode as much as we do, and check out CogRev wherever fine podcasts are sold!Subscribe to the Cognitive Revolution on:* Website* Apple Podcasts* Spotify* YoutubeGood Data is All You NeedThe work of Ronen and Yuanzhi echoes a broader theme emerging in the midgame of 2023: * Falcon-40B (trained on 1T tokens) outperformed LLaMA-65B (trained on 1.4T tokens), primarily due to the RefinedWeb Dataset that runs CommonCrawl through extensive preprocessing and cleaning in their MacroData Refinement pipeline. * UC Berkeley LMSYS’s Vicuna-13B is near GPT-3.5/Bard quality at a tenth of their size, thanks to fine-tuning from 70k user-highlighted ChatGPT conversations (indicating some amount of quality). * Replit’s finetuned 2.7B model outperforms the 12B OpenAI Codex model based on HumanEval, thanks to high quality data from Replit usersThe path to smaller models leans on better data (and tokenization!), whether from cleaning, from user feedback, or from synthetic data generation, i.e. finetuning high quality on outputs from larger models. TinyStories and Phi-1 are the strongest new entries in that line of work, and we hope you’ll pick through the show notes to read up further.Show Notes* TinyStories (Apr 2023)* Paper: TinyStories: How Small Can Language Models Be and Still Speak Coherent English?* Internal presentation with Sebastien Bubeck at MSR* Twitter thread from Ronen Eldan* Will future LLMs be based almost entirely on synthetic training data? In a new paper, we introduce TinyStories, a dataset of short stories generated by GPT-3.5&4. We use it to train tiny LMs (* Phi-1 (Jun 2023)* Paper: Textbooks are all you need (HN discussion)* Twitter announcement from Sebastien Bubeck:* phi-1 achieves 51% on HumanEval w. only 1.3B parameters & 7B tokens training dataset and 8 A100s x 4 days = 800 A100-hours. Any other >50% HumanEval model is >1000x bigger (e.g., WizardCoder from last week is 10x in model size and 100x in dataset size). This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

Commoditizing the Petaflop — with George Hotz of the tiny corp
We are now launching our dedicated new YouTube and Twitter! Any help in amplifying our podcast would be greatly appreciated, and of course, tell your friends! Notable followon discussions collected on Twitter, Reddit, Reddit, Reddit, HN, and HN. Please don’t obsess too much over the GPT4 discussion as it is mostly rumor; we spent much more time on tinybox/tinygrad on which George is the foremost authority!We are excited to share the world’s first interview with George Hotz on the tiny corp!If you don’t know George, he was the first person to unlock the iPhone, jailbreak the PS3, went on to start Comma.ai, and briefly “interned” at the Elon Musk-run Twitter. Tinycorp is the company behind the deep learning framework tinygrad, as well as the recently announced tinybox, a new $15,000 “luxury AI computer” aimed at local model training and inference, aka your “personal compute cluster”:* 738 FP16 TFLOPS* 144 GB GPU RAM* 5.76 TB/s RAM bandwidth* 30 GB/s model load bandwidth (big llama loads in around 4 seconds)* AMD EPYC CPU* 1600W (one 120V outlet)* Runs 65B FP16 LLaMA out of the box (using tinygrad, subject to software development risks)(In the episode, we also talked about the future of the tinybox as the intelligence center of every home that will help run models, at-home robots, and more. Make sure to check the timestamps 👀 )The tiny corp manifestoThere are three main theses to tinycorp:* If XLA/PrimTorch are CISC, tinygrad is RISC: CISC (Complex Instruction Set Computing) are more complex instruction sets where a single instruction can execute many low-level operations. RISC (Reduced Instruction Set Computing) are smaller, and only let you execute a single low-level operation per instruction, leading to faster and more efficient instruction execution. If you’ve used the Apple Silicon M1/M2, AMD Ryzen, or Raspberry Pi, you’ve used a RISC computer.* If you can’t write a fast ML framework for GPU, you can’t write one for your own chip: there are many “AI chips” companies out there, and they all started from taping the chip. Some of them like Cerebras are still building, while others like Graphcore seem to be struggling. But building chips with higher TFLOPS isn’t enough: “There’s a great chip already on the market. For $999, you get a 123 TFLOP card with 24 GB of 960 GB/s RAM. This is the best FLOPS per dollar today, and yet…nobody in ML uses it.”, referring to the AMD RX 7900 XTX. NVIDIA’s lead is not only thanks to high-performing cards, but also thanks to a great developer platform in CUDA. Starting with the chip development rather than the dev toolkit is much more cost-intensive, so tinycorp is starting by writing a framework for off-the-shelf hardware rather than taping their own chip. * Turing completeness considered harmful: Once you call in to Turing complete kernels, you can no longer reason about their behavior. Since they have to be able to execute any instruction, they are much more complex. To optimize Turing kernels performance, you fall back to caching, warp scheduling, and branch prediction. Since neural networks only need ADD/MUL operations and only rely on static memory accesses, there’s no need to have Turing completeness. This design decision allows tinygrad to optimize instructions at a much lower level. As you might have guessed, CUDA is Turing-complete; this is one of the main differences that tinycorp wants to leverage to be competitive. All that — covered in the first 10 minutes of our discussion. George came ready to go deep, so we went for it. Some of the other technical questions we went through:* Laziness: why laziness is important and how operation fusing can help with memory efficiency* Debugging & CI: Why great developer experience is a priority in tinygrad* Quantization: what’s the right level of quantization, how lossless are these transformations, his quick takes on Mojo and ggml, and why fp16 is the target for their out-of-the-box LLaMA. * Building rigs for individual use: we talked a bit about the design tradeoffs of building these machines with low noise and a single power plug, the difference that PCIe 4 vs 3 makes, and more.The “personal compute cluster” is $15,000, but for businesses interested in local training and inference, George also estimates that he will be able to build you a H100-class GPU that is 5-10x faster (than a H100) for the same price.Misc: Bitter Lessons, Core Insights, Remote WorkOutside of tiny, we also talked about one of George’s favorite units of measure “a person of compute”. Much of the AGI talk has been benchmark-driven, but looking at it from a compute throughput can also be interesting. One person of compute is roughly 20 PFLOPS (64 A100s, or a single dense 42U A100 rack); one A100 is ~$10-15,000, so the GPUs by themselves will come out at $640,000-$1,000,000. We also covered a wide range of topics, including his self analysis on GPT-4, Elon Musk, Remote Work, Computer Vision and the Comma Body, and life above/below the API (and above/below
Emergency Pod: OpenAI's new Functions API, 75% Price Drop, 4x Context Length (w/ Alex Volkov, Simon Willison, Riley Goodside, Joshua Lochner, Stefania Druga, Eric Elliott, Mayo Oshin et al)
Full Transcript and show notes: https://www.latent.space/p/function-agents?sd=pfTimestamps:[00:00:00] Intro[00:01:47] Recapping June 2023 Updates[00:06:24] Known Issues with Long Context[00:08:00] New Functions API[00:10:45] Riley Goodside[00:12:28] Simon Willison[00:14:30] Eric Elliott[00:16:05] Functions API and Agents[00:18:25] Functions API vs Google Vertex JSON[00:21:32] From English back to Code[00:26:14] Embedding Price Drop and Pinecone Perspective[00:30:39] Xenova and Huggingface Perspective[00:34:23] Function Selection[00:39:58] Designing Code Agents with Function API[00:42:16] Models as Routers[00:46:48] Prompt Engineering replaced by Finetuning[00:52:15] The 2 Code x LLM Paradigms[00:56:30] Smol Models for the future[00:58:54] The Evolution of the GPT API[01:03:27] Functions API Security vs Prompt Injection[01:16:18] GPT Model Upgrades[01:17:36] JSONformer[01:21:03] Closing Comments - What We Want Next This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

From RLHF to RLHB: The Case for Learning from Human Behavior - with Jeffrey Wang and Joe Reeve of Amplitude
Welcome to the almost 3k latent space explorers that joined us last month! We’re holding our first SF listener meetup with Practical AI next Monday; join us if you want to meet past guests and put faces to voices! All events are in /community.Who among you regularly click the ubiquitous 👍 /👎 buttons in ChatGPT/Bard/etc?Anyone? I don’t see any hands up.OpenAI has told us how important reinforcement learning from human feedback (RLHF) is to creating the magic that is ChatGPT, but we know from our conversation with Databricks’ Mike Conover just how hard it is to get just 15,000 pieces of explicit, high quality human responses. We are shockingly reliant on good human feedback. Andrej Karpathy’s recent keynote at Microsoft Build on the State of GPT demonstrated just how much of the training process relies on contractors to supply the millions of items of human feedback needed to make a ChatGPT-quality LLM (highlighted by us in red):But the collection of good feedback is an incredibly messy problem. First of all, if you have contractors paid by the datapoint, they are incentivized to blast through as many as possible without much thought. So you hire more contractors and double, maybe triple, your costs. Ok, you say, lets recruit missionaries, not mercenaries. People should volunteer their data! Then you run into the same problem we and any consumer review platform run into - the vast majority of people send nothing at all, and those who do are disproportionately representing negative reactions. More subtle problems emerge when you try to capture subjective human responses - the reason that ChatGPT responses tend to be inhumanly verbose, is because humans have a well documented “longer = better” bias when classifying responses in a “laboratory setting”.The fix for this, of course, is to get out of the lab and learn from real human behavior, not artificially constructed human feedback. You don’t see a thumbs up/down button in GitHub Copilot nor Codeium nor Codium. Instead, they work an implicit accept/reject event into the product workflow, such that you cannot help but to give feedback while you use the product. This way you hear from all your users, in their natural environments doing valuable tasks they are familiar with. The prototypal example in this is Midjourney, who unobtrusively collect 1 of 9 types of feedback from every user as part of their workflow, in exchange for much faster first draft image generations:The best known public example of AI product telemetry is in the Copilot-Explorer writeup, which checks for the presence of generated code after 15-600 second intervals, which enables GitHub to claim that 40% of code is generated by Copilot.This is fantastic and “obviously” the future of productized AI. Every AI application should figure out how to learn from all their real users, not some contractors in a foreign country. Most prompt engineers and prompt engineering tooling also tend to focus on pre-production prototyping, but could also benefit from A/B testing their prompts in the real world.In short, AI may need Analytics more than Analytics needs AI.Amplitude’s Month of AIThis is why Amplitude is going hard on AI - and why we recently spent a weekend talking to Jeffrey Wang, cofounder and chief architect at Amplitude, and Joe Reeve, head of AI, recording a live episode at the AI + Product Hackathon where 150+ hackers gathered to compete for over $22.5k in prizes from Amplitude, New Relic, LanceDB, AWS, and more.To put things in perspective, Amplitude is a legendary YC alum with $238M of revenue in 2022 — our first guests representing the AI efforts of a public company!We chatted about how they have been approaching AI in their product (“question to chart” BI, text field autofill, instrumenting Amplitude with Amplitude), some of the issues they’ve had with different models, and the importance of first-party data in the world of LLMs. Another topic that came out of the Q&A was this idea of almost an “AmplitudeGPT”; rather than using language to simply generate a query, you could have these models investigate reasons for why certain behavior is happening in your user base. It was a really good discussion, and hope you all enjoy listening to it! Sections* [00:00:47] Amplitude's founding story and pivot* [00:03:28] Amplitude as an AI company and opportunities* [00:07:14] Limitations and challenges with using AI models* [00:10:56] Using Amplitude's product to build Amplitude - instrumenting AI* [00:12:32] Existing ML models in Amplitude's product and customer use cases* [00:15:50] “A/Z testing” and adaptable products* [00:19:33] The future of analytics and dashboards* [00:21:03] Optimizing for metrics in chatbots and AI products* [00:26:22] Using general models vs. fine-tuned models* [00:30:24] The importance of models vs. data - Amplitude's data set* [00:39:00] Lightning Round + Q&AShow Notes* Amplitude* Sonalight to Amplitude pivot announcement* The Slack origin story* Reverse Engineering Copilot*

Building the AI × UX Scenius — with Linus Lee of Notion AI
Read: https://www.latent.space/p/ai-interfaces-and-notionShow Notes* Linus on Twitter* Linus’ personal blog* Notion* Notion AI* Notion Projects* AI UX Meetup RecapTimestamps* [00:03:30] Starting the AI / UX community* [00:10:01] Most knowledge work is not text generation* [00:16:21] Finding the right constraints and interface for AI* [00:19:06] Linus' journey to working at Notion* [00:23:29] The importance of notations and interfaces* [00:26:07] Setting interface defaults and standards* [00:32:36] The challenges of designing AI agents* [00:39:43] Notion deep dive: “Blocks”, AI, and more* [00:51:00] Prompt engineering at Notion* [01:02:00] Lightning RoundTranscriptAlessio: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO in residence at Decibel Partners. I'm joined by my co-host Swyx, writer and editor of Latent Space. [00:00:20]Swyx: And today we're not in our regular studio. We're actually at the Notion New York headquarters. Thanks to Linus. Welcome. [00:00:28]Linus: Thank you. Thanks for having me. [00:00:29]Swyx: Thanks for having us in your beautiful office. It is actually very startling how gorgeous the Notion offices are. And it's basically the same aesthetic. [00:00:38]Linus: It's a very consistent aesthetic. It's the same aesthetic in San Francisco and the other offices. It's been for many, many years. [00:00:46]Swyx: You take a lot of craft in everything that you guys do. Yeah. [00:00:50]Linus: I think we can, I'm sure, talk about this more later, but there is a consistent kind of focus on taste that I think flows down from Ivan and the founders into the product. [00:00:59]Swyx: So I'll introduce you a little bit, but also there's just, you're a very hard person to introduce because you do a lot of things. You got your BA in computer science at Berkeley. Even while you're at Berkeley, you're involved in a bunch of interesting things at Replit, CatalystX, Hack Club and Dorm Room Fund. I always love seeing people come out of Dorm Room Fund because they tend to be a very entrepreneurial. You're a product engineer at IdeaFlow, residence at Betaworks. You took a year off to do independent research and then you've finally found your home at Notion. What's one thing that people should know about you that's not on your typical LinkedIn profile? [00:01:39]Linus: Putting me on the spot. I think, I mean, just because I have so much work kind of out there, I feel like professionally, at least, anything that you would want to know about me, you can probably dig up, but I'm a big city person, but I don't come from the city. I went to school, I grew up in Indiana, in the middle of nowhere, near Purdue University, a little suburb. I only came out to the Bay for school and then I moved to New York afterwards, which is where I'm currently. I'm in Notion, New York. But I still carry within me a kind of love and affection for small town, Indiana, small town, flyover country. [00:02:10]Swyx: We do have a bit of indulgence in this. I'm from a small country and I think Alessio, you also kind of identified with this a little bit. Is there anything that people should know about Purdue, apart from the chickens? [00:02:24]Linus: Purdue has one of the largest international student populations in the country, which I don't know. I don't know exactly why, but because it's a state school, the focus is a lot on STEM topics. Purdue is well known for engineering and so we tend to have a lot of folks from abroad, which is particularly rare for a university in, I don't know, that's kind of like predominantly white American and kind of Midwestern state. That makes Purdue and the surrounding sort of area kind of like a younger, more diverse international island within the, I guess, broader world that is Indiana. [00:02:58]Swyx: Fair enough. We can always dive into sort of flyover country or, you know, small town insights later, but you and I, all three of us actually recently connected at AIUX SF, which is the first AIUX meetup, essentially which just came out of like a Twitter conversation. You and I have been involved in HCI Twitter is kind of how I think about it for a little bit and when I saw that you were in town, Geoffrey Litt was in town, Maggie Appleton in town, all on the same date, I was like, we have to have a meetup and that's how this thing was born. Well, what did it look like from your end? [00:03:30]Linus: From my end, it looked like you did all of the work and I... [00:03:33]Swyx: Well, you got us the Notion. Yeah, yeah. [00:03:36]Linus: It was also in the Notion office, it was in the San Francisco one and then thereafter there was a New York one that I decided I couldn't make. But yeah, from my end it was, and I'm sure you were too, but I was really surprised by both the mixture of people that we ended up getting and the number of people that we ended up getting. There was just a lot of attention on, obviously there was a lot of attention on the technology itself of GPT and languag
Debugging the Internet with AI agents – with Itamar Friedman of Codium AI and AutoGPT
We are hosting the AI World’s Fair in San Francisco on June 8th! You can RSVP here. Come meet fellow builders, see amazing AI tech showcases at different booths around the venue, all mixed with elements of traditional fairs: live music, drinks, games, and food! We are also at Amplitude’s AI x Product Hackathon and are hosting our first joint Latent Space + Practical AI Podcast Listener Meetup next month!We are honored by the rave reviews for our last episode with MosaicML! They are also welcome on Apple Podcasts and Twitter/HN/LinkedIn/Mastodon etc!We recently spent a wonderful week with Itamar Friedman, visiting all the way from Tel Aviv in Israel: * We first recorded a podcast (releasing with this newsletter) covering Codium AI, the hot new VSCode/Jetbrains IDE extension focused on test generation for Python and JS/TS, with plans for a Code Integrity Agent. * Then we attended Agent Weekend, where the founders of multiple AI/agent projects got together with a presentation from Toran Bruce Richards on Auto-GPT’s roadmap and then from Itamar on Codium’s roadmap* Then some of us stayed to take part in the NextGen Hackathon and won first place with the new AI Maintainer project.So… that makes it really hard to recap everything for you. But we’ll try!Podcast: Codium: Code Integrity with Zero BugsWhen it launched in 2021, there was a lot of skepticism around Github Copilot. Fast forward to 2023, and 40% of all code is checked in unmodified from Copilot. Codium burst on the scene this year, emerging from stealth with an $11m seed, their own foundation model (TestGPT-1) and a vision to revolutionize coding by 2025.You might have heard of "DRY” programming (Don’t Repeat Yourself), which aims to replace repetition with abstraction. Itamar came on the pod to discuss their “extreme DRY” vision: if you already spent time writing a spec, why repeat yourself by writing the code for it? If the spec is thorough enough, automated agents could write the whole thing for you.Live Demo Video SectionThis is referenced in the podcast about 6 minutes in.Timestamps, show notes, and transcript are below the fold. We would really appreciate if you shared our pod with friends on Twitter, LinkedIn, Mastodon, Bluesky, or your social media poison of choice!Auto-GPT: A Roadmap To The Future of WorkMaking his first public appearance, Toran (perhaps better known as @SigGravitas on GitHub) presented at Agents Weekend:Lightly edited notes for those who want a summary of the talk:* What is AutoGPT?AutoGPT is an Al agent that utilizes a Large Language Model to drive its actions and decisions. It can be best described as a user sitting at a computer, planning and interacting with the system based on its goals. Unlike traditional LLM applications, AutoGPT does not require repeated prompting by a human. Instead, it generates its own 'thoughts', criticizes its own strategy and decides what next actions to take.* AutoGPT was released on GitHub in March 2023, and went viral on April 1 with a video showing automatic code generation. 2 months later it has 132k+ stars, is the 29th highest ranked open-source project of all-time, a thriving community of 37.5k+ Discord members, 1M+ downloads.* What’s next for AutoGPT? The initial release required users to know how to build and run a codebase. They recently announced plans for a web/desktop UI and mobile app to enable nontechnical/everyday users to use AutoGPT. They are also working on an extensible plugin ecosystem called the Abilities Hub also targeted at nontechnical users.* Improving Efficacy. AutoGPT has many well documented cases where it trips up. Getting stuck in loops, using instead of actual content incommands, and making obvious mistakes like execute_code("writea cookbook"'. The plan is a new design called Challenge Driven Development - Challenges are goal-orientated tasks or problems thatAuto-GPT has difficulty solving or has not yet been able to accomplish. These may include improving specific functionalities, enhancing the model's understanding of specific domains, or even developing new features that the current version of Auto-GPT lacks. (AI Maintainer was born out of one such challenge). Itamar compared this with Software 1.0 (Test Driven Development), and Software 2.0 (Dataset Driven Development).* Self-Improvement. Auto-GPT will analyze its own codebase and contribute to its own improvement. AI Safety (aka not-kill-everyone-ists) people like Connor Leahy might freak out at this, but for what it’s worth we were pleasantly surprised to learn that Itamar and many other folks on the Auto-GPT team are equally concerned and mindful about x-risk as well.The overwhelming theme of Auto-GPT’s roadmap was accessibility - making AI Agents usable by all instead of the few.Podcast Timestamps* [00:00:00] Introductions* [00:01:30] Itamar’s background and previous startups* [00:03:30] Vision for Codium AI: reaching “zero bugs”* [00:06:00] Demo of Codium AI and how it works* [00:15:30] Building on VS Code
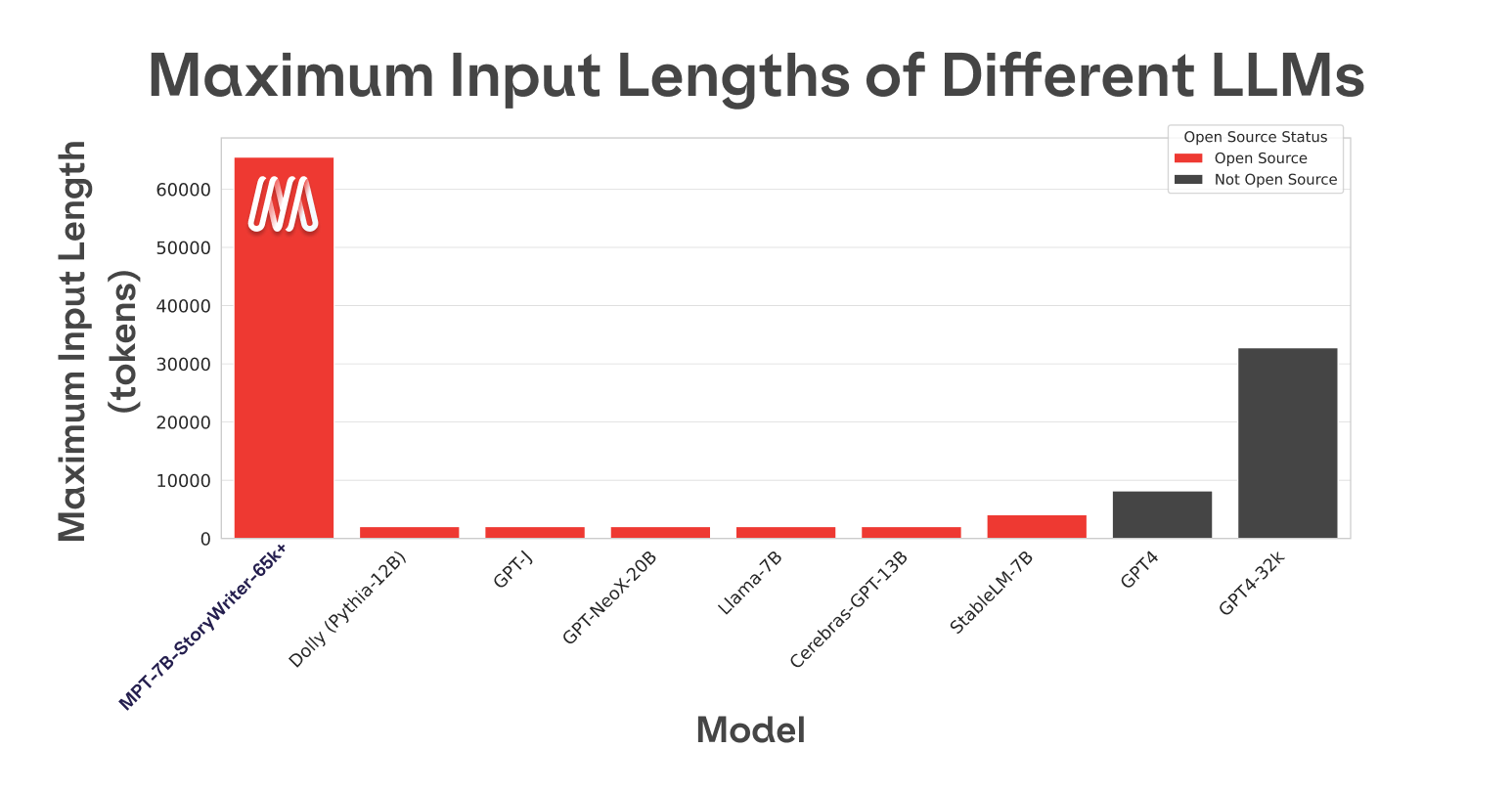
MPT-7B and The Beginning of Context=Infinity — with Jonathan Frankle and Abhinav Venigalla of MosaicML
We are excited to be the first podcast in the world to release an in-depth interview on the new SOTA in commercially licensed open source models - MosiacML MPT-7B!The Latent Space crew will be at the NYC Lux AI Summit next week, and have two meetups in June. As usual, all events are on the Community page! We are also inviting beta testers for the upcoming AI for Engineers course. See you soon!One of GPT3’s biggest limitations is context length - you can only send it up to 4000 tokens (3k words, 6 pages) before it throws a hard error, requiring you to bring in LangChain and other retrieval techniques to process long documents and prompts. But MosaicML recently open sourced MPT-7B, the newest addition to their Foundation Series, with context length going up to 84,000 tokens (63k words, 126 pages):This transformer model, trained from scratch on 1 trillion tokens of text and code (compared to 300B for Pythia and OpenLLaMA, and 800B for StableLM), matches the quality of LLaMA-7B. It was trained on the MosaicML platform in 9.5 days on 440 GPUs with no human intervention, costing approximately $200,000. Unlike many open models, MPT-7B is licensed for commercial use and it’s optimized for fast training and inference through FlashAttention and FasterTransformer.They also released 3 finetuned models starting from the base MPT-7B: * MPT-7B-Instruct: finetuned on dolly_hhrlhf, a dataset built on top of dolly-5k (see our Dolly episode for more details). * MPT-7B-Chat: finetuned on the ShareGPT-Vicuna, HC3, Alpaca, Helpful and Harmless, and Evol-Instruct datasets.* MPT-7B-StoryWriter-65k+: it was finetuned with a context length of 65k tokens on a filtered fiction subset of the books3 dataset. While 65k is the advertised size, the team has gotten up to 84k tokens in response when running on a single node A100-80GB GPUs. ALiBi is the dark magic that makes this possible. Turns out The Great Gatsby is only about 68k tokens, so the team used the model to create new epilogues for it!On top of the model checkpoints, the team also open-sourced the entire codebase for pretraining, finetuning, and evaluating MPT via their new MosaicML LLM Foundry. The table we showed above was created using LLM Foundry in-context-learning eval framework itself!In this episode, we chatted with the leads of MPT-7B at Mosaic: Jonathan Frankle, Chief Scientist, and Abhinav Venigalla, Research Scientist who spearheaded the MPT-7B training run. We talked about some of the innovations they’ve brought into the training process to remove the need for 2am on-call PagerDutys, why the LLM dataset mix is such an important yet dark art, and why some of the traditional multiple-choice benchmarks might not be very helpful for the type of technology we are building.Show Notes* Introducing MPT-7B* Cerebras* Lottery Ticket Hypothesis* Hazy Research* ALiBi* Flash Attention* FasterTransformer* List of naughty words for C4 https://twitter.com/code_star/status/1661386844250963972* What is Sparsity?* Hungry Hungry Hippos* BF16 FPp.s. yes, MPT-7B really is codenamed LLongboi!Timestamps* Introductions [00:00:00]* Intro to Mosaic [00:03:20]* Training and Creating the Models [00:05:45]* Data Choices and the Importance of Repetition [00:08:45]* The Central Question: What Mix of Data Sets Should You Use? [00:10:00]* Evaluation Challenges of LLMs [0:13:00]* Flash Attention [00:16:00]* Fine-tuning for Creativity [00:19:50]* Open Source Licenses and Ethical Considerations [00:23:00]* Training Stability Enhancement [00:25:15]* Data Readiness & Training Preparation [00:30:00]* Dynamic Real-time Model Evaluation [00:34:00]* Open Science for Affordable AI Research [00:36:00]* The Open Approach [00:40:15]* The Future of Mosaic [00:44:11]* Speed and Efficiency [00:48:01]* Trends and Transformers [00:54:00]* Lightning Round and Closing [1:00:55]TranscriptAlessio: [00:00:00] Hey everyone. Welcome to the Latent Space podcast. This is Alessio partner and CTO-in-Residence at Decibel Partners. I'm joined by my co-host, Swyx, writer and editor of Latent Space.Swyx: Hey, and today we have Jonathan and Abhi from Mosaic ML. Welcome to our studio.Jonathan: Guys thank you so much for having us. Thanks so much.Swyx: How's it feel?Jonathan: Honestly, I've been doing a lot of podcasts during the pandemic, and it has not been the same.Swyx: No, not the same actually. So you have on your bio that you're primarily based in Boston,Jonathan: New York. New York, yeah. My Twitter bio was a probability distribution over locations.Swyx: Exactly, exactly. So I DMd you because I was obviously very interested in MPT-7B and DMd you, I was like, for the 0.2% of the time that you're in San Francisco, can you come please come to a podcast studio and you're like, I'm there next week.Jonathan: Yeah, it worked out perfectly. Swyx: We're really lucky to have you, I'll read off a few intros that people should know about you and then you can fill in the blanks.So Jonathan, you did your BS and MS at Princeton in programmin

Guaranteed quality and structure in LLM outputs - with Shreya Rajpal of Guardrails AI
Tomorrow, 5/16, we’re hosting Latent Space Liftoff Day in San Francisco. We have some amazing demos from founders at 5:30pm, and we’ll have an open co-working starting at 2pm. Spaces are limited, so please RSVP here!One of the biggest criticisms of large language models is their inability to tightly follow requirements without extensive prompt engineering. You might have seen examples of ChatGPT playing a game of chess and making many invalid moves, or adding new pieces to the board. Guardrails AI aims to solve these issues by adding a formalized structure around inference calls, which validates both the structure and quality of the output. In this episode, Shreya Rajpal, creator of Guardrails AI, walks us through the inspiration behind the project, why it’s so important for models’ outputs to be predictable, and why she went with an XML-like syntax. Guardrails TLDRGuardrails AI rules are created as RAILs, which have three main “atomic objects”:* Output: what should the output look like?* Prompt: template for requests that can be interpolated* Script: custom rules for validation and correctionEach RAIL can then be used as a “guard” when calling an LLM. You can think of a guard as a wrapper for the API call. Before returning the output, it will validate it, and if it doesn’t pass it will ask the model again. Here’s an example of a bad SQL query being returned, and what the ReAsk query looks like: Each RAIL is also model-agnostic. This allows for output consistency across different models, even if they have slight differences in how they are prompted. Guardrails can easily be used with LangChain and other tools to structure your outputs!Show Notes* Guardrails AI* Text2SQL* Use Guardrails and GPT to play valid chess* Shreya’s AI Tinkerers demo* Hazy Research Lab* AutoPR* Ian Goodfellow* GANs (Generative Adversarial Networks)Timestamps* [00:00:00] Shreya's Intro* [00:02:30] What's Guardrails AI?* [00:05:50] Why XML instead of YAML or JSON?* [00:10:00] SQL as a validation language?* [00:14:00] RAIL composability and package manager?* [00:16:00] Using Guardrails for agents* [00:23:50] Guardrails "contracts" and guarantees* [00:31:30] SLAs for LLMs* [00:40:00] How to prioritize as a solo founder in open source* [00:43:00] Guardrails open source community involvement* [00:46:00] Working with Ian Goodfellow* [00:50:00] Research coming out of Stanford* [00:52:00] Lightning RoundTranscriptAlessio: [00:00:00] Hey everyone. Welcome to the Latent Space Podcast. This is Alessio partner and CTO-in-Residence at Decibel Partners. I'm joined by my cohost Swyx, writer and editor of Latent Space.Swyx: And today we have Shreya Rajpal in the studio. Welcome Shreya.Shreya: Hi. Hi. Excited to be here.Swyx: Excited to have you too.This has been a long time coming, you and I have chatted a little bit and excited to learn more about guardrails. We do a little intro for you and then we have you fill in the blanks. So you, you got your bachelor's at IIT Delhi minor in computer science with focus on AI, which is super relevant now. I bet you didn't think about that in undergrad.Shreya: Yeah, I think it's, it's interesting because like, I started working in AI back in 2014 and back then I was like, oh, it's, it's here. This is like almost changing the world already. So it feels like that that like took nine years, that meme of like, almost like almost arriving the thing.So yeah, I, it's felt this way where [00:01:00] it's almost shared. It's almost changed the world for as long as I've been working in it.Swyx: Yeah. That's awesome. Maybe we can explore your, like the origins of your interests, because then you went on to U I U C to do your master's also in ai. And then it looks like you went to drive.ai to work on Perception and then to Apple S P G as, as the cool kids call it special projects group working with Ian Goodfellow.Yeah, that's right. And then you were at pretty base up until recently? Actually, I don't know if you've quit yet. I have, yeah. Okay, good, good, good. You haven't updated e LinkedIn, but we're getting the by breaking news that you're working on guardrails full-time. Yeah, well that's the professional history.We can double back to fill in the blanks on anything. But what's a personal side? You know, what's not on your LinkedIn that people should know about you?Shreya: I think the most obvious thing, this is like, this is still professional, but the most obvious thing that isn't on my LinkedIn yet is, is Guardrails.So, yeah. Like you mentioned, I haven't updated my LinkedIn yet, but I quit some time ago and I've been devoting like all of my energy. Yeah. Full-time working on Guardrails and growing the open source package and building out exciting features, et cetera. So that's probably the thing that's missing the most.I think another. More personal skill, which I [00:02:00] think I'm like kind of okay for an amateur and that isn't on my LinkedIn is, is pottery. So I really enjoy pottery and yeah, don't know how to

The AI Founder Gene: Being Early, Building Fast, and Believing in Greatness — with Sharif Shameem of Lexica
Thanks to the over 42,000 latent space explorers who checked out our Replit episode! We are hosting/attending a couple more events in SF and NYC this month. See you if in town!Lexica.art was introduced to the world 24 hours after the release of Stable Diffusion as a search engine for prompts, gaining instant product-market fit as a world discovering generative AI also found they needed to learn prompting by example.Lexica is now 8 months old, serving 5B image searches/day, and just shipped V3 of Lexica Aperture, their own text-to-image model! Sharif Shameem breaks his podcast hiatus with us for an exclusive interview covering his journey building everything with AI!The conversation is nominally about Sharif’s journey through his three startups VectorDash, Debuild, and now Lexica, but really a deeper introspection into what it takes to be a top founder in the fastest moving tech startup scene (possibly ever) of AI. We hope you enjoy this conversation as much as we did!Full transcript is below the fold. We would really appreciate if you shared our pod with friends on Twitter, LinkedIn, Mastodon, Bluesky, or your social media poison of choice!Timestamps* [00:00] Introducing Sharif* [02:00] VectorDash* [05:00] The GPT3 Moment and Building Debuild* [09:00] Stable Diffusion and Lexica* [11:00] Lexica’s Launch & How it Works* [15:00] Being Chronically Early* [16:00] From Search to Custom Models* [17:00] AI Grant Learnings* [19:30] The Text to Image Illuminati?* [20:30] How to Learn to Train Models* [24:00] The future of Agents and Human Intervention* [29:30] GPT4 and Multimodality* [33:30] Sharif’s Startup Manual* [38:30] Lexica Aperture V1/2/3* [40:00] Request for AI Startup - LLM Tools* [41:00] Sequencing your Genome* [42:00] Believe in Doing Great Things* [44:30] Lightning RoundShow Notes* Sharif’s website, Twitter, LinkedIn* VectorDash (5x cheaper than AWS)* Debuild Insider, Fast company, MIT review, tweet, tweet* Lexica* Introducing Lexica* Lexica Stats* Aug: “God mode” search* Sep: Lexica API * Sept: Search engine with CLIP * Sept: Reverse image search* Nov: teasing Aperture* Dec: Aperture v1* Dec - Aperture v2* Jan 2023 - Outpainting* Apr 2023 - Aperture v3* Same.energy* AI Grant* Sharif on Agents: prescient Airpods tweet, Reflection* MiniGPT4 - Sharif on Multimodality* Sharif Startup Manual* Sharif Future* 23andMe Genome Sequencing Tool: Promethease* Lightning Round* Fave AI Product: Cursor.so. Swyx ChatGPT Menubar App.* Acceleration: Multimodality of GPT4. Animated Drawings* Request for Startup: Tools for LLMs, Brex for GPT Agents* Message: Build Weird Ideas!TranscriptAlessio: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO on Residence at Decibel Partners. I'm joined by my co-host Wix, writer and editor of Latent Space. And today we have Sharish Amin. Welcome to the studio. Sharif: Awesome. Thanks for the invite.Swyx: Really glad to have you. [00:00] Introducing SharifSwyx: You've been a dream guest, actually, since we started drafting guest lists for this pod. So glad we could finally make this happen. So what I like to do is usually introduce people, offer their LinkedIn, and then prompt you for what's not on your LinkedIn. And to get a little bit of the person behind the awesome projects. So you graduated University of Maryland in CS. Sharif: So I actually didn't graduate, but I did study. Swyx: You did not graduate. You dropped out. Sharif: I did drop out. Swyx: What was the decision behind dropping out? Sharif: So first of all, I wasn't doing too well in any of my classes. I was working on a side project that took up most of my time. Then I spoke to this guy who ended up being one of our investors. And he was like, actually, I ended up dropping out. I did YC. And my company didn't end up working out. And I returned to school and graduated along with my friends. I was like, oh, it's actually a reversible decision. And that was like that. And then I read this book called The Case Against Education by Brian Kaplan. So those two things kind of sealed the deal for me on dropping out. Swyx: Are you still on hiatus? Could you still theoretically go back? Sharif: Theoretically, probably. Yeah. Still on indefinite leave. Swyx: Then you did some work at Mitra? Sharif: Mitra, yeah. So they're lesser known. So they're technically like an FFRDC, a federally funded research and development center. So they're kind of like a large government contractor, but nonprofit. Yeah, I did some computer vision work there as well. [02:00] VectorDashSwyx: But it seems like you always have an independent founder bone in you. Because then you started working on VectorDash, which is distributed GPUs. Sharif: Yes. Yeah. So VectorDash was a really fun project that we ended up working on for a while. So while I was at Mitra, I had a friend who was mining Ethereum. This was, I think, 2016 or 2017. Oh my God. Yeah. And he was mining on his NVIDIA 1080Ti, making around like five or six dollars a day.