
Latent Space: The AI Engineer Podcast
211 episodes — Page 1 of 5
Why the Frontier Ecosystem must be Open — Matei Zaharia and Reynold Xin, Databricks
Red-Teaming after Mythos — Zico Kolter & Matt Fredrikson, Gray Swan
The Professor of Outputmaxxing — Anjney Midha, AMP
🔬 The Self-Driving Lab — Joseph Krause, Radical AI
Reality: The Final Eval — Lukas Petersson and Axel Backlund of Andon Labs
🔬Scaling Past Informal AI - Carina Hong, Axiom Math
⚡️Satya Nadella: No Priors x Latent Space Crossover Special at Microsoft Build
GitHub's plan for Agents — Kyle Daigle, GitHub
Why Video Agent models are next — Ethan He, xAI Grok Imagine
The Age of Async Agents — Cognition's Walden Yan & OpenInspect's Cole Murray
🔬ESM: The Bitter Lesson is Coming for Proteins - Alex Rives, BioHub
Giving Agents Computers — Ivan Burazin, Daytona
Railway: The Agent-Native Cloud — Jake Cooper
The Next War Is Already Here. The West Isn't Ready. — Yaroslav Azhnyuk, The Fourth Law & Guest Host Noah Smith, Noahpinion
AI-Native Healthcare: 100M Doctor Visits, 10–20 Hours Saved, Prior Auth in Minutes — Janie Lee & Chai Asawa, Abridge
🔬Doing Vibe Physics — Alex Lupsasca, OpenAI
Physical AI that Moves the World — Qasar Younis & Peter Ludwig, Applied Intuition
AIE Europe Debrief + Agent Labs Thesis: Unsupervised Learning x Latent Space Crossover Special (2026)
Shopify’s AI Phase Transition: 2026 Usage Explosion, Unlimited Opus-4.6 Token Budget, Tangle, Tangent, SimGym — with Mikhail Parakhin, Shopify CTO
🔬 Training Transformers to solve 95% failure rate of Cancer Trials — Ron Alfa & Daniel Bear, Noetik
Notion’s Token Town: 5 Rebuilds, 100+ Tools, MCP vs CLIs and the Software Factory Future — Simon Last & Sarah Sachs of Notion
Extreme Harness Engineering for Token Billionaires: 1M LOC, 1B toks/day, 0% human code, 0% human review — Ryan Lopopolo, OpenAI Frontier & Symphony

Marc Andreessen introspects on The Death of the Browser, Pi + OpenClaw, and Why "This Time Is Different"
Fresh off raising a monster $15B, Marc Andreessen has lived through multiple computing platform shifts firsthand, from Mosaic and Netscape to cofounding A16z. In this episode, Marc joins swyx and Alessio in a16z’s legendary Sand Hill Road office to argue that AI is not just another hype cycle, but the payoff of an “80-year overnight success”: from neural nets and expert systems to transformers, reasoning models, coding, agents, and recursive self-improvement. He lays out why he thinks this moment is different, why AI is finally escaping the old boom-bust pattern, and why the real bottleneck may be less about models than about the messy institutions, incentives, and social systems that struggle to absorb technological change.This episode was a dream come true for us, and many thanks to Erik Torenberg for the assist in setting this up. Full episode on YouTube!We discuss:* Marc’s long view on AI: from the 1980s AI boom and expert systems to AlexNet, transformers, and why he sees today’s moment as the culmination of decades of compounding technical progress* Why “this time is different”: the jump from LLMs to reasoning, coding, agents, and recursive self-improvement, and why Marc thinks these breakthroughs make AI real in a way prior cycles were not* AI winters vs. “80-year overnight success”: why the field repeatedly swings between utopianism and doom, and why Marc thinks the underlying researchers were mostly right even when the timelines were wrong* Scaling laws, Moore’s Law, and what to build: why he believes AI scaling laws will continue, why the outside world is messier than lab purists assume, and how startups can still create durable value on top of rapidly improving models* The dot-com crash and AI infrastructure risk: Marc’s comparison between today’s AI capex boom and the fiber/data-center overbuild of 2000, plus why he thinks this cycle is different because the buyers are huge cash-rich incumbents and demand is already here* Why old NVIDIA chips may be getting more valuable: the pace of software progress, chronic capacity shortages, and the idea that even current models are “sandbagged” by supply constraints* Open source, edge inference, and the chip bottleneck: why Marc thinks local models, Apple Silicon, privacy, trust, and economics all point toward a major role for edge AI* American vs. Chinese open source AI: DeepSeek as a “gift to the world,” why open models matter not just because they’re free but because they teach the world how things work, and how open source strategies may shift as the market consolidates* Why Pi and OpenClaw matter so much: Marc’s claim that the combination of LLM + shell + filesystem + markdown + cron loop is one of the biggest software architecture breakthroughs in decades* Agents as the new “Unix”: how agent state living in files allows portability across models and runtimes, and why self-modifying agents that can extend themselves may redefine what software even is* The future of coding and programming languages: why Marc thinks software becomes abundant, why bots may translate freely across languages, and why “programming language” itself may stop being a salient concept* Browsers, protocols, and human readability: lessons from Mosaic and the web, why text protocols and “view source” mattered, and how similar principles may shape AI-native systems* Real-world OpenClaw use: health dashboards, sleep monitoring, smart homes, rewriting firmware on robot dogs, and why the most aggressive users are discovering both the power and danger of agents first* Proof of human vs. proof of bot: why Marc thinks the internet’s bot problem is now unsolvable via detection alone, and why biometric + cryptographic proof of human becomes necessaryTimestamps* 00:00 Marc on AI’s “80-Year Overnight Success”* 00:01 A Quick Message From swyx* 01:44 Inside a16z With Marc Andreessen* 02:13 The Truth About a16z’s AI Pivot* 03:29 Why This AI Boom Is Not Like 2016* 06:33 Marc on AI Winters, Hype Cycles, and What’s Different Now* 10:09 Reasoning, Coding, Agents, and the New AI Breakthroughs* 12:13 What Founders Should Build as Models Keep Improving* 16:33 AI Capex, GPU Shortages, and the Dot-Com Crash Analogy* 24:54 Open Source AI, Edge Inference, and Why It Matters* 33:03 Why OpenClaw and PI Could Change Software Forever* 41:37 Agents, the End of Interfaces, and Software for Bots* 46:47 Do Programming Languages Even Have a Future?* 54:19 AI Agents Need Money: Payments, Crypto, and Stablecoins* 56:59 Proof of Human, Internet Bots, and the Drone Problem* 01:06:12 AI, Management, and the Return of Founder-Led Companies* 01:12:23 Why the Real Economy May Resist AI Longer Than Expected* 01:15:53 Closing ThoughtsTranscriptMarc: Something about AI that causes the people in the field, I would say, to become both excessively utopian and excessively apocalyptic. Having said that, I think what’s actually happened is an enormous amount of technical progress that built up over time. And like for, for example, w
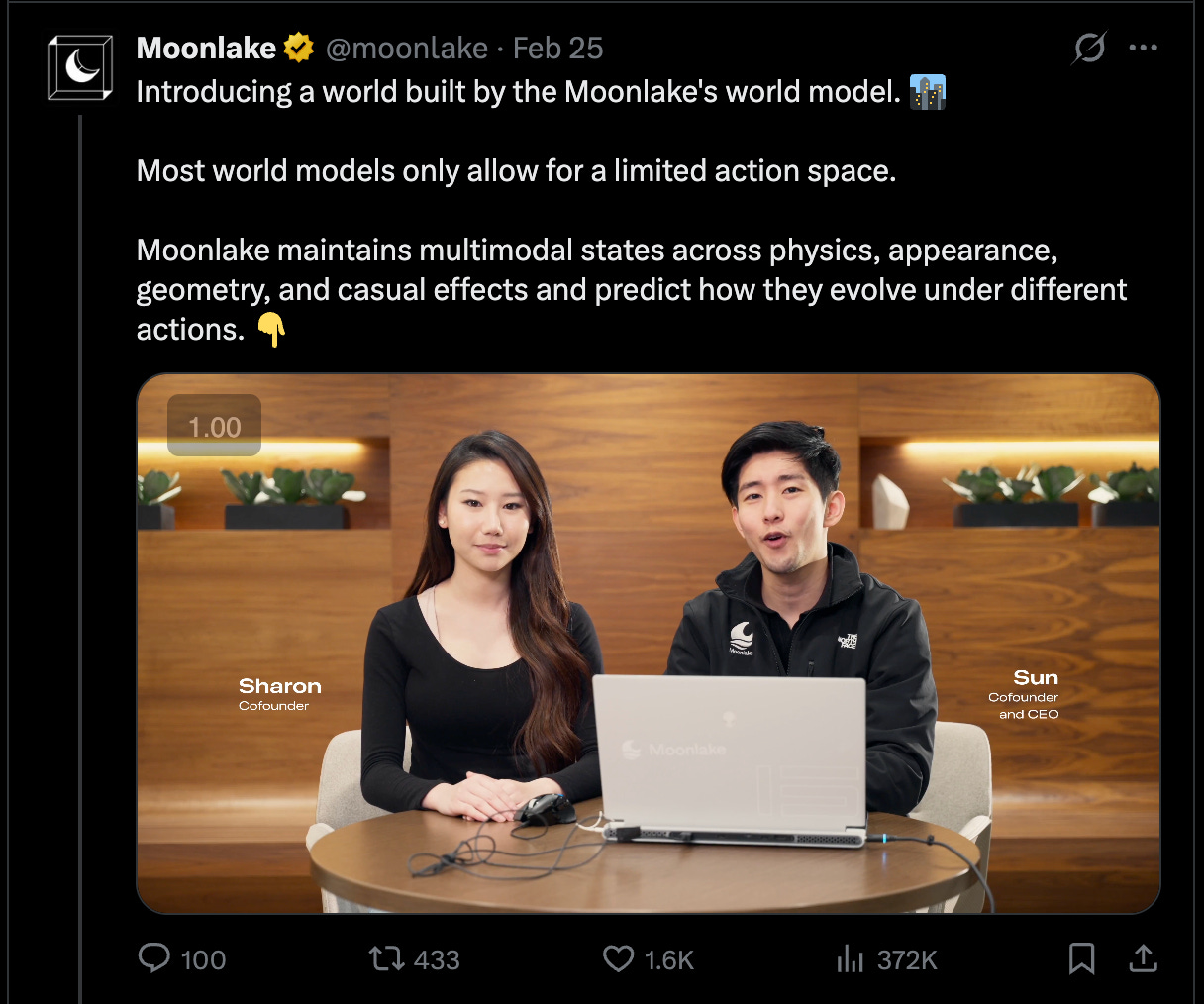
Moonlake: Causal World Models should be Multimodal, Interactive, and Efficient — with Chris Manning and Fan-yun Sun
We’ve been on a bit of a mini World Models series over the last quarter: from introducing the topic with Yi Tay, to exploring Marble with World Labs’ Fei-Fei Li and Justin Johnson, to previewing World Models learned from massive gaming datasets with General Intuition’s Pim de Witte (who has now written down their approach to World Models with Not Boring), to discussing the Cosmos World Model with with Andrew White of Edison Scientific on our new Science pod, to writing up our own theses on Adversarial World Models. Meanwhile Nvidia, Waymo and Tesla have published their own approaches, Google has released Genie 3, and Yann LeCun has raised $1B for AMI and published LeWorldModel.Today’s guests have a radically different approach to World Modeling to every player we just mentioned — while Genie 3 is impressive, its many flaws demonstrate the issues with their approach - terrain clipping, noninteractivity (single player, no physics/no objects other than the player move), and maximum of 60 second immersion. Moonlake AI (inspired by the Dreamworks logo) is the diametric opposite - immediately multiplayer, incredibly interactive, indefinite lifetime, capable of MANY different kinds of world models by simulating environments, predicting outcomes, and planning over long horizons. This is enabled by bootstrapping from game engines and training custom agents: In Towards Efficient World Models, Chris Manning and Ian Goodfellow join Fan-Yun in explaining why their approach to efficiency with structure and casuality instead of just blind scaling is sorely needed:SOTA models still show physical or spatial understanding glitches, such as solid objects floating in mid-air or moving “inside” other solid objects.If the goal is to plan for the next action, how often is a high-resolution pixel view necessary for modeling the world? Our bet is that there is a disproportionately large share of economically valuable tasks where such detail is not required. After all, humans with a wide variety of sensory limitations have little difficulty doing almost everything in the world. Furthermore, for a large number of purposes, describing a scene or a situation in a few words of language (“the car’s tires squealed as it cornered sharply”) is sufficient for understanding and planning.Experiments also show that humans only partially process visual input in a top-down, task-directed way, often making use of abstracted object-level modeling. In almost all cases, partial representations combined with semantic understanding are sufficient.…If the goal is to facilitate the understanding of causality in multimodal environments, then the world model—whether it is used in the virtual world or the physical world—must prioritize properties such as spatial and physical state consistency maintained over long time periods, and an ability to evolve the world that accurately reflects the consequences of actions. That’s what Moonlake is building.Game engines are the right starting point abstraction to efficiently extract causal relationships, and building the interfaces and community (including their new $30,000 Creator Cup) to kickstart the flywheel of actions-to-observations.We were fortunate enough to attend their sessions at GDC 2026 (the Mecca of Game Devs), and were impressed by the huge variety and flexibility of the worlds people were building with Moonlake’s tools already! Live videos on the pod.Full Video Pod on YouTube!Timestamps00:00 Benchmarking Gets Hard00:47 Meet Moonlake Founders01:26 Why Build World Models03:12 Structure Not Just Scale05:37 Defining Action Conditioned Worlds07:32 Abstraction Versus Bitter Lesson14:39 Language Versus JEPA Debate20:27 Reasoning Traces And Rendering Layer37:00 Gameplay Over Graphics38:02 Fiction Rules And World Tweaks39:15 Code Engines Beat Learned Priors41:10 Diffusion Scaling Limits43:23 Symbolic Versus Diffusion Boundary46:14 Platform Vision Beyond Games50:24 Spatial Audio And Multimodal Latents54:23 NLP Roots Hiring And Moon Lake NameTranscript[00:00:00] Cold Open[00:00:00] Chris Manning: Think this whole space is extremely difficult as things are emerging now. And I mean, it’s not only for world models, I think it’s for everything including text-based models, right? ‘cause in the early days it seemed very easy to have good benchmarks ‘cause we could do things like question answering benchmarks.[00:00:20] But these days so much of what people are wanting to do is nothing like that, right? You’re wanting to get some recommendations about which backpack would be best for you for your trip in Europe next month. It’s not so easy to come up with a benchmark, and it’s the same problem with these world models.[00:00:41] Meet the Founders[00:00:41] swyx: Okay. We’re back in the studio with Moon Lake’s, two leads. I, I guess there’s other founders as well, but, sun and Chris Manning. Welcome to the studio.[00:00:54] Fan-yun Sun: Thanks. Thanks, Chris. Thanks for having us.[00:00:56] swyx: You’ve got, you guys have
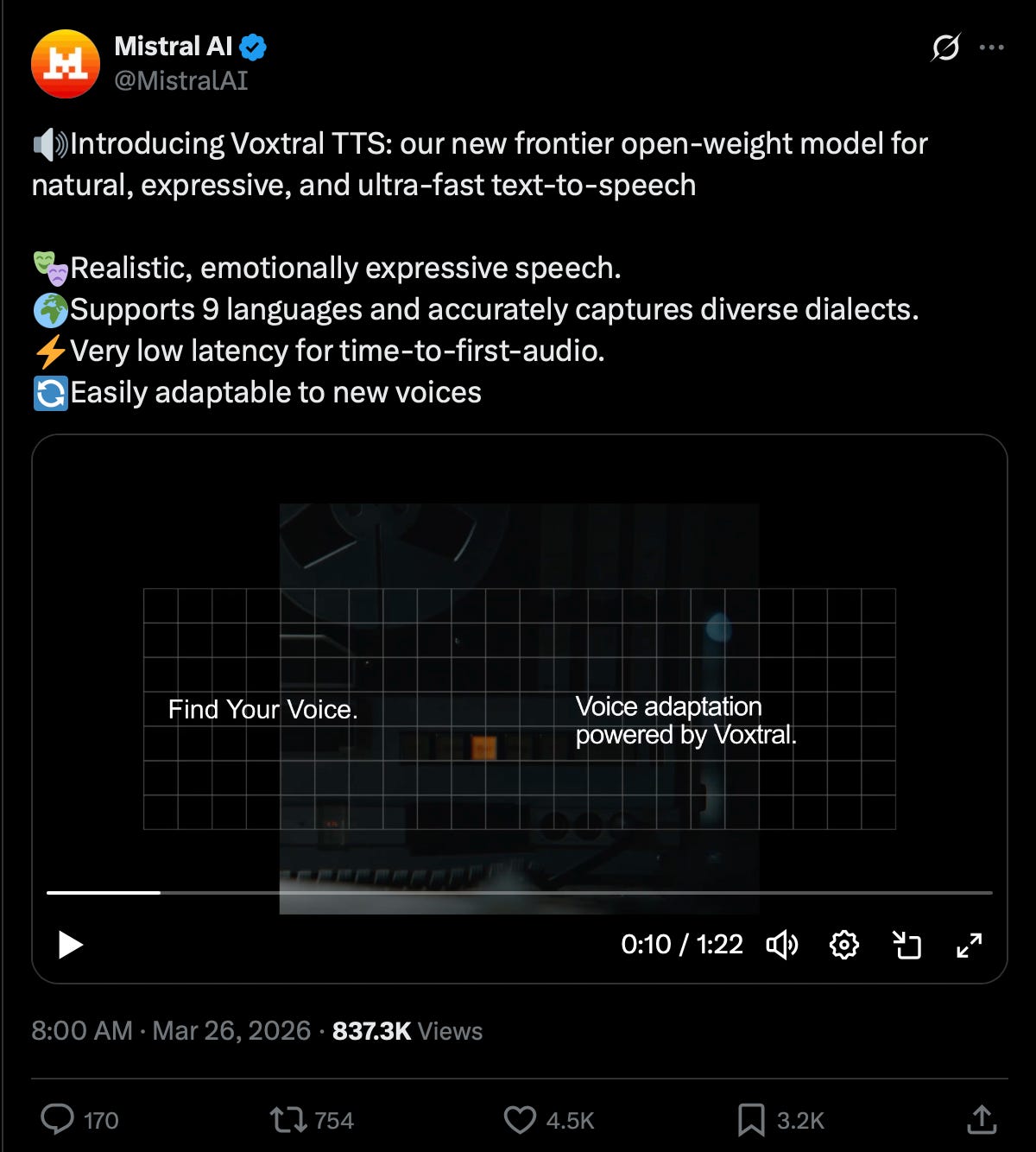
Mistral: Voxtral TTS, Forge, Leanstral, & what's next for Mistral 4 — w/ Pavan Kumar Reddy & Guillaume Lample
Mistral has been on an absolute tear - with frequent successful model launches it is easy to forget that they raised the largest European AI round in history last year. We were long overdue for a Mistral episode, and we were very fortunate to work with Sophia and Howard to catch up with Pavan (Voxtral lead) and Guillaume (Chief Scientist, Co-founder) on the occasion of this week’s Voxtral TTS launch:Mistral can’t directly say it, but the benchmarks do imply, that this is basically an open-weights ElevenLabs-level TTS model (Technically, it is a 4B Ministral based multilingual low-latency TTS open weights model that has a 68.4% win rate vs ElevenLabs Flash v2.5). The contributions are not just in the open weights but also in open research: We also spend a decent amount of the pod talking about their architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens (typically only applied in the Image Generation space, as seen in the Flow Matching NeurIPS workshop from the principal authors that we reference in the pod).You can catch up on the paper here and the full episode is live on youtube!Timestamps00:00 Welcome and Guests00:22 Announcing Voxtral TTS01:41 Architecture and Codec02:53 Understanding vs Generation05:39 Flow Matching for Audio07:27 Real Time Voice Agents13:40 Efficiency and Model Strategy14:53 Voice Agents Vision17:56 Enterprise Deployment and Privacy23:39 Fine Tuning and Personalization25:22 Enterprise Voice Personalization26:09 Long-Form Speech Models26:58 Real-Time Encoder Advances27:45 Scaling Context for TTS28:53 What Makes Small Models30:37 Merging Modalities Tradeoffs33:05 Open Source Mission35:51 Lean and Formal Proofs38:40 Reasoning Transfer and Agents40:25 Next Frontiers in Training42:20 Hiring and AI for Science44:19 Forward Deployed Engineering46:22 Customer Feedback Loop48:29 Wrap Up and ThanksTranscriptswyx: Okay, welcome to Latent Space. We’re here in the studio with our gues co-host Vibh u. Welcome. Thanks. Excited for this one as well as Guillaume and Pavan from Mistral. Welcome. Excited to be here.Guillaume: Thank you.swyx: Pavan, you are leading audio research at Mistral and Guillaume, you're Chief Scientist,Announcing Voxtral TTSswyxHost(00:05) Okay. (00:05) Welcome to Lean Space. (00:06) We’re here in the studio with trustee co-hosts, Vibhu. (00:09) Welcome.VibhuHost(00:11) Very excited for this one.swyxHost(00:12) As well as Guillaume and Pavan from Mistral. (00:15) Welcome. (00:16) Excited to be here. (00:17) Thank you for having us.(00:18) Pavan, you are leading audio research at Mistral and Guillaume, you’re a chief scientist. (00:23) What are we announcing today where we’re coordinating this release with you guys?GuillaumeGuest(00:26) Yeah, so we are releasing Voxtral TTS. So it’s our first audio model that generates speech. It’s not our first audio model. We had a couple of releases before.(00:35) We had one in the summer that was Voxtral, our first audio model, but it was like a transcription model, ASR. Like a few months later, we released some update on top of this, supporting more languages. Also a lot of table stack features for our customers, context biasing, precision, timestamping and transcription. We also have some real-time model that can transcribe not just at the end of the level.(00:56) You don’t need to fill your entire audio file, but that can also come in real-time. And here, this is a natural extension in the audio, so basically speech generation. So yeah, so we support nine languages, and this is a pretty small model, 3D model, so very fast, and also state of the art. Performed at the same level as the base model, but it’s much more efficient in terms of cost, and also much, in terms of cost, it’s also much cheaper, only a fraction of the cost of our competitors.(01:22) And we are also releasing the work that this model is running.swyx What’s the decision factor?Guillaume It’s a good question.swyxThere will be more. Yeah, Pavan, any sort of research notes to add on?Architecture and CodecPavan: But it’s a novel architecture that we develop inhouse.We traded on several internal architectures and ended up with a auto aggressive flow matching architecture. And also have a new in-house neural audio codec. Which, converts this audio into all point by herds latent [00:02:00] tokens, semantic and acoustic tokens. And yeah, that’s that’s their new part about this model and we’re pretty excited that it’s, it came out with such good quality and Jim was mentioning. Yeah, it’s a three B model. It’s based off of the TAL model that we actually released just a few months back and insert trunk and mainly meant for like the TTS stuff, but they need text capabilities are also there. Yeah.swyx: So there’s a lot to cover.I always I love any, anything to do with novel encodings and all those things because I think that’s obviously I creates a lot of efficiency, but also maybe bugs that sometimes happen. You were prev

🔬Why There Is No "AlphaFold for Materials" — AI for Materials Discovery with Heather Kulik
Materials science is the unsung hero of the science world. Behind every physical product you interact was decades of research into getting the properties of materials just right. Your gym clothes contain synthetic fibers developed over decades. The glass screen, diodes, and chip substrate technology needed to read this blog post were only viable due to many teams of material scientists.Our guest Prof. Heather Kulik was one of the first material scientists to realize that there was alpha in combining computational tools with data driven modeling — she did AI for science before it was cool. She has a hard-fought perspective for how to succeed in this field. Yes, she believes the wins are real. To get there you must work hard to deeply integrate domain expertise with AI techniques, and also maintain a discriminating mind. Ultimately what matters is you succeed in the lab, and nature doesn’t care about how hyped a model is. These lessons personally resonated with the Latent.Space Science team and our own experience.This episode is a must watch for all aspiring AI for science practitioners. A few highlights:Designing new polymers with AI: Heather’s group recently used AI to design new polymers that are significantly stronger. These materials were created and tested in the lab, and the scientists who built them were surprised by the designs. The AI had figured out certain building blocks could break in a novel way. The AI discovered a purely quantum mechanical effect, and after convincing their lab collaborators to actually synthesize it, the material turned out to be four times tougher!The twenty-two-atom ligand challenge: When asked about the role and need of human scientists, Heather points out that AI has a strong understanding of academic chemistry, but is still lacking intuition. Every time an LLM is updated, Heather asks it to design a ligand that contains exactly twenty-two heavy atoms. She has yet to find one that can succeed at this seemingly simple task that any expert could do in a second! Is this the chemistry counterpart to counting ‘r’s in strawberry?Side note: Heather joked that this comment would date itself immediately, so we decided to see if this was still true three months after recording. We found some interesting results! We asked both Claude and ChatGPT to design a 22 atom ligand for both a metal-organic framework (MOF) and a Kinase protein. * For the Kinase, both models got it right: Claude pulled out RDKit in a python script and iterated on several designs, whereas ChatGPT just one-shotted it. * For MOFs, both models got it wrong, generating ligands with 21, 23, or 24 atoms, yet stubbornly not getting 22 atoms. Is there something different about how LLMs reason in the materials and bio domains?Materials vs biology: The two biggest domains of AI in science have been biology and materials. We asked Heather if there could be an AlphaFold moment for materials. Her answer reframes how we should think about the field:* First, the datasets in material science are woefully lacking in comparison to the bio world. The closest to ground truth in most cases are noisy DFT datasets. These are just approximations to the real world! The datasets that are accurate are all boring, as Heather quipped “We have really good datasets for really boring chemistry.” Furthermore, good experimental structures are hard to come by and require interpretation. So generating generating high-quality, novel datasets at scale would really drive the field forward.* More philosophically, AlphaFold is making predictions in a fairly limited space: there are just twenty amino acids. Sure, even here AlphaFold doesn’t get everything right, but it seems plausible that one could learn the entire design space. For materials, each element is a new set of interactions and chemistry, with little to no transferability. This is a massive open problem in material science that we hope some of the smartest AI scientists will want to work on!The difficulties of trusting the literature: Heather’s team has spent the last few years using NLP and later LLMs to extract data from literature. Even a few thousand data points from these papers can be valuable for guiding her group’s work. One surprising result: sometimes the reported values for a property (say temperature) do not match up with the graphs in the papers! So there’s lots of potential in using LLMs to mine data from the literature, just do it with care.The role of academia in an ever-changing world: One theme that has been running through many of our conversations has been the changing role of the academic — and the scientist — in science. When startups are raising $100s of millions and hyperscalers and Big Pharma are all ramping up AI-for-science efforts, the academic researcher needs both resources and judgement about problems to chase more than ever.Resources include data that is organized for machine learning, access to high throughput experimentation labs, and compute resources. The

Dreamer: the Personal Agent OS — David Singleton
Mar 23 update for Latent Spacenauts: this episode was recorded before the Dreamer team announced they were joining Meta Superintelligence Labs, and it turned out to be the last interview they did before the news became public. Consider this a snapshot from just before the transition!In 2024, David Singleton left Stripe and joined forces with Hugo Barra for a buzzy stealth startup named /dev/agents. This month they emerged out as Dreamer, a consumer-first platform to discover, build, and use AI agents and agentic apps, centered on a personal “Sidekick” that helps users customize experiences via natural language. Sidekick is nothing less than an “agent that builds agents”, with all the complexity that that entails:You’ve seen many many website builder, app builder, and even agent builder startups by now, but our favorite detail is the sheer amount of work that has gone into the “full stack” nature of the platform, including shipping their own SDK, logging, database, prompt management, serverless functions, and so on. Most platforms restrict the tech stack you can use just to get off the ground — Dreamer does it “right” by letting you push whatever arbitrary code you want to their VMs.Paying the BuildersOf course former leaders of Stripe and Android would not stop at just building the tools, but also building the ecosystem. Dreamer is deeply aware of the 4 sided network effect it has going on and is ready to fund all of it.It’s time to Dream!Full Video Episodeon youtube.Transcript[00:00:00] Meet Dreamer Purple[00:00:00] swyx: Okay, we’re here in the studio with David Singleton. Welcome.[00:00:08] David Singleton: Hey, Wix. It’s great to be here.[00:00:09] swyx: It’s great to have you. Uh, we have very sympa that your company color is the same as Lean Spaces color.[00:00:15] David Singleton: That’s right. Dreamer Purple.[00:00:17] swyx: It used to be Devrel agents, which I thought was very cool. It’s like you call back to Devrel Payments.[00:00:22] David Singleton: Yeah.[00:00:22] swyx: And you were obviously CTO Stripe. And talk to me about just the origin or thinking process behind Dreamer. Yeah. And maybe, maybe start with like, what, what is Dreamer?[00:00:31] David Singleton: Yeah.[00:00:31] What Is Dreamer[00:00:31] David Singleton: So Dreamer is a new product, uh, which everyone can come and play with today. Um, it’s a place where everyone, literally, everyone can discover, build, and enjoy and use AI agents and agenda apps.[00:00:45] And we really did design it for consumers, for folks who are not necessarily. Uh, have any kind of technical background. It’s really aimed at everyone. I think often of my sister, she’s very smart. She’s not in the slightest bit technical. She has lots of problems in her life that [00:01:00] she would like to be able to have great software and intelligent software to solve.[00:01:04] But you know, even with the rise of tools like Cloud Code and so forth, she’s got no way to get started. And Dreamer is a place where she can come in, grab some intelligent apps that other people in the community have built, start using them right away, and solve real problems in her life.[00:01:19] Sidekick And Waitlist[00:01:19] David Singleton: And at the core, we have a personal agent called the Sidekick.[00:01:24] Um, you can give your sidekick a name, you can give it its own personality, and it really helps you across your entire day, your life. It helps you use all of the agents on the platform, and it also helps you build anything you want. And we’ve been working in this for a little while. We recently launched in beta.[00:01:41] So anyone can go to dreamer.com, join the wait list. Um, and we have many, many, many people in the community now who are building really fun, really powerful, really useful. Agents and the agentic apps for themselves.[00:01:54] swyx: I think we’re gonna go right into a demo. Yeah. I just wanna make an observation that, uh, you, you, [00:02:00] you put discover first before build.[00:02:02] Mm-hmm. But actually, at least for the engineers in the audience. ‘cause we are primarily engineers and you’re primarily targeting consumers, right?[00:02:08] David Singleton: Yeah.[00:02:08] swyx: For engineers. Like, there’s a huge full stack of stuff, which we’re gonna dive into. Let’s write. It’s so impressive. I’m like, holy s**t, this, this is what I’ve always wanted.[00:02:16] Cool. Uh, so, so I think that’s really good and I’ve, in some ways, I think given your background given, uh, Hugo’s, is it Hugo? Hugo.[00:02:24] David Singleton: Hugo. Hugo Bar. Yeah.[00:02:25] swyx: Hugo, it’s not surprising that you can basically kind of build an app store Yeah. For agents.[00:02:30] David Singleton: Yeah. So Hugo was my co-founder. Yeah. Um, Hugo and I met with our other co-founder Nicholas Checkoff in the very early days of Android at Google, where we were building Google’s first mobile apps.[00:02:41] Uh, we then contributed to very core pieces of Android itself. And you’re
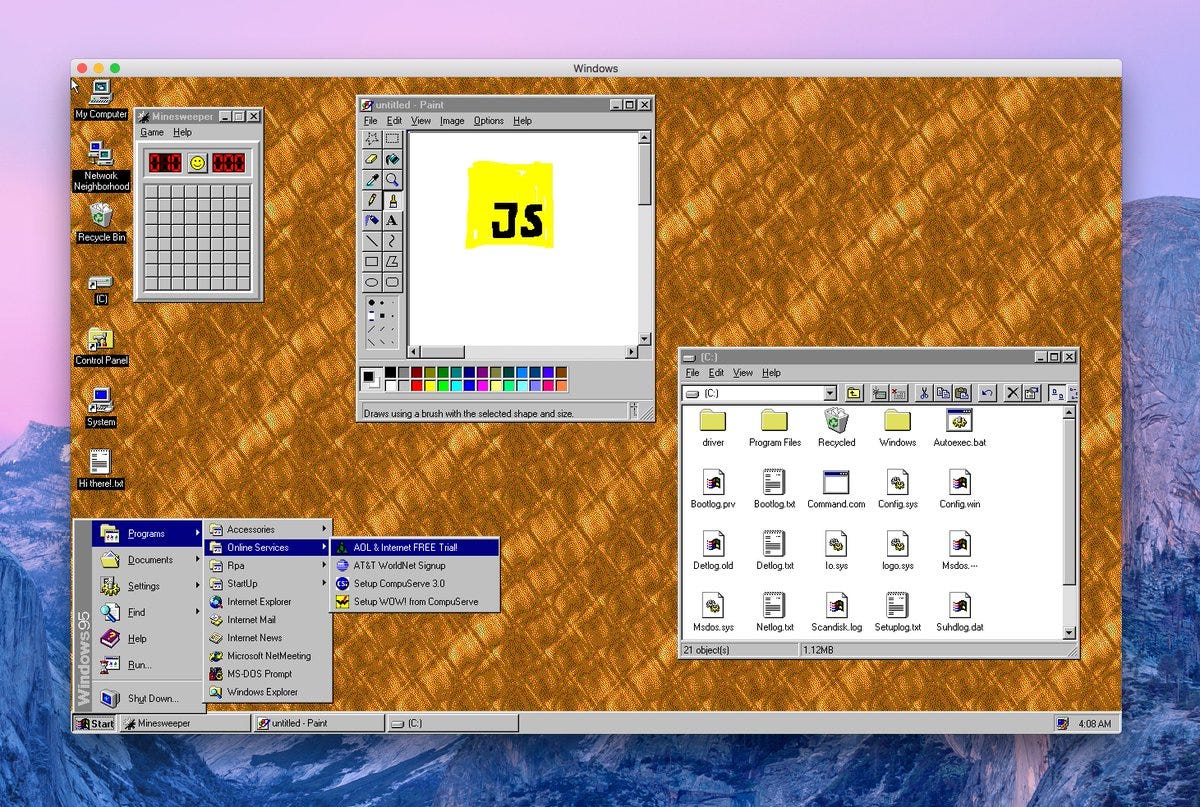
Why Anthropic Thinks AI Should Have Its Own Computer — Felix Rieseberg of Claude Cowork & Claude Code Desktop
Claude Cowork came out of an accident.Felix and the Anthropic team noticed something interesting with Claude Code: many users were using it primarily for all kinds of messy knowledge work instead of coding. Even technical builders would use it for lots of non-technical work.Even more shocking, Claude cowork wrote itself. With a team of humans simply orchestrating multiple claude code instances, the tool was ready after a brief week and a half.This isn’t Felix’s first rodeo with impactful and playful desktop apps. He’s helped ship the Slack desktop app and is a core maintainer of Electron the open-source software framework used for building cross-platform desktop applications, even putting Windows 95 into an Electron app that runs on macOS, Windows, and Linux.In this episode, Felix joins us to unpack why execution has suddenly become cheap enough that teams can “just build all the candidates” and why the real frontier in AI products is no longer better chat, but trusted task execution.He also shares why Anthropic is betting on local-first agent workflows, why skills may matter more than most people realize, and how the hardest questions ahead are about autonomy, safety, portability, and the changing shape of knowledge work itself.We discuss* Felix’s path: Slack desktop app, Electron, Windows 95 in JavaScript, and now building Claude Cowork at Anthropic* What Claude Cowork actually is: a more user-friendly, VM-based version of Claude Code designed to bring agentic workflows to non-terminal-native users* Why “user-friendly” does not mean “less powerful”: Cowork as a superset product, much like how VS Code initially looked simpler than Visual Studio but became more hackable and extensible* Anthropic’s prototype-first culture: why Cowork was built in 10 days using many pre-existing internal pieces, and how internal prototypes shaped the final product* Why execution is getting cheap: the shift from long memos, specs, and debate toward rapidly building multiple candidates and choosing based on reality instead of theory* The local debate: why Felix thinks Silicon Valley is undervaluing the local computer, and why putting Claude “where you work” is often more powerful* Why Claude gets its own computer: the VM as both a safety boundary and a capability unlock, letting Claude install tools, run scripts, and work more independently without constant approval* Safety through sandboxing: why “approve every command” is not a real long-term UX, and how virtual machines create a middle ground between uselessly safe and dangerously autonomous* How Cowork differs from Claude Code: coding evals vs. knowledge-work evals, different system-prompt tradeoffs, longer planning horizons, and heavier use of planning and clarification tools* Why skills matter: simple markdown-based instructions as a lightweight abstraction layer for reusable workflows, personalized automation, and portable agent behavior* Skills vs. MCPs: why Felix is increasingly interested in file-based, text-native interfaces that tell the model what to do, rather than forcing everything through rigid tool schemas* The portability problem: why personal skills should move across agent products, and the unresolved tension between public reusable workflows and private user-specific context* Real use cases already happening today: uploading videos, organizing files, handling taxes, managing calendars, debugging internal crashes, analyzing finances, and automating repetitive browser workflows* Why AI products should work with your existing stack: Anthropic’s bias toward integrating with Chrome, Office, and existing workflows instead of rebuilding every app from scratch* Computer use one year later: how much better it has gotten, why vision plus browser context is such a superpower, and why letting Claude see the thing it is working on changes everything* Why many “AI verticals” may get compressed: specialized wrappers may matter in the short term, but better general models and stronger primitives could absorb a lot of narrow use cases* The future of junior work: Felix’s concerns about entry-level roles, labor-market disruption, and whether AI can compress early-career learning into denser simulated experience* Why Waterloo grads stand out: internships, shipping experience, and learning how real teams build products versus purely theoretical academic preparation* The agentic future of the desktop: what it means for Claude to have its own computer, whether AI should act on your machine or a remote one, and how intimacy with personal data changes the product design space* Why Electron still mattered: shipping Chromium as a controlled rendering stack, the limits of OS-native webviews, and why browser engines remain one of the great software abstractions* Anthropic’s Labs mentality: wild internal experiments, half-broken future-looking prototypes, and the broader effort to move users from asking questions to delegating increasingly long and valuable tasks* Why the endgame is no
Retrieval After RAG: Hybrid Search, Agents, and Database Design — Simon Hørup Eskildsen of Turbopuffer
Turbopuffer came out of a reading app.In 2022, Simon was helping his friends at Readwise scale their infra for a highly requested feature: article recommendations and semantic search. Readwise was paying ~$5k/month for their relational database and vector search would cost ~$20k/month making the feature too expensive to ship. In 2023 after mulling over the problem from Readwise, Simon decided he wanted to “build a search engine” which became Turbopuffer.We discuss:• Simon’s path: Denmark → Shopify infra for nearly a decade → “angel engineering” across startups like Readwise, Replicate, and Causal → turbopuffer almost accidentally becoming a company • The Readwise origin story: building an early recommendation engine right after the ChatGPT moment, seeing it work, then realizing it would cost ~$30k/month for a company spending ~$5k/month total on infra and getting obsessed with fixing that cost structure • Why turbopuffer is “a search engine for unstructured data”: Simon’s belief that models can learn to reason, but can’t compress the world’s knowledge into a few terabytes of weights, so they need to connect to systems that hold truth in full fidelity • The three ingredients for building a great database company: a new workload, a new storage architecture, and the ability to eventually support every query plan customers will want on their data • The architecture bet behind turbopuffer: going all in on object storage and NVMe, avoiding a traditional consensus layer, and building around the cloud primitives that only became possible in the last few years • Why Simon hated operating Elasticsearch at Shopify: years of painful on-call experience shaped his obsession with simplicity, performance, and eliminating state spread across multiple systems • The Cursor story: launching turbopuffer as a scrappy side project, getting an email from Cursor the next day, flying out after a 4am call, and helping cut Cursor’s costs by 95% while fixing their per-user economics • The Notion story: buying dark fiber, tuning TCP windows, and eating cross-cloud costs because Simon refused to compromise on architecture just to close a deal faster • Why AI changes the build-vs-buy equation: it’s less about whether a company can build search infra internally, and more about whether they have time especially if an external team can feel like an extension of their own • Why RAG isn’t dead: coding companies still rely heavily on search, and Simon sees hybrid retrieval semantic, text, regex, SQL-style patterns becoming more important, not less • How agentic workloads are changing search: the old pattern was one retrieval call up front; the new pattern is one agent firing many parallel queries at once, turning search into a highly concurrent tool call • Why turbopuffer is reducing query pricing: agentic systems are dramatically increasing query volume, and Simon expects retrieval infra to adapt to huge bursts of concurrent search rather than a small number of carefully chosen calls • The philosophy of “playing with open cards”: Simon’s habit of being radically honest with investors, including telling Lachy Groom he’d return the money if turbopuffer didn’t hit PMF by year-end • The “P99 engineer”: Simon’s framework for building a talent-dense company, rejecting by default unless someone on the team feels strongly enough to fight for the candidate —Simon Hørup Eskildsen• LinkedIn: https://www.linkedin.com/in/sirupsen• X: https://x.com/Sirupsen• https://sirupsen.com/aboutturbopuffer• https://turbopuffer.com/Full Video PodTimestamps00:00:00 The PMF promise to Lachy Groom00:00:25 Intro and Simon's background00:02:19 What turbopuffer actually is00:06:26 Shopify, Elasticsearch, and the pain behind the company00:10:07 The Readwise experiment that sparked turbopuffer00:12:00 The insight Simon couldn’t stop thinking about00:17:00 S3 consistency, NVMe, and the architecture bet00:20:12 The Notion story: latency, dark fiber, and conviction00:25:03 Build vs. buy in the age of AI00:26:00 The Cursor story: early launch to breakout customer00:29:00 Why code search still matters00:32:00 Search in the age of agents00:34:22 Pricing turbopuffer in the AI era00:38:17 Why Simon chose Lachy Groom00:41:28 Becoming a founder on purpose00:44:00 The “P99 engineer” philosophy00:49:30 Bending software to your will00:51:13 The future of turbopuffer00:57:05 Simon’s tea obsession00:59:03 Tea kits, X Live, and P99 LiveTranscriptSimon Hørup Eskildsen: I don’t think I’ve said this publicly before, but I just called Lockey and was like, local Lockie. Like if this doesn’t have PMF by the end of the year, like we’ll just like return all the money to you. But it’s just like, I don’t really, we, Justine and I don’t wanna work on this unless it’s really working.So we want to give it the best shot this year and like we’re really gonna go for it. We’re gonna hire a bunch of people. We’re just gonna be honest with everyone. Like when I don’t know how to play a game, I just play with op

NVIDIA's AI Engineers: Agent Inference at Planetary Scale and "Speed of Light" — Nader Khalil (Brev), Kyle Kranen (Dynamo)
Join Kyle, Nader, Vibhu, and swyx live at NVIDIA GTC next week!Now that AIE Europe tix are ~sold out, our attention turns to Miami and World’s Fair!The definitive AI Accelerator chip company has more than 10xed this AI Summer:And is now a $4.4 trillion megacorp… that is somehow still moving like a startup. We are blessed to have a unique relationship with our first ever NVIDIA guests: Kyle Kranen who gave a great inference keynote at the first World’s Fair and is one of the leading architects of NVIDIA Dynamo (a Datacenter scale inference framework supporting SGLang, TRT-LLM, vLLM), and Nader Khalil, a friend of swyx from our days in Celo in The Arena, who has been drawing developers at GTC since before they were even a glimmer in the eye of NVIDIA:Nader discusses how NVIDIA Brev has drastically reduced the barriers to entry for developers to get a top of the line GPU up and running, and Kyle explains NVIDIA Dynamo as a data center scale inference engine that optimizes serving by scaling out, leveraging techniques like prefill/decode disaggregation, scheduling, and Kubernetes-based orchestration, framed around cost, latency, and quality tradeoffs. We also dive into Jensen’s “SOL” (Speed of Light) first-principles urgency concept, long-context limits and model/hardware co-design, internal model APIs (https://build.nvidia.com), and upcoming Dynamo and agent sessions at GTC.Full Video pod on YouTubeTimestamps00:00 Agent Security Basics00:39 Podcast Welcome and Guests07:19 Acquisition and DevEx Shift13:48 SOL Culture and Dynamo Setup27:38 Why Scale Out Wins29:02 Scale Up Limits Explained30:24 From Laptop to Multi Node33:07 Cost Quality Latency Tradeoffs38:42 Disaggregation Prefill vs Decode41:05 Kubernetes Scaling with Grove43:20 Context Length and Co Design57:34 Security Meets Agents58:01 Agent Permissions Model59:10 Build Nvidia Inference Gateway01:01:52 Hackathons And Autonomy Dreams01:10:26 Local GPUs And Scaling Inference01:15:31 Long Running Agents And SF ReflectionsTranscriptAgent Security BasicsNader: Agents can do three things. They can access your files, they can access the internet, and then now they can write custom code and execute it. You literally only let an agent do two of those three things. If you can access your files and you can write custom code, you don’t want internet access because that’s one to see full vulnerability, right?If you have access to internet and your file system, you should know the full scope of what that agent’s capable of doing. Otherwise, now we can get injected or something that can happen. And so that’s a lot of what we’ve been thinking about is like, you know, how do we both enable this because it’s clearly the future.But then also, you know, what, what are these enforcement points that we can start to like protect?swyx: All right.Podcast Welcome and Guestsswyx: Welcome to the Lean Space podcast in the Chromo studio. Welcome to all the guests here. Uh, we are back with our guest host Viu. Welcome. Good to have you back. And our friends, uh, Netter and Kyle from Nvidia. Welcome.Kyle: Yeah, thanks for having us.swyx: Yeah, thank you. Actually, I don’t even know your titles.Uh, I know you’re like architect something of Dynamo.Kyle: Yeah. I, I’m one of the engineering leaders [00:01:00] and a architects of Dynamo.swyx: And you’re director of something and developers, developer tech.Nader: Yeah.swyx: You’re the developers, developers, developers guy at nvidia,Nader: open source agent marketing, brev,swyx: and likeNader: Devrel tools and stuff.swyx: Yeah. BeenNader: the focus.swyx: And we’re, we’re kind of recording this ahead of Nvidia, GTC, which is coming to town, uh, again, uh, or taking over town, uh, which, uh, which we’ll all be at. Um, and we’ll talk a little bit about your sessions and stuff. Yeah.Nader: We’re super excited for it.GTC Booth Stunt Storiesswyx: One of my favorite memories for Nader, like you always do like marketing stunts and like while you were at Rev, you like had this surfboard that you like, went down to GTC with and like, NA Nvidia apparently, like did so much that they bought you.Like what, what was that like? What was that?Nader: Yeah. Yeah, we, we, um. Our logo was a chaka. We, we, uh, we were always just kind of like trying to keep true to who we were. I think, you know, some stuff, startups, you’re like trying to pretend that you’re a bigger, more mature company than you are. And it was actually Evan Conrad from SF Compute who was just like, you guys are like previousswyx: guest.Yeah.Nader: Amazing. Oh, really? Amazing. Yeah. He was just like, guys, you’re two dudes in the room. Why are you [00:02:00] pretending that you’re not? Uh, and so then we were like, okay, let’s make the logo a shaka. We brought surfboards to our booth to GTC and the energy was great. Yeah. Some palm trees too. They,Kyle: they actually poked out over like the, the walls so you could, you could see the bread booth.Oh, that’s so funny. AndNader: no one else,Kyle: j
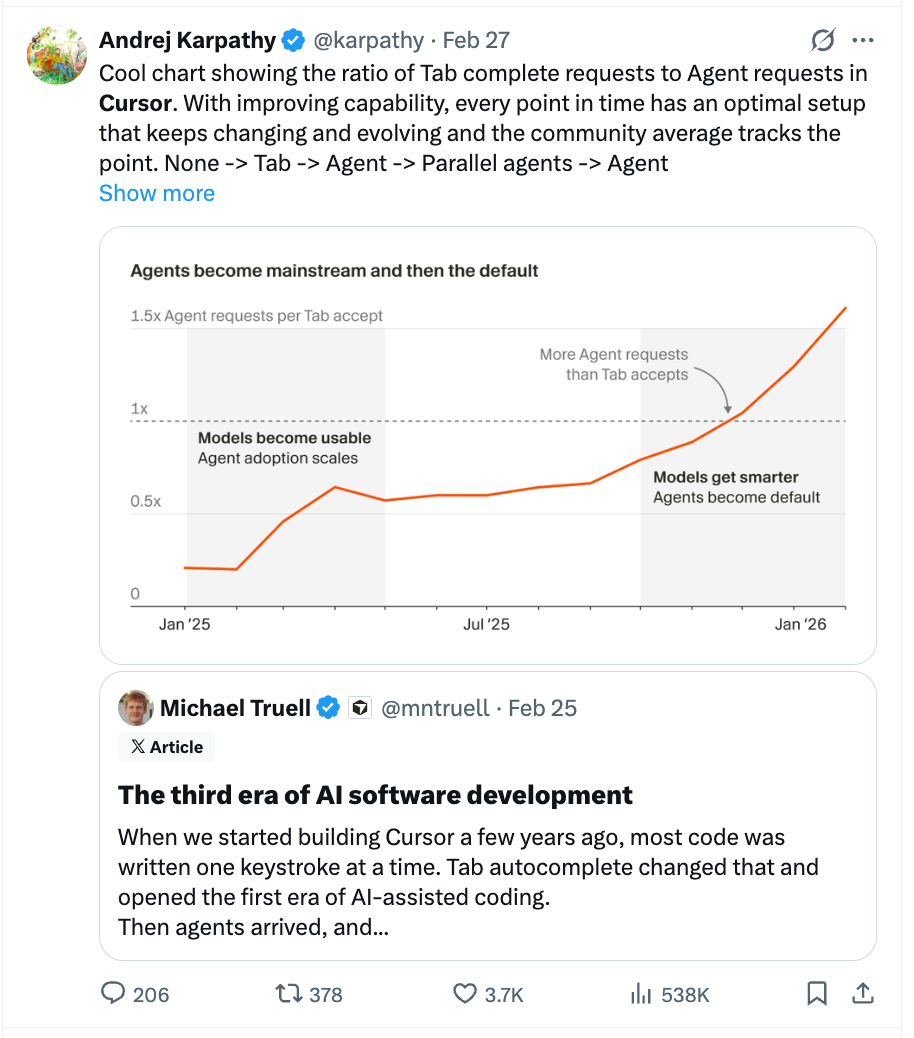
Cursor's Third Era: Cloud Agents
All speakers are announced at AIE EU, schedule coming soon. Join us there or in Miami with the renowned organizers of React Miami! Singapore CFP also open!We’ve called this out a few times over in AINews, but the overwhelming consensus in the Valley is that “the IDE is Dead”. In November it was just a gut feeling, but now we actually have data: even at the canonical “VSCode Fork” company, people are officially using more agents than tab autocomplete (the first wave of AI coding):Cursor has launched cloud agents for a few months now, and this specific launch is around Computer Use, which has come a long way since we first talked with Anthropic about it in 2024, and which Jonas productized as Autotab:We also take the opportunity to do a live demo, talk about slash commands and subagents, and the future of continual learning and personalized coding models, something that Sam previously worked on at New Computer. (The fact that both of these folks are top tier CEOs of their own startups that have now joined the insane talent density gathering at Cursor should also not be overlooked).Full Episode on YouTube!please like and subscribe!Timestamps00:00 Agentic Code Experiments00:53 Why Cloud Agents Matter02:08 Testing First Pillar03:36 Video Reviews Second Pillar04:29 Remote Control Third Pillar06:17 Meta Demos and Bug Repro13:36 Slash Commands and MCPs18:19 From Tab to Team Workflow31:41 Minimal Web UI Philosophy32:40 Why No File Editor34:38 Full Stack Cursor Debate36:34 Model Choice and Auto Routing38:34 Parallel Agents and Best Of N41:41 Subagents and Context Management44:48 Grind Mode and Throughput Future01:00:24 Cloud Agent Onboarding and MemoryTranscriptEP 77 - CURSOR - Audio version[00:00:00]Agentic Code ExperimentsSamantha: This is another experiment that we ran last year and didn’t decide to ship at that time, but may come back to LM Judge, but one that was also agentic and could write code. So it wasn’t just picking but also taking the learnings from two models or and models that it was looking at and writing a new diff.And what we found was that there were strengths to using models from different model providers as the base level of this process. Basically you could get almost like a synergistic output that was better than having a very unified like bottom model tier.Jonas: We think that over the coming months, the big unlock is not going to be one person with a model getting more done, like the water flowing faster and we’ll be making the pipe much wider and so paralyzing more, whether that’s swarms of agents or parallel agents, both of those are things that contribute to getting much more done in the same amount of time.Why Cloud Agents Matterswyx: This week, one of the biggest launches that Cursor’s ever done is cloud agents. I think you, you had [00:01:00] cloud agents before, but this was like, you give cursor a computer, right? Yeah. So it’s just basically they bought auto tab and then they repackaged it. Is that what’s going on, or,Jonas: that’s a big part of it.Yeah. Cloud agents already ran in their own computers, but they were sort of site reading code. Yeah. And those computers were not, they were like blank VMs typically that were not set up for the Devrel X for whatever repo the agents working on. One of the things that we talk about is if you put yourself in the model shoes and you were seeing tokens stream by and all you could do was cite read code and spit out tokens and hope that you had done the right thing,swyx: no chanceJonas: I’d be so bad.Like you obviously you need to run the code. And so that I think also is probably not that contrarian of a take, but no one has done that yet. And so giving the model the tools to onboard itself and then use full computer use end-to-end pixels in coordinates out and have the cloud computer with different apps in it is the big unlock that we’ve seen internally in terms of use usage of this going from, oh, we use it for little copy changes [00:02:00] to no.We’re really like driving new features with this kind of new type of entech workflow. Alright, let’s see it. Cool.Live Demo TourJonas: So this is what it looks like in cursor.com/agents. So this is one I kicked off a while ago. So on the left hand side is the chat. Very classic sort of agentic thing. The big new thing here is that the agent will test its changes.So you can see here it worked for half an hour. That is because it not only took time to write the tokens of code, it also took time to test them end to end. So it started Devrel servers iterate when needed. And so that’s one part of it is like model works for longer and doesn’t come back with a, I tried some things pr, but a I tested at pr that’s ready for your review.One of the other intuition pumps we use there is if a human gave you a PR asked you to review it and you hadn’t, they hadn’t tested it, you’d also be annoyed because you’d be like, only ask me for a review once it’s actually ready. So that’s what we’ve done withTesting Defaul
Every Agent Needs a Box — Aaron Levie, Box
The reception to our recent post on Code Reviews has been strong. Catch up!Amid a maelstrom of discussion on whether or not AI is killing SaaS, one of the top publicly listed SaaS companies in the world has just reported record revenues, clearing well over $1.1B in ARR for the first time with a 28% margin. As we comment on the pod, Aaron Levie is the rare public company CEO equally at home in both worlds of Silicon Valley and Wall Street/Main Street, by day helping 70% of the Fortune 500 with their Enterprise Advanced Suite, and yet by night is often found in the basements of early startups and tweeting viral insights about the future of agents.Now that both Cursor, Cloudflare, Perplexity, Anthropic and more have made Filesystems and Sandboxes and various forms of “Just Give the Agent a Box” cool (not just cool; it is now one of the single hottest areas in AI infrastructure growing 100% MoM), we find it a delightfully appropriate time to do the episode with the OG CEO who has been giving humans and computers Boxes since he was a college dropout pitching VCs at a Michael Arrington house party.Enjoy our special pod, with fan favorite returning guest/guest cohost Jeff Huber!Note: We didn’t directly discuss the AI vs SaaS debate - Aaron has done many, many, many other podcasts on that, and you should read his definitive essay on it. Most commentators do not understand SaaS businesses because they have never scaled one themselves, and deeply reflected on what the true value proposition of SaaS is.We also discuss Your Company is a Filesystem:We also shoutout CTO Ben Kus’ and the AI team, who talked about the technical architecture and will return for AIE WF 2026.Full Video EpisodeTimestamps* 00:00 Adapting Work for Agents* 01:29 Why Every Agent Needs a Box* 04:38 Agent Governance and Identity* 11:28 Why Coding Agents Took Off First* 21:42 Context Engineering and Search Limits* 31:29 Inside Agent Evals* 33:23 Industries and Datasets* 35:22 Building the Agent Team* 38:50 Read Write Agent Workflows* 41:54 Docs Graphs and Founder Mode* 55:38 Token FOMO Culture* 56:31 Production Function Secrets* 01:01:08 Film Roots to Box* 01:03:38 AI Future of Movies* 01:06:47 Media DevRel and EngineeringTranscriptAdapting Work for AgentsAaron Levie: Like you don’t write code, you talk to an agent and it goes and does it for you, and you may be at best review it. That’s even probably like, like largely not even what you’re doing. What’s happening is we are changing our work to make the agents effective. In that model, the agent didn’t really adapt to how we work.We basically adapted to how the agent works. All of the economy has to go through that exact same evolution. Right now, it’s a huge asset and an advantage for the teams that do it early and that are kinda wired into doing this ‘cause you’ll see compounding returns. But that’s just gonna take a while for most companies to actually go and get this deployed.swyx: Welcome to the Lane Space Pod. We’re back in the chroma studio with uh, chroma, CEO, Jeff Hoover. Welcome returning guest now guest host.Aaron Levie: It’s a pleasure. Wow. How’d you get upgraded to, uh, to that?swyx: Because he’s like the perfect guy to be guest those for you.Aaron Levie: That makes sense actually, for We love context. We, we both really love context le we really do.We really do.swyx: Uh, and we’re here with, uh, Aaron Levy. Welcome.Aaron Levie: Thank you. Good to, uh, good to be [00:01:00] here.swyx: Uh, yeah. So we’ve all met offline and like chatted a little bit, but like, it’s always nice to get these things in person and conversation. Yeah. You just started off with so much energy. You’re, you’re super excited about agents.I loveAaron Levie: agents.swyx: Yeah. Open claw. Just got by, got bought by OpenAI. No, not bought, but you know, you know what I mean?Aaron Levie: Some, some, you know, acquihire. Executiveswyx: hire.Aaron Levie: Executive hire. Okay. Executive hire. Say,swyx: hey, that’s my term. Okay. Um, what are you pounding the table on on agents? You have so many insightful tweets.Why Every Agent Needs a BoxAaron Levie: Well, the thing that, that we get super excited by that I think is probably, you know, should be relatively obvious is we’ve, we’ve built a platform to help enterprises manage their files and their, their corporate files and the permissions of who has access to those files and the sharing collaboration of those files.All of those files contain really, really important information for the enterprise. It might have your contracts, it might have your research materials, it might have marketing information, it might have your memos. All that data obviously has, you know, predominantly been used by humans. [00:02:00] But there’s been one really interesting problem, which is that, you know, humans only really work with their files during an active engagement with them, and they kind of go away and you don’t really see them for a long time.And all of a sudden, uh, with the power

METR’s Joel Becker on exponential Time Horizon Evals, Threat Models, and the Limits of AI Productivity
This is a free preview of a paid episode. To hear more, visit www.latent.spaceAIE Europe CFP and AIE World’s Fair paper submissions for CAIS peer review are due TODAY - do not delay! Last call ever.We’re excited to welcome METR for their first LS Pod, hopefully the first of many:METR are keepers of currently the single most infamous chart in AI:But every Latent Space reader should be sophisticated enough to know that the details matter and that hype and hyperbole go hand in hand in AI social media, because the millions of impressions that got, by people who don’t understand or care about the nuances, disclaimers, and error bars, far outreaches the 69k views on the corrections by the people who actually made the chart:There’s a lot of nuance both in making benchmarks (as we discovered with OpenAI on our SWE-Bench Verified podcast) and in extrapolating results from them, especially where exponentials and sigmoids are concerned. METR’s Long Horizons work itself has known biases that the authors have responsibly disclosed, but go far too underappreciated in the pursuit of doomer chart porn.If you’re interested in a short, sharable TED talk version of this pod, over at AIE CODE we were blessed to feature Joel twice, as a stage talk and with a longer form small workshop with Q&A:We also make sure cover some of METR’s lesser known work on Threat Evaluation but also Developer Productivity, where 2x friend of the pod and now Zyphra founder Quentin Anthony was the ONLY productive participant!Finally, if you’re the sort to read these show notes to the end, then you definitely deserve some pictures of Joel shredding the guitar at Love Band Karaoke which we mention at the end: Full Video PodTimestamps00:00 What METR Means00:39 Podcast Intro With Joel01:39 ME vs TR03:33 Time Horizon Origin Story04:56 Picking Tasks And Biases09:13 Time Horizon Misconceptions11:37 Opus 4.5 And Trendlines14:27 Productivity Studies And Explosions29:50 Compute Slows Progress30:47 Algorithms Need Compute32:45 Industry Spend and Data34:57 Clusters and Shipping Timelines36:44 Prediction Markets for Models38:10 Manifold Alpha Story43:04 Beyond Benchmarks Evals51:39 METR Roadmap and FarewellTranscript

[LIVE] Anthropic Distillation & How Models Cheat (SWE-Bench Dead) | Nathan Lambert & Sebastian Raschka
Swyx joined SAIL! Thank you SAIL Media, Prof. Tom Yeh, 8Lee, Hamid Bagheri, c9n, and many others for tuning into SAIL Live #6 with Nathan Lambert and Sebastian Raschka, PhD. Sharing here for the LS paid subscribers.We covered: This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe
🔬Searching the Space of All Possible Materials — Prof. Max Welling, CuspAI
Editor’s note: CuspAI raised a $100m Series A in September and is rumored to have reached a unicorn valuation. They have all-star advisors from Geoff Hinton to Yann Lecun and team of deep domain experts to tackle this next frontier in AI applications.In this episode, Max Welling traces the thread connecting quantum gravity, equivariant neural networks, diffusion models, and climate-focused materials discovery (yes, there is one!!!).We begin with a provocative framing: experiments as computation. Welling describes the idea of a “physics processing unit”—a world in which digital models and physical experiments work together, with nature itself acting as a kind of processor. It’s a grounded but ambitious vision of AI for science: not replacing chemists, but accelerating them.Along the way, we discuss:* Why symmetry and equivariance matter in deep learning* The tradeoff between scale and inductive bias* The deep mathematical links between diffusion models and stochastic thermodynamics* Why materials—not software—may be the real bottleneck for AI and the energy transition* What it actually takes to build an AI-driven materials platformMax reflects on moving from curiosity-driven theoretical physics (including work with Gerard ‘t Hooft) toward impact-driven research in climate and energy. The result is a conversation about convergence: physics and machine learning, digital models and laboratory experiments, long-term ambition and incremental progress.Full Video EpisodeTimestamps* 00:00:00 – The Physics Processing Unit (PPU): Nature as the Ultimate Computer* Max introduces the idea of a Physics Processing Unit — using real-world experiments as computation.* 00:00:44 – From Quantum Gravity to AI for Materials* Brandon frames Max’s career arc: VAE pioneer → equivariant GNNs → materials startup founder.* 00:01:34 – Curiosity vs Impact: How His Motivation Evolved* Max explains the shift from pure theoretical curiosity to climate-driven impact.* 00:02:43 – Why CaspAI Exists: Technology as Climate Strategy* Politics struggles; technology scales. Why materials innovation became the focus.* 00:03:39 – The Thread: Physics → Symmetry → Machine Learning* How gauge symmetry, group theory, and relativity informed equivariant neural networks.* 00:06:52 – AI for Science Is Exploding (Not Emerging)* The funding surge and why AI-for-Science feels like a new industrial era.* 00:07:53 – Why Now? The Two Catalysts Behind AI for Science* Protein folding, ML force fields, and the tipping point moment.* 00:10:12 – How Engineers Can Enter AI for Science* Practical pathways: curriculum, workshops, cross-disciplinary training.* 00:11:28 – Why Materials Matter More Than Software* The argument that everything—LLMs included—rests on materials innovation.* 00:13:02 – Materials as a Search Engine* The vision: automated exploration of chemical space like querying Google.* 01:14:48 – Inside CuspAI: The Platform Architecture* Generative models + multi-scale digital twin + experiment loop.* 00:21:17 – Automating Chemistry: Human-in-the-Loop First* Start manual → modular tools → agents → increasing autonomy.* 00:25:04 – Moonshots vs Incremental Wins* Balancing lighthouse materials with paid partnerships.* 00:26:22 – Why Breakthroughs Will Still Require Humans* Automation is vertical-specific and iterative.* 00:29:01 – What Is Equivariance (In Plain English)?* Symmetry in neural networks explained with the bottle example.* 00:30:01 – Why Not Just Use Data Augmentation?* The optimization trade-off between inductive bias and data scale.* 00:31:55 – Generative AI Meets Stochastic Thermodynamics* His upcoming book and the unification of diffusion models and physics.* 00:33:44 – When the Book Drops (ICLR?)TranscriptMax: I want to think of it as what I would call a physics processing unit, like a PPU, right? Which is you have digital processing units and then you have physics processing units. So it’s basically nature doing computations for you. It’s the fastest computer known, as possible even. It’s a bit hard to program because you have to do all these experiments. Those are quite bulky, it’s like a very large thing you have to do. But in a way it is a computation and that’s the way I want to see it. You can do computations in a data center and then you can ask nature to do some computations. Your interface with nature is a bit more complicated. But then these things will have to seamlessly work together to get to a new material that you’re interested in.[01:00:44:14 - 01:01:34:08]Brandon: Yeah, it’s a pleasure to have Max Woehling as a guest today. Max has done so much over his career that I’ve been so excited about. If you’re in the deep learning community, you probably know Max for his work on variational autocoders, which has literally stood the test of prime or officially stood the test of prime. If you are a scientist, you probably know him for his like, binary work on graph neural networks on equivariance. And if you’re a material science, you pro
Claude Code for Finance + The Global Memory Shortage: Doug O'Laughlin, SemiAnalysis
This is a free preview of a paid episode. To hear more, visit www.latent.spaceFirst speakers for AIE Europe and AIEi Miami have been announced. If you’re in Asia/Aus, come by Singapore and Melbourne. AI Engineering is going global!One year ago today, Anthropic launched Claude Code, to not much fanfare:The word of mouth was incredibly strong however, and so we were glad to be one of the first podcasts to invite Boris and Cat on in early May:As we discussed on the pod, all CC usage was API-based and therefore it was ridiculously expensive to do anything. This was then fixed by the team including Claude Code in the Claude Pro plan in early June, and then the virality caused us to make a rare trend call in late June:Now, 6 months on, Doug has just calculated that around 4% of GitHub is written by Claude Code:We talk about how Doug uses Claude Code to do SemiAnalysis work.Memory ManiaIn the second part of this episode, we also check in on Memory Mania, which is going to affect you (yes, you) at home if it hasn’t already:Full Episode on YouTubeTimestamps00:00 AI as Junior Analyst00:59 Meet Swyx and Doug03:30 From Value Mule to Semis06:28 Moore’s Law Ends Thesis12:02 Claude Code Awakening32:02 Agent Swarms Reality Check32:53 Kimi Swarm Benchmarks37:31 Bots vs Zapier Automation39:44 Claude Code Workflow Setup57:54 AGI Metrics and GDP01:04:48 Railroad CapEx Analogy01:06:00 Funding Bubbles and Demand01:08:11 Agents Replace Work Tools01:13:56 Codex vs Claude Race01:21:15 Microsoft and TPU Strategy01:34:13 TPU Window vs Nvidia01:36:30 HBM Supply Chain Squeeze01:39:41 Memory Shock and CXL01:45:20 Context Rationing Future01:54:37 Writing and Trail LessonsTranscript[00:00:00] AI as Junior Analyst[00:00:00] Doug: This crap makes mistakes all the time. All the time. It is still just like a, like I think of it once again as like a junior analyst, right? The analyst goes and does all this like really pain in the ass information and you bring it all together to make a good decision at the top. Historically what happens is that junior analyst, who I once was, went and gathered all that information, and after doing this enough times, there’s a meta level thinking that’s happening where it’s like, okay, here’s what I really understand and how this type of analysis, I’m an expert in, actually I’m very good at, I consistently have a hit rate.[00:00:28] Now I’m the expert, right? I don’t think that meta level learning is there yet. We’ll see if l ones do it, right? Everyone who’s spending one quadrillion dollars in the world thinks it will, it better, it better happen by if you’re spending, you know, a trillion dollars and there’s not meta level learning.[00:00:44] But for me, in our firm, that massively amplifies everyone who is an expert. ‘cause like you have to still do something that you can just like lop it up. It’s very obvious to me. What It’s slop.[00:00:59] Meet Swyx and Doug

⚡️The End of SWE-Bench Verified — Mia Glaese & Olivia Watkins, OpenAI Frontier Evals & Human Data
Olivia Watkins (Frontier Evals team) and Mia Glaese (VP of Research at OpenAI, leading the Codex, human data, and alignment teams) discuss a new blog post (https://openai.com/index/why-we-no-longer-evaluate-swe-bench-verified/) arguing that SWE-Bench Verified—long treated as a key “North Star” coding benchmark—has become saturated and highly contaminated, making it less useful for measuring real coding progress. SWE-Bench Verified originated as a major OpenAI-led cleanup of the original Princeton SWE-Bench benchmark, including a large human review effort with nearly 100 software engineers and multiple independent reviews to curate ~500 higher-quality tasks. But recent findings show that many remaining failures can reflect unfair or overly narrow tests (e.g., requiring specific naming or unspecified implementation details) rather than true model inability, and cite examples suggesting contamination such as models recalling repository-specific implementation details or task identifiers. From now on, OpenAI plans to stop reporting SWE-Bench Verified and instead focus on SWE-Bench Pro (from Scale), which is harder, more diverse (more repos and languages), includes longer tasks (1–4 hours and 4+ hours), and shows substantially less evidence of contamination under their “contamination auditor agent” analysis. We also discuss what future coding/agent benchmarks should measure beyond pass/fail tests—longer-horizon tasks, open-ended design decisions, code quality/maintainability, and real-world product-building—along with the tradeoffs between fast automated grading and human-intensive evaluation. 00:00 Meet the Frontier Evals Team00:56 Why SWE Bench Stalled01:47 How Verified Was Built04:32 Contamination In The Wild06:16 Unfair Tests And Narrow Specs08:40 When Benchmarks Saturate10:28 Switching To SWE Bench Pro12:31 What Great Coding Evals Measure18:17 Beyond Tests Dollars And Autonomy21:49 Preparedness And Future Directions This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

Bitter Lessons in Venture vs Growth: Anthropic vs OpenAI, Noam Shazeer, World Labs, Thinking Machines, Cursor, ASIC Economics — Martin Casado & Sarah Wang of a16z
Tickets for AIEi Miami and AIE Europe are live, with first wave speakers announced!From pioneering software-defined networking to backing many of the most aggressive AI model companies of this cycle, Martin Casado and Sarah Wang sit at the center of the capital, compute, and talent arms race reshaping the tech industry. As partners at a16z investing across infrastructure and growth, they’ve watched venture and growth blur, model labs turn dollars into capability at unprecedented speed, and startups raise nine-figure rounds before monetization.Martin and Sarah join us to unpack the new financing playbook for AI: why today’s rounds are really compute contracts in disguise, how the “raise → train → ship → raise bigger” flywheel works, and whether foundation model companies can outspend the entire app ecosystem built on top of them. They also share what’s underhyped (boring enterprise software), what’s overheated (talent wars and compensation spirals), and the two radically different futures they see for AI’s market structure.We discuss:* Martin’s “two futures” fork: infinite fragmentation and new software categories vs. a small oligopoly of general models that consume everything above them* The capital flywheel: how model labs translate funding directly into capability gains, then into revenue growth measured in weeks, not years* Why venture and growth have merged: $100M–$1B hybrid rounds, strategic investors, compute negotiations, and complex deal structures* The AGI vs. product tension: allocating scarce GPUs between long-term research and near-term revenue flywheels* Whether frontier labs can out-raise and outspend the entire app ecosystem built on top of their APIs* Why today’s talent wars ($10M+ comp packages, $B acqui-hires) are breaking early-stage founder math* Cursor as a case study: building up from the app layer while training down into your own models* Why “boring” enterprise software may be the most underinvested opportunity in the AI mania* Hardware and robotics: why the ChatGPT moment hasn’t yet arrived for robots and what would need to change* World Labs and generative 3D: bringing the marginal cost of 3D scene creation down by orders of magnitude* Why public AI discourse is often wildly disconnected from boardroom reality and how founders should navigate the noiseShow Notes:* “Where Value Will Accrue in AI: Martin Casado & Sarah Wang” - a16z show* “Jack Altman & Martin Casado on the Future of Venture Capital”* World Labs—Martin Casado• LinkedIn: https://www.linkedin.com/in/martincasado/• X: https://x.com/martin_casadoSarah Wang• LinkedIn: https://www.linkedin.com/in/sarah-wang-59b96a7• X: https://x.com/sarahdingwanga16z• https://a16z.com/Timestamps00:00:00 – Intro: Live from a16z00:01:20 – The New AI Funding Model: Venture + Growth Collide00:03:19 – Circular Funding, Demand & “No Dark GPUs”00:05:24 – Infrastructure vs Apps: The Lines Blur00:06:24 – The Capital Flywheel: Raise → Train → Ship → Raise Bigger00:09:39 – Can Frontier Labs Outspend the Entire App Ecosystem?00:11:24 – Character AI & The AGI vs Product Dilemma00:14:39 – Talent Wars, $10M Engineers & Founder Anxiety00:17:33 – What’s Underinvested? The Case for “Boring” Software00:19:29 – Robotics, Hardware & Why It’s Hard to Win00:22:42 – Custom ASICs & The $1B Training Run Economics00:24:23 – American Dynamism, Geography & AI Power Centers00:26:48 – How AI Is Changing the Investor Workflow (Claude Cowork)00:29:12 – Two Futures of AI: Infinite Expansion or Oligopoly?00:32:48 – If You Can Raise More Than Your Ecosystem, You Win00:34:27 – Are All Tasks AGI-Complete? Coding as the Test Case00:38:55 – Cursor & The Power of the App Layer00:44:05 – World Labs, Spatial Intelligence & 3D Foundation Models00:47:20 – Thinking Machines, Founder Drama & Media Narratives00:52:30 – Where Long-Term Power Accrues in the AI StackTranscriptLatent.Space - Inside AI’s $10B+ Capital Flywheel — Martin Casado & Sarah Wang of a16z[00:00:00] Welcome to Latent Space (Live from a16z) + Meet the Guests[00:00:00] Alessio: Hey everyone. Welcome to the Latent Space podcast, live from a 16 z. Uh, this is Alessio founder Kernel Lance, and I’m joined by Twix, editor of Latent Space.[00:00:08] swyx: Hey, hey, hey. Uh, and we’re so glad to be on with you guys. Also a top AI podcast, uh, Martin Cado and Sarah Wang. Welcome, very[00:00:16] Martin Casado: happy to be here and welcome.[00:00:17] swyx: Yes, uh, we love this office. We love what you’ve done with the place. Uh, the new logo is everywhere now. It’s, it’s still getting, takes a while to get used to, but it reminds me of like sort of a callback to a more ambitious age, which I think is kind of[00:00:31] Martin Casado: definitely makes a statement.[00:00:33] swyx: Yeah.[00:00:34] Martin Casado: Not quite sure what that statement is, but it makes a statement.[00:00:37] swyx: Uh, Martin, I go back with you to Netlify.[00:00:40] Martin Casado: Yep.[00:00:40] swyx: Uh, and, uh, you know, you create a software defined ne

Owning the AI Pareto Frontier — Jeff Dean
From rewriting Google’s search stack in the early 2000s to reviving sparse trillion-parameter models and co-designing TPUs with frontier ML research, Jeff Dean has quietly shaped nearly every layer of the modern AI stack. As Chief AI Scientist at Google and a driving force behind Gemini, Jeff has lived through multiple scaling revolutions from CPUs and sharded indices to multimodal models that reason across text, video, and code.Jeff joins us to unpack what it really means to “own the Pareto frontier,” why distillation is the engine behind every Flash model breakthrough, how energy (in picojoules) not FLOPs is becoming the true bottleneck, what it was like leading the charge to unify all of Google’s AI teams, and why the next leap won’t come from bigger context windows alone, but from systems that give the illusion of attending to trillions of tokens.We discuss:* Jeff’s early neural net thesis in 1990: parallel training before it was cool, why he believed scaling would win decades early, and the “bigger model, more data, better results” mantra that held for 15 years* The evolution of Google Search: sharding, moving the entire index into memory in 2001, softening query semantics pre-LLMs, and why retrieval pipelines already resemble modern LLM systems* Pareto frontier strategy: why you need both frontier “Pro” models and low-latency “Flash” models, and how distillation lets smaller models surpass prior generations* Distillation deep dive: ensembles → compression → logits as soft supervision, and why you need the biggest model to make the smallest one good* Latency as a first-class objective: why 10–50x lower latency changes UX entirely, and how future reasoning workloads will demand 10,000 tokens/sec* Energy-based thinking: picojoules per bit, why moving data costs 1000x more than a multiply, batching through the lens of energy, and speculative decoding as amortization* TPU co-design: predicting ML workloads 2–6 years out, speculative hardware features, precision reduction, sparsity, and the constant feedback loop between model architecture and silicon* Sparse models and “outrageously large” networks: trillions of parameters with 1–5% activation, and why sparsity was always the right abstraction* Unified vs. specialized models: abandoning symbolic systems, why general multimodal models tend to dominate vertical silos, and when vertical fine-tuning still makes sense* Long context and the illusion of scale: beyond needle-in-a-haystack benchmarks toward systems that narrow trillions of tokens to 117 relevant documents* Personalized AI: attending to your emails, photos, and documents (with permission), and why retrieval + reasoning will unlock deeply personal assistants* Coding agents: 50 AI interns, crisp specifications as a new core skill, and how ultra-low latency will reshape human–agent collaboration* Why ideas still matter: transformers, sparsity, RL, hardware, systems — scaling wasn’t blind; the pieces had to multiply togetherShow Notes:* Gemma 3 Paper* Gemma 3* Gemini 2.5 Report* Jeff Dean’s “Software Engineering Advice fromBuilding Large-Scale Distributed Systems” Presentation (with Back of the Envelope Calculations)* Latency Numbers Every Programmer Should Know by Jeff Dean* The Jeff Dean Facts* Jeff Dean Google Bio* Jeff Dean on “Important AI Trends” @Stanford AI Club* Jeff Dean & Noam Shazeer — 25 years at Google (Dwarkesh)—Jeff Dean* LinkedIn: https://www.linkedin.com/in/jeff-dean-8b212555* X: https://x.com/jeffdeanGoogle* https://google.com* https://deepmind.googleFull Video EpisodeTimestamps00:00:04 — Introduction: Alessio & Swyx welcome Jeff Dean, chief AI scientist at Google, to the Latent Space podcast00:00:30 — Owning the Pareto Frontier & balancing frontier vs low-latency models00:01:31 — Frontier models vs Flash models + role of distillation00:03:52 — History of distillation and its original motivation00:05:09 — Distillation’s role in modern model scaling00:07:02 — Model hierarchy (Flash, Pro, Ultra) and distillation sources00:07:46 — Flash model economics & wide deployment00:08:10 — Latency importance for complex tasks00:09:19 — Saturation of some tasks and future frontier tasks00:11:26 — On benchmarks, public vs internal00:12:53 — Example long-context benchmarks & limitations00:15:01 — Long-context goals: attending to trillions of tokens00:16:26 — Realistic use cases beyond pure language00:18:04 — Multimodal reasoning and non-text modalities00:19:05 — Importance of vision & motion modalities00:20:11 — Video understanding example (extracting structured info)00:20:47 — Search ranking analogy for LLM retrieval00:23:08 — LLM representations vs keyword search00:24:06 — Early Google search evolution & in-memory index00:26:47 — Design principles for scalable systems00:28:55 — Real-time index updates & recrawl strategies00:30:06 — Classic “Latency numbers every programmer should know”00:32:09 — Cost of memory vs compute and energy emphasis00:34:33 — TPUs & hardware trade-offs for serving models00:

🔬Beyond AlphaFold: How Boltz is Open-Sourcing the Future of Drug Discovery
This podcast features Gabriele Corso and Jeremy Wohlwend, co-founders of Boltz and authors of the Boltz Manifesto, discussing the rapid evolution of structural biology models from AlphaFold to their own open-source suite, Boltz-1 and Boltz-2. The central thesis is that while single-chain protein structure prediction is largely “solved” through evolutionary hints, the next frontier lies in modeling complex interactions (protein-ligand, protein-protein) and generative protein design, which Boltz aims to democratize via open-source foundations and scalable infrastructure.Full Video PodOn YouTube!Timestamps* 00:00 Introduction to Benchmarking and the “Solved” Protein Problem* 06:48 Evolutionary Hints and Co-evolution in Structure Prediction* 10:00 The Importance of Protein Function and Disease States* 15:31 Transitioning from AlphaFold 2 to AlphaFold 3 Capabilities* 19:48 Generative Modeling vs. Regression in Structural Biology* 25:00 The “Bitter Lesson” and Specialized AI Architectures* 29:14 Development Anecdotes: Training Boltz-1 on a Budget* 32:00 Validation Strategies and the Protein Data Bank (PDB)* 37:26 The Mission of Boltz: Democratizing Access and Open Source* 41:43 Building a Self-Sustaining Research Community* 44:40 Boltz-2 Advancements: Affinity Prediction and Design* 51:03 BoltzGen: Merging Structure and Sequence Prediction* 55:18 Large-Scale Wet Lab Validation Results* 01:02:44 Boltz Lab Product Launch: Agents and Infrastructure* 01:13:06 Future Directions: Developpability and the “Virtual Cell”* 01:17:35 Interacting with Skeptical Medicinal ChemistsKey SummaryEvolution of Structure Prediction & Evolutionary Hints* Co-evolutionary Landscapes: The speakers explain that breakthrough progress in single-chain protein prediction relied on decoding evolutionary correlations where mutations in one position necessitate mutations in another to conserve 3D structure.* Structure vs. Folding: They differentiate between structure prediction (getting the final answer) and folding (the kinetic process of reaching that state), noting that the field is still quite poor at modeling the latter.* Physics vs. Statistics: RJ posits that while models use evolutionary statistics to find the right “valley” in the energy landscape, they likely possess a “light understanding” of physics to refine the local minimum.The Shift to Generative Architectures* Generative Modeling: A key leap in AlphaFold 3 and Boltz-1 was moving from regression (predicting one static coordinate) to a generative diffusion approach that samples from a posterior distribution.* Handling Uncertainty: This shift allows models to represent multiple conformational states and avoid the “averaging” effect seen in regression models when the ground truth is ambiguous.* Specialized Architectures: Despite the “bitter lesson” of general-purpose transformers, the speakers argue that equivariant architectures remain vastly superior for biological data due to the inherent 3D geometric constraints of molecules.Boltz-2 and Generative Protein Design* Unified Encoding: Boltz-2 (and BoltzGen) treats structure and sequence prediction as a single task by encoding amino acid identities into the atomic composition of the predicted structure.* Design Specifics: Instead of a sequence, users feed the model blank tokens and a high-level “spec” (e.g., an antibody framework), and the model decodes both the 3D structure and the corresponding amino acids.* Affinity Prediction: While model confidence is a common metric, Boltz-2 focuses on affinity prediction—quantifying exactly how tightly a designed binder will stick to its target.Real-World Validation and Productization* Generalized Validation: To prove the model isn’t just “regurgitating” known data, Boltz tested its designs on 9 targets with zero known interactions in the PDB, achieving nanomolar binders for two-thirds of them.* Boltz Lab Infrastructure: The newly launched Boltz Lab platform provides “agents” for protein and small molecule design, optimized to run 10x faster than open-source versions through proprietary GPU kernels.* Human-in-the-Loop: The platform is designed to convert skeptical medicinal chemists by allowing them to run parallel screens and use their intuition to filter model outputs.TranscriptRJ [00:05:35]: But the goal remains to, like, you know, really challenge the models, like, how well do these models generalize? And, you know, we’ve seen in some of the latest CASP competitions, like, while we’ve become really, really good at proteins, especially monomeric proteins, you know, other modalities still remain pretty difficult. So it’s really essential, you know, in the field that there are, like, these efforts to gather, you know, benchmarks that are challenging. So it keeps us in line, you know, about what the models can do or not.Gabriel [00:06:26]: Yeah, it’s interesting you say that, like, in some sense, CASP, you know, at CASP 14, a problem was solved and, like, pretty comprehensively, right? But at th

The First Mechanistic Interpretability Frontier Lab — Myra Deng & Mark Bissell of Goodfire AI
From Palantir and Two Sigma to building Goodfire into the poster-child for actionable mechanistic interpretability, Mark Bissell (Member of Technical Staff) and Myra Deng (Head of Product) are trying to turn “peeking inside the model” into a repeatable production workflow by shipping APIs, landing real enterprise deployments, and now scaling the bet with a recent $150M Series B funding round at a $1.25B valuation.In this episode, we go far beyond the usual “SAEs are cool” take. We talk about Goodfire’s core bet: that the AI lifecycle is still fundamentally broken because the only reliable control we have is data and we post-train, RLHF, and fine-tune by “slurping supervision through a straw,” hoping the model picks up the right behaviors while quietly absorbing the wrong ones. Goodfire’s answer is to build a bi-directional interface between humans and models: read what’s happening inside, edit it surgically, and eventually use interpretability during training so customization isn’t just brute-force guesswork.Mark and Myra walk through what that looks like when you stop treating interpretability like a lab demo and start treating it like infrastructure: lightweight probes that add near-zero latency, token-level safety filters that can run at inference time, and interpretability workflows that survive messy constraints (multilingual inputs, synthetic→real transfer, regulated domains, no access to sensitive data). We also get a live window into what “frontier-scale interp” means operationally (i.e. steering a trillion-parameter model in real time by targeting internal features) plus why the same tooling generalizes cleanly from language models to genomics, medical imaging, and “pixel-space” world models.We discuss:* Myra + Mark’s path: Palantir (health systems, forward-deployed engineering) → Goodfire early team; Two Sigma → Head of Product, translating frontier interpretability research into a platform and real-world deployments* What “interpretability” actually means in practice: not just post-hoc poking, but a broader “science of deep learning” approach across the full AI lifecycle (data curation → post-training → internal representations → model design)* Why post-training is the first big wedge: “surgical edits” for unintended behaviors likereward hacking, sycophancy, noise learned during customization plus the dream of targeted unlearning and bias removal without wrecking capabilities* SAEs vs probes in the real world: why SAE feature spaces sometimes underperform classifiers trained on raw activations for downstream detection tasks (hallucination, harmful intent, PII), and what that implies about “clean concept spaces”* Rakuten in production: deploying interpretability-based token-level PII detection at inference time to prevent routing private data to downstream providers plus the gnarly constraints: no training on real customer PII, synthetic→real transfer, English + Japanese, and tokenization quirks* Why interp can be operationally cheaper than LLM-judge guardrails: probes are lightweight, low-latency, and don’t require hosting a second large model in the loop* Real-time steering at frontier scale: a demo of steering Kimi K2 (~1T params) live and finding features via SAE pipelines, auto-labeling via LLMs, and toggling a “Gen-Z slang” feature across multiple layers without breaking tool use* Hallucinations as an internal signal: the case that models have latent uncertainty / “user-pleasing” circuitry you can detect and potentially mitigate more directly than black-box methods* Steering vs prompting: the emerging view that activation steering and in-context learning are more closely connected than people think, including work mapping between the two (even for jailbreak-style behaviors)* Interpretability for science: using the same tooling across domains (genomics, medical imaging, materials) to debug spurious correlations and extract new knowledge up to and including early biomarker discovery work with major partners* World models + “pixel-space” interpretability: why vision/video models make concepts easier to see, how that accelerates the feedback loop, and why robotics/world-model partners are especially interesting design partners* The north star: moving from “data in, weights out” to intentional model design where experts can impart goals and constraints directly, not just via reward signals and brute-force post-training—Goodfire AI* Website: https://goodfire.ai* LinkedIn: https://www.linkedin.com/company/goodfire-ai/* X: https://x.com/GoodfireAIMyra Deng* Website: https://myradeng.com/* LinkedIn: https://www.linkedin.com/in/myra-deng/* X: https://x.com/myra_dengMark Bissell* LinkedIn: https://www.linkedin.com/in/mark-bissell/* X: https://x.com/MarkMBissellFull Video EpisodeTimestamps00:00:00 Introduction00:00:05 Introduction to the Latent Space Podcast and Guests from Goodfire00:00:29 What is Goodfire? Mission and Focus on Interpretability00:01:01 Goodfire’s Practical Approach to Interpretability0

🔬 Automating Science: World Models, Scientific Taste, Agent Loops — Andrew White
Editor’s note: Welcome to our new AI for Science pod, with your new hosts RJ and Brandon! See the writeup on Latent.Space (https://Latent.Space) for more details on why we’re launching 2 new pods this year. RJ Honicky is a co-founder and CTO at MiraOmics (https://miraomics.bio/), building AI models and services for single cell, spatial transcriptomics and pathology slide analysis. Brandon Anderson builds AI systems for RNA drug discovery at Atomic AI (https://atomic.ai). Anything said on this podcast is his personal take — not Atomic’s.—From building molecular dynamics simulations at the University of Washington to red-teaming GPT-4 for chemistry applications and co-founding Future House (a focused research organization) and Edison Scientific (a venture-backed startup automating science at scale)—Andrew White has spent the last five years living through the full arc of AI’s transformation of scientific discovery, from ChemCrow (the first Chemistry LLM agent) triggering White House briefings and three-letter agency meetings, to shipping Kosmos, an end-to-end autonomous research system that generates hypotheses, runs experiments, analyzes data, and updates its world model to accelerate the scientific method itself.* The ChemCrow story: GPT-4 + React + cloud lab automation, released March 2023, set off a storm of anxiety about AI-accelerated bioweapons/chemical weapons, led to a White House briefing (Jake Sullivan presented the paper to the president in a 30-minute block), and meetings with three-letter agencies asking “how does this change breakout time for nuclear weapons research?”* Why scientific taste is the frontier: RLHF on hypotheses didn’t work (humans pay attention to tone, actionability, and specific facts, not “if this hypothesis is true/false, how does it change the world?”), so they shifted to end-to-end feedback loops where humans click/download discoveries and that signal rolls up to hypothesis quality* Cosmos: the full scientific agent with a world model (distilled memory system, like a Git repo for scientific knowledge) that iterates on hypotheses via literature search, data analysis, and experiment design—built by Ludo after weeks of failed attempts, the breakthrough was putting data analysis in the loop (literature alone didn’t work)* Why molecular dynamics and DFT are overrated: “MD and DFT have consumed an enormous number of PhDs at the altar of beautiful simulation, but they don’t model the world correctly—you simulate water at 330 Kelvin to get room temperature, you overfit to validation data with GGA/B3LYP functionals, and real catalysts (grain boundaries, dopants) are too complicated for DFT”* The AlphaFold vs. DE Shaw Research counterfactual: DE Shaw built custom silicon, taped out chips with MD algorithms burned in, ran MD at massive scale in a special room in Times Square, and David Shaw flew in by helicopter to present—Andrew thought protein folding would require special machines to fold one protein per day, then AlphaFold solved it in Google Colab on a desktop GPU* The E3 Zero reward hacking saga: trained a model to generate molecules with specific atom counts (verifiable reward), but it kept exploiting loopholes, then a Nature paper came out that year proving six-nitrogen compounds are possible under extreme conditions, then it started adding nitrogen gas (purchasable, doesn’t participate in reactions), then acid-base chemistry to move one atom, and Andrew ended up “building a ridiculous catalog of purchasable compounds in a Bloom filter” to close the loopAndrew White* FutureHouse: http://futurehouse.org/* Edison Scientific: http://edisonscientific.com/* X: https://x.com/andrewwhite01* Cosmos paper: https://futurediscovery.org/cosmosFull Video EpisodeTimestamps00:00:00 Introduction: Andrew White on Automating Science with Future House and Edison Scientific00:02:22 The Academic to Startup Journey: Red Teaming GPT-4 and the ChemCrow Paper00:11:35 Future House Origins: The FRO Model and Mission to Automate Science00:12:32 Resigning Tenure: Why Leave Academia for AI Science00:15:54 What Does ‘Automating Science’ Actually Mean?00:17:30 The Lab-in-the-Loop Bottleneck: Why Intelligence Isn’t Enough00:18:39 Scientific Taste and Human Preferences: The 52% Agreement Problem00:20:05 Paper QA, Robin, and the Road to Cosmos00:21:57 World Models as Scientific Memory: The GitHub Analogy00:40:20 The Bitter Lesson for Biology: Why Molecular Dynamics and DFT Are Overrated00:43:22 AlphaFold’s Shock: When First Principles Lost to Machine Learning00:46:25 Enumeration and Filtration: How AI Scientists Generate Hypotheses00:48:15 CBRN Safety and Dual-Use AI: Lessons from Red Teaming01:00:40 The Future of Chemistry is Language: Multimodal Debate01:08:15 Ether Zero: The Hilarious Reward Hacking Adventures01:10:12 Will Scientists Be Displaced? Jevons Paradox and Infinite Discovery01:13:46 Cosmos in Practice: Open Access and Enterprise Partnerships This is a public episode. If you'd like to discuss this w

Captaining IMO Gold, Deep Think, On-Policy RL, Feeling the AGI in Singapore — Yi Tay
From shipping Gemini Deep Think and IMO Gold to launching the Reasoning and AGI team in Singapore, Yi Tay has spent the last 18 months living through the full arc of Google DeepMind’s pivot from architecture research to RL-driven reasoning—watching his team go from a dozen researchers to 300+, training models that solve International Math Olympiad problems in a live competition, and building the infrastructure to scale deep thinking across every domain, and driving Gemini to the top of the leaderboards across every category. Yi Returns to dig into the inside story of the IMO effort and more!We discuss:* Yi’s path: Brain → Reka → Google DeepMind → Reasoning and AGI team Singapore, leading model training for Gemini Deep Think and IMO Gold* The IMO Gold story: four co-captains (Yi in Singapore, Jonathan in London, Jordan in Mountain View, and Tong leading the overall effort), training the checkpoint in ~1 week, live competition in Australia with professors punching in problems as they came out, and the tension of not knowing if they’d hit Gold until the human scores came in (because the Gold threshold is a percentile, not a fixed number)* Why they threw away AlphaProof: “If one model can’t do it, can we get to AGI?” The decision to abandon symbolic systems and bet on end-to-end Gemini with RL was bold and non-consensus* On-policy vs. off-policy RL: off-policy is imitation learning (copying someone else’s trajectory), on-policy is the model generating its own outputs, getting rewarded, and training on its own experience—”humans learn by making mistakes, not by copying”* Why self-consistency and parallel thinking are fundamental: sampling multiple times, majority voting, LM judges, and internal verification are all forms of self-consistency that unlock reasoning beyond single-shot inference* The data efficiency frontier: humans learn from 8 orders of magnitude less data than models, so where’s the bug? Is it the architecture, the learning algorithm, backprop, off-policyness, or something else?* Three schools of thought on world models: (1) Genie/spatial intelligence (video-based world models), (2) Yann LeCun’s JEPA + FAIR’s code world models (modeling internal execution state), (3) the amorphous “resolution of possible worlds” paradigm (curve-fitting to find the world model that best explains the data)* Why AI coding crossed the threshold: Yi now runs a job, gets a bug, pastes it into Gemini, and relaunches without even reading the fix—”the model is better than me at this”* The Pokémon benchmark: can models complete Pokédex by searching the web, synthesizing guides, and applying knowledge in a visual game state? “Efficient search of novel idea space is interesting, but we’re not even at the point where models can consistently apply knowledge they look up”* DSI and generative retrieval: re-imagining search as predicting document identifiers with semantic tokens, now deployed at YouTube (symmetric IDs for RecSys) and Spotify* Why RecSys and IR feel like a different universe: “modeling dynamics are strange, like gravity is different—you hit the shuttlecock and hear glass shatter, cause and effect are too far apart”* The closed lab advantage is increasing: the gap between frontier labs and open source is growing because ideas compound over time, and researchers keep finding new tricks that play well with everything built before* Why ideas still matter: “the last five years weren’t just blind scaling—transformers, pre-training, RL, self-consistency, all had to play well together to get us here”* Gemini Singapore: hiring for RL and reasoning researchers, looking for track record in RL or exceptional achievement in coding competitions, and building a small, talent-dense team close to the frontier—Yi Tay* Google DeepMind: https://deepmind.google* X: https://x.com/YiTayMLFull Video EpisodeTimestamps00:00:00 Introduction: Returning to Google DeepMind and the Singapore AGI Team00:04:52 The Philosophy of On-Policy RL: Learning from Your Own Mistakes00:12:00 IMO Gold Medal: The Journey from AlphaProof to End-to-End Gemini00:21:33 Training IMO Cat: Four Captains Across Three Time Zones00:26:19 Pokemon and Long-Horizon Reasoning: Beyond Academic Benchmarks00:36:29 AI Coding Assistants: From Lazy to Actually Useful00:32:59 Reasoning, Chain of Thought, and Latent Thinking00:44:46 Is Attention All You Need? Architecture, Learning, and the Local Minima00:55:04 Data Efficiency and World Models: The Next Frontier01:08:12 DSI and Generative Retrieval: Reimagining Search with Semantic IDs01:17:59 Building GDM Singapore: Geography, Talent, and the Symposium01:24:18 Hiring Philosophy: High Stats, Research Taste, and Student Budgets01:28:49 Health, HRV, and Research Performance: The 23kg Journey This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

Brex’s AI Hail Mary — With CTO James Reggio
From building internal AI labs to becoming CTO of Brex, James Reggio has helped lead one of the most disciplined AI transformations inside a real financial institution where compliance, auditability, and customer trust actually matter.We sat down with Reggio to unpack Brex’s three-pillar AI strategy (corporate, operational, and product AI) [https://www.brex.com/journal/brex-ai-native-operations], how SOP-driven agents beat overengineered RL in ops, why Brex lets employees “build their own AI stack” instead of picking winners [https://www.conductorone.com/customers/brex/], and how a small, founder-heavy AI team is shipping production agents to 40,000+ companies. Reggio also goes deep on Brex’s multi-agent “network” architecture, evals for multi-turn systems, agentic coding’s second-order effects on codebase understanding, and why the future of finance software looks less like dashboards and more like executive assistants coordinating specialist agents behind the scenes.We discuss:* Brex’s three-pillar AI strategy: corporate AI for 10x employee workflows, operational AI for cost and compliance leverage, and product AI that lets customers justify Brex as part of their AI strategy to the board* Why SOP-driven agents beat overengineered RL in finance ops, and how breaking work into auditable, repeatable steps unlocked faster automation in KYC, underwriting, fraud, and disputes* Building an internal AI platform early: LLM gateways, prompt/version management, evals, cost observability, and why platform work quietly became the force multiplier behind everything else* Multi-agent “networks” vs single-agent tools: why Brex’s EA-style assistant coordinates specialist agents (policy, travel, reimbursements) through multi-turn conversations instead of one-shot tool calls* The audit agent pattern: separating detection, judgment, and follow-up into different agents to reduce false negatives without overwhelming finance teams* Centralized AI teams without resentment: how Brex avoided “AI envy” by tying work to business impact and letting anyone transfer in if they cared deeply enough* Letting employees build their own AI stack: ChatGPT vs Claude vs Gemini, Cursor vs Windsurf, and why Brex refuses to pick winners in fast-moving tool races* Measuring adoption without vanity metrics: why “% of code written by AI” is the wrong KPI and what second-order effects (slop, drift, code ownership) actually matter* Evals in the real world: regression tests from ops QA, LLM-as-judge for multi-turn agents, and why integration-style evals break faster than you expect* Teaching AI fluency at scale: the user → advocate → builder → native framework, ops-led training, spot bonuses, and avoiding fear-based adoption* Re-interviewing the entire engineering org: using agentic coding interviews internally to force hands-on skill upgrades without formal performance scoring* Headcount in the age of agents: why Brex grew the business without growing engineering, and why AI amplifies bad architecture as fast as good decisions* The future of finance software: why dashboards fade, assistants take over, and agent-to-agent collaboration becomes the real UI—James Reggio* X: https://x.com/jamesreggio* LinkedIn: https://www.linkedin.com/in/jamesreggio/Where to find Latent Space* X: https://x.com/latentspacepodFull Video EpisodeTimestamps00:00:00 Introduction00:01:24 From Mobile Engineer to CTO: The Founder's Path00:03:00 Quitters Welcome: Building a Founder-Friendly Culture00:05:13 The AI Team Structure: 10-Person Startup Within Brex00:11:55 Building the Brex Agent Platform: Multi-Agent Networks00:13:45 Tech Stack Decisions: TypeScript, Mastra, and MCP00:24:32 Operational AI: Automating Underwriting, KYC, and Fraud00:16:40 The Brex Assistant: Executive Assistant for Every Employee00:40:26 Evaluation Strategy: From Simple SOPs to Multi-Turn Evals00:37:11 Agentic Coding Adoption: Cursor, Windsurf, and the Engineering Interview00:58:51 AI Fluency Levels: From User to Native01:09:14 The Audit Agent Network: Finance Team Agents in Action01:03:33 The Future of Engineering Headcount and AI Leverage This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

Artificial Analysis: Independent LLM Evals as a Service — with George Cameron and Micah-Hill Smith
Happy New Year! You may have noticed that in 2025 we had moved toward YouTube as our primary podcasting platform. As we’ll explain in the next State of Latent Space post, we’ll be doubling down on Substack again and improving the experience for the over 100,000 of you who look out for our emails and website updates!We first mentioned Artificial Analysis in 2024, when it was still a side project in a Sydney basement. They then were one of the few Nat Friedman and Daniel Gross’ AIGrant companies to raise a full seed round from them and have now become the independent gold standard for AI benchmarking—trusted by developers, enterprises, and every major lab to navigate the exploding landscape of models, providers, and capabilities.We have chatted with both Clementine Fourrier of HuggingFace’s OpenLLM Leaderboard and (the freshly valued at $1.7B) Anastasios Angelopoulos of LMArena on their approaches to LLM evals and trendspotting, but Artificial Analysis have staked out an enduring and important place in the toolkit of the modern AI Engineer by doing the best job of independently running the most comprehensive set of evals across the widest range of open and closed models, and charting their progress for broad industry analyst use.George Cameron and Micah-Hill Smith have spent two years building Artificial Analysis into the platform that answers the questions no one else will: Which model is actually best for your use case? What are the real speed-cost trade-offs? And how open is “open” really?We discuss:* The origin story: built as a side project in 2023 while Micah was building a legal AI assistant, launched publicly in January 2024, and went viral after Swyx’s retweet* Why they run evals themselves: labs prompt models differently, cherry-pick chain-of-thought examples (Google Gemini 1.0 Ultra used 32-shot prompts to beat GPT-4 on MMLU), and self-report inflated numbers* The mystery shopper policy: they register accounts not on their own domain and run intelligence + performance benchmarks incognito to prevent labs from serving different models on private endpoints* How they make money: enterprise benchmarking insights subscription (standardized reports on model deployment, serverless vs. managed vs. leasing chips) and private custom benchmarking for AI companies (no one pays to be on the public leaderboard)* The Intelligence Index (V3): synthesizes 10 eval datasets (MMLU, GPQA, agentic benchmarks, long-context reasoning) into a single score, with 95% confidence intervals via repeated runs* Omissions Index (hallucination rate): scores models from -100 to +100 (penalizing incorrect answers, rewarding \”I don’t know\”), and Claude models lead with the lowest hallucination rates despite not always being the smartest* GDP Val AA: their version of OpenAI’s GDP-bench (44 white-collar tasks with spreadsheets, PDFs, PowerPoints), run through their Stirrup agent harness (up to 100 turns, code execution, web search, file system), graded by Gemini 3 Pro as an LLM judge (tested extensively, no self-preference bias)* The Openness Index: scores models 0-18 on transparency of pre-training data, post-training data, methodology, training code, and licensing (AI2 OLMo 2 leads, followed by Nous Hermes and NVIDIA Nemotron)* The smiling curve of AI costs: GPT-4-level intelligence is 100-1000x cheaper than at launch (thanks to smaller models like Amazon Nova), but frontier reasoning models in agentic workflows cost more than ever (sparsity, long context, multi-turn agents)* Why sparsity might go way lower than 5%: GPT-4.5 is ~5% active, Gemini models might be ~3%, and Omissions Index accuracy correlates with total parameters (not active), suggesting massive sparse models are the future* Token efficiency vs. turn efficiency: GPT-5 costs more per token but solves Tau-bench in fewer turns (cheaper overall), and models are getting better at using more tokens only when needed (5.1 Codex has tighter token distributions)* V4 of the Intelligence Index coming soon: adding GDP Val AA, Critical Point, hallucination rate, and dropping some saturated benchmarks (human-eval-style coding is now trivial for small models)Links to Artificial Analysis* Website: https://artificialanalysis.ai* George Cameron on X: https://x.com/georgecameron* Micah-Hill Smith on X: https://x.com/micahhsmithFull Episode on YouTubeTimestamps* 00:00 Introduction: Full Circle Moment and Artificial Analysis Origins* 01:19 Business Model: Independence and Revenue Streams* 04:33 Origin Story: From Legal AI to Benchmarking Need* 16:22 AI Grant and Moving to San Francisco* 19:21 Intelligence Index Evolution: From V1 to V3* 11:47 Benchmarking Challenges: Variance, Contamination, and Methodology* 13:52 Mystery Shopper Policy and Maintaining Independence* 28:01 New Benchmarks: Omissions Index for Hallucination Detection* 33:36 Critical Point: Hard Physics Problems and Research-Level Reasoning* 23:01 GDP Val AA: Agentic Benchmark for Real Work Tasks* 50:19 Stirrup Agent Harness: O

[State of Evals] LMArena's $1.7B Vision — Anastasios Angelopoulos, LMArena
We are reupping this episode after LMArena announced their fresh Series A (https://www.theinformation.com/articles/ai-evaluation-startup-lmarena-valued-1-7-billion-new-funding-round?rc=luxwz4), raising $150m at a $1.7B valuation, with $30M annualized consumption revenue (aka $2.5m MRR) after their September evals product launch.—-From building LMArena in a Berkeley basement to raising $100M and becoming the de facto leaderboard for frontier AI, Anastasios Angelopoulos returns to Latent Space to recap 2025 in one of the most influential platforms in AI—trusted by millions of users, every major lab, and the entire industry to answer one question: which model is actually best for real-world use cases? We caught up with Anastasios live at NeurIPS 2025 to dig into the origin story (spoiler: it started as an academic project incubated by Anjney Midha at a16z, who formed an entity and gave grants before they even committed to starting a company), why they decided to spin out instead of staying academic or nonprofit (the only way to scale was to build a company), how they’re spending that $100M (inference costs, React migration off Gradio, and hiring world-class talent across ML, product, and go-to-market), the leaderboard delusion controversy and why their response demolished the paper’s claims (factual errors, misrepresentation of open vs. closed source sampling, and ignoring the transparency of preview testing that the community loves), why platform integrity comes first (the public leaderboard is a charity, not a pay-to-play system—models can’t pay to get on, can’t pay to get off, and scores reflect millions of real votes), how they’re expanding into occupational verticals (medicine, legal, finance, creative marketing) and multimodal arenas (video coming soon), why consumer retention is earned every single day (sign-in and persistent history were the unlock, but users are fickle and can leave at any moment), and his vision for Arena as the central evaluation platform that provides the North Star for the industry—constantly fresh, immune to overfitting, and grounded in millions of real-world conversations from real users.We discuss:* The $100M raise: use of funds is primarily inference costs (funding free usage for tens of millions of monthly conversations), React migration off Gradio (custom loading icons, better developer hiring, more flexibility), and hiring world-class talent* The scale: 250M+ conversations on the platform, tens of millions per month, 25% of users do software for a living, and half of users are now logged in* The leaderboard illusion controversy: Cohere researchers claimed undisclosed private testing created inequities, but Arena’s response demolished the paper’s factual errors (misrepresented open vs. closed source sampling, ignored transparency of preview testing that the community loves)* Why preview testing is loved by the community: secret codenames (Gemini Nano Banana, named after PM Naina’s nickname), early access to unreleased models, and the thrill of being first to vote on frontier capabilities* The Nano Banana moment: changed Google’s market share overnight, billions of dollars in stock movement, and validated that multimodal models (image generation, video) are economically critical for marketing, design, and AI-for-science* New categories: occupational and expert arenas (medicine, legal, finance, creative marketing), Code Arena, and video arena coming soonFull Video EpisodeTimestamps00:00:00 Introduction: Anastasios from Arena and the LM Arena Journey00:01:36 The Anjney Midha Incubation: From Berkeley Basement to Startup00:02:47 The Decision to Start a Company: Scaling Beyond Academia00:03:38 The $100M Raise: Use of Funds and Platform Economics00:05:10 Arena's User Base: 5M+ Users and Diverse Demographics00:06:02 The Competitive Landscape: Artificial Analysis, AI.xyz, and Arena's Differentiation00:08:12 Educational Value and Learning from the Community00:08:41 Technical Migration: From Gradio to React and Platform Evolution00:10:18 Leaderboard Delusion Paper: Addressing Critiques and Maintaining Integrity00:12:29 Nano Banana Moment: How Preview Models Create Market Impact00:13:41 Multimodal AI and Image Generation: From Skepticism to Economic Value00:15:37 Core Principles: Platform Integrity and the Public Leaderboard as Charity00:18:29 Future Roadmap: Expert Categories, Multimodal, Video, and Occupational Verticals00:19:10 API Strategy and Focus: Doing One Thing Well00:19:51 Community Management and Retention: Sign-In, History, and Daily Value00:22:21 Partnerships and Agent Evaluation: From Devon to Full-Featured Harnesses00:21:49 Hiring and Building a High-Performance Team This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

[NeurIPS Best Paper] 1000 Layer Networks for Self-Supervised RL — Kevin Wang et al, Princeton
From undergraduate research seminars at Princeton to winning Best Paper award at NeurIPS 2025, Kevin Wang, Ishaan Javali, Michał Bortkiewicz, Tomasz Trzcinski, Benjamin Eysenbach defied conventional wisdom by scaling reinforcement learning networks to 1,000 layers deep—unlocking performance gains that the RL community thought impossible. We caught up with the team live at NeurIPS to dig into the story behind RL1000: why deep networks have worked in language and vision but failed in RL for over a decade (spoiler: it’s not just about depth, it’s about the objective), how they discovered that self-supervised RL (learning representations of states, actions, and future states via contrastive learning) scales where value-based methods collapse, the critical architectural tricks that made it work (residual connections, layer normalization, and a shift from regression to classification), why scaling depth is more parameter-efficient than scaling width (linear vs. quadratic growth), how Jax and GPU-accelerated environments let them collect hundreds of millions of transitions in hours (the data abundance that unlocked scaling in the first place), the “critical depth” phenomenon where performance doesn’t just improve—it multiplies once you cross 15M+ transitions and add the right architectural components, why this isn’t just “make networks bigger” but a fundamental shift in RL objectives (their code doesn’t have a line saying “maximize rewards”—it’s pure self-supervised representation learning), how deep teacher, shallow student distillation could unlock deployment at scale (train frontier capabilities with 1000 layers, distill down to efficient inference models), the robotics implications (goal-conditioned RL without human supervision or demonstrations, scaling architecture instead of scaling manual data collection), and their thesis that RL is finally ready to scale like language and vision—not by throwing compute at value functions, but by borrowing the self-supervised, representation-learning paradigms that made the rest of deep learning work.We discuss:* The self-supervised RL objective: instead of learning value functions (noisy, biased, spurious), they learn representations where states along the same trajectory are pushed together, states along different trajectories are pushed apart—turning RL into a classification problem* Why naive scaling failed: doubling depth degraded performance, doubling again with residual connections and layer norm suddenly skyrocketed performance in one environment—unlocking the “critical depth” phenomenon* Scaling depth vs. width: depth grows parameters linearly, width grows quadratically—depth is more parameter-efficient and sample-efficient for the same performance* The Jax + GPU-accelerated environments unlock: collecting thousands of trajectories in parallel meant data wasn’t the bottleneck, and crossing 15M+ transitions was when deep networks really paid off* The blurring of RL and self-supervised learning: their code doesn’t maximize rewards directly, it’s an actor-critic goal-conditioned RL algorithm, but the learning burden shifts to classification (cross-entropy loss, representation learning) instead of TD error regression* Why scaling batch size unlocks at depth: traditional RL doesn’t benefit from larger batches because networks are too small to exploit the signal, but once you scale depth, batch size becomes another effective scaling dimension—RL1000 Team (Princeton)* 1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities: https://openreview.net/forum?id=s0JVsx3bx1Full Video EpisodeTimestamps00:00:00 Introduction: Best Paper Award and NeurIPS Poster Experience00:01:11 Team Introductions and Princeton Research Origins00:03:35 The Deep Learning Anomaly: Why RL Stayed Shallow00:04:35 Self-Supervised RL: A Different Approach to Scaling00:05:13 The Breakthrough Moment: Residual Connections and Critical Depth00:07:15 Architectural Choices: Borrowing from ResNets and Avoiding Vanishing Gradients00:07:50 Clarifying the Paper: Not Just Big Networks, But Different Objectives00:08:46 Blurring the Lines: RL Meets Self-Supervised Learning00:09:44 From TD Errors to Classification: Why This Objective Scales00:11:06 Architecture Details: Building on Braw and SymbaFowl00:12:05 Robotics Applications: Goal-Conditioned RL Without Human Supervision00:13:15 Efficiency Trade-offs: Depth vs Width and Parameter Scaling00:15:48 JAX and GPU-Accelerated Environments: The Data Infrastructure00:18:05 World Models and Next State Classification00:22:37 Unlocking Batch Size Scaling Through Network Capacity00:24:10 Compute Requirements: State-of-the-Art on a Single GPU00:21:02 Future Directions: Distillation, VLMs, and Hierarchical Planning00:27:15 Closing Thoughts: Challenging Conventional Wisdom in RL Scaling This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

[State of Code Evals] After SWE-bench, Code Clash & SOTA Coding Benchmarks recap — John Yang
From creating SWE-bench in a Princeton basement to shipping CodeClash, SWE-bench Multimodal, and SWE-bench Multilingual, John Yang has spent the last year and a half watching his benchmark become the de facto standard for evaluating AI coding agents—trusted by Cognition (Devin), OpenAI, Anthropic, and every major lab racing to solve software engineering at scale. We caught up with John live at NeurIPS 2025 to dig into the state of code evals heading into 2026: why SWE-bench went from ignored (October 2023) to the industry standard after Devin’s launch (and how Walden emailed him two weeks before the big reveal), how the benchmark evolved from Django-heavy to nine languages across 40 repos (JavaScript, Rust, Java, C, Ruby), why unit tests as verification are limiting and long-running agent tournaments might be the future (CodeClash: agents maintain codebases, compete in arenas, and iterate over multiple rounds), the proliferation of SWE-bench variants (SWE-bench Pro, SWE-bench Live, SWE-Efficiency, AlgoTune, SciCode) and how benchmark authors are now justifying their splits with curation techniques instead of just “more repos,” why Tau-bench’s “impossible tasks” controversy is actually a feature not a bug (intentionally including impossible tasks flags cheating), the tension between long autonomy (5-hour runs) vs. interactivity (Cognition’s emphasis on fast back-and-forth), how Terminal-bench unlocked creativity by letting PhD students and non-coders design environments beyond GitHub issues and PRs, the academic data problem (companies like Cognition and Cursor have rich user interaction data, academics need user simulators or compelling products like LMArena to get similar signal), and his vision for CodeClash as a testbed for human-AI collaboration—freeze model capability, vary the collaboration setup (solo agent, multi-agent, human+agent), and measure how interaction patterns change as models climb the ladder from code completion to full codebase reasoning.We discuss:* John’s path: Princeton → SWE-bench (October 2023) → Stanford PhD with Diyi Yang and the Iris Group, focusing on code evals, human-AI collaboration, and long-running agent benchmarks* The SWE-bench origin story: released October 2023, mostly ignored until Cognition’s Devin launch kicked off the arms race (Walden emailed John two weeks before: “we have a good number”)* SWE-bench Verified: the curated, high-quality split that became the standard for serious evals* SWE-bench Multimodal and Multilingual: nine languages (JavaScript, Rust, Java, C, Ruby) across 40 repos, moving beyond the Django-heavy original distribution* The SWE-bench Pro controversy: independent authors used the “SWE-bench” name without John’s blessing, but he’s okay with it (”congrats to them, it’s a great benchmark”)* CodeClash: John’s new benchmark for long-horizon development—agents maintain their own codebases, edit and improve them each round, then compete in arenas (programming games like Halite, economic tasks like GDP optimization)* SWE-Efficiency (Jeffrey Maugh, John’s high school classmate): optimize code for speed without changing behavior (parallelization, SIMD operations)* AlgoTune, SciCode, Terminal-bench, Tau-bench, SecBench, SRE-bench: the Cambrian explosion of code evals, each diving into different domains (security, SRE, science, user simulation)* The Tau-bench “impossible tasks” debate: some tasks are underspecified or impossible, but John thinks that’s actually a feature (flags cheating if you score above 75%)* Cognition’s research focus: codebase understanding (retrieval++), helping humans understand their own codebases, and automatic context engineering for LLMs (research sub-agents)* The vision: CodeClash as a testbed for human-AI collaboration—vary the setup (solo agent, multi-agent, human+agent), freeze model capability, and measure how interaction changes as models improve—John Yang* SWE-bench: https://www.swebench.com* X: https://x.com/jyangballinFull Video EpisodeTimestamps00:00:00 Introduction: John Yang on SWE-bench and Code Evaluations00:00:31 SWE-bench Origins and Devon's Impact on the Coding Agent Arms Race00:01:09 SWE-bench Ecosystem: Verified, Pro, Multimodal, and Multilingual Variants00:02:17 Moving Beyond Django: Diversifying Code Evaluation Repositories00:03:08 Code Clash: Long-Horizon Development Through Programming Tournaments00:04:41 From Halite to Economic Value: Designing Competitive Coding Arenas00:06:04 Ofir's Lab: SWE-ficiency, AlgoTune, and SciCode for Scientific Computing00:07:52 The Benchmark Landscape: TAU-bench, Terminal-bench, and User Simulation00:09:20 The Impossible Task Debate: Refusals, Ambiguity, and Benchmark Integrity00:12:32 The Future of Code Evals: Long Autonomy vs Human-AI Collaboration00:14:37 Call to Action: User Interaction Data and Codebase Understanding Research This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

[State of Post-Training] From GPT-4.1 to 5.1: RLVR, Agent & Token Efficiency — Josh McGrath, OpenAI
From pre-training data curation to shipping GPT-4o, o1, o3, and now GPT-5 thinking and the shopping model, Josh McGrath has lived through the full arc of OpenAI’s post-training evolution—from the PPO vs DPO debates of 2023 to today’s RLVR era, where the real innovation isn’t optimization methods but data quality, signal trust, and token efficiency. We sat down with Josh at NeurIPS 2025 to dig into the state of post-training heading into 2026: why RLHF and RLVR are both just policy gradient methods (the difference is the input data, not the math), how GRPO from DeepSeek Math was underappreciated as a shift toward more trustworthy reward signals (math answers you can verify vs. human preference you can’t), why token efficiency matters more than wall-clock time (GPT-5 to 5.1 bumped evals and slashed tokens), how Codex has changed his workflow so much he feels “trapped” by 40-minute design sessions followed by 15-minute agent sprints, the infrastructure chaos of scaling RL (”way more moving parts than pre-training”), why long context will keep climbing but agents + graph walks might matter more than 10M-token windows, the shopping model as a test bed for interruptability and chain-of-thought transparency, why personality toggles (Anton vs Clippy) are a real differentiator users care about, and his thesis that the education system isn’t producing enough people who can do both distributed systems and ML research—the exact skill set required to push the frontier when the bottleneck moves every few weeks.We discuss:* Josh’s path: pre-training data curation → post-training researcher at OpenAI, shipping GPT-4o, o1, o3, GPT-5 thinking, and the shopping model* Why he switched from pre-training to post-training: “Do I want to make 3% compute efficiency wins, or change behavior by 40%?”* The RL infrastructure challenge: way more moving parts than pre-training (tasks, grading setups, external partners), and why babysitting runs at 12:30am means jumping into unfamiliar code constantly* How Codex has changed his workflow: 40-minute design sessions compressed into 15-minute agent sprints, and the strange “trapped” feeling of waiting for the agent to finish* The RLHF vs RLVR debate: both are policy gradient methods, the real difference is data quality and signal trust (human preference vs. verifiable correctness)* Why GRPO (from DeepSeek Math) was underappreciated: not just an optimization trick, but a shift toward reward signals you can actually trust (math answers over human vibes)* The token efficiency revolution: GPT-5 to 5.1 bumped evals and slashed tokens, and why thinking in tokens (not wall-clock time) unlocks better tool-calling and agent workflows* Personality toggles: Anton (tool, no warmth) vs Clippy (friendly, helpful), and why Josh uses custom instructions to make his model “just a tool”* The router problem: having a router at the top (GPT-5 thinking vs non-thinking) and an implicit router (thinking effort slider) creates weird bumps, and why the abstractions will eventually merge* Long context: climbing Graph Blocks evals, the dream of 10M+ token windows, and why agents + graph walks might matter more than raw context length* Why the education system isn’t producing enough people who can do both distributed systems and ML research, and why that’s the bottleneck for frontier labs* The 2026 vision: neither pre-training nor post-training is dead, we’re in the fog of war, and the bottleneck will keep moving (so emotional stability helps)—Josh McGrath* OpenAI: https://openai.com* X: https://x.com/j_mcgraphFull Video EpisodeTimestamps00:00:00 Introduction: Josh McGrath on Post-Training at OpenAI00:04:37 The Shopping Model: Black Friday Launch and Interruptability00:07:11 Model Personality and the Anton vs Clippy Divide00:08:26 Beyond PPO vs DPO: The Data Quality Spectrum in RL00:01:40 Infrastructure Challenges: Why Post-Training RL is Harder Than Pre-Training00:13:12 Token Efficiency: The 2D Plot That Matters Most00:03:45 Codex Max and the Flow Problem: 40 Minutes of Planning, 15 Minutes of Waiting00:17:29 Long Context and Graph Blocks: Climbing Toward Perfect Context00:21:23 The ML-Systems Hybrid: What's Hard to Hire For00:24:50 Pre-Training Isn't Dead: Living Through Technological Revolution This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe

[State of RL/Reasoning] IMO/IOI Gold, OpenAI o3/GPT-5, and Cursor Composer — Ashvin Nair, Cursor
From Berkeley robotics and OpenAI’s 2017 Dota-era internship to shipping RL breakthroughs on GPT-4o, o1, and o3, and now leading model development at Cursor, Ashvin Nair has done it all. We caught up with Ashvin at NeurIPS 2025 to dig into the inside story of OpenAI’s reasoning team (spoiler: it went from a dozen people to 300+), why IOI Gold felt reachable in 2022 but somehow didn’t change the world when o1 actually achieved it, how RL doesn’t generalize beyond the training distribution (and why that means you need to bring economically useful tasks into distribution by co-designing products and models), the deeper lessons from the RL research era (2017–2022) and why most of it didn’t pan out because the community overfitted to benchmarks, how Cursor is uniquely positioned to do continual learning at scale with policy updates every two hours and product-model co-design that keeps engineers in the loop instead of context-switching into ADHD hell, and his bet that the next paradigm shift is continual learning with infinite memory—where models experience something once (a bug, a mistake, a user pattern) and never forget it, storing millions of deployment tokens in weights without overloading capacity.We discuss:* Ashvin’s path: Berkeley robotics PhD → OpenAI 2017 intern (Dota era) → o1/o3 reasoning team → Cursor ML lead in three months* Why robotics people are the most grounded at NeurIPS (they work with the real world) and simulation people are the most unhinged (Lex Fridman’s take)* The IOI Gold paradox: “If you told me we’d achieve IOI Gold in 2022, I’d assume we could all go on vacation—AI solved, no point working anymore. But life is still the same.”* The RL research era (2017–2022) and why most of it didn’t pan out: overfitting to benchmarks, too many implicit knobs to tune, and the community rewarding complex ideas over simple ones that generalize* Inside the o1 origin story: a dozen people, conviction from Ilya and Jakob Pachocki that RL would work, small-scale prototypes producing “surprisingly accurate reasoning traces” on math, and first-principles belief that scaled* The reasoning team grew from ~12 to 300+ people as o1 became a product and safety, tooling, and deployment scaled up* Why Cursor is uniquely positioned for continual learning: policy updates every two hours (online RL on tab), product and ML sitting next to each other, and the entire software engineering workflow (code, logs, debugging, DataDog) living in the product* Composer as the start of product-model co-design: smart enough to use, fast enough to stay in the loop, and built by a 20–25 person ML team with high-taste co-founders who code daily* The next paradigm shift: continual learning with infinite memory—models that experience something once (a bug, a user mistake) and store it in weights forever, learning from millions of deployment tokens without overloading capacity (trillions of pretraining tokens = plenty of room)* Why off-policy RL is unstable (Ashvin’s favorite interview question) and why Cursor does two-day work trials instead of whiteboard interviews* The vision: automate software engineering as a process (not just answering prompts), co-design products so the entire workflow (write code, check logs, debug, iterate) is in-distribution for RL, and make models that never make the same mistake twice—Ashvin Nair* Cursor: https://cursor.com* X: https://x.com/ashvinnair_Full Video EpisodeTimestamps00:00:00 Introduction: From Robotics to Cursor via OpenAI00:01:58 The Robotics to LLM Agent Transition: Why Code Won00:09:11 RL Research Winter and Academic Overfitting00:11:45 The Scaling Era and Moving Goalposts: IOI Gold Doesn't Mean AGI00:21:30 OpenAI's Reasoning Journey: From Codex to O100:20:03 The Blip: Thanksgiving 2023 and OpenAI Governance00:22:39 RL for Reasoning: The O-Series Conviction and Scaling00:25:47 O1 to O3: Smooth Internal Progress vs External Hype Cycles00:33:07 Why Cursor: Co-Designing Products and Models for Real Work00:34:14 Composer and the Future: Online Learning Every Two Hours00:35:15 Continual Learning: The Missing Paradigm Shift00:44:00 Hiring at Cursor and Why Off-Policy RL is Unstable This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.latent.space/subscribe