Beating GPT-4 with Open Source LLMs — with Michael Royzen of Phind
Latent Space: The AI Engineer Podcast · Michael Royzen
Audio is streamed directly from the publisher (api.substack.com) as published in their RSS feed. Play Podcasts does not host this file. Rights-holders can request removal through the copyright & takedown page.
Show Notes
At the AI Pioneers Summit we announced Latent Space Launchpad, an AI-focused accelerator in partnership with Decibel. If you’re an AI founder of enterprise early adopter, fill out this form and we’ll be in touch with more details.
We also have a lot of events coming up as we wrap up the year, so make sure to check out our community events page and come say hi!
We previously interviewed the founders of many developer productivity startups embedded in the IDE, like Codium AI, Cursor, and Codeium. We also covered Replit’s (former) SOTA model, replit-code-v1-3b and most recently had Amjad and Michele announce replit-code-v1_5-3b at the AI Engineer Summit.
Much has been speculated about the StackOverflow traffic drop since ChatGPT release, but the experience is still not perfect. There’s now a new player in the “search for developers” arena: Phind.
Phind’s goal is to help you find answers to your technical questions, and then help you implement them. For example “What should I use to create a frontend for a Python script?” returns a list of frameworks as well as links to the sources. You can then ask follow up questions on specific implementation details, having it write some code for you, etc. They have both a web version and a VS Code integration
They recently were top of Hacker News with the announcement of their latest model, which is now the #1 rated model on the BigCode Leaderboard, beating their previous version:
TLDR Cheat Sheet:
* Based on CodeLlama-34B, which is trained on 500B tokens
* Further fine-tuned on 70B+ high quality code and reasoning tokens
* Expanded context window to 16k tokens
* 5x faster than GPT-4 (100 tok/s vs 20 tok/s on single stream)
* 74.7% HumanEval vs 45% for the base model
We’ve talked before about HumanEval being limited in a lot of cases and how it needs to be complemented with “vibe based” evals. Phind thinks of evals alongside two axis:
* Context quality: when asking the model to generate code, was the context high quality? Did we put outdated examples in it? Did we retrieve the wrong files?
* Result quality: was the code generated correct? Did it follow the instructions I gave it or did it misunderstand some of it?
If you have bad results with bad context, you might get to a good result by working on better RAG. If you have good context and bad result you might either need to work on your prompting or you have hit the limits of the model, which leads you to fine tuning (like they did).
Michael was really early to this space and started working on CommonCrawl filtering and indexing back in 2020, which led to a lot of the insights that now power Phind. We talked about that evolution, his experience at YC, how he got Paul Graham to invest in Phind and invite him to dinner at his house, and how Ron Conway connected him with Jensen Huang to get access to more GPUs!
Show Notes
* Phind
* LMQL
* People:
* Paul Graham (pg)
* Yacine Jernite from HuggingFace
Timestamps
* [00:00:00] Intros & Michael's early interest in computer vision
* [00:03:14] Pivoting to NLP and natural language question answering models
* [00:07:20] Building a search engine index of Common Crawl and web pages
* [00:11:26] Releasing the first version of Hello based on the search index and BigScience T0 model
* [00:14:02] Deciding to focus the search engine specifically for programmers
* [00:17:39] Overview of Phind's current product and focus on code reasoning
* [00:21:51] The future vision for Phind to go from idea to complete code
* [00:24:03] Transitioning to using the GPT-4 model and the impact it had
* [00:29:43] Developing the Phind model based on CodeLlama and additional training
* [00:32:28] Plans to continue improving the Phind model with open source technologies
* [00:43:59] The story of meeting Paul Graham and Ron Conway and how that impacted the company
* [00:53:02] How Ron Conway helped them get GPUs from Nvidia
* [00:57:12] Tips on how Michael learns complex AI topics
* [01:01:12] Lightning Round
Transcript
Alessio: Hey everyone, welcome to the Latent Space Podcast. This is Alessio, partner and CTO of Residence and Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol AI. [00:00:19]
Swyx: Hey, and today we have in the studio Michael Royzen from Phind. Welcome. [00:00:23]
Michael: Thank you so much. [00:00:24]
Alessio: It's great to be here. [00:00:25]
Swyx: Yeah, we are recording this in a surprisingly hot October in San Francisco. And sometimes the studio works, but the blue angels are flying by right now, so sorry about the noise. So welcome. I've seen Phind blow up this year, mostly, I think since your launch in Feb and V2 and then your Hacker News posts. We tend to like to introduce our guests, but then obviously you can fill in the blanks with the origin story. You actually were a high school entrepreneur. You started SmartLens, which is a computer vision startup in 2017. [00:00:59]
Michael: That's right. I remember when like TensorFlow came out and people started talking about, obviously at the time after AlexNet, the deep learning revolution was already in flow. Good computer vision models were a thing. And what really made me interested in deep learning was I got invited to go to Apple's WWDC conference as a student scholar because I was really into making iOS apps at the time. So I go there and I go to this talk where they added an API that let people run computer vision models on the device using far more efficient GPU primitives. After seeing that, I was like, oh, this is cool. This is going to have a big explosion of different computer vision models running locally on the iPhone. And so I had this crazy idea where it was like, what if I could just make this model that could recognize just about anything and have it run on the device? And that was the genesis for what eventually became SmartLens. I took this data set called ImageNet 22K. So most people, when they think of ImageNet, think of ImageNet 1K. But the full ImageNet actually has, I think, 22,000 different categories. So I took that, filtered it, pre-processed it, and then did a massive fine tune on Inception V3, which was, I think, the state of the art deep convolutional computer vision model at the time. And to my surprise, it actually worked insanely well. I had no idea what would happen if I give a single model. I think it ended up being 17,000 categories approximately that I collapsed them into. It worked so well that it actually worked better than Google Lens, which released its V1 around the same time. And on top of this, the model ran on the device. So it didn't need an internet connection. A big part of the issue with Google Lens at the time was that connections were slower. 4G was around, but it wasn't nearly as fast. So there was a noticeable lag having to upload an image to a server and get it back. But just processing it locally, even on the iPhones of the day in 2017, much faster. It was a cool little project. It got some traction. TechCrunch wrote about it. There was kind of like one big spike in usage, and then over time it tapered off. But people still pay for it, which is wild. [00:03:14]
Swyx: That's awesome. Oh, it's like a monthly or annual subscription? [00:03:16]
Michael: Yeah, it's like a monthly subscription. [00:03:18]
Swyx: Even though you don't actually have any servers? [00:03:19]
Michael: Even though we don't have any servers. That's right. I was in high school. I had a little bit of money. I was like, yeah. [00:03:25]
Swyx: That's awesome. I always wonder what the modern equivalents kind of "Be my eyes". And it would be actually disclosed in the GPT-4 Vision system card recently that the usage was surprisingly not that frequent. The extent to which all three of us have our sense of sight. I would think that if I lost my sense of sight, I would use Be My Eyes all the time. The average usage of Be My Eyes per day is 1.5 times. [00:03:49]
Michael: Exactly. I was thinking about this as well, where I was also looking into image captioning, where you give a model an image and then it tells you what's in the image. But it turns out that what people want is the exact opposite. People want to give a description of an image and then have the AI generate the image. [00:04:04]
Alessio: Oh, the other way. [00:04:06]
Michael: Exactly. And so at the time, I think there were some GANs, NVIDIA was working on this back in 2019, 2020. They had some impressive, I think, face GANs where they had this model that would produce these really high quality portraits, but it wasn't able to take a natural language description the way Midjourney or DALL-E 3 can and just generate you an image with exactly what you described in it. [00:04:32]
Swyx: And how did that get into NLP? [00:04:35]
Michael: Yeah, I released the SmartLens app and that was around the time I was a senior in high school. I was applying to college. College rolls around. I'm still sort of working on updating the app in college. But I start thinking like, hey, what if I make an enterprise version of this as well? At the time, there was Clarify that provided some computer vision APIs, but I thought this massive classification model works so well and it's so small and so fast, might as well build an enterprise product. And I didn't even talk to users or do any of those things that you're supposed to do. I was just mainly interested in building a type of backend I've never built before. So I was mainly just doing it for myself just to learn. I built this enterprise classification product and as part of it, I'm also building an invoice processing product where using some of the aspects that I built previously, although obviously it's very different from classification, I wanted to be able to just extract a bunch of structured data from an unstructured invoice through our API. And that's what led me to Hugnyface for the first time because that involves some natural language components. And so I go to Hugnyface and with various encoder models that were around at the time, I used the standard BERT and also Longformer, which came out around the same time. And Longformer was interesting because it had a much bigger context window than those models at the time, like BERT, all of the first gen encoder only models, they only had a context window of 512 tokens and it's fixed. There's none of this alibi or ROPE that we have now where we can basically massage it to be longer. They're fixed, 512 absolute encodings. Longformer at the time was the only way that you can fit, say, like a sequence length or ask a question about like 4,000 tokens worth of text. Implemented Longformer, it worked super well, but like nobody really kind of used the enterprise product and that's kind of what I expected because at the end of the day, it was COVID. I was building this kind of mostly for me, mostly just kind of to learn. And so nobody really used it and my heart wasn't in it and I kind of just shelved it. But a little later, I went back to HugMeFace and I saw this demo that they had, and this is in the summer of 2020. They had this demo made by this researcher, Yacine Jernite, and he called it long form question answering. And basically, it was this self-contained notebook demo where you can ask a question the way that we do now with ChatGPT. It would do a lookup into some database and it would give you an answer. And it absolutely blew my mind. The demo itself, it used, I think, BART as the model and in the notebook, it had support for both an Elasticsearch index of Wikipedia, as well as a dense index powered by Facebook's FAISS. I think that's how you pronounce it. It was very iffy, but when it worked, I think the question in the demo was, why are all boats white? When it worked, it blew my mind that instead of doing this few shot thing, like people were doing with GPT-3 at the time, which is all the rage, you could just ask a model a question, provide no extra context, and it would know what to do and just give you the answer. It blew my mind to such an extent that I couldn't stop thinking about that. When I started thinking about ways to make it better, I tried training, doing the fine tune with a larger BART model. And this BART model, yeah, it was fine tuned on this Reddit data set called Eli5. So basically... [00:08:02]
Alessio: Subreddit. [00:08:03]
Swyx: Yeah, subreddit. [00:08:04]
Alessio: Yeah. [00:08:05]
Michael: And put it into like a well-formatted, relatively clean data set of like human questions and human answers. And that was a really great bootstrap for that model to be able to answer these types of questions. And so Eli5 actually turned out to be a good data set for training these types of question answering models, because the question is written by a human, the answer is written by a human, and at least helps the model get the format right, even if the model is still very small and it can't really think super well, at least it gets the format right. And so it ends up acting as kind of a glorified summarization model, where if it's fed in high quality context from the retrieval system, it's able to have a reasonably high quality output. And so once I made the model as big as I can, just fine tuning on BART large, I started looking for ways to improve the index. So in the demo, in the notebook, there were instructions for how to make an Elasticsearch index just for Wikipedia. And I was like, why not do all of Common Crawl? So I downloaded Common Crawl, and thankfully, I had like 10 or $15,000 worth of AWS credits left over from the SmartLens project. And that's what really allowed me to do this, because there's no other funding. I was still in college, not a lot of money, and so I was able to spin up a bunch of instances and just process all of Common Crawl, which is massive. So it's roughly like, it's terabytes of text. I went to Alexa to get the top 1,000 websites or 10,000 websites in the world, then filtered only by those websites, and then indexed those websites, because the web pages were already included in Dump. [00:09:38]
Swyx: You mean to supplement Common Crawl or to filter Common Crawl? [00:09:41]
Michael: Filter Common Crawl. [00:09:42]
Alessio: Oh, okay. [00:09:43]
Michael: Yeah, sorry. So we filtered Common Crawl just by the top, I think, 10,000, just to limit this, because obviously there's this massive long tail of small sites that are really cool, actually. There's other projects like, shout out to Marginalia Nu, which is a search engine specialized on the long tail. I think they actually exclude the top 10,000. [00:10:03]
Swyx: That's what they do. [00:10:04]
Alessio: Yeah. [00:10:05]
Swyx: I've seen them around, I just don't really know what their pitch is. Okay, that makes sense. [00:10:08]
Michael: So they exclude all the top stuff. So the long tail is cool, but for this, that was kind of out of the question, and that was most of the data anyway. So we've removed that. And then I indexed the remaining approximately 350 million webpages through Elasticsearch. So I built this index running on AWS with these webpages, and it actually worked quite well. You can ask it general common knowledge, history, politics, current events, questions, and it would be able to do a fast lookup in the index, feed it into the model, and it would give a surprisingly good result. And so when I saw that, I thought that this is definitely doable. And it kind of shocked me that no one else was doing this. And so this was now the fall of 2020. And yeah, I was kind of shocked no one was doing this, but it costs a lot of money to keep it up. I was still in college. There are things going on. I got bogged down by classes. And so I ended up shelving this for almost a full year, actually. When I returned to it in fall of 2021, when BigScience released T0, when BigScience released the T0 models, that was a massive jump in the reasoning ability of the model. And it was better at reasoning, it was better at summarization, it was still a glorified summarizer basically. [00:11:26]
Swyx: Was this a precursor to Bloom? Because Bloom's the one that I know. [00:11:29]
Alessio: Yeah. [00:11:30]
Michael: Actually coming out in 2022. But Bloom had other problems where for whatever reason, the Bloom models just were never really that good, which is so sad because I really wanted to use them. But I think they didn't turn on that much data. I think they used like the original, they were trying to replicate GPT-3. So they just use those numbers, which we now know are like far below Chinchilla Optimal and even Chinchilla Optimal, which we can like talk about later, like what we're currently doing with MIMO goes, yeah, it goes way beyond that. But they weren't trying enough data. I'm not sure how that data was clean, but it probably wasn't super clean. And then they didn't really do any fine tuning until much later. So T0 worked well because they took the T5 models, which were closer to Chinchilla Optimal because I think they were trained on also like 300 something billion tokens, similar to GPT-3, but the models were much smaller. I think T0 is the first model that did large scale instruction tuning from diverse data sources in the fall of 2021. This is before Instruct GPT. This is before Flan T5, which came out in 2022. This is the very, very first, at least well-known example of that. And so it came out and then I did, on top of T0, I also did the Reddit Eli5 fine tune. And that was the first model and system that actually worked well enough to where I didn't get discouraged like I did previously, because the failure cases of the BART based system was so egregious. Sometimes it would just miss a question so horribly that it was just extremely discouraging. But for the first time, it was working reasonably well. Also using a much bigger model. I think the BART model is like 800 million parameters, but T0, we were using 3B. So it was T0, 3B, bigger model. And that was the very first iteration of Hello. So I ended up doing a show HN on Hacker News in January 2022 of that system. Our fine tune T0 model connected to our Elasticsearch index of those 350 million top 10,000 common crawl websites. And to the best of my knowledge, I think that's the first example that I'm aware of a LLM search engine model that's effectively connected to like a large enough index that I consider like an internet scale. So I think we were the first to release like an internet scale LLM powered rag search system In January 2022, around the time me and my future co-founder, Justin, we were like, this seems like the future. [00:14:02]
Alessio: This is really cool. [00:14:03]
Michael: I couldn't really sleep even like I was going to bed and I was like, I was thinking about it. Like I would say up until like 2.30 AM, like reading papers on my phone in bed, go to sleep, wake up the next morning at like eight and just be super excited to keep working. And I was also doing my thesis at the same time, my senior honors thesis at UT Austin about something very similar. We were researching factuality in abstractive question answering systems. So a lot of overlap with this project and the conclusions of my research actually kind of helped guide the development path of Hello. In the research, we found that LLMs, they don't know what they don't know. So the conclusion was, is that you always have to do a search to ensure that the model actually knows what it's talking about. And my favorite example of this even today is kind of with chat GPT browsing, where you can ask chat GPT browsing, how do I run llama.cpp? And chat GPT browsing will think that llama.cpp is some file on your computer that you can just compile with GCC and you're all good. It won't even bother doing a lookup, even though I'm sure somewhere in their internal prompts they have something like, if you're not sure, do a lookup. [00:15:13]
Alessio: That's not good enough. So models don't know what they don't know. [00:15:15]
Michael: You always have to do a search. And so we approached LLM powered question answering from the search angle. We pivoted to make this for programmers in June of 2022, around the time that we were getting into YC. We realized that what we're really interested in is the case where the models actually have to think. Because up until then, the models were kind of more glorified summarization models. We really thought of them like the Google featured snippets, but on steroids. And so we saw a future where the simpler questions would get commoditized. And I still think that's going to happen with like Google SGE and like it's nowadays, it's really not that hard to answer the more basic kind of like summarization, like current events questions with lightweight models that'll only continue to get cheaper over time. And so we kind of started thinking about this trade off where LLM models are going to get both better and cheaper over time. And that's going to force people who run them to make a choice. Either you can run a model of the same intelligence that you could previously for cheaper, or you can run a better model for the same price. So someone like Google, once the price kind of falls low enough, they're going to deploy and they're already doing this with SGE, they're going to deploy a relatively basic glorified summarizer model that can answer very basic questions about like current events, who won the Super Bowl, like, you know, what's going on on Capitol Hill, like those types of things. The flip side of that is like more complex questions where like you have to reason and you have to solve problems and like debug code. And we realized like we're much more interested in kind of going along the bleeding edge of that frontier case. And so we've optimized everything that we do for that. And that's a big reason of why we've built Phind specifically for programmers, as opposed to saying like, you know, we're kind of a search engine for everyone because as these models get more capable, we're very interested in seeing kind of what the emergent properties are in terms of reasoning, in terms of being able to solve complex multi-step problems. And I think that some of those emerging capabilities like we're starting to see, but we don't even fully understand. So I think there's always an opportunity for us to become more general if we wanted, but we've been along this path of like, what is the best, most advanced reasoning engine that's connected to your code base, that's connected to the internet that we can just provide. [00:17:39]
Alessio: What is Phind today, pragmatically, from a product perspective, how do people interact with it? Yeah. Or does it plug into your workflow? [00:17:46]
Michael: Yeah. [00:17:47]
Alessio: So Phind is really a system. [00:17:48]
Michael: Phind is a system for programmers when they have a question or when they're frustrated or when something's not working. [00:17:54]
Swyx: When they're frustrated. [00:17:55]
Alessio: Yeah. [00:17:56]
Michael: For them to get on block. I think like the single, the most abstract page for Phind is like, if you're experiencing really any kind of issue as a programmer, we'll solve that issue for you in 15 seconds as opposed to 15 minutes or longer. Phind has an interface on the web. It has an interface in VS code and more IDEs to come, but ultimately it's just a system where a developer can paste in a question or paste in code that's not working and Phind will do a search on the internet or they will find other code in your code base perhaps that's relevant. And then we'll find the context that it needs to answer your question and then feed it to a reasoning engine powerful enough to actually answer it. So that's really the philosophy behind Phind. It's a system for getting developers the answers that they're looking for. And so right now from a product perspective, this means that we're really all about getting the right context. So the VS code extension that we launched recently is a big part of this because you can just ask a question and it knows where to find the right code context in your code. It can do an internet search as well. So it's up to date and it's not just reliant on what the model knows and it's able to figure out what it needs by itself and answer your question based on that. If it needs some help, you can also get yourself kind of just, there's opportunities for you yourself to put in all that context in. But the issue is also like not everyone wants these VS code. Some people like are real Neovim sticklers or they're using like PyCharm or other IDEs, JetBrains. And so for those people, they're actually like okay with switching tabs, at least for now, if it means them getting their answer. Because really like there's been an explosion of all these like startups doing code, doing search, etc. But really who everyone's competing with is ChatGPT, which only has like that one web interface. Like ChatGPT is really the bar. And so that's what we're up against. [00:19:50]
Alessio: And so your idea, you know, we have Amman from Cursor on the podcast and they've gone through the we need to own the IDE thing. Yours is more like in order to get the right answer, people are happy to like go somewhere else basically. They're happy to get out of their IDE. [00:20:05]
Michael: That was a great podcast, by the way. But yeah, so part of it is that people sometimes perhaps aren't even in an IDE. So like the whole task of software engineering goes way beyond just running code, right? There's also like a design stage. There's a planning stage. A lot of this happens like on whiteboards. It happens in notebooks. And so the web part also exists for that where you're not even coding it and you're just trying to get like a more conceptual understanding of what you're trying to build first. The podcast with Amman was great, but somewhere where I disagree with him is that you need to own the IDE. I think like he made some good points about not having platform risk in the long term. But some of the features that were mentioned like suggesting diffs, for example, those are all doable with an extension. We haven't yet seen with VS Code in particular any functionality that we'd like to do yet in the IDE that we can't either do through directly supported VS Code functionality or something that we kind of hack into there, which we've also done a fair bit of. And so I think it remains to be seen where that goes. But I think what we're looking to be is like we're not trying to just be in an IDE or be an IDE. Like Phind is a system that goes beyond the IDE and like is really meant to cover the entire lifecycle of a developer's thought process in going about like, hey, like I have this idea and I want to get from that idea to a working product. And so then that's what the long term vision of Phind is really about is starting with that. In the future, I think programming is just going to be really just the problem solving. Like you come up with an idea, you come up with like the basic design for the algorithm in your head, and you just tell the AI, hey, just like just do it, just make it work. And that's what we're building towards. [00:21:51]
Swyx: I think we might want to give people an impression about like type of traffic that you have, because when you present it with a text box, you could type in anything. And I don't know if you have some mental categorization of like what are like the top three use cases that people tend to coalesce around. [00:22:08]
Alessio: Yeah, that's a great question. [00:22:09]
Michael: The two main types of searches that we see are how-to questions, like how to do X using Y tool. And this historically has been our bread and butter, because with our embeddings, like we're really, really good at just going over a bunch of developer documentation and figuring out exactly the part that's relevant and just telling you, OK, like you can use this method. But as LLMs have gotten better, and as we've really transitioned to using GPT-4 a lot in our product, people organically just started pasting in code that's not working and just said, fix it for me. [00:22:42]
Swyx: Fix this. [00:22:43]
Alessio: Yeah. [00:22:44]
Michael: And what really shocks us is that a lot of the people who do that, they're coming from chat GPT. So they tried it in chat GPT with chat GPT-4. It didn't work. Maybe it required like some multi-step reasoning. Maybe it required some internet context or something found in either a Stack Overflow post or some documentation to solve it. And so then they paste it into find and then find works. So those are really those two different cases. Like, how can I build this conceptually or like remind me of this one detail that I need to build this thing? Or just like, here's this code. Fix it. And so that's what a big part of our VS Code extension is, is like enabling a much smoother here just like fix it for me type of workflow. That's really its main benefits. Like it's in your code base. It's in the IDE. It knows how to find the relevant context to answer that question. But at the end of the day, like I said previously, that's still a relatively, not to say it's a small part, but it's a limited part of the entire mental life cycle of a programmer. [00:23:47]
Swyx: Yep. So you launched in Feb and then you launched V2 in August. You had a couple other pretty impactful posts slash feature launches. The web search one was massive. So you were mostly a GPT-4 wrapper. We were for a long time. [00:24:03]
Michael: For a long time until recently. Yeah. [00:24:05]
Alessio: Until recently. [00:24:06]
Swyx: So like people coming over from ChatGPT were saying, we're going to say model with your version of web search. Would that be the primary value proposition? [00:24:13]
Michael: Basically yeah. And so what we've seen is that any model plus web search is just significantly better than [00:24:18]
Alessio: that model itself. Do you think that's what you got right in April? [00:24:21]
Swyx: Like so you got 1500 points on Hacking News in April, which is like, if you live on Hacking News a lot, that is unheard of for someone so early on in your journey. [00:24:31]
Alessio: Yeah. [00:24:32]
Michael: We're super, super grateful for that. Definitely was not expecting it. So what we've done with Hacker News is we've just kept launching. [00:24:38]
Alessio: Yeah. [00:24:39]
Michael: Like what they don't tell you is that you can just keep launching. That's what we've been doing. So we launched the very first version of Find in its current incarnation after like the previous demo connected to our own index. Like once we got into YC, we scrapped our own index because it was too cumbersome at the time. So we moved over to using Bing as kind of just the raw source data. We launched as Hello Cognition. Over time, every time we like added some intelligence to the product, a better model, we just keep launching. And every additional time we launched, we got way more traffic. So we actually silently rebranded to Find in late December of last year. But like we didn't have that much traffic. Nobody really knew who we were. [00:25:18]
Swyx: How'd you pick the name out of it? [00:25:19]
Michael: Paul Graham actually picked it for us. [00:25:21]
Swyx: All right. [00:25:22]
Alessio: Tell the story. Yeah. So, oh boy. [00:25:25]
Michael: So this is the biggest side. Should we go for like the full Paul Graham story or just the name? [00:25:29]
Swyx: Do you want to do it now? Or do you want to do it later? I'll give you a choice. [00:25:32]
Alessio: Hmm. [00:25:33]
Michael: I think, okay, let's just start with the name for now and then we can do the full Paul Graham story later. But basically, Paul Graham, when we were lucky enough to meet him, he saw our name and our domain was at the time, sayhello.so and he's just like, guys, like, come on, like, what is this? You know? And we were like, yeah, but like when we bought it, you know, we just kind of broke college students. Like we didn't have that much money. And like, we really liked hello as a name because it was the first like conversational search engine. And that's kind of, that's the angle that we were approaching it from. And so we had sayhello.so and he's like, there's so many problems with that. Like, like, like the say hello, like, what does that even mean? And like .so, like, it's gotta be like a .com. And so we did some time just like with Paul Graham in the room. We just like looked at different domain names, like different things that like popped into our head. And one of the things that popped into like Paul Graham said was fine with the Phind spelling in particular. [00:26:33]
Swyx: Yeah. Which is not typical naming advice, right? Yes. Because it's not when people hear it, they don't spell it that way. [00:26:38]
Michael: Exactly. It's hard to spell. And also it's like very 90s. And so at first, like, we didn't like, I was like, like, ah, like, I don't know. But over time it kept growing on us. And eventually we're like, okay, we like the name. It's owned by this elderly Canadian gentleman who we got to know, and he was willing to sell it to us. [00:26:57]
Michael: And so we bought it and we changed the name. Yeah. [00:27:01]
Swyx: Anyways, where were you? [00:27:02]
Alessio: I had to ask. [00:27:03]
Swyx: I mean, you know, everyone who looks at you is wondering. [00:27:06]
Michael: And a lot of people actually pronounce it Phind, which, you know, by now it's part of the game. But eventually we want to buy Phind.com and then just have that redirect to Phind. So Phind is like definitely the right spelling. But like, we'll just, yeah, we'll have all the cases addressed. [00:27:23]
Swyx: Cool. So Bing web search, and then August you launched V2. Is V2 the Phind as a system pitch? Or have you moved, evolved since then? [00:27:31]
Michael: Yeah, so I don't, like the V2 moniker, like, I don't really think of it that way in my mind. There's like, there's the version we launched during, last summer during YC, which was the Bing version directed towards programmers. And that's kind of like, that's why I call it like the first incarnation of what we currently are. Because it was already directed towards programmers. We had like a code snippet search built in as well, because at the time, you know, the models we were using weren't good enough to generate code snippets. Even GPT, like the text DaVinci 2 was available at the time, wasn't that good at generating code and it would generate like very, very short, very incomplete code snippets. And so we launched that last summer, got some traction, but really like we were only doing like, I don't know, maybe like 10,000 searches a day. [00:28:15]
Alessio: Some people knew about it. [00:28:16]
Michael: Some people used it, which is impressive because looking back, the product like was not that good. And every time we've like made an improvement to the way that we retrieve context through better embeddings, more intelligent, like HTML parsers, and importantly, like better underlying models. Every major version after that was when we introduced a better underlying answering model. Like in February, we had to swallow a bit of our pride when we were like, okay, our own models aren't good enough. We have to go to open AI. And actually that did lead to kind of like our first decent bump of traffic in February. And people kept using it, like our attention was way better too. But we were still kind of running into problems of like more advanced reasoning. Some people tried it, but people were leaving because even like GPT 3.5, both turbo and non-turbo, like still not that great at doing like code related reasoning beyond the how do you do X, like documentation search type of use case. And so it was really only when GPT 4 came around in April that we were like, okay, like this is like our first real opportunity to really make this thing like the way that it should have been all along. And having GPT 4 as the brain is what led to that Hacker News post. And so what we did was we just let anyone use GPT 4 on Fyne for free without a login, [00:29:43]
Alessio: which I actually don't regret. [00:29:45]
Michael: So it was very expensive, obviously. But like at that stage, all we needed to do was show like, we just needed to like show people here's what Fyne can do. That was the main thing. And so that worked. That worked. [00:29:58]
Alessio: Like we got a lot of users. [00:29:59]
Michael: Do you know Fireship? [00:30:01]
Swyx: Yeah. YouTube, Jeff Delaney. [00:30:03]
Michael: Yeah. He made a short about Fyne. [00:30:06]
Alessio: Oh. [00:30:07]
Michael: And that's on top of the Hacker News post. And that's what like really, really made it blow up. It got millions of views in days. And he's just funny. Like what I love about Fireship is like he like you guys, yeah, like humor goes a long a long way towards like really grabbing people's attention. And so that blew up. [00:30:25]
Swyx: Something I would be anxious about as a founder during that period, so obviously we all remember that pretty closely. So there were a couple of people who had access to the GPT-4 API doing this, which is unrestricted access to GPT-4. And I have to imagine OpenAI wasn't that happy about that because it was like kind of de facto access to GPT-4 before they released it. [00:30:46]
Alessio: No, no. [00:30:47]
Michael: GPT-4 was in chat GPT from day one. I think. OpenAI actually came to our support because what happened was we had people building unofficial APIs around to try to get free access to it. And I think OpenAI actually has the right perspective on this where they're like, OK, people can do whatever they want with the API if they're paying for it, like they can do whatever they want, but it's like not OK if, you know, paying customers are being exploite by these other actors. They actually got in touch with us and they helped us like set up better Cloudflare bot monitoring controls to effectively like crack down on those unofficial APIs, which we're very happy about. But yeah, so we launched GPT-4. A lot of people come to the product and yeah, for a long time, we're just we're figuring out like what do we make of this, right? How do we a make it better, but also deal with like our costs, which have just like massively, massively ballooned. Over time, it's become more clear with the release of Llama 2 and Llama 3 on the horizon that we will once again see a return to vertical applications running their own models. As was true last year and before, I think that GPT-4, my hypothesis is that the jump from 4 to 4.5 or 4 to 5 will be smaller than the jump from 3 to 4. And the reason why is because there were a lot of different things. Like there was two plus, effectively two, two and a half years of research that went into going from 3 to 4. Like more data, bigger model, all of the instruction tuning techniques, RLHF, all of that is known. And like Meta, for example, and now there's all these other startups like Mistral too, like there's a bunch of very well-funded open source players that are now working on just like taking the recipe that's now known and scaling it up. So I think that even if a delta exists, the delta between in 2024, the delta between proprietary and open source won't be large enough that a startup like us with a lot of data that we've collected can take the data that we have, fine tune an open source model, and like be able to have it be better than whatever the proprietary model is at the time. That's my hypothesis.
Michael: But we'll once again see a return to these verticalized models. And that's something that we're super excited about because, yeah, that brings us to kind of the fine model because the plan from kind of the start was to be able to return to that if that makes sense. And I think now we're definitely at a point where it does make sense because we have requests from users who like, they want longer context in the model, basically, like they want to be able to ask questions about their entire code base without, you know, context and retrieval and taking a chance of that. Like, I think it's generally been shown that if you have the space to just put the raw files inside of a big context window, that is still better than chunking and retrieval. So there's various things that we could do with longer context, faster speed, lower cost. Super excited about that. And that's the direction that we're going with the fine model. And our big hypothesis there is precisely that we can take a really good open source model and then just train it on absolutely all of the high quality data that we can find. And there's a lot of various, you know, interesting ideas for this. We have our own techniques that we're kind of playing with internally. One of the very interesting ideas that I've seen, I think it's called Octopack from BigCode. I don't think that it made that big waves when it came out, I think in August. But the idea is that they have this data set that maps GitHub commits to a change. So basically there's all this really high quality, like human made, human written diff data out there on every time someone makes a commit in some repo. And you can use that to train models. Take the file state before and like given a commit message, what should that code look like in the future? [00:34:52]
Swyx: Got it. [00:34:53]
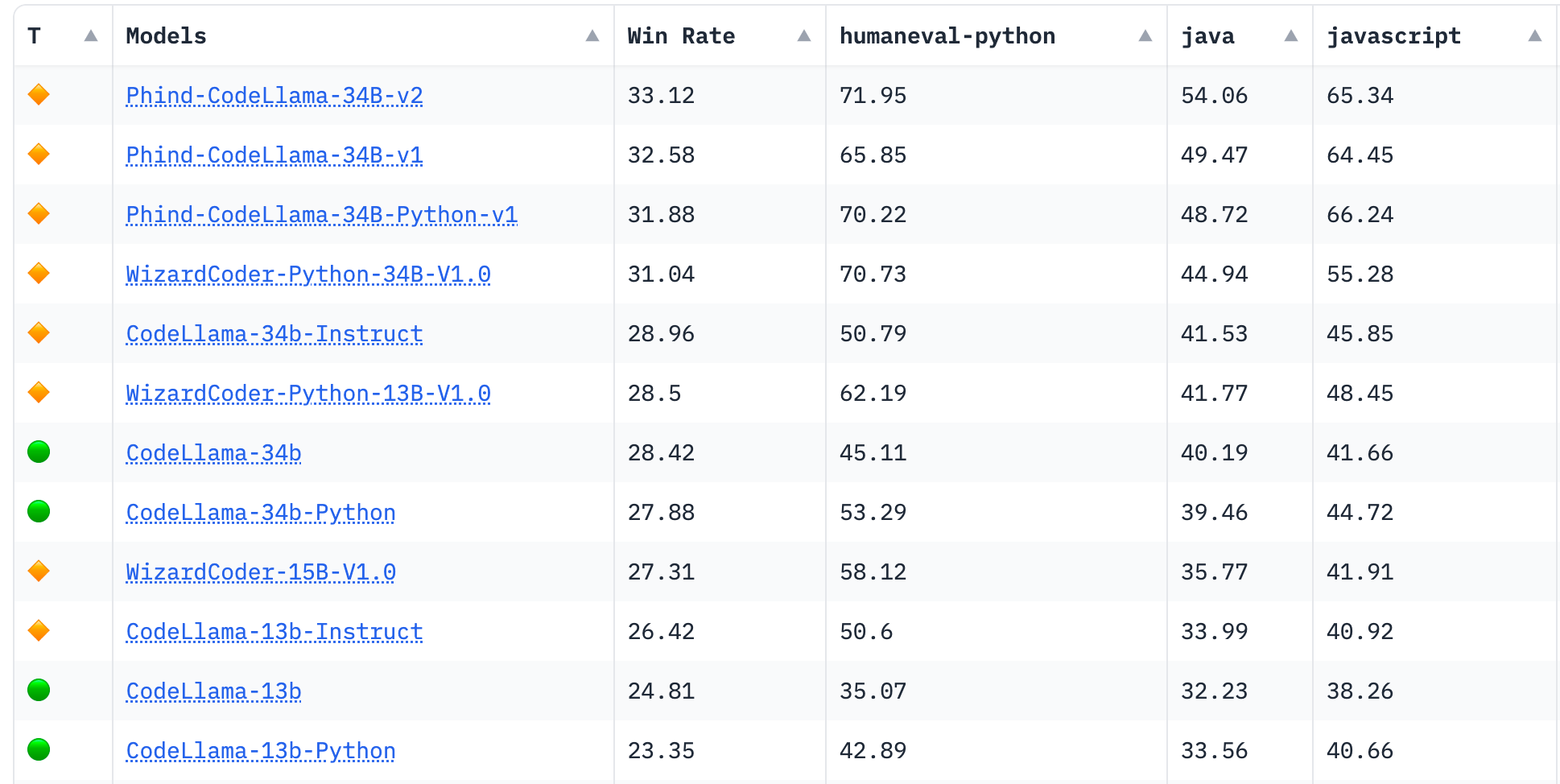
Alessio: Do you think your HumanEval is any good?
Michael: So we ran this experiment. We trained the Phind model. And if you go to the BigCode leaderboard, as of today, October 5th, all of our models are at the top of the BigCode leaderboard by far. It's not close, particularly in languages other than Python. We have a 10 point gap between us and the next best model on JavaScript. I think C sharp, multilingual. And what we kind of learned from that whole experience releasing those models is that human eval doesn't really matter. Not just that, but GPT-4 itself has been trained on human eval. And we know this because GPT-4 is able to predict the exact docstring in many of the problems. I've seen it predict like the specific example values in the docstring, which is extremely improbable. So I think there's a lot of dataset contamination and it only captures a very limited subset of what programmers are actually doing. What we do internally for evaluations are we have GPT-4 score answers. GPT-4 is a really good evaluator. I mean, obviously it's by really good, I mean, it's the best that we have. I'm sure that, you know, a couple of months from now, next year, we'll be like, oh, you know, like GPT-4.5, GPT-5, it's so much better. Like GPT-4 is terrible, but like right now it's the best that we have short of humans. And what we found is that when doing like temperature zero evals, it's actually mostly deterministic GPT-4 across runs in assigning scores to two different answers. So we found it to be a very useful tool in comparing our model to say, GPT-4, but yeah, on our like internal real world, here's what people will be asking this model dataset. And the other thing that we're running is just like releasing the model to our users and just seeing what they think. Because that's like the only thing that really matters is like releasing it for the application that it's intended for, and then seeing how people react. And for the most part, the incredible thing is, is that people don't notice a difference between our model and GPT-4 for the vast majority of searches. There's some reasoning problems that GPT-4 can still do better. We're working on addressing that. But in terms of like the types of questions that people are asking on find, there's not that much difference. And in fact, I've been running my own kind of side by side comparisons, shout out to GodMode, by the way. [00:37:16]
Michael: And I've like myself, I've kind of confirmed this to be the case. And even sometimes it gives a better answer, perhaps like more concise or just like better implementation than GPT-4, which that's what surprises me. And by now we kind of have like this reasoning is all you need kind of hypothesis where we've seen emerging capabilities in the find model, whereby training it on high quality code, it can actually like reason better. It went from not being able to solve world problems, where riddles were like with like temporal placement of objects and moving and stuff like that, that GPT-4 can do pretty well. We went from not being able to do those at all to being able to do them just by training on more code, which is wild. So we're already like starting to see like these emerging capabilities. [00:37:59]
Swyx: So I just wanted to make sure that we have the, I guess, like the model card in our heads. So you started from Code Llama? [00:38:07]
Alessio: Yes. [00:38:08]
Swyx: 65, 34? 34. [00:38:10]
Michael: So unfortunately, there's no Code Llama 70b. If there was, that would be super cool. But there's not. [00:38:15]
Swyx: 34. And then, which in itself was Llama 2, which is on 2 trillion tokens and the added 500 billion code tokens. Y