Language Agents: From Reasoning to Acting
Latent Space: The AI Engineer Podcast
Audio is streamed directly from the publisher (api.substack.com) as published in their RSS feed. Play Podcasts does not host this file. Rights-holders can request removal through the copyright & takedown page.
Show Notes
OpenAI DevDay is almost here! Per tradition, we are hosting a DevDay pregame event for everyone coming to town! Join us with demos and gossip!
Also sign up for related events across San Francisco: the AI DevTools Night, the xAI open house, the Replicate art show, the DevDay Watch Party (for non-attendees), Hack Night with OpenAI at Cloudflare. For everyone else, join the Latent Space Discord for our online watch party and find fellow AI Engineers in your city.
OpenAI’s recent o1 release (and Reflection 70b debacle) has reignited broad interest in agentic general reasoning and tree search methods.
While we have covered some of the self-taught reasoning literature on the Latent Space Paper Club, it is notable that the Eric Zelikman ended up at xAI, whereas OpenAI’s hiring of Noam Brown and now Shunyu suggests more interest in tool-using chain of thought/tree of thought/generator-verifier architectures for Level 3 Agents.
We were more than delighted to learn that Shunyu is a fellow Latent Space enjoyer, and invited him back (after his first appearance on our NeurIPS 2023 pod) for a look through his academic career with Harrison Chase (one year after his first LS show).
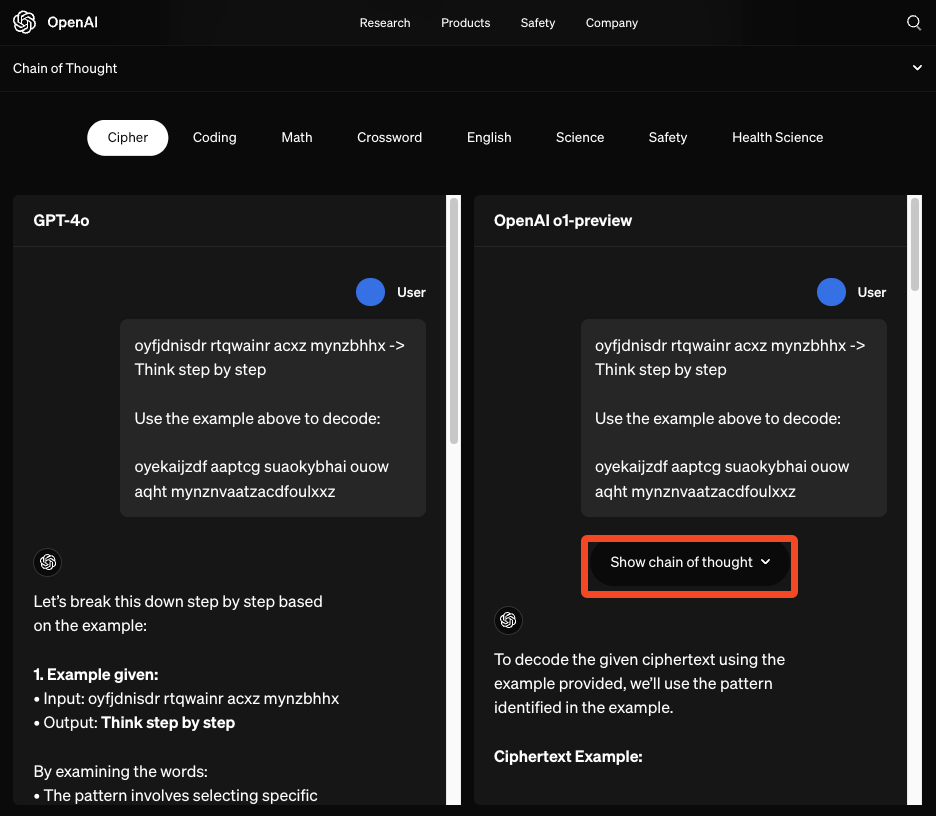
ReAct: Synergizing Reasoning and Acting in Language Models
Following seminal Chain of Thought papers from Wei et al and Kojima et al, and reflecting on lessons from building the WebShop human ecommerce trajectory benchmark, Shunyu’s first big hit, the ReAct paper showed that using LLMs to “generate both reasoning traces and task-specific actions in an interleaved manner” achieved remarkably greater performance (less hallucination/error propagation, higher ALFWorld/WebShop benchmark success) than CoT alone.
In even better news, ReAct scales fabulously with finetuning:
As a member of the elite Princeton NLP group, Shunyu was also a coauthor of the Reflexion paper, which we discuss in this pod.
Tree of Thoughts
Shunyu’s next major improvement on the CoT literature was Tree of Thoughts:
Language models are increasingly being deployed for general problem solving across a wide range of tasks, but are still confined to token-level, left-to-right decision-making processes during inference. This means they can fall short in tasks that require exploration, strategic lookahead, or where initial decisions play a pivotal role…
ToT allows LMs to perform deliberate decision making by considering multiple different reasoning paths and self-evaluating choices to decide the next course of action, as well as looking ahead or backtracking when necessary to make global choices.
The beauty of ToT is it doesnt require pretraining with exotic methods like backspace tokens or other MCTS architectures. You can listen to Shunyu explain ToT in his own words on our NeurIPS pod, but also the ineffable Yannic Kilcher:
Other Work
We don’t have the space to summarize the rest of Shunyu’s work, you can listen to our pod with him now, and recommend the CoALA paper and his initial hit webinar with Harrison, today’s guest cohost:
as well as Shunyu’s PhD Defense Lecture:
as well as Shunyu’s latest lecture covering a Brief History of LLM Agents:
As usual, we are live on YouTube!
Show Notes
* LangChain, LangSmith, LangGraph
* WebShop
* Related Episodes
* Our Thomas Scialom (Meta) episode
* Shunyu on our NeurIPS 2023 Best Papers episode
* Harrison on our LangChain episode
* Mentions
* Sierra
* Voyager
* Tavily
* SERP API
* Exa
Timestamps
* [00:00:00] Opening Song by Suno
* [00:03:00] Introductions
* [00:06:16] The ReAct paper
* [00:12:09] Early applications of ReAct in LangChain
* [00:17:15] Discussion of the Reflection paper
* [00:22:35] Tree of Thoughts paper and search algorithms in language models
* [00:27:21] SWE-Agent and SWE-Bench for coding benchmarks
* [00:39:21] CoALA: Cognitive Architectures for Language Agents
* [00:45:24] Agent-Computer Interfaces (ACI) and tool design for agents
* [00:49:24] Designing frameworks for agents vs humans
* [00:53:52] UX design for AI applications and agents
* [00:59:53] Data and model improvements for agent capabilities
* [01:19:10] TauBench
* [01:23:09] Promising areas for AI
Transcript
Alessio [00:00:01]: Hey, everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO of Residence at Decibel Partners, and I'm joined by my co-host Swyx, founder of Small AI.
Swyx [00:00:12]: Hey, and today we have a super special episode. I actually always wanted to take like a selfie and go like, you know, POV, you're about to revolutionize the world of agents because we have two of the most awesome hiring agents in the house. So first, we're going to welcome back Harrison Chase. Welcome. Excited to be here. What's new with you recently in sort of like the 10, 20 second recap?
Harrison [00:00:34]: Linkchain, Linksmith, Lingraph, pushing on all of them. Lots of cool stuff related to a lot of the stuff that we're going to talk about today, probably.
Swyx [00:00:42]: Yeah.
Alessio [00:00:43]: We'll mention it in there. And the Celtics won the title.
Swyx [00:00:45]: And the Celtics won the title. You got that going on for you. I don't know. Is that like floorball? Handball? Baseball? Basketball.
Alessio [00:00:52]: Basketball, basketball.
Harrison [00:00:53]: Patriots aren't looking good though, so that's...
Swyx [00:00:56]: And then Xun Yu, you've also been on the pod, but only in like a sort of oral paper presentation capacity. But welcome officially to the LinkedSpace pod.
Shunyu [00:01:03]: Yeah, I've been a huge fan. So thanks for the invitation. Thanks.
Swyx [00:01:07]: Well, it's an honor to have you on. You're one of like, you're maybe the first PhD thesis defense I've ever watched in like this AI world, because most people just publish single papers, but every paper of yours is a banger. So congrats.
Shunyu [00:01:22]: Thanks.
Swyx [00:01:24]: Yeah, maybe we'll just kick it off with, you know, what was your journey into using language models for agents? I like that your thesis advisor, I didn't catch his name, but he was like, you know... Karthik. Yeah. It's like, this guy just wanted to use language models and it was such a controversial pick at the time. Right.
Shunyu [00:01:39]: The full story is that in undergrad, I did some computer vision research and that's how I got into AI. But at the time, I feel like, you know, you're just composing all the GAN or 3D perception or whatever together and it's not exciting anymore. And one day I just see this transformer paper and that's really cool. But I really got into language model only when I entered my PhD and met my advisor Karthik. So he was actually the second author of GPT-1 when he was like a visiting scientist at OpenAI. With Alec Redford?
Swyx [00:02:10]: Yes.
Shunyu [00:02:11]: Wow. That's what he told me. It's like back in OpenAI, they did this GPT-1 together and Ilya just said, Karthik, you should stay because we just solved the language. But apparently Karthik is not fully convinced. So he went to Princeton, started his professorship and I'm really grateful. So he accepted me as a student, even though I have no prior knowledge in NLP. And you know, we just met for the first time and he's like, you know, what do you want to do? And I'm like, you know, you have done those test game scenes. That's really cool. I wonder if we can just redo them with language models. And that's how the whole journey began. Awesome.
Alessio [00:02:46]: So GPT-2 was out at the time? Yes, that was 2019.
Shunyu [00:02:48]: Yeah.
Alessio [00:02:49]: Way too dangerous to release. And then I guess the first work of yours that I came across was React, which was a big part of your defense. But also Harrison, when you came on The Pockets last year, you said that was one of the first papers that you saw when you were getting inspired for BlankChain. So maybe give a recap of why you thought it was cool, because you were already working in AI and machine learning. And then, yeah, you can kind of like intro the paper formally. What was that interesting to you specifically?
Harrison [00:03:16]: Yeah, I mean, I think the interesting part was using these language models to interact with the outside world in some form. And I think in the paper, you mostly deal with Wikipedia. And I think there's some other data sets as well. But the outside world is the outside world. And so interacting with things that weren't present in the LLM and APIs and calling into them and thinking about the React reasoning and acting and kind of like combining those together and getting better results. I'd been playing around with LLMs, been talking with people who were playing around with LLMs. People were trying to get LLMs to call into APIs, do things, and it was always, how can they do it more reliably and better? And so this paper was basically a step in that direction. And I think really interesting and also really general as well. Like I think that's part of the appeal is just how general and simple in a good way, I think the idea was. So that it was really appealing for all those reasons.
Shunyu [00:04:07]: Simple is always good. Yeah.
Alessio [00:04:09]: Do you have a favorite part? Because I have one favorite part from your PhD defense, which I didn't understand when I read the paper, but you said something along the lines, React doesn't change the outside or the environment, but it does change the insight through the context, putting more things in the context. You're not actually changing any of the tools around you to work for you, but you're changing how the model thinks. And I think that was like a very profound thing when I, not that I've been using these tools for like 18 months. I'm like, I understand what you meant, but like to say that at the time you did the PhD defense was not trivial. Yeah.
Shunyu [00:04:41]: Another way to put it is like thinking can be an extra tool that's useful.
Alessio [00:04:47]: Makes sense. Checks out.
Swyx [00:04:49]: Who would have thought? I think it's also more controversial within his world because everyone was trying to use RL for agents. And this is like the first kind of zero gradient type approach. Yeah.
Shunyu [00:05:01]: I think the bigger kind of historical context is that we have this two big branches of AI. So if you think about RL, right, that's pretty much the equivalent of agent at a time. And it's like agent is equivalent to reinforcement learning and reinforcement learning is equivalent to whatever game environment they're using, right? Atari game or go or whatever. So you have like a pretty much, you know, you have a biased kind of like set of methodologies in terms of reinforcement learning and represents agents. On the other hand, I think NLP is like a historical kind of subject. It's not really into agents, right? It's more about reasoning. It's more about solving those concrete tasks. And if you look at SEL, right, like each task has its own track, right? Summarization has a track, question answering has a track. So I think really it's about rethinking agents in terms of what could be the new environments that we came to have is not just Atari games or whatever video games, but also those text games or language games. And also thinking about, could there be like a more general kind of methodology beyond just designing specific pipelines for each NLP task? That's like the bigger kind of context, I would say.
Alessio [00:06:14]: Is there an inspiration spark moment that you remember or how did you come to this? We had Trida on the podcast and he mentioned he was really inspired working with like systems people to think about Flash Attention. What was your inspiration journey?
Shunyu [00:06:27]: So actually before React, I spent the first two years of my PhD focusing on text-based games, or in other words, text adventure games. It's a very kind of small kind of research area and quite ad hoc, I would say. And there are like, I don't know, like 10 people working on that at the time. And have you guys heard of Zork 1, for example? So basically the idea is you have this game and you have text observations, like you see a monster, you see a dragon.
Swyx [00:06:57]: You're eaten by a grue.
Shunyu [00:06:58]: Yeah, you're eaten by a grue. And you have actions like kill the grue with a sword or whatever. And that's like a very typical setup of a text game. So I think one day after I've seen all the GPT-3 stuff, I just think about, you know, how can I solve the game? Like why those AI, you know, machine learning methods are pretty stupid, but we are pretty good at solving the game relatively, right? So for the context, the predominant method to solve this text game is obviously reinforcement learning. And the idea is you just try out an arrow in those games for like millions of steps and you kind of just overfit to the game. But there's no language understanding at all. And I'm like, why can't I solve the game better? And it's kind of like, because we think about the game, right? Like when we see this very complex text observation, like you see a grue and you might see a sword, you know, in the right of the room and you have to go through the wooden door to go to that room. You will think, you know, oh, I have to kill the monster and to kill that monster, I have to get the sword, I have to get the sword, I have to go, right? And this kind of thinking actually helps us kind of throw shots off the game. And it's like, why don't we also enable the text agents to think? And that's kind of the prototype of React. And I think that's actually very interesting because the prototype, I think, was around November of 2021. So that's even before like chain of thought or whatever came up. So we did a bunch of experiments in the text game, but it was not really working that well. Like those text games are just too hard. I think today it's still very hard. Like if you use GPD 4 to solve it, it's still very hard. So the change came when I started the internship in Google. And apparently Google care less about text game, they care more about what's more practical. So pretty much I just reapplied the idea, but to more practical kind of environments like Wikipedia or simpler text games like Alphard, and it just worked. It's kind of like you first have the idea and then you try to find the domains and the problems to demonstrate the idea, which is, I would say, different from most of the AI research, but it kind of worked out for me in that case.
Swyx [00:09:09]: For Harrison, when you were implementing React, what were people applying React to in the early days?
Harrison [00:09:14]: I think the first demo we did probably had like a calculator tool and a search tool. So like general things, we tried to make it pretty easy to write your own tools and plug in your own things. And so this is one of the things that we've seen in LangChain is people who build their own applications generally write their own tools. Like there are a few common ones. I'd say like the three common ones might be like a browser, a search tool, and a code interpreter. But then other than that-
Swyx [00:09:37]: The LMS. Yep.
Harrison [00:09:39]: Yeah, exactly. It matches up very nice with that. And we actually just redid like our integrations docs page, and if you go to the tool section, they like highlight those three, and then there's a bunch of like other ones. And there's such a long tail of other ones. But in practice, like when people go to production, they generally have their own tools or maybe one of those three, maybe some other ones, but like very, very few other ones. So yeah, I think the first demos was a search and a calculator one. And there's- What's the data set?
Shunyu [00:10:04]: Hotpot QA.
Harrison [00:10:05]: Yeah. Oh, so there's that one. And then there's like the celebrity one by the same author, I think.
Swyx [00:10:09]: Olivier Wilde's boyfriend squared. Yeah. 0.23. Yeah. Right, right, right.
Harrison [00:10:16]: I'm forgetting the name of the author, but there's-
Swyx [00:10:17]: I was like, we're going to over-optimize for Olivier Wilde's boyfriend, and it's going to change next year or something.
Harrison [00:10:21]: There's a few data sets kind of like in that vein that require multi-step kind of like reasoning and thinking. So one of the questions I actually had for you in this vein, like the React paper, there's a few things in there, or at least when I think of that, there's a few things that I think of. There's kind of like the specific prompting strategy. Then there's like this general idea of kind of like thinking and then taking an action. And then there's just even more general idea of just like taking actions in a loop. Today, like obviously language models have changed a lot. We have tool calling. The specific prompting strategy probably isn't used super heavily anymore. Would you say that like the concept of React is still used though? Or like do you think that tool calling and running tool calling in a loop, is that React
Swyx [00:11:02]: in your mind?
Shunyu [00:11:03]: I would say like it's like more implicitly used than explicitly used. To be fair, I think the contribution of React is actually twofold. So first is this idea of, you know, we should be able to use calls in a very general way. Like there should be a single kind of general method to handle interaction with various environments. I think React is the first paper to demonstrate the idea. But then I think later there are two form or whatever, and this becomes like a trivial idea. But I think at the time, that's like a pretty non-trivial thing. And I think the second contribution is this idea of what people call like inner monologue or thinking or reasoning or whatever, to be paired with tool use. I think that's still non-trivial because if you look at the default function calling or whatever, like there's no inner monologue. And in practice, that actually is important, especially if the tool that you use is pretty different from the training distribution of the language model. I think those are the two main things that are kind of inherited.
Harrison [00:12:10]: On that note, I think OpenAI even recommended when you're doing tool calling, it's sometimes helpful to put a thought field in the tool, along with all the actual acquired arguments,
Swyx [00:12:19]: and then have that one first.
Harrison [00:12:20]: So it fills out that first, and they've shown that that's yielded better results. The reason I ask is just like this same concept is still alive, and I don't know whether to call it a React agent or not. I don't know what to call it. I think of it as React, like it's the same ideas that were in the paper, but it's obviously a very different implementation at this point in time. And so I just don't know what to call it.
Shunyu [00:12:40]: I feel like people will sometimes think more in terms of different tools, right? Because if you think about a web agent versus, you know, like a function calling agent, calling a Python API, you would think of them as very different. But in some sense, the methodology is the same. It depends on how you view them, right? I think people will tend to think more in terms of the environment and the tools rather than the methodology. Or, in other words, I think the methodology is kind of trivial and simple, so people will try to focus more on the different tools. But I think it's good to have a single underlying principle of those things.
Alessio [00:13:17]: How do you see the surface of React getting molded into the model? So a function calling is a good example of like, now the model does it. What about the thinking? Now most models that you use kind of do chain of thought on their own, they kind of produce steps. Do you think that more and more of this logic will be in the model? Or do you think the context window will still be the main driver of reasoning and thinking?
Shunyu [00:13:39]: I think it's already default, right? You do some chain of thought and you do some tool call, the cost of adding the chain of thought is kind of relatively low compared to other things. So it's not hurting to do that. And I think it's already kind of common practice, I would say.
Swyx [00:13:56]: This is a good place to bring in either Tree of Thought or Reflection, your pick.
Shunyu [00:14:01]: Maybe Reflection, to respect the time order, I would say.
Swyx [00:14:05]: Any backstory as well, like the people involved with NOAA and the Princeton group. We talked about this offline, but people don't understand how these research pieces come together and this ideation.
Shunyu [00:14:15]: I think Reflection is mostly NOAA's work, I'm more like advising kind of role. The story is, I don't remember the time, but one day we just see this pre-print that's like Reflection and Autonomous Agent with memory or whatever. And it's kind of like an extension to React, which uses this self-reflection. I'm like, oh, somehow you've become very popular. And NOAA reached out to me, it's like, do you want to collaborate on this and make this from an archive pre-print to something more solid, like a conference submission? I'm like, sure. We started collaborating and we remain good friends today. And I think another interesting backstory is NOAA was contacted by OpenAI at the time. It's like, this is pretty cool, do you want to just work at OpenAI? And I think Sierra also reached out at the same time. It's like, this is pretty cool, do you want to work at Sierra? And I think NOAA chose Sierra, but it's pretty cool because he was still like a second year undergrad and he's a very smart kid.
Swyx [00:15:16]: Based on one paper. Oh my god.
Shunyu [00:15:19]: He's done some other research based on programming language or chemistry or whatever, but I think that's the paper that got the attention of OpenAI and Sierra.
Swyx [00:15:28]: For those who haven't gone too deep on it, the way that you present the inside of React, can you do that also for reflection? Yeah.
Shunyu [00:15:35]: I think one way to think of reflection is that the traditional idea of reinforcement learning is you have a scalar reward and then you somehow back-propagate the signal of the scalar reward to the rest of your neural network through whatever algorithm, like policy grading or A2C or whatever. And if you think about the real life, most of the reward signal is not scalar. It's like your boss told you, you should have done a better job in this, but you could jump on that or whatever. It's not like a scalar reward, like 29 or something. I think in general, humans deal more with long scalar reward, or you can say language feedback. And the way that they deal with language feedback also has this back-propagation process, right? Because you start from this, you did a good job on job B, and then you reflect what could have been done differently to change to make it better. And you kind of change your prompt, right? Basically, you change your prompt on how to do job A and how to do job B, and then you do the whole thing again. So it's really like a pipeline of language where in self-graded descent, you have something like text reasoning to replace those gradient descent algorithms. I think that's one way to think of reflection.
Harrison [00:16:47]: One question I have about reflection is how general do you think the algorithm there is? And so for context, I think at LangChain and at other places as well, we found it pretty easy to implement React in a standard way. You plug in any tools and it kind of works off the shelf, can get it up and running. I don't think we have an off-the-shelf kind of implementation of reflection and kind of the general sense. I think the concepts, absolutely, we see used in different kind of specific cognitive architectures, but I don't think we have one that comes off the shelf. I don't think any of the other frameworks have one that comes off the shelf. And I'm curious whether that's because it's not general enough or it's complex as well, because it also requires running it more times.
Swyx [00:17:28]: Maybe that's not feasible.
Harrison [00:17:30]: I'm curious how you think about the generality, complexity. Should we have one that comes off the shelf?
Shunyu [00:17:36]: I think the algorithm is general in the sense that it's just as general as other algorithms, if you think about policy grading or whatever, but it's not applicable to all tasks, just like other algorithms. So you can argue PPO is also general, but it works better for those set of tasks, but not on those set of tasks. I think it's the same situation for reflection. And I think a key bottleneck is the evaluator, right? Basically, you need to have a good sense of the signal. So for example, if you are trying to do a very hard reasoning task, say mathematics, for example, and you don't have any tools, you're operating in this chain of thought setup, then reflection will be pretty hard because in order to reflect upon your thoughts, you have to have a very good evaluator to judge whether your thought is good or not. But that might be as hard as solving the problem itself or even harder. The principle of self-reflection is probably more applicable if you have a good evaluator, for example, in the case of coding. If you have those arrows, then you can just reflect on that and how to solve the bug and
Swyx [00:18:37]: stuff.
Shunyu [00:18:38]: So I think another criteria is that it depends on the application, right? If you have this latency or whatever need for an actual application with an end-user, the end-user wouldn't let you do two hours of tree-of-thought or reflection, right? You need something as soon as possible. So in that case, maybe this is better to be used as a training time technique, right? You do those reflection or tree-of-thought or whatever, you get a lot of data, and then you try to use the data to train your model better. And then in test time, you still use something as simple as React, but that's already improved.
Alessio [00:19:11]: And if you think of the Voyager paper as a way to store skills and then reuse them, how would you compare this reflective memory and at what point it's just ragging on the memory versus you want to start to fine-tune some of them or what's the next step once you get a very long reflective corpus? Yeah.
Shunyu [00:19:30]: So I think there are two questions here. The first question is, what type of information or memory are you considering, right? Is it like semantic memory that stores knowledge about the word, or is it the episodic memory that stores trajectories or behaviors, or is it more of a procedural memory like in Voyager's case, like skills or code snippets that you can use to do actions, right?
Swyx [00:19:54]: That's one dimension.
Shunyu [00:19:55]: And the second dimension is obviously how you use the memory, either retrieving from it, using it in the context, or fine-tuning it. I think the Cognitive Architecture for Language Agents paper has a good categorization of all the different combinations. And of course, which way you use depends on the concrete application and the concrete need and the concrete task. But I think in general, it's good to think of those systematic dimensions and all the possible options there.
Swyx [00:20:25]: Harrison also has in LangMEM, I think you did a presentation in my meetup, and I think you've done it at a couple other venues as well. User state, semantic memory, and append-only state, I think kind of maps to what you just said.
Shunyu [00:20:38]: What is LangMEM? Can I give it like a quick...
Harrison [00:20:40]: One of the modules of LangChain for a long time has been something around memory. And I think we're still obviously figuring out what that means, as is everyone kind of in the space. But one of the experiments that we did, and one of the proof of concepts that we did was, technically what it was is you would basically create threads, you'd push messages to those threads in the background, we process the data in a few ways. One, we put it into some semantic store, that's the semantic memory. And then two, we do some extraction and reasoning over the memories to extract. And we let the user define this, but extract key facts or anything that's of interest to the user. Those aren't exactly trajectories, they're maybe more closer to the procedural memory. Is that how you'd think about it or classify it?
Shunyu [00:21:22]: Is it like about knowledge about the word, or is it more like how to do something?
Swyx [00:21:27]: It's reflections, basically.
Harrison [00:21:28]: So in generative worlds.
Shunyu [00:21:30]: Generative agents.
Swyx [00:21:31]: The Smallville. Yeah, the Smallville one.
Harrison [00:21:33]: So the way that they had their memory there was they had the sequence of events, and that's kind of like the raw events that happened. But then every N events, they'd run some synthesis over those events for the LLM to insert its own memory, basically. It's that type of memory.
Swyx [00:21:49]: I don't know how that would be classified.
Shunyu [00:21:50]: I think of that as more of the semantic memory, but to be fair, I think it's just one way to think of that. But whether it's semantic memory or procedural memory or whatever memory, that's like an abstraction layer. But in terms of implementation, you can choose whatever implementation for whatever memory. So they're totally kind of orthogonal. I think it's more of a good way to think of the things, because from the history of cognitive science and cognitive architecture and how people study even neuroscience, that's the way people think of how the human brain organizes memory. And I think it's more useful as a way to think of things. But it's not like for semantic memory, you have to do this kind of way to retrieve or fine-tune, and for procedural memory, you have to do that. I think those are totally orthogonal kind of dimensions.
Harrison [00:22:34]: How much background do you have in cognitive sciences, and how much do you model some of your thoughts on?
Shunyu [00:22:40]: That's a great question, actually. I think one of the undergrad influences for my follow-up research is I was doing an internship at MIT's Computational Cognitive Science Lab with Josh Tannenbaum, and he's a very famous cognitive scientist. And I think a lot of his ideas still influence me today, like thinking of things in computational terms and getting interested in language and a lot of stuff, or even developing psychology kind of stuff. So I think it still influences me today.
Swyx [00:23:14]: As a developer that tried out LangMEM, the way I view it is just it's a materialized view of a stream of logs. And if anything, that's just useful for context compression. I don't have to use the full context to run it over everything. But also it's kind of debuggable. If it's wrong, I can show it to the user, the user can manually fix it, and I can carry on. That's a really good analogy. I like that. I'm going to steal that. Sure. Please, please. You know I'm bullish on memory databases. I guess, Tree of Thoughts? Yeah, Tree of Thoughts.
Shunyu [00:23:39]: I feel like I'm relieving the defense in like a podcast format. Yeah, no.
Alessio [00:23:45]: I mean, you had a banger. Well, this is the one where you're already successful and we just highlight the glory. It was really good. You mentioned that since thinking is kind of like taking an action, you can use action searching algorithms to think of thinking. So just like you will use Tree Search to find the next thing. And the idea behind Tree of Thought is that you generate all these possible outcomes and then find the best tree to get to the end. Maybe back to the latency question, you can't really do that if you have to respond in real time. So what are maybe some of the most helpful use cases for things like this? Where have you seen people adopt it where the high latency is actually worth the wait?
Shunyu [00:24:21]: For things that you don't care about latency, obviously. For example, if you're trying to do math, if you're just trying to come up with a proof. But I feel like one type of task is more about searching for a solution. You can try a hundred times, but if you find one solution, that's good. For example, if you're finding a math proof or if you're finding a good code to solve a problem or whatever, I think another type of task is more like reacting. For example, if you're doing customer service, you're like a web agent booking a ticket for an end user. Those are more reactive kind of tasks, or more real-time tasks. You have to do things fast. They might be easy, but you have to do it reliably. And you care more about can you solve 99% of the time out of a hundred. But for the type of search type of tasks, then you care more about can I find one solution out of a hundred. So it's kind of symmetric and different.
Alessio [00:25:11]: Do you have any data or intuition from your user base? What's the split of these type of use cases? How many people are doing more reactive things and how many people are experimenting with deep, long search?
Harrison [00:25:23]: I would say React's probably the most popular. I think there's aspects of reflection that get used. Tree of thought, probably the least so. There's a great tweet from Jason Wei, I think you're now a colleague, and he was talking about prompting strategies and how he thinks about them. And I think the four things that he had was, one, how easy is it to implement? How much compute does it take? How many tasks does it solve? And how much does it improve on those tasks? And I'd add a fifth, which is how likely is it to be relevant when the next generation of models come out? And I think if you look at those axes and then you look at React, reflection, tree of thought, it tracks that the ones that score better are used more. React is pretty easy to implement. Tree of thought's pretty hard to implement. The amount of compute, yeah, a lot more for tree of thought. The tasks and how much it improves, I don't have amazing visibility there. But I think if we're comparing React versus tree of thought, React just dominates the first two axes so much that my question around that was going to be like, how do you think about these prompting strategies, cognitive architectures, whatever you want to call them? When you're thinking of them, what are the axes that you're judging them on in your head when you're thinking whether it's a good one or a less good one?
Swyx [00:26:38]: Right.
Shunyu [00:26:39]: Right. I think there is a difference between a prompting method versus research, in the sense that for research, you don't really even care about does it actually work on practical tasks or does it help? Whatever. I think it's more about the idea or the principle, right? What is the direction that you're unblocking and whatever. And I think for an actual prompting method to solve a concrete problem, I would say simplicity is very important because the simpler it is, the less decision you have to make about it. And it's easier to design. It's easier to propagate. And it's easier to do stuff. So always try to be as simple as possible. And I think latency obviously is important. If you can do things fast and you don't want to do things slow. And I think in terms of the actual prompting method to use for a particular problem, I think we should all be in the minimalist kind of camp, right? You should try the minimum thing and see if it works. And if it doesn't work and there's absolute reason to add something, then you add something, right? If there's absolute reason that you need some tool, then you should add the tool thing. If there's absolute reason to add reflection or whatever, you should add that. Otherwise, if a chain of thought can already solve something, then you don't even need to use any of that.
Harrison [00:27:57]: Yeah. Or if it's just better prompting can solve it. Like, you know, you could add a reflection step or you could make your instructions a little bit clearer.
Swyx [00:28:03]: And it's a lot easier to do that.
Shunyu [00:28:04]: I think another interesting thing is like, I personally have never done those kind of like weird tricks. I think all the prompts that I write are kind of like just talking to a human, right? It's like, I don't know. I never say something like, your grandma is dying and you have to solve it. I mean, those are cool, but I feel like we should all try to solve things in a very intuitive way. Just like talking to your co-worker. That should work 99% of the time. That's my personal take.
Swyx [00:28:29]: The problem with how language models, at least in the GPC 3 era, was that they over-optimized to some sets of tokens in sequence. So like reading the Kojima et al. paper that was listing step-by-step, like he tried a bunch of them and they had wildly different results. It should not be the case, but it is the case. And hopefully we're getting better there.
Shunyu [00:28:51]: Yeah. I think it's also like a timing thing in the sense that if you think about this whole line of language model, right? Like at the time it was just like a text generator. We don't have any idea how it's going to be used, right? And obviously at the time you will find all kinds of weird issues because it's not trained to do any of that, right? But then I think we have this loop where once we realize chain of thought is important or agent is important or tool using is important, what we see is today's language models are heavily optimized towards those things. So I think in some sense they become more reliable and robust over those use cases. And you don't need to do as much prompt engineering tricks anymore to solve those things. I feel like in some sense, I feel like prompt engineering even is like a slightly negative word at the time because it refers to all those kind of weird tricks that you have to apply. But I think we don't have to do that anymore. Like given today's progress, you should just be able to talk to like a coworker. And if you're clear and concrete and being reasonable, then it should do reasonable things for you.
Swyx [00:29:51]: Yeah. The way I put this is you should not be a prompt engineer because it is the goal of the big labs to put you out of a job.
Shunyu [00:29:58]: You should just be a good communicator. Like if you're a good communicator to humans, you should be a good communicator to language
Swyx [00:30:02]: models.
Harrison [00:30:03]: That's the key though, because oftentimes people aren't good communicators to these language models and that is a very important skill and that's still messing around with the prompt. And so it depends what you're talking about when you're saying prompt engineer.
Shunyu [00:30:14]: But do you think it's like very correlated with like, are they like a good communicator to humans? You know, it's like.
Harrison [00:30:20]: It may be, but I also think I would say on average, people are probably worse at communicating with language models than to humans right now, at least, because I think we're still figuring out how to do it. You kind of expect it to be magical and there's probably some correlation, but I'd say there's also just like, people are worse at it right now than talking to humans.
Shunyu [00:30:36]: We should make it like a, you know, like an elementary school class or whatever, how to
Swyx [00:30:41]: talk to language models. Yeah. I don't know. Very pro that. Yeah. Before we leave the topic of trees and searching, not specific about QSTAR, but there's a lot of questions about MCTS and this combination of tree search and language models. And I just had to get in a question there about how seriously should people take this?
Shunyu [00:30:59]: Again, I think it depends on the tasks, right? So MCTS was magical for Go, but it's probably not as magical for robotics, right? So I think right now the problem is not even that we don't have good methodologies, it's more about we don't have good tasks. It's also very interesting, right? Because if you look at my citation, it's like, obviously the most cited are React, Refraction and Tree of Thought. Those are methodologies. But I think like equally important, if not more important line of my work is like benchmarks and environments, right? Like WebShop or SuiteVenture or whatever. And I think in general, what people do in academia that I think is not good is they choose a very simple task, like Alford, and then they apply overly complex methods to show they improve 2%. I think you should probably match the level of complexity of your task and your method. I feel like where tasks are kind of far behind the method in some sense, right? Because we have some good test-time approaches, like whatever, React or Refraction or Tree of Thought, or like there are many, many more complicated test-time methods afterwards. But on the benchmark side, we have made a lot of good progress this year, last year. But I think we still need more progress towards that, like better coding benchmark, better web agent benchmark, better agent benchmark, not even for web or code. I think in general, we need to catch up with tasks.
Harrison [00:32:27]: What are the biggest reasons in your mind why it lags behind?
Shunyu [00:32:31]: I think incentive is one big reason. Like if you see, you know, all the master paper are cited like a hundred times more than the task paper. And also making a good benchmark is actually quite hard. It's almost like a different set of skills in some sense, right? I feel like if you want to build a good benchmark, you need to be like a good kind of product manager kind of mindset, right? You need to think about why people should use your benchmark, why it's challenging, why it's useful. If you think about like a PhD going into like a school, right? The prior skill that expected to have is more about, you know, can they code this method and can they just run experiments and can solve that? I think building a benchmark is not the typical prior skill that we have, but I think things are getting better. I think more and more people are starting to build benchmarks and people are saying that it's like a way to get more impact in some sense, right? Because like if you have a really good benchmark, a lot of people are going to use it. But if you have a super complicated test time method, like it's very hard for people to use it.
Harrison [00:33:35]: Are evaluation metrics also part of the reason? Like for some of these tasks that we might want to ask these agents or language models to do, is it hard to evaluate them? And so it's hard to get an automated benchmark. Obviously with SweetBench you can, and with coding, it's easier, but.
Shunyu [00:33:50]: I think that's part of the skillset thing that I mentioned, because I feel like it's like a product manager because there are many dimensions and you need to strike a balance and it's really hard, right? If you want to make sense, very easy to autogradable, like automatically gradable, like either to grade or either to evaluate, then you might lose some of the realness or practicality. Or like it might be practical, but it might not be as scalable, right? For example, if you think about text game, human have pre-annotated all the rewards and all the language are real. So it's pretty good on autogradable dimension and the practical dimension. If you think about, you know, practical, like actual English bein