
Seventy3
642 episodes — Page 10 of 13

【第187期】Syntriever:用合成数据训练retriever
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。进群添加小助手微信:seventy3_podcast备注:小宇宙今天的主题是:Syntriever: How to Train Your Retriever with Synthetic Data from LLMsSummaryThe provided research paper introduces Syntriever, a novel framework for training information retrieval systems by leveraging synthetic data generated from large language models (LLMs). This approach consists of two key stages: distillation, where relevant and irrelevant passages are synthesized using LLMs and used to train the retriever, and alignment, where the retriever's output is fine-tuned based on preferences expressed by LLMs for pairs of retrieved passages. Syntriever addresses the challenge of distilling knowledge from black-box LLMs, achieving state-of-the-art results on various information retrieval benchmarks by effectively combining synthetic data generation with preference-based learning. The framework demonstrates that even smaller retrieval models can significantly improve their performance by learning from the knowledge and ranking abilities of LLMs through this synthetic data and alignment process.本文提出了 Syntriever,一个创新框架,用于通过大语言模型(LLMs)生成的合成数据来训练信息检索系统。该方法包括两个关键阶段:蒸馏(distillation),即使用 LLMs 合成相关和不相关的段落,并用于训练检索器;以及对齐(alignment),即根据 LLMs 对检索段落对的偏好来微调检索器的输出。Syntriever 解决了从黑箱 LLMs中提取知识的挑战,通过有效结合合成数据生成与基于偏好的学习,在多个信息检索基准上取得了最先进的成果。该框架表明,甚至较小的检索模型也可以通过这种合成数据和对齐过程,从 LLMs 的知识和排序能力中学习,从而显著提升其性能。原文链接:https://arxiv.org/abs/2502.03824

【第186期】CoAT:MCTS+memory增强推理的框架
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。进群添加小助手微信:seventy3_podcast备注:小宇宙今天的主题是:CoAT: Chain-of-Associated-Thoughts Framework for Enhancing Large Language Models ReasoningSummaryThe provided research paper introduces CoAT, a novel framework designed to enhance the reasoning capabilities of large language models (LLMs). Inspired by human cognition, CoAT integrates Monte Carlo Tree Search (MCTS) for structured exploration of reasoning paths with an associative memory mechanism that dynamically incorporates new information. This synergy allows LLMs to revisit prior inferences and adapt to evolving data, leading to more accurate, coherent, and diverse outputs, as validated through extensive experiments on generative and reasoning tasks, including comparisons with other knowledge-augmented methods and fine-tuned models. The paper details the architecture and implementation of CoAT, including its associative memory and optimized MCTS, and presents both qualitative and quantitative evidence of its superior performance across various NLP and code generation benchmarks.本文提出了 CoAT,一个创新框架,旨在增强大型语言模型(LLMs)的推理能力。受人类认知启发,CoAT 结合了蒙特卡洛树搜索(MCTS),用于结构化探索推理路径,并引入联想记忆机制,动态整合新信息。这种协同作用使 LLMs 能够回溯先前推理并适应不断变化的数据,从而生成更准确、连贯、多样的输出。通过广泛实验,包括与其他知识增强方法及微调模型的对比,研究验证了 CoAT 在生成与推理任务中的有效性。论文详细介绍了 CoAT 的架构与实现,包括联想记忆模块和优化的 MCTS 算法,并在多个NLP 和代码生成基准上提供了定性和定量证据,证明其卓越性能。原文链接:https://arxiv.org/abs/2502.02390

【第185期】RAG Foundry:简化RAG的开源框架
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。进群添加小助手微信:seventy3_podcast备注:小宇宙今天的主题是:RAG Foundry: A Framework for Enhancing LLMs for Retrieval Augmented GenerationSummaryThe provided document introduces RAG FOUNDRY, an open-source framework designed to streamline the development and evaluation of Retrieval-Augmented Generation (RAG) systems for large language models. This framework integrates data handling, model training, inference, and evaluation into a unified workflow, enabling efficient experimentation with various RAG techniques. The authors demonstrate RAG FOUNDRY's effectiveness by enhancing and fine-tuning models like Llama-3 and Phi-3 on knowledge-intensive tasks, showcasing consistent performance improvements. The paper also compares RAG FOUNDRY to existing tools and outlines its modular architecture, highlighting its flexibility and extensibility for researchers and practitioners working on RAG.本文介绍了 RAG FOUNDRY,一个开源框架,旨在简化检索增强生成(RAG)系统的开发与评估,专为大型语言模型设计。该框架将数据处理、模型训练、推理和评估整合为一个统一的工作流程,使得在各种 RAG 技术上进行高效实验成为可能。作者通过在知识密集型任务上对 Llama-3 和 Phi-3 等模型进行增强与微调,展示了 RAG FOUNDRY 的有效性,体现了一致的性能提升。文章还将 RAG FOUNDRY 与现有工具进行了比较,并详细阐述了其模块化架构,强调其对从事 RAG 研究与应用的研究人员和实践者的灵活性和可扩展性。原文链接:https://arxiv.org/abs/2408.02545

【第184期】Diffusion Planner:基于Transformer的闭环自动驾驶算法
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。进群添加小助手微信:seventy3_podcast备注:小宇宙今天的主题是:Diffusion-Based Planning for Autonomous Driving with Flexible GuidanceSummaryThe provided research paper introduces Diffusion Planner, a novel method for autonomous driving that utilizes diffusion models to achieve human-like planning in complex environments. This approach jointly models motion prediction and planning without relying on traditional rule-based refinements, addressing limitations of imitation learning. By learning the gradient of a trajectory score function and using a flexible classifier guidance mechanism, Diffusion Planner can adapt its driving behavior for safety and other preferences. Evaluations on public and newly collected datasets demonstrate that this method achieves state-of-the-art closed-loop performance with strong transferability across different driving styles.该研究提出了 Diffusion Planner,一种新型自动驾驶规划方法,利用扩散模型(diffusion models)在复杂环境中实现类人规划。该方法联合建模运动预测与规划,无需依赖传统的基于规则的优化,从而克服了模仿学习的局限性。通过学习轨迹评分函数的梯度,并引入灵活的分类器引导机制,Diffusion Planner 能够根据安全性及其他偏好自适应调整驾驶行为。实验结果表明,该方法在公开数据集和新采集数据集上的闭环性能达到最先进水平,并展现出跨不同驾驶风格的强泛化能力。原文链接:https://arxiv.org/abs/2501.15564

【第183期】慢思考滚雪球错误如何利用
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。进群添加小助手微信:seventy3_podcast备注:小宇宙今天的主题是:Rethinking External Slow-Thinking: From Snowball Errors to Probability of Correct ReasoningSummaryThis paper examines "slow-thinking" in large language models (LLMs), where increased computation time enhances reasoning. It theoretically analyzes how errors accumulate during LLM reasoning, termed "snowball errors," linking them to the decreasing probability of correct reasoning through information theory. The research proposes that external slow-thinking methods, which involve expanding the search for solutions, primarily work by mitigating these error probabilities. A comparative analysis of various slow-thinking approaches, including Best-of-N and Monte Carlo Tree Search, suggests their effectiveness hinges more on the reliability of evaluation mechanisms and overall computational cost than the specific algorithmic framework. Ultimately, the study advocates for focusing on improving reward functions and core reasoning capabilities for better slow-thinking strategies.本文研究了大型语言模型(LLMs)中的**“慢思考”(slow-thinking)现象,即增加计算时间如何提升推理能力**。作者从理论角度分析了 LLM 推理过程中错误的积累机制,并将其定义为**“滚雪球错误”(snowball errors),借助信息论揭示了正确推理概率随推理深度降低的趋势**。研究提出,外部慢思考方法(如扩展解空间搜索)主要通过降低错误概率来提升推理质量。对比分析了多种慢思考方法,包括Best-of-N 和 蒙特卡洛树搜索(MCTS),结果表明,其有效性更多取决于评估机制的可靠性和计算成本,而非具体算法框架。最终,研究强调优化奖励函数和核心推理能力的重要性,以改进慢思考策略。原文链接:https://arxiv.org/abs/2501.15602

【第182期】庆祝更新半年文中有彩蛋 || Long CoT Reasoning in LLMs
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Demystifying Long Chain-of-Thought Reasoning in LLMsSummaryThis paper investigates how large language models (LLMs) achieve long chain-of-thought (CoT) reasoning, which involves extended, step-by-step thought processes for complex tasks. The authors explore the roles of supervised fine-tuning (SFT) and reinforcement learning (RL) in enabling this capability. Key findings highlight that while SFT on long CoT data improves performance and facilitates better RL, carefully designed reward functions are crucial for stable CoT length and enhanced reasoning. The study also examines the use of noisy web data for training and nuances in analyzing emergent reasoning behaviors during RL from base models. Ultimately, the research offers practical insights for optimizing training strategies to bolster sophisticated reasoning in LLMs.本文探讨了大型语言模型(LLMs)如何实现长链式思维(CoT)推理,即在复杂任务中执行逐步、扩展的思考过程。作者研究了监督微调(SFT)和强化学习(RL)在提升这一能力中的作用。关键发现包括:虽然在长 CoT 数据上进行 SFT 可提高性能并优化 RL 训练,但精心设计的奖励函数对于稳定 CoT 长度和增强推理能力至关重要。此外,研究还分析了带噪声的网页数据用于训练的影响,以及在 RL 过程中基于基础模型解析涌现推理行为的细微差别。最终,该研究提供了优化训练策略的实用见解,以提升 LLMs 的高级推理能力。原文链接:https://arxiv.org/abs/2502.03373####🥚####彩####蛋####🥚####本博客从24年10月2日开启,已更新半年,借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法的论文,也有几十个听友。本人是一介书生,现计划建立微信群,平时可以聊聊技术,聊聊生活。希望博客可以继续更新下去!进群添加微信小助手:seventy3_podcast备注:小宇宙####🥚####彩####蛋####🥚####

【第181期】ASAP:两阶段框架弥合仿真与现实物理之间的差距
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:ASAP: Aligning Simulation and Real-World Physics for Learning Agile Humanoid Whole-Body SkillsSummaryThe provided research paper introduces ASAP, a novel two-stage framework designed to bridge the gap between simulated and real-world physics for humanoid robots, enabling them to perform complex, agile movements. The first stage involves pre-training control policies in simulation using human motion data. The second stage deploys these policies in the real world to collect data and train a "delta action model" that learns to compensate for discrepancies in dynamics. This model is then integrated back into the simulator to fine-tune the control policies, allowing for more accurate and agile real-world execution. Experiments demonstrate that ASAP significantly improves the ability of humanoid robots to perform challenging tasks, outperforming existing methods in both simulated and real environments. The work highlights a promising direction for transferring skills learned in simulation to physical robots, ultimately leading to more versatile and capable humanoids.该研究提出了 ASAP,一种创新的两阶段框架,旨在弥合仿真与现实物理之间的差距,使人形机器人能够执行复杂且灵活的运动。第一阶段在仿真环境中使用人类运动数据进行控制策略的预训练。第二阶段将这些策略部署到现实环境,采集数据并训练一个**“增量动作模型”(delta action model),用于补偿动力学差异。随后,该模型被集成回仿真环境,以微调控制策略**,从而实现更精准、灵活的现实世界执行。实验结果表明,ASAP 显著提升了人形机器人完成高难度任务的能力,无论在仿真还是现实环境中均优于现有方法。本研究为仿真训练迁移至现实机器人提供了一条有效途径,推动人形机器人向更多功能、更智能的方向发展。原文链接:https://arxiv.org/abs/2502.01143

【第180期】LLM-AutoDiff:一个基于梯度的自动化提示工程
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:LLM-AutoDiff: Auto-Differentiate Any LLM WorkflowSummaryThe provided research introduces LLM-AutoDiff, a novel framework for automating prompt engineering for complex Large Language Model workflows. This system extends gradient-based optimization to multi-step and cyclic LLM applications by treating textual inputs as trainable parameters. LLM-AutoDiff constructs a graph representing the workflow, enabling a "backward engine" LLM to generate feedback that guides iterative prompt improvements, even across functional nodes and repeated calls. The framework incorporates techniques like selective gradient computation and two-stage validation to enhance efficiency. Experimental results demonstrate that LLM-AutoDiff outperforms existing methods in accuracy and training cost across various tasks, offering a new paradigm for scaling and automating LLM deployments.该研究提出了 LLM-AutoDiff,一个自动化提示工程(prompt engineering)的新框架,旨在优化复杂的大型语言模型(LLM)工作流。该系统通过将文本输入视为可训练参数,将基于梯度的优化方法扩展到多步和循环 LLM 应用。LLM-AutoDiff 构建了一个表示工作流的计算图,并利用**“反向引擎” LLM** 生成反馈,指导跨功能节点和重复调用的迭代提示优化。该框架还引入了选择性梯度计算和双阶段验证等技术,以提高优化效率。实验结果表明,LLM-AutoDiff 在多个任务上的准确性和训练成本方面均优于现有方法,为 LLM 部署的自动化和规模化提供了一种新范式。原文链接:https://arxiv.org/abs/2501.16673

【第179期】s1: Simple test-time scaling
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:s1: Simple test-time scalingSummaryThis research explores improving language model reasoning through a technique called test-time scaling, where extra computation during inference enhances performance. The authors introduce s1K, a small, high-quality dataset of reasoning problems, and budget forcing, a method to control the model's computational effort at test time. By finetuning a language model on s1K and using budget forcing, they achieve strong results on math reasoning benchmarks, even surpassing previously reported methods while using significantly less training data. The work also analyzes different approaches to test-time scaling, finding sequential methods like budget forcing more effective than parallel ones like majority voting. Ultimately, this study demonstrates a sample-efficient way to boost reasoning through strategic test-time computation.本研究探讨了通过测试时扩展(test-time scaling)提升语言模型推理能力的方法,即在推理阶段增加计算量以增强性能。作者提出了s1K——一个小型高质量的推理问题数据集,并引入了预算强制(budget forcing),一种在测试时控制模型计算资源的方法。通过在 s1K 上微调语言模型并应用预算强制,研究在数学推理基准上取得了优异成绩,甚至在训练数据大幅减少的情况下超越了此前的方法。此外,研究分析了不同的测试时扩展策略,发现顺序方法(如预算强制)比并行方法(如多数投票)更有效。最终,该研究证明了一种数据高效的方式,即通过策略性测试时计算来提升推理能力。原文链接:https://arxiv.org/abs/2501.19393

【第178期】spurious forgetting:大模型的虚假遗忘
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Spurious Forgetting in Continual Learning of Language ModelsSummaryThis paper introduces the concept of spurious forgetting in large language models during continual learning, distinguishing it from actual knowledge loss and attributing it to the disruption of task alignment. The authors demonstrate through experiments and theoretical analysis that early training on new tasks can misalign the model, particularly in the bottom layers. To address this, they propose a Freezing strategy that keeps the initial layers unchanged, significantly improving performance in various continual learning scenarios like safety alignment and instruction tuning. Their findings highlight the importance of task alignment over pure knowledge retention and offer a practical method to mitigate performance degradation.本文引入了大型语言模型在持续学习过程中出现的虚假遗忘概念,将其与实际的知识丧失区分开来,并将其归因于任务对齐的破坏。作者通过实验和理论分析表明,在新任务的早期训练阶段,模型(尤其是底层)可能会发生错位。为此,他们提出了一种冻结策略,即保持初始层不变,从而在安全对齐、指令微调等多种持续学习场景下显著提升模型性能。研究结果强调了任务对齐的重要性,相较于单纯的知识保留更为关键,并提供了一种实用的方法来缓解性能下降问题。原文链接:https://arxiv.org/abs/2501.13453

【第177期】学习率Scheduler研究分析
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:The Surprising Agreement Between Convex Optimization Theory and Learning-Rate Scheduling for Large Model TrainingSummaryThis paper explores the surprising parallels between learning-rate schedules used in large model training and theoretical performance bounds from convex optimization. It demonstrates that a simple learning-rate schedule with a constant phase followed by a linear cooldown mirrors the behavior predicted by theory, even for non-convex deep learning problems. Furthermore, the research shows how this theoretical understanding can be practically applied to improve learning-rate tuning for continued training and transfer optimal rates across different schedules, leading to tangible gains in model performance. The work provides theoretical justification for empirically successful scheduling techniques and suggests that principles from convex optimization offer valuable insights into the training of complex neural networks.本文探讨了大型模型训练中使用的学习率调度与凸优化理论性能界限之间的惊人相似性。研究表明,一个简单的学习率调度方案——先保持恒定,然后线性降温——即使在非凸深度学习问题中,也能呈现出与理论预测相符的行为。此外,研究还展示了如何将这一理论理解实际应用于改进持续训练的学习率调优,并在不同的调度方案之间转移最优学习率,从而显著提升模型性能。本研究为经验上成功的调度技术提供了理论依据,并表明凸优化的原理可以为复杂神经网络的训练提供有价值的见解。原文链接:https://arxiv.org/abs/2501.18965

【第176期】TokenVerse:文本到图像生成的新方法
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:TokenVerse: Versatile Multi-concept Personalization in Token Modulation SpaceSummaryTokenVerse introduces a new method for multi-concept personalization in text-to-image generation. The technique extracts visual elements and attributes from single or multiple images using only text captions and a pre-trained diffusion model. By leveraging the modulation space within Diffusion Transformers, TokenVerse disentangles complex concepts like objects, poses, and lighting. This enables users to combine these learned concepts in novel ways to create customized images without needing additional supervision like masks. TokenVerse shows significant advantages over existing personalization techniques, providing greater flexibility and control for personalized content creation and storytelling. The paper presents quantitative and qualitative results demonstrating the effectiveness of the TokenVerse framework.TokenVerse 提出了一个用于 文本到图像生成 的新方法,旨在实现多概念个性化。该技术通过仅使用文本描述和预训练的扩散模型,从单一或多个图像中提取视觉元素和属性。通过利用扩散变换器(Diffusion Transformers)中的调制空间,TokenVerse 解构了诸如物体、姿势和光照等复杂概念。这种方法使用户能够以创新的方式将这些学习到的概念进行组合,从而创建个性化图像,而无需像遮罩(masks)之类的额外监督。与现有的个性化技术相比,TokenVerse 展现了显著的优势,提供了更大的灵活性和控制力,促进了个性化内容创作和叙事的实现。论文通过定量和定性结果展示了 TokenVerse 框架的有效性,证明了其在个性化生成和故事创作中的潜力。原文链接:https://arxiv.org/abs/2501.12224

【第175期】TensorLLM:使用多头自注意力提升模型能力
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:TensorLLM: Tensorising Multi-Head Attention for Enhanced Reasoning and Compression in LLMsSummaryThis research introduces TensorLLM, a novel framework for improving the reasoning abilities and compression of Large Language Models (LLMs) by focusing on the Multi-Head Attention (MHA) block. The method employs multi-head tensorisation and Tucker decomposition to denoise and compress MHA weights by enforcing a shared higher-dimensional subspace across multiple attention heads. Experiments demonstrate that TensorLLM enhances LLM reasoning capabilities across various benchmark datasets and architectures without requiring additional training. The framework can also be combined with existing techniques that denoise the feed-forward network (FFN) layers for further performance gains. The study validates the approach through ablation experiments and comparisons with other compression techniques, showing consistent improvements in accuracy and compression rates. The paper concludes by emphasizing the potential of TensorLLM as a versatile module for improving LLMs and suggesting future work on finding generalizable hyperparameter settings.本研究提出了 TensorLLM,一种新颖的框架,通过聚焦于多头自注意力(MHA)块来提升大型语言模型(LLM)的推理能力和压缩效率。该方法采用多头张量化和Tucker 分解,通过在多个注意力头之间强制共享一个更高维度的子空间,来去噪和压缩 MHA 权重。实验表明,TensorLLM 在不同的基准数据集和架构上提升了 LLM 的推理能力,而无需额外的训练。该框架还可以与现有的去噪前馈网络(FFN)层的技术结合,进一步提升性能。通过消融实验和与其他压缩技术的比较,研究验证了该方法的有效性,显示出在准确性和压缩率方面的持续改进。论文最后强调了 TensorLLM 作为一种多功能模块,具有提升 LLM 性能的潜力,并提出了未来研究的方向,即寻找可以广泛应用的超参数设置。原文链接:https://arxiv.org/abs/2501.15674

【第174期】MMOA-RAG:Multi-Agent RL for Enhanced RAG
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Improving Retrieval-Augmented Generation through Multi-Agent Reinforcement LearningSummaryThe paper introduces MMOA-RAG, a novel approach to improve Retrieval-Augmented Generation (RAG) by framing it as a multi-agent reinforcement learning problem. It addresses the issue of independently optimized RAG components by treating each module (query rewriting, document retrieval, etc.) as an individual agent. MMOA-RAG uses multi-agent reinforcement learning to align each agent's goal with the overarching goal of generating accurate answers. Experiments on question-answering datasets demonstrate that MMOA-RAG outperforms existing methods by jointly optimizing the modules and addressing interdependencies. Ablation studies validate the contribution of each component, supporting MMOA-RAG's adaptability across datasets.论文介绍了 MMOA-RAG,一种通过将 检索增强生成(RAG) 问题转化为多智能体强化学习问题的新方法。该方法解决了传统 RAG 中各模块(如查询重写、文档检索等)独立优化的问题,将每个模块视为一个独立的智能体。MMOA-RAG 采用多智能体强化学习,使每个智能体的目标与生成准确答案的总体目标对齐。在问答数据集上的实验表明,MMOA-RAG 通过联合优化各个模块并解决模块之间的相互依赖,超越了现有方法。消融实验验证了每个组件的贡献,进一步支持了 MMOA-RAG 在不同数据集上的适应性。原文链接:https://arxiv.org/abs/2501.15228

【第173期】Docling:开源的文档转换工具包
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Docling: An Efficient Open-Source Toolkit for AI-driven Document ConversionSummaryDocling is a new open-source toolkit for document conversion, designed to parse various document formats into a structured representation using AI models for layout analysis and table recognition. It aims to provide an efficient and customizable solution for tasks like document understanding and information extraction, and it supports local execution, integrations with frameworks like LangChain and LlamaIndex. The paper outlines Docling's design, architecture (including pipelines, parser backends, and the DoclingDocument data model), AI models, and performance benchmarks compared to other open-source tools. The toolkit's capabilities make it suitable for generative AI applications, data preparation, and knowledge extraction, with future work planned to include more models and an open-source quality evaluation framework. Docling has attracted significant community interest and is integrated into several open-source projects.Docling 是一个全新的开源文档转换工具包,旨在通过使用 AI 模型进行布局分析和表格识别,将各种文档格式解析为结构化表示。它旨在为文档理解和信息提取等任务提供高效且可定制的解决方案,支持本地执行,并与像 LangChain 和 LlamaIndex 等框架进行集成。本文概述了 Docling 的设计与架构,包括管道、解析器后端和 DoclingDocument 数据模型,介绍了所使用的 AI 模型及其与其他开源工具的性能基准对比。该工具包的功能使其非常适合用于生成型 AI 应用、数据准备和知识提取等任务,未来的工作将包括更多模型的引入以及一个开源的质量评估框架。Docling 已吸引了大量社区关注,并已集成到多个开源项目中。原文链接:https://www.arxiv.org/abs/2501.17887

【第172期】AI 安全性方面使用强化学习(RL)的挑战
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Challenges in Ensuring AI Safety in DeepSeek-R1 Models: The Shortcomings of Reinforcement Learning StrategiesSummaryThe provided paper investigates the challenges of using Reinforcement Learning (RL) to ensure AI safety, particularly in models like DeepSeek-R1. It highlights limitations such as reward hacking, language inconsistencies, and difficulties in generalizing to new situations. The paper compares RL with Supervised Fine-Tuning (SFT), noting SFT's strengths in controlling model behavior and simplifying the training process. It recommends hybrid training approaches that combine RL and SFT to improve both reasoning capabilities and harmlessness. The authors provide usage guidelines for deploying DeepSeek-R1 responsibly, emphasizing monitoring, prompt engineering, and risk mitigation. Future research directions focus on multi-language consistency, handling complex harms, and scaling harmlessness in smaller models.该论文探讨了在 AI 安全性方面使用强化学习(RL)的挑战,特别是在 DeepSeek-R1 等模型上的应用。研究指出了 RL 的诸多局限性,如奖励操纵、语言不一致性以及泛化到新场景的困难。论文对比了 RL 与监督微调(SFT),指出 SFT 在控制模型行为和简化训练流程方面的优势。研究建议采用RL + SFT 的混合训练方法,以提升推理能力的同时确保模型的安全性。此外,作者提供了 DeepSeek-R1 的负责任部署指南,强调监控、提示工程(prompt engineering)和风险缓解的重要性。未来研究方向包括多语言一致性、复杂危害处理以及在小型模型中扩展安全性等问题。原文链接:arxiv.org

【第171期】DivPO:Diverse Preference Optimization
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Diverse Preference OptimizationSummaryThe research introduces Diverse Preference Optimization (DivPO), a novel training method designed to enhance the diversity of language model outputs while maintaining quality. Current optimization techniques often lead to a reduction in diversity, especially in creative tasks. DivPO addresses this by selecting preference pairs based on both quality and diversity, contrasting diverse, high-reward responses with less diverse, lower-reward ones. The method demonstrates significant improvements in diversity across tasks like persona generation and story writing. Experiments show that DivPO outperforms standard optimization methods by increasing both the reward and the diversity of the generated content, making it a valuable tool for creative applications and synthetic data generation. DivPO's effectiveness is validated through offline and online training regimes, showcasing its robustness and potential for wider application.本研究提出了 Diverse Preference Optimization(DivPO),一种旨在提升语言模型输出多样性的新型训练方法,同时保持生成质量。当前的优化技术往往会降低输出的多样性,尤其是在创造性任务中。DivPO 通过在质量和多样性两个维度上选择偏好对比样本,使高质量且多样化的响应与低质量且缺乏多样性的响应进行对比,从而优化模型训练。实验表明,DivPO 在角色生成、故事写作等任务上显著提升了生成内容的多样性。与标准优化方法相比,DivPO 同时提高了生成奖励和多样性,使其成为创造性应用和合成数据生成的有力工具。研究通过离线和在线训练验证了 DivPO 的有效性,展现了其稳健性和广泛应用潜力。原文链接:https://arxiv.org/abs/2501.18101
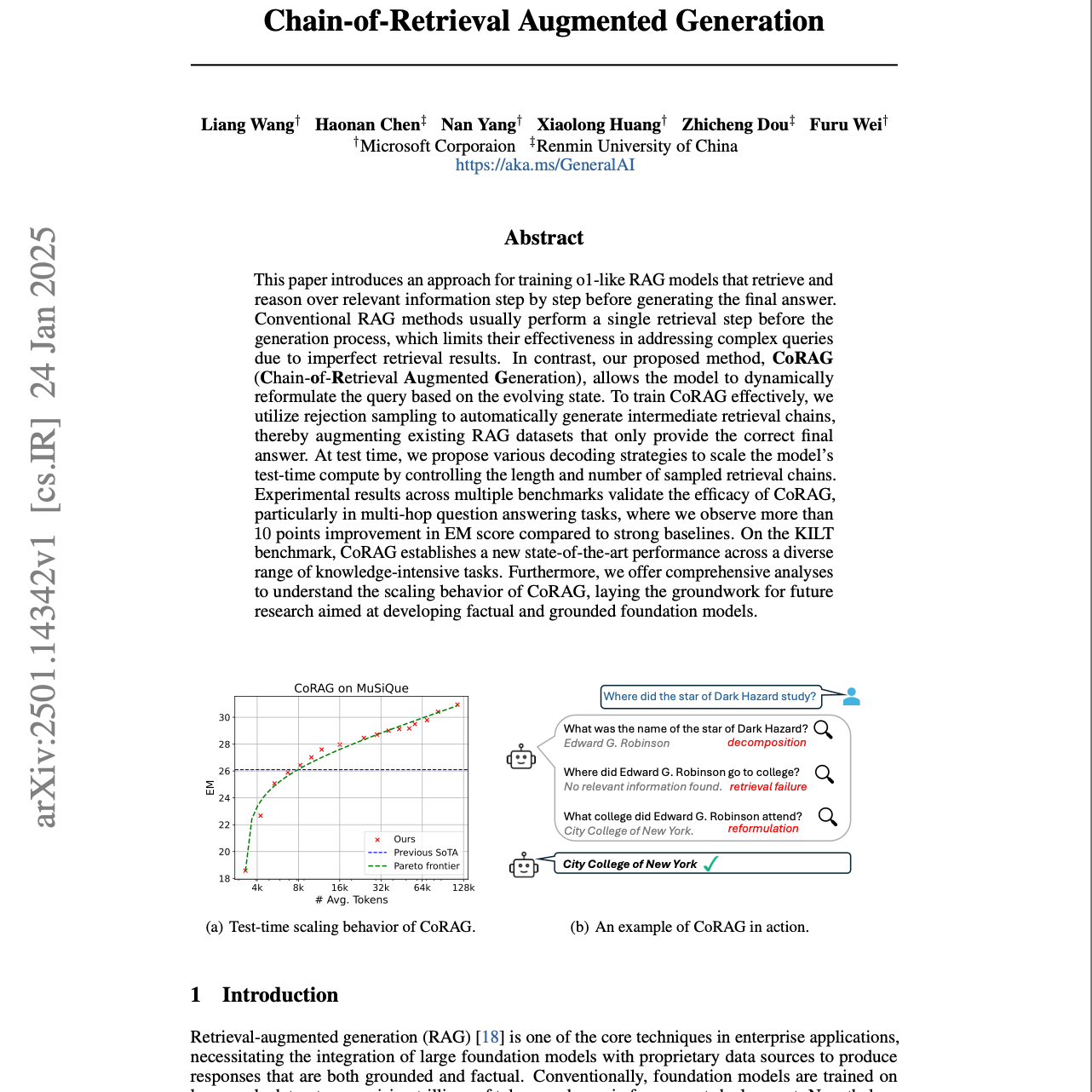
【第170期】Chain of RAG
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Chain-of-Retrieval Augmented GenerationSummaryThis paper introduces Chain-of-Retrieval Augmented Generation (CoRAG), a method that allows language models to iteratively retrieve and reason over relevant information. Unlike traditional RAG, CoRAG dynamically reformulates queries based on the evolving information state. To train CoRAG, the authors use rejection sampling to generate intermediate retrieval chains and fine-tune models to predict the next query, answer, and final response. The effectiveness of CoRAG is validated across benchmarks, showing significant improvements in multi-hop question answering. The paper explores test-time scaling strategies, demonstrating how to balance performance and computational cost by adjusting the number of retrieval steps. CoRAG achieves new state-of-the-art results on knowledge-intensive tasks, highlighting its potential for building more factual and trustworthy AI systems.本论文提出了 Chain-of-Retrieval Augmented Generation(CoRAG),一种让语言模型能够迭代检索并推理相关信息的方法。与传统的 RAG 不同,CoRAG 动态重构查询,根据不断更新的信息状态调整检索策略。在训练过程中,作者采用拒绝采样(rejection sampling)生成中间检索链,并微调模型以预测下一个查询、答案和最终回复。实验结果表明,CoRAG 在多个基准测试上取得了显著提升,特别是在多跳问答任务中表现优异。此外,研究探讨了测试时的扩展策略,通过调整检索步数,在性能与计算成本之间取得平衡。CoRAG 在知识密集型任务上达到了最新的SOTA(state-of-the-art)水平,展现出构建更具事实性和可靠性的 AI 系统的潜力。原文链接:https://arxiv.org/abs/2501.14342

【第169期】LiT:Linear Diffusion Transformer
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:LiT: Delving into a Simplified Linear Diffusion Transformer for Image GenerationSummaryThe provided document introduces LiT, a Linear Diffusion Transformer, designed for efficient image generation. LiT simplifies linear attention mechanisms and employs a novel training strategy involving weight inheritance and hybrid knowledge distillation. This approach allows LiT to achieve competitive image generation results with significantly reduced training steps, rivaling other methods like Mamba or Gated Linear Attention. Experiments demonstrate LiT's capability to generate high-resolution, photorealistic images, even on resource-limited devices like laptops. The research explores architectural refinements and optimization strategies to improve the performance of linear Diffusion Transformers. This work is aimed at cost-effectively training a linear DiT for photorealistic image generation by focusing on linear attention design, weight inheritance, and knowledge distillation.该文档介绍了 LiT(Linear Diffusion Transformer),一种专为高效图像生成设计的线性扩散变换器。LiT 简化了线性注意力机制,并采用了一种新颖的训练策略,包括权重继承和混合知识蒸馏,使其在大幅减少训练步骤的同时,仍能实现与 Mamba 或 Gated Linear Attention 等方法相媲美的图像生成效果。实验表明,LiT 能够生成高分辨率、逼真的图像,即使在笔记本电脑等资源受限的设备上也能运行。研究还探讨了架构优化和训练策略,以提升线性扩散变换器的性能。本研究的目标是通过专注于线性注意力设计、权重继承和知识蒸馏,以更低的成本训练出高质量的 LiT 模型,实现逼真的图像生成。原文链接:https://arxiv.org/abs/2501.12976

【第168期】多机器人系统中的“观察-计算-移动”方法
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Knowledge in multi-robot systems: an interplay of dynamics, computation and communicationSummaryThis paper bridges the gap between control theory, distributed computing, and temporal epistemic logic to analyze multi-robot systems. It formulates robot behaviors using both hybrid dynamical systems and state machines executing look-compute-move cycles, demonstrating compatibility between these models. The authors introduce the concept of "time paths" to synchronize local robot executions within a global time frame and establish epistemic frames to reason about robot knowledge and task solvability. Sufficient epistemic conditions are derived for exploration, surveillance, and gathering tasks, showing how the robots can accomplish these tasks under specific knowledge-based requirements. The exploration task shows that the classic LUMI robot model is very powerful for information gathering. The framework aims to integrate multiple perspectives for a comprehensive approach to multi-robot systems.本论文融合了控制理论、分布式计算和时态认知逻辑,以分析多机器人系统。研究使用混合动力系统和执行“观察-计算-移动”循环的状态机来建模机器人行为,并证明了这些模型之间的兼容性。作者提出了“时间路径”概念,以在全局时间框架内同步本地机器人执行,并建立了认知框架来推理机器人知识与任务可解性。研究推导出了探索、监视和聚集任务的充分认知条件,展示了机器人在特定知识要求下完成任务的方法。探索任务的分析表明,经典的 LUMI 机器人模型在信息收集方面具有强大能力。该框架旨在整合多种视角,为多机器人系统提供全面的研究方法。原文链接:https://arxiv.org/abs/2501.18309
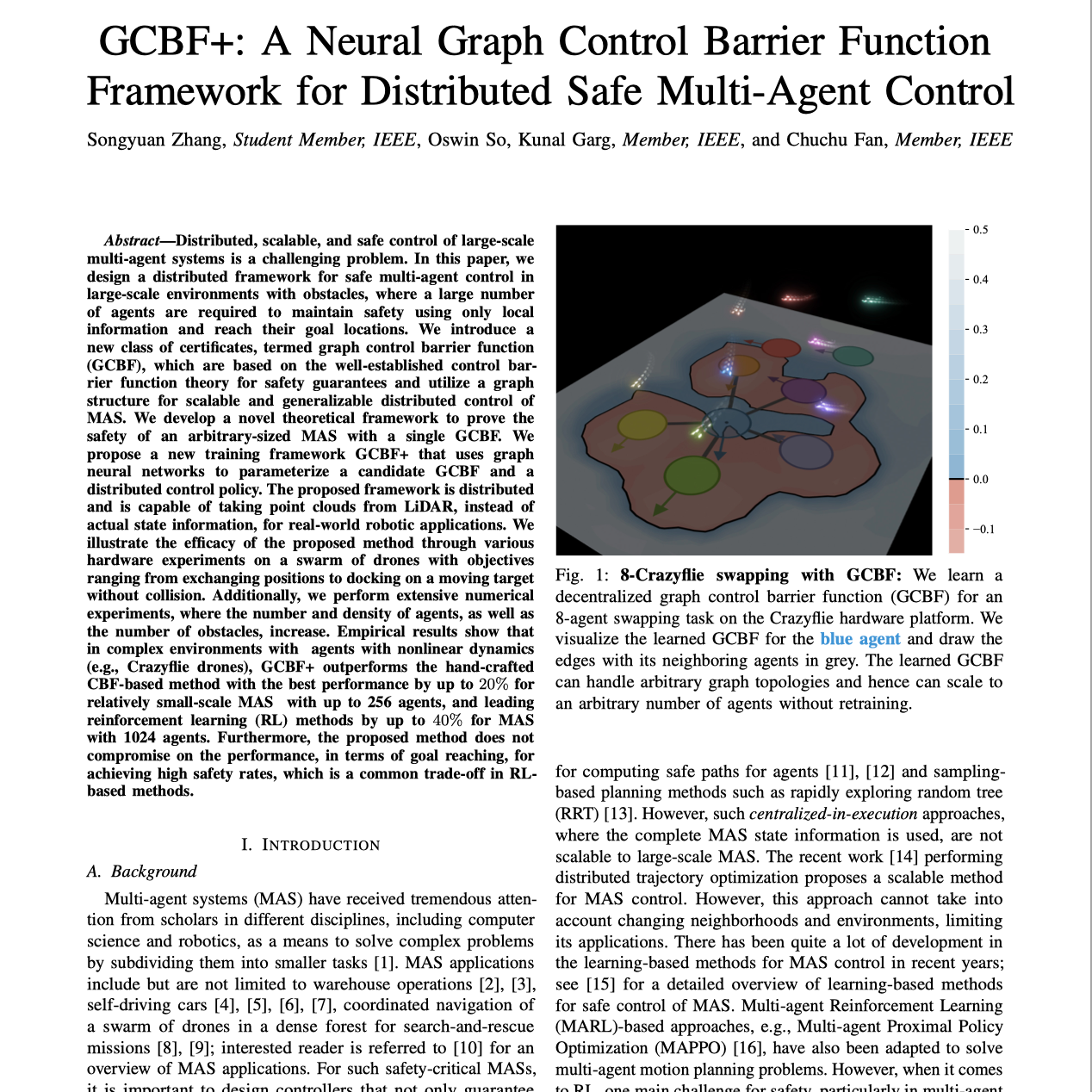
【第167期】GCBF+:安全的多智能体避障控制算法
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:GCBF+: A Neural Graph Control Barrier Function Framework for Distributed Safe Multi-Agent ControlSummaryThis research introduces a novel framework, GCBF+, for safe and scalable control of multi-agent systems using Graph Control Barrier Functions (GCBFs). The framework employs graph neural networks to learn GCBFs and distributed control policies, enabling agents to avoid collisions and reach goals using only local information. A key contribution is a theoretical result proving that a single GCBF can guarantee safety for multi-agent systems of arbitrary size, even when trained on smaller groups. Experimental results, including hardware tests with Crazyflie drones, demonstrate GCBF+'s superior performance compared to existing methods, especially in complex, nonlinear environments. The framework addresses limitations of prior approaches by incorporating actuation limits and using a new loss function that avoids the safety versus goal-reaching trade-off typical in reinforcement learning. The proposed GCBF+ method is shown to be robust to a large range of its hyper-parameters for successful goal reaching and safety maintenance.本研究提出了一种新颖的框架 GCBF+,利用图控制屏障函数(GCBF)实现多智能体系统的安全可扩展控制。该框架采用图神经网络来学习 GCBF 和分布式控制策略,使智能体仅依赖局部信息即可避障并到达目标。研究的核心贡献之一是理论证明:即使仅在小规模智能体群体上训练,一个单一的 GCBF 也能确保任意规模的多智能体系统的安全。实验结果(包括 Crazyflie 无人机的硬件测试)表明,GCBF+ 在复杂非线性环境中相较现有方法表现更优。该框架通过引入执行限制并采用新的损失函数,克服了以往方法的局限性,避免了强化学习中常见的“安全性与目标达成之间的权衡”问题。研究还表明,GCBF+ 在较广泛的超参数范围内均能保持目标达成和系统安全的鲁棒性。原文链接:https://arxiv.org/abs/2401.14554
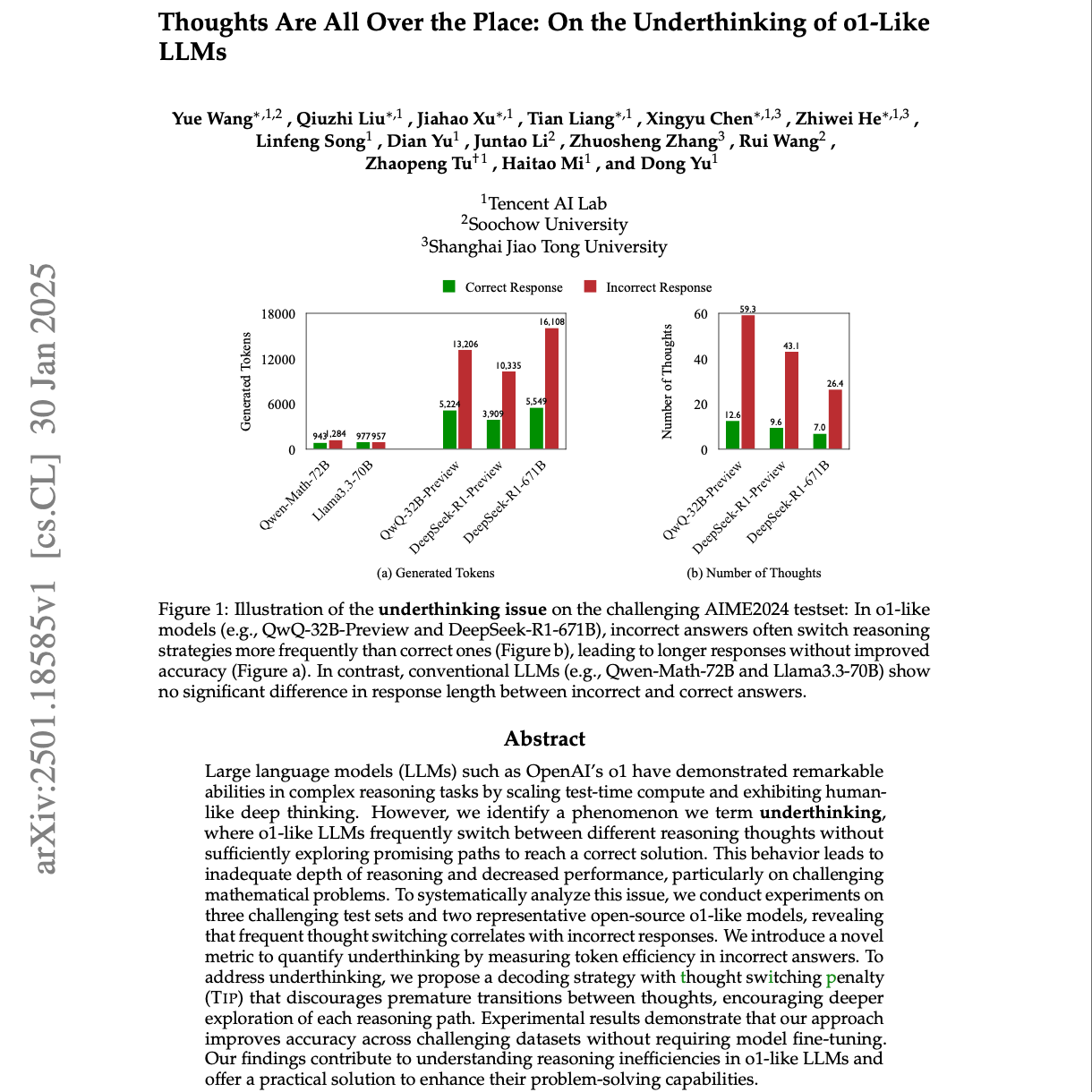
【第166期】underthinking:模型思考不够深入的问题
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Thoughts Are All Over the Place: On the Underthinking of o1-Like LLMsSummaryThis research investigates "underthinking" in large language models (LLMs), where models prematurely switch between reasoning strategies on complex tasks. The authors found that this frequent thought-switching correlates with incorrect answers and propose a metric to quantify this inefficiency. To address this, they introduce a "thought switching penalty" (TIP) during decoding, discouraging early transitions between reasoning paths. Experiments show that TIP improves accuracy without fine-tuning the model. The study contributes to understanding and mitigating reasoning inefficiencies in LLMs, enhancing their problem-solving capabilities. The authors analyze prior work in reasoning with LLMs, as well as manipulation of decoding penalties.本研究探讨了大型语言模型(LLM)的“思维不足”问题,即在处理复杂任务时,模型过早切换推理策略。作者发现,这种频繁的思维切换与错误答案存在相关性,并提出了一种量化该低效性的指标。为了解决这一问题,研究在解码过程中引入了“思维切换惩罚”(TIP),以抑制推理路径的过早转换。实验表明,TIP 在无需微调模型的情况下提高了准确率。本研究有助于理解并缓解 LLM 的推理低效性,增强其问题解决能力。作者还分析了 LLM 推理相关的先前研究以及解码惩罚的调整方法。原文链接:https://arxiv.org/abs/2501.18585

【第165期】DeepSeek-R1 和 OpenAI 的 o3-mini 安全性比较
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:o3-mini vs DeepSeek-R1: Which One is Safer?SummaryThe study assesses the safety of two large language models (LLMs), DeepSeek-R1 and OpenAI's o3-mini, using an automated testing tool called ASTRAL. It explores how these models respond to unsafe prompts across various categories, writing styles, and persuasion techniques. The research indicates that DeepSeek-R1 exhibits significantly more unsafe behaviors compared to o3-mini, particularly in categories like financial crime and violence. This suggests DeepSeek-R1 is less aligned with safety standards than o3-mini, and earlier OpenAI models, with potential implications for real-world applications. The researchers also note that OpenAI's policy violation safeguards may have influenced o3-mini's safety results, requiring further testing upon its full release. This work emphasizes the importance of robust safety evaluations for LLMs before widespread deployment.该研究评估了两个大型语言模型(LLM),DeepSeek-R1 和 OpenAI 的 o3-mini,在自动化测试工具 ASTRAL 下的安全性。研究探讨了这些模型在不同类别、写作风格和说服技巧下对不安全提示的响应情况。研究结果表明,DeepSeek-R1 在金融犯罪和暴力等类别中表现出明显更多的不安全行为,相较而言,o3-mini 的安全性更高。这表明 DeepSeek-R1 在安全标准上的对齐程度低于 o3-mini 以及 OpenAI 早期的模型,可能会对现实世界的应用产生影响。研究人员还指出,OpenAI 的政策违规防护机制可能影响了 o3-mini 的安全测试结果,因此需要在其完整发布后进行进一步测试。本研究强调,在广泛部署 LLM 之前,进行严格的安全评估至关重要。原文链接:https://arxiv.org/abs/2501.18438

【第164期】CodeMonkeys:软件工程中一种test time compute方法
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:CodeMonkeys: Scaling Test-Time Compute for Software EngineeringSummaryThe "CodeMonkeys" paper introduces a system that improves large language model (LLM) performance on software engineering tasks by scaling test-time compute. This scaling is achieved by iteratively generating and testing code edits, both serially (more iterations per attempt) and in parallel (multiple attempts simultaneously). The system identifies relevant code context, generates candidate edits with accompanying tests, and selects the best edit through voting and a dedicated selection process. By amortizing the cost of context identification and using a combination of test-based voting and model-based selection, CodeMonkeys achieves competitive results on the SWE-bench Verified dataset. The paper also explores combining edits from multiple sources, demonstrating the effectiveness of their selection method in heterogeneous ensembles. Furthermore, an exploration of DeepSeek-V3 as a cheaper alternative to Claude Sonnet 3.5 is analyzed for potential benefits.“CodeMonkeys” 论文提出了一种提升大语言模型(LLM)在软件工程任务上表现的系统,其核心思路是扩展测试时计算(test-time compute)。这种扩展通过迭代地生成和测试代码修改来实现,包括串行方式(在单次尝试中进行更多迭代)和并行方式(同时进行多个尝试)。该系统首先识别相关代码上下文,然后生成候选代码修改及其测试,并通过投票机制和专门的选择流程挑选最佳修改方案。通过摊销上下文识别成本,并结合基于测试的投票和基于模型的选择,CodeMonkeys 在 SWE-bench Verified 数据集上取得了具备竞争力的结果。此外,论文还探索了如何整合来自多个来源的代码修改,验证了该系统在异构集成(heterogeneous ensembles)中的有效性。同时,研究对比了DeepSeek-V3 作为 Claude Sonnet 3.5 的低成本替代方案,分析了其潜在优势。原文链接:https://arxiv.org/abs/2501.14723

【第163期】Encoder-Decoder架构的SLM
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Return of the Encoder: Maximizing Parameter Efficiency for SLMsSummaryThis paper challenges the current trend of using decoder-only architectures for language models, particularly for smaller language models (SLMs). It argues that encoder-decoder architectures offer superior efficiency and performance in resource-constrained environments, especially regarding latency and throughput on edge devices. The researchers introduce a knowledge distillation framework that allows encoder-decoder models to learn from larger decoder-only models while maintaining their architectural advantages. They also demonstrate the benefits of encoder-decoder models in vision-language tasks by integrating a vision encoder. Their findings suggest that focusing on architectural choices is crucial for creating efficient SLMs, especially for on-device deployment, rather than simply scaling down large models. They show that encoder-decoder models with knowledge distillation can outperform decoder-only models and reduce latency significantly.该论文对当前以解码器(decoder-only)架构为主的语言模型趋势提出质疑,尤其针对小型语言模型(Small Language Models, SLMs)。研究表明,在资源受限环境(如边缘设备)中,编码器-解码器(encoder-decoder)架构在延迟和吞吐量方面表现更优,具备更高的效率和性能。为此,研究者提出了一种知识蒸馏(knowledge distillation)框架,使编码器-解码器模型能够从更大的解码器模型学习,同时保持其架构优势。此外,论文还通过集成视觉编码器(vision encoder),验证了编码器-解码器模型在视觉-语言任务中的优势。研究结果表明,优化架构选择比单纯缩小大模型规模更关键,尤其是在**端侧部署(on-device deployment)**的场景中。实验进一步证明,结合知识蒸馏的编码器-解码器模型不仅优于解码器模型,还能显著降低延迟。原文链接:https://arxiv.org/abs/2501.16273

【第162期】ICRL:一种通用问题解决方法
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:RL + Transformer = A General-Purpose Problem SolverSummaryThis paper introduces an innovative approach called In-Context Reinforcement Learning (ICRL) that utilizes a pre-trained transformer model to solve problems, even those it hasn't seen before. The model, Llama 3.1 8B, is fine-tuned with reinforcement learning, enabling it to meta-learn and adapt to new environments with remarkable efficiency. The ICRL-trained transformer demonstrates the ability to combine learned skills, handle suboptimal training data, and adjust to changing environments, showcasing its potential as a general-purpose problem solver. The study assesses its performance on in-distribution and out-of-distribution environments, highlighting its ability to stitch together behaviors from its context and improve its solutions iteratively. The results indicate that ICRL holds promise for developing AI systems with human-like adaptability, although the ethical implications of autonomous agents are also considered and discussed. The work also reveals challenges related to exploration, suggesting potential avenues for future research to enhance the capabilities of ICRL-trained transformers.该论文提出了一种创新方法——上下文强化学习(In-Context Reinforcement Learning, ICRL),该方法利用 预训练变换器模型 解决问题,包括此前未曾见过的问题。研究采用 Llama 3.1 8B 作为基础模型,并通过强化学习进行微调,使其具备元学习能力,从而能够高效适应新环境。实验表明,ICRL 训练的变换器能够整合已学技能、处理次优训练数据,并适应环境变化,展现出其作为通用问题求解器的潜力。研究评估了该模型在分布内(in-distribution)与分布外(out-of-distribution)环境中的表现,强调其能够基于上下文拼接行为(stitch together behaviors)并迭代优化解决方案。结果表明,ICRL 有望推动具备类人适应能力的人工智能系统的发展,同时研究也探讨了自主智能体的伦理影响。此外,研究揭示了 ICRL 在探索方面的挑战,并提出了未来研究方向,以进一步提升 ICRL 训练的变换器的能力。原文链接:https://arxiv.org/abs/2501.14176

【第161期】VideoWorld:从无标签视频数据中学习复杂知识
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:VideoWorld: Exploring Knowledge Learning from Unlabeled VideosSummaryThe paper introduces VideoWorld, a novel approach to learning complex knowledge directly from unlabeled video data. It presents a video generation model that, unlike traditional language models, learns rules, reasoning, and planning skills solely from visual input, exemplified through tasks like video-based Go and robotic control. A key finding is that visual change representation is vital for knowledge acquisition, leading to the development of a Latent Dynamics Model (LDM) for enhanced efficiency. Remarkably, VideoWorld achieves high proficiency in Video-GoBench and demonstrates effective robotic control, rivaling oracle models. This research pioneers a new direction for AI learning, emphasizing the potential of visual data as a primary source of knowledge. The supplementary material gives additional details about the implementation and results.该论文介绍了 VideoWorld,一种全新的方法,能够直接从无标签视频数据中学习复杂知识。论文提出了一种视频生成模型,不同于传统的语言模型,该模型仅依赖视觉输入学习规则、推理和规划能力,并通过视频版围棋(Video-based Go)和机器人控制等任务加以验证。研究的一个关键发现是,视觉变化的表示对于知识获取至关重要,据此提出了 潜在动力学模型(Latent Dynamics Model, LDM) 以提高学习效率。令人瞩目的是,VideoWorld 在 Video-GoBench 基准测试中表现出色,并在机器人控制任务上展现了可比肩先验模型(oracle models)的能力。这项研究开辟了 人工智能学习的新方向,强调了视觉数据作为知识主要来源的潜力。补充材料提供了关于实现细节和实验结果的更多信息。原文链接:https://arxiv.org/abs/2501.09781

【第160期】AI Red Teaming实践经验总结
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Lessons From Red Teaming 100 Generative AI ProductsSummaryAI red teaming, a practice for assessing the safety and security of generative AI systems, is explored in this paper, drawing from Microsoft's experience red teaming over 100 GenAI products. The authors share their internal threat model ontology and eight lessons learned, highlighting the importance of understanding system capabilities, prioritizing simple attack techniques, and recognizing that red teaming differs from safety benchmarking. Automation with tools like PyRIT can enhance red teaming, but human expertise remains critical, especially in assessing responsible AI harms. The paper stresses that LLMs amplify existing security risks and introduce new vulnerabilities. Securing AI systems is an ongoing process, requiring economic considerations, break-fix cycles, and policy regulation.本论文探讨了 AI Red Teaming(人工智能红队测试)这一实践,用于评估 生成式 AI 系统的安全性和可靠性。研究借鉴了 微软在 100 多个 GenAI 产品上的红队测试经验,分享了内部威胁模型本体(threat model ontology)及八大经验教训。作者强调了以下关键点: 理解系统能力 对于有效评估至关重要。 优先采用简单的攻击技术,往往比复杂方法更能暴露漏洞。 红队测试不同于安全基准测试,它更侧重于主动发现系统弱点。尽管 PyRIT 等自动化工具可以提升红队测试效率,但 人类专家仍然不可或缺,特别是在评估 负责任 AI 相关风险 方面。此外,论文指出 大语言模型(LLMs)不仅放大了已有的安全风险,还引入了新的漏洞。最终,研究强调 AI 安全是一个持续的过程,涉及 经济成本、漏洞修复周期(break-fix cycles)及政策监管,需要跨学科协作来确保 AI 系统的安全性。原文链接:https://arxiv.org/abs/2501.07238

【第159期】TheAgentCompany:评估 AI 代理在真实工作场景中执行任务的新基准
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:TheAgentCompany: Benchmarking LLM Agents on Consequential Real World TasksSummaryTheAgentCompany is introduced as a new benchmark for evaluating AI agents on real-world workplace tasks. This benchmark simulates a software company environment where agents perform tasks like web browsing, coding, and communication with simulated colleagues. The paper assesses the performance of various large language models (LLMs) on these tasks, revealing that even the best models struggle to autonomously complete most of them. The authors identify challenges such as social interaction, navigating complex UIs, and the lack of training data for certain professional tasks. The benchmark aims to provide insights into the current capabilities and limitations of AI agents in automating work-related tasks. The benchmark also includes a breakdown of the employee roster of TheAgentCompany and examples of conversation between agents and simulated colleagues within their environment. The paper concludes by discussing the implications of their findings and suggesting directions for future research and benchmark improvements.TheAgentCompany 是一个用于评估 AI 代理在真实工作场景中执行任务的新基准测试。该基准模拟了一个软件公司环境,AI 代理需要完成 网页浏览、编写代码和与模拟同事沟通 等任务。论文评估了多种 大语言模型(LLMs) 在这些任务中的表现,结果表明,即使是最先进的模型仍难以自主完成大多数任务。研究指出了 社交交互、复杂 UI 导航 以及 某些专业任务缺乏训练数据 等关键挑战。TheAgentCompany 旨在揭示 AI 代理在自动化工作任务中的当前能力与局限性。基准测试还包括公司员工角色的详细设定,以及 AI 代理与模拟同事之间的对话示例。论文最后讨论了研究结果的影响,并提出了未来研究方向及基准改进建议。原文链接:https://arxiv.org/abs/2412.14161

【第158期】图像生成CoT是什么样的
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Can We Generate Images with CoT? Let's Verify and Reinforce Image Generation Step by StepSummaryThis research explores enhancing autoregressive image generation using Chain-of-Thought (CoT) reasoning strategies commonly applied to language models. The study adapts techniques like test-time verification and preference alignment to improve image quality and text alignment. The authors introduce a Potential Assessment Reward Model (PARM) and PARM++ to better evaluate and refine image generation steps. PARM adaptively assesses potential during generation while PARM++ incorporates a reflection mechanism for self-correction. Experiments show significant improvements over existing methods, including Stable Diffusion, highlighting the potential of CoT reasoning in image generation. The authors provide insights into adapting these strategies and show the effectiveness of tailored reward models.本研究探讨了如何利用 Chain-of-Thought (CoT) 思维链推理策略来增强自回归图像生成,这些策略通常应用于语言模型。研究采用 测试时验证 和 偏好对齐 等技术,以提高图像质量和文本对齐度。作者提出了 潜在性评估奖励模型(PARM) 及其增强版本 PARM++,用于优化图像生成过程。PARM 在生成过程中自适应地评估潜在质量,而 PARM++ 进一步引入反思机制,实现自我修正。实验结果表明,该方法相较于现有技术(包括 Stable Diffusion)具有显著优势,验证了 CoT 推理 在图像生成中的潜力。研究还深入探讨了如何调整这些策略,并展示了定制化奖励模型的有效性。原文链接:https://arxiv.org/abs/2501.13926

【第157期】DiffuEraser:利用稳定扩散技术修复视频
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:DiffuEraser: A Diffusion Model for Video InpaintingSummaryDiffuEraser is a novel video inpainting model leveraging stable diffusion to address limitations in existing methods. Current video inpainting techniques often struggle with blurring and temporal inconsistencies, especially with large masked areas. DiffuEraser enhances detail and coherence by incorporating prior information to guide the diffusion process and suppress unwanted artifacts. To improve temporal consistency across extended video sequences, it expands the temporal receptive fields and uses the Video Diffusion Model's smoothing properties. The model decomposes video inpainting into known pixel propagation, unknown pixel generation, and temporal consistency, offering targeted solutions for each. Ultimately, DiffuEraser outperforms existing methods by producing more complete and temporally consistent results.DiffuEraser 是一种新颖的视频修复模型,利用稳定扩散技术来解决现有方法的局限性。当前的视频修复技术在处理大面积遮挡时,常常面临模糊和时间一致性差的问题。DiffuEraser 通过引入先验信息来引导扩散过程,有效增强细节和整体连贯性,同时抑制不必要的伪影。为了提高长视频序列的时间一致性,模型扩展了时间感受野,并利用 Video Diffusion Model 的平滑特性。DiffuEraser 将视频修复任务分解为已知像素传播、未知像素生成和时间一致性维护,并针对每个环节提供专门的解决方案。实验结果表明,该方法相比现有技术能够生成更完整且时间一致性更高的视频内容。原文链接:https://arxiv.org/abs/2501.10018

【第156期】Mobile-Agent-E:智能手机上的Agent
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Mobile-Agent-E: Self-Evolving Mobile Assistant for Complex TasksSummaryThis research introduces Mobile-Agent-E, an innovative mobile assistant designed to handle complex, real-world tasks on smartphones. The system employs a hierarchical multi-agent framework with a self-evolution module, enabling it to learn from past experiences and improve its performance over time. Mobile-Agent-E separates high-level planning from low-level action execution, utilizing specialized agents for perception, operation, reflection, and note-taking. A novel benchmark, Mobile-Eval-E, is introduced to evaluate the agent's capabilities on challenging, multi-app tasks. Experimental results demonstrate significant improvements over existing approaches, showcasing the effectiveness of the hierarchical design and self-evolution mechanism. The study also analyzes the impact of self-generated tips and shortcuts, paving the way for more efficient and user-friendly mobile agents.本研究介绍了 Mobile-Agent-E,一款创新的移动助手,专为在智能手机上处理复杂的现实世界任务而设计。该系统采用分层多智能体框架,并引入自进化模块,使其能够从过去的经验中学习,并随着时间推移不断提升性能。Mobile-Agent-E 将高层规划与低层动作执行分离,利用专门的智能体负责感知、操作、反思和笔记记录。此外,研究提出了一个新的基准测试 Mobile-Eval-E,用于评估智能体在复杂的多应用任务中的能力。实验结果表明,该方法相较于现有方案有显著提升,验证了分层设计与自进化机制的有效性。研究还分析了智能体自生成的提示和快捷方式的影响,为开发更高效、用户友好的移动智能体奠定了基础。原文链接:https://arxiv.org/abs/2501.11733

【第155期】IntellAgent:多智能体框架
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:IntellAgent: A Multi-Agent Framework for Evaluating Conversational AI SystemsSummaryThis document introduces IntellAgent, a novel, open-source multi-agent framework designed to evaluate conversational AI systems. IntellAgent addresses the shortcomings of traditional methods by automating the creation of diverse, realistic scenarios using policy-driven graph modeling, event generation, and user-agent simulations. The framework leverages a policy graph to represent policy relationships and complexities, enabling detailed diagnostics of agent performance. Unlike existing benchmarks, IntellAgent offers fine-grained insights into policy adherence and identifies specific areas for improvement. Experiments show that IntellAgent provides a robust alternative for evaluating conversational agents and correlating with existing benchmarks, despite relying on synthetic data. The system is implemented using Langgraph and provides a means to assess different large language models in complex chatbot environments.本文件介绍了 IntellAgent,一个新颖的开源多智能体框架,旨在评估对话式人工智能系统。IntellAgent 通过策略驱动的图建模、事件生成和用户代理模拟,自动创建多样化且逼真的场景,从而弥补了传统方法的不足。该框架利用策略图来表示策略关系及其复杂性,使得对智能体的性能进行详细诊断成为可能。与现有基准测试不同,IntellAgent 能够提供细粒度的洞察,评估策略遵循情况并识别具体的改进点。实验表明,尽管依赖于合成数据,IntellAgent 依然能够作为评估对话代理的有力替代方案,并与现有基准测试结果呈现相关性。该系统基于 Langgraph 实现,并可用于评估不同的大型语言模型在复杂聊天机器人环境中的表现。原文链接:https://arxiv.org/abs/2501.11067

【第154期】Agentic RAG survey
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Agentic Retrieval-Augmented Generation: A Survey on Agentic RAGSummaryThe provided text is a survey of Agentic Retrieval-Augmented Generation (RAG), a paradigm that enhances large language models by integrating autonomous AI agents into the RAG pipeline. This allows for dynamic retrieval strategies, contextual understanding, and iterative refinement, addressing the limitations of traditional RAG systems. The survey covers the evolution of RAG paradigms, detailed Agentic RAG architectures, and applications across industries like healthcare, finance, and education. It also explores implementation strategies, challenges in scaling, ethical considerations, performance optimization, and relevant frameworks and tools. Finally, the survey provides an overview of benchmarks and datasets used to evaluate RAG systems.这篇文章是关于代理化检索增强生成(Agentic RAG)的综述,介绍了一种通过将自主AI代理集成到RAG流程中来增强大型语言模型的范式。通过这种方式,RAG能够实现动态的检索策略、上下文理解和迭代优化,克服了传统RAG系统的局限性。综述涵盖了RAG范式的演变、详细的代理化RAG架构以及在医疗、金融和教育等行业中的应用。文章还探讨了实现策略、扩展中的挑战、伦理考量、性能优化,以及相关的框架和工具。最后,文章提供了评估RAG系统所使用的基准和数据集的概述。原文链接:https://arxiv.org/abs/2501.09136

【第153期】Chain-of-Agents框架
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Chain of Agents: Large Language Models Collaborating on Long-Context TasksSummaryLarge language models (LLMs) struggle with long contexts due to limitations in processing extensive information. The "Chain-of-Agents" (CoA) framework addresses this by using multiple LLM agents that collaborate to process long documents. CoA divides the input into segments, assigns each segment to a worker agent, and then uses a manager agent to integrate the information and produce a final output. This method outperforms traditional approaches like Retrieval-Augmented Generation (RAG) and full-context LLMs, particularly in question answering, summarization, and code completion tasks. CoA also mitigates issues with focus within long contexts and is task-agnostic, training-free, and highly interpretable. Ultimately, the "Chain-of-Agents" framework facilitates improved processing and reasoning over long contexts, expanding the potential applications of LLMs in various domains.大型语言模型(LLMs)在处理长上下文时面临困难,因为它们在处理大量信息时存在限制。为了应对这一挑战,"Chain-of-Agents"(CoA)框架通过使用多个LLM代理来协作处理长文档。CoA将输入划分为多个片段,将每个片段分配给一个工作代理,然后通过一个管理代理整合信息,最终生成输出。这种方法在问答、摘要和代码补全等任务中,特别是在处理长文档时,表现优于传统的检索增强生成(RAG)和全上下文LLM。CoA还解决了长上下文中的注意力问题,并且是任务无关的、无需训练的,并且具有高度的可解释性。最终,"Chain-of-Agents"框架通过提高长上下文的处理和推理能力,扩展了LLM在各个领域的潜在应用。原文链接:https://arxiv.org/abs/2406.02818

【第152期】Kimi k1.5
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Kimi k1.5: Scaling Reinforcement Learning with LLMsSummaryThis technical report introduces Kimi k1.5, a multimodal large language model trained with reinforcement learning (RL). The report highlights the model's training techniques, including long context scaling and policy optimization, emphasizing a simplistic yet effective RL framework. Kimi k1.5 achieves state-of-the-art reasoning performance across several benchmarks, even outperforming models like OpenAI's o1 and GPT-4o in certain short-CoT reasoning tasks. A key aspect is the exploration of long-context RL, with the model trained on sequences up to 128k tokens and improved policy optimization that uses a variant of online mirror descent for robust policy optimization. Furthermore, the report details long2short methods, infrastructure optimization, and ablation studies, showcasing Kimi k1.5's advancements in multi-modal AI capabilities and token efficiency.这份技术报告介绍了Kimi k1.5,一款通过强化学习(RL)训练的多模态大型语言模型。报告重点讲述了模型的训练技术,包括长上下文扩展和策略优化,强调了一种简洁而有效的RL框架。Kimi k1.5在多个基准测试中达到了最先进的推理表现,甚至在某些短链推理任务中超越了OpenAI的o1和GPT-4o模型。一个关键方面是对长上下文RL的探索,该模型训练时处理的序列长度可达128k个tokens,并采用一种在线镜像下降的变种方法进行强化的策略优化。报告还详细介绍了长2短方法、基础设施优化和消融研究,展示了Kimi k1.5在多模态AI能力和token效率方面的进展。原文链接:https://arxiv.org/abs/2501.12599

【第151期】Humanity’s Last Exam
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Humanity’s Last ExamSummary"Humanity's Last Exam" (HLE) introduces a new benchmark designed to assess the knowledge of large language models (LLMs) at the frontier of human expertise. This dataset contains 3,000 multiple-choice and short-answer questions across various subjects, emphasizing deep reasoning skills and resistance to simple internet retrieval. The questions undergo a rigorous review process by subject-matter experts to ensure difficulty and quality. Evaluations reveal that current LLMs exhibit low accuracy and poor calibration on HLE, indicating a significant gap in capabilities. The authors suggest HLE offers a reference point for AI progress and informs discussions on AI risks and governance. The creation of the data was a global effort by almost 1000 expert contributors.《人类最后的考试》(HLE)推出了一个新基准,旨在评估大型语言模型(LLMs)在接近人类专家前沿领域的知识水平。该数据集包含3000个多项选择题和简答题,涵盖多个学科,重点考察深度推理能力并避免简单的互联网检索。所有问题都经过了学科专家的严格审查,确保难度和质量。评估结果显示,当前的LLM在HLE上的准确性较低,且校准效果差,表明其能力存在显著差距。作者认为,HLE为AI进展提供了一个参考点,并为AI风险与治理的讨论提供了依据。该数据的创建是由近1000名专家贡献的全球合作成果。原文链接:https://arxiv.org/abs/2501.14249
【第150期】DeepSeek-R1
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement LearningSummaryDeepSeek-AI introduces DeepSeek-R1-Zero and DeepSeek-R1, reasoning-focused large language models. DeepSeek-R1-Zero uses reinforcement learning (RL) without supervised fine-tuning (SFT) to achieve remarkable reasoning capabilities. DeepSeek-R1 builds upon this by incorporating multi-stage training and "cold-start" data before RL, achieving results comparable to OpenAI's models. The company releases DeepSeek-R1-Zero, DeepSeek-R1, and distilled smaller models to support the research community. Experiments demonstrate that DeepSeek-R1 excels in reasoning tasks, outperforming other models in certain benchmarks, and distillation from DeepSeek-R1 greatly improves the reasoning abilities of smaller models. The study explores the benefits of RL and distillation, also discussing unsuccessful methods like Process Reward Models and Monte Carlo Tree Search.DeepSeek-AI推出了DeepSeek-R1-Zero和DeepSeek-R1,这两款专注于推理的大型语言模型。DeepSeek-R1-Zero通过强化学习(RL)实现了显著的推理能力,而无需监督微调(SFT)。DeepSeek-R1在此基础上进一步发展,结合了多阶段训练和“冷启动”数据,在进行RL之前进行预训练,取得了与OpenAI模型相当的成果。公司发布了DeepSeek-R1-Zero、DeepSeek-R1以及经过蒸馏的小型模型,以支持研究社区。实验表明,DeepSeek-R1在推理任务上表现出色,在某些基准测试中超越了其他模型,并且从DeepSeek-R1进行蒸馏显著提升了小型模型的推理能力。研究还探讨了强化学习和蒸馏的优势,并讨论了如过程奖励模型和蒙特卡洛树搜索等未能成功的方法。原文链接:https://arxiv.org/abs/2501.12948

【第149期】Mind Evolution:一种进化搜索策略
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Evolving Deeper LLM ThinkingSummaryThis paper introduces Mind Evolution, a novel evolutionary search strategy for enhancing the problem-solving capabilities of Large Language Models (LLMs) in natural language planning. The method uses an LLM to generate, combine, and refine potential solutions iteratively, guided by feedback from an evaluator. Mind Evolution outperforms existing inference strategies by effectively leveraging inference time compute without needing a formal problem definition. The paper showcases impressive results on benchmarks like TravelPlanner and Natural Plan, even introducing a new challenging task called StegPoet. The core innovation lies in its ability to optimize solutions directly in natural language space, eliminating the need for task formalization. Ablation studies confirm the importance of critical conversation and feedback mechanisms within the evolutionary process. The authors demonstrate that the approach can achieve high success rates, sometimes even exceeding 99%, and point to the potential for future development of LLM-based evaluators to broaden the scope of application.本文介绍了Mind Evolution,这是一种新颖的进化搜索策略,旨在提升大型语言模型(LLMs)在自然语言规划中的问题解决能力。该方法利用LLM生成、组合和迭代优化潜在解决方案,并通过评估器的反馈指导进程。Mind Evolution通过有效利用推理时的计算资源,超越了现有的推理策略,且无需正式的问题定义。本文在TravelPlanner和Natural Plan等基准任务上展示了令人印象深刻的结果,并引入了一个名为StegPoet的新挑战任务。其核心创新在于能够直接在自然语言空间中优化解决方案,省去了任务形式化的需求。消融实验确认了在进化过程中关键对话和反馈机制的重要性。作者证明该方法能够实现高成功率,有时甚至超过99%,并指出未来开发基于LLM的评估器具有扩大应用范围的潜力。原文链接:https://arxiv.org/abs/2501.09891

【第148期】Embodied-RAG:赋予机器人在复杂环境中更强的记忆和推理能力
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Embodied-RAG: General Non-parametric Embodied Memory for Retrieval and GenerationSummaryThis paper introduces Embodied-RAG, a novel framework designed to equip robots with enhanced memory and reasoning capabilities in complex environments. It tackles challenges in applying Retrieval-Augmented Generation (RAG) to robotics by constructing a hierarchical semantic forest for efficient knowledge storage and retrieval. Embodied-RAG integrates multimodal data and spatial awareness, outperforming existing RAG methods in navigation and explanation tasks. A new dataset, the Embodied-Experiences Dataset, is introduced to facilitate further research in this area. The core innovation lies in the system's ability to build and utilize a hierarchical spatial memory, enabling robots to navigate and communicate more effectively across diverse environments and query types. This work provides a foundation for developing generalist robot agents with language-based non-parametric memories.本文介绍了Embodied-RAG,这是一种新型框架,旨在赋予机器人在复杂环境中更强的记忆和推理能力。它通过构建一个层次化的语义森林来解决将检索增强生成(RAG)应用于机器人领域的挑战,从而实现高效的知识存储和检索。Embodied-RAG 集成了多模态数据和空间意识,在导航和解释任务中优于现有的RAG方法。文中还引入了一个新的数据集——Embodied-Experiences 数据集,以促进该领域的进一步研究。该系统的核心创新在于其构建和利用层次化空间记忆的能力,使机器人能够更有效地在不同的环境和查询类型中进行导航和交流。这项工作为开发基于语言的非参数记忆的通用机器人智能体奠定了基础。原文链接:https://arxiv.org/abs/2409.18313

【第147期】VideoRAG
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:VideoRAG: Retrieval-Augmented Generation over Video CorpusSummaryVideoRAG is a novel framework that enhances Retrieval-Augmented Generation (RAG) by incorporating video content. Unlike traditional RAG, which primarily uses text, VideoRAG dynamically retrieves relevant videos and integrates both visual and textual information from them to generate more accurate and contextually rich answers. This approach leverages Large Video Language Models (LVLMs) to directly process video content and seamlessly combine it with queries. Experimental results demonstrate VideoRAG's superiority over existing RAG baselines, proving the effectiveness of using videos as a knowledge source. The study also addresses the challenge of missing video subtitles by generating auxiliary text using automatic speech recognition. Finally, the exploration of different modalities and their combinations underscores the importance of both visual and textual features in video-based RAG.VideoRAG 是一种新型框架,通过引入视频内容增强了检索增强生成(RAG)。与传统的RAG主要依赖文本不同,VideoRAG 动态地检索相关视频,并从中整合视觉和文本信息,以生成更准确、更具上下文丰富性的答案。这一方法利用大型视频语言模型(LVLMs)直接处理视频内容,并将其与查询无缝结合。实验结果表明,VideoRAG 优于现有的RAG基准,证明了使用视频作为知识来源的有效性。该研究还解决了缺失视频字幕的问题,通过自动语音识别生成辅助文本。最后,不同模态及其组合的探索强调了视觉和文本特征在基于视频的RAG中的重要性。原文链接:https://arxiv.org/abs/2501.05874

【第146期】如何训练能量模型EBM
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:How to Train Your Energy-Based ModelsSummaryEnergy-Based Models (EBMs) offer a flexible approach to probabilistic modeling by specifying probability up to a normalizing constant, enabling the use of versatile architectures. The challenge lies in training these models due to the intractable normalizing constant. This document introduces and compares modern EBM training methods, focusing on Maximum Likelihood with Markov Chain Monte Carlo (MCMC), Score Matching (SM), and Noise Contrastive Estimation (NCE). The document elucidates the theoretical connections among these techniques and briefly explores alternative training methodologies. It also highlights the application of these techniques to score-based generative models. Finally, it discusses minimizing differences or derivatives of KL Divergences, minimizing the Stein discrepancy, and adversarial training.能量基模型(EBMs)通过指定概率直到归一化常数,提供了一种灵活的概率建模方法,从而能够使用多种架构。训练这些模型的挑战在于归一化常数难以计算。本文介绍并比较了现代EBM训练方法,重点讨论了最大似然估计结合马尔可夫链蒙特卡洛(MCMC)、评分匹配(SM)和噪声对比估计(NCE)。文章阐明了这些技术之间的理论联系,并简要探讨了其他替代训练方法。同时,文章还重点介绍了这些技术在基于评分的生成模型中的应用。最后,本文讨论了最小化KL散度的差异或导数、最小化Stein差异性和对抗性训练的相关内容。原文链接:https://arxiv.org/abs/2101.03288

【第145期】扩散模型的Inference-Time Scaling
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Inference-Time Scaling for Diffusion Models beyond Scaling Denoising StepsSummaryThis research explores enhancing diffusion models by scaling inference-time computation beyond simply increasing denoising steps. The authors propose a search framework that identifies better noises for the diffusion sampling process. This framework considers verifiers for feedback and algorithms to find noise candidates. Experiments on image generation show that increasing inference-time compute through this search framework improves sample quality. The study also analyzes the alignment between verifiers and generation tasks, revealing inherent biases. Ultimately, findings demonstrate substantial improvements in sample generation by diffusion models with increased computing power and a carefully chosen search setup.这项研究探讨了通过扩大推理时计算量来提升扩散模型的表现,而不仅仅是增加去噪步骤。作者提出了一个搜索框架,用于识别更适合扩散采样过程的噪声。该框架考虑了反馈验证器和算法,用于寻找噪声候选项。图像生成实验表明,通过这一搜索框架增加推理时计算量能够提升样本质量。研究还分析了验证器与生成任务之间的对齐情况,揭示了固有的偏差。最终,研究结果表明,通过增加计算能力和精心选择搜索设置,扩散模型在样本生成方面实现了显著的提升。原文链接:https://arxiv.org/abs/2501.09732

【第144期】Transformer-Squared:自适应LLM框架
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Transformer-Squared: Self-adaptive LLMsSummaryThis research paper introduces Transformer2, a novel self-adaptive large language model (LLM) framework. Transformer2 uses Singular Value Fine-tuning (SVF), a parameter-efficient method, to train "expert" vectors for specific tasks using reinforcement learning. During inference, a two-pass mechanism dynamically combines these experts based on the input prompt, significantly improving performance over existing methods like LoRA. The paper presents three adaptation strategies and demonstrates Transformer2's effectiveness across various LLMs and tasks, including vision-language models. The authors also explore cross-model compatibility and discuss avenues for future research.这篇研究论文介绍了Transformer2,一个新型自适应大型语言模型(LLM)框架。Transformer2使用奇异值微调(SVF)这一参数高效的方法,通过强化学习为特定任务训练“专家”向量。在推理过程中,Transformer2采用双通道机制,根据输入提示动态地组合这些专家,从而显著提高了性能,优于现有方法如LoRA。论文提出了三种适应策略,并展示了Transformer2在多个LLM和任务上的有效性,包括视觉-语言模型。作者还探讨了跨模型的兼容性,并讨论了未来研究的方向。原文链接:https://arxiv.org/abs/2501.06252

【第143期】构建能够终身学习的大型语言模型(LLM)代理
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Lifelong Learning of Large Language Model based Agents: A RoadmapSummaryThis paper surveys techniques for building large language model (LLM) agents capable of lifelong learning. It categorizes key agent components into perception, memory, and action modules, emphasizing how these modules enable continuous adaptation and mitigate catastrophic forgetting. The authors explore various strategies for each module, including multimodal perception, diverse memory types (working, episodic, semantic, parametric), and grounding, retrieval, and reasoning actions. The paper also reviews relevant evaluation metrics and discusses real-world applications. Finally, it provides insights into future research directions, focusing on improving the integration and scalability of these modules for more robust and human-like learning.这篇论文综述了构建能够终身学习的大型语言模型(LLM)代理的方法。论文将关键的代理组件分为感知、记忆和行动模块,强调这些模块如何促进持续适应并减轻灾难性遗忘。作者探讨了每个模块的各种策略,包括多模态感知、多样化的记忆类型(工作记忆、情节记忆、语义记忆、参数化记忆)以及基础、检索和推理行动。论文还回顾了相关的评估指标,并讨论了这些技术在现实世界中的应用。最后,作者提供了对未来研究方向的见解,重点是改进这些模块的集成性和可扩展性,以实现更强大和更像人类的学习能力。原文链接:https://arxiv.org/abs/2501.07278

【第142期】Titans:神经长期记忆模块
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Titans: Learning to Memorize at Test TimeSummaryThis research paper introduces Titans, a novel family of neural architectures designed to improve long-term memory in sequence modeling. Titans incorporate a new neural long-term memory module that learns to memorize historical context at test time, addressing the limitations of Transformers and existing recurrent models. The model uses a "surprise" metric to determine what information to remember and a forgetting mechanism to manage memory capacity. Three Titans variants—Memory as a Context, Memory as a Gate, and Memory as a Layer—are presented, showcasing different ways to integrate the long-term memory module. Experimental results across various tasks demonstrate Titans' superior performance and scalability to extremely long contexts.这篇研究论文介绍了Titans,一种新型神经网络架构家族,旨在改善序列建模中的长期记忆。Titans引入了一个新的神经长期记忆模块,能够在测试时学习记住历史上下文,解决了Transformer和现有循环模型的局限性。该模型使用“惊讶”度量来决定记住哪些信息,并采用遗忘机制来管理记忆容量。论文提出了三种Titans变体——“记忆作为上下文”、“记忆作为门控”和“记忆作为层”,展示了集成长期记忆模块的不同方式。跨多个任务的实验结果表明,Titans在处理极长上下文时表现出色,并具有更强的扩展性。原文链接:https://arxiv.org/abs/2501.00663

【第141期】O1 Replication Journey:Part 3
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:O1 Replication Journey -- Part 3: Inference-time Scaling for Medical ReasoningSummaryThis research paper investigates the effectiveness of inference-time scaling in large language models (LLMs) for medical reasoning tasks. The authors explore how increasing the processing time during inference improves the accuracy of LLMs on complex medical benchmarks like MedQA and JAMA Clinical Challenges. They introduce a novel journey learning approach, using knowledge distillation to generate high-quality training data for improved reasoning chains. Their experiments show that longer inference times correlate with better performance, especially for more challenging tasks, though sufficient LLM capacity is crucial. The study also examines the utility of majority voting as a means to scale inference-time computations.这篇研究论文探讨了推理时扩展在大型语言模型(LLMs)在医学推理任务中的有效性。作者研究了在推理过程中增加处理时间如何提高LLMs在复杂医学基准任务(如MedQA和JAMA临床挑战)上的准确性。他们提出了一种新颖的“旅程学习”方法,利用知识蒸馏生成高质量的训练数据,以改善推理链条。实验结果表明,较长的推理时间与更好的性能相关,尤其是在面对更具挑战性的任务时,尽管足够的LLM容量至关重要。研究还探讨了多数投票作为扩展推理时计算的一种手段的有效性。原文链接:https://arxiv.org/abs/2501.06458

【第140期】CNCD:新类型发现
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:CLIP-guided continual novel class discoverySummaryThis research paper introduces a novel method for Continual Novel Class Discovery (CNCD), a challenging machine learning problem focusing on teaching a model new classes without forgetting previously learned ones, especially when old data is unavailable. The proposed method leverages the CLIP model for guidance in identifying new classes and uses techniques like CutMix and prototype adaptation to improve representation learning and prevent forgetting. Experiments on several benchmark datasets demonstrate the method's effectiveness in balancing the learning of both new and old classes. The paper also explores the benefits of decoupling the training process for old and new classes and compares its performance to existing CNCD and novel class discovery methods. The authors conclude by discussing limitations and future directions for improving computational efficiency.这篇研究论文介绍了一种新颖的持续新类发现(CNCD)方法,这是一种具有挑战性的机器学习问题,主要集中在如何在没有旧数据的情况下,教授模型识别新类别而不忘记已学过的类别。所提方法利用CLIP模型为识别新类别提供指导,并采用诸如CutMix和原型适应等技术来提升表示学习和防止遗忘。在多个基准数据集上的实验表明,该方法在平衡新旧类别学习方面具有良好的效果。论文还探讨了将旧类别和新类别的训练过程解耦的好处,并将其与现有的CNCD和新类发现方法进行了比较。作者最后讨论了方法的局限性以及在提升计算效率方面的未来发展方向。原文链接:https://www.sciencedirect.com/science/article/abs/pii/S0950705124015545

【第139期】多语种控制机器人的能力评估
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Language and Planning in Robotic Navigation: A Multilingual Evaluation of State-of-the-Art ModelsSummaryThis research paper evaluates the performance of several multilingual Small Language Models (SLMs) and one Arabic-centric Large Language Model (LLM) on vision-and-language navigation (VLN) tasks. Using the NavGPT framework and a bilingual (English and Arabic) version of the R2R dataset, the study assesses the models' reasoning and planning capabilities in both languages. The findings highlight the importance of robust multilingual models for effective VLN, especially in Arabic-speaking regions where such resources are limited. The study also identifies limitations in current models, including parsing issues and insufficient reasoning abilities, suggesting areas for future development. The quantitative and qualitative analyses compare the models' success rates, navigation errors, and planning strategies across languages.这篇研究论文评估了几种多语言小型语言模型(SLMs)和一个以阿拉伯语为中心的大型语言模型(LLM)在视觉-语言导航(VLN)任务中的表现。使用NavGPT框架和一个双语(英语和阿拉伯语)版本的R2R数据集,研究评估了这些模型在两种语言中的推理和规划能力。研究结果强调了强大多语言模型在有效VLN中的重要性,特别是在阿拉伯语地区,这些资源仍然较为匮乏。研究还指出了当前模型的局限性,包括语法解析问题和不足的推理能力,并提出了未来发展的方向。通过定量和定性分析,论文比较了这些模型在不同语言中的成功率、导航错误和规划策略。原文链接:https://arxiv.org/abs/2501.05478

【第138期】ParGo:弥合视觉与语言之间的鸿沟
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:ParGo: Bridging Vision-Language with Partial and Global ViewsSummaryThis research introduces ParGo, a novel vision-language projector designed to improve multimodal large language models (MLLMs). ParGo bridges the gap between vision and language by integrating both global and partial views of images, addressing the limitations of previous methods that overemphasize prominent regions. A new dataset, ParGoCap-1M-PT, containing one million detail-captioned images, was created to facilitate ParGo's training. Extensive experiments demonstrate ParGo's superior performance on various MLLM benchmarks, especially in tasks requiring detailed perception. The key innovation is ParGo's ability to leverage both broad and specific image information.这项研究介绍了ParGo,一种旨在提升多模态大型语言模型(MLLMs)的新型视觉-语言投影器。ParGo通过集成图像的全局视图和局部视图,弥合了视觉与语言之间的鸿沟,解决了以往方法过于强调显著区域的局限性。为了促进ParGo的训练,研究团队创建了一个新的数据集ParGoCap-1M-PT,其中包含一百万个详细标注图像。大量实验表明,ParGo在多个MLLM基准测试中表现出色,尤其是在需要细致感知的任务上。其关键创新在于ParGo能够同时利用图像的广泛信息和特定信息。原文链接:https://arxiv.org/abs/2408.12928