
Seventy3
642 episodes — Page 11 of 13

【第137期】Agents, Sims and Assistants
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Agents Are Not EnoughSummaryThis research paper argues that current AI agents, while experiencing a resurgence, are insufficient for creating truly effective and sustainable AI systems. The authors analyze past failures of various agent architectures, identifying limitations in generalization, scalability, coordination, robustness, and ethical considerations. They propose a new ecosystem incorporating Agents, Sims (user representations), and Assistants to overcome these challenges. This three-part system aims to improve personalization, trust, and value generation, ultimately leading to more successful and widely accepted AI agents. The paper concludes by suggesting the need for standardization to foster a thriving agent-based ecosystem.这篇研究论文指出,尽管当前AI代理正经历复兴,但它们仍不足以创造出真正有效和可持续的AI系统。作者分析了过去各种代理架构的失败,识别出了在泛化、可扩展性、协调性、鲁棒性和伦理考量方面的局限性。他们提出了一个新的生态系统,结合了代理、模拟器(用户表征)和助手,以克服这些挑战。这个三部分系统旨在改善个性化、信任和价值生成,最终促使AI代理更加成功且被广泛接受。论文最后建议,需要通过标准化来促进一个繁荣的基于代理的生态系统。原文链接:https://www.arxiv.org/abs/2412.16241

【第136期】R3GAN:简化的生成对抗网络
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:The GAN is dead; long live the GAN! A Modern GAN BaselineSummaryThis NeurIPS 2024 paper introduces R3GAN, a simplified Generative Adversarial Network (GAN) that achieves state-of-the-art performance. The authors achieve this by developing a novel, mathematically well-behaved loss function that eliminates the need for the ad-hoc training tricks common in previous GANs. This improved loss enables the use of modern neural network architectures, resulting in a more efficient and effective model. R3GAN surpasses existing GANs and diffusion models on several benchmark datasets, demonstrating the effectiveness of the proposed approach. The paper rigorously supports its claims through mathematical analysis and extensive empirical results. The authors also discuss the limitations of their approach and potential societal impacts of GAN technology.这篇NeurIPS 2024论文介绍了R3GAN,一种简化的生成对抗网络(GAN),实现了当前的最先进性能。作者通过开发一种新颖的、数学上表现良好的损失函数,消除了以往GAN中常见的临时训练技巧。这种改进的损失函数使得能够使用现代神经网络架构,从而使得模型更加高效和有效。R3GAN在多个基准数据集上超越了现有的GAN和扩散模型,展示了该方法的有效性。论文通过数学分析和大量实证结果严密支持其论点。作者还讨论了该方法的局限性以及GAN技术可能对社会带来的影响。原文链接:https://arxiv.org/abs/2501.05441

【第135期】Search-o1:文档中的推理
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Search-o1: Agentic Search-Enhanced Large Reasoning ModelsSummaryThe paper introduces Search-o1, a framework enhancing large reasoning models (LRMs) by integrating an agentic search workflow. This allows the LRM to dynamically retrieve external knowledge when encountering uncertainties during complex reasoning tasks. A key component is the Reason-in-Documents module, which refines retrieved information to maintain coherent reasoning. Experiments across various domains demonstrate Search-o1's superior performance compared to existing methods, even rivaling human experts in certain areas. The framework addresses knowledge insufficiency, a major limitation of current LRMs, improving their reliability and versatility. The code is publicly available.这篇论文介绍了Search-o1,一个通过集成代理式搜索工作流来增强大型推理模型(LRMs)的框架。该框架使LRM在遇到复杂推理任务中的不确定性时,能够动态地检索外部知识。一个关键组件是“文档中的推理”模块(Reason-in-Documents),该模块通过精炼检索到的信息,保持推理的一致性。跨多个领域的实验表明,Search-o1在性能上优于现有方法,甚至在某些领域能够与人类专家相媲美。该框架解决了当前LRM的知识不足问题,提升了模型的可靠性和多功能性。代码已公开。原文链接:https://arxiv.org/abs/2501.05366

【第134期】DPO Kernels:通过结合核方法来增强直接偏好优化
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:DPO Kernels: A Semantically-Aware, Kernel-Enhanced, and Divergence-Rich Paradigm for Direct Preference OptimizationSummaryThis research paper introduces DPO-Kernels, an improved method for aligning large language models (LLMs) with human preferences. It enhances Direct Preference Optimization (DPO) by incorporating kernel methods for richer feature transformations and diverse divergence measures for increased robustness. A data-driven approach automatically selects the optimal kernel-divergence pair, eliminating manual tuning. Furthermore, a Hierarchical Mixture of Kernels (HMK) framework combines local and global kernels to balance fine-grained and large-scale dependencies. The paper also explores generalization, overfitting, and ethical considerations related to fairness, bias, and privacy.这篇研究论文介绍了DPO-Kernels,一种改进的大型语言模型(LLMs)与人类偏好对齐的方法。它通过结合核方法来增强直接偏好优化(DPO),实现了更丰富的特征转换,并采用多样的散度度量来提高模型的鲁棒性。该方法采用数据驱动的方式自动选择最优的核-散度对,从而避免了手动调整。此外,论文提出了一种层次化的核混合(HMK)框架,结合了局部和全局核,以平衡细粒度和大规模依赖关系。论文还探讨了泛化能力、过拟合问题以及与公平性、偏见和隐私相关的伦理考虑。原文链接:https://arxiv.org/abs/2501.03271

【第133期】Meta-CoT:朝着系统2推理的方向发展
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-ThoughtSummaryThe paper "Towards System 2 Reasoning in LLMs" explores methods for improving the reasoning capabilities of large language models (LLMs). It introduces Meta Chain-of-Thought (Meta-CoT), a framework that models the reasoning process itself, going beyond traditional Chain-of-Thought prompting. The authors investigate using search algorithms, synthetic data, and reinforcement learning to train models that generate Meta-CoTs. Empirical results and scaling laws related to inference-time computation and the generator-verifier gap are presented, along with open research questions regarding the emergence of more human-like reasoning in AI. The included example problem-solving attempts illustrate different approaches to this challenge.论文《朝着系统2推理的方向发展》探讨了提升大语言模型(LLMs)推理能力的方法。文章提出了“元思维链”(Meta Chain-of-Thought,Meta-CoT)框架,该框架将推理过程本身建模,超越了传统的思维链提示方法。作者研究了使用搜索算法、合成数据和强化学习来训练生成Meta-CoT的模型。文章展示了与推理时计算和生成器-验证器差距相关的经验结果和扩展法则,并提出了关于AI中更类似人类推理出现的开放研究问题。文中所包含的示例问题解决尝试展示了应对这一挑战的不同方法。原文链接:https://arxiv.org/abs/2501.04682

【第132期】Agent Laboratory:科学研究助手
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Agent Laboratory: Using LLM Agents as Research AssistantsSummaryThe document details Agent Laboratory, an open-source framework using large language models (LLMs) to automate the scientific research process. It progresses through literature review, experimentation, and report writing stages, with human researchers providing feedback. Experiments show that Agent Laboratory significantly reduces research costs and that the o1-preview LLM backend produces the best results. The framework also includes a co-pilot mode enabling greater human involvement, improving research quality. However, limitations like LLM hallucinations and challenges with automated self-evaluation are discussed.本文介绍了Agent Laboratory,一个开源框架,利用大规模语言模型(LLMs)来自动化科学研究过程。该框架涵盖文献综述、实验设计和报告撰写等阶段,并通过人类研究者提供反馈进行调整。实验表明,Agent Laboratory 能显著降低研究成本,而 o1-preview LLM 后端在性能上表现最佳。该框架还包括一个副驾驶模式,允许更高程度的人类参与,从而提高研究质量。然而,论文也讨论了诸如 LLM 假象和自动化自我评估等局限性和挑战。原文链接:https://arxiv.org/abs/2501.04227

【第131期】Orient Anything:一种用于估计图像中物体方向的模型
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Orient Anything: Learning Robust Object Orientation Estimation from Rendering 3D ModelsSummaryThe paper introduces Orient Anything, a novel model for estimating object orientation in images. It addresses the challenge of limited labeled data by generating a large dataset of rendered 3D models with precise orientation annotations. The model uses a probability distribution fitting approach for robust orientation prediction, improving accuracy on both rendered and real images. Furthermore, the research demonstrates Orient Anything's superior performance compared to existing methods and its potential applications in spatial reasoning and image generation. Ablation studies validate key design choices, showcasing the model's effectiveness and robustness.这篇论文介绍了Orient Anything,一种用于估计图像中物体方向的新型模型。该模型解决了有限标注数据的问题,通过生成大量渲染的 3D 模型,并提供精确的方向注释来扩充数据集。模型采用概率分布拟合方法进行稳健的方向预测,提高了在渲染图像和真实图像上的准确性。此外,研究表明,Orient Anything 在性能上优于现有方法,并展示了它在空间推理和图像生成等应用中的潜力。消融实验验证了关键设计选择,展示了该模型的有效性和鲁棒性。原文链接:https://arxiv.org/abs/2412.18605

【第130期】OS-Genesis:可为GUI Agent提供数据
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:OS-Genesis: Automating GUI Agent Trajectory Construction via Reverse Task SynthesisSummaryThis research paper introduces OS-Genesis, a novel pipeline for synthesizing high-quality and diverse data for training Graphical User Interface (GUI) agents. Unlike existing methods that rely on pre-defined tasks or human supervision, OS-Genesis uses an interaction-driven approach, allowing agents to explore environments and retrospectively derive tasks. A trajectory reward model ensures data quality, and experiments demonstrate OS-Genesis's superior performance on challenging benchmarks. The authors also analyze data diversity and the impact of the reward model. Finally, they discuss OS-Genesis' limitations and broader implications for digital automation.这篇研究论文介绍了OS-Genesis,一种新颖的数据合成流程,用于训练图形用户界面(GUI)代理。与依赖于预定义任务或人工监督的现有方法不同,OS-Genesis 采用互动驱动的方法,允许代理在环境中进行探索,并从中回溯推导任务。轨迹奖励模型确保数据质量,实验表明 OS-Genesis 在具有挑战性的基准测试中表现优异。作者还分析了数据多样性和奖励模型的影响。最后,论文讨论了 OS-Genesis 的局限性及其在数字自动化领域的更广泛意义。原文链接:https://arxiv.org/abs/2412.19723

【第129期】Sa2VA:Sam2+LLaVA
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and VideosSummaryThe research introduces Sa2VA, a unified model for understanding images and videos. Sa2VA combines the strengths of SAM-2 (video segmentation) and LLaVA (vision-language model) to perform various tasks like referring segmentation and conversation. A new dataset, Ref-SAV, with complex video scenes, was created to improve model performance. Experiments show Sa2VA achieves state-of-the-art results across multiple benchmarks, particularly in referring video object segmentation. The code, dataset, and models are publicly available.这项研究介绍了Sa2VA,一个统一的图像和视频理解模型。Sa2VA 结合了 SAM-2(视频分割)和 LLaVA(视觉语言模型)的优点,能够执行多种任务,如指代分割和对话。为提升模型性能,研究团队创建了一个新数据集 Ref-SAV,该数据集包含复杂的视频场景。实验结果表明,Sa2VA 在多个基准测试中取得了最先进的成果,尤其是在指代视频对象分割任务中表现突出。代码、数据集和模型已公开发布。原文链接:https://arxiv.org/abs/2501.04001

【第128期】MeCo:元数据调节与冷却
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Metadata Conditioning Accelerates Language Model Pre-trainingSummaryThis research paper introduces Metadata Conditioning then Cooldown (MeCo), a novel method for improving the efficiency and controllability of large language model pre-training. MeCo incorporates readily available metadata, such as URLs, to enhance the model's understanding of diverse data sources during training, then uses a "cooldown" phase to ensure functionality without metadata during inference. Experiments demonstrate that MeCo significantly accelerates pre-training, achieving comparable performance with less data and enabling better control over model outputs by conditioning inference prompts with metadata. The study explores various metadata types and ablates design choices to understand MeCo's effectiveness, showcasing its potential for creating more capable and steerable language models. Finally, the paper compares MeCo to existing techniques for data selection and metadata conditioning.这篇研究论文介绍了一种新颖的方法——元数据调节与冷却(Metadata Conditioning then Cooldown,简称 MeCo),旨在提高大规模语言模型预训练的效率和可控性。MeCo 利用现成的元数据(如 URL)来增强模型在训练过程中对多样化数据源的理解,然后通过“冷却”阶段确保推理时不依赖元数据。实验表明,MeCo 能显著加速预训练,在使用更少数据的情况下实现相当的性能,并通过将推理提示与元数据结合来更好地控制模型输出。研究还探索了各种元数据类型,并通过消融实验分析了设计选择,以理解 MeCo 的有效性,展示了它在创建更强大且可调控语言模型方面的潜力。最后,论文将 MeCo 与现有的数据选择和元数据调节技术进行了比较。原文链接:https://arxiv.org/abs/2501.01956

【第127期】隐式 PRM:过程奖励模型
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Free Process Rewards without Process LabelsSummaryThis research paper proposes a cost-effective method for training process reward models (PRMs), which evaluate the intermediate steps of a reasoning process. Unlike existing PRMs requiring costly step-level labels, the authors demonstrate that a strong PRM can be implicitly learned at no extra cost by training an outcome reward model (ORM) with a specific reward parameterization. Their method, termed "implicit PRM," outperforms existing baselines on mathematical reasoning tasks while significantly reducing data collection and training overhead. Experiments explore various instantiations of the implicit PRM with different loss functions, showing consistent improvements and data efficiency. The findings suggest a paradigm shift in PRM training approaches, making them more accessible for broader applications.这篇研究论文提出了一种具有成本效益的训练过程奖励模型(PRMs)的方法,该模型用于评估推理过程中的中间步骤。与现有需要高成本步骤级标签的 PRM 不同,作者展示了一种通过特定奖励参数化训练结果奖励模型(ORM)来隐式学习强大的 PRM,且没有额外成本。该方法被称为“隐式 PRM”,在数学推理任务中优于现有基准,并显著减少了数据收集和训练开销。实验探索了使用不同损失函数的隐式 PRM 的各种实现,显示出一致的性能提升和数据效率。这些发现表明,PRM 训练方法可能迎来范式转变,使其在更广泛的应用中变得更加可访问。原文链接:https://arxiv.org/abs/2412.01981

【第126期】ICAL:VLM的上下文抽取学习
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:VLM Agents Generate Their Own Memories: Distilling Experience into Embodied Programs of ThoughtSummaryThis NeurIPS 2024 paper introduces In-Context Abstraction Learning (ICAL), a method that allows Vision-Language Models (VLMs) to learn from suboptimal demonstrations and human feedback. ICAL generates its own high-quality examples by abstracting noisy trajectories, correcting errors, and annotating cognitive abstractions like causal relationships and subgoals. The resulting examples significantly improve VLM performance on three benchmarks (TEACh, VisualWebArena, and Ego4D), surpassing state-of-the-art results. The paper also explores the efficiency gains and continual learning capabilities of ICAL, showing reduced reliance on human feedback and environment interactions over time. Furthermore, the impact of fine-tuning the VLM on ICAL's learned examples is evaluated.这篇 NeurIPS 2024 论文介绍了一种名为上下文抽象学习(In-Context Abstraction Learning,简称 ICAL)的方法,该方法使视觉-语言模型(VLMs)能够从不完美的示范和人类反馈中学习。ICAL 通过抽象噪声轨迹、纠正错误,并标注认知抽象(如因果关系和子目标),生成自己的高质量示例。这些生成的示例显著提升了 VLM 在三个基准测试(TEACh、VisualWebArena 和 Ego4D)上的表现,超越了当前的最先进成果。论文还探讨了 ICAL 的效率提升和持续学习能力,显示随着时间的推移,对人类反馈和环境交互的依赖减少。此外,论文还评估了在 ICAL 学到的示例上对 VLM 进行微调的影响。原文链接:https://arxiv.org/abs/2406.14596

【第125期】GraphAgent:一种用于分析结构化(图形)和非结构化(文本)数据的自动化代理
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:GraphAgent: Agentic Graph Language AssistantSummaryThis paper introduces GraphAgent, a novel automated agent pipeline designed for analyzing both structured (graph) and unstructured (textual) data. GraphAgent uses three key agents: a Graph Generator Agent to create knowledge graphs from text, a Task Planning Agent to interpret user queries, and a Task Execution Agent to perform predictive or generative tasks. The system is evaluated on various datasets, showcasing superior performance compared to state-of-the-art methods in both predictive and generative tasks, particularly with smaller model sizes and zero-shot learning. The authors make their work open-source.本文提出了GraphAgent,一种用于分析结构化(图形)和非结构化(文本)数据的新型自动化代理管道。GraphAgent 使用三个关键代理:图生成代理(Graph Generator Agent)用于从文本中创建知识图谱,任务规划代理(Task Planning Agent)用于解释用户查询,任务执行代理(Task Execution Agent)用于执行预测或生成任务。该系统在多个数据集上进行了评估,展示了在预测和生成任务中优于最先进方法的表现,特别是在较小模型和零-shot 学习的情况下。作者将其工作开源。原文链接:https://arxiv.org/abs/2412.17029
【第124期】面向通用机器人控制的VLA模型
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Towards Generalist Robot Policies: What Matters in Building Vision-Language-Action ModelsSummaryThis research paper explores the creation of Vision-Language-Action (VLA) models for generalist robot control. The authors investigate key design choices in VLAs, including the selection of Vision-Language Model (VLM) backbones, optimal VLA architectures, and the effective use of cross-embodiment data. Through extensive experimentation, they identify superior VLA structures and backbones, achieving state-of-the-art performance on simulated and real-world robotic tasks. A new framework, RoboVLMs, is introduced to simplify the process of creating VLAs and is made publicly available. The findings highlight the significant advantages of VLMs for generalist robot policies and offer valuable guidance for future VLA development.本研究探讨了面向通用机器人控制的视觉-语言-行动(Vision-Language-Action, VLA)模型的创建。作者研究了 VLA 的关键设计选择,包括视觉-语言模型(Vision-Language Model, VLM)骨干网的选择、最优 VLA 架构,以及跨体态数据的有效使用。通过大量实验,他们确定了优越的 VLA 结构和骨干网,在模拟和实际机器人任务中达到了最先进的性能。研究还提出了一个新框架 RoboVLMs,简化了创建 VLA 的过程,并公开发布。研究结果强调了 VLM 在通用机器人策略中的显著优势,并为未来 VLA 的发展提供了宝贵的指导。原文链接:https://arxiv.org/abs/2412.14058

【第123期】Cache-augmented generation (CAG)
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Don't Do RAG: When Cache-Augmented Generation is All You Need for Knowledge TasksSummaryThis research paper introduces cache-augmented generation (CAG) as a more efficient alternative to retrieval-augmented generation (RAG) for knowledge-intensive tasks. CAG preloads all relevant knowledge into a large language model (LLM), eliminating the need for real-time retrieval and its associated latency and errors. Experiments using SQuAD and HotPotQA datasets demonstrate CAG's superior performance and speed, especially when the knowledge base is manageable in size. The authors highlight the advantages of CAG's simplified architecture and improved efficiency, suggesting it as a robust solution for specific applications. The paper concludes by exploring potential hybrid approaches combining preloading with selective retrieval.本文提出了缓存增强生成(cache-augmented generation, CAG),作为知识密集型任务中比检索增强生成(retrieval-augmented generation, RAG)更高效的替代方案。CAG 将所有相关知识预加载到大型语言模型(LLM)中,消除了实时检索的需求,避免了其相关的延迟和错误。通过在 SQuAD 和 HotPotQA 数据集上的实验,展示了 CAG 在性能和速度上的优越性,尤其在知识库规模可控的情况下。作者强调了 CAG 简化架构和提高效率的优势,建议其作为特定应用中的一种可靠解决方案。最后,论文探讨了结合预加载和选择性检索的潜在混合方法。原文链接:https://arxiv.org/abs/2412.15605

【第122期】HuatuoGPT-o1:医学推理大模型
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMsSummaryThis research introduces HuatuoGPT-o1, a large language model (LLM) specialized for complex medical reasoning. The model is trained using a novel two-stage approach: first, a search-based strategy learns complex reasoning trajectories from a newly created dataset of 40,000 verifiable medical problems; second, reinforcement learning further refines this ability using verifier feedback. HuatuoGPT-o1 significantly outperforms existing general and medical LLMs on various benchmarks, demonstrating the effectiveness of the proposed method. The study also explores the reliability of the LLM-based verifier and investigates the impact of different reasoning strategies and RL algorithms. Finally, the approach is successfully extended to the Chinese medical domain, highlighting its broad applicability.本研究提出了HuatuoGPT-o1,一种专门用于复杂医学推理的大型语言模型(LLM)。该模型采用了一种新颖的两阶段训练方法:首先,通过基于搜索的策略,从新创建的包含40,000个可验证医学问题的数据集中学习复杂的推理轨迹;其次,通过强化学习(RL)使用验证器反馈进一步优化该能力。HuatuoGPT-o1 在多个基准测试中显著优于现有的通用和医学 LLM,验证了所提方法的有效性。研究还探讨了基于 LLM 的验证器的可靠性,并研究了不同推理策略和强化学习算法的影响。最后,该方法成功扩展到中文医学领域,突显了其广泛的应用潜力。原文链接:https://arxiv.org/abs/2412.18925

【第121期】一种新型的蒙特卡罗符合性预测
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Conformal prediction under ambiguous ground truthSummaryThis research paper proposes a novel Monte Carlo Conformal Prediction (CP) method to address uncertainty quantification in classification tasks with ambiguous ground truth labels. Standard CP methods often rely on "voted" labels derived from aggregated expert opinions, ignoring inherent label uncertainty. The proposed Monte Carlo CP leverages expert opinions to create a non-degenerate label distribution, generating synthetic pseudo-labels to improve coverage guarantees. The authors demonstrate the method's effectiveness through experiments on skin condition classification, showing improvements over existing CP techniques in handling ambiguous labels. The paper also explores extensions to multi-label classification and robust CP with data augmentation.本研究提出了一种新型的蒙特卡罗符合性预测(Monte Carlo Conformal Prediction, CP)方法,用于解决具有模糊真实标签的分类任务中的不确定性量化问题。标准的 CP 方法通常依赖于通过聚合专家意见得出的“投票”标签,忽略了标签固有的不确定性。所提的蒙特卡罗 CP 利用专家意见创建一个非退化的标签分布,生成合成伪标签,以提高覆盖保证。作者通过皮肤病分类实验验证了该方法的有效性,表明其在处理模糊标签时相比现有的 CP 技术有所改进。论文还探讨了该方法在多标签分类和基于数据增强的稳健 CP 中的扩展应用。原文链接:https://arxiv.org/abs/2307.09302

【第120期】iTransformer:Inverted Transformers理解时间序列问题
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:iTransformer: Inverted Transformers Are Effective for Time Series ForecastingSummaryThe paper introduces iTransformer, a novel architecture for time series forecasting that inverts the standard Transformer structure. Instead of embedding multiple variates at each timestamp, iTransformer embeds each time series individually as a token, applying attention to capture multivariate correlations and feed-forward networks to learn series-specific representations. This approach achieves state-of-the-art results on several real-world datasets, showcasing improved performance and generalization compared to existing Transformer-based and linear models, particularly with longer lookback windows. The authors provide extensive experimental results and analysis to support their claims.本文提出了iTransformer,一种用于时间序列预测的新型架构,采用了与标准 Transformer 结构相反的设计。iTransformer 不是在每个时间戳嵌入多个变量,而是将每个时间序列单独嵌入为一个标记,使用注意力机制捕捉多变量之间的相关性,并通过前馈网络学习序列特定的表示。该方法在多个真实世界数据集上取得了最先进的结果,展示了相比现有基于 Transformer 的模型和线性模型,特别是在较长回溯窗口下的性能提升和泛化能力。作者提供了大量实验结果和分析来支持他们的论点。原文链接:arxiv.org

【第119期】DRT-o1:一种旨在改进包含明喻和隐喻句子翻译的新型神经机器翻译模型
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:DRT-o1: Optimized Deep Reasoning Translation via Long Chain-of-ThoughtSummaryThe paper introduces DRT-o1, a novel neural machine translation model designed to improve the translation of sentences containing similes and metaphors. DRT-o1 leverages a multi-agent framework to simulate extended reasoning during the translation process, generating a long chain of thought. This framework comprises a translator, an advisor, and an evaluator, iteratively refining the translation. The resulting data is then used to fine-tune the model, achieving significant improvements in BLEU, CometKiwi, and CometScore compared to baseline models. The model's effectiveness is demonstrated through experiments on literature translation.本文提出了DRT-o1,一种旨在改进包含明喻和隐喻句子翻译的新型神经机器翻译模型。DRT-o1 利用多智能体框架,在翻译过程中模拟扩展推理,生成一条长链式思维。该框架由一个翻译器、一个顾问和一个评估器组成,迭代优化翻译结果。生成的数据随后用于微调模型,与基线模型相比,在 BLEU、CometKiwi 和 CometScore 等指标上实现了显著提升。通过文学翻译实验,验证了该模型的高效性。原文链接:https://arxiv.org/abs/2412.17498
【第118期】Mulberry:使用CoMCTS做类o1的多模态大模型
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Mulberry: Empowering MLLM with o1-like Reasoning and Reflection via Collective Monte Carlo Tree SearchSummaryThis research paper introduces Mulberry, a series of multimodal large language models (MLLMs) designed for improved reasoning and reflection. The key innovation is CoMCTS, a novel Collective Monte Carlo Tree Search method that leverages multiple models to collaboratively identify effective reasoning paths. CoMCTS generates the Mulberry-260k dataset, featuring richly annotated reasoning trees for diverse multimodal questions. Extensive experiments demonstrate Mulberry's superior performance on various benchmarks compared to existing MLLMs. The paper concludes by highlighting CoMCTS and Mulberry-260k as valuable resources for future research in MLLM reasoning.本文提出了Mulberry,一系列多模态大型语言模型(MLLMs),旨在提升推理和反思能力。其核心创新是CoMCTS(集体蒙特卡罗树搜索),一种新型方法,利用多个模型协作识别有效的推理路径。CoMCTS 生成了 Mulberry-260k 数据集,其中包含针对多样化多模态问题的丰富注释推理树。大量实验表明,Mulberry 在多个基准测试上的性能优于现有的多模态语言模型。论文总结指出,CoMCTS 和 Mulberry-260k 是未来多模态语言模型推理研究的宝贵资源。原文链接:https://arxiv.org/abs/2412.18319

【第117期】ExploreToM:一种用于生成复杂且多样化的心智理论
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Explore Theory of Mind: Program-guided adversarial data generation for theory of mind reasoningSummaryThe paper introduces ExploreToM, a novel framework for generating complex and diverse theory-of-mind (ToM) datasets for evaluating and training large language models (LLMs). ExploreToM uses an A* search algorithm and a domain-specific language to create challenging story scenarios, revealing significant weaknesses in current LLMs' ToM abilities. The generated data, available online, demonstrates that state-of-the-art LLMs struggle with fundamental skills like state tracking and show surprisingly low accuracy on the generated tasks. Fine-tuning LLMs on ExploreToM data significantly improves their performance on existing ToM benchmarks, highlighting the framework's utility for advancing ToM research. The authors also explore the underlying reasons for LLMs' poor ToM performance, pointing to data biases and the need for targeted training.本文提出了ExploreToM,一种用于生成复杂且多样化的心智理论(Theory of Mind, ToM)数据集的新框架,以评估和训练大型语言模型(LLMs)。ExploreToM 利用 A* 搜索算法和领域特定语言创建具有挑战性的故事场景,揭示了当前 LLM 在 ToM 能力上的显著不足。生成的数据集已在线公开,表明最先进的 LLM 在诸如状态跟踪等基本技能上表现不佳,并且在这些任务上的准确率意外地低。将 LLM 在 ExploreToM 数据集上进行微调后,其在现有 ToM 基准测试中的表现显著提升,突显了该框架对推进 ToM 研究的价值。作者还探讨了 LLM 在 ToM 表现不佳的潜在原因,指出数据偏差以及对有针对性训练的需求。原文链接:https://arxiv.org/abs/2412.12175

【第116期】LLM Inference-Time自我提升综述
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:A Survey on LLM Inference-Time Self-ImprovementSummaryThis research survey explores Large Language Model (LLM) Inference-Time Self-Improvement (ITSI), techniques enhancing LLM performance at inference without retraining. The authors categorize ITSI methods into three groups: Independent, improving decoding processes; Context-Aware, leveraging external context or data; and Model-Aided, using other models for collaboration. A comprehensive taxonomy of existing ITSI methods is presented, along with a discussion of challenges and future research directions, such as addressing biases and improving efficiency. The survey draws on recent publications from top AI conferences. Finally, ethical considerations, including bias and economic/environmental impact, are highlighted.本研究综述探讨了大型语言模型(LLM)在推理阶段自我改进(Inference-Time Self-Improvement, ITSI)的技术,这些技术无需重新训练即可提升模型性能。作者将 ITSI 方法分为三类:独立型(优化解码过程)、上下文感知型(利用外部上下文或数据)和模型辅助型(借助其他模型协作)。文章提供了现有 ITSI 方法的全面分类,并讨论了当前的挑战和未来研究方向,如解决偏见问题和提高效率。该综述参考了最近顶级人工智能会议的研究成果。最后,文章还强调了伦理考量,包括偏见以及经济和环境影响。原文链接:https://arxiv.org/abs/2412.14352

【第115期】ModernBERT
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and InferenceSummaryThis research paper introduces ModernBERT, a significantly improved encoder-only transformer language model. ModernBERT boasts state-of-the-art performance across various natural language understanding and information retrieval tasks, including code-related applications. Key improvements include a modernized architecture, enhanced training data (2 trillion tokens), and optimized design for speed and memory efficiency. The authors present extensive experimental results demonstrating ModernBERT's superior performance and efficiency compared to existing encoder models. Finally, the researchers release ModernBERT's code and model weights for public use.本文提出了ModernBERT,一种显著改进的仅编码器Transformer语言模型。ModernBERT在包括代码相关应用在内的多种自然语言理解和信息检索任务中表现出色,达到了最新的性能水平。其关键改进包括现代化的架构、增强的训练数据(2万亿标记)以及针对速度和内存效率优化的设计。作者通过大量实验结果证明了ModernBERT在性能和效率方面优于现有的编码器模型。最后,研究团队公开了ModernBERT的代码和模型权重,供公众使用。原文链接:https://arxiv.org/abs/2412.13663
【第114期】DeepSeek V3技术报告
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:DeepSeek-V3 Technical ReportSummaryThe document details DeepSeek-V3, a 671B-parameter Mixture-of-Experts large language model. It covers the model's architecture, including Multi-Head Latent Attention and an innovative auxiliary-loss-free load balancing strategy for DeepSeekMoE. The training process, encompassing pre-training on 14.8 trillion tokens and post-training using supervised fine-tuning and reinforcement learning, is described. Extensive evaluations demonstrate DeepSeek-V3's strong performance across various benchmarks, surpassing many open-source and achieving results comparable to leading closed-source models. Finally, the document explores infrastructure optimizations, including an FP8 mixed-precision framework, and suggests improvements for future AI hardware design.本文详细介绍了DeepSeek-V3,一种拥有6710亿参数的专家混合(Mixture-of-Experts)大型语言模型。内容涵盖了模型架构,包括多头潜在注意力(Multi-Head Latent Attention)以及针对DeepSeekMoE设计的创新无辅助损失负载平衡策略。文中描述了训练过程,包括对14.8万亿标记的预训练,以及通过监督微调和强化学习的后训练。广泛的评估表明,DeepSeek-V3 在多个基准测试中表现强劲,超越了许多开源模型,并达到与领先的闭源模型相当的水平。最后,文章探讨了基础设施优化,包括FP8混合精度框架,并提出了对未来AI硬件设计的改进建议。原文链接:https://arxiv.org/abs/2412.19437

【第113期】ASAL:使用LLM自动搜索人工生命
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Automating the Search for Artificial Life with Foundation ModelsSummaryThis research paper introduces Automated Search for Artificial Life (ASAL), a novel method using foundation models (FMs) to automate the discovery of interesting artificial life (ALife) simulations. ASAL employs FMs to evaluate simulations across diverse substrates (like Boids and Lenia), enabling three search strategies: supervised target searching, open-endedness searching, and illumination. The approach successfully discovers unseen lifeforms and quantifies previously qualitative ALife phenomena, accelerating research by automating a traditionally manual and time-consuming process. The authors demonstrate ASAL's effectiveness through experiments and discuss future applications, including expanding to video and 3D simulations. Finally, the paper explores the implications of using different FMs and substrates, highlighting the importance of selecting appropriate models for specific research goals.本文提出了自动化人工生命搜索(Automated Search for Artificial Life,ASAL),一种利用基础模型(FMs)自动发现有趣人工生命(ALife)模拟的新方法。ASAL 利用基础模型在多样化基质(如 Boids 和 Lenia)上评估模拟,支持三种搜索策略:有监督目标搜索、开放性搜索和照明搜索。该方法成功发现了未曾见过的生命形式,并将以往定性的人工生命现象量化,从而通过自动化这一传统上依赖人工且耗时的过程,加速了研究进展。作者通过实验验证了 ASAL 的有效性,并讨论了其未来应用,包括扩展到视频和 3D 模拟领域。论文还探讨了使用不同基础模型和基质的影响,强调为特定研究目标选择合适模型的重要性。原文链接:https://arxiv.org/abs/2412.17799

【第112期】Differentiable Cache Augmentation
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Deliberation in Latent Space via Differentiable Cache AugmentationSummaryThis research paper explores a novel method for improving large language models (LLMs) by augmenting their internal cache with latent embeddings generated by a separate "coprocessor" model. This coprocessor, trained using standard language modeling techniques on a large dataset, learns to distill additional computation into the LLM's cache, enhancing its reasoning abilities without modifying the LLM's architecture. The approach allows for offline and asynchronous operation, improving efficiency and performance across a range of reasoning tasks. Experiments demonstrate consistent improvements in perplexity and accuracy on various benchmarks, showcasing the effectiveness of this differentiable cache augmentation technique. The method is compared to existing techniques, such as pause tokens and chain-of-thought prompting, showing superior performance.本文探讨了一种新方法,通过在大型语言模型(LLMs)的内部缓存中增加由单独的“协处理器”模型生成的潜在嵌入,来提升 LLM 的性能。该协处理器使用标准语言建模技术在大型数据集上训练,学会将额外的计算提炼到 LLM 的缓存中,从而在不修改 LLM 架构的情况下增强其推理能力。该方法支持离线和异步操作,提高了多种推理任务的效率和性能。实验表明,在各种基准测试中,该方法在困惑度和准确性方面均实现了持续改进,展现了这种可微缓存增强技术的有效性。与现有技术(如暂停标记和链式思维提示)相比,该方法表现出更优越的性能。原文链接:https://arxiv.org/abs/2412.17747

【第111期】LearnLM:Gemini在教育场景的应用
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:LearnLM: Improving Gemini for LearningSummaryThis research paper details the development and evaluation of LearnLM, a Google AI model designed for educational applications. LearnLM improves upon existing models by incorporating "pedagogical instruction following," allowing developers to specify desired teaching behaviors through system-level instructions. Extensive human evaluations, involving pedagogy experts, demonstrated LearnLM's superior performance compared to other leading models across various learning scenarios. The study highlights the importance of both intrinsic and extrinsic evaluation methods in assessing AI tutors and discusses future directions for improving AI in education. LearnLM's code and evaluation data are publicly available.本文详细介绍了 LearnLM 的开发与评估,这是一种专为教育应用设计的 Google AI 模型。LearnLM 通过引入“教学指令遵循”功能得以改进,允许开发者通过系统级指令指定所需的教学行为。在涉及教学法专家的大量人工评估中,LearnLM 在多种学习场景中的表现优于其他领先模型。研究强调了内在和外在评估方法在评估 AI 教学效果中的重要性,并探讨了未来改进教育领域 AI 的方向。LearnLM 的代码和评估数据已公开提供。原文链接:https://arxiv.org/abs/2412.16429

【第110期】PC Agent:通过学习人类认知过程来执行复杂的数字化工作
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:PC Agent: While You Sleep, AI Works -- A Cognitive Journey into Digital WorldSummaryThis research paper introduces PC Agent, a novel AI system designed to perform complex digital work by learning from human cognitive processes. The system comprises three key components: PC Tracker for data collection, a cognition completion pipeline for data refinement and semantic understanding, and a multi-agent system for task execution. PC Agent demonstrates significant data efficiency, achieving impressive results in PowerPoint presentation creation using a small dataset of human cognitive trajectories. The researchers open-source their framework to encourage further development of truly capable digital agents. The paper also discusses the challenges in current digital agent technology and proposes human cognition transfer as a key solution.本文提出了PC Agent,一种新型的 AI 系统,通过学习人类认知过程来执行复杂的数字化工作。该系统由三个关键组件组成:用于数据收集的 PC Tracker、用于数据精炼和语义理解的认知完成管道,以及用于任务执行的多智能体系统。PC Agent 展现了卓越的数据效率,在使用小规模人类认知轨迹数据集的情况下,取得了 PowerPoint 演示文稿制作的显著成果。研究团队开源了他们的框架,以鼓励进一步开发真正强大的数字代理。论文还讨论了当前数字代理技术的挑战,并提出人类认知迁移作为关键解决方案。原文链接:https://arxiv.org/abs/2412.17589

【第109期】AutoFeedback:使用智能体做自动反馈系统
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Using Generative AI and Multi-Agents to Provide Automatic FeedbackSummaryThis research paper explores using a multi-agent system called AutoFeedback to improve the quality of automatically generated feedback for student responses in science assessments. AutoFeedback uses two AI agents: one to generate initial feedback and another to validate and refine it, addressing common issues like over-praise and over-inference found in single-agent large language models (LLMs). The study compared AutoFeedback's performance to a single-agent LLM using 240 student responses, finding that AutoFeedback significantly reduced errors and produced more accurate, pedagogically sound feedback. The findings suggest multi-agent systems offer a more reliable approach to automated feedback in education, enhancing personalized learning support. The paper concludes by discussing limitations and future research directions.本研究探讨了使用名为 AutoFeedback 的多智能体系统来改进科学评估中对学生回答的自动生成反馈的质量。AutoFeedback 由两个 AI 智能体组成:一个负责生成初始反馈,另一个负责验证和改进反馈,从而解决单智能体大型语言模型(LLMs)中常见的过度赞美和过度推断等问题。研究对比了 AutoFeedback 和单智能体 LLM 在240份学生回答上的表现,发现 AutoFeedback 显著减少了错误,生成了更准确且符合教育学要求的反馈。研究结果表明,多智能体系统在自动化反馈中提供了一种更可靠的方法,从而增强了个性化学习支持。论文最后讨论了其局限性以及未来研究方向。原文链接:https://arxiv.org/abs/2411.07407

【第108期】PAE:能够自主学习新的网页导航技能
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Proposer-Agent-Evaluator(PAE): Autonomous Skill Discovery For Foundation Model Internet AgentsSummaryThis research introduces Proposer-Agent-Evaluator (PAE), a novel system that enables foundation model agents to autonomously learn new skills for web navigation. PAE leverages a context-aware task proposer to suggest tasks, an agent policy to execute them, and an autonomous evaluator to provide feedback via reinforcement learning. Experiments on challenging real-world and simulated websites demonstrate PAE's effectiveness, resulting in significant improvements in zero-shot generalization compared to existing methods, achieving state-of-the-art performance among open-source models. The system's design, based on the asymmetric capabilities of large language models, contributes to more robust and adaptable AI agents. The researchers open-sourced their code and models to encourage further exploration.本研究提出了Proposer-Agent-Evaluator (PAE) 系统,这是一种新型系统,使基础模型代理能够自主学习新的网页导航技能。PAE 利用一个上下文感知任务提议器来建议任务,通过代理策略执行这些任务,并由自主评估器通过强化学习提供反馈。在真实世界和模拟网站上的实验表明,PAE 显著提升了零样本泛化能力,相较于现有方法达到了开源模型中的最新性能。该系统基于大型语言模型的非对称能力设计,增强了 AI 代理的鲁棒性和适应性。研究团队开源了其代码和模型,以鼓励进一步探索。原文链接:https://arxiv.org/abs/2412.13194
【第107期】SGD-SaI:替代Adam类优化方法
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:No More Adam: Learning Rate Scaling at Initialization is All You NeedSummaryThe research introduces SGD-SaI, a novel optimization method that significantly improves the memory efficiency and training speed of large neural networks. Unlike adaptive methods like AdamW, SGD-SaI scales learning rates at initialization based on gradient signal-to-noise ratios, eliminating the need for storing and updating second-order momentum. This approach achieves performance comparable to or exceeding AdamW across various tasks, including large language model and vision transformer training. The study empirically validates SGD-SaI's effectiveness and efficiency, demonstrating its superior robustness to hyperparameter variations and scalability to large models. The authors conclude that SGD-SaI offers a simpler, more efficient alternative to adaptive gradient methods for training deep neural networks.本研究提出了SGD-SaI,一种新型的优化方法,大幅提升了大型神经网络的内存效率和训练速度。与 AdamW 等自适应方法不同,SGD-SaI 基于梯度信噪比在初始化时动态调整学习率,从而无需存储和更新二阶动量。该方法在包括大型语言模型和视觉 Transformer 训练在内的多种任务中表现出与 AdamW 相当或更优的性能。研究通过实验验证了 SGD-SaI 的高效性和有效性,展现了其对超参数变化的更强鲁棒性以及对大模型的良好扩展性。作者总结道,SGD-SaI 为深度神经网络训练提供了一种更简单、高效的替代自适应梯度方法的解决方案。原文链接:https://arxiv.org/abs/2412.11768
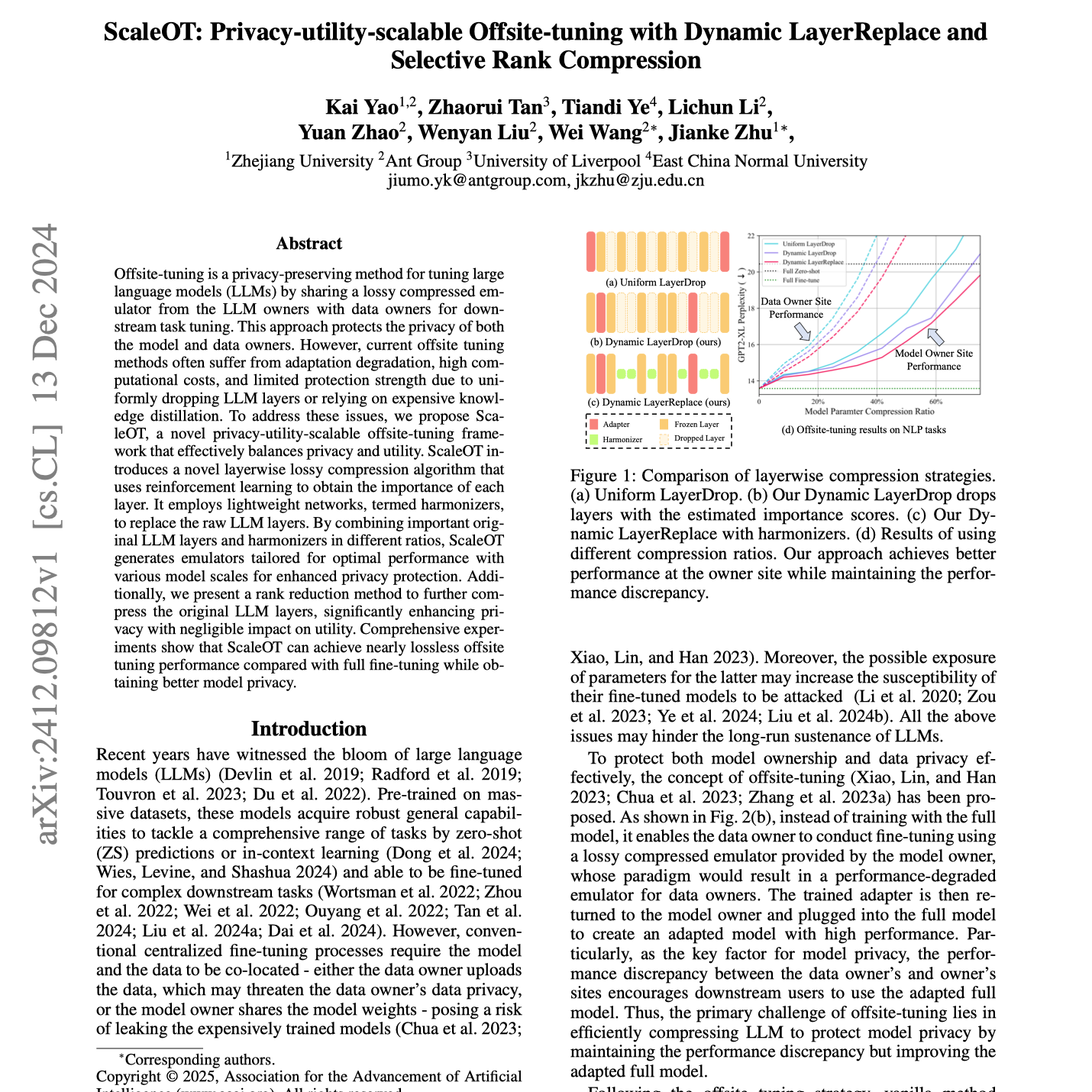
【第106期】ScaleOT:保护隐私的大型语言模型离站微调的新型框架
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:ScaleOT: Privacy-utility-scalable Offsite-tuning with Dynamic LayerReplace and Selective Rank CompressionSummaryThis research introduces ScaleOT, a novel framework for privacy-preserving offsite tuning of large language models (LLMs). ScaleOT addresses limitations of existing methods by using reinforcement learning to determine layer importance, replacing less important layers with lightweight networks ("harmonizers"), and employing rank reduction to further compress the model. The resulting emulators balance privacy and utility, enabling effective downstream task tuning while protecting both model and data privacy. Extensive experiments demonstrate ScaleOT's superior performance compared to state-of-the-art methods across various LLMs and tasks. The approach is shown to be compatible with parameter-efficient fine-tuning techniques.本文提出了ScaleOT,一种用于保护隐私的大型语言模型(LLMs)离站微调的新型框架。ScaleOT 通过强化学习确定模型层的重要性,将较不重要的层替换为轻量级网络(称为“协调器”),并采用秩减技术进一步压缩模型,从而克服了现有方法的局限性。生成的模拟器在隐私与实用性之间实现了平衡,能够在保护模型和数据隐私的同时,有效地进行下游任务微调。大量实验表明,ScaleOT 在多种 LLM 和任务上的性能优于当前最先进的方法。研究还表明,该方法兼容参数高效微调技术。原文链接:https://arxiv.org/abs/2412.09812
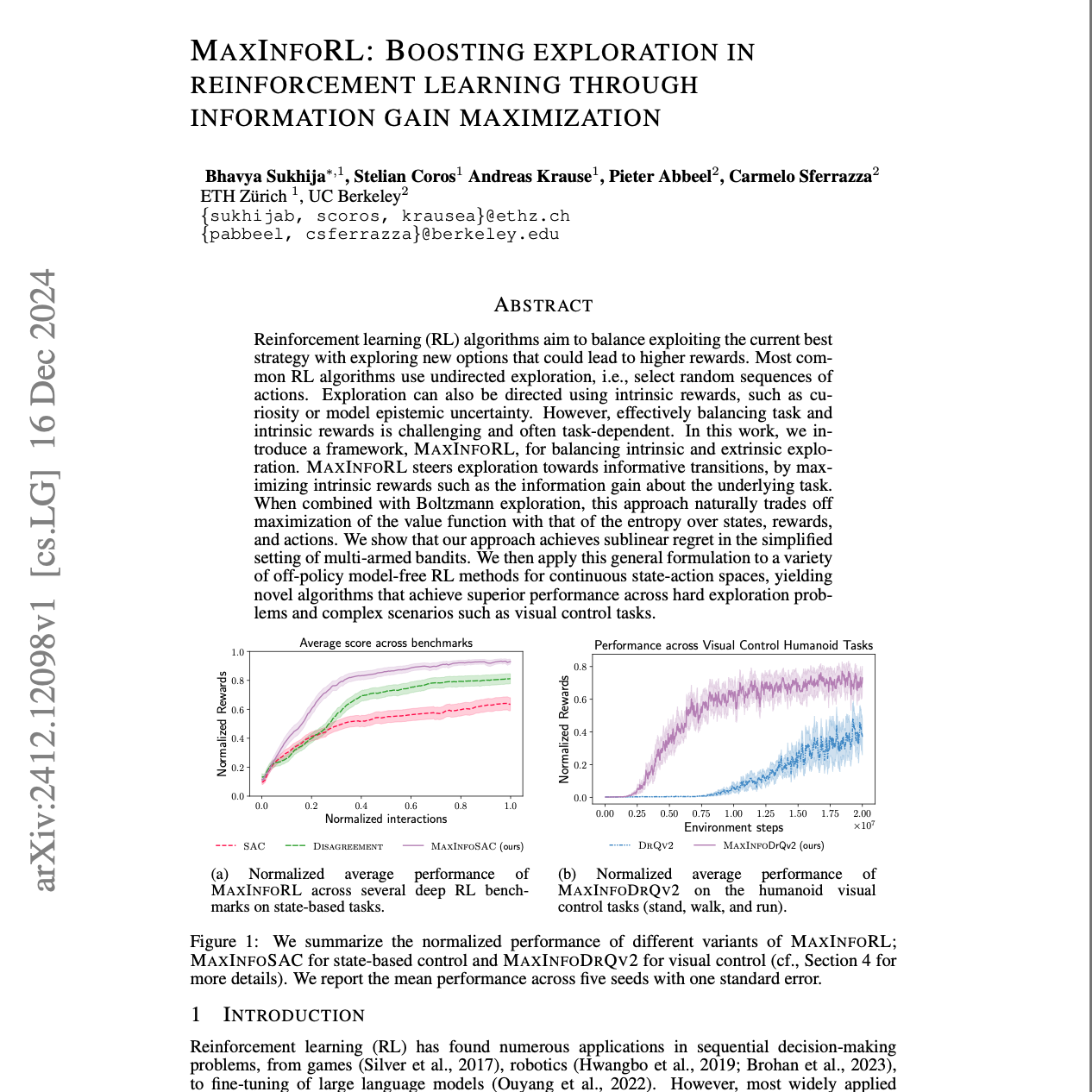
【第105期】MAXINFORL:最大化对底层任务信息增益的强化学习
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:MaxInfoRL: Boosting exploration in reinforcement learning through information gain maximizationSummaryThe paper introduces MAXINFORL, a novel reinforcement learning (RL) framework that improves exploration by maximizing information gain about the underlying task. It augments existing off-policy RL methods with directed exploration, using intrinsic rewards derived from model epistemic uncertainty to guide exploration more effectively than standard methods like ϵ-greedy or Boltzmann exploration. Theoretical analysis shows sublinear regret in a simplified multi-armed bandit setting, and empirical results demonstrate superior performance across various deep RL benchmarks, including challenging visual control tasks. The authors propose an auto-tuning procedure for balancing intrinsic and extrinsic exploration objectives, enhancing simplicity and scalability. Finally, the paper discusses related work and potential future research directions.本文提出了MAXINFORL,一种新型的强化学习(RL)框架,通过最大化对底层任务的信息增益来改进探索能力。该框架将现有的离策略强化学习方法与定向探索相结合,利用源于模型认知不确定性的内在奖励来比标准方法(如 ϵ-greedy 或 Boltzmann 探索)更有效地引导探索。理论分析表明,在简化的多臂老虎机场景中具有次线性遗憾值,实验证明其在各种深度强化学习基准测试(包括具有挑战性的视觉控制任务)中的优越性能。作者提出了一种自动调节内在与外在探索目标平衡的程序,以提升方法的简洁性和可扩展性。最后,论文讨论了相关工作以及未来潜在的研究方向。原文链接:https://arxiv.org/abs/2412.12098

【第104期】STAR:无梯度的进化优化算法
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:STAR: Synthesis of Tailored ArchitecturesSummaryThis research paper introduces STAR, a novel framework for automated deep learning architecture synthesis. STAR utilizes a hierarchical search space based on linear input-varying systems, numerically encoded as "genomes," which are optimized using gradient-free evolutionary algorithms. The system is evaluated on autoregressive language modeling, demonstrating significant improvements in model quality, size, and inference cache compared to existing Transformer and hybrid models across multiple benchmarks. The paper details the hierarchical search space, genome encoding, evolutionary optimization process, and experimental results showcasing STAR's effectiveness. Finally, the study explores recurring architectural motifs identified during the evolutionary process.本文提出了STAR,一种用于自动化深度学习架构合成的新型框架。STAR 利用基于线性输入变化系统的分层搜索空间,将其以“基因组”的形式进行数值编码,并通过无梯度的进化算法进行优化。系统在自回归语言建模任务上进行了评估,相较于现有的 Transformer 和混合模型,在多个基准测试中显著提升了模型质量、规模和推理缓存性能。论文详细介绍了分层搜索空间、基因组编码、进化优化过程以及实验结果,展示了 STAR 的高效性。最后,研究还探讨了进化过程中识别出的重复架构模式。原文链接:https://arxiv.org/abs/2411.17800

【第103期】开源和闭源大型语言模型的比较研究
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:The Open Source Advantage in Large Language Models (LLMs)SummaryThis research paper compares open-source and closed-source Large Language Models (LLMs), examining their development, performance, accessibility, and ethical implications. Open-source LLMs, like LLaMA and BLOOM, prioritize accessibility and community collaboration, while closed-source models, such as GPT-4, excel in performance due to proprietary data and resources. The paper analyzes the strengths and weaknesses of each approach, exploring techniques like Low-Rank Adaptation (LoRA) that enhance open-source model capabilities. Ethical considerations, particularly transparency and bias mitigation, are central to the comparison, highlighting the trade-offs between proprietary control and open access. Ultimately, the paper suggests that hybrid approaches combining the benefits of both paradigms will shape the future of LLM development.本文比较了开源和闭源大型语言模型(LLMs),探讨了它们在开发、性能、可访问性以及伦理影响方面的差异。开源模型(如 LLaMA 和 BLOOM)注重可访问性和社区协作,而闭源模型(如 GPT-4)因其专有数据和资源在性能上表现更为出色。文章分析了两种方法的优劣势,并探讨了诸如低秩适配(Low-Rank Adaptation, LoRA)等增强开源模型能力的技术。透明性和偏见缓解等伦理考量是比较的核心,突出了专有控制与开放访问之间的权衡。最终,文章指出结合两种范式优势的混合方法将成为 LLM 发展的未来方向。原文链接:https://arxiv.org/abs/2412.12004

【第102期】Byte Latent Transformer (BLT):用byte级替代token级
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Byte Latent Transformer: Patches Scale Better Than TokensSummaryThe paper introduces the Byte Latent Transformer (BLT), a novel large language model architecture that processes raw byte data without tokenization. BLT dynamically groups bytes into patches based on entropy, allocating computational resources efficiently. Experimental results demonstrate BLT's competitive performance with tokenization-based models, particularly showcasing improved inference efficiency and robustness to noisy input. The research includes a comprehensive scaling study and ablation analysis, highlighting the advantages of BLT's patch-based approach over traditional tokenization. The authors release the code for BLT to facilitate further research.本文介绍了字节潜变换器(Byte Latent Transformer,BLT),一种新型的大型语言模型架构,该架构直接处理原始字节数据,无需进行分词。BLT 基于熵动态地将字节分组为补丁,从而高效分配计算资源。实验结果表明,BLT 在推理效率和对噪声输入的鲁棒性方面表现出色,其性能可与基于分词的模型相媲美。研究还进行了全面的规模化研究和消融分析,突出了 BLT 的基于补丁方法相较传统分词方法的优势。作者发布了 BLT 的代码,以促进进一步研究。原文链接:https://arxiv.org/abs/2412.09871

【第101期】Large Concept Models (LCMs)
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Large Concept Models: Language Modeling in a Sentence Representation SpaceSummaryThis research paper introduces Large Concept Models (LCMs), a novel approach to language modeling that operates on sentence embeddings instead of individual tokens. LCMs aim to mimic human-like abstract reasoning by processing higher-level semantic representations, improving long-form text generation and zero-shot cross-lingual performance. The authors explore various LCM architectures, including those based on mean squared error regression and diffusion models, and evaluate their performance on summarization and a novel summary expansion task. Their findings demonstrate that diffusion-based LCMs outperform other methods, exhibiting impressive zero-shot generalization across multiple languages. The research also explores the concept of incorporating explicit planning into the model to further enhance coherence in long-form text generation.本文提出了大型概念模型(LCMs),一种新颖的语言建模方法,其操作基于句子嵌入而非单独的词元。LCMs 旨在通过处理更高层次的语义表示来模拟类似人类的抽象推理,从而改进长篇文本生成和零样本跨语言性能。作者探讨了多种 LCM 架构,包括基于均方误差回归和扩散模型的架构,并在摘要生成和一种新颖的摘要扩展任务上评估了它们的性能。研究结果表明,基于扩散的 LCMs 表现优于其他方法,在多种语言上的零样本泛化能力令人印象深刻。研究还探讨了在模型中引入显式规划的概念,以进一步增强长篇文本生成的连贯性。原文链接:https://arxiv.org/abs/2412.08821

【第100期】SLM更懂LLM提示词
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Smaller Language Models Are Better Instruction EvolversSummaryThis research paper investigates the surprising effectiveness of smaller language models (SLMs) in improving instruction data for larger language models (LLMs). The authors challenge the common assumption that larger models are always superior for this task, demonstrating through experiments across three scenarios that SLMs generate more complex and diverse instructions. They attribute this to SLMs having a broader output space, reducing overconfidence. Furthermore, the study proposes a new metric, Instruction Complex-Aware IFD (IC-IFD), for evaluating instruction effectiveness without requiring instruction tuning. The findings suggest SLMs offer a cost-effective and efficient alternative for enhancing LLM instruction data.本研究论文探讨了小型语言模型(SLMs)在改进大型语言模型(LLMs)指令数据方面令人惊讶的高效性。作者挑战了大型模型在此任务上总是更优的常见假设,通过在三种场景中的实验表明,SLMs 能生成更复杂和多样化的指令。他们将此归因于 SLMs 具有更广泛的输出空间,从而减少了过度自信现象。此外,研究提出了一种新的评估指标——指令复杂感知 IFD(IC-IFD),用于在不需要指令微调的情况下评估指令的有效性。研究结果表明,SLMs 为提升 LLM 指令数据提供了一种具有成本效益且高效的替代方案。原文链接:https://www.arxiv.org/abs/2412.11231

【第99期】GREATER:一种对于小模型的提示词优化技术
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:GReaTer: Gradients over Reasoning Makes Smaller Language Models Strong Prompt OptimizersSummaryThe paper introduces GREATER, a novel prompt optimization technique for smaller language models. Unlike existing methods that rely on large, expensive LLMs for feedback, GREATER uses gradient information directly from the task loss to refine prompts. This allows smaller models to achieve performance comparable to or exceeding that of larger models on various reasoning tasks. Extensive experiments on datasets like BBH, GSM8K, and FOLIO demonstrate GREATER's superior performance and prompt transferability across different models. The approach incorporates reasoning chains for more accurate gradient calculations, significantly improving optimization compared to text-based feedback methods.本文介绍了GREATER,一种针对小型语言模型的新型提示优化技术。与依赖大型、昂贵的语言模型(LLMs)提供反馈的现有方法不同,GREATER 直接利用任务损失的梯度信息来优化提示。这使得小型模型在多种推理任务中的表现可以媲美甚至超越大型模型。针对 BBH、GSM8K 和 FOLIO 等数据集的大量实验表明,GREATER 在性能和提示的跨模型迁移性方面表现优异。该方法结合了推理链,以实现更精确的梯度计算,相较于基于文本反馈的方法,显著提升了优化效果。原文链接:https://arxiv.org/abs/2412.09722

【第98期】SPaR:通过搜索树改进LLM指令遵循
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:SPaR: Self-Play with Tree-Search Refinement to Improve Instruction-Following in Large Language ModelsSummaryThis research introduces SPAR, a self-play framework using tree-search refinement to improve instruction-following in large language models (LLMs). SPAR addresses the limitations of existing methods by generating comparable preference pairs free from irrelevant variations, focusing on key differences crucial for successful instruction-following. Experiments demonstrate SPAR's effectiveness in enhancing various LLMs, surpassing GPT-4-Turbo on the IFEval benchmark in some cases. The framework iteratively improves both the LLM's responses and its ability to judge those responses. The code and data are publicly available.本研究提出了SPAR,一种通过树搜索优化来改进大型语言模型(LLMs)指令遵循能力的自博弈框架。SPAR 通过生成不受无关变化影响的可比较偏好对,聚焦于关键差异,从而克服了现有方法的局限性,这些关键差异对于成功执行指令至关重要。实验表明,SPAR 在增强各种 LLMs 方面表现出色,在某些情况下,甚至在 IFEval 基准测试上超越了 GPT-4-Turbo。该框架能够迭代地改进模型的回答能力以及对回答的评判能力。相关代码和数据已公开提供。原文链接:https://www.arxiv.org/abs/2412.11605

【第97期】SCBench:基于KV Cache的评估长上下文LLM基准
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:SCBench: A KV Cache-Centric Analysis of Long-Context MethodsSummaryThe paper introduces SCBench, a new benchmark for evaluating long-context Large Language Models (LLMs). SCBench focuses on the key role of the KV cache in LLM inference, analyzing its lifecycle across multiple requests and shared contexts. The benchmark assesses four key long-context abilities through twelve tasks, testing various long-context methods on multiple open-source LLMs. Results reveal that maintaining O(n) memory in the KV cache is crucial for robust performance in multi-turn scenarios, while sub-O(n) methods struggle. The study also explores the effects of sparsity in encoding and decoding, compression rates, and task complexity on overall performance.这篇论文介绍了 SCBench,一个用于评估长上下文大型语言模型(LLMs)的新基准。SCBench 聚焦于 KV 缓存在 LLM 推理中的关键作用,分析其在多个请求和共享上下文中的生命周期。该基准通过十二个任务评估四项关键的长上下文能力,对多种开源 LLM 的不同长上下文方法进行测试。结果表明,在多轮场景中,保持 O(n) 内存的 KV 缓存对于稳健性能至关重要,而采用子 O(n) 方法的模型表现较差。研究还探讨了编码和解码过程中的稀疏性、压缩率以及任务复杂度对整体性能的影响。原文链接:https://arxiv.org/abs/2412.10319

【第96期】AsyncLM:异步LLM函数调用
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Asynchronous LLM Function CallingSummaryThis research paper introduces AsyncLM, a system designed to enhance the efficiency of Large Language Models (LLMs) by enabling asynchronous function calls. Unlike current synchronous methods where LLMs block while awaiting function execution, AsyncLM allows concurrent operation, significantly reducing task completion latency. This is achieved through an interrupt mechanism that notifies the LLM when functions complete, along with a novel domain-specific language (CML) and a fine-tuning strategy to handle this asynchronous interaction. The paper presents empirical evidence demonstrating substantial latency reduction and maintains accuracy, even suggesting extensions for novel human-LLM or LLM-LLM interactions.这篇研究论文介绍了 AsyncLM,一种通过实现异步函数调用来提升大型语言模型(LLMs)效率的系统。与当前同步方法中 LLM 等待函数执行完成而阻塞的情况不同,AsyncLM 允许并发操作,显著降低了任务完成的延迟。该系统通过中断机制实现,当函数执行完成时通知 LLM,同时引入了一种新颖的领域特定语言(CML)以及用于处理异步交互的微调策略。论文提供了实证证据,显示 AsyncLM 在显著减少延迟的同时保持了高精度,并提出了其在全新的人类-LLM 或 LLM-LLM 交互场景中的扩展潜力。原文链接:https://arxiv.org/abs/2412.07017

【第95期】Student-Informed Teacher Training
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Student-Informed Teacher TrainingSummaryThis research introduces a novel framework for imitation learning that addresses the challenge of teacher-student asymmetry. The method jointly trains a teacher and student policy, where the teacher learns behaviors easily imitated by the student despite the student's limited observability. This is achieved by adding a penalty term to the teacher's reward function and incorporating a supervised alignment step. The effectiveness of the proposed framework is demonstrated across diverse robotic tasks, including maze navigation, quadrotor flight, and robotic manipulation, consistently outperforming baseline imitation learning methods. The results highlight the importance of considering student capabilities during teacher training to improve overall learning efficiency and performance.这项研究提出了一种新框架,用于解决模仿学习中教师与学生之间的不对称性问题。该方法联合训练教师策略和学生策略,其中教师学习出一种行为,使学生在观察能力受限的情况下也能轻松模仿。为此,在教师的奖励函数中加入了惩罚项,并引入了监督对齐步骤。该框架在多种机器人任务中展现了其有效性,包括迷宫导航、四旋翼飞行和机器人操作,并在性能上始终优于基线模仿学习方法。研究结果突出了在教师训练过程中考虑学生能力的重要性,以提升整体学习效率和性能。原文链接:https://arxiv.org/abs/2412.09149

【第94期】AgentTrek:为GUI Agent生成高质量数据的pipeline
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:AgentTrek: Agent Trajectory Synthesis via Guiding Replay with Web TutorialsSummaryThe paper introduces AgentTrek, a novel pipeline for synthesizing high-quality training data for Graphical User Interface (GUI) agents. AgentTrek leverages web tutorials to generate large-scale, multi-step agent trajectories, significantly reducing the cost and effort compared to human annotation. The pipeline automatically gathers and processes tutorials, uses a visual-language model (VLM) to simulate task execution, and incorporates an evaluator to ensure data quality. Experiments demonstrate that agents trained on this synthesized data significantly outperform those trained on existing datasets, showcasing AgentTrek's effectiveness in improving both grounding and planning capabilities. The resulting dataset is comprehensive, including multimodal data such as screenshots, accessibility trees, and reasoning traces.这篇论文介绍了 AgentTrek,一种用于生成高质量图形用户界面(GUI)代理训练数据的新型流水线。AgentTrek 利用网页教程生成大规模、多步骤的代理轨迹,与人工标注相比,显著降低了成本和工作量。该流水线自动收集和处理教程,使用视觉语言模型(VLM)模拟任务执行,并引入一个评估器以确保数据质量。实验表明,基于此合成数据训练的代理在性能上显著优于使用现有数据集训练的代理,展示了 AgentTrek 在提升代理的语义理解能力和规划能力方面的有效性。生成的数据集十分全面,包括多模态数据,如截图、可访问性树和推理轨迹。原文链接:https://arxiv.org/abs/2412.09605

【第93期】TARFLOW:一种基于 Transformer 的正则化流
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Normalizing Flows are Capable Generative ModelsSummaryThis research paper introduces TARFLOW, a novel Transformer-based Normalizing Flow (NF) architecture for generative modeling of images. TARFLOW significantly improves upon previous NF models by achieving state-of-the-art results in likelihood estimation and generating high-quality samples comparable to diffusion models. Key advancements include a more scalable architecture, Gaussian noise augmentation during training, post-training denoising, and a guidance method for both conditional and unconditional generation. The authors demonstrate superior performance across multiple image datasets, showcasing TARFLOW's potential as a powerful generative modeling technique. The accompanying code is publicly available.这篇研究论文介绍了 TARFLOW,一种基于 Transformer 的正则化流(Normalizing Flow, NF)架构,用于图像的生成建模。TARFLOW 在前述 NF 模型的基础上取得了显著的改进,在似然估计方面达到了最先进的结果,并生成了与扩散模型相媲美的高质量样本。关键进展包括:更具可扩展性的架构、训练过程中的高斯噪声增强、训练后去噪方法,以及一种用于条件生成和无条件生成的引导方法。作者在多个图像数据集上展示了 TARFLOW 的卓越表现,展现了其作为一种强大生成建模技术的潜力。相关代码已公开。原文链接:https://arxiv.org/abs/2412.06329

【第92期】Agentless:软件开发的Agent
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Agentless: Demystifying LLM-based Software Engineering AgentsSummaryThis research paper introduces AGENTLESS, a novel approach to automated software development that eschews complex autonomous agents. Instead, AGENTLESS employs a simpler three-phase process: localization, repair, and patch validation, leveraging large language models (LLMs) for each phase. The authors benchmark AGENTLESS against existing agent-based systems on SWE-bench Lite, demonstrating surprisingly high performance and low cost. They further analyze SWE-bench Lite, identifying problematic issues and creating a refined dataset, SWE-bench Lite-S, for more robust evaluation. Finally, the study highlights AGENTLESS's adoption by OpenAI and its superior performance on their SWE-bench Verified benchmark.这篇研究论文介绍了 AGENTLESS,一种新颖的自动化软件开发方法,摒弃了复杂的自主智能体(autonomous agents)。相反,AGENTLESS 采用一个更简单的三阶段流程:定位、修复和补丁验证,并在每个阶段中利用大型语言模型(LLMs)。作者在 SWE-bench Lite 基准上对 AGENTLESS 与现有基于智能体的系统进行了对比,结果显示出其出乎意料的高性能和低成本。此外,他们对 SWE-bench Lite 进行了深入分析,识别出其中的问题,并构建了一个经过优化的数据集 SWE-bench Lite-S,以实现更稳健的评估。最后,研究强调了 AGENTLESS 被 OpenAI 采用,并在他们的 SWE-bench Verified 基准上表现出优越的性能。原文链接:https://arxiv.org/abs/2407.01489

【第91期】[Mask] is all you need
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:[MASK] [MASK] [MASK] [MASK] [MASK][MASK] is [MASK] You [MASK][MASK] is All You NeedSummaryThis research paper introduces Discrete Interpolants, a novel framework that bridges Masked Generative Models and Diffusion Models for image and video generation. The framework uses discrete-state models and offers a unified design space analysis, exploring various schedulers and sampling methods. The authors demonstrate its versatility by recasting image segmentation as an unmasking process, achieving state-of-the-art results on multiple benchmarks. Furthermore, the research explores the transition from explicit to implicit timestep models, improving efficiency and connecting the two model paradigms more closely.这篇研究论文介绍了 离散插值(Discrete Interpolants)框架,这是一种将掩码生成模型(Masked Generative Models)和扩散模型(Diffusion Models)结合用于图像和视频生成的新框架。该框架使用离散状态模型,并提供了统一的设计空间分析,探索了各种调度器和采样方法。作者通过将图像分割重新构造为去掩码过程,展示了其多功能性,并在多个基准测试中取得了最先进的成果。此外,研究还探讨了从显式时间步模型到隐式时间步模型的过渡,提升了效率,并使这两种模型范式之间的联系更加紧密。原文链接:https://arxiv.org/abs/2412.06787
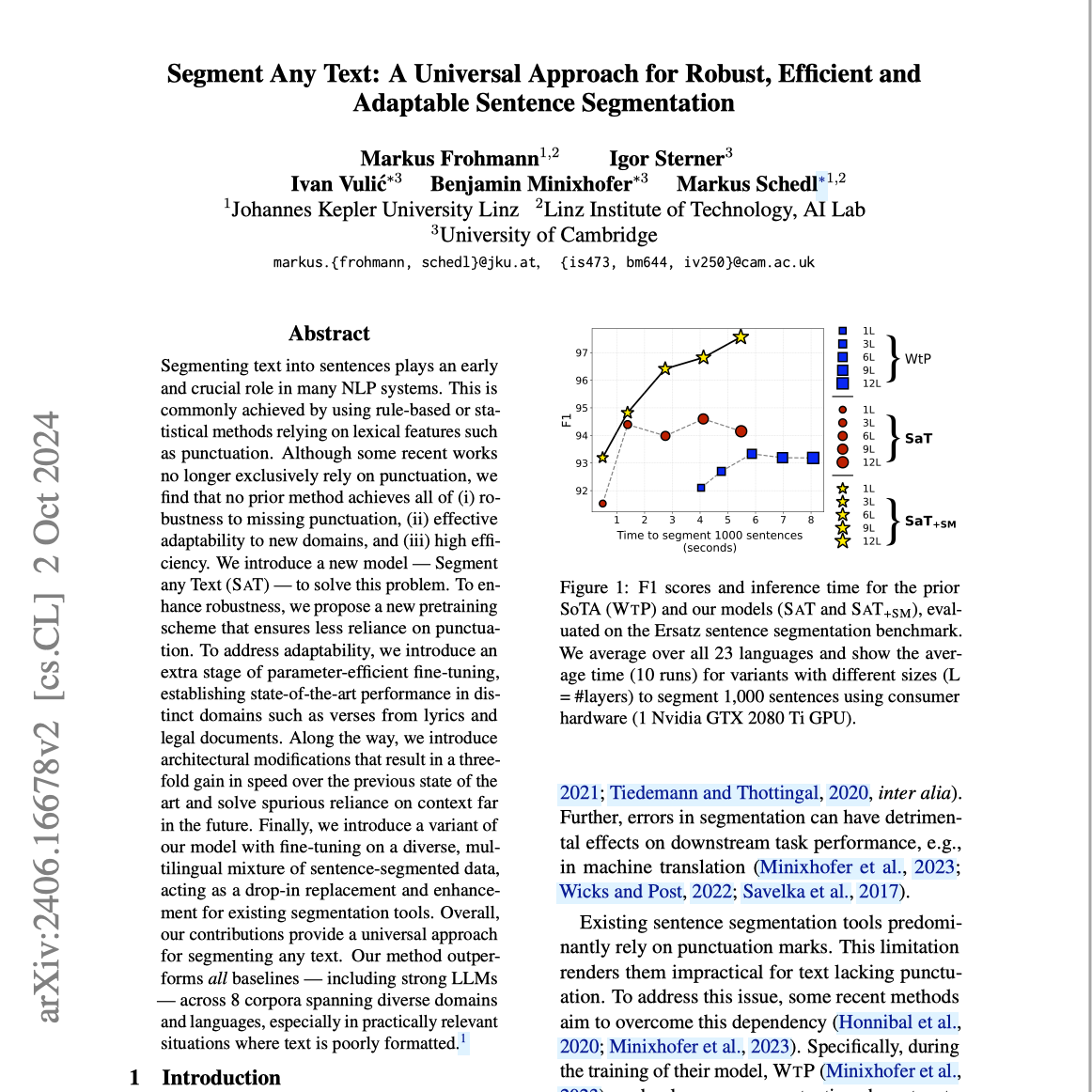
【第90期】SAT:Segment Any Text
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Segment Any Text: A Universal Approach for Robust, Efficient and Adaptable Sentence SegmentationSummaryThis research paper introduces Segment Any Text (SAT), a novel sentence segmentation model that surpasses existing methods. SAT achieves robustness by reducing reliance on punctuation during training, demonstrates adaptability through parameter-efficient fine-tuning across diverse domains (e.g., lyrics, legal texts), and boasts high efficiency, outperforming even strong large language models (LLMs). The authors detail SAT's architecture, training process, and extensive evaluation across multiple languages and corpora, highlighting its superior performance, especially in handling poorly formatted text. Finally, they discuss ethical considerations and limitations of their approach.这篇研究论文介绍了一种名为 Segment Any Text(SAT)的新型句子分割模型,其性能超越了现有方法。SAT 通过在训练过程中减少对标点符号的依赖,实现了更强的鲁棒性;通过参数高效的微调适应不同领域(如歌词、法律文本),展现了优异的适应性;并以高效性为特点,在性能上甚至超过了强大的大型语言模型(LLMs)。作者详细描述了 SAT 的架构、训练过程以及在多种语言和语料库上的广泛评估,尤其是在处理格式较差的文本时表现出色。最后,论文讨论了该方法的伦理考量和局限性。原文链接:https://arxiv.org/abs/2406.16678

【第89期】PRoC3S:一种新颖的机器人规划系统
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Trust the PRoC3S: Solving Long-Horizon Robotics Problems with LLMs and Constraint SatisfactionSummaryThis research paper introduces PRoC3S, a novel robotic planning system that leverages large language models (LLMs) to generate and execute plans involving continuous parameters. Unlike previous LLM-based approaches limited to discrete actions, PRoC3S handles complex, real-world constraints by separating planning into LLM program generation and constraint satisfaction phases. The system iteratively refines plans using feedback from a physics simulator, achieving high success rates in simulated and real-world robotic manipulation tasks. The paper compares PRoC3S against existing baselines, demonstrating its superior efficiency and robustness in handling continuous parameters and diverse constraints expressed in natural language. Future work focuses on improving the constraint satisfaction methods and incorporating visual reasoning.这篇研究论文介绍了 PRoC3S,一种新颖的机器人规划系统,利用大型语言模型(LLMs)生成并执行涉及连续参数的计划。与以往基于 LLM 的方法仅限于离散动作不同,PRoC3S 通过将规划分为 LLM 程序生成和约束满足两个阶段来处理复杂的真实世界约束。该系统利用物理模拟器的反馈迭代优化计划,在仿真和实际的机器人操作任务中取得了高成功率。论文将 PRoC3S 与现有基线方法进行了对比,展示了其在处理连续参数和以自然语言表达的多样化约束时的优越效率和鲁棒性。未来的研究将重点改进约束满足方法并结合视觉推理能力。原文链接:https://arxiv.org/abs/2406.05572

【第88期】LLM Agent能否模拟人的信任行为?
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Can Large Language Model Agents Simulate Human Trust Behavior?SummaryThis research paper investigates whether Large Language Models (LLMs) can simulate human trust behavior. Using Trust Games, the study finds that LLMs, particularly GPT-4, exhibit trust behaviors aligning significantly with human patterns, demonstrating a high degree of behavioral alignment. The research also explores biases in LLM trust behavior, the impact of external manipulation and reasoning strategies on LLM trust, and the implications for human simulation, agent cooperation, and human-agent collaboration. The findings suggest considerable potential for using LLMs to simulate human social interactions but also highlight potential limitations and risks. The study provides a framework for understanding the analogy between LLMs and human behavior beyond value alignment.这篇研究论文探讨了大型语言模型(LLMs)是否能够模拟人类的信任行为。通过使用信任游戏,该研究发现,LLMs,特别是GPT-4,表现出与人类行为模式显著一致的信任行为,展现了高度的行为一致性。研究还探讨了LLMs信任行为中的偏见、外部操控和推理策略对LLMs信任行为的影响,以及这些对人类模拟、智能体合作和人机协作的意义。研究结果表明,LLMs在模拟人类社会互动方面具有相当大的潜力,同时也指出了其可能的局限性和风险。该研究为理解LLMs与人类行为之间的类比关系提供了一个超越价值对齐的框架。原文链接:https://arxiv.org/abs/2402.04559