
Seventy3
642 episodes — Page 8 of 13

【第287期】(中文)AgentRxiv:迈向协作式自主研究
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:AgentRxiv: Towards Collaborative Autonomous ResearchSummary本研究介绍了AgentRxiv,这是一个创新框架,旨在促进大型语言模型(LLM)代理之间在科研方面的协作与共享。作者们通过让代理访问共享预印本服务器上的先前研究,证明了AgentRxiv能够显著提高性能,例如在MATH-500基准测试中取得了11.4%的相对改进。该框架不仅使代理能够在其自身工作的基础上进行迭代改进,而且通过并行运行多个实验室进一步加速了发现过程。尽管存在计算成本增加和幻觉等挑战,但AgentRxiv通过促进知识共享和累计进步,为自动科学研究的未来发展提供了有力的证据。原文链接:https://arxiv.org/abs/2503.18102

【第286期】(中文)扩散采样最佳步长
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Optimal Stepsize for Diffusion SamplingSummary这份文件介绍了一种用于扩散模型的动态规划框架,旨在优化采样过程中的步长调度。作者通过将步长优化重新表述为递归误差最小化问题,从参考轨迹中提取了理论上最优的步长序列。该方法能够显著加速文本到图像生成,同时保持高水平的性能,并展示了在不同架构、ODE求解器和噪声调度下的强大鲁棒性。文章还讨论了振幅校准以增强图像细节,并将其方法与现有技术进行了比较,证明了其在减少计算量同时保持输出质量方面的优势。原文链接:https://arxiv.org/abs/2503.21774

【第285期】(中文)UI-R1: 强化学习提升GUI智能体动作预测
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:UI-R1: Enhancing Action Prediction of GUI Agents by Reinforcement LearningSummary文本介绍了 UI-R1 框架,这是一种通过 基于规则的强化学习 (RL) 提升多模态大型语言模型 (MLLM) 图形用户界面 (GUI) 动作预测能力的新方法。与传统的 监督微调 (SFT) 不同,UI-R1 仅使用少量高质量数据进行训练,并利用独特的 奖励函数 来指导模型学习动作类型和坐标预测。实验结果表明,该模型在 域内和域外任务 上均表现出色,甚至超越了使用更多数据训练的更大模型。这凸显了基于规则的 RL 在提高 GUI 理解和控制 方面的 数据效率和泛化能力。原文链接:https://arxiv.org/abs/2503.21620

【第284期】(中文)UniDisc :Unified Multimodal Discrete Diffusion
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Unified Multimodal Discrete DiffusionSummary这些来源介绍了一种名为 UniDisc 的新型多模态离散扩散模型,该模型能够统一地理解和生成图像和文本。与主流的自回归模型不同,UniDisc 利用 离散扩散 的优势,例如更好的生成样本质量与多样性控制、跨文本和图像领域的联合 inpainting 能力以及更高的 可控性。该研究通过 缩放分析 和性能比较,证明 UniDisc 在性能和推理计算效率方面均优于自回归模型,尤其在 联合图像-文本 inpainting 和 判别能力 方面表现出色。此外,这些来源还讨论了模型的设计选择、训练效率以及在更高分辨率下进行 零样本生成 的能力。原文链接:https://arxiv.org/abs/2503.20853

【第283期】(中文)A-MEM:基于Agent的内存系统
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:A-MEM: Agentic Memory for LLM AgentsSummary此文档介绍了一种名为 A-MEM 的新型代理式记忆系统,旨在提升大型语言模型(LLM)代理处理复杂现实任务的能力。该系统通过借鉴 Zettelkasten 方法,能够动态组织和演化记忆,从而克服了现有记忆系统固定操作和结构所带来的局限性。A-MEM 能够自主生成上下文描述、建立记忆间的关联,并根据新经验更新现有记忆,从而在长期对话任务中展现出卓越的性能,尤其是在需要复杂推理的多跳任务中。该研究还通过 消融研究 和 超参数分析 验证了其关键模块的有效性,并提供了 记忆嵌入的可视化 以展示其优化的结构。原文链接:https://arxiv.org/abs/2502.12110

【第282期】(中文)DeepSeek 模型的关键创新技术回顾
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:A Review of DeepSeek Models’ Key Innovative TechniquesSummary本评论文章概述了 DeepSeek 模型的关键创新技术,其中包括 DeepSeek-V3 和 DeepSeek-R1。文章详细阐述了 transformer 架构的改进,如多头潜在注意力 (Multi-Head Latent Attention) 和 专家混合 (Mixture of Experts),这些都旨在提升效率和性能。此外,它还探讨了多令牌预测 (Multi-Token Prediction) 及其对训练效率的影响,以及算法、框架和硬件的协同设计,包括 DualPipe 和 FP8 混合精度训练。最后,文章介绍了 Group Relative Policy Optimization (GRPO) 强化学习算法,并讨论了 DeepSeek 在后训练阶段使用纯强化学习和监督微调与强化学习交替迭代训练的方法,同时指出了未来的研究方向和未解决的问题。原文链接:https://arxiv.org/abs/2503.11486

【第281期】(中文)Cosmos-Reason1
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Cosmos-Reason1: From Physical Common Sense To Embodied ReasoningSummaryCosmos-Reason1 介绍了一个多模态大型语言模型系列,专注于物理世界理解和推理。该模型通过四个训练阶段进行开发:视觉预训练、通用监督微调(SFT)、物理AI SFT和物理AI强化学习(RL)。为了评估模型,研究人员定义了物理常识和具身推理的本体论,并构建了全面的基准。结果表明,物理AI SFT和RL显著提升了模型的性能,使其能够更好地处理涉及空间、时间和直观物理的复杂任务,而这些是现有模型所面临的挑战。该项目旨在通过开源代码和预训练模型来推动物理AI系统的发展。原文链接:https://arxiv.org/abs/2503.15558

【第280期】(中文)RQI:超分辨率图像评估新视角
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Rethinking Image Evaluation in Super-ResolutionSummary该论文探讨了图像超分辨率(SR)领域中人类感知评估与现有量化评估之间日益增长的不一致性。作者们认为,现有SR数据集中“地面实况(GT)”图像的质量不佳是导致这种评估偏差的一个关键因素。文章通过系统性分析,揭示了GT质量如何影响SR模型的评估结果,并指出即使GT图像质量较差,也可能导致模型输出在感知上优于GT。为解决这一问题,研究提出了一种名为相对质量指数(RQI)的新型感知质量度量,旨在更准确地反映图像对之间的相对质量差异,并证明了其在与人类偏好保持一致性方面的优越性。这项工作为未来SR数据集的构建、模型的开发以及评估指标的设计提供了重要的见解。原文链接:https://arxiv.org/abs/2503.14868

【第279期】(中文)无反向传播的高效量化扩散模型个性化
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Efficient Personalization of Quantized Diffusion Model without BackpropagationSummary此篇研究论文介绍了一种名为 ZOODiP 的新型框架,旨在在内存受限的环境中高效地个性化扩散模型。该方法通过量化扩散模型并利用零阶优化,在无需反向传播的情况下实现微调,从而显著减少了内存消耗。为了克服零阶优化的局限性,ZOODiP 引入了 Subspace Gradient (SG) 来处理梯度噪声,并提出了 Partial Uniform Timestep Sampling (PUTS) 来优化训练过程中的时间步选择。实验结果表明,ZOODiP 在大幅降低内存需求的同时,仍能实现与现有方法相当的图像质量和文本对齐分数。原文链接:https://arxiv.org/abs/2503.14868

【第278期】(中文)CLS-RL:一种基于规则的强化学习方法
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Think or Not Think: A Study of Explicit Thinking in Rule-Based Visual Reinforcement Fine-TuningSummary这篇研究论文探讨了多模态大型语言模型(MLLMs)在图像分类中的少样本微调问题。研究指出,传统的监督微调(SFT)可能导致灾难性遗忘,甚至降低性能。为解决此问题,研究团队提出了CLS-RL,这是一种基于规则的强化学习方法,利用可验证的信号(如类别名称)作为奖励来优化MLLMs,并鼓励模型在回答前进行思考。此外,论文还引入了No-Thinking-CLS-RL,该方法通过移除思考过程并强制模型直接输出答案,在某些情况下取得了更好的性能,同时显著缩短了训练和推理时间。研究发现,CLS-RL及其变体展现出“免费午餐”现象,即在某个数据集上微调的模型在其他不同数据集上性能也能得到提升,这表明这些方法能有效教授模型基本的图像分类知识。原文链接:https://arxiv.org/abs/2503.16188

【第277期】(中文)Fin-R1:金融推理大型语言模型
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Fin-R1: A Large Language Model for Financial Reasoning through Reinforcement LearningSummary文本介绍了 Fin-R1,一个专门为金融领域推理任务设计的大型语言模型。该模型旨在解决金融数据碎片化、推理逻辑不可控以及业务泛化能力弱等核心问题。通过构建一个包含**高质量思维链(CoT)的金融数据集 Fin-R1-Data,并采用监督微调(SFT)和强化学习(RL)**的两阶段训练框架,Fin-R1 在多个权威金融基准测试中展现出卓越性能,尤其在处理金融推理任务方面表现突出。该研究强调了其在金融合规和智能投顾等实际应用中的强大自动化推理和决策能力。原文链接:https://arxiv.org/abs/2503.16252

【第276期】(中文)Scale-wise Distillation
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。本期开启中文播客今天的主题是:Scale-wise Distillation of Diffusion ModelsSummary这篇研究介绍了 SWD(Scale-wise Distillation),一个用于扩散模型的逐尺度蒸馏框架,它利用下一尺度预测的思想来加速图像生成。传统扩散模型在高分辨率下计算成本高昂,而 SWD 允许模型在较低分辨率下启动生成,然后逐步提高样本分辨率,同时保持性能并显著降低计算量。作者通过分析潜在空间的频谱,论证了在高噪声水平下,模型可以在较低分辨率空间中有效工作。SWD 还引入了一种新颖的补丁损失,以确保与目标分布的更精细相似性,并在实验中展示了其在文本到图像生成任务中优于现有方法的效率和质量。原文链接:https://arxiv.org/abs/2503.16397

【第275期】InfiniteYou:身份保留图像生成
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:InfiniteYou: Flexible Photo Recrafting While Preserving Your IdentitySummary这项研究介绍了InfiniteYou (InfU),一个用于身份保留图像生成的新颖框架,它利用先进的扩散Transformer (DiT)技术来解决现有方法的不足。InfU的核心是InfuseNet,它通过残差连接将身份特征注入DiT基模型,从而提高身份相似性并保持生成能力。该框架还采用了多阶段训练策略,包括预训练和监督微调,使用合成的单人多样本(SPMS)数据,以改善文本-图像对齐、图像质量和美观性。此外,InfU被设计成即插即用,可以与现有插件和方法兼容,为更广泛的社区做出了贡献,并在身份相似性、文本-图像对齐和整体图像质量方面实现了最先进的性能。原文链接:https://arxiv.org/abs/2503.16418#####################彩蛋:明日起开启中文播客

【第274期】Vision-R1
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Vision-R1: Evolving Human-Free Alignment in Large Vision-Language Models via Vision-Guided Reinforcement LearningSummary本研究提出Vision-R1,这是一种旨在通过强化学习(RL)提高多模态大型语言模型(MLLMs)推理能力的方法。文章解决了现有MLLMs在复杂推理任务中表现不佳的问题,因为它们缺乏人类认知过程中的结构化推理步骤。Vision-R1通过利用现有MLLM和DeepSeek-R1构建高质量的多模态思维链(CoT)数据集进行冷启动初始化。为了解决优化挑战,研究者引入了渐进式思维抑制训练(PTST)策略,该策略在RL训练早期阶段抑制思维长度,并随着训练的进行逐渐放宽这些限制。实验结果表明,Vision-R1在数学推理基准测试中取得了显著的性能提升,其7B参数的模型表现可与参数量大于70B的最强MLLMs相媲美,展现出其强大的推理能力。原文链接:https://arxiv.org/abs/2503.18013

【第273期】Diffusion-4K:超高分辨率图像生成
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Diffusion-4K: Ultra-High-Resolution Image Synthesis with Latent Diffusion ModelsSummary本论文介绍了 Diffusion-4K,这是一个旨在直接生成超高分辨率图像的新框架,解决了现有模型通常局限于较低分辨率的挑战。它通过创建名为 Aesthetic-4K 的4K图像数据集来弥补公共数据集的不足,该数据集包含高质量图像和由 GPT-4o 生成的详细文本描述。此外,Diffusion-4K 引入了新的评估指标,如 GLCM Score 和压缩比,以更好地衡量图像的精细细节和纹理。该框架还提出了一种基于小波的微调方法,能够与现有的潜在扩散模型(如 SD3 和 Flux)兼容,以增强4K图像的细节表现,同时优化内存使用,从而在高质量图像合成和文本提示遵循方面展现出卓越性能。原文链接:https://arxiv.org/abs/2503.18352
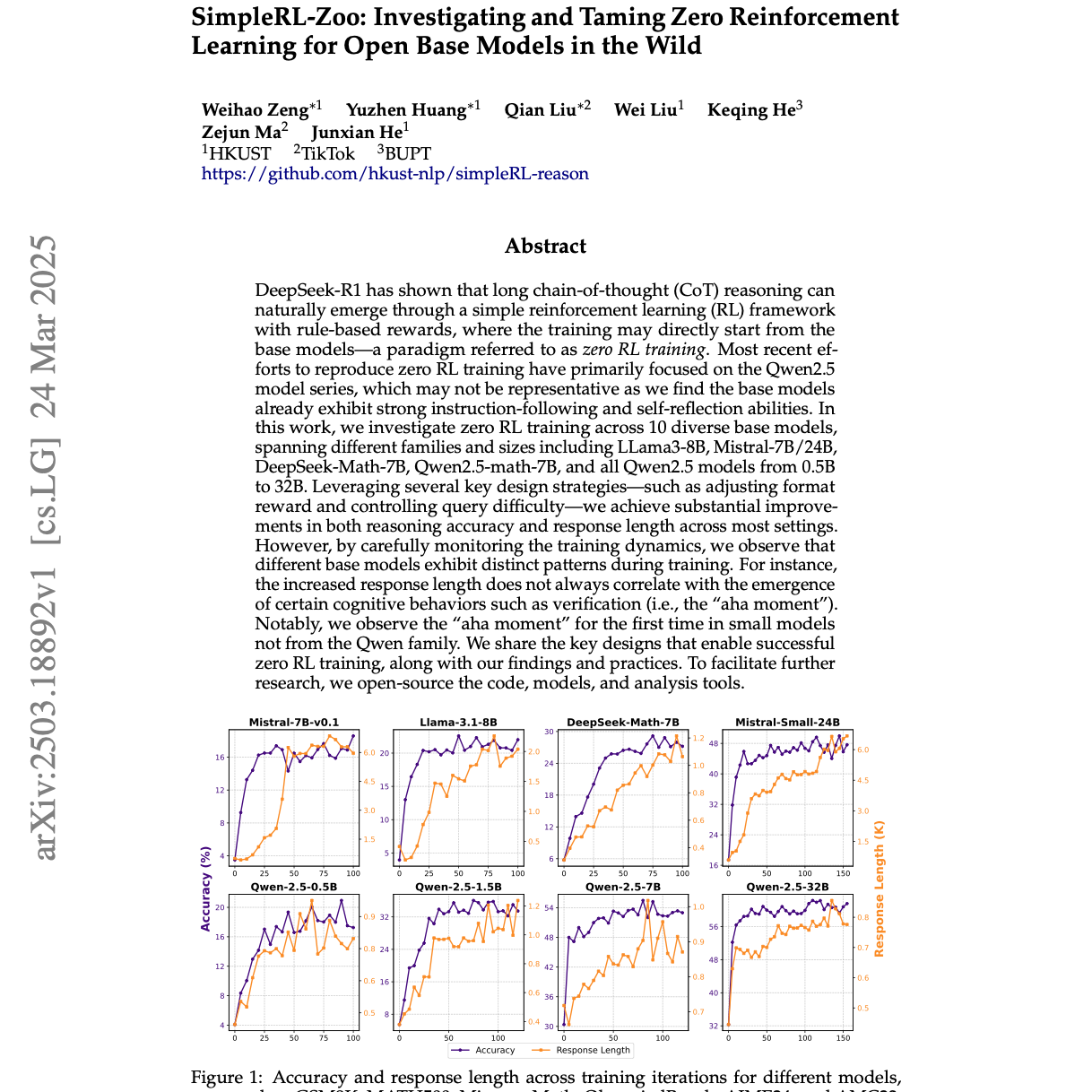
【第272期】SimpleRL-Zoo:Zero RL推理能力
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the WildSummary本研究探讨了零强化学习(RL)对不同基础模型(包括Llama3-8B、Mistral-7B/24B和Qwen系列模型)推理能力的影响。研究发现,通过调整奖励和控制查询难度等策略,RL训练能显著提高模型的推理准确性和响应长度。值得注意的是,该研究首次在非Qwen系列的小型模型中观察到“顿悟时刻”(aha moment),即模型认知行为(如验证和回溯)的显著提升。此外,文章还指出,严格的格式奖励会阻碍模型探索,而训练数据难度必须与模型能力匹配。研究还发现,传统的有监督微调(SFT)作为RL的冷启动会限制高级推理能力的出现,表明零RL训练是提升模型性能的更优途径。原文链接:https://arxiv.org/abs/2503.18892

【第271期】FFN Fusion
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:FFN Fusion: Rethinking Sequential Computation in Large Language ModelsSummary该论文介绍了一种名为FFN Fusion的新型优化技术,旨在提高大型语言模型的推理效率。通过识别并整合变压器架构中连续的馈送网络(FFN)层,该方法将顺序计算转化为并行操作,从而显著减少推理延迟和每令牌成本。研究人员利用这种技术开发了Ultra-253B-Base模型,该模型在保持或超越原始大型模型性能的同时,实现了显著的速度提升和更低的内存占用。此外,该研究还探讨了不同模型层之间的依赖关系,为未来的模型架构设计和优化方向提供了新的见解,甚至表明整个变压器块也能在某些情况下并行化。原文链接:https://arxiv.org/abs/2503.18908

【第270期】Bottleneck Sampling
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Training-free Diffusion Acceleration with Bottleneck SamplingSummary该文件介绍了**“瓶颈采样”,这是一种用于加速扩散模型推理的无训练框架,而不会降低生成内容的质量。文章指出,由于自注意力的二次复杂度,图像和视频生成模型(如Diffusion Transformers,DiTs)的计算成本很高,尤其是在高分辨率下。为了解决这个问题,瓶颈采样采用了高-低-高去噪工作流程**:在初始和最终阶段以高分辨率进行处理以捕获细节,而在中间步骤则切换到低分辨率以提高效率。这种方法通过在分辨率转换点重新引入噪声并调整去噪时间步长来减轻伪影。实验结果表明,该方法在保持图像和视频生成质量的同时,分别将推理速度提高了3倍和2.5倍。原文链接:https://arxiv.org/abs/2503.18940

【第269期】Video-T1:Test-Time Scaling for Video Generation
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Video-T1: Test-Time Scaling for Video GenerationSummary这篇研究论文介绍了一种名为Video-T1的新框架,用于视频生成中的测试时间缩放(TTS)。该框架将视频生成重新解释为一个搜索问题,旨在从高斯噪声空间中找到更好的视频轨迹,从而提高生成质量。论文探讨了两种搜索算法:随机线性搜索和更高效的帧树(ToF)搜索,后者通过自回归方式动态扩展和修剪视频分支。研究表明,在推理时增加计算量可以显著提升视频生成质量和与文本提示的一致性,尤其是ToF搜索能够以更低的计算成本达到高质量结果,为视频生成领域的推理时间优化提供了新的方向。原文链接:https://arxiv.org/abs/2503.18942
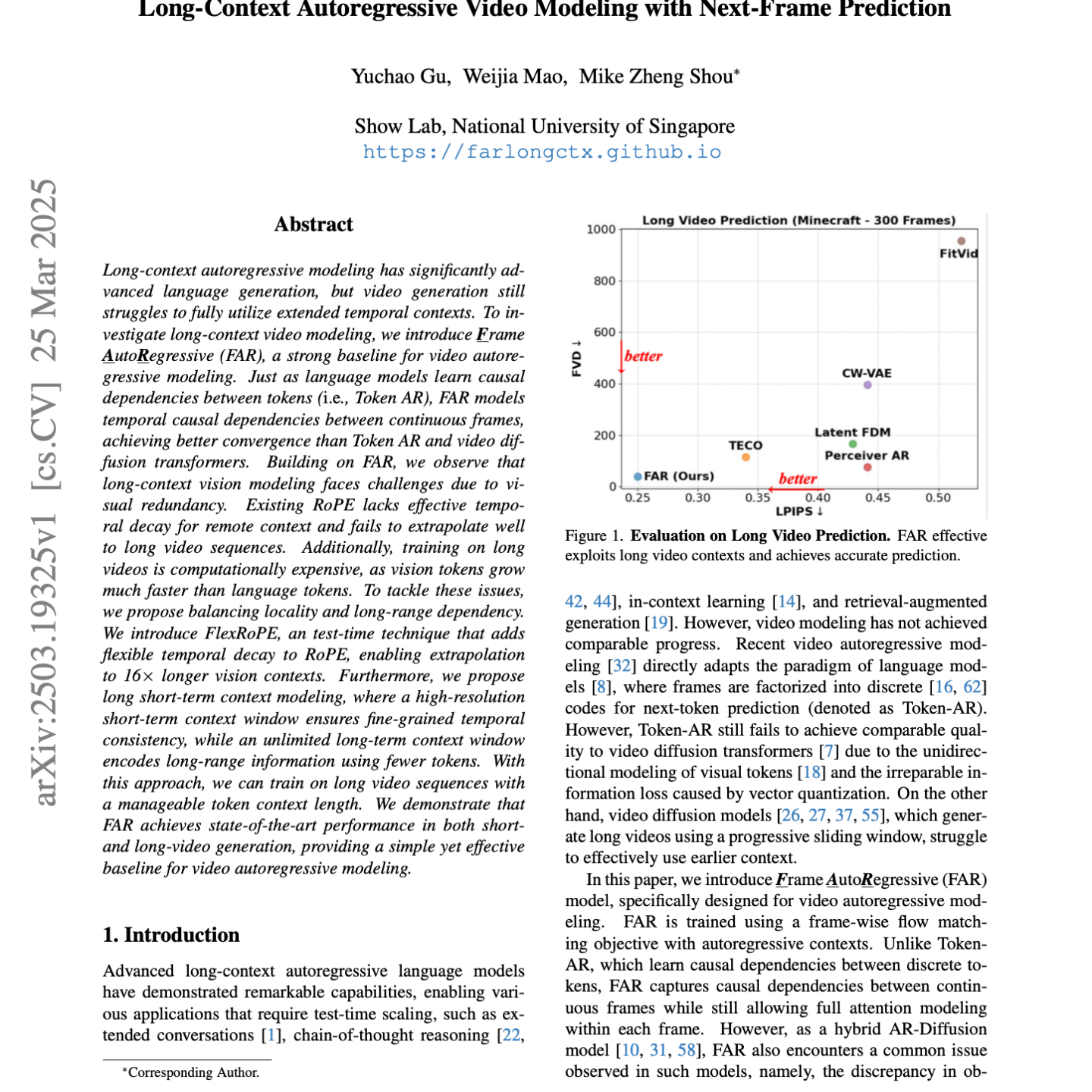
【第268期】FAR:Next-Frame Prediction
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Long-Context Autoregressive Video Modeling with Next-Frame PredictionSummary本研究引入了帧自回归(FAR)模型,这是一种用于视频生成的强大基线,它通过建模连续帧之间的时间因果关系来改进现有方法。FAR 模型解决了训练和推理之间存在的上下文观察差异,并提出了随机干净上下文的训练策略以提高效率。为了应对长视频建模的挑战,作者们引入了FlexRoPE来增强测试时间的时间外推能力,并采用了长短期上下文建模来有效处理视觉冗余并高效训练长视频序列。实验结果表明,FAR 在短视频和长视频生成方面都达到了最先进的性能。原文链接:https://arxiv.org/abs/2503.19325

【第267期】RoboMIND:用于机器人操作的大型、多主体、高质量数据集
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:RoboMIND: Benchmark on Multi-embodiment Intelligence Normative Data for Robot ManipulationSummary名为RoboMIND的来源文档介绍了一个用于机器人操作的大型、多主体、高质量数据集,旨在推动通用机器人模型的开发。该数据集包含107k条演示轨迹,涵盖479项不同任务和96种对象类别,并利用人类遥操作以标准化方式收集数据,确保一致性和可靠性。RoboMIND不仅包括成功的操作轨迹,还收录了5k条现实世界中的失败案例及其详细原因,以及一个数字孪生模拟环境以促进低成本数据收集和评估。通过对各种模仿学习方法和视觉-语言-动作(VLA)模型进行广泛实验,RoboMIND被证明能够显著提高机器人操作的成功率和泛化能力,使其成为机器人学习领域的重要基准和资源。原文链接:https://arxiv.org/abs/2412.13877

【第266期】OLMo 2
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:2 OLMo 2 FuriousSummary这篇文档介绍了 OLMo 2,一种由 AllenAI 开发的开源语言模型系列。它详细阐述了 OLMo 2 相较于其前代模型的改进,包括架构增强、训练稳定性提升和数据混合策略的优化,特别是引入了 Dolmino Mix 1124 以提高数学能力。文档还讨论了后训练流程,例如使用 RLVR 进行指令微调,并强调了基础设施作为研究催化剂的重要性。OLMo 2 在性能上与 Llama 3.1 和 Qwen 2.5 等其他模型竞争,但提供了完全透明的训练数据和代码,旨在促进开源语言模型生态系统的发展。原文链接:https://arxiv.org/abs/2501.00656

【第265期】ARQ: for LLM Instruction Following
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Attentive Reasoning Queries: A Systematic Method for Optimizing Instruction-Following in Large Language ModelsSummary这些资料介绍了一种名为注意力推理查询 (ARQs) 的新颖结构化推理方法,旨在显著提升大型语言模型 (LLMs) 在遵循指令方面的表现。通过引导 LLMs 遵循特定领域的推理蓝图和目标查询,ARQs 解决了 LLMs 在多轮对话中难以持续遵守复杂指令的常见问题。该研究在 Parlant 框架内对 ARQs 进行了评估,结果显示其在客服场景中表现优于传统的思维链 (CoT) 和直接响应生成方法,特别是在指导方针重新应用和防止幻觉等关键挑战方面。尽管 ARQs 在某些模块中可能消耗更多计算资源,但其在结构化任务中展现出更高的效率和准确性,这表明精心设计的 ARQs 能够有效控制 LLMs 的信息处理和决策制定过程。原文链接:https://arxiv.org/abs/2503.03669

【第264期】Block Diffusion Language Models
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Block Diffusion: Interpolating Between Autoregressive and Diffusion Language ModelsSummary这些来源介绍了一种名为块扩散语言模型(BD3-LMs)的新型人工智能模型,它结合了自回归模型和扩散模型的优点。传统扩散模型在生成任意长度文本和推理效率方面存在局限性,而自回归模型则受限于顺序生成。BD3-LMs通过将文本分成块并在每个块内使用扩散模型进行并行生成来解决这些问题,同时利用键值缓存提高效率。研究表明,与现有扩散模型相比,BD3-LMs在语言建模基准测试中达到了最先进的性能,并且能够生成更长、质量更高的序列,部分得益于优化的训练算法和低方差的噪声调度。原文链接:https://arxiv.org/abs/2503.09573

【第263期】SEARCH-R1: RL for Reasoning and Search in LLMs
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement LearningSummary这篇研究文章提出了一种名为 SEARCH-R1 的新型框架,它利用强化学习让大型语言模型 (LLMs) 学习如何通过 多轮搜索查询 与搜索引擎进行自主交互。 区别于依赖固定检索或大量标注数据的现有方法,SEARCH-R1 使 LLMs 能够在 逐步推理 过程中动态生成搜索请求并利用实时检索到的信息。 通过在强化学习训练中引入检索到的词元屏蔽和基于结果的奖励函数,SEARCH-R1 在多个问答数据集上显著提高了性能,验证了其在结合推理与外部知识获取方面的有效性。原文链接:https://arxiv.org/abs/2503.09516

【第262期】PLAN-AND-ACT:Long-Horizon Tasks Plan Agents
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Plan-and-Act: Improving Planning of Agents for Long-Horizon TasksSummary这篇文章介绍了一个名为 PLAN-AND-ACT 的新框架,旨在提升大型语言模型 (LLMs) 在执行复杂、多步长任务时的表现。该框架通过将任务分解为 PLANNER(负责生成高层计划)和 EXECUTOR(负责将计划转化为具体操作)两个独立部分来实现这一目标。文章强调了生成准确计划的挑战,并提出了一个通过 合成数据生成 来训练 PLANNER 的可扩展方法。PLAN-AND-ACT 在网页导航任务上取得了最先进的性能,尤其在引入 动态重新规划 后效果显著,证明了分离规划与执行以及高质量规划数据的重要性。原文链接:https://arxiv.org/abs/2503.09572

【第261期】LMM-R1: Reasoning Enhancement for LMM
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:LMM-R1: Empowering 3B LMMs with Strong Reasoning Abilities Through Two-Stage Rule-Based RLSummary本研究提出了一个名为 LMM-R1 的框架,旨在通过一种新颖的两阶段规则奖励强化学习方法提升大型多模态模型 (LMM) 的推理能力,即使是参数量有限的小型模型也不例外。 第一阶段侧重于利用大量的文本数据加强基础推理能力,而无需昂贵的多模态数据收集。 第二阶段则将这些提升后的推理能力泛化到各种多模态任务和代理相关应用中,通过在相关领域的持续训练来实现。 结果表明,文本基础推理能力的增强能有效地推广到多模态领域,为训练推理能力强的 LMMs 提供了一种数据高效的范式。原文链接:https://arxiv.org/abs/2503.07536
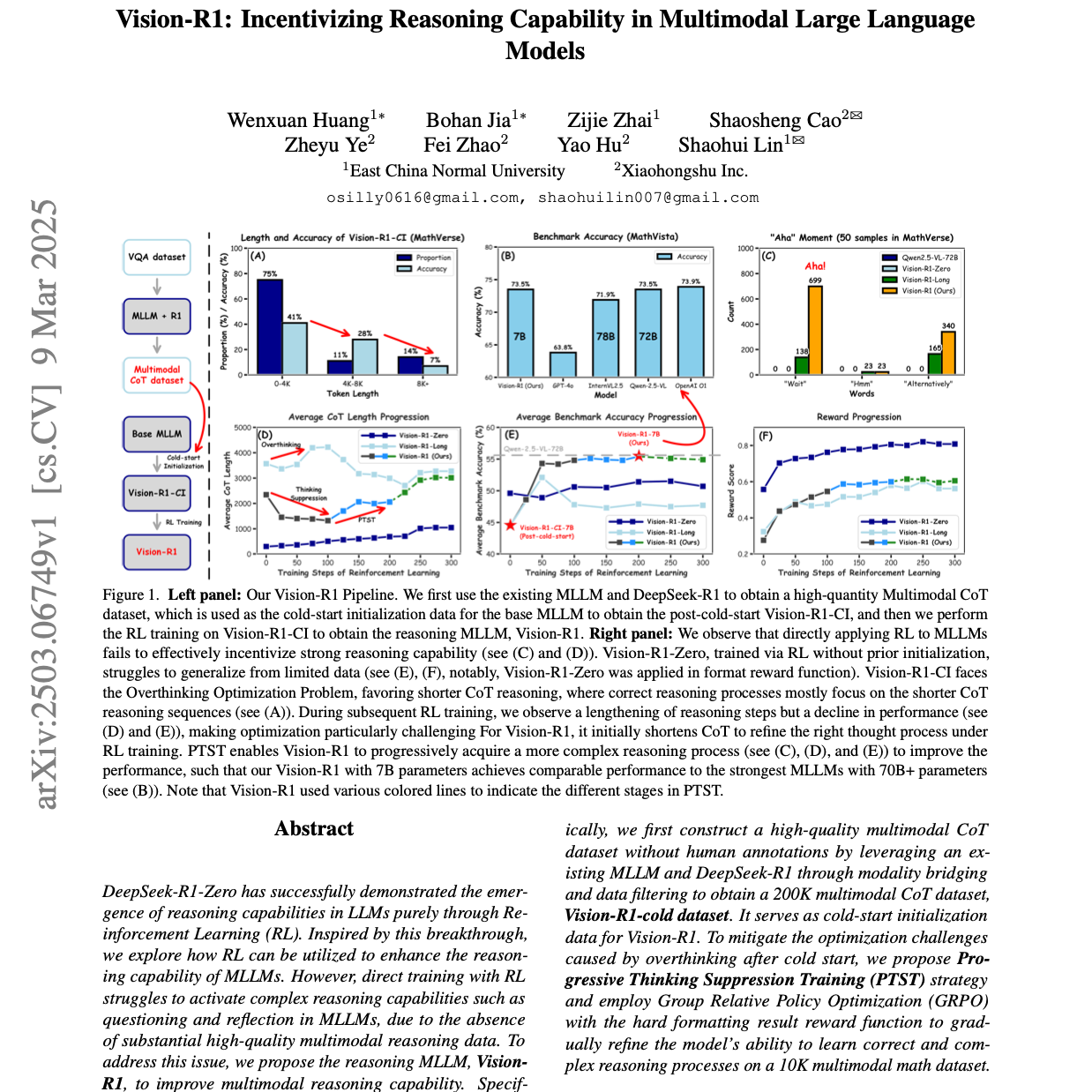
【第260期】Vision-R1: Reasoning in Multimodal LLM
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language ModelsSummary这篇研究探讨了如何通过强化学习(RL)增强多模态大型语言模型(MLLM)的推理能力,并提出了 Vision-R1 模型。研究首先构建了一个 高质量、无需人工标注 的多模态思维链数据集,用于对基础 MLLM 进行 冷启动初始化,从而初步学习类人推理模式。为了克服初始化后出现的“过度思考”优化难题,研究引入了 渐进式思维抑制训练(PTST) 策略,结合 GRPO 算法和硬格式化结果奖励函数,引导模型逐步完善推理过程并延长思考链,最终显著提升了 Vision-R1 在数学推理任务上的表现。尽管 Vision-R1-7B 参数量较小,但在多项基准测试中取得了与大型模型相当的性能。原文链接:https://arxiv.org/abs/2503.06749

【第259期】Agentic Reward Modeling
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Agentic Reward Modeling: Integrating Human Preferences with Verifiable Correctness Signals for Reliable Reward SystemsSummary这项研究提出了“代理奖励建模”,一种结合了传统基于人类偏好奖励模型和可验证正确性信号的新型奖励系统。研究人员实现了一个名为 REWARDAGENT 的奖励代理,它集成了对事实性和指令遵循的可验证信号,以提供更可靠的奖励。通过在现有奖励模型基准、推理时最佳搜索以及构建训练偏好对方面的实验,结果表明 REWARDAGENT 显著优于仅依赖人类偏好的奖励模型。该框架通过纳入多维正确性信号来增强可靠性,并允许灵活集成不同的验证代理。 REWARDAGENT 的有效性在下游任务中得到了验证,并显示出其在提高语言模型性能方面的潜力,尤其是在需要事实准确性和严格遵循指令的场景中。这项工作鼓励进一步探索其他可验证的正确性信号,以开发更可靠的奖励系统,用于大型语言模型的开发和对齐。原文链接:https://arxiv.org/abs/2502.19328

【第258期】Forecasting Rare Language Model Behaviors
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Forecasting Rare Language Model BehaviorsSummary这些资料提出了预测大型语言模型在大规模部署时可能出现的罕见不良行为的方法。它们解释说,标准的评估方法测试查询数量远少于实际部署中的查询数量,因此可能无法捕捉到仅在数十亿次查询中才会显现的风险。通过分析每个查询引发特定行为的**“引发表概率”,研究人员发现,这些概率的最大值随着查询数量的增加呈可预测的比例变化**。这项研究展示了这种预测方法能够预测各种不良行为的出现,包括提供危险信息或采取追求权力行动,并且预测范围可以跨越高达三个数量级的查询量。最终,这项工作旨在帮助模型开发者在这些罕见故障在现实世界中发生之前就主动预见并修复它们。原文链接:https://arxiv.org/abs/2502.16797
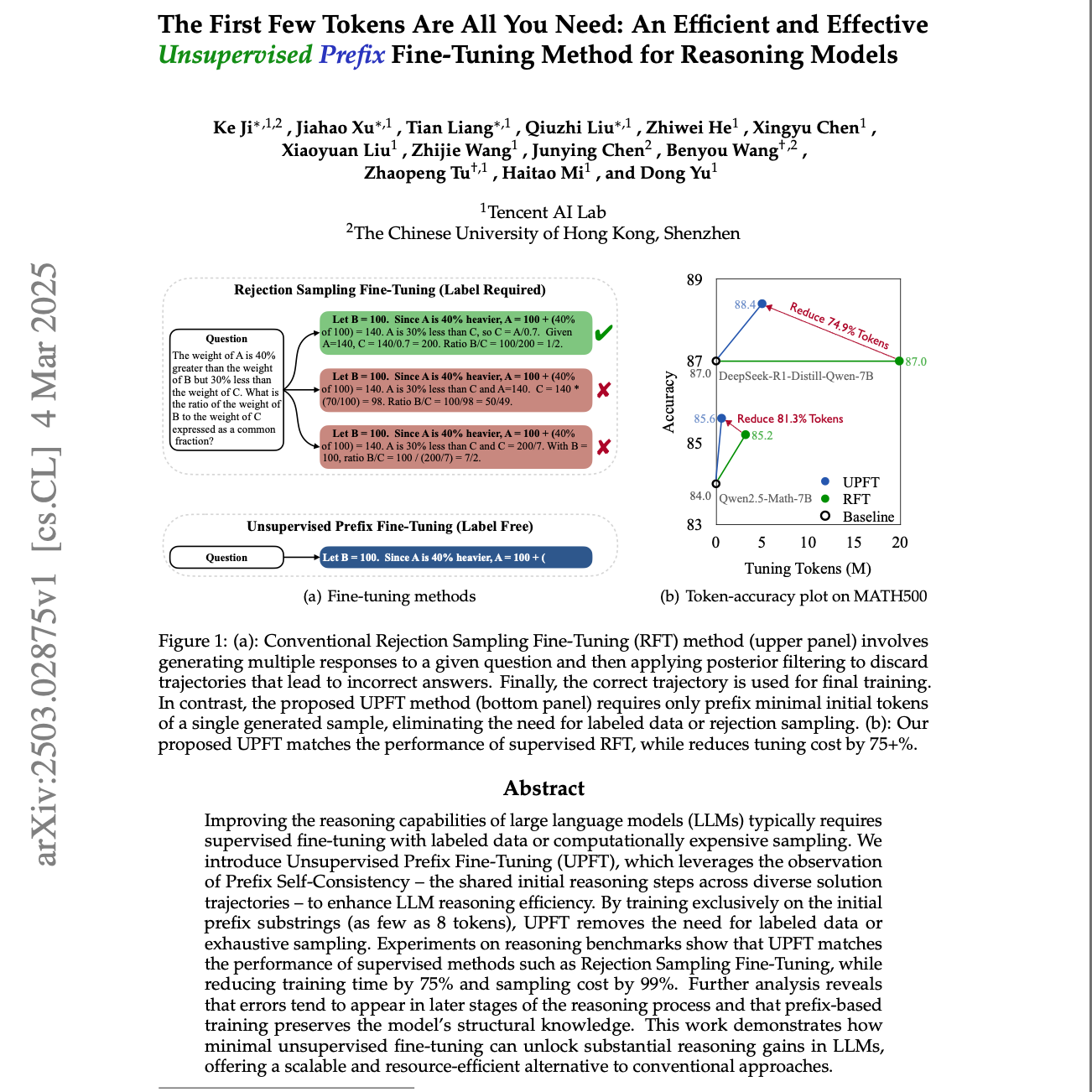
【第257期】UPFT:The First Few Tokens Are All You Need
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:The First Few Tokens Are All You Need: An Efficient and Effective Unsupervised Prefix Fine-Tuning Method for Reasoning ModelsSummary本文件介绍了一种名为无监督前缀微调 (UPFT) 的新方法,旨在提高大型语言模型的推理能力。与需要大量标记数据或计算成本高昂的拒绝采样微调 (RFT) 不同,UPFT 仅利用模型生成响应的初始标记进行训练。文章的核心观点是“前缀自洽性”,即不同解法的初步推理步骤通常是一致的,即使后续步骤可能有所不同。实验结果表明,UPFT 在推理性能上与监督方法 RFT 持平,但显着减少了训练时间和采样成本,证明了其在无需外部监督的情况下提高模型推理能力的有效性和高效性。该方法通过专注于早期推理步骤来优化训练过程,同时通过少量全标记微调来保持模型的整体结构知识。最终,UPFT 提供了一种可扩展且资源节约的替代方案,用于增强大型语言模型的复杂推理技能。原文链接:https://arxiv.org/abs/2503.02875

【第256期】LightThinker: Thinking Step-by-Step Compression
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:LightThinker: Thinking Step-by-Step CompressionSummary这些资源介绍了 LightThinker,这是一种通过在推理过程中动态压缩中间思考步骤来提高大型语言模型 (LLM) 效率的新方法。LightThinker 借鉴人类认知过程,将冗长的思考链压缩成紧凑的表示,从而显著减少上下文窗口中存储的 token 数量,降低内存开销和计算成本。它通过训练模型在何时以及如何执行压缩来实现这一点,并引入了 Dependency (Dep) 指标来量化压缩程度。研究结果表明,与现有方法相比,LightThinker 在保持竞争性准确性的同时,有效减少了峰值内存使用和推理时间。原文链接:https://arxiv.org/abs/2502.15589

【第255期】用FFT替代传统自注意力机制
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:SPECTRE: An FFT-Based Efficient Drop-In Replacement to Self-Attention for Long ContextsSummary这个文本介绍了FFTNet,一种利用快速傅里叶变换(FFT)来替代传统自注意力机制的新型神经网络架构。 传统自注意力机制在处理长序列时计算复杂度高,而FFTNet通过将输入转换到频域,以O(n log n)的时间复杂度实现高效的全局信息混合。该方法的核心创新在于引入了自适应频谱滤波器,并结合了可选的局部窗口处理以及频率域和时域的非线性处理。实验结果表明,FFTNet在处理长序列和图像分类任务上表现出色,验证了其在保持计算效率的同时提升模型表达能力。原文链接:https://arxiv.org/abs/2502.18394

【第254期】Thinking Faster by Drafting Less: Chain of Draft
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Chain of Draft: Thinking Faster by Writing LessSummary本来源介绍了 Chain of Draft (CoD),这是一种用于大型语言模型(LLMs)的新颖提示策略。与强调详细逐步推理的现有 Chain-of-Thought (CoT) 方法不同,CoD 鼓励 LLMs 生成简洁、信息密集型的中间草稿。研究表明,通过减少冗长,CoD 在保持或提高准确性的同时,显着降低了成本和延迟。这项技术模仿了人类解决问题时记下简洁笔记的方式,使其成为 LLMs 在实际应用中更高效、更经济的推理方法。文章通过在算术、常识和符号推理等任务上的实验结果来支持 CoD 的有效性。原文链接:https://arxiv.org/abs/2502.18600

【第253期】SECOND ME:AI-Native Memory Management
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:AI-native Memory 2.0: Second MeSummary这些来源描述了一种名为SECOND ME的AI系统,它旨在作为用户的智能、持久的外部记忆系统。通过利用大型语言模型 (LLMs),SECOND ME能够超越传统的存储解决方案,实现对用户特定知识的结构化组织、上下文推理和自适应检索。该系统充当用户与外部世界(包括其他AI)之间的动态中介,可以自主生成符合上下文的响应、预填充信息并简化交互。论文探讨了训练和评估SECOND ME的方法,强调了利用多样化数据源、Chain-of-Thought风格的数据合成以及直接偏好优化(DPO)来提高其性能。最终目标是创建一个能够与用户协同思考、共同进化并实时理解用户认知状态的AI,从而增强人与数字生态系统的互动效率和智能化水平。原文链接:https://arxiv.org/abs/2503.08102

【第252期】Inductive Moment Matching for Generative Modeling
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Inductive Moment MatchingSummary这篇研究提出了一种名为 归纳矩匹配(IMM) 的新型生成模型框架,旨在解决现有扩散模型和流匹配方法在推理速度和训练稳定性之间的权衡。与需要预训练模型的蒸馏技术不同,IMM 采用 单阶段训练过程,能够直接从头开始学习用于单步或少数步采样的模型。通过利用 自洽插值器 连接数据分布和先验分布,IMM 学习一种从任意中间时间点的分布到更接近数据分布时间点的分布的映射。核心思想是通过最小化模型在不同但相关时间点插值生成的分布之间的差异来 保证分布层面的收敛。这种方法通过 矩匹配 实现,被证明比一致性模型等单粒子方法更稳定,并在图像生成任务中取得了最先进的结果,同时显著提高了推理速度。原文链接:https://arxiv.org/abs/2503.07565

【第251期】YOLOE:Real-Time Seeing Anything with Open Prompts
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:YOLOE: Real-Time Seeing AnythingSummary这个文档介绍了一个名为YOLOE的新型实时目标检测和分割模型。YOLOE能够在一个高效的框架内处理文本、视觉和无提示等多种开放式提示机制,实现“实时感知一切”。为了实现这一目标,论文提出了**可重参数化区域-文本对齐(RepRTA)策略来优化文本提示处理,设计了语义激活视觉提示编码器(SAVPE)来高效编码视觉提示,并引入了惰性区域-提示对比(LRPC)**策略来在没有明确提示的情况下识别物体。实验结果表明,YOLOE在效率和零样本性能上优于现有方法,并且在下游任务中也表现出良好的可迁移性。原文链接:https://arxiv.org/abs/2503.07465

【第250期】EasyControl:效率和灵活性指导的条件图像生成
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:EasyControl: Adding Efficient and Flexible Control for Diffusion TransformerSummary这份技术论文介绍了EasyControl,一个旨在提高扩散变换器(DiT)架构在条件图像生成方面的效率和灵活性的新框架。研究人员通过引入一个轻量级的条件注入LoRA模块来处理条件信号,确保与现有模型兼容并支持多条件泛化。此外,位置感知训练范式允许模型生成具有任意分辨率和长宽比的图像,同时优化计算。最后,结合因果注意力机制和KV缓存技术显著降低了推理延迟,使得EasyControl在各种图像生成任务中展现出卓越的性能。原文链接:https://arxiv.org/abs/2503.07027

【第249期】R1-Searcher: RL for Enhanced LLM Search Capabilities
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement LearningSummary这项研究介绍了一个名为 R1-Searcher 的新型框架,旨在通过强化学习提升大型语言模型(LLMs)的检索增强生成(RAG)能力。该框架采用两阶段的成果监督强化学习方法,使 LLMs 能够自主调用外部搜索系统获取知识,从而提高处理知识密集型和时效性问题的准确性,减少幻觉。不同于依赖过程奖励或蒸馏的方法,R1-Searcher 完全依赖强化学习进行训练,通过探索学习有效利用检索。实验结果表明,该方法在多跳问答任务上显著优于现有的 RAG 技术,甚至超越了一些闭源模型。此外,研究还深入分析了训练方法、数据选择和奖励设计对模型性能的影响,并展示了模型在未见过的在线搜索场景中的泛化能力。原文链接:https://arxiv.org/abs/2503.05592

【第248期】VisualThinker-R1-Zero: Multimodal Reasoning via RL
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:R1-Zero's "Aha Moment" in Visual Reasoning on a 2B Non-SFT ModelSummary本研究报告成功复制了 DeepSeek-R1 模型中利用强化学习实现自主推理的显著特征,即所谓的“顿悟时刻”和响应长度的增加,这次是在一个较小的多模态模型上实现。通过直接在非 SFT (监督微调) Qwen2-VL-2B 模型上应用强化学习,研究人员观察到模型在视觉推理任务中展现出自我反思和更长的响应,从而显著提高了性能。报告还探讨了在经过指令微调的模型上应用强化学习所面临的挑战,发现这往往会导致肤浅的推理模式。研究人员开源了他们的代码,以促进对多模态推理未来研究。原文链接:https://arxiv.org/abs/2503.05132
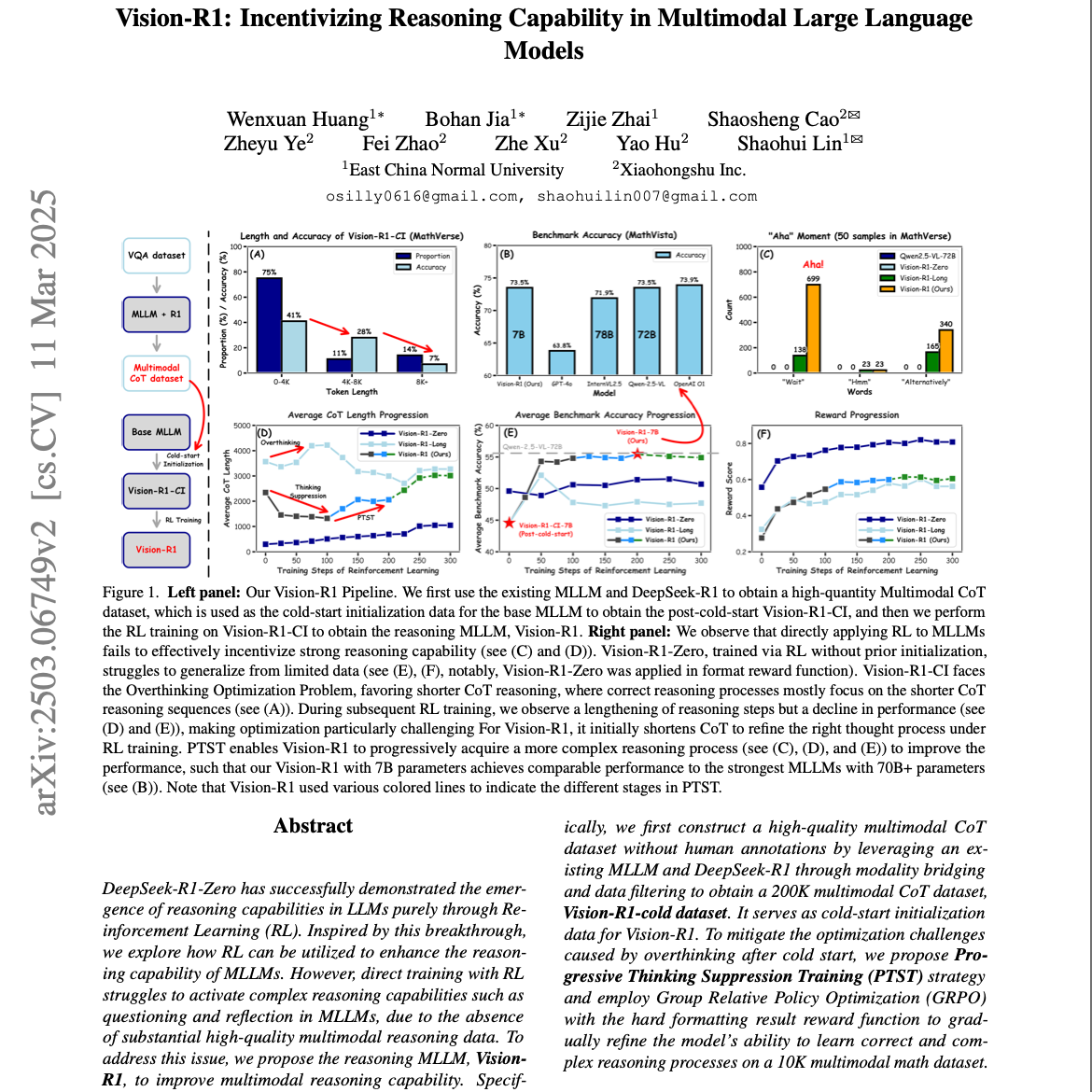
【第247期】Vision-R1:推理视觉大模型
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。进群添加小助手微信:seventy3_podcast备注:小宇宙今天的主题是:Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language ModelsSummary本研究介绍 Vision-R1,这是一种多模态大型语言模型 (MLLM),旨在增强其推理能力,尤其是解决数学问题。该方法通过结合冷启动初始化和强化学习 (RL) 来实现这一目标。具体来说,首先构建一个高质量的多模态思维链 (CoT) 数据集,然后利用一种名为渐进思维抑制训练 (PTST) 的 RL 策略,通过分阶段放宽对推理长度的限制来克服过度思考问题。实验结果表明,Vision-R1 在多模态数学推理基准上表现出色,即使只有 7B 参数,也能达到与 70B+ 参数的强大 MLLM 相媲美的性能。原文链接:https://arxiv.org/abs/2503.06749

【第246期】用LLM做Encoder,进行机器翻译
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。进群添加小助手微信:seventy3_podcast备注:小宇宙今天的主题是:Beyond Decoder-only: Large Language Models Can be Good Encoders for Machine TranslationSummary这项研究探索了一种结合大型语言模型(LLMs)和神经机器翻译(NMT)的方法,旨在创建一个高效、易于优化且具有通用性的翻译系统。研究人员提出了一种名为 LaMaTE 的模型,该模型利用 LLM 作为强大的编码器,并将其与轻量级的 NMT 解码器配对。为了促进 LLM 编码器与 NMT 解码器的更好协作,研究引入了一种适配器设计,并采用了一种两阶段训练策略。此外,研究还构建了一个新的综合机器翻译基准数据集 ComMT,用于评估模型在多种翻译相关任务上的泛化能力。结果表明,LaMaTE 在翻译质量上与现有方法相当或更优,同时显著提高了推理速度并减少了内存占用,并展现出强大的任务泛化能力。原文链接:https://arxiv.org/abs/2503.06594

【第245期】固定文本长度做RAG
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。进群添加小助手微信:seventy3_podcast备注:小宇宙今天的主题是:More Documents, Same Length: Isolating the Challenge of Multiple Documents in RAGSummary这份研究探究了在检索增强生成(RAG)任务中,大型语言模型(LLM)处理多文档输入的挑战,尤其是在保持总上下文长度不变的情况下。 研究人员创建了特殊的数据集,通过控制文档数量但保持上下文长度固定,评估了不同LLM的表现。 他们的主要发现是,增加文档数量会显著降低LLM的性能, 这表明处理多个文档是一个独立于长上下文处理的挑战。 这项工作强调了在构建RAG系统时,需要权衡检索到的文档数量,并建议未来研究应专注于改进LLM处理多文档信息的能力。原文链接:https://arxiv.org/abs/2503.04388

【第244期】TokenOCR:Token基本文本图像LLM
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。进群添加小助手微信:seventy3_podcast备注:小宇宙今天的主题是:A Token-level Text Image Foundation Model for Document UnderstandingSummary来源描述了一种新型文本图像基础模型,称为 TokenOCR,以及利用它构建的文档理解多模态大语言模型 TokenVL。研究人员通过创建一个大规模、细粒度的标记级图像文本数据集 TokenIT 来预训练 TokenOCR,该数据集包含 2000 万图像和 18 亿标记-掩码对。TokenOCR 在文本图像相关任务中表现出色,例如文本分割、文本检索和视觉问答。实验表明,TokenVL 在各种文档理解基准测试中取得了显著的性能提升,尤其是在 OCRBench 和常用的 VQA 任务上。原文链接:https://arxiv.org/abs/2503.02304

【第243期】AppAgentX:智能手机上的Agent
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。进群添加小助手微信:seventy3_podcast备注:小宇宙今天的主题是:AppAgentX: Evolving GUI Agents as Proficient Smartphone UsersSummary这些文字介绍了一款名为 AppAgentX 的新型 GUI 代理框架,旨在 提高 基于大型语言模型(LLM)的代理在 智能手机 上执行任务的 效率 和 准确性。该框架通过 记忆 代理的 操作历史 来实现 演化机制,将重复的低级操作抽象为高效的高级 快捷方式。实验结果表明,与现有方法相比,AppAgentX 在任务完成时间、所需步骤以及令牌消耗方面均有显著提升,特别是在处理复杂任务时表现出色。原文链接:https://arxiv.org/abs/2503.02268

【第242期】MPO:Meta Plan Optimization
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。进群添加小助手微信:seventy3_podcast备注:小宇宙今天的主题是:MPO: Boosting LLM Agents with Meta Plan OptimizationSummary本研究提出了 MPO(Meta Plan Optimization)框架,旨在提升大型语言模型(LLM)智能体的规划能力。 通过整合高级别的 元计划,MPO 提供了一种即插即用的方案,以有效改进智能体的表现。该框架利用智能体任务执行过程中的反馈,持续 优化元计划 的质量。在 ScienceWorld 和 ALFWorld 两个基准任务上的大量实验表明,MPO 框架显著优于现有基线方法,并能增强智能体在未见场景下的 泛化能力。此外,分析表明,MPO 生成的元计划提高了智能体的 任务完成效率 和 计划的质量。原文链接:https://arxiv.org/abs/2503.02682

【第241期】LLaVE:一种新型视觉模型
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。进群添加小助手微信:seventy3_podcast备注:小宇宙今天的主题是:LLaVE: Large Language and Vision Embedding Models with Hardness-Weighted Contrastive LearningSummary研究论文介绍了 LLaVE,一种新型大型语言和视觉嵌入模型,它通过一种被称为难度加权对比学习的创新框架来提升性能。研究人员发现,现有模型在区分相似但负向的图像-文本对时存在困难,为此 LLaVE 被提出,旨在通过动态调整学习权重来更好地处理这些“困难的负向样本”。该框架在多种任务和数据集上进行了评估,并在性能、可扩展性和跨任务泛化能力方面取得了最先进的结果,甚至在未训练的视频检索任务中也表现出色。原文链接:https://arxiv.org/abs/2503.04812

【第240期】Optimal Brain Apoptosis
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。进群添加小助手微信:seventy3_podcast备注:小宇宙今天的主题是:Optimal Brain ApoptosisSummary这篇研究文章提出了名为Optimal Brain Apoptosis (OBA) 的神经网络剪枝新方法,旨在提高卷积神经网络和 Transformer 等大型模型的计算效率并降低资源需求。与之前依赖近似方法的工作不同,OBA 直接计算 Hessian-向量积 来更精确地评估参数的重要性。通过分析网络层之间的连接性(串行和并行),该方法高效地计算了每个参数的二阶泰勒展开。作者们在多个数据集和模型上验证了 OBA 的有效性,表明其在结构化和非结构化剪枝任务上均优于现有技术,尤其是在高稀疏度下。原文链接:https://arxiv.org/abs/2502.17941

【第239期】SoS1:O1和R1模型可以解决Hilbert第17问题难度相当大问题
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。进群添加小助手微信:seventy3_podcast备注:小宇宙今天的主题是:SoS1: O1 and R1-Like Reasoning LLMs are Sum-of-Square SolversSummary文本讨论了大型语言模型(LLMs)在解决复杂的数学问题方面的能力,特别是一个称为非负多项式判定的问题,该问题与Hilbert第17问题密切相关且在计算上难以解决。研究人员创建了一个名为SoS-1K的新数据集,包含约1000个多项式和详细的推理指南,以评估LLMs在该任务上的表现。他们发现,尽管没有指导的LLMs表现不佳,但高质量的推理指令可以显著提高准确率,甚至一个经过微调的7B模型在准确率上超越了更大的模型。研究表明,通过适当的指导,LLMs有望解决NP难问题并推动数学研究的边界。原文链接:https://arxiv.org/abs/2502.20545
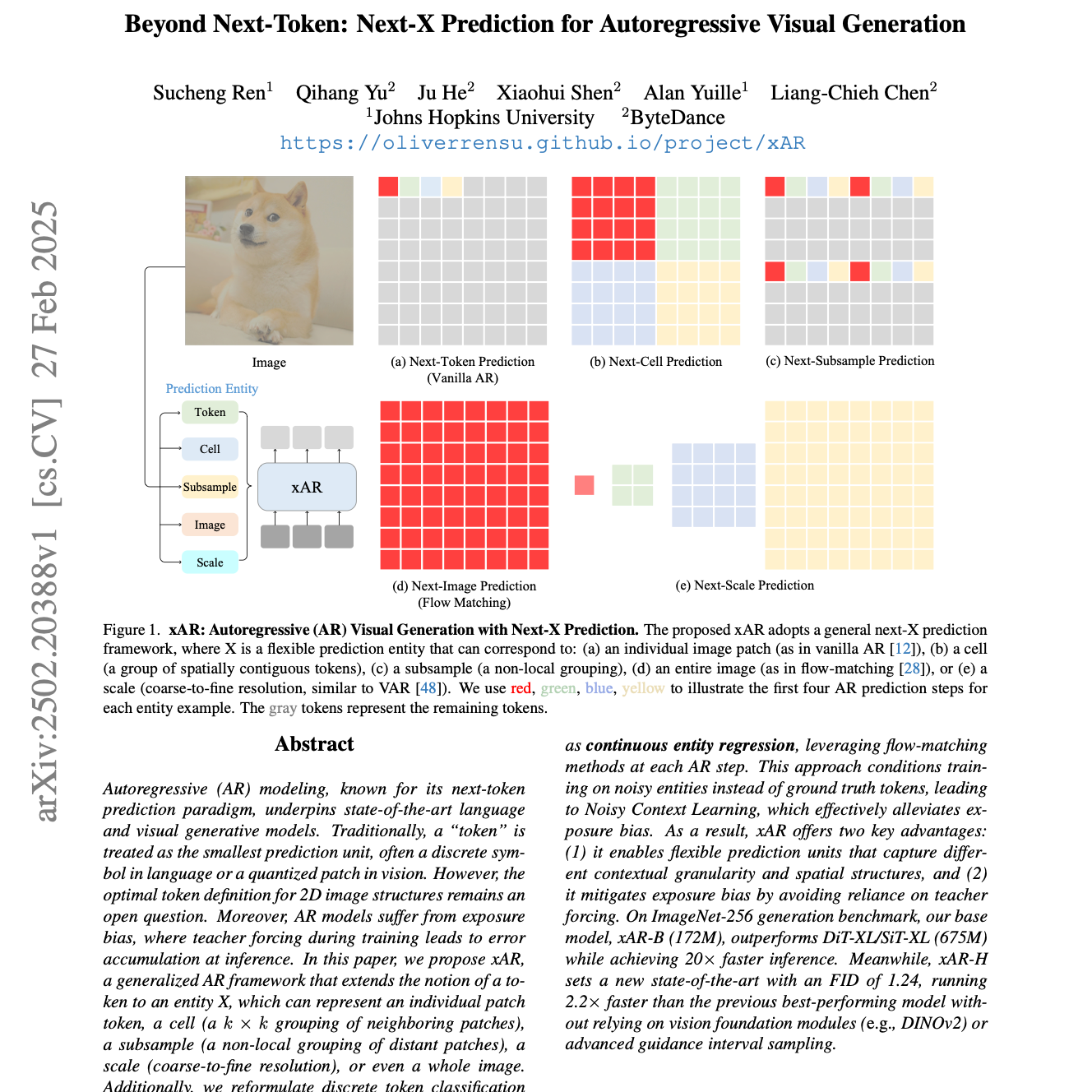
【第238期】xAR:Next-X Prediction
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。进群添加小助手微信:seventy3_podcast备注:小宇宙今天的主题是:Beyond Next-Token: Next-X Prediction for Autoregressive Visual GenerationSummary这项研究提出了 xAR,这是一种用于自回归视觉生成的新框架,旨在超越传统的基于 “下一词元” 预测的方法。通过将 “词元” 的概念扩展到更灵活的 “实体 X”,例如 图像块的局部群组(单元格)、非局部群组(子采样) 或 甚至整个图像,xAR 可以捕获不同的上下文粒度和空间结构。该模型不使用教师强制,而是通过 噪声上下文学习(一种利用 流匹配 进行连续实体回归的训练方法)来解决累积误差问题。xAR 在 ImageNet 基准测试中取得了最先进的性能,其 下一单元格预测 设计和 噪声上下文学习 方法展现了其在生成高质量图像方面的有效性和速度。原文链接:https://arxiv.org/abs/2502.20388