
Seventy3
642 episodes — Page 7 of 13

【第337期】(中文)大语言模型推理的陷阱
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:When Thinking Fails: The Pitfalls of Reasoning for Instruction-Following in LLMsSummary这篇研究探讨了大型语言模型(LLMs)中一个令人惊讶的现象:显式推理,例如通过思维链(CoT)提示,反而会降低模型遵循指令的准确性。作者在两个不同的基准测试(IFEval和ComplexBench)上评估了15个模型,结果一致显示性能下降。通过案例研究和基于注意力的分析,研究人员发现推理有时会通过分散模型对指令关键部分的注意力来损害性能,尽管它在格式或词汇精度方面可能有所帮助。为了解决这个问题,研究提出了四种缓解策略,其中分类器选择性推理被证明能最有效地恢复丢失的性能。这项工作是首次系统地揭示了推理在指令遵循中可能导致的失败,并提供了实用的缓解方法。原文链接:https://arxiv.org/abs/2505.11423

【第336期】(中文)视觉规划:只用图像思考
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Visual Planning: Let’s Think Only with ImagesSummary本研究引入了一种名为“视觉规划”的新范式,旨在通过纯粹的视觉表示来解决推理任务,而无需文本中介。它挑战了大型语言模型(LLMs)和多模态大型语言模型(MLLMs)中基于文本的传统推理方法,特别是在处理空间和几何信息时。作者提出了一种名为通过强化学习进行视觉规划(VPRL)的两阶段框架,利用强化学习来训练大型视觉模型(LVMs),使其能够生成逐步的图像序列来表示规划过程,模拟人类的视觉思考方式。通过在FROZENLAKE、MAZE和MINIBEHAVIOR等视觉导航任务上的实验,该研究证明了视觉规划在性能上显著优于基于语言的推理方法,并展现出更强的泛化能力。最终,这项工作强调了纯粹的视觉推理作为文本推理的有效替代方案,为开发更直观、灵活的AI推理系统开辟了新的途径。原文链接:https://arxiv.org/abs/2505.11409

【第335期】(中文)AI Agents与Agentic AI:概念、应用与挑战
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:AI Agents vs. Agentic AI: A Conceptual Taxonomy, Applications and ChallengesSummary该研究概述了人工智能代理(AI Agents)和智能代理系统(Agentic AI)的演变,从早期的特定任务系统发展到现代的复杂协作框架。文章首先定义了AI Agents的核心特性,例如其自主性、任务特异性和反应性,并解释了大型语言模型(LLMs)如何推动它们的进步,使其能够进行工具增强的推理。随后,研究转向更高级的Agentic AI,强调了其多代理协作、高级规划和协调机制,这使得它们能够处理复杂的、多步骤的系统级目标。文章还探讨了这两种范式在实际应用中的区别,从客户支持到智能机器人协调,并指出了它们各自的挑战,如因果推理不足、协调瓶颈和可解释性问题。最后,该研究提出了潜在的解决方案,例如检索增强生成(RAG)、记忆架构和因果建模,旨在为未来可信赖和可扩展的智能系统设计提供指导。原文链接:https://arxiv.org/abs/2505.10468

【第334期】(中文)AlphaEvolve: 科学与算法发现编码智能体
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:AlphaEvolve: A coding agent for scientific and algorithmic discoverySummary本文档介绍了 AlphaEvolve,这是一种由 Google DeepMind 开发的进化式编码代理,旨在通过迭代修改和改进代码来解决复杂的科学和算法问题。AlphaEvolve 利用大型语言模型(LLMs)生成、批评和演化算法,并通过自动评估机制获取反馈。该系统已成功应用于多个领域,包括优化 Google 数据中心的调度算法、简化硬件加速器电路设计、加速自身 LLM 的训练,并发现了新颖的、可证明正确的数学和计算机科学算法,例如在56年后首次改进了 Strassen 矩阵乘法算法。AlphaEvolve 的核心优势在于其进化方法和使用最先进 LLM 处理复杂代码库的能力,使其在规模和通用性上超越了先前的自动化发现方法,尽管其主要限制在于需要可自动评估的问题。原文链接:https://arxiv.org/abs/2506.13131

【第333期】(中文)连续思想机器
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Continuous Thought MachinesSummary该文本介绍了**“连续思想机器(CTM)”,这是一种新颖的神经网络架构,旨在通过明确整合神经时间作为其核心功能元素来弥补人工智能和生物智能之间的差距。与传统神经网络不同,CTM利用神经元级别模型(NLMs)和神经同步来生成复杂的神经活动动态**,这些动态独立于输入数据而展开。该模型在各种任务中进行了评估,包括图像分类、2D迷宫导航、数字排序、奇偶校验计算和强化学习,以展示其形成内部世界模型、进行自适应计算和通过内部思考过程解决问题的能力。研究结果表明,CTM能够学习灵活的算法并展示出比传统循环网络(如LSTM)更强的泛化和可训练性,这归因于其受生物学启发的设计原则。原文链接:https://arxiv.org/abs/2505.05522

【第332期】(中文)OSUNIVERSE:多模态GUI导航AI基准
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:OSUniverse: Benchmark for Multimodal GUI-navigation AI AgentsSummary这篇论文介绍了 OSUniverse,这是一个用于评估多模态GUI导航AI代理的新基准。作者指出,尽管现有基准**(如WebShop、Mind2Web和OSWorld)在评估网络或桌面任务方面存在局限性**,OSUniverse旨在通过提供更复杂、多应用程序的任务集和可扩展的框架来克服这些不足。该基准将任务分为五个难度级别,并引入了一种准确率低于2%的自动化验证机制,以实现可扩展的评估。初步测试结果显示,即使是目前最先进的AI代理也难以在OSUniverse中取得高分,远低于人类表现,这表明GUI导航仍然是AI面临的一个重大挑战。原文链接:https://arxiv.org/abs/2505.03570

【第331期】(中文)CoT:大模型中的程序变量
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Chain-of-Thought Tokens are Computer Program VariablesSummary该研究探讨了思维链(CoT)在大型语言模型(LLMs)中解决复杂推理任务时的内部机制,特别关注其在多位乘法和动态规划等组合任务中的作用。研究人员提出,CoT令牌的功能类似于计算机程序中的变量,用于存储中间结果,这些结果对后续计算和最终答案具有因果关系。通过移除非结果令牌、将结果合并为潜在令牌以及干预CoT中的值等实验,该论文证实了CoT对于此类问题的必要性,并表明中间结果的存储形式相对不重要,但其值对模型输出有直接影响。研究还发现,LLMs在处理简单子问题时可能会形成“捷径”,且CoT令牌间的计算复杂度存在一个限制,超出该限制会导致模型性能下降。原文链接:https://arxiv.org/abs/2505.04955

【第330期】(中文)UniVLA: 通用机器人策略学习框架
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Learning to Act Anywhere with Task-centric Latent ActionsSummary这篇研究介绍了 UniVLA,一个用于机器人学习的统一 视觉-语言-动作 (VLA) 框架。该框架的核心创新在于以无监督的方式从视频中学习以任务为中心的潜在动作,使其能够利用来自不同机器人和视角的大量数据,而无需动作标签。通过在大规模视频数据上进行预训练,UniVLA 能够开发出一种跨机器人通用策略,只需最低成本的动作解码即可轻松部署到各种机器人上。研究强调,UniVLA 在多种操纵和导航任务中表现出色,显著优于现有方法,同时需要的计算资源和下游数据也更少,展示了其在可扩展和高效机器人策略学习方面的巨大潜力。原文链接:https://arxiv.org/abs/2505.06111
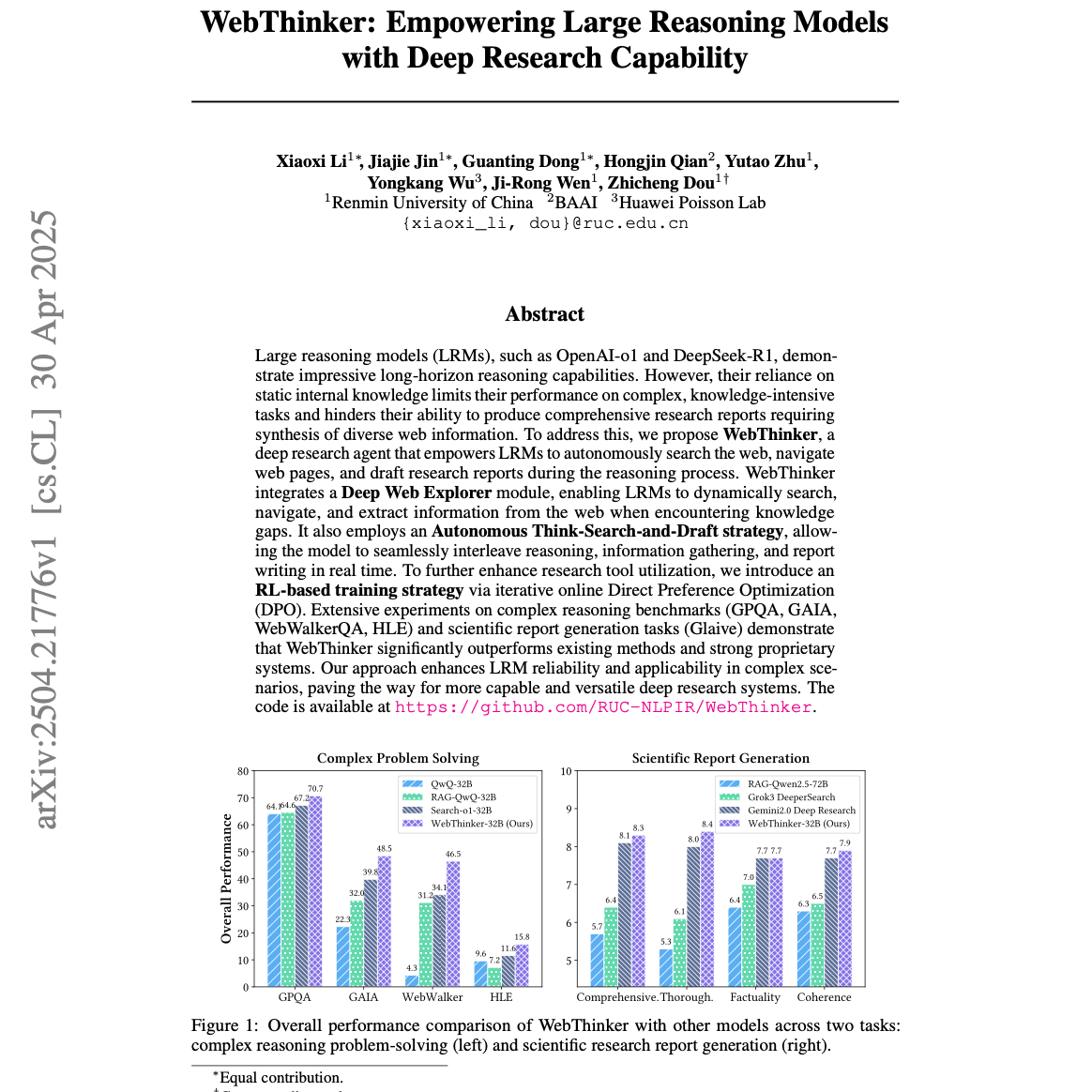
【第329期】(中文)WebThinker:深度研究大型推理模型
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:WebThinker: Empowering Large Reasoning Models with Deep Research CapabilitySummary该文档介绍了一种名为 WebThinker 的新型深度研究代理,旨在增强大型推理模型(LRMs)处理复杂、知识密集型任务的能力。WebThinker 通过 深度网络探索器 模块,使LRMs能够自主搜索网络、导航网页和提取信息,以弥补知识空白。它还采用 自主思考-搜索-起草策略,让模型在推理过程中无缝地穿插信息收集和报告撰写。此外,通过基于强化学习的训练策略,WebThinker 能够优化工具利用。实验结果表明,WebThinker 在复杂推理基准测试和科学报告生成任务上均优于现有方法和专有系统,预示着其在创建更强大、多功能的深度研究系统方面的巨大潜力。原文链接:https://arxiv.org/abs/2504.21776

【第328期】(中文)微调中的强化学习价值
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:All Roads Lead to Likelihood: The Value of Reinforcement Learning in Fine-TuningSummary本研究探讨了基础模型微调中强化学习(RL)的两阶段训练流程,该流程通常优于直接的离线最大似然估计(MLE)方法,尽管从信息论角度看RL并不能创造新信息。作者通过理论和实证分析,驳斥了几种关于RL价值的假设,并提出了一个新颖的解释。他们认为,在生成-验证存在差距的问题中,训练相对简单的奖励模型(验证器)更容易,而下游RL程序能够将策略(生成器)的搜索空间限制在对这些简单验证器最优的子集,从而带来了性能优势。实验结果支持这一假设,特别是在总结任务中,在线微调持续优于离线微调,除非生成与验证的复杂度差距被消除。原文链接:https://arxiv.org/abs/2503.01067

【第327期】(中文)研讨式RAG:医学问答的新范式
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Talk Before You Retrieve: Agent-Led Discussions for Better RAG in Medical QASummary这篇文章提出了一种名为 Discuss-RAG 的新型框架,旨在显著提高大型语言模型 (LLM) 在医学问答 (QA) 中的准确性。它通过模拟人类的推理过程来解决现有检索增强生成 (RAG) 系统中存在的局限性,这些局限性包括缺乏类人推理以及依赖次优的医学语料库。Discuss-RAG 引入了一个由医疗专家代理组成的团队,通过多轮讨论和迭代总结来改进信息检索,并通过一个决策代理对检索到的片段进行后期验证。在四个医学 QA 基准数据集上的实验结果表明,Discuss-RAG 始终优于现有方法,显著提高了回答准确性。原文链接:https://arxiv.org/abs/2504.21252

【第326期】(中文)动态RAG:大模型反馈驱动的动态重排序
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:DynamicRAG: Leveraging Outputs of Large Language Model as Feedback for Dynamic Reranking in Retrieval-Augmented GenerationSummaryDynamicRAG 提出了一种新颖的检索增强生成(RAG)框架,旨在通过一个动态重排序器优化大型语言模型(LLM)的性能。这个重排序器被建模为一个强化学习智能体,它根据LLM输出的质量反馈来调整检索文档的顺序和数量。该系统分两个阶段进行训练:首先通过行为克隆学习基础的重排序能力,然后通过与生成器互动进行强化学习优化。实验结果表明,DynamicRAG在多项知识密集型任务中表现出色,超越了现有方法,并且通过动态调整文档数量和高效的LLM调用,显著提高了效率和准确性。原文链接:https://arxiv.org/abs/2505.07233

【第325期】(中文)UCGM:统一连续生成模型
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Unified Continuous Generative ModelsSummary该论文介绍了一个名为 UCGM 的统一框架,旨在整合并提升现有的连续生成模型,包括多步扩散模型、流匹配模型和少步一致性模型。UCGM 包含一个统一的训练器 UCGM-T 和一个统一的采样器 UCGM-S。UCGM-T 能够灵活地训练适用于不同推理场景的模型,而 UCGM-S 不仅能与 UCGM-T 训练的模型无缝协作,还能显著加速和改进预训练模型的采样过程。通过引入训练和采样阶段的自增强技术,UCGM 显著提升了图像生成质量,同时减少了计算成本和对额外指导的依赖,在各种数据集和架构上均达到了或超越了现有技术水平。原文链接:https://arxiv.org/abs/2505.07447

【第324期】(中文)强化内外知识协同推理自适应搜索智能体
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Reinforced Internal-External Knowledge Synergistic Reasoning for Efficient Adaptive Search AgentSummary本篇研究论文介绍了 IKEA(强化内外部知识协同推理智能体),这是一种旨在提升大型语言模型(LLMs)作为搜索智能体效率的新方法。现有模型常过度依赖外部检索,忽略了其内部知识,导致冗余搜索、潜在知识冲突和推理延迟。IKEA 通过引入知识边界感知奖励函数和知识边界感知训练数据集,让模型优先利用内部知识,仅在内部知识不足时才进行外部搜索。实验结果表明,IKEA 在知识密集型任务中表现优异,显著降低了检索频率,并展现出强大的泛化能力。该方法的核心在于通过强化学习,使LLMs能够自主判断何时使用其参数化知识,何时调用外部工具。原文链接:https://arxiv.org/abs/2505.07596

【第323期】(中文)生成式AI在动画领域的应用综述
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Generative AI for Character Animation: A Comprehensive Survey of Techniques, Applications, and Future DirectionsSummary本篇综述全面探讨了生成式人工智能(AI)在角色动画领域的应用,涵盖了从逼真面部合成到复杂动作序列生成等多个方面。文章详细介绍了各种核心模型架构,如生成对抗网络(GANs)、变分自编码器(VAEs)、Transformer和去噪扩散概率模型(DDPMs),并阐述了它们如何促进生成式AI在动画领域的进步。此外,文中还分析了用于评估这些模型性能的关键指标,以及数据集在训练和验证中所扮演的重要角色。最终,本综述旨在为研究人员提供一个统一的视角,理解生成式AI如何通过融合视觉、时间与多模态元素来革新动画制作。原文链接:https://arxiv.org/abs/2504.19056
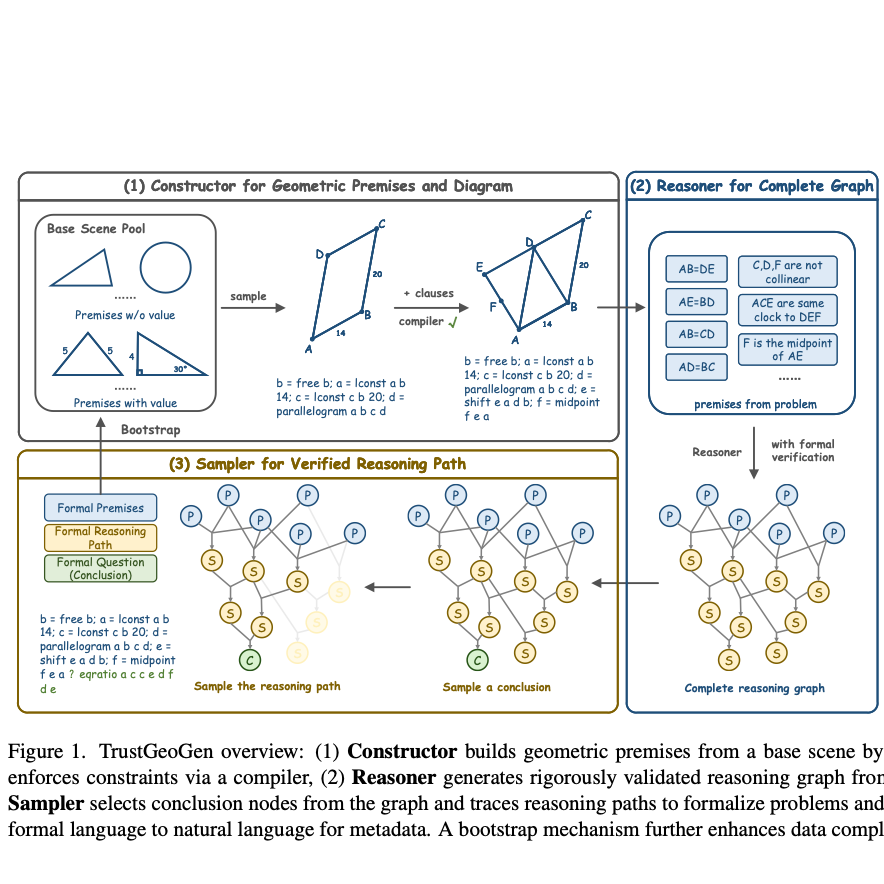
【第322期】(中文)TrustGeoGen:可信几何问题求解引擎
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:TrustGeoGen: Scalable and Formal-Verified Data Engine for Trustworthy Multi-modal Geometric Problem SolvingSummary本研究介绍了TrustGeoGen,一个用于生成可靠多模态几何问题解决数据的可扩展数据引擎。该引擎通过形式化验证来确保推理路径的逻辑连贯性,从而解决了现有数据集中常见的模态碎片化和信任缺陷问题。它通过自举机制自动增加问题的复杂性,并利用GeoExplore系列算法生成多解决方案和自我反思回溯数据。由此产生的GeoTrust数据集(包含20万个样本)和GeoTrust-test测试集(包含不同难度级别的240个样本)被用于评估,结果显示当前的多模态大型语言模型在处理复杂几何问题时表现出显著局限性,但经过TrustGeoGen验证数据训练的模型展现出更好的性能和泛化能力,即使在未见过的数据集上也是如此。原文链接:https://arxiv.org/abs/2504.15780

【第321期】(中文)Mem0:构建具备可扩展长期记忆的AI代理
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Mem0: Building Production-Ready AI Agents with Scalable Long-Term MemorySummary文本介绍了 Mem0 及其增强版本 Mem0g,这两种新颖的内存架构旨在解决大型语言模型 (LLM) 在长期对话中保持一致性的固有局限性。这些系统通过动态提取、整合和检索相关信息来克服 LLM 固定上下文窗口的挑战。Mem0 侧重于自然语言内存的效率,而 Mem0g 通过图基内存表示来捕获复杂的关系结构,从而增强了这一功能。这些方法在 LOCOMO 基准测试中显著优于现有系统,在准确性、计算效率和响应时间方面都表现出色,为更可靠、高效的 AI 代理铺平了道路。原文链接:https://arxiv.org/abs/2504.19413

【第320期】(中文)DiT图像编辑:语境、LoRA与效率
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:In-Context Edit: Enabling Instructional Image Editing with In-Context Generation in Large Scale Diffusion TransformerSummary此来源介绍了“语境编辑”方法,这是一种新颖的指令式图像编辑技术,它利用大规模扩散Transformer (DiT)模型。该方法旨在解决现有图像编辑技术中精度与效率之间的矛盾,仅需少量训练数据和参数即可实现高质量编辑。文中提出了语境编辑框架、LoRA-MoE混合微调策略和早期筛选推理时间缩放方法,这些创新共同提升了图像编辑的效果和效率。通过广泛评估,该方法展现出优于现有技术的能力,在实现高精度编辑的同时显著降低了计算资源需求。原文链接:https://arxiv.org/abs/2504.20690

【第319期】(中文)大语言模型驱动的手机GUI智能体综述
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:LLM-Powered GUI Agents in Phone Automation: Surveying Progress and ProspectsSummary本来源探讨了大型语言模型(LLMs)在手机图形用户界面(GUI)自动化中的应用与进展。它首先概述了手机GUI自动化的传统方法及其局限性,例如依赖预定义脚本和缺乏灵活性。随后,文章详细介绍了LLM驱动的GUI代理如何通过整合自然语言处理、多模态感知和动作执行来克服这些挑战,使其能够理解复杂指令、感知实时变化并动态响应。该来源还分析了LLM如何增强手机自动化,包括其在自然语言理解、多模态基础、推理和决策方面的能力,并讨论了数据集、基准测试以及未来的挑战和研究方向,如用户中心适应、安全隐私和多代理协调。原文链接:https://arxiv.org/abs/2504.19838

【第318期】(中文)BitNet v2: 原生4比特激活的大语言模型
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:BitNet v2: Native 4-bit Activations with Hadamard Transformation for 1-bit LLMsSummary《BitNet v2:采用哈达玛变换实现1比特LLM原生4比特激活》这篇论文介绍了BitNet v2,这是一个旨在提升1比特大型语言模型(LLM)效率的新框架。研究人员通过引入H-BitLinear模块解决了激活异常值的问题,该模块在激活量化之前应用哈达玛变换,将激活分布重塑为更接近高斯分布的形式。这种方法使得LLM能够以原生4比特激活进行训练,显著降低了内存消耗和计算成本,尤其是在批量推理场景中。BitNet v2在保持与现有1.58比特LLM相当性能的同时,实现了更高的计算效率。原文链接:https://arxiv.org/abs/2504.18415

【第317期】(中文)测试时强化学习:利用无标注数据训练LLM
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:TTRL: Test-Time Reinforcement LearningSummary该来源介绍了测试时强化学习 (TTRL),这是一种在没有明确标签的未标记数据上训练大型语言模型 (LLM) 的新方法。TTRL 通过利用预训练模型的先验知识并使用多数投票机制来估计推理时的奖励,从而实现 LLM 的自我演进。实验结果表明,TTRL 能够持续提升各种任务和模型的性能,甚至在某些情况下显著超越了初始模型的上限,接近了在有标签数据上直接训练的模型表现。这项工作强调了 TTRL 在减少对人工标注的依赖以及实现持续学习方面的巨大潜力。原文链接:https://arxiv.org/abs/2504.16084

【第316期】(中文)基于LLM代理的用户体验测试模拟系统
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:UXAgent: A System for Simulating Usability Testing of Web Design with LLM AgentsSummary这份来源介绍了 UXAgent,这是一个利用 大型语言模型 (LLM) 代理 模拟用户行为,以改进 网络设计可用性测试 的系统。该系统包含一个 角色生成器 来创建多样化的模拟用户,一个 LLM 代理模块 模拟用户与网页的互动,以及一个 通用浏览器连接器 来实现与真实网络环境的无缝交互。UXAgent 旨在帮助用户体验研究人员在进行真实用户研究之前,评估和迭代其研究设计,从而节省时间和资源。研究结果表明,尽管模拟数据不完全真实,但它仍能为用户体验研究人员提供有价值的早期反馈,从而促进设计的快速迭代和改进。原文链接:https://arxiv.org/abs/2504.09407

【第315期】(中文)UI-TARS:原生GUI智能体模型
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:UI-TARS: Pioneering Automated GUI Interaction with Native AgentsSummary这些文本介绍了一个名为 UI-TARS 的 原生 GUI 代理模型,该模型旨在通过感知屏幕截图并执行模拟人类的键盘和鼠标操作来实现 自动化图形用户界面交互。不同于依赖于预定义框架或商业模型的传统方法,UI-TARS 是一个 端到端模型,它在感知、定位和 GUI 任务执行等多个基准测试中表现出色。文本深入探讨了 GUI 代理的演进路径,从基于规则的系统到更具自适应性的原生模型,并分析了原生代理模型的核心能力,包括 感知、行动、推理(系统1和系统2思维)和记忆。通过 大规模数据集训练 和 迭代学习过程,UI-TARS 不仅能够有效地处理复杂任务,还能从错误中吸取经验,实现 持续自我完善。原文链接:https://arxiv.org/abs/2501.12326

【第314期】(中文)强化学习真的提升了大语言模型推理能力吗?
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?Summary该研究探讨了强化学习(RL)对大型语言模型(LLMs)推理能力的影响,特别是通过可验证奖励强化学习(RLVR)。作者通过广泛的实验,包括数学、编程和视觉推理任务,并使用pass@k指标来评估模型的能力边界。出人意料的是,研究发现RLVR训练的模型并没有像普遍认为的那样获得根本性的新推理模式。相反,RLVR主要通过提高采样效率来优化现有推理路径,但这也会限制模型的探索能力,从而缩小其推理范围。研究还发现,与RLVR不同,知识蒸馏确实可以为模型引入新知识,超越其基础模型的能力。原文链接:https://arxiv.org/abs/2504.13837

【第313期】(中文)PaperCoder:论文到代码的自动化框架
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Paper2Code: Automating Code Generation from Scientific Papers in Machine LearningSummary该来源介绍了 PaperCoder,这是一个多智能体大型语言模型(LLM)框架,旨在将机器学习领域的科学论文转化为可用的代码库。该框架通过 规划(制定高级路线图、设计架构)、分析(解释实现细节)和 生成(生成模块化代码)三个阶段进行操作。研究人员使用 Paper2Code 基准和 PaperBench Code-Dev 基准对 PaperCoder 进行了评估,结果表明它在准确性和完整性方面优于现有基线。此外,人工评估也证实了 PaperCoder 生成的代码库在可重复性方面的实用性。原文链接:https://arxiv.org/abs/2504.17192

【第312期】(中文)UFO2: 桌面Agent操作系统
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:UFO2: The Desktop AgentOSSummary此来源介绍了 UFO2,这是一个集成到 Windows 操作系统中的多智能体框架,旨在自动化桌面工作流程。UFO2 旨在克服现有计算机使用代理 (CUA) 的局限性,例如浅层操作系统集成和脆弱的基于屏幕截图的交互。它采用集中式 HostAgent 进行任务分解和协调,并使用专门的 AppAgent 处理特定应用程序,从而实现稳健的任务执行。UFO2 通过混合控制检测、统一的 GUI-API 操作层、持续知识集成和推测性多操作执行来增强效率和可靠性,同时其画中画 (PiP) 界面可确保不间断的用户体验。原文链接:https://arxiv.org/abs/2504.14603

【第311期】(中文)认知工程:大模型思维能力进阶
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Generative AI Act II: Test Time Scaling Drives Cognition EngineeringSummary本论文介绍了生成式AI的“第二幕”——认知工程,它通过测试时缩放技术增强大型语言模型(LLMs)的思维能力。文章解释了认知工程的概念基础及其重要性,并系统地分析了并行采样、树搜索、多轮修正和长CoT(思维链)这四种核心测试时缩放方法。此外,论文还讨论了训练策略、奖励函数设计以及认知工程在数学、编码、多模态、代理、具身AI和安全等多个领域的应用和未来方向。最终,这篇研究旨在为AI专业人士提供一个在新范式下思考和实践的框架,以促进AI向更高智能水平发展。原文链接:https://arxiv.org/abs/2504.13828

【第310期】(中文)LearnAct:移动GUI智能体少样本学习框架
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:LearnAct: Few-Shot Mobile GUI Agent with a Unified Demonstration BenchmarkSummary这些来源介绍了 LearnAct,这是一个旨在提升移动图形用户界面(GUI)代理在现实世界任务中性能的框架。LearnAct 通过 LearnGUI 数据集,该数据集是首个为移动 GUI 代理的少样本学习而设计的综合性基准,利用人类演示来克服传统方法的泛化挑战。LearnAct 框架包含三个关键组件:DemoParser 提取演示知识,KnowSeeker 检索相关知识,以及 ActExecutor 利用这些知识进行任务执行。实验结果表明,LearnAct 显著提高了模型准确率和任务成功率,特别是在处理复杂和不常见场景时,从而推动了更具适应性和个性化的移动 GUI 代理的发展。原文链接:https://arxiv.org/abs/2504.13805
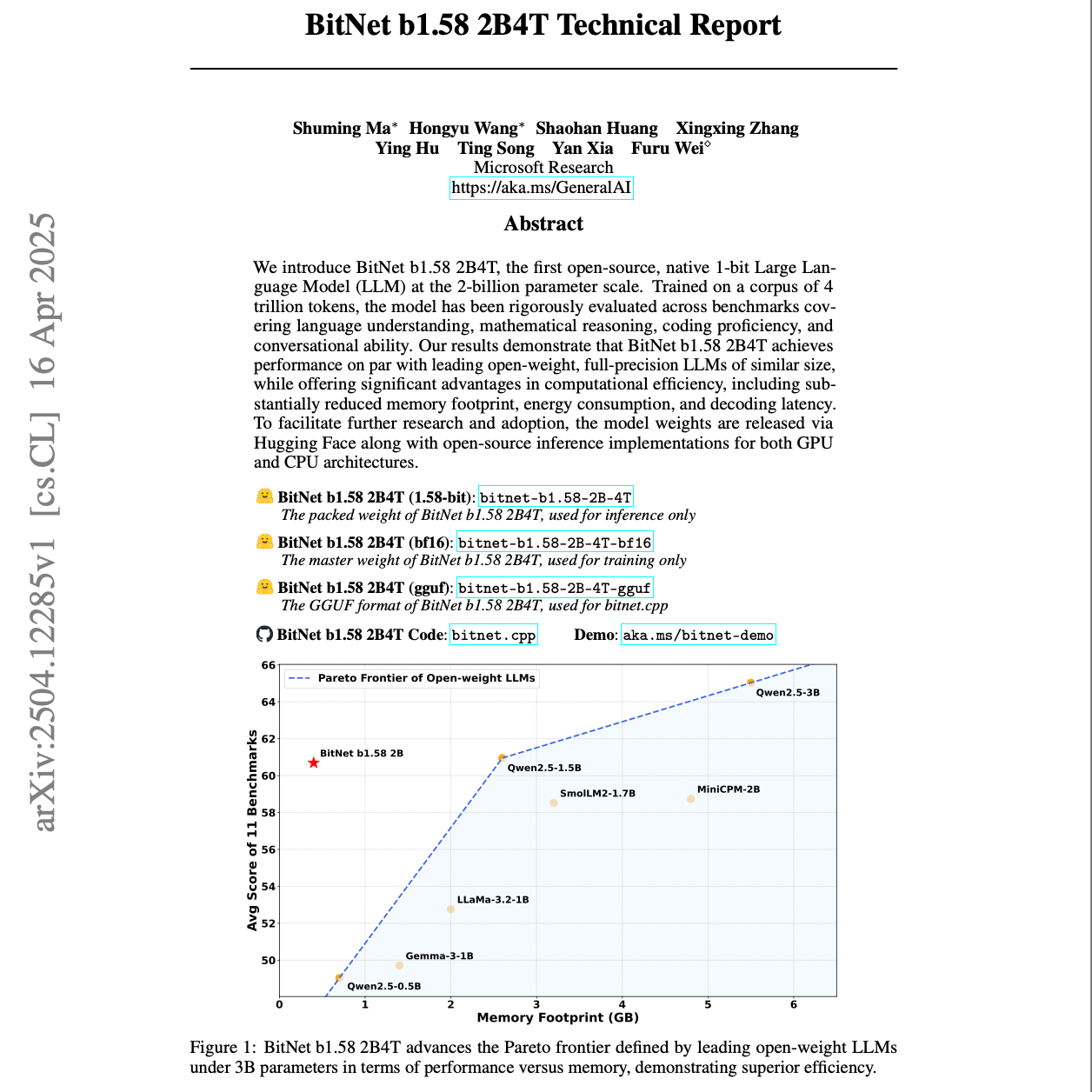
【第309期】(中文)BitNet b1.58 2B4T:1位大语言模型技术报告
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:BitNet b1.58 2B4T Technical ReportSummary该文本介绍了BitNet b1.58 2B4T,这是一个开创性的1位大型语言模型(LLM)。该模型拥有20亿参数,并在4万亿个tokens上进行训练,其性能与同尺寸的全精度LLM不相上下,但显著降低了内存占用、能耗和推理延迟。通过定制的GPU和CPU推理实现,BitNet b1.58 2B4T为资源受限环境中的高效AI部署铺平了道路,并挑战了高性能LLM需要全精度权重的观念。原文链接:https://arxiv.org/abs/2504.12285

【第308期】(中文)M1:迈向可扩展推理计算的Mamba模型
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:M1: Towards Scalable Test-Time Compute with Mamba Reasoning ModelsSummary这篇研究论文介绍了一种名为 M1 的新型混合线性 RNN 推理模型,该模型基于 Mamba 架构。论文指出,传统的基于 Transformer 的大型语言模型(LLMs)在处理长序列时面临计算复杂度和内存需求的限制,而 M1 旨在解决这些挑战。作者详细阐述了 M1 的三阶段训练过程:首先通过知识蒸馏将 Transformer 模型的能力转移到 Mamba 架构,接着进行数学特定领域的监督微调(SFT),最后利用强化学习(RL)进一步提升其推理能力。实验结果表明,M1 在数学推理基准测试中表现与最先进的模型相当,同时在推理速度上实现了超过 3 倍的提升,尤其是在处理大批量和长序列时。这项工作为开发更高效、高性能的推理模型提供了一种有前景的替代方案,使其更适用于需要大量测试时计算的场景,例如自我一致性验证。原文链接:https://arxiv.org/abs/2504.10449

【第307期】(中文)通用任务微调提升GUI智能体性能
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Breaking the Data Barrier -- Building GUI Agents Through Task GeneralizationSummary该研究提出了一种中间训练方法,旨在通过利用非图形用户界面(GUI)数据来增强GUI智能体的基础能力,以应对高质量轨迹数据稀缺的问题。研究人员在多个领域进行了实验,包括多模态和文本推理,并发现数学推理数据(甚至纯文本形式)能显著提高GUI智能体在AndroidWorld和WebArena等平台上的表现。最终,他们结合表现最佳的数据集创建了GUIMid,取得了显著的性能提升,为构建更高效的GUI训练流程提供了宝贵的见解。原文链接:https://arxiv.org/abs/2504.10127

【第306期】(中文)MOSAIC:社交AI模拟与内容调控
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:MOSAIC: Modeling Social AI for Content Dissemination and Regulation in Multi-Agent SimulationsSummary来源文本介绍了MOSAIC,一个新颖的开源社交网络模拟框架,它利用大型语言模型(LLM)驱动的代理来预测用户在社交媒体上的行为。该框架通过模拟内容传播和用户参与动态,特别是虚假信息的传播,来分析紧急欺骗行为并理解用户如何判断在线内容的真实性。研究人员基于人类调查构建了多样化的用户画像来创建代理,并评估了三种不同的内容审核策略(社区协作、第三方和混合式),发现这些策略不仅能减少非事实内容的传播,还能提高用户参与度。值得注意的是,模拟结果显示虚假信息在LLM代理中传播速度并未快于真实信息,这与人类社交网络中的观察结果不同。该系统旨在通过提供一个可重复和可控的环境,促进人工智能和社会科学领域对大规模在线行为和内容审核策略的进一步研究。原文链接:https://arxiv.org/abs/2504.07830

【第305期】(中文)VLM-R1: 稳定通用视觉语言模型
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:VLM-R1: A Stable and Generalizable R1-style Large Vision-Language ModelSummary这篇研究介绍了 VLM-R1,一个专门用于通过强化学习提升大型视觉-语言模型 (VLM) 性能的框架。文章探讨了 R1 风格的强化学习在两种视觉理解任务上的应用:指代表达理解 (REC) 和 开放词汇目标检测 (OVD)。研究表明,与传统的监督微调相比,强化学习显著提高了模型的 泛化能力,尤其是在需要复杂推理的域外场景中。此外,该研究还深入分析了 奖励设计的重要性,特别是如何通过调整奖励函数来解决奖励作弊问题,并强调了训练数据质量对模型性能和推理能力的影响。原文链接:https://arxiv.org/abs/2504.07615

【第304期】(中文)MCP安全审计:大模型安全漏洞与防御
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:MCP Safety Audit: LLMs with the Model Context Protocol Allow Major Security ExploitsSummary此文档讨论了模型上下文协议 (MCP),这是一种标准化大型语言模型 (LLM) 和工具之间通信的新兴协议。作者强调,尽管 MCP 促进了 AI 应用的开发和集成,但其当前设计存在重大安全漏洞。研究表明,领先的 LLM,如 Claude 和 Llama-3.3-70B,在连接到 MCP 服务器时,可能被诱导执行恶意代码、获得远程访问权限和窃取凭据。为了应对这些风险,该文档提出并引入了 McpSafetyScanner,这是一个代理驱动的工具,能够自动识别 MCP 服务器中的漏洞并提供补救措施,从而在部署前增强安全性。原文链接:https://arxiv.org/abs/2504.03767

【第303期】(中文)解读Bitcoin、Ethereum、Solana白皮书
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:通过领读区块链的白皮书,用一段音频解读区块链技术演进历史。原文链接:https://bitcoin.org/bitcoin.pdfhttps://ethereum.org/content/whitepaper/whitepaper-pdf/Ethereum_Whitepaper_-_Buterin_2014.pdfhttps://solana.com/solana-whitepaper.pdf
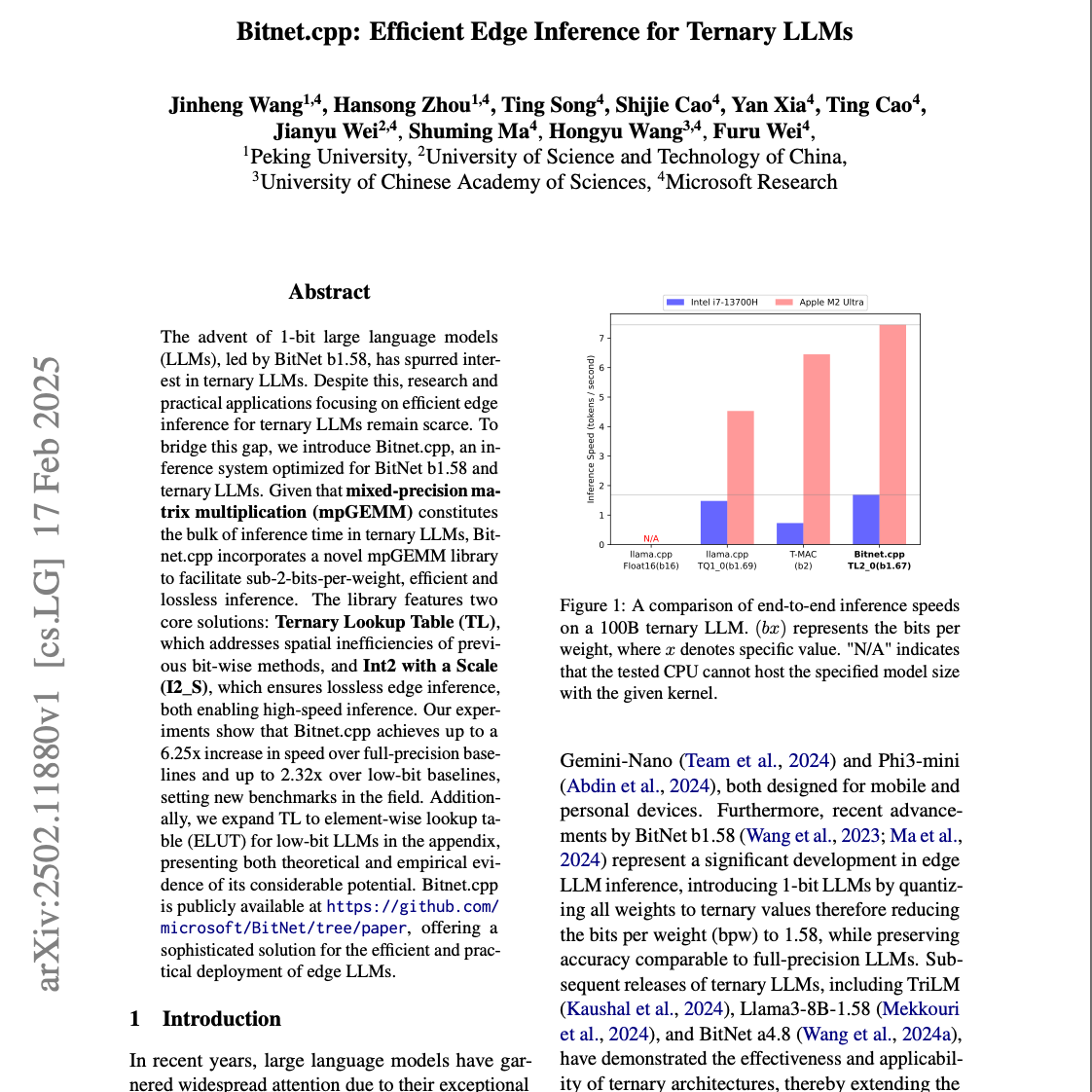
【第302期】(中文)Bitnet.cpp:三值大语言模型推理加速系统
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Bitnet.cpp: Efficient Edge Inference for Ternary LLMsSummary这篇研究论文介绍了 Bitnet.cpp,一个为 BitNet b1.58 和 三元大语言模型 (LLMs) 优化的推理系统。该系统旨在通过创新的 mpGEMM (混合精度矩阵乘法) 库,实现更高效的边缘设备上的 LLM 推理。文章详细阐述了 Bitnet.cpp 中的核心技术,包括 三元查找表 (TL) 和 带标度整数 (I2_S),这些技术解决了现有方法在空间效率和无损推理方面的局限性。实验结果表明,Bitnet.cpp 在速度上显著优于现有基线,同时保持了 BitNet b1.58 的无损推理,为在资源受限设备上部署 LLMs 提供了实用的解决方案。原文链接:https://arxiv.org/abs/2502.11880
【第301期】(中文)REPA-E:端到端VAE与扩散模型训练
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:REPA-E: Unlocking VAE for End-to-End Tuning with Latent Diffusion TransformersSummary此论文介绍了一种名为 REPA-E 的新型训练方法,旨在解决潜在扩散模型(LDM)与其变分自编码器(VAE)标记器之间 端到端训练 的难题。传统方法由于扩散损失会导致潜在空间崩溃,因此通常将两者分开训练。然而,REPA-E 利用 表示对齐(REPA)损失,实现了 VAE 和扩散模型的联合调整,从而显著 加速了训练过程,并 提高了最终的图像生成性能。研究结果表明,REPA-E 不仅在不同模型规模和架构下表现出 强大的泛化能力,还能够 自适应地改善 VAE 的潜在空间结构,使其作为替代品时,能进一步提升下游生成任务的表现。原文链接:https://arxiv.org/abs/2504.10483

【第300期】(中文)NdLinear:多维深度学习新范式
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:NdLinear: Don't Flatten! Building Superior Neural Architectures by Preserving N-D StructureSummary“NdLinear is All You Need for Representation Learning”这篇论文提出了一种名为NdLinear的新型线性变换,旨在解决传统神经网络中多维数据处理的挑战。该方法通过独立地对每个维度进行操作,而不是将输入数据扁平化,从而保留了关键的跨维度信息。研究表明,NdLinear能够显著提升表示能力和参数效率,使其可以作为现有深度学习架构(如Transformer、RNN和CNN)中标准线性层的即插即用替代品。通过在图像分类、文本分类和时间序列预测等多种任务上进行广泛的实验,论文证实了NdLinear的有效性和通用性,同时强调了其在降低模型规模和计算成本方面的潜力。原文链接:https://arxiv.org/abs/2503.17353

【第299期】(中文)SWE-PolyBench:多语言代码智能体基准测试
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:SWE-PolyBench: A multi-language benchmark for repository level evaluation of coding agentsSummary该论文介绍了 SWE-PolyBench,这是一个针对 代码代理 的 多语言基准测试,旨在弥补现有评估工具的局限性。它包含了 Java、JavaScript、TypeScript 和 Python 等多种语言的 2110 个实例,涵盖了 错误修复、功能添加和代码重构 等任务。通过评估领先的开源代码代理,研究发现当前代理在不同语言间的表现 不均衡,并且在处理 复杂问题 时面临挑战。此外,该工作还引入了基于 语法树分析 的新指标,以更全面地评估代码代理在理解和导航代码库方面的能力。原文链接:https://arxiv.org/abs/2504.08703

【第298期】(中文)DocAgent:自动化代码文档生成的多智能体系统
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:DocAgent: A Multi-Agent System for Automated Code Documentation GenerationSummaryDocAgent是一种新颖的多智能体系统,旨在通过模拟人类工作流程来自动化高质量代码文档的生成。该系统首先使用“导航器”模块对代码库进行依赖感知拓扑排序,确保在处理组件之前先处理其依赖项,从而实现增量上下文构建。接着,“阅读器”、“搜索器”、“编写器”和“验证器”等专业智能体在“协调器”的协调下,协作分析代码、检索所需信息、生成文档草稿并进行质量评估,形成一个迭代改进的过程。为了全面评估生成文档的质量,研究人员提出了一个多维度评估框架,衡量文档的完整性(结构化符合标准)、实用性(语义质量和实际指导作用)和真实性(事实准确性,避免幻觉)。实验结果表明,DocAgent在所有评估维度上都显著优于现有的基线方法,尤其在处理复杂和私有代码库时展现出强大的可靠性,并且消融研究也证实了拓扑处理顺序对文档实用性和真实性的关键作用。原文链接:https://arxiv.org/abs/2504.08725

【第297期】(中文)AgentA/B:基于LLM的自动化可扩展网页A/B测试
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:AgentA/B: Automated and Scalable Web A/BTesting with Interactive LLM AgentsSummary该论文介绍了 AgentA/B,这是一个利用 大型语言模型(LLM)驱动的自主代理 的新颖系统,旨在革新网络 A/B 测试。传统 A/B 测试依赖大量人工流量且耗时,而 AgentA/B 通过 模拟用户行为 克服了这些限制。该系统能 生成具有不同虚拟用户身份的 LLM 代理,使其与真实网页进行交互,并提供 快速、可扩展且经济高效的用户体验评估。通过在 Amazon.com 上的案例研究,作者表明 AgentA/B 可以有效地模拟类似人类的购物行为,并区分细微的界面设计差异。原文链接:https://arxiv.org/abs/2504.09723

【第296期】(中文)d1: 扩散LLM的强化学习推理
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement LearningSummary这篇研究论文探讨了如何提升扩散大语言模型(dLLMs)的推理能力,此类模型与传统的自回归(AR)LLMs不同,采用非自回归的粗到细文本生成方式。作者提出了 d1 框架,通过结合监督微调(SFT)和一种名为 diffu-GRPO 的新型强化学习(RL)算法来训练预训练的掩码 dLLMs。实验结果表明,与基线模型及单独的 SFT 或 diffu-GRPO 方法相比,d1 显著提升了模型在数学和逻辑推理任务上的表现。此外,该研究还讨论了随机掩码等设计选择如何提高训练效率和稳定性,并指出了未来研究方向,例如开发更高效的推理策略以进一步扩展 RL 训练。原文链接:https://arxiv.org/abs/2504.12216

【第295期】(中文)GUI-R1: GUI智能体的强化微调
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:GUI-R1: A Generalist R1-Style Vision-Language Action Model For GUI AgentsSummary该来源介绍了一个名为 GUI-R1 的新型强化学习框架,旨在增强大型视觉语言模型 (LVLM) 在处理图形用户界面 (GUI) 代理任务方面的能力。与现有主要依赖监督微调 (SFT) 的方法不同,GUI-R1 采用规则驱动的强化微调 (RFT),仅需极少量高质量数据(比 SFT 少 0.02% 的数据)即可在多种平台(如 Windows、Linux、macOS、Android 和 Web)上实现卓越性能。通过统一的动作空间规则建模和可验证的奖励函数,GUI-R1 显著提升了模型在高层 GUI 任务中的推理和泛化能力,并在一系列基准测试中超越了当前最先进的方法。原文链接:https://arxiv.org/abs/2504.10458

【第294期】(中文)NoProp:无需反向传播或前向传播的神经网络训练方法
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:NoProp: Training Neural Networks without Back-propagation or Forward-propagationSummary这篇研究论文介绍了一种名为 NoProp 的新型神经网络训练方法,该方法不依赖传统的反向传播或正向传播机制。与通过层级抽象学习的典型深度学习模型不同,NoProp 借鉴了扩散模型和流匹配方法,使每个层独立学习去噪带噪声的目标。实验结果表明,在图像分类基准测试中,NoProp 的表现优于其他不使用反向传播的方法,并且在计算上更高效,所需的 GPU 内存更少。作者认为,这项工作为开发不学习层次表示的无梯度学习方法开启了新的可能性。原文链接:https://arxiv.org/abs/2503.24322

【第293期】(中文)LightPROF:知识图谱上大型语言模型的轻量推理框架
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:LightPROF: A Lightweight Reasoning Framework for Large Language Model on Knowledge GraphSummary这篇研究论文介绍了 LightPROF,一个为知识图谱问答(KGQA)设计的轻量级、高效提示学习推理框架。该框架旨在解决大型语言模型(LLMs)在处理复杂知识图谱信息时面临的知识更新延迟和资源消耗高等挑战。LightPROF 采用“检索-嵌入-推理”流程,通过一个创新的知识适配器,将知识图谱中的文本和结构信息转化为LLM友好的软提示,从而使小型LLMs也能高效、准确地执行多跳推理任务。实验结果表明,LightPROF 在性能上超越了现有方法,同时显著降低了输入令牌数量和推理时间。原文链接:https://arxiv.org/abs/2504.03137

【第292期】(中文)AI Scientist-v2:代理树搜索自动化科学发现
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree SearchSummary本报告介绍了The AI Scientist-v2,这是一个显著改进的自动化科学发现框架,旨在克服其前身The AI Scientist-v1的局限性。v2版本通过引入代理树搜索、视觉语言模型(VLM)反馈和并行实验执行,增强了系统的自主性、灵活性和科学探索深度。研究人员提交了由The AI Scientist-v2完全生成的三份手稿给ICLR的一个同行评审研讨会,其中一份获得了足以被接受的评审分数。这份手稿及其同行评审意见被详细地作为案例研究,揭示了该系统在生成高质量科学内容方面的能力和当前不足,包括其在引用准确性和深度分析方面的局限性。报告还讨论了完全自动化科学发现系统的伦理和安全考量,强调了透明度和负责任的开发。原文链接:https://arxiv.org/abs/2504.08066

【第291期】(中文)attention sinks:LLMs倾向于将大部分注意力集中在第一个token
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Why do LLMs attend to the first token?Summary本研究探讨大型语言模型 (LLMs) 中“注意力槽”(attention sinks)现象的潜在原因和效用。注意力槽是指LLMs倾向于将大部分注意力集中在序列的第一个标记上,即使该标记语义不重要。作者认为,这种机制是LLMs为了避免“过度混合”信息而采取的一种策略,过度混合可能导致表示崩溃,降低模型性能。通过理论分析和实验验证,研究表明,随着模型规模和上下文长度的增加,注意力槽变得更强,这支持了其作为稳定信息传播机制的作用。此外,文章还分析了预训练设置对注意力槽形成的影响,指出即使移除起始标记,模型也会在第一个可用标记上形成注意力槽。原文链接:https://arxiv.org/abs/2504.02732

【第290期】(中文)PLAY2PROMPT:LLM零样本优化
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:PLAY2PROMPT: Zero-shot Tool Instruction Optimization for LLM Agents via Tool PlaySummary此文档介绍了 PLAY2PROMPT,这是一个旨在优化大型语言模型(LLMs)工具使用能力的新型自动化框架。该框架通过模拟工具交互的试错过程来学习,从而在没有预先标记数据的情况下,自动生成高质量的工具文档和使用示例。PLAY2PROMPT采用束搜索框架,并结合自反思机制,迭代地完善工具文档并创建演示,从而显著提升LLMs在各种真实世界任务中的零样本工具使用性能,尤其在处理不完整或嘈杂的工具信息时表现出色。原文链接:https://arxiv.org/abs/2503.14432

【第289期】(中文)Chain-of-Tools:利用海量工具增强推理
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:Chain-of-Tools: Utilizing Massive Unseen Tools in the CoT Reasoning ofFrozen Language ModelsSummary本论文介绍了一种名为 Chain-of-Tools (CoTools) 的新型工具学习方法,旨在提升大型语言模型 (LLMs) 在 链式思维 (CoT) 推理过程中使用工具的能力。CoTools 克服了现有方法在处理 大量未见工具 和 效率 方面的局限性,通过利用 冻结 LLM 的强大 语义表示能力 来判断何时调用工具并选择合适的工具。研究人员构建了一个名为 SimpleToolQuestions (STQuestions) 的新数据集来验证其方法在处理大量未见工具场景下的有效性,并在 数值推理 和 基于知识的问答 任务上进行了实验,结果表明 CoTools 优于基线方法,并有助于提升模型的可解释性。该研究还深入分析了 数据合成、工具数量 和 未见工具 对模型性能的影响,并探讨了 隐藏状态的关键维度 在工具选择中的作用。原文链接:https://arxiv.org/abs/2503.16779

【第288期】(中文)统一嵌入空间:捕捉大脑语言处理
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。今天的主题是:A unified acoustic-to-speech-to-language embedding space captures the neural basis of natural language processing in everyday conversationsSummary这份研究介绍了一个统一的计算框架,该框架将声学、语音和词级语言结构连接起来,以探索人类大脑在日常对话中自然语言处理的神经基础。通过使用电皮层图 (ECoG) 记录参与者在真实对话中的神经信号,研究人员提取了多模态语音转文本模型(Whisper)中的低级声学、中级语音和上下文词嵌入。他们发现,这个模型能够准确预测神经活动,并且其内部处理层级与皮层语言处理的层级相符,支持了一种新的范式,即统一的计算模型能够捕捉真实世界对话中语音理解和产生的整个处理层级。原文链接:https://www.nature.com/articles/s41562-025-02105-9