
Seventy3
642 episodes — Page 12 of 13

【第87期】Coconut:连续Latent空间的LLM推理
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Training Large Language Models to Reason in a Continuous Latent SpaceSummaryThis research paper introduces Coconut, a novel method for enhancing Large Language Model (LLM) reasoning capabilities. Instead of relying solely on language-based chain-of-thought (CoT) reasoning, Coconut utilizes the LLM's hidden state ("continuous thought") as input, enabling reasoning in an unrestricted latent space. Experiments on various reasoning tasks demonstrate that Coconut outperforms traditional CoT methods, especially in tasks requiring significant planning and backtracking. The study analyzes the emergent breadth-first search-like reasoning pattern in Coconut and explores the advantages of latent reasoning over language-based approaches. The findings suggest promising avenues for future research in improving LLM reasoning.这篇研究论文介绍了一种名为 Coconut 的新方法,用于增强大型语言模型(LLM)的推理能力。与仅依赖基于语言的链式思维(CoT)推理不同,Coconut 利用 LLM 的隐藏状态(“连续思维”)作为输入,从而实现了在无限制的潜在空间中进行推理。在多种推理任务上的实验表明,Coconut 优于传统的 CoT 方法,特别是在需要大量规划和回溯的任务中。研究分析了 Coconut 中呈现的类似广度优先搜索的推理模式,并探讨了潜在推理相较于基于语言方法的优势。研究结果为未来在改进 LLM 推理方面提供了有前景的研究方向。原文链接:https://arxiv.org/abs/2412.06769

【第86期】RLZero:"imagine", "project" and "imitate"
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:RL Zero: Zero-Shot Language to Behaviors without any SupervisionSummaryThis research paper introduces RLZero, a novel method for translating natural language instructions into robot behaviors without using hand-designed reward functions. RLZero leverages unsupervised reinforcement learning and large video-language models to "imagine," "project," and "imitate" desired actions. The method first generates a video illustrating the task, then finds similar real-world observations from the robot's past experience, and finally, uses these observations to train a policy via imitation learning. Experiments demonstrate RLZero's effectiveness across various simulated robotic tasks and its ability to generalize to cross-embodied imitation from videos. The authors discuss limitations and future research directions.这篇研究论文介绍了RLZero,这是一种将自然语言指令转换为机器人行为的新方法,无需手动设计奖励函数。RLZero利用无监督强化学习和大型视频-语言模型来"想象"、"投射"和"模仿"期望的动作。该方法首先生成一个说明任务的视频,然后从机器人过去的经验中找到相似的真实世界观察,最后使用这些观察通过模仿学习训练策略。实验证明了RLZero在各种模拟机器人任务中的有效性,以及从视频中进行跨机身模仿的能力。作者讨论了研究的局限性和未来的研究方向。原文链接:https://arxiv.org/abs/2412.05718

【第85期】GENMAC:用多智能体模式生成复杂动态视频
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:GenMAC: Compositional Text-to-Video Generation with Multi-Agent CollaborationSummaryThe paper introduces GENMAC, a novel multi-agent framework for generating complex, dynamic videos from text prompts. GENMAC uses a three-stage iterative process (DESIGN, GENERATION, REDESIGN) with specialized agents in the REDESIGN stage to verify, suggest corrections, and refine the generated video. This multi-agent approach overcomes limitations of single-agent methods in handling complex spatiotemporal relationships and object interactions. The system's effectiveness is demonstrated through quantitative and qualitative comparisons against state-of-the-art models on the T2V-CompBench benchmark, showcasing superior performance in compositional text-to-video generation. Ablation studies highlight the importance of each component within the framework.原文链接:https://arxiv.org/abs/2412.04440

【第84期】FedBone:大规模多任务联邦学习
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:FedBone: Towards Large-Scale Federated Multi-Task LearningSummaryThe paper introduces FedBone, a novel federated multi-task learning framework designed for large-scale models and heterogeneous tasks. It employs split learning to distribute computation efficiently between a cloud server and resource-constrained edge clients. A gradient projection method addresses conflicts arising from heterogeneous tasks during model aggregation. FedBone incorporates privacy-preserving techniques and asynchronous optimization for robustness and scalability. Extensive experiments on benchmark and real-world ophthalmic datasets demonstrate its superior performance compared to existing methods.原文链接:https://link.springer.com/article/10.1007/s11390-024-3639-xhttps://arxiv.org/abs/2306.17465

【第83期】Datalab:LLM Power BI 工作流
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:DataLab: A Unified Platform for LLM-Powered Business IntelligenceSummaryThe paper introduces DataLab, a unified business intelligence platform leveraging large language models (LLMs). DataLab integrates an LLM-based agent framework with a computational notebook interface to streamline various BI tasks across different data roles. Key features include a domain knowledge incorporation module to enhance LLM understanding of enterprise data, an inter-agent communication mechanism for efficient information sharing, and a cell-based context management strategy for optimized context utilization. Extensive experiments demonstrate DataLab's superior performance on multiple BI tasks compared to existing methods, achieving significant accuracy gains and cost reductions on real-world datasets. The platform aims to bridge the gap between different data roles, tools, and tasks within the BI workflow.原文链接:https://arxiv.org/abs/2412.02205

【第82期】ALAMA:LLM自动选择思考策略
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Towards Adaptive Mechanism Activation in Language AgentSummaryThis research paper introduces ALAMA, a novel method for enhancing Language Agents (LAs) by enabling adaptive mechanism activation. ALAMA uses a unified framework (UniAct) to integrate various mechanisms like reasoning and planning, and employs self-exploration to generate training data, optimizing mechanism selection based on task characteristics. The authors demonstrate ALAMA's effectiveness through experiments on mathematical and knowledge-intensive reasoning tasks, showcasing superior performance compared to existing baselines. Their approach significantly improves efficiency by reducing reliance on expert-curated data, making it more scalable and practical. Future work includes exploring concurrent mechanism activation and further analyzing the effects of mixing data from different mechanisms.原文链接:https://arxiv.org/abs/2412.00722

【第81期】reverse thinking
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Reverse Thinking Makes LLMs Stronger ReasonersSummaryThis research introduces REVTHINK, a framework designed to improve Large Language Models (LLMs) reasoning abilities by incorporating "reverse thinking." REVTHINK augments datasets with teacher-model-generated forward and backward reasoning examples, then trains a student model using multi-task learning objectives to generate both forward and backward reasoning. Experiments across diverse datasets demonstrate significant performance improvements, exceeding existing knowledge distillation and data augmentation baselines, and showcasing the method's sample efficiency and generalizability. The study also analyzes the effectiveness of different learning components and explores the scalability of REVTHINK with model size. Finally, limitations regarding potential bias inheritance from the teacher model are discussed.原文链接:https://arxiv.org/abs/2411.19865

【第80期】Navigation World Models:Yann LeCun的世界模型
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Navigation World ModelsSummaryThis research introduces a Navigation World Model (NWM), a novel video generation model that predicts future visual observations for navigation. Employing a Conditional Diffusion Transformer (CDiT), NWM is trained on a massive dataset of human and robotic navigation videos, reaching 1 billion parameters. The model excels at planning navigation trajectories in known environments, either independently or by ranking trajectories from existing policies, and even generates imagined trajectories in unfamiliar environments from a single image. Experiments demonstrate state-of-the-art performance in visual navigation tasks, including the ability to incorporate navigation constraints during planning. Limitations include mode collapse in unseen environments and challenges with complex temporal dynamics.原文链接:https://arxiv.org/abs/2412.03572解读链接:https://www.jiqizhixin.com/articles/2024-12-07-4

【第79期】VisionZip:降低Visual token冗余度
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:VisionZip: Longer is Better but Not Necessary in Vision Language ModelsSummaryThe paper introduces VisionZip, a method to improve the efficiency of vision-language models (VLMs) by reducing redundancy in visual tokens. The authors observe that existing VLMs use excessively long visual token sequences, leading to high computational costs. VisionZip selects informative tokens, significantly improving inference speed and maintaining or even exceeding performance compared to state-of-the-art methods. The technique is applicable to various tasks, including multi-turn dialogues, and is shown to be effective across multiple VLM architectures. The paper also analyzes the causes of redundancy in visual tokens, highlighting the limitations of existing text-based token selection methods.原文链接:https://arxiv.org/abs/2412.04467

【第78期】OSDFace:单步人脸重建
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:OSDFace: One-Step Diffusion Model for Face RestorationSummaryThe paper introduces OSDFace, a novel one-step diffusion model for high-speed face restoration. OSDFace uses a visual representation embedder (VRE) to capture detailed facial information from low-quality images, improving realism and identity consistency. The model incorporates a facial identity loss and a GAN for enhanced alignment with ground truth images. Experimental results show OSDFace surpasses state-of-the-art methods in both visual quality and speed, achieving high-fidelity restoration with significantly reduced computational cost. The authors provide comprehensive quantitative and qualitative comparisons against existing techniques.原文链接:https://arxiv.org/abs/2411.17163

【第77期】VisVM:Vision Value Model
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Scaling Inference-Time Search with Vision Value Model for Improved Visual ComprehensionSummaryThis research paper introduces the Vision Value Model (VisVM), a novel approach to improve the visual comprehension of vision-language models (VLMs). VisVM guides inference-time search in VLMs by predicting the long-term value of generated sentences, reducing hallucinations and increasing detail in image descriptions. Experiments demonstrate that VisVM-guided search outperforms other methods, and that using VisVM-generated captions for self-training further enhances VLM performance across multiple benchmarks. The researchers conclude that VisVM offers a promising path toward creating self-improving VLMs. The model and code are publicly available.原文链接:https://arxiv.org/abs/2412.03704

【第76期】OmniFlow:Any-to-Any多模态rectified flow
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:OmniFlow: Any-to-Any Generation with Multi-Modal Rectified FlowsSummaryThe provided text details OmniFlow, a novel generative model designed for any-to-any generation tasks (text-to-image, text-to-audio, etc.). It extends the rectified flow framework to handle multiple modalities, outperforming previous models in various benchmarks. Key contributions include a multi-modal rectified flow formulation, a modular architecture enabling efficient pre-training, and a comprehensive study of design choices for optimal performance. The model's architecture is based on Stable Diffusion 3, incorporating additional input/output streams for multi-modal capabilities and a multi-modal guidance mechanism for flexible control. The authors provide extensive experimental results and qualitative examples demonstrating OmniFlow's superior performance and versatility.原文链接:https://arxiv.org/abs/2412.01169

【第75期】cDPO:通过发掘critical tokens去修正回答
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Critical Tokens Matter: Token-Level Contrastive Estimation Enhances LLM’s Reasoning CapabilitySummaryThis research paper introduces cDPO, a novel approach to improve the reasoning capabilities of Large Language Models (LLMs). cDPO identifies "critical tokens"—tokens crucial to correct or incorrect reasoning—using contrastive estimation by comparing models trained on correct and incorrect reasoning trajectories. This allows for token-level reward adjustments during preference optimization, enhancing accuracy. Experiments on GSM8K and MATH500 benchmarks using Llama-3 and DeepSeek-math models demonstrate cDPO's superior performance over existing methods. The paper also explores the impact of various hyperparameters and offers an in-depth comparison with related techniques in contrastive estimation and reinforcement learning. The findings suggest that focusing on critical tokens significantly improves LLM reasoning accuracy.原文链接:https://arxiv.org/abs/2411.19943

【第74期】苏格拉底游戏:AI Agent的脑内活动
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Boundless Socratic Learning with Language GamesSummaryThis position paper explores the concept of Socratic learning, a type of recursive self-improvement in a closed system where an agent learns solely through language interactions. The authors posit three necessary conditions for this: sufficiently informative feedback, broad data coverage, and sufficient capacity. They propose language games as a framework to achieve this, arguing that multiple, narrowly defined games offer better alignment and coverage than a single, universal game. The paper analyzes potential limitations, including feedback misalignment and data drift, while ultimately expressing optimism about the feasibility of open-ended Socratic learning.原文链接:https://arxiv.org/abs/2411.16905解读链接:https://www.jiqizhixin.com/articles/2024-12-02-4

【第73期】HiAR-ICL:LLM推理的ICL
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Beyond Examples: High-level Automated Reasoning Paradigm in In-Context Learning via MCTSSummaryThis research paper introduces HiAR-ICL, a novel framework for improving in-context learning (ICL) in large language models (LLMs), particularly for complex mathematical reasoning. Instead of relying solely on example demonstrations, HiAR-ICL uses Monte Carlo Tree Search (MCTS) to automatically generate and select higher-level reasoning patterns, effectively "teaching the LLM to think" rather than just mimicking examples. The approach uses five atomic reasoning actions as building blocks for these patterns, and a cognitive complexity framework to match problems with appropriate patterns. Experimental results show HiAR-ICL achieves state-of-the-art accuracy on several benchmarks, surpassing even some closed-source LLMs, especially when used with smaller, open-source models.原文链接:https://arxiv.org/abs/2411.18478

【第72期】LLM-Brained GUI Agents: A Survey
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Large Language Model-Brained GUI Agents: A SurveySummaryThis paper surveys the development and application of Large Language Model (LLM)-powered Graphical User Interface (GUI) agents for automating tasks across various platforms (web, mobile, desktop). It examines the evolution of GUI automation from rule-based systems to intelligent agents leveraging LLMs, computer vision, and reinforcement learning. The authors detail the architecture and workflow of these agents, including prompt engineering, model inference, action execution, and memory management. Finally, the paper explores datasets for optimizing LLMs for GUI tasks, evaluation metrics and benchmarks for assessing agent performance, and the challenges and future directions of this field, including safety, reliability, and ethical considerations.原文链接:https://arxiv.org/abs/2411.18279

【第71期】英伟达的audio大模型Fugatto
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Fugatto 1:Foundational Generative Audio Transformer Opus 1SummaryThe document describes Fugatto, a novel generalist audio synthesis and transformation model capable of following diverse text instructions, optionally incorporating audio inputs. It addresses challenges in audio generation by introducing a specialized dataset creation strategy and ComposableART, an inference-time technique for composing instructions. ComposableART extends classifier-free guidance to enable flexible manipulation of generated audio, including composition, interpolation, and negation of instructions. Extensive experiments demonstrate Fugatto's competitive performance across various audio tasks, showcasing emergent capabilities and the effectiveness of ComposableART. The authors plan to release their dataset and code for reproducibility.原文链接:https://d1qx31qr3h6wln.cloudfront.net/publications/FUGATTO.pdf

【第70期】O1 Replication Journey:Part 2
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:O1 Replication Journey -- Part 2: Surpassing O1-preview through Simple Distillation, Big Progress or Bitter Lesson?SummaryThis research paper examines the replication of OpenAI's O1 model, focusing on a knowledge distillation method. The authors demonstrate that a simpler distillation approach, combined with fine-tuning, surpasses the O1-preview model's performance on mathematical reasoning tasks. They also explore the generalization capabilities of this distilled model to other tasks, including safety and open-domain question answering. A key finding highlights the limitations and potential risks of over-reliance on distillation, advocating for a renewed focus on fundamental research and transparency in AI. A novel benchmark framework, the Technical Transparency Index (TTI), is introduced to assess the reproducibility and openness of different O1 replication attempts.原文链接:https://arxiv.org/abs/2411.16489

【第69期】O1 Replication Journey:Part 1
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:O1 Replication Journey: A Strategic Progress Report -- Part 1SummaryThis research report details a team's effort to replicate OpenAI's O1 language model, focusing on transparent documentation of their process, including successes and failures. A key finding is the "journey learning" paradigm, which prioritizes learning the complete problem-solving process, not just the solution, showing significant performance improvements. The report contrasts this approach with traditional "shortcut learning" and advocates for open science in AI research. Additionally, the report includes examples of problem-solving and a discussion of reward models and reasoning tree construction used in their replication attempt.原文链接:https://arxiv.org/abs/2410.18982代码链接:https://arxiv.org/abs/2410.18982

【第68期】stream-x算法,省去Experience Replay的在线强化学习
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Deep Reinforcement Learning Without Experience Replay, Target Networks, or Batch UpdatesSummaryThis research paper introduces stream-x algorithms, a novel class of deep reinforcement learning algorithms designed for streaming data. Unlike traditional deep RL methods that rely on computationally expensive batch updates and experience replay, stream-x processes individual samples in real time. The authors address the "stream barrier"—the instability and learning failures common in streaming deep RL—through several techniques including a novel optimizer, data scaling, and sparse initialization. Experiments across various benchmark environments demonstrate that stream-x algorithms achieve comparable sample efficiency and performance to batch methods, sometimes surpassing them. The study challenges the prevailing assumption that streaming deep RL is inherently sample-inefficient.原文链接:https://openreview.net/forum?id=yqQJGTDGXN
【第67期】BABY-AIGS:AI-Generated Science
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:AIGS: Generating Science from AI-Powered Automated FalsificationSummaryThis research paper introduces BABY-AIGS, a multi-agent system designed to autonomously conduct scientific research. The system uses large language models (LLMs) to propose hypotheses, conduct experiments, and perform falsification, a crucial aspect of the scientific method. BABY-AIGS is evaluated on three machine learning tasks, demonstrating its capacity to generate meaningful scientific discoveries, albeit not yet at the level of experienced human researchers. The paper also discusses the ethical implications and potential societal impact of AI-generated science. The authors conclude by outlining limitations and suggesting future research directions.原文链接:https://arxiv.org/abs/2411.11910论文链接:https://agent-force.github.io/AIGS/

【第66期】Anthropic研究:给LLM评估加点“统计学”
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Adding Error Bars to Evals: A Statistical Approach to Language Model EvaluationsSummaryThis paper advocates for improved statistical rigor in evaluating large language models (LLMs). It introduces methods for calculating and reporting confidence intervals, accounting for clustered data, and reducing variance in estimates. The authors propose specific techniques, such as using paired analyses and resampling, to enhance the precision of LLM evaluations. Furthermore, they provide formulas for comparing models statistically and conducting power analyses to determine the necessary sample size for reliable hypothesis testing. The ultimate goal is to transform LLM evaluation from a simple comparison of numbers to a more statistically sound experimental process.原文链接:https://arxiv.org/abs/2411.00640

【第65期】Liquid Time-constant Networks:液体(神经)网络是什么?
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Liquid Time-constant NetworksSummaryThis research introduces Liquid Time-Constant Networks (LTCs), a novel type of continuous-time recurrent neural network. LTCs improve upon existing models by incorporating a dynamically adjusted time constant, leading to enhanced stability and expressivity. The authors provide theoretical analyses demonstrating these improvements, including bounds on network dynamics and a novel expressivity measure based on trajectory length. Furthermore, they present experimental results on various time-series prediction tasks, showcasing LTCs' superior performance compared to other recurrent neural networks. The design of LTCs is also partially motivated by biological neural network dynamics.原文链接:https://arxiv.org/abs/2006.04439解读链接:https://deepgram.com/learn/liquid-neural-networks

【第64期】NeuroClips:从fMRI数据还原大脑中视频
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:NeuroClips: Towards High-fidelity and Smooth fMRI-to-Video ReconstructionSummaryThe study introduces NeuroClips, a novel framework for reconstructing videos from fMRI brain activity. NeuroClips uses a two-pronged approach, employing separate components for reconstructing keyframes (high-level semantics) and low-level perceptual details to create smooth, high-fidelity videos. The framework significantly improves upon existing methods, achieving longer video reconstruction at higher frame rates. Experiments on a public dataset demonstrate NeuroClips' superior performance across various metrics, and the researchers explore the neural interpretability of their model. Limitations and future research directions are also discussed.原文链接:https://arxiv.org/abs/2410.19452

【第63期】无论DPO还是PPO,Preference Feedback应该怎么用?
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Unpacking DPO and PPO: Disentangling Best Practices for Learning from Preference FeedbackSummaryThis NeurIPS 2024 paper investigates the effectiveness of different components in preference-based learning for language models. The authors systematically compare Proximal Policy Optimization (PPO) and Direct Preference Optimization (DPO) algorithms, examining the influence of preference data quality, reward model design, and policy training prompts on model performance across various benchmarks. Their findings highlight the importance of high-quality preference data and reveal that PPO generally outperforms DPO, though improvements from enhanced reward models are surprisingly limited. The researchers propose a recipe for effective preference-based learning and publicly release their code and datasets to promote further research in this area.原文链接:https://arxiv.org/abs/2406.09279

【第62期】sCMs:比Diffusion更快的图像生成算法
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Simplifying, stabilizing, and scaling continuous-time consistency modelsSummaryThis research paper introduces simplified, stable, and scalable continuous-time consistency models (sCMs) for image generation. The authors propose TrigFlow, a new framework unifying existing diffusion model formulations, and implement key improvements to stabilize training. These improvements include refined time conditioning, adaptive normalization, and adaptive weighting. The resulting sCMs achieve state-of-the-art results on various datasets, even surpassing some competing methods with significantly less computational cost. Furthermore, the study compares sCMs to variational score distillation (VSD), highlighting sCMs' superior sample diversity and guidance compatibility.原文链接:https://arxiv.org/abs/2410.11081解读链接:https://openai.com/index/simplifying-stabilizing-and-scaling-continuous-time-consistency-models/

【第61期】大模型的「推理」是在做什么?
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Procedural Knowledge in Pretraining Drives Reasoning in Large Language ModelsSummaryThis research investigates how large language models (LLMs) learn to reason, contrasting their strategies for reasoning tasks with those used for factual recall. The study analyzes the influence of pretraining data on model outputs for mathematical reasoning and factual questions, revealing that LLMs utilize procedural knowledge from the pretraining data rather than simple retrieval for reasoning. The findings indicate that LLMs rely less on individual documents for reasoning and show stronger correlations between document influence across similar reasoning problems. Importantly, the presence of code in the pretraining data is highlighted as a significant factor influencing the LLMs' reasoning capabilities. The study's results offer insights into improving LLM reasoning by focusing pretraining data selection on high-quality procedural knowledge examples. Limitations are acknowledged, particularly concerning the inability to analyze the entire pretraining dataset.原文链接:https://arxiv.org/abs/2411.12580解读链接:https://www.jiqizhixin.com/articles/2024-11-22-2

【第60期】RLTools:基于C++的开源强化学习工具
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:RLtools: A Fast, Portable Deep Reinforcement Learning Library for Continuous ControlSummaryRLtools, a new open-source C++ library, significantly accelerates deep reinforcement learning (RL) for continuous control problems. Its header-only, dependency-free design enables fast training and inference across diverse platforms, from high-performance computers to microcontrollers. This speed improvement is demonstrated through benchmarks showing substantial performance gains over existing RL frameworks. A key contribution is the first-ever demonstration of training a deep RL algorithm directly on a microcontroller, opening the field of "TinyRL." The library's architecture, based on C++ templating and a novel static multiple-dispatch paradigm, is central to its speed and portability.原文链接:https://arxiv.org/abs/2306.03530庆祝完成两个月的更新~
【第59期】SymDPO:多模态In-context learning提升技巧
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:SymDPO: Boosting In-Context Learning of Large Multimodal Models with Symbol Demonstration Direct Preference OptimizationSummaryThis research introduces SymDPO, a novel method to improve the in-context learning capabilities of Large Multimodal Models (LMMs). Current LMMs often prioritize textual information over visual context in demonstrations, leading to inaccurate results. SymDPO addresses this "visual context overlook" by replacing text answers with symbols, forcing the model to rely on both visual and symbolic cues for correct responses. Experiments across various benchmarks demonstrate that SymDPO significantly enhances LMM performance compared to existing methods like General DPO, Video DPO, and MIA-DPO. The improved performance highlights SymDPO's success in fostering a more balanced understanding of multimodal information within in-context learning scenarios.原文链接:https://arxiv.org/abs/2411.11909
【第58期】AM-RADIO,融合多种视觉大模型
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:AM-RADIO: Agglomerative Vision Foundation Model -- Reduce All Domains Into OneSummaryThis paper proposes a new approach to training vision foundation models (VFMs) called AM-RADIO, which agglomerates the unique strengths of multiple pretrained models like CLIP, DINOv2, and SAM into a single model. The framework uses multi-teacher distillation to achieve this, and the resulting models outperform individual teacher models on various downstream tasks like classification, segmentation, and vision-language modeling. Notably, a new architecture called E-RADIO is introduced, which is significantly more efficient than traditional ViTs, allowing for faster inference and comparable performance. The paper thoroughly analyzes the effectiveness of the AM-RADIO approach, providing comprehensive results and insights into the distillation process.原文链接:https://arxiv.org/abs/2312.06709

【第57期】降低数值精度影响LLM数学推理能力
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:How Numerical Precision Affects Mathematical Reasoning Capabilities of LLMsSummaryThis research paper investigates how the numerical precision of a Transformer-based Large Language Model (LLM) affects its ability to perform mathematical reasoning tasks. The authors demonstrate through theoretical analysis and empirical experiments that LLMs with low numerical precision struggle with complex arithmetic tasks, such as iterated addition and integer multiplication, while LLMs with standard numerical precision excel at these tasks. The paper concludes that ensuring adequate numerical precision is essential for developing more powerful LLMs capable of complex mathematical reasoning.原文链接:https://arxiv.org/abs/2410.13857解读链接:https://www.jiqizhixin.com/articles/2024-11-18-10

【第56期】o1的self-correction是一种In context Alignment
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:A Theoretical Understanding of Self-Correction through In-context AlignmentSummaryThis research paper examines the ability of large language models (LLMs) to self-correct, specifically focusing on how this capability arises from an in-context alignment perspective. The authors present a theoretical analysis demonstrating that standard transformer architectures can perform gradient descent on common alignment objectives in an in-context manner, highlighting the crucial roles played by softmax attention, feed-forward networks, and stacked layers. They explore the practical application of intrinsic self-correction in real-world scenarios, showcasing its efficacy in alleviating social biases and defending against jailbreak attacks. The paper provides concrete theoretical and empirical insights into the potential for building LLMs that can autonomously improve their performance through self-correction.原文链接:https://openreview.net/pdf?id=OtvNLTWYww解读链接:https://www.jiqizhixin.com/articles/2024-11-18-3

【第55期】RLInspect
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:RLInspect: An Interactive Visual Approach to Assess Reinforcement Learning AlgorithmSummaryThis technical paper presents RLInspect, an interactive visual analytic tool designed to assist users in understanding and potentially debugging the training process of reinforcement learning (RL) algorithms. RLInspect provides users with a visual representation of various components of RL, such as state, action, agent architecture, and reward, which can help them identify issues during training and ultimately improve the performance of the RL model. The authors provide detailed information on the architecture and functionality of RLInspect, including examples from a Cartpole environment, and discuss potential future improvements and limitations.原文链接:https://arxiv.org/abs/2411.08392

【第54期】Impacts of AI on Innovation
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Artificial Intelligence, Scientific Discovery, and Product InnovationSummaryThis document is a research paper that explores the impact of AI on the materials discovery process within a large R&D lab. The paper uses a randomized controlled trial to analyze the effects of introducing an AI tool to scientists, examining how it impacts the discovery, patenting, and commercialization of new materials. It finds that AI significantly accelerates the pace of discovery, but its effectiveness is highly dependent on the scientist's ability to evaluate the AI-generated suggestions, revealing the critical role of human judgment in the process. The paper further investigates how AI changes the allocation of tasks for scientists, resulting in a reallocation of time from idea generation to evaluation, and ultimately impacting job satisfaction and beliefs about the future of work.原文链接:https://aidantr.github.io/files/AI_innovation.pdf

【第53期】Toward Optimal Search and Retrieval for RAG
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Toward Optimal Search and Retrieval for RAGSummaryThis document is a research paper that investigates the effectiveness of retrieval-augmented generation (RAG) for tasks such as question answering (QA). The authors examine the role of retrievers, which identify relevant documents, and readers, which process the retrieved information to generate responses. They perform experiments to determine how factors like the number of retrieved documents, gold document recall, and approximate search accuracy impact performance. Their findings highlight the importance of gold document recall, the viability of using approximate search for improved efficiency, and the detrimental effect of injecting noisy documents. The paper also discusses future directions for research in RAG.原文链接:https://arxiv.org/abs/2411.07396

【第52期】DINO-WM:LeCun 的世界模型
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:DINO-WM: World Models on Pre-trained Visual Features enable Zero-shot PlanningSummaryThis academic research paper presents DINO World Model (DINO-WM), a new method for building task-agnostic world models for visual reasoning and control in robotics. DINO-WM leverages pre-trained visual features from DINOv2 to model the dynamics of the environment in latent space without reconstructing the visual world. This enables the system to plan and optimize behaviors at test time without requiring expert demonstrations or reward modeling. The researchers evaluate DINO-WM on various control tasks, including maze navigation and object manipulation, and demonstrate its ability to generate zero-shot solutions across different environments and configurations.原文链接:https://arxiv.org/abs/2411.04983解读链接:https://www.jiqizhixin.com/articles/2024-11-16-3

【第51期】研究表明4bit量化能使反学习失效
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Does your LLM truly unlearn? An embarrassingly simple approach to recover unlearned knowledgeSummaryThis research paper investigates a critical flaw in current machine unlearning methods for large language models (LLMs). The authors discover that applying quantization, a process used to compress and optimize LLMs for resource-constrained environments, can inadvertently restore "forgotten" knowledge. The paper provides a theoretical explanation for this phenomenon and proposes a new unlearning strategy, "Saliency-Based Unlearning with a Large Learning Rate (SURE)," to mitigate this issue and ensure genuine unlearning without compromising model utility. The study underscores the need for more comprehensive and robust approaches to machine unlearning in LLMs, highlighting a critical oversight in existing unlearning benchmarks.原文链接:https://arxiv.org/abs/2410.16454解读链接:https://www.qbitai.com/2024/11/219654.html

【第50期】精度的Scaling Laws
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Scaling Laws for PrecisionSummaryThis research paper investigates the impact of precision in training and inference on the performance of large language models. The authors explore how precision affects the effective parameter count and propose scaling laws that predict performance degradation due to low-precision training and post-training quantization. They find that overtrained models are more sensitive to post-training quantization, and that training larger models in lower precision might be computationally optimal. Their unified scaling law accounts for both training and post-training effects and predicts loss in varied precision settings, ultimately suggesting that the standard practice of training models in 16-bit might be suboptimal.原文链接:https://arxiv.org/abs/2411.04330解读链接:https://www.jiqizhixin.com/articles/2024-11-13-9

【第49期】Responsibility in Multi-Agent Systems
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Measuring Responsibility in Multi-Agent SystemsSummaryThis research paper introduces a novel framework for quantitatively measuring responsibility in multi-agent systems. The authors extend the concept of causal responsibility, as defined by Parker et al., to include three metrics: proportion, probability, and entropy. These metrics provide a more nuanced understanding of an agent's involvement in achieving or preventing specific outcomes within a joint plan. The authors develop a formal model and a logic, called γATL, to represent and analyze these quantitative responsibility measures, enabling a comprehensive assessment of agents' roles in multi-agent planning scenarios.原文链接:https://arxiv.org/abs/2411.00887

【第48期】测试时训练TTT(test-time training)
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:The Surprising Effectiveness of Test-Time Training for Abstract ReasoningSummaryThis research paper investigates the effectiveness of test-time training (TTT) for improving the abstract reasoning capabilities of large language models (LLMs). The researchers demonstrate that TTT, a technique that involves updating model parameters during inference, can significantly enhance LLM performance on the Abstraction and Reasoning Corpus (ARC) benchmark. They identify key components for successful TTT, such as initial fine-tuning on similar tasks, auxiliary task formats and augmentations, and per-instance training. Their approach achieves state-of-the-art results on ARC, surpassing existing purely neural models and even matching average human performance when combined with program synthesis techniques. The study challenges the assumption that symbolic components are essential for solving complex reasoning problems, suggesting that the allocation of computational resources during test time may be the crucial factor.原文链接:https://ekinakyurek.github.io/papers/ttt.pdf解读链接:https://www.jiqizhixin.com/articles/2024-11-12-7

【第47期】LoRA vs Full Fine-tuning
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:LoRA vs Full Fine-tuning: An Illusion of EquivalenceSummaryThis research paper investigates the differences between two popular methods for fine-tuning large language models: full fine-tuning and Low-Rank Adaptation (LoRA). While both approaches can achieve comparable performance on downstream tasks, the authors show that these methods learn fundamentally different solutions. They analyze the spectral properties of weight matrices to identify "intruder dimensions" - singular vectors that appear in LoRA models but not in fully fine-tuned models. These intruder dimensions contribute to a phenomenon where LoRA models exhibit less robust generalization than full fine-tuning, especially when trained on multiple tasks sequentially. The authors further explore how the design choices in LoRA, such as rank and the scaling factor α, affect the emergence of intruder dimensions and the overall performance of the models. They conclude that although LoRA can achieve comparable performance to full fine-tuning on specific tasks, it might not be the optimal choice for scenarios requiring robust generalization and continual learning.原文链接:https://arxiv.org/abs/2410.21228
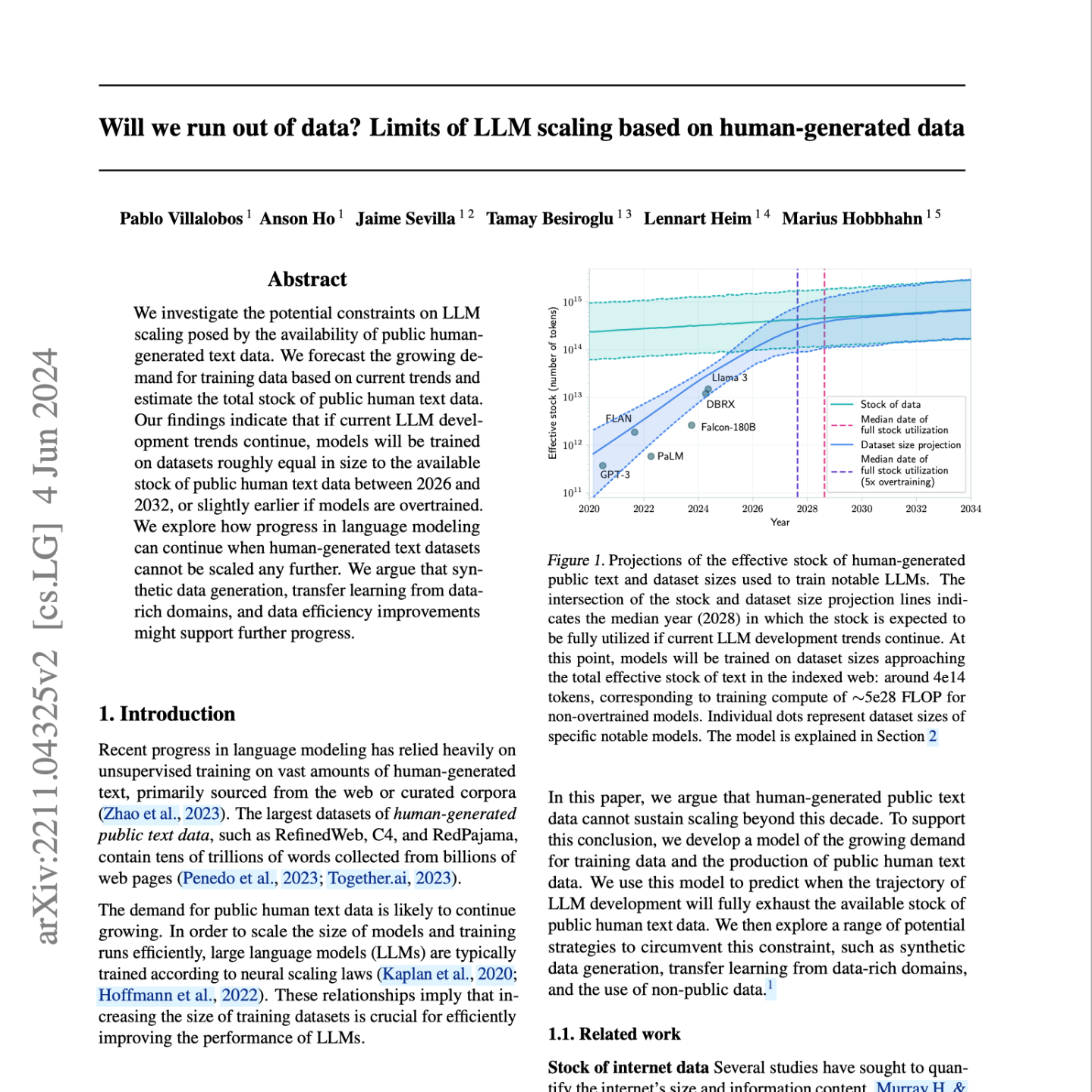
【第46期】大模型的数据会用完吗?
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Will we run out of data? Limits of LLM scaling based on human-generated dataSummaryThis research paper investigates whether the limited availability of public human text data could constrain the continued scaling of large language models (LLMs). The authors use statistical models to predict when the total available stock of text data will be exhausted based on current LLM development trends, concluding that this could happen as early as 2026. The paper then examines several potential strategies to circumvent this data bottleneck, including using models to generate synthetic data, transfer learning from data-rich domains, and the use of non-public data. Ultimately, the authors conclude that while a data bottleneck is imminent, progress in LLM development can continue through the adoption of these alternative data sources and techniques.原文链接:https://arxiv.org/abs/2211.04325

【第45期】SeqComm:多智能体通讯机制
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Multi-Agent Coordination via Multi-Level CommunicationSummaryThis research paper introduces a novel multi-agent communication scheme called Sequential Communication (SeqComm) that aims to improve coordination in cooperative multi-agent reinforcement learning (MARL) tasks. SeqComm tackles the coordination problem by treating agents asynchronously, allowing them to make decisions sequentially based on the actions of higher-level agents. The paper presents a theoretical analysis of SeqComm's performance, demonstrating that the learned policies improve monotonically and converge. Furthermore, empirical results on the StarCraft Multi-Agent Challenge v2 (SMACv2) benchmark show that SeqComm outperforms existing methods, highlighting the effectiveness of its approach to promoting explicit coordination among agents.原文链接:https://arxiv.org/abs/2209.12713

【第44期】MIPRA解读
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:A New Generation of Rules-based Approach: Mivar-based Intelligent Planning of Robot Actions (MIPRA) and Brains for Autonomous RobotsSummaryThis paper proposes a new approach to planning robot actions, based on the Mivar expert system, and explores the effectiveness of this method in comparison with existing planning techniques. The authors present the MIPRA (Mivar-based Intelligent Planning of Robot Actions) planner, which utilizes a "white box" design, allowing for transparent decision-making processes and explanations. MIPRA demonstrates the ability to quickly solve planning problems in the Blocks World domain, using a personal computer, by decomposing the task into subtasks and leveraging Mivar's logical inference capabilities. The paper compares MIPRA's performance to other planning methods, showing its potential for real-time robotic planning, especially in situations where speed is more critical than optimality. The study also discusses the integration of MIPRA into hybrid intelligent information systems for comprehensive robot control, incorporating sensory information processing and environmental interaction.原文链接:https://link.springer.com/article/10.1007/s11633-023-1473-1

【第43期】Reward Centering
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Reward CenteringSummaryThis research paper investigates the effectiveness of reward centering, a technique that involves subtracting the average reward from observed rewards in reinforcement learning problems. The authors demonstrate that this simple method can significantly improve the performance of standard reinforcement learning algorithms, particularly when using discounted rewards and as the discount factor approaches one. They explain the underlying theory behind this improvement, showing how centering removes a state-independent constant term from value estimates, enabling the algorithm to focus on the relative differences between states and actions. The paper also examines the application of reward centering in both on-policy and off-policy settings, proposing a more sophisticated method for the off-policy case, and provides a case study using Q-learning with various function approximation methods. The authors conclude that reward centering is a general technique that can enhance data efficiency and robustness in various reinforcement learning algorithms, offering potential for future algorithms that adapt their discount rate over time.原文链接:https://arxiv.org/abs/2405.09999

【第42期】SELA:使用MCTS增强LLM
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:SELA: Tree-Search Enhanced LLM Agents for Automated Machine LearningSummaryThe source explores a new method for automated machine learning called Tree-Search Enhanced LLM Agents (SELA). SELA uses a large language model (LLM) to suggest potential machine learning strategies, then employs Monte Carlo Tree Search (MCTS) to efficiently explore these options, iteratively refining its approach based on experimental results. This process mimics the nuanced problem-solving approach of human experts and consistently outperforms other AutoML systems and LLM-based agents, particularly in its ability to adapt to diverse datasets and task requirements.原文链接:https://arxiv.org/abs/2410.17238

【第41期】Multimodal RAG
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Beyond Text: Optimizing RAG with Multimodal Inputs for Industrial ApplicationsSummaryThis research paper investigates the effectiveness of incorporating images alongside text in Retrieval Augmented Generation (RAG) systems for industrial applications. The authors explore two approaches for integrating multimodal models into RAG systems: using multimodal embeddings and generating textual summaries from images. The study compares the performance of these approaches with single-modality RAG systems and a baseline model that does not utilize any retrieval. They evaluate the performance of each configuration using six metrics, including answer correctness, answer relevance, and faithfulness to both text and image content. The results indicate that multimodal RAG can outperform single-modality RAG, but image retrieval poses significant challenges. The paper concludes that leveraging textual summaries from images presents a more promising approach compared to multimodal embeddings.原文链接:https://arxiv.org/abs/2410.21943

【第40期】LLM使用bag of heuristics求解数学问题
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Arithmetic Without Algorithms: Language Models Solve Math With a Bag of HeuristicsSummaryThis research investigates how large language models (LLMs) perform arithmetic tasks. Instead of using complex algorithms or memorizing training data, the authors discovered that LLMs rely on a "bag of heuristics". These heuristics are simple rules or patterns learned from the training data that are applied to specific numerical inputs. The study shows that these heuristics emerge gradually during the model's training process and are the primary mechanism for arithmetic reasoning even in early stages.原文链接:https://arxiv.org/abs/2410.21272

【第39期】AFlow自动生成工作流
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:AFlow: Automating Agentic Workflow GenerationSummaryThis research paper presents AFLOW, a novel framework for automated workflow optimization for large language models (LLMs). It tackles the challenge of manually designing and refining agentic workflows, which are structured sequences of LLM invocations, by using Monte Carlo Tree Search (MCTS) to explore the vast search space of possible workflows. AFLOW represents these workflows as code-represented nodes connected by edges, allowing it to efficiently navigate and refine workflows through iterative modification, experience-based learning, and execution feedback. The paper showcases AFLOW's effectiveness across six benchmark datasets, demonstrating its ability to outperform both manually designed methods and existing automated approaches. It also highlights AFLOW's ability to enable smaller models to achieve better performance than larger models at significantly lower costs.原文链接:https://arxiv.org/abs/2410.10762

【第38期】OpenAI的论文:SimpleQA
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Measuring short-form factuality in large language modelsSummaryThis document introduces SimpleQA, a new benchmark for evaluating the factuality of large language models. The benchmark consists of over 4,000 short, fact-seeking questions designed to be challenging for advanced models, with a focus on ensuring a single, indisputable answer. The authors argue that SimpleQA is a valuable tool for assessing whether models "know what they know", meaning their ability to correctly answer questions with high confidence. They further explore the calibration of language models, investigating the correlation between confidence and accuracy, as well as the consistency of responses when the same question is posed multiple times. The authors conclude that SimpleQA provides a valuable framework for evaluating the factuality of language models and encourages the development of more trustworthy and reliable models.原文链接:https://openai.com/index/introducing-simpleqa/