
Seventy3
642 episodes — Page 13 of 13

【第37期】认知的几何特征
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:The Geometry of Concepts: Sparse Autoencoder Feature StructureSummaryThis research paper investigates the structure of the "concept universe" within large language models (LLMs), specifically focusing on sparse autoencoders (SAEs). The authors examine the organization of SAE features at three distinct scales. At the atomic scale, they discover "crystals" reflecting semantic relations between concepts, similar to the well-known "king:man::queen:woman" analogy. At the brain scale, they demonstrate that functionally related SAE features cluster together spatially, forming "lobes" reminiscent of functional areas in the human brain. Finally, at the galaxy scale, the authors analyze the overall shape and clustering of the SAE feature space, finding a power law distribution of eigenvalues and revealing a surprising degree of clustering.原文链接:https://arxiv.org/abs/2410.19750

【第36期】HIL-SERL
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Precise and Dexterous Robotic Manipulation via Human-in-the-Loop Reinforcement LearningSummaryThe research paper "Precise and Dexterous Robotic Manipulation via Human-in-the-Loop Reinforcement Learning" investigates the effectiveness of human-in-the-loop reinforcement learning (HIL-SERL) for training robots to perform complex manipulation tasks. The researchers present a system that combines human demonstrations and corrections with sample-efficient reinforcement learning algorithms to train robots on a diverse set of dexterous manipulation tasks, including dynamic manipulation, precision assembly, and dual-arm coordination. Their findings show that HIL-SERL significantly outperforms imitation learning baselines and prior RL approaches, achieving near-perfect success rates and fast cycle times within just 1 to 2.5 hours of training. The paper also explores the reliability and learned behaviors of the policies, demonstrating their ability to adapt dynamically to variations and handle external disturbances. The research highlights the potential of HIL-SERL as a general framework for acquiring a wide range of manipulation skills with high performance and adaptability, paving the way for the use of reinforcement learning in solving real-world robotic manipulation problems.原文链接:https://hil-serl.github.io解读:强化学习训练一两个小时,100%自主完成任务:机器人ChatGPT时刻真来了?

【第35期】DriveDreamer4D
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:DriveDreamer4D: World Models Are Effective Data Machines for 4D Driving Scene RepresentationSummaryDriveDreamer4D is a novel framework that enhances 4D driving scene representation by leveraging world models. The system uses a world model to synthesize novel trajectory video data, which is then incorporated into a 4D Gaussian Splatting (4DGS) model. The integration of the world model into the 4DGS framework allows for the creation of more realistic and dynamic 4D scenes, particularly when dealing with complex maneuvers like lane changes, acceleration, and deceleration. The authors demonstrate that DriveDreamer4D significantly improves the rendering quality of novel trajectory viewpoints and enhances the spatiotemporal coherence of foreground and background elements in these scenes, leading to more realistic and accurate representations of complex driving scenarios.原文链接:https://arxiv.org/abs/2410.13571

【第34期】Heterogeneous Pre-trained Transformers
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Scaling Proprioceptive-Visual Learning with Heterogeneous Pre-trained TransformersSummaryThis research paper proposes a new architecture called Heterogeneous Pre-trained Transformers (HPT) to address the challenges of training generalist robotic models. HPT leverages a shared "trunk" transformer network to learn a task-agnostic and embodiment-agnostic representation from diverse robotic datasets, including real-world robots, simulations, and human videos. The paper demonstrates that HPT scales effectively with increasing dataset size, model size, and training compute. Importantly, HPT's learned representations can be transferred to new embodiments, tasks, and environments, improving performance in both simulation and real-world settings.原文链接:https://arxiv.org/abs/2409.20537英文解读:https://news.mit.edu/2024/training-general-purpose-robots-faster-better-1028

【第33期】多项式激活函数
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Rethinking Softmax: Self-Attention with Polynomial ActivationsSummaryThis research paper examines the effectiveness of the softmax activation function in transformer architectures, commonly used for attention mechanisms. The authors argue that softmax's success stems not solely from its ability to produce a probability distribution for attention allocation but also from its implicit regularization of the Frobenius norm of the attention matrix. They present a theoretical framework for deriving polynomial activations that achieve similar regularization effects, even though they may violate the typical properties of softmax attention. The paper demonstrates that these alternative activations can perform comparably or better than softmax across various vision and NLP tasks, suggesting new possibilities for attention mechanisms beyond the traditional softmax approach.原文链接:https://arxiv.org/abs/2410.18613
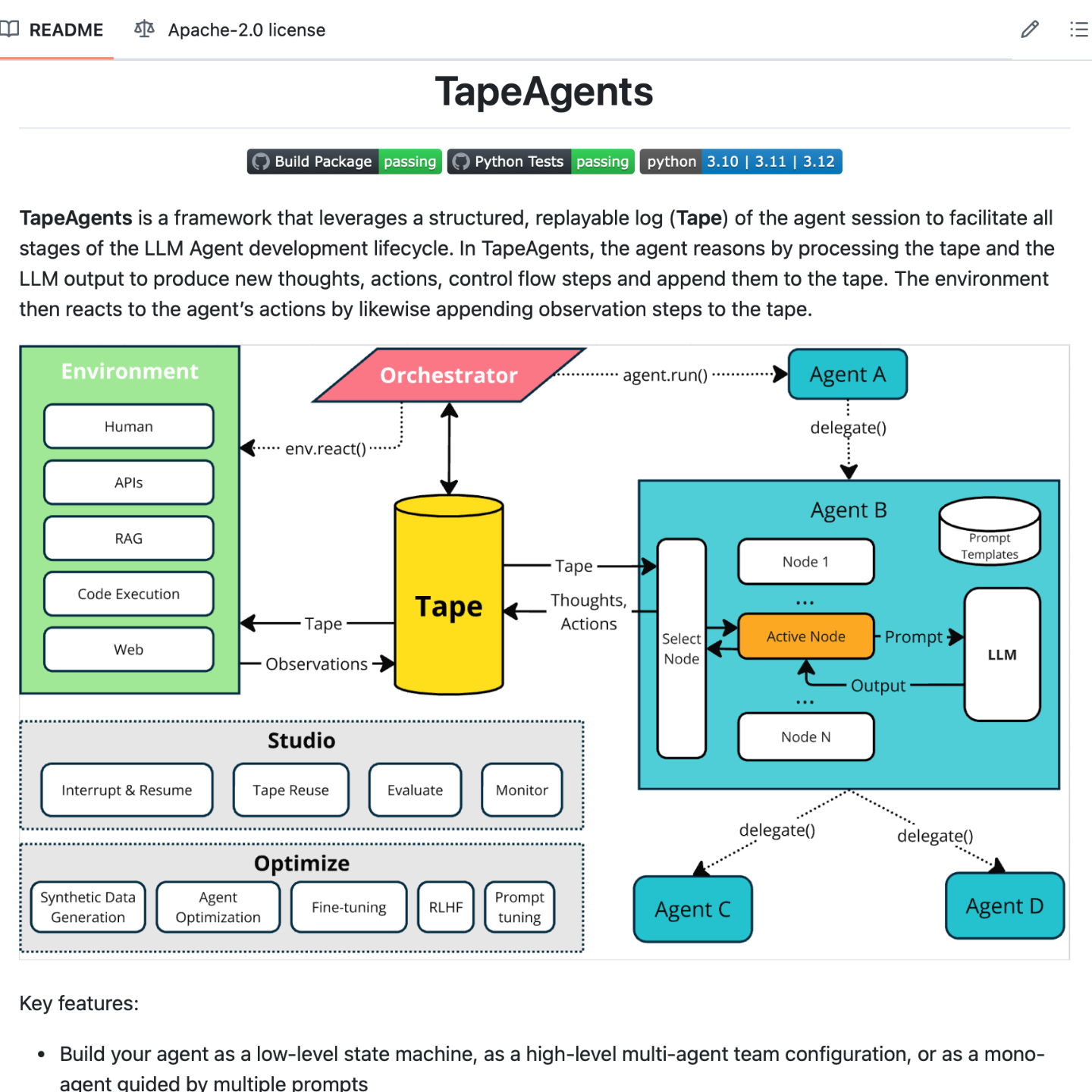
【第32期】TapeAgents:AI Agent+log
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:TapeAgents: a Holistic Framework for Agent Development and OptimizationSummaryThe sources present TapeAgents, a novel framework for developing and optimizing large language model (LLM) agents. It leverages a structured log, called a tape, that records the agent's reasoning and actions, facilitating various aspects of the LLM agent lifecycle. TapeAgents allows for session persistence, debugging, evaluation, and data-driven optimization techniques like prompt-tuning and fine-tuning. The framework is designed to be modular and extensible, supporting both monolithic agents and multi-agent teams. The authors highlight the advantages of TapeAgents over existing frameworks by showcasing its unique combination of features, including resumable state machines, granular logs, and the ability to transform logs into training data. The sources also include examples and a case study demonstrating the use of TapeAgents for building a cost-effective enterprise form-filling assistant.原文链接:https://www.servicenow.com/research/TapeAgentsFramework.pdf代码:https://github.com/ServiceNow/TapeAgents

【第31期】给prompt加一个角色有用吗?
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:When “A Helpful Assistant” Is Not Really Helpful: Personas in System Prompts Do Not Improve Performances of Large Language ModelsSummaryThis research paper investigates the impact of incorporating personas into system prompts used for interacting with large language models (LLMs). The authors conducted a large-scale study using 162 personas across 4 families of LLMs and 2,410 factual questions. They found that adding personas does not generally improve performance and may even negatively affect the model's ability to answer factual questions accurately. The researchers further explored potential mechanisms behind persona-based prompting, analyzing factors like gender, domain alignment, word frequency, and prompt similarity, but concluded that the effects of personas on model performance remain largely unpredictable. Despite the lack of consistent positive effects, they suggest that identifying the best persona for each question could lead to better performance, although automatically identifying the best persona proved challenging.原文链接:https://arxiv.org/abs/2311.10054

【第30期】Diffusion Evolution Algorithm
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Diffusion Models are Evolutionary AlgorithmsSummaryThis research paper proposes a novel approach to evolutionary algorithms called Diffusion Evolution, which draws a parallel between the process of biological evolution and the mathematical framework of diffusion models in machine learning. The authors demonstrate that diffusion models can be interpreted as performing evolutionary algorithms, inherently encompassing selection, mutation, and reproductive isolation. By utilizing the denoising process of diffusion models, the Diffusion Evolution method efficiently identifies multiple optimal solutions in complex parameter spaces, outperforming traditional evolutionary algorithms. Furthermore, the paper introduces Latent Space Diffusion Evolution, which leverages latent space diffusion to find solutions for evolutionary tasks in high-dimensional parameter spaces while significantly reducing computational steps. This new understanding of the connection between diffusion and evolution not only bridges two distinct fields but also opens new avenues for mutual enhancement and raises questions about open-ended evolution and the potential utilization of non-Gaussian or discrete diffusion models in the context of Diffusion Evolution.原文链接:https://arxiv.org/abs/2410.02543v2

【第29期】Contextual Document Embeddings
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Contextual Document EmbeddingsSummaryThis research paper proposes two methods for improving dense document embeddings, which are crucial for neural retrieval. The first method introduces a contextual training procedure that explicitly incorporates neighboring documents into the contrastive learning process. This approach aims to create embeddings that can distinguish between documents even in challenging contexts. The second method introduces a contextual architecture that embeds information about neighboring documents into the encoded representation. The paper demonstrates that both methods achieve better performance than standard biencoders, especially in out-of-domain settings. Through experimentation and analysis, the authors confirm that their proposed methods significantly improve text embedding performance across various retrieval tasks.原文链接:arxiv.org

【第28期】AEVB解读
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Auto-Encoding Variational BayesSummaryThe paper introduces a novel method for performing efficient approximate inference and learning in directed probabilistic models with continuous latent variables. This method, called Auto-Encoding Variational Bayes (AEVB), is based on a reparameterization of the variational lower bound, leading to a stochastic estimator that can be optimized using standard stochastic gradient methods. The paper demonstrates that AEVB can be used to efficiently learn the parameters of a generative model, as well as to perform inference on the latent variables. The authors also show that AEVB has theoretical advantages over other methods for performing approximate inference, and they provide experimental results that support their claims.原文链接:arxiv.org

【第27期】BERT解读
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:BERT: Pre-training of Deep Bidirectional Transformers for Language UnderstandingSummaryThe paper proposes a new language representation model called BERT (Bidirectional Encoder Representations from Transformers), which is designed to learn deep bidirectional representations from unlabeled text. Unlike prior models, BERT jointly conditions on both left and right context in all layers, which allows it to better understand the relationships between sentences. The paper demonstrates BERT's effectiveness on 11 natural language processing tasks, achieving state-of-the-art results and outperforming many task-specific architectures. BERT is conceptually simple and empirically powerful, and its code and pre-trained models are publicly available.原文链接:arxiv.org

【第26期】ELMo解读
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Deep contextualized word representationsSummaryThis research paper introduces a novel approach to deep contextualized word representation called ELMo (Embeddings from Language Models). ELMo utilizes a bidirectional language model (biLM) to learn representations for words that are context-dependent and capture both syntactic and semantic information. By incorporating ELMo into existing models for a variety of challenging natural language processing tasks, the authors demonstrate significant improvements in performance, including state-of-the-art results on question answering, textual entailment, semantic role labeling, coreference resolution, named entity extraction, and sentiment analysis. The paper provides a detailed analysis of ELMo's performance and insights into how different layers of the biLM represent different types of information.原文链接:arxiv.org

【第25期】CoVe解读
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Learned in Translation: Contextualized Word VectorsSummaryThe research paper proposes a method for improving natural language processing (NLP) models by transferring knowledge from a deep learning model trained for machine translation (MT). The authors show that incorporating contextualized word vectors (CoVe), generated by the MT encoder, into models for tasks like sentiment analysis, question classification, entailment, and question answering significantly improves performance. These context vectors capture word meaning in the context of a sentence, which allows for better transfer learning compared to using only unsupervised word vectors. The authors demonstrate that larger and more complex MT datasets lead to higher-quality CoVe representations, resulting in greater performance gains for downstream NLP tasks. They further explore how combining CoVe with other types of word embeddings, such as character n-grams, can further boost model performance.原文链接:arxiv.org

【第24期】BPE解读
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Neural Machine Translation of Rare Words with Subword UnitsSummaryThis research paper focuses on improving the translation of rare and unseen words in neural machine translation (NMT) systems by encoding words as sequences of subword units. The authors argue that using a fixed vocabulary for NMT models limits their ability to translate words not encountered during training. To address this, they propose using a technique called byte pair encoding (BPE) to segment words into smaller units, such as morphemes or phonemes, which can then be translated and combined to form new words. The paper explores various segmentation techniques and empirically demonstrates that subword models significantly outperform baseline systems, especially in the translation of rare and unseen words, including names and compounds.原文链接:https://arxiv.org/abs/1508.07909

【第23期】Diffusion World Model解读
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Diffusion World Model: Future Modeling Beyond Step-by-Step Rollout for Offline Reinforcement LearningSource: Ding et al., "Diffusion World Model: Future Modeling Beyond Step-by-Step Rollout for Offline Reinforcement Learning" (arXiv:2402.03570v4)Main Themes: Compounding errors in long-horizon prediction: Traditional one-step dynamics models suffer from accumulating errors when rolled out over long horizons. Leveraging sequence modeling for multi-step prediction: The paper proposes Diffusion World Model (DWM) as a conditional diffusion model that predicts multiple future states and rewards concurrently, mitigating compounding errors. Offline reinforcement learning: DWM is applied in offline RL to learn policies from static datasets without online interaction.Key Ideas and Facts: DWM outperforms one-step models in long-horizon planning:DWM exhibits robustness to long-horizon simulation, maintaining consistent performance even with a horizon of 31 steps, unlike one-step models which show performance degradation. "DWM-TD3BC and DWM-IQL maintain relatively high returns without significant performance degradation, even using horizon length 31." This robustness is attributed to DWM's ability to generate entire trajectories, reducing error accumulation compared to recursive one-step predictions. DWM acts as value regularization in offline RL:DWM, trained solely on offline data, can be interpreted as a representation of the behavior policy that generated the data. Integrating DWM into value estimation acts as a form of value regularization, preventing the policy from exploiting erroneous values for out-of-distribution actions. DWM offers computational advantages over Decision Diffuser (DD):Unlike DD, which needs to generate the entire trajectory at inference time, DWM only intervenes in critic training. This makes DWM-based policies more efficient to execute, as the world model doesn't need to be invoked during action generation. "This means, at inference time, DD needs to generate the whole trajectory, which is computationally expensive." DWM-based algorithms are comparable to model-free counterparts:DWM-based algorithms like DWM-TD3BC and DWM-IQL achieve performance comparable to, or even slightly exceeding, their model-free counterparts (TD3+BC and IQL) on the D4RL dataset. Key architectural choices:DWM employs a temporal U-net architecture for noise prediction, conditioned on the initial state, action, and target return. Classifier-free guidance is used to enhance the influence of the target return during training. Stride sampling is applied to accelerate the inference process.Important Quotes: Compounding Errors: "When planning for multiple steps into the future, pone is recursively invoked, leading to a rapid accumulation of errors and unreliable predictions for long-horizon rollouts." DWM for Multi-step Prediction: "Conditioning on current state st, action at, and expected return gt, DWM simultaneously predicts multistep future states and rewards." Value Regularization: "As the DWM is trained exclusively on offline data, it can be seen as a synthesis of the behavior policy that generates the offline dataset. In other words, diffusion-MVE introduces a type of value regularization for offline RL through generative modeling." Efficiency Compared to DD: "Our approach, instead, can connect with any MF offline RL methods that is fast to execute for inference."Overall, the paper presents DWM as a promising approach for mitigating compounding errors in long-horizon prediction and improving offline reinforcement learning. It offers a robust and computationally efficient alternative to traditional one-step dynamics models and showcases competitive performance against model-free methods. Further research is warranted to explore the full potential of DWM in various RL applications.原文链接:https://arxiv.org/abs/2402.03570

【第22期】Diffusion-Q Learning解读
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Diffusion Policies as an Expressive Policy Class for Offline Reinforcement LearningSource: Wang, Z., Hunt, J.J., & Zhou, M. (2023). Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning. arXiv preprint arXiv:2208.06193v3.Main Theme: This paper proposes Diffusion Q-learning (Diffusion-QL), a novel offline reinforcement learning (RL) algorithm that utilizes diffusion models for precise policy regularization and leverages Q-learning guidance to achieve state-of-the-art performance on benchmark tasks.Most Important Ideas/Facts: Limitations of Existing Policy Regularization Methods: Existing methods struggle with multimodal behavior policies, often found in real-world datasets collected from diverse sources. They rely on limited expressiveness policy classes like Gaussian distributions, which are inadequate for complex behavior patterns. Two-step regularization approaches involving behavior cloning before policy improvement introduce approximation errors, hindering performance. "The inaccurate policy regularization occurs for two main reasons: 1) policy classes are not expressive enough; 2) the regularization methods are improper." Advantages of Diffusion Models: High Expressiveness: Diffusion models can effectively capture multimodal, skewed, and complex dependencies in behavior policies, leading to more accurate regularization. Strong Distribution Matching: Diffusion model loss acts as a powerful sample-based regularization method, eliminating the need for separate behavior cloning. Iterative Refinement: Guidance from the Q-value function can be injected at each step of the reverse diffusion process, leading to a more directed search for optimal actions. "Applying a diffusion model here has several appealing properties. First, diffusion models are very expressive and can well capture multi-modal distributions." Diffusion-QL Algorithm: Diffusion Policy: A conditional diffusion model generates actions conditioned on the current state, representing the RL policy. Loss Function: Combines a behavior-cloning term encouraging actions similar to the dataset and a Q-learning term maximizing action-values. Q-learning Guidance: Backpropagates gradients through the entire diffusion chain to learn a Q-value function guiding the policy towards optimal actions. "Our contribution is Diffusion-QL, a new offline RL algorithm that leverages diffusion models to do precise policy regularization and successfully injects the Q-learning guidance into the reverse diffusion chain to seek optimal actions." Experimental Results: Superior Performance: Diffusion-QL achieves state-of-the-art results across various D4RL benchmark tasks, including challenging domains like AntMaze, Adroit, and Kitchen. Improved Behavior Cloning: Diffusion models outperform traditional methods like BC-MLE, BC-CVAE, and BC-MMD, demonstrating their ability to capture complex behavior patterns. Effectiveness of Q-learning Guidance: The combined loss function ensures that the learned policy not only mimics the dataset but also actively seeks optimal actions within the explored region. "We test Diffusion-QL on the D4RL benchmark tasks for offline RL and show this method outperforms prior methods on the majority of tasks." Limitations and Future Work: Inference Speed: The iterative nature of diffusion models can result in slower action inference compared to one-step feedforward policies. Future research could focus on improving the sampling efficiency of diffusion models by employing techniques like distillation or advanced sampling methods.Overall, Diffusion-QL presents a significant advancement in offline RL by leveraging the power of diffusion models for policy regularization. The algorithm effectively addresses the limitations of existing methods and demonstrates superior performance on challenging benchmark tasks, offering promising avenues for future research in the field.原文链接:https://arxiv.org/abs/2208.06193

【第21期】DPPO解读
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Diffusion Policy Policy OptimizationThis briefing document reviews the key themes and findings presented in the research paper "DPPO: Diffusion Policy Policy Optimization" (arXiv:2409.00588v1). The paper introduces DPPO, a novel method for fine-tuning pre-trained robot policies parameterized as diffusion models using reinforcement learning (RL).Key Themes Limitations of Behavior Cloning: While behavior cloning with expert data is a popular method for pre-training robot policies, it can result in suboptimal performance due to limitations in expert data quality and coverage. Diffusion Models as Policies: Diffusion models are emerging as a leading parameterization for action policies due to their training stability and ability to represent complex distributions. RL for Fine-tuning Diffusion Policies: DPPO leverages RL, specifically Proximal Policy Optimization (PPO), to fine-tune pre-trained diffusion policies, enabling them to surpass the limitations of demonstration data.Important Ideas and Facts Two-Layer Diffusion Policy MDP: DPPO conceptualizes the fine-tuning process as a two-layer Markov Decision Process (MDP). The outer layer represents the environment MDP, while the inner layer represents the denoising MDP within the diffusion model. This allows for applying policy gradient updates through the entire process. Structured Exploration: DPPO facilitates structured exploration by leveraging the inherent noise within the diffusion model. This is in contrast to traditional Gaussian policies that rely on unstructured exploration noise. Training Stability: DPPO exhibits high training stability attributed to the smooth and gradual refinement of the action distribution during the denoising process. Policy Robustness: DPPO produces robust policies that can handle noise injected into the actions during fine-tuning, further demonstrating its stability. Generalization: DPPO showcases strong generalization capabilities, outperforming baseline methods in various benchmark tasks, including complex long-horizon manipulation tasks.Key Findings Superior Performance: DPPO consistently outperforms existing diffusion-based RL algorithms and traditional policy parameterizations in benchmark tasks, including locomotion and manipulation. Successful Sim-to-Real Transfer: DPPO demonstrates successful sim-to-real transfer in challenging furniture assembly tasks, highlighting its real-world applicability. Corrective Behavior: The fine-tuned policies exhibit corrective behavior, adapting to errors and uncertainties in the environment.Supporting Quotes Suboptimality of Expert Data: "Though behavior cloning with expert data is rapidly emerging as dominant paradigm for pre-training robot policies, their performance can be suboptimal due to expert data being suboptimal or expert data exhibiting limited coverage of possible environment conditions." Diffusion Models as Policies: "Diffusion models [29], which have emerged as a leading parameterization for action policies [15, 63, 52], due in large part to their high training stability and ability to represent complex distributions [65, 57, 39, 30]." Two-Layer Diffusion Policy MDP: "We extend this formalism by embedding the Diffusion MDP into the environmental MDP, obtaining a larger 'Diffusion Policy MDP' denoted MDP, visualized in Fig. 3." Structured Exploration: "DPPO explores in wide coverage around the expert data manifold, whereas Gaussian generates less structured exploration noise (especially in M2) and GMM exhibits narrower coverage." Policy Robustness: "Fine-tuning performance (averaged over five seeds, standard deviation not shown) after pre-training with M2. (Left) Noise is injected into the applied actions after a few training iterations. (Right) The action chunk size Ta is varied." Sim-to-Real Transfer: "Qualitative comparison of pre-trained vs. fine-tuned DPPO policies in hardware evaluation. (A) Successful rollout with the pre-trained policy. (B) Failed rollout with the pre-trained policy due to imprecise insertion. (C) Successful rollout with the fine-tuned policy. (D) Successful rollout with the fine-tuned policy exhibiting corrective behavior."ConclusionDPPO presents a promising approach for leveraging the strengths of diffusion models for robot policy learning. By effectively combining diffusion models with RL fine-tuning, DPPO enables the development of robust and generalizable robot policies that can outperform traditional methods, particularly in complex real-world scenarios.原文链接:https://arxiv.org/abs/2409.00588

【第20期】Diffusion Policy解读
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Diffusion Policies for Out-of-Distribution Generalization in Offline Reinforcement LearningThis briefing doc reviews the paper "Diffusion Policies for Out-of-Distribution Generalization in Offline Reinforcement Learning" by Ada, Oztop, and Ugur. The paper proposes a novel method, State Reconstruction for Diffusion Policies (SRDP), which improves upon existing diffusion-based ORL algorithms by tackling the challenge of out-of-distribution (OOD) state generalization.Key Themes and Ideas: ORL Challenges: The paper emphasizes the core challenges of ORL, namely distribution shift (discrepancy between training and evaluation data distributions) and uncertainty estimation (handling states and actions not encountered during training). OOD Generalization: The authors stress the importance of OOD generalization for building reliable and adaptable RL systems, especially in real-world scenarios. Diffusion Models for ORL: The paper builds upon recent research utilizing diffusion models for representing multimodal behavior in ORL datasets. While effective in capturing multimodality, existing diffusion-based methods lack specific mechanisms for addressing OOD state generalization. State Reconstruction as Guidance: SRDP introduces an auxiliary state reconstruction loss to guide the diffusion process. This loss encourages the model to learn more generalizable state representations, aiding in handling unseen states.Key Facts and Contributions: SRDP Algorithm: SRDP integrates state reconstruction feature learning into diffusion policies. It uses a shared representation layer for both state reconstruction and noise prediction, promoting generalization to OOD states. 2D Multimodal Contextual Bandit Environment: The authors design a novel environment to showcase the benefits of SRDP in handling OOD states and demonstrating faster convergence compared to baseline algorithms. D4RL Benchmark Performance: SRDP achieves state-of-the-art performance on D4RL continuous control benchmarks, including AntMaze and Gym-MuJoCo datasets. These environments encompass complex robotics tasks with varying levels of suboptimal data, demonstrating the robustness and efficacy of SRDP.Key Quotes: On the importance of OOD generalization: "Leveraging large datasets and generalizing to unforeseen situations are critical components of intelligent systems...out-of-distribution (OOD) generalization, is crucial for developing reliable systems that can adapt to unexpected conditions." On the limitations of existing diffusion-based methods: "Even though Diffusion-QL can represent multimodal actions, it is often unstable in OOD state regions." Introducing SRDP: "We introduce a novel method named State Reconstruction for Diffusion Policies (SRDP), incorporating state reconstruction feature learning in the recent class of diffusion policies to address the out-of-distribution generalization problem." On the impact of state reconstruction loss: "State reconstruction loss promotes generalizable representation learning of states to alleviate the distribution shift incurred by the out-of-distribution (OOD) states."Future Directions:The paper suggests evaluating SRDP on more challenging ORL tasks specifically designed for OOD generalization. Further research could explore the application of SRDP in real-world domains and investigate its potential for improving safety and reliability in areas like autonomous driving and robotics.Overall:This paper presents a significant advancement in addressing OOD state generalization within the context of ORL. SRDP demonstrates promising results on benchmark tasks and provides a valuable foundation for future research in this critical area.原文链接:https://arxiv.org/abs/2307.04726

【第19期】Augmented Physics
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Augmented Physics: Bringing Textbook Diagrams to LifAugmented Physics: Creating Interactive and Embedded PhysicsProblem: The limitations of static learning materialsThe authors identify several key challenges in current physics education stemming from the reliance on static visualizations: Difficulty representing time-dependent concepts: Static diagrams struggle to effectively convey concepts involving motion or dynamic systems. Limited interactivity in videos: While videos offer a dynamic representation, they lack the interactivity crucial for intuitive learning and experimentation. Lack of instructional scaffolding in online simulators: Existing simulators often lack the context and guidance found in textbooks, making them challenging for novice learners. Misalignment and distractions from external content: Sourcing external resources like YouTube videos can introduce inconsistencies with classroom materials and lead to distractions.Solution: Augmented Physics, an interactive learning toolAugmented Physics is a machine learning-integrated authoring tool designed to address these challenges. The system enables users to: Semi-automatically extract diagrams from textbooks: Leveraging advanced computer vision techniques like Segment-Anything and Multi-modal LLMs, users can easily isolate and segment elements from textbook images. Generate interactive simulations based on extracted content: The segmented images are converted into simulation-ready objects, allowing for dynamic manipulation and real-time feedback. Seamlessly integrate simulations into textbook pages: The interactive simulations are directly overlaid onto the textbook PDF, providing a contextualized and integrated learning experience.Four Key Augmentation StrategiesInformed by a formative study with physics instructors, the authors implemented four key augmentation strategies: Augmented Experiments: Users can manipulate textbook diagrams and observe real-time changes based on physics principles. For example, adjusting the position of a lens in an optics diagram or modifying resistance values in a circuit. Animated Diagrams: Static diagrams are converted into looped animations to demonstrate dynamic processes. This can involve animating an object's trajectory or visualizing wave propagation. Bi-Directional Binding: Linking parameter values from text to the simulation allows users to modify values within the text and observe real-time effects on the simulation, and vice-versa. Parameter Visualization: Users can visualize selected parameter values through dynamic graphs, providing insights into changing variables like velocity or energy.Technical Evaluation and User StudiesThe system was evaluated through technical evaluations, a usability study with 12 participants, and expert interviews with 12 physics instructors. Key findings include: High success rate for object segmentation: The system achieved an 86% success rate in accurately segmenting objects from diagrams. Varying success rates across simulation types: The overall success rates for generating functional simulations without modification were 64% for kinematics, 44% for optics, and 40% for circuits. Positive user feedback: Users found the system intuitive and engaging, particularly appreciating the Parameter Visualization and Bi-Directional Binding features. Complementary role to existing resources: Experts viewed Augmented Physics as a valuable tool for personalized learning and self-led exploration, complementing rather than replacing existing online resources and live experiments.Limitations and Future DirectionsThe paper acknowledges several limitations and outlines future research directions: Scaling to more complex concepts and broader domains: Future work will focus on expanding the system's capabilities to handle more complex physics topics and diverse diagram styles. Integration with AR devices: The authors envision implementing the system within AR environments to enhance immersion and engagement. Leveraging AI for enhanced learning: Further exploration of multimodal LLMs could enable intelligent tutoring features and automated simulation generation.ConclusionAugmented Physics presents a promising approach to enriching physics education by bringing textbook diagrams to life. By seamlessly integrating interactive simulations into existing learning materials, the system empowers students to engage with complex concepts in a personalized and intuitive manner. Future research will focus on expanding its capabilities and exploring its potential for large-scale deployment and integration with advanced technologies like AR and AI.原文链接:https://arxiv.org/abs/2405.18614

【第18期】Geometry-Informed Neural Networks
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Geometry-Informed Neural NetworksThis document briefs you on the main themes and important findings of the research paper "Geometry-Informed Neural Networks" by Berzins et al. The paper introduces a novel framework called GINNs, which are neural networks trained to generate 3D shapes solely based on user-defined geometric constraints and objectives, without relying on any training data.Key Themes: Data-Free Shape Generation: GINNs address the challenge of limited shape datasets in computer graphics and engineering by using pre-existing knowledge in the form of geometric constraints and objectives. This opens up new possibilities for generative design, especially in domains where data is scarce. Leveraging Geometric Constraints: The core idea behind GINNs is to represent shapes implicitly using neural fields and then train these networks to satisfy user-defined constraints. These constraints can include requirements on shape topology (e.g., number of holes, connectedness), smoothness, interface connections, and more. Generating Diverse Solutions: GINNs incorporate a diversity constraint to prevent mode collapse and encourage the generation of multiple, distinct solutions that meet the specified requirements. This diversity is crucial for design exploration and finding optimal solutions. Structured Latent Space: The use of a latent variable z to condition the neural field enables GINNs to learn a structured latent space. This means that traversing the latent space results in smooth and interpretable variations in the generated shapes, allowing for efficient design space exploration.Key Findings: GINNs Successfully Solve Geometric Problems: The researchers demonstrated the effectiveness of GINNs on various validation problems, including Plateau's problem and generating a parabolic mirror. They also showcased a realistic 3D engineering design task of creating a jet engine bracket, illustrating how GINNs can generate diverse and feasible solutions under complex constraints. Diversity Constraint is Crucial: Experiments showed that adding a diversity constraint significantly improves the performance of GINNs, preventing mode collapse and leading to a wider range of generated shapes. Without the diversity constraint, the network often converged to a single solution, limiting its utility for design exploration. Emergent Latent Space Structure: The diversity constraint also led to the emergence of a structured latent space where similar shapes are clustered together. This structure allows designers to intuitively navigate the latent space and explore different design variations.Important Quotes: "Is it possible to train a shape-generative model on objectives and constraints alone, without relying on any data?" - This question sets the stage for the paper's central theme and the development of GINNs. "GINNs are trained to satisfy specified design constraints and to produce feasible shapes without any training samples." - This highlights the key characteristic of GINNs, differentiating them from traditional data-driven methods. "By complementing the design requirements with a diversity constraint, we can train a shape-generative model without data..." - This emphasizes the importance of the diversity constraint in achieving data-free shape generation. "...this induces a structured latent space, with generalization capacity and interpretable directions." - This showcases the emergent structure of the latent space and its benefits for design exploration.Limitations and Future Work: Further investigation of different shape distances and aggregation methods for the diversity constraint: This could lead to more robust and efficient diversity enforcement. Exploration of more sophisticated neural field conditioning mechanisms: This could enhance the expressiveness and controllability of GINNs. Integration of partial shape observations into the GINN framework: This would allow GINNs to benefit from limited data when available, bridging the gap between data-free and data-driven methods. Comparison with established topology optimization methods: This is crucial for evaluating the practical value of GINNs in engineering design.Conclusion:GINNs represent a significant step towards data-free generative design, demonstrating the feasibility of training shape-generative models solely based on geometric constraints. This research opens up exciting new avenues for exploring design spaces and finding innovative solutions in domains where data is scarce. Further research and development of this framework hold great promise for revolutionizing design processes in various fields.原文链接:https://arxiv.org/abs/2402.14009
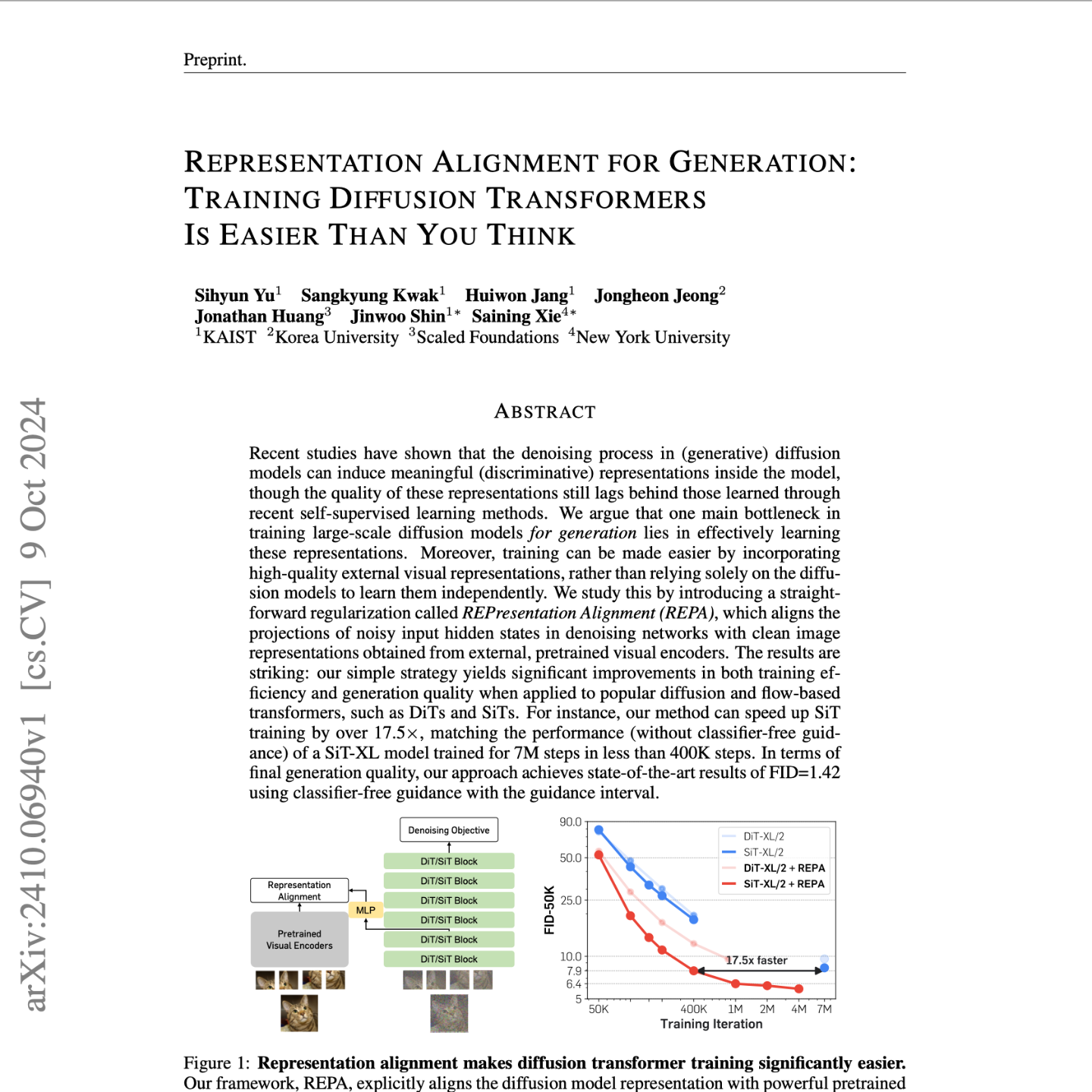
【第17期】REPA解读
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You ThinkMain Theme: This paper introduces REPresentation Alignment (REPA), a novel technique for accelerating and improving the training of diffusion transformers for image generation by aligning their internal representations with high-quality, pre-trained visual representations from self-supervised learning models.Key Findings: Diffusion models learn discriminative representations, but they lag behind dedicated self-supervised methods: While analyzing SiT and DiT models, the authors observed that their hidden states contain semantically meaningful information (demonstrated by linear probing). However, their performance on image classification tasks falls significantly short of models like DINOv2. Weak alignment exists between diffusion model representations and self-supervised representations: Using CKNNA, a representation alignment metric, the authors revealed a weak alignment between diffusion models and DINOv2, suggesting room for improvement. REPA effectively bridges this representation gap: By regularizing the diffusion model to align its hidden states with pre-trained representations (e.g., DINOv2) of clean images, REPA significantly boosts training efficiency and final generation quality. This is evident in improved FID scores, faster convergence, and better linear probing accuracy.Most Important Ideas and Facts: REPA Mechanism: REPA works by maximizing the similarity between a projection of the noisy input's hidden state in the diffusion model and the pre-trained representation of the corresponding clean image. This encourages the diffusion model to learn noise-invariant, semantically rich features early on. "REPA distills the pretrained self-supervised visual representation y∗ of a clean image x into the diffusion transformer representation h of a noisy input x̃." Impact on Training Efficiency: REPA significantly accelerates training convergence. Notably, SiT-XL/2 with REPA achieved an FID of 7.9 in just 400K iterations, surpassing the vanilla SiT-XL/2 trained for 7M iterations. This translates to a >17.5x speedup. "Notably, model training becomes significantly more efficient and effective, and achieves >17.5× faster convergence than the vanilla model." Improved Generation Quality: REPA consistently improves FID scores across different model sizes and architectures. For SiT-XL/2, REPA achieved a state-of-the-art FID of 1.42 with guidance interval scheduling, outperforming existing diffusion models. "In terms of final generation quality, our approach achieves state-of-the-art results of FID=1.42 using classifier-free guidance with the guidance interval." Targeted Regularization: Applying REPA to only the first few transformer blocks proves most effective, allowing later layers to focus on refining high-frequency details based on the already aligned representations. "Interestingly, with REPA, we observe that sufficient representation alignment can be achieved by aligning only the first few transformer blocks." Stronger Encoders Yield Better Results: Utilizing more powerful pre-trained encoders as the target representation consistently leads to improved generation and linear probing results, highlighting the importance of high-quality representations. "When a diffusion transformer is aligned with a pretrained encoder that offers more semantically meaningful representations (i.e., better linear probing results), the model not only captures better semantics but also exhibits enhanced generation performance"Quotes: Figure 1 caption: "Representation alignment makes diffusion transformer training significantly easier. Our framework, REPA, explicitly aligns the diffusion model representation with powerful pretrained visual representation through a simple regularization. Notably, model training becomes significantly more efficient and effective, and achieves >17.5× faster convergence than the vanilla model." Section 3.3: "REPA aligns patch-wise projections of the model’s hidden states with pretrained self-supervised visual representations. Specifically, we use the clean image representation as the target and explore its impact." Section 4.3: "REPA shows consistent and significant improvement across all model variants. In particular, on SiT-XL/2, aligning representation leads to FID=7.9 at 400K iteration, which already exceeds the FID of the vanilla SiT-XL at 7M iteration."Overall, this paper presents a simple yet powerful method for leveraging the strengths of self-supervised representation learning to significantly improve the training process and generation capabilities of diffusion transformers. This opens up promising avenues for future research in combining generative and discriminative learning paradigms for better and more efficient image synthesis.原文链接:https://arxiv.org/abs/2410.06940

【第16期】GSM-Symbolic苹果研究人员表示AI模型可能不具有推理能力
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language ModelsTheme: This document reviews research exploring the limitations of Large Language Models (LLMs) in performing true mathematical reasoning, despite apparent high performance on benchmarks like GSM8K.Key Ideas: LLMs exhibit high performance variance on minor question variations: While LLMs show impressive results on standardized math benchmarks, their performance is surprisingly inconsistent across minimally altered versions of the same questions. This variability raises concerns about the reliability of reported metrics and suggests potential data contamination issues. (See Figure 2, Section 4.1 of the paper)"The performance of all models drops on GSM-Symbolic, hinting at potential data contamination." LLMs are sensitive to numerical changes and question complexity: LLMs demonstrate increased fragility when numerical values in questions are changed, compared to changes in superficial elements like names. Their performance also degrades significantly as the complexity of questions increases, suggesting a lack of genuine logical reasoning and a reliance on pattern matching learned from training data. (See Figure 4, Section 4.2 and Figure 6, Section 4.3 of the paper)"Performance degradation and variance increase as the number of clauses increases, indicating that LLMs’ reasoning capabilities struggle with increased complexity." LLMs struggle to discern relevant information: The researchers introduce a novel dataset, GSM-NoOp, which adds irrelevant clauses to math problems. LLMs fail to ignore these irrelevant details, leading to a drastic drop in performance. This indicates a fundamental flaw in their ability to understand mathematical concepts and apply logical reasoning to problem-solving. (See Figure 7, Section 4.4 of the paper)"This reveals a critical flaw in the models’ ability to discern relevant information for problem-solving, likely because their reasoning is not formal in the common sense term and is mostly based on pattern matching." Few-shot learning and fine-tuning provide limited improvements: Even when provided with multiple examples of the same question, or examples with similar irrelevant information, LLMs struggle to overcome the challenges posed by the GSM-NoOp dataset. This suggests that current mitigation strategies are insufficient to address the underlying issues in their reasoning processes. (See Figure 8, Section 4.4 of the paper)"This suggests deeper issues in their reasoning processes that cannot be alleviated by in-context shots and needs further investigation."Key Facts: GSM-Symbolic: A new benchmark introduced in the paper, created from symbolic templates that allow for generating diverse sets of math questions. GSM-NoOp: A dataset designed to test LLMs' ability to discern relevant information by adding inconsequential clauses to math problems. Performance drops of up to 65%: Observed in LLMs across all state-of-the-art models on the GSM-NoOp dataset.Overall, the research highlights the need for: More reliable evaluation methodologies to assess LLMs' mathematical reasoning abilities. Further research into developing AI models capable of genuine logical reasoning, going beyond pattern recognition to achieve robust and generalizable problem-solving skills.Noteworthy Findings: The performance of even advanced models like o1-preview and o1-mini significantly deteriorates on GSM-NoOp, indicating that limitations persist despite their generally strong performance. Fine-tuning on easier tasks doesn't necessarily translate to improved performance on more difficult tasks, questioning the efficacy of simple scaling approaches.Implications: This research has significant implications for the development and application of LLMs in fields requiring reliable mathematical reasoning. Current LLMs may not be suitable for tasks demanding accurate and consistent mathematical problem-solving. More robust and formal reasoning capabilities are necessary to achieve truly intelligent systems.原文链接:https://arxiv.org/abs/2410.05229v1

【第15期】Truthfulness Encodings
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Exploring Truthfulness Encoding in LLMsThis briefing doc analyzes the paper "LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations" by Orgad et al. (2024). The authors investigate the internal representations of LLMs to understand how they encode information related to the truthfulness of their outputs, a phenomenon often referred to as "hallucinations."Key Themes: Intrinsic Analysis of LLM Hallucinations: The paper focuses on understanding LLM errors from an internal perspective by analyzing intermediate representations, unlike previous research that primarily relied on extrinsic, behavioral analysis. Truthfulness Encoding in Specific Tokens: A key finding is that information about the truthfulness of LLM outputs is concentrated in specific tokens, particularly the exact answer tokens. Skill-Specific Truthfulness Encoding: The paper challenges the notion of "universal truthfulness" encoding, demonstrating that truthfulness encoding is not universal but rather multifaceted and specific to the skill required for a given task. Predictability of Error Types: Internal representations can be used to predict the types of errors an LLM is likely to make, suggesting that LLMs may encode information about their own fallibility. Discrepancy between Internal Encoding and External Behavior: LLMs may internally encode the correct answer but consistently generate an incorrect one, highlighting a potential disconnect between their understanding and output generation.Most Important Ideas/Facts: Localization of Truthfulness Signals:The authors discovered that probing the internal activations of LLMs at the exact answer tokens significantly enhances error detection performance. "We find that truthfulness information is concentrated in the exact answer tokens – e.g., 'Hartford' in 'The capital of Connecticut is Hartford, an iconic city...'" Skill-Specific Truthfulness Features:Probing classifiers trained on one dataset fail to generalize to other datasets, even those with similar overall patterns of truthfulness signals. "This suggests that, although the overall pattern of truthfulness signals across tokens appeared consistent across tasks (...). LLMs have many "skill-specific" truthfulness mechanisms rather than universal ones." Taxonomy of Errors and Their Predictability:The authors introduce a novel taxonomy of LLM errors based on response patterns observed across repeated samples. Error types, such as consistently incorrect answers or the presence of competing answers, are shown to be predictable from the LLM's internal representations. "This classification offers a more nuanced understanding of errors, enabling developers to predict error patterns and implement more targeted mitigation strategies." Potential for Improved Answer Selection:While probes trained to detect errors can be used to select answers from a pool of generated responses, this does not drastically improve accuracy compared to traditional methods. This suggests an alignment between internal truthfulness encoding and external behavior, although further investigation is needed to confirm this.Implications: Enhanced Error Analysis and Mitigation: By understanding how LLMs internally encode truthfulness, researchers can develop better methods for analyzing and mitigating LLM errors. Targeted Intervention Strategies: The predictability of error types opens avenues for developing targeted intervention strategies tailored to specific error patterns. Cautious Deployment of Error Detectors: The study emphasizes the need for caution in deploying trainable error detectors in practical applications, as truthfulness encoding varies across tasks.Future Research Directions: Disentangling Skill-Specific Truthfulness Mechanisms: Further research is needed to understand the various mechanisms by which LLMs encode truthfulness for different tasks. Bridging the Gap between Internal Encoding and External Behavior: Investigating the discrepancies between internal truthfulness representations and actual output generation is crucial for enhancing LLM reliability. Developing Practical Error Mitigation Strategies: Building on the insights gained, researchers can develop practical strategies for mitigating LLM errors in real-world applications.Overall, this paper provides valuable insights into the internal workings of LLMs and their limitations, paving the way for future research aimed at improving LLM accuracy and trustworthiness.原文链接:https://arxiv.org/abs/2410.02707

【第14期】Intelligence at the Edge of Chaos
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Intelligence at the Edge of ChaosMain Themes: This paper explores the emergence of intelligence in artificial systems, particularly focusing on how the complexity of simple rule-based systems influences the capabilities of large language models (LLMs) trained on them. The central hypothesis is that intelligence can emerge not just from exposure to intelligent data, but also from modeling systems with complex behaviors, even if the data generation process itself lacks inherent intelligence. The research uses Elementary Cellular Automata (ECA) as a testbed to investigate the link between system complexity and emergent intelligence in LLMs.Most Important Ideas/Facts: Complexity drives intelligence: The study finds a positive correlation between the complexity of ECA rules and the performance of LLMs trained on them in downstream tasks like reasoning and chess move prediction. As stated in the paper, "Our findings reveal that rules with higher complexity lead to models exhibiting greater intelligence, as demonstrated by their performance on reasoning and chess move prediction tasks." Optimal complexity: the "edge of chaos": The research highlights an "edge of chaos," an optimal level of complexity where systems are structured yet challenging to predict. Both very simple and highly chaotic systems result in poorer downstream performance. This is consistent with the concept of "computation at the edge of chaos," where systems poised between order and disorder exhibit maximal computational capabilities. LLMs learn complex solutions even for simple rules: Analysis of attention patterns reveals that LLMs trained on complex ECA rules learn to integrate information from past states, going beyond simply memorizing the rule itself. This suggests that they are developing more sophisticated reasoning strategies, even when simpler solutions are available. The authors argue that "the fact that the complex models are attending to previous states indicate that they are learning a more complex solution to this simple problem, and we conjecture that this complexity is what makes the model 'intelligent' and capable of repurposing learned reasoning to downstream tasks." Short-term prediction can outperform long-term prediction: Counterintuitively, models trained to predict the next immediate state often outperformed models trained on predicting states further into the future, indicating that complex learning can occur even in short-term prediction tasks.Supporting Evidence: The paper provides extensive quantitative results, including: Correlation coefficients showing significant relationships between rule complexity (measured using Lempel-Ziv complexity, compression complexity, Lyapunov exponent, and Krylov complexity) and downstream task performance. Efficiency comparisons (inverse of epochs to reach 80% accuracy) for reasoning tasks. Accuracy scores for chess move prediction. Visualizations of attention scores demonstrate how models trained on more complex rules leverage information from past states. UMAP projections of Centered Kernel Alignment (CKA) similarities reveal that models trained on rules with similar complexity levels cluster together, indicating shared representational structures.Implications: This work contributes to the growing body of research on emergent abilities in LLMs, highlighting the importance of data complexity and suggesting strategies for data curation and selection. The findings may also offer insights into the nature of human intelligence, particularly its relationship with environmental complexity. Future research directions include training larger LLMs on synthetic data generated by other rule-based systems and exploring the connection between model size, data complexity, and the emergence of specific cognitive abilities.Quotes: "We conjecture that intelligence arises from the ability to predict complexity and that creating intelligence may require only exposure to complexity." "These results highlight the existence of a 'sweet spot' of complexity conducive to intelligence, where the system is still predictable yet hard to predict." "We hypothesize that by learning to incorporate past states, the model develops generalizable logic that can be reused across tasks."Overall, this paper offers a compelling argument for the role of complexity in the emergence of intelligence in artificial systems, supported by rigorous empirical evidence and insightful analysis.原文链接:https://www.arxiv.org/abs/2410.02536

【第13期】n-gram解读
Seventy3: 用NotebookML将论文生成播客,让大家跟着AI一起进步。今天的主题是:Enriching Word Vectors with Subword InformationSource: Bojanowski, Piotr, et al. "Enriching Word Vectors with Subword Information." arXiv preprint arXiv:1607.04606 (2016).Main Theme: This paper introduces a novel method for improving continuous word representations by incorporating subword information, specifically character n-grams, into the skip-gram model. This approach proves particularly beneficial for morphologically rich languages and in scenarios with limited training data.Key Ideas & Facts: Problem: Traditional word representation models assign distinct vectors to each word, neglecting morphology and struggling with rare words. Proposed Solution: Represent each word as a bag of character n-grams (3-6 characters). Each n-gram receives a vector representation, and the word vector is the sum of its n-gram vectors. Advantages:Captures morphological similarities between words. Enables learning representations for out-of-vocabulary (OOV) words. Shows robustness to training data size, achieving good performance even with limited data. Model: Extends the continuous skip-gram model with negative sampling. Evaluation:Word Similarity: Outperforms baselines (Word2Vec) on datasets across nine languages, demonstrating significant improvements for morphologically rich languages like German and Russian. Word Analogies: Shows considerable improvements in syntactic analogies, particularly for morphologically rich languages, while semantic analogies show mixed results. Comparison with Morphological Representations: Achieves comparable or superior performance to other methods incorporating morphological information, including those using complex morphological analysis. Effect of Training Data Size: Outperforms baselines even with significantly smaller training datasets (e.g., 5% of full data). Effect of N-gram Size: Experiments suggest using n-grams of 3-6 characters provides a good balance, with longer n-grams proving more beneficial for languages with compound words (e.g., German). Language Modeling: Initializing a recurrent neural network language model with these subword-informed word vectors reduces perplexity, particularly for morphologically rich languages. Qualitative Analysis:Nearest neighbor analysis shows that the model identifies semantically relevant neighbors for rare and technical words more effectively than the baseline. Analysis of influential n-grams reveals they often correspond to meaningful morphemes, capturing prefixes, suffixes, and roots. Visualization of n-gram similarities for OOV words demonstrates the model's ability to capture relationships based on meaningful subword units.Quotes: "By exploiting the character-level similarities between “Tischtennis” and “Tennis”, our model does not represent the two words as completely different words." "This has a very important practical implication: well performing word vectors can be computed on datasets of a restricted size and still work well on previously unseen words." "This shows the importance of subword information on the language modeling task and exhibits the usefulness of the vectors that we propose for morphologically rich languages."Conclusion: This paper presents a simple yet effective approach for enriching word representations by leveraging subword information. This method exhibits significant advantages over traditional approaches, especially for morphologically rich languages and when training data is limited. This work has important implications for various NLP tasks and opens avenues for further research in subword-level modeling.原文链接:aclanthology.org

【第12期】GloVe解读
Seventy3: 用NotebookML将论文生成播客,让大家跟着AI一起进步。今天的主题是:GloVe: Global Vectors for Word RepresentationThis briefing document reviews the main themes and key findings of the paper "GloVe: Global Vectors for Word Representation" by Pennington, Socher, and Manning. The paper introduces GloVe, a novel model for learning word embeddings that combines the strengths of global matrix factorization and local context window methods.Key Themes: Limitations of Existing Methods: The authors highlight the drawbacks of existing word representation learning methods: Global matrix factorization methods (e.g., LSA) efficiently leverage global corpus statistics but fail to capture the finer linear structure of word relationships, performing poorly on tasks like word analogy. Local context window methods (e.g., skip-gram) excel at capturing semantic and syntactic relationships through vector arithmetic but underutilize global co-occurrence statistics by focusing on local contexts. Derivation of GloVe: The authors propose a new model, GloVe, designed to address these limitations. They argue that: Ratios of co-occurrence probabilities are more informative than raw probabilities for capturing word relationships. They illustrate this with the example of "ice" and "steam" where the ratio P(k|ice)/P(k|steam) effectively distinguishes relevant context words ("solid," "gas") from irrelevant ones ("water," "fashion"). A log-bilinear regression model naturally encodes these ratios in a vector space. A weighted least squares objective is introduced to train the model on global co-occurrence counts while mitigating the impact of noisy, infrequent co-occurrences: J = ∑_{i, j} f(X_{i j}) (w_{i}^{T} \tilde{w}_{j} + b_{i} + \tilde{b}_{j} - log X_{i j})^{2} where: X_{ij} is the co-occurrence count of words i and j w_i, \tilde{w}_j are word and context word vectors b_i, \tilde{b}_j are biases for words i and j f(X_{ij}) is a weighting function that emphasizes frequent co-occurrences without overemphasizing extremely frequent pairs. Relationship to Other Models: The authors demonstrate that while seemingly different, GloVe shares underlying connections with skip-gram and related models. They show how modifying the skip-gram objective function by grouping similar terms and employing a weighted least squares approach leads to a formulation equivalent to GloVe.Key Findings: State-of-the-art Performance: GloVe achieves state-of-the-art results on several benchmark tasks: Word Analogy: Outperforms previous models, including word2vec, achieving 75% accuracy on a large dataset. Word Similarity: Achieves higher Spearman's rank correlation compared to other models on multiple datasets like WordSim-353 and MC. Named Entity Recognition: Improves F1 scores on the CoNLL-2003 dataset compared to baselines using discrete features and other word vector models. Impact of Hyperparameters: The study analyzes the effect of different hyperparameters: Vector size: Increasing vector dimension provides diminishing returns beyond 200 dimensions. Context window size: Larger windows favor semantic tasks while smaller, asymmetric windows are better for syntactic tasks. Corpus size: Larger corpora consistently improve performance on syntactic tasks, while the choice of corpus influences performance on semantic tasks depending on the dataset. Computational Efficiency: GloVe boasts efficient training, with complexity scaling better than online window-based methods due to its reliance on global co-occurrence statistics.Conclusion:GloVe successfully bridges the gap between global matrix factorization and local context window methods by effectively leveraging global co-occurrence statistics while preserving the ability to capture meaningful linear relationships between words. The model achieves impressive performance across various NLP tasks, highlighting its efficacy and potential for broader applications in natural language processing.原文链接:nlp.stanford.edu

【第11期】CBOW解读
Seventy3: 用NotebookML将论文生成播客,让大家跟着AI一起进步。今天的主题是:Efficient Estimation of Word Representations in Vector SpaceSource: Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient Estimation of Word Representations in Vector Space. arXiv preprint arXiv:1301.3781v3.Main Themes: This paper introduces novel, computationally efficient model architectures for learning high-quality word embeddings from large text datasets. The authors propose two models: Continuous Bag-of-Words (CBOW) and Continuous Skip-gram. They demonstrate the effectiveness of these models by evaluating them on a word similarity task and achieving state-of-the-art results.Most Important Ideas/Facts: Limitations of Traditional NLP Techniques: Traditional NLP methods often treat words as atomic units, ignoring semantic and syntactic relationships between them. While simple models like N-grams have been successful with massive datasets, they reach limitations in tasks with limited data. Distributed word representations offer a solution by capturing relationships between words in a continuous vector space. "However, the simple techniques are at their limits in many tasks... Thus, there are situations where simple scaling up of the basic techniques will not result in any significant progress, and we have to focus on more advanced techniques." Novel Model Architectures: CBOW: This model predicts a target word based on the average of its surrounding context words' vector representations. Skip-gram: This model predicts the surrounding context words given a target word, effectively learning to represent words based on their co-occurrence patterns. "The second architecture is similar to CBOW, but instead of predicting the current word based on the context, it tries to maximize classification of a word based on another word in the same sentence." Focus on Computational Efficiency: The proposed architectures are designed to be computationally less demanding than traditional neural network language models (NNLMs). This is achieved by removing the non-linear hidden layer, simplifying the model and enabling training on much larger datasets. "In this section, we propose two new model architectures for learning distributed representations of words that try to minimize computational complexity. The main observation from the previous section was that most of the complexity is caused by the non-linear hidden layer in the model." Evaluation and Results: The authors introduce a new Semantic-Syntactic Word Relationship test set to evaluate the quality of learned word embeddings. This test set measures the ability of the model to capture both semantic and syntactic relationships between words using vector algebra. Both CBOW and Skip-gram models outperform previous state-of-the-art approaches on this benchmark. "We evaluate the overall accuracy for all question types, and for each question type separately (semantic, syntactic). Question is assumed to be correctly answered only if the closest word to the vector computed using the above method is exactly the same as the correct word in the question." Large-Scale Training and Applications: The authors highlight the potential of their models to be trained on massive datasets using distributed computing frameworks like DistBelief. They showcase the applicability of learned word vectors in various NLP tasks like machine translation, information retrieval, and knowledge base completion. "We believe that our comprehensive test set will help the research community to improve the existing techniques for estimating the word vectors. We also expect that high quality word vectors will become an important building block for future NLP applications."Conclusion:This paper significantly contributes to the field of word embeddings by introducing computationally efficient models that can learn high-quality representations from large datasets. The proposed CBOW and Skip-gram models, along with the introduced evaluation methodology, have paved the way for advancements in various NLP applications and continue to be influential in the field.原文链接:arxiv.org

加餐005-ROSA
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Enabling Novel Mission Operations and Interactionswith ROSA: The Robot Operating System AgentIntroductionROSA (Robot Operating System Agent) is a groundbreaking AI-powered agent designed to revolutionize human-robot interaction (HRI) by enabling natural language communication with robotic systems. This briefing doc reviews the main themes and key features of ROSA based on the provided source document.Key Features: Natural Language Interface: ROSA understands and interprets human language, eliminating the need for specialized coding or command-line expertise. ReAct Agent Paradigm: Based on the ReAct (Reasoning and Acting) framework, ROSA combines LLM reasoning with the ability to execute actions, allowing it to interact with the robotic system based on natural language input. Integration with ROS: ROSA seamlessly integrates with both ROS1 and ROS2, providing access to a wide range of tools and functionalities. Tool Invocation and Multi-Tool Usage: ROSA identifies and executes the appropriate ROS tools based on user commands, enabling complex tasks through sequential or parallel tool execution. Safety and Constraint Handling: ROSA prioritizes safety with features like parameter validation, constraint enforcement, and blacklisting of potentially harmful actions. Modularity and Extensibility: The architecture is designed for easy customization and extension, allowing developers to add robot-specific tools and functionalities. Multimodal Interaction: ROSA can be extended to incorporate other input/output modalities like speech and visual perception.Quote: "By integrating with the ROS and ROS2 ecosystems, ROSA provides easy access to a wide range of tools and functionalities that allow users to perform tasks such as system diagnostics, monitoring, and invoking existing navigation and manipulation tasks, without the need for extensive technical training."Implementation DetailsROSA is implemented in Python and relies heavily on the LangChain framework for prompt management, memory handling, and tool integration. Tools are organized into modules based on their functionality and ROS version compatibility. Each tool function is decorated with the @tool decorator from LangChain, registering it as an actionable item. Tools accept well-defined parameters, including filters for targeted queries and blacklists for enhanced safety. ROSA provides comprehensive coverage of standard ROS functionalities, allowing interaction with nodes, topics, services, parameters, packages, launch files, and logs. System prompts provide the LLM with instructions and context, shaping the agent's persona and behavior. The choice of language model (e.g., GPT-4o, Claude 3.5 Sonnet, Llama 3.2) depends on performance, resource constraints, and deployment needs.DemonstrationsThe document showcases ROSA's capabilities through three demonstrations involving different robotic systems: NeBula-Spot: A quadruped robot operating in JPL's Mars Yard, demonstrating navigation, system reporting, and scene interpretation using VLMs. EELS: A serpentine robot tested in a laboratory environment, showcasing waypoint navigation, telemetry retrieval, and integration with visual perception tools. NVIDIA Nova Carter: A simulated robot operating in a Martian environment within NVIDIA IsaacSim, illustrating LiDAR-based collision checking, image capture, and persistence to the local file system.These demonstrations highlight ROSA's adaptability to various robot platforms, its ability to handle complex tasks, and its potential for enhancing human-robot collaboration in diverse environments.Ethical ConsiderationsThe authors emphasize the ethical implications of developing and deploying embodied agents like ROSA. They highlight the importance of: Asimov's Laws of Robotics: Ensuring robot actions prioritize human safety and well-being. Safety and Risk Mitigation: Implementing mechanisms for human intervention, redundancy, failover, parameter validation, and continuous monitoring. Privacy and Data Protection: Safeguarding user data and being transparent about data handling practices. Avoidance of Harm: Preventing the misuse of ROSA for harmful purposes and restricting access to critical functions. Transparency and Accountability: Making the agent's decision-making processes understandable and auditable.ConclusionROSA offers a transformative approach to human-robot interaction, democratizing access to complex robotic systems and empowering users of all expertise levels. Its modularity, extensibility, and emphasis on safety make it a promising framework for advancing the field of robotics and unlocking new possibilities in various domains. Continuous development, ethical considerations, and responsible deployment will be crucial for maximizing the beneficial impact of ROSA and shaping the future of human-robot collaboration.原文链接:https://arxiv.org/abs/2410.06472

【第10期】Skip-gram解读
Seventy3: 用NotebookML将论文生成播客,让大家跟着AI一起进步。今天的主题是:Distributed Representations of Words and Phrases and their CompositionalityThis document summarizes the key themes, ideas, and facts presented in the research paper "Distributed Representations of Words and Phrases and their Compositionality" by Tomas Mikolov et al. (2013). The paper details advancements in learning high-quality word and phrase vector representations using the Skip-gram model, focusing on improving training speed and accuracy.Main Themes: Efficient Learning of Word Representations: The paper introduces modifications to the Skip-gram model for enhanced efficiency and representation quality: Subsampling of Frequent Words: Discarding frequent words like "the" or "a" during training significantly speeds up the process (2x-10x) and improves the accuracy of representations for less frequent words. This is achieved by using a probability formula based on word frequency: "P(wi) = 1− √t/f(wi)" where "f(wi) is the frequency of word wi and t is a chosen threshold" Negative Sampling (NEG): A simplified alternative to hierarchical softmax, NEG distinguishes target words from noise using logistic regression. This method leads to faster training and improved vector representations, particularly for frequent words. Moving from Words to Phrases: Recognizing the limitations of word representations in capturing phrase meanings ("Air Canada" ≠ "Air" + "Canada"), the authors propose treating phrases as individual tokens. Phrase Identification: A data-driven approach identifies phrases based on unigram and bigram counts, merging frequently co-occurring words. Phrase Representations: Training the Skip-gram model on a corpus with identified phrases leads to high-quality phrase vector representations, achieving 72% accuracy on a phrase analogy task with a large dataset. Additive Compositionality: The research reveals an interesting property of Skip-gram representations: meaningful word combinations can often be obtained through simple vector addition. "For example, vec(“Russia”) + vec(“river”) is close to vec(“Volga River”), and vec(“Germany”) + vec(“capital”) is close to vec(“Berlin”)." This is attributed to the vectors capturing the distribution of word contexts, where addition approximates the product of context distributions.Important Findings: Superior Performance of Skip-gram: The Skip-gram model significantly outperforms other neural network-based word representation methods on analogical reasoning tasks. Impact of Data Size: Training on massive datasets (billions of words) is crucial for achieving high-quality representations, particularly for infrequent words and phrases. Syntactic and Semantic Relationships: Skip-gram representations effectively capture both syntactic ("quick":"quickly" :: "slow":"slowly") and semantic ("Germany":"Berlin" :: "France":"Paris") relationships between words. Open-Source Implementation: The authors released their code (word2vec) as an open-source project, contributing to further research and applications in the field.Conclusion:This paper highlights significant improvements in training and applying the Skip-gram model for generating meaningful word and phrase representations. The proposed techniques enable efficient learning from massive datasets, leading to high-quality vectors that capture complex linguistic relationships. This work has significantly impacted natural language processing by providing a powerful tool for representing and understanding text.原文链接:arxiv.org

加餐004-MLP-KAN解读
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:MLP-KAN: Unifying Deep Representation and Function LearningSource: He, Y., Xie, Y., Yuan, Z., & Sun, L. (2024). MLP-KAN: Unifying Deep Representation and Function Learning. arXiv preprint arXiv:2410.03027.Authors: Yunhong He, Yifeng Xie, Zhengqing Yuan, Lichao SunKey Insight: This paper proposes MLP-KAN, a novel framework combining Multi-Layer Perceptrons (MLPs) for representation learning and Kolmogorov-Arnold Networks (KANs) for function learning within a Mixture-of-Experts (MoE) architecture. This approach eliminates manual model selection for different tasks, dynamically adapting to dataset characteristics.Main Themes: Unifying Representation and Function Learning: Traditionally, deep learning models specialized in either representation or function learning. MLP-KAN aims to bridge this gap by incorporating both MLP and KAN experts within a single model. "MLP-KAN was developed to address the problem users encounter when determining whether to apply representation learning or function learning models across diverse datasets." Mixture-of-Experts (MoE) Architecture: The MoE framework dynamically routes input data to the most suitable expert (MLP or KAN). This allows the model to adapt to different task requirements and data characteristics. "Within the architecture of MLP-KAN, Multi-Layer Perceptrons (MLPs) function as representation experts, while Kernel Attention Networks (KANs) are designated as function experts. The MoE mechanism efficiently routes inputs to the appropriate expert, significantly enhancing both efficiency and performance across a diverse range of tasks." Benefits of MLP-KAN: Eliminates the need for manual model selection based on datasets. Achieves high performance in both representation and function learning tasks. Demonstrates versatility and adaptability across diverse domains, including computer vision, natural language processing, and symbolic formula representation. "MLP-KAN effectively combines the strengths of both, ensuring strong performance in representation and function learning, and eliminating the need for task-specific model selection."Important Findings: Function Learning: MLP-KAN consistently outperformed both MLP and KAN on the Feynman dataset, achieving significantly lower RMSEs across various equations. Notably, it excelled in capturing both basic and complex functional relationships, even with fewer parameters than traditional MLPs. "Across almost all equations, MLP-KAN consistently outperforms both KAN and MLP, often achieving RMSEs that are orders of magnitude smaller. This consistent superiority highlights MLP-KAN’s versatility and adaptability to both simple and complex mathematical forms, making it the most robust and efficient solution for function learning across diverse domains." Representation Learning: MLP-KAN achieved competitive results on image classification datasets (CIFAR-10, CIFAR-100, mini-ImageNet), achieving near state-of-the-art performance. Additionally, it achieved superior results on the sentiment analysis dataset SST-2. "MLP-KAN excels in the NLP task on the SST2 dataset, achieving the best results with an accuracy of 0.935 and an F1 score of 0.933. This superior performance highlights MLP-KAN’s versatility and robustness in handling not only image data but also text data, making it an excellent choice for representation learning." Ablation Studies: Increasing the number of experts in the MoE generally improved performance up to a point (8 experts), beyond which gains were marginal. Setting Top-K to 2 yielded the best performance, suggesting a balance between expert selection and computational efficiency.Implications: MLP-KAN simplifies model selection for complex tasks by dynamically adapting to data characteristics. The integration of representation and function learning within a single framework opens new possibilities for tackling more challenging AI problems. Future research could explore the application of MLP-KAN in other domains and investigate the impact of different expert architectures within the MoE framework.Overall: This paper presents a compelling solution for unifying representation and function learning with promising results. MLP-KAN demonstrates strong potential to simplify model development and enhance performance across diverse AI tasks.原文链接:https://arxiv.org/abs/2410.03027
【第九期】Seq2seq解读
Seventy3: 用NotebookML将论文生成播客,让大家跟着AI一起进步。今天的主题是:Sequence to Sequence Learning with Neural NetworksSource: Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. Advances in Neural Information Processing Systems, 27.Main Theme: This paper introduces a novel approach to sequence-to-sequence learning using Long Short-Term Memory (LSTM) neural networks for machine translation tasks. The authors demonstrate the effectiveness of their method on English-to-French translation, achieving state-of-the-art results.Key Ideas & Facts: Challenge of Sequences for DNNs: Traditional Deep Neural Networks (DNNs) struggle with variable-length sequences, limiting their application in tasks like machine translation. LSTM for Sequence-to-Sequence Mapping: The paper proposes using LSTMs to bridge this gap. One LSTM encodes the input sequence into a fixed-dimensional vector, which another LSTM decodes to generate the output sequence. "Our method uses a multilayered Long Short-Term Memory (LSTM) to map the input sequence to a vector of a fixed dimensionality, and then another deep LSTM to decode the target sequence from the vector." Reversing Source Sentence Order: A key innovation is reversing the order of words in the source sentence. This introduces short-term dependencies, simplifying the learning process for the LSTM. "We found it extremely valuable to reverse the order of the words of the input sentence... This way, a is in close proximity to α, b is fairly close to β, and so on, a fact that makes it easy for SGD to “establish communication” between the input and the output." Deep LSTMs Outperform Shallow LSTMs: The authors find that LSTMs with multiple layers achieve significantly better performance compared to single-layer LSTMs. Experimental Results: On the WMT’14 English-to-French translation task: Direct translation using an ensemble of LSTMs achieved a BLEU score of 34.81, surpassing the phrase-based SMT baseline of 33.30. "This is by far the best result achieved by direct translation with large neural networks." Rescoring the SMT baseline's 1000-best list with the LSTM ensemble yielded a BLEU score of 36.5, close to the best published result at that time. Long Sentence Performance: The LSTM model effectively translates long sentences, contrary to the limitations observed in prior research. This is attributed to the reversed source sentence order. "We were surprised to discover that the LSTM did well on long sentences." Sentence Representation: The LSTM learns to represent sentences as fixed-dimensional vectors that capture meaning and are sensitive to word order, as shown through visualization and qualitative analysis. "A useful property of the LSTM is that it learns to map an input sentence of variable length into a fixed-dimensional vector representation. Given that translations tend to be paraphrases of the source sentences, the translation objective encourages the LSTM to find sentence representations that capture their meaning."Significance: This work marks a significant advancement in neural machine translation, demonstrating the potential of LSTMs for sequence-to-sequence learning and paving the way for future research in the field.原文链接:arxiv.org

加餐003-FAN (Fourier Analysis Network)
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:FAN: Fourier Analysis NetworksThis briefing document reviews the key themes and findings from the research paper "FAN: Fourier Analysis Networks". The paper tackles the challenge of modeling periodicity in neural networks, a crucial aspect often overlooked by popular architectures like MLPs and Transformers.Key Problem: Existing neural networks excel at interpolation within the training data domain but struggle with extrapolation, especially when dealing with periodic functions. They tend to memorize periodic data instead of understanding the underlying principles of periodicity, hindering their generalization capabilities.Proposed Solution: The paper introduces FAN (Fourier Analysis Network), a novel architecture that explicitly integrates periodicity into the network structure using Fourier Series. This addresses the limitation of data-driven optimization in traditional networks by introducing an inherent understanding of periodic patterns.Key Features of FAN: Fourier Series Integration: By incorporating Fourier Series, FAN decomposes functions into their constituent frequencies, directly encoding periodic patterns.*"By leveraging the power of Fourier Series, we explicitly encode periodic patterns within the neural network, offering a way to model the general principles from the data." * Enhanced Periodicity Modeling: FAN demonstrates superior performance in fitting both simple and complex periodic functions compared to MLPs, Transformers, and KAN. This advantage is particularly evident in out-of-domain scenarios."FAN significantly outperforms the baselines in all these tasks of periodicity modeling...Moreover, FAN performs exceptionally well on test data both within and outside the domain of the training data, indicating that it is genuinely modeling periodicity rather than merely memorizing the training data." Improved Generalization: Despite being designed for periodicity, FAN demonstrates strong performance in broader applications, including symbolic formula representation, time series forecasting, and language modeling. This suggests that incorporating periodicity modeling can benefit various machine learning tasks, even those without explicit periodic requirements. Efficiency: FAN can seamlessly replace MLP layers in existing models, often leading to reduced parameters and FLOPs without sacrificing performance."As a promising substitute to MLP, FAN improves the model’s generalization performance meanwhile reducing the number of parameters and floating point of operations (FLOPs) employed."Experimental Results: Periodicity Modeling: FAN significantly outperforms MLP, KAN, and Transformer in fitting a range of periodic functions, demonstrating its capability to capture and extrapolate periodic patterns effectively. Symbolic Formula Representation: FAN consistently outperforms baselines in representing mathematical and physical functions, indicating its applicability even for partially periodic or non-periodic functions. Time Series Forecasting: Transformer models enhanced with FAN layers achieve superior performance on four public time series datasets, showcasing the benefits of explicit periodicity modeling in forecasting tasks. Language Modeling: Transformer with FAN demonstrates substantial improvements over the standard Transformer and other sequence models on sentiment analysis tasks, highlighting the potential of periodicity modeling in language understanding and cross-domain generalization.Future Directions:The authors highlight the potential of scaling up FAN and exploring its application to a wider range of tasks. Further investigation into the theoretical properties and practical implications of integrating periodicity into neural networks is also encouraged.Conclusion:FAN presents a novel approach to address the challenge of periodicity modeling in neural networks. Its strong empirical performance across diverse tasks, coupled with its efficiency and potential for broader applications, makes it a promising advancement in the field of deep learning. FAN's success suggests that explicitly incorporating domain-specific knowledge, such as periodicity, into neural network architectures can lead to significant improvements in learning and generalization.原文链接:https://arxiv.org/abs/2410.02675

加餐002-Differential Transformer
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Differential TransformerSource: Ye, Tianzhu, et al. "Differential Transformer." arXiv preprint arXiv:2410.05258 (2024).Main Theme: The paper introduces DIFF Transformer, a novel Transformer architecture designed to enhance the attention mechanism in Large Language Models (LLMs) by mitigating the issue of over-attention to irrelevant context.Key Ideas & Facts: Problem: Transformers often struggle to accurately retrieve key information from long contexts due to "attention noise," where non-negligible attention scores are assigned to irrelevant tokens, drowning out the signal from relevant ones."Transformer tends to allocate only a small proportion of attention scores to the correct answer, while disproportionately focusing on irrelevant context." Solution: DIFF Transformer proposes a differential attention mechanism that leverages the difference between two separate softmax attention maps calculated from partitioned query and key vectors. This subtraction effectively cancels out common noise, promoting sparse attention patterns focused on critical information."The differential attention mechanism eliminates attention noise, encouraging models to focus on critical information. The approach is analogous to noise-canceling headphones and differential amplifiers in electrical engineering, where the difference between two signals cancels out common-mode noise." Benefits:Improved Scalability: DIFF Transformer achieves comparable language modeling performance to standard Transformers with significantly reduced model size (65%) and training data (65%). Enhanced Long-Context Modeling: Demonstrates superior ability to leverage long contexts (up to 64K tokens) compared to standard Transformers, as evidenced by lower perplexity on book data. Superior Key Information Retrieval: Significantly outperforms standard Transformers in retrieving key information embedded within large contexts, particularly in the "Needle-In-A-Haystack" task. Enhanced In-Context Learning: Shows considerable improvements in many-shot classification tasks and exhibits greater robustness to order permutations of in-context examples. Mitigated Hallucination: Reduces contextual hallucinations in text summarization and question answering by focusing on relevant information and minimizing noise influence. Reduced Activation Outliers: Exhibits lower magnitudes of activation outliers, offering potential for efficient quantization and low-bit implementations using techniques like FlashAttention.Quotes: On the mechanism: "The differential attention mechanism calculates attention scores as the difference between two separate softmax attention maps. The subtraction cancels noise, promoting the emergence of sparse attention patterns." On improved performance: "DIFF Transformer outperforms Transformer in various settings of scaling up model size and training tokens. More intriguingly, it offers notable advantages in practical applications, such as long-context modeling, key information retrieval, hallucination mitigation, in-context learning, and reduction of activation outliers." On future work: "In the future, we can develop efficient low-bit attention kernels due to the reduced magnitude of activation outliers. As the attention pattern becomes much sparser, we would also like to utilize the property to compress key-value caches."Overall: DIFF Transformer presents a promising new architecture for enhancing LLMs by addressing the critical issue of attention noise. The proposed differential attention mechanism demonstrates significant potential for improving scalability, long-context understanding, task performance, and efficiency in LLMs.原文链接:https://arxiv.org/abs/2410.05258

【第八期】RNN Encoder-Decoder解读
Seventy3: 用NotebookML将论文生成播客,让大家跟着AI一起进步。今天的主题是:Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine TranslationSource: Cho et al. "Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation"Main Themes: This paper introduces a novel neural network architecture called RNN Encoder-Decoder for improving phrase-based Statistical Machine Translation (SMT). The model utilizes two Recurrent Neural Networks (RNNs): an encoder to map variable-length source phrases into fixed-length vector representations and a decoder to generate variable-length target phrases from these vectors. The authors propose a new hidden unit with "reset" and "update" gates, enhancing the model's ability to learn and retain dependencies across different time scales.Most Important Ideas/Facts: RNN Encoder-Decoder Architecture: The model effectively learns the conditional probability distribution of a target phrase given a source phrase. The encoder processes each word of the source phrase sequentially, updating its hidden state. The final hidden state represents the encoded source phrase. The decoder, conditioned on this encoded representation and the previous target words, generates the target phrase word by word."The encoder maps a variable-length source sequence to a fixed-length vector, and the decoder maps the vector representation back to a variable-length target sequence." Novel Gated Hidden Unit: Inspired by LSTM units, the new hidden unit incorporates "reset" and "update" gates. The reset gate determines the degree to which the previous hidden state is considered, enabling the model to disregard irrelevant information. The update gate, similar to the memory cell in LSTMs, regulates the information flow from the previous hidden state, facilitating long-term dependency learning."This effectively allows the hidden state to drop any information that is found to be irrelevant later in the future, thus, allowing a more compact representation." Integration with Phrase-Based SMT: Instead of replacing the phrase table, the RNN Encoder-Decoder calculates phrase pair scores (conditional probabilities) that are incorporated as additional features into the existing log-linear model of the SMT system."We propose to train the RNN Encoder–Decoder on a table of phrase pairs and use its scores as additional features in the log-linear model." Empirical Evaluation & Results: Experiments on English-to-French translation show significant BLEU score improvements when using RNN Encoder-Decoder scores. Combining these scores with a separately trained neural language model leads to further improvements, highlighting their complementary strengths."The best performance was achieved when we used both CSLM and the phrase scores from the RNN Encoder–Decoder." Qualitative Analysis: The model demonstrates an ability to capture linguistic regularities. It favors more accurate translations, often choosing shorter, more concise phrases. Visualizations of learned word and phrase representations reveal clusters of semantically and syntactically similar units, illustrating the model's capacity to encode linguistic meaning."The qualitative analysis shows that the RNN Encoder–Decoder is better at capturing the linguistic regularities in the phrase table, indirectly explaining the quantitative improvements in the overall translation performance."Future Directions: Exploring the replacement or partial substitution of the phrase table with the RNN Encoder-Decoder for target phrase generation. Applying the architecture to other natural language processing tasks, including speech transcription, leveraging its sequence-to-sequence mapping capabilities.Conclusion: The RNN Encoder-Decoder architecture presents a significant advancement in SMT, effectively learning meaningful linguistic representations and improving translation quality. Its potential extends beyond machine translation to various NLP tasks involving sequence data.原文链接:arxiv.org

【第七期】GRU original解读
Seventy3: 用NotebookML将论文生成播客,让大家跟着AI一起进步。今天的主题是:Empirical Evaluation of Gated Recurrent Neural Networks on Sequence ModelingSource: "Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling" by Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio.Main Focus: This paper compares the performance of different recurrent neural network (RNN) units, specifically focusing on gated units: Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU), against the traditional tanh unit.Key Findings: Gated units (LSTM and GRU) significantly outperform the traditional tanh unit in sequence modeling tasks. This advantage is particularly pronounced in challenging tasks like raw speech signal modeling. While both LSTM and GRU show strong performance, the study doesn't reach a definitive conclusion on which gated unit is superior. The optimal choice seems to depend on the specific dataset and task. Gated units offer faster convergence and achieve better final solutions compared to the tanh unit. This is attributed to their ability to capture long-term dependencies in sequences.Important Ideas & Facts: Recurrent Neural Networks (RNNs): Designed to handle variable-length sequences, RNNs maintain a hidden state that evolves over time, carrying information from previous steps. Vanishing Gradient Problem: A major challenge in training traditional RNNs, where gradients shrink exponentially as they backpropagate through time, making it difficult to learn long-term dependencies. Gated Units (LSTM & GRU): These units address the vanishing gradient problem by introducing gating mechanisms. LSTM: Uses input, forget, and output gates to regulate information flow within the unit, maintaining a separate memory cell. "Unlike the traditional recurrent unit which overwrites its content at each time-step...an LSTM unit is able to decide whether to keep the existing memory via the introduced gates." GRU: Employs update and reset gates to control the combination of previous information with new input, simplifying the architecture compared to LSTM. Advantages of Gated Units:Capture Long-Term Dependencies: Gating allows for selective preservation of information over long sequences, addressing the vanishing gradient issue. Shortcut Paths: Additive updates within gated units create shortcut paths for gradient flow, further mitigating the vanishing gradient problem. Experimental Setup:Tasks: Polyphonic music modeling (using Nottingham, JSB Chorales, MuseData, Piano-midi datasets) and speech signal modeling (using Ubisoft internal datasets). Models: LSTM-RNN, GRU-RNN, and tanh-RNN, each with similar parameter counts for fair comparison. Training: RMSProp optimizer with weight noise, gradient clipping, and early stopping based on validation performance. Results Analysis:Music Datasets: GRU-RNN generally outperforms LSTM-RNN and tanh-RNN, showing faster convergence in terms of updates and CPU time. Speech Datasets: Gated units clearly surpass tanh-RNN, with LSTM-RNN performing best on Ubisoft A and GRU-RNN excelling on Ubisoft B. Learning Curves: Gated units demonstrate consistent and faster learning progress compared to the struggling tanh-RNN.Future Directions:The authors acknowledge the preliminary nature of their study and suggest further research to: Gain a deeper understanding of how gated units facilitate learning. Isolate the individual contributions of specific gating components within LSTM and GRU.Overall, the paper highlights the significant advantages of gated recurrent units (LSTM & GRU) for sequence modeling tasks, showcasing their superiority over traditional RNNs in capturing long-term dependencies and achieving faster, more effective learning.原文链接:arxiv.org

【第六期】GRU-RNN解读
Seventy3: 用NotebookML将论文生成播客,让大家跟着AI一起进步。今天的主题是:On the Properties of Neural Machine Translation: Encoder–DecoderApproachesSource: Cho et al. "On the Properties of Neural Machine Translation: Encoder–Decoder Approaches" (2014)Main Themes: Neural Machine Translation (NMT): This paper analyzes a relatively new approach to statistical machine translation based entirely on neural networks, specifically focusing on the encoder-decoder architecture. Properties and Limitations: The authors investigate the strengths and weaknesses of NMT models, particularly concerning sentence length and unknown words. Comparison with SMT: The study compares the performance of NMT models (RNN Encoder-Decoder and a novel gated recursive convolutional network) with a traditional phrase-based statistical machine translation (SMT) system.Most Important Ideas/Facts: Encoder-Decoder Architecture: NMT models typically consist of an encoder that compresses a variable-length input sentence into a fixed-length vector and a decoder that generates the translation from this vector."At the core of all these recent works lies an encoder–decoder architecture... The encoder processes a variable-length input (source sentence) and builds a fixed-length vector representation... Conditioned on the encoded representation, the decoder generates a variable-length sequence (target sentence)." Sentence Length Limitation: NMT models struggle with longer sentences, exhibiting significantly degraded performance compared to shorter ones. This is attributed to the limited capacity of the fixed-length vector to encode complex information from lengthy sentences."Clearly, both models perform relatively well on short sentences, but suffer significantly as the length of the sentences increases... This suggests that the current neural translation approach has its weakness in handling long sentences." Unknown Words: An increase in the number of unknown words in a sentence leads to a rapid decline in translation performance for NMT models. This highlights the need for larger vocabularies in NMT systems."As expected, the performance degrades rapidly as the number of unknown words increases. This suggests that it will be an important challenge to increase the size of vocabularies used by the neural machine translation system in the future." Performance Compared to SMT: While the traditional phrase-based SMT system outperforms NMT models overall, the gap narrows considerably when focusing on short sentences without unknown words."Clearly the phrase-based SMT system still shows the superior performance over the proposed purely neural machine translation system, but we can see that under certain conditions (no unknown words in both source and reference sentences), the difference diminishes quite significantly." Potential for Integration: NMT models can be used in conjunction with existing SMT systems to improve overall translation quality, as demonstrated in previous studies."Furthermore, it is possible to use the neural machine translation models together with the existing phrase-based system, which was found recently in (Cho et al., 2014; Sutskever et al., 2014) to improve the overall translation performance." Gated Recursive Convolutional Network (grConv): This paper introduces a novel grConv model that exhibits an interesting property of learning a grammatical structure of the input sentence without explicit supervision."The grConv was found to mimic the grammatical structure of an input sentence without any supervision on syntactic structure of language. We believe this property makes it appropriate for natural language processing applications other than machine translation."Future Research Directions: Scaling up NMT Models: Increasing computational efficiency and memory capacity to accommodate larger vocabularies. Addressing Sentence Length Limitation: Exploring methods to improve NMT performance on longer and more complex sentences. Exploring Decoder Architectures: Investigating alternative decoder architectures to enhance representational power and translation quality.Conclusion:This paper provides valuable insights into the properties and limitations of early NMT models. While highlighting the challenges posed by sentence length and unknown words, it also acknowledges the potential of NMT, particularly when integrated with SMT systems. The introduction of grConv opens up new avenues for future research in both NMT and other NLP applications.原文链接:arxiv.org

加餐001-Were RNNs All We Needed?
Seventy3: 用NotebookLM将论文生成播客,让大家跟着AI一起进步。今天的主题是:Were RNNs All We Needed?Main Theme:This research paper revisits traditional recurrent neural networks (RNNs) like LSTMs and GRUs, proposing simplified versions – minLSTM and minGRU – that address the scalability limitations of their predecessors while achieving comparable performance to modern sequence models.Key Ideas and Facts: Limitations of Traditional RNNs and Transformers: Traditional RNNs, while effective for short sequences, are computationally expensive to train on long sequences due to backpropagation through time (BPTT). Transformers, while parallelizable and dominant in recent years, suffer from quadratic computational complexity with respect to sequence length, limiting their scalability. Simplifying LSTMs and GRUs: The authors remove hidden state dependencies from the input, forget, and update gates of LSTMs and GRUs. This allows for parallel training using the parallel scan algorithm, significantly improving training speed. Further simplification involves removing the range restriction imposed by the tanh activation function and ensuring time-independent output scale. This results in minimal versions, minLSTM and minGRU, with significantly fewer parameters. Quote: "These steps result in minimal versions (minLSTMs and minGRUs) that (1) use significantly fewer parameters than their traditional counterpart and (2) are trainable in parallel (175× faster for a context length of 512)." Efficiency of minLSTM and minGRU: Training Speed: minLSTM and minGRU demonstrate significantly faster training times compared to their traditional counterparts (175x and 235x faster for a sequence length of 512 on a T4 GPU). This improvement increases with sequence length. Memory Footprint: While the minimal versions utilize slightly more memory during training due to the parallel scan algorithm, the gains in training speed outweigh this increase. Parameter Efficiency: minGRU and minLSTM utilize significantly fewer parameters compared to GRU and LSTM, especially with increasing state expansion factors (dh = αdx, α ≥ 1). Performance of minLSTM and minGRU: Selective Copying Task: Both minLSTM and minGRU successfully solve the long-range Selective Copying task, matching the performance of Mamba's S6 and outperforming other models like S4, H3, and Hyena. Reinforcement Learning: minLSTM and minGRU, applied within a Decision Transformer framework, achieve competitive performance on MuJoCo locomotion tasks from the D4RL benchmark, outperforming Decision S4 and achieving comparable results to Decision Transformer, Aaren, and Decision Mamba. Language Modeling: On a character-level language modeling task using the Shakespeare dataset, both minLSTM and minGRU achieve comparable test losses to Mamba and Transformers. Importantly, they achieve this with significantly fewer training steps than Transformers.Conclusion:This research challenges the current dominance of Transformers by demonstrating that minimally simplified versions of LSTMs and GRUs can achieve comparable performance with significantly improved efficiency. This opens up new possibilities for leveraging efficient recurrent models for long sequence modeling tasks.Limitations: The experiments were limited by computational resources and used smaller datasets compared to some other works. Further research is needed to fully explore the potential of minLSTM and minGRU on larger-scale tasks and datasets.Overall:This paper presents a compelling case for reconsidering the potential of RNNs in the age of Transformers. By simplifying LSTMs and GRUs, the authors unlock efficiency gains without compromising performance, paving the way for further research and development of efficient recurrent models for long sequence modeling.原文链接:https://arxiv.org/abs/2410.01201

【第五期】Movie Gen
Seventy3: 用NotebookML将论文生成播客,让大家跟着AI一起进步。今天的主题是:Movie Gen: A Cast of Media Foundation ModelsThis briefing document reviews the key themes and findings presented in the research paper "movie-gen-research-paper.pdf", focusing on the development and capabilities of Meta's MovieGen AI system.MovieGen is a suite of AI models designed for high-quality video and audio generation and manipulation. The system comprises several specialized models, including: MovieGen Video: A foundational 30B parameter transformer model capable of generating videos from text prompts, incorporating characters from reference images, and performing precise instruction-guided video editing. MovieGen Audio: A 13B parameter model designed for generating high-quality, synchronized audio for videos, either from text prompts or directly from video input. This model excels in creating realistic sound effects and mood-setting music. MovieGen Edit: An extension of MovieGen Video focused on complex video editing tasks, trained through a novel multi-tasking approach involving both image and video editing.Key Innovations: Flow Matching: The paper highlights the use of Flow Matching for training both video and audio generation models. This iterative approach guides the model to transform samples from a basic distribution (e.g., Gaussian noise) toward the target data distribution, effectively learning complex data representations. Text-Guided Control: Both MovieGen Video and MovieGen Audio demonstrate remarkable controllability through textual prompts. Users can specify desired actions, scenery, camera effects, audio events, music styles, and even audio quality. Example (Video): "A person releases a lantern into the sky. Add tinsel streamers to the lantern bottom. Transform the lantern into a soaring bubble. Change the background to a city park with a lake." Example (Audio): "This audio has quality: 8.0. This audio does not contain speech. This audio has a description: 'gentle waves lapping against the shore, and music plays in the background.' This audio contains music with a 0.90 likelihood. This audio has a music description: 'A beautiful, romantic, and sentimental jazz piano solo.'" Personalized Video Generation (PT2V): An extension of MovieGen Video allows for personalized text-to-video generation by conditioning the model on identity information extracted from a reference image. Audio Extension: MovieGen Audio tackles the challenge of generating long-form, coherent audio by employing a multi-diffusion approach. This allows for generating soundtracks beyond the model's initial training limitations, creating seamless transitions between audio segments. Parallelism and Optimization: The research details extensive work on model parallelism and sharding, optimizing MovieGen for efficient training and inference on large datasets. This includes the use of Tensor Parallelism (TP), Sequence Parallelism (SP), Context Parallelism (CP), and Fully Sharded Data Parallelism (FSDP).Evaluation and Benchmarks:The paper emphasizes the importance of robust evaluation, introducing two new benchmarks: MovieGen Video Bench: A dataset of 1000 diverse text prompts designed to assess video generation quality across various aspects, including human activity, animal behavior, natural scenery, physics-based events, and unusual scenarios. MovieGen Audio Bench: A collection of high-quality videos generated by MovieGen Video, paired with human-annotated audio captions. This benchmark evaluates the model's ability to generate audio aligned with visual content and textual descriptions.Impact and Future Directions:MovieGen represents a significant advancement in generative AI for video and audio, offering: Cinematic Quality: The models demonstrate high fidelity and cinematic qualities in both video and audio generation. Creative Control: Text prompts enable fine-grained control over various aspects of the generated media, empowering artistic expression. Scalability and Efficiency: Through innovative model architectures and parallelism techniques, MovieGen achieves impressive scalability and efficiency in training and inference.Future research directions include: Improved Long-Form Video Generation: While MovieGen excels in short to medium-length videos, generating coherent and engaging long-form content remains a challenge. Enhanced Realism and Diversity: Further research can focus on improving the realism and diversity of generated content, mitigating potential biases and artifacts. Interactive and Collaborative Creation: Exploring possibilities for real-time user interaction and collaborative content creation with MovieGen could open up new avenues for creative applications.原文链接:https://ai.meta.com/static-resource/movie-gen-research-paper

【第四期】LSTM original解读
Seventy3: 用NotebookML将论文生成播客,让大家跟着AI一起进步。今天的主题是:Long Short-Term Memory (LSTM)Source: Hochreiter, S., & Schmidhuber, J. (1997). Long Short-Term Memory. Neural Computation, 9(8), 1735–1780.Main Theme: This paper introduces Long Short-Term Memory (LSTM), a novel recurrent neural network (RNN) architecture designed to address the vanishing gradient problem that plagues traditional RNNs when learning long-term dependencies.Most Important Ideas/Facts: Vanishing Gradient Problem: Traditional RNNs struggle to learn from long-term dependencies in sequences due to exponentially decaying error backflow. The authors analyze this problem extensively, showing that the scaling factor responsible for error propagation either explodes or vanishes exponentially with the length of the time lag. "If | f ′lm(netlm(t−m))wlmlm−1 | < 1.0 for all m, then the largest product decreases exponentially with q. That is, the error vanishes, and nothing can be learned in acceptable time." Constant Error Carousel (CEC): LSTM solves the vanishing gradient problem by introducing a CEC within special units called memory cells. This allows error signals to propagate back indefinitely without being scaled, preserving crucial information from earlier time steps. "To avoid vanishing error signals, how can we achieve constant error flow through a single unit j with a single connection to itself? ... We refer to this as the constant error carousel (CEC). CEC will be LSTM’s central feature." Gate Units: To control the flow of information into and out of the CEC, LSTM utilizes multiplicative gate units. The input gate determines when new information is stored in the memory cell, while the output gate controls the access of other units to the stored information. This mitigates the input and output weight conflicts that arise in conventional RNNs. "To avoid input weight conflicts, inj controls the error flow to memory cell cj’s input connections wcji. To circumvent cj’s output weight conflicts, outj controls the error flow from unit j’s output." Memory Cell Blocks: For efficient information storage and processing, LSTM groups multiple memory cells sharing input and output gates into memory cell blocks. This allows for distributed representations within a block. Truncated Backpropagation: LSTM uses a variant of real-time recurrent learning (RTRL) that truncates error backpropagation at specific points within the network. This ensures constant error flow through the CEC while maintaining computational efficiency. "To ensure nondecaying error backpropagation through internal states of memory cells, as with truncated BPTT (e.g., Williams & Peng, 1990), errors arriving at memory cell net inputs (for cell cj , this includes netcj , netinj , netoutj ) do not get propagated back further in time (although they do serve to change the incoming weights)." Experimental Validation: The paper presents extensive experiments on various artificial tasks, including embedded Reber grammar learning, noise-robust sequence classification, long-time-lag sequence prediction, and problems requiring the storage and retrieval of continuous values. LSTM outperforms traditional RNN algorithms like BPTT and RTRL, demonstrating its ability to learn long-term dependencies effectively. "LSTM also solves complex, artificial long-time-lag tasks that have never been solved by previous recurrent network algorithms."Advantages of LSTM: Bridges very long time lags. Handles noise, distributed representations, and continuous values. Does not require a priori selection of a finite number of states. Offers efficient update complexity comparable to BPTT. Is local in both space and time, unlike full BPTT.Limitations: Early LSTM implementations are computationally more expensive than traditional RNNs. May suffer from internal state drift, requiring careful parameter tuning and function selection.Conclusion: LSTM is a significant advancement in RNN research, providing a solution to the vanishing gradient problem and enabling the learning of long-term dependencies. This has paved the way for numerous applications in natural language processing, speech recognition, and other sequence modeling tasks.原文链接:direct.mit.edu

【第三期】LSTM解读
Seventy3: 用NotebookML将论文生成播客,让大家跟着AI一起进步。今天的主题是:Long Short-Term Memory-Networks for Machine ReadingSource: Cheng, J., Dong, L., & Lapata, M. (2016). Long short-term memory-networks for machine reading. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (pp. 2094-2103).Main Theme: This paper introduces the Long Short-Term Memory-Network (LSTMN), a novel neural network architecture that enhances the ability of recurrent neural networks (RNNs) to handle structured input and model long-term dependencies in text.Key Ideas and Facts: Limitations of Standard LSTMs: While LSTMs have proven successful in sequence modeling tasks, they suffer from memory compression issues and lack an explicit mechanism for handling the inherent structure of language. "As the input sequence gets compressed and blended into a single dense vector, sufficiently large memory capacity is required to store past information. As a result, the network generalizes poorly to long sequences while wasting memory on shorter ones." LSTMN Architecture: The LSTMN addresses these limitations by replacing the single memory cell in an LSTM with a memory network. Each input token is stored in a separate memory slot, and an attention mechanism is used to dynamically access and relate information across memory slots. "This design enables the LSTM to reason about relations between tokens with a neural attention layer and then perform non-Markov state updates." Intra-Attention for Relation Induction: The attention mechanism within the LSTMN acts as a weak inductive module, learning to identify implicit relations between tokens without requiring explicit supervision. "A key idea behind the LSTMN is to use attention for inducing relations between tokens. These relations are soft and differentiable, and components of a larger representation learning network." Modeling Two Sequences: The paper extends the LSTMN to handle tasks involving two input sequences (e.g., machine translation) by incorporating both intra-attention (within sequences) and inter-attention (between sequences) mechanisms. "Shallow fusion simply treats the LSTMN as a separate module that can be readily used in an encoder-decoder architecture, in lieu of a standard RNN or LSTM." "Deep fusion combines inter- and intra-attention (initiated by the decoder) when computing state updates."Experimental Results:The LSTMN is evaluated on three tasks: Language Modeling (Penn Treebank): The LSTMN outperforms standard RNNs and LSTMs, as well as more sophisticated LSTM variants, achieving state-of-the-art perplexity results. Sentiment Analysis (Stanford Sentiment Treebank): The LSTMN achieves competitive accuracy scores on both fine-grained and binary sentiment classification, comparable to top-performing systems. Natural Language Inference (SNLI): The LSTMN outperforms various LSTM baselines, including models with attention mechanisms, and achieves state-of-the-art accuracy on this task.Key Contributions: Proposes the LSTMN, a novel neural architecture that effectively addresses memory compression and structure handling limitations of standard LSTMs. Demonstrates the effectiveness of intra-attention for inducing relations between tokens without requiring explicit supervision. Achieves state-of-the-art or competitive performance on three challenging NLP tasks, highlighting the model's strong capacity for text understanding.Future Directions: Exploring linguistically motivated extensions to the LSTMN for handling nested structures. Investigating the use of weak or indirect supervision for learning compositional representations.Overall: This paper presents a significant advancement in neural network architectures for machine reading by introducing the LSTMN, which effectively addresses key limitations of traditional RNNs and demonstrates promising results on diverse NLP tasks.原文链接:https://arxiv.org/abs/1601.06733

【第二期】Transformer: Attention is All you Need
Seventy3: 用NotebookML将论文生成播客,让大家跟着AI一起进步。今天的主题是:Attention Is All You NeedSource: Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.Main Theme: This paper introduces the Transformer, a novel neural network architecture for sequence transduction tasks like machine translation. The key innovation is the exclusive reliance on attention mechanisms, eliminating the need for recurrent or convolutional layers that have been dominant in previous approaches.Most Important Ideas/Facts: Problem: Existing sequence transduction models, primarily based on RNNs and CNNs, struggle with parallelization and long-range dependencies, leading to increased training time and limitations in capturing global context. Solution: The Transformer utilizes a self-attention mechanism to compute representations of the input and output sequences, enabling parallelization and facilitating the modeling of long-range dependencies. Key Components:Multi-head Attention: Allows the model to attend to different aspects of the input sequence simultaneously, capturing richer representations. Scaled Dot-Product Attention: An efficient attention mechanism that computes weights based on the dot product of query and key vectors, scaled down to prevent gradient issues. Positional Encoding: Since the Transformer lacks inherent sequential information, sinusoidal positional encodings are added to the input embeddings to provide information about the order of tokens. Advantages:Parallelization: The Transformer's architecture allows for significant parallelization, leading to faster training times. Long-Range Dependencies: Self-attention enables the model to capture dependencies between words regardless of their distance in the sequence, addressing a limitation of RNNs. Interpretability: Attention weights provide insights into the model's decision-making process, highlighting which parts of the input sequence are most relevant for a given prediction. Results: The Transformer achieves state-of-the-art results on machine translation tasks, outperforming previous models in terms of BLEU scores and training efficiency. On the WMT 2014 English-to-German translation task, the Transformer achieves a BLEU score of 28.4, surpassing previous best results by over 2 BLEU. On the WMT 2014 English-to-French translation task, the Transformer achieves a BLEU score of 41.0 after training for only 3.5 days on eight GPUs. Key Quotes:"The Transformer allows for significantly more parallelization and can reach a new state of the art in translation quality after being trained for as little as twelve hours on eight P100 GPUs." "Self-attention, sometimes called intra-attention is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence." "Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this."Significance: The Transformer's introduction marked a significant advancement in the field of natural language processing, establishing a new paradigm for sequence transduction tasks. Its impact can be seen in the widespread adoption of attention mechanisms and Transformer-based models in various NLP applications.原文链接:arxiv.org

【第一期】NeRF解读
Seventy3: 用NotebookML将论文生成播客,让大家跟着AI一起进步。今天的主题是:NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis - A Detailed BriefingThis briefing document reviews the key themes and findings presented in the paper "NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis" by Ben Mildenhall et al.Core Idea: The paper introduces NeRF, a novel approach for synthesizing novel views of complex scenes. NeRF utilizes a fully connected neural network to represent a scene as a continuous 5D function, mapping 3D spatial locations (x, y, z) and 2D viewing directions (θ, φ) to color (RGB) and volume density (σ).Key Innovations: Continuous 5D Scene Representation: Unlike traditional methods relying on discrete voxels or meshes, NeRF represents scenes as continuous 5D functions using an MLP network. This allows for highly detailed representations of complex geometry and appearance, overcoming the limitations of discrete sampling in previous volumetric approaches. As the authors state, "We circumvent this problem by instead encoding a continuous volume within the parameters of a deep fully-connected neural network." Differentiable Rendering Pipeline: NeRF employs a differentiable rendering process inspired by classical volume rendering techniques. By leveraging the differentiability of volume rendering, the network can be optimized directly from posed RGB images without relying on 3D supervision. Positional Encoding for High-Frequency Detail: The authors address the challenge of representing high-frequency content by incorporating a positional encoding scheme. This encoding transforms the input 5D coordinates into a higher-dimensional space, enabling the MLP to capture fine details in the scene. The paper states that "reformulating FΘ as a composition of two functions FΘ = F ′Θ ◦ γ, one learned and one not, significantly improves performance". Hierarchical Sampling for Efficiency: To optimize rendering efficiency, a hierarchical sampling strategy is introduced. This approach uses a "coarse" network to guide a more informed sampling of the scene by a "fine" network, concentrating computational resources on regions containing visible content.Experimental Results: The paper presents extensive quantitative and qualitative results demonstrating NeRF’s superiority over state-of-the-art view synthesis methods on various synthetic and real-world datasets.Key Advantages: High-Resolution Rendering: NeRF achieves high-resolution renderings exceeding the quality of prior volumetric approaches due to its continuous representation. Memory Efficiency: Compared to methods like LLFF, NeRF requires significantly less storage as it stores the scene representation compactly within the network weights. Photorealism: Results on challenging scenes with complex geometry and materials showcase NeRF’s capability to generate photorealistic novel views.Limitations and Future Directions: Computational Cost: Despite the efficiency improvements from hierarchical sampling, optimizing and rendering NeRF remains computationally intensive compared to some baselines. Interpretability: Analyzing the learned scene representation and understanding potential failure modes remain open challenges due to the implicit nature of the neural network.Conclusion: NeRF presents a significant advancement in view synthesis by introducing a novel continuous scene representation and differentiable rendering pipeline. The method's ability to generate highly detailed and photorealistic novel views from posed images holds great promise for future applications in various fields. However, addressing the limitations related to computational cost and interpretability will be crucial for wider adoption and further research.原文链接:https://arxiv.org/abs/2003.08934