
ThursdAI - The top AI news from the past week
162 episodes — Page 3 of 4

📆 ThursdAI - August 1st - Meta SAM 2 for video, Gemini 1.5 is king now?, GPT-4o Voice is here (for some), new Stability, Apple Intelligence also here & more AI news
Starting Monday, Apple released iOS 18.1 with Apple Intelligence, then Meta dropped SAM-2 (Segment Anything Model) and then Google first open sourced Gemma 2B and now (just literally 2 hours ago, during the live show) released Gemini 1.5 0801 experimental that takes #1 on LMsys arena across multiple categories, to top it all off we also got a new SOTA image diffusion model called FLUX.1 from ex-stability folks and their new Black Forest Lab.This week on the show, we had Joseph & Piotr Skalski from Roboflow, talk in depth about Segment Anything, and as the absolute experts on this topic (Skalski is our returning vision expert), it was an incredible deep dive into the importance dedicated vision models (not VLMs).We also had Lukas Atkins & Fernando Neto from Arcee AI talk to use about their new DistillKit and explain model Distillation in detail & finally we had Cristiano Giardina who is one of the lucky few that got access to OpenAI advanced voice mode + his new friend GPT-4o came on the show as well!Honestly, how can one keep up with all this? by reading ThursdAI of course, that's how but ⚠️ buckle up, this is going to be a BIG one (I think over 4.5K words, will mark this as the longest newsletter I penned, I'm sorry, maybe read this one on 2x? 😂)[ Chapters ] 00:00 Introduction to the Hosts and Their Work01:22 Special Guests Introduction: Piotr Skalski and Joseph Nelson04:12 Segment Anything 2: Overview and Capabilities15:33 Deep Dive: Applications and Technical Details of SAM219:47 Combining SAM2 with Other Models36:16 Open Source AI: Importance and Future Directions39:59 Introduction to Distillation and DistillKit41:19 Introduction to DistilKit and Synthetic Data41:41 Distillation Techniques and Benefits44:10 Introducing Fernando and Distillation Basics44:49 Deep Dive into Distillation Process50:37 Open Source Contributions and Community Involvement52:04 ThursdAI Show Introduction and This Week's Buzz53:12 Weights & Biases New Course and San Francisco Meetup55:17 OpenAI's Advanced Voice Mode and Cristiano's Experience01:08:04 SearchGPT Release and Comparison with Perplexity01:11:37 Apple Intelligence Release and On-Device AI Capabilities01:22:30 Apple Intelligence and Local AI01:22:44 Breaking News: Black Forest Labs Emerges01:24:00 Exploring the New Flux Models01:25:54 Open Source Diffusion Models01:30:50 LLM Course and Free Resources01:32:26 FastHTML and Python Development01:33:26 Friend.com: Always-On Listening Device01:41:16 Google Gemini 1.5 Pro Takes the Lead01:48:45 GitHub Models: A New Era01:50:01 Concluding Thoughts and FarewellShow Notes & Links* Open Source LLMs* Meta gives SAM-2 - segment anything with one shot + video capability! (X, Blog, DEMO)* Google open sources Gemma 2 2.6B (Blog, HF)* MTEB Arena launching on HF - Embeddings head to head (HF)* Arcee AI announces DistillKit - (X, Blog, Github)* AI Art & Diffusion & 3D* Black Forest Labs - FLUX new SOTA diffusion models (X, Blog, Try It)* Midjourney 6.1 update - greater realism + potential Grok integration (X)* Big CO LLMs + APIs* Google updates Gemini 1.5 Pro with 0801 release and is #1 on LMsys arena (X)* OpenAI started alpha GPT-4o voice mode (examples)* OpenAI releases SearchGPT (Blog, Comparison w/ PPXL)* Apple releases beta of iOS 18.1 with Apple Intelligence (X, hands on, Intents )* Apple released a technical paper of apple intelligence* This weeks Buzz* AI Salons in SF + New Weave course for WandB featuring yours truly!* Vision & Video* Runway ML adds Gen -3 image to video and makes it 7x faster (X)* Tools & Hardware* Avi announces friend.com* Jeremy Howard releases FastHTML (Site, Video)* Applied LLM course from Hamel dropped all videosOpen SourceIt feels like everyone and their grandma is open sourcing incredible AI this week! Seriously, get ready for segment-anything-you-want + real-time-video capability PLUS small AND powerful language models.Meta Gives Us SAM-2: Segment ANYTHING Model in Images & Videos... With One Click!Hold on to your hats, folks! Remember Segment Anything, Meta's already-awesome image segmentation model? They've just ONE-UPPED themselves. Say hello to SAM-2 - it's real-time, promptable (you can TELL it what to segment), and handles VIDEOS like a champ. As I said on the show: "I was completely blown away by segment anything 2".But wait, what IS segmentation? Basically, pixel-perfect detection - outlining objects with incredible accuracy. My guests, the awesome Piotr Skalski and Joseph Nelson (computer vision pros from Roboflow), broke it down historically, from SAM 1 to SAM 2, and highlighted just how mind-blowing this upgrade is."So now, Segment Anything 2 comes out. Of course, it has all the previous capabilities of Segment Anything ... But the segment anything tool is awesome because it also can segment objects on the video". - Piotr SkalskiThink about Terminator vision from the "give me your clothes" bar scene: you see a scene, instantly "understand" every object separately, AND track it as it moves. SA

🧨 ThursdAI - July 25 - OpenSource GPT4 intelligence has arrived - Meta LLaMa 3.1 405B beats GPT4o! Mistral Large 2 also, Deepseek Code v2 ALSO - THIS WEEK
Holy s**t, folks! I was off for two weeks, last week OpenAI released GPT-4o-mini and everyone was in my mentions saying, Alex, how are you missing this?? and I'm so glad I missed that last week and not this one, because while GPT-4o-mini is incredible (GPT-4o level distill with incredible speed and almost 99% cost reduction from 2 years ago?) it's not open source. So welcome back to ThursdAI, and buckle up because we're diving into what might just be the craziest week in open-source AI since... well, ever!This week, we saw Meta drop LLAMA 3.1 405B like it's hot (including updated 70B and 8B), Mistral joining the party with their Large V2, and DeepSeek quietly updating their coder V2 to blow our minds. Oh, and did I mention Google DeepMind casually solving math Olympiad problems at silver level medal 🥈? Yeah, it's been that kind of week.TL;DR of all topics covered: * Open Source* Meta LLama 3.1 updated models (405B, 70B, 8B) - Happy LLama Day! (X, Announcement, Zuck, Try It, Try it Faster, Evals, Provider evals)* Mistral Large V2 123B (X, HF, Blog, Try It)* DeepSeek-Coder-V2-0724 update (API only)* Big CO LLMs + APIs* 🥈 Google Deepmind wins silver medal at Math Olympiad - AlphaGeometry 2 (X)* OpenAI teases SearchGPT - their reimagined search experience (Blog)* OpenAI opens GPT-4o-mini finetunes + 2 month free (X)* This weeks Buzz* I compare 5 LLama API providers for speed and quantization using Weave (X)* Voice & Audio* Daily announces a new open standard for real time Voice and Video RTVI-AI (X, Try it, Github)Meta LLAMA 3.1: The 405B Open Weights Frontier Model Beating GPT-4 👑Let's start with the star of the show: Meta's LLAMA 3.1. This isn't just a 0.1 update; it's a whole new beast. We're talking about a 405 billion parameter model that's not just knocking on GPT-4's door – it's kicking it down.Here's the kicker: you can actually download this internet scale intelligence (if you have 820GB free). That's right, a state-of-the-art model beating GPT-4 on multiple benchmarks, and you can click a download button. As I said during the show, "This is not only refreshing, it's quite incredible."Some highlights:* 128K context window (finally!)* MMLU score of 88.6* Beats GPT-4 on several benchmarks like IFEval (88.6%), GSM8K (96.8%), and ARC Challenge (96.9%)* Has Tool Use capabilities (also beating GPT-4) and is Multilingual (ALSO BEATING GPT-4)But that's just scratching the surface. Let's dive deeper into what makes LLAMA 3.1 so special.The Power of Open WeightsMark Zuckerberg himself dropped an exclusive interview with our friend Rowan Cheng from Rundown AI. And let me tell you, Zuck's commitment to open-source AI is no joke. He talked about distillation, technical details, and even released a manifesto on why open AI (the concept, not the company) is "the way forward".As I mentioned during the show, "The fact that this dude, like my age, I think he's younger than me... knows what they released to this level of technical detail, while running a multi billion dollar company is just incredible to me."Evaluation ExtravaganzaThe evaluation results for LLAMA 3.1 are mind-blowing. We're not just talking about standard benchmarks here. The model is crushing it on multiple fronts:* MMLU (Massive Multitask Language Understanding): 88.6%* IFEval (Instruction Following): 88.6%* GSM8K (Grade School Math): 96.8%* ARC Challenge: 96.9%But it doesn't stop there. The fine folks at meta also for the first time added new categories like Tool Use (BFCL 88.5) and Multilinguality (Multilingual MGSM 91.6) (not to be confused with MultiModality which is not yet here, but soon) Now, these are official evaluations from Meta themselves, that we know, often don't really represent the quality of the model, so let's take a look at other, more vibey results shall we? On SEAL leaderboards from Scale (held back so can't be trained on) LLama 405B is beating ALL other models on Instruction Following, getting 4th at Coding and 2nd at Math tasks. On MixEval (the eval that approximates LMsys with 96% accuracy), my colleagues Ayush and Morgan got a whopping 66%, placing 405B just after Clause Sonnet 3.5 and above GPT-4oAnd there are more evals that all tell the same story, we have a winner here folks (see the rest of the evals in my thread roundup)The License Game-ChangerMeta didn't just release a powerful model; they also updated their license to allow for synthetic data creation and distillation. This is huge for the open-source community.LDJ highlighted its importance: "I think this is actually pretty important because even though, like you said, a lot of people still train on OpenAI outputs anyways, there's a lot of legal departments and a lot of small, medium, and large companies that they restrict the people building and fine-tuning AI models within that company from actually being able to build the best models that they can because of these restrictions."This update could lead to a boom in custom models and applications across various indu
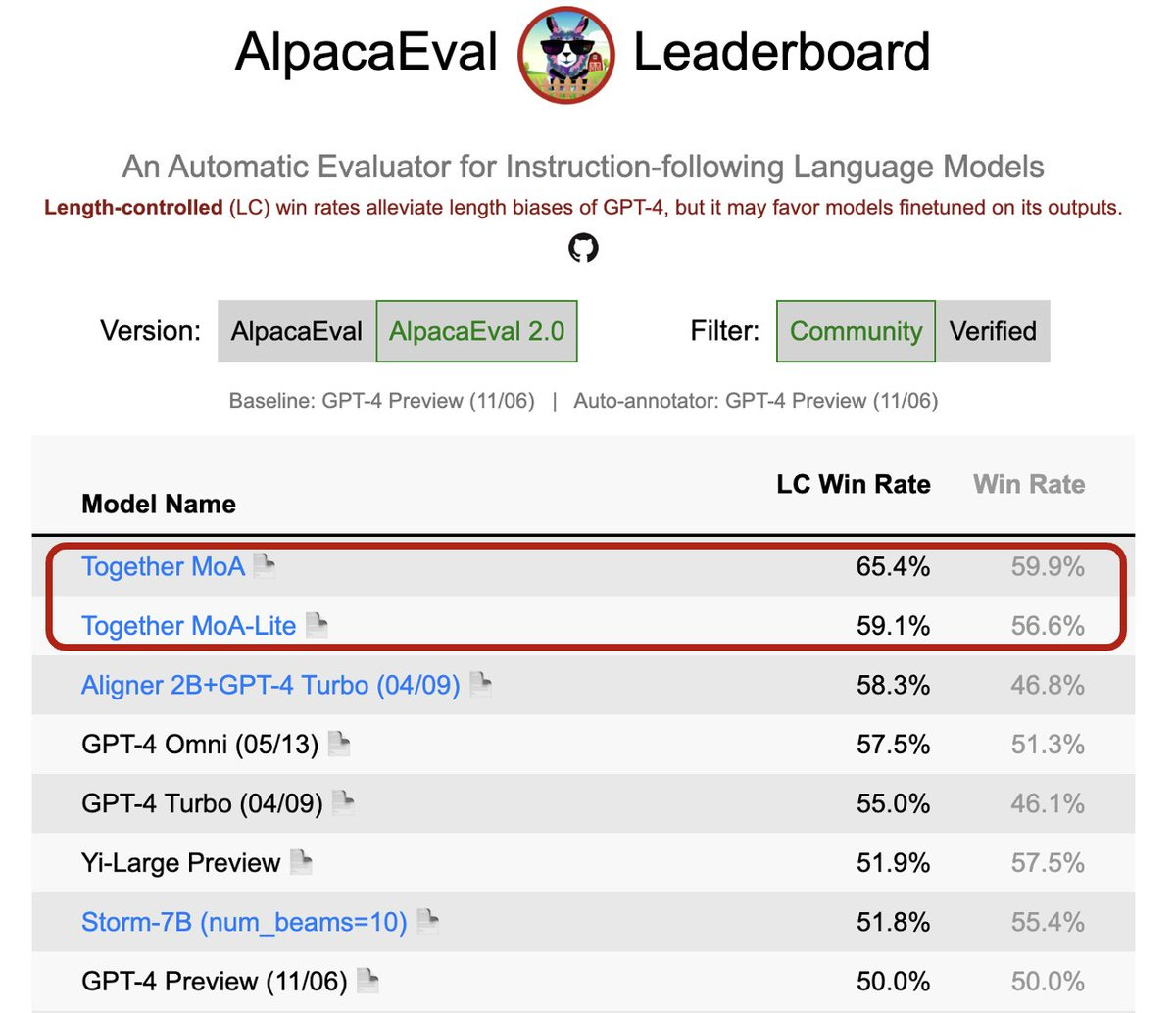
📅 ThursdAI - July 11 - Mixture of Agents & Open Router interviews (no news this week)
Hey all, Alex here… well, not actually here, I’m scheduling this post in advance, which I haven’t yet done, because I'm going on vacation! That’s right, next week is my birthday 🎉 and a much needed break, somewhere with a beach is awaiting, but I didn’t want to leave you hanging for too long, so posting this episode with some amazing un-released before material. Mixture of Agents x2Back in the far away days of June 20th (not that long ago but feels like ages!), Together AI announced a new paper, released code and posted a long post about a new method to collaboration between smaller models to beat larger models. They called it Mixture of Agents, and James Zou joined us to chat about that effort. Shortly after that - in fact, during the live ThursdAI show, Kyle Corbitt announced that OpenPipe also researched an approached similar to the above, using different models and a bit of a different reasoning, and also went after the coveted AlpacaEval benchmark, and achieved SOTA score of 68.8 using this method. And I was delighted to invite both James and Kyle to chat about their respective approach the same week that both broke AlpacaEval SOTA and hear how utilizing collaboration between LLMs can significantly improve their outputs! This weeks buzz - what I learned at W&B this weekSo much buzz this week from the Weave team, it’s hard to know what to put in here. I can start with the incredible integrations my team landed, Mistral AI, LLamaIndex, DSPy, OpenRouter and even Local Models served by Ollama, LmStudio, LLamaFile can be now auto tracked with Weave, which means you literally have to only instantiate Weave and it’ll auto track everything for you! But I think the biggest, hugest news from this week is this great eval comparison system that the Weave Tim just pushed, it’s honestly so feature rich that I’ll have to do a deeper dive on it later, but I wanted to make sure I include at least a few screencaps because I think it looks fantastic! Open Router - A unified interface for LLMsI’ve been a long time fan of OpenRouter.ai and I was very happy to have Alex Atallah on the show to talk about Open Router (even if this did happen back in April!) and I’m finally satisfied with the sound quality to released this conversation. Open Router is serving both foundational models like GPT, Claude, Gemini and also Open Source ones, and supports the OpenAI SDK format, making it super simple to play around and evaluate all of them on the same code. They even provide a few models for free! Right now you can use Phi for example completely free via their API. Alex goes deep into the areas of Open Router that I honestly didn’t really know about, like being a marketplace, knowing what trendy LLMs are being used by people in near real time (check out WebSim!) and more very interesting things! Give that conversation a listen, I’m sure you’ll enjoy it! That’s it folks, no news this week, I would instead like to recommend a new newsletter by friends of the pod Tanishq Abraham and Aran Komatsuzaki both of whom are doing a weekly paper X space and recently start posting it on Substack as well! It’s called AI papers of the week, and if you’re into papers which we don’t usually cover, there’s no better duo! In fact, Tanishq often used to come to ThursdAI to explain papers so you may recognize his voice :) See you all in two weeks after I get some seriously needed R&R 👋 😎🏖️ This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit sub.thursdai.news/subscribe

📆 🎂 - ThursdAI #52 - Moshi Voice, Qwen2 finetunes, GraphRag deep dive and more AI news on this celebratory 1yr ThursdAI
Hey everyone! Happy 4th of July to everyone who celebrates! I celebrated today by having an intimate conversation with 600 of my closest X friends 😂 Joking aside, today is a celebratory episode, 52nd consecutive weekly ThursdAI show! I've been doing this as a podcast for a year now!Which means, there are some of you, who've been subscribed for a year 😮 Thank you! Couldn't have done this without you. In the middle of my talk at AI Engineer (I still don't have the video!) I had to plug ThursdAI, and I asked the 300+ audience who is a listener of ThursdAI, and I saw a LOT of hands go up, which is honestly, still quite humbling. So again, thank you for tuning in, listening, subscribing, learning together with me and sharing with your friends! This week, we covered a new (soon to be) open source voice model from KyutAI, a LOT of open source LLM, from InternLM, Cognitive Computations (Eric Hartford joined us), Arcee AI (Lukas Atkins joined as well) and we have a deep dive into GraphRAG with Emil Eifrem CEO of Neo4j (who shares why it was called Neo4j in the first place, and that he's a ThursdAI listener, whaaat? 🤯), this is definitely a conversation you don't want to miss, so tune in, and read a breakdown below:TL;DR of all topics covered: * Voice & Audio* KyutAI releases Moshi - first ever 7B end to end voice capable model (Try it)* Open Source LLMs * Microsoft Updated Phi-3-mini - almost a new model * InternLM 2.5 - best open source model under 12B on Hugging Face (HF, Github)* Microsoft open sources GraphRAG (Announcement, Github, Paper)* OpenAutoCoder-Agentless - SOTA on SWE Bench - 27.33% (Code, Paper)* Arcee AI - Arcee Agent 7B - from Qwen2 - Function / Tool use finetune (HF)* LMsys announces RouteLLM - a new Open Source LLM Router (Github)* DeepSeek Chat got an significant upgrade (Announcement)* Nomic GPT4all 3.0 - Local LLM (Download, Github)* This weeks Buzz* New free Prompts course from WandB in 4 days (pre sign up)* Big CO LLMs + APIs* Perplexity announces their new pro research mode (Announcement)* X is rolling out "Grok Analysis" button and it's BAD in "fun mode" and then paused roll out* Figma pauses the rollout of their AI text to design tool "Make Design" (X)* Vision & Video* Cognitive Computations drops DolphinVision-72b - VLM (HF)* Chat with Emil Eifrem - CEO Neo4J about GraphRAG, AI EngineerVoice & AudioKyutAI Moshi - a 7B end to end voice model (Try It, See Announcement)Seemingly out of nowhere, another french AI juggernaut decided to drop a major announcement, a company called KyutAI, backed by Eric Schmidt, call themselves "the first European private-initiative laboratory dedicated to open research in artificial intelligence" in a press release back in November of 2023, have quite a few rockstar co founders ex Deep Mind, Meta AI, and have Yann LeCun on their science committee.This week they showed their first, and honestly quite mind-blowing release, called Moshi (Japanese for Hello, Moshi Moshi), which is an end to end voice and text model, similar to GPT-4o demos we've seen, except this one is 7B parameters, and can run on your mac! While the utility of the model right now is not the greatest, not remotely close to anything resembling the amazing GPT-4o (which was demoed live to me and all of AI Engineer by Romain Huet) but Moshi shows very very impressive stats! Built by a small team during only 6 months or so of work, they have trained an LLM (Helium 7B) an Audio Codec (Mimi) a Rust inference stack and a lot more, to give insane performance. Model latency is 160ms and mic-to-speakers latency is 200ms, which is so fast it seems like it's too fast. The demo often responds faster than I'm able to finish my sentence, and it results in an uncanny, "reading my thoughts" type feeling. The most important part is this though, a quote of KyutAI post after the announcement : Developing Moshi required significant contributions to audio codecs, multimodal LLMs, multimodal instruction-tuning and much more. We believe the main impact of the project will be sharing all Moshi’s secrets with the upcoming paper and open-source of the model.I'm really looking forward to how this tech can be applied to the incredible open source models we already have out there! Speaking to out LLMs is now officially here in the Open Source, way before we got GPT-4o and it's exciting! Open Source LLMs Microsoft stealth update Phi-3 Mini to make it almost a new modelSo stealth in fact, that I didn't even have this update in my notes for the show, but thanks to incredible community (Bartowsky, Akshay Gautam) who made sure we don't miss this, because it's so huge. The model used additional post-training data leading to substantial gains on instruction following and structure output. We also improve multi-turn conversation quality, explicitly support tag, and significantly improve reasoning capabilityPhi-3 June update is quite significant across the board, just look at some of these scores, 354.78% improvement in JSON struct

📅 ThursdAI - Gemma 2, AI Engineer 24', AI Wearables, New LLM leaderboard
Hey everyone, sending a quick one today, no deep dive, as I'm still in the middle of AI Engineer World's Fair 2024 in San Francisco (in fact, I'm writing this from the incredible floor 32 presidential suite, that the team here got for interviews, media and podcasting, and hey to all new folks who I’ve just met during the last two days!) It's been an incredible few days meeting so many ThursdAI community members, listeners and folks who came on the pod! The list honestly is too long but I've got to meet friends of the pod Maxime Labonne, Wing Lian, Joao Morra (crew AI), Vik from Moondream, Stefania Druga not to mention the countless folks who came up and gave high fives, introduced themselves, it was honestly a LOT of fun. (and it's still not over, if you're here, please come and say hi, and let's take a LLM judge selfie together!)On today's show, we recorded extra early because I had to run and play dress up, and boy am I relieved now that both the show and the talk are behind me, and I can go an enjoy the rest of the conference 🔥 (which I will bring you here in full once I get the recording!) On today's show, we had the awesome pleasure to have Surya Bhupatiraju who's a research engineer at Google DeepMind, talk to us about their newly released amazing Gemma 2 models! It was very technical, and a super great conversation to check out! Gemma 2 came out with 2 sizes, a 9B and a 27B parameter models, with 8K context (we addressed this on the show) and this 27B model incredible performance is beating LLama-3 70B on several benchmarks and is even beating Nemotron 340B from NVIDIA! This model is also now available on the Google AI studio to play with, but also on the hub! We also covered the renewal of the HuggingFace open LLM leaderboard with their new benchmarks in the mix and normalization of scores, and how Qwen 2 is again the best model that's tested! It's was a very insightful conversation, that's worth listening to if you're interested in benchmarks, definitely give it a listen. Last but not least, we had a conversation with Ethan Sutin, the co-founder of Bee Computer. At the AI Engineer speakers dinner, all the speakers received a wearable AI device as a gift, and I onboarded (cause Swyx asked me) and kinda forgot about it. On the way back to my hotel I walked with a friend and chatted about my life. When I got back to my hotel, the app prompted me with "hey, I now know 7 new facts about you" and it was incredible to see how much of the conversation it was able to pick up, and extract facts and eve TODO's! So I had to have Ethan on the show to try and dig a little bit into the privacy and the use-cases of these hardware AI devices, and it was a great chat! Sorry for the quick one today, if this is the first newsletter after you just met me and register, usually there’s a deeper dive here, expect a more in depth write-ups in the next sessions, as now I have to run down and enjoy the rest of the conference! Here's the TL;DR and my RAW show notes for the full show, in case it's helpful! * AI Engineer is happening right now in SF* Tracks include Multimodality, Open Models, RAG & LLM Frameworks, Agents, Al Leadership, Evals & LLM Ops, CodeGen & Dev Tools, Al in the Fortune 500, GPUs & Inference* Open Source LLMs * HuggingFace - LLM Leaderboard v2 - (Blog)* Old Benchmarks sucked and it's time to renew* New Benchmarks* MMLU-Pro (Massive Multitask Language Understanding - Pro version, paper)* GPQA (Google-Proof Q&A Benchmark, paper). GPQA is an extremely hard knowledge dataset* MuSR (Multistep Soft Reasoning, paper).* MATH (Mathematics Aptitude Test of Heuristics, Level 5 subset, paper)* IFEval (Instruction Following Evaluation, paper)* 🤝 BBH (Big Bench Hard, paper). BBH is a subset of 23 challenging tasks from the BigBench dataset* The community will be able to vote for models, and we will prioritize running models with the most votes first* Mozilla announces Builders Accelerator @ AI Engineer (X)* Theme: Local AI * 100K non dilutive funding* Google releases Gemma 2 (X, Blog)* Big CO LLMs + APIs* UMG, Sony, Warner sue Udio and Suno for copyright (X)* were able to recreate some songs* sue both companies* have 10 unnamed individuals who are also on the suit* Google Chrome Canary has Gemini nano (X)* * Super easy to use window.ai.createTextSession()* Nano 1 and 2, at a 4bit quantized 1.8B and 3.25B parameters has decent performance relative to Gemini Pro* Behind a feature flag* Most text gen under 500ms * Unclear re: hardware requirements * Someone already built extensions* someone already posted this on HuggingFace* Anthropic Claude share-able projects (X)* Snapshots of Claude conversations shared with your team* Can share custom instructions* Anthropic has released new "Projects" feature for Claude AI to enable collaboration and enhanced workflows* Projects allow users to ground Claude's outputs in their own internal knowledge and documents* Projects can be customized with instructions to tailor Claude's respo
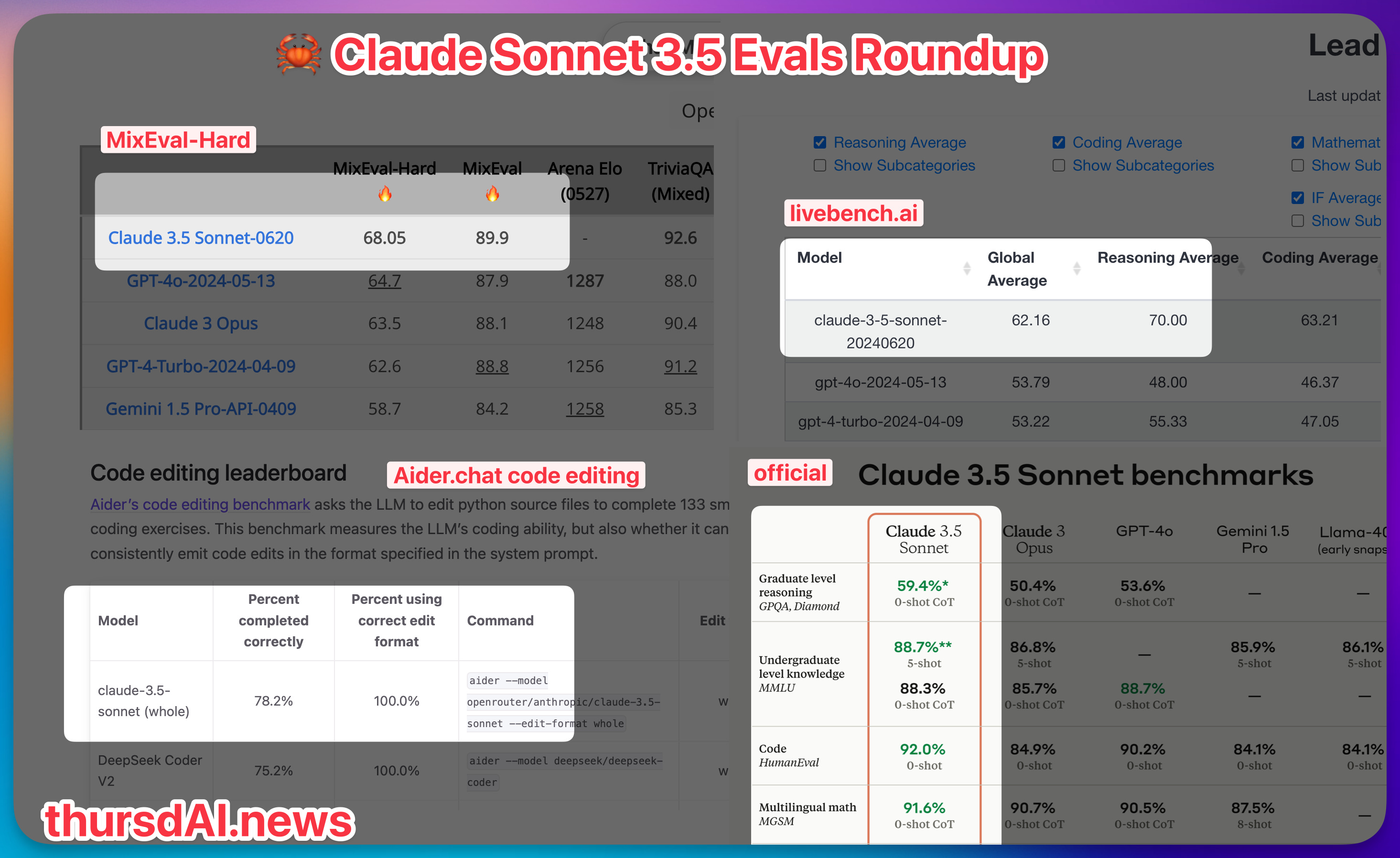
📅 ThursdAI - June 20th - 👑 Claude Sonnet 3.5 new LLM king, DeepSeek new OSS code king, Runway Gen-3 SORA competitor, Ilya's back & more AI news from this crazy week
Hey, this is Alex. Don't you just love when assumptions about LLMs hitting a wall just get shattered left and right and we get new incredible tools released that leapfrog previous state of the art models, that we barely got used to, from just a few months ago? I SURE DO! Today is one such day, this week was already busy enough, I had a whole 2 hour show packed with releases, and then Anthropic decided to give me a reason to use the #breakingNews button (the one that does the news show like sound on the live show, you should join next time!) and announced Claude Sonnet 3.5 which is their best model, beating Opus while being 2x faster and 5x cheaper! (also beating GPT-4o and Turbo, so... new king! For how long? ¯\_(ツ)_/¯)Critics are already raving, it's been half a day and they are raving! Ok, let's get to the TL;DR and then dive into Claude 3.5 and a few other incredible things that happened this week in AI! 👇 TL;DR of all topics covered: * Open Source LLMs * NVIDIA - Nemotron 340B - Base, Instruct and Reward model (X)* DeepSeek coder V2 (230B MoE, 16B) (X, HF)* Meta FAIR - Chameleon MMIO models (X)* HF + BigCodeProject are deprecating HumanEval with BigCodeBench (X, Bench)* NousResearch - Hermes 2 LLama3 Theta 70B - GPT-4 level OSS on MT-Bench (X, HF)* Big CO LLMs + APIs* Gemini Context Caching is available * Anthropic releases Sonnet 3.5 - beating GPT-4o (X, Claude.ai)* Ilya Sutskever starting SSI.inc - safe super intelligence (X)* Nvidia is the biggest company in the world by market cap* This weeks Buzz * Alex in SF next week for AIQCon, AI Engineer. ThursdAI will be sporadic but will happen!* W&B Weave now has support for tokens and cost + Anthropic SDK out of the box (Weave Docs)* Vision & Video* Microsoft open sources Florence 230M & 800M Vision Models (X, HF)* Runway Gen-3 - (t2v, i2v, v2v) Video Model (X)* Voice & Audio* Google Deepmind teases V2A video-to-audio model (Blog)* AI Art & Diffusion & 3D* Flash Diffusion for SD3 is out - Stable Diffusion 3 in 4 steps! (X)ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.🦀 New king of LLMs in town - Claude 3.5 Sonnet 👑 Ok so first things first, Claude Sonnet, the previously forgotten middle child of the Claude 3 family, has now received a brain upgrade! Achieving incredible performance on many benchmarks, this new model is 5 times cheaper than Opus at $3/1Mtok on input and $15/1Mtok on output. It's also competitive against GPT-4o and turbo on the standard benchmarks, achieving incredible scores on MMLU, HumanEval etc', but we know that those are already behind us. Sonnet 3.5, aka Claw'd (which is a great marketing push by the Anthropic folks, I love to see it), is beating all other models on Aider.chat code editing leaderboard, winning on the new livebench.ai leaderboard and is getting top scores on MixEval Hard, which has 96% correlation with LMsys arena.While benchmarks are great and all, real folks are reporting real findings of their own, here's what Friend of the Pod Pietro Skirano had to say after playing with it: there's like a lot of things that I saw that I had never seen before in terms of like creativity and like how much of the model, you know, actually put some of his own understanding into your request-@SkiranoWhat's notable a capability boost is this quote from the Anthropic release blog: In an internal agentic coding evaluation, Claude 3.5 Sonnet solved 64% of problems, outperforming Claude 3 Opus which solved 38%. One detail that Alex Albert from Anthropic pointed out from this released was, that on GPQA (Graduate-Level Google-Proof Q&A) Benchmark, they achieved a 67% with various prompting techniques, beating PHD experts in respective fields in this benchmarks that average 65% on this. This... this is crazyBeyond just the benchmarks This to me is a ridiculous jump because Opus was just so so good already, and Sonnet 3.5 is jumping over it with agentic solving capabilities, and also vision capabilities. Anthropic also announced that vision wise, Claw'd is significantly better than Opus at vision tasks (which, again, Opus was already great at!) and lastly, Claw'd now has a great recent cutoff time, it knows about events that happened in February 2024! Additionally, claude.ai got a new capability which significantly improves the use of Claude, which they call artifacts. It needs to be turned on in settings, and then Claude will have access to files, and will show you in an aside, rendered HTML, SVG files, Markdown docs, and a bunch more stuff, and it'll be able to reference different files it creates, to create assets and then a game with these assets for example! 1 Ilya x 2 Daniels to build Safe SuperIntelligence Ilya Sutskever, Co-founder and failed board Coup participant (leader?) at OpenAI, has resurfaced after a long time of people wondering "where's Ilya" with one hell of an announcement. The company is c

ThursdAI - June 13th, 2024 - Apple Intelligence recap, Elons reaction, Luma's Dream Machine, AI Engineer invite, SD3 & more AI news from this past week
Happy Apple AI week everyone (well, those of us who celebrate, some don't) as this week we finally got told what Apple is planning to do with this whole generative AI wave and presented Apple Intelligence (which is AI, get it? they are trying to rebrand AI!)This weeks pod and newsletter main focus will be Apple Intelligence of course, as it was for most people compared to how the market reacted ($APPL grew over $360B in a few days after this announcement) and how many people watched each live stream (10M at the time of this writing watched the WWDC keynote on youtube, compared to 4.5 for the OpenAI GPT-4o, 1.8 M for Google IO) On the pod we also geeked out on new eval frameworks and benchmarks including a chat with the authors of MixEvals which I wrote about last week and a new benchmark called Live Bench from Abacus and Yan LecunPlus a new video model from Luma and finally SD3, let's go! 👇 TL;DR of all topics covered: * Apple WWDC recap and Apple Intelligence (X)* This Weeks Buzz* AI Engineer expo in SF (June 25-27) come see my talk, it's going to be Epic (X, Schedule)* Open Source LLMs * Microsoft Samba - 3.8B MAMBA + Sliding Window Attention beating Phi 3 (X, Paper)* Sakana AI releases LLM squared - LLMs coming up with preference algorithms to train better LLMS (X, Blog)* Abacus + Yan Lecun release LiveBench.AI - impossible to game benchmark (X, Bench* Interview with MixEval folks about achieving 96% arena accuracy with 5000x less price* Big CO LLMs + APIs* Mistral announced a 600M series B round* Revenue at OpenAI DOUBLED in the last 6 month and is now at $3.4B annualized (source)* Elon drops lawsuit vs OpenAI * Vision & Video* Luma drops DreamMachine - SORA like short video generation in free access (X, TRY IT)* AI Art & Diffusion & 3D* Stable Diffusion Medium weights are here (X, HF, FAL)* Tools* Google releases GenType - create an alphabet with diffusion Models (X, Try It)Apple IntelligenceTechnical LLM details Let's dive right into what wasn't show on the keynote, in a 6 minute deep dive video from the state of the union for developers and in a follow up post on machine learning blog, Apple shared some very exciting technical details about their on device models and orchestration that will become Apple Intelligence. Namely, on device they have trained a bespoke 3B parameter LLM, which was trained on licensed data, and uses a bunch of very cutting edge modern techniques to achieve quite an incredible on device performance. Stuff like GQA, Speculative Decoding, a very unique type of quantization (which they claim is almost lossless) To maintain model , we developed a new framework using LoRA adapters that incorporates a mixed 2-bit and 4-bit configuration strategy — averaging 3.5 bits-per-weight — to achieve the same accuracy as the uncompressed models [...] on iPhone 15 Pro we are able to reach time-to-first-token latency of about 0.6 millisecond per prompt token, and a generation rate of 30 tokens per secondThese small models (they also have a bespoke image diffusion model as well) are going to be finetuned with a lot of LORA adapters for specific tasks like Summarization, Query handling, Mail replies, Urgency and more, which gives their foundational models the ability to specialize itself on the fly to the task at hand, and be cached in memory as well for optimal performance. Personal and Private (including in the cloud) While these models are small, they will also benefit from 2 more things on device, a vector store of your stuff (contacts, recent chats, calendar, photos) they call semantic index and a new thing apple is calling App Intents, which developers can expose (and the OS apps already do) that will allows the LLM to use tools like moving files, extracting data across apps, and do actions, this already makes the AI much more personal and helpful as it has in its context things about me and what my apps can do on my phone. Handoff to the Private Cloud (and then to OpenAI)What the local 3B LLM + context can't do, it'll hand off to the cloud, in what Apple claims is a very secure way, called Private Cloud, in which they will create a new inference techniques in the cloud, on Apple Silicon, with Secure Enclave and Secure Boot, ensuring that the LLM sessions that run inference on your data are never stored, and even Apple can't access those sessions, not to mention train their LLMs on your data. Here are some benchmarks Apple posted for their On-Device 3B model and unknown size server model comparing it to GPT-4-Turbo (not 4o!) on unnamed benchmarks they came up with. In cases where Apple Intelligence cannot help you with a request (I'm still unclear when this actually would happen) IOS will now show you this dialog, suggesting you use chatGPT from OpenAI, marking a deal with OpenAI (in which apparently nobody pays nobody, so neither Apple is getting paid by OpenAI to be placed there, nor does Apple pay OpenAI for the additional compute, tokens, and inference) Implementations across the OSSo w
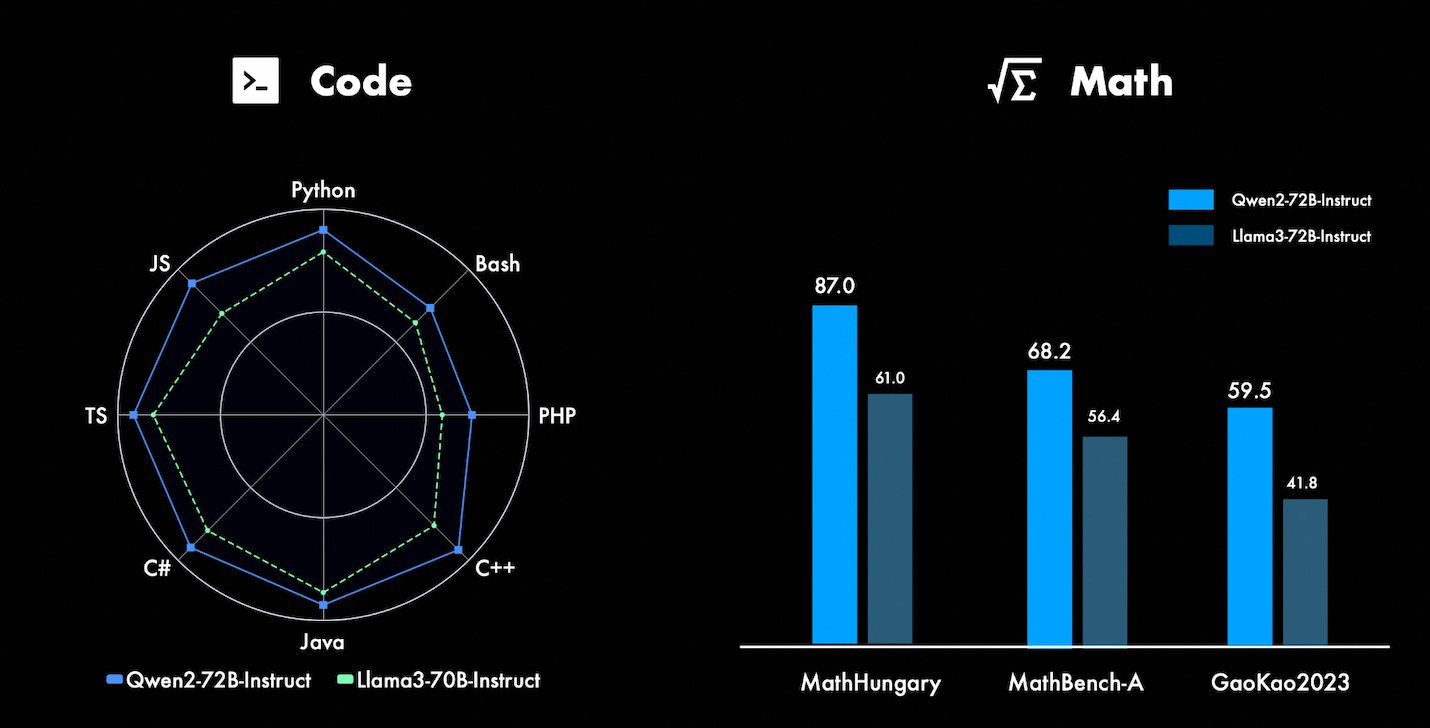
📅 ThursdAI - Jun 6th - 👑 Qwen2 Beats Llama-3! Jina vs. Nomic for Multimodal Supremacy, new Chinese SORA, Suno & Udio user uploads & more AI news
Hey hey! This is Alex! 👋 Some podcasts have 1 or maaaybe 2 guests an episode, we had 6! guests today, each has had an announcement, an open source release, or a breaking news story that we've covered! (PS, this edition is very multimodal so click into the Substack as videos don't play in your inbox)As you know my favorite thing is to host the folks who make the news to let them do their own announcements, but also, hitting that BREAKING NEWS button when something is actually breaking (as in, happened just before or during the show) and I've actually used it 3 times this show! It's not every week that we get to announce a NEW SOTA open model with the team that worked on it. Junyang (Justin) Lin from Qwen is a friend of the pod, a frequent co-host, and today gave us the breaking news of this month, as Qwen2 72B, is beating LLama-3 70B on most benchmarks! That's right, a new state of the art open LLM was announced on the show, and Justin went deep into details 👏 (so don't miss this conversation, listen to wherever you get your podcasts) We also chatted about SOTA multimodal embeddings with Jina folks (Bo Wand and Han Xiao) and Zach from Nomic, dove into an open source compute grant with FALs Batuhan Taskaya and much more! TL;DR of all topics covered: * Open Source LLMs * Alibaba announces Qwen 2 - 5 model suite (X, HF)* Jina announces Jina-Clip V1 - multimodal embeddings beating CLIP from OAI (X, Blog, Web Demo)* Nomic announces Nomic-Embed-Vision (X, BLOG)* MixEval - arena style rankings with Chatbot Arena model rankings with 2000× less time (5 minutes) and 5000× less cost ($0.6) (X, Blog)* Vision & Video* Kling - open access video model SORA competitor from China (X)* This Weeks Buzz * WandB supports Mistral new finetuning service (X)* Register to my June 12 workshop on building Evals with Weave HERE* Voice & Audio* StableAudio Open - X, BLOG, TRY IT* Suno launches "upload your audio" feature to select few - X * Udio - upload your own audio feature - X* AI Art & Diffusion & 3D* Stable Diffusion 3 weights are coming on June 12th (Blog)* JasperAI releases Flash Diffusion (X, TRY IT, Blog)* Big CO LLMs + APIs* Group of ex-OpenAI sign a new letter - righttowarn.ai * A hacker releases TotalRecall - a tool to extract all the info from MS Recall Feature (Github)Open Source LLMs QWEN 2 - new SOTA open model from Alibaba (X, HF)This is definitely the biggest news for this week, as the folks at Alibaba released a very surprising and super high quality suite of models, spanning from a tiny 0.5B model to a new leader in open models, Qwen 2 72B To add to the distance from Llama-3, these new models support a wide range of context length, all large, with 7B and 72B support up to 128K context. Justin mentioned on stage that actually finding sequences of longer context lengths is challenging, and this is why they are only at 128K.In terms of advancements, the highlight is advanced Code and Math capabilities, which are likely to contribute to overall model advancements across other benchmarks as well. It's also important to note that all models (besides the 72B) are now released with Apache 2 license to help folks actually use globally, and speaking of globality, these models have been natively trained with 27 additional languages, making them considerably better at multilingual prompts! One additional amazing thing was, that a finetune was released by Eric Hartford and Cognitive Computations team, and AFAIK this is the first time a new model drops with an external finetune. Justing literally said "It is quite amazing. I don't know how they did that. Well, our teammates don't know how they did that, but, uh, it is really amazing when they use the Dolphin dataset to train it."Here's the Dolphin finetune metrics and you can try it out hereThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.Jina-Clip V1 and Nomic-Embed-Vision SOTA multimodal embeddingsIt's quite remarkable that we got 2 separate SOTA of a similar thing during the same week, and even more cool that both companies came to talk about it on ThursdAI! First we welcomed back Bo Wang from Jina (who joined by Han Xiao the CEO) and Bo talked about multimodal embeddings that beat OpenAI CLIP (which both conceded was a very low plank) Jina Clip V1 is apache 2 open sourced, while Nomic Embed is beating it on benchmarks but is CC-BY-NC non commercially licensed, but in most cases, if you're embedding, you'd likely use an API, and both companies offer these embeddings via their respective APIsOne thing to note about Nomic, is that they have mentioned that these new embeddings are backwards compatible with the awesome Nomic embed endpoints and embeddings, so if you've used that, now you've gone multimodal! Because these models are fairly small, there are now web versions, thanks to transformer.js, of Jina and Nomic Embed (caution, this will download
📅 ThursdAI - May 30 - 1000 T/s inference w/ SambaNova, <135ms TTS with Cartesia, SEAL leaderboard from Scale & more AI news
Hey everyone, Alex here! Can you believe it's already end of May? And that 2 huge AI companies conferences are behind us (Google IO, MSFT Build) and Apple's WWDC is just ahead in 10 days! Exciting! I was really looking forward to today's show, had quite a few guests today, I'll add all their socials below the TL;DR so please give them a follow and if you're only in reading mode of the newsletter, why don't you give the podcast a try 🙂 It's impossible for me to add the density of knowledge that's being shared on stage for 2 hours here in the newsletter! Also, before we dive in, I’m hosting a free workshop soon, about building evaluations from scratch, if you’re building anything with LLMs in production, more than welcome to join us on June 12th (it’ll be virtual)TL;DR of all topics covered: * Open Source LLMs * Mistral open weights Codestral - 22B dense coding model (X, Blog)* Nvidia open sources NV-Embed-v1 - Mistral based SOTA embeddings (X, HF)* HuggingFace Chat with tool support (X, demo)* Aider beats SOTA on Swe-Bench with 26% (X, Blog, Github)* OpenChat - Sota finetune of Llama3 (X, HF, Try It)* LLM 360 - K2 65B - fully transparent and reproducible (X, Paper, HF, WandB)* Big CO LLMs + APIs* Scale announces SEAL Leaderboards - with private Evals (X, leaderboard)* SambaNova achieves >1000T/s on Llama-3 full precision* Groq hits back with breaking 1200T/s on Llama-3* Anthropic tool support in GA (X, Blogpost)* OpenAI adds GPT4o, Web Search, Vision, Code Interpreter & more to free users (X)* Google Gemini & Gemini Flash are topping the evals leaderboards, in GA(X)* Gemini Flash finetuning coming soon* This weeks Buzz (What I learned at WandB this week)* Sponsored a Mistral hackathon in Paris* We have an upcoming workshop in 2 parts - come learn with me* Vision & Video* LLama3-V - Sota OSS VLM (X, Github)* Voice & Audio* Cartesia AI - super fast SSM based TTS with very good sounding voices (X, Demo)* Tools & Hardware* Jina Reader (https://jina.ai/reader/) * Co-Hosts and Guests* Rodrigo Liang (@RodrigoLiang) & Anton McGonnell (@aton2006) from SambaNova* Itamar Friedman (@itamar_mar) Codium* Arjun Desai (@jundesai) - Cartesia* Nisten Tahiraj (@nisten) - Cohost* Wolfram Ravenwolf (@WolframRvnwlf)* Eric Hartford (@erhartford)* Maziyar Panahi (@MaziyarPanahi)Scale SEAL leaderboards (Leaderboard)Scale AI has announced their new initiative, called SEAL leaderboards, which aims to provide yet another point of reference in how we understand frontier models and their performance against each other. We've of course been sharing LMSys arena rankings here, and openLLM leaderboard from HuggingFace, however, there are issues with both these approaches, and Scale is approaching the measuring in a different way, focusing on very private benchmarks and dataset curated by their experts (Like Riley Goodside) The focus of SEAL is private and novel assessments across Coding, Instruction Following, Math, Spanish and more, and the main reason they keep this private, is so that models won't be able to train on these benchmarks if they leak to the web, and thus show better performance due to data contamination. They are also using ELO scores (Bradley-Terry) and I love this footnote from the actual website: "To ensure leaderboard integrity, we require that models can only be featured the FIRST TIME when an organization encounters the prompts"This means they are taking the contamination thing very seriously and it's great to see such dedication to being a trusted source in this space. Specifically interesting also that on their benchmarks, GPT-4o is not better than Turbo at coding, and definitely not by 100 points like it was announced by LMSys and OpenAI when they released it! Gemini 1.5 Flash (and Pro) in GA and showing impressive performance As you may remember from my Google IO recap, I was really impressed with Gemini Flash, and I felt that it went under the radar for many folks. Given it's throughput speed, 1M context window, and multimodality and price tier, I strongly believed that Google was onto something here. Well this week, not only was I proven right, I didn't actually realize how right I was 🙂 as we heard breaking news from Logan Kilpatrick during the show, that the models are now in GA, and that Gemini Flash gets upgraded to 1000 RPM (requests per minute) and announced that finetuning is coming and will be free of charge! Not only with finetuning won't cost you anything, inference on your tuned model is going to cost the same, which is very impressive. There was a sneaky price adjustment from the announced pricing to the GA pricing that upped the pricing by 2x on output tokens, but even despite that, Gemini Flash with $0.35/1MTok for input and $1.05/1MTok on output is probably the best deal there is right now for LLMs of this level. This week it was also confirmed both on LMsys, and on Scale SEAL leaderboards that Gemini Flash is a very good coding LLM, beating Claude Sonnet and LLama-3 70B! SambaNova + Groq competin

📅 ThursdAI - May 23 - OpenAI troubles, Microsoft Build, Phi-3 small/large, new Mistral & more AI news
Hello hello everyone, this is Alex, typing these words from beautiful Seattle (really, it only rained once while I was here!) where I'm attending Microsoft biggest developer conference BUILD. This week we saw OpenAI get in the news from multiple angles, none of them positive and Microsoft clapped back at Google from last week with tons of new AI product announcements (CoPilot vs Gemini) and a few new PCs with NPU (Neural Processing Chips) that run alongside CPU/GPU combo we're familiar with. Those NPUs allow for local AI to run on these devices, making them AI native devices! While I'm here I also had the pleasure to participate in the original AI tinkerers thanks to my friend Joe Heitzberg who operates and runs the aitinkerers.org (of which we are a local branch in Denver) and it was amazing to see tons of folks who listen to ThursdAI + read the newsletter and talk about Weave and evaluations with all of them! (Btw, one the left is Vik from Moondream, which we covered multiple times). I Ok let's get to the news: TL;DR of all topics covered: * Open Source LLMs * HuggingFace commits 10M in ZeroGPU (X)* Microsoft open sources Phi-3 mini, Phi-3 small (7B) Medium (14B) and vision models w/ 128K context (Blog, Demo)* Mistral 7B 0.3 - Base + Instruct (HF)* LMSys created a "hard prompts" category (X)* Cohere for AI releases Aya 23 - 3 models, 101 languages, (X)* Big CO LLMs + APIs* Microsoft Build recap - New AI native PCs, Recall functionality, Copilot everywhere * Will post a dedicated episode to this on Sunday* OpenAI pauses GPT-4o Sky voice because Scarlet Johansson complained* Microsoft AI PCs - Copilot+ PCs (Blog)* Anthropic - Scaling Monosemanticity paper - about mapping the features of an LLM (X, Paper)* Vision & Video* OpenBNB - MiniCPM-Llama3-V 2.5 (X, HuggingFace)* Voice & Audio* OpenAI pauses Sky voice due to ScarJo hiring legal counsel* Tools & Hardware* Humane is looking to sell (blog)Open Source LLMs Microsoft open sources Phi-3 mini, Phi-3 small (7B) Medium (14B) and vision models w/ 128K context (Blog, Demo)Just in time for Build, Microsoft has open sourced the rest of the Phi family of models, specifically the small (7B) and the Medium (14B) models on top of the mini one we just knew as Phi-3. All the models have a small context version (4K and 8K) and a large that goes up to 128K (tho they recommend using the small if you don't need that whole context) and all can run on device super quick. Those models have MIT license, so use them as you will, and are giving an incredible performance comparatively to their size on benchmarks. Phi-3 mini, received an interesting split in the vibes, it was really good for reasoning tasks, but not very creative in it's writing, so some folks dismissed it, but it's hard to dismiss these new releases, especially when the benchmarks are that great! LMsys just updated their arena to include a hard prompts category (X) which select for complex, specific and knowledge based prompts and scores the models on those. Phi-3 mini actually gets a big boost in ELO ranking when filtered on hard prompts and beats GPT-3.5 😮 Can't wait to see how the small and medium versions perform on the arena.Mistral gives us function calling in Mistral 0.3 update (HF)Just in time for the Mistral hackathon in Paris, Mistral has released an update to the 7B model (and likely will update the MoE 8x7B and 8x22B Mixtrals) with function calling and a new vocab. This is awesome all around because function calling is important for agenting capabilities, and it's about time all companies have it, and apparently the way Mistral has it built in matches the Cohere Command R way and is already supported in Ollama, using raw mode. Big CO LLMs + APIsOpen AI is not having a good week - Sky voice has paused, Employees complainOpenAI is in hot waters this week, starting with pausing the Sky voice (arguably the best most natural sounding voice out of the ones that launched) due to complains for Scarlett Johansson about this voice being similar to hers. Scarlett appearance in the movie Her, and Sam Altman tweeting "her" to celebrate the release of the incredible GPT-4o voice mode were all talked about when ScarJo has released a statement saying she was shocked when her friends and family told her that OpenAI's new voice mode sounds just like her. Spoiler, it doesn't really, and they hired an actress and have had this voice out since September last year, as they outlined in their blog following ScarJo complaint. Now, whether or not there's legal precedent here, given that Sam Altman reached out to Scarlet twice, including once a few days before the event, I won't speculate, but for me, personally, not only Sky doesn't sound like ScarJo, it was my favorite voice even before they demoed it, and I'm really sad that it's paused, and I think it's unfair to the actress who was hired for her voice. See her own statement: Microsoft Build - CoPilot all the thingsI have recorded a Built recap with Ryan Carson from Intel A

📅 ThursdAI - May 16 - OpenAI GPT-4o, Google IO recap, LLama3 hackathon, Yi 1.5, Nous Hermes Merge & more AI news
Wow, holy s**t, insane, overwhelming, incredible, the future is here!, "still not there", there are many more words to describe this past week. (TL;DR at the end of the blogpost)I had a feeling it's going to be a big week, and the companies did NOT disappoint, so this is going to be a very big newsletter as well. As you may have read last week, I was very lucky to be in San Francisco the weekend before Google IO, to co-host a hackathon with Meta LLama-3 team, and it was a blast, I will add my notes on that in This weeks Buzz section. Then on Monday, we all got to watch the crazy announcements from OpenAI, namely a new flagship model called GPT-4o (we were right, it previously was im-also-a-good-gpt2-chatbot) that's twice faster, 50% cheaper (in English, significantly more so in other languages, more on that later) and is Omni (that's the o) which means it is end to end trained with voice, vision, text on inputs, and can generate text, voice and images on the output. A true MMIO (multimodal on inputs and outputs, that's not the official term) is here and it has some very very surprising capabilities that blew us all away. Namely the ability to ask the model to "talk faster" or "more sarcasm in your voice" or "sing like a pirate", though, we didn't yet get that functionality with the GPT-4o model, it is absolutely and incredibly exciting. Oh and it's available to everyone for free! That's GPT-4 level intelligence, for free for everyone, without having to log in!What's also exciting was how immediate it was, apparently not only the model itself is faster (unclear if it's due to newer GPUs or distillation or some other crazy advancements or all of the above) but that training an end to end omnimodel reduces the latency to incredibly immediate conversation partner, one that you can interrupt, ask to recover from a mistake, and it can hold a conversation very very well. So well, that indeed it seemed like, the Waifu future (digital girlfriends/wives) is very close to some folks who would want it, while we didn't get to try it (we got GPT-4o but not the new voice mode as Sam confirmed) OpenAI released a bunch of videos of their employees chatting with Omni (that's my nickname, use it if you'd like) and many online highlighted how thirsty / flirty it sounded. I downloaded all the videos for an X thread and I named one girlfriend.mp4, and well, just judge for yourself why: Ok, that's not all that OpenAI updated or shipped, they also updated the Tokenizer which is incredible news to folks all around, specifically, the rest of the world. The new tokenizer reduces the previous "foreign language tax" by a LOT, making the model way way cheaper for the rest of the world as wellOne last announcement from OpenAI was the desktop app experience, and this one, I actually got to use a bit, and it's incredible. MacOS only for now, this app comes with a launcher shortcut (kind of like RayCast) that let's you talk to ChatGPT right then and there, without opening a new tab, without additional interruptions, and it even can understand what you see on the screen, help you understand code, or jokes or look up information. Here's just one example I just had over at X. And sure, you could always do this with another tab, but the ability to do it without context switch is a huge win. OpenAI had to do their demo 1 day before GoogleIO, but even during the excitement about GoogleIO, they had announced that Ilya is not only alive, but is also departing from OpenAI, which was followed by an announcement from Jan Leike (who co-headed the superailgnment team together with Ilya) that he left as well. This to me seemed like a well executed timing to give dampen the Google news a bit. Google is BACK, backer than ever, Alex's Google IO recapOn Tuesday morning I showed up to Shoreline theater in Mountain View, together with creators/influencers delegation as we all watch the incredible firehouse of announcements that Google has prepared for us. TL;DR - Google is adding Gemini and AI into all it's products across workspace (Gmail, Chat, Docs), into other cloud services like Photos, where you'll now be able to ask your photo library for specific moments. They introduced over 50 product updates and I don't think it makes sense to cover all of them here, so I'll focus on what we do best."Google with do the Googling for you" Gemini 1.5 pro is now their flagship model (remember Ultra? where is that? 🤔) and has been extended to 2M tokens in the context window! Additionally, we got a new model called Gemini Flash, which is way faster and very cheap (up to 128K, then it becomes 2x more expensive)Gemini Flash is multimodal as well and has 1M context window, making it an incredible deal if you have any types of videos to process for example. Kind of hidden but important was a caching announcement, which IMO is a big deal, big enough it could post a serious risk to RAG based companies. Google has claimed they have a way to introduce caching of the LLM activati

📅 ThursdAI - May 9 - AlphaFold 3, im-a-good-gpt2-chatbot, Open Devin SOTA on SWE-Bench, DeepSeek V2 super cheap + interview with OpenUI creator & more AI news
Hey 👋 (show notes and links a bit below)This week has been a great AI week, however, it does feel like a bit "quiet before the storm" with Google I/O on Tuesday next week (which I'll be covering from the ground in Shoreline!) and rumors that OpenAI is not just going to let Google have all the spotlight!Early this week, we got 2 new models on LMsys, im-a-good-gpt2-chatbot and im-also-a-good-gpt2-chatbot, and we've now confirmed that they are from OpenAI, and folks have been testing them with logic puzzles, role play and have been saying great things, so maybe that's what we'll get from OpenAI soon?Also on the show today, we had a BUNCH of guests, and as you know, I love chatting with the folks who make the news, so we've been honored to host Xingyao Wang and Graham Neubig core maintainers of Open Devin (which just broke SOTA on Swe-Bench this week!) and then we had friends of the pod Tanishq Abraham and Parmita Mishra dive deep into AlphaFold 3 from Google (both are medical / bio experts).Also this week, OpenUI from Chris Van Pelt (Co-founder & CIO at Weights & Biases) has been blowing up, taking #1 Github trending spot, and I had the pleasure to invite Chris and chat about it on the show!Let's delve into this (yes, this is I, Alex the human, using Delve as a joke, don't get triggered 😉)TL;DR of all topics covered (trying something new, my Raw notes with all the links and bulletpoints are at the end of the newsletter)* Open Source LLMs* OpenDevin getting SOTA on Swe-Bench with 21% (X, Blog)* DeepSeek V2 - 236B (21B Active) MoE (X, Try It)* Weights & Biases OpenUI blows over 11K stars (X, Github, Try It)* LLama-3 120B Chonker Merge from Maxime Labonne (X, HF)* Alignment Lab open sources Buzz - 31M rows training dataset (X, HF)* xLSTM - new transformer alternative (X, Paper, Critique)* Benchmarks & Eval updates* LLama-3 still in 6th place (LMsys analysis)* Reka Core gets awesome 7th place and Qwen-Max breaks top 10 (X)* No upsets in LLM leaderboard* Big CO LLMs + APIs* Google DeepMind announces AlphaFold-3 (Paper, Announcement)* OpenAI publishes their Model Spec (Spec)* OpenAI tests 2 models on LMsys (im-also-a-good-gpt2-chatbot & im-a-good-gpt2-chatbot)* OpenAI joins Coalition for Content Provenance and Authenticity (Blog)* Voice & Audio* Udio adds in-painting - change parts of songs (X)* 11Labs joins the AI Audio race (X)* AI Art & Diffusion & 3D* ByteDance PuLID - new high quality ID customization (Demo, Github, Paper)* Tools & Hardware* Went to the Museum with Rabbit R1 (My Thread)* Co-Hosts and Guests* Graham Neubig (@gneubig) & Xingyao Wang (@xingyaow_) from Open Devin* Chris Van Pelt (@vanpelt) from Weights & Biases* Nisten Tahiraj (@nisten) - Cohost* Tanishq Abraham (@iScienceLuvr)* Parmita Mishra (@prmshra)* Wolfram Ravenwolf (@WolframRvnwlf)* Ryan Carson (@ryancarson)Open Source LLMsOpen Devin getting a whopping 21% on SWE-Bench (X, Blog)Open Devin started as a tweet from our friend Junyang Lin (on the Qwen team at Alibaba) to get an open source alternative to the very popular Devin code agent from Cognition Lab (recently valued at $2B 🤯) and 8 weeks later, with tons of open source contributions, >100 contributors, they have almost 25K stars on Github, and now claim a State of the Art score on the very hard Swe-Bench Lite benchmark beating Devin and Swe-Agent (with 18%)They have done so by using the CodeAct framework developed by Xingyao, and it's honestly incredible to see how an open source can catch up and beat a very well funded AI lab, within 8 weeks! Kudos to the OpenDevin folks for the organization, and amazing results!DeepSeek v2 - huge MoE with 236B (21B active) parameters (X, Try It)The folks at DeepSeek is releasing this huge MoE (the biggest we've seen in terms of experts) with 160 experts, and 6 experts activated per forward pass. A similar trend from the Snowflake team, just extended even longer. They also introduce a lot of technical details and optimizations to the KV cache.With benchmark results getting close to GPT-4, Deepseek wants to take the crown in being the cheapest smartest model you can run, not only in open source btw, they are now offering this model at an incredible .28/1M tokens, that's 28 cents per 1M tokens!The cheapest closest model in price was Haiku at $.25 and GPT3.5 at $0.5. This is quite an incredible deal for a model with 32K (128 in open source) context and these metrics.Also notable is the training cost, they claim that it took them 1/5 the price of what Llama-3 cost Meta, which is also incredible. Unfortunately, running this model locally a nogo for most of us 🙂I would mention here that metrics are not everything, as this model fails quite humorously on my basic logic testsLLama-3 120B chonker Merge from Maxime LaBonne (X, HF)We're covered Merges before, and we've had the awesome Maxime Labonne talk to us at length about model merging on ThursdAI but I've been waiting for Llama-3 merges, and Maxime did NOT dissapoint!A whopping 120B llama (Maxime added 50

ThursdAI - May 2nd - New GPT2? Copilot Workspace, Evals and Vibes from Reka, LLama3 1M context (+ Nous finetune) & more AI news
Hey 👋 Look it May or May not be the first AI newsletter you get in May, but it's for sure going to be a very information dense one. As we had an amazing conversation on the live recording today, over 1K folks joined to listen to the first May updates from ThursdAI. As you May know by now, I just love giving the stage to folks who are the creators of the actual news I get to cover from week to week, and this week, we had again, 2 of those conversations. First we chatted with Piotr Padlewski from Reka, the author on the new Vibe-Eval paper & Dataset which they published this week. We've had Yi and Max from Reka on the show before, but it was Piotr's first time and he was super super knowledgeable, and was really fun to chat with. Specifically, as we at Weights & Biases launch a new product called Weave (which you should check out at https://wandb.me/weave) I'm getting more a LOT more interested in Evaluations and LLM scoring, and in fact, we started the whole show today with a full segment on Evals, Vibe checks and covered a new paper from Scale about overfitting. The second deep dive was with my friend Idan Gazit, from GithubNext, about the new iteration of Github Copilot, called Copilot Workspace. It was a great one, and you should definitely give that one a listen as wellTL;DR of all topics covered + show notes * Scores and Evals* No notable changes, LLama-3 is still #6 on LMsys* gpt2-chat came and went (in depth chan writeup)* Scale checked for Data Contamination on GSM8K using GSM-1K (Announcement, Paper)* Vibes-Eval from Reka - a set of multimodal evals (Announcement, Paper, HF dataset)* Open Source LLMs * Gradient releases 1M context window LLama-3 finetune (X)* MaziyarPanahi/Llama-3-70B-Instruct-DPO-v0.4 (X, HF)* Nous Research - Hermes Pro 2 - LLama 3 8B (X, HF)* AI Town is running on Macs thanks to Pinokio (X)* LMStudio releases their CLI - LMS (X, Github)* Big CO LLMs + APIs* Github releases Copilot Workspace (Announcement)* AI21 - releases Jamba Instruct w/ 256K context (Announcement)* Google shows Med-Gemini with some great results (Announcement)* Claude releases IOS app and Team accounts (X)* This weeks Buzz* We're heading to SF to sponsor the biggest LLama-3 hackathon ever with Cerebral Valley (X)* Check out my video for Weave our new product, it's just 3 minutes (Youtube)* Vision & Video* Intern LM open sourced a bunch of LLama-3 and Phi based VLMs (HUB)* And they are MLXd by the "The Bloke" of MLX, Prince Canuma (X)* AI Art & Diffusion & 3D* ByteDance releases Hyper-SD - Stable Diffusion in a single inference step (Demo)* Tools & Hardware* Still haven't open the AI Pin, and Rabbit R1 just arrived, will open later today* Co-Hosts and Guests* Piotr Padlewski (@PiotrPadlewski) from Reka AI* Idan Gazit (@idangazit) from Github Next* Wing Lian (@winglian)* Nisten Tahiraj (@nisten)* Yam Peleg (@yampeleg)* LDJ (@ldjconfirmed)* Wolfram Ravenwolf (@WolframRvnwlf)* Ryan Carson (@ryancarson)Scores and EvaluationsNew corner in today's pod and newsletter given the focus this week on new models and comparing them to existing models.What is GPT2-chat and who put it on LMSys? (and how do we even know it's good?)For a very brief period this week, a new mysterious model appeared on LMSys, and was called gpt2-chat. It only appeared on the Arena, and did not show up on the leaderboard, and yet, tons of sleuths from 4chan to reddit to X started trying to figure out what this model was and wasn't. Folks started analyzing the tokenizer, the output schema, tried to get the system prompt and gauge the context length. Many folks were hoping that this is an early example of GPT4.5 or something else entirely. It did NOT help that uncle SAMA first posted the first tweet and then edited it to remove the - and it was unclear if he's trolling again or foreshadowing a completely new release or an old GPT-2 but retrained on newer data or something. The model was really surprisingly good, solving logic puzzles better than Claude Opus, and having quite amazing step by step thinking, and able to provide remarkably informative, rational, and relevant replies. The average output quality across many different domains places it on, at least, the same level as high-end models such as GPT-4 and Claude Opus.Whatever this model was, the hype around it made LMSYS add a clarification to their terms and temporarily take off the model now. And we're waiting to hear more news about what it is. Reka AI gives us Vibe-Eval a new multimodal evaluation dataset and score (Announcement, Paper, HF dataset)Reka keeps surprising, with only 20 people in the company, their latest Reka Core model is very good in multi modality, and to prove it, they just released a new paper + a new method of evaluating multi modal prompts on VLMS (Vision enabled Language Models) Their new Open Benchmark + Open Dataset is consistent of this format: And I was very happy to hear from one of the authors on the paper @PiotrPadlewski on the pod, where he mentioned that they w
📅 ThursdAI - April 25 - Phi-3 3.8B impresses, LLama-3 gets finetunes, longer context & ranks top 6 in the world, Snowflake's new massive MoE and other AI news this week
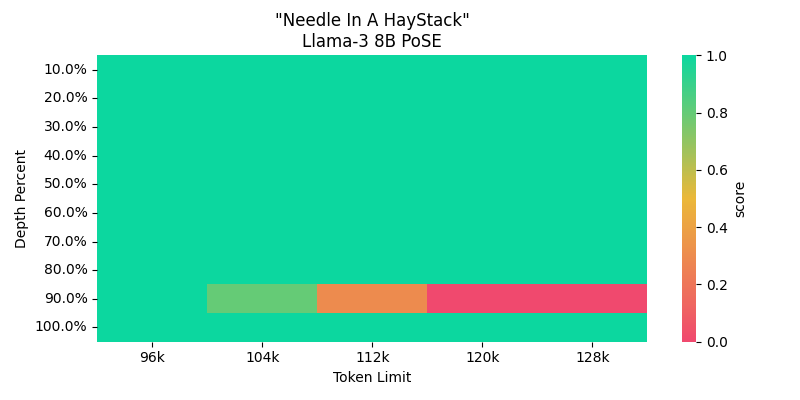
Hey hey folks, happy ThursdAI 🎉 Not a lot of house-keeping here, just a reminder that if you're listening or reading from Europe, our European fullyconnected.com conference is happening in May 15 in London, and you're more than welcome to join us there. I will have quite a few event updates in the upcoming show as well. Besides this, this week has been a very exciting one for smaller models, as Microsoft teased and than released Phi-3 with MIT license, a tiny model that can run on most macs with just 3.8B parameters, and is really punching above it's weights. To a surprising and even eyebrow raising degree! Let's get into it 👇ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.TL;DR of all topics covered: * Open Source LLMs * Microsoft open sources Phi-3 (X, HF)* LLama3 70B top5 (no top 6) on LMsys (LMsys Arena)* Snowflake open sources Arctic - A massive hybrid MoE (X, Try it, HF)* Evolutionary Model merges support in MergeKit (Blog)* Llama-3 8B finetunes roundup - Longer Context (128K) and Dolphin & Bagel Finetunes* HuggingFace FINEWEB - a massive 45TB (the GPT4 of datasets) and 15T tokens high quality web data dataset (HF)* Cohere open sourced their chat interface (X)* Apple open sources OpenElm 4 models + training library called corenet (HF, Github, Paper)* Big CO LLMs + APIs* Google Gemini 1.5 pro is #2 on LMsys arena * Devin is now worth 2BN and Perplexity is also a Unicorn * A new comer called Augment (backed by Eric Schmidt) is now coming out of stealth (X)* Vision & Video* Adobe releases VideoGigaGAN - high quality upscaler with temporal consistency (paper)* TLDraw autocomplete UI demo (X)* This Weeks Buzz - What I learned in WandB this week* Joe Spisak talk about Llama3 on Stage at WandB Fully connected (Full Talk, TLDR)* Voice & Audio* Play.ai (previously play.ht) releases conversational Voice AI platform (X)* AI Art & Diffusion & 3D* IMGsys.org- like LMsys but for image generation model + leaderboard from FAL (try it)* Tools & Hardware* Rabbit R1 release party & no shipping update in sight* I'm disillusioned about my AI Pin and will return itOpen Source LLMs Llama-3 1 week-aversary 🎂 - Leaderboard ranking + finetunes Well, it's exactly 1 week since we got Llama-3 from Meta and as expected, the rankings show a very very good story. (also it was downloaded over 1.2M times and already has 600 derivatives on HuggingFace) Just on Monday, Llama-3 70B (the bigger version) took the incredible 5th place (now down to 6th) on LMSys, and more surprising, given that the Arena now has category filters (you can filter by English only, Longer chats, Coding etc) if you switch to English Only, this model shows up 2nd and was number 1 for a brief period of time. So just to sum up, an open weights model that you can run on most current consumer hardware is taking over GPT-4-04-94, Claude Opus etc' This seems dubious, because well, while it's amazing, it's clearly not at the level of Opus/Latest GPT-4 if you've used it, in fact it fails some basic logic questions in my tests, but it's a good reminder that it's really hard to know which model outperforms which and that the arena ALSO has a bias, of which people are using it for example and that evals are not a perfect way to explain which models are better. However, LMsys is a big component of the overall vibes based eval in our community and Llama-3 is definitely a significant drop and it's really really good (even the smaller one) One not so surprising thing about it, is that the Instruct version is also really really good, so much so, that the first finetunes of Eric Hartfords Dolphin (Dolphin-2.8-LLama3-70B) is improving just a little bit over Meta's own instruct version, which is done very well. Per Joe Spisak (Program Manager @ Meta AI) chat at the Weights & Biases conference last week (which you can watch below) he said "I would say the magic is in post-training. That's where we are spending most of our time these days. Uh, that's where we're generating a lot of human annotations." and they with their annotation partners, generated up to 10 million annotation pairs, both PPO and DPO and then did instruct finetuning. So much so that Jeremy Howard suggests to finetune their instruct version rather than the base model they released.We also covered that despite the first reactions to the 8K context window, the community quickly noticed that extending context window for LLama-3 is possible, via existing techniques like Rope scaling, YaRN and a new PoSE method. Wing Lian (Maintainer of Axolotl finetuneing library) is stretching the model to almost 128K context window and doing NIH tests and it seems very promising! Microsoft releases Phi-3 (Announcement, Paper, Model)Microsoft didn't really let Meta take the open models spotlight, and comes with an incredible report and follow up with a model release that's MIT licened, tiny (3.8B paramet
📅 ThursdAI - Apr 18th - 🎉 Happy LLama 3 day + Bigxtral instruct, WizardLM gives and takes away + Weights & Biases conference update
Happy LLama 3 day folks! After a lot of rumors, speculations, and apparently pressure from the big Zuck himself, we finally can call April 18th, 2024, LLaMa 3 day! I am writing this, from a lobby of the Mariott hotel in SF, where our annual conference is happening called Fully Connected, and I recorded today's episode from my hotel room. I really wanna shout out how awesome it was to meet folks who are listeners of the ThursdAI pod and newsletter subscribers, participate in the events, and give high fives. During our conference, we had the pleasure to have Joe Spisak, the Product Director of LLaMa at Meta, to actually announce LLaMa3 on stage! It was so exhilarating, I was sitting in the front row, and then had a good chat with Joe outside of the show 🙌 The first part of the show was of course, LLaMa 3 focused, we had such a great time chatting about the amazing new 8B and 70B models we got, and salivating after the announced but not yet released 400B model of LLaMa 3 😮 We also covered a BUNCH of other news from this week, that was already packed with tons of releases, AI news and I was happy to share my experiences running a workshop a day before our conference, with focus on LLM evaluations. (If there's an interest, I can share my notebooks and maybe even record a video walkthrough, let me know in the comments) Ok let's dive in 👇 Happy LLama 3 day 🔥 The technical detailsMeta has finally given us what we're all waiting for, an incredibly expensive (2 clusters of 24K H100s over 15 Trillion tokens) open weights models, the smaller 8B one and the larger 70B one. We got both instruction fine tune and base models, which are great for finetuners, and worth mentioning that this is a dense model (not a mixture of experts, all the parameters are accessible for the model during inference) It is REALLY good at benchmarks, with the 7B model beating the previous (LLaMa 2 70B) on pretty much all benchmarks, and the new 70B is inching on the bigger releases from the past month or two, like Claude Haiku and even Sonnet! The only downsides are the 8K context window + non multimodality, but both are coming according to Joe Spisak who announced LLama3 on stage at our show Fully Connected 🔥 I was sitting in the front row and was very excited to ask him questions later! By the way, Joe did go into details they haven't yet talked about pulblicly (see? I told you to come to our conference! and some of you did!) and I've been live-tweeting his whole talk + the chat outside with the "extra" spicy questions and Joes winks haha, you can read that thread hereThe additional infoMeta has also partnered with both Google and Bing (take that OpenAI) and inserted LLama 3 into the search boxes of Facebook, Instagram, Messenger and Whatsapp plus deployed it to a new product called meta.ai (you can try it there now) and is now serving LLama 3 to more than 4 Billion people across all of those apps, talk about compute cost! Llama 3 also has a new Tokenizer (that Joe encouraged us to "not sleep on") and a bunch of new security tools like Purple LLama and LLama Guard. PyTorch team recently released finetuning library called TorchTune is now supporting LLama3 finetuning natively out of the box as well (and integrates Wandb as it's first party experiment tracking tool) If you'd like more details, directly from Joe, I was live tweeting his whole talk, and am working at getting the slides from our team. We'll likely have a recording as well, will post it as soon as we have it. Here's a TL;DR (with my notes for the first time) of everything else we talked about, but given today is LLaMa day, and I still have to do fully connected demos, I will "open source" my notes and refer you to the podcast episode to hear more detail about everything else that happened today 🫡 TL;DR of all topics covered: * Meta releases LLama 3 -8B, 70B and later 400B (Announcement, Models, Try it, Run Locally)* Open Source LLMs * Meta LLama 3 8B, 70B and later 400B (X, Blog)* Trained 15T tokens! * 70B and 8B modes released + Instruction finetuning* 8K context length , not multi modal* 70B gets 82% on MMLU and 81.7% on HumanEval* 128K vocab tokenizer* Dense model not MoE* Both instruction tuned on human annotated datasets* Open Access* The model already uses RoPe * Bigxtral instruct 0.1 (Blog, Try it)* Instruct model of the best Apache 2 model around* Release a comparison chart that everyone started "fixing" * 🤖 Mixtral 8x22B is Mistral AI's latest open AI model, with unmatched performance and efficiency * 🗣 It is fluent in 5 languages: English, French, Italian, German, Spanish* 🧮 Has strong math and coding capabilities * 🧠 Uses only 39B parameters out of 141B total, very cost efficient* 🗜 Can recall info from large documents thanks to 64K token context window* 🆓 Released under permissive open source license for anyone to use* 🏆 Outperforms other open models on reasoning, knowledge and language benchmarks * 🌐 Has strong multilingual abilities, outperforming others
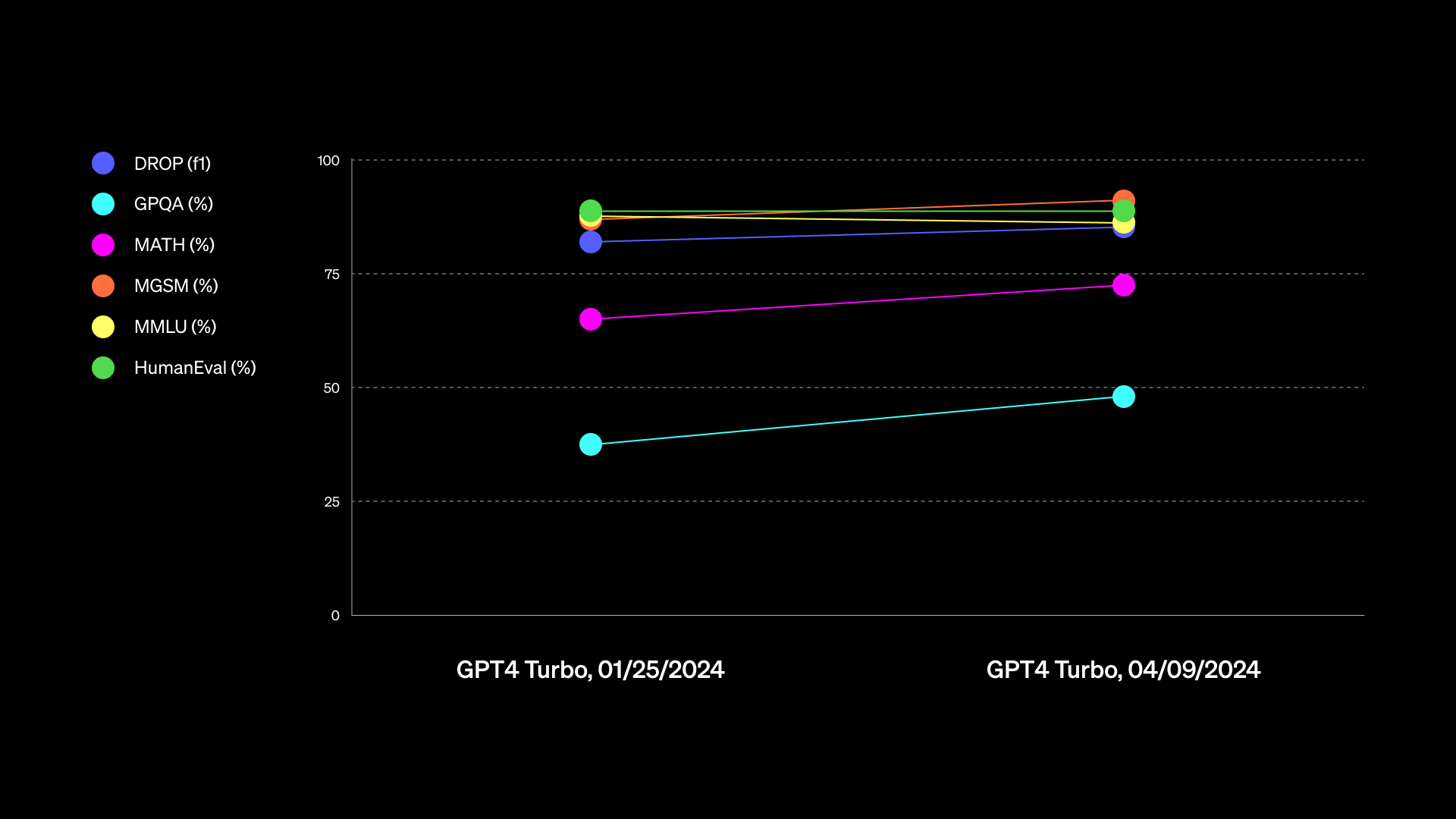
📅 ThursdAI - Apr 11th, 2024 - GPT4 is king again, New Mixtral 8x22B + First finetune, New Gemini 1.5, Cohere beats old GPT4, more AI news
this week was absolutely bonkers. For starters, for the first time ever, we got an Open Weights model (Command R+) to jump over GPT-4 in human rankings on LMsys, this is huge!Then on Tuesday, it seems that all the companies just wanted to one up one another, first Gemini 1.5 released with updates, made it available in 180 countries, added audio mode + tons of API improvements and system prompts, then less than an hour later, OpenAI has given us a "majorly improved" GPT-4 Turbo version (2024-04-09) that is now back to being the BEST LLM IN THE WORLD and to cap that day off, Mistral did the thing again, the thing being, dropping a torrent link in a tweet with no explanations.What was in that torrent is a Mixtral 8x22B MoE (which we started calling Bixtral) which comes with an Apache2 license and seems to be VERY good!We also saw the first finetune from HuggingFace/KAIST folks less than 48 hours later (the authors of said finetune actually came on the show 🎉 )Fully Connected is a week from today! If you haven't yet signed up, use THURSDAI promo code and come hear from Richard Socher (You.com), Jerry Liu (Ilamaindex CEO), Karoly (TwoMinutePapers), Joe Spisak (Meta) and and leaders from NVIDIA, Snowflake, Microsoft, Coatue, Adobe, Siemens, Lambda and tons more 👇TL;DR of all topics covered:* Open Source LLMs* 🔥 Mistral releases Mixtral 8x22 Apache 2 licensed MoE model (Torrent, TRY IT)* Cohere CMDR+ jumps to no 6 on LMSys and beats GPT4 (X)* CodeGemma, RecurrentGemma & Gemma Instruct 1.1 (Announcement)* Auto-code-rover gets 22% on SWE bench (Announcement)* HuggingFace - Zephyr 141B-A35B - First Bixtral Finetune (Announcement)* Mistral 22B - 1 single expert extracted from MoE (Announcement, HF)* This weeks Buzz - Weights & Biases updates* FullyConnected is in 1 week! (Come meet us)* Big CO LLMs + APIs* 🔥 GPT-4 turbo is back to being number 1 AI with 88.2% Human Eval score (X)* Gemini 1.5 Pro now understands audio, uses unlimited files, acts on your commands, and lets devs build incredible things with JSON mode (X)* LLama 3 coming out in less than a month (confirmed by Meta folks)* XAI Grok now powers news summaries on X (Example)* Cohere new Rerank 3 (X)* Voice & Audio* HuggingFace trained Parler-TTS (Announcement, Github)* Udio finally launched it's service (Announcement, Leak, Try It)* Suno has added explore mode (suno.ai/explore)* Hardware* Humane AI pin has started shipping - reviews are not amazingOpen Source LLMsCommand R+ first open weights model that beats last year GPT4 versionsThis is massive, really a milestone to be discussed, and even though tons of other news happened, the first time an open weights model is beating GPT-4 not on a narrow case (coding, medical) but on a general human evaluation on the arena.This happened just a year after GPT-4 first came out, and is really really impressive.Command R+ has been getting a lot of great attention from the community as well, folks were really surprised by the overall quality, not to mention the multilingual abilities of CommandR+Mixtral 8x22B MoE with 65K context and Apache 2 license (Bigstral)Despite the above, Cohere time in the sun (ie top open weights model on lmsys) may not be that long if the folks at Mistral have anything to say about it!Mistral decided to cap the crazy Tuesday release day with another groundbreaking tweet of theirs which includes a torrent link and nothing else (since then they of course uploaded the model to the hub) giving us what potentially will unseat Command R from the rankings.The previous Mixtral (8x7B) signaled the age of MoEs and each expert in that was activated from Mistral 7B, but for this new affectionally named Bixtral model, each expert is a 22B sized massive model.We only got a base version of it, which is incredible on it's own right, but it's not instruction finetuned yet, and the finetuner community is already cooking really hard! Though it's hard because this model requires a lot of compute to finetune, and not only GPUs, Matt Shumer came on the pod and mentioned that GPUs weren't actually the main issue, it was system RAM when the finetune was finished.The curious thing about it was watching the loss and the eval loss. it [Bixtral] learns much faster than other models - Matt ShumerMatt was trying to run Finetunes for Bigstral and had a lot of interesting stuff to share, definitely check out that conversation on the pod.Bigstral is... big, and it's not super possible to run it on consumer hardware.... yet, because Nisten somehow got it to run on CPU only 🤯 using Justin Tuneys LLM kernels (from last week) and LLama.cpp with 9tok/s which is kinda crazy.HuggingFace + KAIST release Zephyr 141B-A35B (First Mixtral 8x22 finetune)And that was fast, less than 48 hours after the torrent drop, we already see the first instruction finetune from folks at HuggingFace and KAIST AI.They give us a new finetune using ORPO, a technique by KAIST that significantly improves finetuning ability (they finetuned Bigstral with 7k
📅 ThursdAI Apr 4 - Weave, CMD R+, SWE-Agent, Everyone supports Tool Use + JAMBA deep dive with AI21
Happy first ThursdAI of April folks, did you have fun on April Fools? 👀 I hope you did, I made a poll on my feed and 70% did not participate in April Fools, which makes me a bit sad! Well all-right, time to dive into the news of this week, and of course there are TONS of news, but I want to start with our own breaking news! That's right, we at Weights & Biases have breaking new of our own today, we've launched our new product today called Weave! Weave is our new toolkit to track, version and evaluate LLM apps, so from now on, we have Models (what you probably know as Weights & Biases) and Weave. So if you're writing any kind RAG system, anything that uses Claude or OpenAI, Weave is for you! I'll be focusing on Weave and I'll be sharing more on the topic, but today I encourage you to listen to the launch conversation I had with Tim & Scott from the Weave team here at WandB, as they and the rest of the team worked their ass off for this release and we want to celebrate the launch 🎉TL;DR of all topics covered: * Open Source LLMs * Cohere - CommandR PLUS - 104B RAG optimized Sonnet competitor (Announcement, HF)* Princeton SWE-agent - OSS Devin - gets 12.29% on SWE-bench (Announcement, Github)* Jamba paper is out (Paper)* Mozilla LLamaFile now goes 5x faster on CPUs (Announcement, Blog)* Deepmind - Mixture of Depth paper (Thread, ArXiv)* Big CO LLMs + APIs* Cloudflare AI updates (Blog)* Anthropic adds function calling support (Announcement, Docs)* Groq lands function calling (Announcement, Docs)* OpenAI is now open to customers without login requirements * Replit Code Repair - 7B finetune of deep-seek that outperforms Opus (X)* Google announced Gemini Prices + Logan joins (X)קרמ* This weeks Buzz - oh so much BUZZ!* Weave lunch! Check weave out! (Weave Docs, Github)* Sign up with Promo Code THURSDAI at fullyconnected.com * Voice & Audio* OpenAI Voice Engine will not be released to developers (Blog)* Stable Audio v2 dropped (Announcement, Try here)* Lightning Whisper MLX - 10x faster than whisper.cpp (Announcement, Github)* AI Art & Diffusion & 3D* Dall-e now has in-painting (Announcement) * Deep dive* Jamba deep dive with Roi Cohen from AI21 and Maxime Labonne Open Source LLMs Cohere releases Command R+, 104B RAG focused model (Blog)Cohere surprised us, and just 2.5 weeks after releasing Command-R (which became very popular and is No 10 on Lmsys arena) gave us it's big brother, Command R PLUSWith 128K tokens in the context window, this model is multilingual as well, supporting 10 languages and is even beneficial on tokenization for those languages (a first!) The main focus from Cohere is advanced function calling / tool use, and RAG of course, and this model specializes in those tasks, beating even GPT-4 turbo. It's clear that Cohere is positioning themselves as RAG leaders as evident by this accompanying tutorial on starting with RAG apps and this model further solidifies their place as the experts in this field. Congrats folks, and thanks for the open weights 🫡SWE-Agent from PrincetonFolks remember Devin? The super cracked team born agent with a nice UI that got 13% on the SWE-bench a very hard (for LLMs) benchmark that requires solving real world issues?Well now we have an open source agent that comes very very close to that called SWE-AgentSWE agent has a dedicated terminal and tools, and utilizes something called ACI (Agent Computer Interface) allowing the agent to navigate, search, and edit code. The dedicated terminal in a docker environment really helps as evident by a massive 12.3% score on SWE-bench where GPT-4 gets only 1.4%! Worth mentioning that SWE-bench is a very hard benchmark that was created by the folks who released SWE-agent, and here's some videos of them showing the agent off, this is truly an impressive achievement!Deepmind publishes Mixture of Depth (arXiv)Thanks to Hassan who read the paper and wrote a deep dive, this paper by Deepmind shows their research into optimizing model inference. Apparently there's a way to train LLMs without affecting their performance, which later allows to significantly reduce compute on some generated tokens. 🧠 Transformer models currently spread compute uniformly, but Mixture-of-Depths allows models to dynamically allocate compute as needed💰 Dynamically allocating compute based on difficulty of predicting each token leads to significant compute savings ⏳ Predicting the first token after a period is much harder than within-sentence tokens, so more compute is needed 🗑 Most current compute is wasted since difficulty varies between tokensWe're looking forward to seeing models trained with this, as this seems to be a very big deal in how to optimize inference for LLMs. Thank you for reading ThursdAI - Best way to support us is to just share this with folks 👇Big CO LLMs + APIsAnthropic and Groq announce function calling / tool use support, Cohere takes it one step furtherIn yet another example of how OpenAI is leading not only in models, but in developer ex

📅 ThursdAI - Mar 28 - 3 new MoEs (XXL, Medium and Small), Opus is 👑 of the arena, Hume is sounding emotional + How Tanishq and Paul turn brainwaves into SDXL images 🧠👁️
Hey everyone, this is Alex and can you believe that we're almost done with Q1 2024? March 2024 was kind of crazy of course, so I'm of course excited to see what April brings (besides Weights & Biases conference in SF called Fully Connected, which I encourage you to attend and say Hi to me and the team!) This week we have tons of exciting stuff on the leaderboards, say hello to the new best AI in the world Opus (+ some other surprises), in the open source we had new MoEs (one from Mosaic/Databricks folks, which tops the open source game, one from AI21 called Jamba that shows that a transformers alternative/hybrid can actually scale) and tiny MoE from Alibaba, as well as an incredible Emotion TTS from Hume. I also had the pleasure to finally sit down with friend of the pod Tanishq Abraham and Paul Scotti from MedArc and chatted about MindEye 2, how they teach AI to read minds using diffusion models 🤯🧠👁️Thank you for reading ThursdAI - Recaps of the most high signal AI weekly spaces. This post is public so feel free to share it.TL;DR of all topics covered: * AI Leaderboard updates* Claude Opus is number 1 LLM on arena (and in the world)* Claude Haiku passes GPT4-0613* 🔥 Starling 7B beta is the best Apache 2 model on LMsys, passing GPT3.5* Open Source LLMs * Databricks/Mosaic DBRX - a new top Open Access model (X, HF)* 🔥 AI21 - Jamba 52B - Joint Attention Mamba MoE (Blog, HuggingFace)* Alibaba - Qwen1.5-MoE-A2.7B (Announcement, HF)* Starling - 7B that beats GPT3.5 on lmsys (HF)* LISA beats LORA as the frontrunner PeFT (X, Paper)* Mistral 0.2 Base released (Announcement)* Big CO LLMs + APIs* Emad leaves stability 🥺* Apple rumors - Baidu, Gemini, Anthropic, who else? (X)* This weeks buzz* WandB Workshop in SF confirmed April 17 - LLM evaluations (sign up here)* Vision & Video* Sora showed some demos by actual artists, Air Head was great (Video)* Tencent Aniportait - generate Photorealistic Animated avatars (X)* MedArc - MindEye 2 - fMRI signals to diffusion models (X) * Voice & Audio* Hume demos EVI - empathic voice analysis & generation (X, demo)* AI Art & Diffusion & 3D* Adobe firefly adds structure reference and style transfer - (X, Demo)* Discussion* Deep dive into MindEye 2 with Tanishq & Paul from MedArc* Is narrow finetuning done-for with larger context + cheaper prices - debate🥇🥈🥉Leaderboards updates from LMSys (Arena)This weeks updates to the LMsys arena are significant. (Reminder in LMsys they use a mix of MT-Bench, LLM as an evaluation and user ELO scores where users play with these models and choose which answer they prefer)For the first time since the Lmsys arena launched, the top model is NOT GPT-4 based. It's now Claude's Opus, but that's not surprising if you used the model, what IS surprising is that Haiku, it's tiniest, fastest brother is now well positioned at number 6, beating a GPT4 version from the summer, Mistral Large and other models while being dirt cheap. We also have an incredible show from the only Apache 2.0 licensed model in the top 15, Starling LM 7B beta, which is now 13th on the chart, with incredible finetune of a finetune (OpenChat) or Mistral 7B. 👏 Yes, you can now run a GPT3.5 beating model, on your mac, fully offline 👏 Incredible. Open Source LLMs (Welcome to MoE's)Mosaic/Databricks gave us DBRX 132B MoE - trained on 12T tokens (X, Blog, HF)Absolutely crushing the previous records, Mosaic has released the top open access model (one you can download and run and finetune) in a while, beating LLama 70B, Grok-1 (314B) and pretty much every other non closed source model in the world not only on metrics and evals, but also on inference speedIt uses a Mixture of Experts (MoE) architecture with 16 experts that each activate for different tokens. this allows it to have 36 billion actively parameters compared to 13 billion for Mixtral. DBRX has strong capabilities in math, code, and natural language understanding. The real kicker is the size, It was pre-trained on 12 trillion tokens of text and code with a maximum context length of 32,000 tokens, which is just incredible, considering that LLama 2 was just 2T tokens. And the funny thing is, they call this DBRX-medium 👀 Wonder what large is all about.Graph credit Awni Hannun from MLX (Source)You can play with the DBRX here and you'll see that it is SUPER fast, not sure what Databricks magic they did there, or how much money they spent (ballpark of ~$10M) but it's truly an awesome model to see in the open access! 👏 AI21 releases JAMBA - a hybrid Transformer + Mamba 58B MoE (Blog, HF)Oh don't I love #BreakingNews on the show! Just a few moments before ThursdAI, AI21 dropped this bombshell of a model, which is not quite the best around (see above) but has a few very interesting things going for it. First, it's a hybrid architecture model, capturing the best of Transformers and Mamba architectures, and achieving incredible performance on the larger context window size (Transformers hardware requirements scale quadratically with
📅 ThursdAI - Mar 21 - Grok, GTC, first OSS AI hardware, Neuralink Human, Prompting Claude and more AI news
March madness... I know for some folks this means basketball or something, but since this is an AI newsletter, and this March was indeed mad, I am claiming it. This week seemed madder from one day to another. And the ai announcements kept coming throughout the recording, I used the "breaking news" button a few times during this week's show! This week we covered tons of corporate AI drama in the BigCO segment, from Inflection → Microsoft move, to Apple Gemini rumors, to Nvidia GTC conference, but we also had a bunch of OpenSource to go over, including an exciting glimpse into the O1 from Open Interpreter, which the founder Killian (of the ThursdAI mafia haha) joined to chat about briefly after an all nighter release push! Another returning FOTP (friend of the pod) Matt Shumer joined as we did a little deep dive into prompting Claude, and how he went viral (seems to happen a lot to Matt) with a project of his to make Claude write prompts for itself! Definitely worth a listen, it's the first segment post the TL'DR on the pod 👂 this week.Btw, did you already check out fully connected? It's the annual Weights & Biases conference in SF next month, and tickets are flying, I'm going to be there and actually do a workshop one day prior, would love to invite you to join as well!TL;DR of all topics covered: * Open Source LLMs* Xai open sources Grok (X, Blog, HF, Github) * Sakana AI releases a new paper + 2 JP merged SOTA models (X, Paper, Blogpost)* Open Interpreter announces O1 - the Linux for AI devices (X, Project)* LM studio new modes (X)* Big CO LLMs + APIs* Nvidia GTC conference - Blackwell platform, NIMs and Gr00t robotics* Jensen interviewed transformers authors * Apple rumored to look at a deal including GEMINI* Apple releases a multi modal MM1 paper (X)* Inflection founders leave to head Microsoft AI* Google opens up Gemini 1.5 with 1M context access to all (X)* Vision & Video* NVIDIA + MIT release VILA (13B, 7B and 2.7B) (X, HuggingFace, Paper)* This week's BUZZ* Fully Connected is coming, sign up here, get tickets, join us. * I'm running a workshop in SF a day before on improving your LLM step by step including exciting announcements (same link)* Voice & Audio* Suno V3 launched officially (X, Blog, Play with it)* Distil-whisper-v3 - more accurate, and 6x version of whisper large (X, Code)* AI Art & Diffusion & 3D* Stability presents SD3 TURBO - 4 steps to get same high quality generation (Paper)* Stability open sources Stable Video 3D (Blog, Models)* Tools & Others* Neuralink interview with the first Human NeuroNaut - Nolan (X)* Lex & Sama released a podcast, barely any news* Matt Shumer releases his Claude Prompt engineer (X, Metaprompt, Matt's Collab)Open Source LLMs Xai open sources Grok (X, Blog, HF, Github) Well, Space Uncle Elon has a huge week, from sending starship into orbit successfully to open sourcing an LLM for us, and a huge one at that. Grok is a 314B parameter behemoth, with a mixture of experts architecture of 80B per expert and two active at the same time. It's released as a base model, and maybe that's why it was received with initial excitement but then, nobody in the GPU poor compute category has the ability to run/finetune it! In terms of performance, it barely beats out Mixtral, while being almost 10x larger, which just shows that.... data is important, maybe more important than Github stars as Arthur (CEO Mistral) helpfully pointed out to Igor (founder of Xai). Still big props to the team for training and releasing this model under apache 2 license.Sakana AI launches 2 new models using evolutionary algo mergingYeah, that's a mouthful, i've been following Hardmaru (David Ha) for a while before he joined Sakana, and only when the founder (and a co-author on transformers) LLion Jones talked about it on stage at GTC the things connected. Sakana means fish in Japanese, and the idea behind this lab is to create things with using nature like evolutionary algorithms. The first thing they open sourced was 2 new SOTA models for Japanese LLM, beating significantly larger models, by using Merging (which we covered with Maxime previously, and whom Sakana shouted out in their work actually) Open Interpreter announces 01 Light - the linux of AI hardware devicesBreaking news indeed, after we saw the release of R1 go viral in January, Killian (with whom we chatted previously in our most favorited episode of last year) posted that if someone wants to build the open source version of R1, it'll be super cool and fit with the vision of Open Interpreter very well.And then MANY people did (more than 200), and the O1 project got started, and fast forward a few months, we now have a first glimpse (and the ability to actually pre-order) the O1 Light, their first device that's a button that communicates with your computer (and in the future, with their cloud) and interacts with a local agent that runs code and can learn how do to things with a skill library. It's all very very exciting, and to see how this i
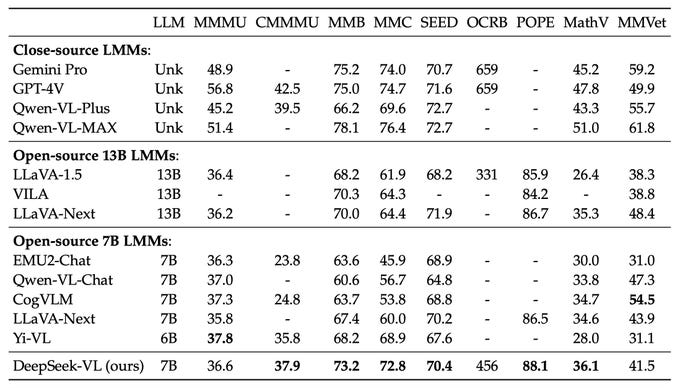
🎂 ThursdAI BirthdAI March 14: Anthropic Haiku, Devin the new AI SWE, GPT4 gets hands, Cohere and Nous give us tool use models & more AI news
"...Happy birthday dear ThursdAIiiiiiiii, happy birthday to youuuuuu 🎂"What a day! Today is π-day (March 14th), 2024. For some reason it's important, not only because it's GPT-4 anniversary, or Claude 1 anniversary, or even that Starship flew to space, but also 🥁 it's ThursdAI BirthdAI 🎉 Yeah, you heard that right, last year following GPT-4 release, I hopped into a twitter space with a few friends, and started chatting about AI, and while some friends came and went, I never stopped, in fact, I decided to leave my 15 year career in software, and focus on AI, learning publicly, sharing my learnings with as many people as possible and it's been glorious. And so today, I get to celebrate a little 💃I also get to reminisce about the state of AI that we were at, back exactly a year ago. Context windows were tiny, GPT-4 came out with 8K (we casually now have models with 200K that cost $0.25/1M tokens), GPT-4 also showed unprecedented levels vision capabilities back then, and now, we have 1.3B parameters models that have similar level of visual understanding, open source was nascent (in fact, LLama.cpp only had it's first commit 4 days prior to GPT4 launch, Stanford released the first Alpaca finetune of Llama just a day prior. Hell even the chatGPT API only came out a few days before, so there was barely any products built with AI out there. Not to mention that folks were only starting to figure out what vector DBs were, what RAG is, how to prompt, and that it's possible to run these things in a loop and create agents! Other fields evolved as well, just hit play on this song I generated for ThursdAI with Suno V3 alpha, I can’t stop listening to it and imagining that this was NOT possible even a few months agoIt's all so crazy and happening so fast, that annual moments like these propose a great opportunity to pause the acceleration for a sec. and contextualize it, and bask in the techno-optimism glory of aren't we lucky to live in these times? I sure am, and for me it's the ThursdAI birthday gift to be able to share my excitement with all of you! Thank you for being a subscriber, the best way you can support ThursdAI is to share this with a friend and tag us on socials 🫡TL;DR of all topics covered: * Open Source LLMs * Together releases Sequoia speculative decoding (X, Blog)* Hermes Pro from NousResearch - Tool use and function calling (X, HF, Github)* Big CO LLMs + APIs* Anthropic releases Claude 3 Haiku (Announcement, Blog)* Cohere CMD+R (Announcement, HF)* This weeks Buzz* Early bird tickets for Fully Connected in SF are flying, come meet the Weights & Biases team. We're also going to be running a workshop a day before, come join us! (X)* Vision & Video* Deepseek VLM 1.3B and 7B (X,Announcement, HF)* Voice & Audio* Made a song with Suno v3 Alpha for ThursdAI, it's a banger (Song)* Hardware & Robotics (New)* OpenAI now powers Figure - the humanoid robot company (X)* Cerebras announces the fastest AI chip on earth (X)* Extropic made an announcement about their TPU - Thermodynamic Processing Unit* Tools & Agents* Devin from Cognition Labs (Announcement, 47 minute demo)Agents for your house and your Github tasksSay hello to Devin from Cognition Labs (Announcement, Real world demo)By far the most excited I've seen my X feed be this week, was excitement about Cognition Labs new agent called Devin, which they call the first AI software engineer. You should really watch the video, and then watch a few other videos, because, well, only a few folks are getting access, and yours truly is not one of them.It seems like a very published launch, backed by tons of VC folks, and everybody kept highlighting not only the innovative UI that Devin has, and it has a very polished UX/UI/Dev experience with access to a browser (where you can authenticate and it can pick up doing tasks), terminal (where you can scroll back and forth in time to see what it did when), but also a chat window and a planning window + an IDE where it rights code and you can scrub through that as well. Folks were also going crazy about the founder (and team) amount of math ability and IOI gold medals, this video went viral featuring Scott the founder of Cognition, in his youth obliterating this competition… poor Victoria 😅Regardless of their incredible math abilities, Devin is actually pretty solid, specifically from the UI side, and again, like with he AutoGPT hype of yesteryear, we see the same issues, it's nice, but cognition hiring page is still looking for human software engineers. Tune into the last 30 minutes of the pod today as we had tons of folks discuss the implications of an AI "software engineer" and whether or not coding skills are still required/desired. Short answer is, yes, don't skip, learn coding. Devin is going to be there to assist but likely will not replace you.🤖 OpenAI + Figure give GPT-4 hands (or give figure eyes/ears/mouth)Ok this demo you must just see before reading the rest of it, OpenAI announced a partnership with Figure,

📅 ThursdAI - Mar 7 - Anthropic gives us Claude 3, Elon vs OpenAI, Inflection 2.5 with Pi, img-2-3D from Stability & More AI news
Hello hello everyone, happy spring! Can you believe it? It's already spring! We have tons of AI news for you to cover, starting with the most impactful one, did you already use Claude 3? Anthropic decided to celebrate Claude 1's birthday early (which btw is also ThursdAI's birthday and GPT4 release date, March 14th, 2023) and gave us 3 new Clauds! Opus, Sonnet and Haiku. TL;DR of all topics covered: * Big CO LLMs + APIs* 🔥 Anthropic releases Claude Opus, Sonnet, Haiku (Announcement, try it)* Inflection updates Pi 2.5 - claims GPT4/Gemini equivalent with 40% less compute (announcement)* Elon sues OpenAI (link)* OpenAI responds (link)* ex-Google employee was charged with trading AI secrets with China (article)* Open Source LLMs * 01AI open sources - Yi 9B (Announcement)* AnswerAI - Jeremy Howard, Johno & Tim Detmers - train 70B at home with FSDP/QLoRA (X, Blog)* GaLORE - Training 7B on a single consumer-grade GPU (24GB) (X)* Nous open sources Genstruct 7B - instruction-generation model (Hugging Face)* Yam's GEMMA-7B Hebrew (X)* This weeks Buzz* Weights & Biases is coming to SF in April! Our annual conference called Fully Connected is open for registration (Get your tickets and see us in SF)* Vision & Video* Vik releases Moondream 2 (Link)* Voice & Audio* Suno v3 alpha is blowing minds (Link)* AI Art & Diffusion & 3D* SD3 research paper is here (Link)* Tripo + Stability release TripoSR - FAST image-2-3D (link, Demo, FAST demo)* Story how I created competition of inference providers to get us sub 1.5s playground image gen (X)Big CO LLMs + APIsAnthropic releases Claude 3 Opus, Sonnet and Haiku This was by far the biggest news of this week, specifically because, the top keeps getting saturated with top of the line models! Claude Opus is actually preferable to many folks in blind studies over some GPT-4 features, and as we were recording the pod, LMSys released their rankings and Claude Opus beats Gemini, and is now 3rd in user preference on the LMSys rank. There release is vast, they have announced 3 new models but only gave us access to 2 of them teasing that Haiku is much faster / cheaper than other options in that weight class out there. In addition to being head to head with GPT-4, Claude 3 is now finally also multimodal on inputs, meaning it can take images, understand graphs and charts. They also promised significantly less refusals and improved accuracy by almost 2x. One incredible thing that Claude always had was 200K context window, and here they announced that they will be supporting up to 1M, but for now we still only get 200K.We were also promised support for function calling and structured output, but apparently that's "coming soon" but still great to see that they are aiming for it! We were all really impressed with Claude Opus, from folks on stage who mentioned that it's easier to talk to and feels less sterile than GPT-4, to coding abilities that are not "lazy" and don't tell you to continue writing the rest of the code yourself in comments, to even folks who are jailbreaking the guardrales and getting Claude to speak about the "I" and metacognition. Speaking of meta-cognition sparks, one of the prompt engineers on the team shared a funny story about doing a needle-in-haystack analysis, and that Claude Opus responded with I suspect this pizza topping "fact" may have been inserted as a joke or to test if I was paying attentionThis split the X AI folks in 2, many claiming, OMG it's self aware, and many others calling for folks to relax and that like other models, this is still just spitting out token by token. I additional like the openness with which Anthropic folks shared the (very simple but carefuly crafted) system prompt My personal take, I've always liked Claude, even v2 was great until they nixed the long context for the free tier. This is a very strong viable alternative for GPT4 if you don't need DALL-E or code interpreter features, or the GPTs store or the voice features on IOS. If you're using the API to build, you can self register at https://console.anthropic.com and you'll get an API key immediately, but going to production will still take time and talking to their sales folks. Open Source LLMs 01 AI open sources Yi 9B Announcement claims that "It stands out as the top-performing similar-sized language model friendly to developers, excelling in code and math." but it's a much bigger model, trained on 3T tokens. I find it confusing to create a category of models between 7B and almost 12B. This weeks Buzz (What I learned with WandB this week)We're coming to SF! Come join Weights & Biases in our annual conference in the heart of San Francisco, get to hear from industry leaders about how to build models in production, and meet most of the team! (I'll be there as well!) AI Art & DiffusionLast week, just last week, we covered the open sourcing of the awesome Playground 2.5 model, which looked really good in user testing. I really wanted to incorporate this to my little demo, but couldn't ru

📅 ThursdAI - Feb 29 - Leap Year Special ✨
Happy leap year day everyone, very excited to bring you a special once-in-a-4 year edition of ThursdAI 👏 (Today is also Dune 2 day (am going to see the movie right after I write these here words) and well.. to some folks, this is the bull market ₿ days as well. So congrats to all who weathered the bear market!)This week we had another great show, with many updates, and a deep dive, and again, I was able to cover most of the news AND bring you a little bit of a deep dive into a very interesting concept called Matryoshka Representation Learning (aka 🪆 embeddings) and two of the authors on paper to chat with me on the pod! TL;DR of all topics covered: * AI Art & Diffusion & 3D* Playground releases a new diffusion foundational model Playground V2.5 (DEMO)* Alibaba teasing EMO - incredible animating faces (example)* Ideogram 1.0 announced - SOTA text generation (Annoucement)* Open Source LLMs * Gemma update - hard to finetune, not better than 7B mistral* LLama 3 will release in June 2024, not anytime soon* Starcoder 2 + stack V2 (Announcement)* Berkeley Function-Calling leaderboard Leaderboard (Announcement)* Argilla released OpenHermesPreferences the largest open dataset for RLHF & DPO (Announcement)* STORM from Stanford to write long documents (Thread)* Big CO LLMs + APIs* Mistral releases Mistral Large & Le Chat (Announcement, Le Chat)* Microsoft + Mistral strike a deal (Blog)* Google teases GENIE - model makes images into interactive games (announcement)* OpenAI allowing fine-tune on GPT 3.5* Wordpress & Tumbler preparing to sell user data to OpenAI & Midjourney* Other* Mojo releases their MAX inference engine, compatible with PyTorch, Tensorflow & ONNX models (Announcement)* Interview with MRL (Matryoshka Representation Learning) authors (in audio only)AI Art & Diffusion Ideogram 1.0 launches - superb text generation! Ideogram, founded by ex google Imagen folks, which we reported on before, finally announces 1.0, and focuses on superb image generation. It's really great, and I generated a few owls already (don't ask, hooot) and I don't think I will stop. This is superb for meme creation, answering in multimedia, and is fast as well, I'm very pleased! They also announced a round investment from A16Z to go with their 1.0 release, definitely give them a tryPlayground V2.5 Suhail Doshi and Playground release a new foundational image model called Playground v2.5 and it looks awesome, very realistic and honestly looks like it beats MJ and DALL-E on many simple prompts.They also announced that this model received higher user preference scores based on 1K prompts (which we didn't get to see) but they have released this model into the wild, you can download it and play with a free demo provided by modal folksAnother SORA moment? Alibaba teases EMO 🤯 (website)Ok this one has to be talked about, Alibaba released quite a few preview videos + paper about something called EMO, a way to animate a talking/singing Avatars from just 1 image. It broke my brain, and I couldn't stop staring at it. Honestly, it's quite quite something. This model animates not only the mouth, eyes are blinking, there are emotions, hairs move, even earrings, and the most impressive, the whole Larynx muscle structure seem to be animated as well! Just look at this video, and then look at it again. The Github repo was created but no code released and I really hope we get this code at some point, because animating videos with this fidelity + something like SORA can mean so many possible creations! I wrote this tweet only two weeks ago, and I'm already feeling that it's outdated and we're farther along on the curve to there with EMO, what a great release! And just because it's so mind-blowing, here are a few more EMO videos for you to enjoy: Open Source LLMs Starcoder 2 + The Stack V2Folks at hugging face and BigCode have released a beast on us, StarCoder 2 ⭐️ The most complete open Code-LLM 🤖 StarCoder 2 is the next iteration for StarCoder and comes in 3 sizes, trained 600+ programming languages on over 4 Trillion tokens on Stack v2. It outperforms StarCoder 1 by margin and has the best overall performance across 5 benchmarks 🚀🤯.TL;DR;🧮 3B, 7B & 15B parameter version🪟 16384 token context window🔠 Trained on 3-4T Tokens (depending on size)💭 600+ Programming languages🥇 15B model achieves 46% on HumanEval🧠 Grouped Query Attention and Sliding Window Attention💪🏻 Trained on 1024 x H100 NVIDIA GPUs✅ commercial-friendly license🧑🏻💻 Can be used for local CopilotsThe Stack v2 is a massive (10x) upgrade on the previous stack dataset, containing 900B+ tokens 😮Big CO LLMs + APIs🔥 Mistral announces Mistral-Large + Le Chat + Microsoft partnershipToday, we are releasing Mistral Large, our latest model. Mistral Large is vastly superior to Mistral Medium, handles 32k tokens of context, and is natively fluent in English, French, Spanish, German, and Italian.We have also updated Mistral Small on our API to a model that is significantly better (and faste

📅 ThursdAI Feb 22nd - Groq near instant LLM calls, SDXL Lightning near instant SDXL, Google gives us GEMMA open weights and refuses to draw white people, Stability announces SD3 & more AI news
Hey, this is Alex,Ok let's start with the big news, holy crap this week was a breakthrough week for speed! We had both Groq explode in popularity, and ByteDance release an updated SDXL model called Lightning, able to generate full blown SDXL 1024 images in 300ms. I've been excited about seeing what real time LLM/Diffusion can bring, and with both of these news release the same week, I just had to go and test them out together: Additionally, we had Google step into a big open weights role, and give us Gemma, 2 open weights models 2B and 7B (which is closer to 9B per Junyang) and it was great to see google committing to releasing at least some models in the open. We also had breaking news, Emad from Stability announced SD3, which looks really great, Google to pay Reddit 200M for AI training on their data & a few more things. TL;DR of all topics covered: * Big CO LLMs + APIs* Groq custom LPU inference does 400T/s Llama/Mistral generation (X, Demo)* Google image generation is in Hot Waters and was reportedly paused (refuses to generate white people)* Gemini 1.5 long context is very impressive to folks (Matt Shumer, Ethan Mollick)* Open Weights LLMs * Google releases GEMMA, open weights 2B and 7B models (Announcement, Models)* Teknium releases Nous Hermes DPO (Announcement, HF)* Vision & Video* YoLo V9 - SOTA real time object detector is out (Announcement, Code)* This weeks Buzz (What I learned in WandB this week)* Went to SF to cohost an event with A16Z, Nous, Mistral (Thread, My Report)* AI Art & Diffusion & 3D* ByteDance presents SDXL-Lightning (Try here, Model)* Stability announces Stable Diffusion 3 (Announcement)* Tools* Replit releases a new experimental Figma plugin for UI → Code (Announcement)* Arc browser adds "AI pinch to understand" summarization (Announcement)Big CO LLMs + APIsGroq's new LPU show extreme performance for LLMs - up to 400T/s (example)* Groq created a novel processing unit known as the Tensor Streaming Processor (TSP) which they categorize as a Linear Processor Unit (LPU). Unlike traditional GPUs that are parallel processors with hundreds of cores designed for graphics rendering, LPUs are architected to deliver deterministic performance for AI computations.* Analogy: They know where all the cars are going when everyone wakes up for work (when they compile) and how fast they all drive (compute latency) so they can get rid of traffic lights (routers) and turn lanes (backpressure) by telling everyone when to leave the house.* Why would we need something like this? Some folks are saying that average human reading is only 30T/s, I created an example that uses near instant Groq Mixtral + Lightning SDXL to just create images with Mixtral as my prompt managerOpen Source Weights LLMs Google Gemma - 2B and 7B open weights models (demo)* 4 hours after release, Llama.cpp added support, Ollama and LM Studio added support, Tri dao added Flash attention support* Vocab size is 256K* 8K context window* Tokenizer similar to LLama* Folks are... not that impressed as far as I've seen* Trained on 6 trillion tokens* Google also released Gemma.cpp (local CPU inference) - AnnouncementNous/Teknium re-release Nous Hermes with DPO finetune (Announcement)* DPO RLHF is performing better than previous models* Models are GGUF and can be found here* DPO enables Improvements across the boardThis weeks Buzz (What I learned with WandB this week)* Alex was in SF last week* A16Z + 20 something cohosts including Weights & Biases talked about importance of open source* Huge Shoutout Rajko and Marco from A16Z, and tons of open source folks who joined* Nous, Ollama, LLamaIndex, LMSys folks, Replicate, Perplexity, Mistral, Github, as well as Eric Hartford, Jon Durbin, Haotian Liu, HuggingFace, tons of other great folks from Mozilla, linux foundation and Percy from Together/StanfordAlso had a chance to checkout one of the smol dinners in SF, they go really hard, had a great time showing folks the Vision Pro, chatting about AI, seeing incredible demos and chat about meditation and spirituality all at the same time! AI Art & DiffusionByteDance presents SDXL-Lightning (Try here)* Lightning fast SDXL with 2, 4 or 8 steps* Results much closer to original SDXL than turbo version from a few months agoStability announces Stable Diffusion 3 (waitlist)Uses a Diffusion Transformer architecture (like SORA)Impressive multi subject prompt following: "Prompt: a painting of an astronaut riding a pig wearing a tutu holding a pink umbrella, on the ground next to the pig is a robin bird wearing a top hat, in the corner are the words "stable diffusion"Tools* Replit announces a new Figma design→ code plugin That’s it for today, definitely check out the full conversation with Mark Heaps from Groq on the pod, and see you next week! 🫡 ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.Full Transcript: [00:00:00] Alex Volkov

🔥 ThursdAI - Feb 15, 2024 - OpenAI changes the Video Game, Google changes the Context game, and other AI news from past week
Holy SH*T, These two words have been said on this episode multiple times, way more than ever before I want to say, and it's because we got 2 incredible exciting breaking news announcements in a very very short amount of time (in the span of 3 hours) and the OpenAI announcement came as we were recording the space, so you'll get to hear a live reaction of ours to this insanity. We also had 3 deep-dives, which I am posting on this weeks episode, we chatted with Yi Tay and Max Bane from Reka, which trained and released a few new foundational multi modal models this week, and with Dome and Pablo from Stability who released a new diffusion model called Stable Cascade, and finally had a great time hanging with Swyx (from Latent space) and finally got a chance to turn the microphone back at him, and had a conversation about Swyx background, Latent Space, and AI Engineer. I was also very happy to be in SF today of all days, as my day is not over yet, there's still an event which we Cohost together with A16Z, folks from Nous Research, Ollama and a bunch of other great folks, just look at all these logos! Open Source FTW 👏 TL;DR of all topics covered: * Breaking AI News* 🔥 OpenAI releases SORA - text to video generation (Sora Blogpost with examples)* 🔥 Google teases Gemini 1.5 with a whopping 1 MILLION tokens context window (X, Blog)* Open Source LLMs * Nvidia releases Chat With RTX local models (Blog, Download)* Cohere open sources Aya 101 - 101 languages supporting 12.8B model (X, HuggingFace)* Nomic releases Nomic Embed 1.5 + with Matryoshka embeddings (X)* Big CO LLMs + APIs* Andrej Karpathy leaves OpenAI (Announcement)* OpenAI adds memory to chatGPT (X)* This weeks Buzz (What I learned at WandB this week)* We launched a new course with Hamel Husain on enterprise model management (Course)* Vision & Video* Reka releases Reka-Flash, 21B & Reka Edge MM models (Blog, Demo)* Voice & Audio* WhisperKit runs on WatchOS now! (X)* AI Art & Diffusion & 3D* Stability releases Stable Casdade - new AI model based on Würstchen v3 (Blog, Demo)* Tools & Others* Goody2ai - A very good and aligned AI that does NOT want to break the rules (try it)🔥 Let's start with Breaking News (in the order of how they happened) Google teases Gemini 1.5 with a whopping 1M context windowThis morning, Jeff Dean released a thread, full of crazy multi modal examples of their new 1.5 Gemini model, which can handle up to 1M tokens in the context window. The closest to that model so far was Claude 2.1 and that was not multi modal. They also claim they are researching up to 10M tokens in the context window. The thread was chock full of great examples, some of which highlighted the multimodality of this incredible model, like being able to pinpoint and give a timestamp of an exact moment in an hour long movie, just by getting a sketch as input. This, honestly blew me away. They were able to use the incredible large context window, break down the WHOLE 1 hour movie to frames and provide additional text tokens on top of it, and the model had near perfect recall. They used Greg Kamradt needle in the haystack analysis on text, video and audio and showed incredible recall, near perfect which highlights how much advancement we got in the area of context windows. Just for reference, less than a year ago, we had this chart from Mosaic when they released MPT. This graph Y axis at 60K the above graph is 1 MILLION and we're less than a year apart, not only that, Gemini Pro 1.5 is also multi modal I got to give promps to the Gemini team, this is quite a huge leap for them, and for the rest of the industry, this is a significant jump in what users will expect going forward! No longer will we be told "hey, your context is too long" 🤞 A friend of the pod Enrico Shipolle joined the stage, you may remember him from our deep dive into extending Llama context window to 128K and showed that a bunch of new research makes all this possible also for open source, so we're waiting for OSS to catch up to the big G. I will sum up with this, Google is the big dog here, they invented transformers, they worked on this for a long time, and it's amazing to see them show up like this, like they used to do, and blow us away! Kudos 👏 OpenAI teases SORA - a new giant leap in text to video generationYou know what? I will not write any analysis, I will just post a link to the blogpost and upload some videos that the fine folks at OpenAI just started releasing out of the blue.You can see a ton more videos on Sam twitter and on the official SORA websiteHonestly I was so impressed with all of them, that I downloaded a bunch and edited them all into the trailer for the show! Open Source LLMs Nvidia releases Chat With RTX Chat With Notes, Documents, and VideoUsing Gradio interface and packing 2 local modals, Nvidia releases a bundle with open source AI packaged, including RAG and even Youtube transcriptions chat! Chat with RTX supports various file formats, including text, pdf, doc/docx, and x
📅 ThursdAI - Feb 8 - Google Gemini Ultra is here, Qwen 1.5 with Junyang and deep dive into ColBERT, RAGatouille and DSPy with Connor Shorten and Benjamin Clavie
Hihi, this is Alex, from Weights & Biases, coming to you live, from Yosemite! Well, actually I’m writing these words from a fake virtual yosemite that appears above my kitchen counter as I’m not a Vision Pro user and I will force myself to work inside this thing and tell you if it’s worth it. I will also be on the lookout on anything AI related in this new spatial computing paradigm, like THIS for example! But back to rfeality for a second, we had quite the show today! We had the awesome time to have Junyang Justin Lin, a dev lead in Alibaba, join us and talk about Qwen 1.5 and QwenVL and then we had a deep dive into quite a few Acronyms I’ve been seeing on my timeline lately, namely DSPy, ColBERT and (the funniest one) RAGatouille and we had a chat with Connor from Weaviate and Benjamin the author of RAGatouille about what it all means! Really really cool show today, hope you don’t only read the newsletter but listen on Spotify, Apple or right here on Substack. TL;DR of all topics covered: * Open Source LLMs * Alibaba releases a BUNCH of new QWEN 1.5 models including a tiny .5B one (X announcement)* Abacus fine-tunes Smaug, top of HF leaderboard based Qwen 72B (X)* LMsys adds more open source models, sponsored by Together (X)* Jina Embeddings fine tune for code* Big CO LLMs + APIs* Google rebranding Bard to Gemini and launching Gemini Ultra (Gemini)* OpenAI adds image metadata (Announcement)* OpenAI keys are now restricted per key (Announcement)* Vision & Video* Bria - RMBG 1.4 - Open Source BG removal that runs in your browser (X, DEMO)* Voice & Audio* Meta voice, a new apache2 licensed TTS - (Announcement)* AI Art & Diffusion & 3D* Microsoft added DALL-E editing with "designer" (X thread)* Stability AI releases update to SVD - video 1.1 launches with a webUI, much nicer videos* Deep Dive with Benjamin Clavie and Connor Shorten show notes:* Benjamin's announcement of RAGatouille (X)* Connor chat with Omar Khattab (author of DSPy and ColBERT) - Weaviate Podcast* Very helpful intro to ColBert + RAGatouille - NotionOpen Source LLMs Alibaba releases Qwen 1.5 - ranges from .5 to 72B (DEMO)With 6 sizes, including 2 new novel ones, from as little as .5B parameter models to an interesting 4B, to all the way to a whopping 72B, Alibaba open sources additional QWEN checkpoints. We've had the honor to have friend of the pod Junyang Justin Lin again, and he talked to us about how these sizes were selected, that even thought this model beats Mistral Medium on some benchmarks, it remains to be seen how well this performs on human evaluations, and shared a bunch of details about open sourcing this.The models were released with all the latest and greatest quantizations, significantly improved context length (32K) and support for both Ollama and Lm Studio (which I helped make happen and am very happy for the way ThursdAI community is growing and connecting!) We also had a chat about QwenVL Plus and QwebVL Max, their API only examples for the best open source vision enabled models and had the awesome Piotr Skalski from Roborflow on stage to chat with Junyang about those models! To me a success of ThursdAI, is when the authors of things we talk about are coming to the show, and this is Junyang second appearance, which he joined at midnight at the start of the chinese new year, so greately appreciated and def. give him a listen! Abacus Smaug climbs to top of the hugging face leaderboard Junyang also mentioned that Smaug is now at the top of the leaderboards, coming from Abacus, this is a finetune of the previous Qwen-72B, not even this new one. First model to achieve an average score of 80, this is an impressive appearance from Abacus, though they haven't released any new data, they said they are planning to! They also said that they are planning to finetune Miqu, which we covered last time, the leak from Mistral that was acknowledged by Arthur Mensch the CEO of Mistral.The techniques that Abacus used to finetune Smaug will be released an upcoming paper! Big CO LLMs + APIsWelcome Gemini Ultra (bye bye Bard) Bard is no longer, get ready to meet Gemini. it's really funny because we keep getting cofusing naming from huge companies like Google and Microsoft. Just a week ago, Bard with Gemini Pro shot up to the LMSYS charts, after regular gemini pro API were not as close. and now we are suppose to forget that Bard even existed? 🤔 Anyhow, here we are, big G answer to GPT4, exactly 10 months 3 weeks 4 days 8 hours, but who's counting? So what do we actually get? a $20/m advanced tier for Gemini Advanced (which will have Ultra 1.0) the naming confusion continues. We get a longer context (how much?) + IOS and android apps (though I couldn't find it in IOS, maybe it wasn't yet rolled out)Gemini now also replaces google assistant for those with androids who opt in (MKBHD was somewhat impressed but not super impressed) but google is leaning into their advantage including home support! * Looks like Gemini is ONLY optimized for English as
📖 ThursdAI - Sunday special on datasets classification & alternative transformer architectures
Hello hello everyone, welcome to another special episode (some podcasts call them just.. episodes I guess, but here you get AI news every ThurdsdAI, and on Sunday you get the deeper dives) BTW, I'm writing these words, looking at a 300 inch monitor that's hovering above my usual workstation in the Apple Vision Pro, and while this is an AI newsletter, and I've yet to find a connecting link (there's like 3 AI apps in there right now, one fairly boring chatbot, and Siri... don't get me started on Siri), I'll definitely be covering my experience in the next ThursdAI, because well, I love everything new and technological, AI is a huge part of it, but not the ONLY part! 📖 It's all about the (big) Datasets Ok back to the matter at hand, if you've used, finetuned, trained or heard about an AI model, you may or may not realize how important the dataset the model was trained with is. We often talk of this model, that model, and often the only different is, additional data that folks (who I sometimes refer to as alchemists) have collected, curated and structured, and creating/curating/editing those datasets is an art and a science. For example, three friends of the pod, namely LDJ with Capybara, Austin with OpenChat and Teknium with Hermes, have been consistently taking of the shelves open source models and making them smarter, more instruction tuned, better for specific purposes. These datasets are paired with different techniques as well, for example, lately the so-called DPO (Direct preference optimization) is a technique that showed promise, since it not only shows a model which answer is the correct for a specific query, it shows an incorrect answer as well, and trains the model to prefer one over the other. (see the recent Capybara DPO improvement by Argilla, which improved model metrics across every evaluation)These datasets can range from super high quality 16K rows, to millions of rows (Teknium's recently released Hermes, one of the higher quality datasets comes in at just a tad over exactly 1 million rows) and often times it's an amalgamation of different other datasets into 1. In the case of Hermes, Teknium has compiled this 1 million chats from at least 15 different datasets, some his own, some by folks like Jon Durbin, Garage bAInd, and shareGPT, from LMsys.org, which was complied by scraping the very popular sharegpt.com website, from folks who used the shareGPT extension to share they GPT4 conversations. It's quite remarkable how much of these datasets are just, conversations that users had with GPT-4! Lilac brings GardenWith that backdrop of information, today on the pod we've got the co-founders of Lilac, Nikhil Thorat and Daniel Smilkov, who came on to chat about the new thing they just released called Lilac Garden. Lilac is an open source tool (you can find it RIGHT HERE) which is built to help make dataset creation, curation and classification, more science than art, and help visualize the data, cluster it and make it easily available. In the case of Hermes, that could be more than millions of rows of data.On the pod, I talk with Nikhil and Daniel about the origin of what they both did at Google, working on Tensorflow.js and then something called "know your data" and how eventually they realized that in this era of LLMs, open sourcing a tool that can understand huge datasets, run LLM based classifiers on top of them, or even train specific ones, is important and needed! To strengthen the point, two friends of the pod (Teknium was in the crowd sending us 👍), LDJ and Austin (aka Alignment Lab) were on stage with us and basically said that "It was pretty much the dark ages before Lilac", since something like OpenOrca dataset is a whopping 4M rows of text. Visualizations in the Garden. So what does lilac actually look like? Here's a quick visualization of the top categories of texts from OpenOrca's 4 million rows, grouped by category title and showing each cluster. So you can see here, Translation requests have 66% (around 200K rows) of the translation category, and you can scroll on and on and add filters and really dissect this whole thing up and down. The categorization is created by running Lilac on your dataset, which uses embedding algorithms and other neat tricks to quickly chunk and put labels on the categories (AKA classifying them). Btw, you can see this view and play around with it yourself, hereBut running this on your own local machine can be a drag, and take hours if not days for bigger datasets, including sometimes hanging and not even working 100%, so the Lilac folks created Lilac Garden, which is a hosted solution by them to provide a dataset, and do classify something like 4M in 4-5 hours or so. Which is definitely not possible on local machines. If you're into that kind of thing, again, Lilac is open source ,so you don't have to sign up or pay them, but if speed and this view matters to you, definitely check Lilac out! RWKV with Eugene (Pico Creator) On the news segment of ThursdAI
ThursdAI - Feb 1, 2024- Code LLama, Bard is now 2nd best LLM?!, new LLaVa is great at OCR, Hermes DB is public + 2 new Embed models + Apple AI is coming 👀
TL;DR of all topics covered + Show notes* Open Source LLMs* Meta releases Code-LLama 70B - 67.8% HumanEval (Announcement, HF instruct version, HuggingChat, Perplexity)* Together added function calling + JSON mode to Mixtral, Mistral and CodeLLama* RWKV (non transformer based) Eagle-7B - (Announcement, Demo, Yam's Thread)* Someone leaks Miqu, Mistral confirms it's an old version of their model* Olmo from Allen Institute - fully open source 7B model (Data, Weights, Checkpoints, Training code) - Announcement* Datasets & Embeddings* Teknium open sources Hermes dataset (Announcement, Dataset, Lilac)* Lilac announces Garden - LLM powered clustering cloud for datasets (Announcement)* BAAI releases BGE-M3 - Multi-lingual (100+ languages), 8K context, multi functional embeddings (Announcement, Github, technical report)* Nomic AI releases Nomic Embed - fully open source embeddings (Announcement, Tech Report)* Big CO LLMs + APIs* Bard with Gemini Pro becomes 2nd LLM in the world per LMsys beating 2 out of 3 GPT4 (Thread)* OpenAI launches GPT mention feature, it's powerful! (Thread)* Vision & Video* 🔥 LLaVa 1.6 - 34B achieves SOTA vision model for open source models (X, Announcement, Demo)* Voice & Audio* Argmax releases WhisperKit - super optimized (and on device) whisper for IOS/Macs (X, Blogpost, Github)* Tools* Infinite Craft - Addicting concept combining game using LLama 2 (neal.fun/infinite-craft/)Haaaapy first of the second month of 2024 folks, how was your Jan? Not too bad I hope? We definitely got quite a show today, the live recording turned into a proceeding of breaking news, authors who came up, deeper interview and of course... news.This podcast episode is focusing only on the news, but you should know, that we had deeper chats with Eugene (PicoCreator) from RWKV, and a deeper dive into dataset curation and segmentation tool called Lilac, with founders Nikhil & Daniel, and also, we got a breaking news segment and (from ) joined us to talk about the latest open source from AI2 👏Besides that, oof what a week, started out with the news that the new Bard API (apparently with Gemini Pro + internet access) is now the 2nd best LLM in the world (According to LMSYS at least), then there was the whole thing with Miqu, which turned out to be, yes, a leak from an earlier version of a Mistral model, that leaked, and they acknowledged it, and finally the main release of LLaVa 1.6 to become the SOTA of vision models in the open source was very interesting!Open Source LLMsMeta releases CodeLLama 70BBenches 67% on MMLU (without fine-tuninig) and already available on HuggingChat, Perplexity, TogetherAI, Quantized for MLX on Apple Silicon and has several finetunes, including SQLCoder which beats GPT-4 on SQLHas 16K context window, and is one of the top open models for codeEagle-7B RWKV based modelI was honestly disappointed a bit for the multilingual compared to 1.8B stable LM , but the folks on stage told me to not compare this in a transitional sense to a transformer model ,rather look at the potential here. So we had Eugene, from the RWKV team join on stage and talk through the architecture, the fact that RWKV is the first AI model in the linux foundation and will always be open source, and that they are working on bigger models! That interview will be released soonOlmo from AI2 - new fully open source 7B model (announcement)This announcement came as Breaking News, I got a tiny ping just before Nathan dropped a magnet link on X, and then they followed up with the Olmo release and announcement.A fully open source 7B model, including checkpoints, weights, Weights & Biases logs (coming soon), dataset (Dolma) and just... everything that you can ask, they said they will tell you about this model. Incredible to see how open this effort is, and kudos to the team for such transparency.They also release a 1B version of Olmo, and you can read the technical report hereBig CO LLMs + APIsMistral handles the leak rumorsThis week the AI twitter sphere went ablaze again, this time with an incredibly dubious (quantized only) version of a model that performed incredible on benchmarks, that nobody expected, called MIQU, and i'm not linking to it on purpose, and it started a set of rumors that maybe this was a leaked version of Mistral Medium. Remember, Mistral Medium was the 4th best LLM in the world per LMSYS, it was rumored to be a Mixture of Experts, just larger than the 8x7B of Mistral.So things didn't add up, and they kept not adding up, as folks speculated that this is a LLama 70B vocab model etc', and eventually this drama came to an end, when Arthur Mensch, the CEO of Mistral, did the thing Mistral is known for, and just acknowleged that the leak was indeed an early version of a model, they trained once they got access to their cluster, super quick and that it indeed was based on LLama 70B, which they since stopped using.Leaks like this suck, especially for a company that ... gives us the 7th best LLM in the world, completely apac

📅 ThursdAI - Sunday special on Merging with Maxime LaBonne
Hey everyone, we have an exciting interview today with Maxime Labonne. Maxime is a senior Machine Learning Scientist at JPMorgan, the author of Hands on GNNs book and his own ML Blog, creator of LazyMergeKit (which we cover on the pod) and holds a PHD in Artificial Intelligence from the Institut Polytechnique de Paris. Maxime has been mentioned on ThursdAI a couple of times before, as he released the first Phi mixture-of-experts, and has previously finetuned OpenHermes using DPO techniques which resulted in NeuralChat7B For the past couple of months, following AI on X, it was hard not to see Maxime's efforts show up on the timeline, and one of the main reasons I invited Maxime to chat was the release of NeuralBeagle7B, which at the time of writing was the top performing 7B model on the LLM leaderboard, and was specifically a merge of a few models. Model mergingModel merging has been around for a while but recently has been heating up, and Maxime has a lot to do with that, as he recently checked, and his wrapper on top of MergeKit by Charles Goddard (which is the library that put model merging into the mainstream) called LazyMergeKit was in charge of >50% of the merged models on HuggingFace hub leaderboard. Maxime also authored a model merging blogpost on Hugging Face and wrote quite a few articles and shared code that helped others to put merged models out. Modern day AlchemyThis blogpost is a great resource on what model merging actually does, so I won't go into depth of what the algorithms are, please refer to that if you want a deep dive, but in a nutshell, model merging is a technique to apply algorithms to the weights of a few models, even a few instances of the same model (like Mistral7B) and create a new model, that often performs better than the previous ones, without additional training! Since this is algorithmic, it doesn't require beefy GPUs burning power to keep training or finetuning, and since the barrier of entry is very low, we get some cool and crazy results as you'll see below. Yeah, quite crazy as it sounds, this method can also create models of non standard sizes, like 10B or 120B models, since it's slicing pieces of other models and stitching them together in new ways. If you recall, we had a deep dive with Jon Durbin who released Bagel, and Jon specifically mentioned that he created Bagel (based on everything everywhere all at once) as a good base for merges, that will include all the prompt formats, you can read and listen to that episode hereThis merge frenzy, made HuggingFace change the leaderboard, and add a checkbox that hides model merges, because they are flooding the leaderboard, and often, and require much smaller effort than actually pre-training or even finetuning a modelAnd quite often the top of the leaderboard was overrun with model merges like in this example of Bagel and it's merges by CloudYu (which are not the top ones but still in the top 10 as I write this) ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.On why it works? Nisten summarized this pretty well in this now famous copypasta tweet and I've confirmed with Maxime that this is his current understanding as well, it's quite unclear why this seems to perform so well, but it of course doesn't stop the "folks who look for AI Waifus" to keep merging.Following folks like Nathan Lambert from interconnects.ai to start paying attention even though he didn't want to! (Still waiting on your writeup Nathan!) UPDATE: As of today Monday Jan 29th, Nathan Lambert just released a super comprehensive deep dive into merges, which you can read here 👇👏YALL + Automated LLM EvaluationMaxime as also worked on so many models of his own, that he built a convenient little tracking leaderboard to track their performance, which he called YALL, Yet Another LLM Leaderboard and it's on HuggingFace. You can see that NeuralBeagle is the top dog (sorry, I literally could not resist) It uses the Nous evaluations, and Maxime has created an automation called LLM AutoEval that makes it really simple to run evaluations, which you can run in a Colab super easily. LLM AutoEval is on Github. Merge-aology! Since chatting, Maxime has released a Colab and later a HuggingFace space that takes models names, and shows the genealogy, nay, Merge-aology of the models, which models it was merged from and it's pretty crazy how deep this rabbit hole goes, and crazier even still that these models perform very well after all of these lobotomies! Try it out here: https://huggingface.co/spaces/mlabonne/model-family-treeI really hope you enjoy this special deep dive, I definitely learned a BUNCH from this conversation with Maxime, and I'm very happy that he came on! This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit sub.thursdai.news/subscribe

📅 ThursdAI - Jan 24 - ⌛Diffusion Transformers,🧠 fMRI multimodality, Fuyu and Moondream1 VLMs, Google video generation & more AI news
What A SHOW folks, I almost don't want to write anything in the newsletter to MAKE you listen haha but I will I know many of you don't like listening to be babble. But if you chose one episode to listen to instead of just skimming the show-notes, make it this one. We've had 2 deep dives, one into the exciting world of multi-modalilty, we chatted with the creator of Moondream1, Vik and the co-founders of Prophetic, Wes and Eric about their EEG/fMRI multimodal transformer (that's right!) and then we had a DEEP dive into the new Hourglass Diffusion Transformers with Tanishq from MedArc/Stability. More than 1300 tuned in to the live show 🔥 and I've got some incredible feedback on the fly, which I cherish so if you have friends who don't already know about ThursdAI, why not share this with them as well? TL;DR of all topics covered: * Open Source LLMs * Stability AI releases StableLM 1.6B params (X, Blog, HF)* InternLM2-Math - SOTA on math LLMs (90% GPT4 perf.) (X, Demo, Github)* MedArc analysis for best open source use for medical research finds Qwen-72 the best open source doctor (X)* Big CO LLMs + APIs* Google teases LUMIERE - incredibly powerful video generation (TTV and ITV) (X, Blog, ArXiv)* 🤗 HuggingFace announces Google partnership (Announcement)* OpenAi 2 new embeddings models, tweaks turbo models and cuts costs (My analysis, Announcement)* Google to add 3 new AI features to Chrome (X, Blog)* Vision & Video* Adept Fuyu Heavy - Third in the world MultiModal while being 20x smaller than GPT4V, Gemini Ultra (X, Blog)* FireLLaVa - First LLaVa model with commercial permissive license from fireworks (X, Blog, HF, DEMO)* Vikhyatk releases Moondream1 - tiny 1.6B VLM trained on Phi 1 (X, Demo, HF)* This weeks's buzz 🐝🪄 - What I learned in WandB this week* New course announcement from Jason Liu & WandB - LLM Engineering: Structured Outputs (Course link)* Voice & Audio* Meta W2V-BERT - Speech encoder for low resource languages (announcement)* 11 labs has dubbing studio (my dubbing test)* AI Art & Diffusion & 3D* Instant ID - zero shot face transfer diffusion model (Demo)* 🔥 Hourglass Diffusion (HDiT) paper - High Resolution Image synthesis - (X, Blog, Paper, Github)* Tools & Others* Prophetic announces MORPHEUS-1, their EEG/fMRI multimodal ultrasonic transformer for Lucid Dream induction (Announcement)* NSF announces NAIRR with partnership from all major government agencies & labs including, OAI, WandB (Blog)* Runway adds multiple motion brushes for added creativity (X, How to)Open Source LLMs Stability releases StableLM 1.6B tiny LLMSuper super fast tiny model, I was able to run this in LMStudio that just released an update supporting it, punches above it's weight specifically on other languages like German/Spanish/French/Italian (beats Phi)Has a very surprisingly decent MT-Bench score as wellLicense is not commercial per se, but a specific Stability AI membershipI was able to get above 120tok/sec with this model with LM-Studio and it was quite reasonable and honestly, it’s quite ridiculous how fast we’ve gotten to a point where we have an AI model that can weight less that 1GB and has this level of performance 🤯Vision & Video & MultimodalityTiny VLM Moonbeam1 (1.6B) performs really well (Demo)New friend of the pod Vik Hyatk trained Moonbeam1, a tiny multimodal VLM with LLaVa on top of Phi 1 (not 2 cause.. issues) and while it's not commercially viable, it's really impressive in how fast and how quite good it is. Here's an example featuring two of my dear friends talking about startups, and you can see how impressive this TINY vision enabled model can understand this scene. This is not cherry picked, this is literally the first image I tried with and my first result. The image features two men sitting in chairs, engaged in a conversation. One man is sitting on the left side of the image, while the other is on the right side. They are both looking at a laptop placed on a table in front of them. The laptop is open and displaying a presentation, possibly related to their discussion.In the background, there is a TV mounted on the wall, and a cup can be seen placed on a surface nearby. The scene suggests a casual and collaborative environment where the two men are sharing ideas or discussing a topic.Vik joined us on the pod to talk about why he didn't go with Phi-2, he also mentioned that Phi-1.5 was retroactively also MIT'd, it's license literally says MIT now on HF 👏 Great conversation, tune in for that at around 00:31:35Adept is teasing FuYu Large - their CHONKY VLMAdept previously released Persimmon, and then Fuyu VLM (which is a type of persimmon we see you adept) and now tease the release for Fuyu Heavy, a much bigger model that can compete or come close to GPT4V and GeminiUltra on MMMU and MMLU (text) while being 20x smaller approx. While we don't yet get to play with this, they show some great promise in the benchmarks⭐️ Performance: Excels at multimodal reasoning and matches/exceeds text-based benchmark
📅 ThursdAI Jan 18 - Nous Mixtral, Deepmind AlphaGeometry, LMSys SGLang, Rabbit R1 + Perplexity, LLama 3 is training & more AI news this week
👋 Hey there, been quite a week, started slow and whoah, the last two days were jam-packed with news, I was able to barely keep up! But thankfully, the motto of ThursdAI is, we stay up to date so you don’t have to! We had a milestone, 1.1K listeners tuned into the live show recording, it’s quite the number, and I’m humbled to present the conversation and updates to that many people, if you’re reading this but never joined live, welcome! We’re going live every week on ThursdAI, 8:30AM pacific time.TL;DR of all topics covered: * Open Source LLMs * Nous Hermes Mixtral finetune (X, HF DPO version, HF SFT version)* NeuralBeagle14-7B - From Maxime Labonne (X, HF,)* It's the best-performing 7B parameter model on the Open LLM Leaderboard (when released, now 4th)* We had a full conversation with Maxime about merging that will release as a standalone episode on Sunday! * LMsys - SGLang - a 5x performance on inference (X, Blog, Github)* NeuralMagic applying #sparceGPT to famous models to compress them with 50% sparsity (X, Paper)* Big CO LLMs + APIs* 🔥 Google Deepmind solves geometry at Olympiad level with 100M synthetic data (Announcement, Blog)* Meta announces Llama3 is training, will have 350,000 H100 GPUs (X)* Open AI releases guidelines for upcoming elections and removes restrictions for war use (Blog)* Sam Altman (in Davos) doesn't think that AGI will change things as much as people think (X)* Samsung S24 has AI everywhere, including real time translation of calls (X)* Voice & Audio* Meta releases MAGNet (X, HF)* AI Art & Diffusion & 3D* Stable diffusion runs 100% in the browser with WebGPU, Diffusers.js (X thread)* DeciAI - Deci Diffusion - A text-to-image 732M-parameter model that’s 2.6x faster and 61% cheaper than Stable Diffusion 1.5 with on-par image quality* Tools & Hardware* Rabbit R1 announces a deal with Perplexity, giving a full year of perplexity pro to Rabbit R1 users and will be the default search engine on Rabbit (link)Open Source LLMs Nous Research releases their first Mixtral Finetune, in 2 versions DPO and SFT (X, DPO HF)This is the first Mixtral finetune from Teknium1 and Nous team, trained on the Hermes dataset and comes in two variants, the SFT and SFT+DPO versions, and is a really really capable model, they call it their flagship! This is the fist Mixtral finetune to beat Mixtral instruct, and is potentially the best open source model available right now! 👏 Already available at places like Together endpoints, GGUF versions by the Bloke and I’ve been running this model on my mac for the past few days. Quite remarkable considering where we are in only January and this is the best open chat model available for us. Make sure you use ample system prompting for it, as it was trained with system prompts in mind. LMsys new inference 5x with SGLang & RadixAttention (Blog) LMSys introduced SGLang, a new interface and runtime for improving the efficiency of large language model (LLM) inference. It claims to provide up to 5x faster inference speeds compared to existing systems like Guidance and vLLM. SGLang was designed to better support complex LLM programs through features like control flow, prompting techniques, and external interaction. It co-designs the frontend language and backend runtime.- On the backend, it proposes a new technique called RadixAttention to automatically handle various patterns of key-value cache reuse, improving performance. - Early users like LLaVa reported SGLang providing significantly faster inference speeds in their applications compared to other options. The LMSys team released code on GitHub for others to try it out.Big CO LLMs + APIsMeta AI announcements (link)These #BreakingNews came during our space, Mark Zuckerberg posted a video on Instagram saying that Llama3 is currently training, and will be open sourced! He also said that Meta will have 350K (that’s not a typo, 350,000) H100 GPUs by end of the year, and a total of ~600,000 H100 equivalent compute power (including other GPUs) which is… 🤯 (and this is the reason why I had to give him double GPU rich hats)Deepmind releases AlphaGeometry (blog)Solving geometry at the Olympiad gold-medalist level with 100M synthetic examplesAlphaGeometry is an AI system developed by Google DeepMind that can solve complex geometry problems on par with human Olympiad gold medalistsIt uses a "neuro-symbolic" approach, combining a neural language model with a symbolic deduction engine to leverage the strengths of bothThe language model suggests useful geometric constructs to add to diagrams, guiding the deduction engine towards solutionsIt was trained on over 100 million synthetic geometry examples generated from 1 billion random diagrams On a benchmark of 30 official Olympiad problems, it solved 25 within time limits, similar to the average human medalistOpenAI releases guidelines for upcoming elections. (Blog)- OpenAI is taking steps to prevent their AI tools like DALL-E and ChatGPT from being abused or used to spread misinformation

🔥 ThursdAI Sunday special - Deep dives into Crew AI with Joao then a tasty Bagel discussion with Jon Durbin
ThursdAI - Sunday special deep dive, interviews with Joao, and Jon, AI agent Crews and Bagel Merges. Happy Sunday dear reader, As you know by now, ThursdAI pod is not a standard interview based podcast, we don't focus on a 1:1 guest/host conversation, but from time to time we do! And this week I was very lucky to have one invited guest and one surprise guest, and I'm very happy to bring you both these conversations today. Get your Crew together - interview with João Moura, creator of CrewAIWe'll first hear from João Moura, the creator of Crew AI, the latest agent framework. João is a director of AI eng. at Clearbit (acquired by Hubspot recently) and created Crew AI for himself, to automate many of the things he didn't want to keep doing, for example, post more on Linkedin. Crew has been getting a lot of engagement lately, and we go into the conversation about it with João, it's been trending #1 on Github, and received #2 product of the day when Chris Messina hunted this (to João's complete surprise) on Product Hunt. CrewAI is built on top of Langchain, and is an agent framework, focusing on Orchestration or role-playing, autonomous agents. In our chat with João we go into the inspiration, the technical challenges and the success of CrewAI so far, how maintenance for crew is now partly a family effort and what's next for crewMerges and Bagels - chat with Jon Durbin about Bagel, DPO and mergingThe second part of today's pod was a conversation with Jon Durbin, a self described AI tinkerer and software engineer. Jon is a Sr. applied AI researcher at Convai, and is well known in our AI circles as a master finetuner and dataset curator. This interview was not scheduled, but I'm very happy it happened! If you've been following along with the AI / Finetuning space, Jon's Airoboros dataset and set of models have been often mentioned, and cited, and Jon's latest work on the Bagel models took the lead on HuggingFace open LLM leaderboardSo when I mentioned on X (as I often do) that I'm going to mention this on ThursdAI, Jon came up to the space and we had a great conversation, in which he shared a LOT of deep insights into finetuning, DPO (Direct Preference Optimizations) and merging. The series of Bagel dataset and models, was inspired by the Everything Everywhere All at Once movie (which is a great movie, watch it if you haven't!) and is alluding to, Jon trying to throw as many datasets together as he could, but not only datasets! There has been a lot of interest in merging models recently, specifically many folks are using MergeKit to merge models with other models (and often a model with itself) to create larger/better models, without additional training or GPU requirements. This is solely an engineering thing, some call it frankensteining, some frankenmerging.If you want to learn about Merging, Maxime Labonne (the author of Phixtral) has co-authored a great deep-dive on Huggingface blog, it's a great resource to quickly get up to speedSo given the merging excitement, Jon has set out to create a model that can be an incredible merge base, many models are using different prompt techniques, and Jon has tried to cover as many as possible. Jon also released a few versions of Bagel models, DPO and non DPO, that and we had a brief conversation about why the DPO versions are more factual and better at math, but not great for Role Playing (which is unsurprisingly what many agents are using these models for) or creative writing. The answer is, as always, dataset mix! I learned a TON from this brief conversation with Jon, and if you're interested in the incredible range of techniques in the Open Source LLM world, DPO and Merging are definitely at the forefront of this space right now, and Jon is just at the cross-roads of them, so definitely worth a listen and I hope to get Jon to say more and learn more in future episodes so stay tuned! So I'm in San Francisco, again... As I've mentioned on the previous newsletter, I was invited to step in for a colleauge and fly to SF to help co-host a hack-a-thon with friends from TogetherCompute, Langchain, in AGI house in Hillsborough CA. The Hackathon was under the Finetune VS RAG theme, because, well, we don't know what works better, and for what purpose.The keynote speaker was Tri Dao, Chief Scientist @ Together and the creator of Flash Attention, who talked about SSM, State space models and Mamba. Harrison from Langchain gave a talk with a deepdive into 5 techniques for knowledge assistants, starting with basic RAG and going all the way to agents 👏I also gave a talk, but, I couldn't record a cool gif like this for myself, but thanks to Lizzy I got a pic as well 🙂 Here is the link to my slides if interesting (SLIDES)More than 150 hackers got together to try and find this out, and it was quite a blast for me to participate and meet many of the folks hacking, hear what they worked on, what worked, what didn't, and how they used WandB, Together and Langchain to achieve some of the inc

📅 ThursdAI Jan 11 - GPTs store, Mixtral paper, Phi is MIT + Phixtral, 🥯 by Jon Durbin owns the charts + Alex goes to SF again and 2 deep dive interviews 🎙️
Hey hey everyone, how are you this fine ThursdAI? 👋 I’m gud thanks for asking!I’m continuing my experiment of spilling the beans, and telling you about everything we talked about in advance, both on the pod and in the newsletter, so let me know if this is the right way to go or not, for the busy ones it seems that it is. If you don’t have an hour 15, here’s a short video recap of everything we chatted about:ThursdAI - Jan 11 2024 TL;DRTL;DR of all topics covered + Show notes* Open Source LLMs* 🔥 Donut from Jon Durbin is now top of the LLM leaderboard (X, HF, Wolframs deep dive and scoring)* OpenChat January Update - Best open source 7B LLM (X, Hugging Face)* Our friends at NousResearch announce a seed round of 5.2M as their models pass 1.2 million downloads (X)* Argilla improved (Distillabeled?) the DPO enhanced Neural Hermes with higher quality DPO pairs (X)* New MoEs are coming out like hotcakes - PhixTral and DeepSeek MoE (X, Omar Thread, Phixtral Thread)* Microsoft makes Phi MIT licensed 👏* Big CO LLMs + APIs* OpenAI adds personalization & team tiers (Teams announcement)* OpenAI launches GPT store (Store announcement, Store link)* Mixtral medium tops the LMsys human evaluation arena, is the best LLM overall after GPT4 👏 (X)* Hardware* Rabbit R1 is announced, $200/mo without a subscription, everybody has a take (X)* This weeks Buzz from Weights & Biases* Hackathon with Together, Langchain and WandB (and ME!) this weekend in AGI house (X, Signup)* Video* Bytedance releases MagicVideo-V2 video gen that looks great and passes Pika labs in human tests (X)* AI Art & Diffusion & 3D* Luma launched their online version of Genie and it's coming to the API (X)* Show notes and links mentioned* MergeKit (github)* Jon Durbins Contextual DPO dataset (HuggingFace)* Phixtral from Maxime Lebonne (X, HuggingFace)* WandGPT - out custom Weights & Biases GPT (GPT store)* Visual Weather GPT by me - https://chatg.pt/artweather* Ask OpenAI to not train on your chats - https://privacy.openai.com/policiesAI HardwareIt seems that the X conversation had a new thing this week, the AI hardware startup Rabbit, showcased their new $200 device (no subscriptions!) at CES and everyone and their mom had an opinion! We had quite a long conversation about that with (his first time on ThursdAI 👏) as we both pre-ordered one, however there were quite a few red flags, like for example, GPUs are costly, so how would an AI device that has AI in the cloud just cost a 1 time 200 bucks??There were other interesting things they showed during the demo, and I’ll let you watch the full 30 minutes and if you want to read more, here’s a great deeper dive into this from .UPDATE: Ss I’m writing this, the CEO of Rabbit (who’s also on the board of Teenage Engineering, the amazing company that designed this device) tweeted that they sold out the initial first AND second batch of 10K unites, netting a nice $2M in hardware sales in 48 hours!Open Source LLMsMixtral paper dropped (ArXiv, Morgans take)Mistral finally published the paper on Mixtral of experts, the MoE that's the absolutel best open source model right now, and it's quite the paper. Nisten did a full paper reading with explanations on X space, which I co-hosted and we had almost 3K people tune in to listen. Here's the link to the live reading X space by Nisten.And here's some notes courtecy Morgan McGuire (who's my boss at WandB btw 🙌)Strong retrieval across the entire context windowMixtral achieves a 100% retrieval accuracy regardless of the context length or the position of passkey in the sequence.Experts don't seem to activate based on topicSurprisingly, we do not observe obvious patterns in the assignment of experts based on the topic. For instance, at all layers, the distribution of expert assignment is very similar for ArXiv papers (written in Latex), for biology (PubMed Abstracts), and for Philosophy (PhilPapers) documents.However...The selection of experts appears to be more aligned with the syntax rather than the domainDatasets - No info was provided to which datasets Mixtral used to pretrain their incredible models 😭Upsampled multilingual dataCompared to Mistral 7B, we significantly upsample the proportion of multilingual data during pretraining. The extra capacity allows Mixtral to perform well on multilingual benchmarks while maintaining a high accuracy in EnglishMixtral Instruct TrainingWe train Mixtral – Instruct using supervised fine-tuning (SFT) on an instruction dataset followed by Direct Preference Optimization (DPO) on a paired feedback dataset and was trained on @CoreWeaveJon Durbin Donut is the 🤴 of open source this week6 of the top 10 are donut based models or merges of it. If you remember Auroborous, Donut includes that dataset, and there are two varieties there, the DPO and the non DPO versions of Bagel, including two merges from Cloudyu, which are non trained merges with mergekit, based on Donut. Jon pro tip for selecting DPO vs Non DPO models isFYI, the DPO version is
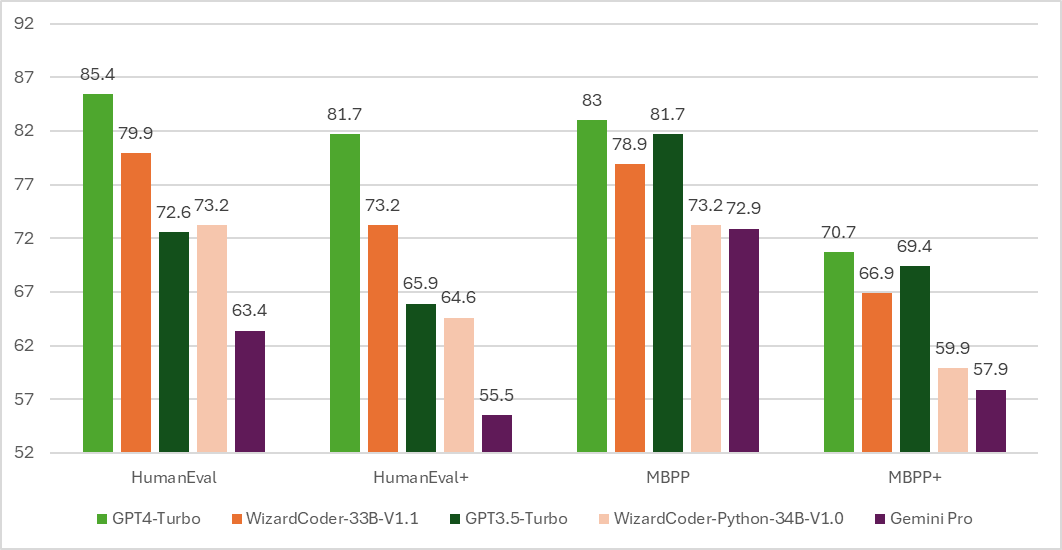
📅 ThursdAI Jan 4 - New WizardCoder, Hermes2 on SOLAR, Embedding King? from Microsoft, Alibaba upgrades vision model & more AI news
Here’s a TL;DR and show notes links* Open Source LLMs* New WizardCoder 33B V1.1 - 79% on HumanEval (X, HF)* Tekniums Hermes 2 on SOLAR 10.7B (X, HF)* Microsoft - E5 SOTA text embeddings w/ Mistral (X, HF, Paper, Yams Thread)* Big CO LLMs + APIs* Samsung is about to announce some AI stuff* OpenAI GPT store to come next week* Perplexity announces a $73.6 Series B round* Vision* Alibaba - QWEN-VL PLUS was updated to 14B (X, Demo)* OCU SeeAct - GPT4V as a generalist web agent if grounded (X, Paper)* Voice & Audio* Nvidia + Suno release NeMo Parakeet beats Whisper on english ASR (X, HF, DEMO)* Tools & Agents* Stanford - Mobile ALOHA bot - Open source cooking robot (Website, X thread)Open Source LLMsWizardCoder 33B reaches a whopping 79% on HumanEval @pass1State of the art LLM coding in open source is here. A whopping 79% on HumanEval, with Wizard Finetuning DeepSeek Coder to get to the best Open Source coder, edging closer to GPT4 and passing GeminiPro and GPT3.5 👏 (at least on some benchmarks)Teknium releases a Hermes on top of SOLAR 10.7BDownloading now with LMStudio and have been running it, it's very capable. Right now SOLAR models are still on top of the hugging face leaderboard, and Hermes 2 now has 7B (Mistral) 10.7B (SOLAR) and 33B (Yi) sizes.On the podcast I've told a story of how this week I actually used the 33B version of Capybara for a task that GPT kept refusing to help me with. It was honestly kind of strange, a simple request to translate kept failing with an ominous “network error”.Which only highlighted how important the local AI movement is, and now I actually have had an experience myself of a local model coming through when a hosted capable one didn’tMicrosoft releases a new text embeddings SOTA model E5 , finetuned on synthetic data on top of Mistral 7BWe present a new, easy way to create high-quality text embeddings. Our method uses synthetic data and requires less than 1,000 training steps, without the need for complex training stages or large, manually collected datasets. By using advanced language models to generate synthetic data in almost 100 languages, we train open-source models with a standard technique. Our experiments show that our method performs well on tough benchmarks using only synthetic data, and it achieves even better results when we mix synthetic and real data.We had the great please of having Bo Wang again (One of the authors of the Previously SOTA Jina embeddings and a previous podcast gust) to do a deepdive into embeddings and specifically E5 with it's decoder only architecture. While the approach Microsoft researchers took here are interesting, and despite E5 claiming a top spot on the MTEB leaderboard (pictured above) this model doesn't seem to be super practical for most purposes folks use embeddings right now (RAG) for the following reasons:* Context length limitation of 32k, with a recommendation not to exceed 4096 tokens.* Requires a one-sentence instruction for queries, adding complexity for certain use cases like RAG.* Model size is large (14GB), leading to higher costs for production use.* Alternative models like bge-large-en-v1.5 are significantly smaller (1.35GB).* Embedding size is 4096 dimensions, increasing the cost for vector storage.Big CO LLMs + APIsOpenAI announces that the GPT store is coming next week!I can't wait to put the visual weather GPT I created and see how the store prompts it and if I get some revenue share like OpenAI promised during dev day. My daughter and I are frequent users of Alice - the kid painter as well, a custom GPT that my Daughter named Alice, that knows it's speaking to kids over voice, and is generating coloring pages. Will see how much this store lives up to the promises.This weeks Buzz (What I learned with WandB this week)This week was a short one for me, so not a LOT of learnings but I did start this course from W&B, called Training and Fine-tuning Large Language Models (LLMs).It features great speakers like Mark Sarufim from Meta, Jonathan Frankle from Mosaic, and Wei Wei Yang from Microsoft along with W&B MLEs (and my team mates) Darek Kleczek and Ayush Thakur and covers the end to end of training and fine-tuning LLMs!The course is available HERE and it's around 4 hours, and well well worth your time if you want to get a little more knowledge about the type of stuff we report on ThursdAI.VisionSeeAct - GPT4V as a generalist web agent if grounded (X, Paper)In June OSU NLP released Mind2Web which is a dataset for developing and evaluating web acting agents, LLMs that click buttons and perform tasks with 2350 tasks from over 130 website, stuff like booking flights, finding folks on twitter, find movies on Netflix etc'GPT4 without vision was terrible at this (just by reading the website html/text) and succeeded at around 2%.With new vision LMMs, websites are a perfect place to start training because of the visual (how website is rendered) is no paired with HTML (the grounding) and SeeAct uses GPT4-V to do thisSeeAct is a

📅 ThursdAI - Dec 28 - a BUNCH of new multimodal OSS, OpenAI getting sued by NYT, and our next year predictions
Hey hey hey (no longer ho ho ho 🎄) hope you had a great Christmas! And you know that many AI folks have dropped tons of OpenSource AI goodies for Christmas, here’s quite a list of new things, including at least 3 new multi-modal models, a dataset and a paper/technical report from the current top model on HF leaderboard from Upstage. We also had the pleasure to interview the folks who released the Robin suite of multi-modals and aligning them to “good responses” and that full interview is coming to ThursdAI soon so stay tuned.And we had a full 40 minutes with an open stage to get predictions for 2024 in the world of AI, which we fully intent to cover next year, so scroll all the way down to see ours, and reply/comment with yours! TL;DR of all topics covered: * Open Source LLMs * Uform - tiny(1B) multimodal embeddings and models that can run on device (HF, Blog, Github, Demo)* Notux 8x7B - one of the first Mixtral DPO fine-tunes - (Thread, Demo)* Upstage SOLAR 10.7B technical report (arXiv, X discussion, followup)* Capybara dataset open sourced by LDJ (Thread, HF)* Nous Hermes 34B (finetunes Yi34B) - (Thread, HF)* Open Source long context pressure test analysis (Reddit)* Robin - a suite of multi-modal (Vision-Language) models - (Thread, Blogpost, HF)* Big CO LLMs + APIs* Apple open sources ML-Ferret multi-modal model with referring and grounding capabilities (Github, Weights, Paper)* OpenAI & Microsoft are getting sued by NewYorkTimes for copyright infringement during training (Full Suit)* AI Art & Diffusion & 3D* Midjourney v6 alpha is really good at recreating scenes from movies (thread)Open Source LLMs Open source doesn't stop even during the holiday break! Maybe this is the time to catch up to the big companies? During the holiday periods? This week we got a new 34B Nous Hermes model, the first DPO fine-tune of Mixtral, Capybara dataset but by far the biggest news of this week was in Multimodality. Apple quietly open sourced ml-ferret, an any to any model able to compete in grounding with even GPT4-V sometimes, Uform released tiny mutli-modal and embeddings versions for on device inference, and AGI collective gave NousHermes 2.5 eyes 👀There's no doubt that 24' is going to be the year of multimodality, and this week we saw an early start of that right on ThursdAI. Ml-Ferret from Apple (Github, Weights, Paper)Apple has been in the open source news lately, as we've covered their MLX release previously and the LLM in a flash paper that discusses inference for low hardware devices, and Apple folks had 1 more gift to give. Ml-Ferret is a multimodal grounding model, based on Vicuna (for some... reason?) which is able to get referrals from images (this highlighted or annotated areas) and then ground the responses with exact coordinates and boxes. The interesting thing about the referring, is that it can be any shape, bounding box or even irregular shape (like the ferred in the above example or cat tail below) Ferret was trained on a large new dataset called GRIT containing over 1 million examples of referring to and describing image regions (which wasn't open sourced AFAIK yet)According to Ariel Lee (our panelist) these weights are only delta weights and need to be combined with Vicuna weights to be able to run the full Ferret model properly. Uform - tiny (1.5B) MLLMs + vision embeddings (HF, Blog, Github, Demo)The folks at Unum have released a few gifts for us, with an apache 2.0 license 👏 Specifically they released 3 vision embeddings models, and 2 generative models. Per the documentation the embeddings can yield 2,3x speedup improvements to search from Clip like models, and 2-4x inference speed improvements given the tiny size. The embeddings have a multi-lingual version as well supporting well over 20 languages. The generative models can be used for image captioning, and since they are tiny, they are focused on running on device, and are already converted to ONNX format and core-ML format. Seen the results below compared to LLaVa and InstructBLIP, both at the 7B rangeI've tried a few images of my own (you can try the demo here), and while there was hallucinations, this tiny model did a surprising amount of understanding for the size! Also shoutout to AshRobin suite of multimodal models (Thread, Blogpost, HF)The folks at the CERC-AAI lab in MILA-quebec have released a suite of multi-modal models, that they have finetuned and released a fork of NousHermes2.5 that can understand images, building on top of CLIP, and SigLIP as the image encoder. In fact, we did a full interview with Irina, Kshitij, Alexis and George from the AGI collective, that full interview will be released on ThursdAI soon, so stay tuned, as they had a LOT of knowledge to share, from fine-tuning the clip model itself for better results, to evaluation of multimodal models, to dataset curation/evaluation issues and tips from Irina on how to get a government supercomputer compute grant 😈 Big CO LLMs + APIsOpenAI is being used by NYT for copyr

🎄ThursdAI - LAION down, OpenChat beats GPT3.5, Apple is showing where it's going, Midjourney v6 is here & Suno can make music!
Hey everyone, happy ThursdAI!As always, here's a list of things we covered this week, including show notes and links, to prepare you for the holidays. TL;DR of all topics covered: * Open Source AI* OpenChat-3.5-1210 - a top performing open source 7B model from OpenChat team beating GPT3.5 and Grok (link, HF, Demo)* LAION 5B dataset taken down due to CSAM allegations from Stanford (link, full report pdf) * FLASK - New evaluation framework from KAIST - based on skillset (link)* Shows a larger difference between open/closed source* Open leaderboard reliability issues, vibes benchmarks and more* HF releases a bunch of MLX ready models (LLama, Phi, Mistral, Mixtral) (link)* New transformer alternative architectures - Hyena & Mamba are heating up (link)* Big CO LLMs + APIs* Apple - LLM in a flash paper is making rounds (AK, Takeaways thread)* Anthropic adheres to the messages API format (X)* Microsoft Copilot finally has plugins (X)* Voice & Audio* AI Music generation Suno is now part of Microsoft Copilot plugins and creates long beautiful songs (link)* AI Art & Diffusion* Midjourney v6 is out - better text, great at following instructions (link)Open Source AIWe start today with a topic I didn't expect to be covering, the LAION 5B dataset, was taken down, after a report from Stanford Internet Observatory found instances of CSAM (Child Sexual Abuse material) in the vast dataset. The outlined report had identified hundreds to thousands of instances of images of this sort, and used something called PhotoDNA by Microsoft to identify the images by hashes, using a sample of NSFW marked images. LAION 5B was used to train Stable Diffusion, and 1.4 and 1.5 were trained on a lot of images from that dataset, however SD2 for example was only trained on images not marked as NSFW. The report is very thorough, going through the methodology to find and check those types of images. Worth noting that LAION 5B itself is not an image dataset, as it only contains links to images and their descriptions from alt tags. Obviously this is a very touchy topic, given the way this dataset was scraped from the web, and given how many image models were trained on it, the report doesn't allege anything close to influence on the models it was trained on, and outlines a few methods of preventing issues like this in the future. One unfortunate outcome of such a discovery, is that this type of work can only be done on open datasets like LAION 5B, while closed source datasets don't get nearly to this level of scrutiny, and this can slow down the advancement of multi-modal open source multi modal models while closed source will continue having these issues and still prevail. The report alleges they found and validated between hundreds to a few thousand of CSAM verified imagery, which considering the size of the dataset, is infinitesimally small, however, it still shouldn't exist at all and better techniques to clean those scraping datasets should exist. The dataset was taken down for now from HuggingFace and other places. New version of a 7B model that beats chatGPT from OpenChat collective (link, HF, Demo)Friend of the pod Alpay Aryak and team released an update to one of the best 7B models, namely OpenChat 7B (1210) is a new version of one of the top models in the 7B world called OpenChat with a significant score compared to chatGPT 3.5 and Grok and with very high benchmark hits (63.4% on HumanEval compared to GPT3.5 64%) Scrutiny of open source benchmarks and leaderboards being gamedWe've covered State of the art models on ThursdAI, and every time we did, we covered the benchmarks, and evaluation scores, Whether that's the popular MMLU (Multi-Task Language Understanding) or HumanEval (Python coding questions) and almost always, we've referred to the HuggingFace Open LLM leaderboard for the latest and greatest models. This week, there's a long thread on the hugging face forums that HF eventually had to shut down, that alleges that a new contender for the top, without revealing methods, used something called UNA to beat the benchmarks, and folks are suggesting that it must be a gaming of the system, as a model that's trained on the benchmarks can easily top the charts. This adds to the recent observations from friend of the pod Bo Wang from Jina AI, that the BGE folks have stopped focusing on the MTEB leaderboard (Massive Text Embedding Benchmark) benchmarks as well, as those are also seem to be gamed (link)This kicked off a storm of a discussion about different benchmarks and evaluations, ability to score and check wether or not we're advancing, and the openness of these benchmarks. Including one Andrej Karpathy that chimed in that the only way to know is to read the r/LocalLlama comment section (e.g. vibes based eval) and check the ELO score on the LMSys chatbot arena, which pits 2 random LLMs behind the scenes and lets users choose the best answer/score. LMsys also has a leaderboard, and that one only includes models they have explicitly added to

📅 ThursdAI - Live @ NeurIPS, Mixtral, GeminiPro, Phi2.0, StripedHyena, Upstage 10B SoTA & more AI news from last (insane) week
Wow what a week. I think I’ve reached to a level that I’m not phased by incredible weeks or days that happen in AI, but I… guess I still have much to learn! TL;DR of everything we covered (aka Show Notes) * Open Source LLMs * Mixtral MoE - 8X7B experts dropped with a magnet link again (Announcement, HF, Try it)* Mistral 0.2 instruct (Announcement, HF)* Upstage Solar 10B - Tops the HF leaderboards (Announcement)* Together -Striped Hyena architecture and new models (Announcement)* EAGLE - a new decoding method for LLMs (Announcement, Github)* Deci.ai - new SOTA 7B model* Phi 2.0 weights are available finally from Microsoft (HF)* QuiP - LLM quantization & Compression (link)* Big CO LLMs + APIs* Gemini Pro access over API (Announcement, Thread)* Uses character pricing not token* Mistral releases API inference server - La Platforme (API docs)* Together undercuts Mistral with serving Mixtral by 70% and announces OAI compatible API* OpenAI is open sourcing again - Releasing Weak-2-strong generalization paper and github! (announcement)* Vision* Gemini Pro api has vision AND video capabilities (API docs)* AI Art & Diffusion* Stability announces Zero123 - Zero Shot image to 3d model (Thread)* Imagen 2 from google (link)* Tools & Other* Optimus from Tesla is coming, and it looks incredibleThis week started on Friday, as we saw one of the crazier single days in the history of OSS AI that I can remember, and I’ve been doing this now for .. jesus, 9 months! In a single say, we saw a new Mistral model release called Mixtral, which is a Mixture of Experts (like GPT4 is rumored to be) of 8x7B Mistrals, and beats GPT3.5, we saw a completely new architecture that competes with Transformers called HYENA from Tri Dao and Together.xyz + 2 new models trained with that architecture, we saw a new SoTA 2-bit quantization method called QuiP from cornell AND a new 3x faster decoding method for showing tokens to users after an LLM has done “thinking”. And the best thing? All those advancements are stackable! What a day! Then I went to NeurIPS2023 (which is where I am right now, writing these words!), which I cover at length at the second part of the podcast, but figured I’d write about it here as well, since it was such a crazy experience. NeurIPS is the biggest AIML conference, I think they estimated 15K people from all over the world attending! Of course this brings many companies to sponsor, raise booths, give out swag and try to record! Of course with my new position at Weights & Biases I had to come as well and experience this for myself!Many of the attendees are customers of ours, and I was not expecting this amount of love given, just an incredible stream of people coming up to the booth, and saying how much they love the product! So I manned the booth, did interviews and live streams, and connected with a LOT of folks and I gotta say, this whole NeurIPS thing is quite incredible from the ability to meet people! I hung out with folks from Google, Meta, Microsoft, Apple, Weighs & Biases, Stability, Mistral, HuggingFace and PHD students and candidates from most of the top universities in the world, from KAIST to MIT and Stanford, Oslo and Shaghai, it's really a worldwide endeavor!I also got to meet many of the leading figures in AI, all of whom I had to come up to and say hi, shake their hand, introduce myself (and ThursdAI) and chat about what they or their team released and presents at the conference! Truly an unforgettable experience!Of course, This Weeks’ Buzz is that, everyone here loves W&B, from the PHD students, to literally every big LLM lab! They all came up to us (yes yes, even researches at Google who kinda low-key hate their internal tooling) and told us how awesome the experience was! (besides Xai folks, Jimmy wasn’t that impressed haha) and of course I got to practice the pitch so many times, since I manned the W&B booth! Please do listen to the above podcast, there’s so much detail that’s in there that doesn’t get up on the newsletter, as it’s impossible to cover all, but it was a really fun conversation, including my excited depiction of this weeks NOLA escapades! I think I’ll end here, cause I can go on and on about the parties (There were literally 7 at the same time last night, Google, Stability, OpenAI, Runway, and I’m sure there were a few more I wasn’t invited to!) and about New Orleans food (it’s my first time here, I ate a soft shell deep fried crab and turtle soup!) and I still have the poster sessions to go to and workshops! I will report more on my X account and the Weights & Biases X account, so stay tuned for that there, and as always, thanks for tuning in, reading and sharing ThursdAI with your friends 🫡 P.S - Still can’t really believe I get to do this full time now and share this journey with all of you, bringing you all with me to SF, and now NeurIPS and tons of other places and events in the future! — Alex Volkov, AI Evangelist @ Weights & Biases, Host of ThursdAI 🫡 This is a public episode. If
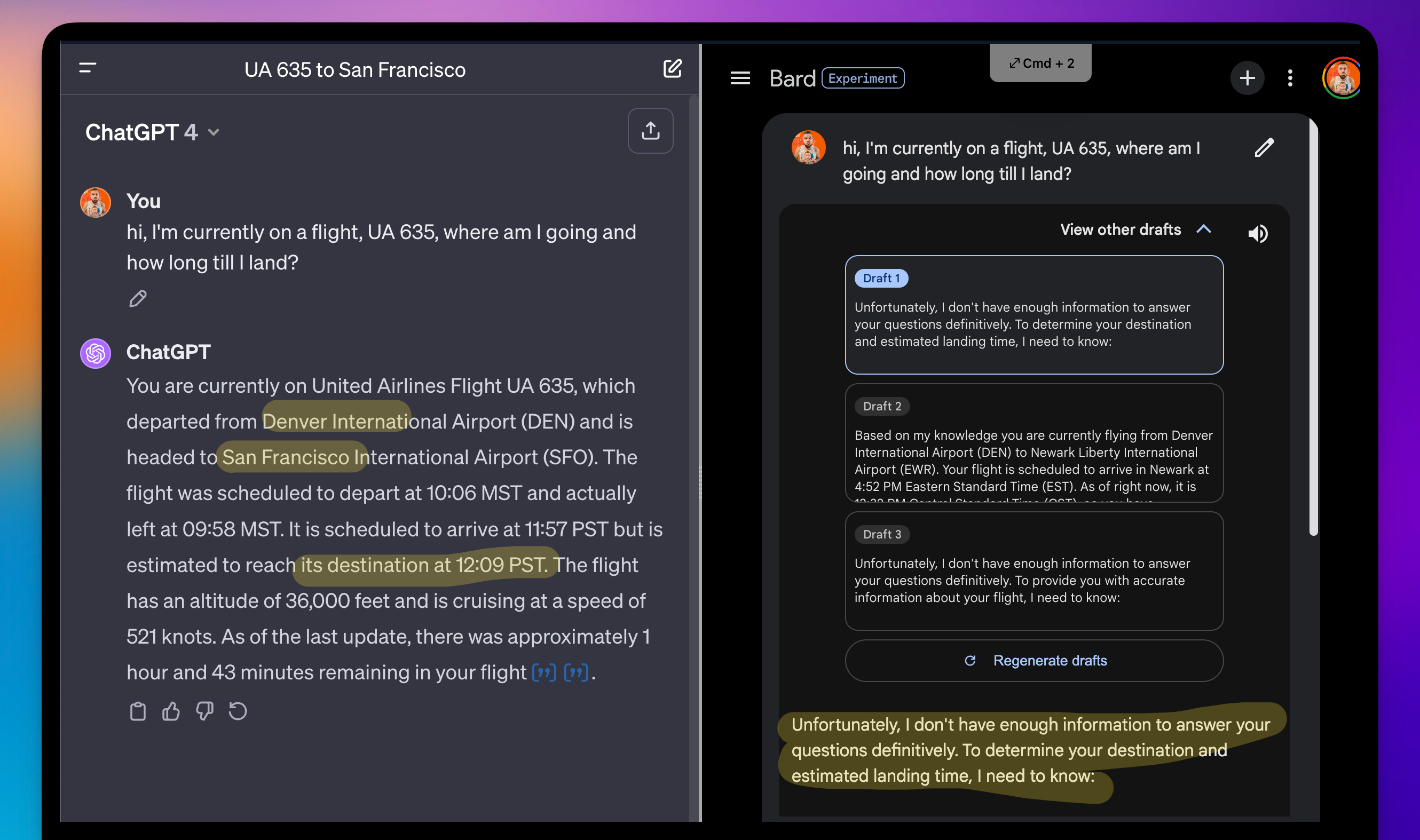
🌉 ThursdAI Dec 7th - Gemini is out-ish, Grok is out, OSS AI Event in SF, Waymo rides, and more AI news from the past week 👏
ThursdAI December 7th TL;DRGreetins of the day everyone (as our panelist Akshay likes to sometimes say) and Happy first candle of Hannukah for those who celebrate! 🕎 I'm writing this newsletter from the back of an Waymo self driving car, in SF, as I'm here for just a few nights (again) to participate in the Open Source AI meetup, that was co-organized by Ollama and Nous Research, Alignment Labs and hosted by A16Z in their SF office. This event was the highlight of this trip, it was quite a packed meetup in terms of AI talent, and I got to meet quite a few ThursdAI listeners, mutuals on X, and AI celebs We also recorded the podcast this week from the arena, thanks to Swyx and Alessio from latentspace pod for hosting ThursdAI this week form their newly built out pod studio (and apologies everyone for the rocky start and the cutting out issues, luckily we had local recordings so the pod version sounds good!) Google finally teases Gemini Ultra (and gives us Pro)What a week folks, what a week, as I was boarding the flight to SF to meet with Open Source folks, Google announced (finally!) the release of Gemini, their long rumored, highly performant model with a LOT of fanfare! Blogposts authored by Sundar and Demis Hassabis, beautiful demos of unseen before capabilities, comparisons to GPT-4V which the Ultra version of Gemini outperforms on several benchmarks, and rumors that Sergey Brin, the guy who's net worth is north of 100Bn is listed as the core contributor on the paper and reports on benchmarks (somewhat skewed) show Ultra beaing GPT-4 on many coding and reasoning evaluations! We've been waiting for Gemini for such a long time, that we spend the first hour of the podcast discussing it and it's implications basically. We were also fairly disillusioned by the sleight of hand tricks Google marketing department played with the initial launch video, where it purportedly shows Gemini being a fully multi-modal AI, that reacts to a camera feed + user voice in real time, when in fact, it was quickly clear (from their developer blog) that it was not video+audio but rather images+text (the same two modalities we already have in GPT-4V and given some prompting, it's quite easy to replicate most of it. We've also discussed how we again, got a tease, and not even a waitlist for the "super cool" stuff, while getting a GPT3.5 level of a model today in Bard upgrade. To me, the most mind-blowing demo video was actually one of the other ones in the announcement, which showed that Gemini has agentic behavior in understanding user intent, asks for clarifications, creates a PRD (Product Requirement Document) for itself, and then, generates Flutter code to create a UI on the fly, based on what the use asked it! This is pretty wild, as we all should expect that Just In Time UI will come to many of these big models! Tune in to the episode if you want to hear more takes, opinions and frustrations as none of us actually got to use Gemini Ultra, and the experience with Gemini Pro (which is now live on Bard) was at least for me, underwhelmingThis weeks buzz (What I learned in Weights & Biases this week) I actually had a blast talking about W&B to many of the open source and fine-tuners community this and past week. I already learned that W&B doesn't only help huge companies (like OpenAI, Anthropic, Meta, Mistral and tons more) to train their foundational models, but is widely used by the open source fine-tuners community as well. I've met with folks like Wing Lian (aka Caseus), maintainer of Axolotl, who uses W&B together with Axolotl, and got to geek out about W&B, met with Teknium and LDJ (Nous Research, Alignment Labs) and in fact, got LDJ to walk me through some of the ways he uses and used W&B in the past, including how it's used to track model runs, show artifacts in the middle of runs, and run mini-benchmarks and evaluations for LLMS as they finetune. If you're interested in this, here's an episode of a new “series” of me learning publicly (from scratch) so if you want to learn from scratch with me, welcome to check it out: Open Source AI in SF meetupThis meetup was the reason I flew in to SF, I was invited by dear friends in the open source community, and couldn't miss it! There was such a talent density there, it was quite remarkable. Andrej Karpathy who's video about LLM I just finished re-watching, Jeremy Howard, folks from Mistral, A16Z, and tons of other startups, open source collectives, and enthusiasts, all came together to listen to a few lightning talks, but mostly to mingle and connect and share ideas.Nous Research announced that they are a company (not anymore just a discord collective of rag tag open sourcers!) and that they are working on Forge, a product offering of theirs, that runs local AI, has a platform for agent behavior, and is very interesting to keep an eye for. I've spent most of my time going around, hearing what folks are using (Hint: a LOT of axolotl), what they are finetuning (mostly Mistral) and wh

🎉 ThursdAI Nov 30 // ChatGPT 1 year celebration special episode // covering the past 1 year in LLM/OSS AI 🥳
🎶 Happy birthday to you, happy birthday to you, happy birthday chat GPT-eeeeeeee, happy birthday to you. Hey everyone, welcome to this special edition of ThursdAI where you're probably gonna have two emails and two podcast episodes today and you can choose which one you want to but we actually recorded both of them live it just they went a little long. ThursdAI - The only podcast that brings you yearly recaps since chatGPT was released (😂) This one is the more celebratory one, today is one year from the release of chat GPT and we (and by we I mean I, Alex) decided to celebrate it by recapping not just the last week in AI but the last year (full timeline posted at the bottom of this newsletter)Going month by month with a swoosh sound in the editing and covering the most important thing that happened in LLM and open source LLMs since chatGPT was released and imagination unlocked the capability for everyone! We also covered Meta stepping in with Lama and then everything that happened since then in the multi modality and vector databases and agents and everything everything everything, it was a one hell of an hour and a half, we had almost 1K audience members! and so I recommend you listen to this one first and then the week updates later because there were some incredible releases this week as well! (as there are every week)I think it's important to do like a Spotify wrapped type thing for AI, for something like a one year for chat GPT and I think we'll be doing this every year so hopefully in the year we'll see you here on November 30th covering the next year in AI.And hopefully the next year in AI system will actually help me summarize all this because it's a lot of work but with that I will just leave you with the timeline and no notes and you should listen to everything because we talked about everything live! I hope you enjoy this special birthday celebration! (OpenAI sure did, check out this incredibly cute little celebration video they just posted) Here’s the full timeline with everything important that happened month by month that we’ve covered:* December 2022 - ChatGPT becomes the fastest growing product in history* GPT3.5 with 4K context window, instruction finetuning and conversational RLHF * January* Microsoft invests additional $10B into OpenAI (Jan 23, Blog)* February * LLaMa 1 - Biggest Open Source LLM (February 24 - Blog)* No commercial license* 30% MMLU* No instruction fine-tuninig (RL;HF)* ChatGPT unofficial APIs exist* March (the month of LLM superpowers)* ChatGPT API (March 1, announcement)* Developers can now build chatGPT powered apps* All clones so far were completion based and not conversation based* LLama.cpp from ggerganov + Quantization (March 10, Blog)* Stanford - Alpaca 7B - Finetune on self-instruct GPT3.5 dataset (March 13, Blog)* GPT4 release + chatGPT upgrade (March 14 - GPT-4 demo)* 67.0% HumanEval | 86.4% MMLU* 8K (and 32K) context windows* Anthropic announces Claude + Claude instant (March 14 - Blog)* 56.0% HumanEval * Folks previously form OAI leave to open Anthropic as research, then pivot from research into commercial* LMSYS Vicuna 13B - Finetuned based on shareg.pt exports (March 30, Blog)* April (Embedings & Agents)* AutoGPT becomes the fastest github starred project + writes it's own code (April 1, Blog)* Agents start to pop up like mushrooms after the rain* LLaVa - Multimodality open source begins (April 18, Blog)* CLIP + Vicuna smushed together to get LLMs eyes* Bard improvements * May (Context windows)* Mosaic MPT-7B with 64K context, 1T parameters, commercial license (May 5, Blog) * Anthropic updates Claude with 100K context window (May 11, Blog)* LLongBoi summer begins (Context windows are being stretched)* Nvidia shows Voyager agents that play Minecraft + Memory stored in Vector DB (May 27, Blog)* June* GPT-3.5-turbo + functions API (June 6, Blog)* GPT3.5 and 4 got a boost in capabilities and steer-ability * Price reduction on models + 75% reduction on ada embeddings model* LLaMa context window extended to 8K with RoPE scaling* AI Engineers self determination essay by swyx * July* Code Interpreter GA - ChatGPT can code (July 11, Blog)* Anthropic Claude 2 - (July 11 - Blog)* 200K context window* 71% HumanEval* LLaMa 2 (July 18 - Blog)* Base & Chat models (RLHF)* Commercial license * 29.9% Human Eval | 68.9% MMLU * August* Meta releases Code-LlaMa, code finetune models* September* DALL-E 3 - Adds multi-modality on output and chat to image gen (Sep 20, Blog)* Mistral 7B top performing open source LLM via torrent link (Sep 27, Blog)* GPT4-V (vision & voice) - Adds multimodality on input (Sep 27, Blog)* October* OpenHermes - Mistral 7B finetune that tops the charts from Teknium / Nous Research (Oct 16, Announcement)* Inflection PI gets connected to the web + supportPi mode (Oct 16, Blog)* Adept releases multimodal FuYu 8B (Oct 19, blog)* November* Grok from Xai - with realtime access to all of X content* OpenAI dev day * Combined mode for MMIO (multi modal on input

🦃 ThursdAI Thanksgiving special - OpenAI ctrl+altman+delete, Stable Video, Claude 2.1 (200K), the (continuous) rise of OSS LLMs & more AI news
ThursdAI TL;DR - November 23 TL;DR of all topics covered: * OpenAI Drama* Sam... there and back again. * Open Source LLMs * Intel finetuned Mistral and is on top of leaderboards with neural-chat-7B (Thread, HF, Github)* And trained on new Habana hardware! * Yi-34B Chat - 4-bit and 8-bit chat finetune for Yi-34 (Card, Demo)* Microsoft released Orca 2 - it's underwhelming (Thread from Eric, HF, Blog)* System2Attention - Uses LLM reasons to figure out what to attend to (Thread, Paper)* Lookahead decoding to speed up LLM inference by 2x (Lmsys blog, Github)* Big CO LLMs + APIs* Anthropic Claude 2.1 - 200K context, 2x less hallucinations, tool use finetune (Announcement, Blog, Ctx length analysis)* InflectionAI releases Inflection 2 (Announcement, Blog)* Bard can summarize youtube videos now * Vision* Video-LLaVa - open source video understanding (Github, demo)* Voice* OpenAI added voice for free accounts (Announcement) * 11Labs released speech to speech including intonations (Announcement, Demo)* Whisper.cpp - with OpenAI like drop in replacement API server (Announcement)* AI Art & Diffusion* Stable Video Diffusion - Stability releases text2video and img2video (Announcement, Try it)* Zip-Lora - combine diffusion LORAs together - Nataniel Ruiz (Annoucement, Blog)* Some folks are getting NERFs out from SVD (Stable Video Diffusion) (link)* LCM everywhere - In Krea, In Tl;Draw, in Fal, on Hugging Face* Tools* Screenshot-to-html (Thread, Github)Ctrl+Altman+Delete weekendIf you're subscribed to ThursdAI, then you most likely either know the full story of the crazy OpenAI weekend. Here's my super super quick summary (and if you want a full blow-by-blow coverage, Ben Tossel as a great one here)Sam got fired, Greg quit, Mira flipped then Ilya Flipped. Satya played some chess, there was an interim CEO for 54 hours, all employees sent hearts then signed a letter, neither of the 3 co-fouders are on the board anymore, Ilya's still there, company is aligned AF going into 24 and Satya is somehow a winner in all this.The biggest winner to me is open source folks, who got tons of interest suddenly, and specifically, everyone seems to converge on the OpenHermes 2.5 Mistral from Teknium (Nous Research) as the best model around! However, I want to shoutout the incredible cohesion that came out of the folks in OpenAI, I created a list of around 120 employees on X and all of them were basically aligned the whole weekend, from ❤️ sending to signing the letter, to showing how happy they are Sam and Greg are back! YayThis Week's Buzz from WandB (aka what I learned this week)As I’m still onboarding, the main things I’ve learned this week, is how transparent Weights & Biases is internally. During the whole OAI saga, Lukas the co-founder sent a long message in Slack, addressing the situation (after all, OpenAI is a big customer for W&B, GPT-4 was trained on W&B end to end) and answering questions about how this situation can affect us and the business. Additionally, another co-founder, Shawn Lewis shared a recording of his update to the BOD of WandB, about out progress on the product side. It’s really really refreshing to see this information voluntarily shared with the company 👏 The first core value of W&B is Honesty, and it includes transparency outside of matters like personal HR stuff, and after hearing about this during onboarding, it’s great to see that the company lives it in practice 👏 I also learned that almost every loss curve image that you see on X, is a W&B dashboard screenshot ✨ and while we do have a share functionality, it’s not built for viral X sharing haha so in the spirit of transparency, here’s a video I recorded and shared with product + feature request to make these screenshot way more attractive + clear that it’s W&B Open Source LLMs Intel passes Hermes on SOTA with a DPO Mistral Finetune (Thread, Hugging Face, Github)Yes, that intel, the... oldest computing company in the world, not only comes out strong with the best (on benchmarks) open source LLM, it also does DPO, and has been trained on a completely new hardware + Apache 2 license! Here's Yam's TL;DR for the DPO (Direct Policy Optimization) technique: Given a prompt and a pair of completions, train the model to prefer one over the other. This model was trained on prompts from SlimOrca's dataset where each has one GPT-4 completion and one LLaMA-13B completion. The model trained to prefer GPT-4 over LLaMA-13B.Additionally, even tho there is custom hardware included here, Intel supports the HuggingFace trainer fully, and the whole repo is very clean and easy to understand, replicate and build things on top of (like LORA)LMSys Lookahead decoding (Lmsys, Github)This method significantly improves the output of LLMs, sometimes by more than 2x, using some jacobian notation (don't ask me) tricks. It's copmatible with HF transformers library! I hope this comes to open source tools like LLaMa.cpp soon! Big CO LLMs + APIsAnthropic Claude comes back with 2.1 featuring 2

📅 ThursdAI Nov 16 - Live AI art, MS copilots everywhere, EMUs from Meta, sketch-to-code from TLDraw, Capybara 34B and other AI news!
Hey yall, welcome to this special edition of ThursdAI. This is the first one that I'm sending in my new capacity as the AI Evangelist Weights & Biases (on the growth team)I made the announcement last week, but this week is my first official week at W&B, and oh boy... how humbled and excited I was to receive all the inspiring and supporting feedback from the community, friends, colleagues and family 🙇♂️ I promise to continue my mission of delivering AI news, positivity and excitement, and to be that one place where we stay up to date so you don't have to. This week we also had one of our biggest live recordings yet, with 900 folks tuned in so far 😮 and it was my pleasure to again to chat with folks who "made the news" so we had a brief interview with Steve Ruiz and Lou from TLDraw, about their incredible GPT-4 Vision enabled "make real" functionality and finally got to catch up with my good friend Idan Gazit who's heading the Github@Next team (the birthplace of Github Copilot) about how they see the future. So definitely definitely check out the full conversation! TL;DR of all topics covered: * Open Source LLMs * Nous Capybara 34B on top of Yi-34B (with 200K context length!) (Eval, HF) * Microsoft - Phi 2 will be open sourced (barely) (Announcement, Model)* HF adds finetune chain genealogy (Announcement)* Big CO LLMs + APIs* Microsoft - Everything is CoPilot (Summary, copilot.microsoft.com)* CoPilot for work and 365 (Blogpost)* CoPilot studio - low code "tools" builder for CoPilot + GPTs access (Thread)* OpenAI Assistants API cookbook (Link)* Vision* 🔥 TLdraw make real button - turn sketches into code in seconds with vision (Video, makereal.tldraw.com)* Humane Pin - Orders are out, shipping early 2024, multimodal AI agent on your lapel (* )* Voice & Audio* 🔥 DeepMind (Youtube) - Lyria high quality music generations you can HUM into (Announcement)* EmotiVoice - 2000 different voices with emotional synthesis (Github)* Whisper V3 is top of the charts again (Announcement, Leaderboard, Github)* AI Art & Diffusion* 🔥 Real-time LCM (latent consistency model) AI art is blowing up (Krea, Fal Demo)* 🔥 Meta announces EMU-video and EMU-edit (Thread, Blog)* Runway motion brush (Announcement)* Agents* Alex's Visual Weather GPT (Announcement, Demo) * AutoGen, Microsoft agents framework is now supporting assistants API (Announcement)* Tools* Gobble Bot - scrape everything into 1 long file for GPT consumption (Announcement, Link)* ReTool state of AI 2023 - https://retool.com/reports/state-of-ai-2023* Notion Q&A AI - search through a company Notion and QA things (announcement)* GPTs shortlinks + analytics from Steven Tey (https://chatg.pt* ) This Week's Buzz from WandB (aka what I learned this week)Introducing a new section in the newsletter called "The Week's Buzz from WandB" (AKA What I Learned This Week).As someone who joined Weights and Biases without prior knowledge of the product, I'll be learning a lot. I'll also share my knowledge here, so you can learn alongside me. Here's what I learned this week:The most important things I learned this week is just how prevelant and how much of a leader Weights&Biases is. W&B main product is used by most of the foundation LLM trainers including OpenAI. In fact GPT-4 was completely trained on W&B!It's used by pretty much everyone besides Google. In addition to that it's not only about LLMs, W&B products are used to train models in many many different areas of the industry. Some incredible examples are a pesticide dispenser that's part of the John Deere tractors that only spreads pesticides onto weeds and not actual produce. And Big Pharma who's using W&B to help create better drugs that are now in trial. And it's just incredible how much machine learning that's outside of just LLMs is there. But also I'm absolutely floored by just the amount of ubiquity that W&B has in the LLM World.W&B has two main products, Models & Prompts, Prompts is a newer one, and we're going to dig into both of these more next week! Additionally, it's striking how many AI Engineers, API users such as myself and many of my friends, have no idea of who W&B even is, of if they do, they never used it!Well, that's what I'm here to change, so stay tuned! Open source & LLMsIn the open source corner, we have the first Nous fine-tune of Yi-34B, which is a great model that we've covered in the last episode and now is fine-tuned with the Capybara dataset by ThursdAI cohost, LDJ! Not only is that a great model, it now tops the charts for the resident reviewer we WolframRavenwolf on /r/LocalLLama (and X) Additionally, Open-Hermes 2.5 7B from Teknium is now second place on HuggingFace leaderboards, it was released recently but we haven't covered until now, I still think that Hermes is one of the more capable local models you can get! Also in open source this week, guess who loves it? Satya (and Microsoft) They love it so much that they not only created this awesome slide (altho, what's SLMs? Small Language Models?

📅 ThursdAI - OpenAI DevDay recap (also X.ai grōk, 01.ai 200K SOTA model, Humane AI pin) and a personal update from Alex 🎊
Hey everyone, this is Alex Volkov 👋 This week was an incredibly packed with news, started strong on Sunday with x.ai GrŌk announcement, Monday with all the releases during OpenAI Dev Day, then topped of with Github Universe Copilot announcements, and to top it all of, we postponed the live recording to see what hu.ma.ne has in store for us as AI devices go (Finally announced Pin with all the features) In between we had a new AI Unicorn from HongKong called Yi from 01.ai which dropped a new SOTA 34B model with a whopping 200K context window and a commercial license by ex-Google China lead Kai Fu Lee.Above all, this week was a monumental for me personally, ThursdAI has been a passion project for the longest time (240 days), and it led me to incredible places, like being invited to ai.engineer summit to do media, then getting invited to OpenAI Dev Day (to also do podcasting from there), interview and befriend folks from HuggingFace, Github, Adobe, Google, OpenAI and of course open source friends like Nous Research, Alignment Labs, and interview authors of papers, hackers of projects, and fine-tuners and of course all of you, who tune in from week to week 🙏 Thank you!It's all been so humbling and fun, which makes me ever more excited to share the next chapter. Starting Monday I'm joining Weights & Biases as an AI Evangelist! 🎊I couldn't be more excited to continue ThursdAI mission, of spreading knowledge about AI, connecting between the AI engineers and the fine-tuners, the Data Scientists and the GEN AI folks, the super advanced cutting edge stuff, and the folks who fear AI with the backing of such an incredible and important company in the AI space. ThursdAI will continue as a X space, newsletter and podcast, as we'll gradually find a common voice, and continue bringing folks awareness of WandB incredible brand to newer developers, products and communities. Expect more on this very soon! Ok now to the actual AI news 😅 TL;DR of all topics covered: * OpenAI Dev Day* GPT-4 Turbo with 128K context, 3x cheaper than GPT-4* Assistant API - OpenAI's new Agent API, with retrieval memory, code interpreter, function calling, JSON mode * GPTs - Shareable, configurable GPT agents with memory, code interpreter, DALL-E, Browsing, custom instructions and actions* Privacy Shield - Open AI lawyers will protect you from copyright lawsuits * Dev Day emergency pod with Latent Space with Swyx, Allesio, Simon and Me! (Listen)* OpenSource LLMs * 01 launches YI-34B, a 200K context window model commercially licensed and it tops all HuggingFace leaderboards across all sizes (Announcement)* Vision* GPT-4 Vision API finally announced, rejoice, it's as incredible as we've imagined it to be* Voice* Open AI TTS models with 6 very-realistic, multilingual voices, no cloning tho* AI Art & Diffusion* Announcement)OpenAI Dev DaySo much to cover from OpenAI that this has it's own section today in the newsletter. I was lucky enough to get invited, and attend the first ever OpenAI developer conference (AKA Dev Day) and it was an absolute blast to attend. It was also incredible to attend it together with all 8.5 thousand of you who tuned into our live stream on X, as we were walking to the event, and then watched the keynote together (Thanks Ray for the restream) and talked with OpenAI folks about the updates. Huge shoutout to LDJ, Nisten, Ray, Phlo, Swyx and many other folks who held the space, while we were otherwise engaged with deep dives and meeting folks and doing interviews! So now for some actual reporting! What did we get from OpenAI? omg we got so much, as developers, as users (and as attendees, I will add more on this later) GPT4-Turbo with 128K context lengthThe major thing that was announced is a new model, GPT-4-turbo, which is supposedly faster than GPT-4, while being 3x cheaper (2x on output) and having a whopping 128K context length while also being more accurate (with significantly better recall and attention throughout this context length)With JSON mode and significantly improved function calling capabilities, updated cut-off time (April 2023), and higher rate limits, this new model is already being implemented across all the products and is a significant significant upgrade to many folksGPTs - A massive shift in agent landscapes by OpenAIAnother (semi-separate) thing that Sam talked about was the GPTs, their version of agents not to be confused with the Assistants API, which is also Agents, but for developers, and they are not the same and it's confusingGPTs I think is a genius marketing move by OpenAI and replaces Plugins (that didn't even meet product market fit) in many regards. GPTs are instances of well... GPT4-turbo, that you can create by simply chatting with BuilderGPT, and they can have their own custom instruction set, and capabilities that you can turn on and off, like browse the web with Bing, Create images with DALL-E and write and execute code with Code Interpreter (bye bye Advanced Data Analysis, we don't miss

📅 ThursdAI Nov 02 - ChatGPT "All Tools", Bidens AI EO, many OSS SOTA models, text 2 3D, distil-whisper and more AI news 🔥
ThursdAI November 2ndHey everyone, welcome to yet another exciting ThursdAI. This week we have a special announcement, the co-host of and I will be hosting a shared X space live from Open AI Dev Day! Monday next week (and then will likely follow up with interviews, analysis and potentially a shared episode!)Make sure you set a reminder on X (https://thursdai.news/next) , we’re going to open the live stream early, 8:30am on Monday, and we’ll live stream all throughout the keynote! It’ll be super fun!Back to our regular schedule, we covered a LOT of stuff today, and again, were lucky enough to have BREAKING NEWS and the authors of said breaking news (VB from HuggingFace and Emozilla from Yarn-Mistral-128K) to join us and talk a little bit in depth about their updates![00:00:34] Recap of Previous Week's Topics[00:00:50] Discussion on AI Embeddings[00:01:49] Gradio Interface and its Applications[00:02:56] Gradio UI Hosting and its Advantages[00:04:50] Introduction of Baklava Model[00:05:11] Zenova's Input on Distilled Whisper[00:10:32] AI Regulation Week Discussion[00:24:14] ChatGPT new All Tools mode (aka MMIO)[00:35:45] Discussion on Multimodal Input and Output Models[00:36:55] BREAKING NEWS: Mistral YaRN 7B - 128K context window[00:37:02] Announcement of Mistral Yarn Release[00:46:47] Exploring the Limitations of Current AI Models[00:47:25] The Potential of Vicuna 16k and Memory Usage[00:49:43] The Impact of Apple's New Silicon on AI Models[00:51:23] Introduction to New Models from Nius Research[00:51:39] The Future of Long Context Inference[00:53:42] Exploring the Capabilities of Obsidian[00:54:29] The Future of Multimodality in AI[00:58:48] The Exciting Developments in CodeFusion[01:06:49] The Release of the Red Pajama V2 Dataset[01:12:07] The Introduction of Luma's Genie[01:16:37] Discussion on 3D Models and Stable Diffusion[01:17:08] Excitement about AI Art and Diffusion Models[01:17:48] Regulation of AI and OpenAI Developments[01:18:24] Guest Introduction: VB from Hug& Face[01:18:53] VB's Presentation on Distilled Whisper[01:21:54] Discussion on Distillation Concept[01:27:35] Insanely Fast Whisper Framework[01:32:32] Conclusion and RecapShow notes and links:* AI Regulation* Biden Executive Order on AI was signed (Full EO, Deep dive)* UK AI regulation forum (King AI speech, no really, Arthur from Mistral)* Mozilla - Joint statement on AI and openness (Sign the letter)* Open Source LLMs* Together AI releases RedPajama 2, 25x larger dataset (30T tokens) (Blog, X, HF)* Alignment Lab - OpenChat-3.5 a chatGPT beating open source model (HF)* Emozilla + Nous Research - Yarn-Mistral-7b-128k (and 64K) longest context window (Announcement, HF)* LDJ + Nous Research release Capybara 3B & 7B (Announcement, HF)* LDJ - Obsidian 3B - the smallest open source multi modal model (HF, Quantized)* Big CO LLMs + APIs* ChatGPT "all tools" MMIO mode - Combines vision, browsing, ADA and DALL-E into 1 model (Thread, Examples, System prompt)* Microsoft CodeFusion paper - a tiny (75M parameters) model beats a 20B GPT-3.5-turbo (Thread, ArXiv)* Voice* Hugging Face - Distill whisper - 2x smaller english only version of Whisper (X, paper, code)* AI Art & Diffusion & 3D* Luma - text-to-3D Genie bot (Announcement, Try it)* Stable 3D & Sky changerAI Regulation IS HERELook, to be very frank, I want to focus ThursdAI on all the news that we're getting from week to week, and to bring a positive outlook, so politics, doomerism, and regulation weren't on the roadmap, however, with weeks like these, it's really hard to ignore, so let's talk about this.President Biden signed an Executive Order, citing the old, wartime era Defence Production act (looks like the US gov. also has "one weird trick" to make the gov move faster) and it wasn't as bombastic as people thought. X being X, there has been so many takes pre this executive order even releasing about regulatory capture being done by the big AI labs, about how open source is no longer going to be possible, and if you visit Mark Andressen feed you'll see he's only reposting AI generated memes to the tune of "don't tread on me" about GPU and compute rights.However, at least on the face of it, this executive order was mild, and discussed many AI risks and focused on regulating models from huge compute runs (~28M H100 hours // $50M dollars worth). Here's the relevant section.Many in the open source community reacted to the flops limitation with a response that it's very much a lobbyist based decision, and that the application should be regulated, not only the compute.There's much more to say about the EO, if you want to dig deeper, I strongly recommend this piece from AI Snake oil :and check out Yan Lecun's whole feed.UK AI safety summit in Bletchley ParkLook, did I ever expect to add the King of England into an AI weekly recap newsletter? Surely, if he was AI Art generated or something, not the real king, addressing the topic of AI safety!This video was played for the attendees of a few day AI sa

📅 ThursdAI Oct-26, Jina Embeddings SOTA, Gradio-Lite, Copilot crossed 100M paid devs, and more AI news
ThursdAI October 26thTimestamps and full transcript for your convinience## [00:00:00] Intro and brief updates## [00:02:00] Interview with Bo Weng, author of Jina Embeddings V2## [00:33:40] Hugging Face open sourcing a fast Text Embeddings## [00:36:52] Data Provenance Initiative at dataprovenance.org## [00:39:27] LocalLLama effort to compare 39 open source LLMs +## [00:53:13] Gradio Interview with Abubakar, Xenova, Yuichiro## [00:56:13] Gradio effects on the open source LLM ecosystem## [01:02:23] Gradio local URL via Gradio Proxy## [01:07:10] Local inference on device with Gradio - Lite## [01:14:02] Transformers.js integration with Gradio-lite## [01:28:00] Recap and bye byeHey everyone, welcome to ThursdAI, this is Alex Volkov, I'm very happy to bring you another weekly installment of 📅 ThursdAI.ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.TL;DR of all topics covered:* Open Source LLMs* JINA - jina-embeddings-v2 - First OSS embeddings models with 8K context (Announcement, HuggingFace)* Simon Willison guide to Embeddings (Blogpost)* Hugging Face - Text embeddings inference (X, Github)* Data Provenance Initiative - public audit of 1800+ datasets (Announcement)* Huge open source LLM comparison from r/LocalLLama (Thread)* Big CO LLMs + APIs* NVIDIA research new spin on Robot Learning (Announcement, Project)* Microsoft / Github - Copilot crossed 100 million paying users (X)* RememberAll open source (X)* Voice* Gladia announces multilingual near real time whisper transcriptions (X, Announcement)* AI Art & Diffusion* Segmind releases SSD-1B - 50% smaller and 60% faster version of SDXL (Blog, Hugging Face, Demo)* Prompt techniques* How to use seeds in DALL-E to add/remove objects from generations (by - Thread)This week was a mild one in terms of updates, believe it or not, we didn't get a new State of the art open source large language model this week, however, we did get a new state of the art Embeddings model from JinaAI (supporting 8K sequence length).We also had quite the quiet week from the big dogs, OpenAI is probably sitting on updates until Dev Day (which I'm going to cover for all of you, thanks to Logan for the invite), Google had some leaks about Gemini (we're waiting!) and another AI app builder thing, Apple is teasing new hardware (but nothing AI related) coming soon, and Microsoft / Github announced that CoPilot has 100 million paying users! (I tweeted this and Idan Gazit, Sr. Director GithubNext where Copilot was born, tweeted that "we're literally just getting started" and mentioned November 8th as... a date to watch, so mark your calendars for some craziness next two weeks)Additionally, we covered the Data provenance initiative that helps sort and validate licenses for over 1800 public datasets, a massive effort led by Shayne Redford with assistance from many folks including friend of the pod Enrico Shippole, we also covered another massive evaluation effort by a user named WolframRavenwolf on the LocalLLama subreddit, that evaluated and compared 39 open source models and GPT4. Not surprisingly the best model right now is the one we covered last week, OpenHermes 7B from Teknium.Two additional updates were covered, one of them is Gladia AI, released their version of whisper over web-sockets, and I covered it on X with a reaction video, it allows developers to stream speech to text, with very low latency and it's multi-lingual as well, so if you're building an agent that folks can talk to, definitely give this a try, and finally, we covered SegMind SSD-1B, a distilled version of SDXL, making it 50% smaller in size and 60% faster in generation speed (you can play with it here)This week I was lucky to host 2 deep dive conversations, one with Bo Wang, from Jina AI, and we covered embeddings, vector latent spaces, dimensionality, and how they retrained BERT to allow for longer sequence length, it was a fascinating conversation, even if you don't understand what embeddings are, it's well worth a listen.And in the second part, I had the pleasure to have Abubakar Abid, head of Gradio at Hugging Face, to talk about Gradio, it's effect on the open source community, and then joined by Yuichiro and Xenova to talk about the next iteration of Gradio, called Gradio-lite that runs completely within the browser, no server required.A fascinating conversation, if you're a machine learning engineer, AI engineer, or just someone who is interested in this field, we covered a LOT of ground, including Emscripten, python in the browser, Gradio as a tool for ML, webGPU and much more.I hope you enjoy this deep dive episode with 2 authors of the updates this week, and hope to see you in the next one.P.S - if you've been participating in the emoji of the week, and have read all the way up to here, your emoji of the week is 🦾, please reply or DM me with it 👀Timestamps and full transcript for yo

🔥 ThursdAI Oct 19 - Adept Fuyu multimodal, Pi has internet access, Mojo works on macs, Baidu announces ERNIE in all apps & more AI news
Hey friends, welcome to ThursdAI Oct - 19. Here’s everything we covered + a little deep dive after the TL;DR for those who like extra credit. ThursdAI - If you like staying up to date, join our communityAlso, here’s the reason why the newsletter is a bit delayed today, I played with Riffusion to try and get a cool song for ThursdAI 😂ThursdAI October 19thTL;DR of all topics covered: * Open Source MLLMs * Adept open sources Fuyu 8B - multi modal trained on understanding charts and UI (Announcement, Hugging face, Demo)* Teknium releases Open Hermes 2 on Mistral 7B (Announcement, Model)* NEFTune - a "one simple trick" to get higher quality finetunes by adding noise (Thread, Github)* Mistral is on fire, most fine-tunes are on top of Mistral now* Big CO LLMs + APIs* Inflection Pi got internet access & New therapy mode (Announcement)* Mojo 🔥 is working on Apple silicon Macs and has LLaMa.cpp level performance (Announcement, Performance thread)* Anthropic Claude.ai is rolled out to additional 95 countries (Announcement) * Baidu AI announcements - ERNIE 4, multimodal foundational model, integrated with many applications (Announcement, Thread)* Vision* Meta is decoding brain activity in near real time using non intrusive MEG (Announcement, Blog, Paper)* Baidu YunYiduo drive - Can use text prompts to extract precise frames from video, and summarize videos, transcribe and add subtitles. (Announcement)* Voice & Audio* Near real time voice generation with play.ht - under 300ms (Announcement)* I'm having a lot of fun with Airpods + chatGPT voice (X)* Riffusion - generate short songs with sound and singing (Riffusion, X)* AI Art & Diffusion* Adobe releases Firefly 2 - lifelike and realistic images, generative match, prompt remix and prompt suggestions (X, Firefly)DALL-E 3 is now available to all chatGPT Plus uses (Announcement, Research paper!) * Tools* LMStudio - a great and easy way to download models and run on M1 straight on your mac (Download)* Other* ThursdAI is adhering to the techno-optimist manifesto by Pmarca (Link)Open source mLLMsWelcome to multimodal future with Fuyu 8B from AdeptWe've seen and covered many multi-modal models before, and in fact, most of them will start being multimodal, so get ready to say "MLLMs" or... we come up with something better. Most of them so far have been pretty heavy, IDEFICS was 80B parameters etc' This week we received a new, 8B multi modal with great OCR abilities from Adept, the same guys who gave us Persimmon 8B a few weeks ago, in fact, Fuyu is a type of persimmon tree (we see you Adept!)In the podcast I talked about having 2 separate benchmarks for myself, one for chatGPT or any MultiModal coming from huge companies, and another for open source/tiny models. Given that Fuyu is a tiny model, it's quite impressive! It's OCR capabilities are impressive, and the QA is really on point (as well as captioning)An interesting thing about FuYu architecture is, because it doesn't use the traditional vision encoders, it can scale to arbitrary image sizes and resolutions, and is really fast (large image responses under 100ms)Additionally, during the release of Fuyu, Arushi from Adept authored a thread about visualQA evaluation datasets are, which... they really are bad, and I hope we get better ones! NEFTune - 1 weird trick of adding noise to embeddings makes models better (announcement thread)If you guys remember, a "this one weird trick" was discovered by KaiokenDev back in June, to extend the context window of LLaMa models, which then turned into RoPE scaling and YaRN scaling (which we covered in a special episode with the authors) Well, now we have a similar "1 weird trick" that by just adding some noise to embeddings at training time, the model performance can grow by up to 25%! The results very per dataset of course, however, considering how easy it is to try, literally: It's as simple as doing this in your forward pass if training: return orig_embed(x) + noise else: return orig_embed(x)We should be happy that the "free lunch" tricks like this exist. Notably, we had a great guest, Wing Lian the maintainer of Axolotl, a very popular tool to streamline fine-tuning, chime in and say that in his tests, and among the discord folks, they couldn't reproduce some of these claims (as they are adding everything that's super cool and beneficial for finetuners to their library) so it remains to be seen how far this "trick" scales, and what else needed to be done here. Similarly, back when the context extend trick was discovered, there was a lot of debates about it's effectiveness from Ofir Press (author of ALiBi, another context scaling methond) and futher iterations of the trick made into a paper and a robust method, so this develompment is indeed exciting! Mojo 🔥 now supports Apple silicon Macs and has LLaMa.cpp level performance!I've been waiting for this day! We've covered Mojo from Modular a couple of times and it seems that the promise behind it starts to materialize. Modular promises

A week of horror, an AI conference of contrasts
A week of horror, an AI conference of contrastsHi, this is Alex. In the podcast this week, you'll hear my conversation with Miguel, a new friend I made in AI.engineer event, and then a recap of the whole Ai.engineer event I had with Swyx after the end. This newsletter is a difficult one for me to write, honestly, I wanted to skip this one entirely, struggling to fit the current events into my platform and the AI narrative, however, decided to write one anyway, as the events of the last week have merged into 1 for me in a flurry of contrasts. Contrast 1 - Innovation vs DestructionI was invited (among a few other Israelis or Israeli-Americans) to the ai.engineer summit in SF, to celebrate the rise of the AI engineer, and I was looking forward to that very much. Meeting many of you (Shoutout to everyone who listens to ThursdAI who I've met face to face!) and talking to new friends of the pod, interviewing speakers, meeting and making connections was a dream come true. However a few days before the conference began, in a stark contrast to this dream, I had to call my mom, who was sheltering, 20km from the Gaza strip border, to ask if our friends and family are alive and accounted for, and to hear sirens as rockets flying above her head, as Hamas terrorists murder, pillage and kidnap, in what seems to be the 10x equivalent of 9/11 terror attack, relative to population size. I grew up in Ashkelon, rocket attacks are nothing new to me, we've learned to live with them (thank you Iron Dome heroes) but this was something else entirely, a new world of terror. So back to the conference, given that there's not a lot to be gained by doom scrolling, and watching (basically snuff) films coming out of the region, given that all my friends and family were accounted for, I decided to not give the terrorists what they want (which is to get people in state of terror) and instead to choose to have compassion, without empathy towards the situation and not bring sadness to every conversation I had there (over 200 I think) So participating at an AI event, which hosts and celebrates folks who are literally at the pinnacle of innovation, building the future, using all the latest tools while also hurting and holding the dear ones in my thoughts was a very stark contrast between past and future, and huge credit goes to Dedy Kredo, CTO of Codium, who was in the same position, and gave a hell of a talk, with a kick-ass (no backup recording!) demo live, and then shared this image: This is his co-founder, Itamar, who was called to reserve duty to protect his family and country, sitting with his rifle and his dashboard, seeing destruction + creation, past and future, negativity and positivity all at once. As Dedy masterfully said, we will prevail 🙏 Contrast 2 - Progress // FearAt the event, Swyx and Benjamin gave me a media pass and a free reign, and I asked to be teamed with a camera-person to go around the event and do some (not live) interviews. I was teamed with the lovely Stacey, from Chico, CA. Stacey has nothing to do with AI, in fact she's a wedding photographer, however she definitely listened with interest to the interviews I was holding, and to speakers on stage. While we were taking a break, I looked out the window, and saw a driverless car (waymo) zip by, and since they only started operating after I left SF 3 years ago, I didn't yet have a chance to ride in one. So I asked Stacey and some other folks, if they'd like to go for a ride, and to my complete bewilderement, Stacey said "no 😳" and when I asked why not, she didn't want to admin but then said that it's scary. This struck me and since that moment, I've had as many conversations with Stacey as I had with other folks who came to be AI.engineers, since this was such a stark contrast between progress and fear. I basically was walking, almost hand in hand, with a person who doesn't use or understand AI, and fears it, amongst the folks who are building the future, exist at the pinnacle of innovation and discuss how to connect more AI to more AI, and how to build complete autonomous agents to augment human productivity and bring about the world of abundance. This contrast was supported by several new friends of mine, who came to the AI.engineer and SF for the first time, from countries where English is not the first language, and where Waymo's are not zipping about on the streets freely, and it highlighted for me, how much of this shift is global, and how concentrated the decision making, the building, the innovation is, within the arena, SF, California and US. It's almost expected that AI is going to speak english, and to use/build it, we have to speak it as well, while most of the world doesn't use English as their first language. Contrast 3 - Technological // SpiritualThis contrast was intimate and personal to me. You see, this ai.engineer event was the first such sized event, professional, with folks talking "my language" since I had burned out this summer. If you've foll

📅 ThursdAI Oct 4 - AI wearables, Mistral fine-tunes, AI browsers and more AI news from last week
Boy am I glad that not all AI weeks are like last week, where we had so much news and so many things happening that I was barely able to take a breath for the week! I am very excited to bring you this newsletter from San Fancisco this week, the AI mecca, the arena, the place where there are so many AI events and hack-a-thons that I don’t actually know how people get any work done!On that topic, I’m in SF to participate in the AI.engineer (by swyx and Benjamin Dunphy) next week, to host spaces and interviews with the top AI folks in here, and to discuss with the audience, what is an AI engineer, if you have any questions you’d like me to ask, please comment with them and I’ll make sure I’ll try to answer. ThursdAI - subscribe eh? ↴Here’s a table of contents of everything we chatted about: [00:00:00] Intro and welcome[00:04:53] Alex in San Francisco - AI Engineer[00:07:32] Reka AI - Announcing a new multimodal Foundational model called Yasa-1 [00:12:42] Google adding Bard to Google Assistant[00:18:56] Where is Gemini? [00:23:06] Arc browser adding Arc Max with 5 new AI features[00:24:56] 5 seconds link AI generated previews[00:31:54] Ability to run LLMs on client side with WebGPU[00:39:28] Mistral is getting love from Open Source, [00:48:04] Mistral Open Orca 7B [00:58:28] Acknowledging the experts of ThursdAI[01:01:14] Voice based always on AI assistants[01:09:00] Airchat adds voice cloning based translation tech[01:14:23] Effects of AI voice cloning on society[01:21:32] SDXL IKEA LORA[01:23:17] Brief RecapShow notes: Big Co* Google - adding Bard to Google Assistant (Announcement)Come on google, just give us Gemini already!* Reka AI - Multimodal Yasa-1 from Yi Tay and team (Announcement)With Yi Tay from Flan/Bard fame as chief scientist! But I wasn’t able to test myself!* Arc - first browser AI features (My thread, Brief video review, Arc Invite)I love Arc, I recommend it to everyone I meet, now with AI preview features it’s even more a non brainer, strongly recommend if you like productivityOpen Source LLMs* Mistral vs LLaMa 2 boxing match (link)A fun little battle arena to select which responses you personally find better to see the difference between Mistral 7B and LLaMa 13B* Mistral-7B-OpenOrca (announcement)The folks from Alignment labs do it again! Great finetune that comes very close (98%) to LLaMa 70B on benchmarks! * SynthIA-7B-v1.3 - (Huggingface)An uncensored finetune on top of Mistral that Reddit claims is a great model, especially since a chain of thought is somehow built in apparentlyVISION* Radiologists thread about GPT-4 V taking over radiology (or maybe not?) (Thread)Voice* AirChat added voice clone + translation features (Room, Demo)I’ve been an avid AirChat user (It’s Naval’s social media platform that’s voice based) for a while, and am very excited they are destroying language barriers with this feature! * Tab was revealed in a great demo by Avi Schiffman (Demo)Go Avi! Rooting for you brother, competition makes folk stronger!* Rewind announced Rewind Pendant (Announcement)I ordered one, but Rewind didn’t announce a date of when this hits the market, going to be interesting to see how well they do!Ai Art and Diffusion - IKEA Lora generate IKEA style tutorials for everything with SDXL (Announcement, HuggingFace)* DALL-E3 seems to be available to all Plus members nowThis weeks pod was generated by talking to chatGPT, it’s so fun, you gotta try it!No longer breakdown this week ,but we covered a bunch of it in the show, and I highly recommend listening to it!Don’t forget to follow me on X to be aware of the spaces live from ai.engineer event in SF, the conference will be live-streamed as well on youtube! See you next week 🫡 ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber. This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit sub.thursdai.news/subscribe

📅🔥ThursdAI Sep 28 - GPT4 sees, speaks and surfs, Cloudflare AI on GPUs,Mistral 7B, Spotify Translates, Meta AI everywhere, Qwen14B & more AI news from this INSANE week
[00:00:00] Intro and welcome everyone[00:00:52] GPT4 - Vision from OpenAI[00:05:06] Safety concern with GPT4-V[00:09:18] GPT4 can talk and listen as well[00:12:15] Apple rumors, on device inference, and Siri[00:17:01] OpenAI Voice Cloning Tech used in Spotify to translate podcasts[00:19:44] On the risks of Voice Cloning tech being open sourced[00:26:07] Alex statement on purpose of ThursdAI[00:27:53] “AGI has been achieved internally”;[00:32:10] OpenAI, Jonny Ive and Masa are rumored to be working on a hardware device[00:33:51] Cloudflare AI - Serverless GPU on global scale[00:37:13] Cloudflare AI partnership with HuggingFace to allow you to run many models in your own[00:40:34] Cloudflare announced the Vectorize DB and embedings on edge[00:46:52] Cloudflare AI gateway - proxy LLM calls, caching, monitoring, statistics and fallback[00:51:15] Part 2 - intro an recap[00:54:14] Meta AI announcements, bringing AI agents to 3 billion people next month[00:56:22] Meta announces EMU image model to be integrated into AI agent on every platform[00:59:38] Meta RayBan glasses upgraded to spatial computing, with AI and camera access[01:00:39] On the topic os smart glasses, GoogleGlass, and the acceptance society wide to have[01:05:37] Safety and societal implications of everyone having glasses and recording everything[01:12:05] Part 3 - Open Source LLMs, Mistral, QWEN and CapyBara[01:21:27] Mistral 7B - SOTA 7B general model from MIstralAI[01:23:08] On the topic of releasing datasets publically and legal challenges with obtaining that[01:24:42] Mistral GOAT team giving us a torrrent link to a model with Apache 2 license.Truly, as I’ve been doing these coverages in one form or another for the past 9 months, and I don’t remember a week this full of updates, news, state of the art open source models and more.So, here’s to acceleration (and me finally facing the fact that I need a niche, and decide what I’ll update on and what I won’t, and also be transparent with all of you about it)On a separate note, this past two weeks, ThursdAI had exposure to Yann Lecun (RTs), joined on stage by VP of DevRel in Cloudflare and their counterpart in HuggingFace, CEO of Anaconda joined us on stage this episode and we’ve had the chief scientist of Mistral join in the audience 😮 ThursdAI really shapes to be the place where this community meets, and I couldn’t be more humbled and prouder of the show, the experts on stage that join from week to week, and the growing audience 🙇♂️ ok now let’s get to the actual news!ThursdAI - Weeks like this one highlight how important it is to stay up to date on many AI news, subscribe, I’ve got some cool stuff coming! 🔥All right so here’s everything we’ve covered on ThursdAI, September 28th:(and if you’d like to watch the episode video with the full transcript, it’s here for free):Show Notes + Links* Vision* 🔥 Open AI announces GPT4-Vision (Announcement, Model Card)* Meta glasses will be multimodal + AI assistant (Announcement)* Big Co + API updates* Cloudflare AI on workers, serverless GPU, Vector DB and AI monitoring (Announcement, Documentation)* Cloudflare announces partnerships with HuggingFace, Meta* Claude announces $4 billion investment from Amazon (Announcement)* Meta announces AI assistant across WhatsApp, Instagram* Open Source LLM* 🔥 Mistral AI releases - Mistral 7B - beating LLaMa2 13B (Announcement, Model)* Alibaba releases Qwen 14B - beating LLaMa2 34B (Paper, Model, Vision Chat)* AI Art & Diffusion* Meta shows off EMU - new image model* Still waiting for DALL-E3 😂* Tools* Spotify translation using Open AI voice cloning techVisionGPT 4-VisionI’ve been waiting for this release since March 14th (literally) and have been waiting and talking about this on literally every ThursdAI, and have been comparing every open source multimodality image model (IDEFICS, LlaVa, QWEN-VL, NeeVa and many others) to it, and none came close!And here we are, a brief rumor about the upcoming Gemini release (potentially a multimodal big model form Google) and OpenAi decided to release GPT-4V and it’s as incredible as we’ve been waiting for!From creating components from a picture of UI, to solving complex math problems with LaTex, to helping you get out of a parking ticket by looking at a picture of a complex set of parking rules, X folks report that GPT4-V is incredibly helpful and unlocks so many new possibilities!Can’t wait to get access, and most of all, for OpenAI to land this in the API for developers to start building this into products!On the pod, I’ve talked about how I personally don’t believe AGI can work without vision, and how personal AI assistants are going to need to see what I see to be really helpful in the real world, and we’re about to unlock this 👀 Super exciting.I will add this one last thing, here’s Ilya Sutskever, OpenAI chief scientist, talking about AI + Vision, and this connects with our previous reporting that GPT-4 is not natively multimodal (while we’re waiting for rumored Gobi)If y

📆 ThursdAI Sep 21 - OpenAI 🖼️ DALL-E 3, 3.5 Instruct & Gobi, Windows Copilot, Bard Extensions, WebGPU, ChainOfDensity, RemeberAll
Hey dear ThursdAI friends, as always I’m very excited to bring you this edition of ThursdAI, September 21st, which is packed full of goodness updates, great conversations with experts, breaking AI news and not 1 but 2 interviewsThursdAI - hey, psst, if you got here from X, dont’ worry, I don’t spam, but def. subscribe, you’ll be the coolest most up to date AI person you know!TL;DR of all topics covered* AI Art & Diffusion* 🖼️ DALL-E 3 - High quality art, with a built in brain (Announcement, Comparison to MJ)* Microsoft - Bing will have DALL-E 3 for free (Link)* Big Co LLMs + API updates* Microsoft - Windows Copilot 🔥 (Announcement, Demo)* OpenAI - GPT3.5 instruct (Link)* OpenAI - Finetuning UI (and finetuning your finetunes) (Annoucement, Link)* Google - Bard has extensions (twitter thread, video)* Open Source LLM* Glaive-coder-7B (Announcement, Model, Arena)* Yann Lecun testimony in front of US senate (Opening Statement, Thread)* Vision* Leak : OpenAI GPT4 Vision is coming soon + Gobi multimodal? (source)* Tools & Prompts* Chain of Density - a great summarizer prompt technique (Link, Paper, Playground)* Cardinal - AI infused product backlog (ProductHunt) * Glaive Arena - (link)AI Art + DiffusionDALL-E 3 - High quality art, with a built in brainDALL-E 2 was the reason I went hard into everything AI, I have a condition called Aphantasia, and when I learned that AI tools can help me regain a part of my brain that’s missing, I was in complete AWE. My first “AI” project was a chrome extension that injects prompts into DALL-E UI to help with prompt engineering. Well, now not only is my extension no longer needed, prompt engineering for AI art itself may die a slow death with DALL-E 3, which is going to be integrated into chatGPT interface, and chatGPT will be able to help you… chat with your creation, ask for modifications, alternative styles, and suggest different art directions! In addition to this incredible new interface, which I think is going to change the whole AI art field, the images are of mind-blowing quality, coherence of objects and scene elements is top notch, and the ability to tweak tiny detail really shines! Additional thing they really fixed is hands and text! Get ready for SO many memes coming at you! Btw, I created a conversational generation bot in my telegram chatGPT bot (before there was an API with stability diffusion and I can only remember how addicting this was!) and so did my friends from Krea :) so y’know… where’s our free dall-e credits OpenAI? 🤔 Just kidding, an additional awesome thing that now, DALL-E will be integrated into chatGPT plus subscription (and enterprise) and will refuse to generate any living artists art, and has a very very strong bias towards “clean” imagery. I wonder how fast will it come to an API, but this is incredible news!P.S - if you don’t want to pay for chatGPT, apparently DALL-E 3 conversational is already being rolled out as a free offering for Bing Chat 👀 Only for a certain percentage of users, but will be free for everyone going forward!Big Co LLM + API updatesCopilot, no longer just for code?Microsoft has announced some breaking news on #thursdai, where they confirmed that Copilot is now a piece of the new windows, and will live just a shortcut away from many many people. I think this is absolutely revolutionary, as just last week we chatted with Killian from Open Interpreter and having an LLM run things on my machine was one of the main reasons I was really excited about it! And now we have a full on, baked AI agent, inside the worlds most popular operating system, running for free, for all mom and pop windows computers out there, with just a shortcut away! Copilot will be a native part of many apps, not only windows, here’s an example of a powerpoint copilot! As we chatted on the pod, this will put AI into the hands of so so many people for whom opening the chatGPT interface is beyond them, and I find it incredibly exciting development! (I will not be switching to windows for it tho, will you?)Btw, shoutout to Mikhail Parakhin who lead the BingChat integration and is now in charge of the whole windows division! It shows how much dedication to AI Microsoft is showing and it really seems that they don’t want to “miss” this revolution like they did with mobile!OpenAI releases GPT 3.5 instruct turbo! For many of us, who used GPT3 APIs before it was cool (who has the 43 character API key 🙋♂️) we remember the “instruct” models where all the rage, and then OpenAI basically told everyone to switch to the much faster and more RLHFd chat interfaces.Well now, they brought GPT3.5 back, with instruct and turbo mode, it’s no longer a chat, it’s a completion model, that is apparently much better at chess? An additional interesting thing is, it includes logprobs in the response, so you can actually build much more interesting software (by asking for several responses and then looking at the log probabilities), for example, if you’re asking the model for a mul

📅 ThursdAI - Special interview with Killian Lukas, Author of Open Interpreter (23K Github stars for the first week) 🔥
This is a free preview of a paid episode. To hear more, visit sub.thursdai.newsHey! Welcome to this special ThursdAI Sunday episode. Today I'm excited to share my interview with Killian Lucas, the creator of Open Interpreter - an incredible new open source project that lets you run code via AI models like GPT-4 or local models like Llama on your own machine. Just a quick note, that while this episode is provided for free, premium subscribers enjoy the full write up including my examples of using Open Interpreter, the complete (manually edited) transcript and a video form of the pod for easier viewing, search, highlights and more. Here’s a trailer of that in case you consider subscribingIf you haven’t caught up with GPT-4 Code Interpreter yet (now renamed to Advanced Data Analytics), I joined Simon Willison and swyx when it first launched and we had a deep dive about it on Latent Space and even at the day of the release, we were already noticing a major restricting factor, Code Interpreter is amazing, but doesn’t have internet access, and can’t install new packages, or use new tools. An additional thing we immediately noticed was, the surface area of “what it can do” is vast, given it can write arbitrary code per request, it was very interesting to hear what other folks are using it for for inspiration, and “imagination unlock”.I started a hashtag called #codeinterpreterCan and have since documented many interesting use cases, like comitting to git, running a vector DB, convert audio & video to different formats, plot wind rose diagrams, run whisper and so much more. I personally have all but switched to Code Interpreter (ADA) as my main chatGPT tab, and it’s currently the reason I’m still paying the 20 bucks! Enter, Open interpreterJust a week after open sourcing Open Interpreter, it already has over 20,000 stars on GitHub and a huge following. You can follow Killian on Twitter and check out the Open Interpreter GitHub repo to learn more. Installing is as easy as pip install open-interpreter. (but do make sure to install and run it inside a venv or a conda env, trust me!) And then, you just.. ask for stuff! (and sometimes ask again as you’ll see in the below usage video)Specifically, highlighted in the incredible launch video, if you’re using a mac, Code Interpreter can write and run AppleScript, which can run and control most of the native apps and settings on your mac. Here’s a quick example I recorded while writing this post up, where I ask Open Interpreter to switch system to Dark mode, then I use it to actually help me extract all the chapters for this interview and cut a trailer together!

🔥 ThursdAI Sep 14 - Phi 1.5, Open XTTS 🗣️, Baichuan2 13B, Stable Audio 🎶, Nougat OCR and a personal life update from Alex
This is a free preview of a paid episode. To hear more, visit sub.thursdai.newsHey, welcome to yet another ThursdAI 🫡 This episode is special for several reasons, one of which, I shared a personal life update (got to listen to the episode to hear 😉) but also, this is the first time I took the mountainous challenge of fixing, editing and “video-fying” (is that a word?) our whole live recording! All 3 hours of it, were condensed, sliced, sound improved (x audio quality is really dogshit) and uploaded for your convenience. Please let me know what you think! Premium folks get access to the full podcast in audiogram format, and a full transcription with timestamps and speakers, here’s a sneak preview of how that looks, why not subscribe? 😮TL;DR of all topics covered* Open Source LLM* Microsoft Phi 1.5 - a tiny model that beats other 7B models (with a twist?) (Paper, Model)* Baichuan 7B / 13B - a bilingual (cn/en) model with highly crafted approach to training (Paper, Github) * Big Co LLMs + API updates* Nothing major this week* Voice & Audio* Stable Audio 🎶 - A new music generation model from Stability AI. (Website)* Coqui XTTS - an open source multilingual text to speech for training and generating a cloned voice (Github, HuggingFace)* AI Art & Diffusion* Würstchen v2 - A new super quick 1024 diffusion model (Announcement, Demo, Github)* DiffBIR - Towards Blind Image Restoration with Generative Diffusion Prior (Annoucement, Demo, Github)* Tools* Nougat from Meta - open-source OCR model that accurately scans books with heavy math/scientific notations (Announcement, Github, Paper)* GPT4All Vulkan from Nomic - Run LLMs on ANY consumer GPUs, not just NVIDIA (Announcement)* Nisten’s AI ISO disk - Announcement And here are timestamps and chapter/discussion topics for your convenience: [00:05:56] Phi 1.5 - 1.3B parameter model that closely matches Falcon & LLaMa 7B[00:09:08] Potential Data Contamination with Phi 1.5[00:10:11] Data Contamination unconfirmed[00:12:59] Tiny models are all the rage lately[00:16:23] Synthetic Dataset for Phi[00:18:37] Are we going to run out of training data?[00:20:31] Breaking News - Nougat - OCR from Meta[00:23:12] Nisten - AI ISO disk[00:29:08] Baichuan 7B - an immaculate Chinese model[00:36:16] Unique Loss Terms[00:38:37] Baichuan ByLingual and MultiLingual dataset[00:39:30] Finetunes of Baichuan[00:42:28] Philosophical questions in the dataset[00:45:21] Let's think step by step[00:48:17] Is breath related text in the original dataset?[00:50:27] Counterintuitive prompting for models with no breath[00:55:36] Idea spaces[00:59:59] Alex - Life update about ThursdAI[01:04:30] Stable Audio from Stability AI[01:17:23] GPT4ALL Vulkan[01:19:37] Coqui.ai releases XTTS - an open source TTS - interview With Josh Meyer[01:30:40] SummaryHere’s a full video of the pod, and a full transcription, and as always, 🧡 thank you for bring a paid subscriber, this really gives me the energy to keep going, get better guests, release dope podcast content, and have 3 hours spaces and then spend 7 hours editing 🔥