
ThursdAI - The top AI news from the past week
162 episodes — Page 4 of 4

🔥🎙️ ThursdAI Sunday special - Extending LLaMa to 128K context window (2 orders of magnitude) with YaRN [Interview with authors]
This is a free preview of a paid episode. To hear more, visit sub.thursdai.newsHappy Sunday everyone, I am very excited to bring you this interview with the folks who took LLaMa 2 and made it LLoooooongMa!Extending LLaMa 2 context window from 4,000 to a whopping 128,000 tokens (Yarn-Llama-2-13b-128k on Hugging Face), these guys also came up with a paper called YaRN (Efficient Context Window Extension of Large Language Models) and showed that YaRN is not only requires 10x less tokens to create these long contexts, but also 2.5x less training steps! And, the models generalize so there’s now no need to collect extremely long sequences (think books length sequences) for the models to understand those context lengths. I have decided also to do something different (which took me half of Sunday so I can’t promise and am not committing to this format, but for the premium subscribers, you can now watch this interview with running Karaoke style subtitles and improved audio! This will be uploaded to Youtube in a week but aren’t you glad you subscribed and is getting this first?) Here’s a teaser preview: And here’s the chapter for your convenience (the only thing that’s ai generated 😂)0:00 - Introduction3:08 - Discussion of extending LLAMA2's context length from 4,000 tokens to 128,000 tokens using the YaRN method8:23 - Explanation of rope scaling for positional encodings in transformers13:21 - How the rope scaling idea allows for longer context through positional interpolation18:51 - Using in-context learning to train models on shorter sequences but still handle long contexts25:18 - Sourcing long-form data like books to train 128k token models31:21 - Whether future models will natively support longer contexts37:33 - New model from Adept with 16k context using rope scaling42:46 - Attention is quadratic - need better algorithms to make long context usable49:39 - Open source community pushing state of the art alongside big labs52:34 - Closing thoughtsAs always, full (manually edited) transcription (and this time a special video version!) is reserved for the premium subscribers, I promise it’ll be worth it, so why not .. y’know? skip a cup of coffee from SB and support ThursdAI?

ThursdAI Sep 7 - Falcon 180B 🦅 , 🔥 Mojo lang finally here, YaRN scaling interview, Many OSS models & more AI news
Hey ya’ll, welcome to yet another ThursdAI, this is Alex coming at you every ThursdAI, including a live recording this time! Which was incredible, we chatted about Falcon 180B,had a great interview in the end with 3 authors of the YaRN scaling paper and LLongMa 128K context, had 3 breaking news! in the middle, MOJO🔥 has been released and Adept released a LLaMa comparable OSS model (and friend of the pod) @reach_vb showed an open ASR leaderboard on hugging face! We also covered an incredible tiny model called StarCoder 1B that was finetuned by friend of the pod (who joined the space to talk to us about it!) As always, you can listen to the whole 3 hour long form conversation (raw, unedited) on our Zealous page (and add it to your podcatcher via this RSS) and this short-form pod is available on Apple, Spotify and everywhere. ThursdAI - Hey, if you enjoy these, how about subscribing for real? Would love to do this full time! Every paid subscriber is like a dear friend 🧡TL;DR of all topics covered* Open Source LLM* Falcon 180B announced by TIIUAE (Announcement, Demo)* YaRN scaling paper - scaling LlaMa to 128K context (link)* OpenHermes-13B from @teknium1 (link)* Persimmon-8B from Adept.AI (link)* Starcoder-1B-sft from @abacaj (link) * Big Co LLMs + API updates* OpenAI first ever Dev conference (link)* Claude announces a $20/mo Claude Pro tier (link)* Modular releases Mojo🔥 with 68,000x improvement over python (Link)* Vision* Real time deepfake with FaceFusion (link)* HeyGen released AI avatars and AI video translation with lipsync (link, translation announcement)* Voice* Open ASR (automatic speech recognition) leaderboard from HuggingFace (link)* Tools* LangChain Hub (re) launched * Open Interpreter (Announcement, Github)Open Source LLM🦅 Falcon 180B - The largest open source LLM to date (Announcement, Demo)The folks at the “Technology Innovation Institute” have open sourced the huge Falcon 180B, and have put it up on Hugging Face. Having previously open sourced Falcon 40B, the folks from TIIUAE have given us a huge model that beats (base) LLaMa 2 on several evaluations, if just slightly by a few percentages points. It’s huge, was trained on 3.5 trillion tokens and weights above 100GB as a file and requires 400GB for inference. Some folks were not as impressed with Falcon performance, given it’s parameter size is 2.5 those of LLaMa 2 (and likely it took a longer time to train) but the relative benchmarks is just a few percentages higher than LLaMa. It also boasts an embarrassingly low context window of just 2K tokens, and code was just 5% of it’s dataset, even though we already know that more code in the dataset, makes the models smarter! Georgi Gerganov is already running this model on his M2 Ultra because he’s the Goat, and co-host of ThursdAI spaces, Nisten, was able to run this model with CPU-only and with just 4GB of ram 🤯 We’re waiting for Nisten to post a Github on how to run this monsterous model on just CPU, because it’s incredible! However, given the Apache2 license and the fine-tuning community excitement about improving these open models, it’s an incredible feat. and we’re very happy that this was released! The complete open sourcing also matters in terms of geopolitics, this model was developed in the UAE, while in the US, the export of A100 GPUs was banned to the middle easy, and folks are talking about regulating foundational models, and this release, size and parameter model that’s coming out of the United Arab Emirates, for free, is going to definitely add to the discussion wether to regulate AI, open source and fine-tuning huge models! YaRN scaling LLaMa to 128K context windowLast week, just in time for ThursdAI, we posted about the release of Yarn-Llama-2-13b-128k, a whopping 32x improvement in context window size on top of the base LLaMa from the folks at Nous Research, Enrico Shippole, @theemozilla with the help of Eluether AI.This week, they released the YaRN: Efficient Context Window Extension of Large Language Models paper which uses Rotary Position Embeddings to stretch the context windows of transformer attention based LLMs significantly. We had friends of the pod Enrico Shippole, theemozilla (Jeff) and Bowen Peng on the twitter space and an special interview with them will be released on Sunday, if you’re interested in scaling and stretching context windows work, definitely subscribe for that episode, it was incredible! It’s great to see that their work is already applied into several places, including CodeLLaMa (which was released with 16K - 100K context) and the problem is now compute, basically, context windows can be stretched, and the models are able to generalize from smaller datasets, such that the next models are predicted to be released with infinite amount of context window, and it’ll depend on your hardware memory requirements.Persimmon-8B from AdeptAI (announcement, github)AdeptAI, the company behind Act-1, a foundational model for AI Agent that does browser driving,

ThursdAI Aug 24 - Seamless Voice Model, LLaMa Code, GPT3.5 FineTune API & IDEFICS vision model from HF
Hey everyone, this week has been incredible (isn’t every week?), and as I’m writing this, I had to pause and go check out breaking news about LLama code which was literally released on ThursdAI as I’m writing the summary! I think Meta deserves their own section in this ThursdAI update 👏A few reminders before we dive in, we now have a website (thursdai.news) which will have all the links to Apple, Spotify, Full recordings with transcripts and will soon have a calendar you can join to never miss a live space!This whole thing would have been possible without Yam, Nisten, Xenova , VB, Far El, LDJ and other expert speakers from different modalities who join and share their expertise from week to week, and there’s a convenient way to follow all of them now!TL;DR of all topics covered* Voice* Seamless M4T Model from Meta (demo)* Open Source LLM* LLaMa2 - code from Meta* Vision* IDEFICS - A multi modal text + image model from Hugging face* AI Art & Diffusion* 1 year of Stable Diffusion 🎂* IdeoGram* Big Co LLMs + API updates* GPT 3.5 Finetuninng API* AI Tools & Things* Cursor IDEVoiceSeamless M4t - A multi lingual, mutli tasking, multimodality voice model.To me, the absolute most mindblowing news of this week was Meta open sourcing (not fully, not commercially licensed) SeamlessM4TThis is a multi lingual model that takes speech (and/or text) can generate the following:* Text* Speech* Translated Text* Translated SpeechIn a single model! For comparison sake, I takes a whole pipeline with whisper and other translators in targum.video not to mention much bigger models, and not to mention I don’t actually generate speech!This incredible news got me giddy and excited so fast, not only because it simplifies and unifies so much of what I do into 1 model, and makes it faster and opens up additional capabilities, but also because I strongly believe in the vision that Language Barriers should not exist and that’s why I built Targum.Meta apparently also believes in this vision, and gave us an incredible new power unlock that understands 100 languages and does so multilingually without effort.Language barriers should not existDefinitely checkout the discussion in the podcast, where VB from the open source audio team on Hugging Face goes in deeper into the exciting implementation details of this model.Open Source LLMs🔥 LLaMa CodeWe were patient and we got it! Thank you Yann!Meta releases LLaMa Code, a LlaMa fine-tuned on coding tasks, including “in the middle” completion tasks, which are what copilot does, not just autocompleting code, but taking into account what’s surrounding the code it needs to generate.Available in 7B, 13B and 34B sizes, the largest model beats GPT3.5 on HumanEval, which is a metric for coding tasks. (you can try it here)In an interesting move, they also separately release a specific python finetuned versions, for python code specifically.Additional incredible thing is, it supports 100K context window of code, which is, a LOT of code. However it’s unlikely to be very useful in open source because of the compute requiredThey also give us instruction fine-tuned versions of these models, and recommend using them, since those are finetuned on being helpful to humans rather than just autocomplete code.Boasting impressive numbers, this is of course, just the beginning, the open source community of finetuners is salivating! This is what they were waiting for, can they finetune these new models to beat GPT-4? 🤔Nous updateFriends of the Pod LDJ and Teknium1 are releasing the latest 70B model of their Nous Hermes 2 70B model 👏* Nous-Puffin-70BWe’re waiting on metrics but it potentially beats chatGPT on a few tasks! Exciting times!Vision & Multi ModalityIDEFICS - a new 80B model from HuggingFace, was released after a years effort, and is quite quite good. We love vision multimodality here on ThursdAI, we’ve been covering it since we say that GPT-4 demo!IDEFICS is a an effort by hugging face to create a foundational model for multimodality, and it is currently the only visual language model of this scale (80 billion parameters) that is available in open-access.It’s made by fusing the vision transformer CLIP-VIT-H-14 and LLaMa 1, I bet LLaMa 2 is coming soon as well!And the best thing, it’s openly available and you can use it in your code with hugging face transformers library!It’s not perfect of course, and can hallucinate quite a bit, but it’s quite remarkable that we get these models weekly now, and this is just the start!AI Art & DiffusionStable Diffusion is 1 year oldHas it been a year? wow, for me, personally, stable diffusion is what started this whole AI fever dream. SD was the first model I actually ran on my own GPU, the first model I learned how to.. run, and use without relying on APIs. It made me way more comfortable with juggling models, learning what weights were, and we’ll here we are :) I now host a podcast and have a newsletter and I’m part of a community of folks who do the same, train models, dis

🎙️ThursdAI - LLM Finetuning deep dive, current top OSS LLMs (Platypus 70B, OrctyPus 13B) authors & what to look forward to
This is a free preview of a paid episode. To hear more, visit sub.thursdai.newsBrief outline for your convenience:[00:00] Introduction by Alex Volkov[06:00] Discussing the Platypus models and data curation process by Ariel, Cole and Nathaniel[15:00] Merging Platypus with OpenOrca model by Alignment Labs* Combining strengths of Platypus and OpenOrca* Achieving state-of-the-art 13B model[40:00] Mixture of Experts (MOE) models explanation by Prateek and Far El[47:00] Ablation studies on different fine-tuning methods by TekniumFull transcript is available for our paid subscribers 👇 Why don’t you become one?Here’s a list of folks and models that appear in this episode please follow all of them on X:* ThursdAI cohosts - Alex Volkov, Yam Peleg, Nisten Tajiraj* Garage Baind - Ariel, Cole and Nataniel (platypus-llm.github.io)* Alignment Lab - Austin, Teknium (Discord server)* SkunkWorks OS - Far El, Prateek Yadav, Alpay Ariak (Discord server)* Platypus2-70B-instruct* Open Orca Platypus 13BI am recording this on August 18th, which marks the one month birthday of the Lama 2 release from Meta. It was the first commercially licensed large language model of its size and quality, and we want to thank the great folks at MetaAI. Yann LeCun, BigZuck and the whole FAIR team. Thank you guys. It's been an incredible month since it was released.We saw a Cambrian explosion of open source communities who make this world better, even since Lama 1. For example, LLaMa.Cpp by Georgi Gerganov is such an incredible example of how open source community comes together and this one guy in the weekend Took the open source weights and made it run on CPUs and much, much faster.Mark Zuckerberg even talked about this, how amazing the open source community has adopted LLAMA, and that Meta is also now adopting many of those techniques and developments back to run their own models cheaper and faster. And so it's been exactly one month since LLAMA 2 was released.And literally every ThursdAI since then, we have covered a new state of the art open source model all based on Lama 2 that topped the open source model charts on Hugging Face.Many of these top models were fine tuned by Discord organizations of super smart folks who just like to work together in the open and open source their work.Many of whom are great friends of the pod.Nous Research, with whom we've had a special episode a couple of weeks back Teknium1 seems to be part of every orgm Alignment Labs and GarageBaind being the last few folks topping the charts.I'm very excited not to only bring you an interview with Alignment Labs and GarageBaind, but also to give you a hint of two additional very exciting efforts that are happening in some of these discords.I also want to highlight how many of those folks do not have data scientist backgrounds. Some of them do. So we had a few PhDs or PhD studies folks, but some of them studied all this at home with the help of GPT 4. And some of them even connected via ThursdAI community and space, which I'm personally very happy about.So this special episode has two parts. The first part we're going to talk with Ariel. Cole and Natniel, currently known as GarageBaind, get it? bAInd, GarageBaind, because they're doing AI in their garage. I love it.🔥 Who are now holding the record for the best performing open source model called Platypus2-70B-Instruct.And then, joining them is Austin from Alignment Labs, the authors of OpenOrca, also a top performing model, will talk about how they've merged and joined forces and trained the best performing 13b model called Open Orca Platypus 13B or Orctypus 13BThis 13b parameters model comes very close to the Base Llama 70b. So, I will say this again, just 1 month after Lama 2 released by the great folks at Meta, we now have a 13 billion parameters model, which is way smaller and cheaper to run that comes very close to the performance benchmarks of a way bigger, very expensive to train and run 70B model.And I find it incredible. And we've only just started, it's been a month. And so the second part you will hear about two additional efforts, one run by Far El, Prateek and Alpay from the SkunksWorks OS Discord, which is an effort to bring everyone an open source mixture of experts model, and you'll hear about what mixture of experts is.And another effort run by a friend of the pod Teknium previously a chart topper himself with Nous Hermes models and many others, to figure out which of the fine tuning methods are the most efficient. and fast and cheap to run. You will hear several mentions of LORAs, which stand for Low Rank Adaptation, which are basically methods of keeping the huge weights of LAMA and other models frozen and retrain and fine tune and align some specific parts of it with new data, which is a method we know from Diffusion World.And it's now applying to the LLM world and showing great promise in how fast, easy, and cheap it is to fine tune these huge models with significantly less hardware costs and time. Spe

ThursdAI Aug 17 - AI Vision, Platypus tops the charts, AI Towns, Self Alignment 📰 and a special interview with Platypus authors!
Hey everyone, this is Alex Volkov, the host of ThursdAI, welcome to yet another recap of yet another incredibly fast past faced week.I want to start with a ThursdAI update, we now have a new website http://thursdai.news and a new dedicated twitter account @thursdai_pod as we build up the ThursdAI community and brand a bit more.As always, a reminder that ThursdAI is a weekly X space, newsletter and 2! podcasts, short form (Apple, Spotify) and the unedited long-form spaces recordings (RSS, Zealous page) for those who’d like the nitty gritty details (and are on a long drive somewhere).Open Source LLMs & FinetuningHonestly, the speed with which LLaMa 2 finetunes are taking over state of the art performance is staggering. We literally talk about a new model every week that’s topping the LLM Benchmark leaderboard, and it hasn’t even been a month since LLaMa 2 release day 🤯 (July 18 for those who are counting)Enter Platypus 70B (🔗)Platypus 70B-instruct is currently the highest ranked open source LLM and other Platypus versionsWe’ve had the great pleasure to chat with new friends of the pod Arielle Lee and Cole Hunter (and long time friend of the pod Nataniel Ruiz, co-author of DreamBooth, and StyleDrop which we’ve covered before) about this incredible effort to finetune LLaMa 2, the open dataset they curated and released as part of this effort and how quick and easy it is possible to train (a smaller 13B) version of Platypus (just 5 hours on a single A100 GPU ~= 6$ on Lambda 🤯)We had a great interview with Garage BAIND the authors of Platypus and we’ll be posting that on a special Sunday episode of ThursdAI so make sure you are subscribed to receive that when it drops.Open Orca + Platypus = OrctyPus 13B? (🔗)We’ve told you about OpenOrca just last week, from our friends at @alignment_lab and not only is Platypus is the best performing 70B model, the open source community comes through with an incredible merge and collaborating to bring you the best 13B model, which is a merge between OpenOrca and Platypus.This 13B model is now very close to the original LLaMa 70B in many of the metrics. LESS THAN A MONTH after the initial open source. It’s quite a remarkable achievement and we salute the whole community for this immense effort 👏 Also, accelerate! 🔥Join the skunksworksSpeaking of fast moving things, In addition to the above interview, we had a great conversation with folks from so called SkunksWorks OS discord, Namely Far El, Prateek Yadav, Alpay Ariak, Teknium and Alignment Labs, and our recurring guest hosts Yam Peleg and Nisten covered two very exciting community efforts, all happening within the SkunksWorks Discord.First effort is called MoE, Open mixture of experts, which is an Open Source attempt at replicating the Mixture of Experts model, which is widely attributed to why GPT-4 is so much better than GPT-3.The second effort is called Ablation studies, which is an effort Teknium is leading to understand once and for all, what is the best, cheapest and most high quality way to finetune open source models, whether it's Qlora or a full finetune or Loras.If you're interested in any of these, either by helping directly or provide resources such as GPU compute, please join the SkunksWorks discord. They will show you how to participate, even if you don't have prior finetuning knowledge! And we’ll keep you apprised of the results once they release any updates!Big Co LLMs + API updatesIn our Big CO corner, we start with an incredible paper from MetaAi, announcing:Self-Alignment w/ Backtranslation method + Humpback LLM - MetaAISummarized briefly (definitely listen to the full episode and @yampeleg detailed overview of this method) it’s a way for an LLM to be trained on a unsupervised way of creating high quality datasets, for itself! Using not a lot of initial “seed” data from a high quality dataset. Think of it this way, fine-tuning a model requires a lot of “question → response” data in your dataset, and back-translation proposes “response → question” dataset generation, coming up with novel ways of saying “what would a potential instruction be that would make an LLM generate this result”This results in a model that effectively learns to learn better and create it’s own datasets without humans (well at least human labelers) in the loop.Here are some more reading material on X for reference.OpenAI new JS SDK (X link)OpenAI has partnered with StainlessAPI to released a major new version 4 of their TS/JS SDK with the following incredible DX improvements for AI engineers* Streaming responses for chat & completions* Carefully crafted TypeScript types* Support for ESM, Vercel edge functions, Cloudflare workers, & Deno* Better file upload API for Whisper, fine-tune files, & DALL·E images* Improved error handling through automatic retries & error classes* Increased performance via TCP connection reuse* Simpler initialization logicThe most exciting part for me is, this is now very easy to get started with AI projects an
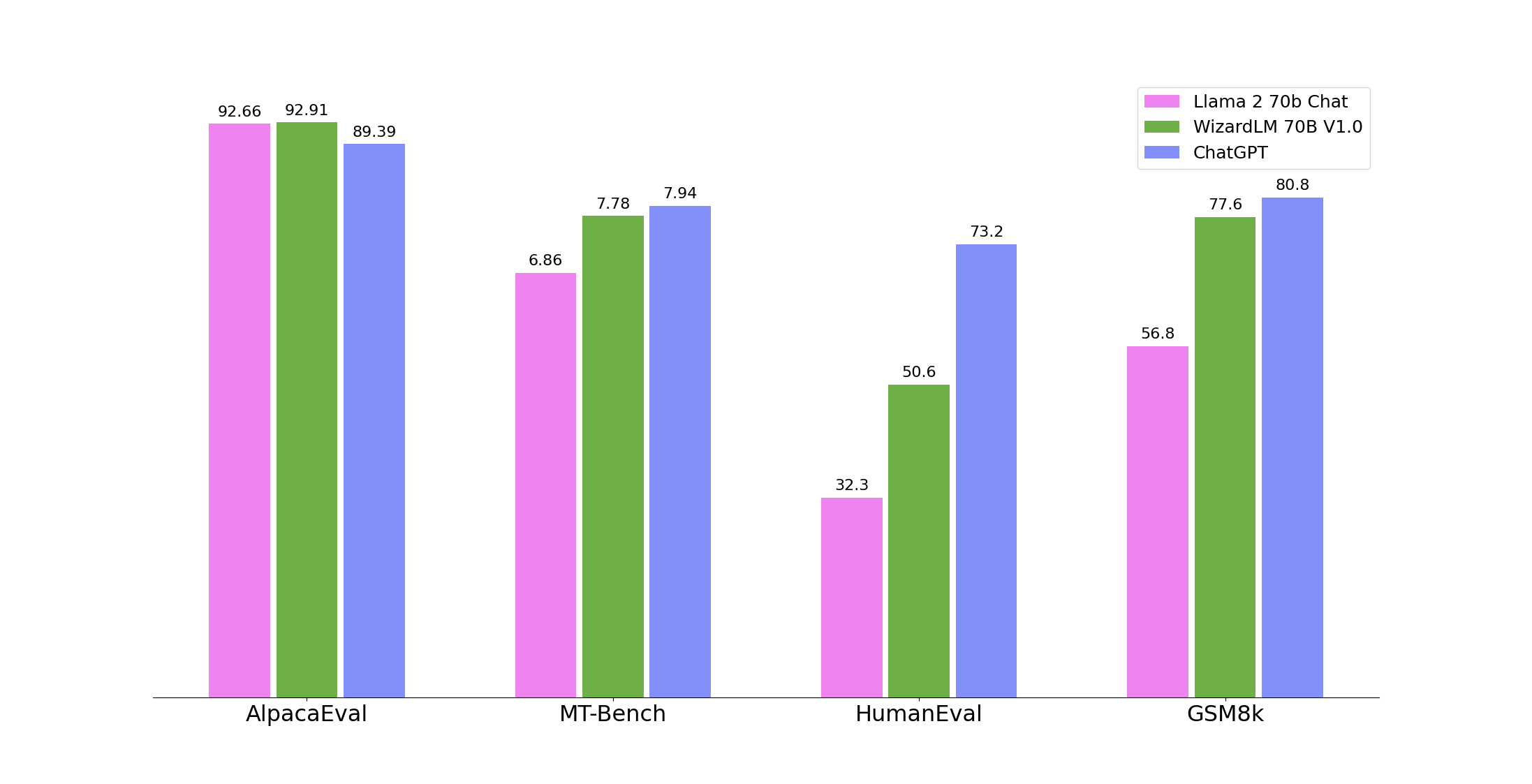
ThursdAI Aug 10 - Deepfakes get real, OSS Embeddings heating up, Wizard 70B tops tops the charts and more!
Hey everyone, welcome to yet another ThursdAI update! As always, I’m your host, Alex Volkov, and every week, ThursdAI is a twitter space that has a panel of experts, guests and AI enthusiasts who join to get up to date with the incredible fast pace of AI updates, learn together and listen to subject matter experts on several of the topics. Pssst, this podcast is now available on Apple, Spotify and everywhere using RSS and a new, long form, raw and uncut, full spaces recording podcast is coming soon! ThursdAI - Is supported by readers, and I promised my wife I’d ask, if you find this valuable, why not upgrade your subscription so I can keep this going? Get better equipment and produce higher quality shows? I started noticing that our updates spaces are split into several themes, and figured to start separating the updates to these themes as well, do let me know if the comments if you have feedback or preference or specific things to focus on. LLMs (Open Source & Proprietary)This section will include updates pertaining to Large Language Models, proprietary (GPT4 & Claude) and open source ones, APIs and prompting. Claude 1.2 instant in Anthropic API (source)Anthropic has released a new version of their Claude Instant, a very very fast model of Claude, with 100K, a very capable model that’s now better at code task, and most of all, very very fast! Anthropic is also better at giving access to these models, so if you’ve waited in their waitlist for a while, and still don’t have access, DM me (@altryne) and I’ll try to get you API access as a member of ThursdAI community. WizardLM-70B V1.0 tops OSS charts (source)WizardLM 70B from WizardLM is now the top dog in open source AI, featuring the same License as LLaMa and much much better code performance than base LLaMa 2, it’s now the top performing code model that’s also does other LLMy things. Per friend of the pod, and Finetuner extraordinaire Teknium, this is the best HumanEval (coding benchmark) we’ve seen in a LLaMa based open source model 🔥Also from Teknium btw, a recent evaluation of the Alibaba Qwen 7B model we talked about last ThursdAI, by Teknium, actually showed that LLaMa 7B is a bit better, however, Qwen should also be evaluated on tool selection and agent use, and we’re waiting for those metrics to surface and will update! Embeddings Embeddings EmbeddingsIt seems that in OpenSource embeddings, we’re now getting state of the art open source models (read: require no internet access) every week!In just the last few months: - Microsoft open-sourced E5 - Alibaba open-sourced General Text Embeddings - BAAI open-sourced FlagEmbedding - Jina open-sourced Jina EmbeddingsAnd now, we have a new metric MTEB and a new leaderboard from hugging face (who else?) to always know which model is currently leading the pack. With a new winner from this week! BGE (large, base and small (just 140MB) ) Embedding models are very important for many AI applications, RAG (retrieval augmented generation) products, semantic search and vector DBs, and the faster, smaller and more offline they are, the better the whole field of AI tools we’re going to get, including, much more capable, and offline agents. 🔥 Worth noting that text-ada-002, the OpenAI embedding API is now ranked 13 on the above MTEB leaderboard! Open Code Interpreter 👏While we’re on the agents topic, we had the privilege to chat with a new friend of the pod, Shroominic who’s told us about his open source project, called codeinterpreter-api which is an open source implementation of code interpreter. We had a great conversation about this effort, the community push, the ability of this open version to install new packages, access the web, run offline and have multiple open source LLMs that run it, and we expect to hear more as this project develops! If you’re not familiar with OpenAI Code Interpreter, we’ve talked about it at length when it just came out here and it’s probably the best “AI Agent” that many folks have access to right now. Deepfakes are upon us! I want to show you this video and you tell me if you saw this not in an AI newsletter, would you have been able to tell it’s AI generated. This video was generated automatically, when I applied to the waitlist by HeyGen and then I registered again and tried to get AI Joshua to generate an ultra realistic ThursdAI promo vid haha. I’ve played with many tools for AI video generation and never saw anything come close to this quality, and can’t wait for this to launch! While this is a significant update for many folks in terms of how well deepfakes can look (and it is! Just look at it, reflections, HQ, lip movement is perfect, just incredible) this isn’t the only progress data point in this space. Play.ht announced version 2.0 which sounds incredibly natural, increased model size 10x and dataset to more than 1 million hours of speech across multiple languages, accents, and speaking styles and emotions and claims to have sub 1s latency and fake your voice with a sample
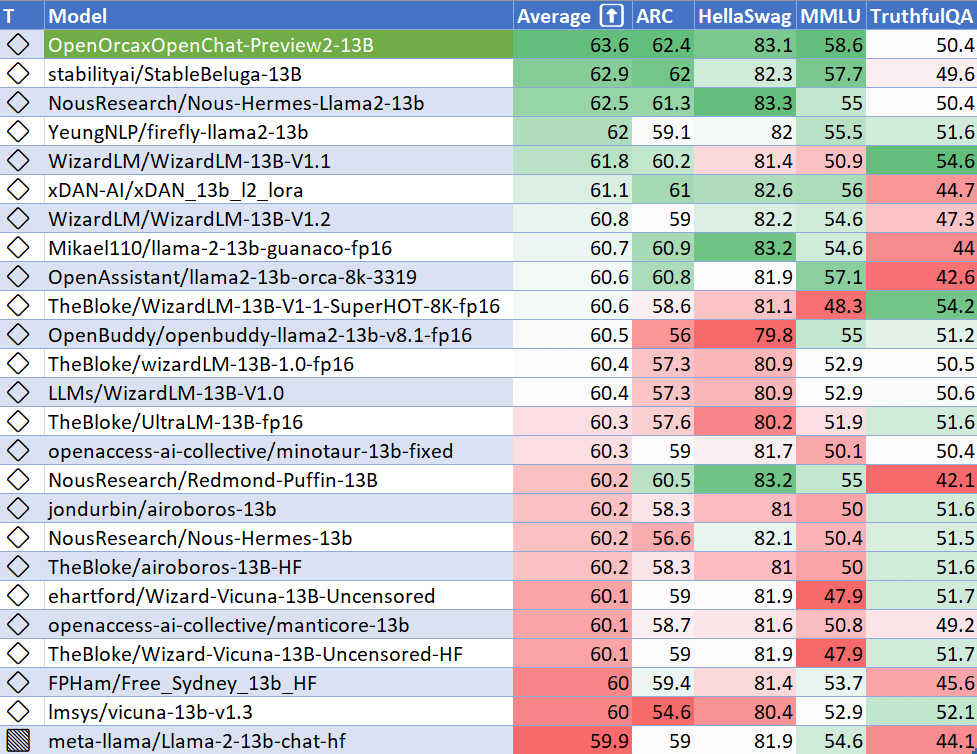
ThursdAI Aug 3 - OpenAI, Qwen 7B beats LLaMa, Orca is replicated, and more AI news
Hi, today’s episode is published on a Friday, it’s been a busy week with at least 4 twitter spaces, countless DMs and research! OpenAI announces UX updates* Example prompts: No more staring at a blank page! * Suggested replies: ChatGPT automatically synthesizes follow up questions. Then you just click a button* GPT-4 by default: When starting a new chat as a Plus user, ChatGPT will remember your previously selected model! * 4. Uploading multiple files is now supported in the Code Interpreter beta for all Plus users.* 5. Stay logged in: You’ll no longer be logged out every 2 weeks and if you do, we have a sweet new welcome page! * 6. Keyboard shortcuts: Work faster with shortcuts, Try ⌘ (Ctrl) + / to see the complete list.ThursdAI - I stay up to date so you don’t have toAlibaba releases Qwen7b* Trained with high-quality pretraining data. Qwen-7B pretrained on a self-constructed large-scale high-quality dataset of over 2.2 trillion tokens. The dataset includes plain texts and codes, and it covers a wide range of domains, including general domain data and professional domain data.* Strong performance. In comparison with the models of the similar model size, outperforms the competitors on a series of benchmark datasets, which evaluates natural language understanding, mathematics, coding, etc.* Better support of languages. New tokenizer, based on a large vocabulary of over 150K tokens, is a more efficient one compared with other tokenizers. It is friendly to many languages, and it is helpful for users to further finetune Qwen-7B for the extension of understanding a certain language.* Support of 8K Context Length. Both Qwen-7B and Qwen-7B-Chat support the context length of 8K, which allows inputs with long contexts.* Support of Plugins. Qwen-7B-Chat is trained with plugin-related alignment data, and thus it is capable of using tools, including APIs, models, databases, etc., and it is capable of playing as an agent.This is an impressive jump in open source capabilities, less than a month after LLaMa 2 release! GTE-large a new embedding model outperforms OPENAI ada-002If you’ve used any “chat with your documents” app or built one, or have used a vector database, chances are, you’ve used openAI ada-002, it’s the most common embedding model (that turns text into embeddings for vector similarity search) This model is ousted by an OpenSource (nee. free) one called GTE-large with improvements on top of ada across most parameters! OpenOrca 2 preview Our friends from AlignmentLab including Teknium and LDJ have discussed the release of OpenOrca 2! If you’re interested in the type of finetuning things these guys do, we had a special interview w/ NousResearch on the pod a few weeks ago OpenOrca tops the charts for the best performing 13B model 👏Hyper-write releases a personal assistantYou know how much we love agents in ThursdAI, and we’re waiting for this field to materialize and I personally am waiting for an agent to summarize the whole links and screenshots for this summary, and… we’re not there yet! But we’re coming close, and our friends from HyperWrite have released their browser controlling agent on ThursdAI. Talk about a full day of releases! I absolutely love the marketing trick they used where one of the examples of how it works, is “upvote us on producthunt” and it actually did work for me, and found out that I already upvotedSuperconductor continuesI was absolutely worried that I won’t make it to this thursdAI or won’t know what to talk about because, well, I’ve become a sort of host and information hub and a interviewer of folks about LK-99. Many people around the world seem interested in it’s properties, replication attempts and to understand this new and exciting thing. We talked about this briefly, but if interests you (and I think it absolutely should) please listen to the below recording. ThursdAI - See ya next week, don’t forget to subscribe and if you are already subscribed, and get value, upgrading will help me buy the proper equipment to make this a professional endeavor and pay for the AI tools! 🫡 This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit sub.thursdai.news/subscribe
🧪 LK99 - The superconductor that can change the world, and the K-drama behind it!
This is a free preview of a paid episode. To hear more, visit sub.thursdai.newsFirst of all, let me address this from the get go, I’m not a material scientist! I am pretty good at finding information in twitter’s incredibly noisy info stream. (hey, this is how I bring you AI updates every ThursdAI) Since LK-99 is potentially groundbreaking and revolutionary, I’ve compiled a twitter list of everyone who I found credible, interested and a source of new information, and there’s now over 1.5K followers to this list alone!Since this clearly is interesting to a lot of you, I reached out to a few prominent people on this list, and asked them to join a twitter space, to try and stitch together an update on the current state of LK-99, replication attempts, history and lore, as it stands a week after the original papers release. If you found this interesting, you’re the type of person who wants to stay up to date, feel free to subscribe and keep this Substack alive!First of all, let’s do some level setting. Superconductors are real, we’ve used them in MRI machines for example, but the currently available superconductors need extremely low temperature and high pressure to well.., and the promise of a room temperature and ambient pressure superconductor is the holy grail of energy use. For a breakdown on what superconductors are, and what they can mean for the world, I strongly recommend this thread from Andrew Cote (published presciently a full two weeks before the LK-99 paper) or watch this incredible breakdown: July 22nd, the LK-99 arXiv day! On July 22nd, two papers describing “worlds first room temperature superconductor” were uploaded to arXiv: 2307.12008 - Sukbae Lee, Ji-Hoon Kim, Young-Wan Kwon (submitted by Kwon)and after 2 hours and 20 minutes another paper was uploaded2307.12037 - Sukbae Lee, Jihoon Kim, Hyun-Tak Kim, Sungyeon Im, SooMin An, Keun Ho Auh (Submitted by Hyuntak Kim)You may notice that the first two authors on both papers are Sukbae Lee and Ji-Hoon Kim, and in fact LK stands for Lee and Kim and 99 in the LK-99 name stands for the year 1999 they have started research on this.You may also notice that YW Kwon who submitted the first paper, is not included on the second one, and in fact, is no longer part of the Quantum Energy Research Institute (Aka QCentre) where he was a CTO (he’s no longer listed on the site) If this shakes out, and SC is replicated, there’s definitely going to be a Netflix series on the events that led to YW Kwon to release the paper, after he was no longer affiliated with QCentre, with limited information so let’s try to connect the dots (a LOT of this connecting happened on the ground by Seo Sanghyeon and his friends, and translated by me. Their original coverage has a LOT of details and is available in Korean hereLet’s go back to the 90sOn the LinkedIn page of Ji-Hoon Kim (the page turned blank shortly before me writing this), JH Kim showed that he started working on this back in 1999, and they estimated they have a material that contained “very small amount of superconductivity” and together with Sukbae Lee, in 2018 they have established QCentre to complete the work of their Professor Emeritus of Chemistry at Korea University, the late Choi Dong-Sik (1943-2017) who apparently first proposed the LK-99 material (following the 1986 bonanza of the discovery of high temperature superconductors by IBM researchers).Fast forward to 2017, a wish expressed in a last will and testament starts everything again Professor Choi passed away, and in this will requested follow-up research on ISB theory and LK-99 and Quantum Energy Research Institute is now established by Lee and Kim (LK) and they continue their work on this material. In 2018, there’s a potential breakthrough, that could have been an accident that led to the discovery of the process behind LK-99? Here’s a snippet of Seo Sanghyeon explaining this:Kwon Young-Wan the ex-CTOKwon is a Research Professor at Korea University & KIST, is the third author on the first arXiv paper, and the submitter, was previously the CTO, but at the time of the paper to arXiv he was not affiliated with QCentre for “some months” according to an interview with Lee. He uploads a paper, names only 3 authors (Lee, Kim and Himself) and then surprisingly presents LK-99 research at the MML2023 international conference held in Seoul a few days later, we haven’t yet found a video recording, however a few reports mention him asking for an interpreter, and talking about bringing samples without demonstration and proper equipment.Important to note, that Enter Hyun-Tak KimH.T Kim is probably the most cited and well-known professor in academia among the folks involved. See his google scholar profile, with a D-index of 43 and has 261 publications and 11,263 citations. He’s a heavy hitter, and is the submitter and listed as the author of paper number 2 submitted to arXiv, 2 hours and 20 minutes after paper number 1 above. In the second paper, he’s listed as the third

🎙️ThursdAI - Jul 27: SDXL1.0, Superconductors? StackOverflowAI and Frontier Model Forum
⏰ Breaking news, ThursdAI is now on Apple Podcasts and in this RSS ! So use your favorite pod-catcher to subscribe or his this button right here: Our friends at Zealous have provided an incredible platform for us to generate these awesome video podcasts from audio or from twitter spaces so if you prefer a more visual format, our deep thanks to them! P.S - You can find the full 2 hour space with speakers on our Zealous page and on TwitterHere’s a summary of the main things that happened in AI since last ThursdAI: 🧑🎨 Stability.ai releases SDXL1.0* Generates 1024px x 1024x stunning images* High high photorealism* Supports hands and text* Different (simpler?) prompting required* Fine-tunes very well! * Supports LORAs, ControlNet in-painting and outcropping and the whole ecosystem built around SD* Refiner is a separate piece that adds high quality detail* Available on Dreamstudio, Github, ClipDrop and HuggingFace* Also, is available with incredible ComfyUI and can be used in a free Colab!Image Credit goes to ThibaudSuperconductors on Hugging Face? What? Honestly, this has nothing immediate to do with AI updates, but, if it pans out, it’s so revolutionary that it will affect AI also!Here’s what we know about LK-99 so far: * 2 papers released on arXiv (and hugging face haha) in the span of several hours* First AND second paper both claim extraordinary claims of solving ambient superconductivity* Ambient pressure and room temp superconductive material called LK-99 * Straightforward process with a clear replication manual and fairly common materials* Papers lack rigor, potentially due to rushing out or due to fighting for credit for nobel prize * The science is potentially sound, and is being “baked and reproduced in multiple labs” per science mag.Potential effects of room temperature superconductivity on AI: While many places (All?) can benefit from the incredible applications of superconductors (think 1000x batteries) the field of AI will benefit as well if the result above replicates.* Production of GPU and CPU is power-constrained and could benefit* GPU/CPUs themselves are power-constrained while running inference* GPT-4 is great but consumes more power (training and inference) than previous models making it hard to scale* Local inference is also power-restricted, so running local models (and local walking robots) could explode with superconductivity * Quantum computing is going to have a field day if this is true* So will fusion reactors (which need superconductors to keep the plasma in place) As we wait for labs to reproduce, I created a twitter list of folks who are following closely, feel free to follow along! AI agents protocol, discussion and state of for July 2023* Participated in an e2b space with tons of AI builders (Full space and recap coming soon!) * Many touted AI agents as a category and discussed their own frameworks* Folks came up and talked about their needs from the agent protocol proposed by e2b* Agents need to be able to communicate with other agents/sub agents* Tasks payloads and artifacts and task completion can be async (think receiving a response email from a colleague) * The ability to debug (with timetravel) and trace and reproduce an agent run* Deployment, running and execution environment issues* Reliability of task finish reporting, and evaluation is hardFrontier model forum* OpenAI, Anthropic, Google, and Microsoft are forming the Frontier Model Forum to promote safe and responsible frontier AI.* The Forum will advance AI safety research, identify best practices, share knowledge on risks, and support using AI for challenges like climate change.* Membership is open to organizations developing frontier models that demonstrate safety commitment.* The Forum will focus on best practices, AI safety research, and information sharing between companies and governments.* Some have expressed concern that this could enable regulatory capture by the “Big LLM” shops that can use the lobbying power to stop innovation. StackOverflow AI - “The reports of my death have been greatly exaggerated” Stack overflow has been in the news lately, when a graphic of it’s decline in traffic has become viral. They have publicly disputed that information claiming they have moved to a different measuring and didn’t update the webpage, but then also… announced Overflow AI!* AI search and aggregation of answers + ability to follow up in natural language* Helps drafting questions* AI answers with a summary, and citations with the ability to “extend” and adjust for your coding level* VSCode integration! * Focusing on “validated and trusted” content* Not only for SO code, stack overflow for teams will also embed other sources (like your company confluence) and will give you attributed answers and tagging abilities on external contentThis has been an insane week in terms of news (👽 anyone?) and superconductors and AI releases! As always, I’m grateful for your attention! Forward this newsletter to 1 friend as a favor

ThursdAI - Special Episode, interview with Nous Research and Enrico Shippole, fine-tuning LLaMa 2, extending it's context and more
Hey there, welcome to this special edition of ThursdAI. This episode is featuring an interview with Nous Research, a group of folks who fine-tune open source large language models to make them better. If you are interested to hear how finetuning an open source model works, dataset preparation, context scaling and more, tune in! You will hear from Karan, Teknium, LBJ from Nous Research and Enrico who worked along side them. To clarify, Enrico is going in depth into the method called Rope Scaling, which is a clever hack, that extends the context length of LLaMa models significantly and his project LLongMa which is an extended version of LLaMa with 8000 token context window. The first voice you will hear is Alex Volkov the host of ThursdAI who doesn’t usually have a lisp, but for some reason, during the recording, twitter spaces decided to mute all the S sounds. Links and acknowledgments: * Nous Research - https://nousresearch.com/ (@nousresearch)* Redmond Puffin 13b - First LLaMa Finetune* LLongMa - LLaMa finetune with 8K context (by Encrico, emozilla and KaioKenDev)* Nous-Hermes-Llama2-13b-GPTQ - Hermes Finetune was released after the recording 🎊Psst, if you like this, why don’t you subscribe? Or if you are subscribed, consider a paid subscription to support #ThursdAIShow transcription with timestamps: Alex Volkov - targum.video (@altryne)[00:00:55] Yeah. That's awesome. So I guess with this, maybe, Karan, if you if you are able to, can you you talk about Nous research and how kind of how it started and what the what are you guys doing, and then we'll dive into the kind of, you know, Hermes and and Puffin and the methods and and all of it.karan (@karan4d)[00:01:16] Absolutely. Nous research. I mean, I I myself and many other of us are just, like, enthusiasts that we're fine tuning models like, you know, GPTJ or GPT 2. And, you know, we all are on Twitter. We're all on Discord, and kind of just found each other and had this same mentality of we wanna we wanna make these models. We wanna kinda take the power back from people like OpenAI and anthropic. We want stuff to be able to run easy for everyone. And a lot of like minds started to show up.karan (@karan4d)[00:01:50] I think that Technium's addition initially to Nous research, Jim, kinda showing up. And himself, I and human working on compiling the Hermes dataset was really what came to attract people when Hermes came out. I think we just have a really strong and robust, like, data curation thesis in terms of that. And I think that have just some of the most talented people who have come to join us and just volunteer and work with us on stuff. And I absolutely must say, I can see in the in the listeners is our compute provider, Redmond AI.karan (@karan4d)[00:02:30] And, you know, none of this none of these models would be possible without Redmond's generous sponsorship for us to be able to deliver these things lightning fast, you know, without making us through a bunch of hoops just a a total total pleasure to work with. So I would I have to shell and say, you know, I highly recommend everyone check out Redmond as because they really make our project possible.Alex Volkov - targum.video (@altryne)[00:02:52] Absolutely. So shout out to Redmond AI and folks give them a follow. They're the the only square avatar in the audience. Go take them out. And, Karan, thanks for that. I wanna just do a mic check for teknium. Teknium. Can you speak now? Can you? Can I hear you?Teknium (e/λ) (@Teknium1)[00:03:08] Yeah. My phone died right when you were introducing me earlier.Alex Volkov - targum.video (@altryne)[00:03:10] Yep. What's up, Eric? -- sometimes on Twitter basis. Welcome, Technium. So briefly, going back to question. I don't know if you heard it. What besides the commercial and kind of the the contact window, what kind of caught your eye in the llama, at least the base until you guys started, or have you also, like, the other guys not had a second to play with the base model and dove into fine tuning directly?Teknium (e/λ) (@Teknium1)[00:03:35] Yeah. The only thing that really caught my eye was the chat model and how horribly RLHF it was.Alex Volkov - targum.video (@altryne)[00:03:41] Yeah. I've seen some conversations about and kind of the point of Ira, RLHF as well. And okay. So so now that we've introduced Neus research, sorry, I wanna talk to you guys about what you guys are cooking. Right? The we've seen, the the Hermes model before this was, like, loved it as one of the, you know, the best fine tunes that I've seen at least and the the the most performing ones. Could you guys talk about the process to get to the Hermes model, the previous one? and then give us things about what coming soon?karan (@karan4d)[00:04:16] Teknium, you got this one. man.Teknium (e/λ) (@Teknium1)[00:04:22] Yeah. It was basically I saw Alpaca, and I wanted to make it like, remake it with GPT 4, and then from there and just pretty much exclusively included anything that was GPT 4 o

ThursdAI July 20 - LLaMa 2, Vision and multimodality for all, and is GPT-4 getting dumber?
ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.If you’d like to hear the whole 2 hour conversation, here’s the link to twitter spaces we had. And if you’d like to add us to your favorite podcatcher - here’s the RSS link while we’re pending approval from Apple/SpotifyHappy LLaMa day! Meta open sourced LLaMa v2 with a fully commercial license. LLaMa 1 was considered the best open source LLM, this one can be used for commercial purposes, unless you have more than 700MM monthly active users (no 🦙 for you Google!)Meta has released the code and weights, and this time around, also a fine-tuned chat version of LLaMa v2 to all, and has put them on HuggingFace. There are already (3 days later) at least 2 models that have fine-tuned LLaMa2 that we know of: * @nousresearch have released Redmond Puffin 13B * @EnricoShippole with collaboration with Nous have released LLongMa, which extends the context window for LLaMa to 8K (and is training a 16K context window LLaMa) * I also invited and had the privilege to interview the folks from @nousresearch group (@karan4d, @teknium1 @Dogesator ) and @EnricoShippole which will be published as a separate episode.Many places already let you play with LLaMa2 for free: * https://www.llama2.ai/* HuggingFace chat* Perplexity LLaMa chat* nat.dev, replicate and a bunch more! The one caveat, the new LLaMa is not that great with code (like at all!) but expect this to change soon!We all just went multi-modal! Bing just got eyes!I’ve been waiting for this moment, and it’s finally here. We all, have access to the best vision + text model, the GPT-4 vision model, via bing! (and also bard, but… we’ll talk about it) Bing chat (which runs GPT-4) has now released an option to upload (or take) a picture, and add a text prompt, and the model that responds understands both! It’s not OCR, it’s an actual vision + text model, and the results are very impressive! I’ve personally took a snap of a food-truck side, and asked Bing to tell me what they offer, it found the name of the truck, searched it online, found the menu and printed out the menu options for me! Google’s Bard also introduced their google lens integration, and many folks tried uploading a screenshot and asking it for code in react to create that UI, and well… it wasn’t amazing. I believe it’s due to the fact that Bard is using google lens API and was not trained in a multi-modal way like GPT-4 has. One caveat is, the same as text models, Bing can and will hallucinate stuff that isn’t in the picture, so YMMV but take this into account. It seems that at the beginning of an image description it will be very precise but then as the description keeps going, the LLM part kicks in and starts hallucinating. Is GPT-4 getting dumber and lazier? Researches from Standford and Berkley (and Matei Zaharia, the CTO of Databricks) have tried to evaluate the vibes and complaints that many folks have been sharing, wether GPT-4 and 3 updates from June, had degraded capabilities and performance. Here’s the link to that paper and twitter thread from Matei. They have evaluated the 0301 and the 0613 versions of both GPT-3.5 and GPT-4 and have concluded that at some tasks, there’s a degraded performance in the newer models! Some reported drops as high as 90% → 2.5% 😮But is there truth to this? Well apparently, some of the methodologies in that paper lacked rigor and the fine folks at AI Snake Oil ( Sayash Kapoor and Arvind) have done a great deep dive into that paper and found very interesting things!They smartly separate between capabilities degradation and behavior degradation, and note that on the 2 tasks (Math, Coding) that the researches noted a capability degradation, their methodology was flawed, and there isn’t in fact any capability degradation, rather, a behavior change and a failure to take into account a few examples. The most frustrating for me was the code evaluation, the researchers scored both the previous model and the new June updated models on “code execution” with the same prompt, however, the new models defaulted to wrap the returned code with ``` which is markdown code snippets. This could have been easily fixed with some prompting, however, the researchers scored the task based on, wether or not the code snippet they get is “instantly executable”, which it obviously isn’t with the ``` in there. So, they haven’t actually seen and evaluated the code itself, just wether or not it runs! I really appreciate the AI Snake Oil deep dive on this, and recommend you all read it for yourself and make your own opinion and don’t give into the hype and scare mongering and twitter thinkfluencer takes. News from OpenAI - Custom Instructions + Longer deprecation cyclesIn response to the developers (and the above paper), OpenAi announced an update to the deprecation schedule of the 0301 models (the one without functions) and they

ThursdAI July 13 - Show recap + Notes
Welcome Friends, to the first episode of ThursdAI recap. If you can’t come to the spaces, subscribing is the next best thing. Distilled, most important updates, every week, including testimony and tips and tricks from a panel of experts. Join our community 👇Every week since the day GPT-4 released, we’ve been meeting in twitter spaces to talk about AI developments, and it slowly by surely created a community that’s thirsty to learn, connect and discuss information. Getting overwhelmed with daily newsletters about tools, folks wanted someone else to do the legwork, prioritize and condense the most important information about what is shaping the future of AI, today! Hosted by AI consultant Alex Volkov (available for hire), CEO of Targum.video, this information-packed edition covered groundbreaking new releases like GPT 4.5, Claude 2, and Stable Diffusion 1.0. We learned how Code Interpreter is pushing boundaries in computer vision, creative writing, and software development. Expert guests dove into the implications of Elon Musk's new XAI startup, the debate around Twitter's data, and pioneering techniques in prompt engineering. If you want to stay on top of the innovations shaping our AI-powered tomorrow, join Alex and the ThursdAI community. Since the audio was recorded from a twitter space, it has quite a lot of overlaps, I think it’s due to the export, so sometimes it sounds like folks talk on top of each other, most of all me (Alex) this was not the case, will have to figure out a fix. Topics we covered in July 13, ThursdAI GPT 4.5/Code Interpreter:00:02:37 - 05:55 - General availability of Chad GPT with code interpreter announced. 8k context window, faster than GPT-4.05:56 - 08:36 - Code interpreter use cases, uploading files, executing code, skills and techniques.08:36 - 10:11 - Uploading large files, executing code, downloading files.Claude V2:20:11 - 21:25 - Anthropic releases Claude V2, considered #2 after OpenAI.21:25 - 23:31 - Claude V2 UI allows uploading files, refreshed UI.23:31 - 24:30 - Claude V2 product experience beats GPT-3.5.24:31 - 27:25 - Claude V2 fine-tuned on code, 100k context window, trained on longer outputs.27:26 - 30:16 - Claude V2 good at comparing essays, creative writing.30:17 - 32:57 - Claude V2 allows multiple file uploads to context window.32:57 - 39:10 - Claude V2 better at languages than GPT-4.39:10 - 40:30 - Claude V2 allows multiple file uploads to context window.X.AI:46:22 - 49:29 - Elon Musk announces X.AI to compete with OpenAI. Has access to Twitter data.49:30 - 51:26 - Discussion on whether Twitter data is useful for training.51:27 - 52:45 - Twitter data can be transformed into other forms.52:45 - 58:32 - Twitter spaces could provide useful training data.58:33 - 59:26 - Speculation on whether XAI will open source their models.59:26 - 61:54 - Twitter data has some advantages over other social media data.Stable Diffusion:89:41 - 91:17 - Stable Diffusion releases SDXL 1.0 in discord, plans to open source it.91:17 - 92:08 - Stable Diffusion releases Stable Doodle.GPT Prompt Engineering:61:54 - 64:18 - Intro to Other Side AI and prompt engineering.64:18 - 71:50 - GPT Prompt Engineer project explained.71:50 - 72:54 - GPT Prompt Engineer results, potential to improve prompts.72:54 - 73:41 - Prompts may work better on same model they were generated for.73:41 - 77:07 - GPT Prompt Engineer is open source, looking for contributions.Related tweets shared: https://twitter.com/altryne/status/1677951313156636672https://twitter.com/altryne/status/1677951330462371840@Surya - Running GPT2 inside code interpreter tomviner - scraped all the internal knowledge about the envPeter got all pypi packages and their descriptionswyx added Claude to to smol menubar (which we also discussed)SkalskiP awesome code interpreter experiments repoSee the rest of the tweets shared and listen to the original space here:https://spacesdashboard.com/space/1YpKkggrRgPKj/thursdai-space-code-interpreter-claude-v2-xai-sdxl-moreFull Transcript: 00:02 (Speaker A) You. First of all, welcome to Thursday. We stay up to date so you don't have to. There's a panel of experts on top here that discuss everything. 00:11 (Speaker A) If we've tried something, we'll talk about this. If we haven't, and somebody in the audience tried that specific new AI stuff, feel free to raise your hand, give us your comment. This is not the space for long debates. 00:25 (Speaker A) We actually had a great place for that yesterday. NISten and Roy fromPine, some other folks, we'll probably do a different one. This should be information dense for folks and this will be recorded and likely we posted at some point. 00:38 (Speaker A) So no debate, just let's drop an opinion and discuss the new stuff and kind of continue. And the goal is to stay up to date so you don'thave to in the audience. And I think with that, I will say hi to AlanJanae and we will get started. 00:58 (Speaker B) Hi everyone, I'm NISten Tahira. I worked on, well, released on