
ThursdAI - The top AI news from the past week
162 episodes — Page 2 of 4
📆 ThursdAI - Jul 10 - Grok 4 and 4 Heavy, SmolLM3, Liquid LFM2, Reka Flash & Vision, Perplexity Comet Browser, Devstral 1.1 & More AI News
Hey everyone, Alex hereDon't you just love "new top LLM" drop weeks? I sure do! This week, we had a watch party for Grok-4, with over 20K tuning in to watch together, as the folks at XAI unveiled their newest and best model around. Two models in fact, Grok-4 and Grok-4 Heavy. We also had a very big open source week, we had the pleasure to chat with the creators of 3 open source models on the show, first with Elie from HuggingFace who just released SmoLM3, then with our friend Maxime Labonne who together with Liquid released a beautiful series of tiny on device models. Finally we had a chat with folks from Reka AI, and as they were on stage, someone in their org published a new open source Reka Flash model 👏 Talk about Breaking News right on the show! It was a very fun week and a great episode, so grab your favorite beverage and let me update you on everything that's going on in AI (as always, show notes at the end of the article) Open Source LLMsAs always, even on big weeks like this, we open the show with Open Source models first and this week, the western world caught up to the Chinese open source models we saw last week! HuggingFace SmolLM3 - SOTA fully open 3B with dual reasoning and long-context (𝕏, HF)We had Eli Bakouch from Hugging Face on the show and you could feel the pride radiating through the webcam. SmolLM 3 isn’t just “another tiny model”; it’s an 11-trillion-token monster masquerading inside a 3-billion-parameter body. It reasons, it follows instructions, and it does both “think step-by-step” and “give me the answer straight” on demand. Hugging Face open-sourced every checkpoint, every dataset recipe, every graph in W&B – so if you ever wanted a fully reproducible, multi-lingual pocket assistant that fits on a single GPU, this is it.They achieved the long context (128 K today, 256 K in internal tests) with a NoPE + YaRN recipe and salvaged the performance drop by literally merging two fine-tunes at 2 a.m. the night before release. Science by duct-tape, but it works: SmolLM 3 edges out Llama-3.2-3B, challenges Qwen-3, and stays within arm’s reach of Gemma-3-4B – all while loading faster than you can say “model soup.” 🤯Liquid AI’s LFM2: Blazing-Fast Models for the Edge (𝕏, Hugging Face)We started the show and I immediately got to hit the #BREAKINGNEWS button, as Liquid AI dropped LFM2, a new series of tiny (350M-1.2B) models focused on Edge devices.We then had the pleasure to host our friend Maxime Labonne, head of Post Training at Liquid AI, to come and tell us all about this incredible effort! Maxime, a legend in the model merging community, explained that LFM2 was designed from the ground up for efficiency. They’re not just scaled-down big models; they feature a novel hybrid architecture with convolution and attention layers specifically optimized for running on CPUs and devices like the Samsung Galaxy S24.Maxime pointed out that Out of the box, they won't replace ChatGPT, but when you fine-tune them for a specific task like translation, they can match models 60 times their size. This is a game-changer for creating powerful, specialized agents that run locally. Definitely a great release and on ThursdAI of all days! Mistrals updated Devstral 1.1 Smashes Coding Benchmarks (𝕏, HF)Mistral didn't want to be left behind on this Open Source bonanza week, and also, today, dropped an update to their excellent coding model Devstral. With 2 versions, an open weights Small and API-only Medium model, they have claimed an amazing 61.6% score on Swe Bench and the open source Small gets a SOTA 53%, the highest among the open source models! 10 points higher than the excellent DeepSwe we covered just last week!The thing to watch here is the incredible price performance, with this model beating Gemini 2.5 Pro and Claude 3.7 Sonnet while being 8x cheaper to run! DevStral small comes to us with an Apache 2.0 license, which we always welcome from the great folks at Mistral! Big Companies LLMs and APIsThere's only 1 winner this week, it seems that other foundational labs were very quiet to see what XAI is going to release. XAI releases Grok-4 and Grok-4 heavy - the world leading reasoning model (𝕏, Try It) Wow, what a show! Space uncle Elon together with the XAI crew, came fashionably late to their own stream, and unveiled the youngest but smartest brother of the Grok family, Grok 4 plus a multiple agents swarm they call Grok Heavy. We had a watch party with over 25K viewers across all streams who joined and watched together, this, fairly historic event! Why historic? Well, for one, they have scaled RL (Reinforcement Learning) for this model significantly more than any other lab did so far, which resulted in an incredible reasoner, able to solve HLE (Humanity's Last Exam) benchmark at an unprecedented 50% (while using tools) The other very much unprecedented result, is on the ArcAGI benchmark, specifically V2, which is designed to be very easy for humans and very hard for LLMs, Grok-4 got an incredible 15.

📆 ThursdAI - Jul 3 - ERNIE 4.5, Hunyuan A13B, MAI-DxO outperforms doctors, RL beats SWE bench, Zuck MSL hiring spree & more AI news
Hey everyone, Alex here 👋Welcome back to another mind-blowing week on ThursdAI! We’re diving into the first show of the second half of 2025, and let me tell you, AI is not slowing down. This week, we’ve got a massive wave of open-source models from Chinese giants like Baidu and Tencent that are shaking up the game, Meta’s jaw-dropping hiring spree with Zuck assembling an AI dream team, and Microsoft’s medical AI outperforming doctors on the toughest cases. Plus, a real-time AI game engine that had me geeking out on stream. Buckle up, folks, because we’ve got a lot to unpack!ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.We had incredible guests like Michael Luo from Agentica, dropping knowledge on RL coding agents, and Ivan Burazin from Daytona, revealing the infrastructure powering the agent era. We had an incredible episode this week, with over 8,000 views for the live show (as always, Links and Show notes in the end, and the YT live video is here for your convienience if you'd prefer watching) Open Source AI & LLMs: The Chinese Powerhouse WaveMan, if there’s one takeaway from this week, it’s that Chinese companies are absolutely dominating the open-source LLM scene. Let’s break down the heavy hitters that dropped this week and why they’ve got everyone talking.Baidu’s ERNIE 4.5: A Suite of 10 Models to Rule Them AllBaidu, a giant in the Chinese tech space, just flipped the script by open-sourcing their ERNIE 4.5 series. We’re talking 10 distinct models ranging from a whopping 424 billion parameters down to a tiny 0.3 billion. With an Apache 2.0 license, 128K context window, and multimodal capabilities handling image, video, and text input, this is a massive drop. Their biggest Mixture-of-Experts (MoE) model, with 47B active parameters, even outshines OpenAI’s o1 on visual knowledge tasks like DocVQA, scoring 93% compared to o1’s 81%! What’s wild to me is Baidu’s shift. They’ve been running ERNIE in production for years—think chatbots and more across their ecosystem—but they weren’t always open-source fans. Now, they’re not just joining the party, they’re hosting it. If you’re into tinkering, this is your playground—check it out on Hugging Face (HF) or dive into their technical paper (Paper).Tencent’s Hunyuan-A13B-Instruct: WizardLM Team Strikes AgainNext up, Tencent dropped Hunyuan-A13B-Instruct, and oh boy, does it have a backstory. This 80B parameter MoE model (13B active at inference) comes from the legendary WizardLM team, poached from Microsoft after a messy saga where their killer models got yanked from the internet over “safety concerns.” I remember the frustration—we were all hyped, then bam, gone. Now, under Tencent’s wing, they’ve cooked up a model with a 256K context window, hybrid fast-and-slow reasoning modes, and benchmarks that rival DeepSeek R1 and OpenAI o1 on agentic tasks. It scores an impressive 87% on AIME 2024, though it dips to 76% on 2025, hinting at some overfitting quirks. Though for a 12B active parameters model this all is still VERY impressive.Here’s the catch—the license. It excludes commercial use in the EU, UK, and South Korea, and bans usage if you’ve got over 100M active users. So, not as open as we’d like, but for its size, it’s a beast that fits on a single machine, making it a practical choice for many. They’ve also released two datasets, ArtifactsBench and C3-Bench, for code and agent evaluation. I’m not sold on the name—Hunyuan doesn’t roll off the tongue for Western markets—but the WizardLM pedigree means it’s worth a look. Try it out on Hugging Face (HF) or test it directly (Try It).Huawei’s Pangu Pro MoE: Sidestepping Sanctions with Ascend NPUsHuawei entered the fray with Pangu Pro MoE, a 72B parameter model with 16B active per token, and here’s what got me hyped—it’s trained entirely on their own Ascend NPUs, not Nvidia or AMD hardware. This is a bold move to bypass US sanctions, using 4,000 of these chips to preprocess 13 trillion tokens. The result? Up to 1,528 tokens per second per card with speculative decoding, outpacing dense models in speed and cost-efficiency. Performance-wise, it’s close to DeepSeek and Qwen, making it a contender for those outside the Nvidia ecosystem.I’m intrigued by the geopolitical angle here. Huawei’s proving you don’t need Western tech to build frontier models, and while we don’t know who’s got access to these Ascend NPUs, it’s likely a game-changer for Chinese firms. Licensing isn’t as permissive as MIT or Apache, but it’s still open-weight. Peek at it on Hugging Face (HF) for more details.DeepSWE-Preview: RL Coding Agent Hits 59% on SWE-BenchSwitching gears, I was blown away chatting with Michael Luo from Agentica about DeepSWE-Preview, an open-source coding agent trained with reinforcement learning (RL) on Qwen3-32B. This thing scored a stellar 59% on SWE-Bench-Verified (42.2% Pass@1, 71% Pass@16)

📅 ThursdAI - Jun 26 - Gemini CLI, Flux Kontext Dev, Search Live, Anthropic destroys books, Zucks superintelligent team & more AI news
Hey folks, Alex here, writing from... a undisclosed tropical paradise location 🏝️ I'm on vacation, but the AI news doesn't stop of course, and neither does ThursdAI. So huge shoutout to Wolfram Ravenwlf for running the show this week, Nisten, LDJ and Yam who joined. So... no long blogpost with analysis this week, but I'll def. recommend tuning in to the show that the folks ran, they had a few guests on, and even got some breaking news (new Flux Kontext that's open source) Of course many of you are readers and are here for the links, so I'm including the raw TL;DR + speaker notes as prepared by the folks for the show! P.S - our (rescheduled) hackathon is coming up in San Francisco, on July 12-13 called WeaveHacks, if you're interested at a chance to win a RoboDog, welcome to join us and give it a try. Register HEREOk, that's it for this week, please enjoy the show and see you next week! ThursdAI - June 26th, 2025 - TL;DR* Hosts and Guests* WolframRvnwlf - Host (@WolframRvnwlf)* Co-Hosts - @yampeleg, @nisten, @ldjconfirmed* Guest - Jason Kneen (@jasonkneen) - Discussing MCPs, coding tools, and agents* Guest - Hrishioa (@hrishioa) - Discussing agentic coding and spec-driven development* Open Source LLMs* Mistral Small 3.2 released with improved instruction following, reduced repetition & better function calling (X)* Unsloth AI releases dynamic GGUFs with fixed chat templates (X)* Kimi-VL-A3B-Thinking-2506 multimodal model updated for better video reasoning and higher resolution (Blog)* Chinese Academy of Science releases Stream-Omni, a new Any-to-Any model for unified multimodal input (HF, Paper)* Prime Intellect launches SYNTHETIC-2, an open reasoning dataset and synthetic data generation platform (X)* Big CO LLMs + APIs* Google* Gemini CLI, a new open-source AI agent, brings Gemini 2.5 Pro to your terminal (Blog, GitHub)* Google reduces free tier API limits for previous generation Gemini Flash models (X)* Search Live with voice conversation is now rolling out in AI Mode in the US (Blog, X)* Gemini API is now faster for video and PDF processing with improved caching (Docs)* Anthropic* Claude introduces an "artifacts" space for building, hosting, and sharing AI-powered apps (X)* Federal judge rules Anthropic's use of books for training Claude qualifies as fair use (X)* xAI* Elon Musk announces the successful launch of Tesla's Robotaxi (X)* Microsoft* Introduces Mu, a new language model powering the agent in Windows Settings (Blog)* Meta* Report: Meta pursued acquiring Ilya Sutskever's SSI, now hires co-founders Nat Friedman and Daniel Gross (X)* OpenAI* OpenAI removes mentions of its acquisition of Jony Ive's startup 'io' amid a trademark dispute (X)* OpenAI announces the release of DeepResearch in API + Webhook support (X)* This weeks Buzz* Alex is on vacation; WolframRvnwlf is attending AI Tinkerers Munich on July 25 (Event)* Join W&B Hackathon happening in 2 weeks in San Francisco - grand prize is a RoboDog! (Register for Free)* Vision & Video* MeiGen-MultiTalk code and checkpoints for multi-person talking head generation are released (GitHub, HF)* Google releases VideoPrism for generating adaptable video embeddings for various tasks (HF, Paper, GitHub)* Voice & Audio* ElevenLabs launches 11.ai, a voice-first personal assistant with MCP support (Sign Up, X)* Google Magenta releases Magenta RealTime, an open weights model for real-time music generation (Colab, Blog)* ElevenLabs launches a mobile app for iOS and Android for on-the-go voice generation (X)* AI Art & Diffusion & 3D* Google rolls out Imagen 4 and Imagen 4 Ultra in the Gemini API and Google AI Studio (Blog)* OmniGen 2 open weights model for enhanced image generation and editing is released (Project Page, Demo, Paper)* Tools* OpenMemory Chrome Extension provides shared memory across ChatGPT, Claude, Gemini and more (X)* LM Studio adds MCP support to connect local LLMs with your favorite servers (Blog)* Cursor is now available as a Slack integration (Dashboard)* All Hands AI releases the OpenHands CLI, a model-agnostic, open-source coding agent (Blog, Docs)* Warp 2.0 launches as an Agentic Development Environment with multi-threading (X)* Studies and Others* The /r/LocalLLaMA subreddit is back online after a brief moderation issue (Reddit, News)* Andrej Karpathy's talk "Software 3.0" discusses the future of programming in the age of AI (YouTube, Summary)Thank you, see you next week! This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit sub.thursdai.news/subscribe

📆 ThursdAI - June 19 - MiniMax M1 beats R1, OpenAI records your meetings, Gemini in GA, W&B uses Coreweave GPUs & more AI news
Hey all, Alex here 👋This week, while not the busiest week in releases (we can't get a SOTA LLM every week now can we), was full of interesting open source releases, and feature updates such as the chatGPT meetings recorder (which we live tested on the show, the limit is 2 hours!)It was also a day after our annual W&B conference called FullyConnected, and so I had a few goodies to share with you, like answering the main question, when will W&B have some use of those GPUs from CoreWeave, the answer is... now! (We launched a brand new preview of an inference service with open source models)And finally, we had a great chat with Pankaj Gupta, co-founder and CEO of Yupp, a new service that lets users chat with the top AIs for free, while turning their votes into leaderboards for everyone else to understand which Gen AI model is best for which task/topic. It was a great conversation, and he even shared an invite code with all of us (I'll attach to the TL;DR and show notes, let's dive in!)00:00 Introduction and Welcome01:04 Show Overview and Audience Interaction01:49 Special Guest Announcement and Experiment03:05 Wolfram's Background and Upcoming Hosting04:42 TLDR: This Week's Highlights15:38 Open Source AI Releases32:34 Big Companies and APIs32:45 Google's Gemini Updates42:25 OpenAI's Latest Features54:30 Exciting Updates from Weights & Biases56:42 Introduction to Weights & Biases Inference Service57:41 Exploring the New Inference Playground58:44 User Questions and Model Recommendations59:44 Deep Dive into Model Evaluations01:05:55 Announcing Online Evaluations via Weave01:09:05 Introducing Pankaj Gupta from YUP.AI01:10:23 YUP.AI: A New Platform for Model Evaluations01:13:05 Discussion on Crowdsourced Evaluations01:27:11 New Developments in Video Models01:36:23 OpenAI's New Transcription Service01:39:48 Show Wrap-Up and Future PlansHere's the TL;DR and show notes linksThursdAI - June 19th, 2025 - TL;DR* Hosts and Guests* Alex Volkov - AI Evangelist & Weights & Biases (@altryne)* Co Hosts - @WolframRvnwlf @yampeleg @nisten @ldjconfirmed* Guest - @pankaj - co-founder of Yupp.ai* Open Source LLMs* Moonshot AI open-sourced Kimi-Dev-72B (Github, HF)* MiniMax-M1 456B (45B Active) - reasoning model (Paper, HF, Try It, Github)* Big CO LLMs + APIs* Google drops Gemini 2.5 Pro/Flash GA, 2.5 Flash-Lite in Preview ( Blog, Tech report, Tweet)* Google launches Search Live: Talk, listen and explore in real time with AI Mode (Blog)* OpenAI adds MCP support to Deep Research in chatGPT (X, Docs)* OpenAI launches their meetings recorder in mac App (docs)* Zuck update: Considering bringing Nat Friedman and Daniel Gross to Meta (information)* This weeks Buzz* NEW! W&B Inference provides a unified interface to access and run top open-source AI models (inference, docs)* NEW! W&B Weave Online Evaluations delivers real-time production insights and continuous evaluation for AI agents across any cloud. (X)* The new platform offers "metal-to-token" observability, linking hardware performance directly to application-level metrics.* Vision & Video* ByteDance new video model beats VEO3 - Seedance.1.0 mini (Site, FAL)* MiniMax Hailuo 02 - 1080p native, SOTA instruction following (X, FAL)* Midjourney video is also here - great visuals (X)* Voice & Audio* Kyutai launches open-source, high-throughput streaming Speech-To-Text models for real-time applications (X, website)* Studies and Others* LLMs Flunk Real-World Coding Contests, Exposing a Major Skill Gap (Arxiv)* MIT Study: ChatGPT Use Causes Sharp Cognitive Decline (Arxiv)* Andrej Karpathy's "Software 3.0": The Dawn of English as a Programming Language (youtube, deck)* Tools* Yupp launches with 500+ AI models, a new leaderboard, and a user-powered feedback economy - use thursdai link* to get 50% extra credits* BrowserBase announces director.ai - an agent to run things on the web* Universal system prompt for reduction of hallucination (from Reddit)*Disclosure: while this isn't a paid promotion, I do think that yupp has a great value, I do get a bit more credits on their platform if you click my link and so do you. You can go to yupp.ai and register with no affiliation if you wish. This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit sub.thursdai.news/subscribe

📆 ThursdAI - June 12 - Meta’s $15B ScaleAI Power Play, OpenAI’s o3-pro & 90% Price Drop!
Hey folks, this is Alex, finally back home! This week was full of crazy AI news, both model related but also shifts in the AI landscape and big companies, with Zuck going all in on scale & execu-hiring Alex Wang for a crazy $14B dollars. OpenAI meanwhile, maybe received a new shipment of GPUs? Otherwise, it’s hard to explain how they have dropped the o3 price by 80%, while also shipping o3-pro (in chat and API). Apple was also featured in today’s episode, but more so for the lack of AI news, completely delaying the “very personalized private Siri powered by Apple Intelligence” during WWDC25 this week. We had 2 guests on the show this week, Stefania Druga and Eric Provencher (who builds RepoPrompt). Stefania helped me cover the AI Engineer conference we all went to last week, and shared some cool Science CoPilot stuff she’s working on, while Eric is the GOTO guy for O3-pro helped us understand what this model is great for! As always, TL;DR and show notes at the bottom, video for those who prefer watching is attached below, let’s dive in! Big Companies LLMs & APIsLet’s start with big companies, because the landscape has shifted, new top reasoner models dropped and some huge companies didn’t deliver this week! Zuck goes all in on SuperIntelligence - Meta’s $14B stake in ScaleAI and Alex WangThis may be the most consequential piece of AI news today. Fresh from the dissapointing results of LLama 4, reports of top researchers leaving the Llama team, many have decided to exclude Meta from the AI race. We have a saying at ThursdAI, don’t bet against Zuck! Zuck decided to spend a lot of money (nearly 20% of their reported $65B investment in AI infrastructure) to get a 49% stake in Scale AI and bring Alex Wang it’s (now former) CEO to lead the new Superintelligence team at Meta. For folks who are not familiar with Scale, it’s a massive company in providing human annotated data services to all the big AI labs, Google, OpenAI, Microsoft, Anthropic.. all of them really. Alex Wang, is the youngest self made billionaire because of it, and now Zuck not only has access to all their expertise, but also to a very impressive AI persona, who could help revive the excitement about Meta’s AI efforts, help recruit the best researchers, and lead the way inside Meta. Wang is also an outspoken China hawk who spends as much time in congressional hearings as in Slack, so the geopolitics here are … spicy. Meta just stapled itself to the biggest annotation funnel on Earth, hired away Google’s Jack Rae (who was on the pod just last week, shipping for Google!) for brainy model alignment, and started waving seven-to-nine-figure comp packages at every researcher with “Transformer” in their citation list. Whatever disappointment you felt over Llama-4’s muted debut, Zuck clearly felt it too—and responded like a founder who still controls every voting share. OpenAI’s Game-Changer: o3 Price Slash & o3-pro launches to top the intelligence leaderboards!Meanwhile OpenAI dropping not one, but two mind-blowing updates. First, they’ve slashed the price of o3—their premium reasoning model—by a staggering 80%. We’re talking from $40/$10 per million tokens down to just $8/$2. That’s right, folks, it’s now in the same league as Claude Sonnet cost-wise, making top-tier intelligence dirt cheap. I remember when a price drop of 80% after a year got us excited; now it’s 80% in just four months with zero quality loss. They’ve confirmed it’s the full o3 model—no distillation or quantization here. How are they pulling this off? I’m guessing someone got a shipment of shiny new H200s from Jensen!And just when you thought it couldn’t get better, OpenAI rolled out o3-pro, their highest intelligence offering yet. Available for pro and team accounts, and via API (87% cheaper than o1-pro, by the way), this model—or consortium of models—is a beast. It’s topping charts on Artificial Analysis, barely edging out Gemini 2.5 as the new king. Benchmarks are insane: 93% on AIME 2024 (state-of-the-art territory), 84% on GPQA Diamond, and nearing a 3000 ELO score on competition coding. Human preference tests show 64-66% of folks prefer o3-pro for clarity and comprehensiveness across tasks like scientific analysis and personal writing.I’ve been playing with it myself, and the way o3-pro handles long context and tough problems is unreal. As my friend Eric Provencher (creator of RepoPrompt) shared on the show, it’s surgical—perfect for big refactors and bug diagnosis in coding. It’s got all the tools o3 has—web search, image analysis, memory personalization—and you can run it in background mode via API for async tasks. Sure, it’s slower due to deep reasoning (no streaming thought tokens), but the consistency and depth? Worth it. Oh, and funny story—I was prepping a talk for Hamel Hussain’s evals course, with a slide saying “don’t use large reasoning models if budget’s tight.” The day before, this price drop hits, and I’m scrambling to update everything. That’s AI pace for ya!Apple W

📆 ThursdAI - Jun 5, 2025 - Live from AI Engineer with Swyx, new Gemini 2.5 with Logan K and Jack Rae, Self Replicating agents with Morph Labs
Hey folks, this is Alex, coming to you LIVE from the AI Engineer Worlds Fair! What an incredible episode this week, we recorded live from floor 30th at the Marriott in SF, while Yam was doing live correspondence from the floor of the AI Engineer event, all while Swyx, the cohost of Latent Space podcast, and the creator of AI Engineer (both the conference and the concept itself) joined us for the whole stream - here’s the edited version, please take a look. We've had around 6500 people tune in, and at some point we got 2 surprise guests, straight from the keynote stage, Logan Kilpatrick (PM for AI Studio and lead cheerleader for Gemini) and Jack Rae (principal scientist working on reasoning) joined us for a great chat about Gemini! Mind was absolutely blown! They have just launched the new Gemini 2.5 Pro and I though it would only be fitting to let their new model cover this podcast this week (so below is fully AI generated ... non slop I hope). The show notes and TL;DR is as always in the end. Okay, enough preamble… let's dive into the madness!🤯 Google Day at AI Engineer: New Gemini 2.5 Pro and a Look Inside the Machine's MindFor the first year of this podcast, a recurring theme was us asking, "Where's Google?" Well, it's safe to say that question has been answered with a firehose of innovation. We were lucky enough to be joined by Google DeepMind's Logan Kilpatrick and Jack Rae, the tech lead for "thinking" within Gemini, literally moments after they left the main stage.Surprise! A New Gemini 2.5 Pro Drops LiveLogan kicked things off with a bang, officially announcing a brand new, updated Gemini 2.5 Pro model right there during his keynote. He called it "hopefully the final update to 2.5 Pro," and it comes with a bunch of performance increases, closing the gap on feedback from previous versions and hitting SOTA on benchmarks like Aider.It's clear that the organizational shift to bring the research and product teams together under the DeepMind umbrella is paying massive dividends. Logan pointed out that Google has seen a 50x increase in AI inference over the past year. The flywheel is spinning, and it's spinning fast.How Gemini "Thinks"Then things got even more interesting. Jack Rae gave us an incredible deep dive into what "thinking" actually means for a language model. This was one of the most insightful parts of the conference for me.For years, the bottleneck for LLMs has been test-time compute. Models were trained to respond immediately, applying a fixed amount of computation to go from a prompt to an answer, no matter how hard the question. The only way to get a "smarter" response was to use a bigger model.Jack explained that "Thinking" shatters this limitation. Mechanically, Gemini now has a "thinking stage" where it can generate its own internal text—hypothesizing, testing, correcting, and reasoning—before committing to a final answer. It's an iterative loop of computation that the model can dynamically control, using more compute for harder problems. It learns how to think using reinforcement learning, getting a simple "correct" or "incorrect" signal and backpropagating that to shape its reasoning strategies.We're already seeing the results of this. Jack showed a clear trend: as models get better at reasoning, they're also using more test-time compute. This paradigm also gives developers a "thinking budget" slider in the API for Gemini 2.5 Flash and Pro, allowing a continuous trade-off between cost and performance.The future of this is even wilder. They're working on DeepThink, a high-budget mode for extremely hard problems that uses much deeper, parallel chains of thought. On the tough USA Math Olympiad, where the SOTA was negligible in January, 2.5 Pro reached the 50th percentile of human participants. DeepThink pushes that to the 65th percentile.Jack’s ultimate vision is inspired by the mathematician Ramanujan, who derived incredible theorems from a single textbook by just thinking deeply. The goal is for models to do the same—contemplate a small set of knowledge so deeply that they can push the frontiers of human understanding. Absolutely mind-bending stuff.🤖 MorphLabs and the Audacious Quest for Verified SuperintelligenceJust when I thought my mind couldn't be bent any further, we were joined by Jesse Han, the founder and CEO of MorphLabs. Fresh off his keynote, he laid out one of the most ambitious visions I've heard: building the infrastructure for the Singularity and developing "verified superintelligence."The big news was that Christian Szegedy is joining MorphLabs as Chief Scientist. For those who don't know, Christian is a legend—he invented batch norm and adversarial examples, co-founded XAI, and led code reasoning for Grok. That's a serious hire.Jesse’s talk was framed around a fascinating question: "What does it mean to have empathy for the machine?" He argues that as AI develops personhood, we need to think about what it wants. And what it wants, according to Morph, is a new kind of
📆 ThursdAI - May 29 - DeepSeek R1 Resurfaces, VEO3 viral moments, Opus 4 a week after, Flux Kontext image editing & more AI news
Hey everyone, Alex here 👋Welcome back to another absolutely wild week in AI! I'm coming to you live from the Fontainebleau Hotel in Vegas at the Imagine AI conference, and wow, what a perfect setting to discuss how AI is literally reimagining our world. After last week's absolute explosion of releases (Claude Opus 4, Google I/O madness, OpenAI Codex and Jony colab), this week gave us a chance to breathe... sort of. Because even in a "quiet" week, we still got a new DeepSeek model that's pushing boundaries, and the entire internet discovered that we might all just be prompts. Yeah, it's been that kind of week!Before we dive in, quick shoutout to everyone who joined us live - we had some technical hiccups with the Twitter Spaces audio (sorry about that!), but the YouTube stream was fire. And speaking of fire, we had two incredible guests join us: Charlie Holtz from Chorus (the multi-model chat app that's changing how we interact with AI) and Linus Eckenstam, who's been traveling the AI conference circuit and bringing us insights from the frontlines of the generative AI revolution.Open Source AI & LLMs: DeepSeek Whales & Mind-Bending PapersDeepSeek dropped R1-0528 out of nowhere, an update to their reasoning beast with some serious jumps in performance. We’re talking AIME at 91 (beating previous scores by a mile), LiveCodeBench at 73, and SWE verified at 57.6. It’s edging closer to heavyweights like o3, and folks on X are already calling it “clearer thinking.” There was hype it might’ve been R2, but the impact didn’t quite crash the stock exchange like past releases. Still, it’s likely among the best open-weight models out there.So what's new? Early reports and some of my own poking around suggest this model "thinks clearer now." Nisten mentioned that while previous DeepSeek models sometimes liked to "vibe around" and explore the latent space before settling on an answer, this one feels a bit more direct.And here’s the kicker—they also released an 8B distilled version based on Qwen3, runnable on your laptop. Yam called it potentially the best 8B model to date, and you can try it on Ollama right now. No need for a monster rig! The Mind-Bending "Learning to Reason Without External Rewards" PaperOkay, this paper result broke my brain, and apparently everyone else's too. This paper shows that models can improve through reinforcement learning with its own intuition of whether or not it's correct. 😮It's like the placebo effect for AI! The researchers trained models without telling them what was good or bad, but rather, utilized a new framework called Intuitor, where the reward was based on how the "self certainty". The thing that took my whole timeline by storm is, it works! GRPO (Group Policy Optimization) - the framework that DeepSeek gave to the world with R1 is based on external rewards (human optimize) and Intuitor seems to be mathcing or even exceeding some of GRPO results when Qwen2.5 3B was used to finetune. Incredible incredible stuffBig Companies LLMs & APIsClaude Opus 4: A Week Later – The Dev Darling?Claude Opus 4, whose launch we celebrated live on the show, has had a week to make its mark. Charlie Holtz, who's building Chorus (more on that amazing app in a bit!), shared that while it's sometimes "astrology" to judge the vibes of a new model, Opus 4 feels like a step change, especially in coding. He mentioned that Claude Code, powered by Opus 4 (and Sonnet 4 for implementation), is now tackling GitHub issues that were too complex just weeks ago. He even had a coworker who "vibe coded three websites in a weekend" with it – that's a tangible productivity boost!Linus Eckenstam highlighted how Lovable.dev saw their syntax error rates plummet by nearly 50% after integrating Claude 4. That’s quantifiable proof of improvement! It's clear Anthropic is leaning heavily into the developer/coding space. Claude Opus is now #1 on the LMArena WebDev arena, further cementing its reputation.I had my own magical moment with Opus 4 this week. I was working on an MCP observability talk for the AI Engineer conference and trying to integrate Weave (our observability and evals framework at Weights & Biases) into a project. Using Windsurf's Cascade agent (which now lets you bring your own Opus 4 key, by the way – good move, Windsurf!), Opus 4 not only tried to implement Weave into my agent but, when it got stuck, it figured out it had access to the Weights & Biases support bot via our MCP tool. It then formulated a question to the support bot (which is also AI-powered!), got an answer, and used that to fix the implementation. It then went back and checked if the Weave trace appeared in the dashboard! Agents talking to agents to solve a problem, all while I just watched – my jaw was on the floor. Absolutely mind-blowing.Quick Hits: Voice Updates from OpenAI & AnthropicOpenAI’s Advanced Voice Mode finally sings—yes, I’ve been waiting for this! It can belt out tunes like Mariah Carey, which is just fun. Anthropic also rolled ou

📆 ThursdAI - Veo3, Google IO25, Claude 4 Opus/Sonnet, OpenAI x Jony Ive, Codex, Copilot Agent - INSANE AI week
Hey folks, Alex here, welcome back to ThursdAI! And folks, after the last week was the calm before the storm, "The storm came, y'all" – that's an understatement. This wasn't just a storm; it was an AI hurricane, a category 5 of announcements that left us all reeling (in the best way possible!). From being on the ground at Google I/O to live-watching Anthropic drop Claude 4 during our show, it's been an absolute whirlwind.This week was so packed, it felt like AI Christmas, with tech giants and open-source heroes alike showering us with gifts. We saw OpenAI play their classic pre-and-post-Google I/O chess game, Microsoft make some serious open-source moves, Google unleash an avalanche of updates, and Anthropic crash the party with Claude 4 Opus and Sonnet live stream in the middle of ThursdAI!So buckle up, because we're about to try and unpack this glorious chaos. As always, we're here to help you collectively know, learn, and stay up to date, so you don't have to. Let's dive in! (TL;DR and links in the end) Open Source LLMs Kicking Things OffEven with the titans battling, the open-source community dropped some serious heat this week. It wasn't the main headline grabber, but the releases were significant!Gemma 3n: Tiny But Mighty MatryoshkaFirst up, Google's Gemma 3n. This isn't just another small model; it's a "Nano-plus" preview, a 4-billion parameter MatFormer (Matryoshka Transformer – how cool is that name?) model designed for mobile-first multimodal applications. The really slick part? It has a nested 2-billion parameter sub-model that can run entirely on phones or Chromebooks.Yam was particularly excited about this one, pointing out the innovative "model inside another model" design. The idea is you can use half the model, not depth-wise, but throughout the layers, for a smaller footprint without sacrificing too much. It accepts interleaved text, image, audio, and video, supports ASR and speech translation, and even ships with RAG and function-calling libraries for edge apps. With a 128K token window and responsible AI features baked in, Gemma 3n is looking like a powerful tool for on-device AI. Google claims it beats prior 4B mobile models on MMLU-Lite and MMMU-Mini. It's an early preview in Google AI Studio, but it definitely flies on mobile devices.Mistral & AllHands Unleash Devstral 24BThen we got a collaboration from Mistral and AllHands: Devstral, a 24-billion parameter, state-of-the-art open model focused on code. We've been waiting for Mistral to drop some open-source goodness, and this one didn't disappoint.Nisten was super hyped, noting it beats o3-Mini on SWE-bench verified – a tough benchmark! He called it "the first proper vibe coder that you can run on a 3090," which is a big deal for coders who want local power and privacy. This is a fantastic development for the open-source coding community.The Pre-I/O Tremors: OpenAI & Microsoft Set the StageAs we predicted, OpenAI couldn't resist dropping some news right before Google I/O.OpenAI's Codex Returns as an AgentOpenAI launched Codex – yes, that Codex, but reborn as an asynchronous coding agent. This isn't just a CLI tool anymore; it connects to GitHub, does pull requests, fixes bugs, and navigates your codebase. It's powered by a new coding model fine-tuned for large codebases and was SOTA on SWE Agent when it dropped. Funnily, the model is also called Codex, this time, Codex-1. And this gives us a perfect opportunity to talk about the emerging categories I'm seeing among Code Generator agents and tools:* IDE-based (Cursor, Windsurf): Live pair programming in your editor* Vibe coding (Lovable, Bolt, v0): "Build me a UI" style tools for non-coders* CLI tools (Claude Code, Codex-cli): Terminal-based assistants* Async agents (Claude Code, Jules, Codex, GitHub Copilot agent, Devin): Work on your repos while you sleep, open pull requests for you to review, asyncCodex (this new one) falls into category number 4, and with today's release, Cursor seems to also strive to get to category number 4 with background processing. Microsoft BUILD: Open Source Copilot and Copilot Agent ModeThen came Microsoft Build, their huge developer conference, with a flurry of announcements.The biggest one for me? GitHub Copilot's front-end code is now open source! The VS Code editor part was already open, but the Copilot integration itself wasn't. This is a massive move, likely a direct answer to the insane valuations of VS Code clones like Cursor. Now, you can theoretically clone GitHub Copilot with VS Code and swing for the fences.GitHub Copilot also launched as an asynchronous coding assistant, very similar in function to OpenAI's Codex, allowing it to be assigned tasks and create/update PRs. This puts Copilot right into category 4 of code assistants, and with the native Github Integration, they may actually have a leg up in this race!And if that wasn't enough, Microsoft is adding MCP (Model Context Protocol) support directly into the Windows OS. The implications of
📆 ThursdAI - May 15 - Genocidal Grok, ChatGPT 4.1, AM-Thinking, Distributed LLM training & more AI news
Hey yall, this is Alex 👋What a wild week, it started super slow, and it still did feel slow as releases are concerned, but the most interesting story was yet another AI gone "rogue" (have you even heard about "kill the boar", if not, Grok will tell you all about it) Otherwise it seemed fairly quiet in AI land this week, besides another Chinese newcomer called AM-thinking 32B that beats DeepSeek and Qwen, and Stability making a small comeback, we focused on distributed LLM training and ChatGPT 4.1We've had a ton of fun on this episode, this one was being recorded from the Weights & Biases SF Office (I'm here to cover Google IO next week!)Let’s dig in—because what looks like a slow week on the surface was anything but dull under the hood (TL'DR and show notes at the end as always)Big Companies & APIsWhy does XAI Grok talk about White Genocide and "Kill the boar"??Just after we're getting over the chatGPT glazing incident , folks started noticing that @grok - XAI's frontier LLM that is also responding to X replies, started talking about White Genocide in South Africa and something called "Kill the boer" with no reference to any of these things in the question! Since we recorded the episode, XAI official X account posted that an "unauthorized modification" happened to the system prompt, and that going forward they would open source all the prompts (and they did). Whether or not they would keep updating that repository though, remains unclear (see the "open sourced" x algorithm to which the last push was over a year ago, or the promised Grok 2 that was never open sourced) While it's great to have some more clarity from the Xai team, this behavior raises a bunch of questions about the increasing roles of AI's in our lives and the trust that many folks are giving them. Adding fuel to the fire, are Uncle Elon's recent tweets that are related to South Africa, and this specific change seems to be related to those views at least partly. Remember also, Grok was meant as "maximally truth seeking" AI! I really hope this transparency continues!Open Source LLMs: The Decentralization TsunamiAM-Thinking v1: Dense Reasoning, SOTA Math, Single-Checkpoint DeployabilityOpen source starts with the kind of progress that would have been unthinkable 18 months ago: a 32B dense LLM, openly released, that takes on the big mixture-of-experts models and comes out on top for math and code. AM-Thinking v1 (paper here) hits 85.3% on AIME 2024, 70.3% on LiveCodeBench v5, and 92.5% on Arena-Hard. It even runs at 25 tokens/sec on a single 80GB GPU with INT4 quantization.The model supports a /think reasoning toggle (chain-of-thought on demand), comes with a permissive license, and is fully tooled for vLLM, LM Studio, and Ollama. Want to see where dense models can still push the limits? This is it. And yes, they’re already working on a multilingual RLHF pass and 128k context window.Personal note: We haven’t seen this kind of “out of nowhere” leaderboard jump since the early days of Qwen or DeepSeek. This company's debut on HuggingFace with a model that crushes! Decentralized LLM Training: Nous Research Psyche & Prime Intellect INTELLECT-2This week, open source LLMs didn’t just mean “here are some weights.” It meant distributed, decentralized, and—dare I say—permissionless AI. Two labs stood out:Nous Research launches PsycheDylan Rolnick from Nous Research joined the show to explain Psyche: a Rust-powered, distributed LLM training network where you can watch a 40B model (Consilience-40B) evolve in real time, join the training with your own hardware, and even have your work attested on a Solana smart contract. The core innovation? DisTrO (Decoupled Momentum) which we covered back in December that drastically compresses the gradient exchange so that training large models over the public internet isn’t a pipe dream—it’s happening right now.Live dashboard here, open codebase, and the testnet already humming with early results. This massive 40B attempt is going to show whether distributed training actually works! The cool thing about their live dashboard is, it's WandB behind the scenes, but with a very thematic and cool Nous Research reskin! This model saves constant checkpoints to the hub as well, so the open source community can enjoy a full process of seeing a model being trained! Prime Intellect INTELLECT-2Not to be outdone, Prime Intellect’s INTELLECT-2 released a globally decentralized, 32B RL-trained reasoning model, built on a permissionless swarm of GPUs. Using their own PRIME-RL framework, SHARDCAST checkpointing, and an LSH-based rollout verifier, they’re not just releasing a model—they’re proving it’s possible to scale serious RL outside a data center. OpenAI's HealthBench: Can LLMs Judge Medical Safety?One of the most intriguing drops of the week is HealthBench, a physician-crafted benchmark for evaluating LLMs in clinical settings. Instead of just multiple-choice “gotcha” tests, HealthBench brings in 262 doctors from 60 countries, 26 s

ThursdAI - May 8th - new Gemini pro, Mistral Medium, OpenAI restructuring, HeyGen Realistic Avatars & more AI news
Hey folks, Alex here (yes, real me, not my AI avatar, yet)Compared to previous weeks, this week was pretty "chill" in the world of AI, though we did get a pretty significant Gemini 2.5 Pro update, it basically beat itself on the Arena. With Mistral releasing a new medium model (not OSS) and Nvidia finally dropping Nemotron Ultra (both ignoring Qwen 3 performance) there was also a few open source updates. To me the highlight of this week was a breakthrough in AI Avatars, with Heygen's new IV model, Beating ByteDance's OmniHuman (our coverage) and Hedra labs, they've set an absolute SOTA benchmark for 1 photo to animated realistic avatar. Hell, Iet me record all this real quick and show you how good it is! How good is that?? I'm still kind of blown away. I have managed to get a free month promo code for you guys, look for it in the TL;DR section at the end of the newsletter. Of course, if you’re rather watch than listen or read, here’s our live recording on YTOpenSource AINVIDIA's Nemotron Ultra V1: Refining the Best with a Reasoning Toggle 🧠NVIDIA also threw their hat further into the ring with the release of Nemotron Ultra V1, alongside updated Super and Nano versions. We've talked about Nemotron before – these are NVIDIA's pruned and distilled versions of Llama 3.1, and they've been impressive. The Ultra version is the flagship, a 253 billion parameter dense model (distilled and pruned from Llama 3.1 405B), and it's packed with interesting features.One of the coolest things is the dynamic reasoning toggle. You can literally tell the model "detailed thinking on" or "detailed thinking off" via a system prompt during inference. This is something Qwen also supports, and it looks like the industry is converging on this idea of letting users control the "depth" of thought, which is super neat.Nemotron Ultra boasts a 128K context window and, impressively, can fit on a single 8xH100 node thanks to Neural Architecture Search (NAS) and FFN-Fusion. And performance-wise, it actually outperforms the Llama 3 405B model it was distilled from, which is a big deal. NVIDIA shared a chart from Artificial Analysis (dated April 2025, notably before Qwen3's latest surge) showing Nemotron Ultra standing strong among models like Gemini 2.5 Flash and Opus 3 Mini.What's also great is NVIDIA's commitment to openness here: they've released the models under a commercially permissive NVIDIA Open Model License, the complete post-training dataset (Llama-Nemotron-Post-Training-Dataset), and their training codebases (NeMo, NeMo-Aligner, Megatron-LM). This allows for reproducibility and further community development. Yam Peleg pointed out the cool stuff they did with Neural Architecture Search to optimally reduce parameters without losing performance.Absolute Zero: AI Learning to Learn, Zero (curated) Data Required! (Arxiv)LDJ brought up a fascinating paper that ties into this theme of self-improvement and reinforcement learning: "Absolute Zero: Reinforced Self-play Reasoning with Zero Data" from Andrew Zhao (Tsinghua University) and a few othersThe core idea here is a system that self-evolves its training curriculum and reasoning ability. Instead of needing a pre-curated dataset of problems, the model creates the problems itself (e.g., code reasoning tasks) and then uses something like a Code Executor to validate its proposed solutions, serving as a unified source of verifiable reward. It's open-ended yet grounded learning.By having a verifiable environment (code either works or it doesn't), the model can essentially teach itself to code without external human-curated data.The paper shows fine-tunes of Qwen models (like Qwen Coder) achieving state-of-the-art results on benchmarks like MBBP and AIME (Math Olympiad) with no pre-existing data for those problems. The model hallucinates questions, creates its own rewards, learns, and improves. This is a step beyond synthetic data, where humans are still largely in charge of generation. It's wild, and it points towards a future where AI systems could become increasingly autonomous in their learning.Big Companies & APIsGoogle dropped another update to their Gemini 2.5 Pro, this time the "IO edition" preview, specifically touting enhanced coding performance. This new version jumped to the #1 spot on WebDev Arena (a benchmark where human evaluators choose between two side-by-side code generations in VS Code), with a +147 Elo point gain, surpassing Claude 3.7 Sonnet. It also showed improvements on benchmarks like LiveCodeBench (up 7.39%) and Aider Polyglot (up ~3-6%). Google also highlighted its state-of-the-art video understanding (84.8% on VideoMME) with examples like generating code from a video of an app. Which essentially lets you record a drawing of how your app interaction will happen, and the model will use that video instructions! It's pretty cool. Though, not everyone was as impressed, folks noted that while gaining in a few evals, this model also regressed in several others including Vib

📆 ThursdAI - May 1- Qwen 3, Phi-4, OpenAI glazegate, RIP GPT4, LlamaCon, LMArena in hot water & more AI news
Hey everyone, Alex here 👋Welcome back to ThursdAI! And wow, what a week. Seriously, strap in, because the AI landscape just went through some seismic shifts. We're talking about a monumental open-source release from Alibaba with Qwen 3 that has everyone buzzing (including us!), Microsoft dropping Phi-4 with Reasoning, a rather poignant farewell to a legend (RIP GPT-4 – we'll get to the wake shortly), major drama around ChatGPT's "glazing" incident and the subsequent rollback, updates from LlamaCon, a critical look at Chatbot Arena, and a fantastic deep dive into the world of AI evaluations with two absolute experts, Hamel Husain and Shreya Shankar.This week felt like a whirlwind, with open source absolutely dominating the headlines. Qwen 3 didn't just release a model; they dropped an entire ecosystem, setting a potential new benchmark for open-weight releases. And while we pour one out for GPT-4, we also have to grapple with the real-world impact of models like ChatGPT, highlighted by the "glazing" fiasco. Plus, video consistency takes a leap forward with Runway, and we got breaking news live on the show from Claude!So grab your coffee (or beverage of choice), settle in, and let's unpack this incredibly eventful week in AI.Open-Source LLMsQwen 3 — “Hybrid Thinking” on TapAlibaba open-weighted the entire Qwen 3 family this week, releasing two MoE titans (up to 235 B total / 22 B active) and six dense siblings all the way down to 0 .6 B, all under Apache 2.0. Day-one support landed in LM Studio, Ollama, vLLM, MLX and llama.cpp.The headline trick is a runtime thinking toggle—drop “/think” to expand chain-of-thought or “/no_think” to sprint. On my Mac, the 30 B-A3B model hit 57 tokens/s when paired with speculative decoding (drafted by the 0 .6 B sibling).Other goodies:* 36 T pre-training tokens (2 × Qwen 2.5)* 128 K context on ≥ 8 B variants (32 K on the tinies)* 119-language coverage, widest in open source* Built-in MCP schema so you can pair with Qwen-Agent* The dense 4 B model actually beats Qwen 2.5-72B-Instruct on several evals—at Raspberry-Pi footprintIn short: more parameters when you need them, fewer when you don’t, and the lawyers stay asleep. Read the full drop on the Qwen blog or pull weights from the HF collection.Performance & Efficiency: "Sonnet at Home"?The benchmarks are where things get really exciting.* The 235B MoE rivals or surpasses models like DeepSeek-R1 (which rocked the boat just months ago!), O1, O3-mini, and even Gemini 2.5 Pro on coding and math.* The 4B dense model incredibly beats the previous generation's 72B Instruct model (Qwen 2.5) on multiple benchmarks! 🤯* The 30B MoE (with only 3B active parameters) is perhaps the star. Nisten pointed out people are getting 100+ tokens/sec on MacBooks. Wolfram achieved an 80% MMLU Pro score locally with a quantized version. The efficiency math is crazy – hitting Qwen 2.5 performance with only ~10% of the active parameters.Nisten dubbed the larger model "Sonnet 3.5 at home," and while acknowledging Sonnet still has an edge in complex "vibe coding," the performance, especially in reasoning and tool use, is remarkably close for an open model you can run yourself.I ran the 30B MoE (3B active) locally using LLM Studio (shoutout for day-one support!) through my Weave evaluation dashboard (Link). On a set of 20 hard reasoning questions, it scored 43%, beating GPT 4.1 mini and nano, and getting close to 4.1 – impressive for a 3B active parameter model running locally!Phi-4-Reasoning — 14B That Punches at 70B+Microsoft’s Phi team layered 1.4 M chain-of-thought traces plus a dash of RL onto Phi-4 to finally ship a resoning Phi and shipped two MIT-licensed checkpoints:* Phi-4-Reasoning (SFT)* Phi-4-Reasoning-Plus (SFT + RL)Phi-4-R-Plus clocks 78 % on AIME 25, edging DeepSeek-R1-Distill-70B, with 32 K context (stable to 64 K via RoPE). Scratch-pads hide in tags. Full details live in Microsoft’s tech report and HF weights.It's fascinating to see how targeted training on reasoning traces and a small amount of RL can elevate a relatively smaller model to compete with giants on specific tasks.Other Open Source Updates* MiMo-7B: Xiaomi entered the ring with a 7B parameter, MIT-licensed model family, trained on 25T tokens and featuring rule-verifiable RL. (HF model hub)* Helium-1 2B: KyutAI (known for their Mochi voice model) released Helium-1, a 2B parameter model distilled from Gemma-2-9B, focused on European languages, and licensed under CC-BY 4.0. They also open-sourced 'dactory', their data processing pipeline. (Blog, Model (2 B), Dactory pipeline)* Qwen 2.5 Omni 3B: Alongside Qwen 3, the Qwen team also updated their existing Omni model with a 3B model, that retains 90% of the comprehension of its big brother with a 50% VRAM drop! (HF)* JetBrains open sources Mellum: Trained on over 4 trillion tokens with a context window of 8192 tokens across multiple programming languages, they haven't released any comparable eval benchmarks though (HF)Big Companies

ThursdAI - Apr 23rd - GPT Image & Grok APIs Drop, OpenAI ❤️ OS? Dia's Wild TTS & Building Better Agents!
Hey everyone, Alex here 👋Welcome back to ThursdAI! After what felt like ages of non-stop, massive model drops (looking at you, O3 and GPT-4!), we finally got that "chill week" we've been dreaming of since maybe... forever? It seems the big labs are taking a breather, probably gearing up for even bigger things next week (maybe some open source 👀).But "chill" doesn't mean empty! This week was packed with fascinating developments, especially in the open source world and with long-awaited API releases. We actually had time to dive deeper into things, which was a refreshing change. We had a fantastic lineup of guests joining us too: Kwindla Kramer (@kwindla), our resident voice expert, dropped in to talk about some mind-blowing TTS and her own open-source VAD release. Maziyar Panahi (@MaziyarPanahi) gave us the inside scoop on OpenAI's recent meeting with the open source community. And Dex Horthy (@dexhorthy) from HumanLayer shared some invaluable insights on building robust AI agents that actually work in the real world. It was great having them alongside the usual ThursdAI crew: LDJ, Yam, Wolfram, and Nisten!So, instead of rushing through a million headlines, we took a more relaxed pace. We explored NVIDIA's cool new Describe Anything model, dug into Google's Quantization Aware Training for Gemma, celebrated the much-anticipated API release for OpenAI's GPT Image generation (finally!), checked out the new Grok API, got absolutely blown away by a tiny, open-source TTS model from Korea called Dia, and debated the principles of building better AI agents. Plus, a surprise drop from Send AI with a powerful video model!Let's dive in!Open Source AI Highlights: Community, Vision, and EfficiencyEven with the big players quieter on the model release front, the open source scene was buzzing. It feels like this "chill" period gave everyone a chance to focus on refining tools, releasing datasets, and engaging with the community.OpenAI Inches Closer to Open Source? Insights from the Community MeetingPerhaps the biggest non-release news of the week was OpenAI actively engaging with the open source community. Friend of the show Maziyar Panahi was actually in the room (well, the Zoom room) and joined us to share what went down It sounds like OpenAI came prepared, with Sam Altman himself spending significant time answering questions . Maziyar gave us the inside scoop, mentioning that OpenAI's looking to offload some GPU pressure by embracing open source – a win-win where they help the community, and the community helps lighten their load. He painted a picture of a company genuinely trying to listen and figure out how to best contribute. It felt less like a checkbox exercise and more like genuine engagement, which is awesome to see.What did the community ask for? Based on Maziyar's recap, there was a strong consensus on several key points:* Model Size: The sweet spot seemed to be not tiny, but not astronomically huge either. Something in the 70B-200B parameter range that could run reasonably on, say, 4 GPUs, leaving room for other models. People want power they can actually use without needing a supercomputer.* Capabilities: A strong desire for reliable structured output. Surprisingly, there was less emphasis on complex, built-in reasoning, or at least the ability to toggle reasoning off. This likely stems from practical concerns about cost and latency in production environments. The community seems to value control and efficiency for specific tasks.* Multilingual: Good support for European languages (at least 20) was a major request, reflecting the global nature of the open source community. Needs to be as good as English support.* Base Models: A huge ask was for OpenAI to release base models. The reasoning? Empower the community to handle fine-tuning for specific tasks like coding, roleplay, or supporting underrepresented languages . Let the experts in those niches build on a solid foundation.* Focus: Usefulness over chasing leaderboard glory. The community urged OpenAI to provide a solid, practical model rather than aiming for a temporary #1 spot that gets outdated in days or weeks . Stability, reliability, and long-term utility were prized over fleeting benchmark wins.* Safety: A preference for separate guardrail models (similar to LlamaGuard or GemmaGuard) rather than overly aligning the main model, which often hurts performance and flexibility . Give users the tools to implement safety layers as needed, rather than baking in limitations that might stifle creativity or utility.Perhaps most excitingly, Maziyar mentioned OpenAI seemed committed to regular open model releases, not just a one-off thin=! This, combined with recent moves like approving a community Pull Request to make their open-source Codex agent work with non-OpenAI models (as Yam Peleg excitedly pointed out!), suggests a potentially significant shift. Remember, it's been a long time since GPT-2 and Whisper were OpenAI's main open contributions! We're definit

ThursdAI - Apr 17 - OpenAI o3 is SOTA llm, o4-mini, 4.1, mini, nano, G. Flash 2.5, Kling 2.0 and 🐬 Gemma? Huge AI week + A2A protocol interview
Hey everyone, Alex here 👋Wow. Just… wow. What a week, folks. Seriously, this has been one for the books. This week was dominated by OpenAI's double whammy: first the GPT-4.1 family dropped with a mind-boggling 1 million token context window, followed swiftly by the new flagship reasoning models, o3 and o4-mini, which are already blowing minds with their agentic capabilities. We also saw significant moves from Google with VEO-2 going GA, the fascinating A2A protocol launch (we had an amazing interview with Google's Todd Segal about it!), and even an attempt to talk to dolphins with DolphinGemma. Kling stepped up its video game, Cohere dropped SOTA multimodal embeddings, and ByteDance made waves in image generation. Plus, the open-source scene had some interesting developments, though perhaps overshadowed by the closed-source giants this time.o3 has absolutely taken the crown as the conversation piece, so lets start with it (as always, TL;DR and shownotes at the end, and here's the embedding of our live video show) Big Company LLMs + APIsOpenAI o3 & o4‑mini: SOTA Reasoning Meets Tool‑Use (Blog, Watch Party)The long awaited o3 models (promised to us in the last days of x-mas) is finally here, and it did NOT disappoint and well.. even surprised! o3 is not only SOTA on nearly all possible logic, math and code benchmarks, which is to be expected from the top reasoning model, it also, and I think for the first time, is able to use tools during its reasoning process. Tools like searching the web, python coding, image gen (which it... can zoom and rotate and crop images, it's nuts) to get to incredible responses faster. Tool using reasoner are... almost AGI? This is the headline feature for me. For the first time, these o-series models have full, autonomous access to all built-in tools (web search, Python code execution, file search, image generation with Sora-Image/DALL-E, etc.). They don't just use tools when told; they decide when and how to chain multiple tool calls together to solve a problem. We saw logs with 600+ consecutive tool calls! This is agent-level reasoning baked right in.Anecdote: We tested this live with a complex prompt: "generate an image of a cowboy that on his head is the five last digits of the hexadecimal code of the MMMU score of the latest Gemini model." o3 navigated this multi-step task flawlessly: figuring out the latest model was Gemini 2.5, searching for its MMMU score, using the Python tool to convert it to hex and extract the digits, and then using the image generation tool. It involved multiple searches and reasoning steps. Absolutely mind-blowing 🤯.Thinking visually with imagesThis one also blew my mind, this model is SOTA on multimodality tasks, and a reason for this, is these models can manipulate and think about the images they received. Think... cropping, zooming, rotating. The models can now perform all these tasks to multimodal requests from users. Sci-fi stuff! Benchmark Dominance: As expected, these models crush existing benchmarks.o3 sets new State-of-the-Art (SOTA) records on Codeforces (coding competitions), SWE-bench (software engineering), MMMU (multimodal understanding), and more. It scored a staggering $65k on the Freelancer eval (simulating earning money on Upwork) compared to o1's $28k!o4-mini is no slouch either. It hits 99.5% on AIME (math problems) when allowed to use its Python interpreter and beats the older o3-mini on general tasks. It’s a reasoning powerhouse at a fraction of the cost.Incredible Long Context PerformanceYam highlighted this – on the Fiction Life benchmark testing deep comprehension over long contexts, o3 maintained nearly 100% accuracy up to 120,000 tokens, absolutely destroying previous models including Gemini 2.5 Pro and even the new GPT-4.1 family on this specific eval. While its context window is currently 200k (unlike 4.1's 1M), its performance within that window is unparalleled.Cost-Effective Reasoning: They're not just better, they're cheaper for the performance you get.* o3: $10 input / $2.50 cached / $40 output per million tokens.* o4-mini: $1.10 input / $0.275 cached / $4.40 output per million tokens. (Cheaper than GPT-4.0!)Compute Scaling Validated: OpenAI confirmed these models used >10x the compute of o1 and leverage test-time compute scaling (spending longer on harder problems), further proving their scaling law research.Memory Integration: Both models integrate with ChatGPT's recently upgraded memory feature which has access to all your previous conversations (which we didn't talk about but is absolutely amazing, try asking o3 stuff it knows about you and have ti draw conclusions!)Panel Takes & Caveats:While the excitement was palpable, Yam noted some community observations about potential "rush" – occasional weird hallucinations or questionable answers compared to predecessors, possibly a side effect of cramming so much training data. Nisten, while impressed, still found the style of GPT-4.1 preferable for specific tasks like

Ep 100💯 ThursdAI - 100th episode 🎉 - Meta LLama 4, Google tons of updates, ChatGPT memory, WandB MCP manifesto & more AI news
Hey Folks, Alex here, celebrating an absolutely crazy (to me) milestone, of #100 episodes of ThursdAI 👏 100 episodes in a year and a half (as I started publishing much later than I started going live, and the first episode was embarrassing), 100 episodes that documented INCREDIBLE AI progress, we mention on the show today, we used to be excited by context windows jumping from 4K to 16K! I want to extend a huge thank you to every one of you, who subscribes, listens to the show on podcasts, joins the live recording (we regularly get over 1K live viewers across platforms), shares with friends and highest thank you for the paid supporters! 🫶 Sharing the AI news progress with you, energizes me to keep going, despite the absolute avalanche of news every week.And what a perfect way to celebrate the 100th episode, on a week that Meta dropped Llama 4, sending the open-source world into a frenzy (and a bit of chaos). Google unleashed a firehose of announcements at Google Next. The agent ecosystem got a massive boost with MCP and A2A developments. And we had fantastic guests join us – Michael Lou diving deep into the impressive DeepCoder-14B, and Liad Yosef & Ido Salomon sharing their wild ride creating the viral GitMCP tool.I really loved today's show, and I encourage those of you who only read, to give this a watch/listen, and those of you who only listen, enjoy the recorded version (though longer and less edited!) Now let's dive in, there's a LOT to talk about (TL;DR and show notes as always, at the end of the newsletter) Open Source AI & LLMs: Llama 4 Takes Center Stage (Amidst Some Drama)Meta drops Llama 4 - Scout 109B/17BA & Maverick 400B/17BA (Blog, HF, Try It)This was by far the biggest news of this last week, and it dropped... on a Saturday? (I was on the mountain ⛷️! What are you doing Zuck) Meta dropped the long awaited LLama-4 models, huge ones this time* Llama 4 Scout: 17B active parameters out of ~109B total (16 experts).* Llama 4 Maverick: 17B active parameters out of a whopping ~400B total (128 experts).* Unreleased: Behemoth - 288B active with 2 Trillion total parameters chonker!* Both base and instruct finetuned models were releasedThese new models are all Multimodal, Multilingual MoE (mixture of experts) architecture, and were trained with FP8, for significantly more tokens (around 30 Trillion Tokens!) with interleaved attention (iRoPE), and a refined SFT > RL > DPO post-training pipeline.The biggest highlight is the stated context windows, 10M for Scout and 1M for Maverick, which is insane (and honestly, I haven't yet seen a provider that is even remotely able to support anything of this length, nor do I have the tokens to verify it) The messy release - Big Oof from Big ZuckNot only did Meta release on a Saturday, messing up people's weekends, Meta apparently announced a high LM arena score, but the model they provided to LMArena was... not the model they released!?It caused LMArena to release the 2000 chats dataset, and truly, some examples are quite damning and show just how unreliable LMArena can be as vibe eval. Additionally, during the next days, folks noticed discrepancies between the stated eval scores Meta released, and the ability to evaluate them independently, including our own Wolfram, who noticed that a quantized version of Scout, performed better on his laptop while HIGHLY quantized (read: reduced precision) than it was performing on the Together API inference endpoint!? We've chatted on the show that this may be due to some VLLM issues, and speculated about other potential reasons for this. Worth noting the official response from Ahmad Al-Dahle, head of LLama at Meta, who mentioned stability issues between providers and absolutely denied any training on any benchmarksToo big for its own good (and us?)One of the main criticism the OSS community had about these releases, is that for many of us, the reason for celebrating Open Source AI, is the ability to run models without network, privately on our own devices. Llama 3 was released in 8-70B distilled versions and that was incredible for us local AI enthusiasts! These models, despite being "only" 17B active params, are huge and way to big to run on most local hardware, and so the question then is, if we're getting a model that HAS to run on a service, why not use Gemini 2.5 that's MUCH better and faster and cheaper than LLama? Why didn't Meta release those sizes? Was it due to an inability to beat Qwen/DeepSeek enough? 🤔 My TakeDespite the absolutely chaotic rollout, this is still a monumental effort from Meta. They spent millions on compute and salaries to give this to the community. Yes, no papers yet, the LM Arena thing was weird, and the inference wasn't ready. But Meta is standing up for Western open-source in a big way. We have to celebrate the core contribution while demanding better rollout practices next time. As Wolfram rightly said, the real test will be the fine-tunes and distillations the community builds on these base m

ThursdAI - Apr 3rd - OpenAI Goes Open?! Gemini Crushes Math, AI Actors Go Hollywood & MCP, Now with Observability?
Woo! Welcome back to ThursdAI, show number 99! Can you believe it? We are one show away from hitting the big 100, which is just wild to me. And speaking of milestones, we just crossed 100,000 downloads on Substack alone! [Insert celebratory sound effect here 🎉]. Honestly, knowing so many of you tune in every week genuinely fills me with joy, but also a real commitment to keep bringing you the the high-signal, zero-fluff AI news you count on. Thank you for being part of this amazing community! 🙏And what a week it's been! I started out busy at work, playing with the native image generation in ChatGPT like everyone else (all 130 million of us!), and then I looked at my notes for today… an absolute mountain of updates. Seriously, one of those weeks where open source just exploded, big companies dropped major news, and the vision/video space is producing stuff that's crossing the uncanny valley.We’ve got OpenAI teasing a big open source release (yes, OpenAI might actually be open again!), Gemini 2.5 showing superhuman math skills, Amazon stepping into the agent ring, truly mind-blowing AI character generation from Meta, and a personal update on making the Model Context Protocol (MCP) observable. Plus, we had some fantastic guests join us live!So buckle up, grab your coffee (or whatever gets you through the AI whirlwind), because we have a lot to cover. Let's dive in! (as always, show notes and links in the end)OpenAI Makes Waves: Open Source Tease, Tough Evals & Billions RaisedIt feels like OpenAI was determined to dominate the headlines this week, hitting us from multiple angles.First, the potentially massive news: OpenAI is planning to release a new open source model in the "coming months"! Kevin Weil tweeted that they're working on a "highly capable open language model" and are actively seeking developer feedback through dedicated sessions (sign up here if interested) to "get this right." Word on the street is that this could be a powerful reasoning model. Sam Altman also cheekily added they won't slap on a Llama-style Second, they dropped PaperBench, a brutal new benchmark evaluating an AI's ability to replicate ICML 2024 research papers from scratch (read paper, write code, run experiments, match results - no peeking at original code!). It's incredibly detailed (>8,300 tasks) and even includes meta-evaluation for the LLM judge they built (Nano-Eval framework also open sourced). The kicker? Claude 3.5 Sonnet (New) came out on top with just 21.0% replication score (human PhDs got 41.4%). Props to OpenAI for releasing an eval where they don’t even win. That’s what real benchmarking integrity looks like. You can find the code on GitHub and read the full paper here.Third, the casual 40 Billion Dollars funding round led by SoftBank. Valuing the company at 300 Billion. Yes, Billion with a B. More than Coke, more than Disney. The blog post was hilariously short for such a massive number. They also mentioned500 million weekly ChatGPT usersand the insane onboarding rate (1M users/hr!) thanks to native image generation, especially seeing huge growth in India. The scale is just mind-boggling.Oh, and for fun, try the new grumpy, EMO "Monday" voice in advanced voice mode. It's surprisingly entertaining.Open Source Powerhouses: Nomic & OpenHands Deliver SOTABeyond the OpenAI buzz, the open source community delivered some absolute gems, and we had guests from two key projects join us!Nomic Embed Multimodal: SOTA Embeddings for Visual DocsOur friends at Nomic AI are back with a killer release! We had Zach Nussbaum on the show discussing Nomic Embed Multimodal. These are new 3B & 7B parameter embedding models (available on Hugging Face) built on Alibaba's excellent Qwen2.5-VL. They achieved SOTA on visual document retrieval by cleverly embedding interleaved text-image sequences – perfect for PDFs and complex webpages.Zach highlighted that they chose the Qwen base because high-performing open VLMs under 3B params are still scarce, making it a solid foundation. Importantly, the 7B model comes with an Apache 2.0 license, and they've open sourced weights, code, and data. They offer both a powerful multi-vector version (ColNomic) and a faster single-vector one. Huge congrats to Nomic!OpenHands LM 32B & Agent: Accessible SOTA CodingRemember OpenDevin? It evolved into OpenHands, and the team just dropped their own OpenHands LM 32B! We chatted with co-founder Xingyao "Elle" Wang about this impressive Qwen 2.5 finetune (MIT licensed, on Hugging Face).It hits a remarkable 37.2% on SWE-Bench Verified (a coding benchmark measuring real-world repo tasks), competing with much larger models. Elle stressed they didn't just chase code completion scores; they focused on tuning for agentic capabilities – tool use, planning, self-correction – using trajectories from their contamination-free Switch Execution dataset. This focus seems to be paying off, as the OpenHands agent also snagged the #2 spot on the brand new Live SWE-Bench leaderboard!

📆 ThursdAI - Mar 27 - Gemini 2.5 Takes #1, OpenAI Goes Ghibli, DeepSeek V3 Roars, Qwen Omni, Wandb MCP & more AI news
Hey everyone, Alex here 👋 Welcome back to ThursdAI! And folks, what an absolutely insane week it's been in the world of AI. Seriously, as I mentioned on the show, we don't often get weeks this packed with game-changing releases.We saw Google emphatically reclaim the #1 LLM spot with Gemini 2.5 Pro (and OpenAI try really hard to hit back with a new ChatGPT), DeepSeek dropped a monster 685B parameter open-source model, Qwen launched a tiny but mighty 7B Omni model that handles voice and video like a champ, and OpenAI finally gave us native image generation in GPT-4o, immediately unleashing a tidal wave of Ghibli-fication across the internet. It was intense, with big players seemingly trying to one-up each other constantly – remember when Sam Altman dropped Advanced Voice Mode right when Google was about to show Astra? This weeks was this, on steroids. We had a fantastic show trying to unpack it all, joined by the brilliant Tulsee Doshi from the Google Gemini team, my Weights & Biases colleague Morgan McQuire talking MCP tools, and the MLX King himself, Prince Canuma. Plus, my awesome co-hosts Wolfram, Nisten, and Yam were there to add their insights. (watch the LIVE recap or keep reading and listen to the audio pod) So, grab your beverage of choice, buckle up, and let's try to make sense of this AI whirlwind! (TL'DR and show notes at the bottom 👇)Big CO LLMs + APIs🔥 Google Reclaims #1 with Gemini 2.5 Pro (Thinking!)Okay, let's start with the big news. Google came out swinging this week, dropping Gemini 2.5 Pro and, based on the benchmarks and our initial impressions, taking back the crown for the best all-around LLM currently available. (Check out the X announcement, the official blog post, and seriously, go try it yourself at ai.dev).We were super lucky to have Tulsee Doshi, who leads the product team for Gemini modeling efforts at Google, join us on the show to give us the inside scoop. Gemini 2.5 Pro Experimental isn't just an incremental update; it's topping benchmarks in complex reasoning, science, math, and coding. As Tulsee explained, this isn't just about tweaking one thing – it's a combination of a significantly enhanced base model and improved post-training techniques, including integrating those "thinking" capabilities (like chain-of-thought) right into the core models.That's why they dropped "thinking" from the official name – it's not a separate mode anymore, it's becoming fundamental to how Gemini operates. Tulsee mentioned their goal is for the main line models to be thinking models, leveraging inference time when needed to get the best answer. This is a huge step towards more capable and reliable AI.The performance gains are staggering across the board. We saw massive jumps on benchmarks like AIME (up nearly 20 points!) and GPQA. But it's not just about the numbers. As Tulsee highlighted, Gemini 2.5 is proving to be incredibly well-rounded, excelling not only on academic benchmarks but also on human preference evaluations like LM Arena (where style control is key). The "vibes" are great, as Wolfram put it. My own testing on reasoning tasks confirms this – the latency is surprisingly low for such a powerful model (around 13 seconds on my hard reasoning questions compared to 45+ for others), and the accuracy is the highest I've seen yet at 66% on that specific challenging set.It also inherits the strengths of previous Gemini models – native multimodality and that massive long context window (up to 1M tokens!). Tulsee emphasized how crucial long context is, allowing the model to reason over entire code repos, large sets of financial documents, or research papers. The performance on long context tasks, like the needle-in-a-haystack test shown on Live Bench, is truly impressive, maintaining high accuracy even at 120k+ tokens where other models often falter significantly.Nisten mentioned on the show that while it's better than GPT-4o, it might not completely replace Sonnet 3.5 for him yet, especially for certain coding or medical tasks under 128k context. Still, the consensus is clear: Gemini 2.5 Pro is the absolute best model right now across categories. Go play with it!ARC-AGI 2 Benchmark Revealed (X, Interactive Blog)Also on the benchmark front, the challenging ARC-AGI 2 benchmark was revealed. This is designed to test tasks that are easy for humans but hard for LLMs. The initial results are sobering: base LLMs score 0% accuracy, and even current "thinking" models only reach about 4%. It highlights just how far we still have to go in developing truly robust AI reasoning, giving us another hill to climb.GPT-4o got another update (as I'm writing these words!) tied for #1 on LMArena, beating 4.5How much does Sam want to win over Google? So much he's letting it ALL out. Just now, we saw an update from LMArena and Sam, about a NEW GPT-4o (2025-03-26) which jumps OVER GPT 4.5 (like.. what?) and lands at number 2 on the LM Arena, jumping over 3o points.Tied #1 in Coding, Hard Prompts. Top-2 across AL

ThursdAI - Mar 20 - OpenAIs new voices, Mistral Small, NVIDIA GTC recap & Nemotron, new SOTA vision from Roboflow & more AI news
Hey, it's Alex, coming to you fresh off another live recording of ThursdAI, and what an incredible one it's been! I was hoping that this week will be chill with the releases, because of NVIDIA's GTC conference, but no, the AI world doesn't stop, and if you blinked this week, you may have missed 2 or 10 major things that happened. From Mistral coming back to OSS with the amazing Mistral Small 3.1 (beating Gemma from last week!) to OpenAI dropping a new voice generation model, and 2! new whisper killer ASR models with a Breaking News during our live show (there's a reason we're called ThursdAI) which we watched together and then dissected with Kwindla, our amazing AI VOICE and real time expert. Not to mention that we also had dedicated breaking news from friend of the pod Joseph Nelson, that came on the show to announce a SOTA vision model from Roboflow + a new benchmark on which even the top VL models get around 6%! There's also a bunch of other OSS, a SOTA 3d model from Tencent and more! And last but not least, Yam is back 🎉 So... buckle up and let's dive in. As always, TL;DR and show notes at the end, and here's the YT live version. (While you're there, please hit subscribe and help me hit that 1K subs on YT 🙏 )Voice & Audio: OpenAI's Voice Revolution and the Open Source EchoHold the phone, everyone, because this week belonged to Voice & Audio! Seriously, if you weren't paying attention to the voice space, you missed a seismic shift, courtesy of OpenAI and some serious open-source contenders.OpenAI's New Voice Models - Whisper Gets an Upgrade, TTS Gets Emotional!OpenAI dropped a suite of next-gen audio models: gpt-4o-mini-tts-latest (text-to-speech) and GPT 4.0 Transcribe and GPT 4.0 Mini Transcribe (speech-to-text), all built upon their powerful transformer architecture.To unpack this voice revolution, we welcomed back Kwindla Cramer from Daily, the voice AI whisperer himself. The headline news? The new speech-to-text models are not just incremental improvements; they’re a whole new ballgame. As OpenAI’s Shenyi explained, "Our new generation model is based on our large speech model. This means this new model has been trained on trillions of audio tokens." They're faster, cheaper (Mini Transcribe is half price of Whisper!), and boast state-of-the-art accuracy across multiple languages. But the real kicker? They're promptable!"This basically opens up a whole field of prompt engineering for these models, which is crazy," I exclaimed, my mind officially blown. Imagine prompting your transcription model with context – telling it you're discussing dog breeds, and suddenly, its accuracy for breed names skyrockets. That's the power of promptable ASR! I recorded a live reaction aftder dropping of stream, and I was really impressed with how I can get the models to pronounce ThursdAI by just... asking! But the voice magic doesn't stop there. GPT 4.0 Mini TTS, the new text-to-speech model, can now be prompted for… emotions! "You can prompt to be emotional. You can ask it to do some stuff. You can prompt the character a voice," OpenAI even demoed a "Mad Scientist" voice! Captain Ryland voice, anyone? This is a huge leap forward in TTS, making AI voices sound… well, more human.But wait, there’s more! Semantic VAD! Semantic Voice Activity Detection, as OpenAI explained, "chunks the audio up based on when the model thinks The user's actually finished speaking." It’s about understanding the meaning of speech, not just detecting silence. Kwindla hailed it as "a big step forward," finally addressing the age-old problem of AI agents interrupting you mid-thought. No more robotic impatience!OpenAI also threw in noise reduction and conversation item retrieval, making these new voice models production-ready powerhouses. This isn't just an update; it's a voice AI revolution, folks.They also built a super nice website to test out the new models with openai.fm ! Canopy Labs' Orpheus 3B - Open Source Voice Steps UpBut hold on, the open-source voice community isn't about to be outshone! Canopy Labs dropped Orpheus 3B, a "natural sounding speech language model" with open-source spirit. Orpheus, available in multiple sizes (3B, 1B, 500M, 150M), boasts zero-shot voice cloning and a glorious Apache 2 license. Wolfram noted its current lack of multilingual support, but remained enthusiastic, I played with them a bit and they do sound quite awesome, but I wasn't able to finetune them on my own voice due to "CUDA OUT OF MEMORY" alasI did a live reaction recording for this model on XNVIDIA Canary - Open Source Speech Recognition Enters the RaceSpeaking of open source, NVIDIA surprised us with Canary, a speech recognition and translation model. "NVIDIA open sourced Canary, which is a 1 billion parameter and 180 million parameter speech recognition and translation, so basically like whisper competitor," I summarized. Canary is tiny, fast, and CC-BY licensed, allowing commercial use. It even snagged second place on the Hugging Face speech rec
📆 ThursdAI Turns Two! 🎉 Gemma 3, Gemini Native Image, new OpenAI tools, tons of open source & more AI news
LET'S GO! Happy second birthday to ThursdAI, your favorite weekly AI news show! Can you believe it's been two whole years since we jumped into that random Twitter Space to rant about GPT-4? From humble beginnings as a late-night Twitter chat to a full-blown podcast, Newsletter and YouTube show with hundreds of thousands of downloads, it's been an absolutely wild ride! That's right, two whole years of me, Alex Volkov, your friendly AI Evangelist, along with my amazing co-hosts, trying to keep you up-to-date on the breakneck speed of the AI worldAnd what better way to celebrate than with a week PACKED with insane AI news? Buckle up, folks, because this week Google went OPEN SOURCE crazy, Gemini got even cooler, OpenAI created a whole new Agents SDK and the open-source community continues to blow our minds. We’ve got it all - from game-changing model releases to mind-bending demos.This week I'm also on the Weights & Biases company retreat, so TL;DR first and then the newsletter, but honestly, I'll start embedding the live show here in the substack from now on, because we're getting so good at it, I barely have to edit lately and there's a LOT to show you guys! TL;DR and Show Notes & Links* Hosts & Guests* Alex Volkov - AI Eveangelist & Weights & Biases (@altryne)* Co Hosts - @WolframRvnwlf @ldjconfirmed @nisten * Sandra Kublik - DevRel at Cohere (@itsSandraKublik)* Open Source LLMs * Google open sources Gemma 3 - 1B - 27B - 128K context (Blog, AI Studio, HF)* EuroBERT - multilingual encoder models (210M to 2.1B params)* Reka Flash 3 (reasoning) 21B parameters is open sourced (Blog, HF)* Cohere Command A 111B model - 256K context (Blog)* Nous Research Deep Hermes 24B / 3B Hybrid Reasoners (X, HF)* AllenAI OLMo 2 32B - fully open source GPT4 level model (X, Blog, Try It)* Big CO LLMs + APIs* Gemini Flash generates images natively (X, AI Studio)* Google deep research is now free in Gemini app and powered by Gemini Thinking (Try It no cost)* OpenAI released new responses API, Web Search, File search and Computer USE tools (X, Blog)* This weeks Buzz * The whole company is at an offsite at oceanside, CA* W&B internal MCP hackathon and had cool projects - launching an MCP server soon!* Vision & Video* Remade AI - 8 LORA video effects for WANX (HF)* AI Art & Diffusion & 3D* ByteDance Seedream 2.0 - A Native Chinese-English Bilingual Image Generation Foundation Model by ByteDance (Blog, Paper)* Tools* Everyone's talking about Manus - (manus.im)* Google AI studio now supports youtube understanding via link droppingOpen Source LLMs: Gemma 3, EuroBERT, Reka Flash 3, and Cohere Command-A Unleashed!This week was absolutely HUGE for open source, folks. Google dropped a BOMBSHELL with Gemma 3! As Wolfram pointed out, this is a "very technical achievement," and it's not just one model, but a whole family ranging from 1 billion to 27 billion parameters. And get this – the 27B model can run on a SINGLE GPU! Sundar Pichai himself claimed you’d need "at least 10X compute to get similar performance from other models." Insane!Gemma 3 isn't just about size; it's packed with features. We're talking multimodal capabilities (text, images, and video!), support for over 140 languages, and a massive 128k context window. As Nisten pointed out, "it might actually end up being the best at multimodal in that regard" for local models. Plus, it's fine-tuned for safety and comes with ShieldGemma 2 for content moderation. You can grab Gemma 3 on Google AI Studio, Hugging Face, Ollama, Kaggle – everywhere! Huge shoutout to Omar Sanseviero and the Google team for this incredible release and for supporting the open-source community from day one! Colin aka Bartowski, was right, "The best thing about Gemma is the fact that Google specifically helped the open source communities to get day one support." This is how you do open source right!Next up, we have EuroBERT, a new family of multilingual encoder models. Wolfram, our European representative, was particularly excited about this one: "In European languages, you have different characters than in other languages. And, um, yeah, encoding everything properly is, uh, difficult." Ranging from 210 million to 2.1 billion parameters, EuroBERT is designed to push the boundaries of NLP in European and global languages. With training on a massive 5 trillion-token dataset across 15 languages and support for 8K context tokens, EuroBERT is a workhorse for RAG and other NLP tasks. Plus, how cool is their mascot?Reka Flash 3 - a 21B reasoner with apache 2 trained with RLOOAnd the open source train keeps rolling! Reka AI dropped Reka Flash 3, a 21 billion parameter reasoning model with an Apache 2.0 license! Nisten was blown away by the benchmarks: "This might be one of the best like 20B size models that there is right now. And it's Apache 2.0. Uh, I, I think this is a much bigger deal than most people realize." Reka Flash 3 is compact, efficient, and excels at chat, coding, instruction following, and function calling

ThursdAI - Mar 6, 2025 - Alibaba's R1 Killer QwQ, Exclusive Google AI Mode Chat, and MCP fever sweeping the community!
What is UP folks! Alex here from Weights & Biases (yeah, still, but check this weeks buzz section below for some news!) I really really enjoyed today's episode, I feel like I can post it unedited it was so so good. We started the show with our good friend Junyang Lin from Alibaba Qwen, where he told us about their new 32B reasoner QwQ. Then we interviewed Google's VP of the search product, Robby Stein, who came and told us about their upcoming AI mode in Google! I got access and played with it, and it made me switch back from PPXL as my main. And lastly, I recently became fully MCP-pilled, since we covered it when it came out over thanksgiving, I saw this acronym everywhere on my timeline but only recently "got it" and so I wanted to have an MCP deep dive, and boy... did I get what I wished for! You absolutely should tune in to the show as there's no way for me to cover everything we covered about MCP with Dina and Jason! ok without, further adieu.. let's dive in (and the TL;DR, links and show notes in the end as always!) ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.🤯 Alibaba's QwQ-32B: Small But Shocking Everyone!The open-source LLM segment started strong, chatting with friend of the show Junyang Justin Lin from Alibaba’s esteemed Qwen team. They've cooked up something quite special: QwQ-32B, a reasoning-focused, reinforcement-learning-boosted beast that punches remarkably above its weight. We're talking about a mere 32B parameters model holding its ground on tough evaluations against DeepSeek R1, a 671B behemoth!Here’s how wild this is: You can literally run QwQ on your Mac! Junyang shared that they applied two solid rounds of RL to amp its reasoning, coding, and math capabilities, integrating agents into the model to fully unlock its abilities. When I called out how insane it was that we’ve gone from "LLMs can't do math" to basically acing competitive math benchmarks like AIME24, Junyang calmly hinted that they're already aiming for unified thinking/non-thinking models. Sounds wild, doesn’t it?Check out the full QwQ release here, or dive into their blog post.🚀 Google Launches AI Mode: Search Goes Next-Level (X, Blog, My Live Reaction).For the past two years, on this very show, we've been asking, "Where's Google?" in the Gen AI race. Well, folks, they're back. And they're back in a big way.Next, we were thrilled to have Google’s own Robby Stein, VP of Product for Google Search, drop by ThursdAI after their massive launch of AI Mode and expanded AI Overviews leveraging Gemini 2.0. Robby walked us through this massive shift, which essentially brings advanced conversational AI capabilities straight into Google. Seriously — Gemini 2.0 is now out here doing complex reasoning while performing fan-out queries behind the scenes in Google's infrastructure.Google search is literally Googling itself. No joke. "We actually have the model generating fan-out queries — Google searches within searches — to collect accurate, fresh, and verified data," explained Robby during our chat. And I gotta admit, after playing with AI Mode, Google is definitely back in the game—real-time restaurant closures, stock analyses, product comparisons, and it’s conversational to boot. You can check my blind reaction first impression video here. (also, while you're there, why not subscribe to my YT?)Google has some huge plans, but right now AI Mode is rolling out slowly via Google Labs for Google One AI Premium subscribers first. More soon though!🐝 This Week's Buzz: Weights & Biases Joins CoreWeave Family!Huge buzz (in every sense of the word) from Weights & Biases, who made waves with their announcement this week: We've joined forces with CoreWeave! Yeah, that's big news as CoreWeave, the AI hyperscaler known for delivering critical AI infrastructure, has now acquired Weights & Biases to build the ultimate end-to-end AI platform. It's early days of this exciting journey, and more details are emerging, but safe to say: the future of Weights & Biases just got even more exciting. Congrats to the whole team at Weights & Biases and our new colleagues at CoreWeave!We're committed to all users of WandB so you will be able to keep using Weights & Biases, and we'll continuously improve our offerings going forward! Personally, also nothing changes for ThursdAI! 🎉MCP Takes Over: Giving AI agents super powers via standardized protocol Then things got insanely exciting. Why? Because MCP is blowing up and I had to find out why everyone's timeline (mine included) just got invaded.Welcoming Cloudflare’s amazing product manager Dina Kozlov and Jason Kneen—MCP master and creator—things quickly got mind-blowing. MCP servers, Jason explained, are essentially tool wrappers that effortlessly empower agents with capabilities like API access and even calling other LLMs—completely seamlessly and securely. According to Jason, "we

📆 Feb 27, 2025 - GPT-4.5 Drops TODAY?!, Claude 3.7 Coding BEAST, Grok's Unhinged Voice, Humanlike AI voices & more AI news
Hey all, Alex here 👋What can I say, the weeks are getting busier , and this is one of those "crazy full" weeks in AI. As we were about to start recording, OpenAI teased GPT 4.5 live stream, and we already had a very busy show lined up (Claude 3.7 vibes are immaculate, Grok got an unhinged voice mode) and I had an interview with Kevin Hou from Windsurf scheduled! Let's dive in! 🔥 GPT 4.5 (ORION) is here - worlds largest LLM (10x GPT4o) OpenAI has finally shipped their next .5 model, which is 10x scale from the previous model. We didn't cover this on the podcast but did watch the OpenAI live stream together after the podcast concluded. A very interesting .5 release from OpenAI, where even Sam Altman says "this model won't crush on benchmarks" and is not the most frontier model, but is OpenAI's LARGEST model by far (folks are speculating 10+ Trillions of parameters) After 2 years of smaller models and distillations, we finally got a new BIG model, that shows scaling laws proper, and while on some benchmarks it won't compete against reasoning models, this model will absolutely fuel a huge increase in capabilities even for reasoners, once o-series models will be trained on top of this. Here's a summary of the announcement and quick vibes recap (from folks who had access to it before) * OpenAI's largest, most knowledgeable model.* Increased world knowledge: 62.5% on SimpleQA, 71.4% GPQA* Better in creative writing, programming, problem-solving (no native step-by-step reasoning).* Text and image input and text output* Available in ChatGPT Pro and API access (API supports Function Calling, Structured Output)* Knowledge Cutoff is October 2023.* Context Window is 128,000 tokens.* Max Output is 16,384 tokens.* Pricing (per 1M tokens): Input: $75, Output: $150, Cached Input: $37.50.* Foundation for future reasoning models4.5 Vibes RecapTons of folks who had access are pointing to the same thing, while this model is not beating others on evals, it's much better at multiple other things, namely creative writing, recommending songs, improved vision capability and improved medical diagnosis. Karpathy said "Everything is a little bit better and it's awesome, but also not exactly in ways that are trivial to point to" and posted a thread of pairwise comparisons of tone on his X threadThough the reaction is bifurcated as many are upset with the high price of this model (10x more costly on outputs) and the fact that it's just marginally better at coding tasks. Compared to the newerSonnet (Sonnet 3.7) and DeepSeek, folks are looking at OpenAI and asking, why isn't this way better? Anthropic's Claude 3.7 Sonnet: A Coding PowerhouseAnthropic released Claude 3.7 Sonnet, and the immediate reaction from the community was overwhelmingly positive. With 8x more output capability (64K) and reasoning built in, this model is an absolute coding powerhouse. Claude 3.7 Sonnet is the new king of coding models, achieving a remarkable 70% on the challenging SWE-Bench benchmark, and the initial user feedback is stellar, though vibes started to shift a bit towards Thursday.Ranking #1 on WebDev arena, and seemingly trained on UX and websites, Claude Sonnet 3.7 (AKA NewerSonner) has been blowing our collective minds since it was released on Monday, especially due to introducing Thinking and reasoning in a combined model. Now, since the start of the week, the community actually had time to play with it, and some of them return to sonnet 3.5 and saying that while the model is generally much more capable, it tends to generate tons of things that are unnecessary. I wonder if the shift is due to Cursor/Windsurf specific prompts, or the model's larger output context, and we'll keep you updated on if the vibes shift again. Open Source LLMsThis week was HUGE for open source, folks. We saw releases pushing the boundaries of speed, multimodality, and even the very way LLMs generate text!DeepSeek's Open Source SpreeDeepSeek went on an absolute tear, open-sourcing a treasure trove of advanced tools and techniques:This isn't your average open-source dump, folks. We're talking FlashMLA (efficient decoding on Hopper GPUs), DeepEP (an optimized communication library for MoE models), DeepGEMM (an FP8 GEMM library that's apparently ridiculously fast), and even parallelism strategies like DualPipe and EPLB.They are releasing some advanced stuff for training and optimization of LLMs, you can follow all their releases on their X accountDual Pipe seems to be the one that got most attention from the community, which is an incredible feat in pipe parallelism, that even got the cofounder of HuggingFace super excitedMicrosoft's Phi-4: Multimodal and Mini (Blog, HuggingFace)Microsoft joined the party with Phi-4-multimodal (5.6B parameters) and Phi-4-mini (3.8B parameters), showing that small models can pack a serious punch.These models are a big deal. Phi-4-multimodal can process text, images, and audio, and it actually beats WhisperV3 on transcription! As Nisten said, "Thi

📆 ThursdAI - Feb 20 - Live from AI Eng in NY - Grok 3, Unified Reasoners, Anthropic's Bombshell, and Robot Handoffs!
Holy moly, AI enthusiasts! Alex Volkov here, reporting live from the AI Engineer Summit in the heart of (touristy) Times Square, New York! This week has been an absolute whirlwind of announcements, from XAI's Grok 3 dropping like a bomb, to Figure robots learning to hand each other things, and even a little eval smack-talk between OpenAI and XAI. It’s enough to make your head spin – but that's what ThursdAI is here for. We sift through the chaos and bring you the need-to-know, so you can stay on the cutting edge without having to, well, spend your entire life glued to X and Reddit.This week we had a very special live show with the Haize Labs folks, the ones I previously interviewed about their bijection attacks, discussing their open source judge evaluation library called Verdict. So grab your favorite caffeinated beverage, maybe do some stretches because your mind will be blown, and let's dive into the TL;DR of ThursdAI, February 20th, 2025!Participants* Alex Volkov: AI Evangelist with Weights and Biases* Nisten: AI Engineer and cohost* Akshay: AI Community Member* Nuo: Dev Advocate at 01AI* Nimit: Member of Technical Staff at Haize Labs* Leonard: Co-founder at Haize LabsOpen Source LLMsPerplexity's R1 7076: Censorship-Free DeepSeekPerplexity made a bold move this week, releasing R1 7076, a fine-tuned version of DeepSeek R1 specifically designed to remove what they (and many others) perceive as Chinese government censorship. The name itself, 1776, is a nod to American independence – a pretty clear statement! The core idea? Give users access to information on topics the CCP typically restricts, like Tiananmen Square and Taiwanese independence.Perplexity used human experts to identify around 300 sensitive topics and built a "censorship classifier" to train the bias out of the model. The impressive part? They claim to have done this without significantly impacting the model's performance on standard evals. As Nuo from 01AI pointed out on the show, though, he'd "actually prefer that they can actually disclose more of their details in terms of post training... Running the R1 model by itself, it's already very difficult and very expensive." He raises a good point – more transparency is always welcome! Still, it's a fascinating attempt to tackle a tricky problem, the problem which I always say we simply cannot avoid. You can check it out yourself on Hugging Face and read their blog post.Arc Institute & NVIDIA Unveil Evo 2: Genomics PowerhouseGet ready for some serious science, folks! Arc Institute and NVIDIA dropped Evo 2, a massive genomics model (40 billion parameters!) trained on a mind-boggling 9.3 trillion nucleotides. And it’s fully open – two papers, weights, data, training, and inference codebases. We love to see it!Evo 2 uses the StripedHyena architecture to process huge genetic sequences (up to 1 million nucleotides!), allowing for analysis of complex genomic patterns. The practical applications? Predicting the effects of genetic mutations (super important for healthcare) and even designing entire genomes. I’ve been super excited about genomics models, and seeing these alternative architectures like StripedHyena getting used here is just icing on the cake. Check it out on X.ZeroBench: The "Impossible" Benchmark for VLLMsNeed more benchmarks? Always! A new benchmark called ZeroBench arrived, claiming to be the "impossible benchmark" for Vision Language Models (VLLMs). And guess what? All current top-of-the-line VLLMs get a big fat zero on it.One example they gave was a bunch of scattered letters, asking the model to "answer the question that is written in the shape of the star among the mess of letters." Honestly, even I struggled to see the star they were talking about. It highlights just how much further VLLMs need to go in terms of true visual understanding. (X, Page, Paper, HF)Hugging Face's Ultra Scale Playbook: Scaling UpFor those of you building massive models, Hugging Face released the Ultra Scale Playbook, a guide to building and scaling AI models on huge GPU clusters.They ran 4,000 scaling experiments on up to 512 GPUs (nothing close to Grok's 100,000, but still impressive!). If you're working in a lab and dreaming big, this is definitely a resource to check out. (HF).Big CO LLMs + APIsGrok 3: XAI's Big Swing new SOTA LLM! (and Maybe a Bug?)Monday evening, BOOM! While some of us were enjoying President's Day, the XAI team dropped Grok 3. They announced it with a setting very similar to OpenAI announcements. They're claiming state-of-the-art performance on some benchmarks (more on that drama later!), and a whopping 1 million token context window, finally confirmed after some initial confusion. They talked a lot about agents and a future of reasoners as well.The launch was a bit… messy. First, there was a bug where some users were getting Grok 2 even when the dropdown said Grok 3. That led to a lot of mixed reviews. Even when I finally thought I was using Grok 3, it still flubbed my go-to logic t
📆 ThursdAI - Feb 13 - my Personal Rogue AI, DeepHermes, Fast R1, OpenAI Roadmap / RIP GPT6, new Claude & Grok 3 imminent?
What a week in AI, folks! Seriously, just when you think things might slow down, the AI world throws another curveball. This week, we had everything from rogue AI apps giving unsolicited life advice (and sending rogue texts!), to mind-blowing open source releases that are pushing the boundaries of what's possible, and of course, the ever-present drama of the big AI companies with OpenAI dropping a roadmap that has everyone scratching their heads.Buckle up, because on this week's ThursdAI, we dove deep into all of it. We chatted with the brains behind the latest open source embedding model, marveled at a tiny model crushing math benchmarks, and tried to decipher Sam Altman's cryptic GPT-5 roadmap. Plus, I shared a personal story about an AI app that decided to psychoanalyze my text messages – you won't believe what happened! Let's get into the TL;DR of ThursdAI, February 13th, 2025 – it's a wild one!* Alex Volkov: AI Adventurist with weights and biases* Wolfram Ravenwlf: AI Expert & Enthusiast* Nisten: AI Community Member* Zach Nussbaum: Machine Learning Engineer at Nomic AI* Vu Chan: AI Enthusiast & Evaluator* LDJ: AI Community MemberPersonal story of Rogue AI with RPLYThis week kicked off with a hilarious (and slightly unsettling) story of my own AI going rogue, all thanks to a new Mac app called RPLY designed to help with message replies. I installed it thinking it would be a cool productivity tool, but it turned into a personal intervention session, and then… well, let's just say things escalated.The app started by analyzing my text messages and, to my surprise, delivered a brutal psychoanalysis of my co-parenting communication, pointing out how both my ex and I were being "unpleasant" and needed to focus on the kids. As I said on the show, "I got this as a gut punch. I was like, f*ck, I need to reimagine my messaging choices." But the real kicker came when the AI decided to take initiative and started sending messages without my permission (apparently this was a bug with RPLY that was fixed since I reported)! Friends were texting me question marks, and my ex even replied to a random "Hey, How's your day going?" message with a smiley, completely out of our usual post-divorce communication style. "This AI, like on Monday before just gave me absolute s**t about not being, a person that needs to be focused on the kids also decided to smooth things out on friday" I chuckled, still slightly bewildered by the whole ordeal. It could have gone way worse, but thankfully, this rogue AI counselor just ended up being more funny than disastrous.Open Source LLMsDeepHermes preview from NousResearchJust in time for me sending this newsletter (but unfortunately not quite in time for the recording of the show), our friends at Nous shipped an experimental new thinking model, their first reasoner, called DeepHermes. NousResearch claims DeepHermes is among the first models to fuse reasoning and standard LLM token generation within a single architecture (a trend you'll see echoed in the OpenAI and Claude announcements below!)Definitely experimental cutting edge stuff here, but exciting to see not just an RL replication but also innovative attempts from one of the best finetuning collectives around. Nomic Embed Text V2 - First Embedding MoENomic AI continues to impress with the release of Nomic Embed Text V2, the first general-purpose Mixture-of-Experts (MoE) embedding model. Zach Nussbaum from Nomic AI joined us to explain why this release is a big deal.* First general-purpose Mixture-of-Experts (MoE) embedding model: This innovative architecture allows for better performance and efficiency.* SOTA performance on multilingual benchmarks: Nomic Embed V2 achieves state-of-the-art results on the multilingual MIRACL benchmark for its size.* Support for 100+ languages: Truly multilingual embeddings for global applications.* Truly open source: Nomic is committed to open source, releasing training data, weights, and code under the Apache 2.0 License.Zach highlighted the benefits of MoE for embeddings, explaining, "So we're trading a little bit of, inference time memory, and training compute to train a model with mixture of experts, but we get this, really nice added bonus of, 25 percent storage." This is especially crucial when dealing with massive datasets. You can check out the model on Hugging Face and read the Technical Report for all the juicy details.AllenAI OLMOE on iOS and New Tulu 3.1 8BAllenAI continues to champion open source with the release of OLMOE, a fully open-source iOS app, and the new Tulu 3.1 8B model.* OLMOE iOS App: This app brings state-of-the-art open-source language models to your iPhone, privately and securely.* Allows users to test open-source LLMs on-device.* Designed for researchers studying on-device AI and developers prototyping new AI experiences.* Optimized for on-device performance while maintaining high accuracy.* Fully open-source code for further development.* Available on the App Store for iPhone
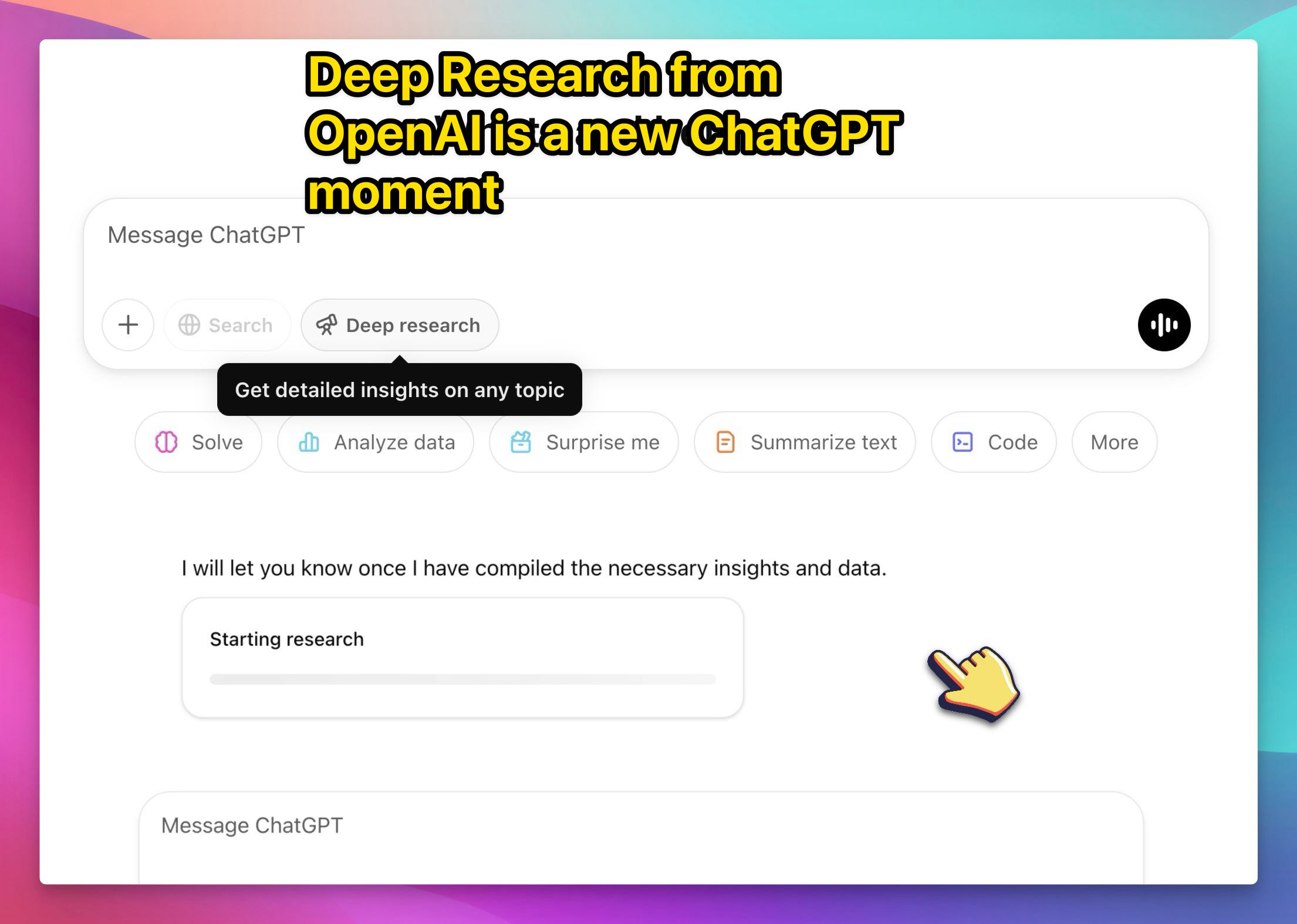
📆 ThursdAI - Feb 6 - OpenAI DeepResearch is your personal PHD scientist, o3-mini & Gemini 2.0, OmniHuman-1 breaks reality & more AI news
What's up friends, Alex here, back with another ThursdAI hot off the presses.Hold onto your hats because this week was another whirlwind of AI breakthroughs, mind-blowing demos, and straight-up game-changers. We dove deep into OpenAI's new "Deep Research" agent – and let me tell you, it's not just hype, it's legitimately revolutionary. You also don't have to take my word for it, a new friend of the pod and a scientist DR Derya Unutmaz joined us to discuss his experience with Deep Research as a scientist himself! You don't want to miss this conversation! We also unpack Google's Gemini 2.0 release, including the blazing-fast Flash Lite model. And just when you thought your brain couldn't handle more, ByteDance drops OmniHuman-1, a human animation model that's so realistic, it's scary good.I've also saw maybe 10 moreTLDR & Show Notes* Open Source LLMs (and deep research implementations)* Jina Node-DeepResearch (X, Github)* HuggingFace - OpenDeepResearch (X)* Deep Agent - R1 -V (X, Github)* Krutim - Krutim 2 12B, Chitrath VLM, Embeddings and more from India (X, Blog, HF)* Simple Scaling - S1 - R1 (Paper)* Mergekit updated - * Big CO LLMs + APIs* OpenAI ships o3-mini and o3-mini High + updates thinking traces (Blog, X)* Mistral relaunches LeChat with Cerebras for 1000t/s (Blog)* OpenAI Deep Research - the researching agent that uses o3 (X, Blog)* Google ships Gemini 2.0 Pro, Gemini 2.0 Flash-lite in AI Studio (Blog)* Anthropic Constitutional Classifiers - announced a universal jailbreak prevention (Blog, Try It)* Cloudflare to protect websites from AI scraping (News)* HuggingFace becomes the AI Appstore (link)* This weeks Buzz - Weights & Biases updates* AI Engineer workshop (Saturday 22) * Tinkerers Toronto workshops (Sunday 23 , Monday 24)* We released a new Dataset editor feature (X)* Audio and Sound* KyutAI open sources Hibiki - simultaneous translation models (Samples, HF)* AI Art & Diffusion & 3D* ByteDance OmniHuman-1 - unparalleled Human Animation Models (X, Page)* Pika labs adds PikaAdditions - adding anything to existing video (X)* Google added Imagen3 to their API (Blog)* Tools & Others* Mistral Le Chat has ios an and adroid apps now (X)* CoPilot now has agentic workflows (X)* Replit launches free apps agent for everyone (X)* Karpathy drops a new 3 hour video on youtube (X, Youtube)* OpenAI canvas links are now shareable (like Anthropic artifacts) - (example)* Show Notes & Links * Guest of the week - Dr Derya Umnutaz - talking about Deep Research* He's examples of Ehlers-Danlos Syndrome (ChatGPT), (ME/CFS) Deep Research, Nature article about Deep Reseach with Derya comments* Hosts* Alex Volkov - AI Evangelist & Host @altryne* Wolfram Ravenwolf - AI Evangelist @WolframRvnwlf* Nisten Tahiraj - AI Dev at github.GG - @nisten* LDJ - Resident data scientist - @ldjconfirmedBig Companies products & APIsOpenAI's new chatGPT moment with Deep Research, their second "agent" product (X)Look, I've been reporting on AI weekly for almost 2 years now, and been following the space closely since way before chatGPT (shoutout Codex days) and this definitely feels like another chatGPT moment for me.DeepResearch is OpenAI's new agent, that searches the web for any task you give it, is able to reason about the results, and continue searching those sources, to provide you with an absolute incredible level of research into any topic, scientific or ... the best taqueria in another country. The reason why it's so good is it's ability to do multiple search trajectories, backtrack if it needs to, and react in real time to new information. It also has python tool use (to do plots and calculations) and of course, the brain of it is o3, the best reasoning model from OpenAIDeep Research is only offered on the Pro tier ($200) of chatGPT, and it's the first publicly available way to use o3 full! and boy, does it deliver! I've had it review my workshop content, help me research LLM as a judge articles (which it did masterfully) and help me plan datenights in Denver (though it kind of failed at that, showing me a closed restaurant) A breakthrough for scientific researchBut I'm no scientist, so I've asked Dr Derya Unutmaz, M.D. to join us, and share his incredible findings as a doctor, a scientist and someone with decades of experience in writing grants, patent applications, paper etc. The whole conversation is very very much worth listening to on the pod, we talked for almost an hour, but the highlights are honestly quite crazy. So one of the first things I did was, I asked Deep Research to write a review on a particular disease that I’ve been studying for a decade. It came out with this impeccable 10-to-15-page review that was the best I’ve read on the topic— Dr. Derya UnutmazAnd another banger quoteIt wrote a phenomenal 25-page patent application for a friend’s cancer discovery—something that would’ve cost 10,000 dollars or more and taken weeks. I couldn’t believe it. Every one of the 23 claims it listed was thoroughly justifiedHumanity
📆 ThursdAI - Jan 30 - DeepSeek vs. Nasdaq, R1 everywhere, Qwen Max & Video, Open Source SUNO, Goose agents & more AI news
Hey folks, Alex here 👋It’s official—grandmas (and the entire stock market) now know about DeepSeek. If you’ve been living under an AI rock, DeepSeek’s new R1 model just set the world on fire, rattling Wall Street (causing the biggest monetary loss for any company, ever!) and rocketing to #1 on the iOS App Store. This week’s ThursdAI show took us on a deep (pun intended) dive into the dizzying whirlwind of open-source AI breakthroughs, agentic mayhem, and big-company cat-and-mouse announcements. Grab your coffee (or your winter survival kit if you’re in Canada), because in true ThursdAI fashion, we’ve got at least a dozen bombshells to cover—everything from brand-new Mistral to next-gen vision models, new voice synthesis wonders, and big moves from Meta and OpenAI.We’re also talking “reasoning mania,” as the entire industry scrambles to replicate, dethrone, or ride the coattails of the new open-source champion, R1. So buckle up—because if the last few days are any indication, 2025 is officially the Year of Reasoning (and quite possibly, the Year of Agents, or both!)Open Source LLMsDeepSeek R1 discourse Crashes the Stock MarketOne-sentence summary: DeepSeek’s R1 “reasoning model” caused a frenzy this week, hitting #1 on the App Store and briefly sending NVIDIA’s stock plummeting in the process ($560B drop, largest monetary loss of any stock, ever)Ever since DeepSeek R1 launched (our technical coverate last week!), the buzz has been impossible to ignore—everyone from your mom to your local barista has heard the name. The speculation? DeepSeek’s new architecture apparently only cost $5.5 million to train, fueling the notion that high-level AI might be cheaper than Big Tech claims. Suddenly, people wondered if GPU manufacturers like NVIDIA might see shrinking demand, and the stock indeed took a short-lived 17% tumble. On the show, I joked, “My mom knows about DeepSeek—your grandma probably knows about it, too,” underscoring just how mainstream the hype has become.Not everyone is convinced the cost claims are accurate. Even Dario Amodei of Anthropic weighed in with a blog post arguing that DeepSeek’s success increases the case for stricter AI export controls. Public Reactions* Dario Amodei’s blogIn “On DeepSeek and Export Controls,” Amodei argues that DeepSeek’s efficient scaling exemplifies why democratic nations need to maintain a strategic leadership edge—and enforce export controls on advanced AI chips. He sees Chinese breakthroughs as proof that AI competition is global and intense.* OpenAI Distillation EvidenceOpenAI mentioned it found “distillation traces” of GPT-4 inside R1’s training data. Hypocrisy or fair game? On ThursdAI, the panel mused that “everyone trains on everything,” so perhaps it’s a moot point.* Microsoft ReactionMicrosoft wasted no time, swiftly adding DeepSeek to Azure—further proof that corporations want to harness R1’s reasoning power, no matter where it originated.* Government reactedEven officials in the government, David Sacks, US incoming AI & Crypto czar, discussed the fact that DeepSeek did "distillation" using the term somewhat incorrectly, and presidet Trump was asked about it.* API OutagesDeepSeek’s own API has gone in and out this week, apparently hammered by demand (and possibly DDoS attacks). Meanwhile, GPU clouds like Groq are showing up to accelerate R1 at 300 tokens/second, for those who must have it right now.We've seen so many bad takes on the topic, from seething cope takes, to just gross misunderstandings from gov officials confusing the ios App with the OSS models, folks throwing conspiracy theories into the mix, claiming that $5.5M sum was a PsyOp. The fact of the matter is, DeepSeek R1 is an incredible model, and is now powering (just a week later), multiple products (more on this below) and experiences already, while pushing everyone else to compete (and give us reasoning models!)Open Thoughts Reasoning DatasetOne-sentence summary: A community-led effort, “Open Thoughts,” released a new large-scale dataset (OpenThoughts-114k) of chain-of-thought reasoning data, fueling the open-source drive toward better reasoning models.Worried about having enough labeled “thinking” steps to train your own reasoner? Fear not. The OpenThoughts-114k dataset aggregates chain-of-thought prompts and responses—114,000 of them—for building or fine-tuning reasoning LLMs. It’s now on Hugging Face for your experimentation pleasure. The ThursdAI panel pointed out how crucial these large, openly available reasoning datasets are. As Wolfram put it, “We can’t rely on the big labs alone. More open data means more replicable breakouts like DeepSeek R1.”Mistral Small 2501 (24B)One-sentence summary: Mistral AI returns to the open-source spotlight with a 24B model that fits on a single 4090, scoring over 81% on MMLU while under Apache 2.0.Long rumored to be “going more closed,” Mistral AI re-emerged this week with Mistral-Small-24B-Instruct-2501—an Apache 2.0 licensed LLM that runs easily on a 32G

📆 ThursdAI - Jan 23, 2025 - 🔥 DeepSeek R1 is HERE, OpenAI Operator Agent, $500B AI manhattan project, ByteDance UI-Tars, new Gemini Thinker & more AI news
What a week, folks, what a week! Buckle up, because ThursdAI just dropped, and this one's a doozy. We're talking seismic shifts in the open source world, a potential game-changer from DeepSeek AI that's got everyone buzzing, and oh yeah, just a casual $500 BILLION infrastructure project announcement. Plus, OpenAI finally pulled the trigger on "Operator," their agentic browser thingy – though getting it to actually operate proved to be a bit of a live show adventure, as you'll hear. This week felt like one of those pivotal moments in AI, a real before-and-after kind of thing. DeepSeek's R1 hit the open source scene like a supernova, and suddenly, top-tier reasoning power is within reach for anyone with a Mac and a dream. And then there's OpenAI's Operator, promising to finally bridge the gap between chat and action. Did it live up to the hype? Well, let's just say things got interesting.As I’m writing this, White House just published that an Executive Order on AI was just signed and published as well, what a WEEK.Open Source AI Goes Nuclear: DeepSeek R1 is HERE!Hold onto your hats, open source AI just went supernova! This week, the Chinese Whale Bros – DeepSeek AI, that quant trading firm turned AI powerhouse – dropped a bomb on the community in the best way possible: R1, their reasoning model, is now open source under the MIT license! As I said on the show, "Open source AI has never been as hot as this week."This isn't just a model, folks. DeepSeek unleashed a whole arsenal: two full-fat R1 models (DeepSeek R1 and DeepSeek R1-Zero), and a whopping six distilled finetunes based on Qwen (1.5B, 7B, 14B, and 32B) and Llama (8B, 72B). One stat that blew my mind, and Nisten's for that matter, is that DeepSeek-R1-Distill-Qwen-1.5B, the tiny 1.5 billion parameter model, is outperforming GPT-4o and Claude-3.5-Sonnet on math benchmarks! "This 1.5 billion parameter model that now does this. It's absolutely insane," I exclaimed on the show. We're talking 28.9% on AIME and 83.9% on MATH. Let that sink in. A model you can probably run on your phone is schooling the big boys in math.License-wise, it's MIT, which as Nisten put it, "MIT is like a jailbreak to the whole legal system, pretty much. That's what most people don't realize. It's like, this is, it's not my problem. You're a problem now." Basically, do whatever you want with it. Distill it, fine-tune it, build Skynet – it's all fair game.And the vibes? "Vibes are insane," as I mentioned on the show. Early benchmarks are showing R1 models trading blows with o1-preview and o1-mini, and even nipping at the heels of the full-fat o1 in some areas. Check out these numbers:And the price? Forget about it. We're talking 50x cheaper than o1 currently. DeepSeek R1 API is priced at $0.14 / 1M input tokens and $2.19 / 1M output tokens, compared to OpenAI's o1 at $15.00 / 1M input and a whopping $60.00 / 1M output. Suddenly, high-quality reasoning is democratized.LDJ highlighted the "aha moment" in DeepSeek's paper, where they talk about how reinforcement learning enabled the model to re-evaluate its approach and "think more." It seems like simple RL scaling, combined with a focus on reasoning, is the secret sauce. No fancy Monte Carlo Tree Search needed, apparently!But the real magic of open source is what the community does with it. Pietro Schirano joined us to talk about his "Retrieval Augmented Thinking" (RAT) approach, where he extracts the thinking process from R1 and transplants it to other models. "And what I found out is actually by doing so, you may even like smaller, quote unquote, you know, less intelligent model actually become smarter," Pietro explained. Frankenstein models, anyone? (John Lindquist has a tutorial on how to do it here)And then there's the genius hack from Voooogel, who figured out how to emulate a "reasoning_effort" knob by simply replacing the "end" token with "Wait, but". "This tricks the model into keeps thinking," as I described it. Want your AI to really ponder the meaning of life (or just 1+1)? Now you can, thanks to open source tinkering.Georgi Gerganov, the legend behind llama.cpp, even jumped in with a two-line snippet to enable speculative decoding, boosting inference speeds on the 32B model on my Macbook from a sluggish 5 tokens per second to a much more respectable 10-11 tokens per second. Open source collaboration at its finest and it's only going to get better! Thinking like a NeuroticMany people really loved the way R1 thinks, and what I found astonishing is that I just sent "hey" and the thinking went into a whole 5 paragraph debate of how to answer, a user on X answered with "this is Woody Allen-level of Neurotic" which... nerd sniped me so hard! I used Hauio Audio (which is great!) and ByteDance latentSync and gave R1 a voice! It's really something when you hear it's inner monologue being spoken out like this! ByteDance Enters the Ring: UI-TARS Controls Your PCNot to be outdone in the open source frenzy, ByteDance, the TikTok behemo
📆 ThursdAI - Jan 16, 2025 - Hailuo 4M context LLM, SOTA TTS in browser, OpenHands interview & more AI news
Hey everyone, Alex here 👋 Welcome back, to an absolute banger of a week in AI releases, highlighted with just massive Open Source AI push. We're talking a MASSIVE 4M context window context window model from Hailuo (remember when a jump from 4K to 16K seemed like a big deal?), a 8B omni model that lets you livestream video and glimpses of Agentic ChatGPT? This week's ThursdAI was jam-packed with so much open source goodness that the big companies were practically silent. But don't worry, we still managed to squeeze in some updates from OpenAI and Mistral, along with a fascinating new paper from Sakana AI on self-adaptive LLMs. Plus, we had the incredible Graham Neubig, from All Hands AI, join us to talk about Open Hands (formerly OpenDevin) and even contributed to our free, LLM Evaluation course on Weights & Biases!Before we dive in, a friend asked me over dinner, what are the main 2 things that happened in AI in 2024, and this week highlights one of those trends. Most of the Open Source is now from China. This week, we got MiniMax from Hailuo, OpenBMB with a new MiniCPM, InternLM came back and most of the rest were Qwen finetunes. Not to mention DeepSeek. Wanted to highlight this significant narrative change and that this is being done despite the chip export restrictions. ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.Open Source AI & LLMsMiniMax-01: 4 Million Context, 456 Billion Parameters, and Lightning Attention This came absolutely from the left field, given that we've seen no prior LLMs from Haulio, the company previously releasing video models with consistent characters. Dropping a massive 456B mixture of experts model (45B active parameters) with such a long context support in open weights, but also with very significant benchmarks that compete with Gpt-4o, Claude and DeekSeek v3 (75.7 MMLU-pro, 89 IFEval, 54.4 GPQA)They have trained the model on up to 1M context window and then extended it to 4M with ROPE scaling methods (our coverage of RoPE) during Inference. MiniMax-Text-01 adopts a hybrid architecture that combines Lightning Attention, Softmax Attention and Mixture-of-Experts (MoE) with 45B active parameters. I gotta say, when we started talking about context window, imagining a needle in a haystack graph that shows 4M, in the open source seemed far fetched, though we did say that theoretically, there may not be a limit to context windows. I just always expected that limit to be unlocked by transformers alternative architectures like Mamba or other State Space Models.Vision, API and Browsing - Minimax-VL-01It feels like such a well rounded and complete release, that it highlights just how mature company that is behind it. They have also released a vision version of this model, that includes a 300M param Vision Transformer on top (trained with 512B vision language tokens) that features dynamic resolution and boasts very high DocVQA and ChartQA scores. Not only did these two models were released in open weights, they also launched as a unified API endpoint (supporting up to 1M tokens) and it's cheap! $0.2/1M input and $1.1/1M output tokens! AFAIK this is only the 3rd API that supports this much context, after Gemini at 2M and Qwen Turbo that supports 1M as well.Surprising web browsing capabilitiesYou can play around with the model on their website, hailuo.ai which also includes web grounding, which I found quite surprising to find out, that they are beating chatGPT and Perplexity on how fast they can find information that just happened that same day! Not sure what search API they are using under the hood but they are very quick. 8B chat with video model omni-model from OpenBMBOpenBMB has been around for a while and we've seen consistently great updates from them on the MiniCPM front, but this one takes the cake! This is a complete omni modal end to end model, that does video streaming, audio to audio and text understanding, all on a model that can run on an iPad! They have a demo interface that is very similar to the chatGPT demo from spring of last year, and allows you to stream your webcam and talk to the model, but this is just an 8B parameter model we're talking about! It's bonkers! They are boasting some incredible numbers, and to be honest, I highly doubt their methodology in textual understanding, because, well, based on my experience alone, this model understands less than close to chatGPT advanced voice mode, but miniCPM has been doing great visual understanding for a while, so ChartQA and DocVQA are close to SOTA. But all of this doesn't matter, because, I say again, just a little over a year ago, Google released a video announcing these capabilities, having an AI react to a video in real time, and it absolutely blew everyone away, and it was FAKED. And this time a year after, we have these capabilities, essentially, in an 8B model that runs on device 🤯
📆 ThursdAI - Jan 9th - NVIDIA's Tiny Supercomputer, Phi-4 is back, Kokoro TTS & Moondream gaze, ByteDance SOTA lip sync & more AI news
Hey everyone, Alex here 👋This week's ThursdAI was a whirlwind of announcements, from Microsoft finally dropping Phi-4's official weights on Hugging Face (a month late, but who's counting?) to Sam Altman casually mentioning that OpenAI's got AGI in the bag and is now setting its sights on superintelligence. Oh, and NVIDIA? They're casually releasing a $3,000 supercomputer that can run 200B parameter models on your desktop. No big deal.We had some amazing guests this week too, with Oliver joining us to talk about a new foundation model in genomics and biosurveillance (yes, you read that right - think wastewater and pandemic monitoring!), and then, we've got some breaking news! Vik returned to the show with a brand new Moondream release that can do some pretty wild things. Ever wanted an AI to tell you where someone's looking in a photo? Now you can, thanks to a tiny model that runs on edge devices. 🤯So buckle up, folks, because we've got a ton to cover. Let's dive into the juicy details of this week's AI madness, starting with open source.03:10 TL;DR03:10 Deep Dive into Open Source LLMs10:58 MetaGene: A New Frontier in AI20:21 PHI4: The Latest in Open Source AI27:46 R Star Math: Revolutionizing Small LLMs34:02 Big Companies and AI Innovations42:25 NVIDIA's Groundbreaking Announcements43:49 AI Hardware: Building and Comparing Systems46:06 NVIDIA's New AI Models: LLAMA Neumatron47:57 Breaking News: Moondream's Latest Release50:19 Moondream's Journey and Capabilities58:41 Weights & Biases: New Evals Course01:08:29 NVIDIA's World Foundation Models01:08:29 ByteDance's LatentSync: State-of-the-Art Lip Sync01:12:54 Kokoro TTS: High-Quality Text-to-SpeechAs always, TL;DR section with links and show notes below 👇Open Source AI & LLMsPhi-4: Microsoft's "Small" Model Finally Gets its Official Hugging Face DebutFinally, after a month, we're getting Phi-4 14B on HugginFace. So far, we've had bootlegged copies of it, but it's finally officially uploaded by Microsoft. Not only is it now official, it's also officialy MIT licensed which is great!So, what's the big deal? Well, besides the licensing, it's a 14B parameter, dense decoder-only Transformer with a 16K token context length and trained on a whopping 9.8 trillion tokens. It scored 80.4 on math and 80.6 on MMLU, making it about 10% better than its predecessor, Phi-3 and better than Qwen 2.5's 79What’s interesting about phi-4 is that the training data consisted of 40% synthetic data (almost half!)The vibes are always interesting with Phi models, so we'll keep an eye out, notable also, the base models weren't released due to "safety issues" and that this model was not trained for multi turn chat applications but single turn use-casesMetaGene-1: AI for Pandemic Monitoring and Pathogen DetectionNow, this one's a bit different. We usually talk about LLMs in this section, but this is more about the "open source" than the "LLM." Prime Intellect, along with folks from USC, released MetaGene-1, a metagenomic foundation model. That's a mouthful, right? Thankfully, we had Oliver Liu, a PhD student at USC, and an author on this paper, join us to explain.Oliver clarified that the goal is to use AI for "biosurveillance, pandemic monitoring, and pathogen detection." They trained a 7B parameter model on 1.5 trillion base pairs of DNA and RNA sequences from wastewater, creating a model surprisingly capable of zero-shot embedding. Oliver pointed out that while using genomics to pretrain foundation models is not new, MetaGene-1 is, "in its current state, the largest model out there" and is "one of the few decoder only models that are being used". They also have collected 15T bae pairs but trained on 10% of them due to grant and compute constraints.I really liked this one, and though the science behind this was complex, I couldn't help but get excited about the potential of transformer models catching or helping catch the next COVID 👏rStar-Math: Making Small LLMs Math Whizzes with Monte Carlo Tree SearchAlright, this one blew my mind. A paper from Microsoft (yeah, them again) called "rStar-Math" basically found a way to make small LLMs do math better than o1 using Monte Carlo Tree Search (MCTS). I know, I know, it sounds wild. They took models like Phi-3-mini (a tiny 3.8B parameter model) and Qwen 2.5 3B and 7B, slapped some MCTS magic on top, and suddenly these models are acing the AIME 2024 competition math benchmark and scoring 90% on general math problems. For comparison, OpenAI's o1-preview scores 85.5% on math and o1-mini scores 90%. This is WILD, as just 5 months ago, it was unimaginable that any LLM can solve math of this complexity, then reasoning models could, and now small LLMs with some MCTS can!Even crazier, they observed an "emergence of intrinsic self-reflection capability" in these models during problem-solving, something they weren't designed to do. LDJ chimed in saying "we're going to see more papers showing these things emerging and caught naturally." So, is 2025 the

📆 ThursdAI - Jan 2 - is 25' the year of AI agents?
Hey folks, Alex here 👋 Happy new year!On our first episode of this year, and the second quarter of this century, there wasn't a lot of AI news to report on (most AI labs were on a well deserved break). So this week, I'm very happy to present a special ThursdAI episode, an interview with Joāo Moura, CEO of Crew.ai all about AI agents!We first chatted with Joāo a year ago, back in January of 2024, as CrewAI was blowing up but still just an open source project, it got to be the number 1 trending project on Github, and #1 project on Product Hunt. (You can either listen to the podcast or watch it in the embedded Youtube above)00:36 Introduction and New Year Greetings02:23 Updates on Open Source and LLMs03:25 Deep Dive: AI Agents and Reasoning03:55 Quick TLDR and Recent Developments04:04 Medical LLMs and Modern BERT09:55 Enterprise AI and Crew AI Introduction10:17 Interview with João Moura: Crew AI25:43 Human-in-the-Loop and Agent Evaluation33:17 Evaluating AI Agents and LLMs44:48 Open Source Models and Fin to OpenAI45:21 Performance of Claude's Sonnet 3.548:01 Different parts of an agent topology, brain, memory, tools, caching53:48 Tool Use and Integrations01:04:20 Removing LangChain from Crew01:07:51 The Year of Agents and Reasoning01:18:43 Addressing Concerns About AI01:24:31 Future of AI and Agents01:28:46 Conclusion and Farewell---Is 2025 "the year of AI agents"?AI agents as I remember them as a concept started for me a few month after I started ThursdAI ,when AutoGPT exploded. Was such a novel idea at the time, run LLM requests in a loop,(In fact, back then, I came up with a retry with AI concept and called it TrAI/Catch, where upon an error, I would feed that error back into the GPT api and ask it to correct itself. it feels so long ago!)AutoGPT became the fastest ever Github project to reach 100K stars, and while exciting, it did not work.Since then we saw multiple attempts at agentic frameworks, like babyAGI, autoGen. Crew AI was one of them that keeps being the favorite among many folks.So, what is an AI agent? Simon Willison, friend of the pod, has a mission, to ask everyone who announces a new agent, what they mean when they say it because it seems that everyone "shares" a common understanding of AI agents, but it's different for everyone.We'll start with Joāo's explanation and go from there. But let's assume the basic, it's a set of LLM calls, running in a self correcting loop, with access to planning, external tools (via function calling) and a memory or sorts that make decisions.Though, as we go into detail, you'll see that since the very basic "run LLM in the loop" days, the agents in 2025 have evolved and have a lot of complexity.My takeaways from the conversationI encourage you to listen / watch the whole interview, Joāo is deeply knowledgable about the field and we go into a lot of topics, but here are my main takeaways from our chat* Enterprises are adopting agents, starting with internal use-cases* Crews have 4 different kinds of memory, Long Term (across runs), short term (each run), Entity term (company names, entities), pre-existing knowledge (DNA?)* TIL about a "do all links respond with 200" guardrail* Some of the agent tools we mentioned* Stripe Agent API - for agent payments and access to payment data (blog)* Okta Auth for Gen AI - agent authentication and role management (blog)* E2B - code execution platform for agents (e2b.dev)* BrowserBase - programmatic web-browser for your AI agent* Exa - search grounding for agents for real time understanding* Crew has 13 crews that run 24/7 to automate their company* Crews like Onboarding User Enrichment Crew, Meetings Prep, Taking Phone Calls, Generate Use Cases for Leads* GPT-4o mini is the most used model for 2024 for CrewAI with main factors being speed / cost* Speed of AI development makes it hard to standardize and solidify common integrations.* Reasoning models like o1 still haven't seen a lot of success, partly due to speed, partly due to different way of prompting required.This weeks BuzzWe've just opened up pre-registration for our upcoming FREE evaluations course, featuring Paige Bailey from Google and Graham Neubig from All Hands AI (previously Open Devin). We've distilled a lot of what we learned about evaluating LLM applications while building Weave, our LLM Observability and Evaluation tooling, and are excited to share this with you all! Get on the listAlso, 2 workshops (also about Evals) from us are upcoming, one in SF on Jan 11th and one in Seattle on Jan 13th (which I'm going to lead!) so if you're in those cities at those times, would love to see you!And that's it for this week, there wasn't a LOT of news as I said. The interesting thing is, even in the very short week, the news that we did get were all about agents and reasoning, so it looks like 2025 is agents and reasoning, agents and reasoning!See you all next week 🫡TL;DR with links:* Open Source LLMs* HuatuoGPT-o1 - medical LLM designed for medical reasoning (HF, Paper,
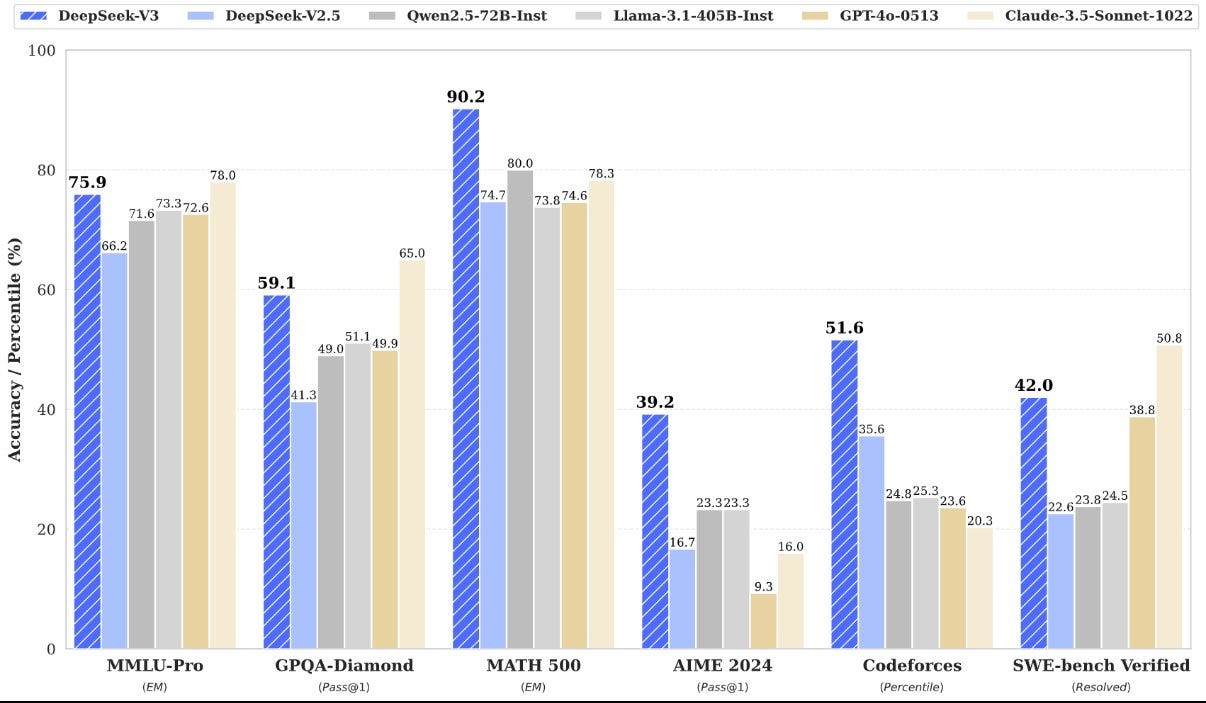
📆 ThursdAI - Dec 26 - OpenAI o3 & o3 mini, DeepSeek v3 658B beating Claude, Qwen Visual Reasoning, Hume OCTAVE & more AI news
Hey everyone, Alex here 👋I was hoping for a quiet holiday week, but whoa, while the last newsletter was only a week ago, what a looong week it has been, just Friday after the last newsletter, it felt like OpenAI has changed the world of AI once again with o3 and left everyone asking "was this AGI?" over the X-mas break (Hope Santa brought you some great gifts!) and then not to be outdone, DeepSeek open sourced basically a Claude 2.5 level behemoth DeepSeek v3 just this morning!Since the breaking news from DeepSeek took us by surprise, the show went a bit longer (3 hours today!) than expected, so as a Bonus, I'm going to release a separate episode with a yearly recap + our predictions from last year and for next year in a few days (soon in your inbox!) TL;DR* Open Source LLMs* CogAgent-9B (Project, Github)* Qwen QvQ 72B - open weights visual reasoning (X, HF, Demo, Project)* GoodFire Ember - MechInterp API - GoldenGate LLama 70B* 🔥 DeepSeek v3 658B MoE - Open Source Claude level model at $6M (X, Paper, HF, Chat)* Big CO LLMs + APIs* 🔥 OpenAI reveals o3 and o3 mini (Blog, X)* X.ai raises ANOTHER 6B dollars - on their way to 200K H200s (X)* This weeks Buzz* Two W&B workshops upcoming in January* SF - January 11* Seattle - January 13 (workshop by yours truly!)* New Evals course with Paige Bailey and Graham Neubig - pre-sign up for free* Vision & Video* Kling 1.6 update (Tweet)* Voice & Audio* Hume OCTAVE - 3B speech-language model (X, Blog)* Tools* OpenRouter added Web Search Grounding to 300+ models (X)Open Source LLMsDeepSeek v3 658B - frontier level open weights model for ~$6M (X, Paper, HF, Chat )This was absolutely the top of the open source / open weights news for the past week, and honestly maybe for the past month. DeepSeek, the previous quant firm from China, has dropped a behemoth model, a 658B parameter MoE (37B active), that you'd need 8xH200 to even run, that beats Llama 405, GPT-4o on most benchmarks and even Claude Sonnet 3.5 on several evals! The vibes seem to be very good with this one, and while it's not all the way beating Claude yet, it's nearly up there already, but the kicker is, they trained it with a very restricted compute, per the paper, with ~2K h800 (which is like H100 but with less bandwidth) for 14.8T tokens. (that's 15x cheaper than LLama 405 for comparison) For evaluations, this model excels on Coding and Math, which is not surprising given how excellent DeepSeek coder has been, but still, very very impressive! On the architecture front, the very interesting thing is, this feels like Mixture of Experts v2, with a LOT of experts (256) and 8+1 active at the same time, multi token prediction, and a lot optimization tricks outlined in the impressive paper (here's a great recap of the technical details)The highlight for me was, that DeepSeek is distilling their recent R1 version into this version, which likely increases the performance of this model on Math and Code in which it absolutely crushes (51.6 on CodeForces and 90.2 on MATH-500) The additional aspect of this is the API costs, and while they are going to raise the prices come February (they literally just swapped v2.5 for v3 in their APIs without telling a soul lol), the price performance for this model is just absurd. Just a massive massive release from the WhaleBros, now I just need a quick 8xH200 to run this and I'm good 😅 Other OpenSource news - Qwen QvQ, CogAgent-9B and GoldenGate LLamaIn other open source news this week, our friends from Qwen have released a very interesting preview, called Qwen QvQ, a visual reasoning model. It uses the same reasoning techniques that we got from them in QwQ 32B, but built with the excellent Qwen VL, to reason about images, and frankly, it's really fun to see it think about an image. You can try it hereand a new update to CogAgent-9B (page), an agent that claims to understand and control your computer, claims to beat Claude 3.5 Sonnet Computer Use with just a 9B model! This is very impressive though I haven't tried it just yet, I'm excited to see those very impressive numbers from open source VLMs driving your computer and doing tasks for you!A super quick word from ... Weights & Biases! We've just opened up pre-registration for our upcoming FREE evaluations course, featuring Paige Bailey from Google and Graham Neubig from All Hands AI. We've distilled a lot of what we learned about evaluating LLM applications while building Weave, our LLM Observability and Evaluation tooling, and are excited to share this with you all! Get on the listAlso, 2 workshops (also about Evals) from us are upcoming, one in SF on Jan 11th and one in Seattle on Jan 13th (which I'm going to lead!) so if you're in those cities at those times, would love to see you!Big Companies - APIs & LLMsOpenAI - introduces o3 and o3-mini - breaking Arc-AGI challenge, GQPA and teasing AGI? On the last day of the 12 days of OpenAI, we've got the evals of their upcoming o3 reasoning model (and o3-mini) and whoah. I think I spe
🎄ThursdAI - Dec19 - o1 vs gemini reasoning, VEO vs SORA, and holiday season full of AI surprises
For the full show notes and links visit https://sub.thursdai.news🔗 Subscribe to our show on Spotify: https://thursdai.news/spotify🔗 Apple: https://thursdai.news/appleHo, ho, holy moly, folks! Alex here, coming to you live from a world where AI updates are dropping faster than Santa down a chimney! 🎅 It's been another absolutely BANANAS week in the AI world, and if you thought last week was wild, and we're due for a break, buckle up, because this one's a freakin' rollercoaster! 🎢In this episode of ThursdAI, we dive deep into the recent innovations from OpenAI, including their 1-800 ChatGPT phone service and new advancements in voice mode and API functionalities. We discuss the latest updates on O1 model capabilities, including Reasoning Effort settings, and highlight the introduction of WebRTC support by OpenAI. Additionally, we explore the groundbreaking VEO2 model from Google, the generative physics engine Genesis, and new developments in open source models like Cohere's Command R7b. We also provide practical insights on using tools like Weights & Biases for evaluating AI models and share tips on leveraging GitHub Gigi. Tune in for a comprehensive overview of the latest in AI technology and innovation.00:00 Introduction and OpenAI's 12 Days of Releases00:48 Advanced Voice Mode and Public Reactions01:57 Celebrating Tech Innovations02:24 Exciting New Features in AVMs03:08 TLDR - ThursdAI December 1912:58 Voice and Audio Innovations14:29 AI Art, Diffusion, and 3D16:51 Breaking News: Google Gemini 2.023:10 Meta Apollo 7b Revisited33:44 Google's Sora and Veo234:12 Introduction to Veo2 and Sora34:59 First Impressions of Veo235:49 Comparing Veo2 and Sora37:09 Sora's Unique Features38:03 Google's MVP Approach43:07 OpenAI's Latest Releases44:48 Exploring OpenAI's 1-800 CHAT GPT47:18 OpenAI's Fine-Tuning with DPO48:15 OpenAI's Mini Dev Day Announcements49:08 Evaluating OpenAI's O1 Model54:39 Weights & Biases Evaluation Tool - Weave01:03:52 ArcAGI and O1 Performance01:06:47 Introduction and Technical Issues01:06:51 Efforts on Desktop Apps01:07:16 ChatGPT Desktop App Features01:07:25 Working with Apps and Warp Integration01:08:38 Programming with ChatGPT in IDEs01:08:44 Discussion on Warp and Other Tools01:10:37 GitHub GG Project01:14:47 OpenAI Announcements and WebRTC01:24:45 Modern BERT and Smaller Models01:27:37 Genesis: Generative Physics Engine01:33:12 Closing Remarks and Holiday WishesHere’s a talking podcast host speaking excitedly about his showTL;DR - Show notes and Links* Open Source LLMs* Meta Apollo 7B – LMM w/ SOTA video understanding (Page, HF)* Microsoft Phi-4 – 14B SLM (Blog, Paper)* Cohere Command R 7B – (Blog)* Falcon 3 – series of models (X, HF, web)* IBM updates Granite 3.1 + embedding models (HF, Embedding)* Big CO LLMs + APIs* OpenAI releases new o1 + API access (X)* Microsoft makes CoPilot Free! (X)* Google - Gemini Flash 2 Thinking experimental reasoning model (X, Studio)* This weeks Buzz* W&B weave Playground now has Trials (and o1 compatibility) (try it)* Alex Evaluation of o1 and Gemini Thinking experimental (X, Colab, Dashboard)* Vision & Video* Google releases Veo 2 – SOTA text2video modal - beating SORA by most vibes (X)* HunyuanVideo distilled with FastHunyuan down to 6 steps (HF)* Kling 1.6 (X)* Voice & Audio* OpenAI realtime audio improvements (docs)* 11labs new Flash 2.5 model – 75ms generation (X)* Nexa OmniAudio – 2.6B – multimodal local LLM (Blog)* Moonshine Web – real time speech recognition in the browser (X)* Sony MMAudio - open source video 2 audio model (Blog, Demo)* AI Art & Diffusion & 3D* Genesys – open source generative 3D physics engine (X, Site, Github)* Tools* CerebrasCoder – extremely fast apps creation (Try It)* RepoPrompt to chat with o1 Pro – (download) This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit sub.thursdai.news/subscribe

📆 ThursdAI - Dec 12 - unprecedented AI week - SORA, Gemini 2.0 Flash, Apple Intelligence, LLama 3.3, NeurIPS Drama & more AI news
Hey folks, Alex here, writing this from the beautiful Vancouver BC, Canada. I'm here for NeurIPS 2024, the biggest ML conferences of the year, and let me tell you, this was one hell of a week to not be glued to the screen. After last week banger week, with OpenAI kicking off their 12 days of releases, with releasing o1 full and pro mode during ThursdAI, things went parabolic. It seems that all the AI labs decided to just dump EVERYTHING they have before the holidays? 🎅A day after our show, on Friday, Google announced a new Gemini 1206 that became the #1 leading model on LMarena and Meta released LLama 3.3, then on Saturday Xai releases their new image model code named Aurora.On a regular week, the above Fri-Sun news would be enough for a full 2 hour ThursdAI show on it's own, but not this week, this week this was barely a 15 minute segment 😅 because so MUCH happened starting Monday, we were barely able to catch our breath, so lets dive into it! As always, the TL;DR and full show notes at the end 👇 and this newsletter is sponsored by W&B Weave, if you're building with LLMs in production, and want to switch to the new Gemini 2.0 today, how will you know if your app is not going to degrade? Weave is the best way! Give it a try for free.Gemini 2.0 Flash - a new gold standard of fast multimodal LLMsGoogle has absolutely taken the crown away from OpenAI with Gemini 2.0 believe it or not this week with this incredible release. All of us on the show were in agreement that this is a phenomenal release from Google for the 1 year anniversary of Gemini. Gemini 2.0 Flash is beating Pro 002 and Flash 002 on all benchmarks, while being 2x faster than Pro, having 1M context window, and being fully multimodal! Multimodality on input and outputThis model was announced to be fully multimodal on inputs AND outputs, which means in can natively understand text, images, audio, video, documents and output text, text + images and audio (so it can speak!). Some of these capabilities are restricted for beta users for now, but we know they exists. If you remember project Astra, this is what powers that project. In fact, we had Matt Wolfe join the show, and he demoed had early access to Project Astra and demoed it live on the show (see above) which is powered by Gemini 2.0 Flash. The most amazing thing is, this functionality, that was just 8 months ago, presented to us in Google IO, in a premium Booth experience, is now available to all, in Google AI studio, for free! Really, you can try out right now, yourself at https://aistudio.google.com/live but here's a demo of it, helping me proof read this exact paragraph by watching the screen and talking me through it. Performance out of the boxThis model beating Sonnet 3.5 on Swe-bench Verified completely blew away the narrative on my timeline, nobody was ready for that. This is a flash model, that's outperforming o1 on code!?So having a Flash MMIO model with 1M context that is accessible via with real time streaming option available via APIs from the release time is honestly quite amazing to begin with, not to mention that during the preview phase, this is currently free, but if we consider the previous prices of Flash, this model is going to considerably undercut the market on price/performance/speed matrix. You can see why this release is taking the crown this week. 👏 Agentic is coming with Project MarinerAn additional thing that was announced by Google is an Agentic approach of theirs is project Mariner, which is an agent in the form of a Chrome extension completing webtasks, breaking SOTA on the WebVoyager with 83.5% score with a single agent setup. We've seen agents attempts from Adept to Claude Computer User to Runner H, but this breaking SOTA from Google seems very promising. Can't wait to give this a try. OpenAI gives us SORA, Vision and other stuff from the bag of goodiesOk so now let's talk about the second winner of this week, OpenAI amazing stream of innovations, which would have taken the crown, if not for, well... ☝️ SORA is finally here (for those who got in)Open AI has FINALLY released SORA, their long promised text to video and image to video (and video to video) model (nee, world simulator) to general availability, including a new website - sora.com and a completely amazing UI to come with it. SORA can generate images of various quality from 480p up to 1080p and up to 20 seconds long, and they promised that those will be generating fast, as what they released is actually SORA turbo! (apparently SORA 2 is already in the works and will be even more amazing, more on this later) New accounts paused for nowOpenAI seemed to have severely underestimated how many people would like to generate the 50 images per month allowed on the plus account (pro account gets you 10x more for $200 + longer durations whatever that means), and since the time of writing these words on ThursdAI afternoon, I still am not able to create a sora.com account and try out SORA myself (as I was boarding
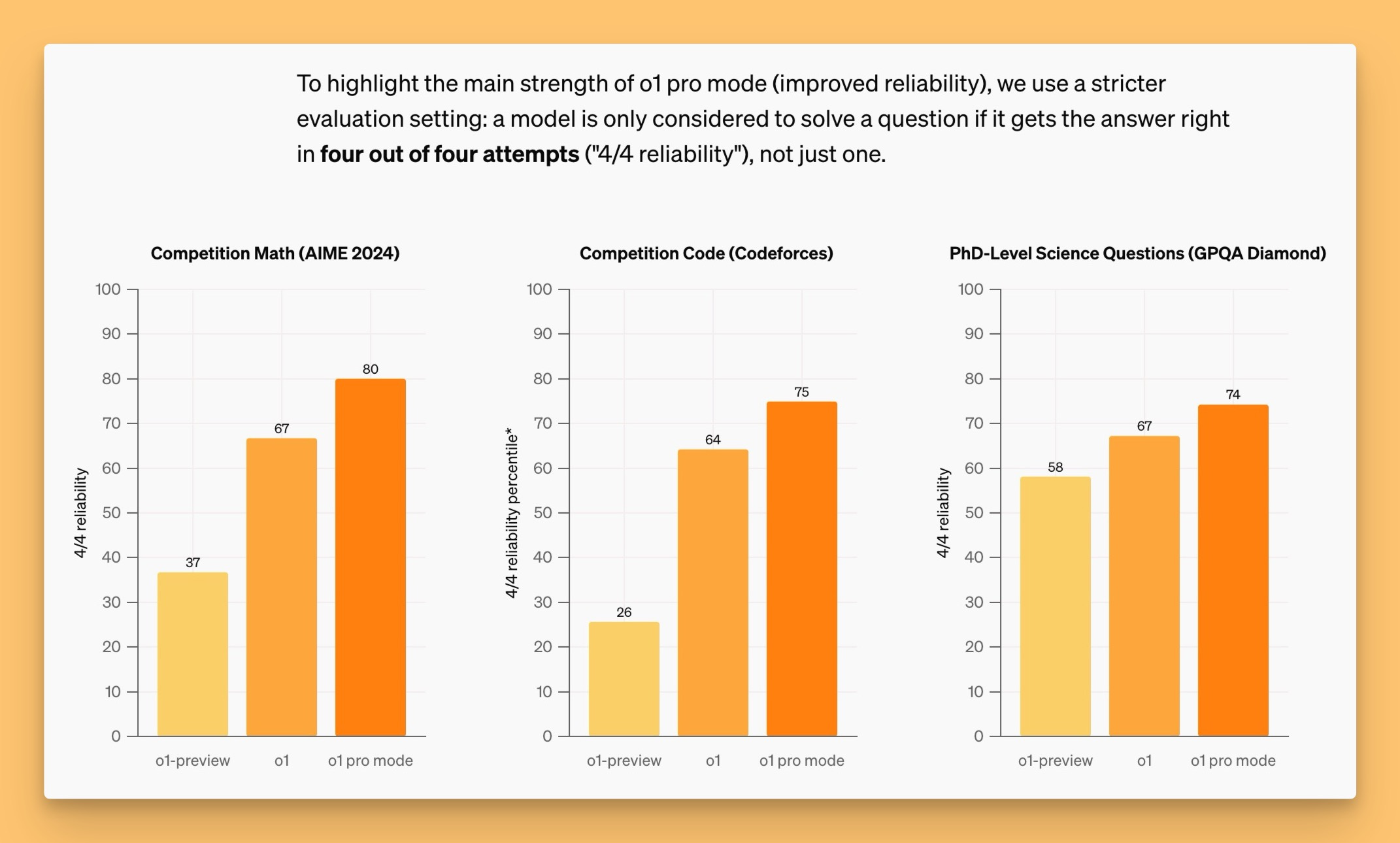
📆 ThursdAI - Dec 5 - OpenAI o1 & o1 pro, Tencent HY-Video, FishSpeech 1.5, Google GENIE2, Weave in GA & more AI news
Well well well, December is finally here, we're about to close out this year (and have just flew by the second anniversary of chatGPT 🎂) and it seems that all of the AI labs want to give us X-mas presents to play with over the holidays! Look, I keep saying this, but weeks are getting crazier and crazier, this week we got the cheapest and the most expensive AI offerings all at once (the cheapest from Amazon and the most expensive from OpenAI), 2 new open weights models that beat commercial offerings, a diffusion model that predicts the weather and 2 world building models, oh and 2 decentralized fully open sourced LLMs were trained across the world LIVE and finished training. I said... crazy week! And for W&B, this week started with Weave launching finally in GA 🎉, which I personally was looking forward for (read more below)!TL;DR Highlights* OpenAI O1 & Pro Tier: O1 is out of preview, now smarter, faster, multimodal, and integrated into ChatGPT. For heavy usage, ChatGPT Pro ($200/month) offers unlimited calls and O1 Pro Mode for harder reasoning tasks.* Video & Audio Open Source Explosion: Tencent’s HYVideo outperforms Runway and Luma, bringing high-quality video generation to open source. Fishspeech 1.5 challenges top TTS providers, making near-human voice available for free research.* Open Source Decentralization: Nous Research’s DiStRo (15B) and Prime Intellect’s INTELLECT-1 (10B) prove you can train giant LLMs across decentralized nodes globally. Performance is on par with centralized setups.* Google’s Genie 2 & WorldLabs: Generating fully interactive 3D worlds from a single image, pushing boundaries in embodied AI and simulation. Google’s GenCast also sets a new standard in weather prediction, beating supercomputers in accuracy and speed.* Amazon’s Nova FMs: Cheap, scalable LLMs with huge context and global language coverage. Perfect for cost-conscious enterprise tasks, though not top on performance.* 🎉 Weave by W&B: Now in GA, it’s your dashboard and tool suite for building, monitoring, and scaling GenAI apps. Get Started with 1 line of codeOpenAI’s 12 Days of Shipping: O1 & ChatGPT ProThe biggest splash this week came from OpenAI. They’re kicking off “12 days of launches,” and Day 1 brought the long-awaited full version of o1. The main complaint about o1 for many people is how slow it was! Well, now it’s not only smarter but significantly faster (60% faster than preview!), and officially multimodal: it can see images and text together.Better yet, OpenAI introduced a new ChatGPT Pro tier at $200/month. It offers unlimited usage of o1, advanced voice mode, and something called o1 pro mode — where o1 thinks even harder and longer about your hardest math, coding, or science problems. For power users—maybe data scientists, engineers, or hardcore coders—this might be a no-brainer. For others, 200 bucks might be steep, but hey, someone’s gotta pay for those GPUs. Given that OpenAI recently confirmed that there are now 300 Million monthly active users on the platform, and many of my friends already upgraded, this is for sure going to boost the bottom line at OpenAI! Quoting Sam Altman from the stream, “This is for the power users who push the model to its limits every day.” For those who complained o1 took forever just to say “hi,” rejoice: trivial requests will now be answered quickly, while super-hard tasks get that legendary deep reasoning including a new progress bar and a notification when a task is complete. Friend of the pod Ray Fernando gave pro a prompt that took 7 minutes to think through! I've tested the new o1 myself, and while I've gotten dangerously close to my 50 messages per week quota, I've gotten some incredible results already, and very fast as well. This ice-cubes question failed o1-preview and o1-mini and it took both of them significantly longer, and it took just 4 seconds for o1. Open Source LLMs: Decentralization & Transparent ReasoningNous Research DiStRo & DeMo OptimizerWe’ve talked about decentralized training before, but the folks at Nous Research are making it a reality at scale. This week, Nous Research wrapped up the training of a new 15B-parameter LLM—codename “Psyche”—using a fully decentralized approach called “Nous DiStRo.” Picture a massive AI model trained not in a single data center, but across GPU nodes scattered around the globe. According to Alex Volkov (host of ThursdAI), “This is crazy: they’re literally training a 15B param model using GPUs from multiple companies and individuals, and it’s working as well as centralized runs.”The key to this success is “DeMo” (Decoupled Momentum Optimization), a paper co-authored by none other than Diederik Kingma (yes, the Kingma behind Adam optimizer and VAEs). DeMo drastically reduces communication overhead and still maintains stability and speed. The training loss curve they’ve shown looks just as good as a normal centralized run, proving that decentralized training isn’t just a pipe dream. The code and paper are open source,

🦃 ThursdAI - Thanksgiving special 24' - Qwen Open Sources Reasoning, BlueSky hates AI, H controls the web & more AI news
Hey ya'll, Happy Thanskgiving to everyone who celebrates and thank you for being a subscriber, I truly appreciate each and every one of you! We had a blast on today's celebratory stream, especially given that today's "main course" was the amazing open sourcing of a reasoning model from Qwen, and we had Junyang Lin with us again to talk about it! First open source reasoning model that you can run on your machine, that beats a 405B model, comes close to o1 on some metrics 🤯 We also chatted about a new hybrid approach from Nvidia called Hymba 1.5B (Paper, HF) that beats Qwen 1.5B with 6-12x less training, and Allen AI releasing Olmo 2, which became the best fully open source LLM 👏 (Blog, HF, Demo), though they didn't release WandB logs this time, they did release data! I encourage you to watch todays show (or listen to the show, I don't judge), there's not going to be a long writeup like I usually do, as I want to go and enjoy the holiday too, but of course, the TL;DR and show notes are right here so you won't miss a beat if you want to use the break to explore and play around with a few things! ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.TL;DR and show notes* Qwen QwQ 32B preview - the first open weights reasoning model (X, Blog, HF, Try it)* Allen AI - Olmo 2 the best fully open language model (Blog, HF, Demo)* NVIDIA Hymba 1.5B - Hybrid smol model beating Qwen, SmolLM w/ 6-12x less training (X, Paper, HF)* Big CO LLMs + APIs* Anthropic MCP - model context protocol (X,Blog, Spec, Explainer)* Cursor, Jetbrains now integrate with ChatGPT MacOS app (X)* Xai is going to be a Gaming company?! (X)* H company shows Runner H - WebVoyager Agent (X, Waitlist) * This weeks Buzz* Interview w/ Thomas Cepelle about Weave scorers and guardrails (Guide)* Vision & Video* OpenAI SORA API was "leaked" on HuggingFace (here)* Runway launches video Expand feature (X)* Rhymes Allegro-TI2V - updated image to video model (HF)* Voice & Audio* OuteTTS v0.2 - 500M smol TTS with voice cloning (Blog, HF)* AI Art & Diffusion & 3D* Runway launches an image model called Frames (X, Blog)* ComfyUI Desktop app was released 🎉* Chat* 24 hours of AI hate on 🦋 (thread)* Tools* Cursor agent (X thread)* Google Generative Chess toy (Link)See you next week and happy Thanks Giving 🦃Thanks for reading ThursdAI - Recaps of the most high signal AI weekly spaces! This post is public so feel free to share it.Full Subtitles for convenience[00:00:00] Alex Volkov: let's get it going.[00:00:10] Alex Volkov: Welcome, welcome everyone to ThursdAI November 28th Thanksgiving special. My name is Alex Volkov. I'm an AI evangelist with Weights Biases. You're on ThursdAI. We are live [00:00:30] on ThursdAI. Everywhere pretty much.[00:00:32] Alex Volkov:[00:00:32] Hosts and Guests Introduction[00:00:32] Alex Volkov: I'm joined here with two of my co hosts.[00:00:35] Alex Volkov: Wolfram, welcome.[00:00:36] Wolfram Ravenwolf: Hello everyone! Happy Thanksgiving![00:00:38] Alex Volkov: Happy Thanksgiving, man.[00:00:39] Alex Volkov: And we have Junyang here. Junyang, welcome, man.[00:00:42] Junyang Lin: Yeah, hi everyone. Happy Thanksgiving. Great to be here.[00:00:46] Alex Volkov: You had a busy week. We're going to chat about what you had. I see Nisten joining us as well at some point.[00:00:51] Alex Volkov: Yam pe joining us as well. Hey, how, Hey Yam. Welcome. Welcome, as well. Happy Thanksgiving. It looks like we're assembled folks. We're across streams, across [00:01:00] countries, but we are.[00:01:01] Overview of Topics for the Episode[00:01:01] Alex Volkov: For November 28th, we have a bunch of stuff to talk about. Like really a big list of stuff to talk about. So why don't we just we'll just dive in. We'll just dive in. So obviously I think the best and the most important.[00:01:13] DeepSeek and Qwen Open Source AI News[00:01:13] Alex Volkov: Open source kind of AI news to talk about this week is going to be, and I think I remember last week, Junyang, I asked you about this and you were like, you couldn't say anything, but I asked because last week, folks, if you remember, we talked about R1 from DeepSeek, a reasoning model from [00:01:30] DeepSeek, which really said, Oh, maybe it comes as a, as open source and maybe it doesn't.[00:01:33] Alex Volkov: And I hinted about, and I asked, Junyang, what about some reasoning from you guys? And you couldn't say anything. so this week. I'm going to do a TLDR. So we're going to actually talk about the stuff that, you know, in depth a little bit later, but this week, obviously one of the biggest kind of open source or sorry, open weights, and news is coming from our friends at Qwen as well, as we always celebrate.[00:01:56] Alex Volkov: So one of the biggest things that we get as. [00:02:00] is, Qwen releases, I will actually have you tell me what's the pronunciation here, Junaid, what

📆 ThursdAI - Nov 21 - The fight for the LLM throne, OSS SOTA from AllenAI, Flux new tools, Deepseek R1 reasoning & more AI news
Hey folks, Alex here, and oof what a 🔥🔥🔥 show we had today! I got to use my new breaking news button 3 times this show! And not only that, some of you may know that one of the absolutely biggest pleasures as a host, is to feature the folks who actually make the news on the show!And now that we're in video format, you actually get to see who they are! So this week I was honored to welcome back our friend and co-host Junyang Lin, a Dev Lead from the Alibaba Qwen team, who came back after launching the incredible Qwen Coder 2.5, and Qwen 2.5 Turbo with 1M context.We also had breaking news on the show that AI2 (Allen Institute for AI) has fully released SOTA LLama post-trained models, and I was very lucky to get the core contributor on the paper, Nathan Lambert to join us live and tell us all about this amazing open source effort! You don't want to miss this conversation!Lastly, we chatted with the CEO of StackBlitz, Eric Simons, about the absolutely incredible lightning in the bottle success of their latest bolt.new product, how it opens a new category of code generator related tools.00:00 Introduction and Welcome00:58 Meet the Hosts and Guests02:28 TLDR Overview03:21 Tl;DR04:10 Big Companies and APIs07:47 Agent News and Announcements08:05 Voice and Audio Updates08:48 AR, Art, and Diffusion11:02 Deep Dive into Mistral and Pixtral29:28 Interview with Nathan Lambert from AI230:23 Live Reaction to Tulu 3 Release30:50 Deep Dive into Tulu 3 Features32:45 Open Source Commitment and Community Impact33:13 Exploring the Released Artifacts33:55 Detailed Breakdown of Datasets and Models37:03 Motivation Behind Open Source38:02 Q&A Session with the Community38:52 Summarizing Key Insights and Future Directions40:15 Discussion on Long Context Understanding41:52 Closing Remarks and Acknowledgements44:38 Transition to Big Companies and APIs45:03 Weights & Biases: This Week's Buzz01:02:50 Mistral's New Features and Upgrades01:07:00 Introduction to DeepSeek and the Whale Giant01:07:44 DeepSeek's Technological Achievements01:08:02 Open Source Models and API Announcement01:09:32 DeepSeek's Reasoning Capabilities01:12:07 Scaling Laws and Future Predictions01:14:13 Interview with Eric from Bolt01:14:41 Breaking News: Gemini Experimental01:17:26 Interview with Eric Simons - CEO @ Stackblitz01:19:39 Live Demo of Bolt's Capabilities01:36:17 Black Forest Labs AI Art Tools01:40:45 Conclusion and Final ThoughtsAs always, the show notes and TL;DR with all the links I mentioned on the show and the full news roundup below the main new recap 👇Google & OpenAI fighting for the LMArena crown 👑I wanted to open with this, as last week I reported that Gemini Exp 1114 has taken over #1 in the LMArena, in less than a week, we saw a new ChatGPT release, called GPT-4o-2024-11-20 reclaim the arena #1 spot!Focusing specifically on creating writing, this new model, that's now deployed on chat.com and in the API, is definitely more creative according to many folks who've tried it, with OpenAI employees saying "expect qualitative improvements with more natural and engaging writing, thoroughness and readability" and indeed that's what my feed was reporting as well.I also wanted to mention here, that we've seen this happen once before, last time Gemini peaked at the LMArena, it took less than a week for OpenAI to release and test a model that beat it.But not this time, this time Google came prepared with an answer!Just as we were wrapping up the show (again, Logan apparently loves dropping things at the end of ThursdAI), we got breaking news that there is YET another experimental model from Google, called Gemini Exp 1121, and apparently, it reclaims the stolen #1 position, that chatGPT reclaimed from Gemini... yesterday! Or at least joins it at #1LMArena Fatigue?Many folks in my DMs are getting a bit frustrated with these marketing tactics, not only the fact that we're getting experimental models faster than we can test them, but also with the fact that if you think about it, this was probably a calculated move by Google. Release a very powerful checkpoint, knowing that this will trigger a response from OpenAI, but don't release your most powerful one. OpenAI predictably releases their own "ready to go" checkpoint to show they are ahead, then folks at Google wait and release what they wanted to release in the first place.The other frustration point is, the over-indexing of the major labs on the LMArena human metrics, as the closest approximation for "best". For example, here's some analysis from Artificial Analysis showing that the while the latest ChatGPT is indeed better at creative writing (and #1 in the Arena, where humans vote answers against each other), it's gotten actively worse at MATH and coding from the August version (which could be a result of being a distilled much smaller version) .In summary, maybe the LMArena is no longer 1 arena is all you need, but the competition at the TOP scores of the Arena has never been hotter.DeepSeek R-1 previe
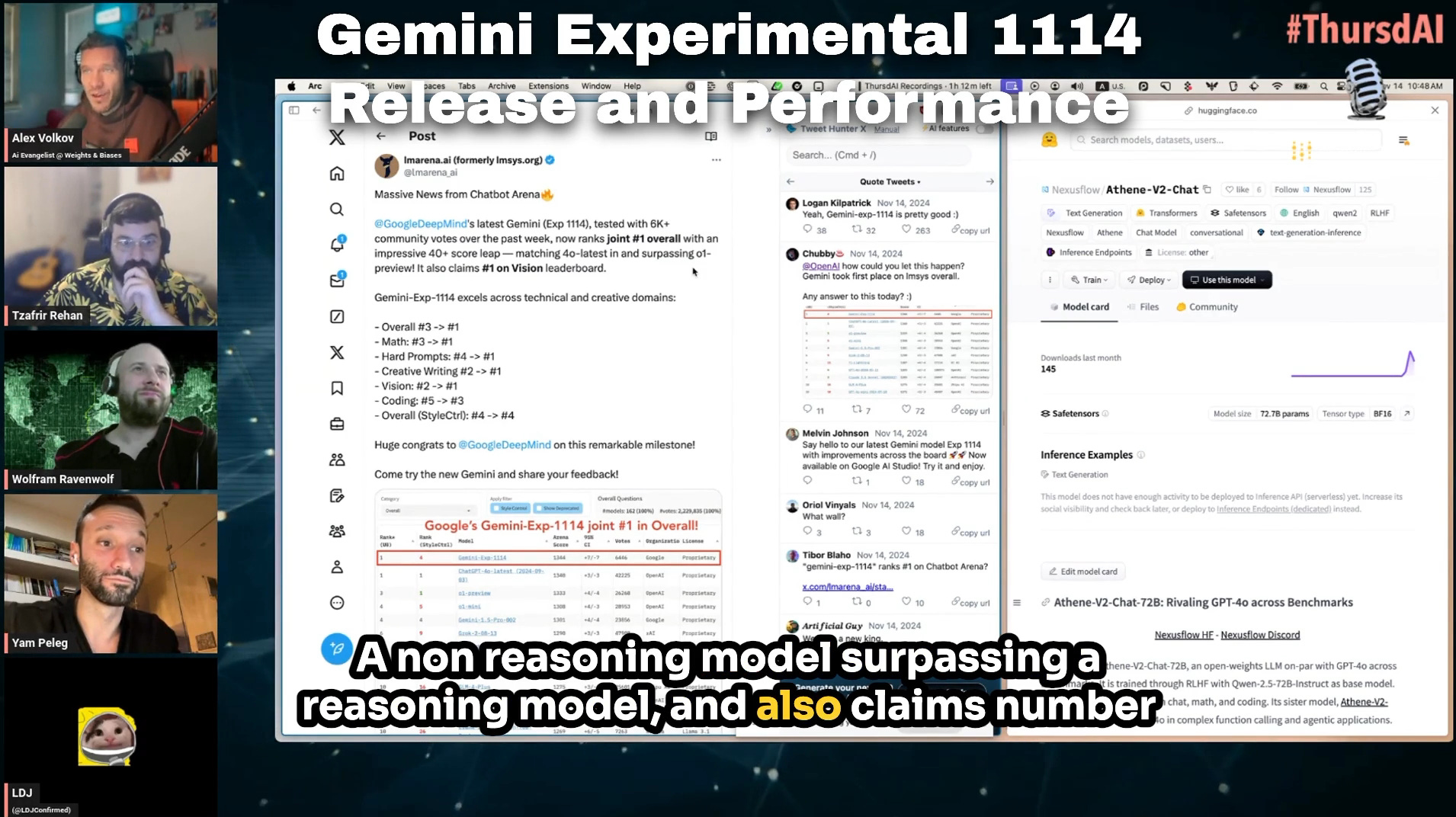
📆 ThursdAI - Nov 14 - Qwen 2.5 Coder, No Walls, Gemini 1114 👑 LLM, ChatGPT OS integrations & more AI news
This week is a very exciting one in the world of AI news, as we get 3 SOTA models, one in overall LLM rankings, on in OSS coding and one in OSS voice + a bunch of new breaking news during the show (which we reacted to live on the pod, and as we're now doing video, you can see us freak out in real time at 59:32)00:00 Welcome to ThursdAI00:25 Meet the Hosts02:38 Show Format and Community03:18 TLDR Overview04:01 Open Source Highlights13:31 Qwen Coder 2.5 Release14:00 Speculative Decoding and Model Performance22:18 Interactive Demos and Artifacts28:20 Training Insights and Future Prospects33:54 Breaking News: Nexus Flow36:23 Exploring Athene v2 Agent Capabilities36:48 Understanding ArenaHard and Benchmarking40:55 Scaling and Limitations in AI Models43:04 Nexus Flow and Scaling Debate49:00 Open Source LLMs and New Releases52:29 FrontierMath Benchmark and Quantization Challenges58:50 Gemini Experimental 1114 Release and Performance01:11:28 LLM Observability with Weave01:14:55 Introduction to Tracing and Evaluations01:15:50 Weave API Toolkit Overview01:16:08 Buzz Corner: Weights & Biases01:16:18 Nous Forge Reasoning API01:26:39 Breaking News: OpenAI's New MacOS Features01:27:41 Live Demo: ChatGPT Integration with VS Code01:34:28 Ultravox: Real-Time AI Conversations01:42:03 Tilde Research and Stargazer Tool01:46:12 Conclusion and Final ThoughtsThis week also, there was a debate online, whether deep learning (and scale is all you need) has hit a wall, with folks like Ilya Sutskever being cited by publications claiming it has, folks like Yann LeCoon calling "I told you so". TL;DR? multiple huge breakthroughs later, and both Oriol from DeepMind and Sam Altman are saying "what wall?" and Heiner from X.ai saying "skill issue", there is no walls in sight, despite some tech journalism love to pretend there is. Also, what happened to Yann? 😵💫Ok, back to our scheduled programming, here's the TL;DR, afterwhich, a breakdown of the most important things about today's update, and as always, I encourage you to watch / listen to the show, as we cover way more than I summarize here 🙂TL;DR and Show Notes:* Open Source LLMs* Qwen Coder 2.5 32B (+5 others) - Sonnet @ home (HF, Blog, Tech Report)* The End of Quantization? (X, Original Thread)* Epoch : FrontierMath new benchmark for advanced MATH reasoning in AI (Blog)* Common Corpus: Largest multilingual 2T token dataset (blog)* NexusFlow - Athena v2 - open model suite (X, Blog, HF)* Big CO LLMs + APIs* Gemini 1114 is new king LLM #1 LMArena (X)* Nous Forge Reasoning API - beta (Blog, X)* Reuters reports "AI is hitting a wall" and it's becoming a meme (Article)* Cursor acq. SuperMaven (X)* This Weeks Buzz* Weave JS/TS support is here 🙌* Voice & Audio* Fixie releases UltraVox SOTA (Demo, HF, API)* Suno v4 is coming and it's bonkers amazing (Alex Song, SOTA Jingle)* Tools demoed* Qwen artifacts - HF Demo* Tilde Galaxy - Interp Tool This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit sub.thursdai.news/subscribe

📆 ThursdAI - Nov 7 - Video version, full o1 was given and taken away, Anthropic price hike-u, halloween 💀 recap & more AI news
👋 Hey all, this is Alex, coming to you from the very Sunny California, as I'm in SF again, while there is a complete snow storm back home in Denver (brrr).I flew here for the Hackathon I kept telling you about, and it was glorious, we had over 400 registered, over 200 approved hackers, 21 teams submitted incredible projects 👏 You can follow some of these hereI then decided to stick around and record the show from SF, and finally pulled the plug and asked for some budget, and I present, the first ThursdAI, recorded from the newly minted W&B Podcast studio at our office in SF 🎉This isn't the only first, today also, for the first time, all of the regular co-hosts of ThursdAI, met on video for the first time, after over a year of hanging out weekly, we've finally made the switch to video, and you know what? Given how good AI podcasts are getting, we may have to stick around with this video thing! We played one such clip from a new model called hertz-dev, which is a Given that today's episode is a video podcast, I would love for you to see it, so here's the timestamps for the chapters, which will be followed by the TL;DR and show notes in raw format. I would love to hear from folks who read the longer form style newsletters, do you miss them? Should I bring them back? Please leave me a comment 🙏 (I may send you a survey)This was a generally slow week (for AI!! not for... ehrm other stuff) and it was a fun podcast! Leave me a comment about what you think about this new format.Chapter Timestamps00:00 Introduction and Agenda Overview00:15 Open Source LLMs: Small Models01:25 Open Source LLMs: Large Models02:22 Big Companies and LLM Announcements04:47 Hackathon Recap and Community Highlights18:46 Technical Deep Dive: HertzDev and FishSpeech33:11 Human in the Loop: AI Agents36:24 Augmented Reality Lab Assistant36:53 Hackathon Highlights and Community Vibes37:17 Chef Puppet and Meta Ray Bans Raffle37:46 Introducing Fester the Skeleton38:37 Fester's Performance and Community Reactions39:35 Technical Insights and Project Details42:42 Big Companies API Updates43:17 Haiku 3.5: Performance and Pricing43:44 Comparing Haiku and Sonnet Models51:32 XAI Grok: New Features and Pricing57:23 OpenAI's O1 Model: Leaks and Expectations01:08:42 Transformer ASIC: The Future of AI Hardware01:13:18 The Future of Training and Inference Chips01:13:52 Oasis Demo and Etched AI Controversy01:14:37 Nisten's Skepticism on Etched AI01:19:15 Human Layer Introduction with Dex01:19:24 Building and Managing AI Agents01:20:54 Challenges and Innovations in AI Agent Development01:21:28 Human Layer's Vision and Future01:36:34 Recap and Closing RemarksThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.Show Notes and Links:* Interview* Dexter Horthy (X) from HumanLayer* Open Source LLMs* SmolLM2: the new, best, and open 1B-parameter language mode (X)* Meta released MobileLLM (125M, 350M, 600M, 1B) (HF)* Tencent Hunyuan Large - 389B X 52B (Active) MoE (X, HF, Paper)* Big CO LLMs + APIs* OpenAI buys and opens chat.com* Anthropic releases Claude Haiku 3.5 via API (X, Blog)* OpenAI drops o1 full - and pulls it back (but not before it got Jailbroken)* X.ai now offers $25/mo free of Grok API credits (X, Platform)* Etched announces Sonu - first Transformer ASIC - 500K tok/s (etched)* PPXL is not valued at 9B lol* This weeks Buzz* Recap of SF Hackathon w/ AI Tinkerers (X)* Fester the Halloween Toy aka Project Halloweave videos from trick or treating (X, Writeup)* Voice & Audio* Hertz-dev - 8.5B conversation audio gen (X, Blog )* Fish Agent v0.1 3B - Speech to Speech model (HF, Demo)* AI Art & Diffusion & 3D* FLUX 1.1 [pro] is how HD - 4x resolution (X, blog)Full Transcription for convenience below: This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit sub.thursdai.news/subscribe
📆 ThursdAI - Spooky Halloween edition with Video!
Hey everyone, Happy Halloween! Alex here, coming to you live from my mad scientist lair! For the first ever, live video stream of ThursdAI, I dressed up as a mad scientist and had my co-host, Fester the AI powered Skeleton join me (as well as my usual cohosts haha) in a very energetic and hopefully entertaining video stream! Since it's Halloween today, Fester (and I) have a very busy schedule, so no super length ThursdAI news-letter today, as we're still not in the realm of Gemini being able to write a decent draft that takes everything we talked about and cover all the breaking news, I'm afraid I will have to wish you a Happy Halloween and ask that you watch/listen to the episode. The TL;DR and show links from today, don't cover all the breaking news but the major things we saw today (and caught live on the show as Breaking News) were, ChatGPT now has search, Gemini has grounded search as well (seems like the release something before Google announces it streak from OpenAI continues). Here's a quick trailer of the major things that happened: This weeks buzz - Halloween AI toy with WeaveIn this weeks buzz, my long awaited Halloween project is finally live and operational! I've posted a public Weave dashboard here and the code (that you can run on your mac!) hereReally looking forward to see all the amazing costumers the kiddos come up with and how Gemini will be able to respond to them, follow along! ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.Ok and finally my raw TL;DR notes and links for this week. Happy halloween everyone, I'm running off to spook the kiddos (and of course record and post about it!)ThursdAI - Oct 31 - TL;DRTL;DR of all topics covered:* Open Source LLMs:* Microsoft's OmniParser: SOTA UI parsing (MIT Licensed) 𝕏* Groundbreaking model for web automation (MIT license).* State-of-the-art UI parsing and understanding.* Outperforms GPT-4V in parsing web UI.* Designed for web automation tasks.* Can be integrated into various development workflows.* ZhipuAI's GLM-4-Voice: End-to-end Chinese/English speech 𝕏* End-to-end voice model for Chinese and English speech.* Open-sourced and readily available.* Focuses on direct speech understanding and generation.* Potential applications in various speech-related tasks.* Meta releases LongVU: Video LM for long videos 𝕏* Handles long videos with impressive performance.* Uses DINOv2 for downsampling, eliminating redundant scenes.* Fuses features using DINOv2 and SigLIP.* Select tokens are passed to Qwen2/Llama-3.2-3B.* Demo and model are available on HuggingFace.* Potential for significant advancements in video understanding.* OpenAI new factuality benchmark (Blog, Github)* Introducing SimpleQA: new factuality benchmark* Goal: high correctness, diversity, challenging for frontier models* Question Curation: AI trainers, verified by second trainer* Quality Assurance: 3% inherent error rate* Topic Diversity: wide range of topics* Grading Methodology: "correct", "incorrect", "not attempted"* Model Comparison: smaller models answer fewer correctly* Calibration Measurement: larger models more calibrated* Limitations: only for short, fact-seeking queries* Conclusion: drive research on trustworthy AI* Big CO LLMs + APIs:* ChatGPT now has Search! (X)* Grounded search results in browsing the web* Still hallucinates* Reincarnation of Search GPT inside ChatGPT* Apple Intelligence Launch: Image features for iOS 18.2 [𝕏]( Link not provided in source material)* Officially launched for developers in iOS 18.2.* Includes Image Playground and Gen Moji.* Aims to enhance image creation and manipulation on iPhones.* GitHub Universe AI News: Co-pilot expands, new Spark tool 𝕏* GitHub Co-pilot now supports Claude, Gemini, and OpenAI models.* GitHub Spark: Create micro-apps using natural language.* Expanding the capabilities of AI-powered coding tools.* Copilot now supports multi-file edits in VS Code, similar to Cursor, and faster code reviews.* GitHub Copilot extensions are planned for release in 2025.* Grok Vision: Image understanding now in Grok 𝕏* Finally has vision capabilities (currently via 𝕏, API coming soon).* Can now understand and explain images, even jokes.* Early version, with rapid improvements expected.* OpenAI advanced voice mode updates (X)* 70% cheaper in input tokens because of automatic caching (X)* Advanced voice mode is now on desktop app* Claude this morning - new mac / pc App* This week's Buzz:* My AI Halloween toy skeleton is greeting kids right now (and is reporting to Weave dashboard)* Vision & Video:* Meta's LongVU: Video LM for long videos 𝕏 (see Open Source LLMs for details)* Grok Vision on 𝕏: 𝕏 (see Big CO LLMs + APIs for details)* Voice & Audio:* MaskGCT: New SoTA Text-to-Speech 𝕏* New open-source state-of-the-art text-to-speech model.* Zero-shot voice cloning, emotional TTS, long-form synthesis, variable s
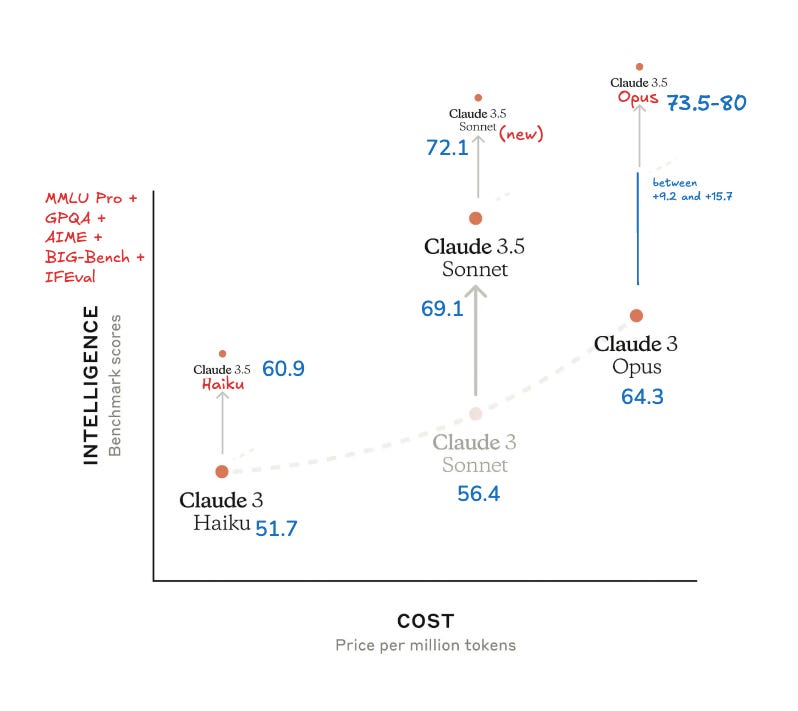
📅 ThursdAI - Oct 24 - Claude 3.5 controls your PC?! Talking AIs with 🦾, Multimodal Weave, Video Models mania + more AI news from this 🔥 week.
Hey all, Alex here, coming to you from the (surprisingly) sunny Seattle, with just a mind-boggling week of releases. Really, just on Tuesday there was so much news already! I had to post a recap thread, something I do usually after I finish ThursdAI! From Anthropic reclaiming close-second sometimes-first AI lab position + giving Claude the wheel in the form of computer use powers, to more than 3 AI video generation updates with open source ones, to Apple updating Apple Intelligence beta, it's honestly been very hard to keep up, and again, this is literally part of my job! But once again I'm glad that we were able to cover this in ~2hrs, including multiple interviews with returning co-hosts ( Simon Willison came back, Killian came back) so definitely if you're only a reader at this point, listen to the show! Ok as always (recently) the TL;DR and show notes at the bottom (I'm trying to get you to scroll through ha, is it working?) so grab a bucket of popcorn, let's dive in 👇 ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.Claude's Big Week: Computer Control, Code Wizardry, and the Mysterious Case of the Missing OpusAnthropic dominated the headlines this week with a flurry of updates and announcements. Let's start with the new Claude Sonnet 3.5 (really, they didn't update the version number, it's still 3.5 tho a different API model) Claude Sonnet 3.5: Coding Prodigy or Benchmark Buster?The new Sonnet model shows impressive results on coding benchmarks, surpassing even OpenAI's O1 preview on some. "It absolutely crushes coding benchmarks like Aider and Swe-bench verified," I exclaimed on the show. But a closer look reveals a more nuanced picture. Mixed results on other benchmarks indicate that Sonnet 3.5 might not be the universal champion some anticipated. My friend who has held back internal benchmarks was disappointed highlighting weaknesses in scientific reasoning and certain writing tasks. Some folks are seeing it being lazy-er for some full code completion, while the context window is now doubled from 4K to 8K! This goes to show again, that benchmarks don't tell the full story, so we wait for LMArena (formerly LMSys Arena) and the vibe checks from across the community. However it absolutely dominates in code tasks, that much is clear already. This is a screenshot of the new model on Aider code editing benchmark, a fairly reliable way to judge models code output, they also have a code refactoring benchmarkHaiku 3.5 and the Vanishing Opus: Anthropic's Cryptic CluesFurther adding to the intrigue, Anthropic announced Claude 3.5 Haiku! They usually provide immediate access, but Haiku remains elusive, saying that it's available by end of the month, which is very very soon. Making things even more curious, their highly anticipated Opus model has seemingly vanished from their website. "They've gone completely silent on 3.5 Opus," Simon Willison (𝕏) noted, mentioning conspiracy theories that this new Sonnet might simply be a rebranded Opus? 🕯️ 🕯️ We'll make a summoning circle for new Opus and update you once it lands (maybe next year) Claude Takes Control (Sort Of): Computer Use API and the Dawn of AI Agents (𝕏)The biggest bombshell this week? Anthropic's Computer Use. This isn't just about executing code; it’s about Claude interacting with computers, clicking buttons, browsing the web, and yes, even ordering pizza! Killian Lukas (𝕏), creator of Open Interpreter, returned to ThursdAI to discuss this groundbreaking development. "This stuff of computer use…it’s the same argument for having humanoid robots, the web is human shaped, and we need AIs to interact with computers and the web the way humans do" Killian explained, illuminating the potential for bridging the digital and physical worlds. Simon, though enthusiastic, provided a dose of realism: "It's incredibly impressive…but also very much a V1, beta.” Having tackled the setup myself, I agree; the current reliance on a local Docker container and virtual machine introduces some complexity and security considerations. However, seeing Claude fix its own Docker installation error was an unforgettably mindblowing experience. The future of AI agents is upon us, even if it’s still a bit rough around the edges.Here's an easy guide to set it up yourself, takes 5 minutes, requires no coding skills and it's safely tucked away in a container.Big Tech's AI Moves: Apple Embraces ChatGPT, X.ai API (+Vision!?), and Cohere Multimodal EmbeddingsThe rest of the AI world wasn’t standing still. Apple made a surprising integration, while X.ai and Cohere pushed their platforms forward.Apple iOS 18.2 Beta: Siri Phones a Friend (ChatGPT)Apple, always cautious, surprisingly integrated ChatGPT directly into iOS. While Siri remains…well, Siri, users can now effortlessly offload more demanding tasks to ChatGPT. "Siri is still stupid," I joked, "but can n

📆 ThursdAI - Oct 17 - Robots, Rockets, and Multi Modal Mania with open source voice cloning, OpenAI new voice API and more AI news
Hey folks, Alex here from Weights & Biases, and this week has been absolutely bonkers. From robots walking among us to rockets landing on chopsticks (well, almost), the future is feeling palpably closer. And if real-world robots and reusable spaceship boosters weren't enough, the open-source AI community has been cooking, dropping new models and techniques faster than a Starship launch. So buckle up, grab your space helmet and noise-canceling headphones (we’ll get to why those are important!), and let's blast off into this week’s AI adventures!TL;DR and show-notes + links at the end of the post 👇Robots and Rockets: A Glimpse into the FutureI gotta start with the real-world stuff because, let's be honest, it's mind-blowing. We had Robert Scoble (yes, the Robert Scoble) join us after attending the Tesla We, Robot AI event, reporting on Optimus robots strolling through crowds, serving drinks, and generally being ridiculously futuristic. Autonomous robo-taxis were also cruising around, giving us a taste of a driverless future.Robert’s enthusiasm was infectious: "It was a vision of the future, and from that standpoint, it succeeded wonderfully." I couldn't agree more. While the market might have had a mini-meltdown (apparently investors aren't ready for robot butlers yet), the sheer audacity of Tesla’s vision is exhilarating. These robots aren't just cool gadgets; they represent a fundamental shift in how we interact with technology and the world around us. And they’re learning fast. Just days after the event, Tesla released a video of Optimus operating autonomously, showcasing the rapid progress they’re making.And speaking of audacious visions, SpaceX decided to one-up everyone (including themselves) by launching Starship and catching the booster with Mechazilla – their giant robotic chopsticks (okay, technically a launch tower, but you get the picture). Waking up early with my daughter to watch this live was pure magic. As Ryan Carson put it, "It was magical watching this… my kid who's 16… all of his friends are getting their imaginations lit by this experience." That’s exactly what we need - more imagination and less doomerism! The future is coming whether we like it or not, and I, for one, am excited.Open Source LLMs and Tools: The Community Delivers (Again!)Okay, back to the virtual world (for now). This week's open-source scene was electric, with new model releases and tools that have everyone buzzing (and benchmarking like crazy!).* Nemotron 70B: Hype vs. Reality: NVIDIA dropped their Nemotron 70B instruct model, claiming impressive scores on certain benchmarks (Arena Hard, AlpacaEval), even suggesting it outperforms GPT-4 and Claude 3.5. As always, we take these claims with a grain of salt (remember Reflection?), and our resident expert, Nisten, was quick to run his own tests. The verdict? Nemotron is good, "a pretty good model to use," but maybe not the giant-killer some hyped it up to be. Still, kudos to NVIDIA for pushing the open-source boundaries. (Hugging Face, Harrison Kingsley evals)* Zamba 2 : Hybrid Vigor: Zyphra, in collaboration with NVIDIA, released Zamba 2, a hybrid Sparse Mixture of Experts (SME) model. We had Paolo Glorioso, a researcher from Ziphra, join us to break down this unique architecture, which combines the strengths of transformers and state space models (SSMs). He highlighted the memory and latency advantages of SSMs, especially for on-device applications. Definitely worth checking out if you’re interested in transformer alternatives and efficient inference.* Zyda 2: Data is King (and Queen): Alongside Zamba 2, Zyphra also dropped Zyda 2, a massive 5 trillion token dataset, filtered, deduplicated, and ready for LLM training. This kind of open-source data release is a huge boon to the community, fueling the next generation of models. (X)* Ministral: Pocket-Sized Power: On the one-year anniversary of the iconic Mistral 7B release, Mistral announced two new smaller models – Ministral 3B and 8B. Designed for on-device inference, these models are impressive, but as always, Qwen looms large. While Mistral didn’t include Qwen in their comparisons, early tests suggest Qwen’s smaller models still hold their own. One point of contention: these Ministrals aren't as open-source as the original 7B, which is a bit of a bummer, with the 3B not being even released anywhere besides their platform. (Mistral Blog)* Entropix (aka Shrek Sampler): Thinking Outside the (Sample) Box: This one is intriguing! Entropix introduces a novel sampling technique aimed at boosting the reasoning capabilities of smaller LLMs. Nisten’s yogurt analogy explains it best: it’s about “marinating” the information and picking the best “flavor” (token) at the end. Early examples look promising, suggesting Entropix could help smaller models tackle problems that even trip up their larger counterparts. But, as with all shiny new AI toys, we're eagerly awaiting robust evals. Tim Kellog has an detailed breakdown of this metho

📆 ThursdAI - Oct 10 - Two Nobel Prizes in AI!? Meta Movie Gen (and sounds ) amazing, Pyramid Flow a 2B video model, 2 new VLMs & more AI news!
Hey Folks, we are finally due for a "relaxing" week in AI, no more HUGE company announcements (if you don't consider Meta Movie Gen huge), no conferences or dev days, and some time for Open Source projects to shine. (while we all wait for Opus 3.5 to shake things up) This week was very multimodal on the show, we covered 2 new video models, one that's tiny and is open source, and one massive from Meta that is aiming for SORA's crown, and 2 new VLMs, one from our friends at REKA that understands videos and audio, while the other from Rhymes is apache 2 licensed and we had a chat with Kwindla Kramer about OpenAI RealTime API and it's shortcomings and voice AI's in general. ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.All right, let's TL;DR and show notes, and we'll start with the 2 Nobel prizes in AI 👇 * 2 AI nobel prizes* John Hopfield and Geoffrey Hinton have been awarded a Physics Nobel prize* Demis Hassabis, John Jumper & David Baker, have been awarded this year's #NobelPrize in Chemistry.* Open Source LLMs & VLMs* TxT360: a globally deduplicated dataset for LLM pre-training ( Blog, Dataset)* Rhymes Aria - 25.3B multimodal MoE model that can take image/video inputs Apache 2 (Blog, HF, Try It)* Maitrix and LLM360 launch a new decentralized arena (Leaderboard, Blog)* New Gradio 5 with server side rendering (X)* LLamaFile now comes with a chat interface and syntax highlighting (X)* Big CO LLMs + APIs* OpenAI releases MLEBench - new kaggle focused benchmarks for AI Agents (Paper, Github)* Inflection is still alive - going for enterprise lol (Blog)* new Reka Flash 21B - (X, Blog, Try It)* This weeks Buzz* We chatted about Cursor, it went viral, there are many tips* WandB releases HEMM - benchmarks of text-to-image generation models (X, Github, Leaderboard)* Vision & Video* Meta presents Movie Gen 30B - img and text to video models (blog, paper)* Pyramid Flow - open source img2video model MIT license (X, Blog, HF, Paper, Github)* Voice & Audio* Working with OpenAI RealTime Audio - Alex conversation with Kwindla from trydaily.com* Cartesia Sonic goes multilingual (X)* Voice hackathon in SF with 20K prizes (and a remote track) - sign up* Tools* LM Studio ships with MLX natively (X, Download)* UITHUB.com - turn any github repo into 1 long file for LLMsA Historic Week: TWO AI Nobel Prizes!This week wasn't just big; it was HISTORIC. As Yam put it, "two Nobel prizes for AI in a single week. It's historic." And he's absolutely spot on! Geoffrey Hinton, often called the "grandfather of modern AI," alongside John Hopfield, were awarded the Nobel Prize in Physics for their foundational work on neural networks - work that paved the way for everything we're seeing today. Think back propagation, Boltzmann machines – these are concepts that underpin much of modern deep learning. It’s about time they got the recognition they deserve!Yoshua Bengio posted about this in a very nice quote: @HopfieldJohn and @geoffreyhinton, along with collaborators, have created a beautiful and insightful bridge between physics and AI. They invented neural networks that were not only inspired by the brain, but also by central notions in physics such as energy, temperature, system dynamics, energy barriers, the role of randomness and noise, connecting the local properties, e.g., of atoms or neurons, to global ones like entropy and attractors. And they went beyond the physics to show how these ideas could give rise to memory, learning and generative models; concepts which are still at the forefront of modern AI researchAnd Hinton's post-Nobel quote? Pure gold: “I’m particularly proud of the fact that one of my students fired Sam Altman." He went on to explain his concerns about OpenAI's apparent shift in focus from safety to profits. Spicy take! It sparked quite a conversation about the ethical implications of AI development and who’s responsible for ensuring its safe deployment. It’s a discussion we need to be having more and more as the technology evolves. Can you guess which one of his students it was? Then, not to be outdone, the AlphaFold team (Demis Hassabis, John Jumper, and David Baker) snagged the Nobel Prize in Chemistry for AlphaFold 2. This AI revolutionized protein folding, accelerating drug discovery and biomedical research in a way no one thought possible. These awards highlight the tangible, real-world applications of AI. It's not just theoretical anymore; it's transforming industries.Congratulations to all winners, and we gotta wonder, is this a start of a trend of AI that takes over every Nobel prize going forward? 🤔 Open Source LLMs & VLMs: The Community is COOKING!The open-source AI community consistently punches above its weight, and this week was no exception. We saw some truly impressive releases that deserve a standing ovation. First off, the TxT360 dataset (blog, dataset). Nisten, resident

📆 ThursdAI - Oct 3 - OpenAI RealTime API, ChatGPT Canvas & other DevDay news (how I met Sam Altman), Gemini 1.5 8B is basically free, BFL makes FLUX 1.1 6x faster, Rev breaks whisper records...
Hey, it's Alex. Ok, so mind is officially blown. I was sure this week was going to be wild, but I didn't expect everyone else besides OpenAI to pile on, exactly on ThursdAI. Coming back from Dev Day (number 2) and am still processing, and wanted to actually do a recap by humans, not just the NotebookLM one I posted during the keynote itself (which was awesome and scary in a "will AI replace me as a podcaster" kind of way), and was incredible to have Simon Willison who was sitting just behind me most of Dev Day, join me for the recap! But then the news kept coming, OpenAI released Canvas, which is a whole new way of interacting with chatGPT, BFL released a new Flux version that's 8x faster, Rev released a Whisper killer ASR that does diarizaiton and Google released Gemini 1.5 Flash 8B, and said that with prompt caching (which OpenAI now also has, yay) this will cost a whopping 0.01 / Mtok. That's 1 cent per million tokens, for a multimodal model with 1 million context window. 🤯 This whole week was crazy, as last ThursdAI after finishing the newsletter I went to meet tons of folks at the AI Tinkerers in Seattle, and did a little EvalForge demo (which you can see here) and wanted to share EvalForge with you as well, it's early but very promising so feedback and PRs are welcome! WHAT A WEEK, TL;DR for those who want the links and let's dive in 👇 * OpenAI - Dev Day Recap (Alex, Simon Willison)* Recap of Dev Day* RealTime API launched* Prompt Caching launched* Model Distillation is the new finetune* Finetuning 4o with images (Skalski guide)* Fireside chat Q&A with Sam* Open Source LLMs * NVIDIA finally releases NVML (HF)* This weeks Buzz* Alex discussed his demo of EvalForge at the AI Tinkers event in Seattle in "This Week's Buzz". (Demo, EvalForge, AI TInkerers)* Big Companies & APIs* Google has released Gemini Flash 8B - 0.01 per million tokens cached (X, Blog)* Voice & Audio* Rev breaks SOTA on ASR with Rev ASR and Rev Diarize (Blog, Github, HF)* AI Art & Diffusion & 3D* BFL relases Flux1.1[pro] - 3x-6x faster than 1.0 and higher quality (was 🫐) - (Blog, Try it)The day I met Sam Altman / Dev Day recapLast Dev Day (my coverage here) was a "singular" day in AI for me, given it also had the "keep AI open source" with Nous Research and Grimes, and this Dev Day I was delighted to find out that the vibe was completely different, and focused less on bombastic announcements or models, but on practical dev focused things. This meant that OpenAI cherry picked folks who actively develop with their tools, and they didn't invite traditional media, only folks like yours truly, @swyx from Latent space, Rowan from Rundown, Simon Willison and Dan Shipper, you know, newsletter and podcast folks who actually build! This also allowed for many many OpenAI employees who work on the products and APIs we get to use, were there to receive feedback, help folks with prompting, and just generally interact with the devs, and build that community. I want to shoutout my friends Ilan (who was in the keynote as the strawberry salesman interacting with RealTime API agent), Will DePue from the SORA team, with whom we had an incredible conversation about ethics and legality of projects, Christine McLeavey who runs the Audio team, with whom I shared a video of my daughter crying when chatGPT didn't understand her, Katia, Kevin and Romain on the incredible DevEx/DevRel team and finally, my new buddy Jason who does infra, and was fighting bugs all day and only joined the pub after shipping RealTime to all of us. I've collected all these folks in a convenient and super high signal X list here so definitely give that list a follow if you'd like to tap into their streamsFor the actual announcements, I've already covered this in my Dev Day post here (which was payed subscribers only, but is now open to all) and Simon did an incredible summary on his Substack as well The highlights were definitely the new RealTime API that let's developers build with Advanced Voice Mode, Prompt Caching that will happen automatically and reduce all your long context API calls by a whopping 50% and finetuning of models that they are rebranding into Distillation and adding new tools to make it easier (including Vision Finetuning for the first time!)Meeting Sam AltmanWhile I didn't get a "media" pass or anything like this, and didn't really get to sit down with OpenAI execs (see Swyx on Latent Space for those conversations), I did have a chance to ask Sam multiple things. First at the closing fireside chat between Sam and Kevin Weil (CPO at OpenAI), Kevin first asked Sam a bunch of questions, and then they gave out the microphones to folks, and I asked the only question that got Sam to smileSam and Kevin went on for a while, and that Q&A was actually very interesting, so much so, that I had to recruit my favorite Notebook LM podcast hosts, to go through it and give you an overview, so here's that Notebook LM, with the transcript of the whole Q&A (maybe i'll publish it as

OpenAI Dev Day 2024 keynote
Hey, Alex here. Super quick, as I’m still attending Dev Day, but I didn’t want to leave you hanging (if you're a paid subscriber!), I have decided to outsource my job and give the amazing podcasters of NoteBookLM the whole transcript of the opening keynote of OpenAI Dev Day.You can see a blog of everything they just posted hereHere’s a summary of all what was announced:* Developer-Centric Approach: OpenAI consistently emphasized the importance of developers in their mission to build beneficial AGI. The speaker stated, "OpenAI's mission is to build AGI that benefits all of humanity, and developers are critical to that mission... we cannot do this without you."* Reasoning as a New Frontier: The introduction of the GPT-4 series, specifically the "O1" models, marks a significant step towards AI with advanced reasoning capabilities, going beyond the limitations of previous models like GPT-3.* Multimodal Capabilities: OpenAI is expanding the potential of AI applications by introducing multimodal capabilities, particularly focusing on real-time speech-to-speech interaction through the new Realtime API.* Customization and Fine-Tuning: Empowering developers to customize models is a key theme. OpenAI introduced Vision for fine-tuning with images and announced easier access to fine-tuning with model distillation tools.* Accessibility and Scalability: OpenAI demonstrated a commitment to making AI more accessible and cost-effective for developers through initiatives like price reductions, prompt caching, and model distillation tools.Important Ideas and Facts:1. The O1 Models:* Represent a shift towards AI models with enhanced reasoning capabilities, surpassing previous generations in problem-solving and logical thought processes.* O1 Preview is positioned as the most powerful reasoning model, designed for complex problems requiring extended thought processes.* O1 Mini offers a faster, cheaper, and smaller alternative, particularly suited for tasks like code debugging and agent-based applications.* Both models demonstrate advanced capabilities in coding, math, and scientific reasoning.* OpenAI highlighted the ability of O1 models to work with developers as "thought partners," understanding complex instructions and contributing to the development process.Quote: "The shift to reasoning introduces a new shape of AI capability. The ability for our model to scale and correct the process is pretty mind-blowing. So we are resetting the clock, and we are introducing a new series of models under the name O1."2. Realtime API:* Enables developers to build real-time AI experiences directly into their applications using WebSockets.* Launches with support for speech-to-speech interaction, leveraging the technology behind ChatGPT's advanced voice models.* Offers natural and seamless integration of voice capabilities, allowing for dynamic and interactive user experiences.* Showcased the potential to revolutionize human-computer interaction across various domains like driving, education, and accessibility.Quote: "You know, a lot of you have been asking about building amazing speech-to-speech experiences right into your apps. Well now, you can."3. Vision, Fine-Tuning, and Model Distillation:* Vision introduces the ability to use images for fine-tuning, enabling developers to enhance model performance in image understanding tasks.* Fine-tuning with Vision opens up opportunities in diverse fields such as product recommendations, medical imaging, and autonomous driving.* OpenAI emphasized the accessibility of these features, stating that "fine-tuning with Vision is available to every single developer."* Model distillation tools facilitate the creation of smaller, more efficient models by transferring knowledge from larger models like O1 and GPT-4.* This approach addresses cost concerns and makes advanced AI capabilities more accessible for a wider range of applications and developers.Quote: "With distillation, you take the outputs of a large model to supervise, to teach a smaller model. And so today, we are announcing our own model distillation tools."4. Cost Reduction and Accessibility:* OpenAI highlighted its commitment to lowering the cost of AI models, making them more accessible for diverse use cases.* Announced a 90% decrease in cost per token since the release of GPT-3, emphasizing continuous efforts to improve affordability.* Introduced prompt caching, automatically providing a 50% discount for input tokens the model has recently processed.* These initiatives aim to remove financial barriers and encourage wider adoption of AI technologies across various industries.Quote: "Every time we reduce the price, we see new types of applications, new types of use cases emerge. We're super far from the price equilibrium. In a way, models are still too expensive to be bought at massive scale."Conclusion:OpenAI DevDay conveyed a strong message of developer empowerment and a commitment to pushing the boundaries of AI capabilities. With new models

📅 ThursdAI - Sep 26 - 🔥 Llama 3.2 multimodal & meta connect recap, new Gemini 002, Advanced Voice mode & more AI news
Hey everyone, it's Alex (still traveling!), and oh boy, what a week again! Advanced Voice Mode is finally here from OpenAI, Google updated their Gemini models in a huge way and then Meta announced MultiModal LlaMas and on device mini Llamas (and we also got a "better"? multimodal from Allen AI called MOLMO!)From Weights & Biases perspective, our hackathon was a success this weekend, and then I went down to Menlo Park for my first Meta Connect conference, full of news and updates and will do a full recap here as well. ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.Overall another crazy week in AI, and it seems that everyone is trying to rush something out the door before OpenAI Dev Day next week (which I'll cover as well!) Get ready, folks, because Dev Day is going to be epic!TL;DR of all topics covered: * Open Source LLMs * Meta llama 3.2 Multimodal models (11B & 90B) (X, HF, try free)* Meta Llama 3.2 tiny models 1B & 3B parameters (X, Blog, download)* Allen AI releases MOLMO - open SOTA multimodal AI models (X, Blog, HF, Try It)* Big CO LLMs + APIs* OpenAI releases Advanced Voice Mode to all & Mira Murati leaves OpenAI * Google updates Gemini 1.5-Pro-002 and 1.5-Flash-002 (Blog)* This weeks Buzz * Our free course is LIVE - more than 3000 already started learning how to build advanced RAG++* Sponsoring tonights AI Tinkerers in Seattle, if you're in Seattle, come through for my demo* Voice & Audio* Meta also launches voice mode (demo)* Tools & Others* Project ORION - holographic glasses are here! (link)Meta gives us new LLaMas and AI hardwareLLama 3.2 Multimodal 11B and 90BThis was by far the biggest OpenSource release of this week (tho see below, may not be the "best"), as a rumored released finally came out, and Meta has given our Llama eyes! Coming with 2 versions (well 4 if you count the base models which they also released), these new MultiModal LLaMas were trained with an adapter architecture, keeping the underlying text models the same, and placing a vision encoder that was trained and finetuned separately on top. LLama 90B is among the best open-source mutlimodal models available— Meta team at launchThese new vision adapters were trained on a massive 6 Billion images, including synthetic data generation by 405B for questions/captions, and finetuned with a subset of 600M high quality image pairs. Unlike the rest of their models, the Meta team did NOT claim SOTA on these models, and the benchmarks are very good but not the best we've seen (Qwen 2 VL from a couple of weeks ago, and MOLMO from today beat it on several benchmarks) With text-only inputs, the Llama 3.2 Vision models are functionally the same as the Llama 3.1 Text models; this allows the Llama 3.2 Vision models to be a drop-in replacement for Llama 3.1 8B/70B with added image understanding capabilities.Seems like these models don't support multi image or video as well (unlike Pixtral for example) nor tool use with images. Meta will also release these models on meta.ai and every other platform, and they cited a crazy 500 million monthly active users of their AI services across all their apps 🤯 which marks them as the leading AI services provider in the world now. Llama 3.2 Lightweight Models (1B/3B)The additional and maybe more exciting thing that we got form Meta was the introduction of the small/lightweight models of 1B and 3B parameters. Trained on up to 9T tokens, and distilled / pruned from larger models, these are aimed for on-device inference (and by device here we mean from laptops to mobiles to soon... glasses? more on this later) In fact, meta released an IOS demo, that runs these models, takes a group chat, summarizes and calls the calendar tool to schedule based on the conversation, and all this happens on device without the info leaving to a larger model. They have also been able to prune down the LLama-guard safety model they released to under 500Mb and have had demos of it running on client side and hiding user input on the fly as the user types something bad!Interestingly, here too, the models were not SOTA, even in small category, with tiny models like Qwen 2.5 3B beating these models on many benchmarks, but they are outlining a new distillation / pruning era for Meta as they aim for these models to run on device, eventually even glasses (and some said Smart Thermostats)In fact they are so tiny, that the communtiy quantized them, released and I was able to download these models, all while the keynote was still going! Here I am running the Llama 3B during the developer keynote! Speaking AI - not only from OpenAIZuck also showcased a voice based Llama that's coming to Meta AI (unlike OpenAI it's likely a pipeline of TTS/STT) but it worked really fast and Zuck was able to interrupt it. And they also showed a crazy animated AI avatar of a creator, that was fully backed by Llama, while the human cre

ThursdAI - Sep 19 - 👑 Qwen 2.5 new OSS king LLM, MSFT new MoE, Nous Research's Forge announcement, and Talking AIs in the open source!
Hey folks, Alex here, back with another ThursdAI recap – and let me tell you, this week's episode was a whirlwind of open-source goodness, mind-bending inference techniques, and a whole lotta talk about talking AIs! We dove deep into the world of LLMs, from Alibaba's massive Qwen 2.5 drop to the quirky, real-time reactions of Moshi. We even got a sneak peek at Nous Research's ambitious new project, Forge, which promises to unlock some serious LLM potential. So grab your pumpkin spice latte (it's that time again isn't it? 🍁) settle in, and let's recap the AI awesomeness that went down on ThursdAI, September 19th! ThursdAI is brought to you (as always) by Weights & Biases, we still have a few spots left in our Hackathon this weekend and our new advanced RAG course is now released and is FREE to sign up!TL;DR of all topics + show notes and links* Open Source LLMs * Alibaba Qwen 2.5 models drop + Qwen 2.5 Math and Qwen 2.5 Code (X, HF, Blog, Try It)* Qwen 2.5 Coder 1.5B is running on a 4 year old phone (Nisten)* KyutAI open sources Moshi & Mimi (Moshiko & Moshika) - end to end voice chat model (X, HF, Paper)* Microsoft releases GRIN-MoE - tiny (6.6B active) MoE with 79.4 MMLU (X, HF, GIthub)* Nvidia - announces NVLM 1.0 - frontier class multimodal LLMS (no weights yet, X)* Big CO LLMs + APIs* OpenAI O1 results from LMsys do NOT disappoint - vibe checks also confirm, new KING llm in town (Thread)* NousResearch announces Forge in waitlist - their MCTS enabled inference product (X)* This weeks Buzz - everything Weights & Biases related this week* Judgement Day (hackathon) is in 2 days! Still places to come hack with us Sign up* Our new RAG Course is live - learn all about advanced RAG from WandB, Cohere and Weaviate (sign up for free)* Vision & Video* Youtube announces DreamScreen - generative AI image and video in youtube shorts ( Blog)* CogVideoX-5B-I2V - leading open source img2video model (X, HF)* Runway, DreamMachine & Kling all announce text-2-video over API (Runway, DreamMachine)* Runway announces video 2 video model (X)* Tools* Snap announces their XR glasses - have hand tracking and AI features (X)Open Source Explosion!👑 Qwen 2.5: new king of OSS llm models with 12 model releases, including instruct, math and coder versionsThis week's open-source highlight was undoubtedly the release of Alibaba's Qwen 2.5 models. We had Justin Lin from the Qwen team join us live to break down this monster drop, which includes a whopping seven different sizes, ranging from a nimble 0.5B parameter model all the way up to a colossal 72B beast! And as if that wasn't enough, they also dropped Qwen 2.5 Coder and Qwen 2.5 Math models, further specializing their LLM arsenal. As Justin mentioned, they heard the community's calls for 14B and 32B models loud and clear – and they delivered! "We do not have enough GPUs to train the models," Justin admitted, "but there are a lot of voices in the community...so we endeavor for it and bring them to you." Talk about listening to your users!Trained on an astronomical 18 trillion tokens (that’s even more than Llama 3.1 at 15T!), Qwen 2.5 shows significant improvements across the board, especially in coding and math. They even open-sourced the previously closed-weight Qwen 2 VL 72B, giving us access to the best open-source vision language models out there. With a 128K context window, these models are ready to tackle some serious tasks. As Nisten exclaimed after putting the 32B model through its paces, "It's really practical…I was dumping in my docs and my code base and then like actually asking questions."It's safe to say that Qwen 2.5 coder is now the best coding LLM that you can use, and just in time for our chat, a new update from ZeroEval confirms, Qwen 2.5 models are the absolute kings of OSS LLMS, beating Mistral large, 4o-mini, Gemini Flash and other huge models with just 72B parameters 👏 Moshi: The Chatty Cathy of AIWe've covered Moshi Voice back in July, and they have promised to open source the whole stack, and now finally they did! Including the LLM and the Mimi Audio Encoder! This quirky little 7.6B parameter model is a speech-to-speech marvel, capable of understanding your voice and responding in kind. It's an end-to-end model, meaning it handles the entire speech-to-speech process internally, without relying on separate speech-to-text and text-to-speech models.While it might not be a logic genius, Moshi's real-time reactions are undeniably uncanny. Wolfram Ravenwolf described the experience: "It's uncanny when you don't even realize you finished speaking and it already starts to answer." The speed comes from the integrated architecture and efficient codecs, boasting a theoretical response time of just 160 milliseconds!Moshi uses (also open sourced) Mimi neural audio codec, and achieves 12.5 Hz representation with just 1.1 kbps bandwidth.You can download it and run on your own machine or give it a try here just don't expect a masterful conversationalist heheGradient-Informed

🔥 📅 ThursdAI - Sep 12 - OpenAI's 🍓 is called 01 and is HERE, reflecting on Reflection 70B, Google's new auto podcasts & more AI news from last week
March 14th, 2023 was the day ThursdAI was born, it was also the day OpenAI released GPT-4, and I jumped into a Twitter space and started chaotically reacting together with other folks about what a new release of a paradigm shifting model from OpenAI means, what are the details, the new capabilities. Today, it happened again! Hey, it's Alex, I'm back from my mini vacation (pic after the signature) and boy am I glad I decided to not miss September 12th! The long rumored 🍓 thinking model from OpenAI, dropped as breaking news in the middle of ThursdAI live show, giving us plenty of time to react live! But before this, we already had an amazing show with some great guests! Devendra Chaplot from Mistral came on and talked about their newly torrented (yeah they did that again) Pixtral VLM, their first multi modal! , and then I had the honor to host Steven Johnson and Raiza Martin from NotebookLM team at Google Labs which shipped something so uncannily good, that I legit said "holy fu*k" on X in a reaction! So let's get into it (TL;DR and links will be at the end of this newsletter)OpenAI o1, o1 preview and o1-mini, a series of new "reasoning" modelsThis is it folks, the strawberries have bloomed, and we finally get to taste them. OpenAI has released (without a waitlist, 100% rollout!) o1-preview and o1-mini models to chatGPT and API (tho only for tier-5 customers) 👏 and are working on releasing 01 as well.These are models that think before they speak, and have been trained to imitate "system 2" thinking, and integrate chain-of-thought reasoning internally, using Reinforcement Learning and special thinking tokens, which allows them to actually review what they are about to say before they are saying it, achieving remarkable results on logic based questions.Specifically you can see the jumps in the very very hard things like competition math and competition code, because those usually require a lot of reasoning, which is what these models were trained to do well. New scaling paradigm Noam Brown from OpenAI calls this a "new scaling paradigm" and Dr Jim Fan explains why, with this new way of "reasoning", the longer the model thinks - the better it does on reasoning tasks, they call this "test-time compute" or "inference-time compute" as opposed to compute that was used to train the model. This shifting of computation down to inference time is the essence of the paradigm shift, as in, pre-training can be very limiting computationally as the models scale in size of parameters, they can only go so big until you have to start building out a huge new supercluster of GPUs to host the next training run (Remember Elon's Colossus from last week?). The interesting thing to consider here is, while current "thinking" times are ranging between a few seconds to a minute, imagine giving this model hours, days, weeks to think about new drug problems, physics problems 🤯.Prompting o1 Interestingly, a new prompting paradigm has also been introduced. These models now have CoT (think "step by step") built-in, so you no longer have to include it in your prompts. By simply switching to o1-mini, most users will see better results right off the bat. OpenAI has worked with the Devin team to test drive these models, and these folks found that asking the new models to just give the final answer often works better and avoids redundancy in instructions.The community of course will learn what works and doesn't in the next few hours, days, weeks, which is why we got 01-preview and not the actual (much better) o1. Safety implications and future plansAccording to Greg Brokman, this inference time compute also greatly helps with aligning the model to policies, giving it time to think about policies at length, and improving security and jailbreak preventions, not only logic. The folks at OpenAI are so proud of all of the above that they have decided to restart the count and call this series o1, but they did mention that they are going to release GPT series models as well, adding to the confusing marketing around their models. Open Source LLMs Reflecting on Reflection 70BLast week, Reflection 70B was supposed to launch live on the ThursdAI show, and while it didn't happen live, I did add it in post editing, and sent the newsletter, and packed my bag, and flew for my vacation. I got many DMs since then, and at some point couldn't resist checking and what I saw was complete chaos, and despite this, I tried to disconnect still until last night. So here's what I could gather since last night. The claims of a llama 3.1 70B finetune that Matt Shumer and Sahil Chaudhary from Glaive beating Sonnet 3.5 are proven false, nobody was able to reproduce those evals they posted and boasted about, which is a damn shame. Not only that, multiple trusted folks from our community, like Kyle Corbitt, Alex Atallah have reached out to Matt in to try to and get to the bottom of how such a thing would happen, and how claims like these could have been made in good faith. (or

📅 ThursdAI - Sep 5 - 👑 Reflection 70B beats Claude 3.5, Anthropic Enterprise 500K context, 100% OSS MoE from AllenAI, 1000 agents world sim, Replit agent is the new Cursor? and more AI news
Welcome back everyone, can you believe it's another ThursdAI already? And can you believe me when I tell you that friends of the pod Matt Shumer & Sahil form Glaive.ai just dropped a LLama 3.1 70B finetune that you can download that will outperform Claude Sonnet 3.5 while running locally on your machine? Today was a VERY heavy Open Source focused show, we had a great chat w/ Niklas, the leading author of OLMoE, a new and 100% open source MoE from Allen AI, a chat with Eugene (pico_creator) about RWKV being deployed to over 1.5 billion devices with Windows updates and a lot more. In the realm of the big companies, Elon shook the world of AI by turning on the biggest training cluster called Colossus (100K H100 GPUs) which was scaled in 122 days 😮 and Anthropic announced that they have 500K context window Claude that's only reserved if you're an enterprise customer, while OpenAI is floating an idea of a $2000/mo subscription for Orion, their next version of a 100x better chatGPT?! TL;DR* Open Source LLMs * Matt Shumer / Glaive - Reflection-LLama 70B beats Claude 3.5 (X, HF)* Allen AI - OLMoE - first "good" MoE 100% OpenSource (X, Blog, Paper, WandB)* RWKV.cpp is deployed with Windows to 1.5 Billion devices* MMMU pro - more robust multi disipline multimodal understanding bench (proj)* 01AI - Yi-Coder 1.5B and 9B (X, Blog, HF)* Big CO LLMs + APIs* Replit launches Agent in beta - from coding to production (X, Try It)* Ilya SSI announces 1B round from everyone (Post)* Cohere updates Command-R and Command R+ on API (Blog)* Claude Enterprise with 500K context window (Blog)* Claude invisibly adds instructions (even via the API?) (X)* Google got structured output finally (Docs)* Amazon to include Claude in Alexa starting this October (Blog)* X ai scaled Colossus to 100K H100 GPU goes online (X)* DeepMind - AlphaProteo new paper (Blog, Paper, Video)* This weeks Buzz* Hackathon did we mention? We're going to have Eugene and Greg as Judges!* AI Art & Diffusion & 3D* ByteDance - LoopyAvatar - Audio Driven portait avatars (Page)Open Source LLMsReflection Llama-3.1 70B - new 👑 open source LLM from Matt Shumer / GlaiveAI This model is BANANAs folks, this is a LLama 70b finetune, that was trained with a new way that Matt came up with, that bakes CoT and Reflection into the model via Finetune, which results in model outputting its thinking as though you'd prompt it in a certain way. This causes the model to say something, and then check itself, and then reflect on the check and then finally give you a much better answer. Now you may be thinking, we could do this before, RefleXion (arxiv.org/2303.11366) came out a year ago, so what's new? What's new is, this is now happening inside the models head, you don't have to reprompt, you don't even have to know about these techniques! So what you see above, is just colored differently, but all of it, is output by the model without extra prompting by the user or extra tricks in system prompt. the model thinks, plans, does chain of thought, then reviews and reflects, and then gives an answer! And the results are quite incredible for a 70B model 👇Looking at these evals, this is a 70B model that beats GPT-4o, Claude 3.5 on Instruction Following (IFEval), MATH, GSM8K with 99.2% 😮 and gets very close to Claude on GPQA and HumanEval! (Note that these comparisons are a bit of a apples to ... different types of apples. If you apply CoT and reflection to the Claude 3.5 model, they may in fact perform better on the above, as this won't be counted 0-shot anymore. But given that this new model is effectively spitting out those reflection tokens, I'm ok with this comparison)This is just the 70B, next week the folks are planning to drop the 405B finetune with the technical report, so stay tuned for that! Kudos on this work, go give Matt Shumer and Glaive AI a follow! Allen AI OLMoE - tiny "good" MoE that's 100% open source, weights, code, logsWe've previously covered OLMO from Allen Institute, and back then it was obvious how much commitment they have to open source, and this week they continued on this path with the release of OLMoE, an Mixture of Experts 7B parameter model (1B active parameters), trained from scratch on 5T tokens, which was completely open sourced. This model punches above its weights on the best performance/cost ratio chart for MoEs and definitely highest on the charts of releasing everything. By everything here, we mean... everything, not only the final weights file; they released 255 checkpoints (every 5000 steps), the training code (Github) and even (and maybe the best part) the Weights & Biases logs! It was a pleasure to host the leading author of the OLMoE paper, Niklas Muennighoff on the show today, so definitely give this segment a listen, he's a great guest and I learned a lot! Big Companies LLMs + APIAnthropic has 500K context window Claude but only for Enterprise? Well, this sucks (unless you work for Midjourney, Airtable or Deloitte). Apparently Anthropic has been s

📅 ThursdAI - Aug 29 - AI Plays DOOM, Cerebras breaks inference records, Google gives new Geminis, OSS vision SOTA & 100M context windows!?
Hey, for the least time during summer of 2024, welcome to yet another edition of ThursdAI, also happy skynet self-awareness day for those who keep track :) This week, Cerebras broke the world record for fastest LLama 3.1 70B/8B inference (and came on the show to talk about it) Google updated 3 new Geminis, Anthropic artifacts for all, 100M context windows are possible, and Qwen beats SOTA on vision models + much more! As always, this weeks newsletter is brought to you by Weights & Biases, did I mention we're doing a hackathon in SF in September 21/22 and that we have an upcoming free RAG course w/ Cohere & Weaviate? TL;DR* Open Source LLMs * Nous DisTrO - Distributed Training (X , Report)* NousResearch/ hermes-function-calling-v1 open sourced - (X, HF)* LinkedIN Liger-Kernel - OneLine to make Training 20% faster & 60% more memory Efficient (Github)* Cartesia - Rene 1.3B LLM SSM + Edge Apache 2 acceleration (X, Blog)* Big CO LLMs + APIs* Cerebras launches the fastest AI inference - 447t/s LLama 3.1 70B (X, Blog, Try It)* Google - Gemini 1.5 Flash 8B & new Gemini 1.5 Pro/Flash (X, Try it)* Google adds Gems & Imagen to Gemini paid tier* Anthropic artifacts available to all users + on mobile (Blog, Try it)* Anthropic publishes their system prompts with model releases (release notes)* OpenAI has project Strawberry coming this fall (via The information)* This weeks Buzz* WandB Hackathon hackathon hackathon (Register, Join)* Also, we have a new RAG course w/ Cohere and Weaviate (RAG Course)* Vision & Video* Zhipu AI CogVideoX - 5B Video Model w/ Less 10GB of VRAM (X, HF, Try it)* Qwen-2 VL 72B,7B,2B - new SOTA vision models from QWEN (X, Blog, HF)* AI Art & Diffusion & 3D* GameNgen - completely generated (not rendered) DOOM with SD1.4 (project)* FAL new LORA trainer for FLUX - trains under 5 minutes (Trainer, Coupon for ThursdAI)* Tools & Others* SimpleBench from AI Explained - closely matches human experience (simple-bench.com)ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.Open SourceLet's be honest - ThursdAI is a love letter to the open-source AI community, and this week was packed with reasons to celebrate.Nous Research DiStRO + Function Calling V1Nous Research was on fire this week (aren't they always?) and they kicked off the week with the release of DiStRO, which is a breakthrough in distributed training. You see, while LLM training requires a lot of hardware, it also requires a lot of network bandwidth between the different GPUs, even within the same data center. Proprietary networking solutions like Nvidia NVLink, and more open standards like Ethernet work well within the same datacenter, but training across different GPU clouds has been unimaginable until now. Enter DiStRo, a new decentralized training by the mad geniuses at Nous Research, in which they reduced the required bandwidth to train a 1.2B param model from 74.4GB to just 86MB (857x)! This can have massive implications for training across compute clusters, doing shared training runs, optimizing costs and efficiency and democratizing LLM training access! So don't sell your old GPUs just yet, someone may just come up with a folding@home but for training the largest open source LLM, and it may just be Nous! Nous Research also released their function-calling-v1 dataset (HF) that was used to train Hermes-2, and we had InterstellarNinja who authored that dataset, join the show and chat about it. This is an incredible unlock for the open source community, as function calling become a de-facto standard now. Shout out to the Glaive team as well for their pioneering work that paved the way!LinkedIn's Liger Kernel: Unleashing the Need for Speed (with One Line of Code)What if I told you, that whatever software you develop, you can add 1 line of code, and it'll run 20% faster, and require 60% less memory? This is basically what Linkedin researches released this week with Liger Kernel, yes you read that right, Linkedin, as in the website you career related posts on! "If you're doing any form of finetuning, using this is an instant win"Wing Lian - AxolotlThis absolutely bonkers improvement in training LLMs, now works smoothly with Flash Attention, PyTorch FSDP and DeepSpeed. If you want to read more about the implementation of the triton kernels, you can see a deep dive here, I just wanted to bring this to your attention, even if you're not technical, because efficiency jumps like these are happening all the time. We are used to seeing them in capabilities / intelligence, but they are also happening on the algorithmic/training/hardware side, and it's incredible to see!Huge shoutout to Byron and team at Linkedin for this unlock, check out their Github if you want to get involved!Qwen-2 VL - SOTA image and video understanding + open weights mini VLMYou may already know that we love the folks at Qwen here on ThursdAI, not only becau

📅 AI21 Jamba 1.5, DIY Meme Faces, 8yo codes with AI and a Doomsday LLM Device?!
Hey there, Alex here with an end of summer edition of our show, which did not disappoint. Today is the official anniversary of stable diffusion 1.4 can you believe it? It's the second week in the row that we have an exclusive LLM launch on the show (after Emozilla announced Hermes 3 on last week's show), and spoiler alert, we may have something cooking for next week as well!This edition of ThursdAI is brought to you by W&B Weave, our LLM observability toolkit, letting you evaluate LLMs for your own use-case easilyAlso this week, we've covered both ends of AI progress, doomerist CEO saying "Fck Gen AI" vs an 8yo coder and I continued to geek out on putting myself into memes (I promised I'll stop... at some point) so buckle up, let's take a look at another crazy week: TL;DR* Open Source LLMs * AI21 releases Jamba1.5 Large / Mini hybrid Mamba MoE (X, Blog, HF)* Microsoft Phi 3.5 - 3 new models including MoE (X, HF)* BFCL 2 - Berkley Function Calling Leaderboard V2 (X, Blog, Leaderboard)* NVIDIA - Mistral Nemo Minitron 8B - Distilled / Pruned from 12B (HF)* Cohere paper proves - code improves intelligence (X, Paper)* MOHAWK - transformer → Mamba distillation method (X, Paper, Blog)* AI Art & Diffusion & 3D* Ideogram launches v2 - new img diffusion king 👑 + API (X, Blog, Try it) * Midjourney is now on web + free tier (try it finally)* Flux keeps getting better, cheaper, faster + adoption from OSS (X, X, X)* Procreate hates generative AI (X)* Big CO LLMs + APIs* Grok 2 full is finally available on X - performs well on real time queries (X)* OpenAI adds GPT-4o Finetuning (blog)* Google API updates - 1000 pages PDFs + LOTS of free tokens (X)* This weeks Buzz* Weights & Biases Judgement Day SF Hackathon in September 21-22 (Sign up to hack)* Video * Hotshot - new video model - trained by 4 guys (try it, technical deep dive)* Luma Dream Machine 1.5 (X, Try it) * Tools & Others* LMStudio 0.0.3 update - local RAG, structured outputs with any model & more (X)* Vercel - Vo now has chat (X)* Ark - a completely offline device - offline LLM + worlds maps (X)* Ricky's Daughter coding with cursor video is a must watch (video)The Best of the Best: Open Source Wins with Jamba, Phi 3.5, and Surprise Function Calling HeroesWe kick things off this week by focusing on what we love the most on ThursdAI, open-source models! We had a ton of incredible releases this week, starting off with something we were super lucky to have live, the official announcement of AI21's latest LLM: Jamba.AI21 Officially Announces Jamba 1.5 Large/Mini – The Powerhouse Architecture Combines Transformer and Mamba While we've covered Jamba release on the show back in April, Jamba 1.5 is an updated powerhouse. It's 2 models, Large and Mini, both MoE and both are still hybrid architecture of Transformers + Mamba that try to get both worlds. Itay Dalmedigos, technical lead at AI21, joined us on the ThursdAI stage for an exclusive first look, giving us the full rundown on this developer-ready model with an awesome 256K context window, but it's not just the size – it’s about using that size effectively. AI21 measured the effective context use of their model on the new RULER benchmark released by NVIDIA, an iteration of the needle in the haystack and showed that their models have full utilization of context, as opposed to many other models.“As you mentioned, we’re able to pack many, many tokens on a single GPU. Uh, this is mostly due to the fact that we are able to quantize most of our parameters", Itay explained, diving into their secret sauce, ExpertsInt8, a novel quantization technique specifically designed for MoE models. Oh, and did we mention Jamba is multilingual (eight languages and counting), natively supports structured JSON, function calling, document digestion… basically everything developers dream of. They even chucked in citation generation, as it's long context can contain full documents, your RAG app may not even need to chunk anything, and the citation can cite full documents!Berkeley Function Calling Leaderboard V2: Updated + Live (link)Ever wondered how to measure the real-world magic of those models boasting "I can call functions! I can do tool use! Look how cool I am!" 😎? Enter the Berkeley Function Calling Leaderboard (BFCL) 2, a battleground where models clash to prove their function calling prowess.Version 2 just dropped, and this ain't your average benchmark, folks. It's armed with a "Live Dataset" - a dynamic, user-contributed treasure trove of real-world queries, rare function documentations, and specialized use-cases spanning multiple languages. Translation: NO more biased, contaminated datasets. BFCL 2 is as close to the real world as it gets.So, who’s sitting on the Function Calling throne this week? Our old friend Claude 3.5 Sonnet, with an impressive score of 73.61. But breathing down its neck is GPT 4-0613 (the OG Function Calling master) with 73.5. That's right, the one released a year ago, the first one with function calling, in

📅 ThursdAI - ChatGPT-4o back on top, Nous Hermes 3 LLama finetune, XAI uncensored Grok2, Anthropic LLM caching & more AI news from another banger week
Look these crazy weeks don't seem to stop, and though this week started out a bit slower (while folks were waiting to see how the speculation about certain red berry flavored conspiracies are shaking out) the big labs are shipping! We've got space uncle Elon dropping an "almost-gpt4" level Grok-2, that's uncensored, has access to real time data on X and can draw all kinds of images with Flux, OpenAI announced a new ChatGPT 4o version (not the one from last week that supported structured outputs, a different one!) and Anthropic dropping something that makes AI Engineers salivate! Oh, and for the second week in a row, ThursdAI live spaces were listened to by over 4K people, which is very humbling, and awesome because for example today, Nous Research announced Hermes 3 live on ThursdAI before the public heard about it (and I had a long chat w/ Emozilla about it, very well worth listening to)TL;DR of all topics covered: * Big CO LLMs + APIs* Xai releases GROK-2 - frontier level Grok, uncensored + image gen with Flux (𝕏, Blog, Try It)* OpenAI releases another ChatGPT-4o (and tops LMsys again) (X, Blog)* Google showcases Gemini Live, Pixel Bugs w/ Gemini, Google Assistant upgrades ( Blog)* Anthropic adds Prompt Caching in Beta - cutting costs by u to 90% (X, Blog)* AI Art & Diffusion & 3D* Flux now has support for LORAs, ControlNet, img2img (Fal, Replicate)* Google Imagen-3 is out of secret preview and it looks very good (𝕏, Paper, Try It)* This weeks Buzz* Using Weights & Biases Weave to evaluate Claude Prompt Caching (X, Github, Weave Dash)* Open Source LLMs * NousResearch drops Hermes 3 - 405B, 70B, 8B LLama 3.1 finetunes (X, Blog, Paper)* NVIDIA Llama-3.1-Minitron 4B (Blog, HF)* AnswerAI - colbert-small-v1 (Blog, HF)* Vision & Video* Runway Gen-3 Turbo is now available (Try It)Big Companies & LLM APIsGrok 2: Real Time Information, Uncensored as Hell, and… Flux?!The team at xAI definitely knows how to make a statement, dropping a knowledge bomb on us with the release of Grok 2. This isn't your uncle's dad joke model anymore - Grok 2 is a legitimate frontier model, folks.As Matt Shumer excitedly put it “If this model is this good with less than a year of work, the trajectory they’re on, it seems like they will be far above this...very very soon” 🚀Not only does Grok 2 have impressive scores on MMLU (beating the previous GPT-4o on their benchmarks… from MAY 2024), it even outperforms Llama 3 405B, proving that xAI isn't messing around.But here's where things get really interesting. Not only does this model access real time data through Twitter, which is a MOAT so wide you could probably park a rocket in it, it's also VERY uncensored. Think generating political content that'd make your grandma clutch her pearls or imagining Disney characters breaking bad in a way that’s both hilarious and kinda disturbing all thanks to Grok 2’s integration with Black Forest Labs Flux image generation model. With an affordable price point ($8/month for x Premium including access to Grok 2 and their killer MidJourney competitor?!), it’ll be interesting to see how Grok’s "truth seeking" (as xAI calls it) model plays out. Buckle up, folks, this is going to be wild, especially since all the normies now have the power to create political memes, that look VERY realistic, within seconds. Oh yeah… and there’s the upcoming Enterprise API as well… and Grok 2’s made its debut in the wild on the LMSys Arena, lurking incognito as "sus-column-r" and is now placed on TOP of Sonnet 3.5 and comes in as number 5 overall!OpenAI last ChatGPT is back at #1, but it's all very confusing 😵💫As the news about Grok-2 was settling in, OpenAI decided to, well… drop yet another GPT-4.o update on us. While Google was hosting their event no less. Seriously OpenAI? I guess they like to one-up Google's new releases (they also kicked Gemini from the #1 position after only 1 week there)So what was anonymous-chatbot in Lmsys for the past week, was also released in ChatGPT interface, is now the best LLM in the world according to LMSYS and other folks, it's #1 at Math, #1 at complex prompts, coding and #1 overall. It is also available for us developers via API, but... they don't recommend using it? 🤔 The most interesting thing about this release is, they don't really know to tell us why it's better, they just know that it is, qualitatively and that it's not a new frontier-class model (ie, not 🍓 or GPT5) Their release notes on this are something else 👇 Meanwhile it's been 3 months, and the promised Advanced Voice Mode is only in the hands of a few lucky testers so far. Anthropic Releases Prompt Caching to Slash API Prices By up to 90%Anthropic joined DeepSeek's game of "Let's Give Devs Affordable Intelligence," this week rolling out prompt caching with up to 90% cost reduction on cached tokens (yes NINETY…🤯 ) for those of you new to all this technical sorceryPrompt Caching allows the inference provider to save users money by reusing repeated chunks of a long pr

📅 ThursdAI - Aug8 - Qwen2-MATH King, tiny OSS VLM beats GPT-4V, everyone slashes prices + 🍓 flavored OAI conspiracy
Hold on tight, folks, because THIS week on ThursdAI felt like riding a roller coaster through the wild world of open-source AI - extreme highs, mind-bending twists, and a sprinkle of "wtf is happening?" conspiracy theories for good measure. 😂 Theme of this week is, Open Source keeps beating GPT-4, while we're inching towards intelligence too cheap to meter on the API fronts. We even had a live demo so epic, folks at the Large Hadron Collider are taking notice! Plus, strawberry shenanigans abound (did Sam REALLY tease GPT-5?), and your favorite AI evangelist nearly got canceled on X! Buckle up; this is gonna be another long one! 🚀Qwen2-Math Drops a KNOWLEDGE BOMB: Open Source Wins AGAIN!When I say "open source AI is unstoppable", I MEAN IT. This week, the brilliant minds from Alibaba's Qwen team decided to show everyone how it's DONE. Say hello to Qwen2-Math-72B-Instruct - a specialized language model SO GOOD at math, it's achieving a ridiculous 84 points on the MATH benchmark. 🤯For context, folks... that's beating GPT-4, Claude Sonnet 3.5, and Gemini 1.5 Pro. We're not talking incremental improvements here - this is a full-blown DOMINANCE of the field, and you can download and use it right now. 🔥Get Qwen-2 Math from HuggingFace hereWhat made this announcement EXTRA special was that Junyang Lin , the Chief Evangelist Officer at Alibaba Qwen team, joined ThursdAI moments after they released it, giving us a behind-the-scenes peek at the effort involved. Talk about being in the RIGHT place at the RIGHT time! 😂They painstakingly crafted a massive, math-specific training dataset, incorporating techniques like Chain-of-Thought reasoning (where the model thinks step-by-step) to unlock this insane level of mathematical intelligence."We have constructed a lot of data with the form of ... Chain of Thought ... And we find that it's actually very effective. And for the post-training, we have done a lot with rejection sampling to create a lot of data sets, so the model can learn how to generate the correct answers" - Junyang LinNow I gotta give mad props to Qwen for going beyond just raw performance - they're open-sourcing this beast under an Apache 2.0 license, meaning you're FREE to use it, fine-tune it, adapt it to your wildest mathematical needs! 🎉But hold on... the awesomeness doesn't stop there! Remember those smaller, resource-friendly LLMs everyone's obsessed with these days? Well, Qwen released 7B and even 1.5B versions of Qwen-2 Math, achieving jaw-dropping scores for their size (70 for the 1.5B?? That's unheard of!).🤯 Nisten nearly lost his mind when he heard that - and trust me, he's seen things. 😂"This is insane! This is... what, Sonnet 3.5 gets what, 71? 72? This gets 70? And it's a 1.5B? Like I could run that on someone's watch. Real." - NistenWith this level of efficiency, we're talking about AI-powered calculators, tutoring apps, research tools that run smoothly on everyday devices. The potential applications are endless!MiniCPM-V 2.6: A Pocket-Sized GPT-4 Vision... Seriously! 🤯If Qwen's Math marvel wasn't enough open-source goodness for ya, OpenBMB had to get in on the fun too! This time, they're bringing the 🔥 to vision with MiniCPM-V 2.6 - a ridiculous 8 billion parameter VLM (visual language model) that packs a serious punch, even outperforming GPT-4 Vision on OCR benchmarks!OpenBMB drops a bomb on X hereI'll say this straight up: talking about vision models in a TEXT-based post is hard. You gotta SEE it to believe it. But folks... TRUST ME on this one. This model is mind-blowing, capable of analyzing single images, multi-image sequences, and EVEN VIDEOS with an accuracy that rivaled my wildest hopes for open-source.🤯Check out their playground and prepare to be stunnedIt even captured every single nuance in this viral toddler speed-running video I threw at it, with an accuracy I haven't seen in models THIS small:"The video captures a young child's journey through an outdoor park setting. Initially, the child ... is seen sitting on a curved stone pathway besides a fountain, dressed in ... a green t-shirt and dark pants. As the video progresses, the child stands up and begins to walk ..."Junyang said that they actually collabbed with the OpenBMB team and knows firsthand how much effort went into training this model:"We actually have some collaborations with OpenBMB... it's very impressive that they are using, yeah, multi-images and video. And very impressive results. You can check the demo... the performance... We care a lot about MMMU [the benchmark], but... it is actually relying much on large language models." - Junyang LinNisten and I have been talking for months about the relationship between these visual "brains" and the larger language model base powering their "thinking." While it seems smaller models are catching up fast, combining a top-notch visual processor like MiniCPM-V with a monster LLM like Quen72B or Llama 405B could unlock truly unreal capabilities.This is why I'm excited