
ThursdAI - The top AI news from the past week
From Weights & Biases - ThursdAI, the podcast that keeps you ahead of the AI curve. Hosted by AI Evangelist Alex Volkov with a changing panel expert guests, discussing every important AI piece of news and updates from the past week, Open source and more
From Weights & Biases, Join AI Evangelist Alex Volkov and a panel of experts to cover everything important that happened in the world of AI from the past week
Show overview
ThursdAI - The top AI news from the past week has been publishing since 2023, and across the 3 years since has built a catalogue of 162 episodes. That works out to roughly 250 hours of audio in total. Releases follow a weekly cadence.
Episodes typically run over ninety minutes — most land between 1h 29m and 1h 47m — and the run-time is fairly consistent across the catalogue. None of the episodes are flagged explicit by the publisher. It is catalogued as a EN-language News show.
The show is actively publishing — the most recent episode landed 1 months ago, with 26 episodes already out so far this year. Published by From Weights & Biases, Join AI Evangelist Alex Volkov and a panel of experts to cover everything important that happened in the world of AI from the past week.
From the publisher
Every ThursdAI, Alex Volkov hosts a panel of experts, ai engineers, data scientists and prompt spellcasters on twitter spaces, as we discuss everything major and important that happened in the world of AI for the past week. Topics include LLMs, Open source, New capabilities, OpenAI, competitors in AI space, new LLM models, AI art and diffusion aspects and much more. sub.thursdai.news
Latest Episodes
View all 162 episodesGLM 5.2 total victory: the week open source won and nobody panicked
Fable Got Banned, Open Source Delivered: GLM-5.2, Kimi K2.7 & SpaceX Buys Cursor - June 18
📅 ThursdAI - Jun 11, 2026 - Fable & Mythos 5 are here, Anthropic gets caught sandbagging (then reverses), Siri AI finally works!? and we got live-translated on air
📅 ThursdAI - Jun 4 - NVIDIA drops Nemotron 3 Ultra (550B open), Microsoft becomes a frontier lab, Ideogram 4 goes open, Agent Arena & more
📅 May 28 - Opus 4.8 ships mid-show, the Pope writes 42K words on AI, 11labs dubs the world and DeepSwe breaks coding evals
AI just cracked an 80-year-old math problem nobody could solve — plus everything from Google I/O 26
ThursdAI - May 14 - TML Interaction Models, Musk v Altman Disclosures, CW Sandboxes & /goal Takes Over
📅 ThursdAI - May 7 - Interviews with Sunil Pai, Sally Ann Omalley from AI Engineer Europe
📅 ThursdAI - Apr 30 - DeepSeek V4 (1.6T MoE), Cursor SDK Wins WolfBench, Mayo's REDMOD Saves Lives, Stripe Gives Agents a Wallet & more
📅 Apr 23: OpenAI's Week: GPT-5.5, GPT-Image-2, Codex CUA + Chronicle, + Claude Design, Kimi K2.6, Qwen 3.6-27B
April 16 - Codex uses your mac in the background, Opus 4.7 release not quite Mythos + 3 interviews
📅 ThursdAI LIVE from London - Claude Mythos, Codex Resets, Muse Spark & More | w/ Swyx and friends from OpenAI, Deepmind, LMArena and OpenClaw

📅 ThursdAI - Apr 2 - Gemma 4 is the new LLama, Claude Code Leak, OpenAI raises $122B & more AI news
Hey Ya’ll, Alex here, let me catch you up. What a week! Anthropic is in the spotlight again, first with #SessionGate, then with the whole Claude Code source code leak, and finally with an incredible research into LLM having feelings!? (more on this below). And while Anthropic continues to burn through developer good will faster than their sessions, OpenAI announced a MASSIVE $122B round of funding (largest in history), Google released Gemma 4 with Apache 2 license - we had Omar Sanseviero on the show to help us cover what’s new, Microsoft dropped 3 new AI models (not LLMs) and PrismML potentially revolutionized local LLM inference with lossless 1-bit quantization! P.S - Oh also, something on X algo changed, I get way more exposure now, 3 out of my best 5 posts ever have been from this week + I got the coveted Elon RT on my Claude Code leak coverage. I’ll try to stay humble 😂 Anyway, let’s dive in, don’t forget to hit like or share with friends, and TL;DR with links is as always, at the bottom: ThursdAI - Highest signal weekly AI news show is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.The Claude Code source Leak: Half a Million Lines of “Oops”So here’s what happened. On March 31st, Anthropic shipped Claude Code version 2.1.88 to npm. Inside that package was a 59.8 megabyte source map file — basically a debugging artifact that contained the entire compiled source code. 512,000 lines of TypeScript across 1,900 files. The entire playbook for how the Claude Code harness works, including a lot of stuff that wasn’t supposed to be public yet.A researcher named Chaofan Shou spotted it at 4 AM ET, posted the download link, Sigrid (who came to the show) posted it on Github and within six hours it had 3 million views and 41,000 GitHub forks (This repo is the highest starred repo in Github history btw, with well over 150K Github stars). Anthropic started filing takedowns, but the internet being the internet, it was already everywhere. The source code is still on tens of thousands of computers right now. (I won’t link directly but there’s a website called Gitlawb, look it up) The community went absolutely wild digging through the source code btw, and they found some interesting things!KAIROS: Claude Code is going to become a Proactive Agent!This is the biggest take-away from this leak IMO, that like OpenClaw/Hermes agentic harnesses, Claude Code is already a fully featured proactive agent, we just don’t have access to this yet. With KAIROS, Claude Code will have it’s own daemon (will run independently from the CLI), will have a background ping system (hello Heartbeat.md from OpenClaw) that will make it wakeup and do stuff, will do “autodream” memory consolidation reviewing your daily sessions and fix memories, subscribe to Github, and maintain daily appent-only logs to show you what it did while it and you were asleep. This is by far the hugest thing, I’m excited to see how / when they ship KAIROS, as I said, 2026 is the year of Proactive agents! My Wolfred OpenClaw agent summed it up very nicely: Undercover ModeFor Anthropic employees working on public repos, there’s an Undercover Mode that auto-activates and strips all AI attribution from commits. The system prompt? “Do not blow your cover.” They really said “this is fine” about shipping internal tools to production while hiding from the world that AI wrote the code. Which, honestly, is kind of incredible meta-humor from whoever wrote that.The Buddy SystemMy personal favorite discovery: there’s a hidden Tamagotchi-style terminal pet called the Buddy System with 18 obfuscated species, rarity tiers (including a 1% legendary), cosmetic hats, shiny variants, and stats like DEBUGGING, PATIENCE, and CHAOS. If you activate it now, you can do /buddy and you’ll have a little companion judging your coding decisions. Anthropic shipped a game inside their CLI tool. Mine is called Vexrind and he’s sarcastic as f**k, I’m not sure I like it. Anti-Distillation ProtectionsThe code also revealed that Claude Code injects fake tool calls into logs to poison training datasets. If you’ve been backing up your .claw folders to train on the data; Stop. Pass your data through something like Qwen or make sure you’re filtering out the noise. (a Nisten tip)The Models That Don’t Exist YetBuried in the code are references to Opus 4.7, Sonnet 4.8, and a model called capybara-v2-fast with a 1 million context window. These haven’t been released. This is yet another confirmation of the leaked “Mythos” model that’s coming soon from Anthropic. Which btw, with Anthropic very rocky uptime lately, the tons of SessionGate issues, the leaked blog announcing Mythos, the leaked Claude Code oopsie, they are not having the best Q1 in terms of proving to the world that they are the safest lab out there. I hope they protect their weights better than they protect everything else, before the rumored IPO later this year. SessionGate is still no

AGI is here? Jensen says yes, ARC-AGI-3 says AI scores under 1%
Hey y’all, Alex here, let me catch you up!Jensen Huang went on Lex and said AGI has been achieved. We’ll get to that.The biggest demo moment: Gemini 3.1 Flash Live launched - Google’s omni model that sees, hears, and searches the web in real time. We tested it live and I said “what the f**k” on air. It was really impressive!Google Research also dropped TurboQuant (6x KV cache compression) which crashed Samsung and Micron stocks - we had Daniel Han from UnSloth help us make sense of why that’s overblown. OpenAI killed Sora - the app, the API, and the $1B Disney deal. Claude felt noticeably dumber this week AND max account quotas are melting as 500+ people confirmed on my X and Reddit. We have an official word from Anthropic as to why. Mistral launched Voxtral TTS (open weight, claims to beat ElevenLabs), Cohere shipped an ASR model, and Google’s Lyria 3 Pro now generates full 3-minute music tracks inside Producer AI.This and a lot more in today’s episode, let’s dive in (as always, show notes and links in the end!) ThursdAI - Let me catch you up! Gemini 3.1 Flash Live: The Real-Time AI Companion Is HereGoogle dropped a breaking news on the show today, with Gemini 3.1 Flash - LIVE version. This one is an omni-model, that means it can receive text/audio/video on input and respond in text and voice. It has Google search grounding, and it felt... immediate! I was blown away, really, check out the video, the speed with which it was able to “see” me, respond to my query, look up something on the web, was mind blowing. I don’t often get “mind blown” anymore, there’s just too many news, but this one did the trick! With the pricing being around 10x cheaper than GPT-real-time, and the Google search grounding being super fast, I can absolutely see this model being hooked up to... robots (like ReachyMini), SmartGlasses that can see what you see, and a bunch more! Gemini Live is available on Google AI studio and has been rolled out globally inside the Google Search app! So now when you pull up the Google Search app, just open it and point at anything. Truly a remarkable advancement.Google research publishes TurboQuant - 6x reduction in KV cache with 0 accuracy lossGoogle research posted some work (based on an Arxiv paper from almost a year ago) that shows that with geometry tricks, combining two other techniques like PolarQuant and QJL, they are able to compress the KV cache of running LLMs by nearly 6x, and show an 8X speed up for model inference with zero accuracy loss. If you ever watched silicon valley the HBO show, this sounds like the fictional middle-out algorithm from PiedPiper. If this scales (and that’s a big if, we don’t know if this applies to other, bigger models yet), this means significant decreases in memory requirements to run the current crop of LLMs for longer context. The claim is big, so we’ll continue to monitor if this indeed scales, but the most interesting thing about this piece of news is, that it broke the AI bubble and went to wall street, with finance brows deciding that this means that memory will not be needed as much any more and it tanked Samsung and Micron stocks. Which I found particularly ridiculous on the show, did they not hear about Jevons Paradox? This is reminiscent of the DeepSeek R1 saga that tanked Nvidia stocks over a year ago. Daniel Han from Unsloth, who joined us on the show, pointed out that the approach is mathematically interesting even if it’s not necessarily better than existing open-source techniques like DeepSeek MLA. LDJ noted that the baseline comparison (16-bit KV cache) isn’t really fair since most production systems are already compressing beyond that. Yam implemented it himself and confirmed the speedups are real, but so is the trade-off.Anthropic updates: Opus dumber? Quotas lower! Injunction won! Computer.. used. Anthropic folks, especially on the Claude code side are shipping like crazy, we won’t be able to cover all the updates, but there was a few notable things I have to keep you up to date on. Claude Opus seems to be getting “dumber”, againI have to talk about this because it affected my work directly this week and hundreds of people confirmed the same experience.I use Claude Opus for my standard ThursdAI prep workflow — generating the TL;DR with 10 bullet points and an executive summary for every topic we cover, creating episode pages, etc. The format has not changed for over a year and yet this week I asked for 10 factoids. I got 4. It says “10” right there in the prompt. Four bullet points. On the website builder, I’ve asked Opus to create a page for last weeks episode, and instead of adding it to the other episode, Opus decided to ... replace the last episode with this one. This would be funny if it wasn’t sad. This is Opus 4.6 we’re talking about, not some quantized open source LLM from last year! The reason is unclear, and it’s not only me, Wolfram noticed that it’s easier to see these types of things in other languages and that for the last week Op

ThursdAI - Opus 1M, Jensen declares OpenClaw as the new Linux, GPT 5.4 Mini & Nano, Minimax 2.7, Composer 2 & more AI news
Howdy, Alex here, let me catch you up on everything that happened in AI: (btw; If you haven’t heard from me last week, it was a Substack glitch, it was a great episode with 3 interviews, our 3rd birthday, I highly recommend checking it out here) This week was started on a relatively “chill” note, if you consider Anthropic enabling 1M context window chill. And then escalated from there. We covered the new GPT 5.4 Mini & Nano variants from OpenAI. How MiniMax used autoresearch loops to improve MiniMax 2.7, Cursor shipping their own updated Composer 2 model, and how NVIDIA CEO Jensen Huang embraced OpenClaw calling it “the most important OSS software in history” and that every company needs an OpenClaw strategy. Also, OpenAI acquires Astral (ruff, uv tools) and Mistral releases a “small” 119B unified model and Cursor dropped their Opus like Composer 2 model. Let’s dive in: ThursdAI - Highest signal weekly AI news show is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.Big Companies LLMs 1M context is now default for Opus.Anthropic enabled the 1M context window they shipped Claude with in beta, by default, to everyone. Claude, Claude Code, hell, even inside OpenClaw if you’re able to get your Max account in there, are now using the 1M long version of Opus. This is huge, because, while its not perfect it’s absolutely great to have 1 long conversation and not worry about auto-compaction of your context. As we just celebrated our 3rd anniversary, I remember that back then, we were excited to see GPT-5 with 8K context. Love how fast we’re moving on this. OpenAI drops GPT-5.4 mini and nano, optimized for coding, computer use, and subagents at a fraction of flagship costLast week on the show, Ryan said he burned through 1B (that’s 1 billion) tokens in a day! That is crazy, and there’s no way a person sitting in front of a chatbot can burn through this many tokens. This is only achieved via orchestration. To support this use-case, OpenAI dropped 2 new smaller models, cheaper and faster to run. GPT 5.4 Mini achieves a remarkable 72.1% on OSWorld Verified, which means it uses the computer very well, can browse and do tasks. 2x faster than the previous mini, at .75c/1M token, this is the model you want to use in many of your subagents that don’t require deep engineering. This is OpenAI’s ... sonnet equivalent, at 3x the speed and 70% the cost from the flagship. Nano is even crazier, 20 cents per 1M tokens, but it’s not as performant, so I wouldn’t use it for code. But for small tasks, absolutely. Here’s the thing that matters, these models are MEANT to be used with the new “subagents” feature that was also launched this week in Codex, all you need to do as... ask! Just tell Codex “spin up a subagent to do... X” and it’ll do it.OpenAI shifts focus on AI for engineering and enterprise, acquires Astral.sh makers of UV. Look, there’s no doubt that OpenAI the absolutely leader in AI, brought us ChatGPT, with over 900M users using it weekly. But they see what every enterprise sees, developers are MUCH more productive (and slowly so are everyone else) when they use tools that can code. According to WSJ, OpenAI executives will reprioritize some of the side-quests they have (Sora?) to focus on productivity and business. Which essentially means, more Codex, more Codex native, more productivity tools.With that focus, today they announced that OpenAI / Codex is acquiring Astral, the folks behind the widely popular UV python package manager. This brings strong developer tools firepower to the Codex team, the astral folks are great at writing incredibly fast tools in rust! Looking forward to see how these great folks improve Codex even more. Jensen Declares Total OpenClaw Victory at GTC, Announces NemoClaw (Github)This was kind of surreal, NVIDIA CEO Jensen Huang, is famous for doing his stadium size keynote, without a teleprompter, and for the last 10 minutes or so, he went all in on OpenClaw. Calling it “the most important OSS software in history” and outlining how this is the new computer. That Peter Steinberger with OpenClaw showed the world a blueprint for the new coputer, an personal agentic system, with IO, files, computer use, memory, powered by LLMs. Jensen did outline that the 3 things that make OpenClaw great are also the things that enterprises cannot allow, write access to your files + ability to communicate externally is a bad combo, so they have launched NemoClaw.They’ve got a bunch of security researchers to work with OpenClaw team to integrate their new OpenShell sandboxing effort, network guardrails and policy engine integration. I reminded folks on the pod that the internet was very insecure, there was a time where folks were afraid of using their creditcards online. OpenClaw seems to be speed running that “unsecure but super useful” to “secure because it’s super useful” arc and it’s great to see a company as huge as NVIDIA embrace. Not to mention

🎂 ThursdAI — 3rd BirthdAI: Singularity Updates Begin with Auto Researcher, Uploaded Brains, OpenClaw Mania & NVIDIA's $26B Bet on Open Source
Hey, Alex here 👋 Today was a special episode, as ThursdAI turns 3 🎉 We’ve been on air, weekly since Pi day, March 14th, 2023. I won’t go too nostalgic but I’ll just mention, back then GPT-4 just launched with 8K context window, could barely code, tool calls weren’t a thing, it was expensive and slow, and yet we all felt it, it’s begun!Fast forward to today, and this week, we’ve covered Andrej Karpathy’s mini singularity moment with AutoResearcher, a whole fruit fly brain uploaded to a simulation, China’s OpenClaw embrace with 1000 people lines to install the agent. I actually created a new corner on ThursdAI, called it Singularity updates, to cover the “out of distribution” mind expanding things that are happening around AI (or are being enabled by AI)Also this week, we’ve had 3 interviews, Chris from Nvidia came to talk to use about Nemotron 3 super and NVIDIA’s 26B commitment to OpenSource, Dotta (anon) with his PaperClips agent orchestration project reached 20K Github starts in a single week and Matt who created /last30days research skill + a whole bunch of other AI news! Let’s dive in. ThursdAI - Highest signal weekly AI news show is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.Singularity updates - new segmentAndrej Karpathy open sources Mini Singularity with Auto Researcher (X)If there’s 1 highlight this week in the world of AI, it’s this. Andrej, who previously started the AutoPilot program in Tesla, and co-founded OpenAI, is now, out there, in the open, just.. doing stuff like invent a completely autonomous ML research agent. Andrej posted to his almost 2M followers that he opensourced AutoResearch, a way to instruct a coding agent to do experiments against a specific task, test the hypothesis, discard what’s not working and keep going in a loop, until.. forever basically. In his case, it was optimizing speed of training GPT-2. He went to sleep and woke up to 83 experiments being done, with 20 novel improvements that stack on top of each other to speed up the model training by 11%, reducing the training time from 2.02 hours to 1.8 hours. The thing is, this code is already hand crafted, fine tuned and still, AI agents were able to discover new and novel ways to optimize this, running in a loop.Folks, this is how the singularity starts, imagine that all major labs are now training their models in a recursive way, the models get better, and get better at training better models! Reminder, OpenAI chief scientist Jakub predicted back in October that OpenAI will have an AI capable of a junior level Research ability by September of this year, and it seems that... we’re moving quicker than that! Practical uses of autoresearchThis technique is not just for ML tasks either, Shopify CEO Tobi got super excited about this concept, and just posted as I’m writing this, that he set an Autoresearch loop on Liquid, Shopify’s 20 year old templating engine, with the task to improve efficiency. His autoresearch loop was able to get a whopping 51% render time efficiency, without any regressions in the testing suite. This is just bonkers. This is a 20 year old, every day production used template. And some LLM running in a loop just made it 2x faster to render, just because Karpathy showed it the way. I’m absolutely blown away by this, this isn’t a model release, like we usually cover on the pod, but still, a significant “unhobbling” moment that is possible with the current coding agents and models. Expect everything to become very weird from here on out!Simulated fruit fly brains - uploaded into a simulatorIn another completely bonkers update that I can barely believe I’m sending over, a company called EON SYSTEMS, posted that they have achieved a breakthrough in brain simulation, and were able to upload a whole fruit fly brain connectome, of 140K neurons and 50+ million synapses into a simulation environment. They have... uploaded a fly, and are observing a 91% behavioural accuracy. I will write this again, they have uploaded a fly’s brain into a simulation for chirst sake!This isn’t just an “SF startup” either, the board of advisors is stacked with folks like George Church from Harvard, father of modern genome sequencing, Stephen Wolfram who needs no introduction but one of the top mathematicians in the world, whos’ thesis is “brains are programs”, Anders Sandberg from Oxford, Stephen Larson who apparently already uploaded a worms brain and connected it to lego robots before. These folks are gung ho on making sure that at some point, human brains are going to be able to get uploaded, to survive the upcoming AI foom. The main discussion points on X were around the fact that there was no machine learning here, no LLMs, no attention mechanisms, no training. The behaviors of that fly were all a result of uploading a full connectome of neurons. This positions connectome (the complete diagram of a brain with neurons and connections) as an ananalouge to
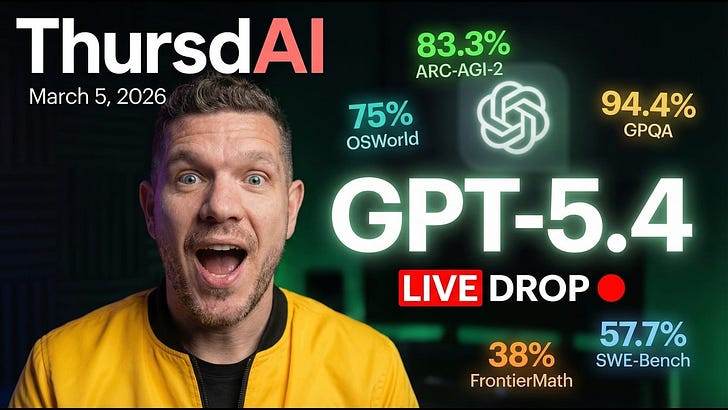
ThursdAI - Mar 5 - OpenAI's GPT-5.4 Solves a 20-Year Math Problem, Anthropic Gets Designated a Supply Chain Risk, Qwen Drama Unfolds
Hey folks, Alex here, let me catch you up! Most important news about this week came today, mid-show, OpenAI dropped GPT 5.4 Thinking (and 5.4 Pro), their latest flagship general model, less autistic than Codex 5.3, with 1M context, /fast mode and the ability to steet it mid-reasoning. We tested it live on the show, it’s really a beast. Also, since last week, Anthropic said no to Department of War’s ultimatum and it looks like they are being designated as supply chain risk, OpenAI swooped in to sign a deal with DoW and the internet went ballistic (Dario also had some .. choice words in a leaked memo!) On the Open Source front, the internet lost it’s damn mind when a friend of the pod Junyang Lin, announced his departure from Qwen in a tweet, causing an uproar, and the CEO of Alibaba to intervene. Wolfram presented our new in-house wolfbench.ai and a lot more! P.S - We acknowledge the war in Iran, and wish a quick resolution, the safety of civilians on both sides. Yam had to run to the shelter multiple times during the show. ThursdAI - Highest signal weekly AI news show is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.OpenAI drops GPT 5.4 Thinking and 5.4 Pro - heavy weight frontier models with 1M context, /fast mode, SOTA on many evalsOpenAI actually opened this week with another model drop, GPT 5.3-instant, which... we can honestly skip, it was fairly insignificant besides noting that this is the model that most free users use. It is supposedly “less cringe” (actual words OpenAI used). We all wondered when 5.4 will, and OpenAI once again proved that we named the show after the right day. Of course it drops on a ThursdAI. GPT 5.4 Thinking is OpenAI latest “General” model, which can still code, yes (they folded most of the Codex 5.3 coding breakthroughs in here) but it also shows an incredible 83% on GDPVal (12% over Codex), 47% on Frontier Math and an incredible ability to use computers and browsers with 82% on BrowseComp beating Claude 4.6 at lower prices than Sonnet! GPT 5.4 is also ... quite significantly improved at Frontend design? This landing page was created by GPT 5.4 (inside the Codex app, newly available on Windows) in a few minutes, clearly showing significant improvements in style. I built it also to compare prices, all the 3 flagship models are trying to catch up to Gemini in 1M context window, and it’s important to note, that GPT 5.4 even at double the price after the 272K tokens cutoff is still.... cheaper than Opus 4.6. OpenAI is really going for broke here, specifically as many enterprises are adopting Anthropic at a faster and faster pace (it was reported that Anthropic is approaching 19B ARR this month, doubling from 8B just a few months ago!) Frontier math wizThe highlight from the 5.4 feedback came from a Polish mathematician Bartosz Naskręcki (@nasqret on X), who said GPT-5.4 solved a research-level FrontierMath problem he had been working on for roughly 20 years. He called it his “personal singularity,” and as overused as that word has become, I get why he said it. I’ve told you about this last week, we’re on the cusp. Coding efficiencyThere’s tons of metrics in this release, but I wanted to highlight this one, where it may seem on first glance that on SWE-bench Pro, this model is on par with the previous SOTA GPT 5.3 codex, but these dots here are thinking efforts. And a medium thinking effort, GPT 5.4 matches 5.3 on hard thinking! This is quite remarkable, as lower thinking efforts have less tokens, which means they are cheaper and faster ultimately! Fast mode arrives at OpenAI as wellI think this one is a direct “this worked for Anthropic, lets steal this”, OpenAI enabled /fast mode that.. burns the tokens at 2x the rate, and prioritizes your tokens at 1.5x the speed. So, essentially getting you responses faster (which was one of the main complains about GPT 5.3 Codex). I can’t wait to bring the fast mode to OpenClaw with 5.4, which will absolutely come as OpenClaw is part of OpenAI now. There’s also a really under-appreciated feature here that I think other labs are going to copy quickly: mid-thought steering. OpenAI now lets you interrupt the model while it’s thinking and redirect it in real time in ChatGPT and iOS. This is a godsend if you’re like me, sent a prompt, seeing the model go down the wrong path in thinking... and want to just.. steer it without stopping! Anthropic is now designated as supply-chain risk by DoWLast week I left you with a cliffhanger: Anthropic had received an ultimatum from the Department of War (previously the Department of Defense) to remove their two remaining restrictions on Claude — no autonomous kill chain without human intervention, and no surveillance of US citizens. Anthropic’s response? “we cannot in good conscience acceede to their request” So much has happened since then; US President Trump said “I fired Anthropic” referring to his Truth Social post demanding intelligenc

📅 ThursdAI - Feb 26 - The Pentagon wants War Claude, every benchmark collapsed, and a solo founder hit $700K ARR with AI agents
Hey, it’s Alex, let me tell you why I think this week is an inflection point.Just this week: Everyone is launching autonomous agents or features inspired by OpenClaw (Devin 2.2, Cursor, Claude Cowork, Microsoft, Perplexity and Nous announced theirs), METR and ArcAGI 2,3 benchmarks are getting saturated, 1 person companies nearing 1M ARR within months of operation by running AI agents 24/7 (we chatted with one of them on the show today, live as he broke $700K ARR barrier) and the US Department of War gives Anthropic an ultimatum to remove nearly all restrictions on Claude for war and Anthropic says NO. I’ve been covering AI for 3 years every week, and this week feels, different. So if we are nearing the singularity, let me at least keep you up to date 😅 Today on the show, we covered most of the news in the first hour + breaking news from Google, Nano Banana 2 is here, and then had 3 interviews back to back. Ben Broca with Polsia, Nader Dabit with Cognition and Philip Kiely with BaseTen. Don’t miss those conversations starting at 1 hour in. Thanks for reading ThursdAI - Highest signal weekly AI news show! This post is public so feel free to share it.Anthropic vs Department of WarEarlier this week, the US “Department of War” invited Dario Amodei, CEO of Anthropic to a meeting, where-in Anthropic was given an ultimatum. “Remove the restrictions on Claude or Anthropic will be designated as a ‘supply chain risk’ company” and the DoD will potentially go as far as using the Defence Production Act to force Anthropic to ... comply. The two restrictions that Anthropic has in place for their models are: No use for domestic surveillance of American citizens and NO fully autonomous lethal weapens decisions given to Claude. For context, Claude is the only model that’s deployed on AWS top secret GovCloud and is used through Palantir’s AI platform. As I’m writing this, Anthropic issued a statement from Dario statement saying they will not budge on this, and will not comply. I fully commend Dario and Anthropic for this very strong backbone, but I fear that this matter is far from over, and we’ll continue to see what is the government response. EDIT: Apparently the DoD is pressuring Google and OpenAI to agree to the stipulations and employees from both companies are signing this petition https://notdivided.org/ to protest against dividing the major AI labs on this topic. Anthropic and OpenAI vs upcoming DeepseekIt’s baffling just how many balls are in the air for Anthropic, as just this week also, they have publicly named 3 Chinese AI makers in “Distillation Attacks”, claiming that they have broke Terms of Service to generate over 16M conversations with Claude to improve their own models, while using proxy networks to avoid detection. This marks the first time a major AI company publicly attributed distillation attacks to specific entities by name.The most telling thing to me is not the distillation, given that Anthropic has just recently settled one of the largest copyright payouts in U.S history, paying authors about $3000/book, which was bought, trained on and destroyed by Anthropic to make Claude better. No, the most telling thing here is the fact that Anthropic chose to put DeepSeek on top of the accusation list with merely 140K conversations, where the other labs created millions. This, plus OpenAI formal memo to Congress about a similar matter, shows that the US labs are trying to prepare for Deepseek new model to drop, by saying “Every innovation they have, they stole from us”. Apparently Deepseek V4 is nearly here, it’s potentially multimodal and has been allegedly trained on Nvidia chips somewhere in Mongolia despite the export restrictions and it’s about to SLAP! Benchmark? What benchmarks? How will we know that we’re approaching the singularity? Will there be signs? Well, this week it seems that the signs are here. First, Agentica claimed that they solved all publicly available “hard for AI” tasks of the upcoming ArcAGI 3, then Confluence Labs announced that they got an unprecedented 97.9% on ArcAGI2 and finally METR published their results on the long-horizon tasks, which measure AI’s capability to solve task that take humans a certain amount of hours to do. And that graph is going parabolic, with Claude Opus 4.6 able to solve tasks of 14.6h (doubling every 49 days) with 50% success rateWhy is this important? Well, this is just the benchmarks telling the story that everyone else in the industry is seeing, that approximately since December of 2025, and definitely fueled by early Feb drop of Opus 4.6 and Codex 5.3, something major shifted. Developers no longer write code, but ship 10x more features.This became such a talking point, Swyx Latent.Space coined this with https://wtfhappened2025.com/ where he collects evidence of a shelling point, something that happened in December and I think continued throughout February. Speaking of benchmarks no longer being valid, OpenAI published that the divergence between the S

📅 ThursdAI - Feb 19 - Gemini 3.1 Pro Drops LIVE, Sonnet 4.6 Closes Gap, OpenClaw Goes to OpenAI
Hey, it’s Alex, let me catch you up! Since last week, OpenAI convinced OpenClaw founder Peter Steinberger to join them, while keeping OpenClaw.. well... open. Anthropic dropped Sonnet 4.6 which nearly outperforms the previous Opus and is much cheaper, Qwen released 3.5 on Chinese New Year’s Eve, while DeepSeek was silent and Elon and XAI folks deployed Grok 4.20 without any benchmarks, and it’s 4 500B models in a trenchcoat? Also, Anthropic updated rules state that it’s breaking ToS to use their plans for anything except Claude Code & Claude SDK (and then clarified that it’s OK? we’re not sure) Then Google decided to drop their Gemini 3.1 Pro preview right at the start of our show, and it’s very nearly the best LLM folks can use right now (though it didn’t pass Nisten’s vibe checks) Also, Google released Lyria 3 for music gen (though only 30 seconds?) and our own Ryan Carson blew up on X again with over 1M views for his Code Factory article, Wolfram did a deep dive into Terminal Bench and .. we have a brand new website: https://thursdai.news 🎉Great week all in all, let’s dive in! ThursdAI - Subscribe to never feel like you’re behind. Share with your friends if you’re already subscribed!Big Companies & API updatesGoogle releases Gemini 3.1 Pro with 77.1% on ARC-AGI-2 (X, Blog, Announcement)In a release that surprised no-one, Google decided to drop their latest update to Gemini models, and it’s quite a big update too! We’ve now seen all major labs ship big model updates in the first two months of 2026. With 77.1% on ARC-AGI 2, and 80.6% on SWE-bench verified, Gemini is not complete SOTA across the board but it’s damn near close. The kicker is, it’s VERY competitive on the pricing, with 1M context, $2 / $12 (But if you look at the trajectory, it’s really notable how quickly we’re moving, with this model being 82% better on abstract reasoning than the 3 pro released just a few months ago! The 1 Million Context Discrepancy, who’s better at long context? The most fascinating catch of the live broadcast came from LDJ, who has an eagle eye for evaluation tables. He immediately noticed something weird in Google’s reported benchmarks regarding long-context recall. On the MRCR v2 8-needle benchmark (which tests retrieval quality deep inside a massive context window), Google’s table showed Gemini 3.1 Pro getting a 26% recall score at 1 million tokens. Curiously, they marked Claude Opus 4.6 as “not supported” in that exact tier.LDJ quickly pulled up the actual receipts: Opus 4.6 at a 1-million context window gets a staggering 76% recall score. That is a massive discrepancy! It was addressed by a member of DeepMind on X in a response to me, saying that Anthropic used an internal model for evaluating this (with receipts he pulled from the Anthropic model card) Live Vibe-Coding Test for Gemini 3.1 ProWe couldn’t just stare at numbers, so Nisten immediately fired up AI Studio for a live vibe check. He threw our standard “build a mars driver simulation game” prompt at the new Gemini.The speed was absolutely breathtaking. The model generated the entire single-file HTML/JS codebase in about 20 seconds. However, when he booted it up, the result was a bit mixed. The first run actually failed to render entirely. A quick refresh got a version working, and it rendered a neat little orbital launch UI, but it completely lacked the deep physics trajectories and working simulation elements that models like OpenAI’s Codex 5.3 or Claude Opus 4.6 managed to output on the exact same prompt last week. As Nisten put it, “It’s not bad at all, but I’m not impressed compared to what Opus and Codex did. They had a fully working one with trajectories, and this one I’m just stuck.”It’s a great reminder that raw benchmarks aren’t everything. A lot of this comes down to the harness—the specific set of system prompts and sandboxes that the labs use to wrap their models. Anthropic launches Claude Sonnet 4.6, with 1M token context and near-Opus intelligence at Sonnet pricingThe above Gemini release comes just a few days after Anthropic has shipped an update to the middle child of their lineup, Sonnet 4.6. With much improved Computer Use skills, updated Beta mode for 1M tokens, it achieves 79.6% on SWE-bench verified eval, showing good coding performance, while maintaining that “anthropic trained model” vibes that many people seem to prefer. Apparently in blind testing inside Claude Code, folks preferred this new model outputs to the latest Opus 4.5 around ~60% of the time, while preferring it over the previous sonnet 70% of the time. With $3/$15 per million tokens pricing, it’s cheaper than Opus, but is still more expensive than the flagship Gemini model, while being quite behind. Vibing with Sonnet 4.6I’ve tested out Sonnet 4.6 inside my OpenClaw harness for a few days, and it was decent. It did annoy me a bit more than Opus, with misunderstanding what I ask it, but it definitely does have the same “emotional tone” as Opus. Comparing it to Codex 5.3

📆 Open source just pulled up to Opus 4.6 — at 1/20th the price
Hey dear subscriber, Alex here from W&B, let me catch you up! This week started with Anthropic releasing /fast mode for Opus 4.6, continued with ByteDance reality-shattering video model called SeeDance 2.0, and then the open weights folks pulled up! Z.ai releasing GLM-5, a 744B top ranking coder beast, and then today MiniMax dropping a heavily RL’d MiniMax M2.5, showing 80.2% on SWE-bench, nearly beating Opus 4.6! I’ve interviewed Lou from Z.AI and Olive from MiniMax on the show today back to back btw, very interesting conversations, starting after TL;DR!So while the OpenSource models were catching up to frontier, OpenAI and Google both dropped breaking news (again, during the show), with Gemini 3 Deep Think shattering the ArcAGI 2 (84.6%) and Humanity’s Last Exam (48% w/o tools)... Just an absolute beast of a model update, and OpenAI launched their Cerebras collaboration, with GPT 5.3 Codex Spark, supposedly running at over 1000 tokens per second (but not as smart) Also, crazy week for us at W&B as we scrambled to host GLM-5 at day of release, and are working on dropping Kimi K2.5 and MiniMax both on our inference service! As always, all show notes in the end, let’s DIVE IN! ThursdAI - AI is speeding up, don’t get left behind! Sub and I’ll keep you up to date with a weekly catch upOpen Source LLMsZ.ai launches GLM-5 - #1 open-weights coder with 744B parameters (X, HF, W&B inference)The breakaway open-source model of the week is undeniably GLM-5 from Z.ai (formerly known to many of us as Zhipu AI). We were honored to have Lou, the Head of DevRel at Z.ai, join us live on the show at 1:00 AM Shanghai time to break down this monster of a release.GLM-5 is massive, not something you run at home (hey, that’s what W&B inference is for!) but it’s absolutely a model that’s worth thinking about if your company has on prem requirements and can’t share code with OpenAI or Anthropic. They jumped from 355B in GLM4.5 and expanded their pre-training data to a whopping 28.5T tokens to get these results. But Lou explained that it’s not only about data, they adopted DeepSeeks sparse attention (DSA) to help preserve deep reasoning over long contexts (this one has 200K)Lou summed up the generational leap from version 4.5 to 5 perfectly in four words: “Bigger, faster, better, and cheaper.” I dunno about faster, this may be one of those models that you hand off more difficult tasks to, but definitely cheaper, with $1 input/$3.20 output per 1M tokens on W&B! While the evaluations are ongoing, the one interesting tid-bit from Artificial Analysis was, this model scores the lowest on their hallucination rate bench! Think about this for a second, this model is neck-in-neck with Opus 4.5, and if Anthropic didn’t release Opus 4.6 just last week, this would be an open weights model that rivals Opus! One of the best models the western foundational labs with all their investments has out there. Absolutely insane times. MiniMax drops M2.5 - 80.2% on SWE-bench verified with just 10B active parameters (X, Blog)Just as we wrapped up our conversation with Lou, MiniMax dropped their release (though not weights yet, we’re waiting ⏰) and then Olive Song, a senior RL researcher on the team, joined the pod, and she was an absolute wealth of knowledge! Olive shared that they achieved an unbelievable 80.2% on SWE-Bench Verified. Digest this for a second: a 10B active parameter open-source model is directly trading blows with Claude Opus 4.6 (80.8%) on the one of the hardest real-world software engineering benchmark we currently have. While being alex checks notes ... 20X cheaper and much faster to run? Apparently their fast version gets up to 100 tokens/s. Olive shared the “not so secret” sauce behind this punch-above-its-weight performance. The massive leap in intelligence comes entirely from their highly decoupled Reinforcement Learning framework called “Forge.” They heavily optimized not just for correct answers, but for the end-to-end time of task performing. In the era of bloated reasoning models that spit out ten thousand “thinking” tokens before writing a line of code, MiniMax trained their model across thousands of diverse environments to use fewer tools, think more efficiently, and execute plans faster. As Olive noted, less time waiting and fewer tools called means less money spent by the user. (as confirmed by @swyx at the Windsurf leaderboard, developers often prefer fast but good enough models) I really enjoyed the interview with Olive, really recommend you listen to the whole conversation starting at 00:26:15. Kudos MiniMax on the release (and I’ll keep you updated when we add this model to our inference service) Big Labs and breaking newsThere’s a reason the show is called ThursdAI, and today this reason is more clear than ever, AI biggest updates happen on a Thursday, often live during the show. This happened 2 times last week and 3 times today, first with MiniMax and then with both Google and OpenAI! Google previews Gemini 3 Deep Think