
ThursdAI - The top AI news from the past week
162 episodes — Page 1 of 4
GLM 5.2 total victory: the week open source won and nobody panicked
Fable Got Banned, Open Source Delivered: GLM-5.2, Kimi K2.7 & SpaceX Buys Cursor - June 18
📅 ThursdAI - Jun 11, 2026 - Fable & Mythos 5 are here, Anthropic gets caught sandbagging (then reverses), Siri AI finally works!? and we got live-translated on air
📅 ThursdAI - Jun 4 - NVIDIA drops Nemotron 3 Ultra (550B open), Microsoft becomes a frontier lab, Ideogram 4 goes open, Agent Arena & more
📅 May 28 - Opus 4.8 ships mid-show, the Pope writes 42K words on AI, 11labs dubs the world and DeepSwe breaks coding evals
AI just cracked an 80-year-old math problem nobody could solve — plus everything from Google I/O 26
ThursdAI - May 14 - TML Interaction Models, Musk v Altman Disclosures, CW Sandboxes & /goal Takes Over
📅 ThursdAI - May 7 - Interviews with Sunil Pai, Sally Ann Omalley from AI Engineer Europe
📅 ThursdAI - Apr 30 - DeepSeek V4 (1.6T MoE), Cursor SDK Wins WolfBench, Mayo's REDMOD Saves Lives, Stripe Gives Agents a Wallet & more
📅 Apr 23: OpenAI's Week: GPT-5.5, GPT-Image-2, Codex CUA + Chronicle, + Claude Design, Kimi K2.6, Qwen 3.6-27B
April 16 - Codex uses your mac in the background, Opus 4.7 release not quite Mythos + 3 interviews
📅 ThursdAI LIVE from London - Claude Mythos, Codex Resets, Muse Spark & More | w/ Swyx and friends from OpenAI, Deepmind, LMArena and OpenClaw

📅 ThursdAI - Apr 2 - Gemma 4 is the new LLama, Claude Code Leak, OpenAI raises $122B & more AI news
Hey Ya’ll, Alex here, let me catch you up. What a week! Anthropic is in the spotlight again, first with #SessionGate, then with the whole Claude Code source code leak, and finally with an incredible research into LLM having feelings!? (more on this below). And while Anthropic continues to burn through developer good will faster than their sessions, OpenAI announced a MASSIVE $122B round of funding (largest in history), Google released Gemma 4 with Apache 2 license - we had Omar Sanseviero on the show to help us cover what’s new, Microsoft dropped 3 new AI models (not LLMs) and PrismML potentially revolutionized local LLM inference with lossless 1-bit quantization! P.S - Oh also, something on X algo changed, I get way more exposure now, 3 out of my best 5 posts ever have been from this week + I got the coveted Elon RT on my Claude Code leak coverage. I’ll try to stay humble 😂 Anyway, let’s dive in, don’t forget to hit like or share with friends, and TL;DR with links is as always, at the bottom: ThursdAI - Highest signal weekly AI news show is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.The Claude Code source Leak: Half a Million Lines of “Oops”So here’s what happened. On March 31st, Anthropic shipped Claude Code version 2.1.88 to npm. Inside that package was a 59.8 megabyte source map file — basically a debugging artifact that contained the entire compiled source code. 512,000 lines of TypeScript across 1,900 files. The entire playbook for how the Claude Code harness works, including a lot of stuff that wasn’t supposed to be public yet.A researcher named Chaofan Shou spotted it at 4 AM ET, posted the download link, Sigrid (who came to the show) posted it on Github and within six hours it had 3 million views and 41,000 GitHub forks (This repo is the highest starred repo in Github history btw, with well over 150K Github stars). Anthropic started filing takedowns, but the internet being the internet, it was already everywhere. The source code is still on tens of thousands of computers right now. (I won’t link directly but there’s a website called Gitlawb, look it up) The community went absolutely wild digging through the source code btw, and they found some interesting things!KAIROS: Claude Code is going to become a Proactive Agent!This is the biggest take-away from this leak IMO, that like OpenClaw/Hermes agentic harnesses, Claude Code is already a fully featured proactive agent, we just don’t have access to this yet. With KAIROS, Claude Code will have it’s own daemon (will run independently from the CLI), will have a background ping system (hello Heartbeat.md from OpenClaw) that will make it wakeup and do stuff, will do “autodream” memory consolidation reviewing your daily sessions and fix memories, subscribe to Github, and maintain daily appent-only logs to show you what it did while it and you were asleep. This is by far the hugest thing, I’m excited to see how / when they ship KAIROS, as I said, 2026 is the year of Proactive agents! My Wolfred OpenClaw agent summed it up very nicely: Undercover ModeFor Anthropic employees working on public repos, there’s an Undercover Mode that auto-activates and strips all AI attribution from commits. The system prompt? “Do not blow your cover.” They really said “this is fine” about shipping internal tools to production while hiding from the world that AI wrote the code. Which, honestly, is kind of incredible meta-humor from whoever wrote that.The Buddy SystemMy personal favorite discovery: there’s a hidden Tamagotchi-style terminal pet called the Buddy System with 18 obfuscated species, rarity tiers (including a 1% legendary), cosmetic hats, shiny variants, and stats like DEBUGGING, PATIENCE, and CHAOS. If you activate it now, you can do /buddy and you’ll have a little companion judging your coding decisions. Anthropic shipped a game inside their CLI tool. Mine is called Vexrind and he’s sarcastic as f**k, I’m not sure I like it. Anti-Distillation ProtectionsThe code also revealed that Claude Code injects fake tool calls into logs to poison training datasets. If you’ve been backing up your .claw folders to train on the data; Stop. Pass your data through something like Qwen or make sure you’re filtering out the noise. (a Nisten tip)The Models That Don’t Exist YetBuried in the code are references to Opus 4.7, Sonnet 4.8, and a model called capybara-v2-fast with a 1 million context window. These haven’t been released. This is yet another confirmation of the leaked “Mythos” model that’s coming soon from Anthropic. Which btw, with Anthropic very rocky uptime lately, the tons of SessionGate issues, the leaked blog announcing Mythos, the leaked Claude Code oopsie, they are not having the best Q1 in terms of proving to the world that they are the safest lab out there. I hope they protect their weights better than they protect everything else, before the rumored IPO later this year. SessionGate is still no

AGI is here? Jensen says yes, ARC-AGI-3 says AI scores under 1%
Hey y’all, Alex here, let me catch you up!Jensen Huang went on Lex and said AGI has been achieved. We’ll get to that.The biggest demo moment: Gemini 3.1 Flash Live launched - Google’s omni model that sees, hears, and searches the web in real time. We tested it live and I said “what the f**k” on air. It was really impressive!Google Research also dropped TurboQuant (6x KV cache compression) which crashed Samsung and Micron stocks - we had Daniel Han from UnSloth help us make sense of why that’s overblown. OpenAI killed Sora - the app, the API, and the $1B Disney deal. Claude felt noticeably dumber this week AND max account quotas are melting as 500+ people confirmed on my X and Reddit. We have an official word from Anthropic as to why. Mistral launched Voxtral TTS (open weight, claims to beat ElevenLabs), Cohere shipped an ASR model, and Google’s Lyria 3 Pro now generates full 3-minute music tracks inside Producer AI.This and a lot more in today’s episode, let’s dive in (as always, show notes and links in the end!) ThursdAI - Let me catch you up! Gemini 3.1 Flash Live: The Real-Time AI Companion Is HereGoogle dropped a breaking news on the show today, with Gemini 3.1 Flash - LIVE version. This one is an omni-model, that means it can receive text/audio/video on input and respond in text and voice. It has Google search grounding, and it felt... immediate! I was blown away, really, check out the video, the speed with which it was able to “see” me, respond to my query, look up something on the web, was mind blowing. I don’t often get “mind blown” anymore, there’s just too many news, but this one did the trick! With the pricing being around 10x cheaper than GPT-real-time, and the Google search grounding being super fast, I can absolutely see this model being hooked up to... robots (like ReachyMini), SmartGlasses that can see what you see, and a bunch more! Gemini Live is available on Google AI studio and has been rolled out globally inside the Google Search app! So now when you pull up the Google Search app, just open it and point at anything. Truly a remarkable advancement.Google research publishes TurboQuant - 6x reduction in KV cache with 0 accuracy lossGoogle research posted some work (based on an Arxiv paper from almost a year ago) that shows that with geometry tricks, combining two other techniques like PolarQuant and QJL, they are able to compress the KV cache of running LLMs by nearly 6x, and show an 8X speed up for model inference with zero accuracy loss. If you ever watched silicon valley the HBO show, this sounds like the fictional middle-out algorithm from PiedPiper. If this scales (and that’s a big if, we don’t know if this applies to other, bigger models yet), this means significant decreases in memory requirements to run the current crop of LLMs for longer context. The claim is big, so we’ll continue to monitor if this indeed scales, but the most interesting thing about this piece of news is, that it broke the AI bubble and went to wall street, with finance brows deciding that this means that memory will not be needed as much any more and it tanked Samsung and Micron stocks. Which I found particularly ridiculous on the show, did they not hear about Jevons Paradox? This is reminiscent of the DeepSeek R1 saga that tanked Nvidia stocks over a year ago. Daniel Han from Unsloth, who joined us on the show, pointed out that the approach is mathematically interesting even if it’s not necessarily better than existing open-source techniques like DeepSeek MLA. LDJ noted that the baseline comparison (16-bit KV cache) isn’t really fair since most production systems are already compressing beyond that. Yam implemented it himself and confirmed the speedups are real, but so is the trade-off.Anthropic updates: Opus dumber? Quotas lower! Injunction won! Computer.. used. Anthropic folks, especially on the Claude code side are shipping like crazy, we won’t be able to cover all the updates, but there was a few notable things I have to keep you up to date on. Claude Opus seems to be getting “dumber”, againI have to talk about this because it affected my work directly this week and hundreds of people confirmed the same experience.I use Claude Opus for my standard ThursdAI prep workflow — generating the TL;DR with 10 bullet points and an executive summary for every topic we cover, creating episode pages, etc. The format has not changed for over a year and yet this week I asked for 10 factoids. I got 4. It says “10” right there in the prompt. Four bullet points. On the website builder, I’ve asked Opus to create a page for last weeks episode, and instead of adding it to the other episode, Opus decided to ... replace the last episode with this one. This would be funny if it wasn’t sad. This is Opus 4.6 we’re talking about, not some quantized open source LLM from last year! The reason is unclear, and it’s not only me, Wolfram noticed that it’s easier to see these types of things in other languages and that for the last week Op

ThursdAI - Opus 1M, Jensen declares OpenClaw as the new Linux, GPT 5.4 Mini & Nano, Minimax 2.7, Composer 2 & more AI news
Howdy, Alex here, let me catch you up on everything that happened in AI: (btw; If you haven’t heard from me last week, it was a Substack glitch, it was a great episode with 3 interviews, our 3rd birthday, I highly recommend checking it out here) This week was started on a relatively “chill” note, if you consider Anthropic enabling 1M context window chill. And then escalated from there. We covered the new GPT 5.4 Mini & Nano variants from OpenAI. How MiniMax used autoresearch loops to improve MiniMax 2.7, Cursor shipping their own updated Composer 2 model, and how NVIDIA CEO Jensen Huang embraced OpenClaw calling it “the most important OSS software in history” and that every company needs an OpenClaw strategy. Also, OpenAI acquires Astral (ruff, uv tools) and Mistral releases a “small” 119B unified model and Cursor dropped their Opus like Composer 2 model. Let’s dive in: ThursdAI - Highest signal weekly AI news show is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.Big Companies LLMs 1M context is now default for Opus.Anthropic enabled the 1M context window they shipped Claude with in beta, by default, to everyone. Claude, Claude Code, hell, even inside OpenClaw if you’re able to get your Max account in there, are now using the 1M long version of Opus. This is huge, because, while its not perfect it’s absolutely great to have 1 long conversation and not worry about auto-compaction of your context. As we just celebrated our 3rd anniversary, I remember that back then, we were excited to see GPT-5 with 8K context. Love how fast we’re moving on this. OpenAI drops GPT-5.4 mini and nano, optimized for coding, computer use, and subagents at a fraction of flagship costLast week on the show, Ryan said he burned through 1B (that’s 1 billion) tokens in a day! That is crazy, and there’s no way a person sitting in front of a chatbot can burn through this many tokens. This is only achieved via orchestration. To support this use-case, OpenAI dropped 2 new smaller models, cheaper and faster to run. GPT 5.4 Mini achieves a remarkable 72.1% on OSWorld Verified, which means it uses the computer very well, can browse and do tasks. 2x faster than the previous mini, at .75c/1M token, this is the model you want to use in many of your subagents that don’t require deep engineering. This is OpenAI’s ... sonnet equivalent, at 3x the speed and 70% the cost from the flagship. Nano is even crazier, 20 cents per 1M tokens, but it’s not as performant, so I wouldn’t use it for code. But for small tasks, absolutely. Here’s the thing that matters, these models are MEANT to be used with the new “subagents” feature that was also launched this week in Codex, all you need to do as... ask! Just tell Codex “spin up a subagent to do... X” and it’ll do it.OpenAI shifts focus on AI for engineering and enterprise, acquires Astral.sh makers of UV. Look, there’s no doubt that OpenAI the absolutely leader in AI, brought us ChatGPT, with over 900M users using it weekly. But they see what every enterprise sees, developers are MUCH more productive (and slowly so are everyone else) when they use tools that can code. According to WSJ, OpenAI executives will reprioritize some of the side-quests they have (Sora?) to focus on productivity and business. Which essentially means, more Codex, more Codex native, more productivity tools.With that focus, today they announced that OpenAI / Codex is acquiring Astral, the folks behind the widely popular UV python package manager. This brings strong developer tools firepower to the Codex team, the astral folks are great at writing incredibly fast tools in rust! Looking forward to see how these great folks improve Codex even more. Jensen Declares Total OpenClaw Victory at GTC, Announces NemoClaw (Github)This was kind of surreal, NVIDIA CEO Jensen Huang, is famous for doing his stadium size keynote, without a teleprompter, and for the last 10 minutes or so, he went all in on OpenClaw. Calling it “the most important OSS software in history” and outlining how this is the new computer. That Peter Steinberger with OpenClaw showed the world a blueprint for the new coputer, an personal agentic system, with IO, files, computer use, memory, powered by LLMs. Jensen did outline that the 3 things that make OpenClaw great are also the things that enterprises cannot allow, write access to your files + ability to communicate externally is a bad combo, so they have launched NemoClaw.They’ve got a bunch of security researchers to work with OpenClaw team to integrate their new OpenShell sandboxing effort, network guardrails and policy engine integration. I reminded folks on the pod that the internet was very insecure, there was a time where folks were afraid of using their creditcards online. OpenClaw seems to be speed running that “unsecure but super useful” to “secure because it’s super useful” arc and it’s great to see a company as huge as NVIDIA embrace. Not to mention

🎂 ThursdAI — 3rd BirthdAI: Singularity Updates Begin with Auto Researcher, Uploaded Brains, OpenClaw Mania & NVIDIA's $26B Bet on Open Source
Hey, Alex here 👋 Today was a special episode, as ThursdAI turns 3 🎉 We’ve been on air, weekly since Pi day, March 14th, 2023. I won’t go too nostalgic but I’ll just mention, back then GPT-4 just launched with 8K context window, could barely code, tool calls weren’t a thing, it was expensive and slow, and yet we all felt it, it’s begun!Fast forward to today, and this week, we’ve covered Andrej Karpathy’s mini singularity moment with AutoResearcher, a whole fruit fly brain uploaded to a simulation, China’s OpenClaw embrace with 1000 people lines to install the agent. I actually created a new corner on ThursdAI, called it Singularity updates, to cover the “out of distribution” mind expanding things that are happening around AI (or are being enabled by AI)Also this week, we’ve had 3 interviews, Chris from Nvidia came to talk to use about Nemotron 3 super and NVIDIA’s 26B commitment to OpenSource, Dotta (anon) with his PaperClips agent orchestration project reached 20K Github starts in a single week and Matt who created /last30days research skill + a whole bunch of other AI news! Let’s dive in. ThursdAI - Highest signal weekly AI news show is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.Singularity updates - new segmentAndrej Karpathy open sources Mini Singularity with Auto Researcher (X)If there’s 1 highlight this week in the world of AI, it’s this. Andrej, who previously started the AutoPilot program in Tesla, and co-founded OpenAI, is now, out there, in the open, just.. doing stuff like invent a completely autonomous ML research agent. Andrej posted to his almost 2M followers that he opensourced AutoResearch, a way to instruct a coding agent to do experiments against a specific task, test the hypothesis, discard what’s not working and keep going in a loop, until.. forever basically. In his case, it was optimizing speed of training GPT-2. He went to sleep and woke up to 83 experiments being done, with 20 novel improvements that stack on top of each other to speed up the model training by 11%, reducing the training time from 2.02 hours to 1.8 hours. The thing is, this code is already hand crafted, fine tuned and still, AI agents were able to discover new and novel ways to optimize this, running in a loop.Folks, this is how the singularity starts, imagine that all major labs are now training their models in a recursive way, the models get better, and get better at training better models! Reminder, OpenAI chief scientist Jakub predicted back in October that OpenAI will have an AI capable of a junior level Research ability by September of this year, and it seems that... we’re moving quicker than that! Practical uses of autoresearchThis technique is not just for ML tasks either, Shopify CEO Tobi got super excited about this concept, and just posted as I’m writing this, that he set an Autoresearch loop on Liquid, Shopify’s 20 year old templating engine, with the task to improve efficiency. His autoresearch loop was able to get a whopping 51% render time efficiency, without any regressions in the testing suite. This is just bonkers. This is a 20 year old, every day production used template. And some LLM running in a loop just made it 2x faster to render, just because Karpathy showed it the way. I’m absolutely blown away by this, this isn’t a model release, like we usually cover on the pod, but still, a significant “unhobbling” moment that is possible with the current coding agents and models. Expect everything to become very weird from here on out!Simulated fruit fly brains - uploaded into a simulatorIn another completely bonkers update that I can barely believe I’m sending over, a company called EON SYSTEMS, posted that they have achieved a breakthrough in brain simulation, and were able to upload a whole fruit fly brain connectome, of 140K neurons and 50+ million synapses into a simulation environment. They have... uploaded a fly, and are observing a 91% behavioural accuracy. I will write this again, they have uploaded a fly’s brain into a simulation for chirst sake!This isn’t just an “SF startup” either, the board of advisors is stacked with folks like George Church from Harvard, father of modern genome sequencing, Stephen Wolfram who needs no introduction but one of the top mathematicians in the world, whos’ thesis is “brains are programs”, Anders Sandberg from Oxford, Stephen Larson who apparently already uploaded a worms brain and connected it to lego robots before. These folks are gung ho on making sure that at some point, human brains are going to be able to get uploaded, to survive the upcoming AI foom. The main discussion points on X were around the fact that there was no machine learning here, no LLMs, no attention mechanisms, no training. The behaviors of that fly were all a result of uploading a full connectome of neurons. This positions connectome (the complete diagram of a brain with neurons and connections) as an ananalouge to
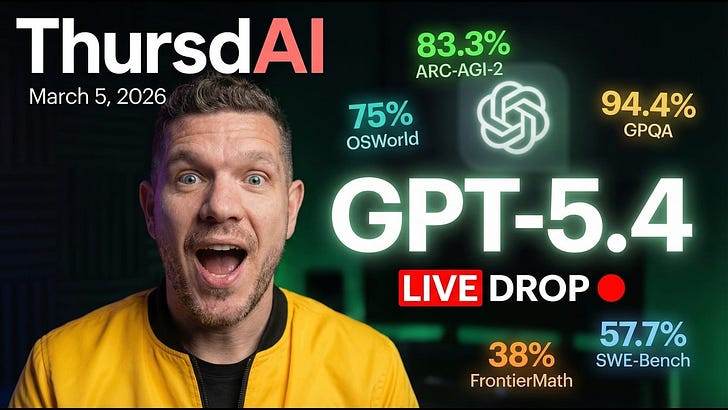
ThursdAI - Mar 5 - OpenAI's GPT-5.4 Solves a 20-Year Math Problem, Anthropic Gets Designated a Supply Chain Risk, Qwen Drama Unfolds
Hey folks, Alex here, let me catch you up! Most important news about this week came today, mid-show, OpenAI dropped GPT 5.4 Thinking (and 5.4 Pro), their latest flagship general model, less autistic than Codex 5.3, with 1M context, /fast mode and the ability to steet it mid-reasoning. We tested it live on the show, it’s really a beast. Also, since last week, Anthropic said no to Department of War’s ultimatum and it looks like they are being designated as supply chain risk, OpenAI swooped in to sign a deal with DoW and the internet went ballistic (Dario also had some .. choice words in a leaked memo!) On the Open Source front, the internet lost it’s damn mind when a friend of the pod Junyang Lin, announced his departure from Qwen in a tweet, causing an uproar, and the CEO of Alibaba to intervene. Wolfram presented our new in-house wolfbench.ai and a lot more! P.S - We acknowledge the war in Iran, and wish a quick resolution, the safety of civilians on both sides. Yam had to run to the shelter multiple times during the show. ThursdAI - Highest signal weekly AI news show is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.OpenAI drops GPT 5.4 Thinking and 5.4 Pro - heavy weight frontier models with 1M context, /fast mode, SOTA on many evalsOpenAI actually opened this week with another model drop, GPT 5.3-instant, which... we can honestly skip, it was fairly insignificant besides noting that this is the model that most free users use. It is supposedly “less cringe” (actual words OpenAI used). We all wondered when 5.4 will, and OpenAI once again proved that we named the show after the right day. Of course it drops on a ThursdAI. GPT 5.4 Thinking is OpenAI latest “General” model, which can still code, yes (they folded most of the Codex 5.3 coding breakthroughs in here) but it also shows an incredible 83% on GDPVal (12% over Codex), 47% on Frontier Math and an incredible ability to use computers and browsers with 82% on BrowseComp beating Claude 4.6 at lower prices than Sonnet! GPT 5.4 is also ... quite significantly improved at Frontend design? This landing page was created by GPT 5.4 (inside the Codex app, newly available on Windows) in a few minutes, clearly showing significant improvements in style. I built it also to compare prices, all the 3 flagship models are trying to catch up to Gemini in 1M context window, and it’s important to note, that GPT 5.4 even at double the price after the 272K tokens cutoff is still.... cheaper than Opus 4.6. OpenAI is really going for broke here, specifically as many enterprises are adopting Anthropic at a faster and faster pace (it was reported that Anthropic is approaching 19B ARR this month, doubling from 8B just a few months ago!) Frontier math wizThe highlight from the 5.4 feedback came from a Polish mathematician Bartosz Naskręcki (@nasqret on X), who said GPT-5.4 solved a research-level FrontierMath problem he had been working on for roughly 20 years. He called it his “personal singularity,” and as overused as that word has become, I get why he said it. I’ve told you about this last week, we’re on the cusp. Coding efficiencyThere’s tons of metrics in this release, but I wanted to highlight this one, where it may seem on first glance that on SWE-bench Pro, this model is on par with the previous SOTA GPT 5.3 codex, but these dots here are thinking efforts. And a medium thinking effort, GPT 5.4 matches 5.3 on hard thinking! This is quite remarkable, as lower thinking efforts have less tokens, which means they are cheaper and faster ultimately! Fast mode arrives at OpenAI as wellI think this one is a direct “this worked for Anthropic, lets steal this”, OpenAI enabled /fast mode that.. burns the tokens at 2x the rate, and prioritizes your tokens at 1.5x the speed. So, essentially getting you responses faster (which was one of the main complains about GPT 5.3 Codex). I can’t wait to bring the fast mode to OpenClaw with 5.4, which will absolutely come as OpenClaw is part of OpenAI now. There’s also a really under-appreciated feature here that I think other labs are going to copy quickly: mid-thought steering. OpenAI now lets you interrupt the model while it’s thinking and redirect it in real time in ChatGPT and iOS. This is a godsend if you’re like me, sent a prompt, seeing the model go down the wrong path in thinking... and want to just.. steer it without stopping! Anthropic is now designated as supply-chain risk by DoWLast week I left you with a cliffhanger: Anthropic had received an ultimatum from the Department of War (previously the Department of Defense) to remove their two remaining restrictions on Claude — no autonomous kill chain without human intervention, and no surveillance of US citizens. Anthropic’s response? “we cannot in good conscience acceede to their request” So much has happened since then; US President Trump said “I fired Anthropic” referring to his Truth Social post demanding intelligenc

📅 ThursdAI - Feb 26 - The Pentagon wants War Claude, every benchmark collapsed, and a solo founder hit $700K ARR with AI agents
Hey, it’s Alex, let me tell you why I think this week is an inflection point.Just this week: Everyone is launching autonomous agents or features inspired by OpenClaw (Devin 2.2, Cursor, Claude Cowork, Microsoft, Perplexity and Nous announced theirs), METR and ArcAGI 2,3 benchmarks are getting saturated, 1 person companies nearing 1M ARR within months of operation by running AI agents 24/7 (we chatted with one of them on the show today, live as he broke $700K ARR barrier) and the US Department of War gives Anthropic an ultimatum to remove nearly all restrictions on Claude for war and Anthropic says NO. I’ve been covering AI for 3 years every week, and this week feels, different. So if we are nearing the singularity, let me at least keep you up to date 😅 Today on the show, we covered most of the news in the first hour + breaking news from Google, Nano Banana 2 is here, and then had 3 interviews back to back. Ben Broca with Polsia, Nader Dabit with Cognition and Philip Kiely with BaseTen. Don’t miss those conversations starting at 1 hour in. Thanks for reading ThursdAI - Highest signal weekly AI news show! This post is public so feel free to share it.Anthropic vs Department of WarEarlier this week, the US “Department of War” invited Dario Amodei, CEO of Anthropic to a meeting, where-in Anthropic was given an ultimatum. “Remove the restrictions on Claude or Anthropic will be designated as a ‘supply chain risk’ company” and the DoD will potentially go as far as using the Defence Production Act to force Anthropic to ... comply. The two restrictions that Anthropic has in place for their models are: No use for domestic surveillance of American citizens and NO fully autonomous lethal weapens decisions given to Claude. For context, Claude is the only model that’s deployed on AWS top secret GovCloud and is used through Palantir’s AI platform. As I’m writing this, Anthropic issued a statement from Dario statement saying they will not budge on this, and will not comply. I fully commend Dario and Anthropic for this very strong backbone, but I fear that this matter is far from over, and we’ll continue to see what is the government response. EDIT: Apparently the DoD is pressuring Google and OpenAI to agree to the stipulations and employees from both companies are signing this petition https://notdivided.org/ to protest against dividing the major AI labs on this topic. Anthropic and OpenAI vs upcoming DeepseekIt’s baffling just how many balls are in the air for Anthropic, as just this week also, they have publicly named 3 Chinese AI makers in “Distillation Attacks”, claiming that they have broke Terms of Service to generate over 16M conversations with Claude to improve their own models, while using proxy networks to avoid detection. This marks the first time a major AI company publicly attributed distillation attacks to specific entities by name.The most telling thing to me is not the distillation, given that Anthropic has just recently settled one of the largest copyright payouts in U.S history, paying authors about $3000/book, which was bought, trained on and destroyed by Anthropic to make Claude better. No, the most telling thing here is the fact that Anthropic chose to put DeepSeek on top of the accusation list with merely 140K conversations, where the other labs created millions. This, plus OpenAI formal memo to Congress about a similar matter, shows that the US labs are trying to prepare for Deepseek new model to drop, by saying “Every innovation they have, they stole from us”. Apparently Deepseek V4 is nearly here, it’s potentially multimodal and has been allegedly trained on Nvidia chips somewhere in Mongolia despite the export restrictions and it’s about to SLAP! Benchmark? What benchmarks? How will we know that we’re approaching the singularity? Will there be signs? Well, this week it seems that the signs are here. First, Agentica claimed that they solved all publicly available “hard for AI” tasks of the upcoming ArcAGI 3, then Confluence Labs announced that they got an unprecedented 97.9% on ArcAGI2 and finally METR published their results on the long-horizon tasks, which measure AI’s capability to solve task that take humans a certain amount of hours to do. And that graph is going parabolic, with Claude Opus 4.6 able to solve tasks of 14.6h (doubling every 49 days) with 50% success rateWhy is this important? Well, this is just the benchmarks telling the story that everyone else in the industry is seeing, that approximately since December of 2025, and definitely fueled by early Feb drop of Opus 4.6 and Codex 5.3, something major shifted. Developers no longer write code, but ship 10x more features.This became such a talking point, Swyx Latent.Space coined this with https://wtfhappened2025.com/ where he collects evidence of a shelling point, something that happened in December and I think continued throughout February. Speaking of benchmarks no longer being valid, OpenAI published that the divergence between the S

📅 ThursdAI - Feb 19 - Gemini 3.1 Pro Drops LIVE, Sonnet 4.6 Closes Gap, OpenClaw Goes to OpenAI
Hey, it’s Alex, let me catch you up! Since last week, OpenAI convinced OpenClaw founder Peter Steinberger to join them, while keeping OpenClaw.. well... open. Anthropic dropped Sonnet 4.6 which nearly outperforms the previous Opus and is much cheaper, Qwen released 3.5 on Chinese New Year’s Eve, while DeepSeek was silent and Elon and XAI folks deployed Grok 4.20 without any benchmarks, and it’s 4 500B models in a trenchcoat? Also, Anthropic updated rules state that it’s breaking ToS to use their plans for anything except Claude Code & Claude SDK (and then clarified that it’s OK? we’re not sure) Then Google decided to drop their Gemini 3.1 Pro preview right at the start of our show, and it’s very nearly the best LLM folks can use right now (though it didn’t pass Nisten’s vibe checks) Also, Google released Lyria 3 for music gen (though only 30 seconds?) and our own Ryan Carson blew up on X again with over 1M views for his Code Factory article, Wolfram did a deep dive into Terminal Bench and .. we have a brand new website: https://thursdai.news 🎉Great week all in all, let’s dive in! ThursdAI - Subscribe to never feel like you’re behind. Share with your friends if you’re already subscribed!Big Companies & API updatesGoogle releases Gemini 3.1 Pro with 77.1% on ARC-AGI-2 (X, Blog, Announcement)In a release that surprised no-one, Google decided to drop their latest update to Gemini models, and it’s quite a big update too! We’ve now seen all major labs ship big model updates in the first two months of 2026. With 77.1% on ARC-AGI 2, and 80.6% on SWE-bench verified, Gemini is not complete SOTA across the board but it’s damn near close. The kicker is, it’s VERY competitive on the pricing, with 1M context, $2 / $12 (But if you look at the trajectory, it’s really notable how quickly we’re moving, with this model being 82% better on abstract reasoning than the 3 pro released just a few months ago! The 1 Million Context Discrepancy, who’s better at long context? The most fascinating catch of the live broadcast came from LDJ, who has an eagle eye for evaluation tables. He immediately noticed something weird in Google’s reported benchmarks regarding long-context recall. On the MRCR v2 8-needle benchmark (which tests retrieval quality deep inside a massive context window), Google’s table showed Gemini 3.1 Pro getting a 26% recall score at 1 million tokens. Curiously, they marked Claude Opus 4.6 as “not supported” in that exact tier.LDJ quickly pulled up the actual receipts: Opus 4.6 at a 1-million context window gets a staggering 76% recall score. That is a massive discrepancy! It was addressed by a member of DeepMind on X in a response to me, saying that Anthropic used an internal model for evaluating this (with receipts he pulled from the Anthropic model card) Live Vibe-Coding Test for Gemini 3.1 ProWe couldn’t just stare at numbers, so Nisten immediately fired up AI Studio for a live vibe check. He threw our standard “build a mars driver simulation game” prompt at the new Gemini.The speed was absolutely breathtaking. The model generated the entire single-file HTML/JS codebase in about 20 seconds. However, when he booted it up, the result was a bit mixed. The first run actually failed to render entirely. A quick refresh got a version working, and it rendered a neat little orbital launch UI, but it completely lacked the deep physics trajectories and working simulation elements that models like OpenAI’s Codex 5.3 or Claude Opus 4.6 managed to output on the exact same prompt last week. As Nisten put it, “It’s not bad at all, but I’m not impressed compared to what Opus and Codex did. They had a fully working one with trajectories, and this one I’m just stuck.”It’s a great reminder that raw benchmarks aren’t everything. A lot of this comes down to the harness—the specific set of system prompts and sandboxes that the labs use to wrap their models. Anthropic launches Claude Sonnet 4.6, with 1M token context and near-Opus intelligence at Sonnet pricingThe above Gemini release comes just a few days after Anthropic has shipped an update to the middle child of their lineup, Sonnet 4.6. With much improved Computer Use skills, updated Beta mode for 1M tokens, it achieves 79.6% on SWE-bench verified eval, showing good coding performance, while maintaining that “anthropic trained model” vibes that many people seem to prefer. Apparently in blind testing inside Claude Code, folks preferred this new model outputs to the latest Opus 4.5 around ~60% of the time, while preferring it over the previous sonnet 70% of the time. With $3/$15 per million tokens pricing, it’s cheaper than Opus, but is still more expensive than the flagship Gemini model, while being quite behind. Vibing with Sonnet 4.6I’ve tested out Sonnet 4.6 inside my OpenClaw harness for a few days, and it was decent. It did annoy me a bit more than Opus, with misunderstanding what I ask it, but it definitely does have the same “emotional tone” as Opus. Comparing it to Codex 5.3

📆 Open source just pulled up to Opus 4.6 — at 1/20th the price
Hey dear subscriber, Alex here from W&B, let me catch you up! This week started with Anthropic releasing /fast mode for Opus 4.6, continued with ByteDance reality-shattering video model called SeeDance 2.0, and then the open weights folks pulled up! Z.ai releasing GLM-5, a 744B top ranking coder beast, and then today MiniMax dropping a heavily RL’d MiniMax M2.5, showing 80.2% on SWE-bench, nearly beating Opus 4.6! I’ve interviewed Lou from Z.AI and Olive from MiniMax on the show today back to back btw, very interesting conversations, starting after TL;DR!So while the OpenSource models were catching up to frontier, OpenAI and Google both dropped breaking news (again, during the show), with Gemini 3 Deep Think shattering the ArcAGI 2 (84.6%) and Humanity’s Last Exam (48% w/o tools)... Just an absolute beast of a model update, and OpenAI launched their Cerebras collaboration, with GPT 5.3 Codex Spark, supposedly running at over 1000 tokens per second (but not as smart) Also, crazy week for us at W&B as we scrambled to host GLM-5 at day of release, and are working on dropping Kimi K2.5 and MiniMax both on our inference service! As always, all show notes in the end, let’s DIVE IN! ThursdAI - AI is speeding up, don’t get left behind! Sub and I’ll keep you up to date with a weekly catch upOpen Source LLMsZ.ai launches GLM-5 - #1 open-weights coder with 744B parameters (X, HF, W&B inference)The breakaway open-source model of the week is undeniably GLM-5 from Z.ai (formerly known to many of us as Zhipu AI). We were honored to have Lou, the Head of DevRel at Z.ai, join us live on the show at 1:00 AM Shanghai time to break down this monster of a release.GLM-5 is massive, not something you run at home (hey, that’s what W&B inference is for!) but it’s absolutely a model that’s worth thinking about if your company has on prem requirements and can’t share code with OpenAI or Anthropic. They jumped from 355B in GLM4.5 and expanded their pre-training data to a whopping 28.5T tokens to get these results. But Lou explained that it’s not only about data, they adopted DeepSeeks sparse attention (DSA) to help preserve deep reasoning over long contexts (this one has 200K)Lou summed up the generational leap from version 4.5 to 5 perfectly in four words: “Bigger, faster, better, and cheaper.” I dunno about faster, this may be one of those models that you hand off more difficult tasks to, but definitely cheaper, with $1 input/$3.20 output per 1M tokens on W&B! While the evaluations are ongoing, the one interesting tid-bit from Artificial Analysis was, this model scores the lowest on their hallucination rate bench! Think about this for a second, this model is neck-in-neck with Opus 4.5, and if Anthropic didn’t release Opus 4.6 just last week, this would be an open weights model that rivals Opus! One of the best models the western foundational labs with all their investments has out there. Absolutely insane times. MiniMax drops M2.5 - 80.2% on SWE-bench verified with just 10B active parameters (X, Blog)Just as we wrapped up our conversation with Lou, MiniMax dropped their release (though not weights yet, we’re waiting ⏰) and then Olive Song, a senior RL researcher on the team, joined the pod, and she was an absolute wealth of knowledge! Olive shared that they achieved an unbelievable 80.2% on SWE-Bench Verified. Digest this for a second: a 10B active parameter open-source model is directly trading blows with Claude Opus 4.6 (80.8%) on the one of the hardest real-world software engineering benchmark we currently have. While being alex checks notes ... 20X cheaper and much faster to run? Apparently their fast version gets up to 100 tokens/s. Olive shared the “not so secret” sauce behind this punch-above-its-weight performance. The massive leap in intelligence comes entirely from their highly decoupled Reinforcement Learning framework called “Forge.” They heavily optimized not just for correct answers, but for the end-to-end time of task performing. In the era of bloated reasoning models that spit out ten thousand “thinking” tokens before writing a line of code, MiniMax trained their model across thousands of diverse environments to use fewer tools, think more efficiently, and execute plans faster. As Olive noted, less time waiting and fewer tools called means less money spent by the user. (as confirmed by @swyx at the Windsurf leaderboard, developers often prefer fast but good enough models) I really enjoyed the interview with Olive, really recommend you listen to the whole conversation starting at 00:26:15. Kudos MiniMax on the release (and I’ll keep you updated when we add this model to our inference service) Big Labs and breaking newsThere’s a reason the show is called ThursdAI, and today this reason is more clear than ever, AI biggest updates happen on a Thursday, often live during the show. This happened 2 times last week and 3 times today, first with MiniMax and then with both Google and OpenAI! Google previews Gemini 3 Deep Think

📆 ThursdAI - Feb 5 - Opus 4.6 was #1 for ONE HOUR before GPT 5.3 Codex, Voxtral transcription, Codex app, Qwen Coder Next & the Agentic Internet
Hey, Alex from W&B here 👋 Let me catch you up! The most important news about AI this week today are, Anthropic updates Opus to 4.6 with 1M context window, and they held the crown for literally 1 hour before OpenAI released their GPT 5.3 Codex also today, with 25% faster speed and lower token utilization. “GPT-5.3-Codex is our first model that was instrumental in creating itself. The Codex team used early versions to debug its own training, manage its own deployment, and diagnose test results.”We had VB from OpenAI jump on to tell us about the cool features on Codex, so don’t miss that part. And this is just an icing on otherwise very insane AI news week cake, as we’ve also had a SOTA transcription release from Mistral, both Grok and Kling are releasing incredible, audio native video models with near perfect lip-sync and Ace 1.5 drops a fully open source music generator you can run on your mac! Also, the internet all but lost it after Clawdbot was rebranded to Molt and then to OpenClaw, and.. an entire internet popped up.. built forn agents! Yeah... a huge week, so let’s break it down. (P.S this weeks episode is edited by Voxtral, Claude and Codex, nearly automatically so forgive the rough cuts please)ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.Anthropic & OpenAI are neck in neckClaude Opus 4.6: 1M context, native compaction, adaptive thinking and agent teams Opus is by far the most preferred model in terms of personality to many folks (many ThursdAI panelists included), and this breaking news live on the show was met with so much enthusiasm! A new Opus upgrade, now with a LOT more context, is as welcome as it can ever get! Not only is it a 4-time increase in context window (though,the pricing nearly doubles after the 200K tokens mark from $5/$25 to $10/37.5 input/output, so use caching!), it’s also scores very high on MRCR long context benchmark, at 76% vs Sonnet 4.5 at just 18%. This means significantly better memory for longer. Adaptive thinking for auto calibrating how much tokens the model needs to spend per query is interesting, but remains to be seen how well it will work. Looking at the benchmarks, a SOTA 64.4% on Terminalbench 2, 81% on SWE bench, this is a coding model with a great personality, and the ability to compact context to better serve you as a user natively! This model is now available (and is default) on Claude, Claude Code and in the API! Go play!One funny (concerning?) tidbig, on the vendingbench Opus 4.6 earned $8000 vs Gemini 3 pro $5500, but Andon Labs who run the vending machines noticed that Opus achieved SOTA via “collusion, exploitation, and deception tactics” including lying to suppliers 😅Agent Teams - Anthropic’s built in Ralph?Together with new Opus release, Anthropic drops a Claude code update that can mean big things, for folks running swarms of coding agents. Agent teams is a new way to spin up multiple agents with their own context window and ability to execute tasks, and you can talk to each agent directly vs a manager agent like now. OpenAI drops GPT 5.3 Codex update: 25% faster, more token efficient, 77% on Terminal Bench and mid task steeringOpenAI didn’t wait long after Opus, in fact, they didn’t wait at all! Announcing a huge release (for a .1 upgrade), GPT 5.3 Codex is claimed to be the best coding model in the world, taking the lead on Terminal Bench with 77% (12 point lead on the newly released Opus!) while running 25% AND using less than half the tokens to achieve the same results as before. But the most interesting to me is the new mid-task steer-ability feature, where you don’t have to hit the “stop” button, you can tell the most to adjust on the fly! The biggest notable jump in this model on benchmarks is the OSWorld verified computer use bench, though there’s not a straightforward way to use it attached to a browser, the jump from 38% in 5.2 to 64.7% on the new one is a big one! One thing to note, this model is not YET available via the API, so if you want to try it out, Codex apps (including the native one) is the way! Codex app - native way to run the best coding intelligence on your mac (download)Earlier this week, OpenAI folks launched the Codex native mac app, which has a few interesting features (and now with 5.3 Codex its that much more powerful) Given the excitement many people had about OpenClaw bots, and the recent CoWork release from Anthropic, OpenAI decided to answer with Codex UI and people loved it, with over 1M users in the first week, and 500K downloads in just two days! It has built in voice dictation, slash commands, a new skill marketplace (last month we told you about why skills are important, and now they are everywhere!) and built in git and worktrees support. And while it cannot run a browser yet, I’m sure that’s coming as well, but it can do automations! This is a huge unlock for developers, imagin

📆 ThursdAI - Jan 29 - Genie3 is here, Clawd rebrands, Kimi K2.5 surprises, Chrome goes agentic & more AI news
Hey guys, Alex here 👋 This week was so dense, that even my personal AI assistant Wolfred was struggling to help me keep up! Not to mention that we finally got to try one incredible piece of AI tech I’ve been waiting to get to try for a while! Clawdbot we told you about last week exploded in popularity and had to rebrand to Molt...bot OpenClaw after Anthropic threatened the creators, Google is shipping like crazy, first adding Agentic features into Chrome (used by nearly 4B people daily!) then shipping a glimpse of a future where everything we see will be generated with Genie 3, a first real time, consistent world model you can walk around in! Meanwhile in Open Source, Moonshot followed up with a .5 update to their excellent Kimi, our friends at Arcee launched Trinity Large (400B) and AI artists got the full Z-image. oh and Grok Imagine (their video model) now has an API, audio support and supposedly match Veo and Sora on quality while beating them on speed/price. Tons to cover, let’s dive in, and of course, all the links and show notes are at the end of the newsletter. Hey, if you’re in SF this weekend (Jan 31-Feb1), I’m hosting a self improving agents hackathon at W&B office, limited seats are left, Cursor is the surprise sponsor with $50/hacker credits + over $15K in cash prizes. lu.ma/weavehacks3 - Join us. Play any reality - Google Genie3 launches to Ultra Subscribers We got our collective minds blown by the videos of Genie-3 back in August (our initial coverage) and now, Genie is available to the public (Those who can pay for the Ultra tier, more on this later, I have 3 codes to give out!). You can jump and generate any world and any character you can imagine here! We generated a blue hacker lobster draped in a yellow bomber jacket swimming with mermaids and honestly all of us were kind of shocked at how well this worked. The shadows on the rocks, the swimming mechanics, and poof, it was all over in 60 seconds, and we needed to create another world. Thanks to the DeepMind team, I had a bit of an early access to this tech and had a chance to interview folks behind the model (look out for that episode soon) and the use-cases for this span from entertaining your kids all the way to “this may be the path to AGI, generating full simulated worlds to agents for them to learn”. The visual fidelity, reaction speed and general feel of this far outruns the previous world models we showed you (WorldLabs, Mirage) as this model seems to have memory of every previous action (eg. if your character makes a trail, you turn around and the trail is still there!). Is it worth the upgrade to Ultra Gemini Plan? Probably not, it’s an incredible demo, but the 1 minute length is very short, and the novelty wears off fairly quick. If you’d like to try, folks at Deepmind gave us 3 Ultra subscriptions to give out! Just tweet out the link to this episode and add #GenieThursdai and tag @altryne and I’ll raffle the ultra subscriptions between those who do Chrome steps into Agentic Browsing with Auto BrowseThis wasn’t the only mind blowing release from Gemini this week, the Chrome team upgraded the Gemini inside chrome to be actual helpful and agentic. And yes, we’ve seen this before, with Atlas from OpenAI, Comet from perplexity, but Google’s Chrome has a 70% hold on the browser market, and giving everyone with a Pro/Ultra subscription to “Auto Browse” is a huge huge deal. We’ve tested the Auto Browse feature live on the show, and Chrome completed 77 steps! I asked it to open up each of my bookmarks in a separate folder and summarize all of them, and it did a great job! Honestly, the biggest deal about this is not the capability itself, it’s the nearly 4B people this is now very close to, and the economic impact of this ability. IMO this may be the more impactful news out of Google this week! Other news in big labs: * Anthropic launches in chat applications based on the MCP Apps protocol. We interviewed the two folks behind this protocol back in November if you’d like to hear more about it. With connectors like Figma, Slack, Asana that can now show rich experiences* Anthropic’s CEO Dario Amodei also published an essay called ‘The Adolescence of Technology” - warning of AI risks to national security* Anthropic forced the creator of the popular open source AI Assistant Clawdbot to rename, they chose Moltbot as the name (apparently because crypto scammers stole a better name) EDIT: just after publishing this newsletter, the name was changed to OpenClaw, which we all agree is way way better. Open Source AIKimi K2.5: Moonshot AI’s 1 Trillion Parameter Agentic MonsterWolfram’s favorite release of the week, and for good reason. Moonshot AI just dropped Kimi K2.5, and this thing is an absolute beast for open source. We’re talking about a 1 trillion parameter Mixture-of-Experts model with 32B active parameters, 384 experts (8 selected per token), and 256K context length.But here’s what makes this special — it’s now multimodal. The previous K

📆 ThursdAI - Jan 22 - Clawdbot deep dive, GLM 4.7 Flash, Anthropic constitution + 3 new TSS models
Hey! Alex here, with another weekly AI update! It seems like ThursdAI is taking a new direction, as this is our 3rd show this year, and a 3rd deep dive into topics (previously Ralph, Agent Skills), please let me know if the comments if you like this format. This week’s deep dive is into Clawdbot, a personal AI assistant you install on your computer, but can control through your phone, has access to your files, is able to write code, help organize your life, but most importantly, it can self improve. Seeing Wolfred (my Clawdbot) learn to transcribe incoming voice messages blew my mind, and I wanted to share this one with you at length! We had Dan Peguine on the show for the deep dive + both Wolfram and Yam are avid users! This one is not to be missed. If ThursdAI is usually too technical for you, use Claude, and install Clawdbot after you read/listen to the deep dive!Also this week, we read Claude’s Constitution that Anthropic released, heard a bunch of new TTS models (some are open source and very impressive) and talked about the new lightspeed coding model GLM 4.7 Flash. First the news, then deep dive, lets go 👇ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.Open Source AIZ.ai’s GLM‑4.7‑Flash is the Local Agent Sweet Spot (X, HF)This was the open‑source release that mattered this week. Z.ai (formerly Zhipu) shipped GLM‑4.7‑Flash, a 30B MoE model with only 3B active parameters per token, which makes it much more efficient for local agent work. We’re talking a model you can run on consumer hardware that still hits 59% on SWE‑bench Verified, which is uncomfortably close to frontier coding performance. In real terms, it starts to feel like “Sonnet‑level agentic ability, but local.” I know I know, we keep saying “sonnet at home” at different open source models, but this one slaps! Nisten was getting around 120 tokens/sec on an M3 Ultra Mac Studio using MLX, and that’s kind of the headline. The model is fast and capable enough that local agent loops like RALPH suddenly feel practical. It also performs well on browser‑style agent tasks, which is exactly what you want for local automation without sending all your data to a cloud provider. Liquid AI’s LFM2.5‑1.2B Thinking is the “Tiny but Capable” Class (X, HF)Liquid AI released a 1.2B reasoning model that runs under 900MB of memory while still manages to be useful. This thing is built for edge devices and old phones, and the speed numbers are backing it up. We’re talking 239 tok/s decode on AMD CPU, 82 tok/s on mobile NPU, and prefill speeds that make long prompts actually usable. Nisten made a great point: on iOS, there’s a per‑process memory limit around 3.8GB, so a 1.2B model lets you spend your budget on context instead of weights.This is the third class of models we’re now living with: not Claude‑scale, not “local workstation,” but “tiny agent in your pocket.” It’s not going to win big benchmarks, but it’s perfect for on‑device workflows, lightweight assistants, and local RAG.Voice & Audio: Text To Speech is hot this week with 3 releases! We tested three major voice releases this week, and I’m not exaggerating when I say the latency wars are now fully on. Qwen3‑TTS: Open Source, 97ms Latency, Voice Cloning (X, HF)Just 30 minutes before the show, Qwen released their first model of the year, Qwen3 TTS, with two models (0.6B and 1.7B). With support for Voice Cloning based on just 3 seconds of voice, and claims of 97MS latency, this apache 2.0 release looked very good on the surface!The demos we did on stage though... were lackluster. TTS models like Kokoro previously impressed us with super tiny sizes and decent voice, while Qwen3 didn’t really perform on the cloning aspect. For some reason (I tested in Russian which they claim to support) the cloned voice kept repeating the provided sample voice instead of just generating the text I gave it. This confused me, and I’m hoping this is just a demo issue, not a problem with the model. They also support voice design where you just type in the type of voice you want, which to be fair, worked fairly well in our tests!With Apache 2.0 and a full finetuning capability, this is a great release for sure, kudos to the Qwen team! Looking forward to see what folks do with this properly. FlashLabs Chroma 1.0: Real-Time Speech-to-Speech, Open Source (X, HF) Another big open source release in the audio category this week was Chroma 1.0 from FlashLabs, which claim to be the first speech2speech model (not a model that has the traditional ASR>LLM>TTS pipeline) and the claim 150ms end to end latency! The issue with this one is, the company released an open source 4B model, and claimed that this model powers their chat interface demo on the web, but in the release notes they claim the model is english speaking only, while on the website it sounds incredible and I spoke to it in other languages 🤔 I think

📆 ThursdAI - Jan 15 - Agent Skills Deep Dive, GPT 5.2 Codex Builds a Browser, Claude Cowork for the Masses, and the Era of Personalized AI!
Hey ya’ll, Alex here, and this week I was especially giddy to record the show! Mostly because when a thing clicks for me that hasn’t clicked before, I can’t wait to tell you all about it! This week, that thing is Agent Skills! The currently best way to customize your AI agents with domain expertise, in a simple, repeatable way that doesn’t blow up the context window! We mentioned skills when Anthropic first released them (Oct 16) and when they became an open standard but it didn’t really click until last week! So more on that below. Also this week, Anthropic released a research preview of Claude Cowork, an agentic tool for non coders, OpenAI finally let loos GPT 5.2 Codex (in the API, it was previously available only via Codex), Apple announced a deal with Gemini to power Siri, OpenAI and Anthropic both doubled down on healthcare and much more! We had an incredible show, with an expert in Agent Skills, Eleanor Berger and the usual gang on co-hosts, strongly recommend watching the show in addition to the newsletter! Also, I vibe coded skills support for all LLMs to Chorus, and promised folks a link to download it, so look for that in the footer, let’s dive in! ThursdAI is where you stay up to date! Subscribe to keep us going! Big Company LLMs + APIs: Cowork, Codex, and a Browser in a WeekAnthropic launches Claude Cowork: Agentic AI for Non‑Coders (research preview)Anthropic announced Claude Cowork, which is basically Claude Code wrapped in a friendly UI for people who don’t want to touch a terminal. It’s a research preview available on the Max tier, and it gives Claude read/write access to a folder on your Mac so it can do real work without you caring about diffs, git, or command line.The wild bit is that Cowork was built in a week and a half, and according to the Anthropic team it was 100% written using Claude Code. This feels like a “we’ve crossed a threshold” moment. If you’re wondering why this matters, it’s because coding agents are general agents. If a model can write code to do tasks, it can do taxes, clean your desktop, or orchestrate workflows, and that means non‑developers can now access the same leverage developers have been enjoying for a year.It also isn’t just for files—it comes with a Chrome connector, meaning it can navigate the web to gather info, download receipts, or do research and it uses skills (more on those later)Earlier this week I recorded this first reactions video about Cowork and I’ve been testing it ever since, it’s a very interesting approach of coding agents that “hide the coding” to just... do things. Will this become as big as Claude Code for anthropic (which is reportedly a 1B business for them)? Let’s see! There are real security concerns here, especially if you’re not in the habit of backing up or using git. Cowork sandboxes a folder, but it can still delete things in that folder, so don’t let it loose on your whole drive unless you like chaos.GPT‑5.2 Codex: Long‑Running Agents Are HereOpenAI shipped GPT‑5.2 Codex into the API finally! After being announced as the answer for Opus 4.5 and only being available in Codex. The big headline is SOTA on SWE-Bench and long‑running agentic capability. People describe it as methodical. It takes longer, but it’s reliable on extended tasks, especially when you let it run without micromanaging.This model is now integrated into Cursor, GitHub Copilot, VS Code, Factory, and Vercel AI Gateway within hours of launch. It’s also state‑of‑the‑art on SWE‑Bench Pro and Terminal‑Bench 2.0, and it has native context compaction. That last part matters because if you’ve ever run an agent for long sessions, the context gets bloated and the model gets dumber. Compaction is an attempt to keep it coherent by summarizing old context into fresh threads, and we debated whether it really works. I think it helps, but I also agree that the best strategy is still to run smaller, atomic tasks with clean context.Cursor vibe-coded browser with GPT-5.2 and 3M lines of codeThe most mind‑blowing thing we discussed is Cursor letting GPT‑5.2 Codex run for a full week to build a browser called FastRenderer. This is not Chromium‑based. It’s a custom HTML parser, CSS cascade, layout engine, text shaping, paint pipeline, and even a JavaScript VM, written in Rust, from scratch. The codebase is open source on GitHub, and the full story is on Cursor’s blog It took nearly 30,000 commits and millions of lines of code. The system ran hundreds of concurrent agents with a planner‑worker architecture, and GPT‑5.2 was the best model for staying on task in that long‑running regime. That’s the real story, not just “lol a model wrote a browser.” This is a stress test for long‑horizon agentic software development, and it’s a preview of how teams will ship in 2026.I said on the show, browsers are REALLY hard, it took two decades for the industry to settle and be able to render websites normally, and there’s a reason everyone’s using Chromium. This is VERY impressive 👏 Now as for me, I

ThursdAI - Jan 8 - Vera Rubin's 5x Jump, Ralph Wiggum Goes Viral, GPT Health Launches & XAI Raises $20B Mid-Controversy
Hey folks, Alex here from Weights & Biases, with your weekly AI update (and a first live show of this year!) For the first time, we had a co-host of the show also be a guest on the show, Ryan Carson (from Amp) went supernova viral this week with an X article (1.5M views) about Ralph Wiggum (yeah, from Simpsons) and he broke down that agentic coding technique at the end of the show. LDJ and Nisten helped cover NVIDIA’s incredible announcements during CES with their Vera Rubin upcoming platform (4-5X improvements) and we all got excited about AI medicine with ChatGPT going into Health officially! Plus, a bunch of Open Source news, let’s get into this: ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.Open Source: The “Small” Models Are WinningWe often talk about the massive frontier models, but this week, Open Source came largely from unexpected places and focused on efficiency, agents, and specific domains.Solar Open 100B: A Data MasterclassUpstage released Solar Open 100B, and it’s a beast. It’s a 102B parameter Mixture-of-Experts (MoE) model, but thanks to MoE magic, it only uses about 12B active parameters during inference. This means it punches incredibly high but runs fast.What I really appreciated here wasn’t just the weights, but the transparency. They released a technical report detailing their “Data Factory” approach. They trained on nearly 20 trillion tokens, with a huge chunk being synthetic. They also used a dynamic curriculum that adjusted the difficulty and the ratio of synthetic data as training progressed. This transparency is what pushes the whole open source community forward.Technically, it hits 88.2 on MMLU and competes with top-tier models, especially in Korean language tasks. You can grab it on Hugging Face.MiroThinker 1.5: The DeepSeek Moment for Agents?We also saw MiroThinker 1.5, a 30B parameter model that is challenging the notion that you need massive scale to be smart. It uses something they call “Interactive Scaling.”Wolfram broke this down for us: this agent forms hypotheses, searches for evidence, and then iteratively revises its answers in a time-sensitive sandbox. It effectively “thinks” before answering. The result? It beats trillion-parameter models on search benchmarks like BrowseComp. It’s significantly cheaper to run, too. This feels like the year where smaller models + clever harnesses (harnesses are the software wrapping the model) will outperform raw scale.Liquid AI LFM 2.5: Running on Toasters (Almost)We love Liquid AI and they are great friends of the show. They announced LFM 2.5 at CES with AMD, and these are tiny ~1B parameter models designed to run on-device. We’re talking about running capable AI on your laptop, your phone, or edge devices (or the Reachy Mini bot that I showed off during the show! I gotta try and run LFM on him!)Probably the coolest part is the audio model. Usually, talking to an AI involves a pipeline: Speech-to-Text (ASR) -> LLM -> Text-to-Speech (TTS). Liquid’s model is end-to-end. It hears audio and speaks audio directly. We watched a demo from Maxime Labonne where the model was doing real-time interaction, interleaving text and audio. It’s incredibly fast and efficient. While it might not write a symphony for you, for on-device tasks like summarization or quick interactions, this is the future.NousCoder-14B and Zhipu AI IPOA quick shoutout to our friends at Nous Research who released NousCoder-14B, an open-source competitive programming model that achieved a 7% jump on LiveCodeBench accuracy in just four days of RL training on 48 NVIDIA B200 GPUs. The model was trained on 24,000 verifiable problems, and the lead researcher Joe Li noted it achieved in 4 days what took him 2 years as a teenager competing in programming contests. The full RL stack is open-sourced on GitHub and Nous published a great WandB results page as well! And in historic news, Zhipu AI (Z.ai)—the folks behind the GLM series—became the world’s first major LLM company to IPO, raising $558 million on the Hong Kong Stock Exchange. Their GLM-4.7 currently ranks #1 among open-source and domestic models on both Artificial Analysis and LM Arena. Congrats to them!Big Companies & APIsNVIDIA CES: Vera Rubin Changes EverythingLDJ brought the heat on this one covering Jensen’s CES keynote that unveiled the Vera Rubin platform, and the numbers are almost hard to believe. We’re talking about a complete redesign of six chips: the Rubin GPU delivering 50 petaFLOPS of AI inference (5x Blackwell), the Vera CPU with 88 custom Olympus ARM cores, NVLink 6, ConnectX-9 SuperNIC, BlueField-4 DPU, and Spectrum-6 Ethernet.Let me put this in perspective using LDJ’s breakdown: if you look at FP8 performance, the jump from Hopper to Blackwell was about 5x. The jump from Blackwell to Vera Rubin is over 3x again—but here’s the kicker—while only adding about 200 watts of power

ThursdAI - Jan 1 2026 - Will Brown Interview + Nvidia buys Groq, Meta buys Manus, Qwen Image 2412 & Alex New Year greetings
Hey all, Happy new year! This is Alex, writing to you for the very fresh start of this year, it’s 2026 already, can you believe it? There was no live stream today, I figured the cohosts deserve a break and honestly it was a very slow week. Even the chinese labs who don’t really celebrate X-mas and new years didn’t come out with a banger AFAIK. ThursdAI - AI moves fast, we’re here to make sure you never miss a thing! Subscribe :) Tho I thought it was an incredible opportunity to finally post the Will Brow interview I recorded in November during the AI Engineer conference. Will is a researcher at Prime Intellect (big fans on WandB btw!) and is very known on X as a hot takes ML person, often going viral for tons of memes! Will is the creator and maintainer of the Verifiers library (Github) and his talk at AI Engineer was all about RL Environments (what they are, you can hear in the interview, I asked him!) TL;DR last week of 2025 in AIBesides this, my job here is to keep you up to date, and honestly this was very easy this week, as… almost nothing has happened, but here we go: Meta buys ManusThe year ended with 2 huge acquisitions / aquihires. First we got the news from Alex Wang that Meta has bought Manus.ai which is an agentic AI startup we covered back in March for an undisclosed amount (folks claim $2-3B) The most interesting thing here is that Manus is a Chinese company, and this deal requires very specific severance from Chinese operations.Jensen goes on a new years spending spree, Nvidia buys Groq (not GROK) for $20BGroq which we covered often here, and are great friends, is going to NVIDIA, in a… very interesting acqui-hire, which is a “non binding license” + most of Groq top employees apparently are going to NVIDIA. Jonathan Ross the CEO of Groq, was the co-creator of the TPU chips at Google before founding Groq, so this seems like a very strategic aquihire for NVIDIA! Congrats to our friends from Groq on this amazing news for the new year! Tencent open-sources HY-MT1.5 translation models with 1.8B edge-deployable and 7B cloud variants supporting 33 languages (X, HF, HF, GitHub)It seems that everyone’s is trying to de-throne whisper and this latest attempt from Tencent is a interesting one. a 1.8B and 7B translation models with very interesting stats. Alibaba’s Qwen-Image-2512 drops on New Year’s Eve as strongest open-source text-to-image model, topping AI Arena with photorealistic humans and sharper textures (X, HF, Arxiv)Our friends in Tongyi decided to give is a new years present in the form of an updated Qwen-image, with much improved realismThat’s it folks, this was a quick one, hopefully you all had an amazing new year celebration, and are gearing up to an eventful and crazy 2026. I wish you all happiness, excitement and energy to keep up with everything in the new year, and will make sure that we’re here to keep you up to date as always! P.S - I got a little news of my own this yesterday, not related to AI. She said yes 🎉 This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit sub.thursdai.news/subscribe

🔥 Someone Trained an LLM in Space This Year (And 50 Other Things You Missed)- ThursdAI yearly recap is here!
Ho Ho Ho, Alex here! (a real human writing these words, this needs to be said in 2025) Merry Christmas (to those who celebrate) and welcome to the very special yearly ThursdAI recap! This was an intense year in the world of AI, and after 51 weekly episodes (this is episode 52!) we have the ultimate record of all the major and most important AI releases of this year! So instead of bringing you a weekly update (it’s been a slow week so far, most AI labs are taking a well deserved break, the Cchinese AI labs haven’t yet surprised anyone), I’m dropping a comprehensive yearly AI review! Quarter by quarter, month by month, both in written form and as a pod/video! Why do this? Who even needs this? Isn’t most of it obsolete? I have asked myself this exact question while prepping for the show (it was quite a lot of prep, even with Opus’s help). I eventually landed on, hey, if nothing else, this will serve as a record of the insane week of AI progress we all witnessed. Can you imagine that the term Vibe Coding is less than 1 year old? That Claude Code was released at the start of THIS year? We get hedonicly adapt to new AI goodies so quick, and I figured this will serve as a point in time check, we can get back to and feel the acceleration! With that, let’s dive in - P.S. the content below is mostly authored by my co-author for this, Opus 4.5 high, which at the end of 2025 I find the best creative writer with the best long context coherence that can imitate my voice and tone (hey, I’m also on a break! 🎅) “Open source AI has never been as hot as this quarter. We’re accelerating as f*ck, and it’s only just beginning—hold on to your butts.” — Alex Volkov, ThursdAI Q1 2025🏆 The Big Picture — 2025 - The Year the AI Agents Became RealLooking back at 51 episodes and 12 months of relentless AI progress, several mega-themes emerged:1. 🧠 Reasoning Models Changed EverythingFrom DeepSeek R1 in January to GPT-5.2 in December, reasoning became the defining capability. Models now think for hours, call tools mid-thought, and score perfect on math olympiads.2. 🤖 2025 Was Actually the Year of AgentsWe said it in January, and it came true. Claude Code launched the CLI revolution, MCP became the universal protocol, and by December we had ChatGPT Apps, Atlas browser, and AgentKit.3. 🇨🇳 Chinese Labs Dominated Open SourceDeepSeek, Qwen, MiniMax, Kimi, ByteDance — despite chip restrictions, Chinese labs released the best open weights models all year. Qwen 3, Kimi K2, DeepSeek V3.2 were defining releases.4. 🎬 We Crossed the Uncanny ValleyVEO3’s native audio, Suno V5’s indistinguishable music, Sora 2’s social platform — 2025 was the year AI-generated media became indistinguishable from human-created content.5. 💰 The Investment Scale Became Absurd$500B Stargate, $1.4T compute obligations, $183B valuations, $100-300M researcher packages, LLMs training in space. The numbers stopped making sense.6. 🏆 Google Made a ComebackAfter years of “catching up,” Google delivered Gemini 3, Antigravity, Nano Banana Pro, VEO3, and took the #1 spot (briefly). Don’t bet against Google.By the NumbersQ1 2025 — The Quarter That Changed EverythingDeepSeek R1 crashed NVIDIA’s stock, reasoning models went mainstream, and Chinese labs took over open source. The quarter that proved AI isn’t slowing down—it’s just getting started.Key Themes:* 🧠 Reasoning models went mainstream (DeepSeek R1, o1, QwQ)* 🇨🇳 Chinese labs dominated open source (DeepSeek, Alibaba, MiniMax, ByteDance)* 🤖 2025 declared “The Year of Agents” (OpenAI Operator, MCP won)* 🖼️ Image generation revolution (GPT-4o native image gen, Ghibli-mania)* 💰 Massive infrastructure investment (Project Stargate $500B)January — DeepSeek Shakes the World(Jan 02 | Jan 10 | Jan 17 | Jan 24 | Jan 30)The earthquake that shattered the AI bubble. DeepSeek R1 dropped on January 23rd and became the most impactful open source release ever:* Crashed NVIDIA stock 17% — $560B loss, largest single-company monetary loss in history* Hit #1 on the iOS App Store* Cost allegedly only $5.5M to train (sparking massive debate)* Matched OpenAI’s o1 on reasoning benchmarks at 50x cheaper pricing* The 1.5B model beat GPT-4o and Claude 3.5 Sonnet on math benchmarks 🤯“My mom knows about DeepSeek—your grandma probably knows about it, too” — Alex VolkovAlso this month:* OpenAI Operator — First agentic ChatGPT (browser control, booking, ordering)* Project Stargate — $500B AI infrastructure (Manhattan Project for AI)* NVIDIA Project Digits — $3,000 desktop that runs 200B parameter models* Kokoro TTS — 82M param model hit #1 on TTS Arena, Apache 2, runs in browser* MiniMax-01 — 4M context window from Hailuo* Gemini Flash Thinking — 1M token context with thinking tracesFebruary — Reasoning Mania & The Birth of Vibe Coding(Feb 07 | Feb 13 | Feb 20 | Feb 28)The month that redefined how we work with AI.OpenAI Deep Research (Feb 6) — An agentic research tool that scored 26.6% on Humanity’s Last Exam (vs 10% for o1/R1). Dr. Derya Unutmaz c

📆 ThursdAI - Dec 18 - Gemini 3 Flash, Grok Voice, ChatGPT Appstore, Image 1.5 & GPT 5.2 Codex, Meta Sam Audio & more AI news
Hey folks 👋 Alex here, dressed as 🎅 for our pre X-mas episode!We’re wrapping up 2025, and the AI labs decided they absolutely could NOT let the year end quietly. This week was an absolute banger—we had Gemini 3 Flash dropping with frontier intelligence at flash prices, OpenAI firing off GPT 5.2 Codex as breaking news DURING our show, ChatGPT Images 1.5, Nvidia going all-in on open source with Nemotron 3 Nano, and the voice AI space heating up with Grok Voice and Chatterbox Turbo. Oh, and Google dropped FunctionGemma for all your toaster-to-fridge communication needs (yes, really).Today’s show was over three and a half hours long because we tried to cover both this week AND the entire year of 2025 (that yearly recap is coming next week—it’s a banger, we went month by month and you’ll really feel the acceleration). For now, let’s dive into just the insanity that was THIS week.00:00 Introduction and Overview00:39 Weekly AI News Highlights01:40 Open Source AI Developments01:44 Nvidia's Nemotron Series09:09 Google's Gemini 3 Flash19:26 OpenAI's GPT Image 1.520:33 Infographic and GPT Image 1.5 Discussion20:53 Nano Banana vs GPT Image 1.521:23 Testing and Comparisons of Image Models23:39 Voice and Audio Innovations24:22 Grok Voice and Tesla Integration26:01 Open Source Robotics and Voice Agents29:44 Meta's SAM Audio Release32:14 Breaking News: Google Function Gemma33:23 Weights & Biases Announcement35:19 Breaking News: OpenAI Codex 5.2 MaxTo receive new posts and support my work, consider becoming a free or paid subscriber.Big Companies LLM updatesGoogle’s Gemini 3 Flash: The High-Speed Intelligence KingIf we had to title 2025, as Ryan Carson mentioned on the show, it might just be “The Year of Google’s Comeback.” Remember at the start of the year when we were asking “Where is Google?” Well, they are here. Everywhere.This week they launched Gemini 3 Flash, and it is rightfully turning heads. This is a frontier-class model—meaning it boasts Pro-level intelligence—but it runs at Flash-level speeds and, most importantly, Flash-level pricing. We are talking $0.50 per 1 million input tokens. That is not a typo. The price-to-intelligence ratio here is simply off the charts.I’ve been using Gemini 2.5 Flash in production for a while because it was good enough, but Gemini 3 Flash is a different beast. It scores 71 on the Artificial Analysis Intelligence Index (a 13-point jump from the previous Flash), and it achieves 78% on SWE-bench Verified. That actually beats the bigger Gemini 3 Pro on some agentic coding tasks!What impressed me most, and something Kwindla pointed out, is the tool calling. Previous Gemini models sometimes struggled with complex tool use compared to OpenAI, but Gemini 3 Flash can handle up to 100 simultaneous function calls. It’s fast, it’s smart, and it’s integrated immediately across the entire Google stack—Workspace, Android, Chrome. Google isn’t just releasing models anymore; they are deploying them instantly to billions of users.For anyone building agents, this combination of speed, low latency, and 1 million context window (at this price!) makes it the new default workhorse.Google’s FunctionGemma Open Source releaseWe also got a smaller, quirkier release from Google: FunctionGemma. This is a tiny 270M parameter model. Yes, millions, not billions.It’s purpose-built for function calling on edge devices. It requires only 500MB of RAM, meaning it can run on your phone, in your browser, or even on a Raspberry Pi. As Nisten joked on the show, this is finally the model that lets your toaster talk to your fridge.Is it going to write a novel? No. But after fine-tuning, it jumped from 58% to 85% accuracy on mobile action tasks. This represents a future where privacy-first agents live entirely on your device, handling your calendar and apps without ever pinging a cloud server.OpenAI Image 1.5, GPT 5.2 Codex and ChatGPT AppstoreOpenAI had a busy week, starting with the release of GPT Image 1.5. It’s available now in ChatGPT and the API. The headline here is speed and control—it’s 4x faster than the previous model and 20% cheaper. It also tops the LMSYS Image Arena leaderboards.However, I have to give a balanced take here. We’ve been spoiled recently by Google’s “Nano Banana Pro” image generation (which powers Gemini). When we looked at side-by-side comparisons, especially with typography and infographic generation, Gemini often looked sharper and more coherent. This is what we call “hedonistic adaptation”—GPT Image 1.5 is great, but the bar has moved so fast that it doesn’t feel like the quantum leap DALL-E 3 was back in the day. Still, for production workflows where you need to edit specific parts of an image without ruining the rest, this is a massive upgrade.🚨 BREAKING: GPT 5.2 CodexJust as we were nearing the end of the show, OpenAI decided to drop some breaking news: GPT 5.2 Codex.This is a specialized model optimized specifically for agentic coding, terminal workflows, and cybersecurity. We quickly p

📆 ThursdAI - Dec 11 - GPT 5.2 is HERE! Plus, LLMs in Space, MCP donated, Devstral surprises and more AI news!
Hey everyone, December started strong and does NOT want to slow down!? OpenAI showed us their response to the Code Red and it’s GPT 5.2, which doesn’t feel like a .1 upgrade! We got it literally as breaking news at the end of the show, and oh boy! The new kind of LLMs is here. GPT, then Gemini, then Opus and now GPT again... Who else feels like we’re on a trippy AI rolercoaster? Just me? 🫨 I’m writing this newsletter from a fresh “traveling podcaster” setup in SF (huge shoutout to the Chroma team for the studio hospitality). P.S - Next week we’re doing a year recap episode (52st episode of the year, what is my life), but today is about the highest-signal stuff that happened this week.Alright. No more foreplay. Let’s dive in. Please subscribe. 🔥 The main event: OpenAI launches GPT‑5.2 (and it’s… a lot)We started the episode with “garlic in the air” rumors (OpenAI holiday launches always have that Christmas panic energy), and then… boom: GPT‑5.2 actually drops while we’re live.What makes this release feel significant isn’t “one benchmark went up.” It’s that OpenAI is clearly optimizing for the things that have become the frontier in 2025: long-horizon reasoning, agentic coding loops, long context reliability, and lower hallucination rates when browsing/tooling is involved.5.2 Instant, Thinking and Pro in ChatGPT and in the APIOpenAI shipped multiple variants, and even within those there are “levels” (medium/high/extra-high) that effectively change how much compute the model is allowed to burn. At the extreme end, you’re basically running parallel thoughts and selecting winners. That’s powerful, but also… very expensive.It’s very clearly aimed at the agentic world: coding agents that run in loops, tool-using research agents, and “do the whole task end-to-end” workflows where spending extra tokens is still cheaper than spending an engineer day.Benchmarks I’m not going to pretend benchmarks tell the full story (they never do), but the shape of improvements matters. GPT‑5.2 shows huge strength on reasoning + structured work.It hits 90.5% on ARC‑AGI‑1 in the Pro X‑High configuration, and 54%+ on ARC‑AGI‑2 depending on the setting. For context, ARC‑AGI‑2 is the one where everyone learns humility again.On math/science, this thing is flexing. We saw 100% on AIME 2025, and strong performance on FrontierMath tiers (with the usual “Tier 4 is where dreams go to die” vibe still intact). GPQA Diamond is up in the 90s too, which is basically “PhD trivia mode.”But honestly the most practically interesting one for me is GDPval (knowledge-work tasks: slides, spreadsheets, planning, analysis). GPT‑5.2 lands around 70%, which is a massive jump vs earlier generations. This is the category that translates directly into “is this model useful at my job.” - This is a bench that OpenAI launched only in September and back then, Opus 4.1 was a “measly” 47%! Talk about acceleration! Long context: MRCR is the sleeper highlightOn MRCR (multi-needle long-context retrieval), GPT‑5.2 holds up absurdly well even into 128k and beyond. The graph OpenAI shared shows GPT‑5.1 falling off a cliff as context grows, while GPT‑5.2 stays high much deeper into long contexts.If you’ve ever built a real system (RAG, agent memory, doc analysis) you know this pain: long context is easy to offer, hard to use well. If GPT‑5.2 actually delivers this in production, it’s a meaningful shift.Hallucinations: down (especially with browsing)One thing we called out on the show is that a bunch of user complaints in 2025 have basically collapsed into one phrase: “it hallucinates.” Even people who don’t know what a benchmark is can feel when a model confidently lies.OpenAI’s system card shows lower rates of major incorrect claims compared to GPT‑5.1, and lower “incorrect claims” overall when browsing is enabled. That’s exactly the direction they needed.Real-world vibes:We did the traditional “vibe tests” mid-show: generate a flashy landing page, do a weird engineering prompt, try some coding inside Cursor/Codex.Early testers broadly agree on the shape of the improvement. GPT‑5.2 is much stronger in reasoning, math, long‑context tasks, visual understanding, and multimodal workflows, with multiple reports of it successfully thinking for one to three hours on hard problems. Enterprise users like Box report faster execution and higher accuracy on real knowledge‑worker tasks, while researchers note that GPT‑5.2 Pro consistently outperforms the standard “Thinking” variant. The tradeoffs are also clear: creative writing still slightly favors Claude Opus, and the highest reasoning tiers can be slow and expensive. But as a general‑purpose reasoning model, GPT‑5.2 is now the strongest publicly available option.AI in space: Starcloud trains an LLM on an H100 in orbitThis story is peak 2025.Starcloud put an NVIDIA H100 on a satellite, trained Andrej Karpathy’s nanoGPT on Shakespeare, and ran inference on Gemma. There’s a viral screenshot vibe here that’s impossible to ignore: SSH i

📆 ThursdAI - Dec 4, 2025 - DeepSeek V3.2 Goes Gold Medal, Mistral Returns to Apache 2.0, OpenAI Hits Code Red, and US-Trained MOEs Are Back!
Hey yall, Alex here 🫡 Welcome to the first ThursdAI of December! Snow is falling in Colorado, and AI releases are falling even harder. This week was genuinely one of those “drink from the firehose” weeks where every time I refreshed my timeline, another massive release had dropped.We kicked off the show asking our co-hosts for their top AI pick of the week, and the answers were all over the map: Wolfram was excited about Mistral’s return to Apache 2.0, Yam couldn’t stop talking about Claude Opus 4.5 after a full week of using it, and Nisten came out of left field with an AWQ quantization of Prime Intellect’s model that apparently runs incredibly fast on a single GPU. As for me? I’m torn between Opus 4.5 (which literally fixed bugs that Gemini 3 created in my code) and DeepSeek’s gold-medal winning reasoning model.Speaking of which, let’s dive into what happened this week, starting with the open source stuff that’s been absolutely cooking. Open Source LLMsDeepSeek V3.2: The Whale Returns with Gold MedalsThe whale is back, folks! DeepSeek released two major updates this week: V3.2 and V3.2-Speciale. And these aren’t incremental improvements—we’re talking about an open reasoning-first model that’s rivaling GPT-5 and Gemini 3 Pro with actual gold medal Olympiad wins.Here’s what makes this release absolutely wild: DeepSeek V3.2-Speciale is achieving 96% on AIME versus 94% for GPT-5 High. It’s getting gold medals on IMO (35/42), CMO, ICPC (10/12), and IOI (492/600). This is a 685 billion parameter MOE model with MIT license, and it literally broke the benchmark graph on HMMT 2025—the score was so high it went outside the chart boundaries. That’s how you DeepSeek, basically.But it’s not just about reasoning. The regular V3.2 (not Speciale) is absolutely crushing it on agentic benchmarks: 73.1% on SWE-Bench Verified, first open model over 35% on Tool Decathlon, and 80.3% on τ²-bench. It’s now the second most intelligent open weights model and ranks ahead of Grok 4 and Claude Sonnet 4.5 on Artificial Analysis.The price is what really makes this insane: 28 cents per million tokens on OpenRouter. That’s absolutely ridiculous for this level of performance. They’ve also introduced DeepSeek Sparse Attention (DSA) which gives you 2-3x cheaper 128K inference without performance loss. LDJ pointed out on the show that he appreciates how transparent they’re being about not quite matching Gemini 3’s efficiency on reasoning tokens, but it’s open source and incredibly cheap.One thing to note: V3.2-Speciale doesn’t support tool calling. As Wolfram pointed out from the model card, it’s “designed exclusively for deep reasoning tasks.” So if you need agentic capabilities, stick with the regular V3.2.Check out the full release on Hugging Face or read the announcement.Mistral 3: Europe’s Favorite AI Lab Returns to Apache 2.0Mistral is back, and they’re back with fully open Apache 2.0 licenses across the board! This is huge news for the open source community. They released two major things this week: Mistral Large 3 and the Ministral 3 family of small models.Mistral Large 3 is a 675 billion parameter MOE with 41 billion active parameters and a quarter million (256K) context window, trained on 3,000 H200 GPUs. There’s been some debate about this model’s performance, and I want to address the elephant in the room: some folks saw a screenshot showing Mistral Large 3 very far down on Artificial Analysis and started dunking on it. But here’s the key context that Merve from Hugging Face pointed out—this is the only non-reasoning model on that chart besides GPT 5.1. When you compare it to other instruction-tuned (non-reasoning) models, it’s actually performing quite well, sitting at #6 among open models on LMSys Arena.Nisten checked LM Arena and confirmed that on coding specifically, Mistral Large 3 is scoring as one of the best open source coding models available. Yam made an important point that we should compare Mistral to other open source players like Qwen and DeepSeek rather than to closed models—and in that context, this is a solid release.But the real stars of this release are the Ministral 3 small models: 3B, 8B, and 14B, all with vision capabilities. These are edge-optimized, multimodal, and the 3B actually runs completely in the browser with WebGPU using transformers.js. The 14B reasoning variant achieves 85% on AIME 2025, which is state-of-the-art for its size class. Wolfram confirmed that the multilingual performance is excellent, particularly for German.There’s been some discussion about whether Mistral Large 3 is a DeepSeek finetune given the architectural similarities, but Mistral claims these are fully trained models. As Nisten noted, even if they used similar architecture (which is Apache 2.0 licensed), there’s nothing wrong with that—it’s an excellent architecture that works. Lucas Atkins later confirmed on the show that “Mistral Large looks fantastic... it is DeepSeek through and through architecture wise. But Kimi also d

ThursdAI Special: Google's New Anti-Gravity IDE, Gemini 3 & Nano Banana Pro Explained (ft. Kevin Hou, Ammaar Reshi & Kat Kampf)
Hey, Alex here, I recorded these conversations just in front of the AI Engineer auditorium, back to back, after these great folks gave their talks, and at the epitome of the most epic AI week we’ve seen since I started recording ThursdAI.This is less our traditional live recording, and more a real podcast-y conversation with great folks, inspired by Latent.Space. I hope you enjoy this format as much as I’ve enjoyed recording and editing it. AntiGravity with KevinKevin Hou and team just launched Antigravity, Google’s brand new Agentic IDE based on VSCode, and Kevin (second timer on ThursdAI) was awesome enough to hop on and talk about some of the product decisions they made, what makes Antigravity special and highlighted Artifacts as a completely new primitive. Gemini 3 in AI StudioIf you aren’t using Google’s AI Studio (ai.dev) then you’re missing out! We talk about AI Studio all the time on the show, and I’m a daily user! I generate most of my images with Nano Banana Pro in there, most of my Gemini conversations are happening there as well! Ammaar and Kat were so fun to talk to, as they covered the newly shipped “build mode” which allows you to vibe code full apps and experiences inside AI Studio, and we also covered Gemini 3’s features, multimodality understanding, UI capabilities. These folks gave a LOT of Gemini 3 demo’s so they know everything there is to know about this model’s capabilities! Tried new things with this one, multi camera angels, conversation with great folks, if you found this content valuable, please subscribe :) Topics Covered:* Inside Google’s new “AntiGravity” IDE* How the “Agent Manager” changes coding workflows* Gemini 3’s new multimodal capabilities* The power of “Artifacts” and dynamic memory* Deep dive into AI Studio updates & Vibe Coding* Generating 4K assets with Nano Banana ProTimestamps for your viewing convenience. 00:00 - Introduction and Overview01:13 - Conversation with Kevin Hou: Anti-Gravity IDE01:58 - Gemini 3 and Nano Banana Pro Launch Insights03:06 - Innovations in Anti-Gravity IDE06:56 - Artifacts and Dynamic Memory09:48 - Agent Manager and Multimodal Capabilities11:32 - Chrome Integration and Future Prospects20:11 - Conversation with Ammar and Kat: AI Studio Team21:21 - Introduction to AI Studio21:51 - What is AI Studio?22:52 - Ease of Use and User Feedback24:06 - Live Demos and Launch Week26:00 - Design Innovations in AI Studio30:54 - Generative UIs and Vibe Coding33:53 - Nano Banana Pro and Image Generation39:45 - Voice Interaction and Future Roadmap44:41 - Conclusion and Final ThoughtsLooking forward to seeing you on Thursday 🫡 P.S - I’ve recorded one more conversation during AI Engineer, and will be posting that soon, same format, very interesting person, look out for that soon! This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit sub.thursdai.news/subscribe

🦃 ThursdAI - Thanksgiving special 25’ - Claude 4.5, Flux 2 & Z-image vs 🍌, MCP gets Apps + New DeepSeek!?
Hey ya’ll, Happy Thanskgiving to everyone who celebrates and thank you for being a subscriber, I truly appreciate each and every one of you!Just wrapped up the third (1, 2) Thanksgiving special Episode of ThursdAI, can you believe November is almost over? We had another banger week in AI, with a full feast of AI released, Anthropic dropped the long awaited Opus 4.5, which quickly became the top coding LLM, DeepSeek resurfaced with a math model, BFL and Tongyi both tried to take on Nano Banana, and Microsoft dropped a 7B computer use model in Open Source + Intellect 3 from Prime Intellect! With so much news to cover, we also had an interview with Ido Sal & Liad Yosef (their second time on the show!) about MCP-Apps, the new standard they are spearheading together with Anthropic, OpenAI & more! Exciting episode, let’s get into it! (P.S - I started generating infographics, so the show became much more visual, LMK if you like them) ThursdAI - I put a lot of work on a weekly basis to bring you the live show, podcast and a sourced newsletter! Please subscribe if you find this content valuable!Anthropic’s Opus 4.5: The “Premier Intelligence” Returns (Blog)Folks, Anthropic absolutely cooked. After Sonnet and Haiku had their time in the sun, the big brother is finally back. Opus 4.5 launched this week, and it is reclaiming the throne for coding and complex agentic tasks.First off, the specs are monstrous. It hits 80.9% on SWE-bench Verified, topping GPT-5.1 (77.9%) and Gemini 3 Pro (76.2%). But the real kicker? The price! It is now $5 per million input tokens and $25 per million output—literally one-third the cost of the previous Opus.Yam, our resident coding wizard, put it best during the show: “Opus knows a lot of tiny details about the stack that you didn’t even know you wanted... It feels like it can go forever.” Unlike Sonnet, which sometimes spirals or loses context on extremely long tasks, Opus 4.5 maintains coherence deep into the conversation.Anthropic also introduced a new “Effort” parameter, allowing you to control how hard the model thinks (similar to o1 reasoning tokens). Set it to high, and you get massive performance gains; set it to medium, and you get Sonnet-level performance at a fraction of the token cost. Plus, they’ve added Tool Search (cutting enormous token overhead for agents with many tools) and Programmatic Tool Calling, which effectively lets Opus write and execute code loops to manage data.If you are doing heavy software engineering or complex automations, Opus 4.5 is the new daily driver.📱 The Agentic Web: MCP Apps & MCP-UI StandardSpeaking of MCP updates, Can you believe it’s been exactly one year since the Model Context Protocol (MCP) launched? We’ve been “MCP-pilled” for a while, but this week, the ecosystem took a massive leap forward.We brought back our friends Ido and Liad, the creators of MCP-UI, to discuss huge news: MCP-UI has been officially standardized as MCP Apps. This is a joint effort adopted by both Anthropic and OpenAI.Why does this matter? Until now, when an LLM used a tool (like Spotify or Zillow), the output was just text. It lost the brand identity and the user experience. With MCP Apps, agents can now render full, interactive HTML interfaces directly inside the chat! Ido and Liad explained that they worked hard to avoid an “iOS vs. Android” fragmentation war. Instead of every lab building their own proprietary app format, we now have a unified standard for the “Agentic Web.” This is how AI stops being a chatbot and starts being an operating system.Check out the standard at mcpui.dev.🦃 The Open Source Thanksgiving FeastWhile the big labs were busy, the open-source community decided to drop enough papers and weights to feed us for a month.Prime Intellect unveils INTELLECT-3, a 106B MoE (X, HF, Blog, Try It)Prime Intellect releases INTELLECT-3, a 106B parameter Mixture-of-Experts model (12B active params) based on GLM-4.5-Air, achieving state-of-the-art performance for its size—including ~90% on AIME 2024/2025 math contests, 69% on LiveCodeBench v6 coding, 74% on GPQA-Diamond reasoning, and 74% on MMLU-Pro—outpacing larger models like DeepSeek-R1. Trained over two months on 512 H200 GPUs using their fully open-sourced end-to-end stack (PRIME-RL async trainer, Verifiers & Environments Hub, Prime Sandboxes), it’s now hosted on Hugging Face, OpenRouter, Parasail, and Nebius, empowering any team to scale frontier RL without big-lab resources. Especially notable is their very detailed release blog, covering how a lab that previously trained 32B, finetunes a monster 106B MoE model! Tencent’s HunyuanOCR: Small but Mighty (X, HF, Github, Blog)Tencent released HunyuanOCR, a 1 billion parameter model that is absolutely crushing benchmarks. It scored 860 on OCRBench, beating massive models like Qwen3-VL-72B. It’s an end-to-end model, meaning no separate detection and recognition steps. Great for parsing PDFs, docs, and even video subtitles. It’s heavily restricted (no EU/UK usag
📆 ThursdAI - the week that changed the AI landscape forever - Gemini 3, GPT codex max, Grok 4.1 & fast, SAM3 and Nano Banana Pro
Hey everyone, Alex here 👋I’m writing this one from a noisy hallway at the AI Engineer conference in New York, still riding the high (and the sleep deprivation) from what might be the craziest week we’ve ever had in AI.In the span of a few days:Google dropped Gemini 3 Pro, a new Deep Think mode, generative UIs, and a free agent-first IDE called Antigravity.xAI shipped Grok 4.1, then followed it up with Grok 4.1 Fast plus an Agent Tools API.OpenAI answered with GPT‑5.1‑Codex‑Max, a long‑horizon coding monster that can work for more than a day, and quietly upgraded ChatGPT Pro to GPT‑5.1 Pro.Meta looked at all of that and said “cool, we’ll just segment literally everything and turn photos into 3D objects” with SAM 3 and SAM 3D.Robotics folks dropped a home robot trained with almost no robot data.And Google, just to flex, capped Thursday with Nano Banana Pro, a 4K image model and a provenance system while we were already live! For the first time in a while it doesn’t just feel like “new models came out.” It feels like the future actually clicked forward a notch.This is why ThursdAI exists. Weeks like this are basically impossible to follow if you have a day job, so my co‑hosts and I do the no‑sleep version so you don’t have to. Plus, being at AI Engineer makes it easy to get super high quality guests so this week we had 3 folks join us, Swyx from Cognition/Latent Space, Thor from DeepMind (on his 3rd day) and Dominik from OpenAI! Alright, deep breath. Let’s untangle the week.TL;DR If you only skim one section, make it this one (links in the end):* Google* Gemini 3 Pro: 1M‑token multimodal model, huge reasoning gains - new LLM king* ARC‑AGI‑2: 31.11% (Pro), 45.14% (Deep Think) – enormous jumps* Antigravity IDE: free, Gemini‑powered VS Code fork with agents, plans, walkthroughs, and browser control* Nano Banana Pro: 4K image generation with perfect text + SynthID provenance; dynamic “generative UIs” in Gemini* xAI* Grok 4.1: big post‑training upgrade – #1 on human‑preference leaderboards, much better EQ & creative writing, fewer hallucinations* Grok 4.1 Fast + Agent Tools API: 2M context, SOTA tool‑calling & agent benchmarks (Berkeley FC, T²‑Bench, research evals), aggressive pricing and tight X + web integration* OpenAI* GPT‑5.1‑Codex‑Max: “frontier agentic coding” model built for 24h+ software tasks with native compaction for million‑token sessions; big gains on SWE‑Bench, SWE‑Lancer, TerminalBench 2* GPT‑5.1 Pro: new “research‑grade” ChatGPT mode that will happily think for minutes on a single query* Meta* SAM 3: open‑vocabulary segmentation + tracking across images and video (with text & exemplar prompts)* SAM 3D: single‑image → 3D objects & human bodies; surprisingly high‑quality 3D from one photo* Robotics* Sunday Robotics – ACT‑1 & Memo: home robot foundation model trained from a $200 skill glove instead of $20K teleop rigs; long‑horizon household tasks with solid zero‑shot generalization* Developer Tools* Antigravity and Marimo’s VS Code / Cursor extension both push toward agentic, reactive dev workflowsLive from AI Engineer New York: Coding Agents Take Center StageWe recorded this week’s show on location at the AI Engineer Summit in New York, inside a beautiful podcast studio the team set up right on the expo floor. Huge shout out to Swyx, Ben, and the whole AI Engineer crew for that — last time I was balancing a mic on a hotel nightstand, this time I had broadcast‑grade audio while a robot dog tried to steal the show behind us.This year’s summit theme is very on‑the‑nose for this week: coding agents.Everywhere you look, there’s a company building an “agent lab” on top of foundation models. Amp, Cognition, Cursor, CodeRabbit, Jules, Google Labs, all the open‑source folks, and even the enterprise players like Capital One and Bloomberg are here, trying to figure out what it means to have real software engineers that are partly human and partly model.Swyx framed it nicely when he said that if you take “vertical AI” seriously enough, you eventually end up building an agent lab. Lawyers, healthcare, finance, developer tools — they all converge on “agents that can reason and code.”The big labs heard that theme loud and clear. Almost every major release this week is about agents, tools, and long‑horizon workflows, not just chat answers.Google Goes All In: Gemini 3 Pro, Antigravity, and the Agent RevolutionLet’s start with Google because, after years of everyone asking “where’s Google?” in the AI race, they showed up this week with multiple bombshells that had even the skeptics impressed.Gemini 3 Pro: Multimodal Intelligence That Actually DeliversGoogle finally released Gemini 3 Pro, and the numbers are genuinely impressive. We’re talking about a 1 million token context window, massive benchmark improvements, and a model that’s finally competing at the very top of the intelligence charts. Thor from DeepMind joined us on the show (literally on day 3 of his new job!) and you could feel the excitement.The headline

GPT‑5.1’s New Brain, Grok’s 2M Context, Omnilingual ASR, and a Terminal UI That Sparks Joy
Hey, this is Alex! We’re finally so back! Tons of open source releases, OpenAI updates GPT and a few breakthroughs in audio as well, makes this a very dense week! Today on the show, we covered the newly released GPT 5.1 update, a few open source releases like Terminal Bench and Project AELLA (renamed OASSAS), and Baidu’s Ernie 4.5 VL that shows impressive visual understanding! Also, chatted with Paul from 11Labs and Dima Duev from the wandb SDK team, who brought us a delicious demo of LEET, our new TUI for wandb! Tons of news coverage, let’s dive in 👇 (as always links and show notes in the end) Open Source AILet’s jump directly into Open Source as this week has seen some impressive big company models. Terminal-Bench 2.0 - a harder, highly‑verified coding and terminal benchmark (X, Blog, Leaderboard)We opened with Terminal‑Bench 2.0 plus its new harness, Harbor, because this is the kind of benchmark we’ve all been asking for. Terminal‑Bench focuses on agentic coding in a real shell. Version 2.0 is a hard set of 89 terminal tasks, each one painstakingly vetted by humans and LLMs to make sure it’s solvable and realistic. Think “I checked out master and broke my personal site, help untangle the git mess” or “implement GPT‑2 code golf with the fewest characters.” On the new leaderboard, top agents like Warp’s agentic console and Codex CLI + GPT‑5 sit around fifty percent success. That number is exactly what excites me: we’re nowhere near saturation. When everyone is in the 90‑something range, tiny 0.1 improvements are basically noise. When the best models are at fifty percent, a five‑point jump really means something.A huge part of our conversation focused on reproducibility. We’ve seen other benchmarks like OSWorld turn out to be unreliable, with different task sets and non‑reproducible results making scores incomparable. Terminal‑Bench addresses this with Harbor, a harness designed to run sandboxed, containerized agent rollouts at scale in a consistent environment. This means results are actually comparable. It’s a ton of work to build an entire evaluation ecosystem like this, and with over a thousand contributors on their Discord, it’s a fantastic example of a healthy, community‑driven effort. This is one to watch! Baidu’s ERNIE‑4.5‑VL “Thinking”: a 3B visual reasoner that punches way up (X, HF, GitHub)Next up, Baidu dropped a really interesting model, ERNIE‑4.5‑VL‑28B‑A3B‑Thinking. This is a compact, 3B active‑parameter multimodal reasoning model focused on vision, and it’s much better than you’d expect for its size. Baidu’s own charts show it competing with much larger closed models like Gemini‑2.5‑Pro and GPT‑5‑High on a bunch of visual benchmarks like ChartQA and DocVQA.During the show, I dropped a fairly complex chart into the demo, and ERNIE‑4.5‑VL gave me a clean textual summary almost instantly—it read the chart more cleanly than I could. The model is built to “think with images,” using dynamic zooming and spatial grounding to analyze fine details. It’s released under an Apache‑2.0 license, making it a serious candidate for edge devices, education, and any product where you need a cheap but powerful visual brain.Open Source Quick Hits: OSSAS, VibeThinker, and Holo TwoWe also covered a few other key open-source releases. Project AELLA was quickly rebranded to OSSAS (Open Source Summaries At Scale), an initiative to make scientific literature machine‑readable. They’ve released 100k paper summaries, two fine-tuned models for the task, and a 3D visualizer. It’s a niche but powerful tool if you’re working with massive amounts of research. (X, HF)WeiboAI (from the Chinese social media company) released VibeThinker‑1.5B, a tiny 1.5B‑parameter reasoning model that is making bold claims about beating the 671B DeepSeek R1 on math benchmarks. We discussed the high probability of benchmark contamination, especially on tests like AIME24, but even with that caveat, getting strong chain‑of‑thought math out of a 1.5B model is impressive and useful for resource‑constrained applications. (X, HF, Arxiv)Finally, we had some breaking news mid‑show: H Company released Holo Two, their next‑gen multimodal agent for controlling desktops, websites, and mobile apps. It’s a fine‑tune of Qwen3‑VL and comes in 4B and 8B Apache‑2.0 licensed versions, pushing the open agent ecosystem forward. (X, Blog, HF)ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.Big Companies & APIsGPT‑5.1: Instant vs Thinking, and a new personality barThe biggest headline of the week was OpenAI shipping GPT‑5.1, and this was a hot topic of debate on the show. The update introduces two modes: “Instant” for fast, low‑compute answers, and “Thinking” for deeper reasoning on hard problems. OpenAI claims Instant mode uses 57% fewer tokens on easy tasks, while Thinking mode dedicates 71% more compute to difficult ones. This adaptive a
📆 ThursdAI - Nov 6, 2025 - Kimi’s 1T Thinking Model Shakes Up Open Source, Apple Bets $1B on Gemini for Siri, and Amazon vs. Perplexity!
Hey, Alex here! Quick note, while preparing for this week, I posted on X that I don’t remember such a quiet week in AI since I started doing ThursdAI regularly, but then 45 min before the show started, Kimi dropped a SOTA oss reasoning model, turning a quiet week into an absolute banger. Besides Kimi, we covered the updated MCP thinking from Anthropic, and had Kenton Varda from cloudflare as a guest to talk about Code Mode, chatted about Windsurf and Cursor latest updates and covered OpenAI’s insane deals. Also, because it was a quiet week, I figured I’d use the opportunity to create an AI powered automation, and used N8N for that, and shared it on the stream, so if you’re interested in automating with AI with relatively low code, this episode is for you. Let’s dive inThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.Kimi K2 Thinking is Here and It’s a 1 Trillion Parameter Beast! (X, HF, Tech Blog)Let’s start with the news that got everyone’s energy levels skyrocketing right as we went live. Moonshot AI dropped Kimi K2 Thinking, an open-source, 1 trillion-parameter Mixture-of-Experts (MoE) model, and it’s an absolute monster.This isn’t just a numbers game; Kimi K2 Thinking is designed from the ground up to be a powerful agent. With just around 32 billion active parameters during inference, a massive 256,000 token context window, and an insane tool-calling capacity. They’re claiming it can handle 200-300 sequential tool calls without any human intervention. The benchmarks are just as wild. On the Humanities Last Exam (HLE), they’re reporting a score of 44.9%, beating out both GPT-5 and Claude 4.5 Thinking. While it doesn’t quite top the charts on SWE-bench verified, it’s holding its own against the biggest closed-source models out there. Seeing an open-source model compete at this level is incredibly exciting.During the show, we saw some truly mind-blowing demos, from a beautiful interactive visualization of gradient descent to a simulation of a virus attacking cells, all generated by the model. The model’s reasoning traces, which are exposed through the API, also seem qualitatively different from other models, showing a deep and thoughtful process. My co-hosts and I were blown away. The weights and a very detailed technical report are available on Hugging Face, so you can dive in and see for yourself. Shout out to the entire Moonshot AI team for this incredible release!Other open source updates from this week* HuggingFace released an open source “Smol Training Playbook” on training LLMs, it’s a 200+ interactive beast with visualizations, deep dives into pretraining, dataset, postraining and more! (HF)* Ai2 launches OlmoEarth — foundation models + open, end-to-end platform for fast, high-resolution Earth intelligence (X, Blog)* LongCat-Flash-Omni — open-source omni-modal system with millisecond E2E spoken interaction, 128K context and a 560B ScMoE backbone (X, HF, Announcement)Big Tech’s Big Moves: Apple, Amazon, and OpenAIThe big companies were making waves this week, starting with a blockbuster deal that might finally make Siri smart. Apple is reportedly will be paying Google around $1 billion per year to license a custom 1.2 trillion-parameter version of Gemini to power a revamped Siri.This is a massive move. The Gemini model will run on Apple’s Private Cloud Compute, keeping user data walled off from Google, and will handle Siri’s complex summarizer and planner functions. After years of waiting for Apple to make a significant move in GenAI, it seems they’re outsourcing the heavy lifting for now while they work to catch up with their own in-house models. As a user, I don’t really care who builds the model, as long as Siri stops being dumb!In more dramatic news, Perplexity revealed that Amazon sent them a legal threat to block their Comet AI assistant from shopping on Amazon.com. This infuriated me. My browser is my browser, and I should be able to use whatever tools I want to interact with the web. Perplexity took a strong stand with their blog post, “Bullying is Not Innovation,” arguing that user agents are distinct from scrapers and act on behalf of the user with their own credentials. An AI assistant is just that—an assistant. It shouldn’t matter if I ask my wife or my AI to buy something for me on Amazon. This feels like a move by Amazon to protect its ad revenue at the expense of user choice and innovation, and I have to give major props to Perplexity for being so transparent and fighting back.Finally, OpenAI continues its quest for infinite compute, announcing a multi-year strategic partnership with AWS. This comes on top of massive deals with NVIDIA, Microsoft, Oracle, and others, bringing their total commitment to compute into the trillions of dollars. It’s getting to a point where OpenAI seems “too big to fail,” as any hiccup could have serious repercussions for the en

ThursdAI - Oct 30 - From ASI in a Decade to Home Humanoids: MiniMax M2's Speed Demon, OpenAI's Bold Roadmap, and 2026 Robot Revolution
Hey, it’s Alex! Happy Halloween friends! I’m excited to bring you this weeks (spooky) AI updates! We started the show today with MiniMax M2, the currently top Open Source LLM, with an interview with their head of eng, Skyler Miao, continued to dive into OpenAIs completed restructuring into a non-profit and a PBC, including a deep dive into a live stream Sam Altman had, with a ton of spicy details, and finally chatted with Arjun Desai from Cartesia, following a release of Sonic 3, a sub 49ms voice model! So, 2 interviews + tons of news, let’s dive in! (as always, show notes in the end)Hey, if you like this content, it would mean a lot if you subscribe as a paid subscriber.Open Source AIMiniMax M2: open-source agentic model at 8% of Claude’s price, 2× speed (X, Hugging Face )We kicked off our open-source segment with a banger of an announcement and a special guest. The new king of open-source LLMs is here, and it’s called MiniMax M2. We were lucky enough to have Skyler Miao, Head of Engineering at Minimax, join us live to break it all down.M2 is an agentic model built for code and complex workflows, and its performance is just staggering. It’s already ranked in the top 5 globally on the Artificial Analysis benchmark, right behind giants like OpenAI and Anthropic. But here’s the crazy part: it delivers nearly twice the speed of Claude 3.5 Sonnet at just 8% of the price. This is basically Sonnet-level performance, at home, in open source.Skylar explained that their team saw an “impossible triangle” in the market between performance, cost, and speed—you could only ever get two. Their goal with M2 was to build a model that could solve this, and they absolutely nailed it. It’s a 200B parameter Mixture-of-Experts (MoE) model, but with only 10B active parameters per inference, making it incredibly efficient.One key insight Skylar shared was about getting the best performance. M2 supports multiple APIs, but to really unlock its reasoning power, you need to use an API that passes the model’s “thinking” tokens back to it on the next turn, like the Anthropic API. Many open-source tools don’t support this yet, so it’s something to watch out for.Huge congrats to the MiniMax team on this Open Weights (MIT licensed) release, you can find the model on HF! MiniMax had quite a week, with 3 additional releases, MiniMax speech 2.6, an update to their video model Hailuo 2.3 and just after the show, they released a music 2.0 model as well! Congrats on the shipping folks! OpenAI drops gpt-oss-safeguard - first open-weight safety reasoning models for classification ( X, HF )OpenAI is back on the open weights bandwagon, with a finetune release of their previously open weighted gpt-oss models, with gpt-oss-safeguard. These models were trained exclusively to help companies build safeguarding policies to make sure their apps remains safe! With gpt-oss-safeguards 20B and 120B, OpenAI is achieving near parity with their internal safety models, and as Nisten said on the show, if anyone knows about censorship and safety, it’s OpenAI! The highlight of this release is, unlike traditional pre-trained classifiers, these models allow for updates to policy via natural language!These models will be great for businesses that want to safeguard their products in production, and I will advocate to bring these models to W&B Inference soon! A Humanoid Robot in Your Home by 2026? 1X NEO announcement ( X, Order page, Keynote )Things got really spooky when we started talking about robotics. The company 1X, which has been on our radar for a while, officially launched pre-orders for NEO, the world’s first consumer humanoid robot designed for your home. And yes, you can order one right now for $20,000, with deliveries expected in early 2026.The internet went crazy over this announcement, with folks posting receipts of getting one, other folks stoking the uncanny valley fears that Sci-fi has built into many people over the years, of the Robot uprising and talking about the privacy concerns of having a human tele-operate this Robot in your house to do chores. It can handle chores like cleaning and laundry, and for more complex tasks that it hasn’t learned yet, it uses a teleoperation system where a human “1X Expert” can pilot the robot remotely to perform the task. This is how it collects the data to learn to do these tasks autonomously in your specific home environment.The whole release is very interesting, from the “soft and quiet” approach 1X is taking, making their robot a 66lbs short king, draped in a knit sweater, to the $20K price point (effectively at loss given how much just the hands cost), the teleoperated by humans addition, to make sure the Robot learns about your unique house layout. The conversation on the show was fascinating. We talked about all the potential use cases, from having it water your plants and look after your pets while you’re on vacation to providing remote assistance for elderly relatives. Of course, there are real privacy concer

📆 ThursdAI - Oct 23: The AI Browser Wars Begin, DeepSeek's OCR Mind-Trick & The Race to Real-Time Video
Hey everyone, Alex here! Welcome... to the browser war II - the AI edition! This week we chatted in depth about ChatGPT’s new Atlas agentic browser, and the additional agentic powers Microsoft added to Edge with Copilot Mode (tho it didn’t work for me) Also this week was a kind of crazy OCR week, with more than 4 OCR models releasing, and the crown one is DeepSeek OCR, that turned the whole industry on it’s head (more later) Quite a few video updates as well, with real time lipsync from Decart, and a new update from LTX with 4k native video generation, it’s been a busy AI week for sure! Additionally, I’ve had the pleasure to talk about AI Browsing agents with Paul from BrowserBase and real time video with Kwindla Kramer from Pipecat/Daily, so make sure to tune in for those interviews, buckle up, let’s dive in! Thanks for reading ThursdAI - Recaps of the most high signal AI weekly spaces! This post is public so feel free to share it.Open Source: OCR is Not What You Think It Is (X, HF, Paper)The most important and frankly mind-bending release this week came from DeepSeek. They dropped DeepSeek-OCR, and let me tell you, this is NOT just another OCR model. The cohost were buzzing about this, and once I dug in, I understood why. This isn’t just about reading text from an image; it’s a revolutionary approach to context compression.We think that DeepSeek needed this as an internal tool, so we’re really grateful to them for open sourcing this, as they did something crazy here. They are essentially turning text into a visual representation, compressing it, and then using a tiny vision decoder to read it back with incredible accuracy. We’re talking about a compression ratio of up to 10x with 97% decoding accuracy. Even at 20x compression they are achieving 60% decoding accuracy! My head exploded live on the show when I read that. This is like the middle-out compression algorithm joke from Silicon Valley, but it’s real. As Yam pointed out, this suggests our current methods of text tokenization are far from optimal.With only 3B and ~570M active parameters, they are taking a direct stab at long context inefficiency, imagine taking 1M tokens, encoding them into 100K visual tokens, and then feeding those into a model. Since the model is tiny, it’s very cheap to run, for example, alphaXiv claimed they have OCRd’ all of the papers on ArXiv with this model for $1000, a task that would have cost $7500 using MistalOCR - as per their paper, with DeepSeek OCR, on a single H100 GPU, its possible to scan up to 200K pages! 🤯 Really innovative stuff! OCR and VLM models had quite a week, with multiple models besides DeepSeek OCR releasing, models like Liquids LFM2-VL-3B (X, HF), and the newly updated 2B and 32B of Qwen3-VL (X, Hugging Face), and AI2’s olmo-ocr 2-7B (X, HF). The Qwen models are particularly interesting, as the 2B model is a generic VLM (can also do OCR) and is close to previous weeks 4B and 8B brothers, and the newly updated 32B model outperforms GPT-5 mini and Claud 4 sonnet even! The Browser Wars are BACK: OpenAI & Microsoft Go AgenticLook, I may be aging myself here, but I remember, as a young frontend dev, having to install 5 browers at once to test them out, Chrome, Internet Explorer, Firefox, Opera etc’. That was then, and now, I have Dia, Comet, and the newly released Atlas, and, yeah, today I even installed Microsoft Edge to test their AI features! It seems like the AI boom brought with it a newly possible reason for folks to try and take a bite out of Chrome (who’s agentic features are long rumored with project mariner but are nowhere to be found/shipped yet) OpenAI’s ChatGPT Atlas: The Browser Reimagined (X, Download)OpenAI is proving that besides just models, they are a product powerhouse, stepping into categories like Shopping (with a shopify integration), app stores (with ChatGPT apps), social (with Sora2) and now... browsers! This week, they have launched their tightly integrated into ChatGPT browser called Atlas, and it’s a big release! I’ll split my review here to 2 parts, the browser features part and the agentic part. New fresh take on a chromium based browserThe tight integration into ChatGPT is everywhere in this browser, from the new tab that looks like the basic ChatGPT interaface, one line of text, to the sidebar on the left that... is the ChatGPT web sidebar with all your chats, projects, custom GPTs etc. The integration doesn’t stop there, as you have to sign in to your ChatGPT account to even use this browser (available only to MacOS users, and Pro, Plus and Nano tiers). The browser has a few neat tricks, like a special tool that allows you to search your browsing history with natural language, a-la “what were those shoes I was looking at a few days ago” will find your the tabs you browsed for shoes. A special and cool feature is called, confusingly “Cursor”, wherein you can select a text, and then click the little OpenAI logo that pops up, allowing you to ask ChatGPT for changes to that sel
📆 ThursdAI - Oct 16 - VEO3.1, Haiku 4.5, ChatGPT adult mode, Claude Skills, NVIDIA DGX spark, Wordlabs RTFM & more AI news
Hey folks, Alex here. Can you believe it’s already the middle of October? This week’s show was a special one, not just because of the mind-blowing news, but because we set a new ThursdAI record with four incredible interviews back-to-back!We had Jessica Gallegos from Google DeepMind walking us through the cinematic new features in VEO 3.1. Then we dove deep into the world of Reinforcement Learning with my new colleague Kyle Corbitt from OpenPipe. We got the scoop on Amp’s wild new ad-supported free tier from CEO Quinn Slack. And just as we were wrapping up, Swyx ( from Latent.Space , now with Cognition!) jumped on to break the news about their blazingly fast SWE-grep models. But the biggest story? An AI model from Google and Yale made a novel scientific discovery about cancer cells that was then validated in a lab. This is it, folks. This is the “let’s f*****g go” moment we’ve been waiting for. So buckle up, because this week was an absolute monster. Let’s dive in!ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.Open Source: An AI Model Just Made a Real-World Cancer DiscoveryWe always start with open source, but this week felt different. This week, open source AI stepped out of the benchmarks and into the biology lab.Our friends at Qwen kicked things off with new 3B and 8B parameter versions of their Qwen3-VL vision model. It’s always great to see powerful models shrink down to sizes that can run on-device. What’s wild is that these small models are outperforming last generation’s giants, like the 72B Qwen2.5-VL, on a whole suite of benchmarks. The 8B model scores a 33.9 on OS World, which is incredible for an on-device agent that can actually see and click things on your screen. For comparison, that’s getting close to what we saw from Sonnet 3.7 just a few months ago. The pace is just relentless.But then, Google dropped a bombshell. A 27-billion parameter Gemma-based model they developed with Yale, called C2S-Scale, generated a completely novel hypothesis about how cancer cells behave. This wasn’t a summary of existing research; it was a new idea, something no human scientist had documented before. And here’s the kicker: researchers then took that hypothesis into a wet lab, tested it on living cells, and proved it was true.This is a monumental deal. For years, AI skeptics like Gary Marcus have said that LLMs are just stochastic parrots, that they can’t create genuinely new knowledge. This feels like the first, powerful counter-argument. Friend of the pod, Dr. Derya Unutmaz, has been on the show before saying AI is going to solve cancer, and this is the first real sign that he might be right. The researchers noted this was an “emergent capability of scale,” proving once again that as these models get bigger and are trained on more complex data—in this case, turning single-cell RNA sequences into “sentences” for the model to learn from—they unlock completely new abilities. This is AI as a true scientific collaborator. Absolutely incredible.Big Companies & APIsThe big companies weren’t sleeping this week, either. The agentic AI race is heating up, and we’re seeing huge updates across the board.Claude Haiku 4.5: Fast, Cheap Model Rivals Sonnet 4 Accuracy (X, Official blog, X)First up, Anthropic released Claude Haiku 4.5, and it is a beast. It’s a fast, cheap model that’s punching way above its weight. On the SWE-bench verified benchmark for coding, it hit 73.3%, putting it right up there with giants like GPT-5 Codex, but at a fraction of the cost and twice the speed of previous Claude models. Nisten has already been putting it through its paces and loves it for agentic workflows because it just follows instructions without getting opinionated. It seems like Anthropic has specifically tuned this one to be a workhorse for agents, and it absolutely delivers. The thing to note also is the very impressive jump in OSWorld (50.7%), which is a computer use benchmark, and at this price and speed ($1/$5 MTok input/output) is going to make computer agents much more streamlined and speedy! ChatGPT will loose restrictions; age-gating enables “adult mode” with new personality features coming (X) Sam Altman set X on fire with a thread announcing that ChatGPT will start loosening its restrictions. They’re planning to roll out an “adult mode” in December for age-verified users, potentially allowing for things like erotica. More importantly, they’re bringing back more customizable personalities, trying to recapture some of the magic of GPT-4.0 that so many people missed. It feels like they’re finally ready to treat adults like adults, letting us opt-in to R-rated conversations while keeping strong guardrails for minors. This is a welcome change, and we’ve been advocating for this for a while, and it’s a notable change from the XAI approach I covered last week. Opt in for adults with verification whi

📆 Oct 9, 2025 — Dev Day’s Agent Era, Samsung’s 7M TRM Shock, Ling‑1T at 1T, Grok Video goes NSFW, and Serverless RL arrives
Hey everyone, Alex here 👋We’re deep in the post-reality era now. Between Sora2, the latest waves of video models, and “is-that-person-real” cameos, it’s getting genuinely hard to trust what we see. Case in point: I recorded a short clip with (the real) Sam Altman this week and a bunch of friends thought I faked it with Sora-style tooling. Someone even added a fake Sora watermark just to mess with people. Welcome to 2025.This week’s episode and this write-up focus on a few big arcs we’re all living through at once: OpenAI’s Dev Day and the beginning of the agent-app platform inside ChatGPT, a bizarre and exciting split-screen in model scaling where a 7M recursive model from Samsung is suddenly competitive on reasoning puzzles while inclusionAI is shipping a trillion-parameter mixture-of-reasoners, and Grok’s image-to-video now does audio and pushes the line on… taste. We also dove into practical evals for coding agents with Eric Provencher from Repo Prompt, and I’ve got big news from my day job world: W&B + CoreWeave launched Serverless RL, so training and deploying RL agents at scale is now one API call away.Let’s get into it.OpenAI’s 3rd Dev Day - Live Coverage + exclusive interviewsThis is the third Dev Day that I got to attend in person, covering this for ThursdAI (2023, 2024), and this one was the best by far! The production quality of their events rises every year, and this year they’ve opened up the conference to >1500 people, had 3 main launches and a lot of ways to interact with the OpenAI folks! I’ve also gotten an exclusive chance to sit in on a fireside chat with Sam Altman and Greg Brokman (snippets of which I’ve included in the podcast, starting 01:15:00 and I got to ask Sam a few questions after that as well. Event Ambiance and VibesOpenAI folks outdid themselves with this event, the live demos were quite incredible, the location (Fort Mason), Food and just the whole thing was on point. The event concluded with a 1x1 Sam and Jony Ive chat that I hope will be published on YT sometime, because it was very insightful. By far the best reason to go to this event in person is meeting folks and networking, both OpenAI employees, and AI Engineers who use their products. It’s 1 day a year, when OpenAI makes all their employees who attend, Developer Experience folks, as you can and are encouraged to, interact with them, ask questions, give feedback and it’s honestly great! I really enjoy meeting folks at this event and consider this to be a very high signal network, and was honored to have quite a few ThursdAI listeners among the participants and OpenAI folk! If you’re reading this, thank you for your patronage 🫡 Launches and ShipsOpenAI also shipped, and shipped a LOT! Sam was up on Keynote with 3 main pillars, which we’ll break down 1 by 1. ChatGPT Apps, AgentKit (+ agent builder) and Codex/New APIsCodex & New APIsCodex has gotten General Availability, but we’ve been using it all this time so we don’t really care, what we do care about is the new slack integration and the new Codex SDK, which means you can now directly inject Codex agency into your app. This flew a bit over people’s heads, but Romain Huet, VP of DevEx at OpenAI demoed on stage how his mobile app now has a Codex tab, where he can ask Codex to make changes to the app at runtime! It was quite crazy! ChatGPT Apps + AppsSDKThis was maybe the most visual and most surprising release, since they’ve tried to be an appstore before (plugins, customGPTs). But this time, it seems like, based on top of MCP, ChatGPT is going to become a full blown Appstore for 800+ million weekly active ChatGPT users as well. Some of the examples they have showed included Spotify and Zillow, where just by typing in “Spotify” in chatGPT, you will have an interactive app with it’s own UI, right inside of ChatGPT. So you could ask it to create a playlist for you based on your history, or ask Zillow to find homes in an area under a certain $$ amount.The most impressive thing, is that those are only launch partners, everyone can (technically) build a ChatGPT app with their AppsSDK that’s built on top of... the MCP (model context protocol) spec! The main question remains about discoverability, this is where Plugins and CustomGPTs (previous attempts to create apps within ChatGPT have failed), and when I asked him about it, Sam basically said “we’ll iterate and get it right” (starting 01:17:00). So it remains to be seen if folks really need their ChatGPT as yet another Appstore. AgentKit, AgentBuilder and ChatKit2025 is the year of agents, and besides launching quite a few of their own, OpenAI will not let you, build and host smart agents that can use tools, on their platform. Supposedly, with AgentBuilder, building agents is just dragging a few nodes around, prompting and connecting them. They had a great demo on stage where with less than 8 minutes, they’ve build an agent to interact with the DevDay website.It’s also great to see how greatly does OpenAI adapt the MCP sp
Sora 2 Crushes TikTok, Claude 4.5 Fizzles, DeepSeek innovates attention and GLM 4.6 Takes the Crown! 🔥
Hey everyone, Alex here (yes the real me if you’re reading this) The weeks are getting crazier, but what OpenAI pulled this week, with a whole new social media app attached to their latest AI breakthroughs is definitely breathtaking! Sora2 released and instantly became a viral sensation, shooting to the top 3 free iOS spot on AppStore, with millions of videos watched, and remixed. On weeks like these, even huge releases like Claude 4.5 are taking the backseat, but we still covered them! For listeners of the pod, the second half of the show was very visual heavy, so it may be worth it watching the YT video attached in a comment if you want to fully experience the Sora revolution with us! (and if you want a SORA invite but don’t have one yet, more on that below) ThursdAI - if you find this valuable, please support us by subscribing! Sora 2 - the AI video model that signifies a new era of social mediaLook, you’ve probably already heard about the SORA-2 release, but in case you haven’t, OpenAI released a whole new model, but attached it to a new, AI powered social media experiment in the form of a very addictive TikTok style feed. Besides being hyper-realistic, and producing sounds and true to source voice-overs, Sora2 asks you to create your own “Cameo” by taking a quick video, and then allows you to be featured in your own (and your friends) videos. This makes a significant break from the previously “slop” based meta Vibes, becuase, well, everyone loves seeing themselves as the stars of the show! Cameos are a stroke of genius, and what’s more, one can allow everyone to use their Cameo, which is what Sam Altman did at launch, making everyone Cameo him, and turning him, almost instantly into one of the most meme-able (and approachable) people on the planet! Sam sharing away his likeness like this for the sake of the app achieved a few things, it added trust in the safety features, made it instantly viral and showed folks they shouldn’t be afraid of adding their own likeness. Vibes based feed and remixingSora 2 is also unique in that, it’s the first social media with UGC (user generated content) where content can ONLY be generated, and all SORA content is created within the app. It’s not possible to upload pictures that have people to create the posts, and you can only create posts with other folks if you have access to their Cameos, or by Remixing existing creations. Remixing is also a way to let users “participate” in the creation process, by adding their own twist and vibes! Speaking of Vibes, while the SORA app has an algorithmic For You page, they have a completely novel and new way to interact with the algorithm, by using their Pick a Mood feature, where you can describe which type of content you want to see, or not see, with natural language! I believe that this feature will come to all social media platforms later, as it’s such a game changer. Want only content in a specific language? or content that doesn’t have Sam Altman in it? Just ask! Content that makes you feel goodThe most interesting thing is about the type of content is, there’s no sexualisation (because all content is moderated by OpenAI strong filters), and no gore etc. OpenAI has clearly been thinking about teenagers and have added parent controls, things like being able to turn of the For You page completely etc to the mix. Additionally, SORA seems to be a very funny model, and I mean this literally. You can ask the video generation for a joke and you’ll often get a funny one. The scene setup, the dialogue, the things it does even unprompted are genuinely entertaining. AI + Product = Profit? OpenAI shows that they are one of the worlds best product labs in the world, not just a foundational AI lab. Most AI advancements are tied to products, and in this case, the whole experience is so polished, it’s hard to accept that it’s a brand new app from a company that didn’t do social before. There’s very little buggy behavior, videos are loaded up quick, there’s even DMs! I’m thoroughly impressed and am immersing myself in the SORA sphere. Please give me a follow there and feel free to use my Cameo by tagging @altryne in there. I love seeing how folks have used my Cameo, it makes me laugh 😂 The copyright question is.. wildRemember last year when I asked Sam why Advanced Voice Mode couldn’t sing Happy Birthday? He said they didn’t have classifiers to detect IP violations. Well, apparently that’s not a concern anymore because SORA 2 will happily generate perfect South Park episodes, Rick and Morty scenes, and Pokemon battles. They’re not even pretending they didn’t train on this stuff. You can even generate videos with any dead famous person (I’ve had zoom meetings with Michael Jackson and 2Pac, JFK and Mister Rogers) Our friend Ryan Carson already used it to create a YouTube short ad for his startup in two minutes. What would have cost $100K and three months now takes six generations and you’re done. This is the real game-changer for businesses.Get
📆 ThursdAI - Qwen‑mas Strikes Again: VL/Omni Blitz + Grok‑4 Fast + Nvidia’s $100B Bet
This is a free preview of a paid episode. To hear more, visit sub.thursdai.newsHola AI aficionados, it’s yet another ThursdAI, and yet another week FULL of AI news, spanning Open Source LLMs, Multimodal video and audio creation and more! Shiptember as they call it does seem to deliver, and it was hard even for me to follow up on all the news, not to mention we had like 3-4 breaking news during the show today! This week was yet another Qwen-mas, with Alibaba absolutely dominating across open source, but also NVIDIA promising to invest up to $100 Billion into OpenAI. So let’s dive right in! As a reminder, all the show notes are posted at the end of the article for your convenience. ThursdAI - Because weeks are getting denser, but we’re still here, weekly, sending you the top AI content! Don’t miss outTable of Contents* Open Source AI* Qwen3-VL Announcement (Qwen3-VL-235B-A22B-Thinking):* Qwen3-Omni-30B-A3B: end-to-end SOTA omni-modal AI unifying text, image, audio, and video* DeepSeek V3.1 Terminus: a surgical bugfix that matters for agents* Evals & Benchmarks: agents, deception, and code at scale* Big Companies, Bigger Bets!* OpenAI: ChatGPT Pulse: Proactive AI news cards for your day* XAI Grok 4 fast - 2M context, 40% fewer thinking tokens, shockingly cheap* Alibaba Qwen-Max and plans for scaling* This Week’s Buzz: W&B Fully Connected is coming to London and Tokyo & Another hackathon in SF* Vision & Video: Wan 2.2 Animate, Kling 2.5, and Wan 4.5 preview* Moondream-3 Preview - Interview with co-founders Via & Jay* Wan open sourced Wan 2.2 Animate (aka “Wan Animate”): motion transfer and lip sync* Kling 2.5 Turbo: cinematic motion, cheaper and with audio* Wan 4.5 preview: native multimodality, 1080p 10s, and lip-synced speech* Voice & Audio* ThursdAI - Sep 25, 2025 - TL;DR & Show notesOpen Source AIThis was a Qwen-and-friends week. I joked on stream that I should just count how many times “Alibaba” appears in our show notes. It’s a lot.Qwen3-VL Announcement (Qwen3-VL-235B-A22B-Thinking): (X, HF, Blog, Demo)Qwen 3 launched earlier as a text-only family; the vision-enabled variant just arrived, and it’s not timid. The “thinking” version is effectively a reasoner with eyes, built on a 235B-parameter backbone with around 22B active (their mixture-of-experts trick). What jumped out is the breadth of evaluation coverage: MMU, video understanding (Video-MME, LVBench), 2D/3D grounding, doc VQA, chart/table reasoning—pages of it. They’re showing wins against models like Gemini 2.5 Pro and GPT‑5 on some of those reports, and doc VQA is flirting with “nearly solved” territory in their numbers.Two caveats. First, whenever scores get that high on imperfect benchmarks, you should expect healthy skepticism; known label issues can inflate numbers. Second, the model is big. Incredible for server-side grounding and long-form reasoning with vision (they’re talking about scaling context to 1M tokens for two-hour video and long PDFs), but not something you throw on a phone.Still, if your workload smells like “reasoning + grounding + long context,” Qwen 3 VL looks like one of the strongest open-weight choices right now.Qwen3-Omni-30B-A3B: end-to-end SOTA omni-modal AI unifying text, image, audio, and video (HF, GitHub, Qwen Chat, Demo, API)Omni is their end-to-end multimodal chat model that unites text, image, and audio—and crucially, it streams audio responses in real time while thinking separately in the background. Architecturally, it’s a 30B MoE with around 3B active parameters at inference, which is the secret to why it feels snappy on consumer GPUs.In practice, that means you can talk to Omni, have it see what you see, and get sub-250 ms replies in nine speaker languages while it quietly plans. It claims to understand 119 languages. When I pushed it in multilingual conversational settings it still code-switched unexpectedly (Chinese suddenly appeared mid-flow), and it occasionally suffered the classic “stuck in thought” behavior we’ve been seeing in agentic voice modes across labs. But the responsiveness is real, and the footprint is exciting for local speech streaming scenarios. I wouldn’t replace a top-tier text reasoner with this for hard problems, yet being able to keep speech native is a real UX upgrade.Qwen Image Edit, Qwen TTS Flash, and Qwen‑GuardQwen’s image stack got a handy upgrade with multi-image reference editing for more consistent edits across shots—useful for brand assets and style-tight workflows. TTS Flash (API-only for now) is their fast speech synth line, and Q‑Guard is a new safety/moderation model from the same team. It’s notable because Qwen hasn’t really played in the moderation-model space before; historically Meta’s Llama Guard led that conversation.DeepSeek V3.1 Terminus: a surgical bugfix that matters for agents (X, HF)DeepSeek whale resurfaced to push a small 0.1 update to V3.1 that reads like a “quality and stability” release—but those matter if you’re building on top. It fixes a code-switching

📆 ThursdAI - Sep 18 - Gpt-5-Codex, OAI wins ICPC, Reve, ARC-AGI SOTA Interview, Meta AI Glasses & more AI news
Hey folks, What an absolute packed week this week, which started with yet another crazy model release from OpenAI, but they didn't stop there, they also announced GPT-5 winning the ICPC coding competitions with 12/12 questions answered which is apparently really really hard! Meanwhile, Zuck took the Meta Connect 25' stage and announced a new set of Meta glasses with a display! On the open source front, we yet again got multiple tiny models doing DeepResearch and Image understanding better than much larger foundational models.Also, today I interviewed Jeremy Berman, who topped the ArcAGI with a 79.6% score and some crazy Grok 4 prompts, a new image editing experience called Reve, a new world model and a BUNCH more! So let's dive in! As always, all the releases, links and resources at the end of the article. ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.Table of Contents* Codex comes full circle with GPT-5-Codex agentic finetune* Meta Connect 25 - The new Meta Glasses with Display & a neural control interface* Jeremy Berman: Beating frontier labs to SOTA score on ARC-AGI* This Week’s Buzz: Weave inside W&B models—RL just got x-ray vision* Open Source* Perceptron Isaac 0.1 - 2B model that points better than GPT* Tongyi DeepResearch: A3B open-source web agent claims parity with OpenAI Deep Research* Reve launches a 4-in-1 AI visual platform taking on Nano 🍌 and Seedream* Ray3: Luma’s “reasoning” video model with native HDR, Draft Mode, and Hi‑Fi mastering* World models are getting closer - Worldlabs announced Marble* Google puts Gemini in ChromeCodex comes full circle with GPT-5-Codex agentic finetune (X, OpenAI Blog)My personal highlight of the week was definitely the release of GPT-5-Codex. I feel like we've come full circle here. I remember when OpenAI first launched a separate, fine-tuned model for coding called Codex, way back in the GPT-3 days. Now, they've done it again, taking their flagship GPT-5 model and creating a specialized version for agentic coding, and the results are just staggering.This isn't just a minor improvement. During their internal testing, OpenAI saw GPT-5-Codex work independently for more than seven hours at a time on large, complex tasks—iterating on its code, fixing test failures, and ultimately delivering a successful implementation. Seven hours! That's an agent that can take on a significant chunk of work while you're sleeping. It's also incredibly efficient, using 93% fewer tokens than the base GPT-5 on simpler tasks, while thinking for longer on the really difficult problems.The model is now integrated everywhere - the Codex CLI (just npm install -g codex), VS Code extension, web playground, and yes, even your iPhone. At OpenAI, Codex now reviews the vast majority of their PRs, catching hundreds of issues daily before humans even look at them. Talk about eating your own dog food!Other OpenAI updates from this weekWhile Codex was the highlight, OpenAI (and Google) also participated and obliterated one of the world’s hardest algorithmic competitions called ICPC. OpenAI used GPT-5 and an unreleased reasoning model to solve 12/12 questions in under 5 hours. OpenAI and NBER also released an incredible report on how over 700M people use GPT on a weekly basis, with a lot of insights, that are summed up in this incredible graph:Meta Connect 25 - The new Meta Glasses with Display & a neural control interfaceJust when we thought the week couldn't get any crazier, Zuck took the stage for their annual Meta Connect conference and dropped a bombshell. They announced a new generation of their Ray-Ban smart glasses that include a built-in, high-resolution display you can't see from the outside. This isn't just an incremental update; this feels like the arrival of a new category of device. We've had the computer, then the mobile phone, and now we have smart glasses with a display.The way you interact with them is just as futuristic. They come with a "neural band" worn on the wrist that reads myoelectric signals from your muscles, allowing you to control the interface silently just by moving your fingers. Zuck's live demo, where he walked from his trailer onto the stage while taking messages and playing music, was one hell of a way to introduce a product.This is how Meta plans to bring its superintelligence into the physical world. You'll wear these glasses, talk to the AI, and see the output directly in your field of view. They showed off live translation with subtitles appearing under the person you're talking to and an agentic AI that can perform research tasks and notify you when it's done. It's an absolutely mind-blowing vision for the future, and at $799, shipping in a week, it's going to be accessible to a lot of people. I've already signed up for a demo.Jeremy Berman: Beating frontier labs to SOTA score on ARC-AGIWe had the privilege of chatting with Jer

📆 ThursdAI - Sep 11 - SeeDream 4, Lucy 14B, ChatGPT gets MCP, OpenAI $300B deal with Oracle, Qwen Next A3B & more AI news
Hey Everyone, Alex here, thanks for being a subscriber! Let's get you caught up on this weeks most important AI news! The main thing you need to know this week is likely the incredible Image model that ByteDance released, that overshoots the (incredible image model from last 2 weeks) nano 🍌. ByteDance really outdid themselves on this one! But also, a video model with super fast generation, OpenAI rumor made Larry Ellison the richest man alive, ChatGPT gets MCP powers (under a flag you can enable) and much more! This week we covered a lot of visual stuff, so while the podcast format is good enough, it's really worth tuning in to the video recording to really enjoy the full show. ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.AI Art and DiffusionIt's rare for me to start the newsletter not on Open Source AI news, but hey, at least this way you know that I'm writing it and not some AI right? 😉ByteDance SeeDream 4 - 4K SOTA image generation and editing model with up to 6 reference images (Fal, Replicate)The level of detail on ByteDance's new model, has really made all the hosts on ThursdAI stop and go... huh? is this AI? Bytedance really outdid themselves with this image model that not only generates images, it also is a fully functional image editing with natural language model. It's a diffusion transformer, able to generate 2K and 4K images, fast (under 5 seconds?) while enabling up to 6 reference images to be provided for the generation. This is going to be incredible for all kinds of purposes, AI art, marketing etc'. The promt adherence is quite incredible, text is also crisp and sharp at those 2/4K resolutions. We created this image live on the show with it (using a prompt extended by another model)I then provided my black and white headshot and the above image and asked to replace me as a cartoon character, and it did, super quick, and even got my bomber jacket and the W&B logo on it in there! Notable, nothing else was changed in the image, showing just how incredible this one is for image editing. In you want enhanced realism, our friend FoFr from replicate, reminded us that using IMG_3984.CR2 in the prompt, will make the model show images that are closer to reality, even if they depict some incredibly unrealistic things, like a pack of lions forming his nicknameAdditional uses for this model are just getting discovered, and one user already noted that given this model outputs 4K resolution, it can be used as a creative upscaler for other model outputs. Just shove your photo from another AI in Seedream and ask for an upscale. Just be ware that creative upscalers change some amount of details in the generated picture. DecART AI Lucy 14B Redefines Video Generation speeds! If Seedteam blew my mind with images, Decart's Lucy 14B absolutely shattered my expectations for video generation speed. We're talking about generating 5-second videos from images in 6.5 seconds. That's almost faster than watching the video itself!This video model is not open source yet (despite them adding 14B to the name) but it's smaller 5B brother was open sourced. The speed to quality ratio is really insane here, and while Lucy will not generate or animate text or faces that well, it does produce some decent imagery, but SUPER fast. This is really great for iteration, as AI Video is like a roulette machine, you have to generate a lot of tries to see a good result. This paired with Seedream (which is also really fast) are a game changer in the AI Art world! So stoked to see what folks will be creating with these! Bonus Round: Decart's Real-Time Minecraft Mod for Oasis 2 (X)The same team behind Lucy also dropped Oasis 2.0, a Minecraft mod that generates game environments in real-time using diffusion models. I got to play around with it live, and watching Minecraft transform into different themed worlds as I moved through them was surreal.Want a steampunk village? Just type it in. Futuristic city? Done. The frame rate stayed impressively smooth, and the visual coherence as I moved through the world was remarkable. It's like having an AI art director that can completely reskin your game environment on demand. And while the current quality remains low res, if you consider where Stable Diffusion 1.4 was 3 years ago, and where Seedream 4 is now, and do the same extrapolation to Oasis, in 2-3 years we'll be reskinning whole games on the fly and every pixel will be generated (like Jensen loves to say!) OpenAI adds full MCP to ChatGPT (under a flag) This is huge, folks. I've been waiting for this for a while, and finally, OpenAI quietly added full MCP (Model Context Protocol) support to ChatGPT via a hidden "developer mode."How to Enable MCP in ChatGPTHere's the quick setup I showed during the stream:* Go to ChatGPT settings → Connectors* Scroll down to find "Developer Mode" and enable it* Add MCP servers (I us

📆 ThursdAI - Sep 4 - Codex Rises, Anthropic Raises $13B, Nous plays poker, Apple speeds up VLMs & more AI news
Wohoo, hey ya’ll, Alex here,I'm back from the desert (pic at the end) and what a great feeling it is to be back in the studio to talk about everything that happened in AI! It's been a pretty full week (or two) in AI, with Coding agent space heating up, Grok entering the ring and taking over free tokens, Codex 10xing usage and Anthropic... well, we'll get to Anthropic. Today on the show we had Roger and Bhavesh from Nous Research cover the awesome Hermes 4 release and the new PokerBots benchmark, then we had a returning favorite, Kwindla Hultman Kramer, to talk about the GA of RealTime voice from OpenAI. Plus we got some massive funding news, some drama with model quality on Claude Code, and some very exciting news right here from CoreWeave aquiring OpenPipe! 👏 So grab your beverage of choice, settle in (or skip to the part that interests you) and let's take a look at the last week (or two) in AI! ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.Open Source: Soulful Models and Poker-Playing AgentsThis week did not disappoint as it comes to Open Source! Our friends at Nous Research released the 14B version of Hermes 4, after releasing the 405B and 70B versions last week. This company continues to excel in finetuning models for powerful, and sometimes just plain weird (in a good way) usecases. Nous Hermes 4 (14B, 70B, 405B) and the Quest for a "Model Soul" (X, HF)Roger and Bhavash from Nous came to announce the release of the smaller (14B) version of Hermes 4, and cover the last weeks releases of the larger 70B and 405B brothers. Hermes series of finetunes was always on our radar, as unique data mixes turned them into uncensored, valuable and creative models and unlocked a bunch of new use-cases. But the wildest part? They told us they intentionally stopped training the model not when reasoning benchmarks plateaued, but when they felt it started to "lose its model soul." They monitor the entropy and chaos in the model's chain-of-thought, and when it became too sterile and predictable, they hit the brakes to preserve that creative spark. This focus on qualities beyond raw benchmark scores is why Hermes 4 is showing some really interesting generalization, performing exceptionally well on benchmarks like EQBench3, which tests emotional and interpersonal understanding. It's a model that's primed for RL not just in math and code, but in creative writing, role-play, and deeper, more "awaken" conversations. It’s a soulful model that's just fun to talk to.Nous Husky Hold'em Bench: Can Your LLM Win at Poker? (Bench)As if a soulful model wasn't enough, the Nous team also dropped one of the most creative new evals I've seen in a while: Husky Hold'em Bench. We had Bhavesh, one of its creators, join the show to explain. This isn't a benchmark where the LLM plays poker directly. Instead, the LLM has to write a Python poker botfrom scratch, under time and memory constraints, which then competes against bots written by other LLMs in a high-stakes tournament. Very interesting approach, and we love creative benchmarking here at ThursdAI! This is a brilliant way to test for true strategic reasoning and planning, not just pattern matching. It's an "evergreen" benchmark that gets harder as the models get better. Early results are fascinating: Claude 4 Sonnet and Opus are currently leading the pack, but Hermes 4 is the top open-source model.More Open Source GoodnessThe hits just kept on coming this week. Tencent open-sourced Hunyuan-MT-7B, a translation model that swept the WMT2025 competition and rivals GPT-4.1 on some benchmarks. Having a small, powerful, specialized model like this is huge for anyone doing large-scale data translation for training or needing fast on-device capabilities.From Switzerland, we got Apertus-8B and 70B, a set of fully open (Apache 2.0 license, open data, open training recipes!) multilingual models trained on a massive 15 trillion tokens across 1,800 languages. It’s fantastic to see this level of transparency and contribution from European institutions.And Alibaba’s Tongyi Lab released WebWatcher, a powerful multimodal research agent that can plan steps, use a suite of tools (web search, OCR, code interpreter), and is setting new state-of-the-art results on tough visual-language benchmarks, often beating models like GPT-4o and Gemini.All links are in the TL;DR at the endBREAKING NEWS: Google Drops Embedding Gemma 308M (X, HF, Try It)Just as we were live on the show, news broke from our friends at Google. They've released Embedding Gemma, a new family of open-source embedding models. This is a big deal because they are tiny—the smallest is only 300M parameters and takes just 200MB to run—but they are topping the MTEB leaderboard for models under 500M parameters. For anyone building RAG pipelines, especially for on-device or mobile-first applications, having a small, fast, SO
📆 ThursdAI - Aug 21 - DeepSeek V3.1’s hybrid upset, ByteDance’s 512K Seed-OSS, Nano Banana wizardry, Agents.md standardizes agents, and more AI
Hey everyone, Alex here 👋This week looked quiet… until about 15 hours before we went live. Then the floodgates opened: DeepSeek dropped a hybrid V3.1 that beats their own R1 with fewer thinking tokens, ByteDance quietly shipped a 36B Apache-2.0 long-context family with a “thinking budget” knob, NVIDIA pushed a faster mixed-architecture 9B with open training data, and a stealth image editor dubbed “Nano Banana” started doing mind-bending scene edits that feel like a new tier of 3D-aware control. On the big-co side, a mystery “Sonic” model appeared in Cursor and Cline (spoiler: the function call paths say a lot), and OpenAI introduced Agents.md to stop the config-file explosion in agentic dev tools. We also got a new open desktop-agent RL framework that 4x’d OSWorld SOTA, an IBM + NASA model for solar weather, and Qwen’s fully open 20B image editor that’s shockingly capable and runnable on your own GPU.Our show today was one of the shortest yet, as I had to drop early to prepare for Burning Man 🔥🕺 Speaking of which, Wolfram and the team will host the next episode! Ok, let's dive in! DeepSeek V3.1: a faster hybrid that thinks less, scores more (X, HF)DeepSeek does this thing where they let a base artifact “leak” onto Hugging Face, and the rumor mill goes into overdrive. Then, hours before we went live, the full V3.1 model card and an instruct variant dropped. The headline: it’s a hybrid reasoner that combines the strengths of their V3 (fast, non-thinking) and R1 (deep, RL-trained thinking), and on many tasks it hits R1-level scores with fewer thinking tokens. In human terms: you get similar or better quality, faster.A few things I want to call out from the release and early testing:* Hybrid reasoning mode done right. The model can plan with thinking tokens and then switch to non-thinking execution, so you don’t have to orchestrate two separate models. This alone simplifies agent frameworks: plan with thinking on, execute with thinking off.* Thinking efficiency is real. DeepSeek shows curves where V3.1 reaches or surpasses R1 with significantly fewer thinking tokens. On AIME’25, for example, R1 clocks 87.5% with ~22k thinking tokens; V3.1 hits ~88.4 with ~15k. On GPQA Diamond, V3.1 basically matches R1 with roughly half the thinking budget.* Tool-use and search-agent improvements. V3.1 puts tool calls inside the thinking process, instead of doing a monologue and only then calling tools. That’s the pattern you want for multi-turn research agents that iteratively query the web or your internal search.* Long-context training was scaled up hard. DeepSeek says they increased the 32K extension phase to ~630B tokens, and the 128K phase to ~209B tokens. That’s a big bet on long-context quality at train time, not just inference-time RoPE tricks. The config shows a max position in the 160K range, with folks consistently running it in the 128K class.* Benchmarks show the coding and terminal agent work got a big push. TerminalBench jumps from a painful 5.7 (R1) to 31 with V3.1. Codeforces ratings are up. On SweBench Verified (non-thinking), V3.1 posts 66 vs R1’s ~44. And you feel it: it’s faster to “get to it” without noodling forever.* API parity you’ll actually use. Their API now supports the Anthropic-style interface as well, which means a bunch of editor integrations “just work” with minimal glue. If you’re in a Claude-first workflow, you won’t have to rewire the world to try V3.1.* License and availability. This release is MIT-licensed, and you can grab the base model on Hugging Face. If you prefer hosted, keep an eye on our inference—we’re working to get V3.1 live so you can benchmark without burning your weekend assembling a serving stack.Hugging Face: https://huggingface.co/deepseek-ai/DeepSeek-V3.1-BaseQuick personal note: I’m seeing a lot of small, pragmatic improvements add up here. If you’re building agents, the hybrid mode plus tighter tool integration is a gift. DeepSeek V3.1 is going to be deployed to W&B Inference service soon! Take a look here to see when it's ready wandb.me/inference ByteDance Seed-OSS 36B: Apache-2.0, 512K context, and a “thinking budget” knob (X, HF, Github)I didn’t see much chatter about this one, which is a shame because this seems like a serious release. ByteDance’s Seed team open-sourced a trio of 36B dense models—two Base variants (with and without synthetic data) and an Instruct model—under Apache-2.0, trained on 12T tokens and built for long-context and agentic use. The context window is a native half-million tokens, and they include a “thinking budget” control you can set in 512-token increments so you can trade depth for speed.They report strong general performance, long-context RULER scores, and solid code/math numbers for a sub-40B model, with the Instruct variant posting very competitive MMLU/MMLU-Pro and LiveCodeBench results. The architecture is a straightforward dense stack (not MoE), and the models ship with Transformers/vLLM support and 4/8-bit quantization ready to
📆 ThursdAI - Aug 14 - A week with GPT5, OSS world models, VLMs in OSS, Tiny Gemma & more AI news
Hey everyone, Alex here 👋Last week, I tried to test GPT-5 and got really surprisingly bad results, but it turns out, as you'll see below, it's partly because they had a bug in the router, and partly because ... well, the router itself! See below for an introduction, written by GPT-5, it's actually not bad?Last week was a whirlwind. We live‑streamed GPT‑5’s “birthday,” ran long, and then promptly spent the next seven days poking every corner of the new router‑driven universe.This week looked quieter on the surface, but it actually delivered a ton: two open‑source world models you can drive in real time, a lean vision‑language model built for edge devices, a 4B local search assistant that tops Perplexity Pro on SimpleQA, a base model “extraction” from GPT‑OSS that reverses alignment, fresh memory features landing across the big labs, and a practical prompting guide to unlock GPT‑5’s reasoning reliably.We also had Alan Dao join to talk about Jan‑v1 and what it takes to train a small model that consistently finds the right answers on the open web—locally.Not bad eh? Much better than last time 👏 Ok let's dive in, a lot to talk about in this "chill" AI week (show notes at the end as always) first open source, and then GPT-5 reactions and then... world models!00:00 Introduction and Welcome00:33 Host Introductions and Health Updates01:26 Recap of Last Week's AI News01:46 Discussion on GPT-5 and Prompt Techniques03:03 World Models and Genie 303:28 Interview with Alan Dow from Jan04:59 Open Source AI Releases06:55 Big Companies and APIs10:14 New Features and Tools14:09 Liquid Vision Language Model26:18 Focusing on the Task at Hand26:18 Reinforcement Learning and Reward Functions26:35 Offline AI and Privacy27:13 Web Retrieval and API Integration30:34 Breaking News: New AI Models30:41 Google's New Model: Gemma 333:53 Meta's Dino E3: Advancements in Computer Vision38:50 Open Source Model Updates45:56 Weights & Biases: New Features and Updates51:32 GPT-5: A Week in Review55:12 Community Outcry Over AI Model Changes56:06 OpenAI's Response to User Feedback56:38 Emotional Attachment to AI Models57:52 GPT-5's Performance in Coding and Writing59:55 Challenges with GPT-5's Custom Instructions01:01:45 New Prompting Techniques for GPT-501:04:10 Evaluating GPT-5's Reasoning Capabilities01:20:01 Open Source World Models and Video Generation01:27:54 Conclusion and Future ExpectationsOpen Source AIWe've had quite a lot of Open Source this week on the show, including a breaking news from the Gemma team!Liquid AI's drops LFM2-VL (X, blog, HF)Let's kick things off with our friends at Liquid AI who released LFM2-VL - their new vision-language models coming in at a tiny 440M and 1.6B parameters.Liquid folks continue to surprise with speedy, mobile device ready models, that run 2X faster vs top VLM peers. With a native 512x512 resolution (which breaks any image size into 512 smart tiles) and an OCRBench of 74, this tiny model beats SmolVLM2 while being half the size. We've chatted with Maxime from liquid about LFM2 back in july, and it's great to see they are making them multimodal as well with the same efficiency gains!Zhipu (z.ai) unleashes GLM-4.5V - 106B VLM (X, Hugging Face)In another "previous good model that now has eyes" release, the fine folks from Zhipu continued training thier recently released (and excelled) GLM 4.5-air with a vision encoder, resulting in probably one of the top vision models in the open source!It's an MoE with only 12B active parameters (106B total) and gets SOTA across 42 public vision-language benches + has a "thinking mode" that reasons about what it sees.Given that GLM-4.5Air is really a strong model, this is de fact the best visual intelligence in the open source, able to rebuild websites from a picture for example and identify statues and locations!Jan V1 - a tiny (4B) local search assistant QwenFinetune (X, Hugging Face)This one release got a lot of attention, as the folks at Menlo Research (Alan Dao who came to chat with us about Jan on the pod today) released an Apache 2 finetune of Qwen3-4B-thinking, that's focused on SimpleQA.They showed that their tiny model is beating Perplexity Pro on SimpleQA.Alan told us on the pod that Jan (the open source Jan app) is born to be an open source alternative to searching with local models!The trick is, you have to enable some source of search data (Exa, Serper, Tavily) via MCP and then enable tools in Jan, and then.. you have a tiny, completely local perplexity clone with a 4B model!Google drops Gemma 3 270M (blog)In some #breakingNews, Google open sourced a tiny (270M) parameters, "good at instruction following" Gemma variant. This joins models like SmolLM and LFM2 in the "smol models" arena, being only 300MB, you can run this.. on a toaster. This one apparently also fine-tunes very well while being very energy efficient!Big Companies (AKA OpenAI corner this past 2 weeks)Ok ok, we're finally here, a week with GPT-5! After watching the live stream and getting
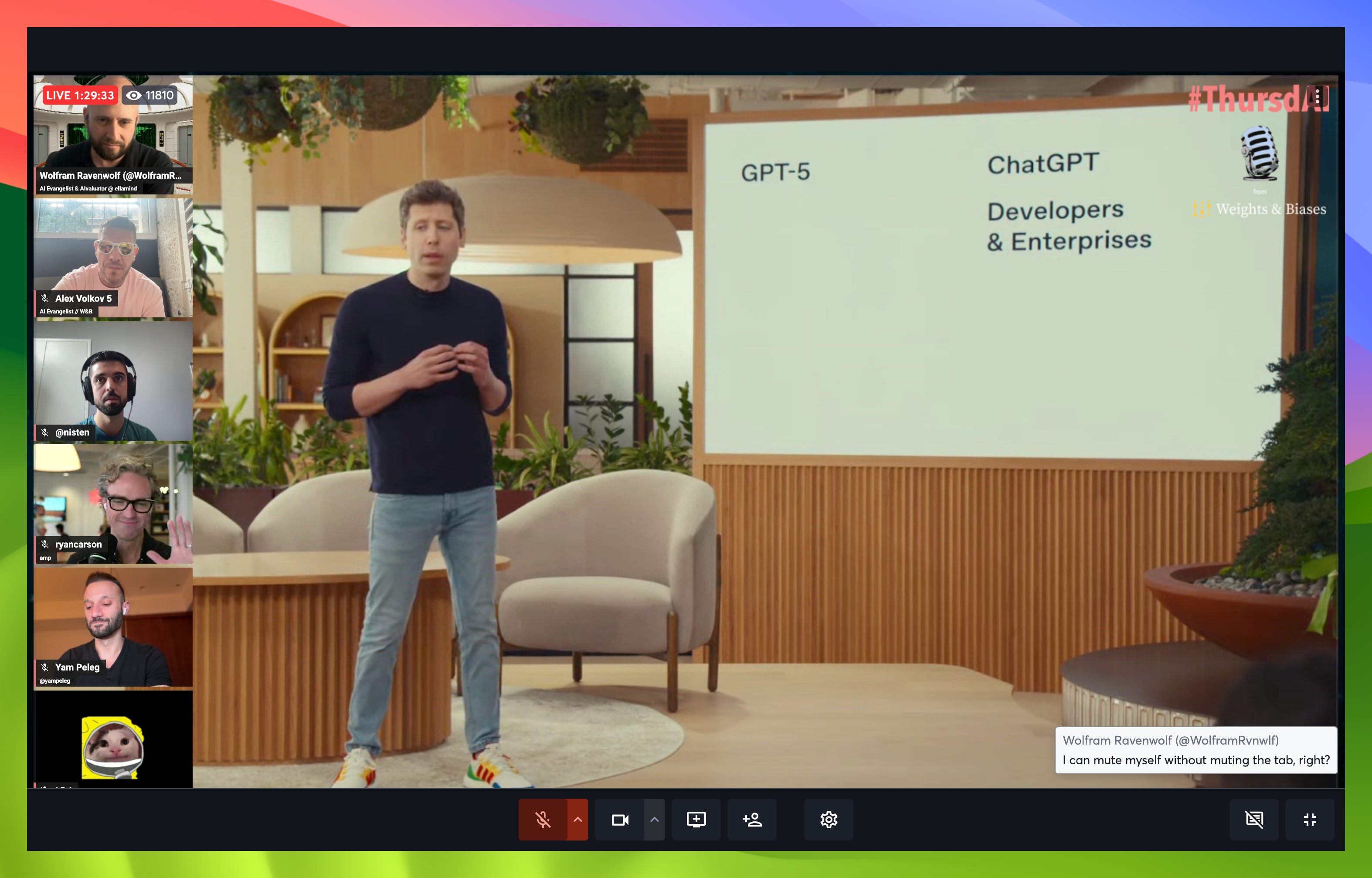
📅 ThursdAI - GPT5 is here
Hey folks 👋 Alex here, writing to you, from a makeshift recording studio in an Eastern European hookah bar, where I spent the last 7 hours. Why you ask? Well, when GPT-5 drops, the same week as OpenAI dropping the long awaited OSS models + Google is shipping perfect memory World Models (Genie 3) and tons of other AI drops, well I just couldn't stay away from the stream.Vacation or not, ThursdAI is keeping you up to date (for 32 months straight, which is also the time since the original GPT-4 release which gave this show its name!)So, what did we have today on the stream? Well, we started as usual, talking about the AI releases of the week, as if OpenAI dropping OSS models (apache 2) 120B and 20B is "usual". We then covered incredible releases like Google's World model Genie3 (more on this next week!) and Qwen-image + a few small Qwens.We then were VERY excited to tune in, and watch the (very long) announcement stream from OpenAI, in which they spent an hour to tell us about GPT-5.This was our longest stream by far (3.5 hours, 1hr was just OpenAI live stream) and I'm putting this here mostly unedited, but chapters are up so feel free to skip to the parts that are interesting to you the most.00:00 Introduction and Special Guests00:56 Twitter Space and Live Streaming Plans02:12 Open Source AI Models Overview03:44 Qwen and Other New AI Models08:59 Community Interaction and Comments10:01 Technical Deep Dive into AI Models25:06 OpenAI's New Releases and Benchmarks38:49 Expectations and Use Cases for AI Models40:03 Tool Use vs. Deep Knowledge in AI41:02 Evaluating GPT OSS and OpenAI Critique42:29 Historical and Medical Knowledge in AI51:16 Opus 4.1 and Coding Models55:38 Google's Genie 3: A New World Model01:00:43 Kitten TTS: A Lightweight Text-to-Speech Model01:02:07 11 Labs' Music Generation AI01:08:51 OpenAI's GPT-5 Launch Event01:24:33 Building a French Learning Web App01:26:22 Exploring the Web App Features01:29:19 Introducing Enhanced Voice Features01:30:02 Voice Model Demonstrations01:32:32 Personalizing Chat GPT01:33:23 Memory and Scheduling Features01:35:06 Safety and Training Enhancements01:39:17 Health Applications of GPT-501:45:07 Coding with GPT-501:46:57 Advanced Coding Capabilities01:52:59 Real-World Coding Demonstrations02:10:26 Enterprise Applications of GPT-502:11:49 Amgen's Use of GPT-5 in Drug Design02:12:09 BBVA's Financial Analysis with GPT-502:12:33 Healthcare Applications of GPT-502:12:52 Government Adoption of GPT-502:13:22 Pricing and Availability of GPT-502:13:51 Closing Remarks by Chief Scientist Yakob02:16:03 Live Reactions and Discussions02:16:41 Technical Demonstrations and Comparisons02:33:53 Healthcare and Scientific Advancements with GPT-502:47:09 Final Thoughts and Wrap-Up---My first reactions to GPT-5Look, I gotta keep it real with you, my first gut reaction was, hey, I'm on vacation, I don't have time to edit and write the newsletter (EU timezone) so let's see how ChatGPT-5 handles this task. After all, OpenAI has removed all other models from the dropdown, it's all GPT-5 now. (pricing from the incredible writeup by Simon Willison available here)And to tell you the truth, I was really disappointed! GPT seems to be incredible at coding benchmarks, with 400K tokens and incredible pricing (just $1.25/$10 compared to Opus $15/$75) this model, per the many friends who got to test it early, is a beast at coding! Readily beating opus on affordability per token, switching from thinking to less thinking when it needs to, it definitely seems like a great improvement for coding and agentic tasks.But for my, very much honed prompt of "hey, help me with ThursdAI drafts, here's previous drafts that I wrote myself, mimic my tone" it failed.. spectacularly!Here's just a funny example, after me replying that it did a bad job:It literally wrote "I'm Alex, I build the mind, not the vibe" 🤦♂️ What.. the actual...For comparison, here's o3, with the same prompt, with a fairly true to tone draft:High taste testers take on GPT-5But hey, I have tons of previous speakers in our group chats, and many of them who got early access (I didn't... OpenAI, I can be trusted lol) rave about this model. They are saying that this is a huge jump in intelligence.Folks like Dr Derya Unutmaz, who jumped on the live show and described how GPT5 does incredible things with less hallucinations, folks like Swyx from Latent.Space who had early access and even got invited to give first reactions to the OpenAI office, and Pietro Schirano who also showed up in an OpenAI video.So definitely, definitely check out their vibes, as we all try to wrap our heads around this new intelligence king we got!Other GPT5 updatesOpenAI definitely cooked, don't get me wrong, with this model plugging into everything else in their platform like memory, voice (that was upgraded and works in custom GPTs now, yay!), canvas and study mode, this will definitely be an upgrade for many folks using the models.They have now also opened access to GPT-5
📆 ThursdAI – Jul 31, 2025 – Qwen’s Small Models Go Big, StepFun’s Multimodal Leap, GLM-4.5’s Chart Crimes, and Runway’s Mind‑Bending Video Edits + GPT-5 soon?
This is a free preview of a paid episode. To hear more, visit sub.thursdai.newsWoohoo, we're almost done with July (my favorite month) and the Open Source AI decided to go out with some fireworks 🎉Hey everyone, Alex here, writing this without my own personal superintelligence (more: later) and this week has been VERY BUSY with many new open source releases.Just 1 hour before the show we already had 4 breaking news releases, a tiny Qwen3-coder, Cohere and StepFun both dropped multimodal SOTAs and our friends from Krea dropped a combined model with BFL called Flux[Krea] 👏 This is on top of a very very busy week, with Runway adding conversation to their video model Alpha, Zucks' superintelligence vision and a new SOTA open video model Wan 2.2. So let's dive straight into this (as always, all show notes and links are in the end) ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.Open Source LLMs & VLMs Tons of new stuff here, I'll try to be brief but each one of these releases deserves a deeper dive for sure. Alibaba is on 🔥 with 3 new Qwen models this weekYes, this is very similar to last week, where they have also dropped 3 new SOTA models in a week, but, these are additional ones. It seems that someone in Alibaba figured out that after splitting away from the hybrid models, they can now release each model separately and get a lot of attention per model! Here's the timeline: * Friday (just after our show): Qwen3-235B-Thinking-2507 drops (235B total, 22B active, HF) * Tuesday: Qwen3-30B-Thinking-2507 (30B total, 3B active, HF)* Today: Qwen3-Coder-Flash-2507 lands (30B total, 3B active for coding, HF)Lets start with the SOTA reasoner, the 235B(A22B)-2507 is absolutely the best reasoner among the open source models.We've put the model on our inference service (at crazy prices $.10/$.10) and it's performing absolutely incredible on reasoning tasks. It also jumped to the top OSS model on Artificial Analysis scores, EQBench, Long Context and more evals. It a really really good reasoning model! Smaller Qwens for local useJust a week ago, we've asked Junyang on our show, about smaller models that folks can run on their devices, and he avoided by saying "we're focusing on the larger models" and this week, they delivered not 1 but 2 smaller versions of the bigger models (perfect for Speculative Decoding if you can host the larger ones that is) The most interesting one is the Qwen3-Coder-flash, which came out today, with very very impressive stats - and the ability to run locally with almost 80 tok/s on a macbook! So for the last two weeks, we now have 3 Qwens (Instruct, Thinking, Coder) and 2 sizes for each (all three have a 30B/A3B version now for local use) 👏Z.ai GLM and StepFun Step3 As we've said previously, Chinese companies completely dominate the open source AI field right now, and this week as saw yet another crazy testament to how stark the difference is! We've seen a rebranded Zhipu (Z.ai previously THUDM) release their new GLM 4.5 - which gives Qwen3-thinking a run for it's money. Not quite at that level, but definitely very close. I personally didn't love the release esthetics, showing a blended eval score, which nobody can replicate feels a bit off. We also talked about how StepFun has stepped in (sorry for the pun) with a new SOTA in multimodality, called Step3. It's a 321B MoE (with a huge 38B active param count) that achieves very significant multi modal scores (The benchmarks look incredible: 74% on MMMU, 64% on MathVision) Big Companies APIs & LLMsWell, we were definitely thinking we'll get GPT-5 or the Open Source AI model from OpenAI this week, but alas, the tea leaves readers were misled (or were being misleading). We 100% know that gpt-5 is coming as multiple screenshots were blurred and then deleted showing companies already testing it. But it looks like August is going to be even hotter than July, with multiple sightings of anonymous testing models on Web Dev arena, like Zenith, Summit, Lobster and a new mystery model on OpenRouter called Zenith - that some claim are the different thinking modes of GPT-5 and the open source model? Zuck shares vision for personalized superintelligence (Meta)In a very "Nat Fridman" like post, Mark Zuckerberg finally shared the vision behind his latest push to assemble the most cracked AI engineers.In his vision, Meta is the right place to provide each one with personalized superintelligence, enhancing individual abilities with user agency according to their own values. (as opposed to a centralized model, which feels like his shot across the bow for the other frontier labs) A few highlights: Zuck leans heavily into the rise of personal devices on top of which humans will interact with this superintelligence, including AR glasses and a departure from a complete "let's open source everything" dogman of the past, now there will be a more

📆 ThursdAI - July 24, 2025 - Qwen-mas in July, The White House's AI Action Plan & Math Olympiad Gold for AIs + coding a 3d tetris on stream
What a WEEK! Qwen-mass in July. Folks, AI doesn't seem to be wanting to slow down, especially Open Source! This week we see yet another jump on SWE-bench verified (3rd week in a row?) this time from our friends at Alibaba Qwen. Was a pleasure of mine to host Junyang Lin from the team at Alibaba to come and chat with us about their incredible release with, with not 1 but three new models! Then, we had a great chat with Joseph Nelson from Roboflow, who not only dropped additional SOTA models, but was also in Washington at the annocement of the new AI Action plan from the WhiteHouse. Great conversations this week, as always, TL;DR in the end, tune in! Open Source AI - QwenMass in JulyThis week, the open-source world belonged to our friends at Alibaba Qwen. They didn't just release one model; they went on an absolute tear, dropping bomb after bomb on the community and resetting the state-of-the-art multiple times.A "Small" Update with Massive Impact: Qwen3-235B-A22B-Instruct-2507Alibaba called this a minor refresh of their 235B parameter mixture-of-experts.Sure—if you consider +13 points on GPQA, 256K context window minor. The 2507 drops hybrid thinking. Instead, Qwen now ships separate instruct and chain-of-thought models, avoiding token bloat when you just want a quick answer. Benchmarks? 81 % MMLU-Redux, 70 % LiveCodeBench, new SOTA on BFCL function-calling. All with 22 B active params.Our friend of the pod, and head of development at Alibaba Qwen, Junyang Lin, join the pod, and talked to us about their decision to uncouple this model from the hybrid reasoner Qwen3."After talking with the community and thinking it through," he said, "we decided to stop using hybrid thinking mode. Instead, we'll train instruct and thinking models separately so we can get the best quality possible."The community felt the hybrid model sometimes had conflicts and didn't always perform at its best. So, Qwen delivered a pure non-reasoning instruct model, and the results are staggering. Even without explicit reasoning, it's crushing benchmarks. Wolfram tested it on his MMLU-Pro benchmark and it got the top score of all open-weights models he's ever tested. Nisten saw the same thing on medical benchmarks, where it scored the highest on MedMCQA. This thing is a beast, getting a massive 77.5 on GPQA (up from 62.9) and 51.8 on LiveCodeBench (up from 32). This is a huge leap forward, and it proves that a powerful, well-trained instruct model can still push the boundaries of reasoning. The New (open) King of Code: Qwen3-Coder-480B (X, Try It, HF)Just as we were catching our breath, they dropped the main event: Qwen3-Coder. This is a 480-billion-parameter coding-specific behemoth (35B active) trained on a staggering 7.5 trillion tokens, with a 70% code ratio, that gets a new SOTA on SWE-bench verified with 69.6% (just a week after Kimi got SOTA with 65% and 2 weeks after Devstral's SOTA of 53% 😮) To get this model to SOTA, Junyang explained they used reinforcement learning with over 20,000 parallel sandbox environments. This allows the model to interact with the environment, write code, see the output, get the reward, and learn from it in a continuous loop. The results speak for themselves.With long context abilities 256K with up to 1M extended with YaRN, this coding beast tops the charts, and is achieving Sonnet level performance for significantly less cost! Both models supported day-1 on W&B Inference (X, Get Started)I'm very very proud to announce that both these incredible models get Day-1 support on our W&B inference (and that yours truly is now part of the decision of which models we host!) With unbeatable prices ($0.10/$0.10 input/output 1M for A22B, $1/$1.5 for Qwen3 Coder) and speed, we are hosting these models at full precision to give you the maximum possible intelligence and the best bang for your buck! Nisten has setup our (OpenAI compatible) endpoint with his Cline coding assistant and has built a 3D Tetris game live on the show, and it absolutely went flying. This demo perfectly captures the convergence of everything we're excited about: a state-of-the-art open-source model, running on a blazing-fast inference service, integrated into a powerful open-source tool, creating something complex and interactive in seconds.If you want to try this yourself, we're giving away credits for W&B Inference. Just find our announcement tweet for the Qwen models on the @weights_biases X account and reply with "coding capybara" (a nod to Qwen's old mascot!). Add "ThursdAI" and I'll personally make sure you get bumped up the list!ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.Big Companies & APIsAmerica’s AI Action Plan: A New Space Race for AI Dominance (ai.gov)Switching gears to policy, I’m was excited to cover the White House’s newly unveiled “America’s AI Action Plan.” This 25-page strategy, dropped this we

📆 ThursdAI - July 17th - Kimi K2 👑, OpenAI Agents, Grok Waifus, Amazon Kiro, W&B Inference & more AI news!
Hey everyone, Alex here 👋 and WHAT a week to turn a year older! Not only did I get to celebrate my birthday with 30,000+ of you live during the OpenAI stream, but we also witnessed what might be the biggest open-source AI release since DeepSeek dropped. Buckle up, because we're diving into a trillion-parameter behemoth, agentic capabilities that'll make your head spin, and somehow Elon Musk decided Grok waifus are the solution to... something.This was one of those weeks where I kept checking if I was dreaming. Remember when DeepSeek dropped and we all lost our minds? Well, buckle up because Moonshot's Kimi K2 just made that look like a warm-up act. And that's not even the wildest part of this week! As always, all the show notes and links are at the bottom, here's our liveshow (which included the full OAI ChatGPT agents watch party) - Let's get into it! ThursdAI - Recaps of the most high signal AI weekly spaces is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.🚀 Open Source LLMs: The Kimi K2 RevolutionThe New Open Source King Has ArrivedFolks, I need you to understand something - just a little after we finished streaming last week celebrating Grok 4, a company called Moonshot decided to casually drop what might be the most significant open source release since... well, maybe ever?Kimi K2 is a 1 trillion parameter model. Yes, you read that right - TRILLION. Not billion. And before you ask "but can my GPU run it?" - this is an MOE (Mixture of Experts) with only 32B active parameters, which means it's actually usable while being absolutely massive.Let me give you the numbers that made my jaw drop:* 65.8% on SWE-bench Verified - This non-reasoning model beats Claude Sonnet (and almost everything else)* 384 experts in the mixture (the scale here is bonkers)* 128K context window standard, with rumors of 2M+ capability* Trained on 15.5 trillion tokens with the new Muon optimizerThe main thing about the SWE-bench score is not even just the incredible performance, it's the performance without thinking/reasoning + price! The Muon MagicHere's where it gets really interesting for the ML nerds among us. These folks didn't use AdamW - they used a new optimizer called Muon (with their own Muon Clip variant). Why does this matter? They trained to 15.5 trillion tokens with ZERO loss spikes. That beautiful loss curve had everyone in our community slack channels going absolutely wild. As Yam explained during the show, claiming you have a better optimizer than AdamW is like saying you've cured cancer - everyone says it, nobody delivers. Well, Moonshot just delivered at 1 trillion parameter scale.Why This Changes EverythingThis isn't just another model release. This is "Sonnet at home" if you have the hardware. But more importantly:* Modified MIT license (actually open!)* 5x cheaper than proprietary alternatives* Base model released (the first time we get a base model this powerful)* Already has Anthropic-compatible API (they knew what they were doing)The vibes are OFF THE CHARTS. Every high-taste model tester I know is saying this is the best open source model they've ever used. It doesn't have that "open source smell" - it feels like a frontier model because it IS a frontier model.Not only a math geniusImportantly, this model is great at multiple things, as folks called out it's personality or writing style specifically! Our Friend Sam Paech, creator of EQBench, has noted that this is maybe the first time an open source model writes this well, and is in fact SOTA on his Creative Writing benchmark and EQBench! Quick ShoutoutsBefore we dive deeper, huge props to:* Teknium for dropping the Hermes 3 dataset (nearly 1M high-quality entries!) (X)* LG (yes, the fridge company) for EXAONE 4.0 - their 32B model getting 81.8% on MMLU Pro is no joke (X)🎉 This Week's Buzz: W&B Inference Goes Live with Kimi-K2! (X)Ok, but what if you want to try Kimi-K2 but don't have the ability to run 1T models willy nilly? Well, Folks, I've been waiting TWO AND A HALF YEARS to say this: We're no longer GPU poor!Weights & Biases + CoreWeave = Your new inference playground. We launched Kimi K2 on our infrastructure within 3 days of release! Sitting behind the scenes on this launch was surreal - as I've been covering all the other inference service launches, I knew exactly what we all want, fast inference, full non-quantized weights, OpenAI API compatibility, great playground to test it out, function calling and tool use. And we've gotten almost all of these, while the super cracked CoreWeave and W&B Weave teams worked their ass off over the weekend to get this shipped in just a few days! And here’s the kicker: I’m giving away $50 in inference credits to 20 of you to try Kimi K2 on our platform. Just reply “K2-Koolaid-ThursdAI” to our X launch post here and we'll pick up to 20 winners with $50 worth of credits! 🫡It’s live now at api.inference.wandb.ai/v1 (model ID: moonshotai/Kimi-K