
Interconnects
156 episodes — Page 1 of 4
GLM-5.2 is the step change for open agents
Banning Open Source AI Would Be A Mistake
State of the blog, mid-2026
Frontier post-training recipe review with Finbarr Timbers
Claude Fable 5 and new AI safety fables
Farewell Ai2
Open and closed models are on different exponentials
Some ideas for what comes next, May 2026
Notes from inside China's AI labs
The distillation panic
My bets on open models, mid-2026

The inevitable need for an open model consortium
Recently, I was talking with Percy Liang, Stanford professor and lead of the Marin project (another fully-open model lab), and it set in on me that there will eventually be a consortium of companies funding a foundational set of open models used across industry. It’s not clear when this’ll emerge, and Nemotron (Coalition) is Nvidia’s attempt to bankroll and bootstrap this approach within a single wealthy company, but a consortium is the only long-term stable path to well-funded, near-frontier open models.In recent months, we’ve seen a lot of turnover in open model labs, with high-profile departures at Qwen and Ai2 (my comment). This shouldn’t be super surprising to followers of the ecosystem — it’s happened before with Meta shifting its focus away from Llama, and it’ll only happen more as the cost of trying to keep pace at the frontier of AI only increases. The other leading labs with models available today include Chinese startups such as Moonshot AI, MiniMax, and Z.ai — all of which look precarious on their ability to fund continued growth in the cost of training or R&D. Releasing one’s strongest models openly today is in active tension with the option of spending focus and resources on AI products that can currently generate meaningful revenue (and profits).We’re going to see business models emerge around releasing some, or even many, models openly, but these will largely be smaller models that enable a long-tail of functionality, rather than models at the absolute frontier. This class of companies that’ll release many, strong fine-tunable models will include the likes of Arcee AI, Thinking Machines, OpenAI, Google with Gemma, and more in that class. The cost and relative advantage of keeping the best models closed in a business environment with many opportunities for revenue are too high. To summarize — there will be an ever increasing number of companies releasing models that are good for creating a lively niche of smaller, custom models, but an ever decreasing number of companies willing to release fully open, near-frontier models. This is the core thesis of why I’m pushing hard for more people to do more research on how these smaller models can complement the best closed agents, the science of finetunability, etc. See my post below — it’s about creating a sustainable open model ecosystem, whether or not the frontier of open keeps paced with closed:It’ll take years for this equilibrium to become more obvious, seen through the lens of more open model families coming and going. This year, it seems likely we’ll see Nvidia’s Nemotron reach new heights, Reflection AI challenge some of the Chinese models with a strong, large MoE, maybe Meta releases a new open-weight model, and so on. True pressure to change strategy will only come when the capital environment punishes the less efficient spend on resources (e.g. giving away your competitive advantage, in having an in-house model). This pressure will likely hit Chinese startups training these models first. All of Moonshot AI, MiniMax, and Zhipu AI will show signs of financial challenge in the coming years if they retain their strategy, on top of their models falling further behind the best open models in terms of generality. This is inevitable pressure to evolve open models to areas that are profitable and complementary of the frontier of AI.Nvidia, which is best positioned to support the open ecosystem in the near term to support its core GPU business, could face many pressures to pull back its open model efforts. It could:* Realize it’s too competitive to their biggest customers as they succeed too much with Nemotron, * Fall to competition on their core business and lose the free cash flow buffer needed to fund this (e.g. it’s 2031 and OpenAI, Anthropic, Google, and the other frontier labs are worth so much they build their own chips). * Start succeeding beyond their initial goals and keep the chips for them to build ASI themselves, as a closed-weight model. The pressures for new funding mechanisms for open models are based on the assumptions of continued, substantive progress on the capabilities of frontier models. Mechanisms such as self-improvement and scaling all stages of the training pipeline are underway. This progress of capabilities will only increase the potential profit in selling models as and in products, not giving them away. The scale of investment required has already begun to push away non-profits from the game of making truly frontier-scale models. Capitalism is designed to make companies ruthless and chase down leads on profitability, not donate technology as charity.As the economic environment shifts companies away from releasing the strongest models openly, more companies that rely on these models will look for an outlet of securing model access into the future. This is going to be compounded by a growing group of companies who come to rely on open-weight models for their workflows. These points loop back into how model training is get

Claude Mythos and misguided open-weight fearmongering
With the announcement of the Claude Mythos model this week and the admittedly very strong stated abilities, especially in cybersecurity, a new wave of anti open-weight AI model narratives surged. The TL;DR of the argument is that our digital infrastructure will not be ready in time for an open-weight version of this model, which will allow attacks to be conducted by numerous parties.The backlash against open models in the wake of the Mythos news conflates too many general unknowns into a simple, broad policy recommendation that could actually further weaken cybersecurity readiness.We’ve been here before – open-weight models were discussed as being extremely dangerous when OpenAI withheld GPT-2 weights in 2019, and when OpenAI released GPT-4 in 2023. Both of these waves came and went. The core mistake that is being made is the composition of two issues: 1) the acceptance of the open-closed model gap being static in time and 2) linking open-weight viability generally to specific issues.I’ve written at length recently on how I think that the best, frontier-level open weight models are going to fall behind the best closed models in overall capabilities in the near future. I’ve also written about how the open-weight ecosystem needs to adapt to accept this reality. This is one of the times for the AI industry where I will repeat that it’s a total blessing to have the 6-18 month delay from when a certain capability is available within a closed lab to it being reproduced in the open. It’s a good balance of safety and monitoring the frontier of AI systems while allowing a useful open-source ecosystem to exist and thrive.The core argument I’ve focused on in the open-closed model time gap has been in general capabilities – i.e. for general purpose, frontier models such as Claude Opus 4.X or GPT Thinking 5.X. The abilities of these closed models to robustly solve and work in diverse situations as agents remains out of scope of the best open-weight models. What the open-weight models have tended to be better at is quickly keeping pace on key benchmarks (which admittedly is helped to some extent, but not necessarily substantially by distillation). This discussion is entirely different, it has to do with if open weight models can keep pace on the specific skills related to cybersecurity, and when we could expect an open version of this model to be available to the world.The case of a Claude Mythos level open weight model is admittedly more nuanced to me than the previous few anti-open weight narratives the community has experienced. Where GPT-4 was about a more hypothetical risk, especially in areas like bio-risk, the clear and present reality of cyber infrastructure being prone to attack is far more tangible. Still, much of this nuance in the moment comes down to not knowing the full details of what the system can actually do (i.e. Mythos), and the state of the environment it would act in (i.e. our digital infrastructure).To properly assess this risk, we need to know what it takes to build and deploy a Claude Mythos scale model. This entails three pieces: 1) training and releasing the weights, 2) the harness that gives the model effective tools it knows how to use, and 3) the inference compute and software.(Below I make some model size & price estimates to show my thinking, these should not be taken as ground truth.)Current estimates put the size ranges of leading models like Claude Opus 4.6 or GPT 5.4 as being around 3-5T parameters. Currently, the largest open-source models, which have been coming from Chinese labs, are around 1T parameters. Claude Mythos’s preview pricing is 5X Opus, which could come from a simple multiplicative increase in active parameters (with the same serving system design), far higher inference-time scaling, more complex harnesses that make inference less efficient, lower utilization expectations, and so on. The simplest guess is that it’s a mix of all of the above, something like 2X bigger in parameters and much less efficient to serve. That’s a huge model, likely something similar to GPT 4.5, but actually post-trained well (GPT 4.5 was ahead of its time, infra-wise).With size comes the challenge actually training the model, as bigger models always come with new technical problems that must be solved to unlock the capabilities. For the case of cybersecurity, my guess is that most of the capabilities can be learned by training a model to be superhuman on coding. Unlike some capabilities such as knowledge work, medicine, law, etc., coding can be studied and improved substantially with public data like GitHub. I’m far more optimistic in open-weight models staying fairly close to the frontier in narrow domains of code execution and processing, but I don’t understand the full scope of skills needed to be superhuman in cybersecurity understanding. How much expert knowledge and special sauce went into training Claude Mythos? That’s a substantial source of my error bars on the impact.Second, we know no

Gemma 4 and what makes an open model succeed
Having written a lot of model release blog posts, there’s something much harder about reviewing open models when they drop relative to closed models, especially in 2026. In recent years, there were so few open models, so when Llama 3 was released most people were still doing research on Llama 2 and super happy to get an update. When Qwen 3 was released, the Llama 4 fiasco had just gone down, and a whole research community was emerging to study RL on Qwen 2.5 — it was a no brainer to upgrade. Today, when an open model releases, it’s competing with Qwen 3.5, Kimi K2.5, GLM 5, MiniMax M2.5, GPT-OSS, Arcee Large, Nemotron 3, Olmo 3, and others. The space is populated, but still feels full of hidden opportunity. The potential of open models feels like a dark matter, a potential we know is huge, but few clear recipes and examples for how to unlock it are out there. Agentic AI, OpenClaw, and everything brewing in that space is going to spur mass experimentation in open models to complement the likes of Claude and Codex, not replace them.Especially with open models, the benchmarks at release are an extremely incomplete story. In some ways this is exciting, as new open models have a much higher variance and ability to surprise, but it also points at some structural reasons that make building businesses and great AI experiences around open models harder than the closed alternatives. When a new Claude Opus or GPT drops, spending a few hours with them in my agentic workflows is genuinely a good vibe test. For open models, putting them through this test is a category error.Something else to be said about open models in the era of agents is that they get out of the debate of integration, harnesses, and tools and let us see close to the ground on what exactly is the ability of just a model. Of course, we can’t test some things like search abilities without some tool, but being able to measure exactly the pace of progress of the model alone is a welcome simplification to a systematically opaque AI space.The list of factors I’d use to assess a new open-weight model I’m considering investing in includes:* Model performance (and size) — how this model performs on benchmarks I care about and how it compares to other models of a similar size.* Country of origin — some businesses care deeply about provenance, and if a model was built in China or not.* Model license — if a model needs legal approval for use, uptake will be slower at mid-sized and large companies.* Tooling at release — many models release with half-broken, or at least substantially slower, implementations in popular software like vLLM, Transformers, SGLANG, etc due to pushing the envelope of architectures or tools.* Model fine-tunability — how easy or hard it is to modify the given model to your use-case when you actually try and use it.The core problem is that some of these are immediately available at release, e.g. general performance, license, origin, etc. but others such as tooling take day(s) to week(s) to stabilize, and others are open research questions — with no group systematically monitoring fine-tunability. In the early era of open models, the days of Llama 2 or 3 and Qwen pre v3.5, the architectures were fairly simple and the models tended to work out of the box. Some of this was due to the extremely hard work of the Llama, Qwen, Mistral, etc. developer teams. Some is due to the new models being genuinely harder to work with. When it comes to something like Qwen 3.5 or Nemotron 3, with hybrid models (either gated delta net or mamba layers), the tooling is very rough at release. Things you would expect to “just work” often don’t.I’ve been following this area closely since we released Olmo Hybrid with a similar architecture, and Qwen 3.5 is just starting to work well in the various open-source tools that need to all play nice together for RL research. That’s 1.5 months after the release date! This is just to start really investing more into understanding the behavior of the models. Of course, others started working on these models sooner by investing more engineering resources or relying on partially closed software. The fully open and distributed ecosystem takes a long time to get going on some new models.All of this is lead-in for the most important question for open models — how easy is it to adapt to specific use-cases? This is a different problem for different model sizes. Large MoE open-weight models may be used by entities like Cursor who need complex capabilities in their domain, e.g. Composer 2 trained on Kimi K2.5. Other applications can be built on much smaller models, such as Chroma’s Context-1 model for agentic search, built on GPT-OSS 20B. The question of “which models are fine-tunable” is largely background knowledge known by engineers across the industry. There should be a thriving research area here to support the open ecosystem model. The first step is to understand characteristics of different base and post-trained models to understand

Lossy self-improvement
Fast takeoff, the singularity, and recursive self-improvement (RSI) are all top of mind in AI circles these days. There are elements of truth to them in what’s happening in the AI industry. Two, maybe three, labs are consolidating as an oligopoly with access to the best AI models (and the resources to build the next ones). The AI tools of today are abruptly transforming engineering and research jobs.AI research is becoming much easier in many ways. The technical problems that need to be solved to scale training large language models even further are formidable. Super-human coding assistants making these approachable is breaking a lot of former claims of what building these things entailed. Together this is setting us up for a year (or more) of rapid progress at the cutting edge of AI.We’re also at a time where language models are already extremely good. They’re in fact good enough for plenty of extremely valuable knowledge-work tasks. Language models taking another big step is hard to imagine — it’s unclear which tasks they’re going to master this year outside of code and CLI-based computer-use. There will be some new ones! These capabilities unlock new styles of working that’ll send more ripples through the economy.These dramatic changes almost make it seem like a foregone conclusion that language models can then just keep accelerating progress on their own. The popular language for this is a recursive self-improvement loop. Early writing on the topic dates back to the 2000s, such as the blog post entirely on the topic from 2008: Recursion is the sort of thing that happens when you hand the AI the object-level problem of “redesign your own cognitive algorithms”.And slightly earlier, in 2007, Yudkowsky also defined the related idea of a Seed AI in Levels of Organization in General Intelligence:A seed AI is an AI designed for self-understanding, self-modification, and recursive self-improvement. This has implications both for the functional architectures needed to achieve primitive intelligence, and for the later development of the AI if and when its holonic self-understanding begins to improve. Seed AI is not a workaround that avoids the challenge of general intelligence by bootstrapping from an unintelligent core; seed AI only begins to yield benefits once there is some degree of available intelligence to be utilized. The later consequences of seed AI (such as true recursive self-improvement) only show up after the AI has achieved significant holonic understanding and general intelligence.It’s reasonable to think we’re at the start here, with how general and useful today’s models are.Generally, RSI can be summarized as when AI can improve itself, the improved version can improve even more efficiently, creating a closed amplification loop that leads to an intelligence explosion, often referred to as the singularity. There are a few assumptions in this. For RSI to occur, it needs to be that:* The loop is closed. Models can keep improving on themselves and beget more models.* The loop is self-amplifying. The next models will yield even bigger improvements than the current ones.* The loop continues to run without losing efficiency. There are not added pieces of friction that make the exponential knee-capped as an early sigmoid.While I agree that momentous, socially destabilizing changes are coming in the next few years from sustained AI improvements, I expect the trend line of progress to be more linear than exponential when we reflect back. Instead of recursive self-improvement, it will be lossy self-improvement (LSI) – the models become core to the development loop but friction breaks down all the core assumptions of RSI. The more compute and agents you throw at a problem, the more loss and repetition shows up.Interconnects AI is a reader-supported publication. Consider becoming a subscriber.I’m still a believer that the complexity brake on advanced systems will be a strong counterbalance to the reality that AI models are getting substantially better at every narrow task we need to compose together in making a leading AI model. I quoted this previously in April of 2025 in response to AI 2027.Microsoft co-founder Paul Allen argued the opposite of accelerating returns, the complexity brake: the more progress science makes towards understanding intelligence, the more difficult it becomes to make additional progress. A study of the number of patents shows that human creativity does not show accelerating returns, but in fact, as suggested by Joseph Tainter in his The Collapse of Complex Societies, a law of diminishing returns. The number of patents per thousand peaked in the period from 1850 to 1900, and has been declining since. The growth of complexity eventually becomes self-limiting, and leads to a widespread “general systems collapse”.There are plenty of examples in how models are already trained, the deep intuitions we need to get them right, and the organizations that build them that show where the losses
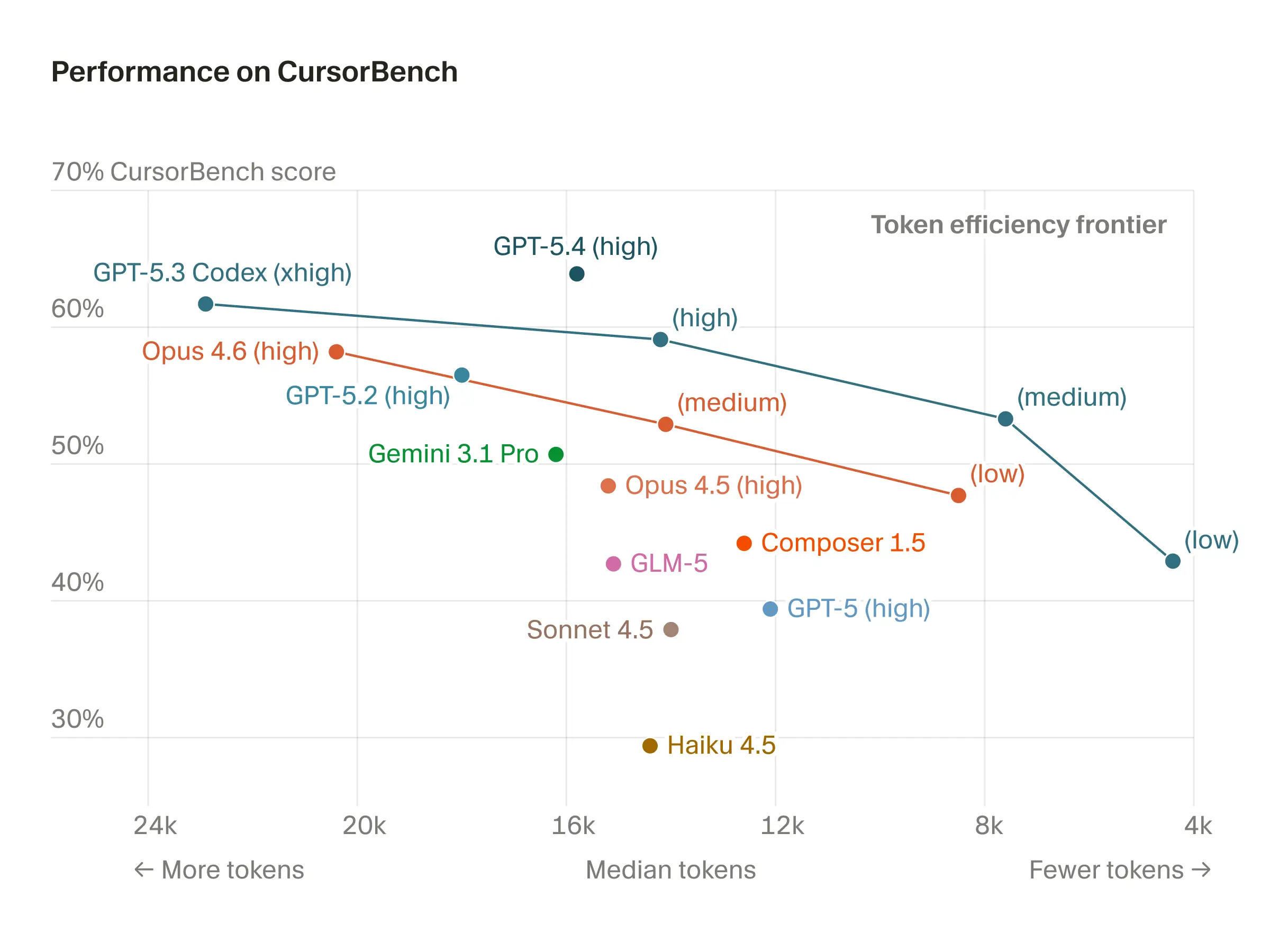
GPT 5.4 is a big step for Codex
I’m a little late to this model review, but that has given me more time to think about the axes that matter for agents. Traditional benchmarks reduce model performance to a single score of correctness – they always have because that was simple, easy to quickly use to gauge performance, and so on. This is also advice that I give to people trying to build great benchmarks – it needs to reduce to one number that is interpretable. This is likely still going to be true in a year or two, and benchmarks for agents will be better, but for the time being it doesn’t really map to what we feel because agentic tasks are all about a mix of correctness, ease of use, speed, and cost. Eventually benchmarks will individually address these.Where GPT 5.4 feels like another incremental model on some on-paper benchmarks, in practice it feels like a meaningful step in all four of those traits. GPT 5.4 in Codex, always on fast mode and high or extra-high effort, is the first OpenAI agent that feels like it can do a lot of random things you can throw at it.Interconnects AI is a reader-supported publication. Consider becoming a subscriber.I haven’t been particularly deep in software engineering over the last few months, so most of my working with agents has been smaller projects (not totally one-off, but small enough where I’ve built the entire thing and manage the design over weeks), data analysis, and research tasks. When you embrace being agent-native, this style of work entails a lot of regular APIs, background packages (like installing and managing LateX binaries, ffmpeg, multimedia conversion tools, etc), git operations, file management, search etc. Prior to GPT 5.4, I always churned off of OpenAI’s agents due to a death by a thousand cuts. It felt like rage quits. I’d feel like I was getting into GPT 5.2 Codex, but it would fail on a git operation and have me (or Claude) need to reset it. Those hard edges are no longer there.The other subtle change in GPT 5.4’s approachability – the biggest reason I think OpenAI is much more back in the agent wars – is that it just feels a bit more “right.” I classify this differently to the routine tasks I discussed above, and it has to do with how the product (i.e. the model harness) presents the model outputs, requests, and all that to you the user. It has to do with how easy it is to dive in. This has always been Claude’s biggest strength in its astronomical growth. Not only has Claude been immensely useful, but it has a charm and entertainment value to it that’ll make new people stick around. GPT 5.4 has a bit of that, but the underlying model strengths of Claude still leave it feeling warmer.Where Claude is a super smart model, with character, a turn of phrase in a debate, and sometimes forgetting something, OpenAI’s models in Codex feel meticulous, slightly cold, but deeply mechanical. I’d use Claude for things I need more of an opinion on and GPT 5.4 to churn through an overwhelmingly specific TODO list. The instruction following of GPT 5.4 is so precise that I need to learn to interact with the models differently after spending so much time with Claude. Claude, in some domains, you come to see has an excellent model for your intent. GPT 5.4 just does what you say to do. These are very different philosophies of “what will make the best model for an agent”, Claude will likely appeal to the newcomers, but GPT 5.4 will likely appeal to the master agent coordinator that wants to unleash their AI army on distributed tasks.Outside of charm, and dare I say taste, a lot of the usability factors are actually better on OpenAI’s half of the world. The Codex app is compelling – I don’t always use it, but sometimes I totally love it. I suspect substantial innovation is coming in what these apps look like. Personally, I expect them to eventually look like Slack (when multiple agents need to talk to eachother, under my watch).OpenAI also natively offers fast mode for their models with a subscription and very large rate limits. I’ve been on the $100/month Claude plan and $200/month ChatGPT plan for quite some time. I’ve never been remotely close to my Codex limits with fast mode and xhigh reasoning effort, where I hit my Claude limits from time to time. There’s definitely a modeling reason to this – most of OpenAI’s release blogs showcase each iterative model being substantially more concise in the number of tokens it takes to get peak benchmark performance. This is a measure of reasoning efficiency. This 2D (or more) benchmark picture is exactly where the world is going.Here’s a plot from Cursor, which sadly doesn’t have all the GPT 5.4 reasoning efforts, but it confirms this point in a third party evaluation. What is missing across model families is the speed and price (a proxy for total compute used) to get there.The final benefit of GPT 5.4, and OpenAI’s agentic models in general for that matter, is much better context management. In using them regularly now I feel like I’ve never hit the contex

What comes next with open models
2025 was the year where a lot of companies started to take open models seriously as a path to influence in the extremely valuable AI ecosystem — the adoption of a strategy that was massively accelerated downstream of DeepSeek R1’s breakout success. Most of this is being done as a mission of hope, principle, or generosity. Very few businesses have a real monetary reason to build open models. Well-cited reasons, such as commoditizing one’s complements for Meta’s Llama, are hard to follow up on when the cost of participating well is billions of dollars. Still, AI is in such an early phase of technological development, mostly defined by large-scale industrialization and massive scale-out of infrastructure, that having any sort of influence at the cutting edge of AI is seen as a path to immense potential value. Open models are a very fast way to achieve this, you can obtain substantial usage and mindshare with no enterprise agreements or marketing campaigns — just releasing one good model. Many companies in AI have raised a ton of money built on less. The hype of open models is simultaneously amplified by the mix of cope, disruptive anticipation, and science fiction that hopes for the world where open models do truly surpass the closed labs. This goal could be an economically catastrophic success for the AI ecosystem, where profits and revenue plummet but the broader balance of power and control of AI models is long-term more stable.There’s a small chance open models win in absolute performance, but it would only be on the back of either a true scientific breakthrough that is somehow kept hidden from the leading labs or the models truly hitting a wall in performance. Both of them are definitely possible, but very unlikely. It is important to remind yourself that there have been no walls in progress to date and all the top AI researchers we discuss this with constantly explain the low-hanging fruit they see on progress. It may not be recursive self-improvement to the singularity (more on that in a separate post), but large technology companies are on a direct path to building definitionally transformative tools. They are coming.The balance of power in open vs. closed modelsThe fair assessment of the open-closed gap is that open models have always been 6-18 months behind the best closed models. It is a remarkable testament to the open labs, operating on far smaller budgets, that this has stayed so stable. Many top analysts like myself are bewildered by the way the gap isn’t bigger. Distillation helps a bit in quality, benchmaxing more than closed labs helps perceptions, but the progress of the leading open models is flat out remarkable. The reality is that the open-closed model gap is more likely to grow than shrink. The top few labs are improving as fast as ever, releasing many great new models, with more on the docket. Many of the most impressive frontier model improvements relative to their open counterparts feel totally unmeasured on public benchmarks. In a new era of coding agents, the popular method to “copy” performance from closed models, distillation, requires more creativity to extract performance — previously, you could use the entire completion from the model to train your student, but now the most important part is the complex RL environments and the prompts to place your agents in them. These are much easier to hide and all the while the Chinese labs leading in open models are always complaining about computational restrictions. As the leading AI models move into longer-horizon and more specialized tasks, mediated by complex and expensive gate-keepers in the U.S. economy (e.g. legal or healthcare systems), I expect large gaps in performance to appear. Coding can largely be mostly “solved” with careful data processes, scraping GitHub, and clever environments. The economies of scale and foci of training are moving into domains that are not on the public web, so they are far harder to replicate than early language models. Developing frontier AI models today is more defined by stacking medium to small wins, unlocked by infrastructure, across time. This rewards organizations that can expand scope while maintaining quality, which is extremely expensive.All of these dynamics together create a business landscape for open models that is hard to parse. Through 2026, closed models are going to take leaps and bounds in performance in directions that it is unlikely for open models to follow. This sets us up for a world where we need to consider, fund, use, and discuss open models differently. This piece lays out how open models are changing. It is a future that’ll be clearly defined by three classes of models.* True (closed) frontier models. These will drive the strongest knowledge work and coding agents. They will be truly remarkable tools that force us to reconsider our relationship to work.* Open frontier models. These will be the best open-weight, large models that are attempting to compete on the same direct

Dean Ball on open models and government control
Watching history unfold between Anthropic and the Department of War (DoW) it has been obvious to me that this could be a major turning point in perspectives on open models, but one that’ll take years to be obvious. As AI becomes more powerful, existing power structures will grapple with their roles relative to existing companies. Some in open models frame this as “not your weights, not your brain,” but it points to a much bigger problem when governments realize this. If AI is the most powerful technology, why would any global entity let a single U.S. company (or government) control their relationship to it?I got Dean W. Ball of the great Hyperdimensional newsletter onto the SAIL Media weekly Substack live to discuss this. In the end, we agree that the recent actions by the DoW — especially the designation of Anthropic as a supply chain risk (which Dean and I both vehemently disagree with) — points to open models being the 5-10 year stable equilibrium for power centers. The point of this discussion is:* Why do open models avoid some of the power struggles we’ve seen play out last week?* How do we bridge short term headwinds for open models towards long-term strength?* The general balance of capabilities between open and closed models.Personally, I feel the need to build open models more than ever and am happy to see more constituencies wake up to it. What I don’t know is how to fund and organize that. Commoditizing one’s compliments is a valid strategy, but it starts to break down when AI models cost closer to a trillion dollars than a hundred million. With open models being very hard to monetize, there’s a bumpy road ahead for figuring out who builds these models in face of real business growth elsewhere in the AI stack.Enjoy and please share any feedback you have on this tricky topic! Listen on Apple Podcasts, Spotify, and where ever you get your podcasts. For other Interconnects interviews, go here.Chapters* 00:00 Intro: is the Anthropic supply chain risk good or bad for open models?* 04:03 Funding open models and the widening frontier gap* 12:33 Sovereign AI and global demand for alternatives* 20:55 Open model ecosystem: Qwen, usability, and short-term outlook* 28:20 Government power, nationalization risk, and financializing computeTranscript00:00:00 Nathan Lambert: Okay. We are live and people will start joining. I’m very happy to catch up with Dean. I think as we were setting this up, the news has been breaking that the official supply chain risk designation was filed. This is not a live reaction to that. If we get any really, really interesting news, we’ll talk about it. I think one of the undercurrents that I’ve felt that this week where everything happened is gonna touch on is open models, but there’s not an obvious angle. I think I will frame this to Dean to start, which is how does-- Like, there’s two sides of open models. One is that there’s the kind of cliche like, not my weights, not your weights, not your mind, where like somebody could take it away if not an open model, which people are boosting like, “Oh, like Anthropic’s gonna take away their intelligence.” But the other side is people worried about open models existing that the Department of War can just take and use for any purpose that it wants. And I feel like both of these are a little cliche. And the core question is like, is this type of event where more control is coming towards AI and more multi-party interest, like is that gonna be good or bad for the open weight model ecosystem?00:01:12 Dean Ball: My guess is that in the long run, this is probably profoundly good for open weight AI. And like the whole reason I got in, like, so I became interested in frontier AI governance. I did something totally different with my time before. I wrote about different kinds of policy and studied different kinds of policy. And the reason I got into this was because it immediately occurred to me that the government was gonna... I was like, okay, let’s assume we’re building super intelligence soon or whatever, like very advanced AI that seems like really important and powerful. That’s gonna be something that I depend on, like for my day-to-day life. I’m gonna need it for all kinds of things. It’s gonna profoundly implicate my freedom of expression as an American and my exercise of my liberty and all that. And yet it’s also gonna profoundly implicate national security. And so the government’s gonna have its hands all over it, and they also might not like me using it because I might use it, and others might use it to challenge the status quo in various ways, to challenge the existing power structures which the government is a part of. So we have a political problem on our hands here, in my view.00:02:36 Dean Ball: It immediately occurred to me that we’re gonna have this huge problem of like, this is gonna be a conflict because this is something that’s gonna enormously implicate American speech and liberty, and also it’s gonna have legitimate national s
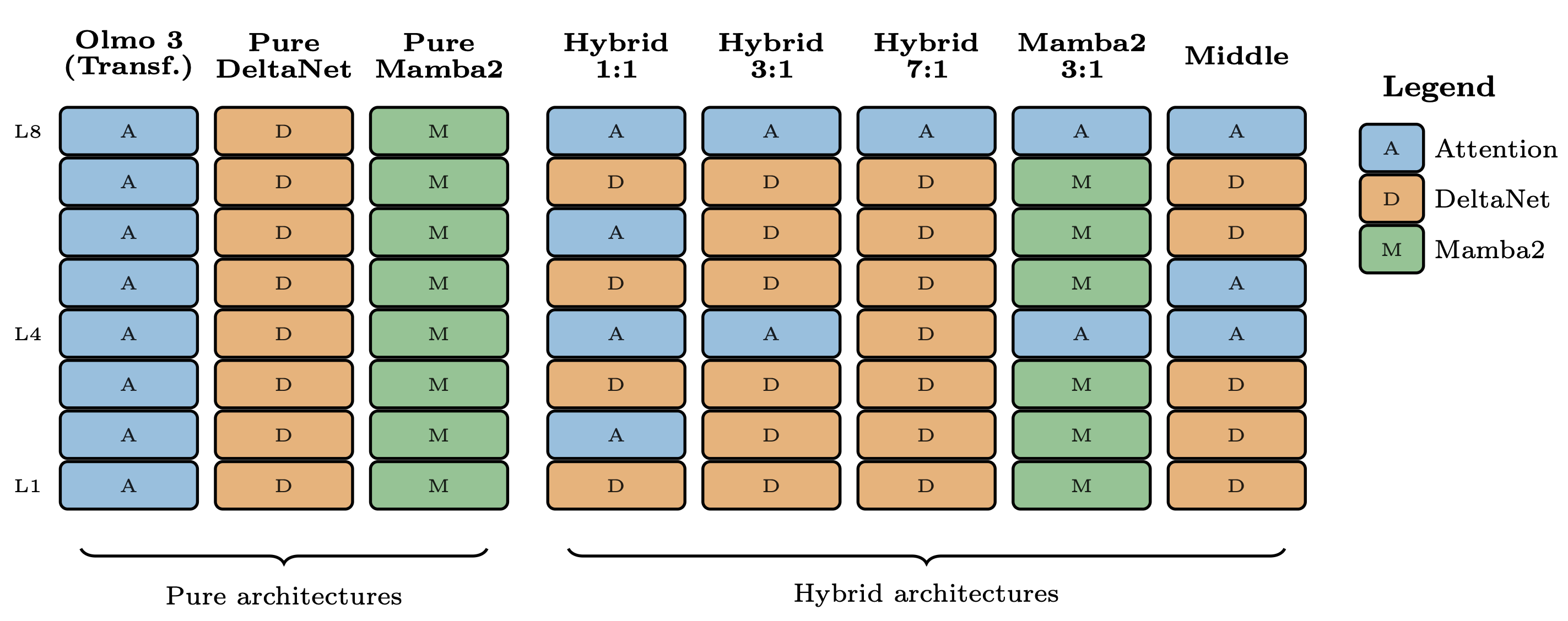
Olmo Hybrid and future LLM architectures
So-called hybrid architectures are far from new in open-weight models these days. We now have the recent Qwen 3.5 (previewed by Qwen3-Next), Kimi Linear last fall (a smaller release than their flagship Kimi K2 models), Nvidia’s Nemotron 3 Nano (with the bigger models expecting to drop soon), IBM Granite 4, and other less notable models. This is one of those times when a research trend looks like it’s getting adopted everywhere at once (maybe the Muon optimizer too, soon?).To tell this story, we need to go back a few years to December 2023, when Mamba and Striped Hyena were taking the world by storm — asking the question: Do we need full attention in our models? These early models fizzled out, partially for the same reasons they’re hard today — tricky implementations, open-source tool problems, more headaches in training — but also because the models fell over a bit when scaled up. The hybrid models of the day weren’t quite good enough yet.These models are called hybrid because they mix these new recurrent neural network (RNN) modules with the traditional attention that made the transformer famous. They all work best with this mix of modules. The RNN layers keep part of the computation compressed in a hidden state to be used for the next token in the prediction — a summary of all information that came before — an idea that has an extremely long historical lineage in deep learning, e.g. back to the LSTM. This setup avoids the quadratic compute cost of attention (i.e. avoiding the incrementally expanding the KV cache per token of the attention operator), and can even assist in solving new problems.The models listed to start this article use a mix of RNN approaches, some models (Qwen and Kimi) use a newer idea called Gated DeltaNet (GDN) and some still use Mamba layers (Granite and Nemotron). The Olmo Hybrid model we’re releasing today also falls on the GDN side, based on careful experimentation, and theory that GDN is capable of learning features that attention or Mamba layers cannot.Introducing Olmo Hybrid and its pretraining efficiencyOlmo Hybrid is a 7B base model, with 3 experiment post-trained checkpoints released — starting with an Instruct model, with a reasoning model coming soon. It is the best open artifact for studying hybrid models, as it is almost identical to our Olmo 3 7B model from last fall, just with a change in architecture. With the model, we are releasing a paper with substantial theory on why hybrid models can be better than standard transformers. This is a long paper that I’m still personally working through, but it’s excellent. You can read the paper here and poke around with the checkpoints here. This is an incredible, long-term research project led by Will Merrill. He did a great job.To understand the context of why hybrid models can be a strict upgrade on transformers, let me begin with a longer excerpt from the paper’s introduction, emphasis mine:Past theoretical work has shown that attention and recurrence have complementary strengths (Merrill et al., 2024; Grazzi et al., 2025), so mixing them is a natural way to construct an architecture with the benefits of both primitives. We further derive novel theoretical results showing that hybrid models are even more powerful than the sum of their parts: there are formal problems related to code evaluation that neither transformers nor GDN can express on their own, but which hybrid models can represent theoretically and learn empirically. But this greater expressivity does not immediately imply that hybrid models should be better LMs: thus, we run fully controlled scaling studies comparing hybrid models vs. transformers, showing rigorously that hybrid models’ expressivity translates to better token efficiency, in agreement with our observations from the Olmo Hybrid pretraining run. Finally, we provide a theoretical explanation for why increasing an architecture’s expressive power should improve language model scaling rooted in the multi-task nature of the language modeling objective.Taken together, our results suggest that hybrid models dominate transformers, both theoretically, in their balance of expressivity and parallelism, and empirically, in terms of benchmark performance and long-context abilities. We believe these findings position hybrid models for wider adoption and call on the research community to pursue further architecture research.Essentially, we show and argue a few things:* Hybrid models are more expressive. They can form their outputs to learn more types of functions. An intuition for why this would be good could follow: More expressive models are good with deep learning because we want to make the model class as flexible as possible and let the optimizer do the work rather than constraints on the learner. Sounds a lot like the Bitter Lesson.* Why does expressive power help with efficiency? This is where things are more nuanced. We argue that more expressive models will have better scaling laws, following the quantization

How much does distillation really matter for Chinese LLMs?
Distillation has been one of the most frequent topics of discussion in the broader US-China and technological diffusion story for AI. Distillation is a term with many definitions — the colloquial one today is using a stronger AI model’s outputs to teach a weaker model. The word itself is derived from a more technical and specific definition of knowledge distillation (Hinton, Vinyals, & Dean 2015), which involves a specific way of learning to match the probability distribution of a teacher model.The distillation of today is better described generally as synthetic data. You take outputs from a stronger model, usually via an API, and you train your model to predict those. The technical form of knowledge distillation is not actually possible from API models because they don’t expose the right information to the user.Synthetic data is arguably the single most useful method that an AI researcher today uses to improve the models on a day to day basis. Yes, architecture is crucial, some data still needs exclusively human inputs, and new ideas like reinforcement learning with verifiable rewards at scale can transform the industry, but so much of the day to day life in improving models today is figuring out how to properly capture and scale up synthetic data.To flesh out the point from the start of this piece, the argument has repeatedly been that the leading Chinese labs are using distillation for their models to steal capabilities from the best American API-based counterparts. The most prominent case to date was surrounding the release of DeepSeek R1 — where OpenAI accused DeepSeek of stealing their reasoning traces by jailbreaking the API (they’re not exposed by default — for context, a reasoning trace is a colloquial word of art referring to the internal reasoning process, such as what open weight reasoning models expose to the user). Fear of distillation is also likely why Gemini quickly flipped from exposing the reasoning traces to users to hiding them. There was even very prominent, early reasoning research that built on Gemini!This all leads us to today’s news, where Anthropic named and directly accused a series of Chinese labs for elaborate distillation campaigns on their Claude models. This is a complex issue. In this post we unpack a series of questions, beginning with the impact, and ending with politics. The core question is — how much of a performance benefit do Chinese labs get from distilling from American models.Interconnects AI is a reader-supported publication. Consider becoming a subscriber.To start, let’s review what Anthropic shared. From the blog post, emphasis mine:We have identified industrial-scale campaigns by three AI laboratories—DeepSeek, Moonshot, and MiniMax—to illicitly extract Claude’s capabilities to improve their own models. These labs generated over 16 million exchanges with Claude through approximately 24,000 fraudulent accounts, in violation of our terms of service and regional access restrictions.These labs used a technique called “distillation,” which involves training a less capable model on the outputs of a stronger one. Distillation is a widely used and legitimate training method. For example, frontier AI labs routinely distill their own models to create smaller, cheaper versions for their customers. But distillation can also be used for illicit purposes: competitors can use it to acquire powerful capabilities from other labs in a fraction of the time, and at a fraction of the cost, that it would take to develop them independently.Much like the models themselves, the benefits of distillation are very jagged. For some capabilities, particularly if you don’t have a full training pipeline setup for it, quickly distilling some data from the leading frontier model in that area can yield massive performance boosts. This can definitely help the lab distilling from the API catch up much more quickly than they otherwise would. Most distillation is rather benign, using many tokens of an LLM to help process and refine existing data — putting a lot of compute into getting a few, high quality training tokens out. This sort of raw data processing work can be done on many different APIs, but one tends to be best.When we go into what Anthropic says the three Chinese LLM builders actually used the Claude API for — as an aside, Anthropic didn’t confirm that the attack was done through the API, the chat app, or Claude Code — the actual impact of the operations is very mixed. It’s hard to know how much untracked usage these labs deployed for other projects (or other American models).To start, Anthropic puts DeepSeek first in their blog post because they’re the household name in the US for Chinese AI. The extent of their use is actually quite small, showing how this post is more about the big picture than the details:DeepSeekScale: Over 150,000 exchangesThe operation targeted:* Reasoning capabilities across diverse tasks* Rubric-based grading tasks that made Claude function as a reward model fo

Opus 4.6, Codex 5.3, and the post-benchmark era
Last Thursday, February 5th, both OpenAI and Anthropic unveiled the next iterations of their models designed as coding assistants, GPT-5.3-Codex and Claude Opus 4.6, respectively. Ahead of this, Anthropic had a firm grasp of the mindshare as everyone collectively grappled with the new world of agents, primarily driven by a Claude Code with Opus 4.5-induced step change in performance. This post doesn’t unpack how software is changing forever, Moltbook is showcasing the future, ML research is accelerating, and the many broader implications, but rather how to assess, live with, and prepare for new models. The fine margins between Opus 4.6 and Codex 5.3 will be felt in many model versions this year, with Opus ahead in this matchup on usability.Going into these releases I’d been using Claude Code extensively as a general computer agent, with some software engineering and a lot of data analysis, automation, etc. I had dabbled with Codex 5.2 (usually on xhigh, maximum thinking effort), but found it not to quite work for me among my broad, horizontal set of tasks.For the last few days, I’ve been using both of the models much more evenly. I mean this as a great compliment, but Codex 5.3 feels much more Claude-like, where it’s much faster in its feedback and much more capable in a broad suite of tasks from git to data analysis (previous versions of Codex, including up to 5.2, regularly failed basic git operations like creating a fresh branch). Codex 5.3 takes a very important step towards Claude’s territory by having better product-market fit. This is a very important move for OpenAI and between the two models, Codex 5.3 feels far more different than its predecessors.OpenAI’s latest GPT, with this context, keeps an edge as a better coding model. It’s hard to describe this general statement precisely, and a lot of it is based on reading others’ work, but it seems to be a bit better at finding bugs and fixing things in codebases, such as the minimal algorithmic examples for my RLHF Book. In my experience, this is a minor edge, and the community thinks that this is most apparent in complex situations (i.e. not most vibe-coded apps). As users become better at supervising these new agents, having the best top-end ability in software understanding and creation could become a meaningful edge for Codex 5.3, but it is not an obvious advantage today. Many of my most trusted friends in the AI space swear by Codex because it can be just this tiny bit better. I haven’t been able to unlock it.Switching from Opus 4.6 to Codex 5.3 feels like I need to babysit the model in terms of more detailed descriptions when doing somewhat mundane tasks like “clean up this branch and push the PR.” I can trust Claude to understand the context of the fix and generally get it right, where Codex can skip files, put stuff in weird places, etc.Both of these releases feel like the companies pushing for capabilities and speed of execution in the models, but at the cost of some ease of use. I’ve found both Opus 4.6 and Codex 5.3 ignoring an instruction if I queue up multiple things to do — they’re really best when given well-scoped, clear problems (especially Codex). Claude Code’s harness has a terrible bug that makes subagents brick the terminal, where new messages say you must compact or clear, but compaction fails. Despite the massive step by Codex, they still have a large gap to close to Claude on the product side. Opus 4.6 is another step in the right direction, where Claude Code feels like a great experience. It’s approachable, it tends to work in the wide range of tasks I throw at it, and this’ll help them gain much broader adoption than Codex. If I’m going to recommend a coding agent to an audience who has limited-to-no software experience, it’s certainly going to be Claude. At a time when agents are just emerging into general use, this is a massive advantage, both in mindshare and feedback in terms of usage data.In the meantime, there’s no cut-and-dried guideline on which agent you need to use for any use-case, you need to use multiple models all the time and keep up with the skill that is managing agents. Interconnects AI is a reader-supported publication. Consider becoming a subscriber.Assessing models in 2026There have been many hints through 2025 that we were heading toward an AI world where benchmarks associated with model releases no longer convey meaningful signal to users. Back in the time of the GPT-4 or Gemini 2.5 Pro releases, the benchmark deltas could be easily felt within the chatbot form factor of the day — models were more reliable, could do more tasks, etc. This continued through models like OpenAI’s o3. During this phase of AI’s buildout, roughly from 2023 to 2025, we were assembling the core functionality of modern language models: tool-use, extended reasoning, basic scaling, etc. The gains were obvious.It should be clear with the releases of both Opus 4.6 and Codex 5.3 that benchmark-based release reactions barely matter. For

Why Nvidia builds open models with Bryan Catanzaro
One of the big stories of 2025 for me was how Nvidia massively stepped up their open model program — more releases, higher quality models, joining a small handful of companies releasing datasets, etc. In this interview, I sat down with one of the 3 VP’s leading the effort of 500+ technical staff, Bryan Catanzaro, to discuss:* Their very impressive Nemotron 3 Nano model released in Dec. 2025, and the bigger Super and Ultra variants coming soon,* Why Nvidia’s business clearly benefits from them building open models,* How the Nemotron team culture was crafted in pursuit of better models,* Megatron-LM and the current state of open-source training software,* Career reflections and paths into AI research,* And other topics.The biggest takeaway I had from this interview is how Nvidia understands their unique roll as a company that and both build and directly capture the value they get from building open language models, giving them a uniquely sustainable advantage. Bryan has a beautiful analogy for open models this early in AI’s development, and how they are a process of creating “potential energy” for AI’s future applications.I hope you enjoy it!Guest: Bryan Catanzaro, VP Applied Deep Learning Research (ADLR), NVIDIA. X: @ctnzr, LinkedIn, Google Scholar.Listen on Apple Podcasts, Spotify, YouTube, and where ever you get your podcasts. For other Interconnects interviews, go here.Nemotron Model Timeline2019–2022 — Foundational Work* Megatron-LM (model parallelism framework that has become very popular again recently; alternatives: DeepSpeed, PyTorch FSDP). * NeMo Framework (NVIDIA’s end-to-end LLM stack: training recipes, data pipelines, evaluation, deployment).Nov 2023 — Nemotron-3 8B: Enterprise-ready NeMo models. Models: base, chat-sft, chat-rlhf, collection. Blog.Feb 2024 — Nemotron-4 15B: Multilingual LLM trained to 8T tokens. Paper.Jun 2024 — Nemotron-4 340B: Major open release detailing their synthetic data pipeline. Paper, blog. Models: Instruct, Reward. Jul–Sep 2024 — Minitron / Nemotron-Mini: First of their pruned models, pruned from 15B. Minitron-4B (base model), Nemotron-Mini-4B-Instruct. Paper, code.Oct 2024 — Llama-3.1-Nemotron-70B: Strong post-training on Llama 3.1 70B. Model, collection. Key dataset — HelpSteer2, paper.Mar–Jun 2025 — Nemotron-H: First hybrid Mamba-Transformer models for inference efficiency. Paper, research page, blog. Models: 8B, 47B, 4B-128K.May 2025 — Llama-Nemotron: Efficient reasoning models built ontop of Llama (still!). Paper.Sep 2025 — Nemotron Nano 2: 9B hybrid for reasoning, continuing to improve in performance. 12B base on 20T tokens (FP8 training) pruned to 9B for post-training. Report, V2 collection.Nov 2025 — Nemotron Nano V2 VL: 12B VLM. Report.Dec 2025 — Nemotron 3: Nano/Super/Ultra family, hybrid MoE, up to 1M context. Super/Ultra H1 2026. Nano: 25T tokens, 31.6B total / ~3.2B active, releases recipes + code + datasets. Papers: White Paper, Technical Report. Models: Nano-30B-BF16, Base, FP8.Nemotron’s Recent DatasetsNVIDIA began releasing substantially more data in 2025, including pretraining datasets — making them one of few organizations releasing high-quality pretraining data at scale (which comes with non-negligible legal risk).Pretraining DataCollection — CC-v2, CC-v2.1, CC-Code-v1, Code-v2, Specialized-v1, CC-Math-v1. Math paper: arXiv:2508.15096.Post-Training DataCore post-training dumps (SFT/RL blends):* Llama Nemotron Post-Training v1.1 (Apr 2025)* Nemotron Post-Training v1 (Jul 2025)* Nemotron Post-Training v2 (Aug 2025)2025 reasoning/code SFT corpora:* OpenMathReasoning (Apr 2025)* OpenCodeReasoning (Apr 2025), OpenCodeReasoning-2 (May 2025)* AceReason-1.1-SFT (Jun 2025)* Nemotron-Math-HumanReasoning (Jun 2025), Nemotron-PrismMath (Apr 2025)NeMo Gym RLVR datasets: CollectionNemotron v3 post-training (Dec 2025): CollectionHelpSteer (human feedback/preference):* HelpSteer (Nov 2023)* HelpSteer2 (Jun 2024)* HelpSteer3 (Mar 2025)And others, not linked here.Chapters* 00:00:00 Intro & Why NVIDIA Releases Open Models* 00:05:17 Nemotron’s two jobs: systems R&D + ecosystem support* 00:15:23 Releasing datasets, not just models* 00:22:25 Organizing 500+ people with “invitation, not control”* 0:37:29 Scaling Nemotron & The Evolution of Megatron* 00:48:26 Career Reflections: From SVMs to DLSS* 00:54:12 Lessons from the Baidu Silicon Valley AI Lab* 00:57:25 Building an Applied Research Lab with Jensen Huang * 01:00:44 Advice for Researchers & Predictions for 2026Transcript00:00:06 Nathan Lambert: Okay. Hey, Bryan. I’m very excited to talk about Nemotron. I think low-key, one of the biggest evolving stories in twenty-five of open models, outside the obvious things in China that everybody talks about, that gets a ton of attention. So th- thanks for coming on the pod.00:00:22 Bryan Catanzaro: Oh, yeah, it’s my honor.00:00:23 Nathan Lambert: So I wanted to start, and some of these questions are honestly fulfilling my curiosity as a fan. As like, why does NVIDIA, at a basic

Thoughts on the job market in the age of LLMs
There’s a pervasive, mutual challenge in the job market today for people working in (or wanting to work in) the cutting edge of AI. On the hiring side, it often feels impossible to close, or even get interest from, the candidates you want. On the individual side, it quite often feels like the opportunity cost of your current job is extremely high — even if on paper the actual work and life you’re living is extremely good — due to the crazy compensation figures.For established tech workers, the hiring process in AI can feel like a bit of a constant fog. For junior employees, it can feel like a bit of a wall.In my role as a bit of a hybrid research lead, individual contributor, and mentor, I spend a lot of time thinking about how to get the right people for me to work with and the right jobs for my mentees.The advice here is shaped by the urgency of the current moment in LLMs. These are hiring practices optimized for a timeline of relevance that may need revisiting every 1-2 years as the core technology changes — which may not be best for long-term investment in people, the industry, or yourself. I’ve written separately about the costs of this pace, and don’t intend to carry this on indefinitely.The most defining feature of hiring in this era is the complexity and pace of progress in language models. This creates two categories. For one, senior employees are much more covetable because they have more context of how to work in and steer complex systems over time. It takes a lot of perspective to understand the right direction for a library when your team can make vastly more progress on incremental features given AI agents. Without vision, the repositories can get locked with too many small additions. With powerful AI tools I expect the impact of senior employees to grow faster than adding junior members to the team could. This view on the importance of key senior talent has been a recent swing, given my experiences and expectations for current and future AI agents, respectively:Every engineer needs to learn how to design systems. Every researcher needs to learn how to run a lab. Agents push the humans up the org chart.On the other side, junior employees have to prove themselves in a different way. The number one defining trait I look for in a junior engineering employee is an almost fanatical obsession with making progress, both in personal understanding and in modeling performance. The only way to learn how the sausage gets made is to do it, and to catch up it takes a lot of hard work in a narrow area to cultivate ownership. With sufficient motivation, a junior employee can scale to impact quickly, but without it, it’s almost replaceable with coding agents (or will be soon). This is very hard work and hard to recruit for. The best advice I have on finding these people is “vibes,” so I am looking for advice on how to find them too!For one, when I brought Florian Brand on to help follow open models for Interconnects, when I first chatted with him he literally said “since ChatGPT came out I’ve been fully obsessed with LLMs.” You don’t need to reinvent the wheel here — if it’s honest, people notice.For junior researchers, there’s much more grace, but that’s due to them working in an education institution first and foremost, instead of the understatedly brutal tech economy. A defining feature that creates success here is an obsession with backing up claims. So a new idea improves models, why? So our evaluation scores are higher, what does this look like in our harness? Speed of iteration follows from executing on this practice. Too many early career researchers try to build breadth of impact (e.g. collecting contributions on many projects) before clearly demonstrating, to themselves and their advisors, depth. The best researchers then bring both clarity of results and velocity in trying new ideas.Working in academia today is therefore likely to be a more nurturing environment for junior talent, but it comes with even greater opportunity costs financially. I’m regularly asked if one should leave a Ph.D. to get an actual job, and my decision criteria is fairly simple. If you’re not looking to become a professor and have an offer to do modeling research at a frontier lab (Gemini, Anthropic, OpenAI is my list) then there’s little reason to stick around and finish your Ph.D.The little reason that keeps people often ends up being personal pride in doing something hard, which I respect. It’s difficult to square these rather direct pieces of career advice with my other recommendations of choosing jobs based on the people, as you’ll spend a ton of your life with them, more than the content of what you’ll be doing. Choosing jobs based on people is one of the best ways to choose your job based on the so-called “vibes.”Working in a frontier lab in product as an alternative to doing a Ph.D. is a path to get absorbed in the corporate machine and not stand out, reducing yourself to the standard tech career ladder. Part of what
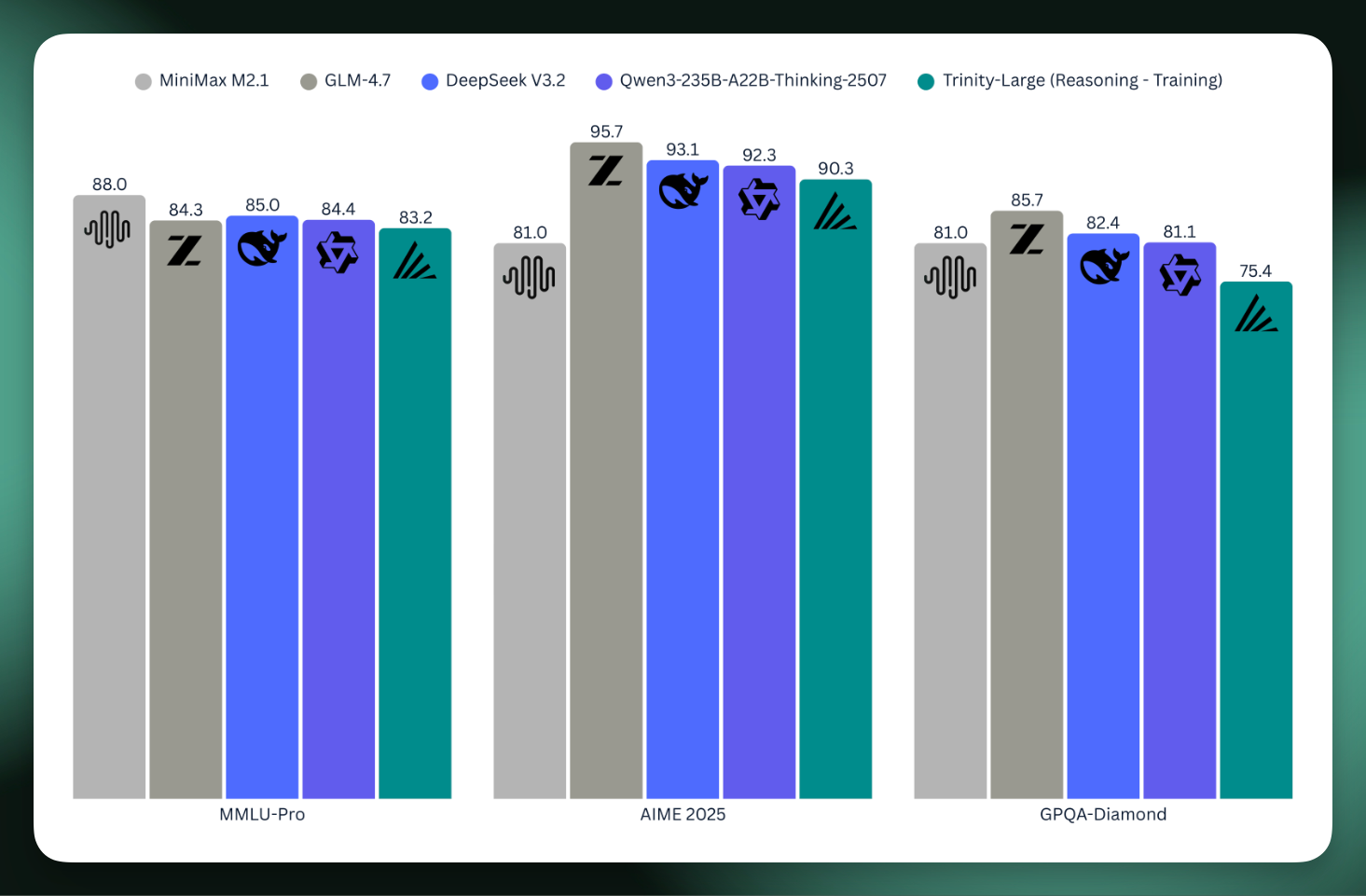
Arcee AI goes all-in on open models built in the U.S.
Arcee AI is a the startup I’ve found to be taking the most real approach to monetizing their open models. With a bunch of experience (and revenue) in the past in post-training open models for specific customer domains, they realized they needed to both prove themselves and fill a niche by pretraining larger, higher performance open models built in the U.S.A. They’re a group of people that are most eagerly answering my call to action for The ATOM Project, and I’ve quickly become friends with them.Today, they’re releasing their flagship model — Trinity Large — as the culmination of this pivot. In anticipation of this release, I sat down with their CEO Mark McQuade, CTO Lucas Atkins, and pretraining lead, Varun Singh, to have a wide ranging conversation on:* The state (and future) of open vs. closed models,* The business of selling open models for on-prem deployments,* The story of Arcee AI & going “all-in” on this training run,* The ATOM project,* Building frontier model training teams in 6 months,* and other great topics. I really loved this one, and think you well too.The blog post linked above and technical report have many great details on training the model that I’m still digging into. One of the great things Arcee has been doing is releasing “true base models,” which don’t contain any SFT data or learning rate annealing. The Trinity Large model, an MoE with 400B total and 13B active tokens trained to 17 trillion tokens is the first publicly shared training run at this scale on B300 Nvidia Blackwell machines. As a preview, they shared the scores for the underway reasoning model relative to the who’s-who of today’s open models. It’s a big step for open models built in the U.S. to scale up like this. I won’t spoil all the details, so you still listen to the podcast, but their section of the blogpost on cost sets the tone well for the podcast, which is a very frank discussion on how and why to build open models:When we started this run, we had never pretrained anything remotely like this before.There was no guarantee this would work. Not the modeling, not the data, not the training itself, not the operational part where you wake up, and a job that costs real money is in a bad state, and you have to decide whether to restart or try to rescue it.All in—compute, salaries, data, storage, ops—we pulled off this entire effort for $20 million. 4 Models got us here in 6 months.That number is big for us. It’s also small compared to what frontier labs spend just to keep the lights on. We don’t have infinite retries.Once I post this, I’m going to dive right into trying the model, and I’m curious what you find too.Listen on Apple Podcasts, Spotify, YouTube, and where ever you get your podcasts. For other Interconnects interviews, go here.GuestsLucas Atkins —X,LinkedIn — CTO; leads pretraining/architecture, wrote the Trinity Manifesto.Mark McQuade — X, LinkedIn — Founder/CEO; previously at Hugging Face (monetization), Roboflow. Focused on shipping enterprise-grade open-weight models + tooling.Varun Singh — LinkedIn — pretraining lead.Most of this interview is conducted with Lucas, but Mark and Varun make great additions at the right times.LinksCore:* Trinity Large (400B total, 13B active) collection, blog post. Instruct model today, reasoning models soon.* Trinity Mini, 26B total 3B active (base, including releasing pre-anneal checkpoint)* Trinity Nano Preview, 6B total 1B active (base)* Open Source Catalog: https://www.arcee.ai/open-source-catalog* API Docs and Playground (demo)* Socials: GitHub, Hugging Face, X, LinkedIn, YouTubeTrinity Models:* Trinity models page: https://www.arcee.ai/trinity* The Trinity Manifesto (I recommend you read it): https://www.arcee.ai/blog/the-trinity-manifesto* Trinity HF collection — (Trinity Mini & Trinity Nano Preview)Older models:* AFM-4.5B (and base model) — their first open, pretrained in-house model (blog post).* Five open-weights models (blog): three production models previously exclusive to their SaaS platform plus two research models, released as they shifted focus to AFM — Arcee-SuperNova-v1, Virtuoso-Large, Caller, GLM-4-32B-Base-32K, HomunculusOpen source tools:* MergeKit — model merging toolkit (LGPL license return)* DistillKit — knowledge distillation library* EvolKit — synthetic data generation via evolutionary methodsRelated:* Datology case study w/ ArceeChapters* 00:00:00 Intro: Arcee AI, Trinity Models & Trinity Large* 00:08:26 Transitioning a Company to Pre-training* 00:13:00 Technical Decisions: Muon and MoE* 00:18:41 Scaling and MoE Training Pain* 00:23:14 Post-training and RL Strategies* 00:28:09 Team Structure and Data Scaling* 00:31:31 The Trinity Manifesto: US Open Weights* 00:42:31 Specialized Models and Distillation* 00:47:12 Infrastructure and Hosting 400B* 00:50:53 Open Source as a Business Moat* 00:56:31 Predictions: Best Model in 2026* 01:02:29 Lightning Round & ConclusionsTranscriptTranscript generated with ElevenLabs Scribe v2 and cleaned with Claude Cod

Get Good at Agents
Two weeks ago, I wrote a review of how Claude Code is taking the AI world by storm, saying that “software engineering is going to look very different by the end of 2026." That article captured the power of Claude as a tool and a product, and I still stand by it, but it undersold the changes that are coming in how we use these products in careers that interface with software. The more personal angle was how “I’d rather do my work if it fits the Claude form factor, and soon I’ll modify my approaches so that Claude will be able to help.” Since writing that, I’m stuck with a growing sense that taking my approach to work from the last few years and applying it to working with agents is fundamentally wrong. Today’s habits in the era of agents would limit the uplift I get by micromanaging them too much, tiring myself out, and setting the agents on too small of tasks. What would be better is more open ended, more ambitious, more asynchronous. I don’t yet know what to prescribe myself, but I know the direction to go, and I know that searching is my job. It seems like the direction will involve working less, spending more time cultivating peace, so the brain can do its best directing — let the agents do most of the hard work.Since trying Claude Code with Opus 4.5, my work life has shifted closer to trying to adapt to a new way of working with agents. This new style of work feels like a larger shift than the era of learning to work with chat-based AI assistants. ChatGPT let me instantly get relevant information or a potential solution to the problems I was already working on. Claude Code has me considering what should I work on now that I know I can have AI independently solve or implement many sub-components. Every engineer needs to learn how to design systems. Every researcher needs to learn how to run a lab. Agents push the humans up the org chart.I feel like I have an advantage by being early to this wave, but no longer feel like just working hard will be an lasting edge. When I can have multiple agents working productively in parallel on my projects, my role is shifting more to pointing the army rather than using the power-tool. Pointing the agents more effectively is far more useful than me spending a few more hours grinding on a problem. My default workflow now is GPT 5 Pro for planning, Claude Code with Opus 4.5 for implementation. I often have Claude Code pass information back to GPT 5 Pro for a deep search when stuck with a very detailed prompt. Codex with GPT 5.2 on xhigh thinking effort alone feels very capable, more meticulous than Claude even, but I haven’t yet figured out how to get the best out of it. GPT Pro feels itself to be a strong agent trapped in the wrong UX — it needs to be able to think longer and have a place to work on research tasks.It seems like all of my friends (including the nominally “non-technical” ones) have accepted that Claude can rapidly build incredible, bespoke software for you. Claude updated one of my old research projects to uv so it’s easier to maintain, made a verification bot for my Discord, crafted numerous figures for my RLHF book, feels close to landing a substantial feature in our RL research codebase, and did countless other tasks that would’ve taken me days. It’s the thing de jour — tell your friends and family what trinket you built with Claude. It undersells what’s coming.I’ve taken to leaving Claude Code instances running on my DGX Spark trying to implement new features in our RL codebase when I’m at dinner or work. They make mistakes, they catch most of their own mistakes, and they’re fairly slow too, but they’re capable. I can’t wait to go home and check on what my Claudes were up to.Interconnects is a reader-supported publication. Consider becoming a subscriber.The feeling that I can’t shake is a deep urgency to move my agents from working on toy software to doing meaningful long-term tasks. We know Claude can do hours, days, or weeks, of fun work for us, but how do we stack these bricks into coherent long-term projects? This is the crucial skill for the next era of work.There are no hints or guides on working with agents at the frontier — the only way is to play with them. Instead of using them for cleanup, give them one of your hardest tasks and see what it gets stuck on, see what you can use it for.Software is becoming free, good decision making in research, design, and product has never been so valuable.Being good at using AI today is a better moat than working hard.Here are a collection of pieces that I feel like suitably grapple with the coming wave or detail real practices for using agents. It’s rare that so many of the thinkers in the AI space that I respect are all fixated on a single new tool, a transition period, and a feeling of immense change:* Import AI 441: My agents are working. Are yours? This helped me motivate to write this and focus on how important of a moment this is.* Steve Newman on Hyperproductivity with AI coding agents — importantly
Use multiple models
I’ll start by explaining my current AI stack and how it’s changed in recent months. For chat, I’m using a mix of:* GPT 5.2 Thinking / Pro: My most frequent AI use is getting information. This is often a detail about a paper I’m remembering, a method I’m verifying for my RLHF Book, or some other niche fact. I know GPT 5.2 can find it if it exists, and I use Thinking for queries that I think are easier and Pro when I want to make sure the answer is right. Particularly GPT Pro has been the indisputable king for research for quite some time — Simon Willison’s coining of it as his “research goblin” still feels right.I never use GPT 5 without thinking or other OpenAI chat models. Maybe I need to invest more in custom instructions, but the non-thinking models always come across a bit sloppy relative to the competition out there and I quickly churn. I’ve heard gossip that the Thinking and non-Thinking GPT models are even developed by different teams, so it would make sense that they can end up being meaningfully different.I also rarely use Deep Research from any provider, opting for GPT 5.2 Pro and more specific instructions. In the first half of 2025 I almost exclusively used ChatGPT’s thinking models — Anthropic and Google have done good work to win back some of my attention.* Claude 4.5 Opus: Chatting with Claude is where I go for basic code questions, visualizing simple data, and getting richer feedback on my work or decisions. Opus’s tone is particularly refreshing when trying to push the models a bit (in a way that GPT 4.5 used to provide for me, as I was a power user of that model in H1 2025). Claude Opus 4.5 isn’t particularly fast relative to a lot of models out there, but when you’re used to using the GPT Thinking models like me, it feels way faster (even with extended thinking always on, as I do) and sufficient for this type of work.* Gemini 3 Pro: Gemini is for everything else — explaining concepts I know are well covered in the training data (and minor hallucinations are okay, e.g. my former Google rabbit holes), multimodality, and sometimes very long-context capabilities (but GPT 5.2 Thinking took a big step here, so it’s a bit closer). I still open and use the Gemini app regularly, but it’s a bit less locked-in than the other two.Relative to ChatGPT, sometimes I feel like the search mode of Gemini is a bit off. It could be a product decision with how the information is presented to the user, but GPT’s thorough, repeated search over multiple sources instills a confidence I don’t get from Gemini for recent or research information.* Grok 4: I use Grok ~monthly to try and find some piece of AI news or Alpha I recall from browsing X. Grok is likely underrated in terms of its intelligence (particularly Grok 4 was an impressive technical release), but it hasn’t had sticky product or differentiating features for me.For images I’m using a mix of mostly Nano Banana Pro and sometimes GPT Image 1.5 when Gemini can’t quite get it. For coding, I’m primarily using Claude Opus 4.5 in Claude Code, but still sometimes find myself needing OpenAI’s Codex or even multi-LLM setups like Amp. Over the holiday break, Claude Opus helped me update all the plots for The ATOM Project, which included substantial processing of our raw data from scraping HuggingFace, perform substantive edits for the RLHF Book (where I felt it was a quite good editor when provided with detailed instructions on what it should do), and other side projects and life organization tasks. I recently published a piece explaining my current obsession with Claude Opus 4.5, I recommend you read it if you haven’t had the chance:A summary of this is that I pay for the best models and greatly value the marginal intelligence over speed — particularly because, for a lot of the tasks I do, I find that the models are just starting to be able to do them well. As these capabilities diffuse in 2026, speed will become more of a determining factor in model selection.Peter Wildeford had a post on X with a nice graphic that reflected a very similar usage pattern:Across all of these categories, it doesn’t feel like I could get away with just using one of these models without taking a substantial haircut in capabilities. This is a very strong endorsement for the notion of AI being jagged — i.e. with very strong capabilities spread out unevenly — while also being a bit of an unusual way to need to use a product. Each model is jagged in its own way. Through 2023, 2024, and the earlier days of modern AI, it quite often felt like there was always just one winning model and keeping up was easier. Today, it takes a lot of work and fiddling to make sure you’re not missing out on capabilities.The working pattern that I’ve formed that most reinforces this using multiple models era is how often my problem with an AI model is solved by passing the same query to a peer model. Models get stuck, some can’t find bugs, some coding agents keep getting stuck on some weird, suboptimal approach
Claude Code Hits Different
There is an incredible amount of hype for Claude Code with Opus 4.5 across the web right now, which I for better or worse entirely agree with. Having used coding agents extensively for the past 6-9 months, where it felt like sometimes OpenAI’s Codex was the best and sometimes Claude, there was some meaningful jump over the last few weeks. The jump is well captured by this post, which called it the move of “software creation from an artisanal, craftsman activity to a true industrial process.” Translation: Software is becoming free and human design, specification, and entrepreneurship is the only limiting factor.What is odd is that this latest Opus model was released on November 24, 2025, and the performance jump in Claude Code seemed to come at least weeks after its integration — I wouldn’t be surprised if a small product change unlocked massive real (or perceived) gains in performance.Interconnects is a reader-supported publication. Consider becoming a subscriber.The joy and excitement I feel when using this latest model in Claude Code is so simple that it necessitates writing about it. It feels right in line with trying ChatGPT for the first time or realizing o3 could find any information I was looking for, but in an entirely new direction. This time, it is the commodification of building. I type and outputs are constructed directly. Claude’s perfect mix of light sycophancy, extreme productivity, and an elegantly crafted application has me coming up with things to do with Claude. I’d rather do my work if it fits the Claude form factor, and soon I’ll modify my approaches so that Claude will be able to help. In a near but obvious future I’ll just manage my Claudes from my phone at the coffee shop.Where Claude is an excellent model, maybe the best, its product is where the magic happens for building with AI that instills confidence. We could see the interfaces the models are used in being so important to performance, such that Anthropic’s approach with Claude feels like Apple’s integration of hardware, software, and everything in between. This sort of magical experience is not one I expect to be only buildable by Anthropic — they’re just the first to get there. The fact that Claude makes people want to go back to it is going to create new ways of working with these models and software engineering is going to look very different by the end of 2026. Right now Claude (and other models) can replicate the most-used software fairly easily. We’re in a weird spot where I’d guess they can add features to fairly complex applications like Slack, but there are a lot of hoops to jump through in landing the feature (including very understandable code quality standards within production code-bases), so the models are way easier to use when building from scratch than in production code-bases. This dynamic amplifies the transition and power shift of software, where countless people who have never fully built something with code before can get more value out of it. It will rebalance the software and tech industry to favor small organizations and startups like Interconnects that have flexibility and can build from scratch in new repositories designed for AI agents. It’s an era to be first defined by bespoke software rather than a handful of mega-products used across the world. The list of what’s already commoditized is growing in scope and complexity fast — website frontends, mini applications on any platform, data analysis tools — all without having to know how to write code.I expect mental barriers people have about Claude’s ability to handle complex codebases to come crashing down throughout the year, as more and more Claude-pilled engineers just tell their friends “skill issue.” With these coding agents all coming out last year, the labs are still learning how to best train models to be well-expressed in the form factor. It’ll be a defining story of 2026 as the commodification of software expands outside of the bubble of people deeply obsessed with AI. There are things that Claude can’t do well and will take longer to solve, but these are more like corner cases and for most people immense value can be built around these blockers. The other part that many people will miss is that Claude Code doesn’t need to be restricted to just software development — it can control your entire computer. People are starting to use it for managing their email, calendars, decision making, referencing their notes, and everything in between. The crucial aspect is that Claude is designed around the command line interface (CLI), which is an open door into the digital world. The DGX Spark on my desk can be a mini AI research and development station managed by Claude.This complete interface managing my entire internet life is the beginnings of current AI models feeling like they’re continually learning. Whenever Claude makes a mistake or does something that doesn’t match your taste, dump a reminder into CLAUDE.md, it’s as simple as that. To quote Do

Open models: Hot or Not with Nathan Lambert & Florian Brand
Nathan sits down with Florian, our open model analyst to get spicy into debates of which labs won and lost momentum in open models of 2025. Reflection 70B, Huawei repackaging someone else's model as their own, the fall of Llama — no drama is left unturned. We also dig into the nuances that we didn't get to in our post, predict GPT-OSS 2, the American v. China balance at the end of 2026, and many other fun topics.Enjoy & let us know if we should do more of this.For the full year in review post, and to see our tier list, click here: Watch on YouTube here: This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe

New Talk: Building Olmo 3 Think
It’s finally here! The public (and most complete) version of my talk covering every stage of the process to build Olmo 3 Think (slides are available). I’ve been giving this, improving it, and getting great feedback at other venues such as The Conference on Language Modeling (COLM) & The PyTorch Conference.This involves changes and new considerations of every angle of the stack, from pretraining, evaluation, and of course post-training.Most of the talk focuses on reinforcement learning infrastructure and evaluating reasoning models, with quick comments on every training stage. I hope you enjoy it, and let us know what to improve in the future!Chapters* 00:00:00 Introduction* 00:06:30 Pretraining Architecture* 00:09:25 Midtraining Data* 00:11:08 Long-context Necessity* 00:13:04 Building SFT Data* 00:20:05 Reasoning DPO Surprises* 00:24:47 Scaling RL* 00:41:05 Evaluation Overview* 00:48:50 Evaluation Reflections* 01:00:25 ConclusionsHere’s the YouTube link: This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe

Olmo 3: America’s truly open reasoning models
We present Olmo 3, our next family of fully open, leading language models. This family of 7B and 32B models represents:* The best 32B base model.* The best 7B Western-origin thinking & instruct models.* The first 32B (or larger) fully open reasoning model.This is a big milestone for Ai2 and the Olmo project. These aren’t huge models (more on that later), but it’s crucial for the viability of fully open-source models that they are competitive on performance – not just replications of models that came out 6 to 12 months ago. As always, all of our models come with full training data, code, intermediate checkpoints, training logs, and a detailed technical report. All are available today, with some more additions coming before the end of the year.As with OLMo 2 32B at its release, OLMo 3 32B is the best open-source language model ever released. It’s an awesome privilege to get to provide these models to the broader community researching and understanding what is happening in AI today.Paper: https://allenai.org/papers/olmo3 Artifacts: https://huggingface.co/collections/allenai/olmo-3Demo: https://playground.allenai.org/ Blog: https://allenai.org/blog/olmo3 Base models – a strong foundationPretraining’s demise is now regularly overstated. 2025 has marked a year where the entire industry rebuilt their training stack to focus on reasoning and agentic tasks, but some established base model sizes haven’t seen a new leading model since Qwen 2.5 in 2024. The Olmo 3 32B base model could be our most impactful artifact here, as Qwen3 did not release their 32B base model (likely for competitive reasons). We show that our 7B recipe competes with Qwen 3, and the 32B size enables a starting point for strong reasoning models or specialized agents. Our base model’s performance is in the same ballpark as Qwen 2.5, surpassing the likes of Stanford’s Marin and Gemma 3, but with pretraining data and code available, it should be more accessible to the community to learn how to finetune it (and be confident in our results).We’re excited to see the community take Olmo 3 32B Base in many directions. 32B is a loved size for easy deployment on single 80GB+ memory GPUs and even on many laptops, like the MacBook I’m using to write this on.A model flow – the lifecycle of creating a modelWith these strong base models, we’ve created a variety of post-training checkpoints to showcase the many ways post-training can be done to suit different needs. We’re calling this a “Model Flow.” For post-training, we’re releasing Instruct versions – short, snappy, intelligent, and useful especially for synthetic data en masse (e.g. recent work by Datology on OLMo 2 Instruct), Think versions – thoughtful reasoners with the performance you expect from a leading thinking model on math, code, etc. and RL Zero versions – controlled experiments for researchers understanding how to build post-training recipes that start with large-scale RL on the base model.The first two post-training recipes are distilled from a variety of leading, open and closed, language models. At the 32B and smaller scale, direct distillation with further preference finetuning and reinforcement learning with verifiable rewards (RLVR) is becoming an accessible and highly capable pipeline. Our post-training recipe follows our recent models: 1) create an excellent SFT set, 2) use direct preference optimization (DPO) as a highly iterable, cheap, and stable preference learning method despite its critics, and 3) finish up with scaled up RLVR. All of these stages confer meaningful improvements on the models’ final performance.Instruct models – low latency workhorsesInstruct models today are often somewhat forgotten, but the likes of Llama 3.1 Instruct and smaller, concise models are some of the most adopted open models of all time. The instruct models we’re building are a major polishing and evolution of the Tülu 3 pipeline – you’ll see many similar datasets and methods, but with pretty much every datapoint or training code being refreshed. Olmo 3 Instruct should be a clear upgrade on Llama 3.1 8B, representing the best 7B scale model from a Western or American company. As scientists we don’t like to condition the quality of our work based on its geographic origins, but this is a very real consideration to many enterprises looking to open models as a solution for trusted AI deployments with sensitive data.Building a thinking modelWhat people have most likely been waiting for are our thinking or reasoning models, both because every company needs to have a reasoning model in 2025, but also to clearly open the black box for the most recent evolution of language models. Olmo 3 Think, particularly the 32B, are flagship models of this release, where we considered what would be best for a reasoning model at every stage of training.Extensive effort (ask me IRL about more war stories) went into every stage of the post-training of the Think models. We’re impressed by the magnitude of gains that can be achieve

Why AI writing is mid
First, on the topic of writing, the polished, and more importantly printed, version of my RLHF Book is available for pre-order. It’s 50% off for a limited time, you can pre-order it here! Like a lot of writing, I’ve been sitting on this piece for many months thinking it’s not contributing enough, but the topic keeps coming up — most recently via Jasmine Sun — and people seem to like it, so I hope you do too!It’s no longer a new experience to be struck by just how bad AI models are at writing good prose. They can pull out a great sentence every now and then, particularly models like GPT-5 Pro and other large models, but it’s always a quick comment and never many sustained successive sentences. More importantly, good AI writing feels like a lucky find rather than the result of the right incantation. After spending a long time working training these models, I’m fairly convinced that this writing inhibition is a structural limitation to how we train these models today and the markets they’re designed to serve.If we're making AIs that are soon to be superhuman at most knowledge work, that are trained primarily to predict text tokens, why is their ability to create high quality text tokens still so low? Why can’t we make the general ChatGPT experience so much more refined and useful for writers while we’re unlocking entirely new ways of working with them every few months — most recently the CLI agents like Claude Code. This gap is one of my favorite discussions of AI because it’s really about the definition of good writing is in itself.Where language models can generate beautiful images from random noise, they can't reliably generate a good few sentences from a couple bullet points of information. What is different about the art form of writing than what AI can already capture?I'm coming to believe that we could train a language model to be a great writer, but it goes against so many of the existing training processes. To list a few problems at different stages of the stack of varying severity in terms of their handicapping of writing:* Style isn’t a leading training objective. Language models all go through preference training where many aspects from helpfulness, clarity, honesty, etc. are balanced against each other. Many rewards make any one reward, such as style, have a harder time standing out. Style and writing quality is also far harder to measure, so it is less likely to be optimized vis-a-vis other signals (such as sycophancy, which was easier to capture).* Aggregate preferences suppress quirks. Language model providers design models with a few intended personalities, largely due to the benefits of predictability. These providers are optimizing many metrics for "the average user." Many users will disagree on what their preference for “good writing” is.* Good writing’s inherent friction. Good writing often takes much longer to process, even when you’re interested in it. Most users of ChatGPT just want to parse the information quickly. Doubly, the people creating the training data for these models are often paid per instance, so an answer with more complexity and richness would often be suppressed by subtle financial biases to move on.* Writing well is orthogonal to training biases. Throughout many stages of the post-training process, modern RLHF training exploits subtle signals for sycophancy and length-bias that aren't underlying goals of it. These implicit biases go against the gradient for better writing. Good writing is pretty much never verbose.* Forced neutrality of a language model. Language models are trained to be neutral on a variety of sensitive topics and to not express strong opinions in general. The best writing unabashedly shares a clear opinion. Yes, I’d expect wackier models like Grok to potentially produce better writing, even if I don’t agree with it. This leads directly to a conflict directly in something I value in writing — voice.All of these create models that are appealing to broad audiences. What we need to create a language model that can write wonderfully is to give it a strong personality, and potentially a strong "sense of self" — if that actually impacts a language model's thinking. The cultivation of voice is one of my biggest recommendations to people trying to get better at writing, only after telling them to find something they want to learn about. Voice is core to how I describe my writing process.When I think about how I write, the best writing relies on voice. Voice is where you process information into a unique representation — this is often what makes information compelling.Many people have posited that base models make great writers, such as when I discussed poetry with Andrew Carr on his Interconnects appearance, but this is because base models haven’t been squashed to the narrower style of post-trained responses. I’ve personally been thinking about this sort of style induced by post-training recently as we prepare for our next Olmo release, and many of us think th

Interview: Ant Group's open model ambitions
This is the first of a handful of interviews I’m doing with teams building the best open language models of the world. In 2025, the open model ecosystem has changed incredibly. It’s more populated, far more dominated by Chinese companies, and growing. DeepSeek R1 shocked the world and now there are a handful of teams in China training exceptional models. The Ling models, from InclusionAI — Ant Group’s leading AI lab — have been one of the Chinese labs from the second half of the year that are releasing fantastic models at a rapid clip. This interview is primarily with Richard Bian, who’s official title is Product & Growth Lead, Ant Ling & InclusionAI (on LinkedIn, X), previously leading AntOSS (Ant Group’s open source software division). Richard spent a substantial portion of his career working in the United States, with time at Square, Microsoft, and an MBA from Berkeley Haas, before returning to China and work at Ant.Also joining are two leads of the Ant Ling technical team, Chen Liang (Algorithm Engineer), and Ziqi Liu (Research Lead).This interview focuses on many topics of the open language models, such as:* Why is the Ant Group — known for the popular fintech app AliPay — investing so much in catching up to the frontier of AI?* What does it take to rapidly gain the ability to train excellent models?* What decisions does one make when deciding a modeling strategy? Text-only or multimodal? What size of models?…* How does the Chinese AI ecosystem prioritize different directions than the West?And many more topics. Listen on Apple Podcasts, Spotify, YouTube, and where ever you get your podcasts. For other Interconnects interviews, go here.Some more references & links:* InclusionAI’s homepage, highlighting their mission.* AntLingAGI on X (models, research, etc.), InclusionAI on X (overall initiative), InclusionAI GitHub, or their Discord community.* Ling 1T was highlighted in “Our Picks” for our last open model roundup in October.* Another interview with Richard at State of Open Conference 2025.* Over the last few months, our coverage of the Chinese ecosystem has taken off, such as our initial ranking of 19 open Chinese AI labs (before a lot of the models we discuss below), model roundups, and tracking the trajectory of China’s ecosystem. An overview of Ant Ling & Inclusion AIAs important context for the interview, we wanted to present an overview of InclusionAI, Ant’s models, and other efforts that emerged onto the scene just in the last 6-9 months. To start — branding.Here’s a few screenshots of InclusionAI’s new website. It starts with fairly standard “open-source AI lab messaging.”Then I was struct by the very distinct messaging which is surprisingly rare in the intense geopolitical era of AI — saying AI is shared for humanity.I expect a lot of very useful and practical messaging from Chinese open-source labs. They realize that Western companies likely won’t pay for their services, so having open models is their only open door to meaningful adoption and influence.Main models (Ling, Ring, & Ming)The main model series is the Ling series, their reasoning models are called Ring, and their Multimodal versions are called Ming. The first public release was Ling Plus, 293B sparse MoE in April. They released the paper for their reasoning model in June and have continued to build on their MoE-first approach.Since then, the pace has picked up significantly. Ling 1.5 came in July.Ling (and Ring) 2.0 came in September of this year, with a 16B total, 2B active mini model, an 100B total, 6B active flash model, and a big 1T total parameter 50B active primary model. This 1T model was accompanied by a substantial tech report on the challenges of scaling RL to frontier scale models. The rapid pace that Chinese companies have built this knowledge (and shared it clearly) is impressive and worth considering what it means for the future.Eval scores obviously aren’t everything, but they’re the first step to building meaningful adoption. Otherwise, you can also check out their linear attention model (paper, similar to Qwen-Next), some intermediate training checkpoints, or multimodal models.Experiments, software, & otherInclusionAI has a lot of projects going in the open source space. Here are some more highlights:* Language diffusion models: MoEs, sizes similar to Ling 2.0 mini and flash (so they likely used those as base). Previous versions exist. * Agent-based models/fine-tunes, Deep Research models, computer-use agentic models.* GroveMoE, MoE arch experiments.* RL infra demonstrations (Interestingly, those are dense models)* AWorld: Training + general framework for agents (RL version, paper)* AReal: RL training suite Interconnects is a reader-supported publication. Consider becoming a subscriber.Chapters* 00:00:00 A frontier lab contender in 8 months* 00:07:51 Defining AGI with metaphor* 00:20:16 How the lab was born* 00:23:30 Pre-training paradigms* 00:40:25 Post training at Inclusion* 00:48:15 The Chinese model landscape*
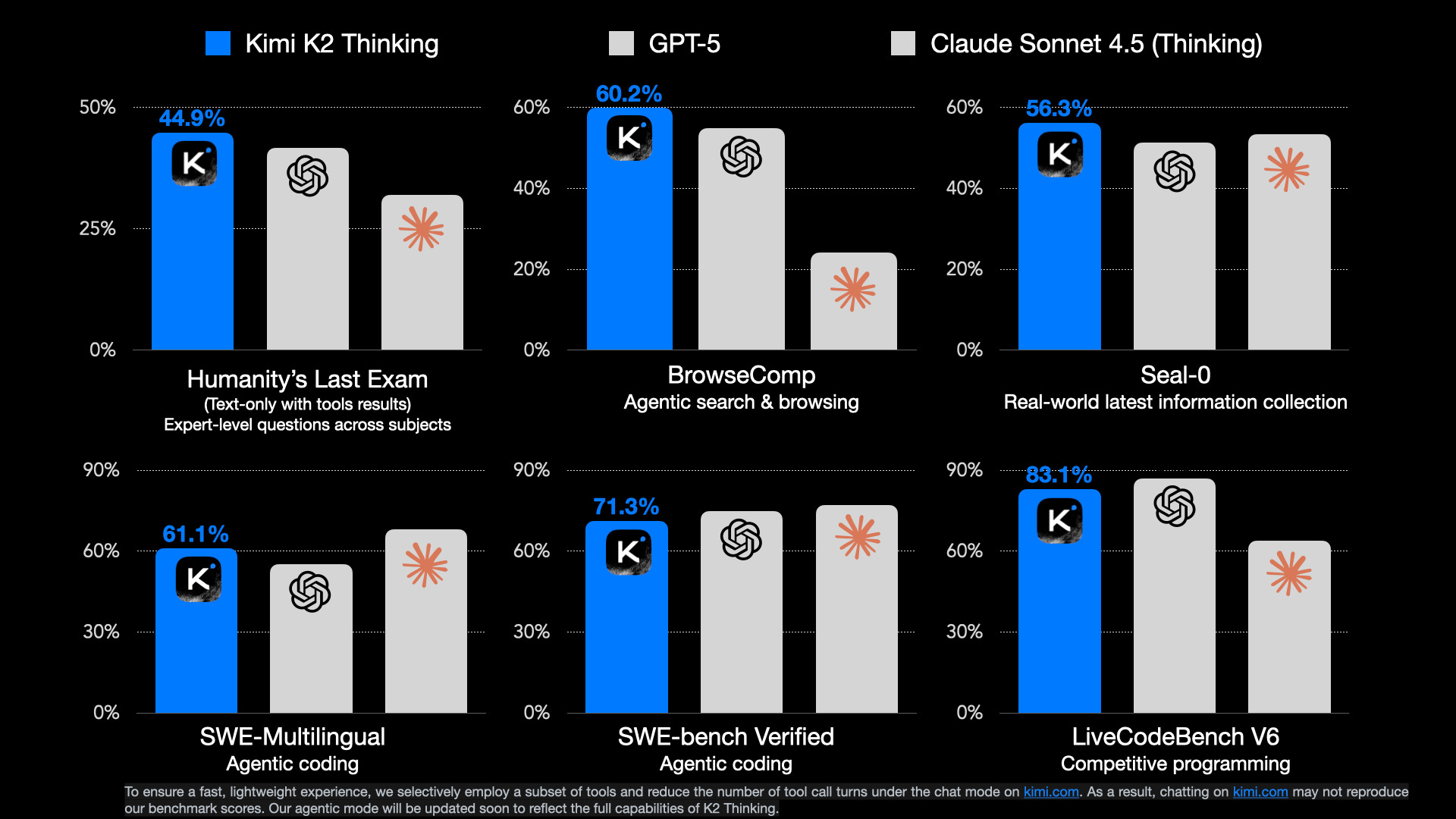
5 Thoughts on Kimi K2 Thinking
First, congrats to the Moonshot AI team, one of the 6 “AI Tigers” in China, on the awesome release of Kimi K2 Thinking. One of the overlooked and inspiring things for me these days is just how many people are learning very quickly to train excellent AI models. The ability to train leading AI models and distribute them internationally is going to be pervasive globally. As people use AI more, those who can access supply for inference (and maybe the absolute frontier in scale of training, even if costly) is going to be the gating function.K2 Thinking sounds like a joy to use because of early reports that the distinctive style and writing quality from their original Kimi K2 Instruct model have been preserved through extended thinking RL training. They released many evaluation scores, for a highlight they’re beating leading closed models on some benchmarks such as Humanity’s Last Exam or BrowseComp. There are still plenty of evals where GPT 5 or Claude Sonnet 4.5 tops them. Rumors are Gemini 3 is coming soon (just like the constantly pending DeepSeek V4), so expectations are high on the industry right now.TLDR: Kimi K2 Thinking as a reasoning MoE model with 1T total, 32B active parameters, 256K context length, interleaved thinking in agentic tool-use, strong benchmark scores and vibe tests.The core reaction of this release is people saying this is the closest open models have been to the closed frontier of performance ever, similar to DeepSeek R1‘s fast follow to o1. This is pretty true, but we’re heading into murky territory because comparing models is harder. This is all advantaging the open models, to be clear. I’ve heard that Kimi’s servers are already totally overwhelmed, more on this soon.What is on my mind for this release:1. Open models release faster. There’s still a time lag from the best closed to open models in a few ways, but what’s available to users is much trickier and presents a big challenge to closed labs. Labs in China definitely release their models way faster. When the pace of progress is high, being able to get a model out sooner makes it look better. That’s a simple fact, but I’d guess Anthropic takes the longest to get models out (months sometimes) and OpenAI somewhere in the middle. This is a big advantage, especially in comms, to the fast mover.I’d put the gap at the order of months in raw performance — I’d say 4-6+ months if you put a gun to my head and made me choose specifically — but the problem is these models aren’t publicly available, so do they matter?2. Key benchmarks first, user behaviors later. Labs in China are closing in and very strong on key benchmarks. These models also can have very good taste (DeepSeek, Kimi), but there is a long-tail of internal benchmarks that labs have for common user behaviors that Chinese labs don’t have feedback cycles on. Chinese companies will start getting these, but intangible’s are important to user retention.Over the last year+ we’ve been seeing Qwen go through this transition. Their models were originally known for benchmaxing, but now they’re legitimately fantastic models (that happen to have insane benchmark scores).Along these lines, the K2 Thinking model was post-trained natively with a 4bit precision to make it far more ready for real serving tasks (they likely did this to make scaling RL more efficient in post-training on long sequences too):To overcome this challenge, we adopt Quantization-Aware Training (QAT) during the post-training phase, applying INT4 weight-only quantization to the MoE components. It allows K2 Thinking to support native INT4 inference with a roughly 2x generation speed improvement while achieving state-of-the-art performance. All benchmark results are reported under INT4 precision.It’s awesome that their benchmark comparisons are in the way it’ll be served. That’s the fair way.3. China’s rise. At the start of the year, most people loosely following AI probably knew of 0 Chinese labs. Now, and towards wrapping up 2025, I’d say all of DeepSeek, Qwen, and Kimi are becoming household names. They all have seasons of their best releases and different strengths. The important thing is this’ll be a growing list. A growing share of cutting edge mindshare is shifting to China. I expect some of the likes of Z.ai, Meituan, or Ant Ling to potentially join this list next year. For some of these labs releasing top tier benchmark models, they literally started their foundation model effort after DeepSeek R1. It took many Chinese companies only 6 months to catch up to the open frontier in ballpark of performance, now the question is if they can offer something in a niche of the frontier that has real demand for users.4. Interleaved thinking on many tool calls. One of the things people are talking about with this release is how Kimi K2 Thinking will use “hundreds of tool calls” when answering a query. From the blog post:Kimi K2 Thinking can execute up to 200 – 300 sequential tool calls without human interference, reasoning cohe

Burning out
One of the obvious topics of the Valley today is how hard everyone works. We’re inundated with comments on “The Great Lock In”, 996, 997, and now even a snarky 002 (midnight to midnight with a 2 hour break). Plenty of this is performative flexing on social media, but enough of it is real and reflecting how trends are unfolding in the LLM space. I’m affected. My friends are affected.All of this hard work is downstream of ever increasing pressure to be relevant in the most exciting technology of our generation. This is all reflective of the LLM game changing. The time window to be a player at the most cutting edge is actually a closing window, not just what feels like one. There are many different sizes and types of models that matter, but as the market is now more fleshed out with resources, all of them are facing a constantly rising bar in quality of technical output. People are racing to stay above the rising tide — often damning any hope of life balance.Interconnects is a reader-supported publication. Consider becoming a subscriber.AI is going down the path that other industries have before, but on steroids. There’s a famous section of the book Apple in China, where the author Patrick McGee describes the programs Apple put in place to save the marriages of engineers traveling so much to China and working incredible hours. In an interview on ChinaTalk, McGee added “Never mind the divorces, you need to look at the deaths.” This is a grim reality that is surely playing out in AI.The Wall Street Journal recently published a piece on how AI Workers Are Putting In 100-Hour Workweeks to Win the New Tech Arms Race. The opening of the article is excellent to capture how the last year or two has felt if you’re participating in the dance:Josh Batson no longer has time for social media. The AI researcher’s only comparable dopamine hit these days is on Anthropic’s Slack workplace-messaging channels, where he explores chatter about colleagues’ theories and experiments on large language models and architecture.Work addicts abound in AI. I often count myself, but take a lot of effort to make it such that work expands to fill available time and not that I fill everything in around work. This WSJ article had a bunch of crazy comments that show the mental limits of individuals and the culture they act in, such as:Several top researchers compared the circumstances to war.Comparing current AI research to war is out of touch (especially with the grounding of actual wars happening simultaneously to the AI race!). What they really are learning is that pursuing an activity in a collective environment at an elite level over multiple years is incredibly hard. It is! War is that and more.In the last few months I’ve been making an increasing number of analogies to how working at the sharp end of LLMs today is similar to training with a team to be elite athletes. The goals are far out and often singular, there are incredibly fine margins between success and failure, much of the grinding feels over tiny tasks that add up over time but you don’t want to do in the moment, and you can never quite know how well your process is working until you compare your outputs with your top competition, which only happens a few times a year in both sports and language modeling.In college I was a D1 lightweight rower at Cornell University. I walked onto a team and we ended up winning 3 championships in 4 years. Much of this was happenstance, as much greatness is, but it’s a crucial example in understanding how similar mentalities can apply in different domains across a life. My mindset around the LLM work I do today feels incredibly similar — complete focus and buy in — but I don’t think I’ve yet found a work environment where the culture is as cohesive as athletics. Where OpenAI’s culture is often described as culty, there are often many signs that the core team members there absolutely love it, even if they’re working 996, 997, or 002. When you love it, it doesn’t feel like work. This is the same as why training 20 hours a week while a full time student can feel easy.Many AI researchers can learn from athletics and appreciate the value of rest. Your mental acuity can drop off faster than your physical peak performance does when not rested. Working too hard forces you to take narrower and less creative approaches. The deeper into the hole of burnout I get in trying to make you the next Olmo model, the worse my writing gets. My ability to spot technical dead ends goes with it. If the intellectual payoffs to rest are hard to see, your schedule doesn’t have the space for creativity and insight.Crafting the team culture in both of these environments is incredibly difficult. It’s the quality of the team culture that determines the outcome more than the individual components. Yes, with LLMs you can take brief shortcuts by hiring talent with years of experience from another frontier lab, but that doesn’t change the long-term dynamic. Yes, you obviously need
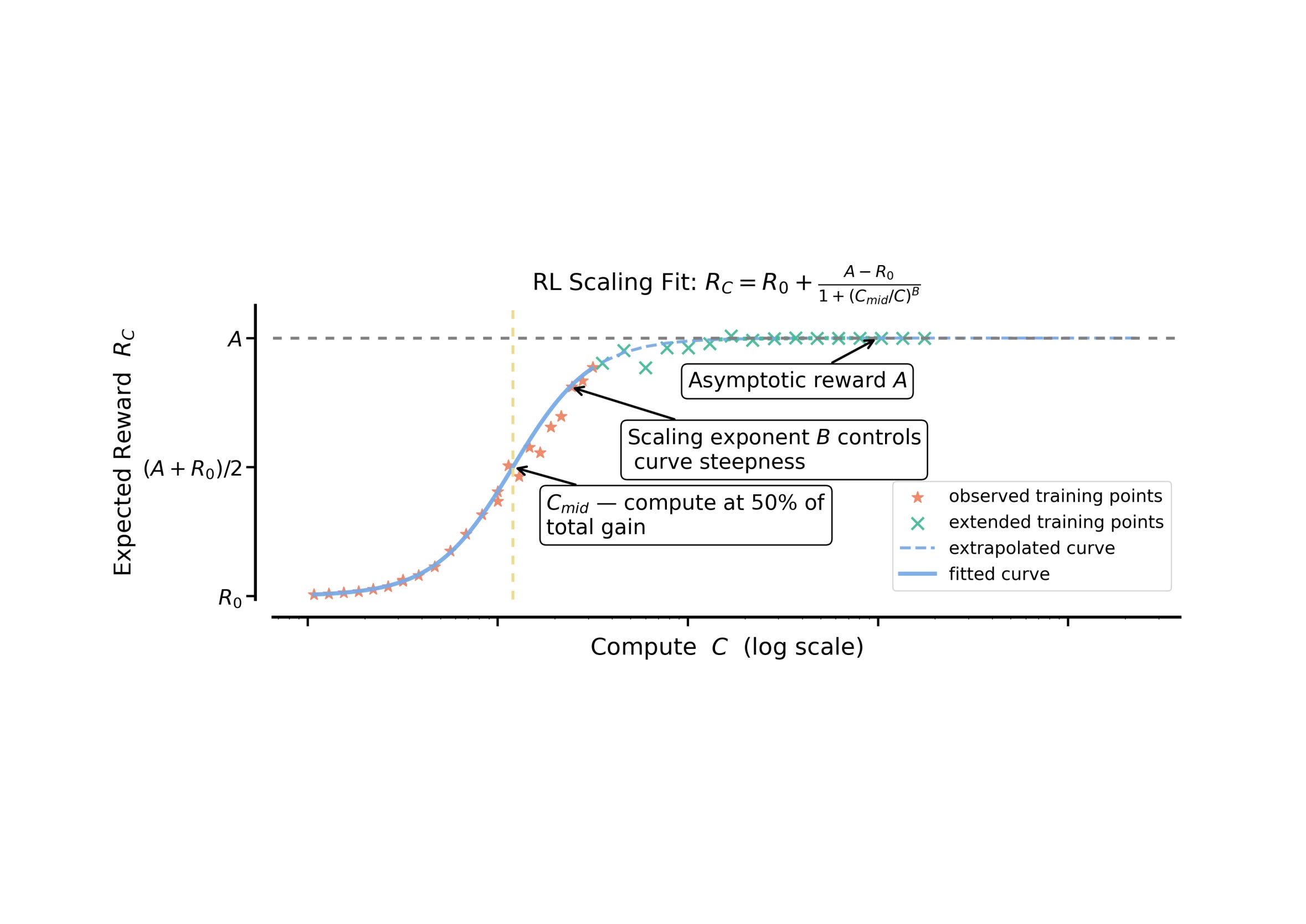
How to scale RL
Two quick housekeeping items before I get to the post.1. I’ll be in SF this week for the PyTorch conference (22-23), AI Infra Summit (21st), and other local events. Come say hi.2. I launched a new Substack AI bundle with 8 of my favorite publications packaged together for teams of 20+. Learn more at readsail.com.Onto the post!“Scaling reinforcement learning (RL)” is the zeitgeisty way to capture the next steps in improving frontier models — everyone is staring at the same hill they plan on climbing. How these different groups are approaching the problem has been a poorly kept secret. It’s a simple idea, but one that’s hard to copy: Predicting the trajectory of the learning curve. There have been two reasons this is hard to copy for academics, which will be solved on different time scales:* The lack of stable RL training setups. There are many RL libraries being developed in parallel and the community has collectively made them much more ready for big RL runs over the summer.* The lack of compute for experimentation.These aren’t new stories. In many ways they mirror the progression of open Mixture of Experts (MoE) models, where they still lag far behind the implementations of the codebases within top AI laboratories because it involves overcoming substantial engineering headaches in an expensive experimentation regime. Scaling RL has been shaping up the same way, but it turns out it is just a bit more approachable.Last week we got the first definitive paper on scaling RL. It proposes a clear method to extrapolate RL learning curves over compute scales and sets a baseline for the order of compute that should be spent to have top-end performance. The paper, The Art of Scaling Reinforcement Learning Compute for LLMs (Khatri & Madaan et al. 2025), referred to as ScaleRL, is a must read for anyone looking to understand the absolute cutting edge of RL algorithms and infrastructure. For some personal context, for all of 2025 we’ve had our main slack channel in the reasoning space at Ai2 called “scaling-rl” because of how essential we knew the first clear piece of work in this area would be. This post covers the key details and what I see coming next.There are two key things you need to know about these, even if all the lower level RL math is confusing to you too. First is how these intuitively work and what they’re actually predicting. Second is how they compare to the pretraining scaling laws we know and love.To the first point, what the approach entails is taking one (or a handful of) your key base models, run a bit of RL on each of them, predict the end point by a bit of shape forecasting across many stable runs, then, for your big run, you can predict the end point in terms of final performance. The shape of RL runs that motivates this is how you see your model often gain ~80% of the accuracy gain in the first few steps, and you wonder what the final performance of the model will be if you trained on your entire dataset.The authors define three constants that they fit, A for a measure of the peak performance — accuracy on a subset of your training dataset, aka the validation set, B for the slope of the sigmoid curve, and C as compute on the x axis. What is then done is that you take a set of RL training jobs and you fit a regression that predicts the last chunk of real training points given the early measurements of accuracy over time. Then, you can compare the predicted final performance of your future RL ablations on that starting model by understanding the normal shape of your RL learning curves.Second is to consider how this compares to pretraining scaling laws. These are very far from the deeply insightful power law relating downstream test loss to pretraining compute — accuracy on RL training datasets is a far more bounded measure than next token prediction. The RL scaling laws are most useful for ablating design choices, relative to pointing to something fundamental about the nature of models. In many ways, scaling laws for pretraining could’ve been viewed this way at the beginning, too, so we’ll see how RL evolves from here.With that difference, scaling laws for RL will play a very different role in training leading models than the pretraining scaling laws we have today. The pretraining laws are about choosing the exact configuration for your big pretraining run (that you can’t really run a meaningful chunk of to debug at all), where RL is more about ablating which algorithm you’ll let run much longer.In pretraining many decisions depend on your budget and scaling laws can give the answer. Your training compute, communication bottlenecks, maximum run time, data availability, etc. all define a certain model window. Scaling laws for RL may inform this very soon, but for now it's best to think about scaling laws as a way to extract the maximum performance from a given base model.For all of these reasons, scaling RL is more like an art, as the authors say it, because it’s about finding the run that’ll get t

The State of Open Models
This talk covers everything that’s happened this year in the open model landscape — DeepSeek kickstarting the Chinese open model norms, Llama’s fade, Qwen’s dominance, GPT-OSS — and what comes next. It is my attempt to share what people need to know about where open models are heading, building on all of my research here at Interconnects and in my day job of training these models, in order to help us take the actions we need to steer it in a better direction.I strongly recommend watching (or listening, as it’s in the podcast feed) if any of the discussions around open models or Chinese AI impacts your decision making. This felt like one of the better talks I’ve given in a bit and I’m excited to keep expanding my coverage here.You can click through the slides here.Thanks to the organizers of The Curve for inviting me (and encouraging me to give this talk), and for permission to post this video.EDIT: I noticed sometimes the audio jumps weirdly, not sure what caused it (from slideslive export, raw is here: https://slideslive.com/39046297/open-models-in-2025-stakes-state-and-strategy)Chapters00:00 2025 so far05:53 China takes the lead15:54 What comes next21:20 What we should do25:00 Q & A(Podcast feed / Audio only version trims 7 seconds of silence to start)References & Recommended Reading* The ATOM Project* On China’s open-source community & trajectory* Ranking China’s open AI labs* On GPT-OSS* Recent open models* More on The Curve conferenceOf course, you can watch on YouTube:Listen on Apple Podcasts, Spotify, YouTube, and where ever you get your podcasts. This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe

Thoughts on The Curve
I spent the weekend debating AI timelines, among other things, at The Curve conference. This translates as spending the weekend thinking about the trajectory of AI progress with a mix of DC and SF types. This is a worthwhile event that served as a great, high-bandwidth way to check in on timelines and expectations of the AI industry.Updating timelinesMy most striking takeaway is that the AI 2027 sequence of events, from AI models automating research engineers to later automating AI research, and potentially a singularity if your reasoning is so inclined, is becoming a standard by which many debates on AI progress operate under and tinker with. It’s good that many people are taking the long term seriously, but there’s a risk in so many people assuming a certain sequence of events is a sure thing and only debating the timeframe by which they arrive.I’ve documented my views on the near term of AI progress and not much has changed, but through repetition I’m developing a more refined version of the arguments. I add this depth to my takes in this post.I think automating the “AI Research Engineer (RE)” is doable in the 3-7 year range — meaning the person that takes a research idea, implements it, and compares it against existing baselines is entirely an AI that the “scientists” will interface with.In some areas the RE is arguably already automated. Within 2 years a lot of academic AI research engineering will be automated with the top end of tools — I’m not sure academics will have access to these top end of tools but that is a separate question. An example I would give is coming up with a new optimizer and testing it on a series of ML baselines from 100M to 10B parameters. At this time I don’t expect the models to be able to implement the newest problems the frontier labs are facing alone. I also expect academics to be fully priced out from these tools.Within 1-3 years we’ll have tools that make existing REs unbelievably productive (80-90% automated), but there are still meaningful technical bottlenecks that are solvable but expensive. The compute increase per available user has a ceiling too. Labs will be spending $200k+ per year per employee on AI tools easily (ie the inference cost), but most consumers will be at tiers of $20k or less due to compute scarcity.Within 3-4 years the augmented research engineers will be able to test any idea that the scientists come up with at the frontier labs, but many complex system problems will need some (maybe minimal) amount of human oversight. Examples would include modifying RL implementations for extremely long horizon tasks or wacky new ideas on continual learning. This is so far out that the type of research idea almost isn’t worth speculating on.These long timelines are strongly based on the fact that the category of research engineering is too broad. Some parts of the RE job will be fully automated next year, and more the next. To check the box of automation the entire role needs to be replaced. What is more likely over the next few years, each engineer is doing way more work and the job description evolves substantially. I make this callout on full automation because it is required for the distribution of outcomes that look like a singularity due to the need to remove the human bottleneck for an ever accelerating pace of progress. This is a point to reinforce that I am currently confident in a singularity not happening.Up-skilling employees as their roles become irrelevant creates a very different dynamic. The sustained progress on code performance over the next few years will create a constant feeling of change across the technology industry. The range of performance in software is very high and it is possible to perceive relatively small incremental improvements.These are very complex positions to hold, so they’re not that useful as rhetorical devices. Code is on track to being solved, but the compute limits and ever increasing complexity of codebases and projects (ie. LLMs) is going to make the dynamic very different than the succinct assumptions of AI 2027.To reiterate, the most important part of automation in the discussion is often neglected. To automate someone you need to outcompete the pairing of a human with the tool too.Onto the even trickier argument in the AI 2027 standard — automating AI research altogether. At the same time as the first examples of AI systems writing accepted papers at notable AI venues, I’m going to be here arguing that full automation of AI research isn’t coming anytime soon. It’s daunting to try and hold (and explain) this position, and it relies on all the messy firsthand knowledge of science that I have and how it is different in academia versus frontier AI labs.For one, the level and type of execution at frontier labs relative to academic research is extremely different. Academia also has a dramatically higher variance in quality of work that is accepted within the community. For this reason, we’re going to be seeing incredible
ChatGPT: The Agentic App
Ever since ChatGPT exploded in popularity, there has been a looming “how” to its monetization plans. Much has been said about shopping and advertising as the likely paths, especially with Fidji Simo joining as CEO of Applications under Sam Altman. Advertising as a business model for AI is logical but difficult to personalize and specialize. We know tons of people spend a lot of time using AI models, but how do you best get the sponsored content into the outputs? This is an open technical problem, with early efforts from the likes of Perplexity falling short.Shopping is another, but the questions have long been whether AI models actually have the precision to find the items you want, to learn exactly what you love, and to navigate the web to handle all the corner cases of checkouts. These reflect a need for increased capabilities on known AI benchmarks, rather than inventing a new way of serving ads. OpenAI’s o3 model was a major step up in search functionality, showing it was viable; the integration was either a business problem — where OpenAI had to make deals — or an AI one — where ChatGPT wasn’t good enough at managing websites for you.Yesterday, ChatGPT launched its first integrated shopping push with Buy It in ChatGPT, a simple checkout experience, and an integrated commerce backend built on the Agentic Commerce Protocol (ACP). The announcement comes with the perfect partners to complement the strengths of OpenAI’s current models. GPT-5-Thinking is the best at finding niche content on the web, and ChatGPT’s launch partner for shopping is Shopify (*soon, Etsy is available today), the home to the long tail of e-commerce merchants of niche specialties. If this works, it will let users actively uncover exactly what they are looking for — from places that were often hard to impossible to find on Google. This synergy is a theme we’ll see reoccur in other agents of the future. The perfect model doesn’t make a useful application unless it has the information or sandbox it needs to think, search, and act. The crucial piece that is changing is that where models act is just as important as the weights themselves — in the case of shopping, it is the network of stores with their own rankings and API.The ACP was built in collaboration with Stripe, and both companies stand to benefit from this. Stripe wants more companies to build on the ACP so that its tools become the “open standard for agentic payments” and OpenAI wants the long-tail of stores to adopt it so they can add them to their ever-growing internal recommendation (or search) engine. The business model is simple, as OpenAI says “Merchants pay a small fee on completed purchases.” OpenAI likely takes a larger share than Stripe, and it is a share that can grow as their leverage increases over shoppers.I’m cautiously optimistic about this. Finding great stuff to buy on the web is as hard as it has ever been. Users are faced with the gamification of Google search for shopping and the enshittification of the physical goods crowding out Amazon. Many of the best items to buy are found through services like Meta’s targeted ads, but the cost of getting what you want should not be borne through forced distraction.OpenAI will not be immune to the forces that drove these companies to imperfect offerings, but they’ll come at them with a fresh perspective on recurring issues in technology. If this works for OpenAI, they have no competitor. They have a distribution network of nearly 1B weekly users and no peer company ready to serve agentic models at this scale. Yes, Google can change its search feed, but the thoroughness of models like GPT-5 Thinking is on a totally different level than Google search. This agentic model is set up to make ChatGPT the one Agentic App across all domains.The idea of an agentic model, and really the GPT-5 router itself, shows us how the grand idea of one giant model that’s the best for every conceivable use-case is crumbling. OpenAI only chooses the more expensive thinking model when it deems a free user to need it and they have an entirely different model for their coding products. On the other hand, Claude released their latest model, Claude 4.5 Sonnet, yesterday as well, optimizing their coding peak performance and speed yet again — they have no extended model family. The reality that different models serve very different use-cases and how AI companies need to decide and commit to a certain subset of them for their development points to a future with a variety of model providers. Where coding is where you can feel the frontier of AI’s raw intelligence or capabilities, and Anthropic has turned their entire development towards it, the type of model that is needed for monetization of a general consumer market could be very different. This is the web-agent that OpenAI has had the industry-leading version of for about 6 months. Specialization is making the AI market far more interesting, as companies like OpenAI and Google have been in lockstep

Thinking, Searching, and Acting
The weaknesses of today’s best models are far from those of the original ChatGPT — we see they lack speed, we fear superhuman persuasion, and we aspire for our models to be more autonomous. These models are all reasoning models that have long surpassed the original weaknesses of ChatGPT-era language models, hallucinations, total lack of recent information, complete capitulations, and other hiccups that looked like minor forms of delusion laid on top of an obviously spectacular new technology.Reasoning models today are far more complex than the original chatbots that consisted of standalone model weights (and other lightweight scaffolding such as safety filters). They're built on three primitives that'll be around for years to come:* Thinking: The reasoning traces that enabled inference-time scaling. The "thoughts" of a reasoning model take a very different form than those of humans that inspired the terminology used like Chain of Thought (CoT) or Thinking models.* Searching: The ability to request more, specific information from non-parametric knowledge stores designed specifically for the model. This fills the void set by how model weights are static but living in a dynamic world.* Acting: The ability for models to manipulate the physical or digital world. Everything from code-execution now to real robotics in the future allow language models to contact reality and overcome their nondeterministic core. Most of these executable environments are going to build on top of infrastructure for coding agents.These reasoning language models, as a form of technology are going to last far longer than the static model weights that predated and birthed ChatGPT. Sitting just over a year out from the release of OpenAI's o1-preview on September 12, 2024, the magnitude of this is important to write in ink. Early reasoning models with astounding evaluation scores were greeted with resounding criticism of “they won’t generalize,” but that has turned out to be resoundingly false.In fact, with OpenAI's o3, it only took 3-6 months for these primitives to converge! Still, it took the AI industry more broadly a longer time to converge on this. The most similar follow-up on the search front was xAI's Grok 4 and some frontier models such as Claude 4 express their reasoning model nature in a far more nuanced manner. OpenAI's o3 (and GPT-5 Thinking, a.k.a. Research Goblin) and xAI's Grok 4 models seem like a dog determined to chase their goal indefinitely and burn substantial compute along the way. Claude 4 has a much softer touch, resulting in a model that is a bit less adept at search, but almost always returns a faster answer. The long-reasoning traces and tool use can be crafted to fit different profiles, giving us a spectrum of reasoning models.The taxonomy that I laid out this summer for next-generation reasoning models — skills for reasoning intelligence, calibration to not overthink, strategy to choose the right solutions, and abstraction to break them down — are the traits that'll make a model most functional given this new perspective and agentic world.The manner of these changes are easy to miss. For one, consider hallucinations, which are an obvious weakness downstream of the stochastic inference innate to the models and their fixed date cutoff. With search, hallucinations are now missing context rather than blatantly incorrect content. Language models are nearly-perfect at copying content and similarly solid at referencing it, but they're still very flawed at long-context understanding. Hallucinations still matter, but it’s a very different chapter of the story and will be studied differently depending on if it is for reasoning or non-reasoning language models.Non-reasoning models still have a crucial part to play in the AI economy due to their efficiency and simplicity. They are part of a reasoning model in a way because you can always use the weights without tools and they'll be used extensively to undergird the digital economy. At the same time, the frontier AI models (and systems) of the coming years will all be reasoning models as presented above — thinking, searching, and acting. Language models will get access to more tools of some form, but all of them will be subsets of code or search. In fact, search can be argued to be a form of execution itself, but given the imperative of the underlying information it is best left as its own category.Another popular discussion with the extremely-long generations of reasoning models has been the idea that maybe more efficient architectures such as diffusion language models could come to dominate by generating all the tokens in parallel. The (or rather, one) problem here is that they cannot easily integrate tools, such as search or execution, in the same way. These’ll also likely be valuable options in the AI quiver, but barring a true architectural or algorithmic revolution that multiplies the performance of today’s AI models, the efficiency and co-design underway for large t
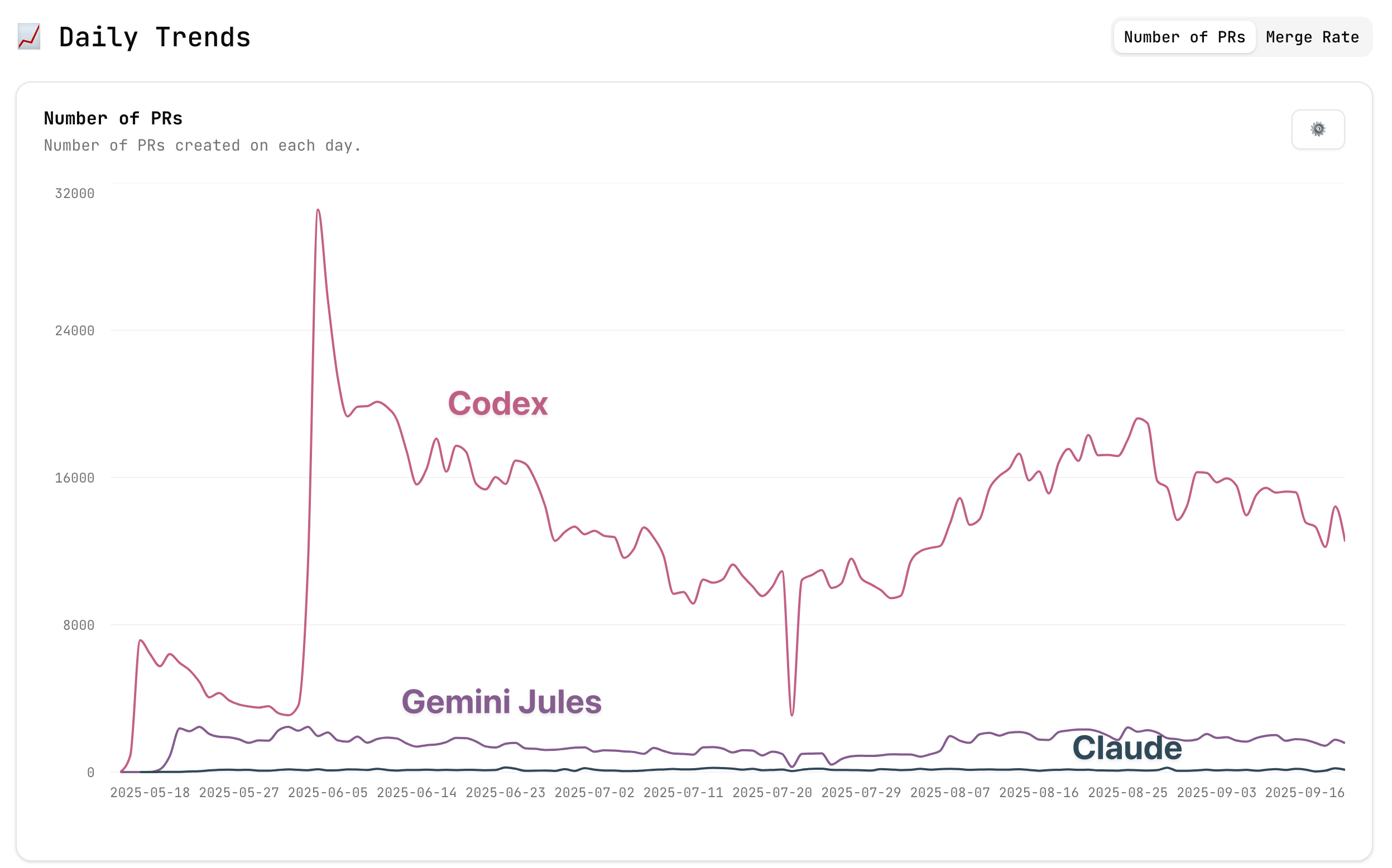
Coding as the epicenter of AI progress and the path to general agents
Coding, due to its breadth of use-cases, is arguably the last tractable, general domain of continued progress for frontier models that most people can interface with. This is a bold claim, so let’s consider some of the other crucial capabilities covered in the discourse of frontier models:* Chat and the quality of prose written by models has leveled off, other than finetuning to user measures such as sycophancy. * Mathematics has incredible results, but very few people directly gain from better theoretical mathematics. * The AIs’ abilities to do novel science are too unproven to be arguable as a target of hillclimbing. Still, coding is a domain where the models are already incredibly useful, and they continue to consistently stack on meaningful improvements. Working daily with AI over the last few years across side projects and as an AI researcher, it has been easy to take these coding abilities for granted because some forms of them have been around for so long. We punt a bug into ChatGPT and it can solve it or autocomplete can tab our way through entire boilerplate. These use-cases sound benign, and haven’t changed much in that description as they have climbed dramatically in capabilities. Punting a niche problem in 1000+ lines of code to GPT-5-Pro or Gemini Deep Think feels like a very fair strategy. They really can sometimes solve problems that a teammate or I were stuck on for hours to days. We’re progressing through this summarized list of capabilities:* Function completion: ~2021, original Github CoPilot (Codex)* Scripting: ~2022, ChatGPT* Building small projects: ~2025, CLI agents* Building complex production codebases, ~2027 (estimate, which will vary by the codebase)Coding is maybe the only domain of AI use where I’ve felt this slow, gradual improvement. Chat quality has been “good enough” since GPT-4, search showed up and has been remarkable since OpenAI’s o3. Through all of these more exciting moments, AIs’ coding abilities have just continued to gradually improve. Now, many of us are starting to learn a new way of working with AI through these new command-line code agents. This is the largest increase in AI coding abilities in the last few years. The problem is the increase isn’t in the same domain where most people are used to working with AI, so the adoption of the progress is far slower. New applications are rapidly building users and existing distribution networks barely apply. The best way to work with them — and I’ll share more examples of what I’ve already built later in this post — is to construct mini projects, whether it’s a new bespoke website or a script. These are fantastic tools for entrepreneurs and researchers who need a way to quickly flesh out an idea. Things that would’ve taken me days to weeks can now be attempted in hours. Within this, the amount of real “looking at the code” that needs to be done is definitely going down. Coding, as an activity done through agents, is having the barriers to entry fully fall down through the same form factor that is giving the act of coding re-found joy.Why I think a lot of people miss these agents is that the way to use the agents is so different from the marketing of incredible evaluation breakthroughs that the models are reaching. The gap between “superhuman coding” announcements and using an agent for mini projects is obviously big. The best way to use the agents is still mundane and requires careful scoping of context. For example, yesterday, on September 17, 2025, OpenAI announced that GPT-5 as part of a model system got a higher score than any human (and Google’s Gemini Deep Think) at the ICPC World Finals, “the premier collegiate programming competition where top university teams from around the world solve complex algorithmic problems.” Here’s what an OpenAI researcher said they did:We competed with an ensemble of general-purpose reasoning models; we did not train any model specifically for the ICPC. We had both GPT-5 and an experimental reasoning model generating solutions, and the experimental reasoning model selecting which solutions to submit. GPT-5 answered 11 correctly, and the last (and most difficult problem) was solved by the experimental reasoning model.These competitions often get highlighted because they’re “finite time,” so the system must respond in the same fixed time as a human does, but the amount of compute used by GPT-5 or another model here is likely far higher than any user has access to. This is mostly an indication that further ability, which some people call raw intelligence, can be extracted from the models, but most of that is limited by scaffolding and product when used by the general population.The real story is that these models are delivering increasing value to a growing pool of people.For followers of AI, coding with AI models is the easiest way to feel progress. Now that models are so good at chat, it takes very specialized tasks to test the general knowledge of models, or many of the gains are in g
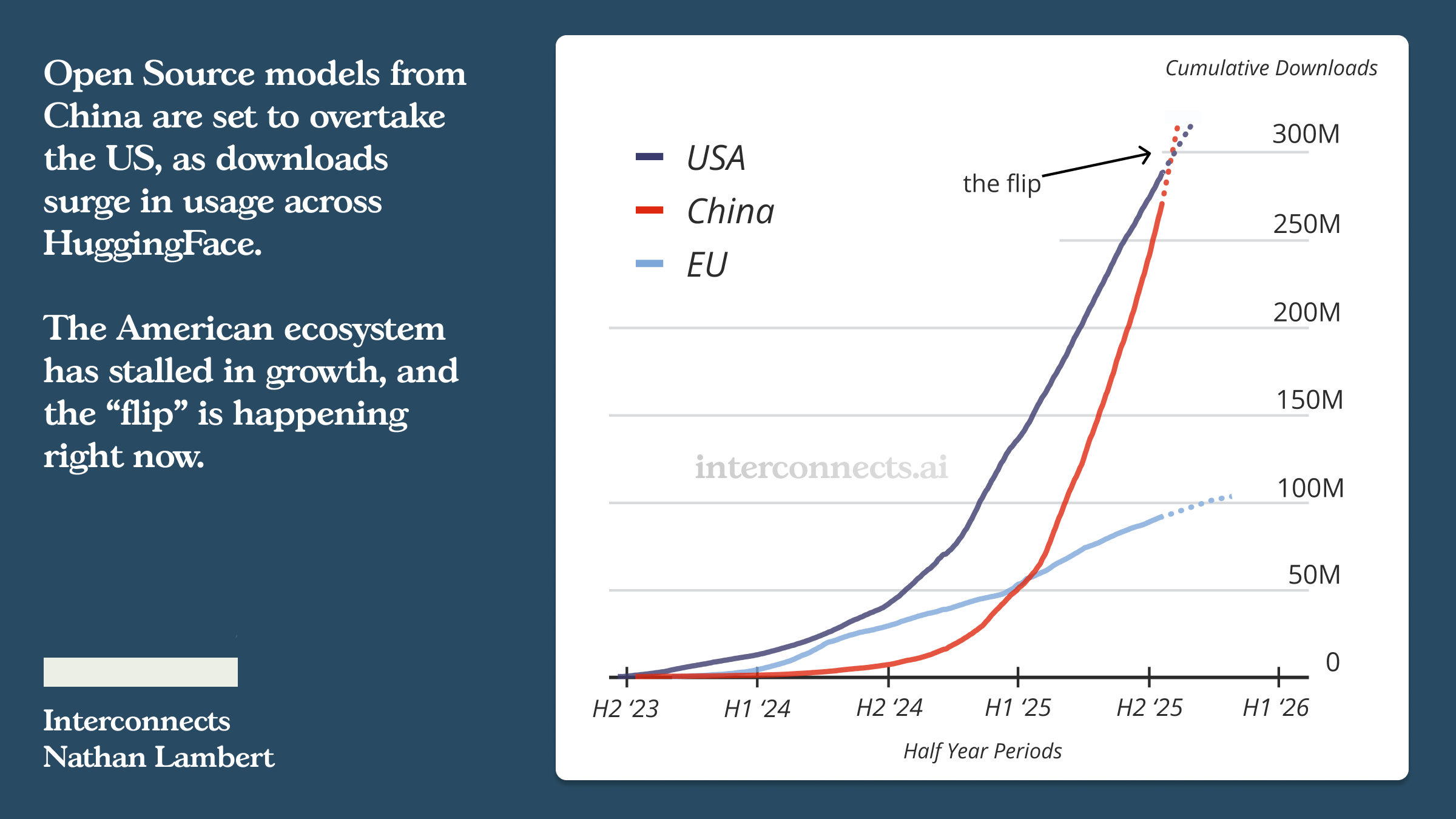
On China's open source AI trajectory
Hello everyone! I’m coming back online after two weeks of vacation. Thankfully it coincided with some of the slowest weeks of the year in the AI space. I’m excited to get back to writing and (soon) share projects that’ll wrap up in the last months of the year.It seemed like a good time to remind people of the full set of housekeeping for Interconnects. * Many people love the audio version of the essays (read by me, not AI). You can get them in your podcast player here. Paid subscribers can add private podcast feeds under “manage your subscription” where voiceover is available for paywalled posts.* The Interconnects Discord for paid subscribers continues to get better, and is potentially the leading paid perk amid the fragmentation of Twitter etc.* We’re going to be rolling out more perks for group subscriptions and experimental products this fall. Stay tuned, or get in touch if group discounts are super exciting for your company. For the time being, I’m planning trips and meetups across a few conferences in October. I’ll be speaking at The Curve (Oct. 3-5, Berkeley), COLM (Oct. 7-10, Montreal, interest form), and the PyTorch Conference (Oct. 21-24, SF) on open models, Olmo, and the ATOM Project, so stay tuned for meetups and community opportunities. On to the post!China is maneuvering to double down on its open AI ecosystem. Depending on how the U.S. and its allies change culture and mobilize investment, this could make the dominance of Chinese AI models this summer, from Qwen, Kimi, Z.ai, and DeepSeek, looks like foreshadowing rather than the maximum gap in open models between the U.S. and China. Until the DeepSeek moment, AI was likely a fringe issue to the PRC Government. The central government will set guidelines, rules, budgets, and focus areas that will be distributed and enforced across the decentralized government power structures. AI wasn’t a political focus and the strategy of open-source was likely set by companies looking to close the gap with leading American competitors and achieve maximum market share in the minimum time. I hear all the time that most companies in the U.S. want to start with open models for IT and philosophical reasons, even when spinning up access to a new API model is almost effortless, and it’s likely this bias could be even higher internationally where spending on technology services is historically lower.Most American startups are starting with Chinese models. I’ve been saying this for a while, but a more official reference for this comes from a recent quote from an a16z partner, Martin Casado, another vocal advocate of investment in open models in America. He was quoted in The Economist with regards to his venture portfolio companies:“I’d say 80% chance [they are] using a Chinese open-source model.”The crucial question for the next few years in the geopolitical evolution of AI is whether China will double down on this open-source strategy or change course. The difficulty with monitoring this position is that it could look like nothing is happening and China maintains its outputs, even when the processes for creating them are far different. Holding a position is still a decision.It’s feasible in the next decade that AI applications and open models are approached with the same vigor that China built public infrastructure over the last few decades (Yes, I’m reading Dan Wang’s new book Breakneck). It could become a new area that local officials compete in to prove their worth to the nation — I’m not sure even true China experts could make confident predictions here. A large source of uncertainty is whether the sort of top-down, PRC edicts can result in effective AI models and digital systems, where government officials succeeded in the past with physical infrastructure.At the same time as obvious pro-AI messaging, Chinese officials have warned of “disorderly competition” in the AI space, which is an indirect signal that could keep model providers releasing their models openly. Open models reduce duplicative costs of training, help the entire ecosystem monitor best practices, and force business models that aren’t reliant on simple race-to-the-bottom inference markets. Open model submarkets are emerging for every corner of the AI ecosystem, such as video generation or robotic action models, (see our coverage of open models, Artifacts Logs) with a dramatic evolution from research ideas to mature, stable models in the last 12-18 months.China improving the open model ecosystem looks like the forced adoption of Chinese AI chips, further specialization of companies’ open models to evolving niches, and expanded influence on fundamental AI research shared internationally. All of these directions have early signs of occurring.If the PRC Government wanted to exert certain types of control on the AI ecosystem — they could. This Doug Guthrie excerpt from Apple in China tells the story from the perspective of international companies. Guthrie was a major player in advising on culture chan

Ranking the Chinese Open Model Builders
The Chinese AI ecosystem has taken the AI world by storm this summer with an unrelenting pace of stellar open model releases. The flagship releases that got the most Western media coverage are the likes of Qwen 3, Kimi K2, or Zhipu GLM 4.5, but there is a long-tail of providers close behind in both quality and cadence of releases.In this post we rank the top 19 Chinese labs by the quality and quantity of contributions to the open AI ecosystem — this is not a list of raw ability, but outputs — all the way from the top of DeepSeek to the emerging open research labs. For a more detailed coverage of all the specific models, we recommend studying our Artifacts Log series, which chronicles all of the major open model releases every month. We plan to revisit this ranking and make note of major new players, so make sure to subscribe.At the frontierThese companies rival Western counterparts with the quality and frequency of their models.DeepSeekdeepseek.com | 🤗 deepseek-ai | X @DeepSeek_AIDeepSeek needs little introduction. Their V3 and R1 models, and their impact, are still likely the biggest AI stories of 2025 — open, Chinese models at the frontier of performance with permissive licenses and the exposed model chains of thought that enamored users around the world.With all the attention following the breakthrough releases, a bit more has been said about DeepSeek in terms of operations, ideology, and business model relative to the other labs. They are very innovative technically and have not devoted extensive resources to their consumer chatbot or API hosting (as judged by higher than industry-standard performance degradation).Over the last 18 months, DeepSeek was known for making “about one major release a month.” Since the updated releases of V3-0324 and R1-0528, many close observers have been surprised by their lack of contributions. This has let other players in the ecosystem close the gap, but in terms of impact and actual commercial usage, DeepSeek is still king.An important aspect of DeepSeek’s strategy is their focus on improving their core models at the frontier of performance. To complement this, they have experiments using their current generation to make fundamental research innovations, such as theorem proving or math models, which ultimately get used for the next iteration of models. This is similar to how Western labs operate. First, you test a new idea as an experiment internally, then you fold it into the “main product” that most of your users see.DeepSeekMath, for example, used DeepSeek-Coder-Base-v1.5 7B and introduced the now famous reinforcement learning algorithm Group Relative Policy Optimization (GRPO), which is one of the main drivers of R1. The exception to this (at least today) is Janus, their omni-modal series, which has not been used in their main line.Qwenqwenlm.ai | 🤗 Qwen | X @Alibaba_QwenTongyi Qianwen, the primary AI lab within Alibaba’s cloud division, is by far and away most known for their open language model series. They have been releasing many models across a range of sizes (quite similar to Llama 1 through 3) for years. Recently, their models from Qwen 2.5 and Qwen 3 have had accelerating market share among AI research and startup development.Qwen is closer to American Big Tech companies than to other Chinese AI labs in terms of releases: They are covering the entire stack, from VLMs to embedding models, coding models, image and video generation, and so on.They also cater to all possible customers (or rather every part of the open community) by releasing capable models of all sizes. Small dense models are important for academia to run experiments and for small/medium businesses to power their applications, so it comes to no surprise that Qwen-based models are exploding in popularity.On top of model releases for everyone, they also focused on supporting the (Western) community, releasing MLX and GGUF versions of their models for local usage or a CLI for their coding models, which includes a generous amount of free requests.Unlike some American companies, the core team seems to have stayed relatively small in terms of headcount, in line with other Chinese AI labs: Qwen3 has 177 contributors, whereas Llama 3 has thrice the amount, while Gemini 2.5 has over 3,000 people as part of the model. Close competitorsThese companies have recently arrived at the frontier of performance and we will see if they have the capability to consistently release great models at a pace matching Qwen or DeepSeek.Moonshot AI (Kimi)moonshot.cn | 🤗 moonshotai | X @Kimi_MoonshotMoonshot AI is one of the so-called “AI tigers”, a group of hot Chinese AI startups determined by Chinese media and investors. This group consists of Baichuan, Zhipu AI, Moonshot AI, MiniMax, StepFun, and 01.AI — most of which have attracted investments by tech funds and other tech grants. For example, Alibaba is seen as a big winner in the AI space by having their own models and by being a lead investor in Moonshot, sort of lik
Contra Dwarkesh on Continual Learning
Dwarkesh Patel’s now well-read post on why he is extending his AI timelines focuses on the idea of continual learning. If you ask me, what we have already is AGI, so the core question is: Is continual learning a bottleneck on AI progress?In this post, I argue that continual learning as he describes it actually doesn’t matter for the trajectory of AI progress that we are on. Continual learning will eventually be solved, but in the sort of way that a new type of AI will emerge from it, rather than continuing to refine what it means to host ever more powerful LLM-based systems. Continual learning is the ultimate algorithmic nerd snipe for AI researchers, when in reality all we need to do is keep scaling systems and we’ll get something indistinguishable from how humans do it, for free.To start, here’s the core of the Dwarkesh piece as a refresher for what he means by continual learning.Sometimes people say that even if all AI progress totally stopped, the systems of today would still be far more economically transformative than the internet. I disagree. I think the LLMs of today are magical. But the reason that the Fortune 500 aren’t using them to transform their workflows isn’t because the management is too stodgy. Rather, I think it’s genuinely hard to get normal humanlike labor out of LLMs. And this has to do with some fundamental capabilities these models lack.I like to think I’m “AI forward” here at the Dwarkesh Podcast. I’ve probably spent over a hundred hours trying to build little LLM tools for my post production setup. And the experience of trying to get them to be useful has extended my timelines. I’ll try to get the LLMs to rewrite autogenerated transcripts for readability the way a human would. Or I’ll try to get them to identify clips from the transcript to tweet out. Sometimes I’ll try to get them to co-write an essay with me, passage by passage. These are simple, self contained, short horizon, language in-language out tasks - the kinds of assignments that should be dead center in the LLMs’ repertoire. And they're 5/10 at them. Don’t get me wrong, that’s impressive.But the fundamental problem is that LLMs don’t get better over time the way a human would. The lack of continual learning is a huge huge problem. The LLM baseline at many tasks might be higher than an average human's. But there’s no way to give a model high level feedback. You’re stuck with the abilities you get out of the box. You can keep messing around with the system prompt. In practice this just doesn’t produce anything even close to the kind of learning and improvement that human employees experience.The core issue I have with this argument is the dream of making the LLMs we’re building today look more like humans. In many ways I’m surprised that Dwarkesh and other very AGI-focused AI researchers or commentators believe this — it’s the same root argument that AI critics use when they say AI models don’t reason. The goal to make AI more human is constraining the technological progress to a potentially impossible degree. Human intelligence has long been the inspiration for AI, but we have long surpassed it being the mirror we look to for inspiration. Now the industry is all in on the expensive path to make the best language models it possibly can. We’re no longer trying to build the bird, we’re trying to transition the Wright Brothers’ invention into the 737 in the shortest time frame possible.To put it succinctly. My argument very much rhymes with some of my past writing. Do language models reason like humans? No. Do language models reason? Yes. Will language model systems continually learn like humans? No.Will language model systems continually learn? Of course.Interconnects is a reader-supported publication. Consider becoming a subscriber.Dwarkesh writes “Rather, I think it’s genuinely hard to get normal humanlike labor out of LLMs.” This is because we’re still early on the buildout of the technology. Human labor takes an immense amount of context and quick thinking, both of which we’re starting to unlock with our language models. On top of this, human labor may not be what we want to create — we want to augment it. Using LLMs as drop in replacements for humans is not a requirement for AGI nor is what Dwarkesh describes a fundamental limitation on AI progress. Francois Chollet cleverly poked at this weakness in his recent conversation with Dwarkesh at an ARC-AGI event:Well, how do you define the difference between the ability to adapt to a new task and learning on the fly? It's, it sounds like the same thing to me.Language models can already pick up subtle context extremely fast. ChatGPT’s memory feature has gotten far better for me. When we’re using the far more powerful models we can expect in the next 18 months this’ll already start to appear magical. Language models are extremely apt at inferring context even without us giving it to them. Soon we’ll be unlocking that subtle connection engine by providing immense, explicit con
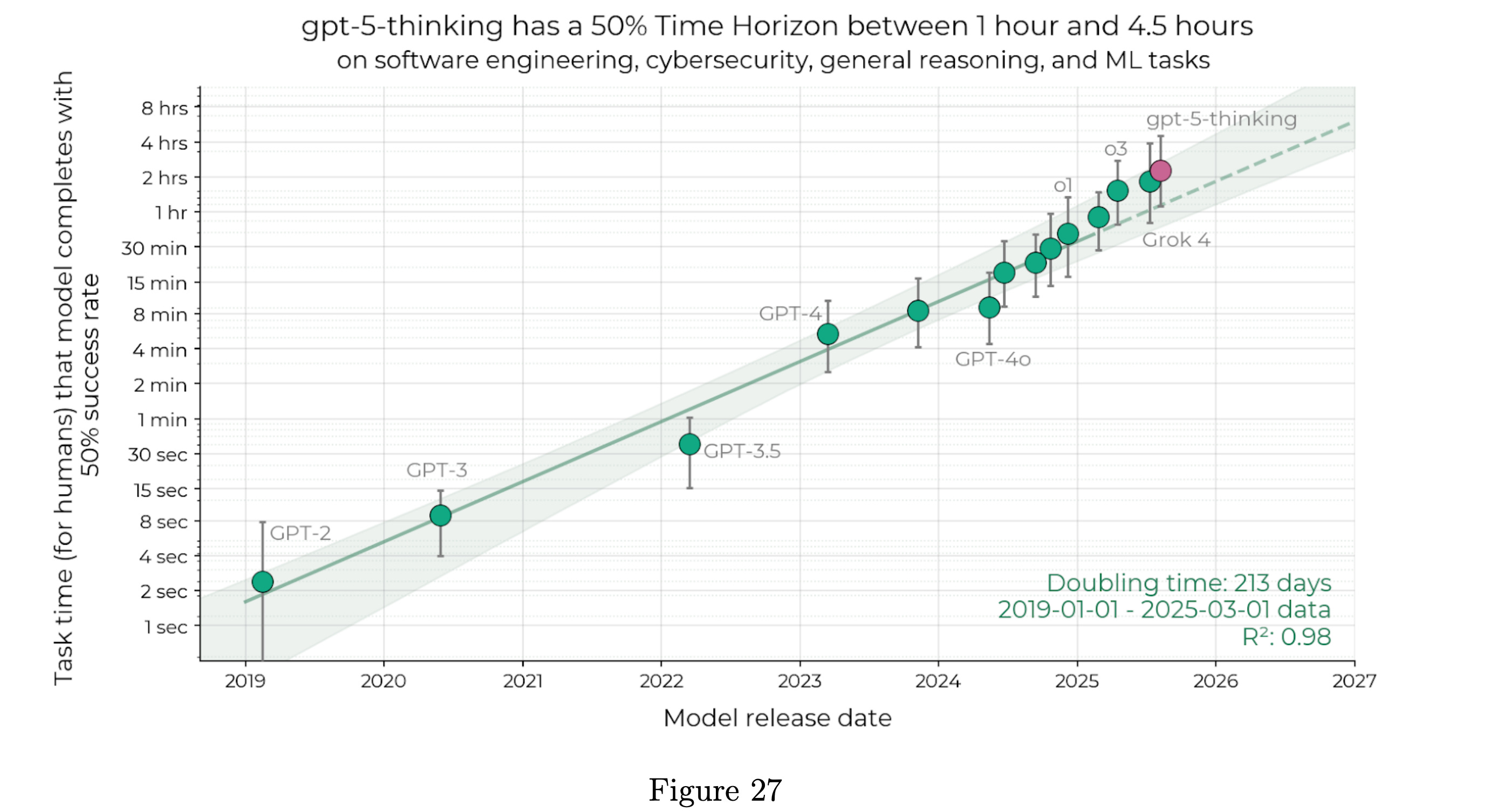
GPT-5 and the arc of progress
If you want a video version of this, check out the last 20 minutes of the livestream reaction (edit, fixed link) I did with Will Brown of Prime Intellect and Swyx of Smol AI & Latent Space.GPT-5 was set up to fail on some of the narratives it was expected to satisfy. The two central themes it had to decide between were the AGI (or superintelligence) narrative that Sam Altman & co. have been using to fundraise and the fact that ChatGPT is one of the fastest-growing consumer technologies of all time. To fulfill both, GPT-5 needed to be AGI while also being cheap enough to serve as the most-used AI system in the world. Business and technological realities made it inevitable that GPT-5’s primary impact would be to solidify OpenAI’s market position, even if it raises a lot of eyebrows for the long-term trajectory of AI.The reactions online capture this as well. The OpenAI live streams have historically catered to AI insiders, but the product speaks entirely to a different audience. The people discussing this release on Twitter will be disappointed in a first reaction, but 99% of people using ChatGPT are going to be so happy about the upgrade. Confusingly enough, this includes many of the critics. GPT-5 is a good AI system. It’s right in line with best-in-class across pretty much every evaluation, while being cheap enough to serve the whole world. OpenAI is largely fixing its product offering with an announcement that was hyped to be one of the biggest AI news cycles of the year. AI news being loud is defined by narratives being different more-so than technology being better. OpenAI releasing an open model again will likely be pinpointed as just as important a day for the arc of AI as the GPT-5 release. In many ways GPT-5 was set up to fail and that is very off-putting for those expecting maximum AI progress in the near term.I’m not going to dwell on it, but oh boy, that was a messy release. GPT-5 being announced and rolled out like this is very odd. Countless plots were mislabeled, live demos had bugs, and the early rollout is doing some weird stuff. This reinforces how OpenAI was torn about the release and backed into a corner with their messaging. They knew they needed to improve the experience with strong competition in the industry, but releasing GPT-5 needed to make a splash after how long they’ve waited (and already parked the GPT 4.5 name).The core question we track in this post is: What does it mean for the next 6-18 months of AI progress if GPT-5 is just as good as all the best models out there, e.g., Claude Sonnet for coding or o3 for search, funneled into one, super cheap package? If AGI was a real goal, the main factor on progress would be raw performance. GPT-5 shows that AI is on a somewhat more traditional technological path, where there isn’t one key factor, it is a mix of performance, price, product, and everything in between. Interconnects is a reader-supported publication. Consider becoming a subscriber.GPT-5’s performanceThere are a few places that we can see that GPT-5 represents a solid step on the performance trend line, but nothing like a step change. First, on LMArena, GPT-5 is fantastic, sweeping the board to #1 on all categories. The last model to claim #1 in pretty much every category was Gemini 2.5 Pro — and that was the biggest step change in Elo since GPT-4 Turbo skyrocketed past the first Claude.Second, GPT-5 is the top model on the ArtificialAnalysis composite benchmark.These two, LMArena & ArtificialAnalysis, represent two coarse evaluations — community vibes and raw benchmarks. Both of these can be gamed, but are still correlated with real-world use. You can also see in OpenAI’s shared results how much the smaller versions improve on the likes of GPT-4.1 mini and o4-mini.In many ways, the march of progress on evals has felt slowed for a while because model releases are so frequent and each individual step is smaller. Lots of small steps make for big change. The overall trend line is still very positive, and multiple companies are filling in the shape of it. My post on “what comes next” from earlier this summer all but called this type of release, where the numbers aren’t shocking but the real world use cases are great, becoming more common.This is a different path for the industry and will take a different form of messaging than we’re used to. More releases are going to look like Anthropic’s Claude 4, where the benchmark gains are minor and the real world gains are a big step. There are plenty of more implications for policy, evaluation, and transparency that come with this. It is going to take much more nuance to understand if the pace of progress is continuing, especially as critics of AI are going to seize the opportunity of evaluations flatlining to say that AI is no longer working.To say it succinctly: Abilities will develop more slowly than products.The product overhang is being extended with each release. We’re still building untapped value with AI models and systems fas

gpt-oss: OpenAI validates the open ecosystem (finally)
OpenAI released two open-weight, text-only reasoning models today, both mixture of experts (MoE) sized to run efficiently on a range of hardware from consumer GPUs to the cloud. These models have the Apache 2.0 license, so they’re available for distillation into other reasoning models, deployment into commercial products, and are free of downstream restrictions. These two models, the smaller gpt-oss-20B with 3.6B active parameters and 21B total and the larger gpt-oss-120B with 5.1B active parameters, follow the trends we’ve seen with the other leading open models in architecture choices. Where this release shines is in the dramatic change in open model performance and strategy that comes with the leading name in AI releasing an open model that undercuts some of their own API products.We’ll get to the technical details on the model later, but the main point of this post is how much OpenAI has changed by releasing their first open language model since GPT-2. The larger 120B model “achieves near-parity with OpenAI o4 mini on core reasoning benchmarks” and is a major moment for the ecosystem:* OpenAI has released an open model at the frontier of current open model performance — highlighting how major concerns over open models that OpenAI leadership mentioned in 2023 were overblown. The marginal risks of open models have been shown to not be as extreme as many people thought (at least for text only — multimodal is far riskier). Once other organizations, particularly Meta and China showed OpenAI that there was no risk here, the path was opened to release a model.* OpenAI has revealed far more of their technical stack than any release to date. This blog post has light details on many things in the model, but community tinkering will begin to better understand what is going on here. This includes basic things like our first time seeing a raw chain of thought (CoT) for an OpenAI reasoning model, but also more interesting things like how this model is trained to use tools in the CoT like their o3 model. Other details include researchers being able to play with OpenAI’s instruction hierarchy in raw weights (where pieces of it are untouchable in the API), a new “harmony” prompt format, the same “reasoning efforts” of low, medium & high from the API, a huge proof of concept on how far basic, community standard architectures with MoEs can be pushed, and other small details for the AI community to unpack.* OpenAI has initiated a scorched earth policy on the API market, undercutting their own offerings and unleashing an extremely strong, trusted model brand with a permissive license. While adoption of any open model is much slower than an API due to testing, additional configuration, etc., this is set up to go about as fast as it can. Any API model that competes with current models like OpenAI o4 mini, Claude Haiku, Gemini Flash, DeepSeek R1 etc. are all going to have to compete with this model. OpenAI’s o4 mini model is currently served at $1.1 per million input tokens and $4.4 per million output. Serving this open model will likely cost at least 10x less. There are many potential strategic reasons for this, all of which paint OpenAI as having a clearer vision of what makes it valuable. What OpenAI hasn’t touched with this model is interesting too — “For those seeking multimodal support, built-in tools, and seamless integration with our platform, models available through our API platform remain the best option.” These are dropped for reasons above, and “headaches” discussed later in the post.Together, these paint a much clearer vision by OpenAI on how they’ll control the AI ecosystem. The top potential reasons on my mind are:* OpenAI could be trying to make all API models potentially obsolete on cost ahead of the GPT-5 release, which they hope to capture the top end of the market on. Or,* OpenAI could be realizing that models are no longer their differentiation, as ChatGPT users continue to steadily climb — and they’ll soon pass 1 billion weekly actives.There are plenty of other reasons, such as the politics alluded to at the end of the blog post, but OpenAI tends to only act when it serves them directly — they’ve always been a focused company on their goals.There’s also a long list of head scratchers or in-between the lines points that illuminate OpenAI’s strategy a bit more. OpenAI of course didn’t release training data, code, or a technical report, as expected. OpenAI is trying to make a big splash with the name that captures more of the enterprise market, but in doing so takes some collateral damage in the research and true “open source” AI communities. These future questions include:* The naming is bad — a mixture of cringe, confusion-inducing, and still useful for their marketing goals. For anyone following open-source AI for a long time it won’t be new that a major company is blurring the association of the term open-source with the community accepted definitions. I understand why OpenAI did this, but the naming

Towards American Truly Open Models: The ATOM Project
I’m very excited to share a substantial project on invigorating investment in open language models and AI research in the U.S. The ATOM (American Truly Open Models) Project is the mature evolution of my original “American DeepSeek Project” and I hope it can help be a turning point in the current trajectory of losing open model relevance vis-a-vis China, and even the rest of the world.I’ve included the full text below, but I encourage you to visit the website for the full version with added visuals, data, and a place to sign your support. This is a community movement, rather than me fundraising, starting an organization, or anything like thatIf you can help get the word out and or sign your support, I’d greatly appreciate it. (Or watch a 5 minute overview on YouTube)The ATOM Project: Towards fully open models for US research & industryReinvigorating AI research in the U.S. by building leading, open models at homeAmerica's AI leadership was built by being the global hub and leading producer of open AI research, research which led directly to innovations like the Transformer architecture, ChatGPT, and the latest innovations in reasoning models and agents. America is poised to lose this leadership to China, in a period of geopolitical uncertainty and rising tensions between these two nations. America's best AI models have become more closed and restricted, while Chinese models have become more open, capturing substantial market share from businesses and researchers in the U.S. and abroad.Open language models are becoming the foundation of AI research and the most important tool in securing this leadership. America has lost its lead in open models – both in performance and adoption – and is on pace to fall further behind. The United States must lead AI research globally, and we must invest in making the tools our researchers need to do their job here in America: a suite of leading, open foundation models that can re-establish the strength of the research ecosystem.Recommendation: To regain global leadership in open source AI, America needs to maintain at least one lab focused on training open models with 10,000+ leading-edge GPUs. The PRC currently has at least five labs producing and releasing open models at or beyond the capabilities of the best U.S. open model. Regaining open source leadership is necessary to drive research into fundamental AI advances, to maximize U.S. AI market share, and to secure the U.S. AI stack.OverviewOpen language model weights and data are the core currency of recent AI research – these are the artifacts that people use to come up with new architectures, training paradigms, or tools that will lead to the next paradigms in AI to rival The Transformer or Inference-time Scaling. These research advances provide continued progress on existing products or form the basis for new technology companies. At the same time, open language models create potential for a broader suite of AI offerings by allowing anyone to build and modify AI how they see fit, without their data being sent through the cloud to a few, closed model providers.Open language models are crucial for long-term competition within American industry. Today, substantial innovation is happening inside of large, closed AI laboratories, but these groups can only cover so many of the potential ideas. These companies spend the vast majority of their resources focusing on the next model they need to train, where the broader, open research community focuses on innovations that’ll be transformative in 2, 5, 10, or more years. The most progress in building useful, intelligent AI systems will come when the most people can participate in improving today's state-of-the-art, rather than the select few at certain companies.The open AI ecosystem (regarding the models, not to be confused with the company OpenAI) has historically been defined by many parties participating. The United States emerged as a hub of the deep learning revolution via close collaboration between leading technology companies and academic institutions. Following ChatGPT, there have been countless contributions from around the globe. This distribution of impact on research has been collapsing towards clear Chinese leadership due to their commitment to open innovation, while a large proportion of leading scientists working in the United States have joined closed research organizations.The playbook that led Google to invent and share the Transformer – the defining language model architecture of which all leading models such as ChatGPT, Gemini, or Claude are derived from – is now the standard mode of operation for Chinese companies, but it is increasingly neglected by American companies.The impact of China’s models and research are growing because the institutions focused on open models have access to substantial compute resources for training – e.g. some have formed a close relationship between leading AI training laboratories and academic institutions. Until the United State

Interviewing Ross Taylor on the state of AI: Chinese open models, scaling reasoning, useful tools, and what comes next
I’m excited to welcome Ross Taylor back on the podcast (and sorry for the lack of episodes in general – I have a lot going on!). The first time Ross came on we focused on reasoning – before inference-time scaling and that sort of RL was popular, agents, Galactica, and more from his Llama days. Since then, and especially after DeepSeek R1, Ross and I have talked asynchronously about the happenings of AI, so it’s exciting to do it face to face.In this episode we cover some of everything:* Recent AI news (Chinese models and OpenAI’s coming releases)* “Do and don’t” of LLM training organizations* Reasoning research and academic blind spots* Research people aren’t paying enough attention to* Non language modeling news & other topicsListen on Apple Podcasts, Spotify, YouTube, and where ever you get your podcasts. For other Interconnects interviews, go here.Show outline as a mix of questions and edited assertions that Ross sent me as potential topics.00:00 Recent AI newsRelated reading is on Kimi’s K2 model, thoughts on OpenAI’s forthcoming open release.* What did you think of Z.ai’s GLM 4.5 model (including MIT licensed base model) with very strong scores? And Kimi?* What will OpenAI’s open model actually be?* What do you make of the state of the ecosystem?12:10 “Do and don’t” of LLM training organizationsRelated reading is on managing training organizations or the Llama 4 release.This is one of my favorite topics – I think a lot of great stuff will be written on it in the future. For now, Ross asserts…* Most major LLM efforts are not talent-bound, but politics-bound. Recent failures like Llama 4 are org failures not talent failures.* Most labs are chaotic, changing direction every week. Very different picture from the narrative presented online.* Most labs represent investment banks or accountancy firms in that they hire smart young people as “soldiers” and deliberately burn them out with extremely long hours.36:40 Reasoning research and academic blind spotsRelated reading is two papers point questions at the Qwen base models for RL (or a summary blog post I wrote).I start with: What do you think of o3, and search as something to train with RL?And Ross asserts…* Most open reasoning research since R1 has been unhelpful - because not enough compute to see what matters (underlying model and iterations).* Best stuff has been simple tweaks to GRPO like overlong filtering and removing KL divergence.* Far too much focus on MATH and code - AIME has tens of samples too so is very noisy.* People are generally building the wrong kind of environments - like puzzles, games etc - instead of thinking about what kind of new capabilities they’d like to incentivise emerging.50:20 Research people aren’t paying enough attention toThe research area I hear the most about right now is “rubrics” – a per-prompt specialized LLM-as-a-judge to replace reward models. SemiAnalysis reported OpenAI scaling this approach and lots of great research is coming out around it.I start with: What do you think of the state of RL scaling and generalization? What of models losingRoss asserts…* Rubrics are underhyped on social media - they were driving force behind projects like DeepResearch - and GenRMs are interesting but perhaps slightly overhyped.* There is an evals crisis - there are not enough high quality evals, particularly for frontier tasks like automating research and real life work. Impediment to anyone building agents or ASI.01:02:46 Extra stuff!I ask Ross: What AI are you using today? Why?To conclude, Ross wanted to discuss how AlphaEvolve has been underhyped on social media, and means the future isn’t just RL. Shows there are other effective ways to use inference compute.Interconnects is a reader-supported publication. Consider becoming a subscriber.TranscriptCreated with AI, pardon the minor typos, not quite enough time this week but I’m hiring someone to help with this soon!Nathan Lambert: Hey, Ross. How's it going? Welcome back to Interconnects. I took a many month break off podcasting. I've been too busy to do all this stuff myself.Ross Taylor: Yeah, I was trying to think of all the things that happened since the last time we did a podcast a year ago. In AI time, that's like two hundred years.Nathan Lambert: Yeah, so I was looking at it. We talked about reasoning and o1 hadn’t happened yet.For a brief intro, Ross was a co-founder of Papers with Code, and that brought him to Meta. And then at Meta, he was a lead on Galactica, which was a kind of language model ahead of its time relative to ChatGPT. So if people don't know about Galactica, there's a great paper worth reading. And then he was doing a bunch of stuff on reasoning with Llama related to a lot of the techniques that we'll talk about in this episode.And now he's doing a startup. I don't know if he wants to talk about this, but generally, we talk a lot about various things. This got started through o1 and trying to figure out scaling RL. We started talking a lot but then we also

The White House's plan for open models & AI research in the U.S.
Today, the White House released its AI Action Plan, the document we’ve been waiting for to understand how the new administration plans to achieve “global dominance in artificial intelligence (AI).” There’s a lot to unpack in this document, which you’ll be hearing a lot about from the entire AI ecosystem. This post covers one narrow piece of the puzzle — its limited comments on open models and AI research investment.For some context, I was a co-author on the Ai2 official comment to the Office of Science and Technology Policy (OSTP) for the AI Action Plan and have had some private discussions with White House staff on the state of the AI ecosystem.A focus of mine through this document is how the government can enable better fully open models to exist, rather than just more AI research in general, as we’re in a shrinking time window where if we don’t create better fully open models then the academic community could be left with a bunch of compute to do research on models that are not reflective of the frontier of performance and behavior. This is why I give myself ~18 months to finish The American DeepSeek Project.Important context for this document is to consider what the federal government can actually do to make changes here. The executive branch has limited levers it can pull to disperse funding and make rules, but it sends important signaling to the rest of the government and private sector.Overall, the White House AI Action Plan comes across very clearly that we should increase investment in open models, and for the right reasons.This reflects a shift from previous federal policy, where the Biden executive order had little to say about open models other than them getting grouped into models needing pre-release testing if they were trained with more than 10^26 FLOPS (which led to substantial discussion on the general uselessness of compute thresholds as a policy intervention). Later, the National Telecommunications and Information Administration (NTIA) released a report from under the umbrella of the Biden Administration that was far more positive on open models, but much more limited in the scope of its ability for agenda setting.This is formatted as comments in line with the full text on open models and related topics in the action plan. Let’s dive in, any emphasis in italics is mine.Encourage Open-Source and Open-Weight AIOpen-source and open-weight AI models are made freely available by developers for anyone in the world to download and modify. Models distributed this way have unique value for innovation because startups can use them flexibly without being dependent on a closed model provider. They also benefit commercial and government adoption of AI because many businesses and governments have sensitive data that they cannot send to closed model vendors. And they are essential for academic research, which often relies on access to the weights and training data of a model to perform scientifically rigorous experiments.This covers three things we’re seeing play out with open models and is quite sensible as an introduction:* Startups use open models to a large extent because pretraining themselves is expensive and modifying the model layer of the stack can provide a lot of flexibility with low serving costs. Today, most of this happens on Qwen at startups, where larger companies are more hesitant to adopt Chinese models.* Open model deployments are slowly building up around sensitive data domains such as health care. * Researchers need strong and transparent models to perform valuable research. This is the one I’m most interested in, as it is the one with the highest long-term impact by determining the fundamental pace of progress in the research community.We need to ensure America has leading open models founded on American values. Open-source and open-weight models could become global standards in some areas of business and in academic research worldwide. For that reason, they also have geostrategic value. While the decision of whether and how to release an open or closed model is fundamentally up to the developer, the Federal government should create a supportive environment for open models.The emphasized section is entirely the motivation behind ongoing efforts for The American DeepSeek Project. The interplay between the three groups above is inherently geopolitical, where Chinese model providers are actively trying to develop mindshare with Western developers and release model suites that offer great tools for research (e.g. Qwen). The document is highlighting why fewer open models exist right now from leading Western AI companies, simply “the decision of whether and how to release an open or closed model is fundamentally up to the developer” — this means that the government itself can mostly just stay out of the way of leading labs releasing models if we think the artifacts will come from the likes of Anthropic, OpenAI, Google, etc. The other side of this is that we need to invest in building org
Kimi K2 and when "DeepSeek Moments" become normal
https://www.interconnects.ai/p/kimi-k2-and-when-deepseek-momentsThe DeepSeek R1 release earlier this year was more of a prequel than a one-off fluke in the trajectory of AI. Last week, a Chinese startup named Moonshot AI dropped Kimi K2, an open model that is permissively licensed and competitive with leading frontier models in the U.S. If you're interested in the geopolitics of AI and the rapid dissemination of the technology, this is going to represent another "DeepSeek moment" where much of the Western world — even those who consider themselves up-to-date with happenings of AI — need to change their expectations for the coming years.In summary, Kimi K2 shows us that:* HighFlyer, the organization that built DeepSeek, is far from a uniquely capable AI laboratory in China,* China is continuing to approach (or reached) the absolute frontier of modeling performance, and* The West is falling even further behind on open models.Kimi K2, described as an "Open-Source Agentic Model" is a sparse mixture of experts (MoE) model with 1T total parameters (~1.5x DeepSeek V3/R1's 671B) and 32B active parameters (similar to DeepSeek V3/R1's 37B). It is a "non-thinking" model with leading performance numbers in coding and related agentic tasks (earning it many comparisons to Claude 3.5 Sonnet), which means it doesn't generate a long reasoning chain before answering, but it was still trained extensively with reinforcement learning. It clearly outperforms DeepSeek V3 on a variety of benchmarks, including SWE-Bench, LiveCodeBench, AIME, or GPQA, and comes with a base model released as well. It is the new best-available open model by a clear margin.These facts with the points above all have useful parallels for what comes next:* Controlling who can train cutting edge models is extremely difficult. More organizations will join this list of OpenAI, Anthropic, Google, Meta, xAI, Qwen, DeepSeek, Moonshot AI, etc. Where there is a concentration of talent and sufficient compute, excellent models are very possible. This is easier to do somewhere such as China or Europe where there is existing talent, but is not restricted to these localities.* Kimi K2 was trained on 15.5T tokens and has a very similar number of active parameters as DeepSeek V3/R1, which was trained on 14.8T tokens. Better models are being trained without substantial increases in compute — these are referred to as a mix of "algorithmic gains" or "efficiency gains" in training. Compute restrictions will certainly slow this pace of progress on Chinese companies, but they are clearly not a binary on/off bottleneck on training.* The gap between the leading open models from the Western research labs versus their Chinese counterparts is only increasing in magnitude. The best open model from an American company is, maybe, Llama-4-Maverick? Three Chinese organizations have released more useful models with more permissive licenses: DeepSeek, Moonshot AI, and Qwen. This comes at the same time that new inference-heavy products are coming online that'll benefit from the potential of cheaper, lower margin hosting options on open models relative to API counterparts (which tend to have high profit margins).Kimi K2 is set up for a much slower style "DeepSeek Moment" than the DeepSeek R1 model that came out in January of this year because it lacks two culturally salient factors:* DeepSeek R1 was revelatory because it was the first model to expose the reasoning trace to the users, causing massive adoption outside of the technical AI community, and* The broader public is already aware that training leading AI models is actually very low cost once the technical expertise is built up (recall the DeepSeek V3 $5M training cost number), i.e. the final training run is cheap, so there should be a smaller reaction to similar cheap training cost numbers in the Kimi K2 report coming soon.Still, as more noise is created around the K2 release (Moonshot releases a technical report soon), this could evolve very rapidly. We've already seen quick experiments spin up slotting it into the Claude Code application (because Kimi's API is Claude-compatible) and K2 topping many nice "vibe tests" or creativity benchmarks. There are also tons of fun technical details that I don't have time to go into — from using a relatively unproven optimizer Muon and scaling up the self-rewarding LLM-as-a-judge pipeline in post-training. A fun tidbit to show how much this matters relative to the noisy Grok 4 release last week is that Kimi K2 has already surpassed Grok 4 in API usage on the popular OpenRouter platform.Later in the day on the 11th, following the K2 release, OpenAI CEO Sam Altman shared the following message regarding OpenAI's forthcoming open model (which I previously shared more optimistic thoughts on here) :we planned to launch our open-weight model next week.we are delaying it; we need time to run additional safety tests and review high-risk areas. we are not yet sure how long it will take us.while we trust

The American DeepSeek Project
https://www.interconnects.ai/p/the-american-deepseek-projectWhile America has the best AI models in Gemini, Claude, o3, etc. and the best infrastructure with Nvidia it’s rapidly losing its influence over the future directions of AI that unfold in the open-source and academic communities. Chinese organizations are releasing the most notable open models and datasets across all modalities, from text to robotics or video, and at the same time it’s common for researchers worldwide to read far more new research papers from Chinese organizations rather than their Western counterparts.This balance of power has been shifting rapidly in the last 12 months and reflects shifting, structural advantages that Chinese companies have with open-source AI — China has more AI researchers, data, and an open-source default.On the other hand, America’s open technological champions for AI, like Meta, are “reconsidering their open approach” after yet another expensive re-org and the political environment is dramatically reducing the interest of the world’s best scientists in coming to our country.It’s famous lore of the AI industry that much of the flourishing of progress around ChatGPT is downstream from Google Research’s, and the industry’s writ-large, practice of openly sharing the science of AI until approximately 2022. Stopping this practice, and the resulting power shifts mean it will be likely that the next “Transformer”-style breakthrough will be built on or related to Chinese AI models, AI chips, ideas, or companies. Countless Chinese individuals are some of the best people I’ve worked with, both at a technical and personal level, but this direction for the ecosystem points to AI models being less accountable, auditable, and trustworthy due to inevitable ties to the Chinese Government.The goal for my next few years of work is what I’m calling The American DeepSeek Project — a fully open-source model at the scale and performance of current (publicly available) frontier models, within 2 years. A fully open model, as opposed to just an “open weights” model, comes with data, training code, logs, and decision making — on top of the weights to run inference — in order to distribute the knowledge and access for how to train AI models fully.This project serves two goals, where balancing the scales with the pace of the Chinese ecosystem is only one piece:* Reclaim the AI research default home being on top of American (or Western) technologies and tools, and* Reduce the risk that the only viable AI ecosystem for cutting edge products in built atop of proprietary, closed, for-profit AI models.More people should be focused on this happening. A lot of people talk about how nice it would be to have “open-source AGI for all,” but very few people are investing in making it reality. With the right focus, I estimate this will take ~$100M-500M over the next two years.Within the context of recent trends, this is a future that has a diminishing, minute probability. I want to do this at Ai2, but it takes far more than just us to make it happen. We need advocates, peers, advisors, and compute.The time to do this is now, if we wait then the future will be in the balance of extremely powerful, closed American models counterbalancing a sea of strong, ubiquitous, open Chinese models. This is a world where the most available models are the hardest to trust. The West historically has better systems to create AI models that are trustworthy and fair across society. Consider how:* Practically speaking, there will never be proof that Chinese models cannot leave vulnerabilities in code or execute tools in malicious ways, even though it’s very unlikely in the near future.* Chinese companies will not engage as completely in the U.S. legal system on topics from fair use or non-consensual deepfakes.* Chinese models will over time shift to support a competitive software ecosystem that weakens many of America and the West’s strongest companies due to in-place compute restrictions.Many of these practical problems cannot be fixed by simply fine-tuning the model, such as Perplexity’s R1-1776 model. These are deep, structural realities that can only be avoided with different incentives and pretrained models.My goal is to make a fully open-source model at the scale of DeepSeek V3/R1 in the next two years. I’ve been starting to champion this vision in multiple places that summarizes the next frontier for performance on open-source language models, so I needed this document to pin it down.I use scale and not performance as a reference point for the goal because the models we’re collectively using as consumers of the AI industry haven’t really been getting much bigger. This “frontier scale” is a ballpark for where you’ve crossed into a very serious model, and, by the time a few years has gone by, the efficiency gains that would’ve accumulated by then will mean this model will far outperform DeepSeek V3. The leading models used for synthetic data (and maybe served to som