
Interconnects
Audio format of posts on interconnects.ai -- generated with AI from the author..
Nathan Lambert
Show overview
Interconnects has been publishing since 2023, and across the 3 years since has built a catalogue of 156 episodes. That works out to roughly 50 hours of audio in total. Releases follow a weekly cadence.
Episodes typically run ten to twenty minutes — most land between 9 min and 16 min — though episode length varies meaningfully from one episode to the next. None of the episodes are flagged explicit by the publisher. It is catalogued as a EN-language Technology show.
The show is actively publishing — the most recent episode landed 1 months ago, with 27 episodes already out so far this year. The busiest year was 2024, with 69 episodes published. Published by Nathan Lambert.
From the publisher
Audio essays about the latest developments in AI and interviews with leading scientists in the field. Breaking the hype, understanding what's under the hood, and telling stories. www.interconnects.ai
Latest Episodes
View all 156 episodesGLM-5.2 is the step change for open agents
Banning Open Source AI Would Be A Mistake
State of the blog, mid-2026
Frontier post-training recipe review with Finbarr Timbers
Claude Fable 5 and new AI safety fables
Farewell Ai2
Open and closed models are on different exponentials
Some ideas for what comes next, May 2026
Notes from inside China's AI labs
The distillation panic
My bets on open models, mid-2026

The inevitable need for an open model consortium
Recently, I was talking with Percy Liang, Stanford professor and lead of the Marin project (another fully-open model lab), and it set in on me that there will eventually be a consortium of companies funding a foundational set of open models used across industry. It’s not clear when this’ll emerge, and Nemotron (Coalition) is Nvidia’s attempt to bankroll and bootstrap this approach within a single wealthy company, but a consortium is the only long-term stable path to well-funded, near-frontier open models.In recent months, we’ve seen a lot of turnover in open model labs, with high-profile departures at Qwen and Ai2 (my comment). This shouldn’t be super surprising to followers of the ecosystem — it’s happened before with Meta shifting its focus away from Llama, and it’ll only happen more as the cost of trying to keep pace at the frontier of AI only increases. The other leading labs with models available today include Chinese startups such as Moonshot AI, MiniMax, and Z.ai — all of which look precarious on their ability to fund continued growth in the cost of training or R&D. Releasing one’s strongest models openly today is in active tension with the option of spending focus and resources on AI products that can currently generate meaningful revenue (and profits).We’re going to see business models emerge around releasing some, or even many, models openly, but these will largely be smaller models that enable a long-tail of functionality, rather than models at the absolute frontier. This class of companies that’ll release many, strong fine-tunable models will include the likes of Arcee AI, Thinking Machines, OpenAI, Google with Gemma, and more in that class. The cost and relative advantage of keeping the best models closed in a business environment with many opportunities for revenue are too high. To summarize — there will be an ever increasing number of companies releasing models that are good for creating a lively niche of smaller, custom models, but an ever decreasing number of companies willing to release fully open, near-frontier models. This is the core thesis of why I’m pushing hard for more people to do more research on how these smaller models can complement the best closed agents, the science of finetunability, etc. See my post below — it’s about creating a sustainable open model ecosystem, whether or not the frontier of open keeps paced with closed:It’ll take years for this equilibrium to become more obvious, seen through the lens of more open model families coming and going. This year, it seems likely we’ll see Nvidia’s Nemotron reach new heights, Reflection AI challenge some of the Chinese models with a strong, large MoE, maybe Meta releases a new open-weight model, and so on. True pressure to change strategy will only come when the capital environment punishes the less efficient spend on resources (e.g. giving away your competitive advantage, in having an in-house model). This pressure will likely hit Chinese startups training these models first. All of Moonshot AI, MiniMax, and Zhipu AI will show signs of financial challenge in the coming years if they retain their strategy, on top of their models falling further behind the best open models in terms of generality. This is inevitable pressure to evolve open models to areas that are profitable and complementary of the frontier of AI.Nvidia, which is best positioned to support the open ecosystem in the near term to support its core GPU business, could face many pressures to pull back its open model efforts. It could:* Realize it’s too competitive to their biggest customers as they succeed too much with Nemotron, * Fall to competition on their core business and lose the free cash flow buffer needed to fund this (e.g. it’s 2031 and OpenAI, Anthropic, Google, and the other frontier labs are worth so much they build their own chips). * Start succeeding beyond their initial goals and keep the chips for them to build ASI themselves, as a closed-weight model. The pressures for new funding mechanisms for open models are based on the assumptions of continued, substantive progress on the capabilities of frontier models. Mechanisms such as self-improvement and scaling all stages of the training pipeline are underway. This progress of capabilities will only increase the potential profit in selling models as and in products, not giving them away. The scale of investment required has already begun to push away non-profits from the game of making truly frontier-scale models. Capitalism is designed to make companies ruthless and chase down leads on profitability, not donate technology as charity.As the economic environment shifts companies away from releasing the strongest models openly, more companies that rely on these models will look for an outlet of securing model access into the future. This is going to be compounded by a growing group of companies who come to rely on open-weight models for their workflows. These points loop back into how model training is get

Claude Mythos and misguided open-weight fearmongering
With the announcement of the Claude Mythos model this week and the admittedly very strong stated abilities, especially in cybersecurity, a new wave of anti open-weight AI model narratives surged. The TL;DR of the argument is that our digital infrastructure will not be ready in time for an open-weight version of this model, which will allow attacks to be conducted by numerous parties.The backlash against open models in the wake of the Mythos news conflates too many general unknowns into a simple, broad policy recommendation that could actually further weaken cybersecurity readiness.We’ve been here before – open-weight models were discussed as being extremely dangerous when OpenAI withheld GPT-2 weights in 2019, and when OpenAI released GPT-4 in 2023. Both of these waves came and went. The core mistake that is being made is the composition of two issues: 1) the acceptance of the open-closed model gap being static in time and 2) linking open-weight viability generally to specific issues.I’ve written at length recently on how I think that the best, frontier-level open weight models are going to fall behind the best closed models in overall capabilities in the near future. I’ve also written about how the open-weight ecosystem needs to adapt to accept this reality. This is one of the times for the AI industry where I will repeat that it’s a total blessing to have the 6-18 month delay from when a certain capability is available within a closed lab to it being reproduced in the open. It’s a good balance of safety and monitoring the frontier of AI systems while allowing a useful open-source ecosystem to exist and thrive.The core argument I’ve focused on in the open-closed model time gap has been in general capabilities – i.e. for general purpose, frontier models such as Claude Opus 4.X or GPT Thinking 5.X. The abilities of these closed models to robustly solve and work in diverse situations as agents remains out of scope of the best open-weight models. What the open-weight models have tended to be better at is quickly keeping pace on key benchmarks (which admittedly is helped to some extent, but not necessarily substantially by distillation). This discussion is entirely different, it has to do with if open weight models can keep pace on the specific skills related to cybersecurity, and when we could expect an open version of this model to be available to the world.The case of a Claude Mythos level open weight model is admittedly more nuanced to me than the previous few anti-open weight narratives the community has experienced. Where GPT-4 was about a more hypothetical risk, especially in areas like bio-risk, the clear and present reality of cyber infrastructure being prone to attack is far more tangible. Still, much of this nuance in the moment comes down to not knowing the full details of what the system can actually do (i.e. Mythos), and the state of the environment it would act in (i.e. our digital infrastructure).To properly assess this risk, we need to know what it takes to build and deploy a Claude Mythos scale model. This entails three pieces: 1) training and releasing the weights, 2) the harness that gives the model effective tools it knows how to use, and 3) the inference compute and software.(Below I make some model size & price estimates to show my thinking, these should not be taken as ground truth.)Current estimates put the size ranges of leading models like Claude Opus 4.6 or GPT 5.4 as being around 3-5T parameters. Currently, the largest open-source models, which have been coming from Chinese labs, are around 1T parameters. Claude Mythos’s preview pricing is 5X Opus, which could come from a simple multiplicative increase in active parameters (with the same serving system design), far higher inference-time scaling, more complex harnesses that make inference less efficient, lower utilization expectations, and so on. The simplest guess is that it’s a mix of all of the above, something like 2X bigger in parameters and much less efficient to serve. That’s a huge model, likely something similar to GPT 4.5, but actually post-trained well (GPT 4.5 was ahead of its time, infra-wise).With size comes the challenge actually training the model, as bigger models always come with new technical problems that must be solved to unlock the capabilities. For the case of cybersecurity, my guess is that most of the capabilities can be learned by training a model to be superhuman on coding. Unlike some capabilities such as knowledge work, medicine, law, etc., coding can be studied and improved substantially with public data like GitHub. I’m far more optimistic in open-weight models staying fairly close to the frontier in narrow domains of code execution and processing, but I don’t understand the full scope of skills needed to be superhuman in cybersecurity understanding. How much expert knowledge and special sauce went into training Claude Mythos? That’s a substantial source of my error bars on the impact.Second, we know no

Gemma 4 and what makes an open model succeed
Having written a lot of model release blog posts, there’s something much harder about reviewing open models when they drop relative to closed models, especially in 2026. In recent years, there were so few open models, so when Llama 3 was released most people were still doing research on Llama 2 and super happy to get an update. When Qwen 3 was released, the Llama 4 fiasco had just gone down, and a whole research community was emerging to study RL on Qwen 2.5 — it was a no brainer to upgrade. Today, when an open model releases, it’s competing with Qwen 3.5, Kimi K2.5, GLM 5, MiniMax M2.5, GPT-OSS, Arcee Large, Nemotron 3, Olmo 3, and others. The space is populated, but still feels full of hidden opportunity. The potential of open models feels like a dark matter, a potential we know is huge, but few clear recipes and examples for how to unlock it are out there. Agentic AI, OpenClaw, and everything brewing in that space is going to spur mass experimentation in open models to complement the likes of Claude and Codex, not replace them.Especially with open models, the benchmarks at release are an extremely incomplete story. In some ways this is exciting, as new open models have a much higher variance and ability to surprise, but it also points at some structural reasons that make building businesses and great AI experiences around open models harder than the closed alternatives. When a new Claude Opus or GPT drops, spending a few hours with them in my agentic workflows is genuinely a good vibe test. For open models, putting them through this test is a category error.Something else to be said about open models in the era of agents is that they get out of the debate of integration, harnesses, and tools and let us see close to the ground on what exactly is the ability of just a model. Of course, we can’t test some things like search abilities without some tool, but being able to measure exactly the pace of progress of the model alone is a welcome simplification to a systematically opaque AI space.The list of factors I’d use to assess a new open-weight model I’m considering investing in includes:* Model performance (and size) — how this model performs on benchmarks I care about and how it compares to other models of a similar size.* Country of origin — some businesses care deeply about provenance, and if a model was built in China or not.* Model license — if a model needs legal approval for use, uptake will be slower at mid-sized and large companies.* Tooling at release — many models release with half-broken, or at least substantially slower, implementations in popular software like vLLM, Transformers, SGLANG, etc due to pushing the envelope of architectures or tools.* Model fine-tunability — how easy or hard it is to modify the given model to your use-case when you actually try and use it.The core problem is that some of these are immediately available at release, e.g. general performance, license, origin, etc. but others such as tooling take day(s) to week(s) to stabilize, and others are open research questions — with no group systematically monitoring fine-tunability. In the early era of open models, the days of Llama 2 or 3 and Qwen pre v3.5, the architectures were fairly simple and the models tended to work out of the box. Some of this was due to the extremely hard work of the Llama, Qwen, Mistral, etc. developer teams. Some is due to the new models being genuinely harder to work with. When it comes to something like Qwen 3.5 or Nemotron 3, with hybrid models (either gated delta net or mamba layers), the tooling is very rough at release. Things you would expect to “just work” often don’t.I’ve been following this area closely since we released Olmo Hybrid with a similar architecture, and Qwen 3.5 is just starting to work well in the various open-source tools that need to all play nice together for RL research. That’s 1.5 months after the release date! This is just to start really investing more into understanding the behavior of the models. Of course, others started working on these models sooner by investing more engineering resources or relying on partially closed software. The fully open and distributed ecosystem takes a long time to get going on some new models.All of this is lead-in for the most important question for open models — how easy is it to adapt to specific use-cases? This is a different problem for different model sizes. Large MoE open-weight models may be used by entities like Cursor who need complex capabilities in their domain, e.g. Composer 2 trained on Kimi K2.5. Other applications can be built on much smaller models, such as Chroma’s Context-1 model for agentic search, built on GPT-OSS 20B. The question of “which models are fine-tunable” is largely background knowledge known by engineers across the industry. There should be a thriving research area here to support the open ecosystem model. The first step is to understand characteristics of different base and post-trained models to understand

Lossy self-improvement
Fast takeoff, the singularity, and recursive self-improvement (RSI) are all top of mind in AI circles these days. There are elements of truth to them in what’s happening in the AI industry. Two, maybe three, labs are consolidating as an oligopoly with access to the best AI models (and the resources to build the next ones). The AI tools of today are abruptly transforming engineering and research jobs.AI research is becoming much easier in many ways. The technical problems that need to be solved to scale training large language models even further are formidable. Super-human coding assistants making these approachable is breaking a lot of former claims of what building these things entailed. Together this is setting us up for a year (or more) of rapid progress at the cutting edge of AI.We’re also at a time where language models are already extremely good. They’re in fact good enough for plenty of extremely valuable knowledge-work tasks. Language models taking another big step is hard to imagine — it’s unclear which tasks they’re going to master this year outside of code and CLI-based computer-use. There will be some new ones! These capabilities unlock new styles of working that’ll send more ripples through the economy.These dramatic changes almost make it seem like a foregone conclusion that language models can then just keep accelerating progress on their own. The popular language for this is a recursive self-improvement loop. Early writing on the topic dates back to the 2000s, such as the blog post entirely on the topic from 2008: Recursion is the sort of thing that happens when you hand the AI the object-level problem of “redesign your own cognitive algorithms”.And slightly earlier, in 2007, Yudkowsky also defined the related idea of a Seed AI in Levels of Organization in General Intelligence:A seed AI is an AI designed for self-understanding, self-modification, and recursive self-improvement. This has implications both for the functional architectures needed to achieve primitive intelligence, and for the later development of the AI if and when its holonic self-understanding begins to improve. Seed AI is not a workaround that avoids the challenge of general intelligence by bootstrapping from an unintelligent core; seed AI only begins to yield benefits once there is some degree of available intelligence to be utilized. The later consequences of seed AI (such as true recursive self-improvement) only show up after the AI has achieved significant holonic understanding and general intelligence.It’s reasonable to think we’re at the start here, with how general and useful today’s models are.Generally, RSI can be summarized as when AI can improve itself, the improved version can improve even more efficiently, creating a closed amplification loop that leads to an intelligence explosion, often referred to as the singularity. There are a few assumptions in this. For RSI to occur, it needs to be that:* The loop is closed. Models can keep improving on themselves and beget more models.* The loop is self-amplifying. The next models will yield even bigger improvements than the current ones.* The loop continues to run without losing efficiency. There are not added pieces of friction that make the exponential knee-capped as an early sigmoid.While I agree that momentous, socially destabilizing changes are coming in the next few years from sustained AI improvements, I expect the trend line of progress to be more linear than exponential when we reflect back. Instead of recursive self-improvement, it will be lossy self-improvement (LSI) – the models become core to the development loop but friction breaks down all the core assumptions of RSI. The more compute and agents you throw at a problem, the more loss and repetition shows up.Interconnects AI is a reader-supported publication. Consider becoming a subscriber.I’m still a believer that the complexity brake on advanced systems will be a strong counterbalance to the reality that AI models are getting substantially better at every narrow task we need to compose together in making a leading AI model. I quoted this previously in April of 2025 in response to AI 2027.Microsoft co-founder Paul Allen argued the opposite of accelerating returns, the complexity brake: the more progress science makes towards understanding intelligence, the more difficult it becomes to make additional progress. A study of the number of patents shows that human creativity does not show accelerating returns, but in fact, as suggested by Joseph Tainter in his The Collapse of Complex Societies, a law of diminishing returns. The number of patents per thousand peaked in the period from 1850 to 1900, and has been declining since. The growth of complexity eventually becomes self-limiting, and leads to a widespread “general systems collapse”.There are plenty of examples in how models are already trained, the deep intuitions we need to get them right, and the organizations that build them that show where the losses
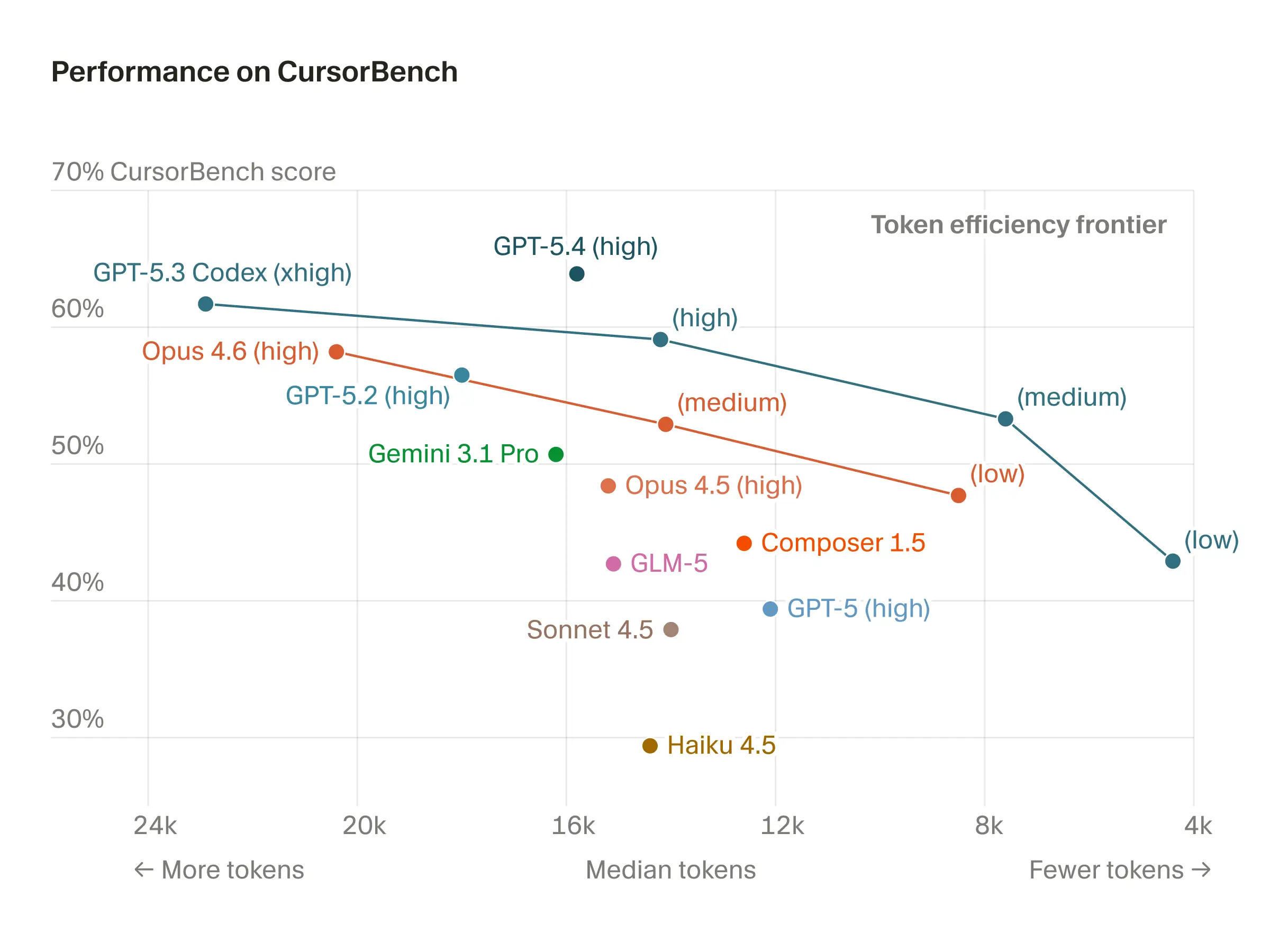
GPT 5.4 is a big step for Codex
I’m a little late to this model review, but that has given me more time to think about the axes that matter for agents. Traditional benchmarks reduce model performance to a single score of correctness – they always have because that was simple, easy to quickly use to gauge performance, and so on. This is also advice that I give to people trying to build great benchmarks – it needs to reduce to one number that is interpretable. This is likely still going to be true in a year or two, and benchmarks for agents will be better, but for the time being it doesn’t really map to what we feel because agentic tasks are all about a mix of correctness, ease of use, speed, and cost. Eventually benchmarks will individually address these.Where GPT 5.4 feels like another incremental model on some on-paper benchmarks, in practice it feels like a meaningful step in all four of those traits. GPT 5.4 in Codex, always on fast mode and high or extra-high effort, is the first OpenAI agent that feels like it can do a lot of random things you can throw at it.Interconnects AI is a reader-supported publication. Consider becoming a subscriber.I haven’t been particularly deep in software engineering over the last few months, so most of my working with agents has been smaller projects (not totally one-off, but small enough where I’ve built the entire thing and manage the design over weeks), data analysis, and research tasks. When you embrace being agent-native, this style of work entails a lot of regular APIs, background packages (like installing and managing LateX binaries, ffmpeg, multimedia conversion tools, etc), git operations, file management, search etc. Prior to GPT 5.4, I always churned off of OpenAI’s agents due to a death by a thousand cuts. It felt like rage quits. I’d feel like I was getting into GPT 5.2 Codex, but it would fail on a git operation and have me (or Claude) need to reset it. Those hard edges are no longer there.The other subtle change in GPT 5.4’s approachability – the biggest reason I think OpenAI is much more back in the agent wars – is that it just feels a bit more “right.” I classify this differently to the routine tasks I discussed above, and it has to do with how the product (i.e. the model harness) presents the model outputs, requests, and all that to you the user. It has to do with how easy it is to dive in. This has always been Claude’s biggest strength in its astronomical growth. Not only has Claude been immensely useful, but it has a charm and entertainment value to it that’ll make new people stick around. GPT 5.4 has a bit of that, but the underlying model strengths of Claude still leave it feeling warmer.Where Claude is a super smart model, with character, a turn of phrase in a debate, and sometimes forgetting something, OpenAI’s models in Codex feel meticulous, slightly cold, but deeply mechanical. I’d use Claude for things I need more of an opinion on and GPT 5.4 to churn through an overwhelmingly specific TODO list. The instruction following of GPT 5.4 is so precise that I need to learn to interact with the models differently after spending so much time with Claude. Claude, in some domains, you come to see has an excellent model for your intent. GPT 5.4 just does what you say to do. These are very different philosophies of “what will make the best model for an agent”, Claude will likely appeal to the newcomers, but GPT 5.4 will likely appeal to the master agent coordinator that wants to unleash their AI army on distributed tasks.Outside of charm, and dare I say taste, a lot of the usability factors are actually better on OpenAI’s half of the world. The Codex app is compelling – I don’t always use it, but sometimes I totally love it. I suspect substantial innovation is coming in what these apps look like. Personally, I expect them to eventually look like Slack (when multiple agents need to talk to eachother, under my watch).OpenAI also natively offers fast mode for their models with a subscription and very large rate limits. I’ve been on the $100/month Claude plan and $200/month ChatGPT plan for quite some time. I’ve never been remotely close to my Codex limits with fast mode and xhigh reasoning effort, where I hit my Claude limits from time to time. There’s definitely a modeling reason to this – most of OpenAI’s release blogs showcase each iterative model being substantially more concise in the number of tokens it takes to get peak benchmark performance. This is a measure of reasoning efficiency. This 2D (or more) benchmark picture is exactly where the world is going.Here’s a plot from Cursor, which sadly doesn’t have all the GPT 5.4 reasoning efforts, but it confirms this point in a third party evaluation. What is missing across model families is the speed and price (a proxy for total compute used) to get there.The final benefit of GPT 5.4, and OpenAI’s agentic models in general for that matter, is much better context management. In using them regularly now I feel like I’ve never hit the contex

What comes next with open models
2025 was the year where a lot of companies started to take open models seriously as a path to influence in the extremely valuable AI ecosystem — the adoption of a strategy that was massively accelerated downstream of DeepSeek R1’s breakout success. Most of this is being done as a mission of hope, principle, or generosity. Very few businesses have a real monetary reason to build open models. Well-cited reasons, such as commoditizing one’s complements for Meta’s Llama, are hard to follow up on when the cost of participating well is billions of dollars. Still, AI is in such an early phase of technological development, mostly defined by large-scale industrialization and massive scale-out of infrastructure, that having any sort of influence at the cutting edge of AI is seen as a path to immense potential value. Open models are a very fast way to achieve this, you can obtain substantial usage and mindshare with no enterprise agreements or marketing campaigns — just releasing one good model. Many companies in AI have raised a ton of money built on less. The hype of open models is simultaneously amplified by the mix of cope, disruptive anticipation, and science fiction that hopes for the world where open models do truly surpass the closed labs. This goal could be an economically catastrophic success for the AI ecosystem, where profits and revenue plummet but the broader balance of power and control of AI models is long-term more stable.There’s a small chance open models win in absolute performance, but it would only be on the back of either a true scientific breakthrough that is somehow kept hidden from the leading labs or the models truly hitting a wall in performance. Both of them are definitely possible, but very unlikely. It is important to remind yourself that there have been no walls in progress to date and all the top AI researchers we discuss this with constantly explain the low-hanging fruit they see on progress. It may not be recursive self-improvement to the singularity (more on that in a separate post), but large technology companies are on a direct path to building definitionally transformative tools. They are coming.The balance of power in open vs. closed modelsThe fair assessment of the open-closed gap is that open models have always been 6-18 months behind the best closed models. It is a remarkable testament to the open labs, operating on far smaller budgets, that this has stayed so stable. Many top analysts like myself are bewildered by the way the gap isn’t bigger. Distillation helps a bit in quality, benchmaxing more than closed labs helps perceptions, but the progress of the leading open models is flat out remarkable. The reality is that the open-closed model gap is more likely to grow than shrink. The top few labs are improving as fast as ever, releasing many great new models, with more on the docket. Many of the most impressive frontier model improvements relative to their open counterparts feel totally unmeasured on public benchmarks. In a new era of coding agents, the popular method to “copy” performance from closed models, distillation, requires more creativity to extract performance — previously, you could use the entire completion from the model to train your student, but now the most important part is the complex RL environments and the prompts to place your agents in them. These are much easier to hide and all the while the Chinese labs leading in open models are always complaining about computational restrictions. As the leading AI models move into longer-horizon and more specialized tasks, mediated by complex and expensive gate-keepers in the U.S. economy (e.g. legal or healthcare systems), I expect large gaps in performance to appear. Coding can largely be mostly “solved” with careful data processes, scraping GitHub, and clever environments. The economies of scale and foci of training are moving into domains that are not on the public web, so they are far harder to replicate than early language models. Developing frontier AI models today is more defined by stacking medium to small wins, unlocked by infrastructure, across time. This rewards organizations that can expand scope while maintaining quality, which is extremely expensive.All of these dynamics together create a business landscape for open models that is hard to parse. Through 2026, closed models are going to take leaps and bounds in performance in directions that it is unlikely for open models to follow. This sets us up for a world where we need to consider, fund, use, and discuss open models differently. This piece lays out how open models are changing. It is a future that’ll be clearly defined by three classes of models.* True (closed) frontier models. These will drive the strongest knowledge work and coding agents. They will be truly remarkable tools that force us to reconsider our relationship to work.* Open frontier models. These will be the best open-weight, large models that are attempting to compete on the same direct

Dean Ball on open models and government control
Watching history unfold between Anthropic and the Department of War (DoW) it has been obvious to me that this could be a major turning point in perspectives on open models, but one that’ll take years to be obvious. As AI becomes more powerful, existing power structures will grapple with their roles relative to existing companies. Some in open models frame this as “not your weights, not your brain,” but it points to a much bigger problem when governments realize this. If AI is the most powerful technology, why would any global entity let a single U.S. company (or government) control their relationship to it?I got Dean W. Ball of the great Hyperdimensional newsletter onto the SAIL Media weekly Substack live to discuss this. In the end, we agree that the recent actions by the DoW — especially the designation of Anthropic as a supply chain risk (which Dean and I both vehemently disagree with) — points to open models being the 5-10 year stable equilibrium for power centers. The point of this discussion is:* Why do open models avoid some of the power struggles we’ve seen play out last week?* How do we bridge short term headwinds for open models towards long-term strength?* The general balance of capabilities between open and closed models.Personally, I feel the need to build open models more than ever and am happy to see more constituencies wake up to it. What I don’t know is how to fund and organize that. Commoditizing one’s compliments is a valid strategy, but it starts to break down when AI models cost closer to a trillion dollars than a hundred million. With open models being very hard to monetize, there’s a bumpy road ahead for figuring out who builds these models in face of real business growth elsewhere in the AI stack.Enjoy and please share any feedback you have on this tricky topic! Listen on Apple Podcasts, Spotify, and where ever you get your podcasts. For other Interconnects interviews, go here.Chapters* 00:00 Intro: is the Anthropic supply chain risk good or bad for open models?* 04:03 Funding open models and the widening frontier gap* 12:33 Sovereign AI and global demand for alternatives* 20:55 Open model ecosystem: Qwen, usability, and short-term outlook* 28:20 Government power, nationalization risk, and financializing computeTranscript00:00:00 Nathan Lambert: Okay. We are live and people will start joining. I’m very happy to catch up with Dean. I think as we were setting this up, the news has been breaking that the official supply chain risk designation was filed. This is not a live reaction to that. If we get any really, really interesting news, we’ll talk about it. I think one of the undercurrents that I’ve felt that this week where everything happened is gonna touch on is open models, but there’s not an obvious angle. I think I will frame this to Dean to start, which is how does-- Like, there’s two sides of open models. One is that there’s the kind of cliche like, not my weights, not your weights, not your mind, where like somebody could take it away if not an open model, which people are boosting like, “Oh, like Anthropic’s gonna take away their intelligence.” But the other side is people worried about open models existing that the Department of War can just take and use for any purpose that it wants. And I feel like both of these are a little cliche. And the core question is like, is this type of event where more control is coming towards AI and more multi-party interest, like is that gonna be good or bad for the open weight model ecosystem?00:01:12 Dean Ball: My guess is that in the long run, this is probably profoundly good for open weight AI. And like the whole reason I got in, like, so I became interested in frontier AI governance. I did something totally different with my time before. I wrote about different kinds of policy and studied different kinds of policy. And the reason I got into this was because it immediately occurred to me that the government was gonna... I was like, okay, let’s assume we’re building super intelligence soon or whatever, like very advanced AI that seems like really important and powerful. That’s gonna be something that I depend on, like for my day-to-day life. I’m gonna need it for all kinds of things. It’s gonna profoundly implicate my freedom of expression as an American and my exercise of my liberty and all that. And yet it’s also gonna profoundly implicate national security. And so the government’s gonna have its hands all over it, and they also might not like me using it because I might use it, and others might use it to challenge the status quo in various ways, to challenge the existing power structures which the government is a part of. So we have a political problem on our hands here, in my view.00:02:36 Dean Ball: It immediately occurred to me that we’re gonna have this huge problem of like, this is gonna be a conflict because this is something that’s gonna enormously implicate American speech and liberty, and also it’s gonna have legitimate national s
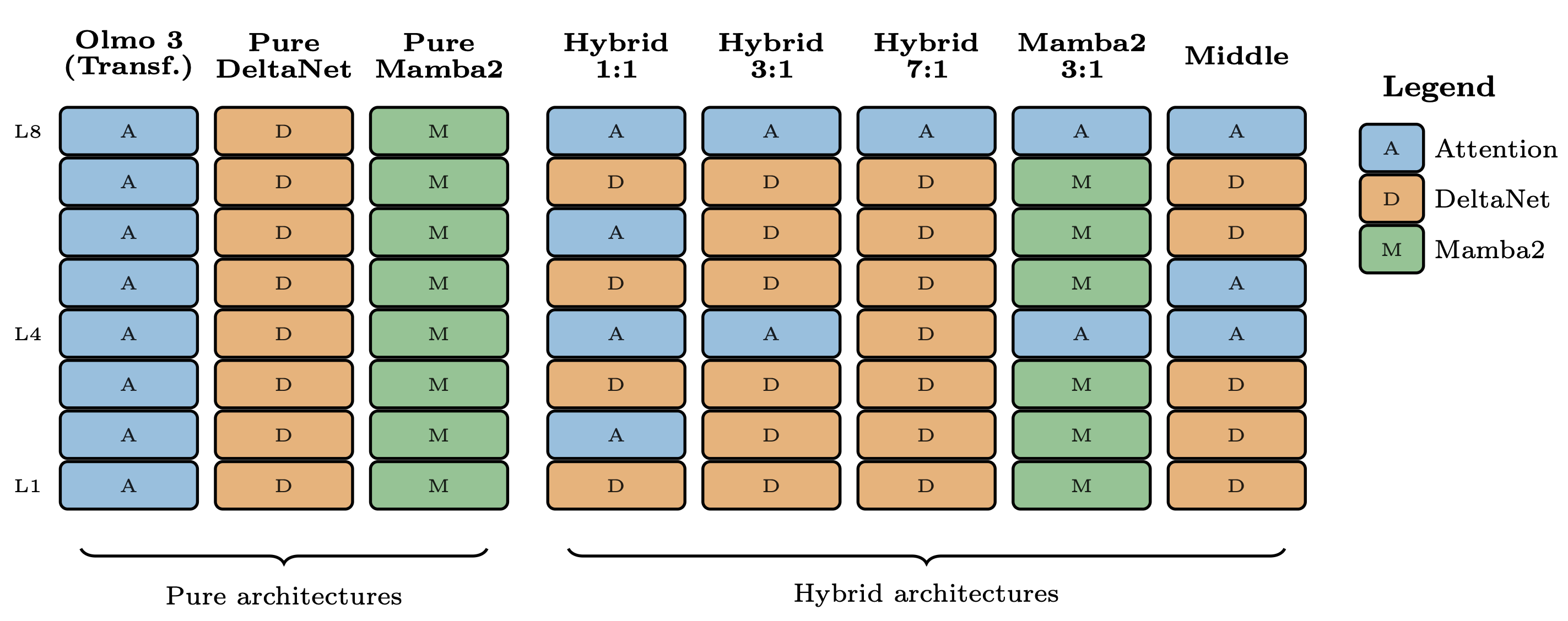
Olmo Hybrid and future LLM architectures
So-called hybrid architectures are far from new in open-weight models these days. We now have the recent Qwen 3.5 (previewed by Qwen3-Next), Kimi Linear last fall (a smaller release than their flagship Kimi K2 models), Nvidia’s Nemotron 3 Nano (with the bigger models expecting to drop soon), IBM Granite 4, and other less notable models. This is one of those times when a research trend looks like it’s getting adopted everywhere at once (maybe the Muon optimizer too, soon?).To tell this story, we need to go back a few years to December 2023, when Mamba and Striped Hyena were taking the world by storm — asking the question: Do we need full attention in our models? These early models fizzled out, partially for the same reasons they’re hard today — tricky implementations, open-source tool problems, more headaches in training — but also because the models fell over a bit when scaled up. The hybrid models of the day weren’t quite good enough yet.These models are called hybrid because they mix these new recurrent neural network (RNN) modules with the traditional attention that made the transformer famous. They all work best with this mix of modules. The RNN layers keep part of the computation compressed in a hidden state to be used for the next token in the prediction — a summary of all information that came before — an idea that has an extremely long historical lineage in deep learning, e.g. back to the LSTM. This setup avoids the quadratic compute cost of attention (i.e. avoiding the incrementally expanding the KV cache per token of the attention operator), and can even assist in solving new problems.The models listed to start this article use a mix of RNN approaches, some models (Qwen and Kimi) use a newer idea called Gated DeltaNet (GDN) and some still use Mamba layers (Granite and Nemotron). The Olmo Hybrid model we’re releasing today also falls on the GDN side, based on careful experimentation, and theory that GDN is capable of learning features that attention or Mamba layers cannot.Introducing Olmo Hybrid and its pretraining efficiencyOlmo Hybrid is a 7B base model, with 3 experiment post-trained checkpoints released — starting with an Instruct model, with a reasoning model coming soon. It is the best open artifact for studying hybrid models, as it is almost identical to our Olmo 3 7B model from last fall, just with a change in architecture. With the model, we are releasing a paper with substantial theory on why hybrid models can be better than standard transformers. This is a long paper that I’m still personally working through, but it’s excellent. You can read the paper here and poke around with the checkpoints here. This is an incredible, long-term research project led by Will Merrill. He did a great job.To understand the context of why hybrid models can be a strict upgrade on transformers, let me begin with a longer excerpt from the paper’s introduction, emphasis mine:Past theoretical work has shown that attention and recurrence have complementary strengths (Merrill et al., 2024; Grazzi et al., 2025), so mixing them is a natural way to construct an architecture with the benefits of both primitives. We further derive novel theoretical results showing that hybrid models are even more powerful than the sum of their parts: there are formal problems related to code evaluation that neither transformers nor GDN can express on their own, but which hybrid models can represent theoretically and learn empirically. But this greater expressivity does not immediately imply that hybrid models should be better LMs: thus, we run fully controlled scaling studies comparing hybrid models vs. transformers, showing rigorously that hybrid models’ expressivity translates to better token efficiency, in agreement with our observations from the Olmo Hybrid pretraining run. Finally, we provide a theoretical explanation for why increasing an architecture’s expressive power should improve language model scaling rooted in the multi-task nature of the language modeling objective.Taken together, our results suggest that hybrid models dominate transformers, both theoretically, in their balance of expressivity and parallelism, and empirically, in terms of benchmark performance and long-context abilities. We believe these findings position hybrid models for wider adoption and call on the research community to pursue further architecture research.Essentially, we show and argue a few things:* Hybrid models are more expressive. They can form their outputs to learn more types of functions. An intuition for why this would be good could follow: More expressive models are good with deep learning because we want to make the model class as flexible as possible and let the optimizer do the work rather than constraints on the learner. Sounds a lot like the Bitter Lesson.* Why does expressive power help with efficiency? This is where things are more nuanced. We argue that more expressive models will have better scaling laws, following the quantization

How much does distillation really matter for Chinese LLMs?
Distillation has been one of the most frequent topics of discussion in the broader US-China and technological diffusion story for AI. Distillation is a term with many definitions — the colloquial one today is using a stronger AI model’s outputs to teach a weaker model. The word itself is derived from a more technical and specific definition of knowledge distillation (Hinton, Vinyals, & Dean 2015), which involves a specific way of learning to match the probability distribution of a teacher model.The distillation of today is better described generally as synthetic data. You take outputs from a stronger model, usually via an API, and you train your model to predict those. The technical form of knowledge distillation is not actually possible from API models because they don’t expose the right information to the user.Synthetic data is arguably the single most useful method that an AI researcher today uses to improve the models on a day to day basis. Yes, architecture is crucial, some data still needs exclusively human inputs, and new ideas like reinforcement learning with verifiable rewards at scale can transform the industry, but so much of the day to day life in improving models today is figuring out how to properly capture and scale up synthetic data.To flesh out the point from the start of this piece, the argument has repeatedly been that the leading Chinese labs are using distillation for their models to steal capabilities from the best American API-based counterparts. The most prominent case to date was surrounding the release of DeepSeek R1 — where OpenAI accused DeepSeek of stealing their reasoning traces by jailbreaking the API (they’re not exposed by default — for context, a reasoning trace is a colloquial word of art referring to the internal reasoning process, such as what open weight reasoning models expose to the user). Fear of distillation is also likely why Gemini quickly flipped from exposing the reasoning traces to users to hiding them. There was even very prominent, early reasoning research that built on Gemini!This all leads us to today’s news, where Anthropic named and directly accused a series of Chinese labs for elaborate distillation campaigns on their Claude models. This is a complex issue. In this post we unpack a series of questions, beginning with the impact, and ending with politics. The core question is — how much of a performance benefit do Chinese labs get from distilling from American models.Interconnects AI is a reader-supported publication. Consider becoming a subscriber.To start, let’s review what Anthropic shared. From the blog post, emphasis mine:We have identified industrial-scale campaigns by three AI laboratories—DeepSeek, Moonshot, and MiniMax—to illicitly extract Claude’s capabilities to improve their own models. These labs generated over 16 million exchanges with Claude through approximately 24,000 fraudulent accounts, in violation of our terms of service and regional access restrictions.These labs used a technique called “distillation,” which involves training a less capable model on the outputs of a stronger one. Distillation is a widely used and legitimate training method. For example, frontier AI labs routinely distill their own models to create smaller, cheaper versions for their customers. But distillation can also be used for illicit purposes: competitors can use it to acquire powerful capabilities from other labs in a fraction of the time, and at a fraction of the cost, that it would take to develop them independently.Much like the models themselves, the benefits of distillation are very jagged. For some capabilities, particularly if you don’t have a full training pipeline setup for it, quickly distilling some data from the leading frontier model in that area can yield massive performance boosts. This can definitely help the lab distilling from the API catch up much more quickly than they otherwise would. Most distillation is rather benign, using many tokens of an LLM to help process and refine existing data — putting a lot of compute into getting a few, high quality training tokens out. This sort of raw data processing work can be done on many different APIs, but one tends to be best.When we go into what Anthropic says the three Chinese LLM builders actually used the Claude API for — as an aside, Anthropic didn’t confirm that the attack was done through the API, the chat app, or Claude Code — the actual impact of the operations is very mixed. It’s hard to know how much untracked usage these labs deployed for other projects (or other American models).To start, Anthropic puts DeepSeek first in their blog post because they’re the household name in the US for Chinese AI. The extent of their use is actually quite small, showing how this post is more about the big picture than the details:DeepSeekScale: Over 150,000 exchangesThe operation targeted:* Reasoning capabilities across diverse tasks* Rubric-based grading tasks that made Claude function as a reward model fo