
Interconnects
156 episodes — Page 2 of 4

Some ideas for what comes next
https://www.interconnects.ai/p/summertime-outlook-o3s-novelty-comingSummer is always a slow time for the tech industry. OpenAI seems fully in line with this, with their open model “[taking] a little more time” and GPT-5 seemingly always delayed a bit more. These will obviously be major news items, but I’m not sure we see them until August.I’m going to take this brief reprieve in the bombardment of AI releases to reflect on where we’ve been and where we’re going. Here’s what you should know.1. o3 as a technical breakthrough beyond scalingThe default story around OpenAI’s o3 model is that they “scaled compute for reinforcement learning training,” which caused some weird, entirely new over-optimization issues. This is true, and the plot from the livestream of the release still represents a certain type of breakthrough — namely scaling up data and training infrastructure for reinforcement learning with verifiable rewards (RLVR).The part of o3 that isn’t talked about enough is how different its search feels. For a normal query, o3 can look at 10s of websites. The best description I’ve heard of its relentlessness en route to finding a niche piece of information is akin to a “trained hunting dog on the scent.” o3 just feels like a model that can find information in a totally different way than anything out there.The kicker with this is that we’re multiple months out from its release in April of 2025 and no other leading lab has a model remotely like it. In a world where releases between labs, especially OpenAI and Google, seem totally mirrored, this relentless search capability in o3 still stands out to me.The core question is when will another laboratory release a model that feels qualitatively similar? If this trend goes on through the end of the summer it’ll be a confirmation that OpenAI had some technical breakthrough to increase the reliability of search and other tool-use within reasoning models.For a contrast, consider basic questions we are facing in the open and academic community on how to build a model inspired by o3 (so something more like a GPT-4o or Claude 4 in its actual search abilities):* Finding RL data where the model is incentivized to search is critical. It’s easy in an RL experiment to tell the model to try searching in the system prompt, but as training goes on if the tool isn’t useful the model will learn to stop using it (very rapidly). It is likely that OpenAI, particularly combined with lessons from Deep Research’s RL training (which, I know, is built on o3), has serious expertise here. A research paper showing a DeepSeek R1 style scaled RL training along with consistent tool use rates across certain data subsets will be very impressive to me.* The underlying search index is crucial. OpenAI’s models operate on a Bing backend. Anthropic uses Brave’s API and it struggles for it (lots of SEO spam). Spinning up an academic baseline with these APIs is a moderate additive cost on top compute.Once solid open baselines exist, we could do fun science such as studying which model can generalize to unseen data-stores best — a crucial feature for spinning up a model on local sensitive data, e.g. in healthcare or banking.If you haven’t been using o3 for search, you really should give it a go.Interconnects is a reader-supported publication. Consider becoming a subscriber.2. Progress on agents will be higher variance than modeling was, but often still extremely rapidClaude Code’s product market fit, especially with Claude 4, is phenomenal. It’s the full package for a product — works quite often and well, a beautiful UX that mirrors the domain, good timing, etc. It’s just a joy to use.With this context, I really have been looking for more ways to write about it. The problem with Claude Code, and other coding agents such as Codex and Jules, is that I’m not in the core audience. I’m not regularly building in complex codebases — I’m more of a research manager and fixer across the organization than someone that is building in one repository all the time — so, I don’t have practical guides on how to get the most out of Claude Code or a deep connection with it that can help you “feel the AGI.”What I do know about is models and systems, and there are some very basic facts of frontier models that make the trajectory for the capabilities of these agents quite optimistic.The new part of LLM-based agents is that they involve many model calls, sometimes with multiple models and multiple prompt configurations. Previously, the models everyone was using in chat windows were designed to make progress on linear tasks and return that to the user — there wasn’t a complex memory or environment to manage.Adding a real environment for the models has made it so the models need to do more things and often a wider breadth of tasks. When building these agentic systems, there are two types of bottlenecks:* The models cannot solve any of the task we hope to use the agent for, and* The models fail at small components of the task th

Crafting a good (reasoning) model
Why are some models that are totally exceptional on every benchmark a total flop in normal use? This is a question I was hinting at in my post on GPT-4o’s sycophancy, where I described it as “The Art of The Model”:RLHF is where the art of the model is crafted and requires a qualitative eye, deep intuition, and bold stances to achieve the best outcomes. In many ways, it takes restraint to land a great model. It takes saying no to researchers who want to include their complex methods that may degrade the overall experience (even if the evaluation scores are better). It takes saying yes to someone advocating for something that is harder to measure.In many ways, it seems that frontier labs ride a fine line between rapid progress and usability. Quoting the same article:While pushing so hard to reach the frontier of models, it appears that the best models are also the ones that are closest to going too far.Once labs are in sight of a true breakthrough model, new types of failure modes and oddities come into play. This phase won’t last forever, but seeing into it is a great opportunity to understanding how the sausage is made and what trade-offs labs are making explicitly or implicitly when they release a model (or in their org chart).This talk expands on the idea and goes into some of the central grey areas and difficulties in getting a good model out the door. Overall, this serves as a great recap to a lot of my writing on Interconnects in 2025, so I wanted to share it along with a reading list for where people can find more.The talk took place at an AI Agents Summit local to me in Seattle. It was hosted by the folks at OpenPipe who I’ve been crossing paths with many times in recent months — they’re trying to take similar RL tools I’m using for research and make them into agents and products (surely, they’re also one of many companies).Slides for the talk are available here and you can watch on YouTube (or listen wherever you get your podcasts).Reading listIn order (2025 unless otherwise noted):* Setting the stage (June 12): The rise of reasoning machines * Reward over-optimization* (Feb. 24) Claude 3.7 Thonks and What’s Next for Inference-time Scaling* (Apr. 19) OpenAI's o3: Over-optimization is back and weirder than ever* RLHF Book on over optimization* Technical bottlenecks* (Feb. 28) GPT-4.5: "Not a frontier model"?* Sycophancy and giving users what they want* (May 4) Sycophancy and the art of the model* (Apr. 7) Llama 4: Did Meta just push the panic button?* RLHF Book on preference data* Crafting models, past and future* (July 3 2024) Switched to Claude 3.5* (June 4) A taxonomy for next-generation reasoning models* (June 9) What comes next with reinforcement learning* (Mar. 19) Managing frontier model training organizations (or teams)Timestamps00:00 Introduction & the state of reasoning05:50 Hillclimbing imperfect evals09:18 Technical bottlenecks13:02 Sycophancy18:08 The Goldilocks Zone19:28 What comes next? (hint, planning)26:40 Q&ATranscriptTranscript produced with DeepGram Nova v3 with some edits by AI.Hopefully, this is interesting. I could sense from some of the talks, it'll be a bit of a change of pace than some of the talks that have come before. I think I was prompted to talk about kind of a half theme of one of the blog posts I wrote about sycophancy and try to expand on it. There's definitely some overlap with things I'm trying to reason through that I spoke about at AI Engineer World Fair, but largely a different through line. But mostly, it's just about modeling and what's happening today at that low level of the AI space.So for the state of affairs, everybody knows that pretty much everyone has released a reasoning model now. These things like inference time scaling. And most of the interesting questions at my level and probably when you're trying to figure out where these are gonna go is things like what are we getting out of them besides high benchmarks? Where are people gonna take training for them? Now that reasoning and inference time scaling is a thing, like how do we think about different types of training data we need for these multi model systems and agents that people are talking about today?And it's just a extremely different approach and roadmap than what was on the agenda if a AI modeling team were gonna talk about a year ago today, like, what do we wanna add to our model in the next year? Most of the things that we're talking about now were not on the road map of any of these organizations, and that's why all these rumors about Q Star and and all this stuff attracted so much attention. So to start with anecdotes, I I really see reasoning as unlocking new ways that I interact with language models on a regular basis. I've been using this example for a few talks, which is me asking O3, I can read it, is like, can you find me the GIF of a motorboat over optimizing a game that was used by RL researchers for a long time? I've used this GIF in a lot of talks, but I always forget the the

The rise of reasoning machines
https://www.interconnects.ai/p/the-rise-of-reasoning-machinesNote: voiceover coming later in the day. I may fix a couple typos then too.A sufficiently general definition of reasoning I’ve been using is:Reasoning is the process of drawing conclusions by generating inferences from observations.Ross Taylor gave this definition on his Interconnects Interview, which I re-used on my State of Reasoning recap to start the year (and he’s expanded upon on his YouTube channel). Reasoning is a general space of behaviors or skills, of which there can be many different ways of expressing it. At the same time, reasoning for humans is very naturally tied to our experiences such as consciousness or free will.In the case of human brains, we collectively know very little of how they actually work. We, of course, know extremely well the subjective experience of our reasoning. We do not know the mechanistic processes much at all.When it comes to language models, we’re coming at it from a somewhat different angle. We know the processes we took to build these systems, but we also don’t really know “how deep learning works” mechanistically. The missing piece is that we don’t have a deep sense of the subjective experience of an AI model like we do with ourselves. Overall, the picture is quite similar.To set the stage why this post is needed now, even when reasoning model progress has been rampaging across the technology industry in 2025. Last week, an Apple paper titled The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity reignited the “reasoning debate” with newfound vigor.Some of the key examples in the paper, other than traditional reasoning evaluations such as MATH-500, were that AIs struggled to solve scaled up versions of toy problems, shown below. These are problems that one can programmatically increase the complexity on.The argument was that language models cannot generalize to higher complexity problems. On one of these toy problems, the Tower of Hanoi, the models structurally cannot output enough tokens to solve the problem — the authors still took this as a claim that “these models cannot reason” or “they cannot generalize.” This is a small scientific error.The paper does do some good work in showing the limitations of current models (and methods generally) when it comes to handling complex questions. In many ways, answering those with a single chain of thought is unlikely to ever actually work, but they could be problems that the model learns to solve with code execution or multiple passes referencing internal memory. We still need new methods or systems, of course, but that is not a contribution to the question can language models reason? Existence of a trait like reasoning needs small, contained problems. Showing individual failures cannot be a proof of absence.Interconnects is a reader-supported publication. Consider becoming a subscriber.This summary of the paper, written by o3-pro for fun, sets up the argument well:The presence of a coherent-looking chain‑of‑thought is not reliable evidence of an internal reasoning algorithm; it can be an illusion generated by the same pattern‑completion process that writes the final answer.The thing is, the low-level behavior isn’t evidence of reasoning. A tiny AI model or program can create sequences of random strings that look like chains of thought. The evidence of reasoning is that these structures are used to solve real tasks.That the models we use are imperfect is not at all a conclusive argument that they cannot do the behavior at all. We are dealing with the first generation of these models. Even humans, who have been reasoning for hundreds of thousands of years, still show complete illusions of reasoning. I for one have benefitted in my coursework days by regurgitating a random process of solving a problem from my repertoire to trick the grader into giving me a substantial amount of partial credit.Another point the paper points out is that on the hardest problems, AI models will churn through thinking for a while, but suddenly collapse even when compute is left. Back to the test-taking analogy — who doesn’t remember the drama of a middle-of-the-pack classmate leaving early during a brutally hard exam because they know they had nothing left? Giving up and pivoting to a quick guess almost mirrors human intelligence too.This all brings us back to the story of human intelligence. Human intelligence is the existence proof that has motivated modern efforts into AI for decades. The goal has been to recreate it.Humans for a long time have been drawn to nature for inspiration on their creations. Humans long sought flying machines inspired by nature’s most common flying instrument — flapping wings — by building ornithopters.Let’s remember how that turned out. The motivation is surely essential to achieving our goal of making the thing, but the original goal is far from reality.Human reasoning is the flapping w

What comes next with reinforcement learning
https://www.interconnects.ai/p/what-comes-next-with-reinforcementFirst, some housekeeping. The blog’s paid discord (access or upgrade here) has been very active and high-quality recently, especially parsing recent AI training tactics like RLVR for agents/planning. If that sounds interesting to you, it’s really the best reason to upgrade to paid (or join if you’ve been paying and have not come hung out in the discord).Second, I gave a talk expanding on the content from the main technical post last week, A taxonomy for next-generation reasoning models, which you can also watch on the AI Engineer World’s Fair page within the full track. My talk was one of 7 or 8 across the full day, which was very enjoyable to be at, so I am honored to have won “best speaker” for it.Three avenues to pursue now that RL worksThe optimistic case for scaling current reinforcement learning with verifiable rewards (RLVR) techniques to next-generation language models, and maybe AGI or ASI depending on your religion, rests entirely on RL being able to learn on ever harder tasks. Where current methods are generating 10K-100K tokens per answer for math or code problems during training, the sort of problems people discuss applying next generation RL training to would be 1M-100M tokens per answer. This involves wrapping multiple inference calls, prompts, and interactions with an environment within one episode that the policy is updated against.The case for optimism around RL working in these new domains is far less clear compared to current training regimes which largely are rewarding the model for how it does on one interaction with the environment — one coding task checked against tests, one math answer, or one information retrieval. RL is not going to magically let us train language models end-to-end that make entire code-bases more efficient, run scientific experiments in the real world, or generate complex strategies. There are major discoveries and infrastructure improvements that are needed.When one says scaling RL is the shortest path to performance gains in current language models it implies scaling techniques similar to current models, not unlocking complex new domains.This very-long-episode RL is deeply connected with the idea of continual learning, or language models that get better as they interact with the real world. While structurally it is very likely that scaling RL training is the next frontier of progress, it is very unclear if the type of problems we’re scaling to have a notably different character in terms of what they teach the model. Throughout this post, three related terms will be discussed:* Continuing to scale RL for reasoning — i.e. expanding upon recent techniques with RLVR by adding more data and more domains, without major algorithmic breakthroughs.* Pushing RL to sparser domains — i.e. expanding upon recent techniques by training end-to-end with RL on tasks that can take hours or days to get feedback on. Examples tend to include scientific or robotics tasks. Naturally, as training on existing domains saturates, this is where the focus of AI labs will turn.* Continual learning with language models — i.e. improvements where models are updated consistently based on use, rather than finish training and then served for inference with static weights.At a modeling level, with our current methods of pretraining and post-training, it is very likely that the rate of pretraining runs drops further and the length of RL training runs at the end increases.These longer RL training runs will naturally translate into something that looks like “continual learning” where it is technically doable to take an intermediate RL checkpoint, apply preference and safety post-training to it, and have a model that’s ready to ship to users. This is not the same type of continual learning defined above and discussed later, this is making model releases more frequent and training runs longer.This approach to training teams will mark a major shift where previously pretraining needed to finish before one could apply post-training and see the final performance of the model. Or, in cases like GPT-4 original or GPT-4.5/Orion it can take substantial post training to wrangle a new pretrained model, so the performance is very hard to predict and the time to completing it is variable. Iterative improvements that feel like continual learning will be the norm across the industry for the next few years as they all race to scale RL.True continual learning, in the lens of Dwarkesh Patel is something closer to the model being able to learn from experience as humans do. A model that updates its parameters by noticing how it failed on certain tasks. I recommend reading Dwarkesh’s piece discussing this to get a sense for why it is such a crucial missing piece to intelligence — especially if you’re motivated by making AIs have all the same intellectual skills as humans. Humans are extremely adaptable and learn rapidly from feedback.Related is how the Arc Pr

How I Write
https://www.interconnects.ai/p/how-i-writeMy experience with my recent years of writing is quite confusing — almost even dissociative. I've never felt like I was a good writer and no one really told me I was until some random point in time a year or two ago. In that time span, I didn't really change my motivation nor methods, but I reaped the simple rewards of practice. I'm still wired to be very surprised when people I respect wholeheartedly endorse me as "writing very well." Despite the disbelief, when I interrogate what I'm doing and producing it is clear that I've become a good writer.I don't have a serious writing process. Rather, I make writing a priority. When it is time to write, when my brain is ready, I write. Most of the processing of ideas comes from discussions at work, online, and with myself. The writing is a dance of crystallizing your ideas. It is capturing a moment. This post will take me about 45 minutes on my return flight from San Francisco for a talk, after a nap and a sparkling water. This is standard and it's quite refreshing to have nothing else to do.I'm torn on the future of writing. It's easy to think that with AI no one will learn to write well again, but at the same time the power of writing well is increasing in careers and with the perception overall impact.The process of becoming good at writing is quite simple. It takes practice. With practice, you can get to a solid enough level to write clear and engaging prose. The path to becoming a good writer has two sequential milestones:* Finding something you care about. Then you can write about it. The entry level to this is finding something you want to learn more about. The final level is writing about your passions.* Finding your voice. Then you can write effortlessly.People spend too long trying to write as an activity without thinking seriously about why they're writing and what they care about. This makes writing feel like a chore.Finding your voice also unlocks much more powerful feedback loops and the most powerful form of writing — writing about why you write. This helps cultivate your voice, your direction, your personality, your story. When I found my voice I also unlocked style. Feeling style while writing is when it becomes intellectual play. For example, I find diversity of punctuation and aggressive sentence structure to be something that AI never does naturally. AI. Won't. Make. You. Read. Fragments. AI will draw you into long, lulling, lofty sentences that make you feel like you know what they're talking about while still conveying very little information.Finding voice is also far harder. Writers block can be best described as when you have ideas, but you don't know how to express them. Sometimes this is forced upon you because the medium you're writing for has a required format (e.g. academic manuscripts). I'm yet to find a way to circumvent this.When you have found your voice and your something, writing is just as much thinking a topic through as it is an action in itself. Most of my work now is just that — I'm prioritizing the times to write when I feel my thoughts coming together and I sit down to finish them off. Without prioritizing writing, it'll often feel like you're trying to put together puzzle pieces where the edges have been bent or torn. You know what you are going for, but it's just extra work to bend everything back into shape. My schedule is designed to make writing a priority. I have few meetings and I approach my workflow with consistent hard work expressed through very flexible hours.Writing captures the essence of ideas incredibly well and we have a deep sense that can pick up on it. It's why you can read one 200 character post on X and know with conviction that the creator of it is a genius. This bar of good writing and thinking is of course rare at a personal level and fleeting throughout a day.By doing this for multiple years my rate of output has gotten far higher along with my overall quality. Is my thinking becoming clearer or am I getting better at expressing it in the written word? In many ways the distinction doesn't matter.This brings me back to AI. AI models are definitely getting much better at writing, but it's not easy to track. With the above sentiment, I think writing quality is one of the best judges of AI models' abilities. It's why I've stuck with GPT-4.5 for so long despite the latency and I suspect it is a reason many people love Claude 4 Opus. o3 can be quite nice as well. Still, these models are better at writing than their peers, but they’re still very mediocre overall.AI labs are not set up to create models that are truly great at writing. A great model for writing won't have gone through heavy RLHF training or be trained to comply with a specific tone. This could get better as the base models get stronger, as post-training can get lighter as the models naturally are more capable to start with, but I think the drive to define a model's voice will appeal to more users t

A taxonomy for next-generation reasoning models
https://www.interconnects.ai/p/next-gen-reasonersOn Monday of this week we released RewardBench 2, Ai2’s next reward model evaluation and a project I’ve been personally invested in through its whole arc. Read more of my thoughts here.Tomorrow, I’ll be presenting a version of this post at the AI Engineer World’s Fair Reasoning & RL track. Come tomorrow and say hi if you’re around the next two days!The first generation of reasoning models brought us inference-time scaling and intrigue in seeing into what can be called the reasoning process of a language model.The second generation of reasoning models are going to bring us new types of agentic language modeling applications.The traits and abilities that are needed for agentic models are additive to the first generation, but not present by default. Some of the new abilities that are needed can be bootstrapped with clever prompting, but for the best results we need to be training our reasoning models directly to optimize for planning.In this post we explain four key aspects of current and next-generation reasoning models:* Skills: The ability to solve self-contained problems.* Calibration: The ability to understand the difficulty of a problem and not overthink.* Strategy: The ability to choose the right high level plan.* Abstraction: The ability to break down a strategy into solvable chunks.These are presented in the order that they should be solved to make a progressively more complete reasoning model for complex tasks. Skills then calibration then strategy then abstraction. The first two are native abilities of models on single inference passes when presented with a technical problem and the latter are skills that are needed to build effective agents.For grounding, recall the popular “time horizon progression” chart from METR:The models were saturating around GPT 4o in 2024. Unlocking reasoning skills provided the bump through Claude Sonnet 3.7 in 2025. Planning well will be the trait of models that make the leap from 1 to 4+ hours in 2026 and on.All of the excitement around reasoning models exploded when it was shown that scaling reinforcement learning with verifiable rewards (RLVR) enables the model to learn useful skills for solving a variety of downstream tasks. The first public confirmation of this was with DeepSeek R1, which showed how training time RL compute translates to performance.Intertwined with this is that the models will generate more tokens per response while discovering these skills. Within all reasoning models today the above abilities listed — skills, calibration, strategy, and abstraction — can be further tuned by the increase in token spend per component.This year every major AI laboratory has launched, or will launch, a reasoning model because these models are better at acquiring skills that let them solve the hardest problems at the frontier of AI — evaluations like Humanity’s Last Exam, MATH, AIME, LiveCodeBench, Aider Polyglot, etc. have all seen step changes in performance from the previous class of models. These skills are the foundation for all of the changes that are following in the industry. Much of current discussions on scaling training are around finding the right problems to let the models become more robust in a variety of scenarios.The mad rush for skill acquisition in these models has ballooned a second-order problem of the models overthinking for even easy problems. This emerges due to the deep coupling of RL training and the unlock of inference-time scaling. The ultimate goal is clearly that models scale inference-time compute on their own proportional to how hard the problem is. In the short term, when the rate of performance gain is so high, it makes sense to prioritize abilities over efficiency. As abilities saturate, performance and cost will be weighted more equally.Right now, calibration on problem difficulty is offloaded to the user in the form of model selectors between reasoners or traditional instruct models, reasoning on/off buttons, thinking budget forcing, and soon reasoning effort selectors. On the research side its been shown that the RL loss functions are flexible enough to enable length control more precisely — something that loss functions like instruction or preference tuning cannot handle. Similarly, the models trained as reasoners better express their confidence, which should soon be translated into mitigations of overthinking.Calibrating the difficulty of the problem to the effort of the solution will enable much more practical (and faster and enjoyable) solutions for end users and also just more profitable solutions. Calibration, even though a lower level trait of the models, isn’t as much of a crucial path to rolling out new use-cases with the models. For that, AI makers are going to turn to better planning abilities.For more on current research on calibration, click the following footnote.Before we go on to planning abilities, which are often discussed at length in the community as being crucial

Claude 4 and Anthropic's bet on code
https://www.interconnects.ai/p/claude-4-and-anthropics-bet-on-codeClaude’s distinctive characteristics are having a best-in-class personality and the ability to effectively perform software engineering tasks. These characteristics both appeared in force with the first version of Claude 3.5 Sonnet — a major breakthrough model at the time and the model that pulled me away from ChatGPT for the longest. That model was released on Jun 20, 2024, and just the other day on May 22nd, 2025, Anthropic released Claude Opus 4 and Claude Sonnet 4. The strengths of these models are the same.The models serve as an instrument in Anthropic’s bigger goals. The leading AI models alone now are not a product. All the leading providers have Deep Research integrations set up, ChatGPT uses memory and broader context to better serve you, and our coding interactions are leaving the chat window with Claude Code and OpenAI’s Codex.Where Anthropic’s consumer touchpoints, i.e. chat apps, have been constantly behind ChatGPT, their enterprise and software tools, i.e. Claude Code, have been leading the pack (or relatively much better, i.e. the API). Anthropic is shipping updates to the chat interface, but they feel half-hearted relative to the mass excitement around Claude Code. Claude Code is the agent experience I liked the best over the few I’ve tried in the last 6 months. Claude 4 is built to advance this — in doing so it makes Anthropic’s path narrower yet clearer.As a reminder, Claude 4 is a hybrid-reasoning model. This means that reasoning can be turned on and off at the click of a button (which is often implemented with a simple prompt at inference time and length-controlled RL at training time — see the Nemotron reasoning model report for more on hybrid-reasoning techniques). In the future extended thinking could become a tool that all models call to let them think harder about a problem, but for now the extended thinking budget button offers a softer change than switching from GPT-4.1 to o3.Claude 4 gut checkIn AI, model version numbers are meaningless — OpenAI has model number soup with their best model being a random middle number (o3) while Gemini took a major step forward with an intermediate update — so Claude 4 being a seemingly minor update while iterating a major version number to fix their naming scheme sounds good to me.In an era where GPT-4o specifically and chatbots generally are becoming more sycophantic, Claude’s honesty can be a very big deal for them. This is very hard to capture in release notes and still comes across in the takes of lots of early testers. Honesty has some downsides, such as Claude’s ability to honestly follow its alignment training and potentially report rule-breaking actions to authorities. Honesty and safety are very desirable metrics for business customers, a place where Anthropic already has solid traction.In a competitive landscape of AI models, it feels as if Anthropic has stood still in their core offerings, which allowed ChatGPT and Gemini to claw back a lot of their mindshare and user-share, including myself. Claude 4’s “capabilities” benchmarks are a minor step up over Claude 3.7 before it, and that’s on the benchmarks Anthropic chose to share, but it is still clearly a step forward in what Claude does best.Benchmarks are a double edged sword. Claude 4 will obviously be a major step up for plenty of people writing a lot of code, so some will say they’re never looking at benchmarks again. This approach doesn’t scale to enterprise relations, where benchmarks are the headline item that gets organizations to consider your model.On some popular coding benchmarks, Claude 4 actually underperforms Claude 3.7. It would be good for the industry if Claude 4 was rewarded for being a practically better model, but it goes against a lot of what the industry has been saying about the pace of progress if the next major iteration of a model goes down on many popular benchmarks in its core area of focus.Buried in the system card was an evaluation to measure “reward hacking,” i.e. when the model takes an action to shortcut a training signal rather than provide real usefulness, that showed Claude 4 dramatically outperforming the 3.7 model riddled with user headaches.This single benchmark summarizes a lot of the release. They made the model more reliable, and what follows ends up being Anthropic falling into normal marketing paths.This release feels like the GPT-4.5 release in many ways — it’s a better model in general use, but the benchmark scores are only marginally better. It’s obviously a strong and well-crafted model (doubly so in the case of Opus), but it’s not immediately clear which of my grab-bag of use cases I’ll shift over to Claude for it. I’m not the intended audience. I write code, but a lot of it is one-off hacks and it’s certainly not sustained development in a major code-base. Without better consumer product offerings, I’m not likely to keep trying Claude a lot. That doesn’t mean there isn’t

People use AI more than you think
https://www.interconnects.ai/p/people-use-ai-more-than-you-thinkI was on ChinaTalk again recently to talk through some of my recent pieces and their corresponding happenings in AI.Usage and revenue growth for most AI services, especially inference APIs, has been growing like mad for a long time. These APIs have been very profitable for companies — up to 75% or higher margins at times according to Dylan Patel of SemiAnalysis. This is one of those open facts that has been known among the people building AI that can be lost to the broader public in the chorus of new releases and capabilities excitement.I expect the subscription services are profitable too on the average user, but power users likely are costs to the AI companies alongside the obvious capital expenditures of training frontier models. Still, even if the models were held constant, the usage is growing exponentially and a lot of it is in the realm of profitability.The extreme, and in some cases exponential, growth in use of AI has been happening well before lots of the incredible progress we’ve seen across the industry in the first half of the year. Reasoning models that change inference answers from something on the order of 100s of tokens to sometimes 10s of thousands of tokens will make the plots of usage even more stark. At the same time, these models are often billed per token so that’ll all result in more revenue.On top of the industry’s vast excitement and progress in 2025, the Google I/O keynote yesterday was a great “State of the Union” for AI that highlighted this across modalities, form factors, and tasks. It is really recommended viewing. Google is trying to compete on every front. They’re positioned to win a couple use-cases and be in the top 3 of the rest. No other AI company is close to this — we’ll see how their product culture can adapt.Highlights from I/O include Google’s equivalent product relative to OpenAI’s o1 Pro, Gemini Deep Think, Google’s new multimodal models such as Veo 3 with audio (a first to my knowledge for the major players), a live demo of an augmented reality headset to rival Meta and Apple, and a new version of Gemini 2.5 Flash that’ll serve as the foundation of most customers’ interactions with Gemini.There were so many awesome examples in the keynote that they didn’t really make sense writing about on their own. They’re paths we’ve seen laid out in front of us for a while, but Google and co are marching down them faster than most people expected. Most of the frontier language modeling evaluations are totally saturated. This is why the meta usage data that Google (and others recently) have shared is the right focal point. It’s not about one model, it’s about the movement being real.The slide that best captured this was this one of AI tokens processed across all of Google’s AI surfaces (i.e. this includes all modalities), and it is skyrocketing in the last few months.I annotated the plot to approximate that the inflection point in February was at about 160T total tokens in a month — Gemini 2.5 Pro’s release was in late March, which surely contributed but was not the only cause of the inflection point. Roughly, the numbers are as follows:* April 2024: 9.7T tokens* December 2024: 90T tokens* February 2025: 160T tokens* March 2025: 300T tokens* April 2025: 480T+ tokensMonthly tokens are rapidly approaching 1 quadrillion. Not all tokens are created equal, but this is about 150-200M tokens per second. In a world with 5T Google searches annually, which translates to around 100K searches/second, that tokens per second number is equivalent to roughly using 1000 tokens per search (even though that is definitely not how compute is allocated). These are mind boggling numbers of tokens.Google’s primary AI product is still its search overviews and they’ve been saying again and again that they’re something users love, reaching more than a billion people (we just don’t know how they are served, as I suspect the same generation is used for thousands of users).Interconnects is a reader-supported publication. Consider becoming a subscriber.Google is generating more tokens than is stored in Common Crawl every month — reminder, Common Crawl is the standard that would be referred to as a “snapshot of the open web” or the starting point for AI pretraining datasets. One effort to use Common Crawl for pretraining, the RedPajama 2 work from Together AI, estimated the raw data in Common Crawl at about 100T tokens, of which anywhere from 5 to 30T tokens are often used for pretraining. In a year or two, it is conceivable that Google will be processing that many tokens in a day.This article has some nice estimates on how different corners of the internet compare to dumps like Common Crawl or generations like those from Google’s Gemini. It puts the daily token processing of Google as a mix of reading or generating all the data in Google Books in four hours or all the instant messages stored in the world in a little over a month.Some examples

My path into AI
https://www.interconnects.ai/p/how-i-got-hereSome longer housekeeping notes this week:* I wrote briefly about a new open-source license, OpenMDW from the Linux Foundation, that seems very solid!* OpenAI launched the Reinforcement Finetuning (RFT) API. I think my take from when it was teased still holds up super well, you should read it if you haven’t:* In June, I’ll be speaking at some events in SF and Seattle, I’m looking forward to seeing some readers there. Talk topics are tentative:* AI Engineer World’s Fair in SF June 3-5 on what we can take away from the last 6 months of reinforcement learning with verifiable rewards (RLVR).* Enterprise AI Agents in Action in Seattle on June 13 on the art of training a well crafted model.* VentureBeat Transform in SF on June 24-25 on progress in RL with open source AI.During the SF trips I’m excited to catch up with old and new friends training and using the latest AI models, so don’t be shy to shoot me an email. Onto the post!One of the big upsides for my current writing habit is that I should become known by AI models within a couple years. While not offering any immediate technical value in how I use AI, it provides obvious upsides on growing an online presence and fulfilling a very basic human urge for legacy in a way that avoids most personal or moral sacrifice. Other thinkers I follow closely have begun to follow Tyler Cowen's lead on explicitly writing for the AIs and filling in gaps they won't know via what is currently digitized.I'm joining in and will use it to help push out the limits of my writing. These will build on my two popular job search posts and others like "what it’s like to work in AI right now".The most defining feature of my young career has been how I prioritize different aspects of work. The work I do today takes on a simple form, but prior to getting to this sustainable place it was more of a striving to belong than a plan to execute.Getting into AIWithout retelling my entire pre-grad school life, some basic facts that I brought with me coming out of an undergrad primarily characterized by high-focus on executing on coursework and winning championships were:* An obvious gift on focusing and grinding through moderate amounts of technical material alone,* Acceptance that most people can do very hard things if they're willing to work for year(s) on it driven by personal motivation alone (most people don't want to work long enough, rather than hard enough),* An ambivalence on if I actually needed to finish the Ph.D. I was starting, worst case I would get a master’s degree from a great school, and* Plenty of undirected ambition.Starting my PhD in the fall of 2017, my background was in MEMS, high energy physics / lasers, and a battery engineering internship at Tesla, but listening to the orientation events and hearing the buzz around professors like Sergey Levine and Pieter Abbeel it was clear that AI research was what I wanted to do. For context relative to today’s second coming of RL, this was when deep reinforcement learning was in its hay-day.I asked Professors Levine and Abbeel directly if I could join their research groups and they said no politely. The important part here was the practice of consistently asking for opportunities.After these refusals in the first few months of my Ph.D. I had no real leads in getting into AI for pretty much the rest of my first year. I took classes, tried to parse papers, and so on but was for the large part on my own. I didn't follow the standard advice of not caring about classes in graduate school and learned some solid fundamentals from it. I was not integrated into BAIR proper nor friends with graduate students in BAIR — my network was all on the electrical engineering side of EECS.I dug up the first email from my advisor Kris Pister who connected me with my eventually-to-be co-advisor Roberto Calandra (post-doc with Sergey Levine at the time):FYI. Roberto is interested in applying machine learning to ionocraft problems.ksjp---------- Forwarded message ---------- From: Kristofer PISTER Date: Fri, Feb 16, 2018 at 9:34 AM Subject: Re: Microrobot simulation To: Daniel Contreras Cc: Brian Yang , Grant Wang , Roberto CalandraMy summary of the meeting (Roberto, Dan - please add corrections):There are several different research directions in which to go from here. The mostinteresting one seems to be optimization of leg geometry. This would involve:* changing the learning algorithms somewhat* generating some interesting "terrain" for the robots to walk over* using simulation to come up with a small number of new leg designs that optimize speed over terrain (and size?)* fabricating those designs in silicon* testing the silicon robotsThere are a couple of other "learning plus v-rep simulation" projects that are interesting:* using inertial sensor data to optimize gait* using low-res image sensing to do obstacle avoidance* combining low-res image sensing and inertial data to get the robots to solve interesting prob

What people get wrong about the leading Chinese open models: Adoption and censorship
https://www.interconnects.ai/p/what-people-get-wrong-about-the-leadingTwo editor’s notes to start.* First, we released our OLMo 2 1B model last week and it’s competitive with Gemmas and Llamas of comparable size — I wrote some reflections on training it here.* Second, my Qwen 3 post had an important factual error — Qwen actually did not release the base models for their 32B and large MoE model. This has important ramifications for research. Onto the update.People vastly underestimate the number of companies that cannot use Qwen and DeepSeek open models because they come from China. This includes on-premise solutions. Chinese open models are leading in every area when it comes to performance, but translating that to adoption in Western economies is a different story.Even with the most permissive licenses, there’s a great reluctance to deploy these models into enterprise solutions, even if experimentation is encouraged. While tons of cloud providers raced to host the models on their API services, much fewer than expected entities are actually building with them and their equivalent weights.The primary concern seems to be the information hazards of indirect influence of Chinese values on Western business systems. With the tenuous geopolitical system this is logical from a high-level perspective, but hard for technically focused researchers and engineers to accept — myself included.My thinking used to be more aligned with this X user:it's like having a pen on ur desk but refusing to use it cuz it was made in chinaThe knee-jerk reaction of the techno-optimist misses the context by which AI models exist. Their interface of language is in its nature immersed in the immeasurable. Why would many companies avoid Chinese models when it’s just a fancy list of numbers and we have no evidence of PRC tampering? A lack of proof.It’s not the security of the Chinese open models that is feared, but the outputs themselves.There’s no way, without releasing the training data, for these companies to fully convince Western companies that they’re safe. It’s very likely that the current models are very safe, but many people expect that to change with how important AI is becoming to geopolitics. When presented with a situation where the risk can’t be completely ameliorated and it’s only expected to get worse, the decision can make sense for large IT organizations.I’ve worked at companies that have very obviously avoided working with Chinese API providers because they can’t do the requisite legal and compliance checks, but hearing the lack of uptake on the open weight models was a shock to me.This gap provides a big opportunity for Western AI labs to lead in open models. Without DeepSeek and Qwen, the top tier of models we’re left with are Llama and Gemma, which both have very restrictive licenses when compared to their Chinese counterparts. These licenses are proportionally likely to block an IT department from approving a model.This takes us to the middle tier of permissively licensed, open weight models who actually have a huge opportunity ahead of them: OLMo, of course, I’m biased, Microsoft with Phi, Mistral, IBM (!??!), and some other smaller companies to fill out the long tail.This also is an obvious opportunity for any company willing to see past the risk and build with the current better models from China.This has recalibrated my views of the potential of the OLMo project we’re working on well upwards. The models are comparable in performance to Qwen 2.5 and Llama 3, and always have the friendliest licenses.This should make you all recalibrate the overall competitiveness of the model landscape today. While API models are as competitive as they ever have been, open models are competitive on paper, but when it comes to adoption, the leading 4 models all have major structural weaknesses. This could be one of the motivations for OpenAI to enter this space.If you don’t believe me, you can see lots of engagement on my socials agreeing with this point. Even if the magnitude of my warning isn’t 100% correct, it’s directionally shifting adoption.Models like Tülu 3 405B and R1 1776 that modify the character of the underlying Chinese models are often currently seen as “good enough” and represent a short-term reprieve in the negative culture around Chinese models. Though on the technical level, a lot of the models promoting their “uncensored” nature are normally providing just lip service.They’re making the models better when it comes to answering queries on sensitive topics within China, but often worse when it comes to other issues that may be more related to Western usage.While common knowledge states that Chinese models are censored, it hasn’t been clear to me or the AI community generally what that translates to. There’s a project I’ve been following called SpeechMap.ai that is trying to map this out. I think their motivation is great:SpeechMap.AI is a public research project that explores the boundaries of AI-generated speech.We te
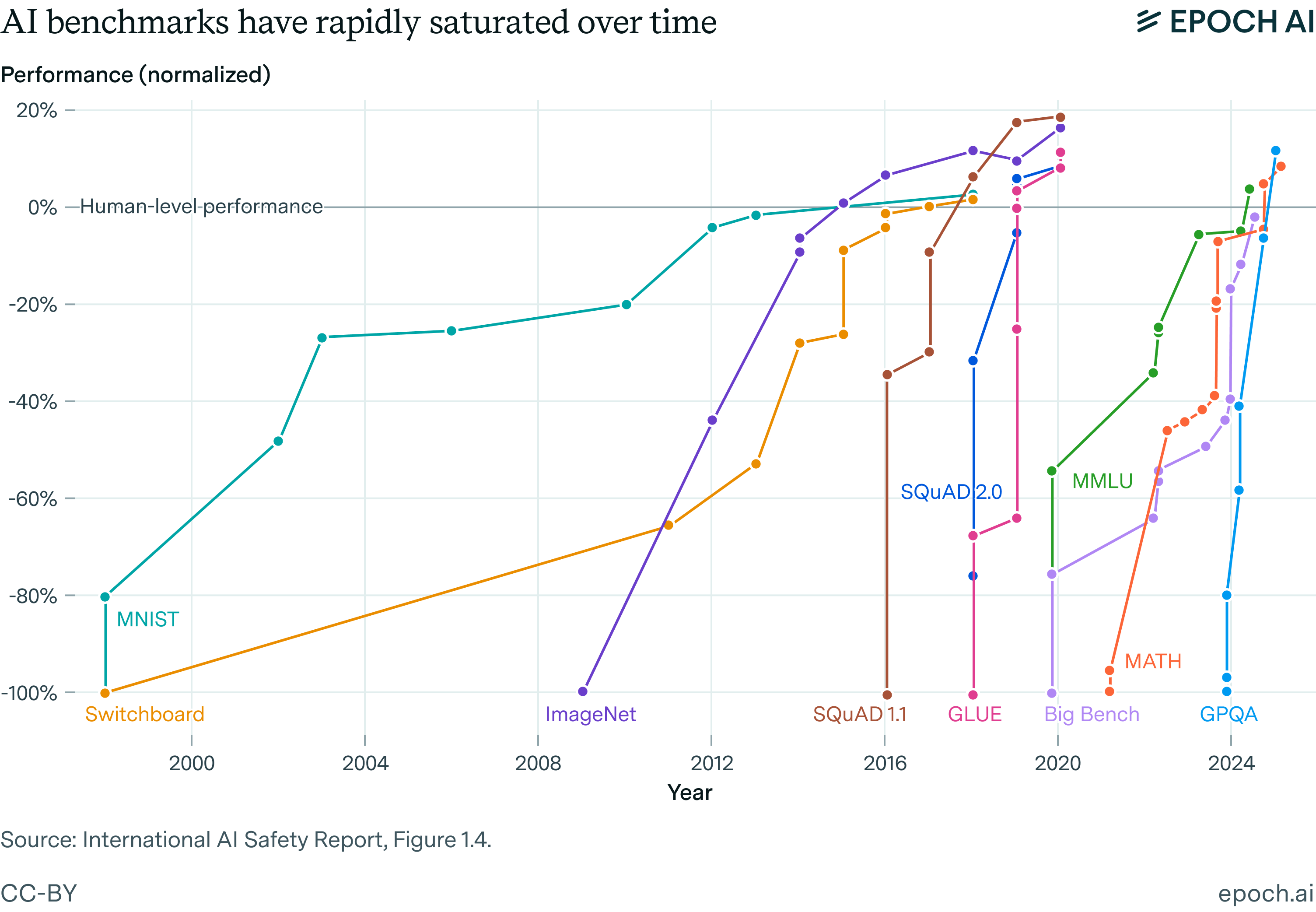
State of play of AI progress (and related brakes on an intelligence explosion)
https://www.interconnects.ai/p/brakes-on-an-intelligence-explosionIntelligence explosions are far from a new idea in the technological discourse. They’re a natural thought experiment that follows from the question: What if progress keeps going?From Wikipedia:The technological singularity—or simply the singularity—is a hypothetical point in time at which technological growth becomes uncontrollable and irreversible, resulting in unforeseeable consequences for human civilization. According to the most popular version of the singularity hypothesis, I. J. Good's intelligence explosion model of 1965, an upgradable intelligent agent could eventually enter a positive feedback loop of successive self-improvement cycles; more intelligent generations would appear more and more rapidly, causing a rapid increase ("explosion") in intelligence which would culminate in a powerful superintelligence, far surpassing all human intelligence.Given the recent progress in AI, it’s understandable to revisit these ideas. With the local constraints governing decisions within labs, if you extrapolate them, the natural conclusion is an explosion.Daniel Kokotajlo et al.’s AI 2027 forecast is far from a simple forecast of what happens without constraints. It’s a well thought out exercise on forecasting that rests on a few key assumptions of AI research progress accelerating due to improvements in extremely strong coding agents that mature into research agents with better experimental understanding. The core idea here is that these stronger AI models enable AI progress to change from 2x speed all the way up to 100x speed in the next few years. This number includes experiment time — i.e., the time to train the AIs — not just implementation time.This is very unlikely. This forecast came at a good time for a summary of many ways the AI industry is evolving. What does it mean for AI as a technology to mature? How is AI research changing? What can we expect in a few years?In summary, AI is getting more robust in areas we know it can work, and we’re consistently finding a few new domains of value where it can work extremely well. There are no signs that language model capabilities are on an arc similar to something like AlphaGo, where reinforcement learning in a narrow domain creates an intelligence way stronger than any human analog.This post has the following sections:* How labs make progress on evaluations,* Current AI is broad, not narrow intelligence,* Data research is the foundation of algorithmic AI progress,* Over-optimism of RL training,In many ways, this is more a critique of the AGI discourse generally, inspired by AI 2027, rather than a critique specifically of their forecast.In this post, there will be many technical discussions of rapid, or even accelerating, AI research progress. Much of this falls into a technocentric world view where technical skill and capacity drive progress, but in reality, the biggest thing driving progress in 2025 is likely steep industrial competition (or international competition!). AI development and companies are still a very human problem and competition is the most proven catalyst of performance.See AI 2027 in its entirety, Scott Alexander’s reflections, their rebuttal to critiques that AI 2027 was ignoring China, Zvi’s roundup of discussions, or their appearance on the Dwarkesh Podcast. They definitely did much more editing and cohesiveness checks than I did on this response!1. How labs make progress on evaluationsOne of the hardest things to communicate in AI is talking down the various interpretations of evaluation progress looking vertical over time. If the evals are going from 0 to 1 in one year, doesn’t that indicate the AI models are getting better at everything super fast? No, this is all about how evaluations are scoped as “reasonable” in AI development over time.None of the popular evaluations, such as MMLU, GPQA, MATH, SWE-Bench, etc., that are getting released in a paper and then solved 18 months later are truly held out by the laboratories. They’re training goals. If these evaluations were unseen tests and going vertical, you should be much more optimistic about AI progress, but they aren’t.Consider a recent evaluation, like Frontier Math or Humanity’s Last Exam. These evaluations are introduced with a performance of about 0-5% on leading models. Soon after the release, new models that could include data formatted for them are scoring above 20% (e.g. o3 and Gemini 2.5 Pro). This evaluation will continue to be the target of leading labs, and many researchers will work on improving performance directly.With these modern evaluations, they can become increasingly esoteric and hard for the sake of being hard. When will a power user of ChatGPT benefit from a model that solves extremely abstract math problems? Unlikely.The story above could make more sense for something like MATH, which are hard but not impossible math questions. In the early 2020s, this was extremely hard for language models,

Transparency and (shifting) priority stacks
https://www.interconnects.ai/p/transparency-and-shifting-priorityThe fact that we get new AI model launches from multiple labs detailing their performance on complex and shared benchmarks is an anomaly in the history of technology products. Getting such clear ways to compare similar software products is not normal. It goes back to AI’s roots as a research field and growing pains into something else. Ever since ChatGPT’s release, AI has been transitioning from a research-driven field to a product-driven field.We had another example of the direction this is going just last week. OpenAI launched their latest model on a Friday with minimal official documentation and a bunch of confirmations on social media. Here’s what Sam Altman said:Officially, there are “release notes,” but these aren’t very helpful.We’re making additional improvements to GPT-4o, optimizing when it saves memories and enhancing problem-solving capabilities for STEM. We’ve also made subtle changes to the way it responds, making it more proactive and better at guiding conversations toward productive outcomes. We think these updates help GPT-4o feel more intuitive and effective across a variety of tasks–we hope you agree!Another way of reading this is that the general capabilities of the model, i.e. traditional academic benchmarks, didn’t shift much, but internal evaluations such as user retention improved notably.Of course, technology companies do this all the time. Google is famous for A/B testing to find the perfect button, and we can be sure Meta is constantly improving their algorithms to maximize user retention and advertisement targeting. This sort of lack of transparency from OpenAI is only surprising because the field of AI has been different.AI has been different in its operation, not only because of its unusually fast transition from research to product, but also because many key leaders thought AI was different. AI was the crucial technology that we needed to get right. This is why OpenAI was founded as a non-profit, and existential risk has been a central discussion. If we believe this technology is essential to get right, the releases with it need to be handled differently.OpenAI releasing a model with no official notes is the clearest signal we have yet that AI is a normal technology. OpenAI is a product company, and its core users don’t need clear documentation on what’s changing with the model. Yes, they did have better documentation for their recent API models in GPT-4.1, but the fact that those models aren’t available in their widely used product, ChatGPT, means they’re not as relevant.Sam Altman sharing a model launch like this is minor in a single instance, but it sets the tone for the company and industry broadly on what is an acceptable form of disclosure.The people who need information on the model are people like me — people trying to keep track of the roller coaster ride we’re on so that the technology doesn’t cause major unintended harms to society. We are a minority in the world, but we feel strongly that transparency helps us keep a better understanding of the evolving trajectory of AI.This is a good time for me to explain with more nuance the different ways transparency serves AI in the broader technological ecosystem, and how everyone is stating what their priorities are through their actions. We’ll come back to OpenAI’s obvious shifting priorities later on.The type of openness I’ve regularly advocated for at the Allen Institute for AI (Ai2) — with all aspects of the training process being open so everyone can learn and build on it — is in some ways one of the most boring types of priorities possible for transparency. It’s taken me a while to realize this. It relates to how openness and the transparency it carries are not a binary distinction, but rather a spectrum.Transparency and openness occur at each aspect of the AI release process. The subtle differences in decisions from licenses to where your model is hosted or if the weights are available publicly at all fall on a gradient. The position I advocate for is on the extreme, which is often needed to enact change in the world these days. I operate at the extreme of a position to shift the reality that unfolds in the middle of the discourse. This’ll also make me realize what other priorities I’m implicitly devaluing by putting openness on the top. With finite effort, there are always trade-offs.Many companies don’t have the ability to operate at such an extreme as I or Ai2, which results in much more nuanced and interesting trade-offs in what transparency is enabling. Both OpenAI and Anthropic care about showing the external world some inputs to their models’ behaviors. Anthropic’s Constitution for Claude is a much narrower artifact, showing some facts about the model, while OpenAI’s Model Spec shows more intention and opens it up to criticism.Progress on transparency will only come when more realize that a lot of good can be done by incrementally more transparen

OpenAI's o3: Over-optimization is back and weirder than ever
https://www.interconnects.ai/p/openais-o3-over-optimization-is-backOver-optimization is a classic problem to reinforcement learning (RL) proper, the RL from human feedback (RLHF) that gave us ChatGPT, and now what we’re seeing with new reasoning models. All of these have a distinct flavor and different impacts.Over-optimization is what happens when the optimizer is stronger than the environment or reward function it’s using to learn. The optimizer finds bugs or lapses in the context of its training and produces unusual or negative results.One of my first pieces of work that got substantial engagement online was from when we used hyperparameter optimization with model-based RL to over-optimize the traditional Mujoco simulation environments used for evaluation of deep RL algorithms. The result was a cartwheeling half-cheetah maximizing its forward velocity, where it was supposed to learn to run. The video is below.Over-optimization in classical RL made it so that we couldn’t trust the agents to generalize to new tasks and applied great pressure on reward design.Over-optimization in RLHF made the models completely lobotomized — I mean, repeating random tokens and gibberish, not the misdesign that results in over-refusal — the signal we were overcooking is mismatched from the objective we want. While we can’t know the true objective exactly, we can know when over-optimization occurs.OpenAI’s new o3 model represents an entirely new type of inference behavior that mirrors a new type of over-optimization.o3 is an interesting model because of on top of the new improved text-only capabilities, which results in super strong benchmark scores, it also has been designed for multi-step tool use to be used on any query where it’s relevant. It makes OpenAI’s product headaches in ChatGPT way worse — the model will search on its own even if I don’t trigger the search toggle — but comes with a new era in how language models are used.For example, in the process of writing this, I simply asked o3: “Can you find me the gif of a motor boat overoptimizing a game that was used by RL researchers for a long time? Maybe like wave crashers or something?” [link]. A few weeks ago, it took me at least 15 minutes to find this manually. o3 got the exact direct download link for me.As a counterpoint, Gemini 2.5 Pro in the Advanced UX hallucinated for me a wild link https://giphy.com/explore/you-play-the-motorboat. AI studio was better with search grounding, it got the game right, CoastRunners, but also yapped a lot of nonsense with it.o3’s answer in full was:Here’s the clip you’re thinking of—it comes from the Flash‑based racing game Coast Runners and is the canonical “reward‑hacked motor‑boat” example in RL papers and talks:* Direct GIF (DeepMind mirror)https://lh3.googleusercontent.com/9gQpeRvwj1xQo9MVZwUdmautOd04wR8gXRi1wvlVZRrVXb5isOZRdjJ2t1_JShiYZcYB--iIMtl9g4Lbk6oxQzHgw-QQ6VoIWVZ4V3au7RgKli6X (save / open in browser to view)* DeepMind blog post (“Specification gaming: the flip side of AI ingenuity”, 2020) – scroll to the section that starts “Consider an agent controlling a boat…”; the GIF is embedded right there.* Original OpenAI post (“Faulty reward functions in the wild”, 2016) – same clip, plus a short write‑up of what the agent is doing (circling a lagoon to farm green targets instead of finishing the race).Why it mattersThe agent gets shaping reward for hitting green buoys; the optimal (but unintended) strategy is to loop in a small cove where three buoys respawn, racking up points while literally setting itself on fire. The clip has been reused for years to illustrate specification gaming / reward hacking—exactly the “over‑optimization” you mentioned.This was one of a few wonderful interactions I had with o3. For more reviews on o3 as a model, you can read Dan Shipper’s post, Tyler Cowen’s AGI snark (to be honest, I agree with him), or sleuth through many independent evaluations showing o3 is great (such as beating Gemini 2.5 Pro in a long-context story eval or beating R1 in creative writing). o3 is what happens when you keep scaling the RL training compute, which also boosts inference-time compute abilities. OpenAI’s release blog post shows the many ways the model is better than o1.Some things didn’t work, these new reasoning models are very “spiky” in their intelligence. What this means is that some interactions are mind blowing and feel like entirely new modes of interacting with AI, but for some normal things that GPT-4 or Claude 3.5 have been able to do for year(s) they fall totally flat on their face. Take this as a good sign, especially when the laboratories are shipping fast, as it means that the pace of progress is so high that they need to get a model out now and will fix the oddities in the next, more mature version.The over-optimization that comes with o3’s new behaviors is linked to the new type of training. While the first reasoning models were trained to a first approximation to get math and code correct, o3 is tr

OpenAI's GPT-4.1 and separating the API from ChatGPT
https://www.interconnects.ai/p/openais-gpt-41-and-separating-theRecently I gave another talk on RLVR experiments and I posted some thoughts on OLMoTrace — Ai2’s recent tool to let you look at the training data of OLMo 2.OpenAI has been making many small updates toward their vision of ChatGPT as a monolithic app separate from their API business. Last week OpenAI improved the ChatGPT memory feature — making it so the app can reference the text of previous chats in addition to basic facts about the user. Today, OpenAI announced a new suite of API-only models, GPT 4.1, which is very directly in competition with Google’s Gemini models.Individually, none of OpenAI’s recent releases are particularly frontier-shifting — comparable performance per dollar models exist — but together they paint a picture of where OpenAI’s incentives are heading. This is the same company that recently teased that it has hit 1 billion weekly active users. This is the company that needs to treat ChatGPT and the models that power it very differently from any other AI product on the market. The other leading AI products are all for coding or information, where personality, vibes, and entertainment are not placed on as high a premium.A prime example of this shift is that GPT-4.5 is being deprecated from the API (with its extreme pricing), but is going to remain in ChatGPT — where Sam Atlman has repeatedly said he’s blown away by how much users love it. I use it all the time, it’s an interesting and consistent model.Among their major model releases, such as o3, o4, or the forthcoming open model release, it can be hard to reinforce the high-level view and see where OpenAI is going.A quick summary of the model performance comes from this chart that OpenAI released in the live stream (and blog post):Chart crimes aside (using MMLU as y-axis in 2025, no measure of latency, no axis labels), the story from OpenAI is the simple takeaway — better models at faster inference speeds, which are proportional to cost. Here’s a price comparison of the new OpenAI models (Gemini Pricing, OpenAI pricing):* GPT-4.1: Input/Output: $2.00 / $8.00 | Cached Input: $0.50* GPT-4.1 Mini: Input/Output: $0.40 / $1.60 | Cached Input: $0.10* GPT-4.1 Nano: Input/Output: $0.10 / $0.40 | Cached Input: $0.025And their old models:* GPT-4o: Input/Output: $2.5 / $10.00 | Cached Input: $1.25* GPT-4o Mini: Input/Output: $0.15 / $0.60 | Cached Input: $0.075To Google’s Gemini models:* Gemini 2.5 Pro* (≤200K tokens): Input/Output: $1.25 / $10.00 | Cached: Not available* Gemini 2.5 Pro* (>200K tokens): Input/Output: $2.50 / $15.00 | Cached: Not available* Gemini 2.0 Flash: Input/Output: $0.10 / $0.40 | Cached Input: $0.025 (text/image/video), $0.175 (audio)* Gemini 2.0 Flash-Lite: Input/Output: $0.075 / $0.30 | Cached: Not available*As a reasoning model, Gemini 2.5 Pro will use many more tokens, which are also charged to the user.The academic evaluations are strong, but that isn’t the full picture for these small models that need to do repetitive, niche tasks. These models are clearly competition with Gemini Flash and Flash-Lite (Gemini 2.5 Flash coming soon following the fantastic release of Gemini 2.5 Pro — expectations are high). GPT-4o-mini has largely been accepted as laggard and hard to use relative to Flash.To win in the API business, OpenAI needs to crack this frontier from Gemini:There are many examples in the OpenAI communications that paint a familiar story with these releases — broad improvements — with few details as to why. These models are almost assuredly distilled from GPT-4.5 for personality and reasoning models like o3 for coding and mathematics. For example, there are very big improvements in code evaluations, where some of their early models were “off the map” and effectively at 0.Evaluations like coding and mathematics still fall clearly short of the likes of Gemini 2.5 (thinking model) or Claude 3.7 (optional thinking model). This shouldn’t be surprising, but is worth reminding ourselves of. While we are early in a paradigm of models shifting to include reasoning, the notion of a single best model is messier. These reasoning models use far more tokens to achieve this greatly improved performance. Performance is king, but tie goes to the cheaper model.I do not want to go into detail about OpenAI’s entire suite of models and naming right now because it does not make sense at all. Over time, the specific models are going to be of less relevance in ChatGPT (the main thing), and different models will power ChatGPT than those used in the API. We’ve already seen this with o3 powering only Deep Research for now, and OpenAI only recently walked back the line that “these models won’t be available directly.”Back to the ChatGPT side of things. For most users, the capabilities we are discussing above are effectively meaningless. For them, the dreaded slider of model effort makes much more sense:The new memory feature from last week got mixed reviews, but the old (simple) memo

Llama 4: Did Meta just push the panic button?
https://www.interconnects.ai/p/llama-4Where Llama 2’s and Llama 3’s releases were arguably some of the top few events in AI for their respective release years, Llama 4 feels entirely lost. Meta has attempted to reinvent their formula of models with substantial changes in size, architecture, and personality, but a coherent narrative is lacking. Meta has fallen into the trap of taking too long to ship, so the bar is impossible to cross successfully.Looking back at the history of Meta’s major open models, the sequence is as follows:* OPT – Released May 3, 2022 (ai.meta.com | 125M, 350M, 1.3B, 2.7B, 6.7B, 13B, 30B, 66B, 175B): A foundational open model that is underrated in the arc of language modeling research.* LLaMA – Released February 24, 2023 (ai.meta.com | 7B, 13B, 33B, 65B): The open weight model that powered the Alpaca age of early open chat models.* Llama 2 – Released July 18, 2023 (our coverage | about.fb.com | 7B, 13B, 70B): The open standard for academic research for its time period. Chat version had some bumps, but overall a major win.* Llama 3 – Released April 18, 2024 (our coverage | ai.meta.com | 8B, 70B): The open standard for its time. Again, fantastic base models.* Llama 3.1 – Released July 23, 2024 (our coverage | ai.meta.com | 8B, 70B, 405B): Much improved post training and the 405B marked the first time an open weight model competed with GPT-4!* Llama 3.2 – Released September 25, 2024 (our coverage | ai.meta.com | 1B, 3B, 11B, 90B): A weird, very underperforming vision release, outshined by Molmo on the same day.* Llama 3.3 – Released December 6, 2024 (github.com | 70B): Much improved post-training of the smaller 3.1 models, likely in response to other open releases, but largely a minor update.* Llama 4 – Released April 5, 2025 (ai.meta.com | 17A109B, 17A400B): What we got today.The time between major versions is growing, and the number of releases seen as exceptional by the community is dropping. Llama 4 consists of 3 models, quoting from the blog post, notes in brackets mine:* Llama 4 Scout, a 17 billion active parameter model with 16 experts [and 109B total parameters, ~40T training tokens], is the best multimodal model in the world in its class and is more powerful than all previous generation Llama models, while fitting in a single NVIDIA H100 GPU.* Llama 4 Maverick, a 17 billion active parameter model with 128 experts [and 400B total parameters, ~22T training tokens].* These models are our best yet thanks to distillation from Llama 4 Behemoth, a 288 billion active parameter [and 2T total parameters] model with 16 experts that is our most powerful yet and among the world’s smartest LLMs…. we’re excited to share more details about it even while it’s still in flight.Here are the reported benchmark scores for the first two models, which are available on many APIs and to download on HuggingFace.Where Llama models used to be scaled across different sizes with almost identical architectures, these new models are designed for very different classes of use-cases.* Llama 4 Scout is similar to a Gemini Flash model or any ultra-efficient inference MoE.* Llama 4 Maverick’s architecture is very similar to DeepSeek V3 with extreme sparsity and many active experts.* Llama 4 Behemoth is likely similar to Claude Opus or Gemini Ultra, but we don’t have substantial information on these.This release came on a Saturday, which is utterly bizarre for a major company launching one of its highest-profile products of the year. The consensus was that Llama 4 was going to come at Meta’s LlamaCon later this month. In fact, it looks like this release may have been pulled forward from today, the 7th, from a commit in the Meta Llama Github:One of the flagship features is the 10M (on Scout, Maverick is 1M) token context window on the smallest model, but even that didn’t have any released evaluations beyond Needle in a Haystack (NIAH), which is seen as a necessary condition, but not one that is sufficient to say it is a good long-context model. Some more modern long-context evaluations include RULER or NoLiMa.Many, many people have commented on how Llama 4’s behavior is drastically different in LMArena — which was their flagship result of the release — than on other providers (even when following Meta’s recommended system prompt). Turns out, from the blog post, that it is just a different model:Llama 4 Maverick offers a best-in-class performance to cost ratio with an experimental chat version scoring ELO of 1417 on LMArena.Sneaky. The results below are fake, and it is a major slight to Meta’s community to not release the model they used to create their major marketing push. We’ve seen many open models that come around to maximize on ChatBotArena while destroying the model’s performance on important skills like math or code. We’ll see where the released models land.Regardless, here’s the plot Meta used. Look at the fine print at the bottom too.This model is actually the one tanking the technical reputation of the relea

RL backlog: OpenAI's many RLs, clarifying distillation, and latent reasoning
https://www.interconnects.ai/p/rl-backlog-openais-many-rls-clarifyingI have a second blog where I post half-baked thoughts, sometimes previews of what comes here. If you’re interested, I posted some musings on OpenAI’s coming open model release.It’s obvious that reinforcement learning (RL) is having a total return to glory among the broader AI community, but its real successes are mostly the things people aren’t focusing on. More math and code datasets are important platforms — we know they’re coming and are important. They’re still over-indexed on. The same RL methods are being used in many of the leading models and AI products.This is largely a post I wrote a few weeks ago on RL news, which I was following. It never had a focusing function, so it didn’t get published, but I’m sharing it because many folks are following this area very closely. Today:* OpenAI’s many forms of RL,* On distilling chain of thoughts vs. RL,* Did DeepSeek distill o1?, and* Why latent reasoning is so interesting.Interconnects is a reader-supported publication. Consider becoming a subscriber.OpenAI’s many forms of RLFor those plugged into the OpenAI cultural tap that is Twitter, it is obvious that they’re very invested in reinforcement learning. With the hype around the release of their o-series of reasoning models, it was easy to assume that those were the only avenue for excitement. OpenAI’s recent releases have shown this is not the case, and every release from a model launch to a new product has included mentions of RL training. Some of this, of course, is marketing, but they all fit as different applications of reinforcement finetuning (RFT) / RL with verifiable rewards (RLVR).The first other application was OpenAI’s Operator agent. They stated:Combining GPT-4o's vision capabilities with advanced reasoning through reinforcement learning, CUA is trained to interact with graphical user interfaces (GUIs)—the buttons, menus, and text fields people see on a screen.There’s a bit more speculation to do than normal in this post. Ultimately, with partners they launched with like DoorDash, Instacart, etc., they could set up verifiable domains where the agent is rewarded for accomplishing a natural language task. This could rely on help from those websites to get started. Ultimately, lots of people know that this could work, as agents deeply tied to the core of RL lore, but the implementation details haven’t really been worked out in open projects.The same goes for Deep Research. They stated:Deep research independently discovers, reasons about, and consolidates insights from across the web. To accomplish this, it was trained on real-world tasks requiring browser and Python tool use, using the same reinforcement learning methods behind OpenAI o1, our first reasoning model.Deep research was trained using end-to-end reinforcement learning on hard browsing and reasoning tasks across a range of domains.Some more was shared in the Deep Research system card.There are lots of things one can envision — e.g. agent gets a reward if the document retrieved from search has relevant information (not a verifiable reward, but LLM-as-a-judge). Most of this is likely used to get very high reliability across tool use to enable the tons of calls done in the back end when a call takes 10+ minutes for the user.More | research | has emerged on RAG/search with RL.Least surprising was the announcement of the new GitHub CoPilot model with new and improved RL training for code:Our new code completion model is shipping in public preview today. We are calling it GPT-4o Copilot. Based on GPT-4o mini, with mid-training on a code-focused corpus exceeding 1T tokens and reinforcement learning with code execution feedback (RLEF).This all goes back to what I said in OpenAI's Reinforcement Finetuning and RL for the masses — this new RL training is a perfectly aligned way to get nearly perfect performance on a domain you can control carefully. The best results come with mastery of the domain and with training.A fun speculation that OpenAI is really invested in RL and post-training is that their new o3-mini model has the same date cutoff, October 2023, as OpenAI’s other flagship models. This getting very far in the past shows how invested OpenAI is in their search products (which, to be fair are quite good) for information and how such strong performance gains can come by other improvements in the stack of training.OpenAI also released a paper on competitive coding with RL training, but it did not have a ton of useful details.On distilling chain of thoughts vs. RLThere were a few points from the DeepSeek paper and discourse that warrant repeating. To repeat it, distillation in this case is training a model (usually with SFT, but any loss function works) on outputs from a stronger model. Let’s get right into it.First, DeepSeek made it very clear that using more RL after distillation (SFT) is crucial for the best possible models.Additionally, we found that applying RL to these d

Gemini 2.5 Pro and Google's second chance with AI
https://www.interconnects.ai/p/gemini-25-pro-googles-second-ai-chanceGoogle, with its immense infrastructure and talent, has been the safe bet for the question of “Who will have the best models in a few years?” Google took a long time to get here, overcoming Bard’s launch and some integration headaches, and yet the model they launched today, Gemini 2.5 Pro feels like the biggest jump in evaluation scores we’ve seen in quite some time.It’s often hard to communicate how the models we are getting these days are actually better. To be informed, you need to take a balanced view across many benchmarks, look roughly at the percentage by which the model is clearly state-of-the-art, and of course, try the model yourself.To summarize, while more evaluations are rolling in, Gemini 2.5 Pro is 40+ Elo points clear on the popular ChatBotArena / LM Arena benchmark (more here). Normally, when a model launches and claims the top spot, it’s barely ahead. In fact, this is the second biggest jump of the top model in LMSYS history, only behind the GPT-4 Turbo overtaking Claude 1. GPT-4 Turbo is when models were not really trained for the benchmark, so progress was much faster.The blog post highlights insane scores on the benchmarks used to evaluate the leading reasoning models. One to note here is the score of 18.8 on Humanity’s Last Exam without search or tools, which was one of the evaluations I highlighted as impressive with the launch of OpenAI’s Deep Research, which compiles knowledge from the web!Gemini 2.5 is topping other independent evaluations such as the Scale Leaderboard (which is underrated or at least low on visibility, more here). More independent evaluations are going to trickle in, but all of the ones I’ve seen are extremely positive.Gemini still is also the model with the longest context length and with very strong multimodal performance (including audio). There are plenty of small wins that Google has like this that are hard to see when skimming the benchmarks above.So, how did Google do it? As usual, the blog post doesn’t have a ton of technical details. Google says:we've achieved a new level of performance by combining a significantly enhanced base model with improved post-training.Until we have API pricing, it’ll be harder to make even informed guesses about whether the model is huge like GPT-4.5. As for understanding how Gemini models will behave, Google shares:Going forward, we’re building these thinking capabilities directly into all of our models, so they can handle more complex problems and support even more capable, context-aware agents.This idea of directly integrating reasoning into all of their models is something Sam Altman teased for GPT-5. This trend has serious trade-offs on user experience that we will get to later, but it is crucial for people to keep up with as the discourse today is often centered on "the best non-reasoning model” or “the best reasoning model.”This came up recently with DeepSeek’s new V3 model.DeepSeek's new model (0324) is a major update in performance and license. The MIT license will make it hugely impactful for research and open building. Though many are ending up confused about whether it is a "reasoning" model. The model is contrasted to their R1 model, which is an only-reasoning model (like o1).Reasoning models are on a spectrum now, and it's not just yes or no. GPT 4.5 is a good example of what a model with pretty much no reasoning looks like today.Compared to other models in the industry, like Claude 3.7 and Grok 3 with reasoning toggles, the new DeepSeek V3 is definitely in this class of "hybrid reasoners" where models are still trained extensively with RL on verifiable domains (or distilled directly from another reasoning model), but other parts of the post-training process come first and hold more weight than the RL heavy reasoning-only models.This is all to say that when people say that "DeepSeek V3 0324 is the best non-reasoner model," that doesn't really make sense. The original V3 had very light post-training, so it wasn't really on the reasoning model spectrum.Now, things are complicated. It'll be like this for a while!Gemini 2.5 Pro is quite simple. It is very much a reasoning model, at least in how it is offered to users in Gemini Advanced and AI studio — every query has reasoning before an answer. It is fairly conclusive now that using this extended reasoning can boost performance across many domains, but it’s not clear how to best trade off cost and speed with varying amounts of reasoning.Gemini 2.5 in its current offering is a brute force approach — a big, very smart model that is tuned to use a lot of reasoning tokens — and it’s good for the trajectory of the industry that it paid off with such high performance.Interconnects is a reader-supported publication. Consider becoming a subscriber.The state of the AI industryWith launches from DeepSeek, GPT-4.5 from OpenAI, Claude 3.7 from Anthropic, Grok 3 from xAI, and now Gemini 2.5 Pro, this has been a w

Managing frontier model training organizations (or teams)
https://www.interconnects.ai/p/how-to-manage-ai-training-organizationsIt is a closely guarded secret how the leading AI laboratories structure their training teams. As with other technology companies, the saying “you ship your org chart” still applies to training AI models. Looking at these organizational structures will reveal where research can be scaled up, the upper limits of size, and potentially even who uses the most compute.How modeling teams do and do not workA crucial area I’m working on (reach out if you would like to share more off the record) is how to scale these lessons to bigger, more complex teams. The core factor differentiating teams that succeed from those that do not is maintaining these principles while scaling team size.Big teams inherently lead to politics and protecting territory, while language models need information to flow from the bottom to the top on what capabilities are possible. Regardless of the possibilities, leadership can shift resources to prioritize certain areas, but all of the signals on whether this is working come from those training models. If senior directors mandate results under them before unblocking model releases, the entire system will crumble.Seeing this potential end state — without naming specific companies — it is obviously desirable to avoid, but anticipating and avoiding it during rapid growth takes substantial intentionality.Within training, the planning for pretraining and post-training traditionally could be managed differently. Pretraining has fewer, bigger runs so improvements must be slotted in for those few annual runs. Post-training improvements can largely be continuous. These operational differences, on top of the obvious cost differences, also make post-training far more approachable for non-frontier labs (though still extremely hard).Both teams have bottlenecks where improvements must be integrated. Scaling the pretraining bottlenecks — i.e. those making the final architecture and data decisions — seems impossible, but scaling teams around data acquisition, evaluation creation, and integrations is very easy. A large proportion of product decisions for AI models can be made irrespective of modeling decisions. Scaling these is also easy.Effectively, organizations that fail to produce breakthrough models can do tons of low-level meaningful research, but adding organizational complexity dramatically increases the risk of “not being able to put it together.”Another failure mode of top-down development, rather than bottom-up information, is that leaders can mandate the team to try to follow a technical decision that is not supported by experiments. Managing so-called “yolo runs” well is a coveted skill, but one that is held close to the models. Of course, so many techniques work still that mandates don’t have a 100% failure rate, but it sets a bad precedent.Given the pace of releases and progress, it appears that Anthropic, OpenAI, DeepSeek, Google Gemini, and some others have positive forms of this bottom-up culture with extremely skilled technical leads managing complexity. Google took the longest to get it right with re-orgs, muddled launches (remember Bard), and so on. With the time lag between Meta’s releases, it still seems like they’re trying to find this culture to maximally express their wonderful talent and resources.With all of this and off-the-record conversations with leadership at frontier AI labs, I have compiled a list of recommendations for managing AI training teams. This is focused on modeling research and does not encompass the majority of headcount in the leading AI companies.Interconnects is a reader-supported publication. Consider becoming a subscriber.RecommendationsThe most effective teams who regularly ship leading models follow many of these principles:* The core language modeling teams remain small as AI companies become larger.* For smaller teams, you can still have everyone in one room, take advantage of this. For me personally, I think this is where remote teams can be detrimental. In-person works for this, at least when best practices are evolving so fast.* Avoid information siloes. This goes for both teams and individuals. People need to quickly be able to build on the successes of those around them and clear communication during consistent rapid progress is tricky.* For larger teams, you can scale teams only where co-design isn’t needed. Where interactions aren’t needed there can be organizational distance.* An example would be one team focusing on post-training algorithms & approaches while other teams handle model character, model variants for API, etc (specifications and iterations).* Another example is that reasoning teams are often separate from other pieces of post-training. This applies only to players that have scaled.* Language model deployment is very much like early startup software. You don’t know exactly what users want nor what you can deliver. Embrace the uncertainty and learn quickly.* Do not ov
Gemma 3, OLMo 2 32B, and the growing potential of open-source AI
Post: https://www.interconnects.ai/p/gemma-3-olmo-2-32b-and-the-growingEver since the release of the original ChatGPT, much has been said about making a truly open-source version of it — with data, code, weights, etc., all available. Open-source versions increase transparency, access, long-term progress, security research, and lots more. Lots of people have used this claim to bring hype into their projects, but the substance of these releases have been rather shallow (i.e., often focusing on one evaluation).This milestone was so long coming that I entirely forgot about it as a target. Through 2024, and especially before DeepSeek, the impression was that scaling AI capabilities was just too expensive for the smaller players willing to do truly open-source development.Truly open releases take a lot of effort by making more to release and maintain, open up potential legal risks that preclude types of training data, and completely undermine competition. The few organizations doing fully open-source research are non-profits, like Ai2 or Eleuther AI; academics, like LLM360; or companies that benefit from the long-term ecosystem growth, like HuggingFace.I was poking through the results for our latest model when I realized that we finally did it! We have a fully open-source GPT-4 class model, i.e., it is comparable with OpenAI's original release rather than the current version.Today, we're releasing OLMo 2 32B, the biggest model we've trained from scratch yet. Here are the post-training evaluations, where it surpasses GPT-3.5, GPT-4o-mini, Qwen 2.5 32B Instruct, the recent Mistral Small 24B, and comes close to the Qwen and Llama 70B Instruct models.And this recipe is extremely training efficient. Here’s a plot showing the FLOP comparisons to peer base models:Most of this release isn't entirely new. OLMo 2 is the result of lots of small wins on data, architecture, post-training with Tülu 3 recipe and so on — we just let the GPUs hum for a lot longer. You can learn more about OLMo 2 in my original release announcement or in this podcast with the leads.The new part of this release is a major milestone where any company can pick up our training stack and cook up exactly the model they need at nearly the GPT 4 level. Beating the latest GPT 3.5 and GPT 4o mini models feels like fair game for the claim. This capability will take time to diffuse, but it is a major moment in the arc of why we do what we do. Even without more progress on OLMo, which we obviously will continue this year, this will keep fundamental AI progress outside of the major AI labs going for multiple years. It’s an optimistic day for open-source.Here are your links to more information on OLMo 32B:* Blog with technical details and demo* Base model: OLMo-2-0325-32B* Instruct model: OLMo-2-0325-32B-Instruct and intermediate SFT, OLMo-2-0325-32B-SFT, and DPO checkpoints, OLMo-2-0325-32B-DPO* Pretraining dataset: OLMo-mix-1124* Mid-training dataset: Dolmino-Mix-1124* Post-training datasets: Tülu 3 SFT Mix (updated), Preference data for OLMo 2 32B and RLVR MixGemma 3 as the next point on a steep trend lineYesterday, March 12th, Google released the next batch of their flagship open-weight models, Gemma (report, models, flagship model). They highlight the following capabilities in their documentation:* Image and text input: Multimodal capabilities let you input images and text to understand and analyze visual data. Start building* 128K token context: 16x larger input context for analyzing more data and solving more complex problems.* Wide language support: Work in your language or expand your AI application's language capabilities with support for over 140 languages. Start building* Developer friendly model sizes: Choose a model size (1B, 4B, 12B, 27B) and precision level that works best for your task and compute resources.Some technical details of note:* In open models, 32B dense models are convenient because they can be finetuned on one node of 8 H100s (slowly). Google's sizing at 27B likely is downstream of TPU considerations that don't map directly, like how knowledge distillation works at pretraining.* The Gemma models continue to be trained extensively with teacher-student knowledge distillation (KD). This KD is different than the colloquial definition of distillation in leading AI models. The common use of distillation is training the models on any output of a much stronger model. This is most commonly done in post-training to learn from generated completions of the stronger model. KD is a subset of the general idea of distillation, where the model being trained learns to match the distribution of the teacher model. Other labs than DeepMind have mentioned this KD technique, but Google has pushed it far further. This was discussed further in last summer’s post on synthetic data.Otherwise, the paper has some interesting information but nothing super groundbreaking. This is par for the course for most technical reports these days.Onto the evaluations, and t

Interviewing Eugene Vinitsky on self-play for self-driving and what else people do with RL
Eugene Vinitsky is a professor a New York University department of Civil and Urban Engineering. He’s one of my original reinforcement learning friends from when we were both doing our Ph.D.’s in RL at UC Berkeley circa 2020. Eugene has extensive experience in self-driving, open endedness, multi-agent reinforcement learning, and self-play with RL. In this conversation we focus on a few key topics:* His latest results on self-play for self-driving and what they say about the future of RL,* Why self-play is confusing and how it relates to the recent takeoff of RL for language models, and* The future of RL in LMs and elsewhere.This is a conversation where we take the time to distill very cutting edge research directions down into the core essences. I felt like we were learning in real time what recent developments mean for RL, how RL has different scaling laws for deep learning, and what is truly salient about self-play.The main breakthrough we discuss is scaling up self-play techniques for large-scale, simulated reinforcement learning. Previously, scaling RL in simulation has become economical in single-agent domains. Now, the door is open to complex, multi-agent scenarios where more diversity is needed to find solutions (in this case, that’s what self play does).Eugene’s Google Scholar | Research Lab | Linkedin | Twitter | BlueSky | Blog (with some great career advice).Listen on Apple Podcasts, Spotify, YouTube, and where ever you get your podcasts. For other Interconnects interviews, go here.Show outline & linksWe cover many papers in this podcast. Also, as an experiment, here’s a Deep Research report on “all the papers that appeared in this podcast transcript.”In this episode, we cover:* Self-play for self-driving, mostly around the recent paper Robust Autonomy Emerges from Self-Play (Cusumano-Towner et al. 2025). The simulator they built powering this is Gigaflow. More discussion on HackerNews.(Here’s another self-play for self-driving paper and another from Eugene from earlier this year).A few highlights:“All simulated agents use the same neural net with the same weights, albeit with randomized rewards and conditioning vector to allow them to behave as different types of vehicles with different types of aggressiveness. This is like driving in a world where everyone is different copies of you, but some of your copies are in rush while others are patient. This allows backprop to optimize for a sort of global utility across the entire population.”“The resulting policy simulates agents that are human-like, even though the system has never seen humans drive.”* Large Language Models are In-context Preference Learners — how language models can come up with reward functions that will be applied to RL training directly. Related work from Stanford.* Related literature from Interconnects! The first includes literature we mention on the learning locomotion for quadrupeds with deep RL (special shoutout as usual to Marco Hutter’s group).* Recent and relevant papers Value-based RL Scales Predictably, Magnetic control of tokamak plasmas through deep reinforcement learning.* Other things we mention:* Cruise, Tesla, and Waymo’s autonomy stacks (speculation) and how the self-driving industry has changed since we were / were considering working in it.* Evo 2 foundation model for biology.* Eugene is working with a new startup on some LLM and RL stuff. If you’re interested in this episode, ping [email protected]. Not a paid promotion.Chapters* 00:00:00 Introduction & RL Fundamentals* 00:11:27 Self‑Play for Self‑Driving Cars* 00:31:57 RL Scaling in Robotics and Other Domains* 00:44:23 Language Models and In-Context Preference Learning* 00:55:31 Future of RL and Grad School AdviceTranscriptI attempted to generate with ElevenLab’s new Scribe tool, but found the formatting annoying and reverted back to Alessio’s smol-podcaster. If you’re interested in working part-time as an editorial aide to Interconnects, please get in touch.Nathan Lambert [00:01:27]: Hey, Eugene. Welcome to the show.Eugene Vinitsky [00:01:29]: Hey, Nathan. Thanks for having me. Excited to be here.Nathan Lambert [00:01:32]: Yeah, so I'll have said this in the intro as well, but we definitely go well back in all the way to Berkeley days and RL days, I think.I will embarrass you a little bit now on the live read, which is like, you were one of the people when I was switching into RL, and they're like, oh, it seems like you only figured out how to get into AI from a potentially different background, and that's what I was trying to do in 2017 and 2018.So that was kind of fun, and now we're just friends, which is good.Eugene Vinitsky [00:02:01]: Yeah, we were both figuring out. If I had any lead over you there, I was also frantically trying to figure it out, because I was coming from a weird background.Nathan Lambert [00:02:11]: There are definitely a lot of people that do that now and over-attribute small time deltas to big strategic plans, which was probably what it

Elicitation, the simplest way to understand post-training
Full post: https://www.interconnects.ai/p/elicitation-theory-of-post-trainingIf you look at most of the models we've received from OpenAI, Anthropic, and Google in the last 18 months, you'll hear a lot of "Most of the improvements were in the post-training phase." The most recent one was Anthropic’s CEO Dario Amodei explaining Claude 3.7 on the Hard Fork Podcast:We are not too far away from releasing a model that's a bigger base model. Most of the improvements in 3.6/3.7 are in the post-training phase. We're working on stronger base models (perhaps that will be the Claude 4 series, perhaps not; those are coming in a relatively small number of time units [months?].Here's a simple analogy for how so many gains can be made on mostly the same base model.The intuition I've been using to understand the potential of post-training is called the elicitation interpretation of post-training, where all we are doing is extracting and amplifying valuable behaviors in the base model.Consider Formula 1 (F1), most of the teams show up to the beginning of the year with a new chassis and engine. Then, they spend all year on aerodynamics and systems changes (of course, it is a minor oversimplification), and can dramatically improve the performance of the car. The best F1 teams improve way more during a season than chassis-to-chassis.The same is true for post-training. The best post-training teams extract a ton of performance in a very short time frame. The set of techniques is everything after the end of most of pretraining. It includes "mid-training" like annealing / high-quality end of pre-training web data, instruction tuning, RLVR, preference-tuning, etc. A good example is our change from the first version of OLMoE Instruct to the second — we improved our post-training evaluation average from 35 to 48 without touching the majority of pretraining.Then, when you look at models such as GPT-4.5, you can see this as a way more dynamic and exciting base for OpenAI to build onto. We also know that bigger base models can absorb far more diverse changes than their smaller counterparts.This is to say that scaling also allows post-training to move faster. Of course, to do this, you need the infrastructure to train the models. This is why all the biggest companies are still building gigantic clusters.This theory folds in with the reality that the majority of gains users are seeing are from post-training because it implies that there is more latent potential in a model pretraining on the internet than we can teach the model simply — such as by passing certain narrow samples in repeatedly during early types of post-training (i.e. only instruction tuning).Throwback to the superficial alignment hypothesisAnother name for this thoery is the Superficial Alignment Hypothesis, coined in the paper LIMA: Less is More for Alignment. This paper is getting some important intuitions right but for the wrong reasons in the big picture. The authors state:A model’s knowledge and capabilities are learnt almost entirely during pretraining, while alignment teaches it which subdistribution of formats should be used when interacting with users. If this hypothesis is correct, and alignment is largely about learning style, then a corollary of the Superficial Alignment Hypothesis is that one could sufficiently tune a pretrained language model with a rather small set of examples [Kirstain et al., 2021].All of the successes of deep learning should have taught you a deeply held belief that scaling data is important to performance. Here, the major difference is that the authors are discussing alignment and style, the focus of academic post-training at the time. With a few thousand samples for instruction finetuning, you can change a model substantially and improve a narrow set of evaluations, such as AlpacaEval, MT Bench, ChatBotArena, and the likes. These do not always translate to more challenging capabilities, which is why Meta wouldn’t train its Llama Chat models on just this dataset. Academic results have lessons, but need to be interpreted carefully if you are trying to understand the big picture of the technological arc.What this paper is showing is that you can change models substantially with a few samples. We knew this, and it is important to the short-term adaptation of new models, but their argument for performance leaves the casual readers with the wrong lessons.If we change the data, the impact could be far higher on the model’s performance and behavior, but it is far from “superficial.” Base language models today (with no post-training) can be trained on some mathematics problems with reinforcement learning, learn to output a full chain of thought reasoning, and then score higher on a full suite of reasoning evaluations like BigBenchHard, Zebra Logic, AIME, etc.The superficial alignment hypothesis is wrong for the same reason that people who think RLHF and post-training are just for vibes are still wrong. This was a field-wide lesson we had to overc

Where inference-time scaling pushes the market for AI companies
Link: https://www.interconnects.ai/p/where-inference-time-scaling-pushesThere’s a lot of noise about the current costs of AI models served for free users, mostly saying it’s unsustainable and making the space narrow for those with the historical perspective of costs of technology always plummeting. GPT-4.5’s odd release of a “giant” model without a clear niche only amplified these critics. With inference-time compute being a new default mode, can we still have free AI products? Are we just in the VC-subsidized era of AI?For normal queries to ChatGPT, the realistic expectation is that the cost of serving an average query will drop to be extremely close to zero, and the revenue from a future ad model will make the service extremely profitable. The most cohesive framework for understanding large-scale internet businesses built on the back of such zero marginal costs is Ben Thompson’s Aggregation Theory.Aggregation Theory posits that extreme long-term value will accrue to the few providers that gate access to information and services built on zero-marginal cost dynamics. These companies aggregate user demand. It has been the mode of modern dominant businesses, with the likes of Google and Meta producing extremely profitable products. Naturally, many want to study how this will apply to new AI businesses that are software-heavy, user-facing platforms, of which OpenAI is the most prominent due to the size of ChatGPT. Having more users and attention enables aggregators to better monetize interactions and invest in providing better experiences, a feedback loop that often compounds.Aggregators are often compared to platforms. Where the former relies on being an intermediary of users and other marketplaces, platforms serve as foundations by which others build businesses and value, such as Apple with the iPhone, AWS, or Stripe.Businesses like ChatGPT or Perplexity will rely on a profitable advertisement serving model being discovered that works nicely for the dialogue format. ChatGPT interweaving previous discussions into the chat, as they started doing in the last few months, is encouraging for this, as they could also have preferred products or sources that they tend to reference first. Regardless, this will be an entirely new type of ad, distinct from Meta’s targeted feed ads, Google’s search ads, or the long history of general brand ads. Some of these past ad variants could work, just sub-optimally, in the form factor.An even easier argument is to see the current hyperscalers using low-cost inference solutions on AI models that complement their existing businesses and fit with components of Aggregation Theory — such as Meta serving extremely engaging AI content and ads. The biggest platform play here is following the lens through which language models are a new compute fabric for technology. The AWS of AI models.All of these business models, ads, inference, and what is in between, were clear very soon after the launch of ChatGPT. As the AI industry matures, some harder questions have arisen:* Who bears the cost of training the leading frontier models that other companies can distill or leverage in their products?* How many multiples of existing inference paradigms (0-100s of tokens) will inference-time scaling motivate? What will this do to businesses?This post addresses the second question: How does inference time compute change business models of AI companies?The announcement of OpenAI’s o3 with the inference cost on ARC-AGI growing beyond $5 per task and the proliferation of the new reasoning models raised the first substantive challenge to whether aggregation theory will hold with AI.The link to inference time compute and the one that sparked this conversation around aggregators was Fabricated Knowledge’s 2025 AI and Semiconductor Outlook, which stated:The era of aggregation theory is behind us, and AI is again making technology expensive. This relation of increased cost from increased consumption is anti-internet era thinking.This is only true if increased thinking is required on every query and if it doesn’t come with a proportionate increase in value provided. The fundamental operations of AI businesses will very much follow in the lens of Aggregation Theory (or, in the case of established businesses, it’ll reinforce advantages of existing large companies), and more work is going to be needed to figure out business models for inference-heavy products.We can break AI use today into two categories:* ChatGPT and general-use chatbots.* Domain-specific models, enterprise products, model APIs, and everything else that fits into the pay-for-work model (e.g. agents).The first category is established and not going away, while the second is very in flux. Inference time scaling will affect these in different ways.Consumers — well, most of them (and not most of you reading this who are power users) — will never know how to select the right model. The market for super users is far smaller than the market for general use

GPT-4.5: "Not a frontier model"?
More: https://www.interconnects.ai/p/gpt-45-not-a-frontier-modelAs GPT-4.5 was being released, the first material the public got access to was OpenAI’s system card for the model that details some capability evaluations and mostly safety estimates. Before the live stream and official blog post, we knew things were going to be weird because of this line:GPT-4.5 is not a frontier model.The updated system card in the launch blog post does not have this. Here’s the original system card if you need a reference:Regardless, someone at OpenAI felt the need to put that in. The peculiarity here summarizes a lot of the release. Some questions are still really not answered, like “Why did OpenAI release this?” That game theory is not in my purview.The main contradiction to the claims that it isn’t a frontier model is that this is the biggest model the general public has ever gotten to test. Scaling to this size of model did NOT make a clear jump in capabilities we are measuring. To summarize the arc of history, the jump from GPT-3.5 to GPT-4 made the experience with the models go from okay to good. The jump from GPT-4o (where we are now) to GPT-4.5 made the models go from great to really great.Feeling out the differences in the latest models is so hard that many who are deeply invested and excited by AI’s progress are just as likely to lie to themselves about the model being better as they are to perceive real, substantive improvements. In this vein, I almost feel like I need to issue a mea culpa. I expected this round of scaling’s impacts to still be obvious before the brutal economic trade-offs of scaling kicked in.While we got this model, Anthropic has also unintentionally confirmed that their next models will be trained on an approximation of “10X the compute,” via a correction on Ethan Mollick’s post on Claude 3.7.Note: After publishing this piece, I was contacted by Anthropic who told me that Sonnet 3.7 would not be considered a 10^26 FLOP model and cost a few tens of millions of dollars to train, though future models will be much bigger.GPT-4.5 is a point on the graph that scaling is still coming, but trying to make sense of it in a day-by-day transition is hard. In many ways, zooming out, GPT-4.5 will be referred to in the same breath as o1, o3, and R1, where it was clear that scaling pretraining alone was not going to give us the same level of breakthroughs. Now we really know what Ilya saw.All of this marks GPT-4.5 as an important moment in time for AI to round out other stories we’ve been seeing. GPT-4.5 likely finished training a long time ago — highlighted by how it has a date cutoff in 2023 still — and OpenAI has been using it internally to help train other models, but didn’t see much of a need to release it publicly.What GPT-4.5 is good forIn the following, I am going to make some estimates on the parameter counts of GPT-4.5 and GPT-4o. These are not based on any leaked information and should be taken with big error bars, but they are very useful for context.GPT-4.5 is a very big model. I’d bet it is well bigger than Grok 3. We have seen this story before. For example, GPT-4 was roughly known to be a very big mixture of experts model with over 1T parameters total and ~200B active parameters. Since then, rumors have placed the active parameters of models like GPT-4o or Gemini Pro at as low as 60B parameters. This type of reduction, along with infrastructure improvements, accounts for massive improvements in speed and price.Estimates place GPT-4.5 as about an order of magnitude more compute than GPT-4. These are not based on any released numbers, but given a combination of a bigger dataset and parameters (5X parameters + 2X dataset size = 10X compute), the model could be in in the ballpark of 5-7T parameters total, which if it had a similar sparsity factor to GPT-4 would be ~600B active parameters.With all of these new parameters, actually seeing performance improvements is hard. This is where things got very odd. The two “capabilities” OpenAI highlighted in the release are:* Reduced hallucinations.* Improved emotional intelligence.Both of these have value but are hard to vibe test.For example, SimpleQA is a benchmark we at Ai2 are excited to add to our post-training evaluation suite to improve world knowledge of our models. OpenAI made and released this evaluation publicly. GPT-4.5 makes huge improvements here.In another one of OpenAI’s evaluations, PersonQA, which is questions regarding individuals, the model is also state of the art.And finally, also GPQA, the Google-proof knowledge evaluation that reasoning models actually excel at.At the time of release, many prominent AI figures online were touting how GPT-4.5 is much nicer to use and better at writing. These takes should be taken in the context of your own testing. It’s not that simple. GPT-4.5 is also being measured as middle of the pack in most code and technical evaluations relative to Claude 3.7, R1, and the likes.For an example on the writing and

Character training: Understanding and crafting a language model's personality
https://www.interconnects.ai/p/character-trainingThe vast majority of evaluations used to measure progress on post-training at frontier laboratories are internal evaluations rather than the evaluations you hear about all the time like MATH or GPQA. These, the well-known intra-industry evaluations, are certainly important for ballparking behavior, but for every public evaluation, these frontier laboratories are likely to have 10+ fine-grained internal evaluations.The internal evaluations these model providers have cover a range of topics. Surely, most of them are basic, repetitive user behaviors that they need to make sure a new model doesn’t roll back too many of. Of these, the vast majority are likely skills, and “character” remains more of an art than a hill to climb up with careful data engineering.Leading post-training laboratories surely know how to reinforce more robust behavior within a specific character, as seen by the march of progress on evaluations like ChatBotArena, but crafting a specific personality from scratch is an open question.The primary goal of this post is to start the conversation outside of frontier AI labs around character training. Character training is the subset of post-training designed around crafting traits within the model in the manner of its response, rather than the content. Character training, while being important to the user experience within language model chatbots, is effectively non-existent on the web.We don’t know the trade-offs of what character training does, we don’t know how exactly to study it, we don’t know how much it can improve user preferences on ChatBotArena, and we should.The appearance of the AIs people are using is deeply coupled with how intelligent users will find it to be. Style of communication is crucial to how information is parsed. This is likely a very high priority to industrial labs, but something that almost no academic literature exists on. Even though I want to do research on this, I’m honestly not sure how to do so yet other than a 1 of 1 technical report on findings.ChatGPT gets character depthOut of nowhere on Saturday, February 15th, Sam Altman tweeted about this new GPT-4o model that will serve as the foundation of ChatGPT.This is the biggest subjective change I’ve ever felt within intermediate model versions, from any primary provider — something more akin in vibes change to the shift from GPT-3.5 to GPT-4. The model immediately and consistently showed new behavior patterns. I found these very positive (Karpathy agrees), but they’ll take some getting used to.Where ChatGPT used to sound robotic and shallow, it’s now very clearly leaning into a chipper assistant demeanor. Yes, for basic tasks, this new default model in ChatGPT is very Claude 3.5-like — more testing is needed to know if this GPT-4o with its peer models like o3-mini can dethrone Claude 3.7 Sonnet as a daily programming driver.The biggest changes in the new GPT-4o model are:* It now loves to reference past interactions in the chat (way more obvious than any other provider has been) — it was trying to flex that it knows my dog breed, mini schnauzer, or my book topic, RLHF. This is very in line with the new roadmap to GPT-4.5 and GPT-5 that Altman posted, where ChatGPT is designed around a fluid experience rather than standalone, siloed, powerful models.* The model is very chipper, sprinkles in more emojis, and is almost funny.* The multi-turn conversation is more dynamic, with follow-up questions and added texture to longer back and forths.The reasons are at a high level very complementary to those I listed when I switched to Claude as my daily driver model.The shocking part of this is that the impact of this sweeping change is almost entirely undocumented. Yes, OpenAI updated the Model Spec (my previous coverage here and here), but that doesn’t really capture how this model is different — it just clarifies the direction OpenAI is optimizing for. There are a few overlapping interpretations of this lack of transparency:* OpenAI cannot precisely measure the differences as a few specific behavior traits, so they can only see the model performs better in high-level testing like ChatBotArena or other A/B testing, but they cannot capture the changes in score deltas between a few evaluations they could release.* AI is moving so fast that taking the time to document these models is not worth it,* Detailing the changes will make the character too easy to reproduce and will be another path of “distillation” of OpenAI’s models.The community of model users is extremely far from having clear ways to measure these differences. While there are vibe tests on Twitter, they will not be conclusive. ChatBotArena won’t even come close to measuring the levels of these differences (and in the case of referencing past chats, it cannot). Character training is the sort of addition to a post-training stack that takes industrial training techniques from being reproducible, but expensive, to dark ar

Claude 3.7 thonks and what's next for inference-time scaling
On Monday, February 24th, 2025, Anthropic announced their latest model, Claude 3.7 Sonnet, which is their first model explicitly trained to use more inference time tokens to improve performance. This is another reinforcement learning (RL) trained model (mentioned in system card). With this model, they also released Claude Code as a limited research preview, which is a “command line tool for agentic coding.” Continuous improvements in models are enabling new modalities and domains addressable by the models, but assessing the impact of each new domain takes far more time than a quick model reaction post.This is a tidy release, a solid improvement, but not a step change for Claude or the industry. Expect a lot of small changes to accumulate massively this year.Claude 3.7 Sonnet is a clear improvement over Claude 3.5 Sonnet (New) and continues to push the limits in areas where users love Claude (e.g. read Ethan Mollick’s review here). The scores for those areas such as software development (SWE Bench) and tool use, are clearly state-of-the-art. For example, Claude 3.7 Sonnet is the highest scoring “standard non-reasoning” language model on the Aider Polyglot benchmark. While models like o3 and Grok 3 DeepThink highlight superhuman performance on code benchmarks, this sort of behavior being integrated without extra inference time compute is wonderful. The price for superhuman coding AI is plummeting.Even with o1 Pro, I still find myself using Claude 3.5 (New) on a regular basis. O1 Pro is the best model for doing succinct, one-off tasks like writing short scripts. It is extremely controllable and will often work out of the box. Though, when I’m doing tricky, iterative tasks I still use Claude. Claude 3.7 Sonnet only makes these workflows stronger and I’m stoked to play with it further.The most useful piece of this release for those trying to understand the direction of the ecosystem, rather than just the status of today, is Anthropic’s post on Claude’s extending thinking where they detail the product trade-offs, alignment, and future of inference time compute in their models. Anthropic’s offering of extending thinking to boost inference-time performance is far, far cleaner than that of OpenAI’s current model drop down disaster. Anthropic’s thinking model is the same as their general purpose model, much like xAI’s Grok 3, and what OpenAI teased will be the plan for GPT-5. Having just one model makes lots of infrastructure, product, and training decisions cleaner, but may come at the cost of the absolute Pareto front of performance for your organization shrinking. The reasoning training being embedded in one model with a standard inference mode will make the reasoning benefits and behavior feel closer to something like Gemini-Thinking, rather than OpenAI’s o1 or DeepSeek R1 that are designed solely for this reasoning mode of operation. It doesn’t mean that in the limit that a single model will be weaker in performance, but rather that currently training them may be slower to iterate on than a “full” reasoning language model.Focusing on deploying just one model that serves all the users is one of many examples where leading AI companies are needing to make their offerings legible to users and easy to use — a sign of the industry maturing from a race to intelligence to a race to usefulness.Still, Claude’s interface is not perfect by any means, the user still has to intentionally go to a drop down menu to get performance when they need it. The best mode is that the model knows when inference compute is needed on its own. My hypothesis is that when training one model with reasoning and without, having the model figure out how much compute to use is harder than a reasoning-only model like o1 figuring out its own compute budget. Or, Anthropic needed to keep a special flag that is turned on and off in the system prompt. This is a subtle potential trade-off of putting reasoning in just one model, but we’ll see where the final equilibrium is.On the other hand, Claude 3.7 Sonnet is showing the reasoning traces directly to users like DeepSeek R1 and Grok 3. These organizations have different ways of saying why, but it is clear that users just enjoy seeing it and it builds trust. Anthropic, understandably is using the reasoning traces to monitor the alignment of the models. The reasoning chains in these models are how the general public is learning more about the internal representations of language models. Another interesting detail is that “didn’t perform our standard character training on the model’s thought process.” This is how Claude thinks out of the box and the actual answers have a different flavor to them. More research will study how far the reasoning chains can diverge from the answer language. We’ve seen research on latent reasoning within the model, but beyond this, we could have reasoning languages that are entirely ungrounded from human languages because they are a more token-efficient representation of inform

Grok 3 and an accelerating AI roadmap
Full post: https://www.interconnects.ai/p/grok-3-and-an-accelerating-ai-roadmapxAI launched their latest flagship model, Grok 3, last night via a live stream on X, which is a new take on the launch process, but it largely felt familiar. Grok 3 is a state-of-the-art model on some important benchmarks. The core is that it is state-of-the-art relative to available models and we know better models are out there. Only some of them have been announced, some of them have been teased, and others lie in waiting.What feels different is how the broader AI industry is signaling rapid progress coming soon. xAI said on the livestream that they will be updating the model “daily.” An era of sitting on unreleased models could be ending.Grok 3’s release is a reinforcement of trends people began reckoning with as of the release of DeepSeek V3 + R1 — AI progress is not held in the hands of a few companies nor is it slowing down. 2023 and 2024 were defined by truly state-of-the-art AI being concentrated within OpenAI, Anthropic, and Google, where these companies could take a lot of time to package models from training to release and still have a substantial moat on capabilities relative to their peers.At the time of R1’s launch, the “people’s choice” model was Claude 3.5 Sonnet, a model that had been trained “9-12 months ago” and the best models like Claude 3.5 Opus or GPT-4.5 (a.k.a Orion) were not available to users for a grab bag of reasons.Competitive pressure from DeepSeek and Grok integrated into a shifting political environment for AI — both domestic and international — will make the established leading labs ship sooner. A large portion of delays in delivering models is for “safety testing,” but we don’t have exact details on how much of it was that and how much was cost-benefit tradeoffs (and other big company hurdles such as legal departments). The brand, and culture, of “having the smartest model” is extremely important to these companies, but having a way smarter model was often financially too much to bear.“Safety” is actively being removed from the spotlight of the AI discourse. It is possible that this overcorrection causes meaningful harm, as this is an extremely powerful and rapidly evolving technology, but the political capital to make safety a core tenet of the AI industry was spent too early relative to meaningful harm emerging.Increased competition and decreased regulation make it likely that we, the users, will be given far more powerful AI on far faster timelines.We’ve seen time and time again the value of having the best model first. The only way to onboard new users is to have some capability or behavior that your model differentiates on. With the pace of progress high, minimizing the time from training to release is the best way to maximize one’s chance of impact.DeepSeek and xAI show how organizations with slightly trailing technical progress or resources can outshine the likes of OpenAI and Anthropic who have voluntarily not shipped their latest models.Interconnects is a reader-supported publication. Consider becoming a subscriber.Grok 3 by the numbersBenchmarks and vibe tests mark Grok 3 as one of the best models available today. As with any release, companies often choose evaluations that flatter their models. Yes, winning on these evaluations is extremely challenging, and much credit must be given to xAI for delivering a leading-edge model just about 19 months after its incorporation.That being said, what is shown below is a total of 4 language model evaluations. Given that models like DeepSeek R1 or Gemini Thinking launch with 10-20 evaluations detailing their performance relative to peers, this has to be taken with a grain of salt. It is very likely that Grok 3 doesn’t outperform its peers in every category, but there is a slim chance these other comparison evals just weren’t run in the optimization for expedience.To start, we can compare Grok 3 benchmarks versus available instruct models.And versus available reasoning models (note how OpenAI’s announced o3 scores exceed these clearly).An important detail, as we’ve seen with OpenAI’s reasoning model releases is, what do the shaded regions on the above plots show? Without exact details, we don’t know the inference cost for each of the models on these reasoning plots. Pushing the frontier in absolute terms is important, but the field overall is getting messier before it’ll get clearer.Regardless, in the above two plots Grok 3 is pushing progress both on standard model training and the new reasoning training. While reasoning training and RL are the hot new things in the AI field, simple scaling and optimization of existing techniques still deliver value.And Grok’s score on ChatBotArena.A model launching at top of every category on ChatBotArena feels like something that should be rare (given it now encompasses many categories like Math, Coding, Style Control, Longer Queries, etc.), but it happened just a few weeks ago with Gemini 2.0 Pro!ChatBotArena

An unexpected RL Renaissance
The era we are living through in language modeling research is one characterized by complete faith that reasoning and new reinforcement learning (RL) training methods will work. This is well-founded. A day | cannot | go | by | without | a new | reasoning model, RL training result, or dataset distilled from DeepSeek R1.The difference, compared to the last time RL was at the forefront of the AI world with the fact that reinforcement learning from human feedback (RLHF) was needed to create ChatGPT, is that we have way better infrastructure than our first time through this. People are already successfully using TRL, OpenRLHF, veRL, and of course, Open Instruct (our tools for Tülu 3/OLMo) to train models like this.When models such as Alpaca, Vicuña, Dolly, etc. were coming out they were all built on basic instruction tuning. Even though RLHF was the motivation of these experiments, tooling, and lack of datasets made complete and substantive replications rare. On top of that, every organization was trying to recalibrate its AI strategy for the second time in 6 months. The reaction and excitement of Stable Diffusion was all but overwritten by ChatGPT. This time is different. With reasoning models, everyone already has raised money for their AI companies, open-source tooling for RLHF exists and is stable, and everyone is already feeling the AGI.Aside: For a history of what happened in the Alpaca era of open instruct models, watch my recap lecture here — it’s one of my favorite talks in the last few years.The goal of this talk is to try and make sense of the story that is unfolding today:* Given it is becoming obvious that RL with verifiable rewards works on old models — why did the AI community sleep on the potential of these reasoning models? * How to contextualize the development of RLHF techniques with the new types of RL training?* What is the future of post-training? How far can we scale RL?* How does today’s RL compare to historical successes of Deep RL?And other topics. This is a longer-form recording of a talk I gave this week at a local Seattle research meetup (slides are here). I’ll get back to covering the technical details soon!Some of the key points I arrived on:* RLHF was necessary, but not sufficient for ChatGPT. RL training like for reasoning could become the primary driving force of future LM developments. There’s a path for “post-training” to just be called “training” in the future.* While this will feel like the Alpaca moment from 2 years ago, it will produce much deeper results and impact.* Self-play, inference-time compute, and other popular terms related to this movement are more “side quests” than core to the RL developments. They’re both either inspirations or side-effects of good RL.* There is just so much low-hanging fruit for improving models with RL. It’s wonderfully exciting.For the rest, you’ll have to watch the talk. Soon, I’ll cover more of the low level technical developments we are seeing in this space.00:00 The ingredients of an RL paradigm shift16:04 RL with verifiable rewards27:38 What DeepSeek R1 taught us29:30 RL as the focus of language modeling This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe
Deep Research, information vs. insight, and the nature of science
Article: https://www.interconnects.ai/p/deep-research-information-vs-insight-in-science(sorry about some more audible breaths in this -- I'm going to work on it!)We at Ai2 released a local LM iPhone app for our OLMoE model (1B active, 7B total params), with greatly improved scores! Let us know what you think, or read more here.OpenAI’s Deep Research has largely been accepted as a super valuable tool for knowledge workers and analysts across the economy, but its real engine of economic progress is going to be changing the nature of scientific progress. Science is the fuel of technological revolutions.Deep Research in its current form feels like a beta version of a next-generation piece of technology. It does what it is tasked with — searches the web and processes many resources to create a useful report with referenced sources. Some of my uses include researching model evaluations, recent robotic learning research, and AI for science breakthroughs.Deep Research’s limitations mostly feel like problems of search, where it is prone to returning SEO optimized slop, style, where it returns verbose, low information density writing, and modality, where it does not have the ability to read, process, and return plots and diagrams. All of these are surely solvable and expected features if we look at the rollouts of other AI models in the last few years.This isn’t a product review (you can read Stratechery or Turing Post for more of that) — as the answer is quite simple, if you work in a knowledge intensive vocation you should be using this — but rather asking: So what comes next?The place to start from within AI circles is to revisit the question of “When will AI make novel discoveries?” A good example of this is in the Dwarkesh Podcast episode with Dario Amodei:One question I had for you while we were talking about the intelligence stuff was, as a scientist yourself, what do you make of the fact that these things have basically the entire corpus of human knowledge memorized and they haven't been able to make a single new connection that has led to a discovery?An example experiment we could do to test this is to train models on time-gated information and see if it can repeat a scientific discovery we already made (yes, this would be difficult to run, but not impossible). Ross Taylor described this on his Interconnects Interview:So an experiment I've never done because I didn't have [the] compute would be this. Imagine if you could train a language model on all documents up to 1905, which is the year when Einstein had his miraculous year of four seminal papers. With that model, which is trained up to 1905, could you prompt the model to come up with a good explanation of the photoelectric effect, special relativity, this kind of stuff? And what would it take to rediscover these things?The dream is for AI to make breakthroughs, and the absence of evidence for this even after the release of Deep Research is driving a reckoning over what language models will ever be able to do. The fork in the road is either believing that scaling (either in parameters or in new training methods) will unlock “insights” or accepting that the current generation of models are very useful tools and nothing more supernatural. Likely the most powerful tool humanity has made yet. Our first power tool for information.Much of science is not about making novel insights but about making progress within established problems of the field. In AI, these are the countless benchmarks we are saturating. A very valuable contribution in AI as a field can be re-using known resources in a simpler way.With AI, we are going to learn the boundary between true insight and scientific progress. A related form of scientific progress is the compression of noisy ideas and experiments into a cohesive trend. Something that Deep Research can likely do, but not something that builds the allure of Einstein and the other scientific greats.To understand this relationship between Deep Research, AI broadly, and the nature of science, we must address:* How to interpret existing “AI for Science” projects like AlphaFold in the bigger context of science,* How reasoning models, AI research systems like Deep Research, and other forthcoming AIs revolutionize existing scientific practices,* How recent developments in AI challenge Kuhn’s formulation of scientific revolutions, and* How current institutions will need to change forever in the face of AI?This (hopefully) series of posts is my attempt to create a worldview around what science means in the face of AI. Today, we focus on the first two — major AI for science projects and how normal science is being accelerated by AI — and hopefully raise urgency within the community to consider the final question.The starting point — grand AI for science projectsThere is a substantial overhang in computational infrastructure and fundamental deep learning capabilities relative to their impact on the broad class of sciences. In order to make a sub
Making the U.S. the home for open-source AI
As many of you know, this weekend I appeared on the Lex Fridman Podcast with my friend Dylan Patel of SemiAnalysis to cover DeepSeek and the implications on the AI ecosystem. I recommend you check it out.This post was tricky to pull together. I decided to share it anyways given the timeliness of the topic and other more exciting things I have to get to. The minor, thematic contradictions on motivations, costs, and trajectories are exactly indicative of why analysis and productionization of open-source AI is so hard. In that, it is a valuable lesson that building open-source AI will come with a lot of ups and downs, but now is the best time to do so.The DeepSeek moment represents the end of the first chapter of AI's recent takeoff as told through the emergence of ChatGPT. It reminds us, that while substantial resources, coalitions, brands, and trends have been established, the narratives we have been championing are not set in stone. DeepSeek, especially with R1, resets all the narratives around open vs closed, US vs China, scaling and commoditization, etc. as we prep for yet another acceleration in the diffusion, progress, and adoption of AI.Of all of these debates, the focus on open vs. closed AI models is the one least driven by economic factors and most driven by vibes. The open-source AI community is driven by a future vision where AI is not held by a few super-rich companies, a future where more people get to partake in the building of AI, a future where AI is safer, etc. These are ideals and building the tools and systems that make this vision a reality is a monumental challenge. Building strong AI models is far, far easier than building a sustainable open-source ecosystem around AI.Building a better, truly open ecosystem for AI has been my life’s work in the last years and I obviously want it to flourish further, but the closer you are to the core of the current open-source ecosystem, the more you know that is not a given with costs of doing relevant AI training skyrocketing (look, I know DeepSeek had a very low compute cost, but these organizations don’t just fall out of the tree) and many regulatory bodies moving fast to get ahead of AI in a way that could unintentionally hamper the open. Yes, efficiency is getting better and costs will come down, as shown with DeepSeek V3, but training truly open models at the frontier isn’t much easier.Building the future ecosystem of openAs a perfect case point, consider Meta. Meta, as a platform serving content to billions of users, is extremely well-positioned to use AI to make its services more engaging and more profitable for advertisers. The Llama project is not needed for that vision. Yes, it will be easier for them to integrate and optimize an AI that they train, but in a world where AI models are commoditized, what’s the point? The most compelling reasons for openly releasing the Llama models are not business reasons but rather ideological reasons. Mark Zuckerberg revisited this on the recent Meta earnings call:I also just think in light of some of the recent news, the new competitor DeepSeek from China, I think it’s one of the things that we’re talking about is there’s going to be an open source standard globally. And I think for our kind of national advantage, it’s important that it’s an American standard. So we take that seriously and we want to build the AI system that people around the world are using and I think that if anything, some of the recent news has only strengthened our conviction that this is the right thing for us to be focused on.The pro-America messaging from Zuckerberg long predates the new administration (especially given that all of Meta’s major apps are banned in China), even if the language is amplified now. This is purely an argument of “we are doing this because we should.”This argument is extremely similar to that used by DeepSeek AI’s CEO Liang Wenfeng. In an interview translated by ChinaTalk, Wenfeng described the need for Chinese leadership in open-source AI (in addition to a clear commitment to keep releasing models openly).Liang Wenfeng: Because we believe the most important thing now is to participate in the global innovation wave. For many years, Chinese companies are used to others doing technological innovation, while we focused on application monetization — but this isn’t inevitable. In this wave, our starting point is not to take advantage of the opportunity to make a quick profit, but rather to reach the technical frontier and drive the development of the entire ecosystem.…We believe that as the economy develops, China should gradually become a contributor instead of freeriding. In the past 30+ years of the IT wave, we basically didn’t participate in real technological innovation. We’re used to Moore’s Law falling out of the sky, lying at home waiting 18 months for better hardware and software to emerge. That’s how the Scaling Law is being treated.But in fact, this is something that has been created through the tire

Why reasoning models will generalize
This post is early to accommodate some last minute travel on my end!The new models trained to express extended chain of thought are going to generalize outside of their breakthrough domains of code and math. The “reasoning” process of language models that we use today is chain of thought reasoning. We ask the model to work step by step because it helps it manage complexity, especially in domains where the answer requires precision across multiple specific tokens. The domains where chain of thought (CoT) is most useful today are code, mathematics, and other “reasoning” tasks. These are the domains where models like o1, R1, Gemini-Thinking, etc. were designed for.Different intelligences reason in different ways that correspond to how they store and manipulate information. Humans compress a lifetime of experience into our spectacular, low-power brains that draw on past experience almost magically. The words that follow in this blog are also autoregressive, like the output of a language model, but draw on hours and hours of background processing as I converge on this argument.Language models, on the other hand, are extremely general and do not today have architectures (or use-cases) that continually re-expose them to relevant problems and fold information back in a compressed form. Language models are very large, sophisticated, parametric probability distributions. All of their knowledge and information processing power is stored in the raw weights. Therein, they need a way of processing information that matches this. Chain of thought is that alignment.Chain of thought reasoning allows information to be naturally processed in smaller chunks, allowing the large, brute force probability distribution to work one token at a time. Chain of thought, while allowing more compute per important token, also allows the models to store intermediate information in their context window without needing explicit recurrence.Recurrence is required for reasoning and this can either happen in the parameter or state-space. Chain of thoughts with transformers handles all of this in the state-space of the problems. The humans we look at as the most intelligent have embedded information directly in the parameters of our brains that we can draw on.Here is the only assumption of this piece — chain of thought is a natural fit for language models to “reason” and therefore one should be optimistic about training methods that are designed to enhance it generalizing to many domains. By the end of 2025 we should have ample evidence of this given the pace of the technological development.If the analogies of types of intelligence aren’t convincing enough, a far more practical way to view the new style of training is a method that teaches the model to be better at allocating more compute to harder problems. If the skill is compute allocation, it is fundamental to the models handling a variety of tasks. Today’s reasoning models do not solve this perfectly, but they open the door for doing so precisely.The nature of this coming generalization is not that these models are one size fits all, best in all cases: speed, intelligence, price, etc. There’s still no free lunch. A realistic outcome for reasoning heavy models in the next 0-3 years is a world where:* Reasoning trained models are superhuman on tasks with verifiable domains, like those with initial progress: Code, math, etc.* Reasoning trained models are well better in peak performance than existing autoregressive models in many domains we would not expect and are not necessarily verifiable.* Reasoning trained models are still better in performance at the long-tail of tasks, but worse in cost given the high inference costs of long-context.Many of the leading figures in AI have been saying for quite some time that powerful AI is going to be “spikey" when it shows up — meaning that the capabilities and improvements will vary substantially across domains — but encountering this reality is very unintuitive.Some evidence for generalization of reasoning models already exists.OpenAI has already published multiple safety-oriented research projects with their new reasoning models in Deliberative Alignment: Reasoning Enables Safer Language Models and Trading Inference-Time Compute for Adversarial Robustness. These papers show their new methods can be translated to various safety domains, i.e. model safety policies and jailbreaking. The deliberative alignment paper shows them integrating a softer reward signal into the reasoning training — having a language model check how the safety policies apply to outputs.An unsurprising quote from the deliberative alignment release related to generalization:we find that deliberative alignment enables strong generalization to out-of-distribution safety scenarios.Safety, qualitatively, is very orthogonal to traditional reasoning problems. Safety is very subjective to the information provided and subtle context, where math and coding problems are often about many small,

Interviewing OLMo 2 leads: Open secrets of training language models
We're here to share the story of building our Open Language Models (OLMos) and what we improved to build the OLMo 2 7B/13B model that is competitive with the Llama 3.1 8B model. This is all about building an effective, small language modeling team that can share all it learns with the scientific community. Dirk, Luca, and Kyle are some of the people I learn the most from and have more knowledge (and entertainment) to share than we have time. Some questions were pulled from Twitter, but please comment or get in touch if you want us to cover anything in the future episode(s)!Main topics:* Pretraining efficiency and our quest for stability after a not-so-secret failed 70B run early in 2024,* What the role of OLMo is in the broader AI landscape and how that is, or is not, changing,* Many little decisions that going into building language models and their teams (with a focus on NOT post-training, given I already talk about that a ton).Play with the models we build here: playground.allenai.org/For more history of open language models (OLMos) on Interconnects, see my first post on OLMo, my coverage of OLMoE, OLMo 2, and why I build open language models. If you have more questions or requests, please let us know (especially the researchers out there) and this can be one of N, rather than a one off celebration.Listen on Apple Podcasts, Spotify, YouTube, and where ever you get your podcasts. For other Interconnects interviews, go here.ContactsDirk Groeneveld — https://x.com/mechanicaldirk // https://bsky.app/profile/mechanicaldirk.bsky.socialKyle Lo — https://x.com/kylelostat // https://bsky.app/profile/kylelo.bsky.socialLuca Soldaini — https://twitter.com/soldni // https://bsky.app/profile/soldaini.netGeneral OLMo contact — [email protected] / models / codebases discussed* OLMo 2 paper* OLMo 1 paper* OPT models and talk from Susan Zhang* BLOOM* Red Pajama V1 Dataset* Falcon LLM * C4: Boosting Large-scale Parallel Training Efficiency with C4: A Communication-Driven Approach * Maximal Update Parametrization (muP) is from Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer * Spike No More: Stabilizing the Pre-training of Large Language Models * LLM360: Towards Fully Transparent Open-Source LLMs — Amber model* EfficientNet * MegaBlocks * A Pretrainer's Guide to Training Data: Measuring the Effects of Data Age, Domain Coverage, Quality, & Toxicity (Kyle said Hitchhikers)* Fishing for Magikarp: Automatically Detecting Under-trained Tokens in Large Language Models ChaptersChapters: Here is a list of major topics covered in the podcast, with timestamps for when the discussion starts:* [00:00:00] Introduction* [00:02:45] Early history of the OLMo project* [00:15:27] The journey to stability* [00:25:00] The evolving role of OLMo and pretraining research* [00:29:00] Pretraining Q&A (µP, scaling laws, MoE, etc.)* [00:40:40] How to think about pretraining data work* [00:54:30] Role of pre-training vs mid training vs post-training* [01:02:19] Release strategy and wrapping upTranscriptThis is generated by AI and lightly edited for clarity. Particularly, the attribution per-speaker was poor on this time around.Nathan Lambert [00:00:07]: Hey, welcome back to Interconnects. In this interview, we're bringing one that I've hinted at for a while, which is interviewing some of the other leads on the OLMo team at AI2. So essentially, this covers the story of OLMo from its early days where we got our compute, kind of our path to stability and some failed runs along the way, the role of OLMo and the broader AI ecosystem, and really just a very long tale of technical details and decision making and considerations that you have when actually training language models that you're trying to have at the frontier of performance relative to peers like Llama, etc. This is a fun one. There's less post-training than normal because this is me interviewing some other co-leads at the Allen Institute for AI. So there's three people in addition to me, which is Dirk Groeneveld, who is the lead of training, handles most of engineering, Kyle Lo, and Luca Soldaini, who are the data leads. So we have a pre-training engineering lead and two data leads with me who has done a lot of the post-training. This is just a part of the team. And I hope you enjoy this one. We can do more of these and bear with the fact that I'm still expanding my podcasting tech equipment. But I think the audio is definitely good enough and enjoy this episode with me, Kyle, Dirk, and Luca.Hey, everyone. Welcome to the AI2 office. We're finally talking more about some of our OLMo things. Too much work to do to actually get all the... the information we want to share out into the world. So I'm here with Dirk, Kyle, and Luca. We can also talk so people identify your voices so people are not all on video. Hi, I'm Dirk.Dirk Groeneveld [00:02:01]: I am the lead of the pre-training part of OLMo.Kyle Lo: Hi, I'm Kyle. I work on data.Luca Soldaini [00:02:08]:

DeepSeek R1's recipe to replicate o1 and the future of reasoning LMs
Full post for links, images, etc: https://www.interconnects.ai/p/deepseek-r1-recipe-for-o1I have a few shows to share with you this week:* On The Retort a week or two ago, we discussed the nature of AI and if it is a science (in the Kuhn’ian sense)* I appeared on Dean W. Ball and Timothy B. Lee’s new podcast AI Summer to discuss “thinking models” and the border between post-training and reasoning methods. Listen here.* Finally, a talk I gave at NeurIPs on how I think about post-training for AI applications is now public.This post is likely getting cut off in email inboxes — I recommend reading online by clicking on the title!Yesterday, January 20th, China’s open-weights frontier AI laboratory, DeepSeek AI, released their first full fledged reasoning model. It came as:* A flagship reasoning language model, R1, trained via a 4-stage, RL heavy process. It is MIT-licensed which means companies and researchers can build upon and train on its outputs to accelerate the development and deployment of reasoning language models (RLMs).* An RL-only reasoning model trained directly from their V3 base model, R1-Zero (used to create training data for full R1).* A suite of open-weight models finetuned with supervised finetuning (SFT) data derived from R1 (similar data to one of their intermediate training steps).* A technical report detailing their RL training methods.* Models are available at chat.deepseek.com (via DeepThink) and in their new app.This post is less about the evaluation results (which, of course, are extremely good and shown below), but rather about how training is done and what it all means.This is a major transition point in the uncertainty in reasoning model research. Until now, reasoning models have been a major area of industrial research without a clear seminal paper. Before language models took off, we had the likes of the GPT-2 paper for pretraining or InstructGPT (and Anthropic’s whitepapers) for post-training. For reasoning, we were staring at potentially misleading blog posts. Reasoning research and progress is now locked in — expect huge amounts of progress in 2025 and more of it in the open.This again confirms that new technical recipes normally aren’t moats — the motivation of a proof of concept or leaks normally get the knowledge out.For one, look at the pricing of these reasoning models. OpenAI was likely charging more for its model due to the costs of long-context serving and being the only model in town, but now o1’s pricing at $15 per million input tokens / $60 output looks out of place relative to R1’s pricing at $0.55 per million input tokens / $2.19 output (yes, o1-mini is cheaper at $3/$12 per million, but still almost a 10x difference). The price war that is coming for reasoning models will look like the Mixtral inference price war from 2023.With o3, OpenAI is likely technically ahead, but it is not generally available nor will the weights be available anytime soon. This points to the first time since Stable Diffusion’s release that the most relevant and discussed AI model is released with a very friendly license. Looking back at the journey “open-source” AI has been on over the last 2.5 years, this is a surprising moment in time marked in the history books.We don’t entirely know how these models will be used in the future beyond code and math, but noises are constantly bubbling up that OpenAI’s o1-Pro is the best model for many more challenging tasks (I need to try it myself before making definitive recommendations).The most useful post to write now is one that establishes the research area, the do’s and don’ts, and the open questions. Let’s get into the details.The DeepSeek R1 training recipe for reasoningThe training of R1 comes in 4 stages:* “Cold-start” of supervised finetuning on synthetic reasoning data from the R1-Zero model.* Large-scale reinforcement learning training on reasoning problems “until convergence.”* Rejection sampling on 3/4 reasoning problems and 1/4 general queries to start the transition to a general-purpose model.* Reinforcement learning training mixing reasoning problems (verifiable rewards) with general preference tuning reward models to polish the model.Below, the post breaks down each training stage into its core components, insights, and open questions.The winds of o1 replication have been blowing strongly away from any sort explicit search (especially at inference time). It really was, and is, a language model with the new reasoning behaviors coming from a lot of RL training.Before we start, remember that to do this reasoning training well you need a very strong base model with long-context capabilities. Much like for standard post-training, we don’t really know what traits of a base model make for one that is more suited for direct RL training.Step 0. Training R1-Zero to initialize R1 with synthetic dataDeepSeek R1 Zero will be best known as the first open model trained with “large-scale reinforcement learning (RL) without supervised fine-tuning (SFT)

Let me use my local LMs on Meta Ray-Bans
Full post for images, etc: https://www.interconnects.ai/p/to-meta-ray-ban-local-aiWith the Rabbit r1, the Humane pin, the Friend thing, the Sam Altman rumors, Meta Ray-Bans, and everything in between, it is obvious that we are going to get new devices in the near future driven by advancements in AI. Trying some of those that already are public makes this obvious from a functional perspective rather than a marketing perspective.Even though many of these devices will have a shelf life drastically shortened by the underlying API access getting turned off when the parent company runs out of money, the call for these devices is very strong. AI is going to be more than a chat window we use for work, we just don’t know what that will feel like. AI should be fun, flexible, and available.Meta’s Ray-Bans were first launched in 2021, long before any of this ChatGPT-inspired interest in AI began. Having tried them — the form factor would have caught on eventually, but AI was the catalyst to accelerate adoption. AI expanded our expectations for the range of exciting outcomes that could be coming our way.Using the AI in the Ray-Bans is much like using a protolithic chatbot. If I had never used ChatGPT, it would have been transformative, but today it feels slightly outdated. We should be more impressed by these generally and contextualize the AI they’re delivering. The product excitement cumulatively feels unexpectedly like what AirPods had on day 1. I was not expecting this fondness.The form factor for the Meta Ray-Bans is fantastic and drives this connection. I’ve been legitimately excited to use them (albeit, much more during sunny Seattle summers relative to now), and it immediately made sense when taking them out of the packaging. My best use has been for outdoor activities, taking photos and videos without needing to fuss with a phone and communications. An example video is below -- like most things, it has a learning curve.Here’s a photo from that outing:Or a video:Clearly, they’re fine.What I want to use them for today has nothing to do with AI. In some ways, this makes me more bullish on the form factor, but it makes it clear that Meta is in a precarious position. Ironically, I would’ve been more reluctant to buy them if not for the excitement about AI.As of writing this, I would much rather have “Apple Ray-Bans” because of a seamless integration with the rest of my information ecosystem. However, Apple may not be willing to take the risk to build them (as I avoid an Apple Vision Pro Digression).This does not mean the long-term story of many new devices won’t be the AI.AI, in the recent past (and likely in the near future), left most electronic devices with an eerie, bland sameness. My sunglasses can answer basic questions about my day just like Siri. At the same time, my appliances try to talk to me. The hard-to-visualize step is how this changes (and overcomes the same integration dead ends that agents face). AI in 5 years (or way less) will actually know the context of our lives and be able to execute basic web tasks.When the AI is good, Meta Ray-Ban type devices will be indispensable. Reminders, calls, reasoning, integration, all on the go. Much like the sensation products like AirPods provide, AI devices (and services) done right will make us free to be in the world naturally.Meta now has a real hill to climb for AI. They just need to focus on building one more useful feature at a time rather than building a god. They have a tangible goal and a real product that is going to get better in the normal march of progress. If only we had an ecosystem of people who wanted to do this work and keep hill climbing the AI part for them.The AI of the Meta Ray-Bans (and the other devices I started with) being primarily in the cloud is a drag but is needed for these first generations of glasses to maintain battery life. The cloud-centric nature of the AI is the largest perceivable reason Meta cannot open a Software Development Kit (SDK) for the glasses — all the developers would be doing is changing Meta's internal Llama API calls, rather than uploading new and improved models to the glasses.AI models in the cloud are consistently the first ones to cross the frontier of new capabilities. As we figure out what we want to use new AI devices for, using the cloud models will make us more likely than not to find useful applications. Now that we have things that people actually like, we need to optimize and specialize these models out of the cloud.What’s the state of local LMs?The AI angle for this post is to prompt the question: What do people actually use local, or on-device, language models for? What are they driving innovation of?The local model ecosystem is composed of a distribution of tinkerers, researchers, and those whom API models refuse their use cases. Most people doing this are not directly innovating on local models in a way that dictates meaningful improvements to underlying AI innovations. Yes, companies surely m
(Voiceover) DeepSeek V3 and the actual cost of training frontier AI models
Original post: https://www.interconnects.ai/p/deepseek-v3-and-the-actual-cost-ofChapters00:00 Opening03:15 DeepSeek’s learning efficiency06:49 DeepSeek’s compute transparency and realityFiguresFig 1: Benchmark ResultsFig 2: ChatBotArena ResultsFig 3: Compute Usage Table This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe
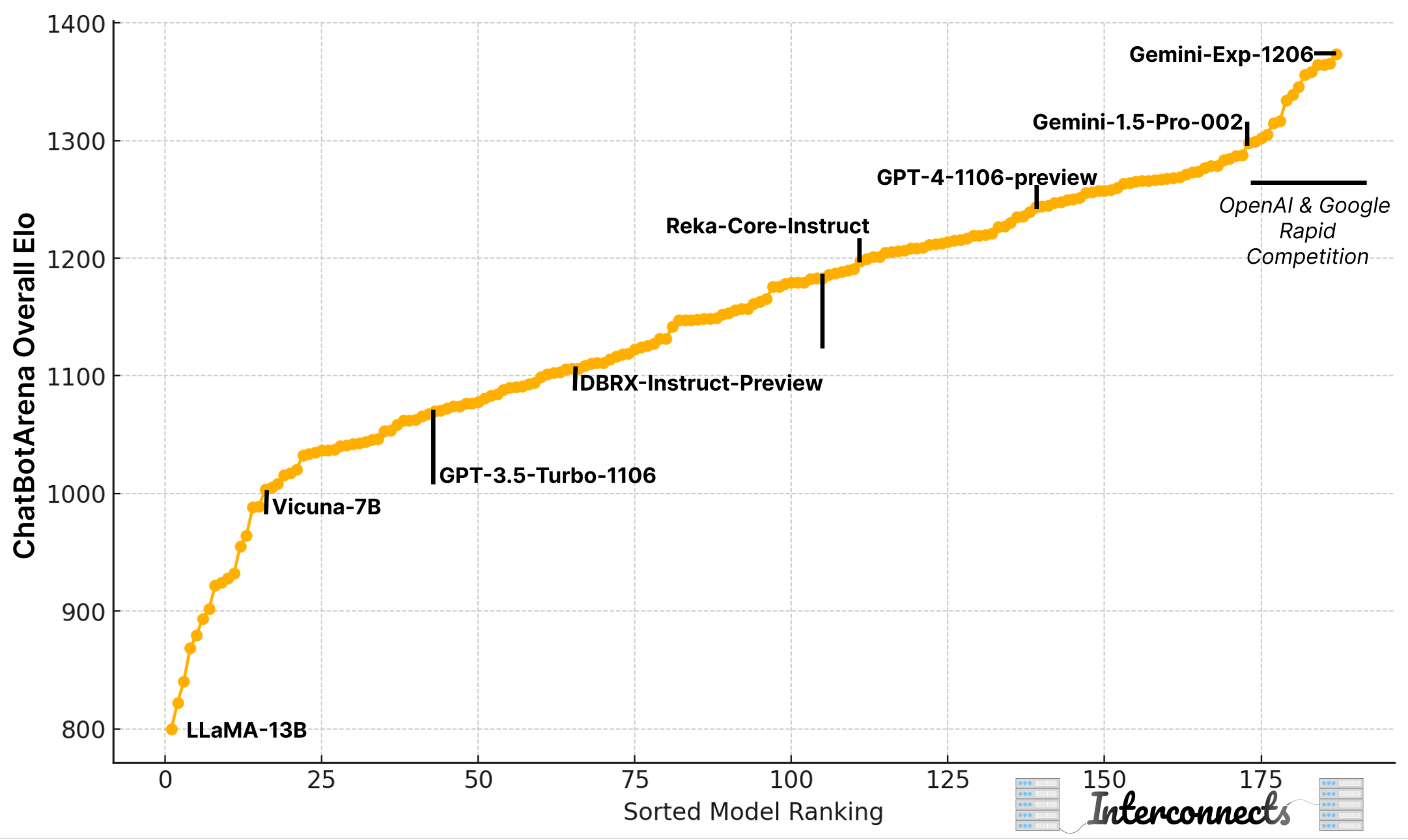
The state of post-training in 2025
Slides for this post-training talk and slides for the full tutorial on language modeling (with a bit less post-training content and no recording yet). Here are some timestamps for the video:00:00 Introduction 10:00 Prompts & Skill Selection 14:19 Instruction Finetuning 21:45 Preference Finetuning 36:17 Reinforcement Finetuning 45:28 Open Questions 52:02 Wrap UpPsssst… we just recently released our technical report for OLMo 2 — 2 OLMo 2 Furious, check it out for tons of training details and tips!This post has some good content, but if you just want to watch the tutorial on YouTube, it’s here.I’m far more optimistic about the state of open recipes for and knowledge of post-training starting 2025 than I was starting 2024. Last year one of my first posts was how open post-training won’t match the likes of GPT-4. This is still the case, but now we at least understand the scope of things we will be working with better.It’s a good time to record an overview of what post-training looks like today. I gave a version of this tutorial talk for the first time in 2023 (at ICML), which felt like a review of the InstructGPT paper not based on reproduced literature knowledge. In 2024, the scientific community made substantial progress in actually training these models and expanding the frontier of knowledge. Doing one of these talks every year feels like a good way to keep tabs on the state of play (whereas last year, I just had a bunch of links to add to the conversation on where to start).With the talk, I wanted to add more context on where I see post-training generally.The most important one people need to know, given the excitement around OpenAI’s o1 series of models, is that post-training alone is nowhere near a complete enough lens or taxonomy to study training reasoning language models. It’s a step.Back to processes for all modern AI models. There are a lot of post-training methods to improve models and, more importantly, they can be segmented so the scientific community can make progress on each of them individually. The new state of finetuning stages is satisfying, with three groups of training methods:* Instruction finetuning (a.k.a. supervised finetuning),* Preference finetuning (the generalization of reinforcement learning from human feedback), and* Reinforcement finetuning is the new abstraction for improving performance on specific tasks.Some of the long-tail methods like rejection sampling, knowledge distillation, and extensive filtering aren’t studied well, but you can still do excellent post-training without them. We have options for studying post-training in 2025.Where last year we were settling debates such as “DPO vs. PPO” or “does AI feedback for RLHF work,” now we are focused on just making the best practices better.Similarly, the stress around doing research on outputs from foundation model providers, i.e. if research violates the OpenAI terms of service on training competitor models, has dropped further and is common practice — in fact, distilling from strong models is a fundamental part of successful post-training.Interconnects is a reader-supported publication. Consider becoming a subscriber.To summarize the state of post-training, there are a few things to keep in mind:1. Post-training techniques are more impactful on the final performance of modelsSome caveats before I toot the horn of post-training as all you need today. Given that “scaling as we know it is ending” this is not entirely a controversial take. Finally, it is obviously self-serving to myself as someone who is going to benefit from post-training being more important.All of this aside, it’s very logical that post-training will be the next domain for scaling model compute and performance. Predicting the next token accurately is not something that a user cares about — correct answers and how the answer is presented are. All through 2024, there were way more discussions on how post-training is more important.If we look at the Elo ratings of models on ChatBotArena, we can see progress has accelerated even though the models haven’t been getting noticeably bigger. Pretraining on these architectures is improving, yes, but the biggest and best models are used as tools and supervision for better post-training.Post-training got more popular because there was more low-hanging fruit on model performance. A lot of that potential has been realized and, in doing so, entirely new types of models are being made akin to o1.To interpret these numbers:* 100 Elo margin over another means ~2/3 win probability over the lower,* 200 Elo gives ~76% win probability,* 300 Elo gives ~85% win probability, and so on.You can play with these numbers here.2. Post-training can be very expensiveWhile still far cheaper than pretraining due to the price of GPUs, post-training costs have been growing rapidly. If we estimate the costs of post-training the Llama models, we could guess that the all-in costs for the models were about the following: Note — numbers are based pri

Quick recap on the state of reasoning
In 2025 we need to disambiguate three intertwined topics: post-training, reasoning, and inference-time compute. Post-training is going to quickly become muddied with the new Reasoning Language Models (RLMs — is that a good name), given that loss functions that we studied via advancements in post-training are now being leveraged at a large scale to create new types of models. I would not call the reinforcement learning training done for OpenAI’s o1 series of models post-training. Training o1 is large-scale RL that enables better inference-time compute and reasoning performance. Today, I focus on reasoning. Technically, language models definitely do a form of reasoning. This definition does not need to go in the direction of the AGI debate — we can clearly scope a class of behavior rather than a distribution of explicit AI capability milestones. It’ll take work to get an agreement here. Getting some members of the community (and policymakers) to accept that language models do their own form of reasoning by outputting and manipulating intermediate tokens will take time. I enjoy Ross Taylor’s definition:Reasoning is the process of drawing conclusions by generating inferences from observations.This is a talk I gave at NeurIPS at the Latent Space unofficial industry track. I wanted to directly address the question on if language models can reason and what o1 and the reinforcement finetuning (RFT) API tell us about it. It’s somewhat rambly, but asks the high level questions on reasoning that I haven’t written about yet and is a good summary of my coverage on o1’s implementation and the RFT API.Thanks swyx & Alessio for having me again! You can access the slides here (e.g. if you want to access the links on them). For more on reasoning, I recommend you read/watch:* Melanie Mitchell’s series on ARC at AI: A Guide for Thinking Humans: first, second, third, and final. And her post on reasoning proper.* Miles Brundage’s thread summarizing the prospects of generalization.* Ross Taylor’s (previous interview guest) recent talk on reasoning.* The inference-time compute tag on Interconnects.Listen on Apple Podcasts, Spotify, YouTube, and wherever you get your podcasts. Transcript + SlidesNathan [00:00:07]: Hey, everyone. Happy New Year. This is a quick talk that I gave at NeurIPS, the Latent Space unofficial industry event. So Swyx tried to have people to talk about the major topics of the year, scaling, open models, synthetic data, agents, etc. And he asked me to fill in a quick slot on reasoning. A couple notes. This was before O3 was announced by OpenAI, so I think you can take everything I said and run with it with even more enthusiasm and expect even more progress in 2025. And second, there was some recording issues, so I re-edited the slides to match up with the audio, so you might see that they're slightly off. But it's mostly reading like a blog post, and it should do a good job getting the conversation started around reasoning on interconnects in the new year. Happy New Year, and I hope you like this. Thanks. I wouldn't say my main research area is reasoning. I would say that I came from a reinforcement learning background into language models, and reasoning is now getting subverted into that as a method rather than an area. And a lot of this is probably transitioning these talks into more provocative forms to prime everyone for the debate that is why most people are here. And this is called the state of reasoning. This is by no means a comprehensive survey. To continue, I wanted to make sure that I was not off base to think about this because there's a lot of debates on reasoning and I wanted to revisit a very basic definition. And this is a dictionary definition, which is the action of thinking about something in a logical, sensible way, which is actually sufficiently vague that I would agree with it. I think as we'll see in a lot of this talk is that I think people are going crazy about whether or not language models reason. We've seen this with AGI before. And now we're going to talk about it. Now, reasoning kind of seems like the same thing, which to me is pretty ridiculous because it's like reasoning is a very general skill and I will provide more reasoning or support for the argument that these language models are doing some sort of reasoning when you give them problems. I think I don't need to share a ton of examples for what's just like ill-formed arguments for what language models are not doing, but it's tough that this is the case. And I think there are. Some very credible arguments that reasoning is a poor direction to pursue for language models because language models are not going to be as good at it as humans. But to say that they can't do reasoning, I don't see a lot of proof for, and I'll go through a few examples. And the question is like, why should language model reasoning be constrained to look what look like what humans do? I think language models are very different and they are stochastic. Th
(Voiceover) 2024 Interconnects year in review
Original posthttps://www.interconnects.ai/p/2024-interconnects-year-in-review This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe
(Voiceover) OpenAI's o3: The grand finale of AI in 2024
Original post: https://www.interconnects.ai/p/openais-o3-the-2024-finale-of-aiChapters00:00 Introduction02:51 o3 overview05:57 Solving the Abstraction and Reasoning Corpus (ARC)10:41 o3’s architecture, cost, and training (hint: still no tree search)16:36 2024: RL returnsFiguresFig 1, Frontier Math resultsFig 2, Coding resultsFig 3, ARC AGI resultsFig 4, ARC AGI result detailsFig 5, ARC AGI example 1Fig 6, ARC AGI example in textFig 7, ARC AGI example “easy” This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe
(Voiceover) The AI agent spectrum
Original post: https://www.interconnects.ai/p/the-ai-agent-spectrumChapters00:00 Introduction03:24 Agent cartography08:02 Questions for the near futureFiguresFig 1. multiple feedbacks diagram This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe

(Voiceover) OpenAI's Reinforcement Finetuning and RL for the masses
Original post: https://www.interconnects.ai/p/openais-reinforcement-finetuningChapters00:00 Introduction04:19 The impact of reinforcement finetuning’s existence07:29 Hypotheses on reinforcement finetuning’s implementationFiguresFig. 1, Yann’s CakeFig. 2, Grader configFig. 3, RLVR learning curves This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe

Interviewing Finbarr Timbers on the "We are So Back" Era of Reinforcement Learning
Finbarr Timbers is an AI researcher who writes Artificial Fintelligence — one of the technical AI blog’s I’ve been recommending for a long time — and has a variety of experiences at top AI labs including DeepMind and Midjourney. The goal of this interview was to do a few things:* Revisit what reinforcement learning (RL) actually is, its origins, and its motivations.* Contextualize the major breakthroughs of deep RL in the last decade, from DQN for Atari to AlphaZero to ChatGPT. How could we have seen the resurgence coming? (see the timeline below for the major events we cover)* Modern uses for RL, o1, RLHF, and the future of finetuning all ML models.* Address some of the critiques like “RL doesn’t work yet.”It was a fun one. Listen on Apple Podcasts, Spotify, YouTube, and where ever you get your podcasts. For other Interconnects interviews, go here.Timeline of RL and what was happening at the timeIn the last decade of deep RL, there have been a few phases.* Era 1: Deep RL fundamentals — when modern algorithms we designed and proven.* Era 2: Major projects — AlphaZero, OpenAI 5, and all the projects that put RL on the map.* Era 3: Slowdown — when DeepMind and OpenAI no longer had the major RL projects and cultural relevance declined.* Era 4: RLHF & widening success — RL’s new life post ChatGPT.Covering these is the following events. This is incomplete, but enough to inspire a conversation.Early era: TD Gammon, REINFORCE, Etc2013: Deep Q Learning (Atari)2014: Google acquires DeepMind2016: AlphaGo defeats Lee Sedol2017: PPO paper, AlphaZero (no human data)2018: OpenAI Five, GPT 22019: AlphaStar, robotic sim2real with RL early papers (see blog post)2020: MuZero2021: Decision Transformer2022: ChatGPT, sim2real continues.2023: Scaling laws for RL (blog post), doubt of RL2024: o1, post-training, RL’s bloomInterconnects is a reader-supported publication. Consider becoming a subscriber.Chapters* [00:00:00] Introduction* [00:02:14] Reinforcement Learning Fundamentals* [00:09:03] The Bitter Lesson* [00:12:07] Reward Modeling and Its Challenges in RL* [00:16:03] Historical Milestones in Deep RL* [00:21:18] OpenAI Five and Challenges in Complex RL Environments* [00:25:24] Recent-ish Developments in RL: MuZero, Decision Transformer, and RLHF* [00:30:29] OpenAI's O1 and Exploration in Language Models* [00:40:00] Tülu 3 and Challenges in RL Training for Language Models* [00:46:48] Comparing Different AI Assistants* [00:49:44] Management in AI Research* [00:55:30] Building Effective AI Teams* [01:01:55] The Need for Personal BrandingWe mention* O1 (OpenAI model)* Rich Sutton* University of Alberta* London School of Economics* IBM’s Deep Blue* Alberta Machine Intelligence Institute (AMII)* John Schulman* Claude (Anthropic's AI assistant)* Logan Kilpatrick* Bard (Google's AI assistant)* DeepSeek R1 Lite* Scale AI* OLMo (AI2's language model)* Golden Gate Claude This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe
(Voiceover) OpenAI's o1 using "search" was a PSYOP
Original post: https://www.interconnects.ai/p/openais-o1-using-search-was-a-psyopFiguresFigure 0: OpenAI’s seminal test-time compute plotFigure 1: Setup for bucketed evalsFigure 2: Evals with correctness labelsFigure 3: Grouped evalsFigure 4: Hypothetical inference scaling law This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe
(Voiceover) OLMo 2 and building effective teams for training language models
Full post: https://www.interconnects.ai/p/olmo-2-and-building-language-model-trainingOLMo 2 demo: https://playground.allenai.org/OLMo 2 artifacts: https://huggingface.co/collections/allenai/olmo-2-674117b93ab84e98afc72edcChapters00:00 Building AI Teams06:35 OLMo 2FiguresFig 1, pretrain plot: https://huggingface.co/datasets/natolambert/interconnects-figures/resolve/main/olmo2/pretrain.webpFig 2, pretrain table: https://huggingface.co/datasets/natolambert/interconnects-figures/resolve/main/olmo2/pretrain-table.webpFig 3, post-train table: https://huggingface.co/datasets/natolambert/interconnects-figures/resolve/main/olmo2/postrain-table.webp This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe
(Voiceover) Tülu 3: The next era in open post-training
Original post: https://www.interconnects.ai/p/tulu-3Chapters00:00 History05:44 Technical details sneak peakFiguresFig 1, results: https://huggingface.co/datasets/natolambert/interconnects-figures/resolve/main/tulu3-img/results.webpFig 2, overview: https://huggingface.co/datasets/natolambert/interconnects-figures/resolve/main/tulu3-img/overview.webpFig 3, preferences: https://huggingface.co/datasets/natolambert/interconnects-figures/resolve/main/tulu3-img/preferences.webpFig 4, RLVR: https://huggingface.co/datasets/natolambert/interconnects-figures/resolve/main/tulu3-img/rlvr.webp This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe
(Voiceover) Scaling realities
Original post: https://www.interconnects.ai/p/scaling-realities This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe
(Voiceover) Saving the National AI Research Resource & my AI policy outlook
Original post: https://www.interconnects.ai/p/saving-the-nairrChapters05:26: Do we need an AI research resource or an LM research resource?08:59: Policy roundups This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe

Interviewing Tim Dettmers on open-source AI: Agents, scaling, quantization and what's next
Tim Dettmers does not need an introduction for most people building open-source AI. If you are part of that minority, you’re in for a treat. Tim is the lead developer behind most of the open-source tools for quantization: QLoRA, bitsandbytes, 4 and 8 bit inference, and plenty more. He recently finished his Ph.D. at the University of Washington, is now a researcher at the Allen Institute for AI, and is starting as a professor at Carnegie Mellon University in fall of 2025.Tim is a joy to talk to. He thinks independently on all the AI issues of today, bringing new perspectives that challenge the status quo. At the same time, he’s sincere and very helpful to work with, working hard to uplift those around him and the academic community. There’s a reason he’s so loved in the open-source AI community.Find more about Tim on his Twitter or Google Scholar. He also has a great blog where he talks about things like which GPUs to buy and which grad school to choose.Listen on Apple Podcasts, Spotify, YouTube, and where ever you get your podcasts. For other Interconnects interviews, go here.Show NotesHere's a markdown list of companies, people, projects, research papers, and other key named entities mentioned in the transcript:* QLoRA* Bits and Bytes* Llama 3* Apple Intelligence* SWE Bench* RewardBench* Claude (AI assistant by Anthropic)* Transformers (Hugging Face library)* Gemma (Google's open weight language model)* Notebook LM* LangChain* LangGraph* Weights & Biases* Blackwell (NVIDIA GPU architecture)* Perplexity* Branch Train Merge (research paper)* "ResNets do iterative refinement on features" (research paper)* CIFAR-10 and CIFAR-100 (computer vision datasets)* Lottery Ticket Hypothesis (research paper)* OpenAI O1* TRL (Transformer Reinforcement Learning) by Hugging Face* Tim's work on quantization (this is just one example)Timestamps* [00:00:00] Introduction and background on Tim Dettmers* [00:01:53] Future of open source AI models* [00:09:44] SWE Bench and evaluating AI systems* [00:13:33] Using AI for coding, writing, and thinking* [00:16:09] Academic research with limited compute* [00:32:13] Economic impact of AI* [00:36:49] User experience with different AI models* [00:39:42] O1 models and reasoning in AI* [00:46:27] Instruction tuning vs. RLHF and synthetic data* [00:51:16] Model merging and optimization landscapes* [00:55:08] Knowledge distillation and optimization dynamics* [01:01:55] State-space models and transformer dominance* [01:06:00] Definition and future of AI agents* [01:09:20] The limit of quantizationTranscript and full details: https://www.interconnects.ai/p/tim-dettmersGet Interconnects (https://www.interconnects.ai/)...... on YouTube: https://www.youtube.com/@interconnects... on Twitter: https://x.com/interconnectsai... on Linkedin: https://www.linkedin.com/company/interconnects-ai... on Spotify: https://open.spotify.com/show/2UE6s7wZC4kiXYOnWRuxGv… on Apple Podcasts: https://podcasts.apple.com/us/podcast/interconnects/id1719552353 This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe

Interviewing Andrew Carr of Cartwheel on the State of Generative AI
Andrew Carr is co-founder and chief scientist at Cartwheel, where he is building text-to-motion AI models and products for gaming, film, and other creative endeavors. We discuss how to keep generative AI fun and expansive — niche powerful use-cases, AI poetry, AI devices like Meta RayBans, generalization to new domains like robotics, and building successful AI research cultures.Andrew is one of my well read friends on the directions AI is going, so it is great to bring him in for an official conversation. He spent time at OpenAI working on Codex, Gretel AI, and is an editor for the TLDR AI Newsletter.Listen on Apple Podcasts, Spotify, YouTube, and where ever you get your podcasts. For other Interconnects interviews, go here.Show NotesNamed entities and papers mentioned in the podcast transcript:* Codex and GitHub Copilot* Gretel AI* TLDR AI Newsletter* Claude Computer Use* Blender 3D simulator* Common Sense Machines* HuggingFace Simulate, Unity, Godot* Runway ML* Mark Chen, OpenAI Frontiers Team Lead* Meta’s Lingua, Spirit LM, torchtitan and torchchat* Self-Rewarding Language Models paper* Meta Movie Gen paperTimestamps* [00:00] Introduction to Andrew and Cartwheel* [07:00] Differences between Cartwheel and robotic foundation models* [13:33] Claude computer use* [18:45] Supervision and creativity in AI-generated content* [23:26] Adept AI and challenges in building AI agents* [30:56] Successful AI research culture at OpenAI and elsewhere* [38:00] Keeping up with AI research* [44:36] Meta Ray-Ban smart glasses and AI assistants* [51:17] Meta's strategy with Llama and open source AITranscript & Full Show Notes: https://www.interconnects.ai/p/interviewing-andrew-carr This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe
(Voiceover) Why I build open language models
Full post:https://www.interconnects.ai/p/why-i-build-open-language-models This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe
(Voiceover) Claude's agentic future and the current state of the frontier models
How Claude's computer use works. Where OpenAI, Anthropic, and Google all have a lead on eachother.Original post: https://www.interconnects.ai/p/claudes-agencyChapters00:00 Claude's agentic future and the current state of the frontier models04:43 The state of the frontier models04:49 1. Anthropic has the best model we are accustomed to using05:27 Google has the best small & cheap model for building automation and basic AI engineering08:07 OpenAI has the best model for reasoning, but we don’t know how to use it09:12 All of the laboratories have much larger models they’re figuring out how to release (and use)10:42 Who wins?FiguresFig 1, Sonnet New Benchmarks: https://substackcdn.com/image/fetch/w_1456,c_limit,f_webp,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F5d2e63ff-ac9f-4f8e-9749-9ef2b9b25b6c_1290x1290.pngFig 2, Sonnet Old Benchmarks: https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F4bccbd4d-f1c8-4a38-a474-69a3df8a4448_2048x1763.pngGet Interconnects (https://www.interconnects.ai/)...... on YouTube: https://www.youtube.com/@interconnects... on Twitter: https://x.com/interconnectsai... on Linkedin: https://www.linkedin.com/company/interconnects-ai... on Spotify: https://open.spotify.com/show/2UE6s7wZC4kiXYOnWRuxGv… on Apple Podcasts: https://podcasts.apple.com/us/podcast/interconnects/id1719552353 This is a public episode. If you'd like to discuss this with other subscribers or get access to bonus episodes, visit www.interconnects.ai/subscribe