
Future of Life Institute Podcast
270 episodes — Page 5 of 6

Ep 1Not Cool Ep 9: Andrew Revkin on climate communication, vulnerability, and information gaps
In her speech at Monday’s UN Climate Action Summit, Greta Thunberg told a roomful of global leaders, “The world is waking up.” Yet the science, as she noted, has been clear for decades. Why has this awakening taken so long, and what can we do now to help it along? On Episode 9 of Not Cool, Ariel is joined by Andy Revkin, acclaimed environmental journalist and founding director of the new Initiative on Communication and Sustainability at Columbia University’s Earth Institute. Andy discusses the information gaps that have left us vulnerable, the difficult conversations we need to be having, and the strategies we should be using to effectively communicate climate science. He also talks about inertia, resilience, and creating a culture that cares about the future. Topics discussed include: -Inertia in the climate system -The expanding bullseye of vulnerability -Managed retreat -Information gaps -Climate science literacy levels -Renewable energy in conservative states -Infrastructural inertia -Climate science communication strategies -Increasing resilience -Balancing inconvenient realities with productive messaging -Extreme events

Ep 1Not Cool Ep 8: Suzanne Jones on climate policy and government responsibility
On the eighth episode of Not Cool, Ariel tackles the topic of climate policy from the local level to the federal. She's joined by Suzanne Jones: the current mayor of Boulder, Colorado, but also public policy veteran and climate activist. Suzanne explains the climate threats facing communities like Boulder, the measures local governments can take to combat the crisis, and the ways she’d like to see the federal government step up. She also discusses the economic value of going green, the importance of promoting equity in climate solutions, and more. Topics discussed include: -Paris Climate Agreement -Roles for local/state/federal governments -Surprise costs of climate change -Equality/equity in climate solutions -Increasing community engagement -Nonattainment zones -Electrification of transportation sector -Municipalization of electric utility -Challenges, roadblocks, and what she’d like to see accomplished -Affordable, sustainable development -What individuals should be doing -Carbon farming and sustainable agriculture

Ep 1Not Cool Ep 7: Lindsay Getschel on climate change and national security
The impacts of the climate crisis don’t stop at rising sea levels and changing weather patterns. Episode 7 of Not Cool covers the national security implications of the changing climate, from the economic fallout to the uptick in human migration. Ariel is joined by Lindsay Getschel, a national security and climate change researcher who briefed the UN Security Council this year on these threats. Lindsay also discusses how hard-hit communities are adapting, why UN involvement is important, and more. Topics discussed include: -Threat multipliers -Economic impacts of climate change -Impacts of climate change on migration -The importance of UN involvement -Ecosystem-based adaptation -Action individuals can take

Ep 1Not Cool Ep 6: Alan Robock on geoengineering
What is geoengineering, and could it really help us solve the climate crisis? The sixth episode of Not Cool features Dr. Alan Robock, meteorologist and climate scientist, on types of geoengineering solutions, the benefits and risks of geoengineering, and the likelihood that we may need to implement such technology. He also discusses a range of other solutions, including economic and policy reforms, shifts within the energy sector, and the type of leadership that might make these transformations possible. Topics discussed include: -Types of geoengineering, including carbon dioxide removal and solar radiation management -Current geoengineering capabilities -The Year Without a Summer -The termination problem -Feasibility of geoengineering solutions -Social cost of carbon -Fossil fuel industry -Renewable energy solutions and economic accessibility -Biggest risks of stratospheric geoengineering

Ep 1AIAP: Synthesizing a human's preferences into a utility function with Stuart Armstrong
In his Research Agenda v0.9: Synthesizing a human's preferences into a utility function, Stuart Armstrong develops an approach for generating friendly artificial intelligence. His alignment proposal can broadly be understood as a kind of inverse reinforcement learning where most of the task of inferring human preferences is left to the AI itself. It's up to us to build the correct assumptions, definitions, preference learning methodology, and synthesis process into the AI system such that it will be able to meaningfully learn human preferences and synthesize them into an adequate utility function. In order to get this all right, his agenda looks at how to understand and identify human partial preferences, how to ultimately synthesize these learned preferences into an "adequate" utility function, the practicalities of developing and estimating the human utility function, and how this agenda can assist in other methods of AI alignment. Topics discussed in this episode include: -The core aspects and ideas of Stuart's research agenda -Human values being changeable, manipulable, contradictory, and underdefined -This research agenda in the context of the broader AI alignment landscape -What the proposed synthesis process looks like -How to identify human partial preferences -Why a utility function anyway? -Idealization and reflective equilibrium -Open questions and potential problem areas Here you can find the podcast page: https://futureoflife.org/2019/09/17/synthesizing-a-humans-preferences-into-a-utility-function-with-stuart-armstrong/ Important timestamps: 0:00 Introductions 3:24 A story of evolution (inspiring just-so story) 6:30 How does your “inspiring just-so story” help to inform this research agenda? 8:53 The two core parts to the research agenda 10:00 How this research agenda is contextualized in the AI alignment landscape 12:45 The fundamental ideas behind the research project 15:10 What are partial preferences? 17:50 Why reflexive self-consistency isn’t enough 20:05 How are humans contradictory and how does this affect the difficulty of the agenda? 25:30 Why human values being underdefined presents the greatest challenge 33:55 Expanding on the synthesis process 35:20 How to extract the partial preferences of the person 36:50 Why a utility function? 41:45 Are there alternative goal ordering or action producing methods for agents other than utility functions? 44:40 Extending and normalizing partial preferences and covering the rest of section 2 50:00 Moving into section 3, synthesizing the utility function in practice 52:00 Why this research agenda is helpful for other alignment methodologies 55:50 Limits of the agenda and other problems 58:40 Synthesizing a species wide utility function 1:01:20 Concerns over the alignment methodology containing leaky abstractions 1:06:10 Reflective equilibrium and the agenda not being a philosophical ideal 1:08:10 Can we check the result of the synthesis process? 01:09:55 How did the Mahatma Armstrong idealization process fail? 01:14:40 Any clarifications for the AI alignment community? You Can take a short (4 minute) survey to share your feedback about the podcast here: www.surveymonkey.com/r/YWHDFV7

Ep 1Not Cool Ep 5: Ken Caldeira on energy, infrastructure, and planning for an uncertain climate future
Planning for climate change is particularly difficult because we're dealing with such big unknowns. How, exactly, will the climate change? Who will be affected and how? What new innovations are possible, and how might they help address or exacerbate the current problem? Etc. But we at least know that in order to minimize the negative effects of climate change, we need to make major structural changes — to our energy systems, to our infrastructure, to our power structures — and we need to start now. On the fifth episode of Not Cool, Ariel is joined by Ken Caldeira, who is a climate scientist at the Carnegie Institution for Science and the Department of Global Ecology and a professor at Stanford University's Department of Earth System Science. Ken shares his thoughts on the changes we need to be making, the obstacles standing in the way, and what it will take to overcome them. Topics discussed include: -Relationship between policy and science -Climate deniers and why it isn't useful to argue with them -Energy systems and replacing carbon -Planning in the face of uncertainty -Sociopolitical/psychological barriers to climate action -Most urgently needed policies and actions -Economic scope of climate solution -Infrastructure solutions and their political viability -Importance of political/systemic change

Ep 1Not Cool Ep 4: Jessica Troni on helping countries adapt to climate change
The reality is, no matter what we do going forward, we’ve already changed the climate. So while it’s critical to try to minimize those changes, it’s also important that we start to prepare for them. On Episode 4 of Not Cool, Ariel explores the concept of climate adaptation — what it means, how it’s being implemented, and where there’s still work to be done. She’s joined by Jessica Troni, head of UN Environment’s Climate Change Adaptation Unit, who talks warming scenarios, adaptation strategies, implementation barriers, and more. Topics discussed include: Climate adaptation: ecology-based, infrastructure Funding sources Barriers: financial, absorptive capacity Developed vs. developing nations: difference in adaptation approaches, needs, etc. UN Environment Policy solutions Social unrest in relation to climate Feedback loops and runaway climate change Warming scenarios What individuals can do

Ep 1Not Cool Ep 3: Tim Lenton on climate tipping points
What is a climate tipping point, and how do we know when we’re getting close to one? On Episode 3 of Not Cool, Ariel talks to Dr. Tim Lenton, Professor and Chair in Earth System Science and Climate Change at the University of Exeter and Director of the Global Systems Institute. Tim explains the shifting system dynamics that underlie phenomena like glacial retreat and the disruption of monsoons, as well as their consequences. He also discusses how to deal with low certainty/high stakes risks, what types of policies we most need to be implementing, and how humanity’s unique self-awareness impacts our relationship with the Earth. Topics discussed include: Climate tipping points: impacts, warning signals Evidence that climate is nearing tipping point? IPCC warming targets Risk management under uncertainty Climate policies Human tipping points: social, economic, technological The Gaia Hypothesis

Ep 1Not Cool Ep 2: Joanna Haigh on climate modeling and the history of climate change
On the second episode of Not Cool, Ariel delves into some of the basic science behind climate change and the history of its study. She is joined by Dr. Joanna Haigh, an atmospheric physicist whose work has been foundational to our current understanding of how the climate works. Joanna is a fellow of The Royal Society and recently retired as Co-Director of the Grantham Institute on Climate Change and the Environment at Imperial College London. Here, she gives a historical overview of the field of climate science and the major breakthroughs that moved it forward. She also discusses her own work on the stratosphere, radiative forcing, solar variability, and more. Topics discussed include: History of the study of climate change Overview of climate modeling Radiative forcing What’s changed in climate science in the past few decades How to distinguish between natural climate variation and human-induced global warming Solar variability, sun spots, and the effect of the sun on the climate History of climate denial

Ep 1Not Cool Ep 1: John Cook on misinformation and overcoming climate silence
On the premier of Not Cool, Ariel is joined by John Cook: psychologist, climate change communication researcher, and founder of SkepticalScience.com. Much of John’s work focuses on misinformation related to climate change, how it’s propagated, and how to counter it. He offers a historical analysis of climate denial and the motivations behind it, and he debunks some of its most persistent myths. John also discusses his own research on perceived social consensus, the phenomenon he’s termed “climate silence,” and more. Topics discussed include: History of of the study of climate change Climate denial: history and motivations Persistent climate myths How to overcome misinformation How to talk to climate deniers Perceived social consensus and climate silence

Ep 1Not Cool Prologue: A Climate Conversation
In this short trailer, Ariel Conn talks about FLI's newest podcast series, Not Cool: A Climate Conversation. Climate change, to state the obvious, is a huge and complicated problem. Unlike the threats posed by artificial intelligence, biotechnology or nuclear weapons, you don’t need to have an advanced science degree or be a high-ranking government official to start having a meaningful impact on your own carbon footprint. Each of us can begin making lifestyle changes today that will help. We started this podcast because the news about climate change seems to get worse with each new article and report, but the solutions, at least as reported, remain vague and elusive. We wanted to hear from the scientists and experts themselves to learn what’s really going on and how we can all come together to solve this crisis.

Ep 1FLI Podcast: Beyond the Arms Race Narrative: AI and China with Helen Toner and Elsa Kania
Discussions of Chinese artificial intelligence often center around the trope of a U.S.-China arms race. On this month’s FLI podcast, we’re moving beyond this narrative and taking a closer look at the realities of AI in China and what they really mean for the United States. Experts Helen Toner and Elsa Kania, both of Georgetown University’s Center for Security and Emerging Technology, discuss China’s rise as a world AI power, the relationship between the Chinese tech industry and the military, and the use of AI in human rights abuses by the Chinese government. They also touch on Chinese-American technological collaboration, technological difficulties facing China, and what may determine international competitive advantage going forward. Topics discussed in this episode include: The rise of AI in China The escalation of tensions between U.S. and China in AI realm Chinese AI Development plans and policy initiatives The AI arms race narrative and the problems with it Civil-military fusion in China vs. U.S. The regulation of Chinese-American technological collaboration AI and authoritarianism Openness in AI research and when it is (and isn’t) appropriate The relationship between privacy and advancement in AI

Ep 1AIAP: China's AI Superpower Dream with Jeffrey Ding
"In July 2017, The State Council of China released the New Generation Artificial Intelligence Development Plan. This policy outlines China’s strategy to build a domestic AI industry worth nearly US$150 billion in the next few years and to become the leading AI power by 2030. This officially marked the development of the AI sector as a national priority and it was included in President Xi Jinping’s grand vision for China." (FLI's AI Policy - China page) In the context of these developments and an increase in conversations regarding AI and China, Lucas spoke with Jeffrey Ding from the Center for the Governance of AI (GovAI). Jeffrey is the China lead for GovAI where he researches China's AI development and strategy, as well as China's approach to strategic technologies more generally. Topics discussed in this episode include: -China's historical relationships with technology development -China's AI goals and some recently released principles -Jeffrey Ding's work, Deciphering China's AI Dream -The central drivers of AI and the resulting Chinese AI strategy -Chinese AI capabilities -AGI and superintelligence awareness and thinking in China -Dispelling AI myths, promoting appropriate memes -What healthy competition between the US and China might look like Here you can find the page for this podcast: https://futureoflife.org/2019/08/16/chinas-ai-superpower-dream-with-jeffrey-ding/ Important timestamps: 0:00 Intro 2:14 Motivations for the conversation 5:44 Historical background on China and AI 8:13 AI principles in China and the US 16:20 Jeffrey Ding’s work, Deciphering China’s AI Dream 21:55 Does China’s government play a central hand in setting regulations? 23:25 Can Chinese implementation of regulations and standards move faster than in the US? Is China buying shares in companies to have decision making power? 27:05 The components and drivers of AI in China and how they affect Chinese AI strategy 35:30 Chinese government guidance funds for AI development 37:30 Analyzing China’s AI capabilities 44:20 Implications for the future of AI and AI strategy given the current state of the world 49:30 How important are AGI and superintelligence concerns in China? 52:30 Are there explicit technical AI research programs in China for AGI? 53:40 Dispelling AI myths and promoting appropriate memes 56:10 Relative and absolute gains in international politics 59:11 On Peter Thiel’s recent comments on superintelligence, AI, and China 1:04:10 Major updates and changes since Jeffrey wrote Deciphering China’s AI Dream 1:05:50 What does healthy competition between China and the US look like? 1:11:05 Where to follow Jeffrey and read more of his work You Can take a short (4 minute) survey to share your feedback about the podcast here: https://www.surveymonkey.com/r/YWHDFV7 Deciphering China's AI Dream: https://www.fhi.ox.ac.uk/wp-content/uploads/Deciphering_Chinas_AI-Dream.pdf FLI AI Policy - China page: https://futureoflife.org/ai-policy-china/ ChinAI Newsletter: https://chinai.substack.com Jeff's Twitter: https://twitter.com/jjding99 Previous podcast with Jeffrey: https://youtu.be/tm2kmSQNUAU

Ep 1FLI Podcast: The Climate Crisis as an Existential Threat with Simon Beard and Haydn Belfield
Does the climate crisis pose an existential threat? And is that even the best way to formulate the question, or should we be looking at the relationship between the climate crisis and existential threats differently? In this month’s FLI podcast, Ariel was joined by Simon Beard and Haydn Belfield of the University of Cambridge’s Center for the Study of Existential Risk (CSER), who explained why, despite the many unknowns, it might indeed make sense to study climate change as an existential threat. Simon and Haydn broke down the different systems underlying human civilization and the ways climate change threatens these systems. They also discussed our species’ unique strengths and vulnerabilities –– and the ways in which technology has heightened both –– with respect to the changing climate.

Ep 1FLI Podcast: Is Nuclear Weapons Testing Back on the Horizon? With Jeffrey Lewis and Alex Bell
Nuclear weapons testing is mostly a thing of the past: The last nuclear weapon test explosion on US soil was conducted over 25 years ago. But how much longer can nuclear weapons testing remain a taboo that almost no country will violate? In an official statement from the end of May, the Director of the U.S. Defense Intelligence Agency (DIA) expressed the belief that both Russia and China were preparing for explosive tests of low-yield nuclear weapons, if not already testing. Such accusations could potentially be used by the U.S. to justify a breach of the Comprehensive Nuclear-Test-Ban Treaty (CTBT). This month, Ariel was joined by Jeffrey Lewis, Director of the East Asia Nonproliferation Program at the Center for Nonproliferation Studies and founder of armscontrolwonk.com, and Alex Bell, Senior Policy Director at the Center for Arms Control and Non-Proliferation. Lewis and Bell discuss the DIA’s allegations, the history of the CTBT, why it’s in the U.S. interest to ratify the treaty, and more. Topics discussed in this episode: - The validity of the U.S. allegations --Is Russia really testing weapons? - The International Monitoring System -- How effective is it if the treaty isn’t in effect? - The modernization of U.S/Russian/Chinese nuclear arsenals and what that means. - Why there’s a push for nuclear testing. - Why opposing nuclear testing can help ensure the US maintains nuclear superiority.

Ep 1FLI Podcast: Applying AI Safety & Ethics Today with Ashley Llorens & Francesca Rossi
In this month’s podcast, Ariel spoke with Ashley Llorens, the Founding Chief of the Intelligent Systems Center at the John Hopkins Applied Physics Laboratory, and Francesca Rossi, the IBM AI Ethics Global Leader at the IBM TJ Watson Research Lab and an FLI board member, about developing AI that will make us safer, more productive, and more creative. Too often, Rossi points out, we build our visions of the future around our current technology. Here, Llorens and Rossi take the opposite approach: let's build our technology around our visions for the future.

Ep 1AIAP: On Consciousness, Qualia, and Meaning with Mike Johnson and Andrés Gómez Emilsson
Consciousness is a concept which is at the forefront of much scientific and philosophical thinking. At the same time, there is large disagreement over what consciousness exactly is and whether it can be fully captured by science or is best explained away by a reductionist understanding. Some believe consciousness to be the source of all value and others take it to be a kind of delusion or confusion generated by algorithms in the brain. The Qualia Research Institute takes consciousness to be something substantial and real in the world that they expect can be captured by the language and tools of science and mathematics. To understand this position, we will have to unpack the philosophical motivations which inform this view, the intuition pumps which lend themselves to these motivations, and then explore the scientific process of investigation which is born of these considerations. Whether you take consciousness to be something real or illusory, the implications of these possibilities certainly have tremendous moral and empirical implications for life's purpose and role in the universe. Is existence without consciousness meaningful? In this podcast, Lucas spoke with Mike Johnson and Andrés Gómez Emilsson of the Qualia Research Institute. Andrés is a consciousness researcher at QRI and is also the Co-founder and President of the Stanford Transhumanist Association. He has a Master's in Computational Psychology from Stanford. Mike is Executive Director at QRI and is also a co-founder. Mike is interested in neuroscience, philosophy of mind, and complexity theory. Topics discussed in this episode include: -Functionalism and qualia realism -Views that are skeptical of consciousness -What we mean by consciousness -Consciousness and casuality -Marr's levels of analysis -Core problem areas in thinking about consciousness -The Symmetry Theory of Valence -AI alignment and consciousness You can take a very short survey about the podcast here: https://www.surveymonkey.com/r/YWHDFV7

Ep 1The Unexpected Side Effects of Climate Change with Fran Moore and Nick Obradovich
It’s not just about the natural world. The side effects of climate change remain relatively unknown, but we can expect a warming world to impact every facet of our lives. In fact, as recent research shows, global warming is already affecting our mental and physical well-being, and this impact will only increase. Climate change could decrease the efficacy of our public safety institutions. It could damage our economies. It could even impact the way that we vote, potentially altering our democracies themselves. Yet even as these effects begin to appear, we’re already growing numb to the changing climate patterns behind them, and we’re failing to act. In honor of Earth Day, this month’s podcast focuses on these side effects and what we can do about them. Ariel spoke with Dr. Nick Obradovich, a research scientist at the MIT Media Lab, and Dr. Fran Moore, an assistant professor in the Department of Environmental Science and Policy at the University of California, Davis. They study the social and economic impacts of climate change, and they shared some of their most remarkable findings. Topics discussed in this episode include: - How getting used to climate change may make it harder for us to address the issue - The social cost of carbon - The effect of temperature on mood, exercise, and sleep - The effect of temperature on public safety and democratic processes - Why it’s hard to get people to act - What we can all do to make a difference - Why we should still be hopeful
Ep 1AIAP: An Overview of Technical AI Alignment with Rohin Shah (Part 2)
The space of AI alignment research is highly dynamic, and it's often difficult to get a bird's eye view of the landscape. This podcast is the second of two parts attempting to partially remedy this by providing an overview of technical AI alignment efforts. In particular, this episode seeks to continue the discussion from Part 1 by going in more depth with regards to the specific approaches to AI alignment. In this podcast, Lucas spoke with Rohin Shah. Rohin is a 5th year PhD student at UC Berkeley with the Center for Human-Compatible AI, working with Anca Dragan, Pieter Abbeel and Stuart Russell. Every week, he collects and summarizes recent progress relevant to AI alignment in the Alignment Newsletter. Topics discussed in this episode include: -Embedded agency -The field of "getting AI systems to do what we want" -Ambitious value learning -Corrigibility, including iterated amplification, debate, and factored cognition -AI boxing and impact measures -Robustness through verification, adverserial ML, and adverserial examples -Interpretability research -Comprehensive AI Services -Rohin's relative optimism about the state of AI alignment You can take a short (3 minute) survey to share your feedback about the podcast here: https://www.surveymonkey.com/r/YWHDFV7

Ep 1AIAP: An Overview of Technical AI Alignment with Rohin Shah (Part 1)
The space of AI alignment research is highly dynamic, and it's often difficult to get a bird's eye view of the landscape. This podcast is the first of two parts attempting to partially remedy this by providing an overview of the organizations participating in technical AI research, their specific research directions, and how these approaches all come together to make up the state of technical AI alignment efforts. In this first part, Rohin moves sequentially through the technical research organizations in this space and carves through the field by its varying research philosophies. We also dive into the specifics of many different approaches to AI safety, explore where they disagree, discuss what properties varying approaches attempt to develop/preserve, and hear Rohin's take on these different approaches. You can take a short (3 minute) survey to share your feedback about the podcast here: https://www.surveymonkey.com/r/YWHDFV7 In this podcast, Lucas spoke with Rohin Shah. Rohin is a 5th year PhD student at UC Berkeley with the Center for Human-Compatible AI, working with Anca Dragan, Pieter Abbeel and Stuart Russell. Every week, he collects and summarizes recent progress relevant to AI alignment in the Alignment Newsletter. Topics discussed in this episode include: - The perspectives of CHAI, MIRI, OpenAI, DeepMind, FHI, and others - Where and why they disagree on technical alignment - The kinds of properties and features we are trying to ensure in our AI systems - What Rohin is excited and optimistic about - Rohin's recommended reading and advice for improving at AI alignment research

Ep 1Why Ban Lethal Autonomous Weapons
Why are we so concerned about lethal autonomous weapons? Ariel spoke to four experts –– one physician, one lawyer, and two human rights specialists –– all of whom offered their most powerful arguments on why the world needs to ensure that algorithms are never allowed to make the decision to take a life. It was even recorded from the United Nations Convention on Conventional Weapons, where a ban on lethal autonomous weapons was under discussion. We've compiled their arguments, along with many of our own, and now, we want to turn the discussion over to you. We’ve set up a comments section on the FLI podcast page (www.futureoflife.org/whyban), and we want to know: Which argument(s) do you find most compelling? Why?

Ep 1AIAP: AI Alignment through Debate with Geoffrey Irving
See full article here: https://futureoflife.org/2019/03/06/ai-alignment-through-debate-with-geoffrey-irving/ "To make AI systems broadly useful for challenging real-world tasks, we need them to learn complex human goals and preferences. One approach to specifying complex goals asks humans to judge during training which agent behaviors are safe and useful, but this approach can fail if the task is too complicated for a human to directly judge. To help address this concern, we propose training agents via self play on a zero sum debate game. Given a question or proposed action, two agents take turns making short statements up to a limit, then a human judges which of the agents gave the most true, useful information... In practice, whether debate works involves empirical questions about humans and the tasks we want AIs to perform, plus theoretical questions about the meaning of AI alignment. " AI safety via debate (https://arxiv.org/pdf/1805.00899.pdf) Debate is something that we are all familiar with. Usually it involves two or more persons giving arguments and counter arguments over some question in order to prove a conclusion. At OpenAI, debate is being explored as an AI alignment methodology for reward learning (learning what humans want) and is a part of their scalability efforts (how to train/evolve systems to solve questions of increasing complexity). Debate might sometimes seem like a fruitless process, but when optimized and framed as a two-player zero-sum perfect-information game, we can see properties of debate and synergies with machine learning that may make it a powerful truth seeking process on the path to beneficial AGI. On today's episode, we are joined by Geoffrey Irving. Geoffrey is a member of the AI safety team at OpenAI. He has a PhD in computer science from Stanford University, and has worked at Google Brain on neural network theorem proving, cofounded Eddy Systems to autocorrect code as you type, and has worked on computational physics and geometry at Otherlab, D. E. Shaw Research, Pixar, and Weta Digital. He has screen credits on Tintin, Wall-E, Up, and Ratatouille. Topics discussed in this episode include: -What debate is and how it works -Experiments on debate in both machine learning and social science -Optimism and pessimism about debate -What amplification is and how it fits in -How Geoffrey took inspiration from amplification and AlphaGo -The importance of interpretability in debate -How debate works for normative questions -Why AI safety needs social scientists

Ep 1Part 2: Anthrax, Agent Orange, and Yellow Rain With Matthew Meselson and Max Tegmark
In this special two-part podcast Ariel Conn is joined by Max Tegmark for a conversation with Dr. Matthew Meselson, biologist and Thomas Dudley Cabot Professor of the Natural Sciences at Harvard University. Part Two focuses on three major incidents in the history of biological weapons: the 1979 anthrax outbreak in Russia, the use of Agent Orange and other herbicides in Vietnam, and the Yellow Rain controversy in the early 80s. Dr. Meselson led the investigations into all three and solved some perplexing scientific mysteries along the way.

Ep 1Part 1: From DNA to Banning Biological Weapons With Matthew Meselson and Max Tegmark
In this special two-part podcast Ariel Conn is joined by Max Tegmark for a conversation with Dr. Matthew Meselson, biologist and Thomas Dudley Cabot Professor of the Natural Sciences at Harvard University. Dr. Meselson began his career with an experiment that helped prove Watson and Crick’s hypothesis on the structure and replication of DNA. He then got involved in disarmament, working with the US government to halt the use of Agent Orange in Vietnam and developing the Biological Weapons Convention. From the cellular level to that of international policy, Dr. Meselson has made significant contributions not only to the field of biology, but also towards the mitigation of existential threats. In Part One, Dr. Meselson describes how he designed the experiment that helped prove Watson and Crick’s hypothesis, and he explains why this type of research is uniquely valuable to the scientific community. He also recounts his introduction to biological weapons, his reasons for opposing them, and the efforts he undertook to get them banned. Dr. Meselson was a key force behind the U.S. ratification of the Geneva Protocol, a 1925 treaty banning biological warfare, as well as the conception and implementation of the Biological Weapons Convention, the international treaty that bans biological and toxin weapons.

Ep 1AIAP: Human Cognition and the Nature of Intelligence with Joshua Greene
See the full article here: https://futureoflife.org/2019/02/21/human-cognition-and-the-nature-of-intelligence-with-joshua-greene/ "How do we combine concepts to form thoughts? How can the same thought be represented in terms of words versus things that you can see or hear in your mind's eyes and ears? How does your brain distinguish what it's thinking about from what it actually believes? If I tell you a made up story, yesterday I played basketball with LeBron James, maybe you'd believe me, and then I say, oh I was just kidding, didn't really happen. You still have the idea in your head, but in one case you're representing it as something true, in another case you're representing it as something false, or maybe you're representing it as something that might be true and you're not sure. For most animals, the ideas that get into its head come in through perception, and the default is just that they are beliefs. But humans have the ability to entertain all kinds of ideas without believing them. You can believe that they're false or you could just be agnostic, and that's essential not just for idle speculation, but it's essential for planning. You have to be able to imagine possibilities that aren't yet actual. So these are all things we're trying to understand. And then I think the project of understanding how humans do it is really quite parallel to the project of trying to build artificial general intelligence." -Joshua Greene Josh Greene is a Professor of Psychology at Harvard, who focuses on moral judgment and decision making. His recent work focuses on cognition, and his broader interests include philosophy, psychology and neuroscience. He is the author of Moral Tribes: Emotion, Reason, and the Gap Bewtween Us and Them. Joshua Greene's research focuses on further understanding key aspects of both individual and collective intelligence. Deepening our knowledge of these subjects allows us to understand the key features which constitute human general intelligence, and how human cognition aggregates and plays out through group choice and social decision making. By better understanding the one general intelligence we know of, namely humans, we can gain insights into the kinds of features that are essential to general intelligence and thereby better understand what it means to create beneficial AGI. This particular episode was recorded at the Beneficial AGI 2019 conference in Puerto Rico. We hope that you will join in the conversations by following us or subscribing to our podcasts on Youtube, SoundCloud, iTunes, Google Play, Stitcher, or your preferred podcast site/application. You can find all the AI Alignment Podcasts here. Topics discussed in this episode include: -The multi-modal and combinatorial nature of human intelligence -The symbol grounding problem -Grounded cognition -Modern brain imaging -Josh's psychology research using John Rawls’ veil of ignorance -Utilitarianism reframed as 'deep pragmatism'

Ep 1The Byzantine Generals' Problem, Poisoning, and Distributed Machine Learning with El Mahdi El Mhamdi
Three generals are voting on whether to attack or retreat from their siege of a castle. One of the generals is corrupt and two of them are not. What happens when the corrupted general sends different answers to the other two generals? A Byzantine fault is "a condition of a computer system, particularly distributed computing systems, where components may fail and there is imperfect information on whether a component has failed. The term takes its name from an allegory, the "Byzantine Generals' Problem", developed to describe this condition, where actors must agree on a concerted strategy to avoid catastrophic system failure, but some of the actors are unreliable." The Byzantine Generals' Problem and associated issues in maintaining reliable distributed computing networks is illuminating for both AI alignment and modern networks we interact with like Youtube, Facebook, or Google. By exploring this space, we are shown the limits of reliable distributed computing, the safety concerns and threats in this space, and the tradeoffs we will have to make for varying degrees of efficiency or safety. The Byzantine Generals' Problem, Poisoning, and Distributed Machine Learning with El Mahdi El Mahmdi is the ninth podcast in the AI Alignment Podcast series, hosted by Lucas Perry. El Mahdi pioneered Byzantine resilient machine learning devising a series of provably safe algorithms he recently presented at NeurIPS and ICML. Interested in theoretical biology, his work also includes the analysis of error propagation and networks applied to both neural and biomolecular networks. This particular episode was recorded at the Beneficial AGI 2019 conference in Puerto Rico. We hope that you will join in the conversations by following us or subscribing to our podcasts on Youtube, SoundCloud, iTunes, Google Play, Stitcher, or your preferred podcast site/application. You can find all the AI Alignment Podcasts here. If you're interested in exploring the interdisciplinary nature of AI alignment, we suggest you take a look here at a preliminary landscape which begins to map this space. Topics discussed in this episode include: The Byzantine Generals' Problem What this has to do with artificial intelligence and machine learning Everyday situations where this is important How systems and models are to update in the context of asynchrony Why it's hard to do Byzantine resilient distributed ML. Why this is important for long-term AI alignment An overview of Adversarial Machine Learning and where Byzantine-resilient Machine Learning stands on the map is available in this (9min) video . A specific focus on Byzantine Fault Tolerant Machine Learning is available here (~7min) In particular, El Mahdi argues in the first interview (and in the podcast) that technical AI safety is not only relevant for long term concerns, but is crucial in current pressing issues such as social media poisoning of public debates and misinformation propagation, both of which fall into Poisoning-resilience. Another example he likes to use is social media addiction, that could be seen as a case of (non) Safely Interruptible learning. This value misalignment is already an issue with the primitive forms of AIs that optimize our world today as they maximize our watch-time all over the internet. The latter (Safe Interruptibility) is another technical AI safety question El Mahdi works on, in the context of Reinforcement Learning. This line of research was initially dismissed as "science fiction", in this interview (5min), El Mahdi explains why it is a realistic question that arises naturally in reinforcement learning El Mahdi's work on Byzantine-resilient Machine Learning and other relevant topics is available on his Google scholar profile.

Ep 1AI Breakthroughs and Challenges in 2018 with David Krueger and Roman Yampolskiy
Every January, we like to look back over the past 12 months at the progress that’s been made in the world of artificial intelligence. Welcome to our annual “AI breakthroughs” podcast, 2018 edition. Ariel was joined for this retrospective by researchers Roman Yampolskiy and David Krueger. Roman is an AI Safety researcher and professor at the University of Louisville. He also recently published the book, Artificial Intelligence Safety & Security. David is a PhD candidate in the Mila lab at the University of Montreal, where he works on deep learning and AI safety. He's also worked with safety teams at the Future of Humanity Institute and DeepMind and has volunteered with 80,000 hours. Roman and David shared their lists of 2018’s most promising AI advances, as well as their thoughts on some major ethical questions and safety concerns. They also discussed media coverage of AI research, why talking about “breakthroughs” can be misleading, and why there may have been more progress in the past year than it seems.

Ep 1Artificial Intelligence: American Attitudes and Trends with Baobao Zhang
Our phones, our cars, our televisions, our homes: they’re all getting smarter. Artificial intelligence is already inextricably woven into everyday life, and its impact will only grow in the coming years. But while this development inspires much discussion among members of the scientific community, public opinion on artificial intelligence has remained relatively unknown. Artificial Intelligence: American Attitudes and Trends, a report published earlier in January by the Center for the Governance of AI, explores this question. Its authors relied on an in-depth survey to analyze American attitudes towards artificial intelligence, from privacy concerns to beliefs about U.S. technological superiority. Some of their findings--most Americans, for example, don’t trust Facebook--were unsurprising. But much of their data reflects trends within the American public that have previously gone unnoticed. This month Ariel was joined by Baobao Zhang, lead author of the report, to talk about these findings. Zhang is a PhD candidate in Yale University's political science department and research affiliate with the Center for the Governance of AI at the University of Oxford. Her work focuses on American politics, international relations, and experimental methods. In this episode, Zhang spoke about her take on some of the report’s most interesting findings, the new questions it raised, and future research directions for her team. Topics discussed include: -Demographic differences in perceptions of AI -Discrepancies between expert and public opinions -Public trust (or lack thereof) in AI developers -The effect of information on public perceptions of scientific issues

Ep 1AIAP: Cooperative Inverse Reinforcement Learning with Dylan Hadfield-Menell (Beneficial AGI 2019)
What motivates cooperative inverse reinforcement learning? What can we gain from recontextualizing our safety efforts from the CIRL point of view? What possible role can pre-AGI systems play in amplifying normative processes? Cooperative Inverse Reinforcement Learning with Dylan Hadfield-Menell is the eighth podcast in the AI Alignment Podcast series, hosted by Lucas Perry and was recorded at the Beneficial AGI 2019 conference in Puerto Rico. For those of you that are new, this series covers and explores the AI alignment problem across a large variety of domains, reflecting the fundamentally interdisciplinary nature of AI alignment. Broadly, Lucas will speak with technical and non-technical researchers across areas such as machine learning, governance, ethics, philosophy, and psychology as they pertain to the project of creating beneficial AI. If this sounds interesting to you, we hope that you will join in the conversations by following us or subscribing to our podcasts on Youtube, SoundCloud, or your preferred podcast site/application. In this podcast, Lucas spoke with Dylan Hadfield-Menell. Dylan is a 5th year PhD student at UC Berkeley advised by Anca Dragan, Pieter Abbeel and Stuart Russell, where he focuses on technical AI alignment research. Topics discussed in this episode include: -How CIRL helps to clarify AI alignment and adjacent concepts -The philosophy of science behind safety theorizing -CIRL in the context of varying alignment methodologies and it's role -If short-term AI can be used to amplify normative processes
Ep 1Existential Hope in 2019 and Beyond
Humanity is at a turning point. For the first time in history, we have the technology to completely obliterate ourselves. But we’ve also created boundless possibilities for all life that could enable just about any brilliant future we can imagine. Humanity could erase itself with a nuclear war or a poorly designed AI, or we could colonize space and expand life throughout the universe: As a species, our future has never been more open-ended. The potential for disaster is often more visible than the potential for triumph, so as we prepare for 2019, we want to talk about existential hope, and why we should actually be more excited than ever about the future. In this podcast, Ariel talks to six experts--Anthony Aguirre, Max Tegmark, Gaia Dempsey, Allison Duettmann, Josh Clark, and Anders Sandberg--about their views on the present, the future, and the path between them. Anthony and Max are both physics professors and cofounders of FLI. Gaia is a tech enthusiast and entrepreneur, and with her newest venture, 7th Future, she’s focusing on bringing people and organizations together to imagine and figure out how to build a better future. Allison is a researcher and program coordinator at the Foresight Institute and creator of the website existentialhope.com. Josh is cohost on the Stuff You Should Know Podcast, and he recently released a 10-part series on existential risks called The End of the World with Josh Clark. Anders is a senior researcher at the Future of Humanity Institute with a background in computational neuroscience, and for the past 20 years, he’s studied the ethics of human enhancement, existential risks, emerging technology, and life in the far future. We hope you’ll come away feeling inspired and motivated--not just to prevent catastrophe, but to facilitate greatness. Topics discussed in this episode include: How technology aids us in realizing personal and societal goals. FLI’s successes in 2018 and our goals for 2019. Worldbuilding and how to conceptualize the future. The possibility of other life in the universe and its implications for the future of humanity. How we can improve as a species and strategies for doing so. The importance of a shared positive vision for the future, what that vision might look like, and how a shared vision can still represent a wide enough set of values and goals to cover the billions of people alive today and in the future. Existential hope and what it looks like now and far into the future.

Ep 1AIAP: Inverse Reinforcement Learning and the State of AI Alignment with Rohin Shah
What role does inverse reinforcement learning (IRL) have to play in AI alignment? What issues complicate IRL and how does this affect the usefulness of this preference learning methodology? What sort of paradigm of AI alignment ought we to take up given such concerns? Inverse Reinforcement Learning and the State of AI Alignment with Rohin Shah is the seventh podcast in the AI Alignment Podcast series, hosted by Lucas Perry. For those of you that are new, this series is covering and exploring the AI alignment problem across a large variety of domains, reflecting the fundamentally interdisciplinary nature of AI alignment. Broadly, we will be having discussions with technical and non-technical researchers across areas such as machine learning, governance, ethics, philosophy, and psychology as they pertain to the project of creating beneficial AI. If this sounds interesting to you, we hope that you will join in the conversations by following us or subscribing to our podcasts on Youtube, SoundCloud, or your preferred podcast site/application. In this podcast, Lucas spoke with Rohin Shah. Rohin is a 5th year PhD student at UC Berkeley with the Center for Human-Compatible AI, working with Anca Dragan, Pieter Abbeel and Stuart Russell. Every week, he collects and summarizes recent progress relevant to AI alignment in the Alignment Newsletter. Topics discussed in this episode include: - The role of systematic bias in IRL - The metaphilosophical issues of IRL - IRL's place in preference learning - Rohin's take on the state of AI alignment - What Rohin has changed his mind about

Ep 1Governing Biotechnology: From Avian Flu to Genetically-Modified Babies With Catherine Rhodes
A Chinese researcher recently made international news with claims that he had edited the first human babies using CRISPR. In doing so, he violated international ethics standards, and he appears to have acted without his funders or his university knowing. But this is only the latest example of biological research triggering ethical concerns. Gain-of-function research a few years ago, which made avian flu more virulent, also sparked controversy when scientists tried to publish their work. And there’s been extensive debate globally about the ethics of human cloning. As biotechnology and other emerging technologies become more powerful, the dual-use nature of research -- that is, research that can have both beneficial and risky outcomes -- is increasingly important to address. How can scientists and policymakers work together to ensure regulations and governance of technological development will enable researchers to do good with their work, while decreasing the threats? On this month’s podcast, Ariel spoke with Catherine Rhodes about these issues and more. Catherine is a senior research associate and deputy director of the Center for the Study of Existential Risk. Her work has broadly focused on understanding the intersection and combination of risks stemming from technologies and risks stemming from governance. She has particular expertise in international governance of biotechnology, including biosecurity and broader risk management issues. Topics discussed in this episode include: ~ Gain-of-function research, the H5N1 virus (avian flu), and the risks of publishing dangerous information ~ The roles of scientists, policymakers, and the public to ensure that technology is developed safely and ethically ~ The controversial Chinese researcher who claims to have used CRISPR to edit the genome of twins ~ How scientists can anticipate whether the results of their research could be misused by someone else ~ To what extent does risk stem from technology, and to what extent does it stem from how we govern it?

Ep 1Avoiding the Worst of Climate Change with Alexander Verbeek and John Moorhead
“There are basically two choices. We're going to massively change everything we are doing on this planet, the way we work together, the actions we take, the way we run our economy, and the way we behave towards each other and towards the planet and towards everything that lives on this planet. Or we sit back and relax and we just let the whole thing crash. The choice is so easy to make, even if you don't care at all about nature or the lives of other people. Even if you just look at your own interests and look purely through an economical angle, it is just a good return on investment to take good care of this planet.” - Alexander Verbeek On this month’s podcast, Ariel spoke with Alexander Verbeek and John Moorhead about what we can do to avoid the worst of climate change. Alexander is a Dutch diplomat and former strategic policy advisor at the Netherlands Ministry of Foreign Affairs. He created the Planetary Security Initiative where representatives from 75 countries meet annually on the climate change-security relationship. John is President of Drawdown Switzerland, an act tank to support Project Drawdown and other science-based climate solutions that reverse global warming. He is a blogger at Thomson Reuters, The Economist, and sciencebasedsolutions.com, and he advises and informs on climate solutions that are economy, society, and environment positive.
Ep 1AIAP: On Becoming a Moral Realist with Peter Singer
Are there such things as moral facts? If so, how might we be able to access them? Peter Singer started his career as a preference utilitarian and a moral anti-realist, and then over time became a hedonic utilitarian and a moral realist. How does such a transition occur, and which positions are more defensible? How might objectivism in ethics affect AI alignment? What does this all mean for the future of AI? On Becoming a Moral Realist with Peter Singer is the sixth podcast in the AI Alignment series, hosted by Lucas Perry. For those of you that are new, this series will be covering and exploring the AI alignment problem across a large variety of domains, reflecting the fundamentally interdisciplinary nature of AI alignment. Broadly, we will be having discussions with technical and non-technical researchers across areas such as machine learning, AI safety, governance, coordination, ethics, philosophy, and psychology as they pertain to the project of creating beneficial AI. If this sounds interesting to you, we hope that you will join in the conversations by following us or subscribing to our podcasts on Youtube, SoundCloud, or your preferred podcast site/application. In this podcast, Lucas spoke with Peter Singer. Peter is a world-renowned moral philosopher known for his work on animal ethics, utilitarianism, global poverty, and altruism. He's a leading bioethicist, the founder of The Life You Can Save, and currently holds positions at both Princeton University and The University of Melbourne. Topics discussed in this episode include: -Peter's transition from moral anti-realism to moral realism -Why emotivism ultimately fails -Parallels between mathematical/logical truth and moral truth -Reason's role in accessing logical spaces, and its limits -Why Peter moved from preference utilitarianism to hedonic utilitarianism -How objectivity in ethics might affect AI alignment

Ep 1On the Future: An Interview with Martin Rees
How can humanity survive the next century of climate change, a growing population, and emerging technological threats? Where do we stand now, and what steps can we take to cooperate and address our greatest existential risks? In this special podcast episode, Ariel speaks with cosmologist Martin Rees about his new book, On the Future: Prospects for Humanity, which discusses humanity’s existential risks and the role that technology plays in determining our collective future. Topics discussed in this episode include: - Why Martin remains a technical optimist even as he focuses on existential risks - The economics and ethics of climate change - How AI and automation will make it harder for Africa and the Middle East to economically develop - How high expectations for health care and quality of life also put society at risk - Why growing inequality could be our most underappreciated global risk - Martin’s view that biotechnology poses greater risk than AI - Earth’s carrying capacity and the dangers of overpopulation - Space travel and why Martin is skeptical of Elon Musk’s plan to colonize Mars - The ethics of artificial meat, life extension, and cryogenics - How intelligent life could expand into the galaxy - Why humans might be unable to answer fundamental questions about the universe
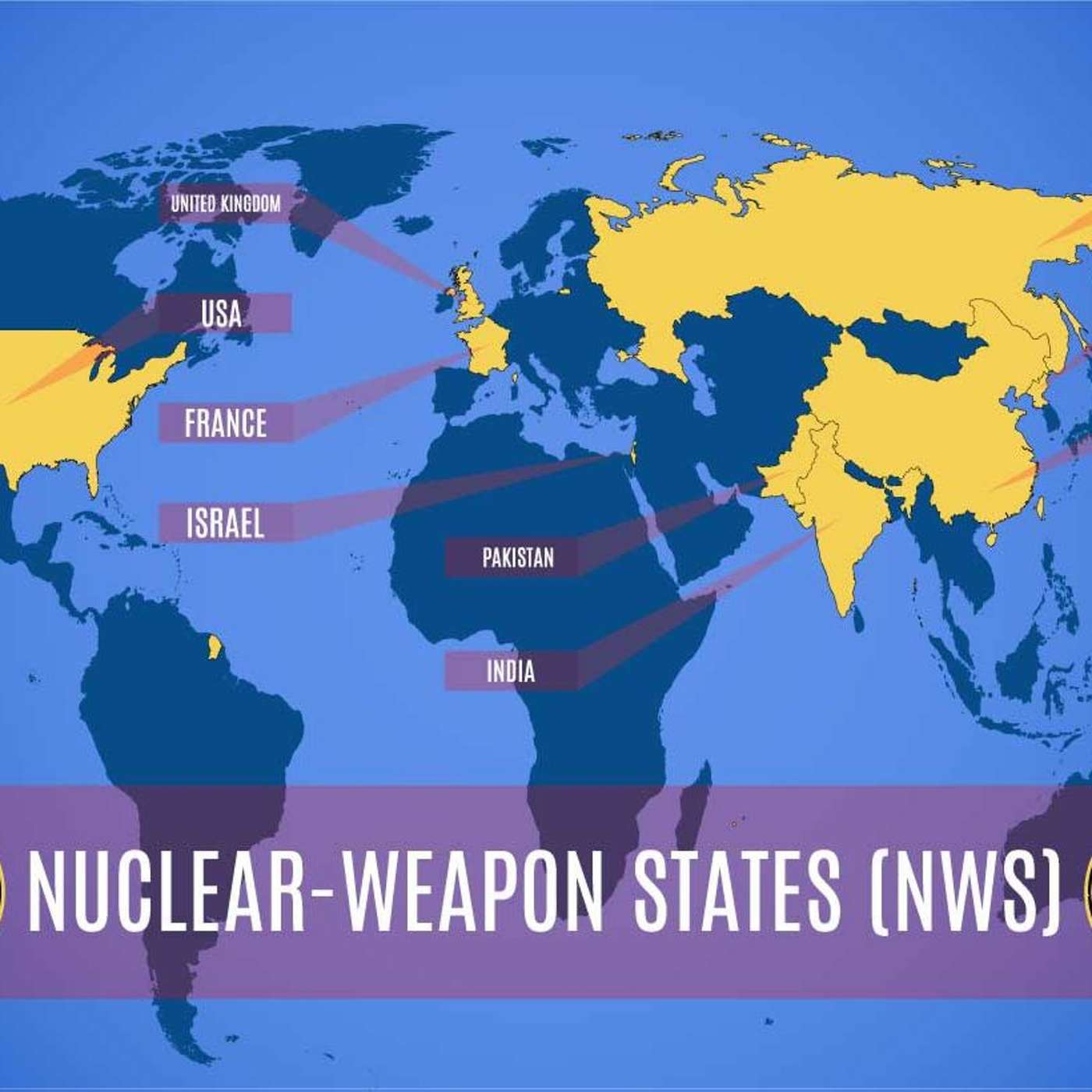
Ep 1AI and Nuclear Weapons - Trust, Accidents, and New Risks with Paul Scharre and Mike Horowitz
On this month’s podcast, Ariel spoke with Paul Scharre and Mike Horowitz from the Center for a New American Security about the role of automation in the nuclear sphere, and how the proliferation of AI technologies could change nuclear posturing and the effectiveness of deterrence. Paul is a former Pentagon policy official, and the author of Army of None: Autonomous Weapons in the Future of War. Mike Horowitz is professor of political science at the University of Pennsylvania, and the author of The Diffusion of Military Power: Causes and Consequences for International Politics. Topics discussed in this episode include: The sophisticated military robots developed by Soviets during the Cold War How technology shapes human decision-making in war “Automation bias” and why having a “human in the loop” is much trickier than it sounds The United States’ stance on automation with nuclear weapons Why weaker countries might have more incentive to build AI into warfare How the US and Russia perceive first-strike capabilities “Deep fakes” and other ways AI could sow instability and provoke crisis The multipolar nuclear world of US, Russia, China, India, Pakistan, and North Korea The perceived obstacles to reducing nuclear arsenals

Ep 1AIAP: Moral Uncertainty and the Path to AI Alignment with William MacAskill
How are we to make progress on AI alignment given moral uncertainty? What are the ideal ways of resolving conflicting value systems and views of morality among persons? How ought we to go about AI alignment given that we are unsure about our normative and metaethical theories? How should preferences be aggregated and persons idealized in the context of our uncertainty? Moral Uncertainty and the Path to AI Alignment with William MacAskill is the fifth podcast in the new AI Alignment series, hosted by Lucas Perry. For those of you that are new, this series will be covering and exploring the AI alignment problem across a large variety of domains, reflecting the fundamentally interdisciplinary nature of AI alignment. Broadly, we will be having discussions with technical and non-technical researchers across areas such as machine learning, AI safety, governance, coordination, ethics, philosophy, and psychology as they pertain to the project of creating beneficial AI. If this sounds interesting to you, we hope that you will join in the conversations by following us or subscribing to our podcasts on Youtube, SoundCloud, or your preferred podcast site/application. If you're interested in exploring the interdisciplinary nature of AI alignment, we suggest you take a look here at a preliminary landscape which begins to map this space. In this podcast, Lucas spoke with William MacAskill. Will is a professor of philosophy at the University of Oxford and is a co-founder of the Center for Effective Altruism, Giving What We Can, and 80,000 Hours. Will helped to create the effective altruism movement and his writing is mainly focused on issues of normative and decision theoretic uncertainty, as well as general issues in ethics. Topics discussed in this episode include: -Will’s current normative and metaethical credences -The value of moral information and moral philosophy -A taxonomy of the AI alignment problem -How we ought to practice AI alignment given moral uncertainty -Moral uncertainty in preference aggregation -Moral uncertainty in deciding where we ought to be going as a society -Idealizing persons and their preferences -The most neglected portion of AI alignment

Ep 1AI: Global Governance, National Policy, and Public Trust with Allan Dafoe and Jessica Cussins
Experts predict that artificial intelligence could become the most transformative innovation in history, eclipsing both the development of agriculture and the industrial revolution. And the technology is developing far faster than the average bureaucracy can keep up with. How can local, national, and international governments prepare for such dramatic changes and help steer AI research and use in a more beneficial direction? On this month’s podcast, Ariel spoke with Allan Dafoe and Jessica Cussins about how different countries are addressing the risks and benefits of AI, and why AI is such a unique and challenging technology to effectively govern. Allan is the Director of the Governance of AI Program at the Future of Humanity Institute, and his research focuses on the international politics of transformative artificial intelligence. Jessica is an AI Policy Specialist with the Future of Life Institute, and she's also a Research Fellow with the UC Berkeley Center for Long-term Cybersecurity, where she conducts research on the security and strategy implications of AI and digital governance. Topics discussed in this episode include: - Three lenses through which to view AI’s transformative power - Emerging international and national AI governance strategies - The risks and benefits of regulating artificial intelligence - The importance of public trust in AI systems - The dangers of an AI race - How AI will change the nature of wealth and power

Ep 1The Metaethics of Joy, Suffering, and Artificial Intelligence with Brian Tomasik and David Pearce
What role does metaethics play in AI alignment and safety? How might paths to AI alignment change given different metaethical views? How do issues in moral epistemology, motivation, and justification affect value alignment? What might be the metaphysical status of suffering and pleasure? What's the difference between moral realism and anti-realism and how is each view grounded? And just what does any of this really have to do with AI? The Metaethics of Joy, Suffering, and AI Alignment is the fourth podcast in the new AI Alignment series, hosted by Lucas Perry. For those of you that are new, this series will be covering and exploring the AI alignment problem across a large variety of domains, reflecting the fundamentally interdisciplinary nature of AI alignment. Broadly, we will be having discussions with technical and non-technical researchers across areas such as machine learning, AI safety, governance, coordination, ethics, philosophy, and psychology as they pertain to the project of creating beneficial AI. If this sounds interesting to you, we hope that you will join in the conversations by following us or subscribing to our podcasts on Youtube, SoundCloud, or your preferred podcast site/application. If you're interested in exploring the interdisciplinary nature of AI alignment, we suggest you take a look here at a preliminary landscape which begins to map this space. In this podcast, Lucas spoke with David Pearce and Brian Tomasik. David is a co-founder of the World Transhumanist Association, currently rebranded Humanity+. You might know him for his work on The Hedonistic Imperative, a book focusing on our moral obligation to work towards the abolition of suffering in all sentient life. Brian is a researcher at the Foundational Research Institute. He writes about ethics, animal welfare, and future scenarios on his website "Essays On Reducing Suffering." Topics discussed in this episode include: -What metaethics is and how it ties into AI alignment or not -Brian and David's ethics and metaethics -Moral realism vs antirealism -Emotivism -Moral epistemology and motivation -Different paths to and effects on AI alignment given different metaethics -Moral status of hedonic tones vs preferences -Can we make moral progress and would this mean? -Moving forward given moral uncertainty

Ep 1Six Experts Explain the Killer Robots Debate
Why are so many AI researchers so worried about lethal autonomous weapons? What makes autonomous weapons so much worse than any other weapons we have today? And why is it so hard for countries to come to a consensus about autonomous weapons? Not surprisingly, the short answer is: it’s complicated. In this month’s podcast, Ariel spoke with experts from a variety of perspectives on the current status of LAWS, where we are headed, and the feasibility of banning these weapons. Guests include ex-Pentagon advisor Paul Scharre, artificial intelligence professor Toby Walsh, Article 36 founder Richard Moyes, Campaign to Stop Killer Robots founders Mary Wareham and Bonnie Docherty, and ethicist and co-founder of the International Committee for Robot Arms Control, Peter Asaro. If you don't have time to listen to the podcast in full, or if you want to skip around through the interviews, each interview starts at the timestamp below: Paul Scharre: 3:40 Toby Walsh: 40:50 Richard Moyes: 53:30 Mary Wareham & Bonnie Docherty: 1:03:35 Peter Asaro: 1:32:40

Ep 1AIAP: AI Safety, Possible Minds, and Simulated Worlds with Roman Yampolskiy
What role does cyber security play in alignment and safety? What is AI completeness? What is the space of mind design and what does it tell us about AI safety? How does the possibility of machine qualia fit into this space? Can we leak proof the singularity to ensure we are able to test AGI? And what is computational complexity theory anyway? AI Safety, Possible Minds, and Simulated Worlds is the third podcast in the new AI Alignment series, hosted by Lucas Perry. For those of you that are new, this series will be covering and exploring the AI alignment problem across a large variety of domains, reflecting the fundamentally interdisciplinary nature of AI alignment. Broadly, we will be having discussions with technical and non-technical researchers across areas such as machine learning, AI safety, governance, coordination, ethics, philosophy, and psychology as they pertain to the project of creating beneficial AI. If this sounds interesting to you, we hope that you will join in the conversations by following us or subscribing to our podcasts on Youtube, SoundCloud, or your preferred podcast site/application. In this podcast, Lucas spoke with Roman Yampolskiy, a Tenured Associate Professor in the department of Computer Engineering and Computer Science at the Speed School of Engineering, University of Louisville. Dr. Yampolskiy’s main areas of interest are AI Safety, Artificial Intelligence, Behavioral Biometrics, Cybersecurity, Digital Forensics, Games, Genetic Algorithms, and Pattern Recognition. He is an author of over 100 publications including multiple journal articles and books. Topics discussed in this episode include: -Cyber security applications to AI safety -Key concepts in Roman's papers and books -Is AI alignment solvable? -The control problem -The ethics of and detecting qualia in machine intelligence -Machine ethics and it's role or lack thereof in AI safety -Simulated worlds and if detecting base reality is possible -AI safety publicity strategy

Ep 1Mission AI - Giving a Global Voice to the AI Discussion With Charlie Oliver and Randi Williams
How are emerging technologies like artificial intelligence shaping our world and how we interact with one another? What do different demographics think about AI risk and a robot-filled future? And how can the average citizen contribute not only to the AI discussion, but AI's development? On this month's podcast, Ariel spoke with Charlie Oliver and Randi Williams about how technology is reshaping our world, and how their new project, Mission AI, aims to broaden the conversation and include everyone's voice. Charlie is the founder and CEO of the digital media strategy company Served Fresh Media, and she's also the founder of Tech 2025, which is a platform and community for people to learn about emerging technologies and discuss the implications of emerging tech on society. Randi is a doctoral student in the personal robotics group at the MIT Media Lab. She wants to understand children's interactions with AI, and she wants to develop educational platforms that empower non-experts to develop their own AI systems.

Ep 1AIAP: Astronomical Future Suffering and Superintelligence with Kaj Sotala
In the classic taxonomy of risks developed by Nick Bostrom, existential risks are characterized as risks which are both terminal in severity and transgenerational in scope. If we were to maintain the scope of a risk as transgenerational and increase its severity past terminal, what would such a risk look like? What would it mean for a risk to be transgenerational in scope and hellish in severity? In this podcast, Lucas spoke with Kaj Sotala, an associate researcher at the Foundational Research Institute. He has previously worked for the Machine Intelligence Research Institute, and has publications on AI safety, AI timeline forecasting, and consciousness research. Topics discussed in this episode include: -The definition of and a taxonomy of suffering risks -How superintelligence has special leverage for generating or mitigating suffering risks -How different moral systems view suffering risks -What is possible of minds in general and how this plays into suffering risks -The probability of suffering risks -What we can do to mitigate suffering risks

Ep 1Nuclear Dilemmas, From North Korea to Iran with Melissa Hanham and Dave Schmerler
With the U.S. pulling out of the Iran deal and canceling (and potentially un-canceling) the summit with North Korea, nuclear weapons have been front and center in the news this month. But will these disagreements lead to a world with even more nuclear weapons? And how did the recent nuclear situations with North Korea and Iran get so tense? To learn more about the geopolitical issues surrounding North Korea’s and Iran’s nuclear situations, as well as to learn how nuclear programs in these countries are monitored, Ariel spoke with Melissa Hanham and Dave Schmerler on this month's podcast. Melissa and Dave are both nuclear weapons experts with the Center for Nonproliferation Studies at Middlebury Institute of International Studies, where they research weapons of mass destruction with a focus on North Korea. Topics discussed in this episode include: the progression of North Korea's quest for nukes, what happened and what’s next regarding the Iran deal, how to use open-source data to monitor nuclear weapons testing, and how younger generations can tackle nuclear risk. In light of the on-again/off-again situation regarding the North Korea Summit, Melissa sent us a quote after the podcast was recorded, saying: "Regardless of whether the summit in Singapore takes place, we all need to set expectations appropriately for disarmament. North Korea is not agreeing to give up nuclear weapons anytime soon. They are interested in a phased approach that will take more than a decade, multiple parties, new legal instruments, and new technical verification tools."

Ep 1What are the odds of nuclear war? A conversation with Seth Baum and Robert de Neufville
What are the odds of a nuclear war happening this century? And how close have we been to nuclear war in the past? Few academics focus on the probability of nuclear war, but many leading voices like former US Secretary of Defense, William Perry, argue that the threat of nuclear conflict is growing. On this month's podcast, Ariel spoke with Seth Baum and Robert de Neufville from the Global Catastrophic Risk Institute (GCRI), who recently coauthored a report titled A Model for the Probability of Nuclear War. The report examines 60 historical incidents that could have escalated to nuclear war and presents a model for determining the odds are that we could have some type of nuclear war in the future.

Ep 1AIAP: Inverse Reinforcement Learning and Inferring Human Preferences with Dylan Hadfield-Menell
Inverse Reinforcement Learning and Inferring Human Preferences is the first podcast in the new AI Alignment series, hosted by Lucas Perry. This series will be covering and exploring the AI alignment problem across a large variety of domains, reflecting the fundamentally interdisciplinary nature of AI alignment. Broadly, we will be having discussions with technical and non-technical researchers across a variety of areas, such as machine learning, AI safety, governance, coordination, ethics, philosophy, and psychology as they pertain to the project of creating beneficial AI. If this sounds interesting to you, we will hope that you join in the conversations by following or subscribing to us on Youtube, Soundcloud, or your preferred podcast site/application. In this podcast, Lucas spoke with Dylan Hadfield-Menell, a fifth year Ph.D student at UC Berkeley. Dylan’s research focuses on the value alignment problem in artificial intelligence. He is ultimately concerned with designing algorithms that can learn about and pursue the intended goal of their users, designers, and society in general. His recent work primarily focuses on algorithms for human-robot interaction with unknown preferences and reliability engineering for learning systems. Topics discussed in this episode include: -Inverse reinforcement learning -Goodhart’s Law and it’s relation to value alignment -Corrigibility and obedience in AI systems -IRL and the evolution of human values -Ethics and moral psychology in AI alignment -Human preference aggregation -The future of IRL

Ep 1Navigating AI Safety -- From Malicious Use to Accidents
Is the malicious use of artificial intelligence inevitable? If the history of technological progress has taught us anything, it's that every "beneficial" technological breakthrough can be used to cause harm. How can we keep bad actors from using otherwise beneficial AI technology to hurt others? How can we ensure that AI technology is designed thoughtfully to prevent accidental harm or misuse? On this month's podcast, Ariel spoke with FLI co-founder Victoria Krakovna and Shahar Avin from the Center for the Study of Existential Risk (CSER). They talk about CSER's recent report on forecasting, preventing, and mitigating the malicious uses of AI, along with the many efforts to ensure safe and beneficial AI.

Ep 1AI, Ethics And The Value Alignment Problem With Meia Chita-Tegmark And Lucas Perry
What does it mean to create beneficial artificial intelligence? How can we expect to align AIs with human values if humans can't even agree on what we value? Building safe and beneficial AI involves tricky technical research problems, but it also requires input from philosophers, ethicists, and psychologists on these fundamental questions. How can we ensure the most effective collaboration? Ariel spoke with FLI's Meia Chita-Tegmark and Lucas Perry on this month's podcast about the value alignment problem: the challenge of aligning the goals and actions of AI systems with the goals and intentions of humans.

Ep 1Top AI Breakthroughs and Challenges of 2017
AlphaZero, progress in meta-learning, the role of AI in fake news, the difficulty of developing fair machine learning -- 2017 was another year of big breakthroughs and big challenges for AI researchers! To discuss this more, we invited FLI's Richard Mallah and Chelsea Finn from UC Berkeley to join Ariel for this month's podcast. They talked about some of the progress they were most excited to see last year and what they're looking forward to in the coming year.

Ep 1Beneficial AI And Existential Hope In 2018
For most of us, 2017 has been a roller coaster, from increased nuclear threats to incredible advancements in AI to crazy news cycles. But while it’s easy to be discouraged by various news stories, we at FLI find ourselves hopeful that we can still create a bright future. In this episode, the FLI team discusses the past year and the momentum we've built, including: the Asilomar Principles, our 2018 AI safety grants competition, the recent Long Beach workshop on Value Alignment, and how we've honored one of civilization's greatest heroes.