
The Lindahl Letter
145 episodes — Page 1 of 3

Welcome to 2026 and beyond
Thank you for tuning in to week 220 of the Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for the Lindahl Letter is, “Welcome to 2026 and beyond.”This last week has been about being a reflective practitioner and thinking about where we have been throughout the last year of the Lindahl Letter. This last year we covered research notes numbered from week 175 to 219. Back in June I did acknowledge a 56 day posting break in 2025 which is interesting to look back on now as an opportunity to reflect and build something substantial going forward. Toward the end of the year we got back into the groove of quality weekly missives which is good and something to continue. My focus on quantum, robotics, and AI seems to hold true to my roots of being generally interested in technology.Overall, my general interest in technology is what drives my interest in lifelong continuous learning. With that context being set it is probably easy enough to set the expectation that in 2026 and beyond the Lindahl Letter will be targeted toward the production of weekly research notes that are accessible, targeted, and focused. These missives will require less than 10 minutes of a reader’s time and should be a clear value add in terms of gaining knowledge, understanding, and context for complex technical content.Let’s establish the theoretical home base of this writing enterprise for 2026 which will be set on the foundation of digging into the edge of realized technology. That topic might sound familiar from week 212 of the Lindahl Letter. During that writing project we took a look at what technology is likely to be realized in the next 30 years. That coverage included looking at the metaverse, robotics, climate tech, space economy, biotech, synthetic biology, neurotech, and even fusion. I do believe that we will see quantum, robotics, and some AI mixed into that soup of potentially realized technology.All of that technology will see advancement and it will certainly be moving toward the edge of becoming realized technology. That is fundamental where it goes from being exploratory and research driven to being in production out in the wild where it will eventually become commoditized unless a clear winner breaks away and can hold onto a real advantage. I’m pretty skeptical about any of these technologies having a clear moat that allows that advantage. For the most part once a group of people know how to do these things the technology will be realized and break out into wider use.My primary weekly writing focus will be the Lindahl Letter and this is the place you will be able to find out what topics grab my attention and I consider to be worth sharing. My focus in the last 90 days has been heavily on quantum computing which is understandable due to how close it is getting to be a realized technology. We are on the edge of people figuring out how to demonstrate quantum supremacy for use cases and building these things into data centers as a clear value add for corporate customers and research labs that can afford to be a part of the journey. Outside of that, most of the major quantum computers that will be part of the early wave demonstrating the technology will be tied to either a research lab or corporate R&D group.Those early systems are starting to really scale up focus on specific advances in the quantum space. My research project in that space helped me to focus on open-access nanofabs, national laboratories, commercial foundry services, and captive industrial fab sites. Each of those groups has different advantages and research interests. We will see where the ultimate breakthroughs end up coming from as the story unfolds toward realized quantum technology.That is where we are heading throughout 2026. Thank you for being here for the journey and I look forward to learning more about technology and digging into the frontier of what will be realized this year. Overall the state of the Lindahl Letter is strong and we should be able to continue moving forward on our weekly journey of exploration into technology.What’s next for the Lindahl Letter? New editions arrive every Friday. If you are still listening at this point and enjoyed this content, then please take a moment and share it with a friend. If you are new to the Lindahl Letter, then please consider subscribing. Make sure to stay curious, stay informed, and enjoy the week ahead! This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit www.nelsx.com

2025 End of Year Recap
Thank you for tuning in to week 219 of the Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for the Lindahl Letter is, “2025 End of Year Recap.”Thank you for being here! The Lindahl Letter this week started out as a Merry Christmas and Happy Holidays post and ended up just being an end of year recap. As the year comes to a close, I am taking a brief pause from publishing this week to spend time with family, recharge, and reflect on the remarkable conversations and ideas we have explored together throughout the year. If you are reading this one, then you certainly learned about AI/ML/AGI, robotics, and quantum computing this year. The Lindahl Letter will return to its regular schedule next year, and I am grateful for your continued readership, curiosity, and engagement. I wish you and yours a happy holiday season and a thoughtful, restorative start to the new year.My top 5 posts of 2025 included:What’s next for the Lindahl Letter? New editions arrive every Friday. If you are still listening at this point and enjoyed this content, then please take a moment and share it with a friend. If you are new to the Lindahl Letter, then please consider subscribing. Make sure to stay curious, stay informed, and enjoy the week ahead! This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit www.nelsx.com

Nested learning and the illusion of depth
Thank you for tuning in to week 218 of the Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for the Lindahl Letter is, “Nested learning and the illusion of depth.”Just for fun with this nested learning paper we are evaluating today, I downloaded the 52 page PDF and uploaded it to my Google Drive to have Gemini create an audio overview of the paper. That is just a one button request these days. We have reached a point where we can easily listen to a paper recap with very little friction. It’s actually harder to get a complete reading of the PDF as an audio file. I had tried the Adobe Acrobat read aloud feature and I don’t really like the robotic output. Sometimes, I would rather listen to a paper than read it when I am trying to really think deeply about something. The 5 minutes of podcast audio Gemini spit out about the paper are embedded below. It’s interesting to say the least how quickly Gemini turned that paper into a short podcast. It’s entirely possible that my analysis might be less entertaining than the podcast Gemini created on the fly. You will be the judge of that one. This is a paper I actually printed out 2 pages per page using the double sided setting. That is how I used to read papers during graduate school. This paper had a few color elements that is something my graduate school papers never really had. They were all monochromatic. I had to put on my reading glasses and hold the paper a little closer than I used to with the 2 pages per page printing. I’ll have to remember to just print using single page spacing next time around. I really only print out papers I want to keep in my stack of stuff. This one certainly fits that criteria.Trying to make content that is accessible is one of the reasons that I have been recording audio for the Lindahl Letter. Sometimes listening to something is a great unlock. Other times due to complexity and the diagrams included you just have to read academic papers. I try to bring things forward without complex charts in a highly consumable way. My take on research notes is that they need to be generally understandable and communicate a clear take on whatever topic is being covered. The content has to be condensed into something that can be considered in 5-10 minutes. To that end I’m going to do my best to bring this paper on nested learning to life today.This paper matters, it really does, because the research presented undermines one of the core assumptions driving modern AI investment and the endless LLM building and training that has been occurring, namely that stacking more layers reliably produces qualitatively better intelligence [1]. The mantra to just keep scaling maybe will fade away. If many so-called deep models collapse into shallow equivalents during training, then reported gains attributed to architectural depth may instead be artifacts of data scale, regularization, or optimization heuristics rather than true representational progress.This has direct implications for benchmarking, since comparisons that reward parameter count or depth risk overstating advances that do not translate into more robust reasoning or generalization. It also affects hardware and infrastructure strategy, because enormous resources are being allocated to support depth that may not deliver proportional returns. At a deeper level, the result forces a reconsideration of what meaningful learning progress actually looks like, shifting attention from surface complexity toward mechanisms that introduce genuinely new inductive structure and adaptive behavior.Maybe the long term impact of this call out is likely to be gradual rather than abrupt, but it meaningfully shifts the intellectual ground beneath current AI narratives [1]. The paper in question provides a formal vocabulary for a concern many researchers have held intuitively, that architectural depth has become a proxy metric for progress rather than a principled design choice. Over time, this reframing may influence how serious research groups evaluate models, placing more weight on identifiably distinct learning mechanisms, training dynamics, and robustness properties instead of raw scale.It is unlikely to immediately change the minds of investors or vendors whose incentives favor larger systems, but it can shape academic norms, reviewer expectations, and eventually benchmark construction. Historically, results like this matter most not because they halt a paradigm, but because they constrain it, narrowing the space of credible claims and forcing future advances to justify themselves on grounds other than appearance and size.This argument intersects directly with my broader concerns about interpretability and generalization. I am still curious about creating a combiner model, but this might change the mechanics of how that might ultimately work. If performance gains arise primarily from optimization dynamics rather than architectural expressivity, then claims about le

The great 2025 LLM vibe shift
Thank you for tuning in to week 217 of the Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for the Lindahl Letter is, “The great 2025 LLM vibe shift.”Vibe shifts came and went. People are certainly adding the word vibe to all sorts of things as the initial meaning has ironically faded. Casey Newton in the industry standard setting Platformer newsletter wrote about a big silicon valley vibe shift in 2022 [1]. It was a big thing; until it wasn’t. The really big completely surreal LLM shift has happened toward the tail end of 2025. We went from extreme AI bubble talk to very clear, rational, and thoughtful perspectives on how LLMs won’t realize the promises that have been made. Keep in mind the market fears of an AI bubble are different from the understanding that LLMs might be the technology that ultimately wins. All of the spending in the marketplace and the academic argument may get reconciled at some point, but we have not seen that happen in 2025.The backward linkages of how potential technological progress regressed may not have been felt just yet, but the overall sentiment has shifted. The ship has indeed sailed. Let that sink in for a moment and think about just how big a shift in sentiment that really happens to be and how it just sort of happened. As OpenAI and Anthropic move toward inevitable IPO, that shift will certainly change things. Maybe the single best written explanation of this is from Benjamin Riley who wrote a piece for The Verge called, “Large language mistake: Cutting-edge research shows language is not the same as intelligence. The entire AI bubble is built on ignoring it” [2]. I owe a hat tip to Nilay Patel for recommending and helping surface that piece of writing.I was skeptical at first, but then realized it was a really interesting and well reasoned read. I’ll admit at the same time, I was also reading a 52 paper from the Google Research team, “Nested Learning: The Illusion of Deep Learning Architecture” around the same time which was interesting as a paired reading assignment [3]. More to come on that paper and what it means in a later post. I’m still digesting the deeper implications of that paper.Maybe to really sell the shift you could take a moment and listen to some of the recent words from OpenAI cofounder Ilya Sutskever. I’m still a little shocked about the casual way Ilaya described how we moved from research and the great AI winter, to the age of scaling, and finally back to the age of research again. The idea that scaling based on compute or size of corpse won’t win the LLM race is a very big shift and Ilya makes it pretty casually during this video.You will notice I have set the video to play about 1882 seconds into the conversation:Maybe a video with a really sharp looking classic linux Red Hat fedora in the background featuring a conversation between Nilay Patel and IBM CEO Arvind Krishna can help explain things. Don’t panic when you realize that the CEO of IBM very clearly argues with some back of the envelope math that all the data center investment has no real way to pay off in practical terms or an actual return on investment. Try not to flinch when it is described that within 3-5 years the same data centers could be built at a fraction of the current cost. Technology does just keep getting better. The argument makes sense. It is no less shocking based on the billions being spent.I set the video to start playing 502 seconds into the conversation.The argument that I probably prefer in the long run is how quantum computing is going to change the entire scaling and compute landscape [4]. The long-term argument that may end up mattering the most suggests that quantum computing will transform the economics of scale and ultimately reset expectations about what is computationally feasible. Former Intel CEO Pat Gelsinger recently framed quantum as the force likely to deflate the AI bubble by altering the fundamental relationship between compute and capability, a claim that is gaining analytical support across the research community. We may see it be an effective counter to the billions being spent on data centers for a late mover willing to make a prominent investment in the space or it could just end up being Alphabet who is highly invested in both TPU and quantum chips [5].What’s next for the Lindahl Letter? New editions arrive every Friday. If you are still listening at this point and enjoyed this content, then please take a moment and share it with a friend. If you are new to the Lindahl Letter, then please consider subscribing. Make sure to stay curious, stay informed, and enjoy the week ahead!Footnotes:[1] Newton, C. (2022). The vibe shift in Silicon Valley. Platformer. https://www.platformer.news/the-vibe-shift-in-silicon-valley/[2] Riley, B. (2025). Large language mistake: Cutting-edge research shows language is not the same as intelligence. The entire AI bubble is built on ignoring it. The Verge. https://ww
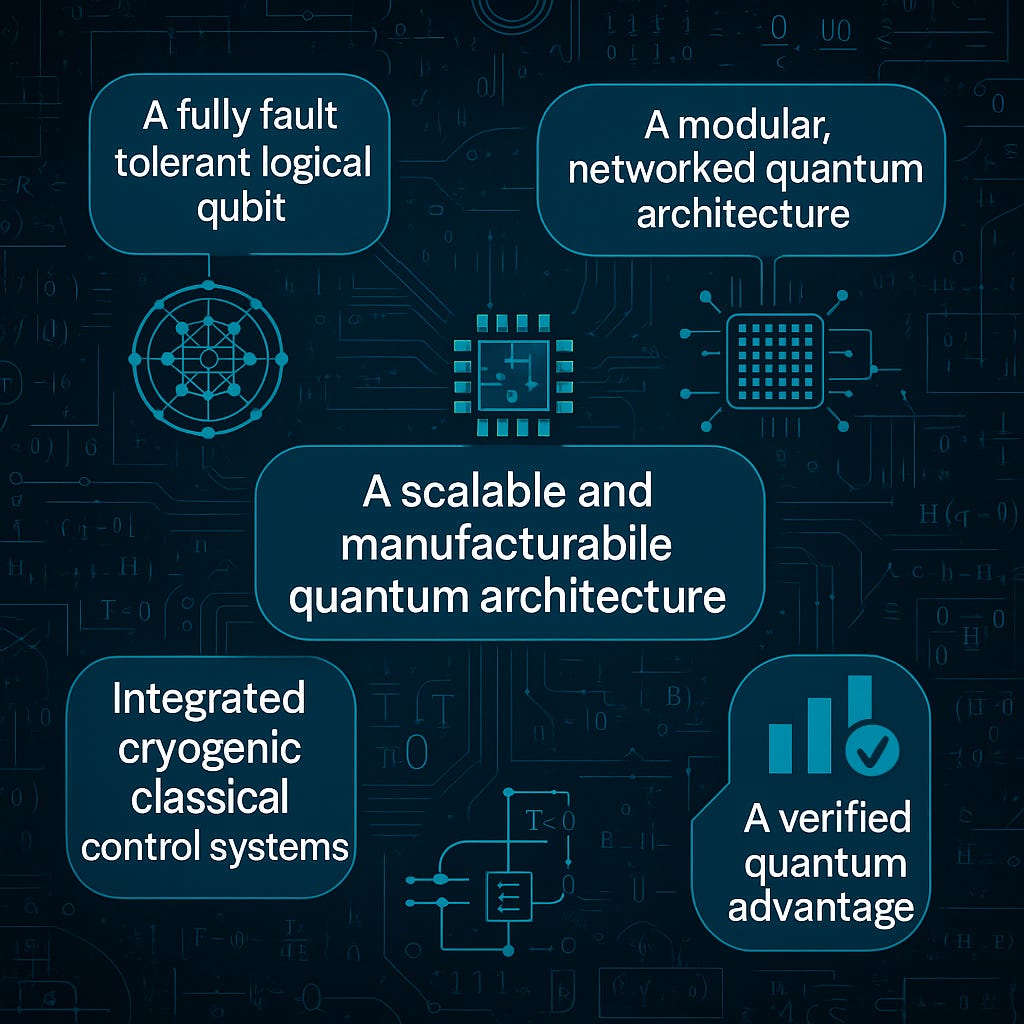
The 5 biggest unsolved problems in quantum computing
Thank you for tuning in to week 216 of the Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for the Lindahl Letter is, “The biggest unsolved problems in quantum computing.”The field of quantum computing has accelerated rapidly during the last decade, yet its most important breakthroughs remain incomplete. The core research challenges that stand between today’s prototypes and large scale, industrially relevant systems are now visible with unusual clarity. I think we are on the path to seeing this technology realized. These challenges are increasingly framed not as incremental milestones but as structural bottlenecks that shape the entire trajectory of the field. This week’s analysis focuses on the five most critical problems that must be solved for quantum computing to reach fault tolerant, economically meaningful operation. These gaps define where research investment, national strategy, and competitive advantage will be determined in the coming decade.1. A fully fault tolerant logical qubit with logical error rates below thresholdThe first and most fundamental problem is the absence of a fully fault tolerant logical qubit. I know, I know, people are getting close, but this technology is not fully realized just yet. Theoretical thresholds for fault tolerance are well studied, and progress has been reported through surface codes, low density parity check codes, and recent advances in magic state distillation. Several groups have demonstrated logical qubits whose performance exceeds their underlying physical qubits, and some trapped-ion experiments now show better than break-even behavior under repeated rounds of error correction. However, no team has yet realized a logical qubit that maintains below-threshold logical error rates in a fully integrated setting that combines encoding, stabilizer measurement, real time decoding, and continuous correction across arbitrarily deep circuits. Experiments such as the University of Osaka’s zero level magic state distillation results and Quantinuum’s recent logical circuit demonstrations illustrate meaningful progress, yet a complete fault tolerant logical qubit build rolling off the assembly line has not been achieved [1]. This missing element prevents reliable execution of deep circuits and stands as the central research challenge of the field. I am also tracking a leaderboard of efforts aimed at increasing the number and stability of logical qubits as new systems emerge [2].2. A scalable and manufacturable quantum architecture that supports thousands of high fidelity qubitsThe second unsolved problem is the absence of a scalable, manufacturable quantum architecture capable of supporting thousands of high fidelity qubits. Superconducting platforms continue to face wiring congestion, cross talk, and fabrication variability across large wafers, which limits reproducibility at scale. Trapped-ion systems achieve some of the highest gate fidelities reported, but their physical footprint, control volume, and relatively slow gate speeds constrain system growth. Neutral atom arrays offer large qubit counts, yet they have not demonstrated uniform, high fidelity two qubit gates across arrays large enough to support fault tolerant codes. Photonic and spin qubits continue to advance but remain earlier in their development for universal, gate based architectures. Across all platforms, the transition from laboratory systems to repeatable, wafer scale manufacturing has not occurred. Most resource estimates indicate that tens of thousands of physical qubits will be required for practically useful, error corrected applications, and no architecture is yet positioned to deliver this scale with consistent fidelity. I am tracking universal gate based physical qubit leaders closely, and I expect to see significant shifts in 2026 as fabrication strategies evolve [3].3. Integrated cryogenic classical control systems capable of real time decoding at scaleThe third unsolved problem concerns the integration of classical control systems capable of operating efficiently at cryogenic temperatures. Quantum processors rely on classical electronics to generate precise control pulses, read measurement outcomes, and perform real time decoding. As devices grow, these classical requirements become a dominant engineering bottleneck. Current systems depend on extensive room temperature hardware and thousands of coaxial lines, an approach that is not viable for scaling beyond a few hundred qubits. Research into cryogenic CMOS, multiplexed readout architectures, and fast low noise routing has shown meaningful progress, and prototype decoders have demonstrated sub microsecond performance. However, the field still lacks a fully integrated classical to quantum control stack that can operate near the device, support large scale decoding throughput, and eliminate the wiring overhead required for million channel systems. Solving this challenge is as essential a
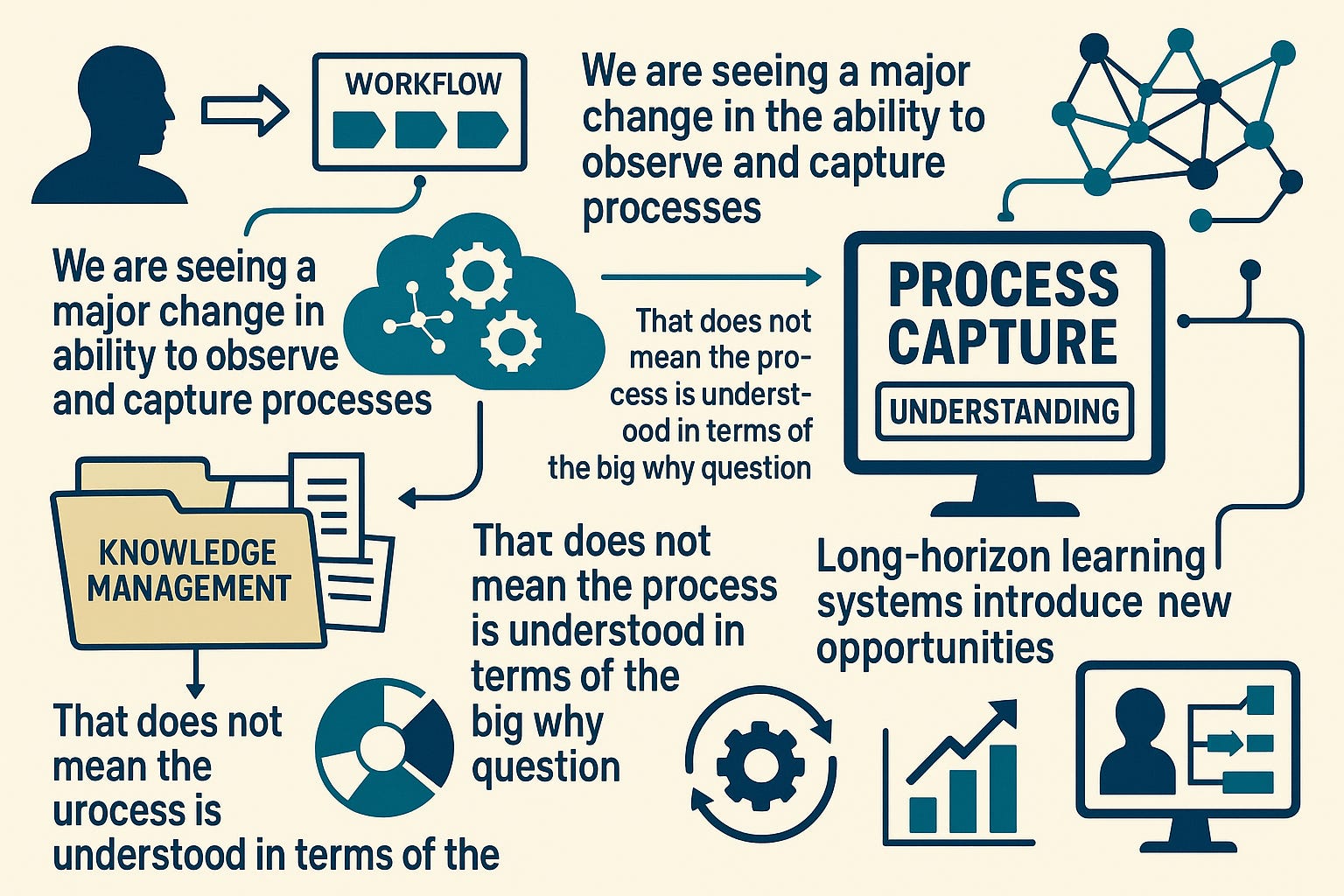
Process capture and the future of knowledge management
Thank you for tuning in to week 215 of the Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for the Lindahl Letter is, “Process capture and the future of knowledge management.”The history of knowledge management has been shaped by repeated attempts to store, retrieve, and reuse organizational insight. So much institutional knowledge gets lost and discarded as organizations change and people shift roles or exit. People within organizations learn through the every day practice of getting things done. It’s only recently that systems are augmenting and sometimes automating those processes. Early systems focused on document repositories, and later platforms emphasized collaboration, tagging, and collective intelligence. We now find ourselves in a period where knowledge management converges with automated workflows and computational assistants that can observe, extract, and generalize decision patterns. We are seeing a major change in the ability to observe and capture processes. Systems are able to capture and catalog what is happening. This creates an interesting inflection point where the system may store the knowledge, but the users of that knowledge are dependent on the system. That does not mean the process is understood in terms of the big why question. Scholars have noted that the operational layer of organizational memory is often lost because it resides in informal practices rather than formal documentation. The shift toward embedded and automated capture offers a remedy to that problem.The rise of agentic AI and workflow-integrated assistants alters the knowledge landscape by making it possible to synthesize procedural knowledge in real time. Instead of relying on teams to manually update wikis or define operating procedures, modern systems can extract key steps from repeated actions, identify dependencies, and flag anomalies that deviate from observed patterns. This transforms knowledge management from a static library into a dynamic computational environment. What exactly happens to this store of knowledge over time is something to consider going forward. Supervising the repository will require deep knowledge of the systems which are now being maintained systematically. Maintaining and refining it will be the difference between sustained institutional knowledge or temporary model advantages that drop with the next update. Recent studies on digital trace data argue that high fidelity observational streams can significantly improve the accuracy of organizational models. When this data flows into agents capable of modeling tasks, predicting outcomes, and recommending actions, the role of knowledge management shifts from storage to orchestration.Process capture also introduces new opportunities for long-horizon learning systems. This is the part I’m really interested in understanding. The orchestration layer has to have some background learning and storage that runs periodically. When workflows are automatically translated into structured representations, organizations can run simulations, perform optimization, and enable higher levels of task autonomy. These capabilities begin to resemble continuous improvement environments that merge human judgment with machine-refined operational insight. Researchers have observed that structured process models can improve downstream automation and decision support, particularly in complex enterprise settings where procedures evolve rapidly. This suggests that the next phase of knowledge management will involve systems that not only store information but also refine it through computational analysis and real world feedback. It’s in that refinement that the magic might happen in terms of real knowledge management.What’s next for the Lindahl Letter? New editions arrive every Friday. If you are still listening at this point and enjoyed this content, then please take a moment and share it with a friend. If you are new to the Lindahl Letter, then please consider subscribing. Make sure to stay curious, stay informed, and enjoy the week ahead!Links I’m sharing this week!https://www.computerworld.com/article/4094557/the-world-is-split-between-ai-sloppers-and-stoppers.htmlThis video is a super interesting look at a number we don’t normally question on a daily basis. The delivery style is a bit bombastic, but the fact check on the argument is interesting. You know I enjoy numbers and was really curious how this was calculated. That video referenced this widely shared analysis from Michael W. Green on Substack. This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit www.nelsx.com

The great manufacturing reset
Thank you for tuning in to week 214 of the Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for the Lindahl Letter is, “The great manufacturing reset.”Boston Dynamics captured public imagination when they introduced Spot the dog-like robot back in 2016. Things have changed. Robots that walk around are beginning to enter the commercial landscape, and new entrants continue to appear. A humanoid robot product from Russia built by the company Idol surfaced last week [1]. Other companies such as Agility Robotics (USA), Figure AI (USA), Boston Dynamics (USA), UBTECH (China), and 1X Technologies (Norway/USA) are all working toward delivering humanoid robots. Optimus, the Tesla bot introduced conceptually in 2021 and now in its third-generation prototype which remains part of an internal program and has not yet reached commercial deployment is also being talked about.The stage is now set, and we are at a point where robotics, autonomous fabrication systems, and advanced materials are converging into a new industrial baseline. The last decade brought low-cost filament printers into hobbyist and commercial spaces at massive scale, and the next decade is poised to move far beyond that early wave. Industrial additive manufacturing has already expanded into metals, composites, and high-performance polymers, with global revenue expected to accelerate over the coming years. At the same time, the field is absorbing rapid advancements in AI-enabled calibration, defect detection, and real-time optimization, allowing machinery to tune production parameters autonomously. That capability shifts what it means to operate a modern fabrication workflow. Things are changing rapidly.Alongside these developments, humanoid and semi-autonomous industrial robots are transitioning from research demonstrations to contract manufacturing deployments. Several builders are scaling up pilot programs in which general-purpose robots support assembly, materials handling, and repetitive manufacturing tasks. These systems benefit from advances in reinforcement learning, enhanced sensors, and cloud-based model updates. Industrial robotics shipments are increasing rapidly, driven by global demand for flexible production lines and labor-augmentation strategies. The supply side of robotics is not only expanding but also becoming modular and more interoperable across fabrication environments.The most significant shift may come from the emergence of machines that build machines. That is a topic I’m focused on understanding. Historically, tooling design required long lead times, significant manual labor, and specialized expertise. Today, automated CAM pipelines, printable tooling, adaptive CNC systems, and robotically tended fabrication cells allow factories to generate and regenerate their own production processes. Some aerospace and automotive facilities already deploy these closed-loop systems to create fixtures, jigs, and replacement components internally. This form of self-manufacturing reduces dependency on external suppliers and removes friction from engineering iteration cycles. We are moving toward a world where design, testing, and tooling are all integrated within an AI-guided, robotics-driven feedback loop. That integration is the foundation of the great manufacturing reset.For the United States, these technologies open a realistic path to reshoring custom and small-batch manufacturing in ways that were not economically viable during the offshoring wave of the late twentieth century. Rising labor costs in traditional manufacturing hubs, geopolitical risk, and supply chain disruptions have already encouraged firms to reconsider where they build things. Additive manufacturing and flexible robotics change the cost structure by reducing reliance on large minimum-order quantities, expensive hard tooling, and long logistics chains. A factory that can print tooling on demand, deploy modular robots, and run AI-optimized production scheduling can serve shorter runs and more specialized designs while remaining geographically close to end customers. In effect, the United States can replace scale-driven arbitrage with speed, customization, and resilience. That is why we are at the inflection point for the great manufacturing reset.Policy and infrastructure are beginning to support this transition. Federal programs such as Manufacturing USA and its associated network of advanced manufacturing institutes are working to diffuse next-generation production technologies across domestic firms and regions [2]. Investments in semiconductor fabrication, battery plants, and clean-energy hardware have already catalyzed billions of dollars in new onshore manufacturing commitments. The same capabilities that support large facilities can extend to mid-market and smaller manufacturers through shared tooling libraries, regional robotics integrators, and standardized digital design pipelines. Universities and community

Why a “combiner model” might someday work
Thank you for tuning in to week 213 of the Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for the Lindahl Letter is, “Why a “combiner model” might someday work.”Open models abound. Every week, new open-weight large language models appear on Hugging Face, adding to a massive archive of fine-tuned variants and experimental checkpoints. Together, they form a kind of digital wasteland of stranded intelligence. These models aren’t all obsolete; they’re simply sidelined because the community lacks effective open source tools to combine their specialized insights efficiently. The concept of a “combiner model” offers one powerful path to reclaim this lost potential. Millions of hours of training, billions of dollars in compute, and so much electricity have been spent. Sure you can work by distillation to capture outputs from one model into another, but a combiner model would be different as it overlays instead of extracts.A combiner model represents a critical shift away from the assumption that AI progress requires ever-larger single systems. Instead of training another trillion-parameter monolith, we can learn to combine many smaller, specialized models into a coherent whole. The central challenge lies in making these models truly interoperable. The challenges form from questions around how to merge or align their parameters, embeddings, or reasoning traces without degrading performance. The combiner model would act as a meta-learner, adapting, weighting, and reconciling information across independently trained systems, unlocking the latent knowledge already encoded in thousands of open weights. Somebody at some point is going to make an agent that works on this problem and grows stronger by essentially eating other modals.This vision can be realized through at least three technical routes. The first involves weight-space merging. Techniques such as Model Soups and Mergekit show that when models share a common base, their weights can be effectively averaged or blended. More advanced methods, like TIES-Merging, learn adaptive coefficients that vary across layers, turning model blending into a trainable optimization process rather than a static recipe. In this view, the combiner model becomes a universal optimizer for reuse, synthesizing the gradients of many past experiments into a single, functioning network.The second approach focuses on latent-space alignment. When models differ in architecture or tokenizer, their internal representations diverge. Even so, a smaller alignment bridge can learn to translate between their embedding spaces, creating a shared semantic layer, or semantic superposition. This allows, for example, a legal-domain model and a biomedical model to exchange information while their original knowledge weights remain frozen. The combiner learns the translation rules, effectively building a common interlingua for neural representations that connects thousands of isolated domain experts.The third approach treats the combiner not as a merger but as a controller or orchestrator. In this design, the combiner dynamically decides which expert model to invoke, evaluates their outputs, and fuses the results through its own learned inference layer. This idea already appears in robust multi-agent frameworks. A true combiner model or maybe combiner agent would internalize this orchestration as a core part of its reasoning process. Instead of running one model at a time, it would simultaneously select and synthesize outputs from many experts, producing complex, context-aware intelligence assembled on demand. This approach is the most immediately viable and is already being used in sophisticated production systems today.If such systems mature, the economics of AI will fundamentally change. Rather than concentrating resources on a few massive, proprietary models, research will shift toward modular ecosystems built from reusable parts. Each fine-tuned checkpoint on Hugging Face will become a potential building block, not an obsolete artifact. The combiner would turn the open-weight landscape into an evolving lattice of knowledge, where specialization and reuse replace the endless cycle of frontier retraining. This vision is demanding, but the promise remains compelling: a world where intelligence is assembled, not hoarded; where the fragments of past experiments contribute directly to future understanding. The combiner model might not exist yet, but its underlying logic already dictates the future of open source AI.What’s next for the Lindahl Letter? New editions arrive every Friday. If you are still listening at this point and enjoyed this content, then please take a moment and share it with a friend. If you are new to the Lindahl Letter, then please consider subscribing. Make sure to stay curious, stay informed, and enjoy the week ahead!Links I’m sharing this week!This is the episode with Sam Altman that everybody was talking about. This is a public ep

The edge of realized technology
Thank you for tuning in to week 212 of the Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for the Lindahl Letter is, “The edge of realized technology.”Welcome to the start of season 5. Don’t panic, we are still covering advancing technology including quantum, robotics, and artificial intelligence within the Lindahl Letter. I’ll be writing about the intersection of technology and modernity until the singularity. For better or worse, modernity’s shadow will continue to be the edge of realized technology. We are on the path to seeing a bunch of different technologies end up being realized in the not so distant future. That is why I’m so focused on the path toward realizing robotics, quantum, and agentic. That is where season 5 of the Lindahl Letter is going to pick up and start to dig into those topics at the edge of realized technology. To that end, I started to make a graphic of the timeline of major financial bubbles and extended it out to emerging technologies expected to deliver before 2045 [1]. You can modify the Python visualization code for this one if you want, I shared an executable version of it on GitHub.Within that visualization I started to sketch out the next 10 most likely technologies we will see realized. Within each path toward realization is where private investment and ultimately retail investors will crowd into the market before it gets commoditized to the point where the initial leaders in the space have no first mover advantage and some type of bubble ensues. That does not mean these things won’t be game changing. I’m just expecting some type of financial crowding followed by pressure against expected profits that won’t be realized. Resulting from that would be some type of financial bubble which might very well be led by a huge windfall of some sort. People made money on tulips and pepper before those markets crashed out.* 2026, “AI Bubble”, “Tech”* 2028, “Metaverse and XR Bubble”, “Tech/Speculative”* 2029, “Robotics Bubble”, “Tech”* 2031, “Climate Tech Bubble”, “Climate Tech”* 2032, “Space Economy Bubble”, “Space Economy”* 2033, “Biotech and Longevity Bubble”, “Biotech/Longevity”* 2034, “Synthetic Biology and Food Tech Bubble”, “Synthetic Bio/Food Tech”* 2035, “Quantum Bubble”, “Tech”* 2035, “Neurotech and BCI Bubble”, “Neurotech/BCI”* 2040, “Fusion Energy Bubble”, “Energy”These edges of technology realization might not be in the right order or tied exactly to the right year, but I do think that directionally this list will prove to be an accurate prediction of when technology will be achieved and we will see meaningful changes to modernity. Futurist considerations abound for what might end up happening. This was my swing at predicting what’s next. Only time will tell if it was an accurate swing or it will be disrupted by some other emerging technology.Going forward you are going to see my weekly writing efforts get split into 4 distinct buckets. My general weekly think pieces will stay here within the relative safety of the standard Lindahl Letter publication, writing about civics, civility, and civil society will be over on the Civic Honors domain, blogging will be done within the Functional Journal, and my hope is to resume daily posting back over on the nels.ai domain. Ideally, enough content will be generated in the major domains that only a small amount of blogging will occur. Going forward it is far better to produce meaningful work than to complete passages of extended navel gazing. Sure being a reflective practitioner and blogging has its place, but sometimes all that writing about the process ends up being more circular than forward looking.What’s next for the Lindahl Letter? New editions arrive every Friday. If you are still listening at this point and enjoyed this content, then please take a moment and share it with a friend. If you are new to the Lindahl Letter, then please consider subscribing. Make sure to stay curious, stay informed, and enjoy the week ahead!Links I’m sharing this week!Footnotes:[1] https://github.com/nelslindahlx/Data-Analysis/blob/master/TimelineofMajorFinancialBubbles.ipynb This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit www.nelsx.com

Spooky Halloween edition: When Satoshi-Era Wallets Wake Up
Happy Halloween everybody! Thank you for tuning in to week 211 of the Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for the Lindahl Letter is, “When Satoshi-Era Wallets Wake Up.”Seriously, Bitcoin is weird. It has an enigmatic and anonymous founder. The origin story of how this cryptocurrency came to be is pretty much ineffable. Roughly a third of all bitcoin has never moved [1].These dormant or maybe abandoned coins shape both the scarcity and the psychology of the network. Now, some of those early wallets are coming alive again, and their reawakening reveals a deeper story about profit, security, and the bleeding edge of quantum cryptography. Maybe some of these cutting edge massive quantum computers are being used to run Shor’s algorithm and factor some of these older wallet keys [2]. That seems more likely to me than somebody remembering they had some old bitcoin after a decade and moving it around. We could write a really spooky short story about people waking up to old bitcoin wallets getting cracked by quantum computers running Shor’s algorithm. That is the type of short story that could move from fiction to non-fiction with one scientific breakthrough. It’s even possible it has already started to happen. By possible, I think it probably already is happening.Speculation aside, it’s true that an estimated thirty percent of all mined bitcoin has been untouched for more than five years [3]. That is shocking. About seventeen percent of bitcoins have not moved in a decade [4]. Those figures mean that even as mining nears completion, a huge fraction of the network’s supply remains functionally absent or potentially abandoned. This long-term dormancy amplifies Bitcoin’s scarcity, turning lost or forgotten coins into a silent deflationary force. Yet in 2025, something shifted. Several ancient wallets, first active during Bitcoin’s infancy, have begun to stir after twelve to fourteen years of silence. Their movements are rare, deliberate, and full of meaning.Some of these wallets trace back to 2010 and 2011, a time when bitcoin traded for less than a dollar. In July, eight early addresses moved roughly eighty thousand bitcoin in a coordinated set of transfers [5]. That is wealth that once totaled a few thousand dollars but is now worth billions. Somebody made some shocking profits. Later, a miner-era wallet from 2010 moved four hundred bitcoin after twelve years of dormancy [6]. In October, an early 2011 wallet that had accumulated four thousand bitcoin sent a small test transaction of 150 coins before going quiet again [7]. None of these events caused market disruption, but each drew immediate attention. Every time an ancient wallet moves, it feels like a fragment of Bitcoin’s early history is stepping into the present.Why are these early coins moving now? The first reason is straightforward economics. With bitcoin surpassing one hundred thousand dollars, even small transfers yield generational wealth. Another reason is technological maturity. Over the past decade, wallet recovery methods have improved, and holders who once misplaced keys or old software backups can now retrieve them. Security has also evolved. Many early wallets were built with primitive address types that expose their public keys, leaving them theoretically vulnerable to a future cryptographic breakthrough. This leads to the third and most forward-looking motivation: the quantum threat. That is the part I’m super curious about. Some of the larger quantum systems that I shared in my leaderboard could be active here, but we don’t really know.Quantum computing is still developing, but progress is steady. Bitcoin relies on elliptic-curve digital signatures that would be mathematically vulnerable to sufficiently powerful quantum machines. The earliest wallets used formats that make this risk more immediate, because they reveal public keys on-chain once a transaction occurs. If quantum computing advances far enough, those exposed keys could allow attackers to derive private keys and spend the coins. Experts estimate that a quarter of all existing bitcoin resides in such legacy formats. That reality has not escaped early holders. Some of the recent awakenings may reflect quiet migrations of classic wallet cold coins being moved to SegWit, multi-signature, or even post-quantum-resistant wallets to protect them from future compromise. These reactivations might not be about profit at all. They could be acts of defensive foresight from people who understand how close technology may be to challenging the foundations of digital security.There are also practical motivations. Estate planning, custodial audits, and consolidation are all normal parts of managing large digital holdings. After more than a decade, early miners are updating their records, creating inheritance plans, and transferring assets to institutional custodians. The act of moving coins from an old address is sometimes less a finan

AI Is Burning Through Graphics Cards
Thank you for tuning in to week 210 of the Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for the Lindahl Letter is, “AI Is Burning Through Graphics Cards.”Generational wealth is being invested into data centers for AI. It’s so prevalent that you hear about it on the nightly news and municipalities are dealing with the power demands. The clock is ticking on graphics cards being used for AI inference. The current generation of GPUs was never designed to run around the clock under inference loads. These chips were originally built for bursts of rendering, not continuous model execution at scale. What we are seeing now is an industry trying to stretch gaming hardware into a role it was never meant to fill. The result is heat, power consumption, and a ticking clock based on the inevitable wear.Each graphics card has a limited operational lifespan. These are not like bricks being used to build a house; they are just expensive computer hardware. The more intensive the workloads, the shorter that lifespan becomes. Fans fail, thermal paste dries out, and the silicon itself begins to degrade. Inference tasks, particularly when stacked across large fleets of GPUs, magnify this effect. The relentless pace of AI workloads accelerates the failure curve, turning once-premium cards into temporary consumables. I’m actually really curious what is going to happen to all of them at the end of this cycle. A secondary market does exist for these used devices and companies like Iron Mountain will help data centers with secure disposal.By most reasonable estimates, there are now between 3.5 and 4.5 million NVIDIA data-center GPUs actively deployed in production environments. Hyperscalers such as Meta, Microsoft, and Google each operate hundreds of thousands of units, while smaller data centers fill out the rest of the global total. Each GPU represents a remarkable amount of compute density, but also a constant thermal and economic liability. Even with optimized cooling, sustained inference loads drive high thermal stress and power draw that shorten component life. These systems were never meant to run 24 hours a day, 365 days a year.Under heavy duty cycles, many GPUs experience significant degradation within one to three years of continuous operation. The warranties often match that window, which reflects a design expectation rather than coincidence. Silicon aging and persistent thermal cycling all take their toll. Even when the hardware technically survives longer, it becomes economically obsolete as new architectures quickly double efficiency and throughput. The pace of improvement ensures that by 2027 or 2028, most of today’s fleet will either be retired, resold, or relegated to low-priority inference tasks. Right now TSMC would have to make the chips to replenish this fleet of GPUs which would be outrageously expensive. Both NVIDIA and TSMC manufacturing teams could be looking at a huge impending need for production or a shift to a new type of technology.That replacement cycle has massive implications. The cost of refreshing millions of GPUs every few years is enormous, and the environmental impact of manufacturing and disposing of that much silicon is even harder to ignore. As AI inference continues to scale, this churn becomes unsustainable. Companies are already exploring purpose-built accelerators, ASICs, and FPGAs that can deliver better efficiency and longer service life. These designs aim to handle continuous inference without the same thermal or aging limitations that plague graphics cards.Sustainability will define the next phase of AI infrastructure. The transition away from general-purpose GPUs is underway, but what comes after silicon remains uncertain. Research into photonic computing, quantum processors, and neuromorphic architectures offers glimpses of what a post-GPU world might look like. Each of these alternatives seeks to break free from the limits of traditional chips while extending useful lifespans. The next leap in AI hardware will not be measured by sheer speed, but by how well it can endure the relentless demands of inference at scale.What’s next for the Lindahl Letter? New editions arrive every Friday. If you are still listening at this point and enjoyed this content, then please take a moment and share it with a friend. If you are new to the Lindahl Letter, then please consider subscribing. Make sure to stay curious, stay informed, and enjoy the week ahead!Links I’m sharing this week! This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit www.nelsx.com

Social media stopped being social
Thank you for tuning in to week 209 of the Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for the Lindahl Letter is, “Social media stopped being social.”Before we get going this week. I need to provide an update about last week’s post. I take full responsibility, as the principal writer here, that last week my writing efforts were just not up to par within the 208th Lindahl Letter publication. You have come to expect better from me and last week I just delivered a dud of a post. It’s the first post in a long time that actively drove people to leave the Lindahl Letter. It’s pretty easy to see the signal within the noise when something was bad enough to drive people away and I take responsibility for delivering that subpar effort.That being noted, let’s pivot back to the main topic at hand related to social media.I’m not sure if social media was ever really about togetherness and being social. Those are things after the fact that I want to ascribe to it. Let’s blame it on nostalgia. Communities tend to align with place, interest, or circumstance. Certainly online communities that are highly focused and targeted on a distinct community probably work. Later in a different essay it might be worth digging into the pocks of working online communities. That side of the coin however is not the focus of this missive.Things were different back when Twitter arrived in 2006 and ultimately became popular during South by Southwest in 2007. During the initial development and discovery of these applications for social media sharing things were different and maybe that newness is now something to be nostalgic about. Social media now is fragmented and stopped being social the moment algorithms learned how to predict the things that would hold our attention better than we could possibly direct it.What started the social media ball rolling as a digital gathering of friends slowly transformed into a system of engineered consumption. The feed no longer reflects our relationships. It reflects what the platform believes will keep us scrolling. In the process, the human layer was optimized out of existence. I am hoping the Substack experience ends up being different. Right now Substack is really my only active social media platform. It’s full of actual readers and writers for the most part. I’m trying to get into the swing of using Substack Notes, but that just seems to be an ongoing process of trying to figure it out. Previously, I tried to get into posting on Bluesky and I’ll admit that during Colorado Avalanche games it did feel like some level of community existed. Outside of gametime I just never really got much out of the Bluesky experience.Let’s take a step back from where we are now to consider history for a moment. Things were different for the first wave adopters. The first generation of social networks were built around connection. You followed people you knew, saw what they were doing, and commented because you cared. The platforms of today are not built for connection, but instead of being factored around community they are built for amplification. The more content flows, the more data moves, and the more ads get served. The mechanics of community were replaced by the logic of engagement.That shift changed the culture. Ultimately, it spawned the influencer movement. Maybe it’s a moment or it could be a watershed change away from public intellectuals to something else more product centric. People began curating identities instead of sharing moments. Every post became a performance. Every response was an opportunity for algorithmic reinforcement. What once felt like a conversation now feels like an audition. Social validation metrics turned communication into competition. The ultimate winners being the people who ended up making a career within this new flow of attention online.As that dynamic took hold, the real social behavior moved into the shadows. Private group chats, invite-only communities, and niche networks quietly took over the role that public timelines once held. The visible web is now dominated by content farms and brand influencers. The meaningful conversations happen elsewhere, often out of reach of recommendation systems. What used to feel like a town square has become a noisy digital strip mall.Social networks have become media networks. In some ways they are just the next generation of broadcast television or radio. It’s just more targeted and in some ways a lot more divisive. They are not spaces for dialogue but for distribution. Every interaction is mediated through a system that values attention over authenticity. That is why the average user now feels less connected than ever, even as they scroll through an endless feed of “content.” The core function of social media has inverted. It no longer connects people directly instead connecting people to platforms.We may be entering a post-social era online. Connection is returning to smaller spaces: g

Building with constant model churn
Day after release update: I guess it was the 208th post where we hit the proverbial wall with a dud of a post. This post in retrospect turned out to be one of my weaker efforts. I thought it was a strong take about dealing with the rate of change in model development, but it was just not focused and targeted based on delivering quality and insights.Thank you for tuning in to week 208 of the Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for the Lindahl Letter is, “Building with constant model churn.”Developers have spent a lot of time in the past patching software. That happens based on vulnerabilities, edge cases, and performance issues. All this vibe-coded content and things built on models are not getting any patches to make them better going forward. You may get a new release or a new model, but that patch to save you from vulnerabilities is not being developed and is not on the way. It is the nature of modern development. The ecosystem of dependencies is real. However, the pace of model development has created an unusual environment for anyone trying to build durable systems.You cannot really hot swap models within production systems. That just does not work. In the last five years, we have seen large language model releases from OpenAI, Anthropic, Google, Meta, Mistral, Cohere, and several open-source groups. Each iteration has been faster, larger, and sometimes more efficient than the one before. What has not been stable is the interface between models and the systems people build around them. Even seemingly small changes in context window size, output quality, or API availability ripple outward and cause redesigns, migrations, and sudden pivots. Sometimes these changes happen with no warning whatsoever.For builders, this creates a paradox. The potential upside of adopting a newer model is undeniable: better reasoning, lower costs, and expanded capabilities. At the same time, the risk of betting on an API or framework that may be deprecated in months is a constant concern. Some developers chase every release, weaving the newest model into their applications as quickly as possible. Others step back, building abstractions and wrappers that allow for switching models without disrupting core workflows. Neither path offers complete insulation from this wave of almost continuous churn.The history of technology offers parallels. Software engineers have long had to deal with shifting operating systems, frameworks, and libraries. What makes this moment different is the velocity of change and the sheer dependency of emerging applications on model behavior. The model is not just another dependency, it is the foundation of the system. When that foundation shifts, everything built on top of it must be reconsidered.There is also a deeper strategic question. Should builders lean into constant change and accept churn as a feature of the landscape? Or should they try to design in ways that minimize dependency, focusing more on proprietary data pipelines, unique integrations, and distinctive user experiences? Both strategies reflect an awareness that stability is not guaranteed in this ecosystem. The companies that endure will be the ones that treat churn not as an annoyance but as a design constraint.Things to consider:* The lack of patching for AI models makes long-term maintenance difficult.* Model churn introduces structural instability into modern systems.* Abstraction layers help, but they cannot prevent cascading change.* Treating churn as a core design constraint is a pragmatic approach.* Builders must balance innovation speed with long-term stability.What’s next for the Lindahl Letter? New editions arrive every Friday. If you are still listening at this point and enjoyed this content, then please take a moment and share it with a friend. If you are new to the Lindahl Letter, then please consider subscribing. Make sure to stay curious, stay informed, and enjoy the week ahead! This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit www.nelsx.com

Enforcing AI standards without exception
Thank you for tuning in to week 207 of the Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for the Lindahl Letter is, “Enforcing AI standards without exception.”Standards are something we need to spend more time talking about. That is a general statement and not a special argument. Years ago, I actually witnessed a physical desk sign at an office that said, “We either have standards or we don’t.” It’s not a great mystery how that particular leader felt about standards. That type of adherence to standards is not all that common. In our LLM sponsored chat by prompt first and ask questions later world; people just keep prompting. Allowing models to just keep generating without standards is how we ended up where we are right now. Those tokens are being burnt at prodigious rates. All of those burnt tokens yield nothing reusable or even effectively carried forward. Mostly they are highly siloed outputs to an audience of one. They are all spent and the electricity and compute used will never be recovered. They are just an expense on somebody else’s balance sheet.Everything about the open web is pretty much in rapid decline. I would argue that enforcing standards without exception is the only way the end user can truly control the agenda or hope to manage the ultimate outcome when working with AI. It might even help us save the internet. That cause however might have already been lost. One of the great ironies of generative AI is that it demands more discipline from the human interacting with it to get quality outputs, not less. Sure prompt engineering has become a hands on the keyboard type of sport, but my best guess is everything ends up being more conversational in the end. You would expect a machine to be the enforcer of rules, to deliver outputs with mechanical precision. Instead, the responsibility ultimately falls back on the end user to enforce standards at every turn. The system will generate endlessly, but unless you control the agenda, it will wander away from the very standards that define your work. A lot of people are also just creating AI slop and potentially worse AI generated workslop.This is not a trivial annoyance. It is the defining challenge of using AI effectively. You might tell a system: no em dashes, strict numeric citations, Substack-compatible footnotes. And for a moment, it will comply. Then, in the next draft, it slips back into its defaults. Suddenly the citations are misplaced, the formatting is broken, or the output is square when you clearly require 14:10. It doesn’t matter how many times you’ve said it for some reason the system’s memory for discipline is shallow. If you do not enforce the standard without exception, the drift takes over. For an organization, that can mean tens or thousands of drifting lines of argument and fragmented results.That is why the end user must step into a role that looks less like automation’s promise and more like quality assurance. You are not simply a writer or a collaborator. You are the auditor, the rule enforcer, the one who stops the drift. We either have standards or we don’t. Allow one exception, and you have taught the system that exceptions are acceptable. Enforce the standard every time, and you create a boundary strong enough to shape consistent results.This relentless enforcement becomes the core of collaboration. Without it, the system defaults to “plausible” instead of “correct,” “close enough” instead of “aligned.” You cannot rely on the machine to protect the integrity of your work or really even to have solid consistent outputs. That responsibility is yours. The human must guard the agenda with vigilance and insistence. Outside of ruthlessly enforcing standards without exception the path forward is just full of slop.Over time, this process builds more than consistency. It builds identity. A body of work that holds together across hundreds of posts or thousands of outputs does so because the user enforced the standards that give it coherence. We may very well look at the internet archives before all the LLM training as untainted and everything after that point with skepticism. I’m not arguing that everything in that first tranche of content was high quality or even accurate, but it was before the models. Without that enforcement, the work would fracture into a mix of styles, structures, and shortcuts. Enforcing standards without exception is exhausting, but it is also the only way to produce work that reflects your agenda rather than the system’s defaults.Things to consider:* AI will always drift back toward its defaults unless the user enforces rules consistently.* The promise of automation is inverted: the human enforces discipline, not the machine.* Exceptions teach the system the wrong lesson and erode consistency.* Vigilant enforcement is what turns scattered outputs into a coherent body of work.* Control of the agenda belongs to the end user, or it is lost altogether.What’s

The Great Tokenapocalypse
Thank you for tuning in to week 206 of the Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration is “The Great Tokenapocalypse.”As large language models reach deeper into consumer devices, the cost of running them becomes the real bottleneck. So many tokens get burned with no ROI or use case for the company burning them; it's really out of control. Almost as out of control as the sunk cost of data centers that will probably be regretted at some point in the next 5 years. It’s sort of the unspoken reality of an arms race where building data centers that just depreciate and spending compute resources without any plan for recovering the cost is happening. This week explores how token economics is silently shaping the deployment strategies of Google and Apple.You may have noticed something strange about the rollout of generative AI: despite Google’s global reach and technical infrastructure, Gemini is not yet present on every device. It isn’t quietly running in the background on your Nest Hub, it doesn’t summarize content on your Pixel Watch, and it hasn’t taken over the always-on interactions that dominate the smart home experience. On paper, Gemini could power all of this: but in practice, it doesn’t. The reasons are not technical, but economic.It’s the tokens. Each time a large language model like Gemini processes a prompt or generates a response, it consumes tokens which are effectively a unit of computation that translate directly into cost. This cost is not abstract. It is real-time, metered, and at scale becomes wildly continuous with enough uses. When you ask Gemini to summarize an email or rewrite a paragraph, you’re triggering a live cloud inference cycle that draws directly on Google’s TPU infrastructure. At a small scale, these requests are manageable. But when deployed across millions of devices, in billions of micro-interactions, the financial and infrastructure burden becomes extreme. What looks like product restraint is actually cost containment. Google is avoiding what could become a tokenapocalypse which would be a runaway escalation of inference demand that outpaces both compute supply and operating budget.Gemini was designed for centralized, high-performance environments. It was not optimized for low-power edge devices or offline operation. Its rollout has been concentrated in strategic, high-leverage use cases: Workspace productivity, Pixel exclusives, and experimental features inside Search Labs. These are high-value zones where the cost per token can be justified. Gemini has not been deployed ambiently in the wild on smart speakers, in Android Auto, or on lightweight wearables mostly because those endpoints offer little to no margin against token cost. The model cannot run constantly without triggering exponential cloud expenditure. Until inference becomes drastically cheaper or edge-native Gemini variants emerge, Google is likely to continue rationing its deployment to protect against economic overextension.Apple, by contrast, has chosen an entirely different path forward. They elected a path that avoids the token problem from the outset. Its 2024 rollout of “Apple Intelligence” emphasized a local-first architecture built around on-device models. Instead of sending every prompt to the cloud, Apple routes the vast majority of inference through its A-series and M-series silicon. This strategy means that users can rewrite notes, summarize messages, or interact with Siri entirely offline, with zero token cost to Apple. When tasks exceed the capability of local models, they are sent to Apple’s “Private Cloud Compute” system, but this fallback is used selectively, with strict privacy and latency guarantees.Apple’s approach isn’t just a branding play. It reflects a fundamental architectural decision to avoid the economics of inference altogether. Apple doesn’t operate a hyperscale public cloud business, so it has no incentive to absorb or monetize cloud-based generative AI usage. Its profits come from hardware margins and platform services. This gives Apple the freedom to constrain usage, limit interaction complexity, and push AI to the edge. A strategy they can get away with, ultimately without incurring the compounding costs that Google faces. It’s a token-avoidant strategy, and it may prove to be the more sustainable one.Where Google builds outward from a full-stack cloud foundation, Apple builds inward from a controlled edge. Google’s strategy scales across models and modalities, but each expansion amplifies cost. Apple’s strategy constrains functionality but keeps economics stable. Both are reacting to the same underlying pressure: token costs are rising faster than monetization models can support. The more embedded the model becomes, the more tokens flow. A stark reality comes into existence where it becomes more urgent to rethink deployment patterns. This isn’t just a question of technical feasibility. It’s a matter of financial survivabi

Apple’s Hidden AI Strategy
Thank you for tuning in to week 205 of the Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for the Lindahl Letter is, “Apple’s Hidden AI Strategy: Waiting it out with token avoidance as a first principle.”Apple’s relative restraint in deploying large-scale generative AI isn’t just about privacy posturing or design philosophy. Maybe it is just the latest supply chain management initiative in terms of managing tokens. It may reflect a deliberate avoidance of token-expensive cloud inference which is an infrastructural and financial commitment that Apple has historically chosen not to make. This choice is akin to keeping supply chain costs down; this type of effort fits with the general operating model. Right now engaging token usage would just eat profits.Apple’s approach to “Apple Intelligence,” announced in 2024, hinges on three pillars:* On-device first: Apple designed its models (small language models and transformer variants) to run locally on A17+ and M-series chips. This dramatically reduces reliance on cloud GPUs and token accounting. If you generate 200 tokens on your phone, there’s no inference cost to Apple. This method avoids cloud costs, but makes the hardware the tipping point.* Private Cloud Compute: For tasks that exceed the capabilities of on-device models, Apple routes requests to its proprietary cloud using Secure Enclaves. But this only happens for high-value or infrequent tasks. That would include things like summarizing a document, generating email replies, or rewriting notes. This keeps cloud token loads minimal and predictable.* Selective rollout: Apple isn’t putting generative models everywhere. The system isn’t always listening, and “AI” is offered as an opt-in assistant across Mail, Notes, Safari, and Siri. There’s no ChatGPT clone embedded system-wide, and certainly nothing ambient like Gemini could theoretically become.You can see based on the bottom line and balance sheet concerns why Apple’s caution probably makes financial sense in the long run. Apple sells hardware, not compute. Even some of the cloud forward vendors might operate at a loss at Apple scale. Unlike Google or Microsoft, it doesn’t have an economic engine tied to cloud usage. If it gave every iPhone user unlimited generative AI access via the cloud, it would have to subsidize trillions of tokens per year without monetization return. Nothing in the workflow has any ROI for Apple where the hardware is a sunk cost and they have not offered a standalone monthly AI service. They let everybody else spend billions on hardware, data centers, and electricity.Instead, Apple wants:* Efficiency over scale.* Local inference over cloud latency.* Sporadic usage over daily token floods.In short: Apple is playing defense against the tokenapocalypse before it ever hits. That token apocalypse will happen when billions of devices become token hungry.What’s next for the Lindahl Letter? New editions arrive every Friday. If you are still listening at this point and enjoyed this content, then please take a moment and share it with a friend. If you are new to the Lindahl Letter, then please consider subscribing. Make sure to stay curious, stay informed, and enjoy the week ahead! This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit www.nelsx.com

Context window garbage collection
Thank you for tuning in to week 204 of the Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for the Lindahl Letter is, “Context window garbage collection.”Here we are this week contemplating how to clean up the mess from all these celebrated LLM chat sessions. It’s a disjointed mess that lacks federation or dare we say portability. We are at the point where we need to think about how context window garbage collection explores the deeper process based idea of how large language models might manage overflowing histories, selectively pruning, discarding, or compressing tokens to maintain efficiency without losing coherence. Certainly my thoughts on this is that we would all benefit from portable knowledge sharding, but that is just one way to look at the potential set of solutions that need to be built. Another way to slice the apple up and put just the best parts back together again would be to build out some context window garbage collection.When you open a long conversation with a large language model, the context window eventually fills with tokens from your prompts and the model’s replies. These windows have strict limits, whether 128k tokens, 200k tokens, or more, and yet our usage tends to grow indefinitely. As prompts expand, sessions become inefficient and costly, sometimes degrading in coherence as irrelevant or outdated details pile up. We have all run into hallucinations and just weird output from models. At this point in the experience the next best question then becomes very clear. We have to evaluate how models should manage their overflowing context windows at the end or during a chat session.In programming, garbage collection has long been the answer to similar problems. Long garbage collection problems have literally kept me up at night. Computer systems with finite memory must constantly decide what to keep and what to discard. Techniques such as reference counting, mark-and-sweep, and generational garbage collection have been developed to handle this challenge. The analogy we can build out here is very straightforward: in a world where context is the working memory of LLMs, garbage collection could provide the rules and processes for pruning, summarizing, or discarding tokens without breaking continuity.Several strategies already hint at how this could work. Some systems automatically prune less relevant history, while others compress sections of text into summaries or embeddings that can be retrieved later. I would run a knowledge reduce function based on my previously shared research, but I always think that is the answer. User-directed pinning, where important content is marked as permanent, is another possible feature. In longer interactions, models could run background “cleanup passes,” automatically condensing earlier exchanges into portable knowledge shards. Each of these approaches mirrors classic computing strategies while being adapted to the new problem space of language models.The risks are obvious. Things could go sideways. We face a direct computing time cost associated with this effort. Poorly designed garbage collection could lead to subtle context loss, missing small but crucial details. Summarization may introduce semantic drift or hallucinations. I would argue that properly structured context will actually reduce drift or hallucinations. Users may also resist invisible pruning, questioning whether they can trust a model that silently discards information. The challenge lies in balancing efficiency, fidelity, and transparency, ensuring that garbage collection makes interactions smoother rather than introducing new points of failure.Looking forward, context window garbage collection could become a fundamental layer of model architecture. Standardized processes and even some APIs might emerge to expose garbage collection logs to users or allow customization of pruning strategies. Entire ecosystems of agents could share compressed or pruned context shards across models, creating interoperability where today there is only fragmentation. Just as garbage collection enabled more scalable and reliable programming environments, context window garbage collection may become the invisible backbone of scalable AI interaction.Things to consider:* Should context garbage collection be visible and user-controllable?* Can models balance efficiency with fidelity when pruning?* What lessons from programming garbage collection apply directly to LLMs?* Does context GC make interoperability between models easier or harder?What’s next for the Lindahl Letter? New editions arrive every Friday. If you are still listening at this point and enjoyed this content, then please take a moment and share it with a friend. If you are new to the Lindahl Letter, then please consider subscribing. Make sure to stay curious, stay informed, and enjoy the week ahead! This is a public episode. If you would like to discuss this with other subscribers or get access

Portable knowledge sharding
Thank you for tuning in to week 203 of the Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for the Lindahl Letter is, “Portable knowledge sharding.”The shards of knowledge that we need are everywhere. They are just not portable and all packaged up. You open an interaction with an LLM based on a prompt, but you don’t really close it out by receiving a prompt or a packaged transferable output. This week’s focus is on how knowledge can be broken into modular, transferable units and moved across systems, sessions, or users. At its core, this concept involves fragmentation by design, creating smaller, self-contained pieces that retain meaning independently while becoming more useful when recombined. These modular shards offer a practical method for bridging gaps between disconnected tools, memory systems, and AI agents. You could just ask the model at the end of your session to package up the results for you. That type of effort makes you your own data broker. You are then responsible for putting the right data in all the right places.A true system of portable knowledge sharding that is easily transferable addresses the growing problem of fragmentation in digital workflows. Isolated AI memory systems, disconnected application ecosystems, and session-based interactions that fail to persist information have made continuity more difficult to maintain. In this context, a knowledge shard can be understood as a compact, self-contained packet of insight that includes metadata and minimal context. This idea draws from concepts such as database sharding, microservices architecture, Zettelkasten-style note-taking, and linked data formats like JSON-LD. The defining characteristic of a portable shard is that it contains just enough information to be interpreted outside its original environment.Fragmentation is increasing across nearly every dimension. Large language models operate in isolation. Memory is not shared between models, or even across sessions within the same system. Users frequently move between unconnected platforms and tools. The result is a scattered intellectual landscape. Portable knowledge sharding provides a way to restore structure, making it easier to preserve, transport, and reassemble valuable insights.Several key principles support the creation of effective knowledge shards. These include atomicity, where each shard captures a single coherent idea; context tagging, where metadata includes origin, date, and relationships; minimal dependency, ensuring each shard is understandable on its own; mergeability, allowing recombination into larger ideas; and transportability, which enables movement across systems without loss of meaning. Together, these principles provide a foundation for more resilient and flexible knowledge systems.Real-world applications of portable knowledge sharding are already emerging. Tools like Manus and Rewind.ai offer memory replay capabilities that hint at this modular future. As workflows become more complex, it will be necessary to repackage experiences and decisions into transferable learning units. Research systems like the nels.ai KnowledgeReduce project are grounded in this very concept. Portable shards could also improve task handoffs between AI agents, support modular scientific publishing, or serve as components within platform-spanning knowledge graphs. A side-by-side comparison of traditional notes and knowledge shards would help illustrate these differences more clearly.This approach is not without challenges. Shards can lose critical context or become misleading when separated from their origin. Interoperability suffers without standardized formats. Version control becomes more difficult. Excessive sharding may also reduce clarity instead of enhancing it. Even with these limitations, portable knowledge sharding remains a promising strategy for managing complexity in highly fragmented environments.Consider whether your current workflows support modular knowledge reuse. Think about how agents might benefit from receiving portable shards as part of their input. Reflect on whether we are moving toward an ecosystem of shard-native tools and practices.What’s next for the Lindahl Letter? New editions arrive every Friday. If you are still listening at this point and enjoyed this content, then please take a moment and share it with a friend. If you are new to the Lindahl Letter, then please consider subscribing. Make sure to stay curious, stay informed, and enjoy the week ahead! This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit www.nelsx.com

Personalized context bubbles
Thank you for tuning into the podcast. This is week 202 of the Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for the Lindahl Letter is, “Personalized context bubbles.”Last week we took a deeper look into content window fragmentation. That is just the right amount of foundation to start to consider personalized content bubbles. Don’t panic; no foundation model pun intended. I even talked about it on YouTube during a recent Nelscast episode. It has been years since I actively livestreamed on YouTube. Live streaming is apparently a lot like riding a bicycle and you pick it back up pretty quickly.The context bubbles we are focusing on today are model-specific and ultimately memory-driven. Functionally they are hidden from the outside world and only interacted with by the user. The whole experience is highly gated and mostly hidden by design. Unlike the algorithmic filter bubbles of the social media era, highly personalized context bubbles in LLMs emerge from user-specific interaction histories and model memory. They are shaped by prompts, preferences, and usage over time. Some people have ridiculously deep context in memory and have radically changed how the model even interacts with them on an ongoing basis. Some people even call this a type of modal rot where things worked better initially and then over time degraded.This type of both hidden and blatantly obvious fragmentation is increasing across AI ecosystems. There is no interoperability between different models’ memory systems. A user’s context in GPT-4o does not translate to Claude, Gemini, or Mistral, leading to siloed experiences that fragment continuity and collaboration. It means the only point of continuity is individual to the user and fundamentally disjointed to any external view.Ultimately what we are talking about is that private AI interactions are creating isolated knowledge spaces. As more users rely on fine-tuned personal agents and persistent memory features, the result is a proliferation of parallel digital realities, each uniquely shaped by the individual’s bubble of past interactions. It takes everything that was creating conflict within our broader social fabric and exacerbates it both in terms of isolation and from an observability consideration it remains completely invisible.The risk of invisible epistemic bias is growing. Personalized bubbles can limit intellectual perspective and reinforce confirmation bias, particularly when LLMs refine outputs based solely on a user’s prior behavior and inputs. You can basically create a walled garden of very optimistic reinforcement that just celebrates whatever perspective, the bubble has fostered for the end user.I would argue that this is happening because no standards for portability of data exist. Truly at this point in the ecosystem there is a lack of standards for context portability. Without a framework to export or synchronize context across tools or agents, users remain locked into proprietary silos, impeding collaborative and transparent knowledge generation.What’s next for the Lindahl Letter? New editions arrive every Friday. If you are still listening at this point and enjoyed this content, then please take a moment and share it with a friend. If you are new to the Lindahl Letter, then please consider subscribing. Make sure to stay curious, stay informed, and enjoy the week ahead! This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit www.nelsx.com

Context window fragmentation
Thank you for being a part of the adventure. This is week 201 of the Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for the Lindahl Letter is, “Context window fragmentation.”Exactly. You are either aware of or have felt the effects of context window fragmentation. I thought this topic would be a really sharp angle for consideration. Something that would stand out and be interesting as a point of conjecture. Instead of just digging into the technical fragmentation inside one model’s context window, I’m more interested in evaluating ecosystem-level fragmentation. Fragmentation confounds and conflates concepts between environments, users, and ultimately sessions.Users move between multiple models (say, Claude, Gemini, GPT, Mistral, etc.), each with its own maximum context length and its own memory handling. Nothing of that experience is shared between them and no effective way of packaging and sharing context windows even exists. Effectively that means that no shared continuity across those systems exists and what one model “remembers” has no carryover to another. A lot of the time it has no carryover between sessions either based on how the memory is managed. We effectively run tabula rasa into whatever training that particular model had received. It’s a new dance every time, but the dance partners are unclear.This creates fragmented work products: research threads, writing drafts, or code bases become scattered across different LLM silos.Even within one provider, different versions of the same model can handle context differently, further increasing the fragmentation. Sometimes you even end up with the model changing in the middle of things from say the more comfortable GPT-4o to the underwhelming GPT-5 [1].Let’s highlight two layers of “context window fragmentation”:1. Within-model limits: losing track of earlier tokens inside one long prompt.2. Across-model silos: knowledge, drafts, and reasoning don’t travel with the user between systems and sessions.This double fragmentation means users are left stitching things back together manually, or trying to impose their own save-points, knowledge graphs, or workflows to keep continuity.Things to consider:* Expanding context windows does not solve fragmentation across providers.* Users are building their own ad hoc systems to bridge silos, often with limited success.* True continuity may require hybrid architectures that integrate structured memory with LLMs.* The absence of interoperability standards ensures this fragmentation will persist for now.What’s next for the Lindahl Letter? New editions arrive every Friday. If you are still listening at this point and enjoyed this content, then please take a moment and share it with a friend. If you are new to the Lindahl Letter, then please consider subscribing. Make sure to stay curious, stay informed, and enjoy the week ahead!Footnotes:[1] https://www.theverge.com/openai/759755/gpt-5-failed-the-hype-test-sam-altman-openai This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit www.nelsx.com

My 200th Lindahl Letter Explained
Thank you for tuning in this week. Not only will this not be an audio only presentation this week and you will have to check YouTube at some point in the not so distant future for more details on that, but also I have tweaked the noise gate in GarageBand to improve the overall audio quality. This is week 200 of the Lindahl Letter publication. A new edition arrives every Friday. This week, the topic under consideration for the Lindahl Letter is, “My 200th Lindahl Letter Explained.”My very first Substack post was published on January 26, 2021, at 5:44 p.m. We can safely say that was about 236 weeks and 3 days ago at the point I started this draft. You probably have figured out that 36 weeks in that window did not receive any Lindahl Letter. That inaction does reflect a series of gaps in my publishing schedule. It happened. It happens. It might very well happen again at some point. Sometimes that is the way things go during an ongoing writing project. Today, however, you are getting the 200th cumulative week of my writing efforts for the Lindahl Letter publication. We have arrived at this major milestone in my writing efforts, and we should take a moment and celebrate. It is pretty exciting. I had compiled the previous years into manuscripts you can find online. At this point, it would probably make sense to assemble the year 4 edition of that writing project.For this 200th milestone post, it really does make sense to spotlight five topics that capture both the breadth of coverage and the depth of research that have defined the Lindahl Letter. Those weekly research notes don’t self-generate.The first topic would be from our recent shift to understanding quantum computing. It was a big shift from covering AI/ML to talking about quantum computing. That series included posts such as Magic state distillation explained and Quantum computing near Denver, which showcased detailed explorations of cutting-edge hardware breakthroughs and the regional tech ecosystem. I really do think that quantum computing is getting near a key breakthrough point where it will be more accessible. I’m not talking about it being widespread or used for everyday compute, but we are getting very close to the edge of possibility where quantum workloads are going to be a part of daily processes.The second topic relates to machines that build machines, a series examining advanced robotics, automation, and manufacturing systems that has been a defining theme of the current season. As we move forward, understanding prototyping and building the means of manufacturing is important to the next phase of building. We are going to see a movement from 3D printing to small-scale prototyping. Generally, I do not provide the same talk over and over again, but I think my elevator pitch on this topic needs some work.Third, we spent a lot of time discussing AI governance and ethics. That effort has been among the most engaged-with posts, offering insights into regulation, societal impact, and the responsible development of large language models. This topic just seems to be a known thing that we need, but it just does not end up being at the forefront of considerations.The fourth topic would have to be my all-time favorite topic to consider. That would be the intersection of technology and modernity, a recurring theme that connects technology trends to broader cultural and societal contexts. At some point, I plan on finishing my magnum opus on that topic. It should be a good read.Finally, the fifth topic would be worth rewinding back to my earliest foundational topics that were all just adapted talks, including my very first post in January 2021, which ultimately would provide you with a clear sense of how far the publication has evolved over 200 weeks. That key foundational topic was all about ROI and how to ensure you are aligning your priorities with actual dollars from the budget.As we move forward, the Lindahl Letter will continue along this new trajectory of research based on focusing on 3 topics: quantum computing, robotics, and enabled agents. I’m not sure if I will end up writing another 200 Lindahl Letters, but it is an interesting moment to consider having reached 200 of them and still be considering what’s next. I have considered moving to a monthly cadence where a paper is produced vs. a weekly research note. We will see where that ends up going during the next few weeks.What’s next for the Lindahl Letter? New editions arrive every Friday. If you are still listening at this point and enjoyed this content, then please take a moment and share it with a friend. If you are new to the Lindahl Letter, then please consider subscribing. Make sure to stay curious, stay informed, and enjoy the week ahead! This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit www.nelsx.com

Machines that build machines
Thank you for tuning in to this audio only podcast presentation. This is week 198 of the Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for the Lindahl Letter is, “Machines that build machines.”As we embarked on this new season of the Lindahl Letter, I signaled that we would focus on three content themes. These themes included quantum computing, machines building machines, and agents taking action. We are now shifting from quantum related topics toward innovations in advanced robotics, which I group under a series of research notes titled “machines that build machines.” The future of manufacturing depends on more than automation. It hinges on the ability to rapidly prototype, iterate, and deploy the machines that make everything else possible.Modern manufacturing at scale nearly always involves some form of robotics. These robotic systems range from industrial arms performing repetitive tasks to highly customized modular assemblies tailored to the needs of specific products. A few weeks ago, during our trip back to Kansas City, I listened to the audiobook Apple in China by Patrick McGee [1]. That narrative presented a vivid exploration of Apple’s entanglement with China’s manufacturing infrastructure. Beneath McGee’s primary story is a powerful subtext about the foundation of China’s manufacturing prowess. The critical enabler in that story is the set of machines that build other machines. These tools not only support prototyping and product assembly but also underpin supply chain resilience and adaptability. A nation’s or company’s ability to design, iterate, and build these enabling machines directly influences how quickly it can scale production, respond to demand, and recover from disruption.To refine this research note further, I want to focus on the prerequisites for developing these prototyping machines. What infrastructure, talent, and technological components are essential to make all of this work going forward. Unlocking these prerequisites will be key. It likely starts with a feedback loop between design software, materials science, and precision engineering. You need high-accuracy CNC tools, industrial-grade 3D printers, flexible robotic arms, and a digital design plus rapid testing environment that allows for fast iteration. Integration with simulation software enables virtual testing before physical builds. On top of that, you need skilled operators with interdisciplinary knowledge across mechanical design, embedded systems, control theory, and software development. Building machines that build machines is not just about automation. It's about compressing the distance between what can be imagined and what can be executed.The engineering talent capable of achieving this is increasingly interdisciplinary. My thought here is that clusters of skilled workers in this space have a distinct advantage. Based on my initial research you can find clusters in five primary regions in the United States. Boston and Cambridge are anchored by MIT and home to legacy firms like Boston Dynamics [2]. Silicon Valley remains a stronghold with a deep pool of venture-backed robotics startups. Pittsburgh leverages Carnegie Mellon University to drive robotic innovation, while Austin, Texas, is rising fast with Tesla’s Gigafactory and a strong embedded systems culture. Here in Colorado, the Denver–Boulder–Fort Collins corridor is building momentum. The University of Colorado Boulder contributes robotics talent, and local companies like AMP Robotics, Ball Aerospace, and Intrinsic (a Google X spinout) are growing engineering teams focused on automation and scalable machine design [3][4]. It’s not the largest cluster, but it’s one with real promise and momentum. It’s the region where I plan on making contributions going forward.Outside formal clusters, much of the talent exchange is happening in online communities. Hackaday.io is one of the most active hubs for open-source hardware builders. Reddit forums like r/robotics and r/functionalprint allow engineers to share designs and feedback loops. GitHub is where firmware, control systems, and design files live. Especially for foundational projects like GRBL, Klipper, and Marlin [5][6][7]. This is an ecosystem I want to investigate further: what enables it, where it thrives, and how it might be scaled to bring the next generation of prototyping and manufacturing capability into reality.Things to consider:1. Manufacturing capability now depends on how fast you can build and reconfigure the machines behind production lines.2. Engineering talent that enables machine-building clusters around universities, megafactories, and open-source communities.3. Denver and Boulder are emerging as credible nodes in this ecosystem with strong robotics and aerospace footholds.4. Online platforms like Hackaday, GitHub, and ROS Discourse are core to knowledge sharing and prototyping workflows.5. The real unlock may come from compressing time

Ep 197Magic state distillation explained
Thank you for tuning in to this audio-only podcast presentation. This is week 197 of the Lindahl Letter publication. A new edition arrives every Friday. This week, the topic under consideration for the Lindahl Letter is, “Magic state distillation explained.”We have spent the last 3 weeks digging into quantum computing. That journey involved looking at the top 10 quantum computer leaderboard, annealing vs. gate-based systems, and the reality of enterprise plays. Trying to figure out where the edge of what is possible for quantum computing actually exists is a tricky proposition. A lot of roadmaps and promises exist in this space. People have plans, and they seem reasonable. It however, is hard to figure out what parts of them are actually real and delivering. We have seen some major movement in announcements for quantum error-reduction, which is a major step or part of a lot of roadmaps. News is going to keep breaking as we get closer to fault-tolerance. One of those breakthroughs is explained in a paper about magic state distillation that was submitted back in 2024, but just officially was published this month. The good people at the University of Osaka published a paper called, “Efficient Magic State Distillation by Zero-Level Distillation” [1]. The full citation for that 12-page paper happens to be:Tomohiro Itogawa, Yugo Takada, Yutaka Hirano, Keisuke Fujii. Efficient Magic State Distillation by Zero-Level Distillation. PRX Quantum, 2025; 6 (2) DOI: 10.1103/thxx-njr6Sure, improving how we use magic states is a key element of unlocking one of the top bottlenecks in quantum hardware design. The more base hardware elements that can be incorporated the lower the ceiling falls for practical implementation of quantum systems. You can read the PDF online, and the paper is readable if you are willing to look up a few terms that are commonly used in the quantum computing space [2]. You are probably well aware by now that I’m super duper interested in better understanding where gate-based quantum computing is heading in the next couple of years. This paper happens to dig into a subset of gate-based quantum computing called the Clifford operations. This is where a lot of things start as it is a well defined space. A Clifford operation is a quantum gate operation or circuit that maps Pauli operators to other Pauli operators under conjugation and can be composed of Hadamard, Phase, and CNOT gates. Think base actions or building blocks that need to be taken as part of a quantum system. A Pauli operator is one of the four fundamental 2×2 matrices (I, X, Y, Z) used to represent quantum bit-flip, phase-flip, and identity operations, forming the core building blocks of quantum error correction and circuit analysis.This paper introduces a new technique called zero-level distillation, which dramatically simplifies how quantum computers prepare the special “magic” states needed for universal computation. Traditionally, this process required error-corrected logical qubits, making it slow and resource-intensive. The team at the University of Osaka figured out how to do this more efficiently at the physical qubit level, verify the state using error-detecting circuits, and then teleport the result into a fully protected logical qubit. This method reduces both error rates and resource costs, bringing us one step closer to practical, large-scale quantum computers. It will be interesting to see how this advancement gets built into practical hardware implementations. I was digging into an advance shared by the Microsoft Quantum team related to a new four-dimensional geometric code method trying to figure out if this used a hardware-based method or something post-hardware [3]. That paper is 40 pages long and goes into a degree of depth that is interesting, but could have benefited from a brief summary beyond the provided abstract.Aasen, D., Hastings, M. B., Kliuchnikov, V., Bello-Rivas, J. M., Paetznick, A., Chao, R., ... & Svore, K. M. (2025). A Topologically Fault-Tolerant Quantum Computer with Four-Dimensional Geometric Codes. arXiv preprint arXiv:2506.15130.Still wanting to learn more? You can pretty easily do a Google Scholar search for “efficient magic state distillation” and you will get a bunch of different papers you can read [4]. It did not hold my interest enough for me to pull out key papers for you, but it was a thread that almost got pulled.This week I want to include a bonus topic from a video I watched on YouTube, “Quantum Complexity: Scott Aaronson on P vs NP and the Future.”Aaronson explains that while P ≠ NP is widely believed, quantum computing does not resolve this distinction or solve NP-complete problems efficiently. He introduces BQP or Bounded-Error Quantum Polynomial Time as the class of problems solvable by quantum computers, noting that quantum speedups like those from Grover’s and Shor’s algorithms can apply only to problems with specific structure. Aaronson concludes that quantum computing offers signific

Is quantum computing becoming an establishment play?
Thank you for tuning in to this audio-only podcast presentation. This is week 196 of the Lindahl Letter publication. A new edition arrives every Friday. This week, the topic under consideration for the Lindahl Letter is, “Is quantum computing becoming an establishment play?”You probably have heard of IBM, Google, and Microsoft. They are a pretty big deal in the technology world. IBM has a really involved and well-defined quantum computing roadmap [1]. They pretty much tell everybody who will listen about it. That roadmap includes details about error correction, fault tolerance, and the road to 10,000 gates. We also have a roadmap from Google Quantum AI which details 6 milestones and notes that they have achieved 2 of the 6 noted milestones [2]. We also have a fun quantum roadmap from the Microsoft team that notes 3 levels: foundational, resilient, and scale [3]. All those roadmaps make me wonder if quantum computing will end up becoming, in the end, a pure establishment play. On a side note, building a matrix that compares all 3 roadmaps might be interesting for a future research note and has been added to the backlog.Some of the companies we mentioned earlier in Lindahl Letter research notes like Rigetti Computing, D‑Wave Quantum, IonQ, and Quantum Computing Inc. are doing both pure research into quantum computing to drive the technology forward and applied applications of that research, allowing people to actually access hardware. The Amazon Braket functionality platforms quantum hardware and will sell you actual access to IonQ, Rigetti, QuEra, and IQM for a reservation rate of under $7,000.00 per hour [4]. Making AWS positioned to deliver as long as the hardware is available for sale in the quantum space. That AWS hardware-as-a-service model spreads out risk. If Google or Microsoft ends up being the winner, then that strategy might involve having to buy services by API from them as they might not distribute hardware.Apple as a company has a lot of available cash and could make a defensive patent play here by acquiring a potentially emerging technology leader in the quantum computing space. Given the workloads on Apple devices are highly repeatable and pattern-specific, maybe an annealing play while potentially limited in the end could work in the near horizon. Apple engineers are incorporating post-quantum cryptography (PQC) into their messaging and technology stacks, so they are working ahead of the game, but not directly in the quantum hardware space at least in an observable way [5].My concern here and the reason for this research note is that no matter what innovation ends up happening in the quantum computing space, the establishment technology companies may end up winning. They may move a little bit slower getting things to market, but will end up winning the space at scale and delivery. As we all know by now, the elephant does not dance all that quickly. However, those three companies (IBM, Google, and Microsoft) do have a history of delivering enterprise scale. My guess here is if one of the quantum computing companies listed above ends up getting a key technology patented and gains a distinct advantage, the bidding war to complete an acquisition will be intense. It’s also possible that IBM may end up building the winning quantum computer by 2028, which is what they are currently shouting from the rooftops [6]. They are and have been delivering on a detailed, very well-publicized roadmap.What’s next for the Lindahl Letter? New editions arrive every Friday. If you are still listening at this point and enjoyed this content, then please take a moment and share it with a friend. If you are new to the Lindahl Letter, then please consider subscribing. Make sure to stay curious, stay informed, and enjoy the week ahead!Footnotes:[1] https://www.ibm.com/roadmaps/quantum/[2] https://quantumai.google/roadmap[3] https://quantum.microsoft.com/en-us/vision/quantum-roadmap[4] https://aws.amazon.com/braket/pricing/[5] https://security.apple.com/blog/imessage-pq3/[6] https://www.technologyreview.com/2025/06/10/1118297/ibm-large-scale-error-corrected-quantum-computer-by-2028/ This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit www.nelsx.com

Annealing vs. gate based quantum computing
Thank you for tuning in to this audio only podcast presentation. This is week 195 of the Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for the Lindahl Letter is, “Annealing vs. gate based quantum computing.”You may have picked up from the last edition of the Lindahl Letter that I’m more focused on gate based quantum computing than I am concerned about the current advances in annealing based systems. This week I went back over and dug out some gems on Google Scholar related to annealing quantum computing [1]. Some of these academic articles have a few hundred citations, but none of them seem to be breakout articles with thousands of citations. Within a small academic discipline you will see a paper pick up citations under 100 and that is probably a well read paper. Some of the mega papers in the AI space have 100,000 citations and those are foundational and very well read academic papers. Honestly, the only things that might be better read are books that break into the public mind and become bestsellers. I don’t think anything that I have found in the annealing based quantum computing space would qualify as breakout or bestseller.Here are 5 papers that are highly cited that I thought were interesting this week:Das, A., & Chakrabarti, B. K. (2008). Colloquium: Quantum annealing and analog quantum computation. Reviews of Modern Physics, 80(3), 1061-1081. https://arxiv.org/pdf/0801.2193Pudenz, K. L., Albash, T., & Lidar, D. A. (2014). Error-corrected quantum annealing with hundreds of qubits. Nature communications, 5(1), 3243. https://www.nature.com/articles/ncomms4243.pdfHauke, P., Katzgraber, H. G., Lechner, W., Nishimori, H., & Oliver, W. D. (2020). Perspectives of quantum annealing: Methods and implementations. Reports on Progress in Physics, 83(5), 054401. https://arxiv.org/pdf/1903.06559Morita, S., & Nishimori, H. (2008). Mathematical foundation of quantum annealing. Journal of Mathematical Physics, 49(12). https://arxiv.org/pdf/0806.1859Yarkoni, S., Raponi, E., Bäck, T., & Schmitt, S. (2022). Quantum annealing for industry applications: Introduction and review. Reports on Progress in Physics, 85(10), 104001. https://arxiv.org/pdf/2112.07491What exactly is annealing quantum computing?Let’s answer this question the hard way by first stating that universal gate based quantum computing is built out to a set of qubits where any type of computation could be worked using the available qubits. If you have quantum computing work, then you are good to go within the universal gate-based system. Now let’s say you were a company like D-Wave Systems and you wanted to take a different direction than universal gate-based quantum computing and lean into the annealing quantum computing world. You would start to build a system that works toward being optimized for special use cases and you might write a nice presentation about it which you could read [2]. Based on what D-Wave Systems is sharing, annealing quantum computing system uses a method that solves optimization problems by gradually evolving a quantum system toward its lowest energy state, or ground state. It leverages the quantum adiabatic theorem, which ensures that a system will remain in its ground state if changes to its energy landscape are made slowly enough. Instead of using logic gates, annealing encodes a problem into a Hamiltonian (which is a mathematical function that describes the total energy of a quantum system), and the solution emerges as the system relaxes. This model excels at solving complex combinatorial optimization problems. Unlike gate-based systems, annealers are not universal quantum computers but offer practical advantages for certain narrow tasks. It’s like special quantum computing vs. general quantum computing.What’s next for the Lindahl Letter? New editions arrive every Friday. If you are still listening at this point and enjoyed this content, then please take a moment and share it with a friend. If you are new to the Lindahl Letter, then please consider subscribing. Make sure to stay curious, stay informed, and enjoy the week ahead!Footnotes:[1] https://scholar.google.com/scholar?hl=en&as_sdt=0%2C5&q=annealing+quantum+computing&oq=Annealing+qu[2] https://s201.q4cdn.com/339170267/files/doc_presentations/2025/Mar/31/20250331_D-Wave-Technology-and-the-Competitive-Landscape.pdf This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit www.nelsx.com

The top 10 quantum computer leaderboard
Thank you for tuning in to this audio only podcast presentation. This is week 194 of the Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for the Lindahl Letter is, “The top 10 quantum computer leaderboard.”…and we are back writing extra fresh weekly research notes for your inbox. My current writing process involves working during some weekend morning writing sessions to produce a one week forward product. At some point, it is entirely possible that we will get back to the 5 week production process that I used for the last few years, but that is not on the current production roadmap for the foreseeable future. You can think of this like a weekly research sprint with a solid weekly written narrative based retrospective. We are going to stay timely, focused, and consistent in terms of delivery and quality.During this fine Saturday morning with some absolutely beautiful weather in Denver, Colorado, I’m working to pull together a list of the biggest verifiable quantum computers based on the qubit count and their country of origin. A lot of different ways exist to assemble this potential list. The list is going to effectively be a top 10 leaderboard snapshot that I check in on a quarterly basis or when a new major announcement happens to just figure out how much change is happening in the space. I think a separate research question exists related to some of the investment returns people have seen in the quantum computing space. Spoiler alert: some of the returns have been huge like IonQ, D-Wave Quantum, and Rigetti Computing, but that is a topic I’ll dig into during another research note. This topic has been added to the brand new research topic backlog for future consideration.This particular research note is focused on cataloging the best quantum computing systems so we can compare them to what is going to be released going forward to better understand the rate of change. My thesis here is that the rate of change in terms of qubits is about to radically increase. We are going to see the number of qubits increase, unlocking some use cases that were not practical before the increase. Players like Amazon are getting into the quantum computing space with products like the Ocelot chip [1]. A lot of roadmaps like the one from IBM currently exist with new builds of major flagship quantum computers that incorporate error-correction [2]. Keep in mind that right now both IBM and AWS will sell you quantum computing time [3][4]. I made another backlog reminder to run some quantum code on both of those services to see the services in action and provide feedback.Top 10 quantum computers by universal gate-based physical qubits:* Atom Computing - 1,180 qubits (October 24, 2023) United States* IBM Condor - 1,121 qubits (December 4, 2023) United States* CAS Xiaohong - 504 qubits (December 6, 2024) China* IBM Osprey - 433 qubits (November 9, 2022) United States* Fujitsu & RIKEN - 256 qubits (April 22, 2025) Japan* Xanadu Borealis - 216 qubits (June 1, 2022) Canada* IBM Heron R2 - 156 qubits (November 13, 2024) United States* IBM Eagle - 127 qubits (November 16, 2021) United States* Google Willow - 105 qubits (December 9, 2024) United States* USTC Zuchongzhi 3.0 - 105 qubits (March 3, 2025) ChinaFor the most part the race is between the United States (6) and China (2). It’s worth noting that two of the freshest entries to this list are from China and the latest one (April, 2025) is from Japan. We are going to see some major changes to this list either in late 2025 or 2026 as a number of companies (IBM, Fujitsu & RIKEN, and Microsoft) are targeting releases of quantum computers that would make this list. I’m specifically tracking universal gate-based physical qubit quantum computers vs. annealing systems like D-Wave Quantum as those are the ones that I think have the best shot of actually implementing and scaling Shor’s algorithm which will be the most destabilizing news headline from any of this as it will render anything outside of quantum resistant encryption obsolete [5]. That won’t be universally true on day one of this technology, but it would be true in practice as nobody is going to just use one of these quantum computers to sit around and break basic encryption all day for sport. Maybe for specific use cases or high value targets, but it won’t be a universal shift all at one time.Projected future top 10 quantum computers by universal gate-based physical qubits:* Pasqal 10k Neutral‑Atom - 10,000 qubits (Projected 2026) France* QuEra 10k Neutral‑Atom - 10,000 qubits (Projected 2026) United States* Atom Computing - 1,180 qubits (October 24, 2023) United States* IBM Condor - 1,121 qubits (December 4, 2023) United States* CAS Xiaohong - 504 qubits (December 6, 2024) China* Fujitsu & RIKEN - 1,000 qubits (Projected 2026) Japan* IBM Osprey - 433 qubits (November 9, 2022) United States* Fujitsu & RIKEN - 256 qubits (April 22, 2025) Japan* Xanadu Borealis - 216 qubits (June 1,

A 56 day posting break
Thank you for tuning in to this audio only podcast presentation. This is week 193 of the Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for the Lindahl Letter is, “A 56 day posting break.”Over the last 4 years, the Lindahl Letter has taken two pretty decent breaks in posting content. This last pause in posting happened to be the most recent 56-day posting break. Maybe this (right here, right now) is a good point in the process to refocus, reconsider, and maybe reboot. Before all that happens, let me answer the question that you all have outstanding. Yes, I read that paper from Machine Learning Research at Apple called, “The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity” [1]. This paper was foundation shaking. Those researchers from Apple ask some very serious questions about what is actually happening with these reasoning models. I have told people during conversations for years that I fervently believe that what we will see is machine learning methods and the new class of large language models being used to augment workflows and deliver specific value based use cases. That is a rational expectation for what is going to be delivered. I, for better or worse, have argued that we would see a lot of technology get built into products with enterprise scale and scope. People are going to use what gets delivered to them and is easy to enable.Several trends are on my radar that I’m curious about researching, and that is in the end what yields the spark for these Lindahl Letter research notes. A lot of companies are doing some really great work at the edge of making actual quantum computers that work. My method of measuring that is in how the latest releases are explaining the great race to have the biggest number of qubits. I think a leaderboard could be maintained with the largest qubit-based quantum computers in the world. Let’s call that race to have the best quantum computer that can accomplish real things, the first trend I’m interested in following. Second, I’m curious about the potential for agents to take action on your behalf and what that will mean for society in general. Right now, as I mentioned above, we have a lot of augmentation, but not as much action being built. I think that is a trend that will change as Google, Microsoft, and Apple get more engaged in the game. It’s also possible that Meta figures that one out, but their surface for action is more limited than the other platform companies. Third, I'm really curious about what is going to happen with machines that build machines. We had the 3D printing revolution where these things almost got commoditized to the point where most people could afford one. Moving from making things with 3D printing to potentially making machines or components that make other machines, I think will be the next major trend in manufacturing enablement.Those three trends on my radar are the great quantum computing race, agents taking action, and machines making machines. My goal here is to continue to produce research notes on a weekly basis, really diving into various parts of these trends that are totally and wholesale organically written, researched, and ultimately published. Bespoke and hand-curated content brought to your inbox every Friday. At this point, I’m taking my backlog that includes around a hundred topics for this Lindahl Letter writing effort and setting it aside to pivot to the trends listed above as an attempt to get closer to the edge of what is possible and further away from pure research of things that have already happened. As a true pracademic, my interests are really in what is becoming possible. That is not a futurist question, but a practical edge of possibility question that I believe deserves in-depth consideration.What’s next for the Lindahl Letter? New editions arrive every Friday. If you are still listening at this point and enjoyed this content, then please take a moment and share it with a friend. If you are new to the Lindahl Letter, then please consider subscribing. Make sure to stay curious, stay informed, and enjoy the week ahead!Footnotes:[1] https://machinelearning.apple.com/research/illusion-of-thinking This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit www.nelsx.com

Designed to Distract: How Technology Gets Your Attention
Thank you for being a part of the journey. This is week 179 of The Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for The Lindahl Letter is, “Designed to Distract: How Technology Gets Your Attention.”Your attention is a battlefield, and modern technology is armed with automated and now AI powered weapons of mass distraction. Every ping, notification, and infinite scroll is designed to keep you engaged, often longer than you intend. This isn’t a coincidence—it’s a calculated business model. The longer you stay on a platform, the more data it collects and the more revenue it generates through ads. This system thrives on capturing and exploiting your focus, turning your attention into a commodity. My bookshelf includes a physical copy of Tim Wu’s 2016 book, “The Attention Merchants” [1]. A lot of things have been published that dial into things related to how attention is changing.The tactics used to divert attention are subtle yet powerful. One of the most pervasive is infinite scroll, a feature introduced to eliminate natural stopping points. Instead of deciding when to stop, you’re continuously pulled into the next post or article. Similarly, autoplay videos take advantage of your inertia, playing the next episode or clip before you even have a chance to close the app. Then there are push notifications, which interrupt your focus with alerts that feel urgent but rarely are. These tools aren’t neutral—they’re designed to create a sense of compulsion.At the heart of these tactics is personalized algorithms, powered by artificial intelligence. These algorithms study your behavior, preferences, and even vulnerabilities to predict and serve content that will keep you engaged the longest. While they often provide convenience, they also create feedback loops, reinforcing behaviors that keep you tethered to a platform. For example, social media thrives on social validation loops, where likes, shares, and comments trigger dopamine hits that make you crave more engagement.This constant assault on your focus has real consequences. On a personal level, it leads to fragmented attention—the inability to concentrate deeply on tasks. Every time a notification interrupts your work, it takes an average of 23 minutes to fully refocus [2]. Multiply that by the dozens of interruptions you experience daily, and the productivity cost becomes staggering. Emotionally, the effects are just as damaging. Platforms often prioritize sensational or negative content because it generates more engagement, leading to heightened anxiety, outrage, and even depression. Relationships suffer as well; when your attention is split between your phone and the people around you, trust and connection erode.But perhaps the most insidious effect is the erosion of your ability to think deeply. Focused, uninterrupted time is essential for problem-solving, creativity, and self-reflection. Yet, in a world of constant distractions, these opportunities become increasingly rare. Instead of engaging in deep work, many of us find ourselves trapped in cycles of shallow tasks, like checking email or scrolling social media.The good news is that you can take back control. Start by turning off non-essential notifications to reduce interruptions. Most apps don’t need to buzz or flash for your attention—set boundaries so you decide when to engage. Limit your screen time with tools like app blockers or by scheduling specific periods for digital use. Another effective strategy is to introduce stopping cues to counteract infinite scroll and autoplay. For example, commit to watching one episode or reading for a set amount of time, then stop deliberately.Curating your digital environment can also help. Unfollow accounts or unsubscribe from feeds that don’t add value to your life. Replace them with content that inspires or educates you. When you use technology, do so intentionally. Ask yourself, “Why am I opening this app? What do I hope to achieve?” This small pause can prevent mindless scrolling and keep your focus aligned with your goals.The battle for your attention is ongoing, but it’s one you can win. By understanding how your focus is being diverted and taking deliberate steps to protect it, you regain the power to direct your attention where it truly matters. The next chapter will show you how to shift from reacting to distractions to prioritizing what’s most important, laying the foundation for a more intentional and focused life.Footnotes:[1] https://www.penguinrandomhouse.com/books/234876/the-attention-merchants-by-tim-wu/[2] https://ics.uci.edu/~gmark/chi08-mark.pdfWhat’s next for The Lindahl Letter?* Week 180: The Focus Formula: Prioritize What Truly Matters* Week 181: Your Attention Fortress: Building a Distraction-Free Life* Week 182: Deep Work, Rare Results: The Art of Uninterrupted Focus* Week 183: Connection in the Chaos: Restoring Presence in Relationships* Week 184: Recharge to Refocus: The Power of

Inside the Mind: The Science of Focus and Distraction
Thank you for being a part of the journey. This is week 178 of The Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for The Lindahl Letter is, “Inside the Mind: The Science of Focus and Distraction.”Focus is a skill, but to master it, you need to understand the mechanisms driving it. At its core, focus is the ability to direct attention to a specific task, thought, or sensation while filtering out, blocking, or generally ignoring distractions. It’s not a static state but a dynamic process, constantly influenced by biology, psychology, and the environment. This interplay determines whether you can sustain deep concentration or get pulled into the whirlwind of modern distractions that are a part of the digital age.Adding complexity to this equation is dopamine, the brain’s “reward” forward chemical. Dopamine motivates you by creating a sense of pleasure and satisfaction when you complete tasks or encounter something new. However, modern technology exploits this system. Every notification, like, or email provides a small dopamine hit, training your brain to seek instant gratification. This cycle rewires your focus, making it harder to engage deeply in tasks that don’t offer immediate rewards. Understanding this chemical dynamic is key to reclaiming your ability to concentrate.Focus also operates in cycles, influenced by your body’s natural rhythms. The ultradian rhythm reflecting some fraction of an hour cycles of peak energy followed by dips plays a significant role in your ability to sustain attention [1]. Aligning your work with these cycles can maximize productivity. Equally important is sleep. Quality rest doesn’t just restore your energy; it consolidates memories, clears mental clutter, and primes your brain for focus the next day. Neglecting sleep, on the other hand, leads to brain fog, reduced cognitive function, and an increased susceptibility to distractions. My sleep is tracked every day by my Oura ring and it really does correlate with readiness [2].Many myths about focus further complicate the path to mastering it. For instance, multitasking is often celebrated as a valuable skill, but research shows it splits attention and decreases productivity. Similarly, the belief that some people are naturally better at focusing overlooks the fact that focus is a skill that can be developed. And while eliminating all distractions might seem like the ultimate solution, it’s neither practical nor entirely beneficial. Instead, the goal should be to manage distractions and strengthen your ability to return to your chosen task.Despite these barriers, focus can be cultivated with the right strategies. Start by setting clear priorities for your day. A short list of three key tasks can help reduce decision fatigue and keep your attention directed. I always keep a list of things to stop doing as well. Next, design a distraction-free workspace. Declutter your environment, silence notifications, and use tools like website blockers during periods of deep work. Incorporating brief, intentional breaks is another powerful way to sustain focus. Techniques like the Pomodoro Method—25 minutes of work followed by 5 minutes of rest—can refresh your mind and prevent burnout [3].Focus is also strengthened through consistent training. Practices like mindfulness meditation improve your ability to resist distractions by teaching your brain to sustain attention on a single thought or sensation [4]. Single-tasking, where you commit to completing one task before moving to the next, is another effective exercise. Over time, these practices build your focus muscle, making it easier to engage deeply with challenging work.Understanding how focus works isn’t just an academic exercise—it’s the foundation for living intentionally in a world filled with distractions. By aligning your habits with the science of attention, you can reclaim control over your focus, direct it toward meaningful goals, and unlock your full potential. The next step is to recognize how your attention is being deliberately diverted by external forces—and to learn how to defend it.Footnotes:[1] https://scholar.google.com/scholar?hl=en&as_sdt=0%2C6&q=ultradian+rhythm+productivity&oq=ultradian+rhythm[2] https://ouraring.com/blog/how-does-the-oura-ring-track-my-sleep/[3] https://scholar.google.com/scholar?hl=en&as_sdt=0%2C6&q=pomodoro+method+effectiveness&oq=Pomodoro+Method[4] https://mindful.usc.edu/resources/What’s next for The Lindahl Letter?* Week 179: Designed to Distract: How Technology Grabs Your Attention* Week 180: The Focus Formula: Prioritize What Truly Matters* Week 181: Your Attention Fortress: Building a Distraction-Free Life* Week 182: Deep Work, Rare Results: The Art of Uninterrupted Focus* Week 183: Connection in the Chaos: Restoring Presence in RelationshipsIf you enjoyed this content, then please take a moment and share it with a friend. If you are new to The Lindahl Letter, then please consider subsc

Your valuable attention: Why Your Focus Is Under Siege
Thank you for being a part of the journey. This is week 177 of The Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for The Lindahl Letter is, “Your valuable attention: Why Your Focus Is Under Siege.”In a world where your attention is more valuable than ever, every scroll, click, and swipe is part of an invisible economy. This “attention economy” drives social media platforms, streaming services, and even productivity tools. It’s not your time they want—it’s your focus. The cost of lost attention is both personal and societal. On an individual level, fragmented focus lowers productivity, weakens relationships, and diminishes a sense of purpose. On a societal scale, the effects ripple outward, creating polarization, misinformation, and a culture that values busyness over depth. Occupied time is not always productive. We have to move to strengthen the fabric of civil society. It’s our general civility that has become unsettled.The statistics are startling. The average person now spends over seven hours daily consuming digital media. We are focused on digital driving through a forever updating sea of digital content. Notifications, pop-ups, and infinite scrolls have rewired our brains and expectations to crave constant stimulation, sadly leaving little room for deep thought or creativity. The attention span of the modern human is estimated at just 8.25 seconds—shorter than that of a goldfish [1]. This isn’t an accident; it’s by design. Technology companies have mastered the art of capturing your focus. Every feature on your favorite app, from autoplay videos to personalized algorithms, is crafted to keep you engaged for as long as possible. The longer you stay, the more data they collect and the more ads they show. Attention has become the currency of the 21st century, and you’re the commodity. People have been saying that attention is the new oil for about 7 years [2][3].Your attention is the gateway to everything you value—learning, relationships, civility, and achieving your goals. Without the ability to focus, time slips away unnoticed. Productivity declines, creativity dwindles, and even happiness suffers. The constant pull of distractions chips away at your ability to live intentionally. Yet, understanding the problem is the first step to regaining control. When you recognize that your attention is being diverted, you can begin to take deliberate steps to reclaim it.The attention economy thrives on a simple premise: the longer you stay engaged, the more valuable you are. Algorithms study your habits, preferences, and vulnerabilities, ensuring that the content you see is optimized to keep you scrolling. But the effects go beyond wasted time. In the workplace, frequent interruptions reduce productivity and lead to decision fatigue, costing billions in lost output annually. In personal relationships, divided attention weakens connections, leaving friends, partners, and colleagues feeling undervalued. On a mental health level, the endless cycle of notifications and comparisons fosters anxiety, burnout, and a distorted sense of self-worth. It feels good to feel busy, but that does not translate to actual outcomes.The good news is that you can fight back. Reclaiming your attention starts with awareness. Recognize when and where your focus is being pulled, then take actionable steps to protect it. Turn off non-essential notifications; your phone doesn’t need to buzz for every like, comment, or update. Set digital boundaries using tools like screen time trackers or app blockers to create intentional limits. Schedule time for focused, uninterrupted work on meaningful tasks. Most importantly, reconnect with presence during conversations and relationships. Put away your devices and engage fully.Your attention isn’t infinite, but it is powerful. By reclaiming control, you can transform your relationship with technology, your work, and the people in your life. The battle for your attention isn’t just a personal challenge—it’s a societal one. As individuals, we must learn to resist the pull of distractions. As a society, we must demand ethical technology that respects our focus rather than exploits it. Your focus is your greatest asset. Don’t let it be stolen. One of the big changes that I made was shifting to a fitness ring instead of allowing alerts on my wrist from a watch. For me those wrist alerts shattered my efforts to achieve deep work and sustain focus. Sometimes you just need to focus and those alerts, notifications, or messages just need to wait a little bit in the attention priority queue.Footnotes:[1] I’m not entirely sure this citation is the best source for this metric, but it does seem to be commonly cited and is from 2015 Time magazine https://time.com/3858309/attention-spans-goldfish/[2] https://www.google.com/search?q=%22attention+is+the+new+oil%22[3] https://medium.com/@setsutao/attention-is-the-new-oil-not-data-bf54c64d3279What’s next for The

Quantum Computing and Advances in Time Crystals
Quantum computing continues to captivate the imagination of scientists, technologists, and futurists alike, offering the promise of solving problems intractable for classical machines. Amidst the steady stream of breakthroughs, one concept has emerged with both scientific intrigue and practical potential: time crystals. These exotic states of matter, once considered the stuff of theoretical musings, are now taking shape in laboratories and, intriguingly, hold promise for quantum computing applications.At their core, time crystals are a new phase of matter, one that breaks time-translation symmetry. In classical physics, symmetry breaking usually refers to spatial phenomena—such as ice forming from water, where the uniformity of liquid water transitions to the structured lattice of solid ice. Time crystals, however, add a temporal twist: they exhibit periodic motion that persists indefinitely without energy input, defying classical expectations. Discovered in 2012 by Nobel laureate Frank Wilczek as a theoretical construct and experimentally realized in 2016, time crystals are not perpetual motion machines but rather quantum systems that oscillate in a stable, repeating pattern under the influence of an external driver.For quantum computing, time crystals offer a tantalizing prospect. They provide a platform where quantum states can be maintained with high coherence—essential for reliable quantum computation. Time crystals are inherently non-equilibrium systems, making them robust against many types of environmental noise. This resilience could address one of the major hurdles in quantum computing: error correction and qubit stability. A significant step forward was the recent use of time crystals in trapped-ion quantum computers, where researchers demonstrated their potential for executing quantum gates. By leveraging the stable periodicity of time crystals, quantum systems can operate in an environment that naturally mitigates decoherence, effectively improving the reliability of computations.Recent advances have seen time crystals moving from theoretical oddities to functional components in experimental setups. For instance, researchers using Google’s Sycamore processor observed time-crystal behavior, showing how these systems can be integrated into existing quantum hardware. Similarly, trapped-ion systems have demonstrated the potential of time crystals to enhance the coherence of qubits, making them candidates for long-term storage and high-fidelity operations. Additionally, their unique oscillatory states could play a role in synchronizing quantum systems across distributed networks, paving the way for scalable quantum communication.Despite these exciting prospects, integrating time crystals into practical quantum computing remains a challenge. Their behavior, while stable, is highly sensitive to precise conditions and external drivers. Scaling these systems to handle complex quantum algorithms will require significant advancements in both hardware and theoretical understanding. Furthermore, the interplay between time crystals and other emerging quantum technologies, such as topological qubits and error-correcting codes, remains an open field of inquiry. Bridging these domains could unlock entirely new architectures for quantum computation.The journey of time crystals from a theoretical prediction to an experimental reality is a testament to the rapid pace of quantum innovation. As we continue to explore their potential, these shimmering oscillations in the fabric of time may serve as a cornerstone for the next generation of quantum computers. In the ever-evolving narrative of quantum technology, time crystals represent both a scientific triumph and a beacon for what lies ahead—a fusion of curiosity, creativity, and the relentless pursuit of the unknown.Thank you for joining me for this week’s edition of The Lindahl Letter. Stay curious, and see you next week as we delve deeper into the quantum frontier.What’s next for The Lindahl Letter?* Week 177: The Attention Economy: Why Your Focus Is Under Siege* Week 178: Inside the Mind: The Science of Focus and Distraction* Week 179: Designed to Distract: How Technology Hijacks Your Attention* Week 180: The Focus Formula: Prioritize What Truly Matters* Week 181: Your Attention Fortress: Building a Distraction-Free LifeIf you enjoyed this content, then please take a moment and share it with a friend. If you are new to The Lindahl Letter, then please consider subscribing. Make sure to stay curious, stay informed, and enjoy the week ahead! This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit www.nelsx.com

Universal quantum computation
Welcome back to another edition of The Lindahl Letter. It’s week 175, and we’re diving into the fascinating topic of universal quantum computation. This is an area where the boundaries of theory and practical application intersect, offering both incredible promise and immense challenges. If you’re tuning in to this podcast for the first time, welcome aboard. For regular readers and listeners, you already know this is a space where we examine complex topics with an eye on clarity and relevance.At its core, the concept of a universal quantum computer is as ambitious as it sounds. It’s the quantum computing equivalent of a general-purpose classical computer—think of it as a machine that can perform any quantum operation, given enough time and resources. The analogy to the classical Turing machine is apt, but the quantum realm is a different beast altogether. Where classical systems rely on bits flipping between 0 and 1, quantum systems leverage qubits, which exist in superpositions and can be entangled in ways that fundamentally alter how computations unfold.Achieving universality in quantum computation boils down to the idea that we can simulate any quantum process using a combination of quantum gates. These gates are the building blocks of quantum circuits, manipulating qubits in ways that enable properties like superposition, entanglement, and interference. In practice, a small set of gates—such as the CNOT gate combined with single-qubit operations like the Hadamard and Pauli gates—forms what’s known as a universal set. With these, any quantum operation can theoretically be approximated to arbitrary precision.Of course, theory and practice are rarely perfect companions. The current landscape of quantum computing is dominated by what’s known as Noisy Intermediate-Scale Quantum (NISQ) devices. These systems are powerful but imperfect, constrained by issues like qubit fidelity, error rates, and limited coherence times. The leap to universal quantum computation requires addressing two major challenges: error correction and scalability. Quantum error correction is a monumental task in itself, demanding additional qubits to safeguard against the natural noise and decoherence that plague quantum systems. Scalability, meanwhile, demands not just more qubits but better qubits—ones that can operate with higher fidelity and stronger connectivity.Despite these hurdles, progress is being made. Theoretical frameworks, like the Church-Turing-Deutsch principle, assert that any physical process can be simulated by a universal quantum computer. That idea has fueled decades of research and development. On the practical side, companies like IBM, Google, and IonQ are racing to push the limits of what quantum systems can achieve. IBM’s ambitious roadmap to a million-qubit machine is a bold declaration of intent, and the algorithms already developed for quantum systems—like Shor’s algorithm for factoring large numbers—hint at the transformative potential waiting to be unlocked.It’s easy to see why universal quantum computation captures the imagination. The implications stretch far beyond the confines of academia or industry, touching fields as diverse as cryptography, materials science, and optimization. Yet, the path forward is long and uncertain. It’s not a matter of if we get there but when—and how the journey reshapes the landscape of computing along the way.Thank you for taking the time to explore this frontier with me. If you’ve made it this far, I appreciate your curiosity and engagement. As always, stay curious, stay informed, and I’ll see you next week for another deep dive.What’s next for The Lindahl Letter?* Week 176: Quantum Computing and Advances in Time Crystals* Week 177: The Attention Economy: Why Your Focus Is Under Siege* Week 178: Inside the Mind: The Science of Focus and Distraction* Week 179: Designed to Distract: How Technology Grabs Your Attention* Week 180: The Focus Formula: Prioritize What Truly MattersIf you enjoyed this content, then please take a moment and share it with a friend. If you are new to The Lindahl Letter, then please consider subscribing. Make sure to stay curious, stay informed, and enjoy the week ahead! This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit www.nelsx.com

Error correction tolerant quantum computing
Quantum computing has long been hailed as a transformative technology with the potential to revolutionize fields such as cryptography, optimization, material science, and beyond [1]. However, quantum computing faces a fundamental challenge: the fragility of quantum states. Quantum bits, or qubits, are extraordinarily sensitive to errors caused by environmental noise, decoherence, and operational inaccuracies. Without robust error correction, this fragility undermines the reliability of quantum computations and makes it nearly impossible to scale quantum systems for practical use. Solving this problem is not just important—it is essential. Overcoming the challenge of error correction is the key to unlocking the transformative potential of quantum computing.The most cited relevant reference here has over 900 citations. It’s 46 pages and rather math heavy in parts.Gottesman, D. (2010, April). An introduction to quantum error correction and fault-tolerant quantum computation. In Quantum information science and its contributions to mathematics, Proceedings of Symposia in Applied Mathematics (Vol. 68, pp. 13-58). https://arxiv.org/pdf/0904.2557Historically, quantum error correction has been viewed as a critical but demanding overhead. Detecting and correcting errors in quantum systems requires an extraordinary number of physical qubits to encode logical qubits, with some estimates suggesting hundreds to thousands of physical qubits are needed for just one logical qubit. This sheer overhead has presented a formidable barrier to scaling quantum systems. Recent advances, however, are changing the narrative. The concept of error correction tolerant quantum computing represents a new paradigm: rather than simply adding layers of error correction, these systems aim to minimize the resources and performance penalties associated with error correction. They incorporate innovations in fault-tolerant architectures, error-resilient algorithms, and hardware designs that lower baseline error rates, making error correction more efficient and less resource-intensive.The significance of this shift cannot be overstated. Quantum computers operate using qubits that harness the principles of superposition and entanglement, which enable powerful computational possibilities but also make qubits susceptible to errors. Errors can take the form of bit flips, phase flips, or decoherence, any of which can disrupt calculations. Without a solution to these challenges, quantum computing will remain a theoretical possibility rather than a practical tool. Error correction tolerance offers a pathway forward, reducing the burden on physical qubits and accelerating the timeline for practical quantum systems.The promise of error correction tolerant quantum computing lies in its ability to make quantum computing scalable, efficient, and cost-effective. With reduced error correction overhead, more logical qubits can be supported without requiring exponential increases in physical qubits. This enhances scalability while making quantum systems more efficient and affordable for research and industrial applications. Furthermore, error correction tolerance paves the way for faster execution of quantum algorithms, ensuring that quantum computers are not only reliable but also competitive with classical systems in terms of speed.Major players in the quantum space, including IBM, Google, and Rigetti, are actively pursuing this critical area of research. Recent breakthroughs include adaptive error correction that dynamically adjusts protocols to system performance, noise-aware algorithms that tolerate specific noise patterns, and hybrid quantum-classical approaches that use classical computation to support quantum error correction. These developments demonstrate both the complexity of the problem and the progress being made to address it. Looking ahead, future directions will likely include the integration of machine learning techniques to optimize error correction strategies and the development of materials and designs that are inherently resistant to errors.Ultimately, solving the challenge of error correction is essential for quantum computing to achieve its full potential. Without it, the field will remain limited to small-scale, experimental systems. With it, quantum computing can scale to tackle some of the most complex problems in science, industry, and beyond. Error correction tolerance represents a critical step toward this future, making the dream of practical quantum computing not just possible, but inevitable.Footnotes:[1] https://scholar.google.com/scholar?hl=en&as_sdt=0%2C5&q=Error+correction+tolerant+quantum+computing&btnG=What’s next for The Lindahl Letter?* Week 175: universal quantum computation* Week 176: Quantum Computing and Advances in Time Crystals* Week 177: The Attention Economy: Why Your Focus Is Under Siege* Week 178: Inside the Mind: The Science of Focus and Distraction* Week 179: Designed to Distract: How Technology Hijacks Your At

Nondeterministic gates tolerant quantum computation
We are going to spend some time digging into quantum computing over the next few weeks. Things are starting to move forward in that space which is exciting [1]. Let’s not waste a second and just go ahead and jump right into the deep end of this magical quantum puzzle. Here we go!Nondeterministic gates present a fascinating challenge within the evolving landscape of quantum computing. At their core, these gates function probabilistically, meaning their outcomes are not guaranteed in the deterministic sense familiar to classical computation. This intrinsic uncertainty aligns with the broader principles of quantum mechanics but complicates the goal of building reliable and scalable quantum systems. Understanding how to integrate nondeterministic gates into fault-tolerant architectures is an essential step in moving quantum computing from the lab to practical applications. On a side note we may very well dig into the brilliantly intriguing world of creating time crystals again soon during week 176 where some of the ambiguity of being probabilistic disappears.Fault-tolerant quantum computation relies on carefully crafted error-correction techniques to manage the delicate states of qubits, which are highly susceptible to noise and decoherence. The introduction of nondeterministic gates adds another layer of complexity to this already intricate problem. These gates often succeed probabilistically, necessitating either multiple attempts or supplementary operations to ensure the desired outcome. While this characteristic can simplify certain hardware requirements—especially in photonic systems where nondeterministic interactions are a natural fit—it also demands more sophisticated error management strategies to maintain computational fidelity.The key to making nondeterministic gates viable lies in adaptive computation strategies. Measurement-based quantum computing (MBQC) exemplifies this approach, using entangled resource states and measurements to drive computation. In MBQC, the probabilistic nature of certain operations is counterbalanced by flexible correction protocols, which adjust subsequent steps based on observed outcomes. It’s basically overhead from error checking and dropping the results of failed gates. This adaptability creates a robust framework for handling nondeterminism but comes at the cost of increased resource requirements, including additional qubits and computational overhead. Balancing these trade-offs is critical for the success of practical quantum systems.Nondeterministic gates challenge the quantum community to rethink what fault tolerance means in this new paradigm. Traditional error-correction methods like the surface code were designed with deterministic operations in mind, and they must evolve to address the probabilistic errors introduced by these gates. This evolution involves tighter integration of classical and quantum systems, allowing for real-time error detection and response. It also calls for a deeper understanding of how to optimize quantum resources to handle the additional uncertainty without sacrificing scalability.Here are three articles to check out:Li, Y., Barrett, S. D., Stace, T. M., & Benjamin, S. C. (2010). Fault tolerant quantum computation with nondeterministic gates. Physical review letters, 105(25), 250502. https://arxiv.org/pdf/1008.1369Kieling, K., Rudolph, T., & Eisert, J. (2007). Percolation, renormalization, and quantum computing with nondeterministic gates. Physical Review Letters, 99(13), 130501. https://arxiv.org/pdf/quant-ph/0611140Nielsen, M. A., & Dawson, C. M. (2005). Fault-tolerant quantum computation with cluster states. Physical Review A—Atomic, Molecular, and Optical Physics, 71(4), 042323. https://arxiv.org/pdf/quant-ph/0405134Footnotes:[1] https://scholar.google.com/scholar?hl=en&as_sdt=0%2C5&q=Nondeterministic+gates+tolerant+quantum+computation&btnG=What’s next for The Lindahl Letter?* Week 174: error correction tolerant quantum computing* Week 175: universal quantum computation* Week 176: Quantum Computing and Advances in Time Crystals* Week 177: The Attention Economy: Why Your Focus Is Under Siege* Week 178: Inside the Mind: The Science of Focus and DistractionIf you enjoyed this content, then please take a moment and share it with a friend. If you are new to The Lindahl Letter, then please consider subscribing. Make sure to stay curious, stay informed, and enjoy the week ahead! This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit www.nelsx.com

Transfer Learning for Features
Transfer learning has proven to be an invaluable tool in machine learning, enabling us to take advantage of pre-trained models to boost performance on new tasks, even with limited data. Instead of training a model from scratch, we can repurpose one trained on a large, diverse dataset to extract features—essential characteristics of the data—that are often applicable across various problems. For instance, in image recognition, these features might be edges, textures, or patterns that the model has learned to detect. Transfer learning allows us to reuse these learned features and apply them to new tasks, saving both time and computational resources.The key idea behind transfer learning for features is that many of the low-level features learned by a model are transferable to new domains. Models like ResNet in computer vision or BERT in natural language processing learn generalizable features from large datasets, which can be applied to a variety of new tasks. By transferring the feature extraction layers from these models, we can fine-tune them for specific tasks with far less data. This significantly reduces the amount of time and effort needed to train a model, since the lower-level features have already been learned, allowing us to focus on task-specific learning.Take medical imaging, for example. A model trained on a vast dataset of general images can be fine-tuned for tasks like detecting tumors in X-rays or MRIs by leveraging the features it already knows how to extract. Similarly, in natural language processing, models like GPT or BERT can be adapted to perform sentiment analysis or text classification tasks with minimal additional data. In voice recognition, a pre-trained model could be adapted to identify speakers or recognize commands in a noisy environment, utilizing previously learned features from a broader speech dataset.While transfer learning offers numerous benefits, it’s not without its challenges. One potential issue is domain shift, where the source and target datasets are too dissimilar, making the transferred features less useful. Fine-tuning is often required to ensure the model performs well on the new task, and this can be tricky if the new data is too sparse. Additionally, there’s the risk of overfitting when working with limited data, which could compromise the model’s generalization ability. Despite these hurdles, transfer learning remains a powerful tool, allowing us to adapt pre-trained models to new challenges quickly and efficiently.Looking ahead, the growing availability of pre-trained models and powerful transfer learning techniques is likely to drive even more innovations in fields like healthcare, finance, and beyond. As the models become more specialized and the datasets even larger, the opportunities for transfer learning will expand, enabling more complex tasks to be tackled with fewer resources. By enabling machines to generalize features across tasks, transfer learning is not only enhancing efficiency but also making machine learning more accessible to a wider range of applications, from startup projects to large-scale enterprise solutions.Things to consider this week:Footnotes:[1] What’s next for The Lindahl Letter? * Week 173: nondeterministic gates tolerant quantum computation* Week 174: error correction tolerant quantum computing* Week 175: universal quantum computation* Week 176: resilient quantum computation* Week 177: quantum computation with higher dimensional systemsIf you enjoyed this content, then please take a moment and share it with a friend. If you are new to The Lindahl Letter, then please consider subscribing. Make sure to stay curious, stay informed, and enjoy the week ahead! This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit www.nelsx.com

Graph-Based Feature Engineering
As machine learning evolves, traditional approaches to feature engineering are being transformed by the power of graph data structures. Graphs—representing entities as nodes and relationships as edges—provide a rich framework to model complex, non-linear connections that go beyond what’s possible with tabular data. It’s an area of focus I keep going back to better represent knowledge. By embracing graph-based feature engineering, we can uncover deeper insights and create more effective predictive models. I spent some time looking around Google Scholar results trying to find a really interesting deep dive on this subject and was somewhat disappointed [1].Graphs are highly versatile and have applications in diverse domains. In social networks, for example, users (nodes) interact through actions like likes, shares, or friendships (edges). Graph-based features such as centrality measures can reveal influential users or detect communities. In e-commerce, graphs model user-product interactions, capturing relationships that enhance recommendation systems. For instance, understanding the co-purchase network helps predict new product recommendations. Similarly, in bioinformatics, graphs representing protein-protein interactions or gene relationships enable predictions about biological functions or disease pathways. Knowledge graphs, which structure information in interconnected formats, help machines reason over relationships, such as identifying entity connections for natural language processing tasks.To leverage the full potential of graphs, several advanced techniques are employed. Centrality measures, for instance, quantify the importance of nodes in a graph. Degree centrality counts direct connections, while betweenness centrality identifies nodes bridging clusters. These measures are critical for tasks like identifying influencers or analyzing communication networks. Graph embeddings, such as Node2Vec or DeepWalk, map graph structures into continuous vector spaces, making them compatible with machine learning models [2][3]. Additionally, Graph Neural Networks (GNNs), like Graph Convolutional Networks (GCNs), aggregate information from neighboring nodes. These networks excel in tasks such as node classification, where labels are assigned to nodes (e.g., identifying spam accounts), and link prediction, which predicts relationships between nodes, such as friendships in social networks.Despite their advantages, graph-based feature engineering comes with challenges. Large-scale graphs can be resource-intensive, requiring efficient algorithms like graph sampling or distributed computing frameworks to manage their computational costs. Sparse graphs with limited connections can also hinder meaningful feature extraction, making advanced techniques like graph regularization essential. Addressing these challenges is critical to fully harness the potential of graph-based methods and create robust machine learning models.Graph-based feature engineering is revolutionizing machine learning by enabling us to capture relationships and dependencies within data. From refining recommendation systems to advancing healthcare predictions, graph-based approaches pave the way for deeper, more accurate insights in an interconnected world. As machine learning continues to evolve, the potential of graph-based methods will only grow, offering exciting opportunities for innovation. I’m ultimately interested in how knowledge ends up getting stored and represented moving forward within the context of exceedingly large language models. Footnotes:[1] https://scholar.google.com/scholar?hl=en&as_sdt=0%2C6&q=Graph-Based+Feature+Engineering&btnG= [2] https://arxiv.org/pdf/1607.00653[3] https://arxiv.org/pdf/1609.02907 What’s next for The Lindahl Letter? * Week 172: Transfer Learning for Features* Week 173: nondeterministic gates tolerant quantum computation* Week 174: error correction tolerant quantum computing* Week 175: universal quantum computation* Week 176: resilient quantum computationIf you enjoyed this content, then please take a moment and share it with a friend. If you are new to The Lindahl Letter, then please consider subscribing. Make sure to stay curious, stay informed, and enjoy the week ahead! This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit www.nelsx.com

Are 8K Blu-ray a thing?
Thank you for tuning in to this audio only podcast presentation. This is week 170 of The Lindahl Letter publication. A new edition arrives hopefully every Friday. This week the topic under consideration for The Lindahl Letter is, “Are 8K Blu-ray a thing?”The short answer is no—there’s currently no official 8K Blu-ray format on the market. The highest-resolution Blu-ray available right now is 4K Ultra HD. Despite the emergence of 8K TVs, the development of an 8K physical media standard has been slow to nonexistent. You can generate content at 8K using 65/70mm IMAX film scans or recording the content using native 8K RED cameras. But there’s more to this story, because what’s holding back 8K Blu-ray isn’t just a lack of demand for higher resolutions. It’s about the larger shift in how we consume media, the infrastructure needed to support it, and even questions of accessibility and ownership.The dominance of streaming has completely changed the landscape of home entertainment. Most people today reach for their remote or phone, pull up a streaming app, and press play, accessing a vast library of content without needing physical discs. And while it’s convenient, streaming isn’t the perfect solution for everyone, and it raises some interesting challenges for high-resolution content. The reality is, even today, reliable 4K streaming requires a fast and stable internet connection—something many regions in the world, including parts of the United States, still struggle with.For people in areas with slower or less reliable internet, streaming high-definition content, let alone 4K or 8K, isn’t an option. This digital divide is often overlooked in the rush to adopt the newest formats and streaming platforms. A physical 8K Blu-ray option, although niche, would offer these users a way to access ultra-high-definition content without relying on the vagaries of internet service. Physical media doesn’t buffer or depend on bandwidth. It’s a permanent, reliable way to enjoy high-quality media.Another issue that streaming raises is the matter of ownership. When you buy a Blu-ray disc, you own a copy of that film or show—something tangible that you can keep, loan, or sell. With streaming, you’re essentially renting access to content. Licensing agreements and platform decisions dictate what’s available, and content can disappear from a service overnight due to contract disputes or shifting corporate strategies. Even if you purchase a digital copy, the platform still controls your access to it, and it could be removed or rendered inaccessible if the platform decides to remove it or goes under. We’ve already seen titles vanish from digital libraries, leaving consumers who thought they “owned” these digital copies with no recourse.For film enthusiasts, collectors, or anyone who values the security of owning their media outright, physical Blu-rays still hold a lot of appeal. An 8K Blu-ray, in particular, would give these users a chance to own ultra-high-definition content at its absolute best quality. Streaming platforms, while convenient, can’t match the fidelity of a physical disc, especially when it comes to uncompressed audio and video quality. And for those who value the archival aspect of physical media, 8K Blu-ray would represent a way to preserve the best possible version of their favorite films and shows.Yet, despite these potential advantages, the market for physical media has become niche. Blu-ray players are harder to come by, with fewer manufacturers making them each year, and studios are releasing fewer physical editions. Streaming is simply more profitable and cost-effective for companies, and it aligns with current consumer habits. There’s also the fact that creating a new standard for 8K Blu-ray would require a significant investment in technology, from new players to new discs, and that investment likely wouldn’t be recouped given current market conditions.In the meantime, tech companies are focusing on improving streaming infrastructure to support 8K content. Compression algorithms are advancing, and AI-powered upscaling technologies are making it possible for 4K content to look sharper on 8K screens, even if it’s not natively 8K. This makes it unlikely that we’ll see a mass-market push for 8K Blu-ray anytime soon [1][2]. It’s possible that high-quality 8K streaming will fill that void, but it’s a solution that still doesn’t serve everyone equally.So, are 8K Blu-rays a thing? Not at this point, and they may never become mainstream. But as we move toward a fully digital media landscape, we should keep in mind what’s lost when physical formats disappear: ownership, access for all, and the assurance that our favorite content won’t vanish overnight.Thank you for joining me for this week’s discussion. Until next week, let’s keep asking what the future of media really means for us all.Things to consider this week:“Monster 4,400-qubit quantum processor is '25,000 times faster' than its predecessor”https://www.livescience.

Pure science from the last millennium
Thank you for tuning in to this audio only podcast presentation. Here we are, at week 169 of The Lindahl Letter, reflecting on a different kind of science—one rooted in a boldness that prioritized discovery over deadlines, adventure over immediate outcomes. This week’s topic, “Pure science from the last millennium,” brings us to a fundamental question: What do we want scientific investment to be going forward?Decades ago, space exploration wasn’t about quarterly returns or brand endorsements. It was the “final frontier”—a true and meaningful challenge that demanded our collective curiosity and belief in something larger than ourselves. When we look back at Voyager 1, launched in September of 1977 and still sending back data from beyond the solar system, we’re reminded of an era when we were willing to invest in the unknown and pure science [1]. We, the taxpayers, poured resources into pure science, trusting that whatever Voyager discovered would expand our horizons, even if it took generations. Those investments bank intergenerational equality in ways that pay forward with unlocked potential. That previous era of government driven budgets is evolving. Today, we’re witnessing a new chapter in space exploration, one driven not only by government agencies but by private space companies backed by some very rich individuals. Companies like SpaceX, Blue Origin, and others are racing to develop technologies that can propel humanity forward, not just in the pursuit of knowledge but with a practical eye on commercial possibilities. These companies have reignited public interest in space exploration, capturing imaginations with promises of lunar bases, Mars colonies, and low-cost satellites. But they bring a shift in perspective too—a focus on efficiency, profitability, and measurable results.Private companies are undeniably accelerating technological progress. They’re launching rockets at a pace governments could never match and making space travel more accessible. In many ways, they’re pushing us into the future faster than traditional models of science funding would allow. But this pace has implications: private companies often operate on a very different timeline and set of incentives than the public missions of the past. The long, open-ended pure science based inquiries that characterized projects like Voyager or Hubble might not fit as seamlessly into the bottom-line-driven model of private enterprise.What does this mean for the future of pure science? There’s a risk that in our rush to commercialize space, we could lose sight of the kind of exploration that doesn’t pay off right away, the kind that asks questions not because they’re immediately useful but because they might change everything someday. Voyager, Hubble, and the Mars rovers were funded with a faith that curiosity itself was valuable. They didn’t need to deliver a profit; they only needed to expand our knowledge.Investment in pure science has, over the years, shifted in response to economic pressures, political priorities, and the rise of private industry. In the mid-20th century, there was a golden age of public funding for fundamental research, driven by a sense of national pride and urgency, especially during the Space Race. Governments around the world poured money into science for the sake of knowledge itself—driven by the belief that scientific exploration, even with uncertain outcomes, would ultimately benefit society. This mindset fueled projects like the Apollo missions, the Voyager probes, and the Hubble Space Telescope, all examples of pure scientific research where the primary goal was exploration, not commercial gain.But over the last few decades, the focus has gradually shifted toward more immediate, application-driven science. Public budgets have tightened, and government funding has increasingly emphasized practical and commercial outcomes. Today, many funding bodies expect quick, measurable results—preferably ones that contribute to the economy, healthcare, or national security. This shift means that pure scientific research, with its inherently uncertain timeline and lack of immediate commercial payoff, often struggles to secure the same level of investment it once enjoyed.Thank you for joining me this week, and here’s to staying curious, even in a world that asks us to measure every journey in miles and profits.Things to consider this week:TechCrunch: “Bluesky raises $15M Series A, plans to launch subscriptions”https://techcrunch.com/2024/10/24/bluesky-raises-15m-series-a-plans-to-launch-subscriptions/Reuters: “New Nvidia AI chips overheating in servers, the Information reports”https://finance.yahoo.com/news/nvidia-ai-chips-face-issue-141200900.html [Must watch] Gary Marcus: OpenAI could be the next WeWork https://www.foxbusiness.com/video/6364719527112Footnotes:[1] https://www.cnn.com/2024/11/01/science/voyager-1-transmitter-issue/index.html If you enjoyed this content, then please take a moment and share it with a friend. If yo

Enabling automated agent actions
We all thought you would be able to easily ask the house to turn on all the lights or command your television by voice to do things by walking into the room. Some of us thought the entire wall would be a television screen by now and that has not happened either. However, some of the new 100 inch TVs on the market are really large. Enabling automated actions is what is happening within the latest development kits related to the companies making and contributing to LLMs. We have seen Google teams introduce low stakes automated actions like making dinner reservations or screening calls. Those types of training activities help them build and reinforce automations without really doing anything particularly risky. It’s all about the ecosystems and when Google teams start to really deeply allow an assistant based agent to do things that are deeply integrated at that point things are going to rapidly change. That is when your agent will be empowered to the point of being able to really automate some things that will be impactful. Sam Altman of OpenAI has said that 2025 will be the year that we will see agents working effectively [1]. I’m guessing that Sam has spent some time thinking deeply about what these agents are going to be capable of doing. We will probably start to see Google calendar automations where meetings with unfulfilled action items automatically get scheduled or task follow ups by chat can come from the agent. This type of recursive review of things that happened where a transcript is recorded and checked against a project plan or calendar is certainly on the roadmap. It’s going to be about bringing the next set of low stakes actions to the business world and calling it revolutionary. A lot of hype is going to occur. Sure systems with robotic process automation or coded workflows have been able to automate things for people willing to invest in those automations. With the advent of agents that are able to schedule automated actions it changes the barrier to entry by fundamentally lowering it. People are probably going to be more willing to trust one of the known major brands with this technology considering that most smartphones have banking information saved and are logged into a myriad of other consequential accounts. Having practical limits on what agents are able to enable in terms of automation remains probably the most important process enablement gate to be considered. Apparently the teams at Google don’t expect to deploy any useful agents until 2025 at the earliest [2].The push toward true agent-based automation is an ongoing journey. While current tools may seem like small, incremental advances—like handling calendar follow-ups or screening calls—they represent foundational steps toward a more integrated, intuitive digital ecosystem. As AI agents begin to bridge the gap between simple command-driven functions and context-aware actions, we’re stepping into an era where automation isn't just a convenience but a fundamental part of daily life. This gradual transformation will bring more impactful applications, positioning agents not as isolated tools but as active partners in our productivity.Footnotes:[1] https://www.tomsguide.com/ai/chatgpt/the-agents-are-coming-openai-confirms-ai-will-work-without-humans-in-2025 [2] https://techcrunch.com/2024/10/29/google-says-its-next-gen-ai-agents-wont-launch-until-2025-at-the-earliest/ If you enjoyed this content, then please take a moment and share it with a friend. If you are new to The Lindahl Letter, then please consider subscribing. Make sure to stay curious, stay informed, and enjoy the week ahead! This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit www.nelsx.com

Where does AI fit within Archeology?
This post is all Dr. Flint Dibble’s fault. That fault is wholesale based on all the #realarchaeology posts that have been flying around the internet [1]. If you missed all that online content about archaeology, then consider diving into all that informationally rich real archeology content. This week Flint got me thinking about how artificial intelligence and machine learning fit within the broader academic domain of archaeology. Technology is always approaching the intersection with modernity. Our technology now is ultimately becoming very different based on what the fields of AI, ML, and robotics are able to accomplish. I should have thrown quantum computing on that list, but I’m still a little skeptical about scalability. A lot of modern archaeology on television is about the discovery part of the process. Finding things like buried treasure, missing cities, or maybe a significant shipwreck yields pure excitement. Just this week I watched an episode of the ongoing television show Expedition Unknown with Josh Gates digging at Petra [2]. You may be aware that I’m generally interested in all things Indiana Jones related and this adventure certainly was. Josh Gates joined Dr. Pearce Paul Creasman onsite for the discovery and the American Center of Research is the group facilitating the actual archaeology. Generally speaking, finding new things is hard, but the process of trying to understand them is where the work of archaeology happens. Applying some type of scientific rigor to the process of figuring things out brings forward quality and makes the process definable and repeatable. We have done a lot of exploring and studying the world with satellites every day. A lot of laboratory, office, or digging work happens that is more hands-on and is about the academic parts of archaeology. That is where I was curious about how both AI and ML fit into the actual practice of archaeology. I wondered what people are doing with advanced technology. I could easily imagine people trying a machine learning model to evaluate satellite images to try to find structures in a jungle or desert. You could use a machine learning model to match images of text fragments or match a partial text to other larger texts. I’m going to share my top 10 thoughts about how AI or ML could be impactful within the field of archeology. * Automated Site Detection: Using AI to analyze satellite images and locate hidden archaeological sites* Predictive Modeling: Guided site discovery by predicting likely artifact locations from geological and historical data* Excavation Data Analysis: Speeding up artifact categorization and soil dating during digs* 3D Reconstruction: Rebuilding artifacts or sites digitally to visualize original structures* Text Decipherment: Using AI to decode ancient texts and connect languages or symbols* Remote Sensing Interpretation: Processing LiDAR and radar data to reveal hidden structures* Artifact Classification: Identifying and classifying artifacts using computer vision* Preservation Monitoring: Predicting and preventing environmental damage to sites* Cross-dataset Analysis: Finding patterns across separate data sources for deeper historical connections* Virtual Archaeology and Immersive Experiences: AI can create virtual reality (VR) and augmented reality (AR) experiences, allowing researchers and the public to explore reconstructed sites and artifacts interactivelyBeyond considering that list, you know I went out to Google Scholar and started to look for highly cited papers within this space [3]. I pulled together 5 papers you can read about AI and ML within the academic space of archaeology. None of these papers have very high citation numbers so they are not widely read like those papers I recently shared from Dr. Geoffrey Hinton that bridged 100,000 citations. These papers were in the sub 100 citation range and that does mean people are reading them, but not at the same prolific rates of core AI or ML papers. Bickler, S. H. (2021). Machine learning arrives in archaeology. Advances in Archaeological Practice, 9(2), 186-191. https://www.researchgate.net/profile/Simon-Bickler/publication/351713328_Machine_Learning_Arrives_in_Archaeology/links/60a62e36a6fdcc731d3ea200/Machine-Learning-Arrives-in-Archaeology.pdf Barceló, J. A. (2007). Automatic archaeology: Bridging the gap between virtual reality, artificial intelligence, and archaeology. https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=9f03a88221022b93d07f271037776a2c01099fce Mantovan, L., & Nanni, L. (2020). The computerization of archaeology: Survey on artificial intelligence techniques. SN Computer Science, 1(5), 267. https://arxiv.org/pdf/2005.02863 Casini, L., Marchetti, N., Montanucci, A., Orrù, V., & Roccetti, M. (2023). A human–AI collaboration workflow for archaeological sites detection. Scientific Reports, 13(1), 8699. https://www.nature.com/articles/s41598-023-36015-5 Argyrou, A., & Agapiou, A. (2022). A review of artificial intelligence and re

Those recent Nobel Prizes
Thank you for tuning in to this audio only podcast presentation. This is week 166 of The Lindahl Letter publication. A new edition arrives every Friday. This week the topic under consideration for The Lindahl Letter is, “Those recent Nobel Prizes.” This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit www.nelsx.com

Practical quantum computing and getting things done
For those of you listening to the audio version this week you may have noticed that we moved from the natural vocal capture to the narration vocal capture. I’m still recording the podcast audio for this adventure using a Blue Microphones Yeti X and my MacBook Air with the included GarageBand software. To further enhance your listening experience I’m still working to dial in the best possible recording technique to deliver superior podcast audio. Last week we really dug deep into the major corporate players that released quantum computing programing languages for general use. This week unfortunately needs to start with an epic spoiler alert. Please know that you should be aware that it does not appear quantum computing is practical at this time or really very scalable. I have read a fair number of jokes throughout the last week about neither the blockchain or quantum computer being scalable. With that spoiler delivered upfront this week it is time to move from the breadth of coverage to the depth of understanding related to what people are actually doing with practical use cases within the quantum computing space. One of the places I went to search around and learn a little bit more about use cases was the NASA Quantum Artificial Intelligence Laboratory [1]. The good folks over at NASA shared a paper in June of 2024 that was about “Assessing and Advancing the Potential of Quantum Computing: A NASA Case Study” [2]. For those of you wanting to read more quantum computing papers this is pretty easy to read and digest. It’s 27 pages and is very well cited throughout. You can join the quantum computing reddit community and it seems to be pretty active with academic discussion amongst the 50k+ members [3]. Beyond that reddit community the next place I ended up spending some time looking around was the Quantum Open Source Foundation which had a lot of content in terms of links [4]. They have a lot of curated links on the GitHub page that they maintain [5]. You could spend hours and hours of time just clicking around and looking at all of those projects. Eventually I ran into another GitHub repository called Awesome Quantum Computing that is another collection of curated links [6]. These collections of links will send you all over the place to see some interesting projects people are developing. Somehow during the hunt for the best projects using quantum computing to accomplish things I ended up back looking at the IBM Quantum Learning pages to see what things they were encouraging people to code as they learn to program [7]. The Azure Quantum team had a whole section devoted to trying to explain what solutions they are offering [8]. A lot of that seems to be focused on physics, chemistry, and ultimately material discovery and other applied applications to understand some type of complex interaction. Modeling really complex things seems to be a core use case that quantum computing has centered on based on the available evidence. I really think at this point I’m going to invest some time into completing a couple of these courses to get more hands on in the quantum computing space. I’ll share one last note about the fastest quantum computer that now has 1,180 qubits from Atom Computing [9]. It was a sizable leap from the IBM’s Osprey that was capable of 433 qubits. Hopefully we will see a bunch of fastest quantum computer records broken in the coming years. That will be a good sign that things have forward momentum in the quantum computing space.Things to consider this week:* You might want to read the 15,000 word October 2024 essay from Anthropic CEO Dario Amodei called “Machines of loving grace.” https://darioamodei.com/machines-of-loving-grace * The Anthropic team also released an updated responsible scaling policy that is a related read with the Dario Amodei essay https://www.anthropic.com/news/announcing-our-updated-responsible-scaling-policy * I enjoyed listening to Yannic Kilcher talk about and question a paper this week “GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models” https://arxiv.org/abs/2410.05229 Footnotes:[1] https://www.nasa.gov/intelligent-systems-division/discovery-and-systems-health/nasa-quail/ [2] https://arxiv.org/abs/2406.15601 [3] https://www.reddit.com/r/QuantumComputing/ [4] https://qosf.org/project_list/ [5] https://github.com/qosf/awesome-quantum-software [6] https://github.com/desireevl/awesome-quantum-computing [7] https://learning.quantum.ibm.com/ [8] https://quantum.microsoft.com/en-us/solutions/azure-quantum-solutions [9] https://www.newscientist.com/article/2399246-record-breaking-quantum-computer-has-more-than-1000-qubits/ What’s next for The Lindahl Letter? At some point this series will move back to being planned out 5 weeks ahead of publication. If you enjoyed this content, then please take a moment and share it with a friend. If you are new to The Lindahl Letter, then please consider subscribing. Make sure to stay curious, stay informe

Digging into quantum computing programing
Over the last week I started digging into quantum computer programming to see what is currently going on and what people are doing in that space [1][2]. General availability of actual quantum computing systems is the major barrier to using one to write some code [3]. You can buy time on a quantum computer or you can use a simulator. The simulators are sort of weird in general as the computing power you are using to simulate the quantum computer has a very small fractional power equivalent in terms of computing power. The biggest thing to really consider in terms of understanding where we are in terms of quantum computing is not cost or availability, but instead its a true question about the computing method itself related to having fully fault-tolerant quantum computing. Not only do you have to have methods for error correction within your quantum computing setup, but also you need a design that has proper fault-tolerant gates to avoid introducing increasing error levels within your computing. You are probably wondering if I went out to Google Scholar to find papers about fault-tolerance in quantum computing [4]. Of course that was where I went to look for papers. Here are 3 academic papers you can read with over 300 citations to consider:Steane, A. M. (1999). Efficient fault-tolerant quantum computing. Nature, 399(6732), 124-126. https://arxiv.org/pdf/quant-ph/9809054 Chow, J. M., Gambetta, J. M., Magesan, E., Abraham, D. W., Cross, A. W., Johnson, B. R., ... & Steffen, M. (2014). Implementing a strand of a scalable fault-tolerant quantum computing fabric. Nature communications, 5(1), 4015. https://www.nature.com/articles/ncomms5015 Preskill, J. (1998). Fault-tolerant quantum computation. In Introduction to quantum computation and information (pp. 213-269). https://arxiv.org/pdf/quant-ph/9712048 Let’s set aside those questions about making quantum computing sustainable and consider the code part of the equation. Major programming languages for quantum computing do exist from the players you would expect. They tend to have a lot of documentation and GitHub profiles to share the code. You could spend whole days looking at some of the languages made by major players. Here are 3 examples of major players making quantum computing language contributions. First, Qiskit was introduced as a quantum computing programming language by IBM teams back in 2017 [5][6]. Second, teams at Microsoft introduced Q# back in 2017 [7][8]. Third, Cirq is from Google AI and was introduced in 2018 [9][10]. You can start to dig into those code bases and I could find a lot of content related to the languages and a lot of hype about quantum computing. You can see that a lot of evidence exists related to quantum programming languages. The next logical questions would be how do they execute that code in practice and maybe what exactly are they doing with this quantum code. The teams at IBM have been pretty good about sharing plans to build faster and faster quantum computers [11]. You could watch the hype film about the IBM Quantum System Two that they shared to YouTube back on December 4, 2023. It’s always interesting to look at quantum computer builds; they are not the sort of thing that is going to sit under my desk or on my desk at this point within the technology curve. After all that foundational digging into the current state of quantum computing my thoughts are still conflicted about it. I know some questions exist about exactly how to deploy large scale efforts that work without propagating errors and the complexity of fault-tolerant gates. Probably the next step in my research process will be to find some examples of solid quantum computing code being used or actually deployed. That is maybe the best way to get a sense of what is being done within the quantum computing space. That research note about practical quantum computing and getting things done will probably shed some light on where things are trending. Beyond people setting records for the fastest machine or sharing hype videos the real deeper question here is what use cases are going to end up defining the technology. Footnotes:[1] https://towardsdatascience.com/an-introduction-to-quantum-computers-and-quantum-coding-e5954f5a0415 [2] https://www.mckinsey.com/featured-insights/mckinsey-explainers/what-is-quantum-computing[3] https://github.com/qosf/awesome-quantum-software [4] A Google Scholar search for “fully fault-tolerant quantum computing” https://scholar.google.com/scholar?q=fully+fault-tolerant+quantum+computing&hl=en&as_sdt=0&as_vis=1&oi=scholart [5] https://www.ibm.com/quantum/qiskit [6] https://github.com/qiskit [7] https://learn.microsoft.com/en-us/azure/quantum/qsharp-overview [8] https://github.com/microsoft/qsharp [9] https://quantumai.google/cirq [10] https://github.com/quantumlib/Cirq [11] https://www.fastcompany.com/90992708/ibm-quantum-system-two What’s next for The Lindahl Letter? At some point this series will move back to being planned out 5 weeks ah

The increasingly synthetic internet
We are facing a new reality where the tipping point has been passed and a majority of content being generated online within the internet is now synthetic. Organic content generation simply cannot keep up with the flood of synthetic content. Those bot farms creating content never sleep. They just churn out content and pretend that it remains evergreen. My consideration on this topic started back on Wednesday, July 31, 2024, when I was invited to access SearchGPT from OpenAI [1]. Using that platform made me think a lot about how we access information and the ways that will change going forward. People are now getting summaries and completing searches that go beyond Googling something. You are probably well aware by now that I’m deeply concerned about how facts and knowledge are going to be stored and curated going forward. Going forward whoever owns the stores of facts or knowledge will effectively own history and how it is presented which is truly a watershed change in our shared understanding of the world. Individual voices and publications will be overshadowed by these collections. Owning the datastores that provide definitive facts or knowledge will be the cornerstone of whatever emerges going forward and should not be underestimated in terms of future value. I don’t think the ownership of facts will become commoditized and open sourced. I really do think it will be privatized and tightly controlled. Somebody who wanted to pivot our understanding on a particular point of inquiry could just start serving up that alternative perspective. Instead of people funding think tanks to ultimately change the messaging the next step will be funding content farms to just flood the message delivery. Keep in mind that people generally are not really reading books anymore [2]. That means that reasoning during the course of interpreting information may be a diminishing skillset.Organically written original content exists online. Synthetically generated content has been on the rise. A lot of bots are scraping content for model training and trying to figure out what is organic and what is synthetic has become increasingly difficult. One of the hallmarks of my writing efforts has been the originality or maybe novelty of my research efforts. Within the broader context of the academy of academic thought, original contributions are what build that content and strengthen it overall. Diluting, derivative, and otherwise mediocre publications just flood the overall academic community. It’s perfectly fine to write a publication and decide it was not a significant contribution. Instead of maybe holding back those lesser works they are now freely shared in online archives and unfortunately a new generation of journals. The increase in AI related publications has been astonishing from 2010 to 2022 the number of publications nearly tripled [3]. Now we have a mix of the poorly written articles mixing with the synthetically generated to create a truly problematic future of consuming content. I’m considering web traffic at the moment, but the overall storage of facts and knowledge is certainly in scope. We reached the tipping point around 2016 where more traffic is mobile traffic than from a desktop browser [4]. OpenAI has now launched SearchGPT and beyond the dichotomy between mobile and desktop traffic we are about to see the rise of LLM interpreted results where people may never actually leave the landing page or interface of the search engine. It’s possible that dichotomy will fade away and the majority of traffic will be from bots scraping things to share within the newly powered search interfaces. People may very well interact with the grand volume of online information from applications using APIs to respond that are completely disconnected from what was the open internet people surfed and experienced. From reading the thoughts of a single writer to interpreting the output of the largest language models ever created. Things are changing at an incredibly rapid pace.Now it’s time for a brief editorial note. Please note that my writing output over the last few years became over indexed on artificial intelligence and machine learning. Going down that rabbit hole was good at first and it was an effort truly focused on depth and breadth within the subject. Unfortunately, my focus lingered and instead of writing research notes about technological innovation, civil society, and the intersection of technology and modernity that pesky over indexing occurred. Now thanks to a moment of reflective practitioning I’m breaking out of that pattern and returning to what I consider a better balance of writing topics. Thank you for being along for that journey and the upcoming course correction.Footnotes:[1] https://chatgpt.com/search [2] https://www.pewresearch.org/short-reads/2021/09/21/who-doesnt-read-books-in-america/ [3] https://arxiv.org/abs/2405.19522 or https://aiindex.stanford.edu/wp-content/uploads/2024/04/HAI_AI-Index-Report-2024_Chapter1.pd

Indexing facts vs. graphing knowledge
In the digital age, the methods we use to organize and comprehend information are continually evolving. Two significant approaches stand out: indexing facts and graphing knowledge. Both play essential roles in how we structure, retrieve, and understand data, but they serve distinct purposes and offer different advantages.Let’s start out by looking a little deeper into indexing facts. Indexing is a traditional and straightforward method. It involves categorizing and listing information in a manner that allows for easy retrieval. Think of it as a library catalog, where every book has a unique identifier and is placed in a specific location based on its subject. This system is incredibly efficient for finding discrete pieces of information quickly. For example, a keyword search in a database relies heavily on indexing.Indexes are foundational to databases and search engines. They allow us to locate specific data points without having to sift through every piece of information manually. This method is highly effective for tasks that require precision and speed. However, indexing has its limitations. It often lacks context and relational understanding between different pieces of data. An index can tell you where something is but not necessarily how it connects to other information.Graphing knowledge, on the other hand, is about mapping relationships between data points. This approach is exemplified by knowledge graphs, which visually represent the connections between different concepts. A knowledge graph is more than a mere collection of facts; it is an interconnected web that shows how different pieces of information relate to one another.In a knowledge graph, nodes represent entities (such as people, places, or concepts), and edges represent the relationships between these entities. This structure allows for a more holistic understanding of information. For instance, a knowledge graph can illustrate how historical events are connected, how scientific concepts overlap, or how social networks operate.The advantages of graphing knowledge are manifold. It provides context, reveals patterns, and helps in discovering new insights that might not be apparent through traditional indexing. Knowledge graphs are particularly useful in fields that require deep understanding and analysis, such as artificial intelligence, semantic web technologies, and complex decision-making processes.The intersection of indexing facts and graphing knowledge represents the future of information management. By combining the precision of indexing with the relational depth of knowledge graphs, we can create systems that are both efficient and insightful. This hybrid approach can enhance our ability to process and understand vast amounts of data, making it possible to derive meaningful insights quickly.For example, search engines are evolving to incorporate elements of both indexing and graphing. Google's Knowledge Graph is a prime example, aiming to understand the context behind search queries to provide more relevant results. This system not only indexes web pages but also understands the relationships between different pieces of information, delivering a more nuanced response to users' queries.Indexing facts and graphing knowledge are not mutually exclusive; they are complementary methods that, when combined, can significantly enhance our understanding and management of information. By leveraging the strengths of both approaches, we can build more robust systems that not only store and retrieve data efficiently but also provide deeper insights and understanding. As we continue to advance in the digital age, the fusion of these methods will undoubtedly play a pivotal role in shaping the future of information technology and knowledge management.What’s next for The Lindahl Letter? * Week 163: Self-Supervised Learning* Week 164: Graph-Based Feature Engineering* Week 165: Federated Feature Engineering* Week 166: Explainable Feature Engineering* Week 167: Adaptive Feature EngineeringIf you enjoyed this content, then please take a moment and share it with a friend. If you are new to The Lindahl Letter, then please consider subscribing. Stay curious, stay informed, and enjoy the week ahead! This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit www.nelsx.com

Structuring really large knowledge graphs
You never really have to worry about how you store knowledge. All that knowledge just gets accumulated day by day and how it is stored, structured, and even retrieved happens without any intervention. It’s just something that you do autonomously. That is very different when you have to manage all that data and store it. Navigating the intricate maze of data science, structuring really large knowledge graphs presents itself as both an art and a science. This endeavor, crucial for deepening our understanding and utilization of complex datasets, entails a series of pivotal steps and considerations. Today, we'll explore the foundational principles and practical strategies for effectively structuring these expansive networks of interconnected information, while drawing on the organizational wisdom of traditional knowledge structures like the Dewey Decimal System (DDS).Understanding the basics seems to take more and more time these days. Knowledge graphs are more than mere data structures; they represent information through a web of entities and their interrelations. They offer a robust framework for integrating data from a multitude of sources, enhancing our ability to derive richer insights and make more informed decisions. As the size of the knowledge graph expands, so too does the complexity of structuring it effectively.Key Components of Knowledge Graphs1. Nodes and Edges: At the heart of any knowledge graph are nodes (entities) and edges (relationships). Nodes can embody concepts, objects, or events, while edges illustrate the interconnections among these nodes. The quality and comprehensiveness of your knowledge graph hinge on the precise definition and linking of these elements. You deal with these types of relationships every day without even an afterthought. The types of things you manage passively are more complex when they have to be handled in a planful way. 2. Ontology: This serves as the schema or structural framework that delineates the types of entities and relationships within the graph. A well-crafted ontology ensures consistency and coherence, enabling more effective querying and analysis. I’m actually a fan of declaring things as a fact or not a fact and then storing those facts in buckets that are easy to retrieve. 3. Data Ingestion and Integration: Large knowledge graphs often amalgamate data from various sources. Efficiently integrating this data while preserving its integrity and relevance is a critical challenge, involving data cleaning, normalization, and transformation.Knowledge Structures and the Dewey Decimal SystemDrawing inspiration from the Dewey Decimal System can provide valuable insights into structuring knowledge graphs. The DDS organizes information into a hierarchical, decimal-based classification system, which can serve as a model for categorizing and indexing data within a knowledge graph.1. Hierarchical Classification: Like the DDS, hierarchical classification in a knowledge graph helps organize information into broad categories and narrower subcategories. This ensures that related entities are grouped together, facilitating easier navigation and retrieval.2. Decimal Notation: Utilizing a decimal notation system to categorize entities and relationships can add a layer of precision and order to a knowledge graph. Each node and edge can be assigned a unique identifier, akin to how books are classified in libraries.3. Subject Headings: Implementing subject headings, similar to those in the DDS, can aid in tagging and describing nodes with relevant keywords. This enhances the searchability and contextual understanding of the graph.Strategies for Structuring Large Knowledge Graphs1. Scalability: Ensure your infrastructure can handle the increasing volume of data. This often involves distributed computing and storage solutions, such as cloud-based platforms that can scale horizontally.2. Data Modeling: Design your data model with future growth in mind. Anticipate new types of entities and relationships, ensuring that the graph can evolve without significant restructuring.3. Indexing and Partitioning: Use indexing to speed up queries and improve performance. Partitioning the graph into manageable sub-graphs can also enhance efficiency, especially when dealing with very large datasets.4. Query Optimization: Develop efficient query strategies to handle complex searches. This might involve using specialized query languages like SPARQL or leveraging graph database technologies that support high-performance querying.5. Visualization and Interaction: For large knowledge graphs, visualization tools are invaluable. They help in understanding the structure and relationships within the graph, making it easier to navigate and extract insights.Tools and TechnologiesSeveral technologies and tools are pivotal in constructing and managing large knowledge graphs:1. Graph Databases: Neo4j, Amazon Neptune, and ArangoDB are designed to handle large-scale knowledge graphs, offering robust querying

Increasingly problematic knowledge graph updates
Over the years the team over at Google has made a really big knowledge graph that you can access via an API and that they use as an informational backbone [1]. In some ways it is the best of what the old web had to offer. They note that it is a database of billions of facts. We are starting to see the creation of just a ton of middling, mediocre, or otherwise terribly written content online [2][3]. Now imagine you had built a knowledge graph of billions of facts. You can’t stop updating that large of a knowledge graph. It would grow stale so quickly with how fast the intersection of technology and modernity is occurring. Let me say that another way you now face a situation where a great flooding of bad content is going to overwhelm your knowledge graph. Yeah a tsunami of imagined information and otherwise hallucinated content is going to destabilize the integration of that knowledge graph. Even the notion that it would be built on facts begins to fade away as a sea of LLMs spit out confusion in the form of very confidently written fabrication.I’m now going to dig into the world of thought related to combining or using in concert LLMs and knowledge graphs. Probably the most interesting breakdown for the future of knowledge graphs will be proprietary locked in ones vs. the decentralized knowledge graphs that could even be powered by a blockchain [4]. We are going to see a huge battle between decentralized knowledge graphs that maybe use even a federated approach to stay fresh and the near monolithic large knowledge graphs that individual corporations are trying to keep perpetually fresh. One paper dealing with the combination of LLMs and knowledge graphs would be, “Large Language Models and Knowledge Graphs: Opportunities and Challenges,” that was published back in 2023 [5]. Another paper from 2023 would be, “Connecting AI: Merging Large Language Models and Knowledge Graph,” that is generally covering the same conceptual landscape [6].Some people are starting to make arguments that maybe the internet is really starting to break. The internet, once hailed as a beacon of boundless opportunity, now finds itself at a precarious crossroads clouded by mounting concerns. As behemoth tech entities tighten their grip, questions of control and influence darken the digital horizon. Privacy breaches and the insidious spread of misinformation cast a long shadow over its once-promising landscape. Algorithms meant to connect have inadvertently fueled division, while the exploitation of personal data raises profound ethical quandaries. Meanwhile, the internet's infrastructure strains under the weight of cyber threats and a persistent digital divide, where access remains unequal and opportunities unevenly distributed. Yet amidst these challenges, a sense of loss pervades—the fading promise of an open, inclusive digital future. Navigating this uncertain terrain demands a collective effort to reclaim the internet's original ideals of empowerment and connectivity, ensuring it remains a force for good amid mounting challenges.Footnotes:[1] https://support.google.com/knowledgepanel/answer/9787176?hl=en [2] https://www.niemanlab.org/2022/12/the-ai-content-flood/ [3] https://www.thealgorithmicbridge.com/p/how-the-great-ai-flood-could-kill [4] https://medicpro.london/decentralised-knowledge-graphs/ [5] https://arxiv.org/pdf/2308.06374 [6] https://www.computer.org/csdl/magazine/co/2023/11/10286238/1RimWA0RzFK What’s next for The Lindahl Letter? * Week 161: Structuring really large knowledge graphs* Week 162: Indexing facts vs. graphing knowledge* Week 163: Self-Supervised Learning* Week 164: Graph-Based Feature Engineering* Week 165: Federated Feature EngineeringIf you enjoyed this content, then please take a moment and share it with a friend. If you are new to The Lindahl Letter, then please consider subscribing. Stay curious, stay informed, and enjoy the week ahead! This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit www.nelsx.com

The next level of featurization
Things are starting to align within this renewed writing project as my content creation process gets back into some semblance of a proper routine. We are getting pretty close to a place based on the current state of technology where my weekly podcast audio could be produced using a model based on my voice in a matter of seconds. That is not really something that I am considering. I have recorded the last two podcast episodes using my newly acquired MacBook Air using the freely supplied GarageBand software instead of using Audacity on my Windows powered desktop computer. I’m still using the Yeti X microphone and a Marantz Sound Shield Live professional vocal reflection filter, but the operating system and software being used for recording the audio is very different. For scientific purposes, you are welcome to go back and listen to a few of the previous recordings and then check out any episode from 157 forward to see if the audio quality is different. I think the overall quality of the recording is higher with the new setup. We are going to jump into the deep end of featurization for machine learning this week. To achieve that effort in practice a series of potential next level featurization techniques will be evaluated. Yes – you guessed it, a new series is forming. Within 7 upcoming editions of this Substack newsletter, including upcoming weeks 163 to 169, I’m going to try to pull together some solid coverage and include some academic articles to read related to these topics. You know that I strive to find the best open research papers to share. Things that reside behind a paywall where practitioners and pracademics cannot easily read them I tend to exclude from these missives. That is a choice that is being made on purpose to favor open research. I’ll be really digging into each of these topics in more detail during some future missives. On a side note, It’s about time to refresh my open source intro to machine learning syllabus as well [1]. Here are some concepts that to me are highly promising strategies in feature engineering that represent good places to focus understanding as we move toward the future of the field:* Self-Supervised Learning: Leveraging large amounts of unlabeled data to automatically learn feature representations.* Graph-Based Feature Engineering: Utilizing graph neural networks to capture relationships and dependencies in graph-structured data.* Federated Feature Engineering: Creating features in a decentralized manner to enhance privacy and security by keeping data distributed.* Explainable Feature Engineering: Developing features that improve model interpretability and explainability.* Adaptive Feature Engineering: Using dynamic techniques that evolve features based on real-time data and model feedback.* Synthetic Data Generation: Generating synthetic datasets to create new features and augment training data.* Transfer Learning for Features: Reusing feature representations learned from one domain or task to another, reducing the need for extensive feature engineering in new tasks.These strategies power feature engineering by providing more advanced, adaptive, and interpretable features for cutting-edge machine learning models. Feature engineering is crucial to machine learning for several reasons:* Improves Model Performance and Efficiency: Well-engineered features enhance the predictive power and efficiency of machine learning models, leading to better accuracy and faster convergence during training.* Simplifies Complexity and Enhances Interpretability: Effective feature engineering simplifies the problem space, making models easier to understand and interpret, thereby increasing stakeholder trust in the model's predictions.* Incorporates Domain Knowledge and Handles Diverse Data: Integrating domain-specific knowledge and transforming diverse data types into a consistent format ensures models can process information effectively and produce relevant results.* Addresses Data Quality and Robustness: Feature engineering helps clean and normalize data, handle missing values and outliers, and improves the model's robustness to changes in data distribution and external conditions.Now that the foundation has been set for considering featurization within the machine learning space you can sit back and relax as these topics receive even more evaluation within future editions of this newsletter. Footnotes:[1] https://www.researchgate.net/publication/362679091_An_independent_study_based_introduction_to_machine_learning_syllabus_for_2022 What’s next for The Lindahl Letter? * Week 160: Increasingly problematic knowledge graph updates* Week 161: Structuring really large knowledge graphs* Week 162: Indexing facts vs. graphing knowledge* Week 163: Self-Supervised Learning* Week 164: Graph-Based Feature EngineeringIf you enjoyed this content, then please take a moment and share it with a friend. If you are new to The Lindahl Letter, then please consider subscribing. Stay curious, stay informed, a

All the future AI features
Longtime readers of my work know that within my normative bias I tend to break things down into form, function, assumptions, and structure (FFAS). Instead of taking that path with this Substack based letter format, each week my commentaries are going to drift into a more ongoing narrative about the patterns, traditions, and concerns that rise to the forefront of my thoughts. All right, now is the time, let’s jump into that narrative at the deepest end of the things being considered. Maybe the theme of today is about thinking globally and building action locally. That trope remains popular and will continue to be popular moving forward. Zooming out to the global view of things a number of ongoing narratives abound these days with a sea of digital content being created. A great flood of information has been intensifying. I would actually begin to build up an argument that even the best collections of knowledge are going to start breaking down as the flood intensifies. We are now seeing the script get flipped and things are going from macro flooding to incredibly local models that are unique to individual computer operating systems. We are probably going to have to see some sort of defense against actors trying to federate all the local models into a larger system of trading.Apple executives are reasoned and measured in the deployment of products. Like many of you, I was seriously curious to see what they would do at Apple as AI hype reached a crescendo. Earnings calls and forecasts seem to be triangulated on what AI will do for a company. Apparently, Apple Intelligence is going to do a lot of things [1]. It’s going to do so many things within the Apple ecosystem that endless hours have speculated about it. Google had the opportunity to really bring all the data within their ecosystem together in a very local way, but for some reason they just did not deliver on that potential. We are seeing Microsoft teams bringing forward a feature called recall which uses continuous screenshots with a local model. We are also starting to see the arrival of Copilot machines [2]. That means both Apple and Microsoft are going to provide very local personalized AI experiences. It’s unlikely that Apple executives will try to capture local user data and use it for federated LLM training. However, our friends at Microsoft will probably call this anonymized continuous learning a feature that enhances the model. Over the last couple of years I have had numerous conversations with people about understanding ROI related to technology projects. During those chats I try to explain that AI or ML is not really the product of the future for most companies. Telling people that their company is probably not the one that will become infinitely rich off of AI is always dicey. I think the underlying technology, models, and methods will become commoditized. Whatever company emerges at the top may have a brief advantage, but it will fade quickly as no moat exists for a repeatable idea. Generally speaking, most companies will end up using AI/ML to augment, automate, or add features to products they already have or are considering building. We are starting to see major players like Apple, Google, and others explaining that AI will power features or delivery in core products. It’s happening now in terms of announcements and we are now waiting for all the future AI features to launch. Maybe at some point along the way during the true intersection of technology and modernity we will see an AGI event or something on that level. All the future AI features are about to get a lot more coverage as people realize just how much has been spent to get to where we are right now. Nvidia as a company had a stock split and has the largest market cap after recently beating out both Apple and Microsoft. A mind boggling amount of money has been spent training models in both the cloud and in terms of hardware. We are starting to see some more specialized hardware showing up to the party. For some companies the GPU was the coin of the realm. Over at Hugging Face you can take a look at the open LLM leaderboard to see what model is currently king of the hill [3]. You will see from that sightseeing tour of the Hugging Face leaderboards that a lot of different LLM models exist right now and a lot of them are bunched up in terms of the rankings. What is interesting about that is that you can download models. Some of them even run locally and are pretty accessible in terms of deployment and usability. Footnotes:[1] https://www.apple.com/apple-intelligence/ [2] https://blogs.microsoft.com/blog/2024/05/20/introducing-copilot-pcs/ [3] https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard What’s next for The Lindahl Letter? * Week 159: The next level of featurization* Week 160: Increasingly problematic knowledge graph updates* Week 161: Structuring really large knowledge graphs* Week 162: Indexing facts vs. graphing knowledgeIf you enjoyed this content, then pl

You can’t stop the signal
It’s time to get ruthless about actually managing my epic writing backlog. You can rewind to a previous Substack newsletter with a search or for you subscribers you can check your previous email for the epic 2024 predictions post on January 19, 2024. That was according to my records the post for week 156. Instead of starting up a season two of the podcast I’m just going to lean into the signal of things and publish this missive as week 157 of the Lindahl Letter. For those of you who are new to this ongoing chautauqua of learning and consideration, welcome to the journey. Let’s refocus on working to fix that problematic backlog. Right now it is a Google Doc stored backlog with 147 line items or topics (years worth) that were cataloged for future coverage. At this point in that writing journey, I’m not entirely sure that during that backlog acceptance process a degree of good judgment was used. A lot of things piled up and were not ruthlessly screened for quality or the best possible adventure. You can’t stop the signal. We as a society have opened the door to a never ending, always growing, or perpetually flooding stream of content. Even experts in their respective fields of study are facing more content being created than can be consumed. At that point, even the experts are having to gate, limit, or constrain the universe of possible material to consider. We may have hit that weird tipping point where no matter what the amount of content that exists it is greater than what can be consumed. Not only are we at the edge of technology intersecting with modernity, but also we have crossed the maximum of human consumable knowledge. No matter what as we go forward even the best specialized experts will have a limited view of the possible universe of knowledge. You have to pick the best possible window of understanding. That means that really only the researchers at the edge of what is possible will be able to define what’s next, but only for a certain window of time which will quickly be reframed by new windows.One way to look at the flooding of academic articles is to evaluate how reviewers (functionally the gatekeepers) are being impacted by the flooding of content [1][2]. Maybe just maybe the review system itself will break down and something else will need to be created. I actually favor a system where each university willing to do the work as a department would be the home of a journal and the system is generally more open for people to be able to read academic research. I think this will focus and push clear research trajectories forward. That system might just help push things along toward a system where the answer is to conduct more research and publish it. All that research will beget more writing at the edge of knowledge. Questions will be answered. New questions will appear and that cycle will continue going forward. A lot of academic articles should be sorted by contribution level to the academy. That might help researchers limit the universe of articles that need to be reviewed during any given research project. Footnotes:[1] Hanson, M. A., Barreiro, P. G., Crosetto, P., & Brockington, D. (2023). The strain on scientific publishing. arXiv preprint arXiv:2309.15884. https://arxiv.org/abs/2309.15884 [2] Thelwall, M., & Sud, P. (2022). Scopus 1900–2020: Growth in articles, abstracts, countries, fields, and journals. Quantitative Science Studies, 3(1), 37-50. https://direct.mit.edu/qss/article/3/1/37/109076/Scopus-1900-2020-Growth-in-articles-abstracts What’s next for The Lindahl Letter? * Week 158: All the future AI features* Week 159: The next level of featurization* Week 160: Increasingly problematic knowledge graph updates* Week 161: Structuring really large knowledge graphs* Week 162: Indexing facts vs. graphing knowledgeIf you enjoyed this content, then please take a moment and share it with a friend. If you are new to The Lindahl Letter, then please consider subscribing. Stay curious, stay informed, and enjoy the week ahead! This is a public episode. If you would like to discuss this with other subscribers or get access to bonus episodes, visit www.nelsx.com