
Software Engineering Daily
2,200 episodes — Page 39 of 44
Ep 362Uber’s Postgres Problems with Evan Klitzke
When a company switches the relational database it uses, you wouldn’t expect the news of the switch to go viral. Most engineers are not interested in the subtle differences between MySQL and Postgres, right? Uber recently switched from having Postgres as its main relational database to using MySQL. Evan Klitzke wrote a detailed blog post about the migration, and post got very popular for at least three reasons: If you are even slightly interested in distributed systems or databases, I recommend reading Evan’s blog post in detail.
Ep 361Relational Databases with Craig Kerstiens
Relational databases are used by most applications. MySQL, Postgres, Microsoft SQL Server, and other products implement the core features of a relational database in different ways. A developer who has never studied this space in detail may not know the differences between these databases, and in this episode we describe some tradeoffs that relational databases can make. Craig Kerstiens is an engineer at Citus Data, a company that makes scalable Postgres. We talk about the requirements for a relational database, ACID compliance, how different databases handle different distributed systems problems, and the recent blog post from Uber about the company’s switch from Postgres to MySQL.
Ep 360The Recurse Center with Nick Bergson-Shilcock
Learning to program is about self-driven exploration. Universities help guide you, coding boot camps provide a rigorous environment to work in, and online coding courses provide content for you to study. But none of this will turn you into a great programmer unless you have the drive to improve and the curiosity to explore. The Recurse Center is a place where people can come to become better programmers. Nick Bergson-Shilcock is a founder of The Recurse Center and he joins the show to discuss how it works and why he started it. This episode is a continuation of our exploration of coding boot camps, online courses, and universities, which are the pillars of programming education. The Recurse Center presents another unique model for improving as a programmer.
Ep 359Facebook Relationship Algorithms with Jon Kleinberg
Facebook users provide lots of information about the structure of their relationship graph. Facebook uses that information to provide content and services that are expected to be important to users. If Facebook knows who the most important people in my life are, Facebook can use that knowledge to serve me content that is more relevant to me. Jon Kleinberg studied Facebook network structures together with Lars Backstrom, creating a paper called “Romantic Partnerships and the Dispersion of Social Ties: A Network Analysis of Relationship Status on Facebook”. The goal of this study was to find a metric that could help rank the strength of relationships on Facebook, and the results have implications for sociology as well as the way that we think about building social networks. Jon is a professor of Computer Science at Cornell, and wrote the textbook “Algorithm Design” which I used in college, so it was a privilege to get to talk to him.
Ep 358Drones with Buddy Michini
Drones will become a central part of our lives. Drones are delivering packages, surveying cell phone towers, providing wi-fi, or fertilizing crops. Drones are assisting humans in dangerous work, and serving as an entirely new computing platform, providing services that were previously nonexistent. Airware is a company that is building a full-stack drone platform. In this episode, Buddy Michini takes us through the software architecture of a drone. Airware’s drones have two operating systems–one for the real-time flight critical aspects and one for application developers who want to build their own software for drones.
Ep 357Music Deep Learning with Feynman Liang
Machine learning can be used to generate music. In the case of Feynman Liang’s research project BachBot, the machine learning model is seeded with the music of famous composer Bach. The music that BachBot creates sounds remarkably similar to Bach, although it has been generated by an algorithm, not by a human. BachBot is a research project on computational creativity. Feynman Liang created BachBot using Python machine learning tools to build a long-short term memory model. Our conversation explores artificial intelligence, music, and his approach to this research project.
Ep 356Automated Content with Robbie Allen
You have probably read a news article that was written by a machine. When earnings reports come out, or a series of sports events like the Olympics occurs, there are so many small stories that need to be written that a news organization like the Associated Press would have to use all of its resources to write enough content to cover it all. Wordsmith is a tool for automated content generation, and today’s guest Robbie Allen is the CEO of Automated Insights, the company that makes Wordsmith. He talks today about the wide range of uses for automated content, as well as how to engineer a product that takes data from a spreadsheet and turns it into a human-readable sentence. Robbie is also speaking at the O’Reilly Artificial Intelligence Conference in New York, September 26-27.
Ep 355Haskell in Production with Carl Baatz
The Haskell programming language is often thought of as an academic tool, useful for teaching students about monads and functors, but not much else. But there are advantages to using Haskell as a production backend language. Better is a company built with Haskell on the backend, and Carl Baatz wrote a blog post detailing his experiences using Haskell. He joins the show to give a detailed explanation of why a company might want to use Haskell on the backend, from software architecture, to testing, to hiring.

Ep 354CoreOS with Brandon Philips
Google’s infrastructure has been the source inspiration for research papers, software projects, and entire companies. Google pioneered the idea that we care less about the individual machines we are running our applications on, and more about the applications themselves. Containers are the abstraction we use to separate the concerns of the application from those of the underlying hardware. CoreOS is an operating system built with this paradigm shift in mind. In a data center, the main job of the operating system is to be a platform for containers to run smoothly on. Brandon Philips is the CTO of CoreOS and he joins the show to explain what CoreOS does differently to power the applications that get deployed on top of it.
Ep 353Artificial Intelligence with Oren Etzioni
Research in artificial intelligence takes place mostly at universities and large corporations, but both of these types of institutions have constraints that cause the research to proceed a certain way. In a university, basic research might be hindered by lack of funding. At a big corporation, the researcher might be encouraged to study a domain that is not squarely in the interest of public good–such as targeted advertising. Oren Etzioni is the CEO of the Allen Institute for Artificial Intelligence, and in this episode we discuss AI research–from the doomful premonitions of Nick Bostrom to the unbridled optimism of Ray Kurzweil, as well as the realities of how AI research actually proceeds. Projects at the Allen Institute are defined and structured to solve problems in an intelligent, scalable fashion, so that engineering can proceed steadily from the local maxima of a problem domain to the global maxima. The Allen Institute seeks to bridge the gap by providing ample funding for open source AI research for the common good. Oren is also speaking at the O’Reilly Artificial Intelligence Conference in New York, September 26-27.

Ep 352Uber’s Ringpop with Jeff Wolski
Uber has a software architecture with unique requirements. Uber does not have the firehose of user engagement data that Twitter or Facebook has, but each transaction on Uber is both high value and time-sensitive. Users are paying for transportation that they expect to be available and reasonably close by. When Uber’s system is trying to match a rider with a driver, availability is favored over consistency. It is important that the rider can always get some driver, even if it is not the best driver. Ringpop is a system built at Uber to provide scalable, fault-tolerant, application layer sharding. Ringpop consists of a membership protocol, consistent hashing, and forwarding capabilities. Jeff Wolski is a software engineer at Uber working in Ringpop, and he joins the show to explain how Ringpop brings coordination to distributed applications.
Ep 351Kubernetes Migration with Sheriff Mohamed
Kubernetes is a cluster management tool open sourced by Google. On Software Engineering Daily, we’ve done numerous shows on how Kubernetes works in theory. Today’s episode is a case study in how to deploy Kubernetes to production at a company with existing infrastructure. GolfNow is a fifteen year-old application written in C# .NET. It is a successful, growing business that is a division of NBC Sports. As GolfNow has grown, it has encountered scalability issues, and the engineering team at GolfNow decided to move its entire monolithic infrastructure to microservices running in Docker containers, managed by Kubernetes. Sheriff Mohamed joins the show today to discuss migrating his company’s application to Kubernetes. It’s a great show for anyone who is moving a large team to Kubernetes, or considering the technology for their application.
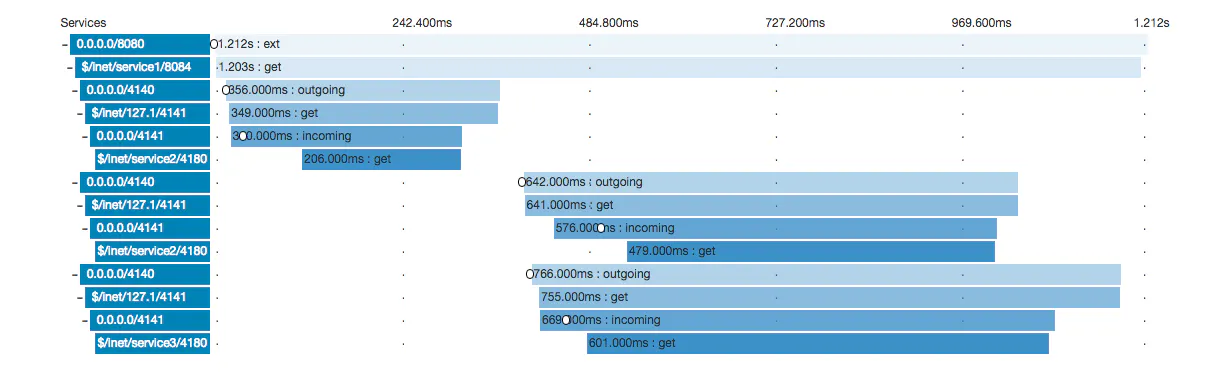
Ep 350Distributed Tracing with Reshmi Krishna
In a microservices architecture, a user request will often make its way through several different services before it returns a result to the end user. If a user experiences a failed request, the root cause could be in any of the services along that request path. Even more problematic is the challenge of debugging latency in this kind of request chain. Reshmi Krishna joins the show today to discuss distributed tracing, the process of tracking the path of a request through multiple services in order to determine the root cause of latency or errors. A popular tool for distributed tracing is Zipkin, which is largely based off of a paper published by Google called “Dapper”. Reshmi is also speaking at the upcoming O’Reilly Velocity Conference in New York, September 20-22, so check that out if you are interested in web performance, continuous delivery, or anything else related to web and mobile development.
Ep 349Serverless Architecture with Mike Roberts
“Serverless” usually refers to an architectural pattern where the server side logic is run in stateless compute containers that are event-triggered and ephemeral. Mike Roberts has written a series of articles about serverless computing, in which he discusses theories and patterns around serverless architecture. In this episode, Mike and I discuss how to reimagine our software architecture using functions-as-a-service. We go into the costs, benefits, and modern limitations of current serverless platforms like AWS Lambda.
Ep 348Akka Reactive Streams with Konrad Malawski
Akka is a toolkit for building concurrent, distributed, message-driven applications on the JVM. Akka provides an implementation of the actor model of concurrency, which simplifies concurrency by adding a lighter weight abstraction than threads and thread pools. Konrad Malawski joins the show today to discuss Akka and reactive streams. Reactive streams is an initiative to provide a standard for asynchronous stream processing. This show goes deep into modern concurrent programming and is a great companion to some of the shows we have done about reactive programming.
Ep 347Apache Beam with Frances Perry
Unbounded data streams create difficult challenges for our application architectures. The data never stops coming, and we are forced to assume that we will never know if or when we have seen all of our data. Some streaming systems give us the tools to deal partially with unbounded data streams, but we have to complement those streaming systems with batch processing, in a technique known as the Lambda Architecture. Apache Beam is a unified model for defining and executing data processing workflows, and Frances Perry joins the show to explain how Beam provides a way for us to model our data processing, agnostic of whether we choose to run those workflows on Spark, Flink, or Google’s Dataflow.

Ep 346TensorFlow in Practice with Rajat Monga
TensorFlow is Google’s open source machine learning library. Rajat Monga is the engineering director for TensorFlow. In this episode, we cover how to use TensorFlow, including an example of how to build a machine learning model to identify whether a picture contains a cat or not. TensorFlow was built with the mission of simplifying the process of deploying a machine learning model from research to production, so we also talk about that, as well as how TensorFlow can be used effectively in combination with Google’s open-source cluster manager, Kubernetes.
Ep 345Data Validation with Dan Morris
Data Validation is the process of ensuring that data is accurate. In many software domains, an application is pulling in large quantities of data from external sources. That data will eventually be exposed to users, and it needs to be correct. Radius Intelligence is a company that aggregates data on small businesses. In order to ensure that business addresses and phone numbers are correct, Radius uses human data validation to ensure that their machine-gathered data is correct. On today’s episode, Srini Kadamati interviews Dan Morris about human data validation, and how it fits into a machine learning pipeline.
Ep 344Machine Learning for Sales with Per Harald Borgen
Machine learning has become simplified. Similar to how Ruby on Rails made web development approachable, scikit-learn takes away much of the frustrating aspects of machine learning, and lets the developer focus on building functionality with high-level APIs. Per Harald Borgen is a developer at Xeneta. He started programming fairly recently, but has already built a machine learning application that cuts down on the time his sales team has to spend qualifying leads. What I found most interesting about this episode was that machine learning gets used by a single developer to solve a simple business problem and deliver solid value. This is in contrast to how many of us think about machine learning–as an intimidating domain that requires a large team to build anything meaningful.

Ep 343Flexport Engineering with Amos Elliston
Flexport is a technology company that makes logistics, supply chain management, and freight forwarding software. Shipping freight across the world requires container ships, airplanes, trains, warehouses, and trucks. Flexport’s software integrates with many of these different shipping companies, and provides a dashboard for the end user to understand how their products are being shipped around the world. Amos Elliston is the CTO of Flexport, and he joins the show to discuss building software for the global supply chain.
Ep 342Data Breaches with Troy Hunt
When you hear about massive data breaches like the recent ones from LinkedIn, MySpace, or Ashley Madison, how can you find out whether your own data was compromised? Troy Hunt created the website HaveIBeenPwned.com to answer this question. When a major data breach occurs, Troy acquires a copy of the stolen data and provides a safe way for individuals to check if their credentials have been stolen. Troy is an expert on data breaches, and he works as a regional director at Microsoft. Our conversation explores passwords, IoT security, Stuxnet, and the dark, bizarre world of data breaches.
Ep 341unikernels and unik with Scott Weiss
The Linux kernel of many popular operating system distributions contains 200-500 million lines of code. The average user never touches many of the libraries that are contained in these operating system distributions. For example, if you spin up a virtual machine on a cloud service provider, the virtual machine will have a USB driver. This is wasted space, because you can’t even interact with the USB port on a virtual machine. Unikernels are a way to rethink our usage of operating systems. A unikernel uses a stripped down operating system called a library operating system–it contains only the libraries you need for the applications you are running. Today’s guest Scott Weiss joins the show to talk about unikernels, and a project he is working on called UniK, a tool for compiling application sources into unikernels.

Ep 340Prometheus Monitoring with Brian Brazil
Prometheus is a tool for monitoring our distributed applications. It allows us to focus on the services we are deploying rather than the individual machines that make up instances of that service. The monitoring service itself is a portion of a distributed system that is treated differently than the services we are monitoring. We don’t want to use a consensus-based tool like Zookeeper or Consul because we can’t afford the strong consistency. Brian Brazil’s company Robust Perception is built around Prometheus, and he joins the show to discuss why and how to use Prometheus.
Ep 339Podcast Infrastructure with Mikael Emtinger
The technology underlying podcasts is simple–a podcaster publishes mp3 files to an RSS feed, and the listener subscribes to that feed, receiving mp3s whenever the feed is updated. Unfortunately, the simplicity of podcasts makes it difficult to build automated advertising infrastructure on top of that simple RSS model. This lack of rich automated advertising has kept podcasting from flourishing. aCast is a company that is trying to change that by providing a better podcast experience for both the publisher and the listener. Today’s guest Mikael Emtinger is a creative technologist at aCast, and we discuss the infrastructure around podcasts, and how aCast is trying to improve it.
Ep 338GraphQL as a Service with Scaphold.io
GraphQL was open sourced out of Facebook, and gave developers a way to unify their different data sources into a single endpoint. Although the promise of GraphQL is appealing, the process of setting up a GraphQL server that can communicate with each disparate data source can prove to be complex. Scaphold.io provides GraphQL as a service, and today’s guests are the creators of Scaphold, Vince Ning and Michael Paris. Scaphold.io lets developers configure their schema, and hosts their data. Vince and Michael explain the basics of GraphQL, and also discuss how they are building a GraphQL as a service platform.Sponsors

Ep 336Industries of the Future with Alec Ross
Alec Ross worked in the White House as a Senior Policy Advisor to Hillary Clinton. His book Industries of the Future explores the biggest technological opportunities and threats to our society. The industries addressed in his book include robotics, genetics, and cybersecurity. Technological familiarity is increasingly correlated with an individual’s optimism. Cyberwarfare presents attack vectors that are difficult to insulate against. Arguments about surveillance center disproportionately on governmental surveillance rather than that of the private sector. In our conversation, Alec discusses these topics and others.
Ep 335Clojure with Alex Miller
Clojure is a dynamically typed functional language that runs on the JVM. Today’s guest Alex Miller gives us an overview of Clojure’s core functionality. Alex is a developer of Cognitect, and a founder of the the Strange Loop conference. We discuss the data structures, garbage collection, and concurrency support. How does Clojure compare to other JVM languages like Scala and Groovy? How does Clojure copy immutable data structures without copying all of the data? How does a Clojure program get evaluated and converted to Java bytecode? These questions, and many others are discussed in this episode.
Ep 334Odd Networks with Kris Walker
Odd Networks is building a platform for anyone to launch their own over-the-top streaming video service. With Odd Networks, you can deploy your own video channel using a Roku, Amazon Fire TV, Apple TV, and other services. Creating a streaming video service with interoperability between these different platforms presents numerous technical challenges, and today’s guest Kris Walker explains how Odd Networks is addressing those challenges. We discuss the open source projects of Odd Networks, including oddworks, which encompases the SDKs, stores, services, and middleware, and the event bus, called oddcast.Sponsors
Ep 333Mobycraft with Aditya Gupta
MobyCraft is a client-side Minecraft mod to manage and visualize Docker containers. MobyCraft was created by Aditya Gupta. I met him at DockerCon, where he gave a presentation about his project. He also discussed his interaction with the Netflix team, who integrated MobyCraft with their container management tool called Titus. You can watch a video online of Titus managing hundreds of 3-D containers within MineCraft. In this episode, we discuss how and why Aditya built MobyCraft, and how he got started programming at such a young age.
Ep 332Prometheus with Julius Volz
Prometheus is an open-source monitoring tool built at SoundCloud. It can be used to produce detailed time-series data about a distributed architecture. Prometheus is based on the monitoring system inside Google’s infrastructure, called Borgmon. Julius Volz is the creator of Prometheus, and he joins the show to explain why he built Prometheus and how it differs from previous monitoring tools. Prometheus is widely used to monitor Kubernetes clusters, just like Google uses Borgmon to monitor its Borg clusters.
Ep 330Fintech Hiring with Ed Donner
Financial technology has changed significantly in the last decade, and companies both new and old are adapting to that change. Newer companies like TransferWise and Stripe are often called “fintech” companies–short for “financial technology”. Established companies like banks may not refer to themselves as fintech companies, but the way that they do business is changing, due to technological advances like blockchain. Ed Donner is the CEO of untapt, a hiring platform for fintech companies, and he joins the show to talk about the fundamental changes that are causing so many new fintech companies to be created. Before starting untapt, Ed worked at JP Morgan Chase, where he spent much of his time leading engineers and hiring engineers, which makes him well-equipped to build a platform for hiring software engineers into fintech companies, driven by machine intelligence.
Ep 329Scaling github with Sam Lambert
github has grown to have 10 million users and 30 million repositories. Getting to this scale has required innovation in many places–github has significantly altered the code for git itself, and has built unique infrastructure and written low level code to architect for git repository management at scale. Despite the need for cutting-edge technologies to support github, the development culture at github values tried and true technologies, and today’s guest Sam Lambert explains the value of maintaining a Rails monolith as the frontend of github, and the other battle-tested tools that github uses.
Ep 328Pixar in a Box with Kitt Hirasaki
Pixar has made some of the most successful movies of all time: Toy Story, WALL-E, Monsters Inc, and many others. These movies are made with cutting-edge computer animation techniques that Pixar often has to invent in order to tell the story it wants to tell. Pixar has teamed up with Khan Academy to teach anyone who wants to learn the basics of computer animation–Pixar-style. The collaboration with Khan Academy is called “Pixar in a Box”, and Kitt Hirasaki joins the show to talk about it. Kitt has worked two stints at Pixar, starting in 1996 and again in 2008, and today he works at Khan Academy–so we also get into his experiences at Pixar, and how the software engineering at Pixar works.
Ep 327Open Source Culture with Rachel Roumeliotis
Open source software has become the rule for how software is written rather than the exception. OSCON is O’Reilly’s open source conference, where companies and individuals talk about where the open-source world is going. Rachel Roumeliotis is the chair of OSCON, and she joins the show today to talk about the state of open source, and how the conference has developed since she started working at O’Reilly. We are giving away a free ticket to O’Reilly’s Velocity 2016 conference in New York. If you want to be entered to win that ticket, send a tweet about your favorite SE Daily episode about dev ops or web performance, and tag software_daily, as well as #velocityconf.
Ep 326Android on iPhone with Nick Lee
Finally–the Android operating system has been put on an iPhone, and today’s guest is Nick Lee, who accomplished that feat. Nick works at Tendigi, a design and engineering firm. In the past, Nick has put Windows 95 on an Apple Watch. Why would you do something like this? In today’s interview with Nick, we talk about the technical challenges of bringing Nick’s bizarre sense of technological irony into reality.

Ep 324Container Platforms with Darren Shepherd
Container management systems like Kubernetes and Docker Swarm give us a higher level management tool for architectures built out of distributed containers. Container platforms like Rancher provide a higher layer of usability, and today’s guest Darren Shepherd of Rancher Labs takes us through what a container platform is. This interview is part of our continued coverage of Kubernetes, Docker, and the other components of the growing container ecosystem.
Ep 322Apache Arrow with Uwe Korn
In a typical data analytics system, there are a variety of technologies interacting. HDFS for storing files, Spark for distributed machine learning, pandas for data analysis in Python–each of these different technologies has a different format for how data is represented. Serialization and deserialization between these different formats causes significant latency across the overall system. Apache Arrow is a tool for improving performance of in-memory analytics systems, and today’s guest Uwe Korn explains how Arrow enables these systems with interoperability.
Ep 321Economics of Software with Russ Roberts
EconTalk is a weekly economics podcast that has been going for a decade. On EconTalk, Russ Roberts brings on writers, intellectuals, and entrepreneurs for engaging conversations about the world as seen through the lens of economics. Russ Roberts is today’s guest, and it is a treat because I have been listening to EconTalk since 2006 and it was a central point of inspiration for what Software Engineering Daily has become. On this episode, we talk about how software impacts the world economically, from bitcoin’s promise of zero cost transactions to the opportunities and regulatory challenges of the software-enabled gig economy.
Ep 320IoT Analytics with Jean-Christophe Cimono
On smart thermostats, sensor-driven assembly lines, and electronically monitored farms, the internet of things is producing huge volumes of data. To take advantage of that data, an application needs tools for storing and analyzing that data. Today’s guest is Jean-Cristophe Cimono, the CTO of mnubo, a cloud platform for connected objects. Today we walk through the architecture of mnubo and the use cases of an IoT analytics platform. Thanks to Manuel Vonthron and Eduardo Siman for contributing to the preparation of this show.
Ep 317Platforms with Bridget Kromhout
At software conferences, I like to walk around the vendor booths and talk to the representatives from different companies. By talking to the vendors about their marketing pitches, I get an idea of how those companies are positioning themselves for the future, and the complex business landscape of software becomes slightly easier to understand. At recent conferences, many of the big vendors have been talking about their cloud platform. With Cloud Foundry, OpenShift, Kubernetes, OpenStack and so many other cloud platforms, it is hard to keep track of the different offerings, and how they differentiate. Bridget Kromhout joins the show today to talk about these different platforms, and how they have changed modern software development. We also talk about her podcast Arrested DevOps, a great show where she interviews some of the luminaries of the operations and software development world. You can also hear Bridget speak at O’Reilly’s Velocity 2016 conference in New York. We are giving away a free ticket to Velocity New York. If you want to be entered to win that ticket, send a tweet about your favorite SE Daily episode about dev ops or web performance, and tag software_daily, as well as #velocityconf.

Ep 316Scalable Architecture with Lee Atchison
Lee Atchison spent seven years at Amazon working in retail, software distribution, and Amazon Web Services. He then moved to New Relic, where he has spent four years scaling the company’s internal architecture. From his decade of experience at fast growing web technology companies, Lee has written the book Architecting for Scale, from O’Reilly. As an application scales, it becomes significantly more complicated while at the same time receiving more traffic. The intersection of these two problems leads to a variety of discussions around availability, risk management, and microservices. Lee and I didn’t have time to get through everything in his book Architecting for Scale, but if you enjoy this episode, check out the book. Lee also spoke recently at the O’Reilly Velocity conference in Santa Clara, so you can check out his talk. We are giving away a free ticket to O’Reilly’s Velocity 2016 conference in New York. If you want to be entered to win that ticket, send a tweet about your favorite SE Daily episode about dev ops or web performance, and tag software_daily, as well as #velocityconf.
Ep 315Schedulers with Adrian Cockcroft
Scheduling is the method by which work is assigned to resources to complete that work. At the operating system level, this can mean scheduling of threads and processes. At the data center level, this can mean scheduling Hadoop jobs or other workflows that require the orchestration of a network of computers. Adrian Cockcroft worked on scheduling at Sun Microsystems, eBay, and Netflix. In each of these environments, the nature of what was being scheduled was different, but the goals of the scheduling algorithms were analogous–throughput, response time, and cache affinity are relevant in different ways at each layer of the stack. Adrian is well-known for helping bring Netflix onto Amazon Web Services, and I recommend watching the numerous YouTube videos of Adrian talking about that transformation.
Ep 314Security and Machine Learning in the Call Center with Pindrop Security’s Chris Halaschek
Call centers are a vulnerable point of attack for large enterprises. Fraud accounts for more than $20 billion in lost money every year, and a significant portion of that fraud is due to customer service representatives being fraudulent social engineering attacks. Chris Halaschek joins the show today to discuss how Pindrop Security is addressing this attack vector. Every phone call that gets made to a call center has a unique phoneprint, and the machine learning model at Pindrop Security uses these phoneprints to assign a risk score to each call. Chris also discusses the challenges associated with scaling a cloud security company.
Ep 312KubeCloud: Tangible Cloud Computing with Kasper Nissen and Martin Jensen
At most universities, there is not a course titled “cloud computing”. Most students leave college without an understanding of distributed systems, cloud service providers, and the fundamentals of how a data center works. Kasper Nissen and Martin Jensen are changing that with KubeCloud, a small tangible cloud computing cluster that runs on Raspberry Pis. Kasper and Martin started KubeCloud as a masters thesis, and it is grown to a textbook-sized treatise on cloud computing. KubeCloud is both software and a curriculum to teach students microservices, containers management, and the real-world problems of distributed systems.

Ep 310P2P Money Transfer with TransferWise’s Harsh Sinha
Transferring money from one country to another is expensive, and the banks that facilitate money transfer have tricked us into believing that it should be expensive. On today’s show, Harsh Sinha explains the peer-to-peer system of transferring money with TransferWise, where he works as VP of engineering. Harsh also discusses the larger picture of FinTech companies. The emergence of so many companies at the intersection of finance and technology is no accident. The 2008 financial crisis created a loss of trust in the existing financial system. Simultaneously, smart phones and cheap cloud computing has created opportunities for newer companies like TransferWise to position themselves as a new option for consumer banking.

Ep 309Cassandra Compliant ScyllaDB with Dor Laor
Apache Cassandra is a distributed database that can handle large amounts of data with no single point of failure. Since 2008, Cassandra has been widely adopted and the software and the community around it have grown steadily. A software developer interacting with Cassandra uses CQL, the Cassandra Query Language. ScyllaDB is another open-source database that has been created to be totally compatible with CQL. By complying with CQL, the internals of ScyllaDB can be a vastly different rewrite from Cassandra. ScyllaDB uses C++, whereas Cassandra uses Java. ScyllaDB improves upon the performance characteristics of Cassandra, by optimizing for modern hardware, and Dor Laor joins the show today to discuss how ScyllaDB does all of this.

Ep 308Apache Guacamole and Remote Desktop with Mike Jumper
In order to use a remote desktop experience, software engineers have a limited number of options, and most of them are proprietary, like VMWare or Oracle. Remote desktop is a functionality that many engineers use every day, so it is surprising that the open source world has taken awhile to displace the functionality of proprietary software. In 2010, Mike Jumper started working on Guacamole, a way to access remote desktops through your browser. Over the last six years, Mike has worked continuously to create a simple, open-source software tool to access desktops remotely, and this year Guacamole joined the Apache Incubator and became Apache Guacamole. In this episode, we discuss the past, present, and future of remote desktop, and the technical internals of Apache Guacamole.
Ep 305Scaling Twitter with Buoyant.io’s William Morgan
Six years ago, Twitter was experiencing outages due to high traffic. Back in 2010 Twitter was built as a monolithic Ruby on Rails application. Twitter migrated to a microservices architecture to fix these problems. During this migration, the engineers at Twitter learned how to build and scale highly distributed microservice architectures. William Morgan was an engineer at Twitter during that time, and he is now the CEO of Buoyant.io, a company building open-source microservices infrastructure. Some of the big problems at Twitter were solved at the communication layer, using an RPC library called Finagle. At Buoyant, those lessons are being applied to a project called Linkerd, an RPC proxy.
Ep 304Manufacturing and Microservices with Cimpress’ Jim Sokoloff and Maarten Wensveen
Mass customization is the process of making customized, personalized products that are accessible to individuals and small businesses. The process involves manufacturing, assembly lines, supply chains, and software at every step along the way. Today’s guests are Jim Sokoloff and Maarten Wensveen, who work on infrastructure and technology at Cimpress, a mass customization platform. Cimpress has t shirt printers, warehousing machines, supply chain management tools, and lots of other computers that come together in the computer-integrated manufacturing process. The company has been around for a few decades, and more recently they have moved to microservices for many of the reasons that have been discussed in previous episodes. If you work at a big company with some monolithic characteristics, this episode might give you some good arguments to bring to your manager about why and how to move to microservices.
Ep 303Serverless Code with Ryan Scott Brown
The unit of computation has evolved from on premise servers to virtual machines in the cloud to containers running in those virtual machines. Serverless computation is another stage in the evolution of computational unit management. With a serverless architecture, a function call to the cloud spins up a transient container, calls the function on that container, and then spins down the container. Ryan Scott Brown joins the show today to discuss the benefits and consequences of serverless computing. With containers and VMs, we still have to worry that the resources we are spinning up in the cloud will run without being utilized. Serverless computing gives us more control over these compute resources, so that we don’t have unused servers that we are paying for.