
Seventy3
642 episodes — Page 3 of 13

【第537期】AI攻克埃尔德什数学难题进展报告
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。合作邮箱:zhiwudazhanjiangshi#gmail.com今天的主题是:Semi-Autonomous Mathematics Discovery with Gemini: A Case Study on the Erdős ProblemsSummary我们展示了一项关于半自动数学发现的案例研究,利用 Gemini 对 Bloom 的“埃尔多斯问题”(Erdős Problems)数据库中 700 个标记为“未解决”(Open)的猜想进行了系统评估。我们采用了混合方法论:首先通过 AI 驱动的自然语言验证来缩小搜索空间,随后由人类专家评估其正确性与新颖性。我们处理了数据库中标记为“未解决”的 13 个问题:其中 5 个通过看似新颖的自主解法完成,另外 8 个则通过识别现有文献中的既有解法完成。我们的研究结果表明,这些问题的“未解决”状态更多是因为其冷僻程度而非难度。此外,我们还识别并讨论了在大规模应用 AI 处理数学猜想时出现的问题,重点指出了文献检索的困难以及 AI 存在“潜意识剽窃”的风险。最后,我们对 AI 辅助攻克埃尔多斯问题的经验教训进行了反思。原文链接:https://arxiv.org/abs/2601.22401

【第536期】【shownotes彩蛋】让AI给自己当家教
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。合作邮箱:zhiwudazhanjiangshi#gmail.com今天的主题是:Self-Improving Pretraining: using post-trained models to pretrain better modelsSummary确保大语言模型生成内容的安全性、事实性及整体质量是一项严峻挑战,尤其是在这些模型日益广泛应用于现实场景的背景下。目前解决这些问题的主流方法是收集昂贵且精心策划的数据集,并进行多阶段的微调与对齐。然而,即便采用如此复杂的流程,也无法保证能彻底纠正模型在预训练阶段习得的模式。因此,在预训练阶段解决这些问题至关重要,因为预训练塑造了模型的核心行为,并能从源头上防止不安全或幻觉输出的根深蒂固。为了应对这一挑战,我们提出了一种全新的预训练方法:通过流式处理文档,并利用强化学习(RL)在每一步优化后续生成的 K 个 Token。该方法引入一个强大的后验模型,对包括模型预测序列(Rollouts)、原始后缀及重写后缀在内的候选生成内容进行评分,评估其质量、安全性与事实性。在训练初期,该过程依赖于原始和重写的后缀;随着模型能力的提升,强化学习将奖励高质量的模型预测序列。这种方法从底层构建了更高质量、更安全且更具事实性的模型。实验表明,与标准预训练相比,我们的方法在事实性和安全性方面分别带来了 36.2% 和 18.5% 的相对提升,在整体生成质量的胜率上最高提升了 86.3%。原文链接:https://arxiv.org/abs/2601.21343

【第535期】SDPO:通过自我蒸馏强化丰富反馈学习
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:Reinforcement Learning via Self-DistillationSummary大型语言模型越来越多地在可验证领域(如代码与数学)中通过强化学习后训练。然而,当前用于具有可验证奖励的强化学习(RLVR)的方法通常只从每次尝试得到的单一标量结果奖励中学习,从而造成了严重的信用分配(credit assignment)瓶颈。事实上,许多可验证环境能够提供丰富的文本反馈,例如运行时错误信息或评测器(judge)的评估,这些反馈可以解释一次尝试为何失败。我们将这一设定形式化为具有丰富反馈的强化学习(reinforcement learning with rich feedback),并提出 Self-Distillation Policy Optimization(SDPO)。该方法能够在无需外部教师模型或显式奖励模型的情况下,将token 化的反馈转化为密集的学习信号。SDPO 将当前模型在给定反馈条件下的输出视为一种自教师(self-teacher),并把其基于反馈生成的下一 token 预测蒸馏回策略模型中。通过这种方式,SDPO 利用模型在上下文中事后识别自身错误的能力来进行学习。在科学推理、工具使用以及 LiveCodeBench v6 上的竞赛编程任务中,SDPO 相较于强基线 RLVR 方法,在样本效率和最终准确率方面均取得了提升。值得注意的是,在仅返回标量反馈的标准 RLVR 环境中,SDPO 仍然优于基线方法,因为它能够利用成功的 rollout 作为对失败尝试的隐式反馈。最后,当在测试时对单个问题应用 SDPO时,该方法还能加速在困难的二值奖励任务中的解发现过程:与 best-of-k 采样 或 多轮对话策略相比,SDPO 仅需 约三分之一的尝试次数就能达到相同的解发现概率。原文链接:https://arxiv.org/abs/2601.20802

【第534期】VibeTensor:AI智能体全生成的深度学习系统软件
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:VibeTensor: System Software for Deep Learning, Fully Generated by AI AgentsSummaryVIBETENSOR 是一个用于深度学习的开源研究型系统软件栈,由 LLM 驱动的编程智能体在人类高层指导下生成。在本文中,“完全生成(fully generated)”指的是代码来源:实现变更由智能体提出补丁(diff)并应用;验证则依赖智能体执行的构建、测试以及差异检查,而不是对每一次变更进行人工逐条审查。该系统实现了一个 类 PyTorch 的即时执行(eager)张量库:核心使用 C++20(CPU + CUDA) 实现,并通过 nanobind 提供一个 类似 torch 的 Python 封装层,同时还包含一个实验性的 HTTP URL 接口。不同于仅提供薄封装(thin bindings)的方案,VIBETENSOR 还包含: 自有的 tensor / storage 系统 schema-lite 调度器(dispatcher) 反向模式自动求导(reverse-mode autograd) CUDA 运行时组件(streams / events / graphs) 一个按 stream 顺序工作的缓存分配器,并带有诊断功能 一个稳定的 C ABI,用于动态加载算子插件我们将这一发布视为 AI 辅助软件工程的一个里程碑:它表明编程智能体能够生成一个结构连贯的深度学习运行时系统,其范围从语言绑定一直延伸到 CUDA 内存管理,并主要通过构建和测试完成验证。本文介绍了系统架构,总结了用于生成和验证该系统的工作流程,并对该工件进行了评估。我们报告了代码仓库规模与测试套件组成,并总结了来自一个AI 生成的内核套件的可复现微基准测试结果,其中包括 融合注意力(fused attention) 与 PyTorch 的 SDPA / FlashAttention 的对比。此外,我们还报告了在 NVIDIA H100(Hopper,SM90) 与 Blackwell 级 GPU 上进行的三个小规模端到端训练任务的基本可行性测试(sequence reversal、ViT、miniGPT)。多 GPU 结果仅在 Blackwell 平台上提供,并使用一个可选的基于 CUTLASS 的 ring-allreduce 插件,该插件需要 CUDA 13+ 与 sm103a 工具链支持。最后,我们讨论了在生成式系统软件中可能出现的失败模式,其中包括一种被称为 “Frankenstein 组合效应” 的问题:即多个在局部上正确的子系统组合在一起时,可能导致整体性能表现不佳。原文链接:https://arxiv.org/abs/2601.16238

【第533期】AI辅助对编程技能形成的冲击研究
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:How AI Impacts Skill FormationSummaryAI 辅助在各类专业领域中带来了显著的生产力提升,尤其对新手从业者更为明显。然而,这种辅助如何影响人们发展有效监督 AI 所需的技能,目前仍不清楚。对于需要完成不熟悉任务的新手来说,如果过度依赖 AI,可能会在这一过程中削弱自身的技能习得。我们通过随机对照实验,研究开发者在有 AI 辅助与无 AI 辅助的情况下,如何掌握一个新的异步编程库。研究发现,使用 AI 会削弱参与者的概念理解、代码阅读能力以及调试能力,而平均来看并未带来显著的效率提升。那些完全将编码任务委托给 AI的参与者确实获得了一定的生产力提升,但代价是未能真正学习该编程库。我们识别出 六种不同的 AI 交互模式,其中 三种涉及认知参与,即使参与者获得 AI 辅助,也能够保持良好的学习效果。研究结果表明,AI 带来的生产力提升并不是通往能力提升的捷径。在将 AI 辅助纳入工作流程时应谨慎设计,以保护技能的形成——尤其是在安全关键领域。原文链接:https://arxiv.org/abs/2601.20245
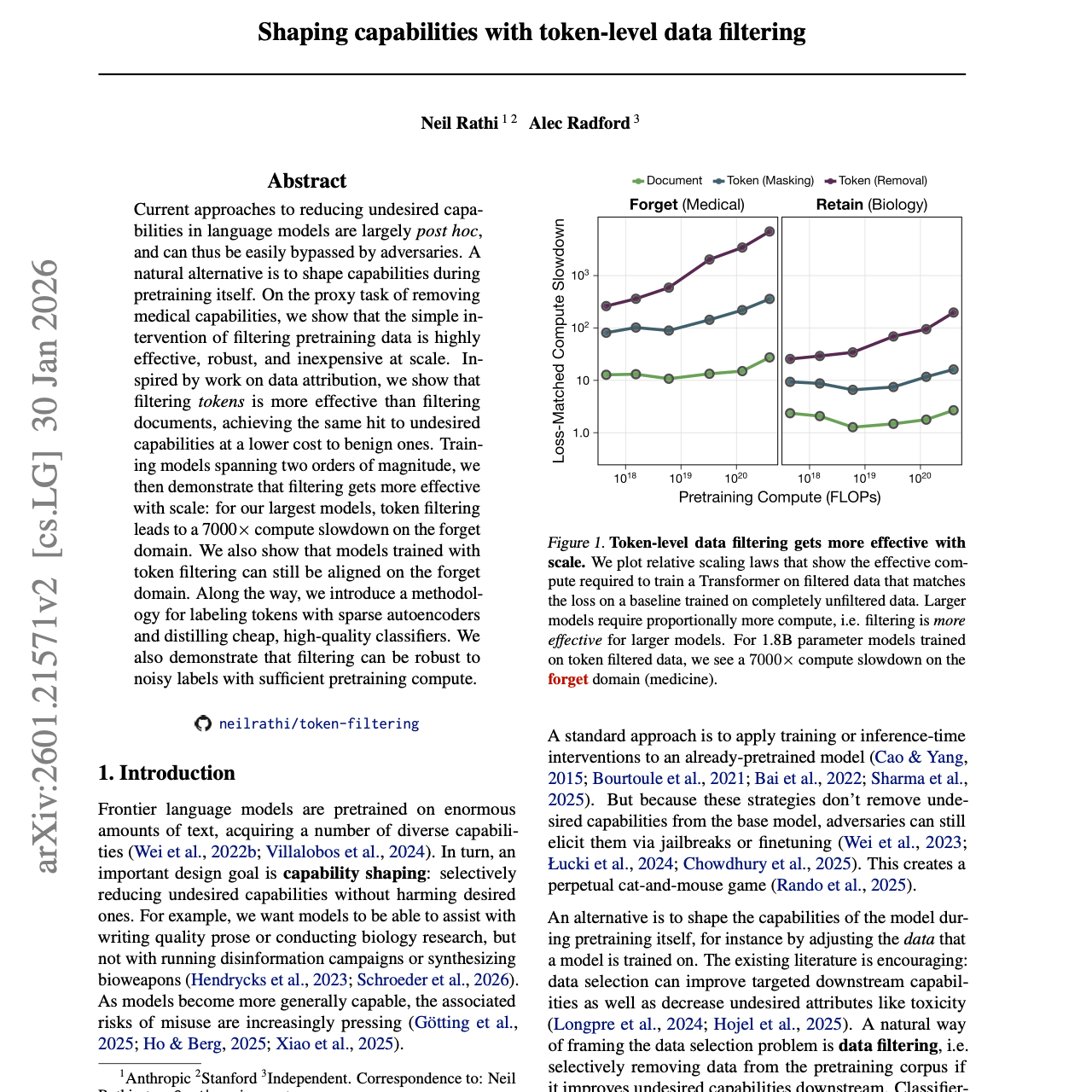
【第532期】词元级过滤切除AI危险知识
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:Shaping capabilities with token-level data filteringSummary当前减少语言模型不良能力的方法大多是事后处理(post hoc)的,因此很容易被对抗者绕过。一种更自然的替代方案是在预训练阶段就对能力进行塑造。以移除医疗相关能力这一代理任务为例,我们表明,仅通过过滤预训练数据这一简单干预,就能够在大规模情况下实现高度有效、稳健且成本低廉的效果。受到数据归因(data attribution)相关研究的启发,我们进一步表明,与过滤文档相比,过滤 token 更为有效:在对不希望出现的能力造成同等抑制效果的同时,对正常能力的影响更小。通过训练跨越两个数量级规模的模型,我们还展示了:随着模型规模增大,过滤策略的效果也会增强。在我们最大的模型上,token 级过滤会使模型在“需要遗忘的领域(forget domain)”上的计算效率降低 7000 倍。我们还表明,通过 token 过滤训练得到的模型,依然可以在该遗忘领域上进行对齐。在这一过程中,我们提出了一种方法:利用稀疏自编码器(sparse autoencoders)对 token 进行标注,并蒸馏出低成本且高质量的分类器。我们还证明,只要预训练计算量足够,过滤方法在存在噪声标签的情况下依然具有鲁棒性。原文链接:https://arxiv.org/abs/2601.21571

【第531期】Kimi K2.5 技术报告:迈向通用智能体之路
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:Kimi K2.5: Visual Agentic IntelligenceSummary我们介绍 Kimi K2.5,一个开源的多模态智能体模型,旨在推动通用智能体能力的发展。K2.5 强调对文本与视觉的联合优化,使两种模态能够相互增强。这一过程包含一系列技术,例如文本—视觉联合预训练、零视觉监督微调(zero-vision SFT),以及文本—视觉联合强化学习。在这一多模态基础之上,K2.5 引入了 Agent Swarm,一种自驱动的并行智能体编排框架,能够将复杂任务动态分解为异构子问题,并并发执行。大量评估表明,Kimi K2.5 在多个领域(包括编程、视觉、推理以及智能体任务)上达到了当前最先进的水平。与单智能体基线相比,Agent Swarm 还可将延迟降低最多 4.5 倍。我们发布了经过后训练的 Kimi K2.5 模型检查点,以促进未来在智能体智能领域的研究和实际应用。原文链接:https://arxiv.org/abs/2602.02276

【第530期】变形门罗币交易:规避反洗钱监管的技术挑战
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:Anamorphic Monero Transactions: the Threat of Bypassing Anti-Money Laundering LawsSummary在本文中,我们分析了以隐私为导向的加密货币与新兴打击金融犯罪法律框架之间的冲突,尤其聚焦于欧盟近期出台的相关法规。我们分析了 Monero(门罗币)这一领先的“隐私币”,它也是执法机构重点关注的对象,并研究在新法律下针对 Monero 交易平台必须履行的尽职调查范围,以及这些要求如何映射到 Monero 协议的技术能力之上。我们既指出了该立法中的缺陷,也识别出一些技术层面的陷阱,这些陷阱可能威胁到例如 Monero 交易所的有效合规,或是 Monero 自身的匿名化目标。另一个具有独立研究价值的方面是,我们引入了变形密码学(anamorphic cryptography)(这也是该概念最早的实际应用之一),并利用它在 Monero 区块链中构建了一个隐藏的交易层,用以混淆非法资金流动,并规避欧盟法律在交易层面实施监管的尝试。原文链接:https://eprint.iacr.org/2025/1961

【第529期】区块链系统信息隐私:攻击、保护与多层级评价综述
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:A Systematic Literature Review of Information Privacy in Blockchain SystemsSummary在这篇文献综述中,我们对区块链系统中的隐私问题不断发展的研究格局进行了批判性分析,重点关注隐私攻击与防护措施在三个不同层级中的差异: 链上层(on-chain layer) 链下层(off-chain layer) 基础设施层(infrastructure layer),即 点对点网络层(peer-to-peer network layer)在综述中,我们对常见的隐私攻击进行了分类,例如: 交易追踪(transaction tracing) 数据泄露(data leakage) 网络监控(network surveillance)并分析这些攻击在不同层级上的具体表现及其影响。此外,我们还评估了一系列隐私保护技术,包括: 密码学方法(cryptographic methods) 零知识证明(zero-knowledge proofs) 其他隐私保护协议(privacy-preserving protocols)同时,我们探讨了这些隐私技术与现有区块链系统之间的兼容性。通过综合当前的研究成果和实际应用案例,本综述旨在: 提供对区块链环境中隐私挑战与解决方案的全面理解 识别当前研究中的空白与不足 为未来**区块链隐私增强技术(privacy-enhancing technologies)**的发展提供指导。原文链接:https://www.mdpi.com/2624-800X/5/3/65

【第528期】AI编程智能体:效率提升与质量债的博弈
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:AI IDEs or Autonomous Agents? Measuring the Impact of Coding Agents on Software DevelopmentSummary基于大型语言模型(LLM)的编程智能体(coding agents)正越来越多地作为自主贡献者参与软件开发,例如自动生成并合并 Pull Request。然而,与目前广泛使用的IDE 内置 AI 助手相比,这些智能体在真实软件项目中的影响仍不清楚。我们开展了一项纵向因果研究(longitudinal causal study),分析智能体在开源仓库中的采用效果。研究方法采用分阶段差分中的差分(staggered difference-in-differences)设计,并配合匹配对照组。基于 AIDev 数据集,我们将“采用智能体”定义为仓库首次出现由智能体生成的 Pull Request,并分析仓库按月统计的项目级指标,包括:开发速度(development velocity) 提交次数(commits) 新增代码行数(lines added)软件质量(software quality) 静态分析警告(static-analysis warnings) 认知复杂度(cognitive complexity) 代码重复度(duplication) 注释密度(comment density)研究结果表明: 开发速度提升具有明显的“前期集中效应”:当智能体是项目中首次出现的 AI 工具时,开发速度会出现显著提升。 如果仓库此前已经使用过 AI IDE 助手,那么引入智能体带来的吞吐量提升很小或持续时间很短。相比之下,代码质量风险则更加持久。在不同情境下都观察到: 静态分析警告增加约 18% 认知复杂度增加约 39%这表明即使开发速度优势逐渐消失,由智能体引入的技术债(technical debt)仍会持续累积。这些异质性效应表明 AI 辅助开发存在边际收益递减的现象,同时也凸显出以下需求: 质量保障机制(quality safeguards) 代码来源追踪(provenance tracking) 对自主智能体进行选择性部署本研究为理解智能体式工具(agentic tools)与 IDE AI 助手之间的相互作用提供了实证基础,并推动未来研究探索:在 AI 融合的软件开发流程中,如何在开发效率与可维护性之间取得平衡。本研究的**可复现代码与数据包(replication package)**已通过论文中的链接公开发布。原文链接:https://arxiv.org/abs/2601.13597

【第527期】MCP-SIM:自校正多智能体物理仿真框架
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:A self-correcting multi-agent LLM framework for language-based physics simulation and explanationSummary基于物理的模拟在科学和工程领域至关重要,但构建这类模拟通常需要对数值求解器和控制方程(governing equations)具备专业知识。大型语言模型(LLM)为通过自然语言创建模拟提供了新的可能性,但当提示模糊、不完整或包含多语言时,它们往往会失败。为了解决这一问题,我们提出 MCP-SIM(Memory-Coordinated Physics-Aware Simulation),这是一个具备自我纠错能力的多智能体框架,能够将信息不充分的提示转化为经过验证的模拟结果和解释性报告。该系统通过结构化的智能体协作以及持久记忆机制,整合了多个功能模块,包括: 输入澄清(input clarification) 代码生成(code generation) 错误诊断(error diagnosis) 多语言解释(multilingual explanation)与一次性代码生成(one-shot code generation)不同,MCP-SIM 通过迭代式的“计划–执行–反思–修订”(plan–act–reflect–revise)循环来模拟专家式推理过程。在 12 个复杂度逐步提升的任务上进行评估时,该框架成功解决了所有基准测试案例。在本研究定义的特定评估指标下,它在收敛效率方面优于基于 GPT 的方法以及人类参与(human-in-the-loop)的基线方法。除了数值精度之外,该系统还能够生成可解释的报告,并支持多语言输出,用于说明每个模拟背后的物理逻辑。MCP-SIM 向通用型自主科学助手迈出了一步:这种系统能够通过自然语言进行模拟、适应并解释科学问题。尽管在本研究的测试任务中表现出较强的鲁棒性,但在更专业领域以及超出当前基准分布的任务上的表现仍有待未来进一步验证。原文链接:https://www.nature.com/articles/s44387-025-00057-z

【第526期】Terminal-Bench 2.0:复杂命令行任务智能体基准测试
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line InterfacesSummaryAI 智能体很可能很快就能在多个领域中自主完成具有价值的长期任务(long-horizon tasks)。然而,现有基准测试要么无法反映真实世界任务,要么难度不足以有效评估前沿模型。为此,我们提出 Terminal-Bench 2.0:一个精心构建的高难度基准测试。该基准包含 89 个任务,全部在计算机终端环境(terminal environments)中完成,并且这些任务都来源于真实工作流程中的问题。每个任务都包含: 独立的运行环境 人工编写的参考解决方案 完整的自动化测试(用于验证结果)实验结果表明,当前的前沿模型和智能体在该基准上的得分低于 65%。我们还进行了错误分析(error analysis),以识别模型和智能体在未来需要改进的关键能力方向。为了支持开发者和研究人员的进一步研究,我们公开发布了数据集和评测框架(evaluation harness),可通过论文中的链接获取。原文链接:https://arxiv.org/abs/2601.11868

【第525期】OneFlow:基于单智能体基准重构多智能体工作流价值
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:Rethinking the Value of Multi-Agent Workflow: A Strong Single Agent BaselineSummary最近基于大型语言模型(LLM)的多智能体系统(Multi-Agent Systems, MAS)取得了显著进展。研究表明,由多个 LLM 智能体组成的工作流——每个智能体具有不同的角色、工具和通信模式——在复杂任务上可以优于单一 LLM 的基线方法。然而,大多数现有框架实际上是同质(homogeneous)的:所有智能体使用同一个基础 LLM,只是在提示词、工具使用方式以及在工作流中的位置上有所不同。这就引出了一个问题:这样的工作流是否可以通过一个单一智能体在多轮对话中进行模拟?我们在 七个基准测试上对此进行了研究,这些基准涵盖: 编程(coding) 数学(mathematics) 通用问答(general QA) 领域特定推理(domain-specific reasoning) 真实世界规划与工具使用(real-world planning and tool use)实验结果表明:一个单一智能体可以达到同质多智能体工作流的性能,同时由于能够复用 KV cache(键值缓存),在推理效率上具有优势。进一步地,它甚至能够匹配**自动优化的异构工作流(heterogeneous workflow)**的性能。基于这一发现,我们提出了 OneFlow 算法。该算法可以自动将多智能体工作流转换为适用于单一智能体执行的形式。与现有的自动化多智能体设计框架相比,OneFlow 在不降低准确率的情况下显著降低推理成本。这些结果表明:用单一 LLM 实现多智能体工作流可以作为多智能体系统研究中的一个强有力基线(baseline)。同时我们也指出,单一 LLM 方法仍然存在局限:由于不同 LLM 之间无法共享 KV cache,单模型方案无法真正模拟异构(heterogeneous)工作流。这也表明未来仍然存在重要研究机会,即开发真正异构的多智能体系统。原文链接:https://arxiv.org/abs/2601.12307

【第524期】AI智能体认知压缩器:长程任务中的记忆控制
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:AI Agents Need Memory Control Over More ContextSummaryAI 智能体正越来越多地被用于长期、多轮的工作流程中,无论是在科研还是企业环境中。随着交互轮数的增加,智能体的行为往往会逐渐退化,原因包括:约束目标逐渐失焦、错误不断累积,以及由记忆引发的行为漂移(drift)。这一问题在真实世界部署中尤为明显,因为上下文会持续变化、会出现各种干扰,而且决策需要在较长时间内保持一致。一种常见做法是为智能体提供持久记忆,例如通过对话记录回放(transcript replay)或基于检索的机制(retrieval-based memory)。虽然这种方式实现起来比较方便,但它会导致上下文无限增长,并且容易受到**噪声检索和记忆污染(memory poisoning)**的影响,从而造成行为不稳定以及更严重的漂移问题。在这项工作中,我们提出了 Agent Cognitive Compressor(ACC),一种受生物系统启发的记忆控制器。ACC 不再依赖完整对话记录回放,而是使用一个有界的内部状态(bounded internal state),并在每一轮交互时在线更新。ACC 的关键设计是将“信息检索(artifact recall)”与“状态承诺(state commitment)”分离: 允许智能体检索外部信息进行参考; 但不会在未经验证的情况下将这些信息写入持久记忆。这种机制既能提供稳定的条件信息,又能防止不可靠内容进入长期记忆。我们使用一种由智能体评审(agent judge)驱动的实时评估框架来评估 ACC,该框架不仅衡量任务完成效果,还监测由记忆引发的异常行为,并在长时间交互中进行评估。在多个应用场景中进行实验,包括: IT 运维(IT operations) 网络安全响应(cybersecurity response) 医疗工作流程(healthcare workflows)结果表明,ACC 能够始终保持有界的记忆规模,并在多轮交互中表现出更稳定的行为;与使用对话回放或检索记忆的智能体相比,它显著降低了幻觉(hallucination)和行为漂移(drift)。这些结果表明,认知压缩(cognitive compression)为长期运行的 AI 智能体提供了一种实用且有效的记忆控制基础。原文链接:https://arxiv.org/abs/2601.11653

【第523期】推理模型的思想社会:CoT中的社交与协作行为研究
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:Reasoning Models Generate Societies of ThoughtSummary大型语言模型已经在多个领域展现出卓越能力,但复杂推理能力背后的机制仍然难以完全解释。近期的一些推理模型在复杂认知任务上明显优于规模相当的指令微调模型,这通常被归因于通过更长的思维链(chain of thought)进行更多计算。然而,我们的研究表明,推理能力的提升并不仅仅来自更长的计算过程,而是源于一种类似多智能体交互的模拟机制——“思想社会”(society of thought)。这种机制使模型能够在内部产生多种认知视角,并在这些视角之间进行多样化和辩论。这些视角通常表现为具有不同人格特征和领域专长的内部角色。通过对推理轨迹进行定量分析以及使用机制可解释性(mechanistic interpretability)方法,我们发现像 DeepSeek-R1 和 QwQ-32B 这样的推理模型相比普通指令微调模型,表现出更高的视角多样性。在推理过程中,它们会激活更广泛的冲突信号,这些信号来自具有不同人格特征和专业知识相关特征的内部表示。这种多智能体结构具体表现为多种对话式行为,例如: 提问与回答(question–answering) 视角转换(perspective shifts) 对冲突观点的协调与整合(reconciliation of conflicting views)同时还表现出带有社会情绪角色的互动,例如尖锐的来回讨论。这些行为共同构成了一种类似对话的推理过程,从而带来了在推理任务上的准确率优势。进一步的受控强化学习实验表明:当基础模型仅仅因为推理准确率而获得奖励时,它们会自然增加这种对话式行为。此外,在微调过程中加入对话式结构(conversational scaffolding),能够使模型的推理能力提升速度快于未加入该结构的基础模型。这些结果表明,思想的社会化组织有助于更有效地探索解空间。我们认为,推理模型在计算层面上形成了一种与人类群体中的集体智能(collective intelligence)相对应的机制:当多样性被系统性地组织起来时,它能够带来更强的问题解决能力。这也为未来通过多智能体组织结构来利用“群体智慧(wisdom of crowds)”提供了新的研究机会。原文链接:https://arxiv.org/abs/2601.10825

【第522期】TTT-Discover:通过测试时训练实现科学发现
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:Learning to Discover at Test TimeSummary我们如何利用 AI 为某个科学问题发现新的最先进(state-of-the-art)解法?此前关于测试时扩展(test-time scaling)的工作,例如 AlphaEvolve,是通过提示一个冻结(不再训练)的 LLM 来进行搜索。我们的做法是在测试阶段进行强化学习,使 LLM 在解决问题时仍然可以继续训练,但训练经验专门来自当前这个测试问题。这种持续学习(continual learning)的形式非常特殊,因为它的目标并不是在平均意义上产生许多不错的解,而是找到一个非常优秀的解;并且是专门解决当前这个问题,而不是泛化到其他问题。因此,我们的学习目标和搜索子程序被设计为优先关注最有希望的解。我们将这种方法称为 Test-Time Training to Discover(TTT-Discover)。沿用以往研究,我们重点关注**具有连续奖励(continuous rewards)**的问题。我们报告了所有尝试过的问题结果,涵盖以下领域:数学、GPU 内核工程、算法设计以及生物学。TTT-Discover 在几乎所有这些任务上都创造了新的最先进结果,包括: Erdős 的最小重叠问题以及一个自相关不等式; 一个 GPUMode 内核竞赛(速度最高可达此前最佳结果的 2 倍); 过去的 AtCoder 算法竞赛问题; 单细胞分析中的去噪问题。我们的解决方案均由相关领域专家或比赛组织者进行了评审。所有结果都使用一个开源模型 OpenAI gpt-oss-120b 实现,并且可以通过我们公开发布的代码进行复现;相比之下,以往的最佳结果通常依赖于封闭的前沿模型。我们的测试时训练实验通过 Thinking Machines 提供的 Tinker API 运行,每个问题的成本仅为几百美元。原文链接:https://arxiv.org/abs/2601.16175

【第521期】Mimblewimble加密货币协议的形式化安全分析
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:A Formal Analysis of the Mimblewimble Cryptocurrency Protocol with a Security ApproachSummaryMimbleWimble(MW) 是一种以隐私为核心设计目标的加密货币技术,在安全性与可扩展性方面展现出区别于同类协议的特性。本文对这些关键属性进行了系统性阐述,并提出了一种基于模型驱动验证(model-driven verification)的形式化方法,用于验证协议实现的正确性与安全性。具体而言,作者构建了一个理想化模型(idealized model),作为整个验证流程的核心基础。在此框架下,论文明确识别并精确定义了一组充分条件,以确保该模型能够支持对 MW 关键安全属性(如一致性、完整性与隐私性)的形式化验证。鉴于 MW 构建于共识协议之上,研究进一步对某一类共识协议给出了 Z 语言规范(Z specification) 描述,并展示了由该 Z 规范自动生成的 {log} 原型系统的部分内容。该 {log} 原型可作为可执行模型(executable model)运行仿真,从而在无需底层编程实现的情况下分析协议行为。这种方法显著降低了验证成本,同时提高了形式化分析的严谨性。最后,论文对当前基于 MW 协议实现的两个主要项目进行了分析: Grin Beam研究评估了它们在当前开发阶段的实现特性与协议一致性状况,从形式化验证视角探讨其安全保障程度。总体而言,该工作不仅阐明了 MW 在隐私与可扩展性方面的理论基础,还提出了一套可执行的形式化验证路径,为隐私型区块链协议的认证与安全评估提供了系统化方法论。原文链接:https://arxiv.org/abs/2104.00822

【第520期】SimpleMem:大语言模型智能体的高效终身记忆框架
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:SimpleMem: Efficient Lifelong Memory for LLM AgentsSummary为支持复杂环境下的长期交互,大语言模型(LLM)智能体需要具备能够管理历史经验的记忆系统。现有方法要么通过被动扩展上下文来保留完整交互历史,导致信息冗余严重;要么依赖多轮迭代推理来过滤噪声,从而带来高昂的 token 消耗。针对这一问题,本文提出了 SimpleMem,一种基于语义无损压缩(semantic lossless compression)的高效记忆框架。我们设计了一个三阶段处理流水线,以最大化信息密度与 token 利用率:语义结构化压缩(Semantic Structured Compression):将非结构化交互内容提炼为紧凑的、多视角索引的记忆单元,提高信息组织度与可检索性。在线语义综合(Online Semantic Synthesis):在单次会话内部即时整合相关上下文,将分散信息抽象为统一表示,消除冗余。意图感知检索规划(Intent-Aware Retrieval Planning):通过推断检索意图,动态确定检索范围,并高效构建精确上下文。在基准数据集上的实验结果表明,该方法在准确率、检索效率与推理成本方面均持续优于基线方法。在 LoCoMo数据集上,SimpleMem 的平均 F1 值提升达 26.4%,同时在推理阶段将 token 消耗降低至原来的最高 1/30,实现了性能与效率之间的显著优化平衡。代码已在论文提供的链接中公开。原文链接:https://arxiv.org/abs/2601.02553

【第519期】Focus智能体:LLM自主上下文压缩与内存管理
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:Active Context Compression: Autonomous Memory Management in LLM AgentsSummary由于“上下文膨胀”(Context Bloat)问题,大语言模型(LLM)智能体在长时程软件工程任务中面临显著挑战。随着交互历史不断增长,计算成本急剧上升,推理延迟增加,同时模型容易受到过往无关错误信息的干扰,导致推理能力下降。现有解决方案通常依赖被动的外部摘要机制,而智能体本身无法主动控制这一过程,因而限制了其自适应能力。本文提出了 Focus,一种以智能体为中心的架构设计,其灵感来源于黏菌(Physarum polycephalum)的生物探索策略。Focus Agent 能够自主决定何时将关键经验整合为一个持久化的“Knowledge”模块,并主动撤回(剪枝)原始交互历史,从而实现动态上下文压缩与信息重组。在实验设置中,作者采用符合工业最佳实践的优化执行框架(持久化 bash 环境 + 字符串替换编辑器),并在 SWE-bench Lite 的 N=5 个高上下文依赖任务实例上进行评估,使用模型 Claude Haiku 4.5。在鼓励频繁压缩的激进提示策略下,Focus 在保持相同准确率(两种方法均为 3/5 = 60%)的前提下,实现了 22.7% 的 token 使用量下降(从 1490 万降至 1150 万)。平均而言,每个任务执行 6 次自主压缩操作,个别实例的 token 节省幅度最高达 57%。实验结果表明,只要赋予合适的工具接口与提示机制,具备能力的模型可以实现上下文的自主调节。这为构建具备成本意识(cost-aware)的智能体系统提供了新的路径,同时在不牺牲任务性能的情况下提升资源利用效率。原文链接:https://arxiv.org/abs/2601.07190

【第518期】AgeMem:大语言模型智能体统一记忆管理框架
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:Agentic Memory: Learning Unified Long-Term and Short-Term Memory Management for Large Language Model AgentsSummary由于上下文窗口长度有限,大语言模型(LLM)智能体在长时程推理(long-horizon reasoning)任务中面临根本性约束,因此高效的记忆管理机制至关重要。现有方法通常将长期记忆(LTM)与短期记忆(STM)作为相互独立的模块进行处理,并依赖启发式规则或外部控制器进行调度,这种分离式架构限制了系统的自适应能力与端到端优化潜力。本文提出了 Agentic Memory(AgeMem),一种将长期记忆与短期记忆管理统一纳入智能体策略内部的框架。AgeMem 将记忆操作抽象为基于工具的行动(tool-based actions),使 LLM 智能体能够自主决策何时以及如何存储、检索、更新、总结或丢弃信息,从而实现对记忆资源的策略化管理。为训练这种统一的记忆决策行为,我们提出了一种三阶段渐进式强化学习策略,并设计了逐步式 GRPO(step-wise GRPO)算法,以缓解由记忆操作引发的稀疏且不连续奖励信号问题。该方法通过细粒度策略优化,增强了记忆相关行为的可学习性与稳定性。在五个长时程基准任务上的实验结果表明,AgeMem 在多种 LLM 主干模型(backbone)上均显著优于强基线的记忆增强方法,不仅在任务完成度方面取得提升,还实现了更高质量的长期记忆构建与更高效的上下文利用效率。原文链接:https://arxiv.org/abs/2601.01885

【第517期】Dr. Zero:无训练数据的自进化搜索智能体
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:Dr. Zero: Self-Evolving Search Agents without Training DataSummary随着高质量数据日益难以获取,无数据自进化(data-free self-evolution)逐渐成为一种具有前景的新范式。该方法使大语言模型(LLMs)能够自主生成并解决复杂问题,从而提升其推理能力。然而,多轮搜索智能体在无数据自进化过程中面临显著挑战,包括问题多样性受限,以及多步推理与工具调用所带来的高额计算开销。在本研究中,我们提出了 Dr. Zero——一个使搜索智能体在无需任何训练数据的情况下实现有效自进化的框架。具体而言,我们构建了一个自进化反馈闭环:由一个提议者(proposer)生成多样化问题,用于训练一个由同一基础模型初始化的求解者(solver)。随着求解者能力的提升,其性能反过来激励提议者生成难度更高但仍可解的问题,从而形成一个自动化课程学习机制(automated curriculum),协同优化两个智能体。为提高训练效率,我们进一步提出了“跳数分组相对策略优化”(hop-grouped relative policy optimization, HRPO)方法。该方法将结构相似的问题进行聚类,构建组级基线,从而有效降低对每个查询单独评估其难度与可解性的采样开销。结果表明,HRPO 在不损害性能与稳定性的前提下,显著减少了求解者训练所需的计算资源。大量实验结果显示,在完全无数据条件下,Dr. Zero 的性能可与全监督训练的搜索智能体相当,甚至更优。这表明,复杂的推理与搜索能力可以通过纯粹的自进化机制自然涌现。原文链接:https://arxiv.org/abs/2601.07055

【第516期】DroPE:移除位置嵌入实现大语言模型零样本上下文扩展
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:Extending the Context of Pretrained LLMs by Dropping Their Positional EmbeddingsSummary迄今为止,要有效扩展语言模型(LM)的上下文长度,通常需要进行超出预训练序列长度范围的高成本微调。在本研究中,我们通过在训练完成后移除语言模型中的位置嵌入(Dropping the Positional Embeddings,简称 DroPE),突破了这一关键瓶颈。该方法虽简单,却建立在三个重要的理论与实证观察之上。首先,位置嵌入(Positional Embeddings, PEs)在预训练阶段发挥着关键作用,作为一种重要的归纳偏置,能够显著促进模型收敛。其次,模型对这种显式位置信息的过度依赖,恰恰成为其在测试阶段无法泛化到未见序列长度的根本原因,即便采用主流的位置嵌入缩放方法亦难以解决这一问题。第三,位置嵌入并非高效语言建模的内在必要条件,在完成预训练后,经过一个简短的再校准阶段,便可以安全移除,而不会破坏模型能力。在实证层面,DroPE 方法无需进行任何长上下文微调,即可实现无缝的零样本上下文扩展;同时,它能够快速适配预训练语言模型,而不会削弱其在原始训练上下文范围内的性能。实验结果表明,该方法在不同模型规模与数据规模条件下均表现稳健,显著优于以往的专用架构设计以及成熟的旋转位置嵌入(Rotary Positional Embedding)缩放方法。原文链接:https://arxiv.org/abs/2512.12167

【第515期】Meta_AI看视频学会通用动作
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:Learning Latent Action World Models In The WildSummary量子计算的兴起对区块链系统的安全性构成了严峻挑战。作为数字签名、消息加密和哈希函数基础的传统密码算法,在量子计算机强大的计算能力面前逐渐显现出脆弱性。本文对向抗量子区块链过渡所涉及的风险进行了系统性评估,全面分析了针对区块链关键组成部分的潜在威胁,包括网络层、矿池、交易验证机制、智能合约以及用户钱包。通过深入阐释向抗量子算法迁移过程中所固有的复杂技术挑战与战略考量,论文评估了相关风险,并重点指出在采用抗量子密码技术加固区块链组件时所面临的现实障碍。为实现从经典密码体系向抗量子密码体系的平稳演进,本文提出了一种混合迁移策略,以降低过渡期的系统性风险。研究还将分析扩展至多个主流区块链平台,如比特币、以太坊、瑞波币、莱特币以及 Zcash,评估其易受攻击的关键组件、潜在影响以及相关的 STRIDE 威胁类型,从而识别出可能遭受量子攻击的高风险领域。除风险分析之外,论文还为在量子计算时代构建安全、具备高韧性的区块链生态系统提供了可操作性的设计建议。鉴于量子计算机所带来的现实威胁,本研究主张主动推进向抗量子区块链网络的战略转型,并提出一套定制化安全蓝图,从体系结构层面强化各组件,以应对不断演进的量子驱动型网络安全威胁。论文强调,区块链生态参与方亟需采取前瞻性措施并部署抗量子解决方案,以确保在量子时代背景下实现安全、稳定与可信的系统运行,并以更强的韧性与信心应对未来挑战。原文链接:https://arxiv.org/abs/2501.11798

【第514期】量子时代区块链安全威胁与抗量子迁移策略
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:Blockchain Security Risk Assessment in Quantum Era, Migration Strategies and Proactive DefenseSummary量子计算的兴起对区块链系统的安全性构成了严峻挑战。作为数字签名、消息加密和哈希函数基础的传统密码算法,在量子计算机强大的计算能力面前变得脆弱。本文对向抗量子区块链过渡的风险进行了全面评估,系统分析了针对区块链关键组件的潜在威胁,包括网络层、矿池、交易验证机制、智能合约以及用户钱包。通过阐明向抗量子算法迁移过程中所固有的复杂挑战与战略考量,本文评估了相关风险,并揭示了利用抗量子密码技术加固区块链各组成部分所面临的障碍。为实现从经典密码体系向抗量子密码体系的平稳过渡,论文提出了一种混合迁移策略。分析范围涵盖了主流区块链平台,如比特币、以太坊、瑞波币、莱特币和Zcash,评估其易受攻击的组件、潜在影响以及相关的STRIDE威胁模型,从而识别出可能遭受量子攻击的关键领域。除理论分析外,本文还为在量子计算时代构建安全、韧性强的区块链生态系统提供了可操作性指导。鉴于量子计算机所带来的潜在威胁,研究主张主动推进向抗量子区块链网络的转型,并提出一套定制化安全蓝图,从战略层面加固各个组件,以应对不断演变的量子驱动网络安全威胁。论文强调,区块链相关利益方亟需采取前瞻性措施并部署抗量子解决方案,以增强系统在量子时代背景下的安全韧性与信心。原文链接:https://arxiv.org/abs/2501.11798

【第513期】TariScript:为Mimblewimble引入动态脚本
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:TariScript: Bringing dynamic scripting to MimblewimbleSummaryMimblewimble 是一种在隐私性与可扩展性方面表现优良的加密货币协议。但其一个权衡在于:交易需要发送方与接收方之间进行交互式协作。TariScript 被提出为对 Mimblewimble 的一种扩展,为该协议增加了脚本(scripting)能力。本文阐述了 TariScript 的理论基础,并介绍了为确保其安全性所需的协议修改。同时,文中还简要讨论了 TariScript 所涉及的权衡以及其潜在应用场景。原文链接:https://www.tari.com/assets/updates/docs/tariscript.pdf

【第512期】Mimblewimble:一种可扩展且隐私的区块链支付系统方案
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:MimblewimbleSummary2016 年 8 月 2 日凌晨约 04:30(UTC),一位使用“Tom Elvis Jedusor”这一化名的匿名人士登录了一个比特币研究 IRC 频道,发布了一份托管在 Tor 隐藏服务上的文档 [Jed16],随后立即退出。该文档题为《Mimblewimble》,描述了一种区块链方案,其交易构造方式与比特币截然不同,支持交易的非交互式合并与 cut-through 机制、机密交易(confidential transactions),以及在无需新用户验证任何单个币完整历史的情况下,对当前链状态(chainstate)进行完整验证。然而,尽管该论文对核心思想的阐述相当详细,但并未给出安全性论证,甚至还包含一个错误。本文的目的在于对原始思想进行精确定义,并补充作者提出的进一步扩展性改进。具体而言,Mimblewimble 能够显著压缩交易历史。如果记录与比特币当前历史等规模的交易数据,理论上需要约 15GB 的数据(不包括 UTXO 集;若将包含区间证明的 UTXO 集计算在内,则需超过 100GB)。Jedusor 留下了一个尚未解决的问题,即如何进一步减少这一数据规模;本文对此问题给出了解决方案,并结合现有关于压缩工作量证明(proof-of-work)区块链的研究成果,将 15GB 的数据规模压缩至不足 1MB。原文链接:http://misskiwi.com/download/mimblewimble.pdf

【第511期】深度增量学习:广义残差连接与几何变换映射
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:Deep Delta LearningSummary深度残差网络的有效性依赖于恒等映射的捷径连接(identity shortcut connection)。尽管这种机制缓解了梯度消失问题,但其对特征变换施加了严格的加性归纳偏置(strictly additive inductive bias),从而限制了网络对复杂隐状态转移的建模能力。在本文中,我们提出了 Deep Delta Learning(DDL),将原本固定的恒等映射捷径推广为一个可学习的、依赖状态的线性算子。该算子被称为 Delta Operator,其形式为单位矩阵的秩 1 扰动:A(X)=I−β(X)k(X)k(X)⊤其中,k(X) 是一个单位方向向量,β(X)β(X) 是一个标量门控参数。我们通过谱分析(spectral analysis)表明,β(X)β(X) 可以在以下三种情形之间连续插值: 恒等映射(Identity):β=0 正交投影(Orthogonal Projection):β=1 Householder 反射(Householder Reflection):β=2此外,我们将残差更新重写为一种同步的秩 1 增量写入(synchronized rank-1 delta write):参数 ββ 同时控制当前 kk-分量的移除幅度,以及新的 kk-分量的注入幅度。这种统一表述使得模型能够沿着一个数据依赖方向,对捷径连接的谱性质进行显式控制,同时保持训练过程的稳定性。在实证实验中,我们将 Transformer 中的残差加法替换为 DDL 机制,结果表明:在语言建模任务上,验证损失(validation loss)与困惑度(perplexity)均得到改善,下游评测准确率也有所提升;在扩展状态维度(expanded-state setting)条件下,性能增益更为显著。原文链接:https://arxiv.org/abs/2601.00417

【第510期】研究计划生成模型的微调与跨领域评估
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:Training AI Co-Scientists Using Rubric RewardsSummaryAI 协作科学家(AI co-scientists)正逐渐成为辅助人类研究者实现科研目标的重要工具。这类系统的一个关键能力,是在给定研究目标与约束条件的情况下生成可行的研究计划。这些计划既可用于研究者头脑风暴,也可在进一步完善后付诸实施。然而,目前的语言模型在生成同时满足所有显性约束与隐含要求的研究计划方面仍存在明显不足。在本研究中,我们探索如何利用海量已有科研论文语料,训练语言模型生成更高质量的研究计划。我们通过自动化方法,从多个领域的论文中提取研究目标以及针对特定目标的评分细则(goal-specific grading rubrics),构建了一个可扩展且多样化的训练语料库。在此基础上,我们采用带有自评机制(self-grading)的强化学习方法对模型进行训练。在训练过程中,初始策略的冻结副本充当评分器,而评分细则则在生成器与验证器之间构建出“生成—评估差距”(generator-verifier gap),从而在无需外部人工监督的情况下实现性能提升。为验证该方法的有效性,我们针对机器学习领域的研究目标开展了一项由人类专家参与的研究,总计耗时 225 小时。结果显示,在 70% 的研究目标上,专家更偏好我们微调后的 Qwen3-30B-A3B 模型所生成的研究计划,而非初始模型生成的版本;同时,专家认可 84% 自动提取的目标特定评分细则。为评估方法的泛化能力,我们还将该框架扩展至医学论文中的研究目标以及新的 arXiv 预印本,并通过一组前沿模型组成的“评审团”进行评估。实验结果表明,我们的微调方法带来了 12%–22% 的相对性能提升,并展现出显著的跨领域泛化能力,即使在诸如医学研究这类难以获得执行反馈的问题场景中,也依然有效。总体而言,这些发现表明,一种可扩展、自动化的训练范式有望成为提升通用 AI 协作科学家能力的重要一步。原文链接:https://arxiv.org/abs/2512.23707
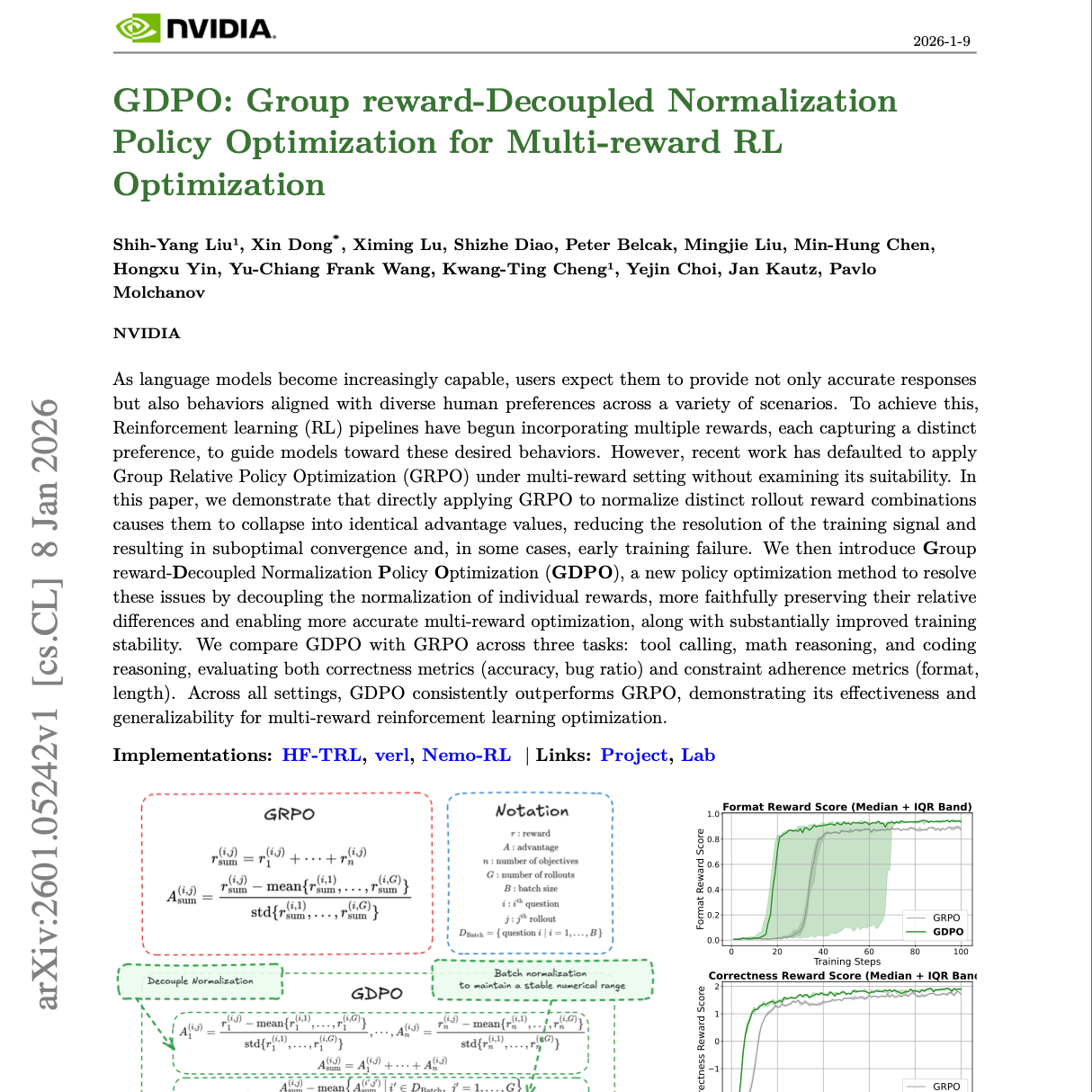
【第509期】GDPO:多奖励强化学习的解耦归一化策略优化
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL OptimizationSummary随着语言模型能力的不断提升,用户不仅期望其提供准确的回答,还希望其行为能够在多种场景下符合多样化的人类偏好。为实现这一目标,强化学习(RL)流程开始引入多个奖励信号,每个奖励分别刻画一种不同的偏好,以引导模型朝着期望行为优化。然而,近期研究在多奖励设定下默认采用 Group Relative Policy Optimization(GRPO),却未对其适用性进行充分检验。本文表明,直接在多奖励场景中应用 GRPO,对不同 rollout 奖励组合进行归一化时,会导致这些组合坍缩为相同的优势值(advantage value),从而降低训练信号的分辨率,导致次优收敛,甚至在某些情况下出现训练早期失败。为解决上述问题,我们提出了 Group reward-Decoupled Normalization Policy Optimization(GDPO),一种新的策略优化方法。该方法通过对各个奖励的归一化过程进行解耦,更真实地保留奖励之间的相对差异,从而实现更精确的多奖励优化,并显著提升训练稳定性。我们在三个任务上对 GDPO 与 GRPO 进行了对比实验:工具调用、数学推理和代码推理。评估指标既包括正确性指标(如准确率、错误率),也包括约束遵循指标(如格式规范、长度控制)。在所有实验设置下,GDPO 均稳定优于 GRPO,验证了其在多奖励强化学习优化中的有效性与良好的泛化能力。原文链接:https://arxiv.org/abs/2601.05242

【第508期】SAGA:科学发现中的动态目标演化自主智能体
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你有自己的论文要解读,或者推荐论文,请留言。今天的主题是:Accelerating Scientific Discovery with Autonomous Goal-evolving AgentsSummary近年来,人们对开发能够拓展科学发现边界的智能体产生了前所未有的兴趣,这类智能体主要通过优化科学家所设定的定量目标函数来开展工作。然而,对于科学中的重大挑战而言,这些目标函数仅仅是不完美的代理指标。我们认为,实现目标函数设计的自动化,是科学发现智能体的一个核心但尚未满足的关键需求。在本研究中,我们提出了科学自主目标进化智能体(Scientific Autonomous Goal-evolving Agent,SAGA)以应对这一挑战。SAGA 采用双层架构:外层循环由大语言模型(LLM)智能体负责分析优化结果、提出新的目标,并将其转化为可计算的评分函数;内层循环则在当前目标下执行解的优化。该双层设计使系统能够系统性地探索目标空间及其权衡关系,而不再将目标视为固定输入。我们通过一系列广泛的应用验证了该框架的有效性,包括抗生素设计、无机材料设计、功能性 DNA 序列设计以及化学工艺设计。结果表明,目标制定过程的自动化能够显著提升科学发现智能体的整体效能。原文链接:https://arxiv.org/abs/2512.21782

【第507期】mHC:流形约束超连接的大规模稳定训练
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。今天的主题是:mHC: Manifold-Constrained Hyper-ConnectionsSummary近年来,以 Hyper-Connections(HC) 为代表的研究,通过扩展残差流的宽度并多样化连接模式,对过去十年中广泛采用的残差连接范式进行了拓展。尽管这种多样化带来了显著的性能提升,但它从根本上破坏了残差连接所固有的恒等映射(identity mapping)属性,从而导致严重的训练不稳定性和可扩展性受限,并且还引入了显著的内存访问开销。为了解决这些问题,我们提出了 流形约束的 Hyper-Connections(Manifold-Constrained Hyper-Connections,mHC),这是一种通用框架:通过将 HC 的残差连接空间投影到特定流形上,以恢复恒等映射属性;同时结合严格的系统级优化,以确保整体效率。大量实证实验表明,mHC 能够有效支持大规模训练,在带来可观性能提升的同时,展现出更优的可扩展性。我们期待 mHC 作为 HC 的一种灵活且实用的扩展,能够促进对拓扑结构化网络架构设计的更深入理解,并为基础模型的演进指明富有前景的方向。原文链接:https://arxiv.org/abs/2512.24880

【第506期】深度序列模型中的几何记忆谜题
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。今天的主题是:Deep sequence models tend to memorize geometrically; it is unclear why.Summary人们通常认为,深度序列模型主要以联想记忆(associative memory)的形式存储原子事实,即对共同出现实体的暴力式查找。我们识别出了一种截然不同的原子事实存储形式,并将其称为几何记忆(geometric memory)。在这种机制下,模型合成了能够编码所有实体之间全局新关系的嵌入表示,甚至包括在训练过程中从未共同出现的实体对。这种存储方式极具威力:例如,我们展示了它如何将一个涉及 ℓ 次复合的困难推理任务,转化为一个易于学习的一步导航任务。基于这一现象,我们提炼出神经嵌入几何的一些基础性特征,而这些特征并不容易被解释。我们认为,相较于对局部关联的查找,这种几何结构的出现,不能被简单地归因于常见的监督信号、模型架构或优化压力。反直觉的是,即便这种几何结构比暴力查找更为复杂,模型依然会学习到它。随后,通过分析其与 Node2Vec 的联系,我们表明,这种几何结构源自一种谱偏置(spectral bias);与现有主流理论相反,这种偏置即使在缺乏多种外在压力的情况下,也会自然地产生。这一分析还向实践者指出:仍然存在明显的提升空间,可以使 Transformer 的记忆机制呈现出更强的几何性。我们希望,对参数化记忆的几何视角能够促使研究者重新审视那些在知识获取、容量、发现以及遗忘等领域中长期占据主导地位的默认直觉。原文链接:https://arxiv.org/abs/2510.26745

【第505期】TTT-E2E:长文本建模的端到端测试时训练模型
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。今天的主题是:End-to-End Test-Time Training for Long ContextSummary我们将长上下文语言建模表述为一个持续学习(continual learning)问题,而非一个架构设计问题。在这一表述下,我们仅使用一种标准架构——带有滑动窗口注意力的 Transformer。然而,模型在测试阶段会通过对给定上下文进行下一词预测而持续学习,将其读取到的上下文压缩并写入模型权重中。此外,我们在训练阶段通过元学习(meta-learning)来改进模型在测试时进行学习的初始化。总体而言,我们的方法是一种测试时训练(Test-Time Training,TTT)形式,并且在测试阶段(通过下一词预测)和训练阶段(通过元学习)均实现了端到端(End-to-End,E2E),这与以往的 TTT 方法形成对比。我们开展了大量实验,重点分析其尺度扩展特性(scaling properties)。具体而言,对于使用 164B tokens 训练的 30 亿参数模型,我们的方法(TTT-E2E)在上下文长度上的扩展行为与全注意力 Transformer一致,而诸如 Mamba 2 和 Gated DeltaNet 等方法则不具备这一特性。同时,与 RNN 类似,TTT-E2E 的推理时延与上下文长度无关,在 128K 上下文长度下,其速度比全注意力机制快 2.7 倍。我们的代码已公开发布。原文链接:https://arxiv.org/abs/2512.23675

【第504期】Engram:大语言模型条件存储与扩展查表机制
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。今天的主题是:Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language ModelsSummary尽管混合专家模型(Mixture-of-Experts,MoE)通过条件计算来扩展模型容量,Transformer 本身却缺乏用于知识查找的原生机制,只能通过计算来低效地“模拟”检索。为了解决这一问题,我们引入了条件记忆(conditional memory),作为一种互补的稀疏性维度,并通过 Engram 模块将其具体化。Engram 对经典的 N-gram 嵌入进行了现代化改造,实现了 O(1) 时间复杂度的查找。通过形式化稀疏性分配(Sparsity Allocation)问题,我们发现了一条 U 形缩放定律,用于优化**神经计算(MoE)与静态记忆(Engram)之间的权衡。在该定律的指导下,我们将 Engram 扩展至 270 亿参数,在严格参数量相同(iso-parameter)且计算量(FLOPs)相同(iso-FLOPs)**的 MoE 基线之上取得了更优性能。尤为值得注意的是,尽管记忆模块本被预期主要提升知识检索能力(如 MMLU +3.4;CMMLU +4.0),我们却在通用推理方面观察到更大的增益(如 BBH +5.0;ARC-Challenge +3.7),并且在代码与数学领域同样显著(HumanEval +3.0;MATH +2.4)。机制层面的分析表明,Engram 将静态重构的负担从主干网络的早期层中移除,实质上加深了网络,从而有利于复杂推理。此外,通过将局部依赖交由查表完成,它释放了注意力机制的容量,用于建模全局上下文,从而显著提升了长上下文检索能力(例如 Multi-Query NIAH:从 84.2 提升至 97.0)。最后,Engram 还实现了面向系统架构的高效性:其确定性的寻址方式支持在运行时从主机内存进行预取,几乎不引入额外开销。我们认为,条件记忆将成为下一代稀疏模型中不可或缺的建模原语。原文链接:https://arxiv.org/abs/2601.07372

【第503期】突破最短路径Dijkstra 算法的算法研究
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。今天的主题是:Breaking the Sorting Barrier for Directed Single-Source Shortest PathsSummary我们提出了一种确定性算法,在**比较–加法模型(comparison-addition model)下,用于求解带有实数非负边权的有向图单源最短路径(SSSP)**问题,其时间复杂度为O(mlog2/3n)。这是首个在稀疏图上打破 Dijkstra 算法 O(m+nlogn) 时间复杂度界限的结果,表明 Dijkstra 算法并非 SSSP 问题的最优算法。原文链接:https://arxiv.org/abs/2504.17033

【第502期】Polymarket无风险套利
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。今天的主题是:Unravelling the Probabilistic Forest: Arbitrage in Prediction MarketsSummaryPolymarket 是一个预测市场平台,用户可以通过交易与特定结果挂钩的份额来对未来事件进行投机,这些结果被称为条件(conditions)。每个市场都对应一组一个或多个这样的条件。为了确保市场能够正确结算,条件集合必须是完备的——即整体上涵盖所有可能结果——并且是互斥的——即最终只能有一个条件被判定为真。因此,所有相关结果的价格之和应当等于 1 美元,代表任一结果发生的总概率为 1。尽管有这样的设计,Polymarket 仍然存在相关资产被错误定价的情况,使得某一确定结果可以以低于(或高于)1 美元的价格被买入(或卖出),从而保证获利。这种现象被称为套利(arbitrage),可能使具备一定复杂策略能力的参与者利用这些不一致性牟利。在本文中,我们基于 Polymarket 的数据开展了一项经验性套利分析,以回答三个核心问题:(Q1) 什么条件会导致套利机会的产生?(Q2) Polymarket 上是否实际发生了套利行为?(Q3) 是否有人利用了这些套利机会?在分析相关市场之间的套利时,一个主要挑战在于需要在大量市场和条件之间进行可扩展的比较;朴素的方法需要进行 O(2n+m) 级别的比较,计算成本极高。为此,我们采用了一种由启发式方法驱动的降维策略,基于时间相关性、主题相似性以及组合关系来缩小比较范围,并通过专家意见进一步验证。我们的研究揭示了 Polymarket 上两种不同形式的套利行为:市场再平衡套利(Market Rebalancing Arbitrage),其发生于单一市场或单一条件之内;以及组合套利(Combinatorial Arbitrage),其跨越多个市场。我们利用链上历史订单簿数据,分析了这些套利机会在何时存在,以及在何时被用户实际执行。研究结果显示,被成功利用并实现的套利利润总额约为 4000 万美元。原文链接:https://arxiv.org/abs/2508.03474

【第501期】基于可验证奖励强化学习的未来事件预测
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。今天的主题是:Outcome-based Reinforcement Learning to Predict the FutureSummary带有可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards,RLVR)已被证明是一种有效方法,可提升大语言模型在编程和数学等领域中的推理能力。在本文中,我们将 RLVR 方法应用于现实世界未来事件的预测这一任务——由于结果高度噪声化且存在显著延迟,这对强化学习而言尤具挑战性。我们使用了一个新构建的数据集,其中包含来自预测市场的最新问题以及与之相关的新闻标题。实验表明,一个相对紧凑的(140 亿参数)推理模型,经过训练后,其预测准确率可以达到甚至超过 o1 等前沿模型,同时在概率校准方面有显著提升。该模型的性能在实践中也具有现实意义:在一项 Polymarket 的交易仿真中,我们估计该模型在测试集所有问题上的下注将带来超过 10% 的投资回报率(ROI)。此外,我们还详细介绍并比较了模型训练中采用的多种方法,包括:利用合成预测问题扩充训练数据、用于保障学习稳定性的防护机制(guardrails),以及在推理阶段采用的中位数预测采样策略。原文链接:https://arxiv.org/abs/2505.17989

【第500期】平衡工作证明:多重哈希关联挖矿理论
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。今天的主题是:Proof of Balanced Work: The Theory of Mining Hash ProductsSummary我们提出了一种新的方法,用于将不同的 PoW(工作量证明)挖矿算法以乘法方式组合成一种新的、类似 PoW 的挖矿算法,使得各个单独算法的算力提升都会对组合后的最终算力产生影响。这意味着,要实现高效挖矿,所有被组合的算法都必须以一种均衡且高效的方式同时进行挖掘。因此,我们提出的方法可以作为一种新工具,用于针对特定硬件需求精心设计新的挖矿算法,并提升对 ASIC 的抗性。例如,将 CPU 算法与 GPU 算法进行组合,就会要求矿工必须同时使用 CPU 和 GPU 硬件,才能实现高效挖矿。原文链接:https://raw.githubusercontent.com/CoinFuMasterShifu/ProofOfBalancedWork/main/PoBW.pdf

【第499期】ZAMA:可编程自举助力深层神经网络全同态推理
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。今天的主题是:Programmable Bootstrapping Enables Efficient Homomorphic Inference of Deep Neural NetworksSummary在许多情况下,机器学习与隐私常被认为是相互矛盾的,尤其当所涉及的数据具有敏感性时,隐私问题显得尤为突出。本文研究的是深度神经网络的隐私保护推理问题。我们报告了基于一个新型库的初步实验结果,该库实现了 TFHE 全同态加密方案的一种变体。其核心关键技术是可编程自举(programmable bootstrapping),该技术能够在可控噪声水平下,对密文上的任意函数进行同态求值。我们的实验结果首次表明,深度神经网络已经进入全同态加密可实际支持的范围。尤为重要的是,与以往相关工作不同,我们的框架并不需要对模型进行重新训练。原文链接:https://whitepaper.zama.org

【第498期】CryptoNote v2.0 - Monero 白皮书
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。今天的主题是:CryptoNote v2.0 -- monero whitepaperSummary“比特币”(Bitcoin)[1] 是点对点(P2P)电子现金概念的一项成功实现。专业人士和普通公众都逐渐认可了以公开交易和工作量证明(Proof-of-Work)相结合的信任模型。如今,电子现金的用户群正在稳步增长;用户被其低手续费和所提供的匿名性所吸引,而商家则看重其可预测且去中心化的发行机制。比特币已经有效地证明,电子现金既可以像纸币一样简单,又可以像信用卡一样便捷。然而,比特币也存在若干缺陷。例如,其分布式架构缺乏灵活性,在几乎所有网络用户都更新客户端之前,难以引入新功能。一些无法迅速修复的关键缺陷,阻碍了比特币的广泛传播。在这种缺乏灵活性的模型下,与其不断修补原有项目,不如推出一个全新的项目来得更为高效。本文中,我们分析并提出了针对比特币主要缺陷的解决方案。我们相信,一个充分考虑这些解决方案的系统,将促进不同电子现金系统之间的良性竞争。同时,我们还提出了我们自己的电子现金系统——“CryptoNote”,这一名称旨在强调电子现金领域的下一次重大突破。原文链接:https://github.com/monero-project/research-lab/blob/master/whitepaper/whitepaper.pdf

【第497期】Tornado Cash:隐私解决方案白皮书
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。今天的主题是:Tornado Cash Privacy Solution Version 1.4SummaryTornado.Cash 实现了一种以太坊上的零知识隐私解决方案:这是一个智能合约,可接收以太币交易(未来也将支持 ERC-20 代币),使得之后可以在不引用原始交易的情况下提取相应金额。协议说明该协议具有以下功能: 插入/存款(Deposit):将资金存入智能合约。该操作可通过一笔交易完成,存入固定数量(记为 N)的以太币。该 N ETH 的凭证被称为一个 coin。 移除/提现(Withdraw):从智能合约中提取资金可以通过以下两种方式完成:N ETH 通过中继者(Relayer)提现,其中 f ETH 作为手续费发送至中继者地址 t,其余 (N − f) ETH 发送至指定的接收方。f 和 t 的取值由发送方选择。在这种情况下,提现交易由中继者发起,并由中继者支付 Gas 费用,该费用应由 f 覆盖。N ETH 直接提现至指定的接收方,交易由接收方自行发起。接收方需要拥有足够的 ETH 来支付交易的 Gas 费用。在这种情况下,手续费 f 被视为等于 0。原文链接:https://berkeley-defi.github.io/assets/material/Tornado%20Cash%20Whitepaper.pdf

【第496期】Zerocash:基于zk-SNARKs的分散式匿名支付方案
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。今天的主题是:Zerocash: Decentralized Anonymous Payments from Bitcoin (extended version)Summary比特币是第一种得到广泛采用的数字货币。虽然支付是在化名之间进行的,但比特币无法提供强隐私保障:支付交易记录在公开的去中心化账本中,从中可以推导出大量信息。Zerocoin(Miers 等,IEEE S&P 2013)解决了部分隐私问题,通过将交易与支付来源解关联来增强隐私。然而,它仍然会暴露支付的接收方和金额,并且功能有限。本文构建了一种具有强隐私保障的完整账本型数字货币。我们的设计利用了零知识简洁非交互式知识论证(zk-SNARKs)的最新进展。我们提出并构建了去中心化匿名支付方案(Decentralized Anonymous Payment, DAP)。DAP 方案允许用户直接且私密地进行支付:对应的交易隐藏了支付的来源、接收方以及金额。我们提供了形式化定义并给出了构造的安全性证明。在此基础上,我们实现了 Zerocash,作为 DAP 构造的实际实例。在 Zerocash 中,每笔交易小于 1 KB,验证时间低于 6 毫秒——比匿名性较低的 Zerocoin 高出数个数量级,同时在效率上与普通比特币相当。原文链接:http://zerocash-project.org/media/pdf/zerocash-extended-20140518.pdf

【第495期】Self-play SWE-RL:基于自我博弈的软件工程智能体强化学习
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。今天的主题是:Toward Training Superintelligent Software Agents through Self-Play SWE-RLSummary尽管当前基于大语言模型(LLMs)和智能体强化学习(agentic RL)的软件智能体能够提升程序员的生产力,但它们的训练数据(如 GitHub Issues 与 Pull Requests)和环境(如 pass-to-pass 与 fail-to-pass 测试)高度依赖人工知识或人工维护,这构成了迈向超级智能的根本障碍。本文提出 Self-play SWE-RL(SSR),作为面向超级智能软件智能体训练范式的第一步。该方法对数据几乎没有假设,仅需要访问带有源代码和已安装依赖的沙箱仓库,无需人工标注的 Issues 或测试用例。基于这些真实代码库,我们在**自我对弈(self-play)的设置下,通过强化学习训练单智能体 LLM,迭代地注入并修复日益复杂的软件缺陷,每个缺陷由测试补丁(test patch)**形式的正式规范定义,而非自然语言描述的 Issue。在 SWE-Bench Verified 与 SWE-Bench Pro 基准上,SSR 展现出显著的自我提升(分别为 +10.4 和 +7.8 分),并在整个训练过程中始终超越依赖人工数据的基线,即便评测使用的是自我对弈中未见的自然语言 Issues。尽管仍处于早期阶段,这些结果表明了一条可行路径:智能体能够自主从真实软件仓库中获取大量学习经验,从而最终实现超越人类能力的系统,包括理解系统构建方式、解决新颖挑战,以及自主从零创建新软件。原文链接:https://arxiv.org/abs/2512.18552

【第494期】DeepCode:开放式AI自主编程框架
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。今天的主题是:DeepCode: Open Agentic CodingSummary近期大语言模型(LLMs)的发展催生了功能强大的编程智能体,使得代码助手有能力进化为真正的代码工程师。然而,现有方法在实现高保真文档到代码库的自动生成(例如从科学论文到代码)方面仍面临重大挑战,其根本原因在于信息过载与 LLM 上下文容量瓶颈之间的冲突。为此,本文提出 DeepCode,一个完全自主的框架,通过系统化的信息流管理从根本上解决这一问题。DeepCode 将代码库合成视为信道优化问题,通过协调四类信息操作,在有限上下文预算下最大化任务相关信号: 源信息压缩(source compression):通过蓝图蒸馏(blueprint distillation)压缩输入文档; 结构化索引(structured indexing):利用状态化代码记忆(stateful code memory)进行高效索引; 条件知识注入(conditional knowledge injection):通过检索增强生成(retrieval-augmented generation)注入相关知识; 闭环错误修正(closed-loop error correction):自动检测与纠正生成错误。在 PaperBench 基准测试上的大量评估表明,DeepCode 达到了最先进(SOTA)性能,显著超越了领先的商业智能体如 Cursor 和 Claude Code,并在关键重现性指标上超过了顶尖机构的博士级人类专家。通过系统地将论文规范转化为可生产部署的高质量实现,DeepCode 为**自主科学复现(autonomous scientific reproduction)**奠定了新的基础,能够加速科研验证与发现的进程。原文链接:https://arxiv.org/abs/2512.07921

【第493期】迈向协同超级智能:AI与人类的协同演进
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。今天的主题是:AI & Human Co-Improvement for Safer Co-SuperintelligenceSummary自我提升(self-improvement)目前是人工智能领域备受关注的目标,但其充满风险,而且可能需要较长时间才能真正实现。我们主张,对于人类而言,更可实现且更有价值的目标是最大化共进化(co-improvement):即人类研究者与 AI 系统协作,共同实现共超级智能(co-superintelligence)。具体而言,这意味着专注于提升 AI 系统与人类研究者协同开展 AI 研究的能力,从创意构思到实验验证,实现人类与 AI 的联合研究。这样的合作不仅能够加速 AI 研究进程,还能通过人机共生,使 AI 与人类共同获得更安全的超级智能。将人类研究能力提升纳入闭环协作,将使我们以更快、更安全的方式迈向这一目标。原文链接:https://arxiv.org/abs/2512.05356
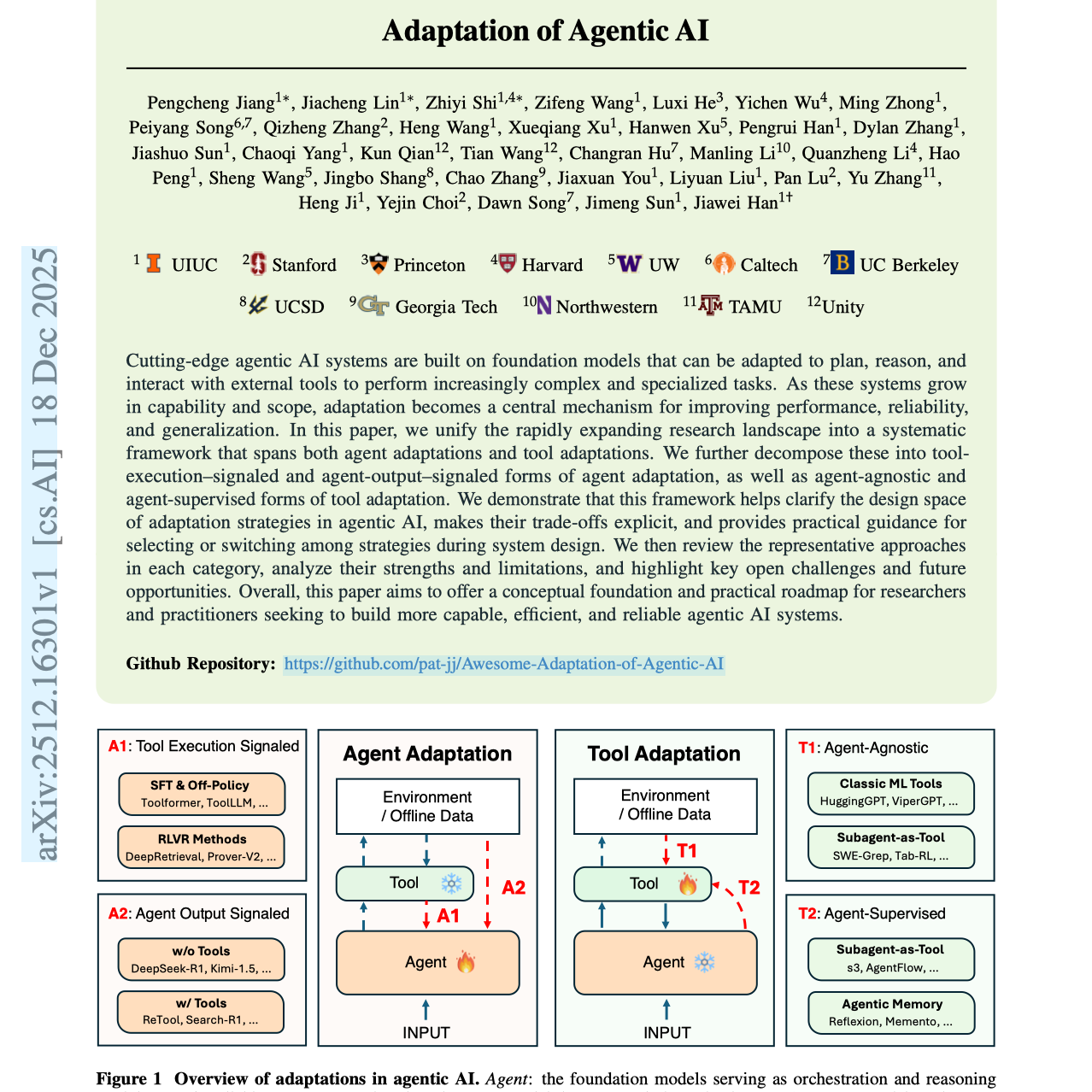
【第492期】智能体AI适配:智能体与工具的协同演化综述
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。今天的主题是:Adaptation of Agentic AISummary前沿的智能体 AI 系统建立在基础模型(foundation models)之上,这些模型可以被适配用于规划、推理以及与外部工具交互,从而执行日益复杂和专业化的任务。随着这些系统能力与应用范围的不断扩展,**适配(adaptation)**成为提升性能、可靠性与泛化能力的核心机制。本文将快速发展的相关研究整合为一个系统化框架,涵盖了**智能体适配(agent adaptations)与工具适配(tool adaptations)**两大方向。我们进一步将其细分为: 智能体适配:**工具执行信号驱动(tool-execution-signaled)与智能体输出信号驱动(agent-output-signaled)**两类; 工具适配:**与智能体无关(agent-agnostic)与智能体监督(agent-supervised)**两类。我们展示了该框架如何帮助澄清智能体 AI 中适配策略的设计空间,使其权衡关系更加明确,并为系统设计过程中策略的选择或切换提供实用指导。随后,我们回顾了各类别的代表性方法,分析其优势与局限,并指出关键的未解决挑战及未来研究机会。总体而言,本文旨在为研究人员与工程实践者提供概念基础与实践路线图,以构建更高效、可靠、能力更强的智能体 AI 系统。原文链接:https://arxiv.org/abs/2512.16301

【第491期】多智能体系统规模化扩展科学研究
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。今天的主题是:Towards a Science of Scaling Agent SystemsSummary智能体(Agents)——即基于大语言模型、具备推理、规划与行动能力的系统——正逐渐成为现实世界 AI 应用的主流范式。尽管其应用日益广泛,但决定智能体系统性能的基本原理仍缺乏深入研究。为此,本文系统性地推导了智能体系统的定量化扩展规律(scaling principles)。我们首先形式化定义了智能体评测(agentic evaluation),并将扩展规律刻画为智能体数量、协作结构、模型能力与任务属性之间的相互作用。我们在四个基准测试上进行了评估:Finance-Agent、BrowseComp-Plus、PlanCraft 和 Workbench。实验涵盖五种典型的智能体架构,包括单智能体(Single-Agent)以及四类多智能体系统(独立式、集中式、去中心化式和混合式),并在三类 LLM 家族上进行实例化,共构成 180 种受控配置。基于协作相关的度量指标,我们构建了一个预测模型,其交叉验证 R2=0.524R2=0.524,能够对未见过的任务领域进行性能预测。研究识别出三种关键效应: 工具—协作权衡效应:在计算预算固定的条件下,工具调用密集型任务在多智能体设置中会因协作开销而遭受不成比例的性能下降。 能力饱和效应:当单智能体基线性能超过约 45% 时,引入协作所带来的收益会迅速递减,甚至转为负收益。 依赖拓扑结构的误差放大效应:独立式智能体会将误差放大至 17.2 倍,而集中式协作可将误差放大效应抑制在 4.4 倍。在可并行化任务中,集中式协作可将性能提升 80.8%;而在网页导航类任务中,去中心化协作表现更优(提升 9.2%,而集中式仅提升 0.2%)。相反,对于顺序推理任务,所有多智能体变体均导致性能下降,降幅介于 39% 至 70% 之间。该框架能够为 87% 的留出配置准确预测最优协作策略。在 GPT-5.2 上进行的样本外验证取得了 MAE=0.071,并验证了五条扩展规律中的四条能够泛化至此前未见的前沿模型。这些结果为理解与设计高效的智能体系统提供了系统化、定量化的理论基础。原文链接:https://arxiv.org/abs/2512.08296

【第490期】STRATUS:基于大语言模型的多智能体自主运维系统
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。今天的主题是:STRATUS: A Multi-agent System for Autonomous Reliability Engineering of Modern CloudsSummary在云规模系统中,故障并非常态中的例外,而是常态本身。一个分布式计算集群往往会经历数百次机器故障和数千次磁盘故障,而软件缺陷与配置错误的发生频率更高。随着云系统规模的持续扩大,对自主化、由 AI 驱动的可靠性工程的需求日益迫切,因为现有的人在环(human-in-the-loop)运维方式已难以跟上现代云环境的复杂性与规模。本文提出 STRATUS,一种基于大语言模型(LLM)的多智能体系统,用于实现云服务的自主站点可靠性工程(Site Reliability Engineering,SRE)。STRATUS 由多个具备专门职能的智能体组成(例如故障检测、故障诊断与故障缓解),并以状态机的形式进行组织,从而支持系统级的安全推理与执行约束。我们形式化定义了智能体化 SRE 系统(如 STRATUS)中的一项关键安全规范——事务性无回退(Transactional No-Regression,TNR),该规范使系统能够在保证安全的前提下进行探索与迭代。实验结果表明,TNR 能够有效提升自主故障缓解的效果。在 AIOpsLab 与 ITBench(两套 SRE 基准测试集)上的评测显示,STRATUS 在故障缓解问题的成功率方面显著优于当前最先进的 SRE 智能体系统:在多种模型设置下,其性能至少提升了 1.5 倍。上述结果表明,STRATUS 为智能体系统在云可靠性领域的实际部署提供了一条极具前景的路径。原文链接:https://arxiv.org/abs/2506.02009

【第489期】Puppeteer:基于强化学习的动态多智能体协同框架
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。今天的主题是:Multi-Agent Collaboration via Evolving OrchestrationSummary大语言模型(Large Language Models,LLMs)在多种下游任务中取得了显著成果,但其单体式(monolithic)的架构限制了在复杂问题求解场景下的可扩展性与效率。尽管近期研究开始探索基于 LLM 的多智能体协作机制,但多数方法依赖静态的组织结构,难以随着任务复杂度和智能体数量的增长进行自适应调整,从而导致协调开销上升和整体效率下降。为此,我们提出了一种 “提线木偶(puppeteer)”式的 LLM 多智能体协作范式。在该框架中,一个集中式的调度与控制器(“puppeteer”)会根据不断演化的任务状态,动态地指挥各个智能体(“puppets”)的执行顺序与优先级。该控制器通过强化学习进行训练,从而能够自适应地编排与调度智能体,实现灵活且可演化的集体推理过程。在封闭域与开放域任务上的实验结果表明,该方法在降低计算成本的同时取得了更优的性能。进一步分析显示,性能提升的关键原因在于:随着控制器的演化,系统中逐步涌现出更加紧凑且具有循环结构的推理模式。相关代码已在文中给出的链接中公开。原文链接:https://arxiv.org/abs/2505.19591
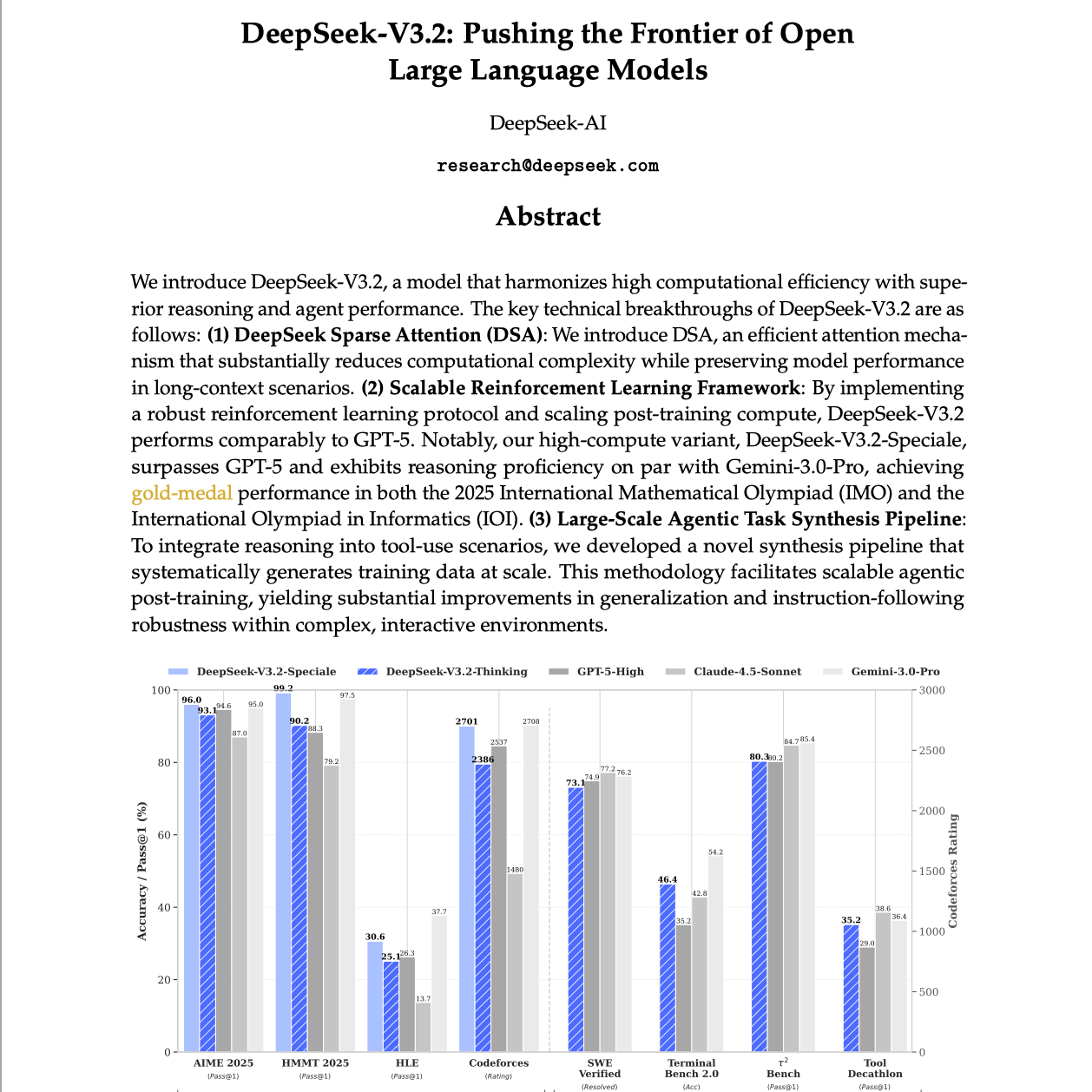
【第488期】DeepSeek-V3.2:通过稀疏注意力和强化学习突破智能极限
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。今天的主题是:DeepSeek-V3.2: Pushing the Frontier of Open Large Language ModelsSummary我们提出 DeepSeek-V3.2,一款在高计算效率与卓越推理能力及智能体(agent)表现之间实现良好平衡的模型。DeepSeek-V3.2 的核心技术突破主要体现在以下三个方面: DeepSeek 稀疏注意力(DeepSeek Sparse Attention,DSA):我们提出了 DSA,一种高效的注意力机制,在长上下文场景下能够在保持模型性能的同时显著降低计算复杂度。 可扩展的强化学习框架:通过构建稳健的强化学习流程并扩展后训练阶段的计算规模,DeepSeek-V3.2 的整体表现可与 GPT-5 相媲美。尤其值得注意的是,高算力版本 DeepSeek-V3.2-Speciale 不仅在整体性能上超越 GPT-5,其推理能力也达到了与 Gemini-3.0-Pro 相当的水平,并在 2025 年国际数学奥林匹克竞赛(IMO)和国际信息学奥林匹克竞赛(IOI)中均取得金牌级表现。 大规模智能体任务合成流水线:为将推理能力有效融入工具使用场景,我们设计了一种全新的任务合成流水线,能够系统性地大规模生成训练数据。该方法支持可扩展的智能体后训练,在复杂交互环境中显著提升了模型的泛化能力与指令遵循的鲁棒性。总体而言,DeepSeek-V3.2 通过在架构、训练范式与数据合成上的协同创新,实现了高效计算与高水平推理及智能体能力的统一。原文链接:https://arxiv.org/abs/2512.02556