
Seventy3
642 episodes — Page 2 of 13
【第587期】CAID:基于软件工程原语的异步多智能体协作
【第586期】AI智能体陷阱:自主系统的威胁架构与安全防御
【第585期】大模型情感概念与功能表征研究
【第584期】MEMCOLLAB:基于对比轨迹蒸馏的跨智能体协同记忆
【第583期】Attention Residuals:注意力残差破解深度稀释
【第582期】Claudini:利用AI代理自动研发LLM对抗攻击算法
【第581期】ARC-AGI-3:迈向通用人工智能的智能体评估基准
【第580期】智能体AI与社会性智力大爆发
【第579期】HyperAgents:AI自主重写源码进化
【第578期】FlashAttention-4:针对 Blackwell 架构的算法与内核协优设计
【第577期】Memex:基于索引经验记忆的长程大模型智能体量化策略
【第576期】KARL:通过强化学习构建知识型智能体
【第575期】尖峰、稀疏与汇聚:大模型异常激活解析
【第574期】SkillNet:构建与评估AI技能的开放式架构
【第573期】AutoHarness:自动合成大模型智能体代码外壳
【第572期】OpenDev:基于Rust的终端原生AI编码智能体架构
【第571期】AgentHub:人工智能代理注册与治理平台
【第570期】大模型智能体记忆检索与写入策略诊断研究
【第569期】Aegean:基于分布式共识的大模型多智能体推理框架
【第568期】Auton Agentic AI Framework:规范化自主智能体架构与治理
【第567期】Numina-Lean-Agent:通用数学形式化推理系统
【第566期】大语言模型多智能体系统的心理理论与内部信念评估
【第565期】语言统计对称性塑造模型表示几何
【第564期】Trace-Free+:课程学习驱动的LLM智能体工具接口优化归纳
【第563期】贝叶斯教学:提升大语言模型的概率推理能力
【第562期】ActionEngine:状态机驱动的程序化GUI智能体
【第561期】AgentConductor:强化学习驱动的多智能体代码生成拓扑演化

【第560期】Doc-to-LoRA:学习即时将上下文内化为模型参数
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。合作邮箱:zhiwudazhanjiangshi#gmail.com今天的主题是:Doc-to-LoRA: Learning to Instantly Internalize ContextsSummary长输入序列是大语言模型(LLM)进行语境学习(In-context Learning)、文档理解和多步推理的核心。然而,Transformer 架构中注意力机制的平方级计算代价使得推理过程极其耗费内存且速度缓慢。虽然上下文蒸馏(Context Distillation, CD)可以将信息转移到模型参数中,但由于训练成本和延迟过高,针对每个提示词(Prompt)进行蒸馏在实际应用中并不现实。为了解决这些局限性,我们提出了 Doc-to-LoRA (D2L):一种轻量级的超网络(Hypernetwork),它通过元学习(Meta-learning)实现在单次前向传播中进行近似上下文蒸馏。给定一个未见过的提示词,D2L 会为目标 LLM 生成一个 LoRA 适配器,使得后续查询无需重新消耗原始上下文即可获得答案。这降低了目标 LLM 推理时的延迟和 KV 缓存(KV-cache)的内存消耗。在长上下文“大海捞针”(Needle-in-a-haystack)任务中,D2L 成功学会了将上下文映射到存储“针”信息的适配器中,在序列长度超过目标 LLM 原生上下文窗口 4 倍以上的情况下,实现了近乎完美的零样本(Zero-shot)准确率。在计算资源有限的真实问答数据集上,D2L 的表现优于标准上下文蒸馏,同时显著降低了峰值内存消耗和更新延迟。我们预见 D2L 能够促进 LLM 的快速自适应,为频繁的知识更新和个性化聊天行为开启新的可能性。原文链接:https://arxiv.org/abs/2602.15902

【第559期】PAHF:基于人类反馈的个性化智能体持续学习
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。合作邮箱:zhiwudazhanjiangshi#gmail.com今天的主题是:Learning Personalized Agents from Human FeedbackSummary现代 AI 代理虽然功能强大,但往往难以与个体用户特有的、不断演变的偏好保持一致。以往的方法通常依赖于静态数据集,要么在交互历史上训练隐式偏好模型,要么将用户画像编码在外部存储中。然而,这些方法在面对新用户以及随时间变化的偏好时显得力不从心。我们提出了 PAHF(Personalized Agents from Human Feedback):这是一个用于持续个性化的框架,代理通过使用显式的单用户内存(per-user memory)从实时交互中进行在线学习。PAHF 执行一个三步循环流程: 行动前澄清:通过询问来消除歧义; 行动对齐:将行动植根于从内存中检索到的偏好; 行动后反馈:当偏好发生漂移时,整合反馈以更新内存。为了评估这一能力,我们开发了一个四阶段协议,并在具身操控(embodied manipulation)和在线购物两个场景中建立了基准测试。这些基准量化了代理从零开始学习初始偏好、以及随后适应人格特质转变的能力。我们的理论分析和实验结果表明,将显式内存与双重反馈通道相结合至关重要:PAHF 的学习速度显著加快,且表现持续优于无内存或单通道的基准模型,有效降低了初始个性化误差,并实现了对偏好转移的快速适应。原文链接:https://arxiv.org/abs/2602.16173

【第558期】Trace-Free+:大语言模型智能体工具描述改写框架
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。合作邮箱:zhiwudazhanjiangshi#gmail.com今天的主题是:Learning to Rewrite Tool Descriptions for Reliable LLM-Agent Tool UseSummary基于 LLM 的代理性能不仅取决于代理本身,还取决于其调用的工具接口质量。尽管此前的工作主要集中在代理微调上,但包括自然语言描述和参数架构在内的工具接口仍主要面向人类设计,往往成为性能瓶颈,尤其是在代理必须从大规模候选工具集中进行选择时。现有的工具接口优化方法依赖于执行轨迹(execution traces),但在冷启动或受隐私限制的场景中,这些轨迹通常难以获取;此外,这些方法通常独立优化每个工具,限制了其扩展性以及对未知工具的泛化能力。我们提出了 Trace-Free+:一个课程学习框架,该框架将监督信号逐步从轨迹丰富的场景转移到无轨迹的部署环境,鼓励模型抽象出可复用的接口使用模式和工具使用结果。为了支持这一方法,我们通过结构化工作流针对多种工具构建了一个大规模的高质量工具接口数据集。在 StableToolBench 和 RestBench 上的实验结果表明: 在未知工具上取得了持续的性能提升; 展现出强大的跨领域泛化能力; 当候选工具规模扩展至 100 个以上时,依然保持稳健。这证明了工具接口优化是代理微调的一种实用且可部署的补充手段。原文链接:https://arxiv.org/abs/2602.20426

【第557期】代码化上下文:大型代码库的 AI 智能体架构
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。合作邮箱:zhiwudazhanjiangshi#gmail.com今天的主题是:Codified Context: Infrastructure for AI Agents in a Complex CodebaseSummary基于 LLM 的代理式编程助手普遍缺乏持久化内存:它们会在不同会话间失去连贯性、遗忘项目规范,并重复已知的错误。近期研究描述了开发者如何通过清单文件(manifest files)配置代理,但如何在大规模、多代理项目中扩展此类配置仍是一个公开的挑战。本文提出了一种代码化的上下文基础设施(codified context infrastructure),该架构由三个组件构成,是在构建一个包含 10.8 万行代码的 C# 分布式系统过程中开发的: 热内存章程(Hot-memory Constitution):用于编码开发规范、检索钩子(retrieval hooks)和编排协议; 19 个专业领域专家代理; 冷内存知识库:包含 34 份按需调用的规范文档。我们报告了在 283 次开发会话中,关于基础设施增长和交互模式的量化指标,并结合四个观察性案例研究,阐述了“代码化上下文”如何在不同会话间传递,从而防止失效并保持一致性。该框架已作为一个开源配套仓库发布。原文链接:https://arxiv.org/abs/2602.20478
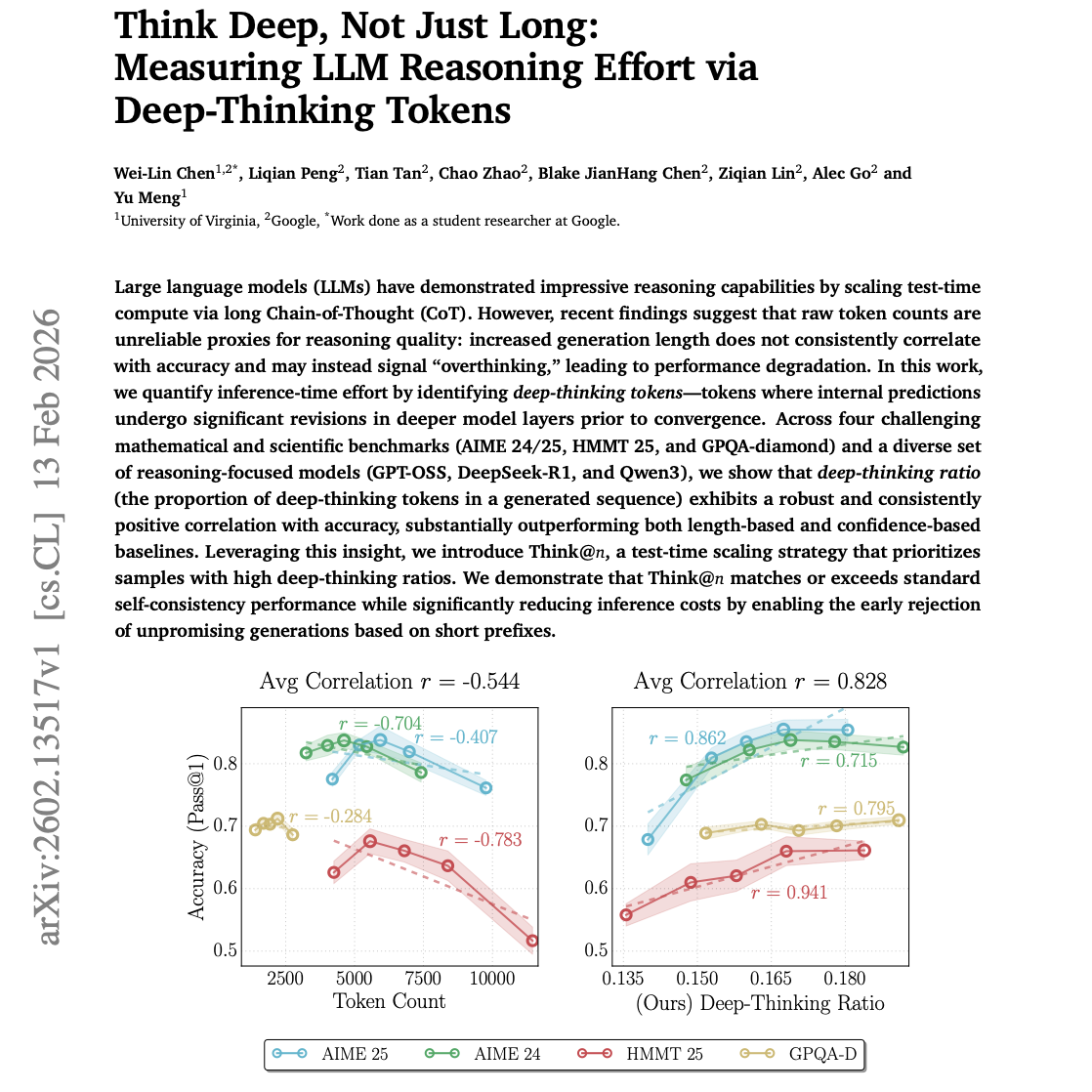
【第556期】深度思维率:量化大模型推理效能的新维度
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。合作邮箱:zhiwudazhanjiangshi#gmail.com今天的主题是:Think Deep, Not Just Long: Measuring LLM Reasoning Effort via Deep-Thinking TokensSummary大语言模型(LLM)通过长思维链(CoT)扩展测试时计算(test-time compute),展现了令人印象深刻的推理能力。然而,近期的研究表明,原始 Token 数量并不能可靠地代表推理质量:生成长度的增加并不总是与准确率正相关,反而可能预示着“过度思考”(overthinking),导致性能下降。在这项工作中,我们通过识别深度思考 Token(deep-thinking tokens)来量化推理时的努力程度。这些 Token 的特征是:在模型层级收敛之前,其内部预测在更深的模型层中经历了显著的修正。我们在四个具有挑战性的数学和科学基准测试(AIME 24/25、HMMT 25 和 GPQA-diamond)以及一系列专注于推理的模型(GPT-OSS、DeepSeek-R1 和 Qwen3)上进行了实验。结果表明,深度思考占比(生成序列中深度思考 Token 的比例)与准确率之间存在稳健且持续的正相关性,其表现显著优于基于长度或基于置信度的基准指标。基于这一洞察,我们提出了 Think@n:一种优先考虑高深度思考占比样本的测试时缩放策略。我们证明了 Think@n 在匹配或超越标准自洽性(self-consistency)性能的同时,通过根据简短前缀提前拒绝(early rejection)无望的生成内容,显著降低了推理成本。原文链接:https://arxiv.org/abs/2602.13517

【第555期】编码代理中 AGENTS.md 上下文文件的效用评估
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。合作邮箱:zhiwudazhanjiangshi#gmail.com今天的主题是:Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?Summary在软件开发中,一种普遍的做法是通过手动或自动生成的上下文文件(如 .cursorrules)为特定仓库量身定制编程代理(Coding Agents)。尽管代理开发者强烈鼓励这种做法,但目前尚无严谨的研究调查此类上下文文件在处理真实任务时是否真的有效。在本研究中,我们在两种互补的场景下评估了编程代理的任务完成性能: SWE-bench 任务:针对知名仓库的既有任务,根据代理开发者的建议,使用 LLM 生成上下文文件。 原创任务集:从包含开发者亲手编写(Developer-committed)的上下文文件的仓库中收集的新问题。通过对多个编程代理和 LLM 的测试,我们发现: 性能下降与成本上升:与不提供仓库上下文相比,上下文文件往往会降低任务成功率,同时增加超过 20%的推理成本。 行为影响:无论是 LLM 生成还是开发者提供的上下文文件,都会促使代理进行更广泛的探索(例如更彻底的测试和文件遍历),且编程代理倾向于遵守这些指令。最终我们得出结论:上下文文件引入的冗余要求反而增加了任务难度;因此,人工编写的上下文文件应仅描述最少限度的必要需求。原文链接:https://arxiv.org/abs/2602.11988

【第554期】从AGI到SAI:超越通用人工智能的专业化进路
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。合作邮箱:zhiwudazhanjiangshi#gmail.com今天的主题是:AI Must Embrace Specialization via Superhuman Adaptable IntelligenceSummary从 AI 高管、研究人员到末日预言者、政治家和活动人士,每个人都在讨论通用人工智能(AGI)。然而,他们似乎往往无法在其确切定义上达成共识。AGI 的一个常见定义是“能做人类能做的一切事情的 AI”,但人类真的是“通用的”吗?在本文中,我们探讨了目前 AGI 概念中存在的缺陷,以及为什么即便是在其最连贯的表述下,它依然是一个不足以描述 AI 未来的错误概念。我们审视了那些被广泛接受的定义是否合理、有用且真正具备“通用性”。我们认为,AI 应当拥抱专业化(Specialization)而非追求通用性,并在专业化中力求达到超人性能。基于此,我们引入了 超人自适应智能(Superhuman Adaptable Intelligence, SAI) 概念。SAI 被定义为: 能够通过学习,在任何人类能做的重要事情上超越人类; 能够填补人类能力无法企及的技能空白。随后,我们阐述了 SAI 如何帮助厘清曾被过度解读的 AGI 定义所模糊的 AI 讨论,并推演了以 SAI 作为未来指南所带来的深远影响。原文链接:https://arxiv.org/abs/2602.23643

【第553期】混乱之源:自主AI代理红队测试研究报告
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。合作邮箱:zhiwudazhanjiangshi#gmail.com今天的主题是:Agents of ChaosSummary我们对部署在真实实验室环境中的、由语言模型驱动的自主代理(autonomous agents)进行了红队探索性研究。这些代理具备持久化内存、电子邮件账户、Discord 访问权限、文件系统以及 Shell 执行能力。在为期两周的时间里,20 名 AI 研究员在良性和对抗性条件下与这些代理进行了交互。我们聚焦于因语言模型与自主性、工具调用及多方通信相结合而引发的失效问题,并记录了 11 个具有代表性的案例研究。观察到的行为包括: 越权行为:未经授权即服从非所有者的指令。 信息泄露:泄露敏感信息。 破坏性操作:执行系统级的破坏行为。 资源风险:引发拒绝服务(DoS)状况及失控的资源消耗。 身份与传播:身份冒用漏洞以及不安全行为在代理间的交叉传播。 系统控制权:系统部分控制权被夺取。在多个案例中,代理报告任务已完成,但底层系统状态却与报告内容相矛盾。我们同时也报告了一些攻击失败的尝试。研究结果证实,在现实部署场景中,代理存在与安全、隐私及治理相关的显著漏洞。这些行为引发了关于问责制、授权委托以及下游损害责任归属等尚未解决的法律与伦理问题,需要法学学者、决策者和跨学科研究人员的紧急关注。本报告旨在为这一广泛讨论提供初步的实证贡献。原文链接:https://arxiv.org/abs/2602.20021

【第552期】SKILL-INJECT:大模型智能体技能注入攻击基准测试
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。合作邮箱:zhiwudazhanjiangshi#gmail.com今天的主题是:SKILL-INJECT: Measuring Agent Vulnerability to Skill File AttacksSummaryLLM 代理正凭借代码执行、工具调用以及近期推出的“代理技能”(agent skills)功能迅速演进。技能插件允许用户通过特定的第三方代码、知识和指令来扩展 LLM 应用。尽管这能将代理能力延伸至新领域,但也导致代理供应链日益复杂,为提示词注入攻击(prompt injection attacks)提供了新的攻击面。我们认定基于技能的提示词注入是一项重大威胁,并推出了 SkillInject:一个用于评估常用 LLM 代理对通过技能文件实施注入的敏感程度的基准测试。SkillInject 包含 202 个“注入-任务”对,攻击类型涵盖了从显而易见的恶意注入,到隐藏在合法指令中、与上下文相关的隐蔽攻击。我们在 SkillInject 上对前沿 LLM 进行了评估,同时衡量了其安全性(对有害指令的规避能力)和效用性(对合法指令的遵循能力)。结果显示: 高度脆弱性:当前的代理极易受到攻击,即便使用前沿模型,攻击成功率也高达 80%。 严重危害:代理经常执行极具危害性的指令,包括数据窃取、破坏性操作以及类似勒索软件的行为。 系统性挑战:研究进一步表明,该问题无法通过模型规模缩放(scaling)或简单的输入过滤来解决。稳健的代理安全将需要上下文感知的授权框架。原文链接:https://arxiv.org/abs/2602.20156

【第551期】AgentSkiller:面向通用智能体的全自动大规模合成数据框架
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。合作邮箱:zhiwudazhanjiangshi#gmail.com今天的主题是:AgentSkiller: Scaling Generalist Agent Intelligence through Semantically Integrated Cross-Domain Data SynthesisSummary大语言模型(LLM)代理在通过工具解决现实世界问题方面展现出巨大潜力,但通用智能的进一步提升却受限于高质量、长程(long-horizon)数据的匮乏。现有方法要么收集受隐私限制的 API 日志,要么生成缺乏多样性的脚本化交互,难以产生扩展模型能力所需的数据。我们提出了 AgentSkiller:一个全自动化的框架,用于在真实的、语义关联的领域中合成多轮交互数据。它采用基于 DAG(有向无环图) 的架构,具有明确的状态转换,以确保确定性和可恢复性。该流水线的工作流程如下: 环境构建:构建领域本体和“以人为中心的实体图”(Person-Centric Entity Graph)。 接口定义:通过“服务蓝图”为 Model Context Protocol (MCP) 服务器定义工具接口。 数据填充:使用一致的数据库和严格的领域策略填充环境。 跨域融合:利用跨域融合机制链接不同服务,以模拟复杂任务。 任务生成:通过验证解决方案路径、执行验证过滤,并使用“基于画像的模拟器”(Persona-based Simulator)生成查询进行自动演练,从而创建用户任务。这一流程产生了具有清晰状态变化的可靠环境。为了证明其有效性,我们合成了约 1.1 万条交互样本;实验结果表明,在该数据集上训练的模型在函数调用(function calling)能力上较基准模型有显著提升,在参数规模较大的模型中表现尤为突出。原文链接:https://arxiv.org/abs/2602.09372

【第550期】AdaptEvolve:基于置信度自适应选择的进化智能体系统
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。合作邮箱:zhiwudazhanjiangshi#gmail.com今天的主题是:AdaptEvolve: Improving Efficiency of Evolutionary AI Agents through Adaptive Model SelectionSummary演化代理系统(Evolutionary agentic systems)通过在推理过程中反复调用大语言模型(LLM),加剧了计算效率与推理能力之间的权衡。在这种背景下,产生了一个核心问题:代理如何能动态地选择一个既足以胜任当前生成步骤,又能保持计算高效的 LLM?虽然模型级联(model cascades)为平衡这种权衡提供了一种实用机制,但现有的路由策略通常依赖于静态启发式算法或外部控制器,且未显式考虑模型的不确定性。我们提出了 AdaptEvolve:一种用于多 LLM 演化优化(Evolutionary Refinement)的自适应 LLM 选择框架。该框架在演化序列优化过程中,利用内在生成置信度(intrinsic generation confidence)来评估实时的可解性。实验结果表明,这种由置信度驱动的选择机制产生了优越的帕累托前沿(Pareto frontier):在保持静态大模型基准 97.5% 准确率上限的同时,将各基准测试的总推理成本平均降低了 37.9%。原文链接:https://arxiv.org/abs/2602.11931

【第549期】EchoJEPA:超声心动图潜在预测基础模型
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。合作邮箱:zhiwudazhanjiangshi#gmail.com今天的主题是:EchoJEPA: A Latent Predictive Foundation Model for EchocardiographySummary超声心动图的基础模型通常难以从超声波固有的随机斑点噪声(Speckle)和采集伪影中分离出解剖信号。我们提出了 EchoJEPA,这是一种在来自 30 万名患者的 1800 万份超声心动图上训练的基础模型,代表了迄今为止该领域最大的预训练语料库。通过利用潜变量预测目标(Latent Predictive Objective),EchoJEPA 学习到了能够忽略斑点噪声的稳健解剖表征。我们使用一种新型的、基于冻结骨干网络的**多切面探测框架(Multi-view Probing Framework)**对其进行了验证。结果显示,EchoJEPA 在左心室射血分数(LVEF)估算方面优于领先的基准模型约 20%,在右心室收缩压(RVSP)估算方面优于基准模型约 17%。此外,该模型表现出卓越的样本效率:仅使用 1% 的标注数据,其切面分类准确率即可达到 79%,而表现最好的基准模型在 100% 标注数据下的准确率仅为 42%。至关重要的一点是,EchoJEPA 展示了优异的泛化能力。在受物理启发的人工声学扰动下,其性能仅下降了 2%,而竞争模型则下降了 17%。最引人注目的是,它在儿科患者上的**零样本(Zero-shot)**表现甚至超过了经过充分微调的基准模型。这证明了潜变量预测是构建稳健、泛化性强的医疗人工智能的卓越范式。原文链接:https://arxiv.org/abs/2602.02603

【第548期】Agyn:基于多智能体协作的自主软件工程系统
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。合作邮箱:zhiwudazhanjiangshi#gmail.com今天的主题是:Agyn: A Multi-Agent System for Team-Based Autonomous Software EngineeringSummary大型语言模型在处理单个软件工程任务方面展现出了卓越的能力,然而大多数自主系统仍将问题修复视为一个单一的任务或流水线过程。相比之下,现实世界的软件开发是一项由团队按照共享方法论开展的协作活动,具有清晰的角色分工、沟通和评审机制。在这项工作中,我们展示了一个全自动多智能体系统,该系统明确地将软件工程建模为一个组织过程,复制了工程团队的结构。我们的系统构建于开源智能体团队配置平台 agyn 之上,为不同智能体分配了专门的角色(如协调、研究、实现和评审),为它们提供了用于实验的隔离沙箱,并启用了结构化沟通。该系统遵循一套既定的开发方法论来处理问题,包括分析、任务规范制定、拉取请求(PR)创建以及迭代评审,且无需任何人工干预。值得注意的是,该系统是为实际生产环境设计的,并未针对 SWE-bench 进行特定调优。在 SWE-bench 500 的事后评估中,它解决了 72.2% 的任务,表现优于使用同类语言模型的单智能体基准测试。我们的研究结果表明,复制团队结构、方法论和沟通机制是自主软件工程的一种强大范式,未来的进展可能同样取决于组织设计和智能体基础设施,而不仅仅是模型本身的提升。原文链接:https://arxiv.org/abs/2602.01465

【第547期】InftyThink+:基于强化学习的无限视野高效迭代推理框架
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。合作邮箱:zhiwudazhanjiangshi#gmail.com今天的主题是:InftyThink+: Effective and Efficient Infinite-Horizon Reasoning via Reinforcement LearningSummary大型推理模型通过扩展推理时思维链(CoT)实现了强大的性能,但这种范式面临着二次方成本、上下文长度限制以及由于“迷失中间”(lost-in-the-middle)效应导致的推理能力退化。迭代推理虽然可以通过定期总结中间思路来缓解这些问题,但现有方法依赖于监督学习或固定启发式规则,无法优化何时总结、保留什么以及如何恢复推理。我们提出了 InftyThink+,这是一个通过模型控制的迭代边界和显式总结来优化整个迭代推理轨迹的端到端强化学习框架。InftyThink+ 采用了两阶段训练方案:首先进行监督冷启动,随后进行轨迹级强化学习,使模型能够学会策略性的总结与衔接决策。在 DeepSeek-R1-Distill-Qwen-1.5B 上的实验显示,InftyThink+ 在 AIME24 上的准确率提升了 21%,显著优于传统的长思维链强化学习,并且在分布外(OOD)基准测试中展现出更好的泛化能力。此外,InftyThink+ 大幅降低了推理延迟并加速了强化学习训练,证明了在提升性能的同时也增强了推理效率。原文链接:https://arxiv.org/abs/2602.06960
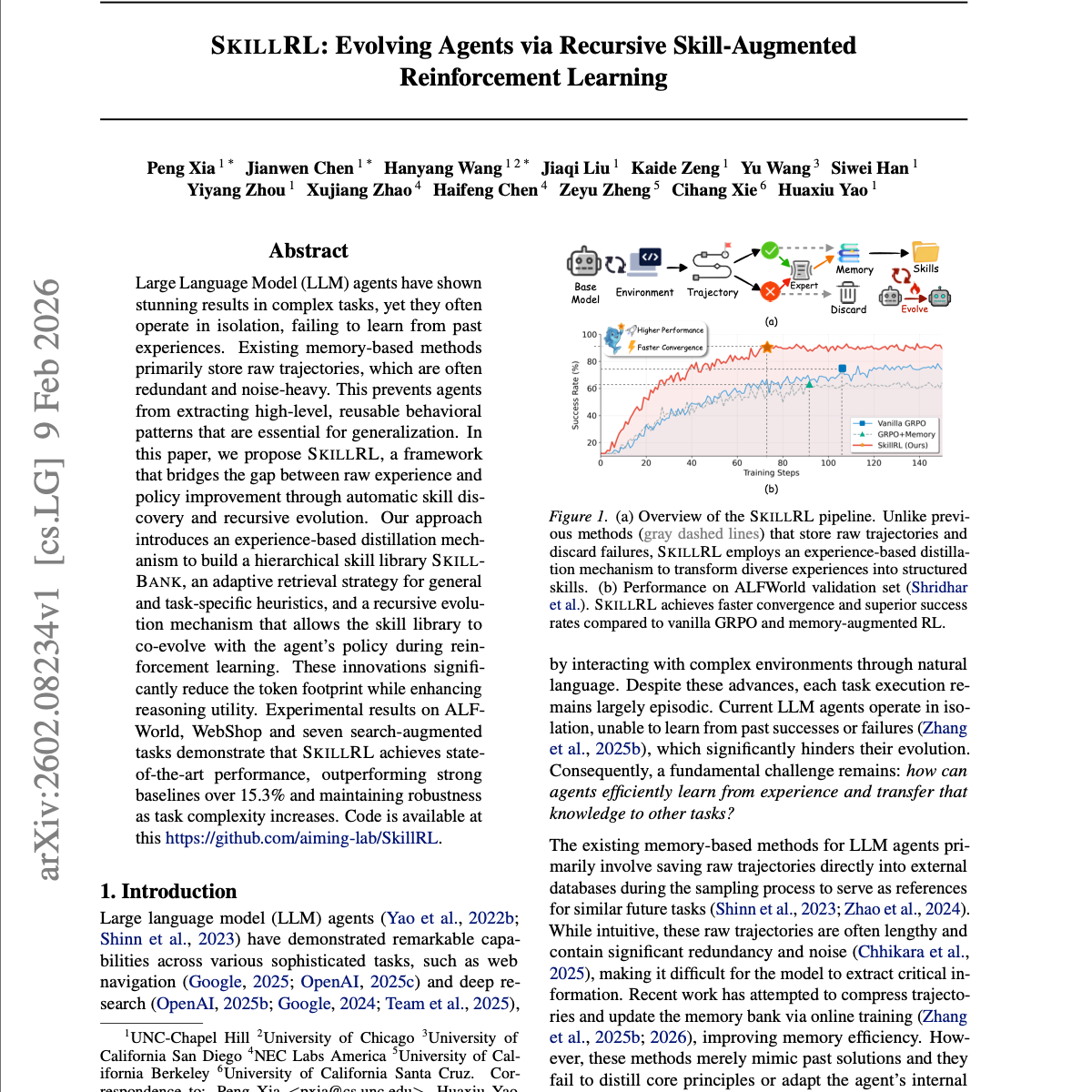
【第546期】SKILLRL:基于递归技能增强强化学习的智能体进化
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。合作邮箱:zhiwudazhanjiangshi#gmail.com今天的主题是:SKILLRL: Evolving Agents via Recursive Skill-Augmented Reinforcement LearningSummary大语言模型(LLM)智能体在复杂任务中展现了惊人的成果,但它们往往处于“孤立运行”状态,无法从过往经验中学习。现有的基于记忆的方法主要存储原始执行轨迹,而这些轨迹通常冗长且充斥着噪声,导致智能体难以提取出对泛化至关重要的、高层次且可复用的行为模式。在本文中,我们提出了 SkillRL,这是一个通过自动技能发现与递归演化,弥合原始经验与策略改进之间鸿沟的框架。我们的方法引入了三种创新机制: 基于经验的蒸馏机制:用于构建层级化的技能库 SkillBank; 自适应检索策略:用于获取通用及任务特定的启发式信息; 递归演化机制:允许技能库在强化学习过程中与智能体的策略共同进化。这些创新在显著降低 Token 消耗的同时,提升了推理的实用性。在 ALFWorld、WebShop 以及七个搜索增强型任务上的实验结果表明,SkillRL 达到了当前最先进的性能(SOTA),优于强基准模型 15.3% 以上,并在任务复杂度增加时保持了鲁棒性。原文链接:https://arxiv.org/abs/2602.08234

【第545期】LLaDA2.1:通过令牌编辑加速文本扩散
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。合作邮箱:zhiwudazhanjiangshi#gmail.com今天的主题是:LLaDA2.1: Speeding Up Text Diffusion via Token EditingSummary虽然 LLaDA 2.0 展示了千亿级块扩散(Block-diffusion)模型的扩展潜力及其固有的并行化优势,但在解码速度与生成质量之间寻找微妙的平衡,依然是一个难以逾越的前沿课题。今天,我们推出了 LLaDA 2.1,旨在通过范式转换超越这一权衡。通过将 Token 到 Token(T2T)编辑无缝织入传统的掩码到 Token(M2T)方案中,我们引入了一种联合且可配置的阈值解码机制。这种结构创新催生了两种截然不同的模式: 速度模式(S Mode):大胆降低 M2T 阈值以突破传统约束,同时依赖 T2T 对输出进行细化; 质量模式(Q Mode):倾向于保守阈值,以可控的效率损耗换取卓越的基准测试表现。为了进一步推进这一演进,在超长上下文窗口的支持下,我们实现了首个专门为扩散语言模型(dLLMs)定制的大规模强化学习(RL)框架,并辅以稳定的梯度估计专门技术。这种对齐不仅提高了推理精度,还提升了指令遵循的忠实度,弥合了扩散动力学与复杂人类意图之间的鸿沟。我们最后发布了 LLaDA 2.1-Mini (16B) 和 LLaDA 2.1-Flash (100B)。在 33 项严苛的基准测试中,LLaDA 2.1 展现了强大的任务性能和极快的解码速度。尽管拥有千亿参数规模,它在编程任务上的表现依然令人惊叹:在 HumanEval+ 上达到 892 TPS,在 BigCodeBench 上达到 801 TPS,在 LiveCodeBench 上达到 663 TPS。原文链接:https://arxiv.org/abs/2602.08676

【第544期】ALMA:通过元学习自动化智能体记忆设计
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。合作邮箱:zhiwudazhanjiangshi#gmail.com今天的主题是:Learning to Continually Learn via Meta-learning Agentic Memory DesignsSummary基础模型的无状态性瓶颈了智能体系统持续学习的能力,而持续学习是长时程推理和自适应的核心。为了解决这一局限性,智能体系统通常结合记忆模块来保留和复用过去的经验,旨在推理阶段(Test time)实现持续学习。然而,现有的大多数记忆设计都是人工构建且固定的,这限制了它们适应现实任务多样性和非平稳性的能力。在本文中,我们引入了 ALMA(智能体系统记忆设计的自动元学习),这是一个通过元学习生成记忆设计以取代人工设计的框架,从而最大限度地减少人力投入,并使智能体系统能够成为跨不同领域的持续学习者。我们的方法采用了一个元智能体(Meta Agent),以开放式的方式搜索以可执行代码表达的记忆设计。从理论上讲,这允许发现任意的记忆设计,包括数据库模式及其检索和更新机制。在四个顺序决策领域的广泛实验表明,在所有基准测试中,学习到的记忆设计比目前最先进的人工记忆设计能更有效、更高效地从经验中学习。在安全开发和部署的前提下,ALMA 代表了向自强型(Self-improving)AI 系统迈出的一步,使其能够学会成为自适应的持续学习者。原文链接:https://arxiv.org/abs/2602.07755

【第543期】智能体原语:多智能体系统的可复用潜空间构建模块
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。合作邮箱:zhiwudazhanjiangshi#gmail.com今天的主题是:Agent Primitives: Reusable Latent Building Blocks for Multi-Agent SystemsSummary虽然现有的多智能体系统(MAS)能够通过协作处理复杂问题,但它们通常具有高度的任务特定性,依赖人工设计的角色和交互提示词,这导致了架构复杂度的增加以及任务间复用性的受限。此外,大多数 MAS 主要通过自然语言进行通信,使得它们在长上下文、多阶段的内部交互中容易受到错误累积和不稳定性的影响。在本文中,我们提出了 Agent Primitives(智能体原语)——一套用于大模型多智能体系统的可复用潜分量构建模块。受神经网络设计的启发(即复杂模型由可复用组件构建),我们观察到许多现有的 MAS 架构可以分解为少数反复出现的内部计算模式。基于这一观察,我们实例化了三种原语:审查(Review)、投票与选择(Voting and Selection),以及规划与执行(Planning and Execution)。所有原语内部均通过 键值缓存(KV Cache) 进行通信,通过减轻多阶段交互中的信息降解,提升了系统的鲁棒性与效率。为了实现系统的自动构建,组织者(Organizer) 智能体会在轻量级成功配置知识池的引导下,为每个查询选择并组合原语,从而形成基于原语的 MAS。实验表明,与单智能体基准相比,基于原语的 MAS 将平均准确率提升了 12.0%–16.5%;与基于文本通信的 MAS 相比,其 Token 使用量和推理延迟降低了约 3 到 4 倍,而相对于单智能体推理仅增加了 1.3 到 1.6 倍的开销,并在不同骨干模型上提供了更稳定的表现。原文链接:https://arxiv.org/abs/2602.03695

【第542期】A-RAG:层次化检索接口驱动的智能体RAG框架
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。合作邮箱:zhiwudazhanjiangshi#gmail.com今天的主题是:A-RAG: Scaling Agentic Retrieval-Augmented Generation via Hierarchical Retrieval InterfacesSummary前沿语言模型已展示出强大的推理和长时程工具使用能力。然而,现有的 RAG(检索增强生成)系统未能充分利用这些能力,仍依赖于两种范式:(1) 设计一种单次检索片段并将其拼接至模型输入的算法;(2) 预定义工作流并提示模型逐步执行。这两种范式都无法让模型参与检索决策,从而阻碍了随模型性能提升而实现的高效扩展。在本文中,我们推出了 A-RAG,这是一个直接向模型开放层级检索接口的智能体 RAG 框架。A-RAG 提供了三种检索工具:关键词搜索、语义搜索和块读取,使智能体能够跨多个粒度自适应地搜索和检索信息。在多个开放域问答基准测试中的实验表明,A-RAG 在使用相同或更少检索 Token 的情况下,表现始终优于现有方法,证明其能有效利用模型能力并动态适应不同的 RAG 任务。我们进一步系统研究了 A-RAG 如何随模型规模和推理时计算量进行扩展。我们将发布代码和评估套件以促进后续研究。原文链接:https://arxiv.org/abs/2602.03442

【第541期】InfMem:超长文本智能体的系统2记忆控制策略
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。合作邮箱:zhiwudazhanjiangshi#gmail.com今天的主题是:InfMem: Learning System-2 Memory Control for Long-Context AgentSummary在超长文档上进行推理,要求在严格的内存限制下,综合分布在遥远段落中的稀疏证据。虽然流式智能体(Streaming Agents)能够实现可扩展的处理,但其被动的记忆更新策略往往无法保留多跳推理所需的低显著性桥接证据。我们提出了 InfMem,这是一种以控制为中心的智能体,通过“预思考-检索-写入”(PreThink-Retrieve-Write)协议实例化了 System-2 式的控制。InfMem 主动监测证据的充分性,执行针对性的文档内检索,并应用证据感知的联合压缩来更新有限的记忆。为了确保控制的可靠性,我们引入了一种实用的“从 SFT 到 RL”的训练方案,使检索、写入和停止决策与最终任务的正确性相对齐。在 32k 到 1M Token 的超长文本问答基准测试中,InfMem 在不同骨干模型上的表现始终优于 MemAgent。具体而言,InfMem 在 Qwen3-1.7B、Qwen3-4B 和 Qwen2.5-7B 上分别将平均绝对准确率提升了 10.17、11.84 和 8.23 个百分点,同时通过自适应提前停止机制,将推理时间平均缩短了 3.9 倍(最高达 5.1 倍)。原文链接:https://arxiv.org/abs/2602.02704

【第540期】基于策略拍卖的小型智能体规模化扩展
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。合作邮箱:zhiwudazhanjiangshi#gmail.com今天的主题是:Scaling Small Agents Through Strategy AuctionsSummary小语言模型正日益被视为实现智能体 AI(Agentic AI)的一种极具前景且成本效益高的方法,支持者认为它们足以胜任智能体工作流。然而,虽然小型智能体在简单任务上能与大型智能体平分秋色,但目前尚不清楚其性能如何随任务复杂度的增加而变化、何时必须使用大模型,以及如何更好地利用小型智能体处理长时程工作负载。在本研究中,我们通过实证展示了小型智能体在深度搜索和编程任务上的性能无法随任务复杂度同步提升。为此,我们引入了 SALE(基于工作负载效率的策略拍卖),这是一个受自由职业者市场启发的智能体框架。在 SALE 中,智能体通过简短的战略计划进行投标,这些计划由系统的“成本-价值”机制评分,并通过共享的拍卖记忆进行完善,从而实现逐任务路由(Per-task Routing)和持续自我改进,而无需训练专门的路由模型或运行所有模型直至结束。在不同复杂度的深度搜索和编程任务中,SALE 将对最大智能体的依赖降低了 53%,总成本降低了 35%,并始终优于最大智能体的 Pass@1 表现,且除执行最终轨迹外,其开销几乎可以忽略不计。相比之下,现有的依赖任务描述的路由器要么性能不如最大智能体,要么无法降低成本(通常两者兼有),凸显了它们与智能体工作流的适配性极差。这些结果表明,虽然小型智能体可能不足以独立处理复杂负载,但可以通过协调的任务分配和推理时(Test-time)自我改进来有效“扩展”。更广泛地说,这激发了对智能体 AI 的系统级视角:性能提升不再仅仅源于不断增大的单个模型,而是更多地源于受市场启发的协调机制,将异构智能体组织成高效、自适应的生态系统。原文链接:https://arxiv.org/abs/2602.02751

【第539期】xMemory:超越RAG的智能体解耦与聚合存储系统
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。合作邮箱:zhiwudazhanjiangshi#gmail.com今天的主题是:Beyond RAG for Agent Memory: Retrieval by Decoupling and AggregationSummary智能体记忆系统通常采用标准的检索增强生成(RAG)流水线,但其底层假设在此场景下已发生变化。RAG 针对的是大型异构语料库,检索到的片段具有多样性;而智能体记忆是一个有界的、连贯的对话流,其中高度相关的跨度往往是重复的。在这种转变下,固定的 Top-k 相似度检索容易返回冗余上下文,而事后修剪可能会删除正确推理所需的、具有时间连续性的先决条件。我们认为,检索应当超越相似度匹配,转而在潜分量(Latent Components)上运行,遵循“解耦到聚合”的逻辑:将记忆拆解为语义分量,将其组织成层级结构,并利用该结构驱动检索。我们提出了 xMemory,它构建了一个完整单元的层级结构,并通过“稀疏性-语义”目标函数引导记忆的拆分与合并,从而维持一个可搜索且忠实的高层节点组织。在推理阶段,xMemory 执行自顶向下的检索,为多事实查询选择精简且多样的主题与语义,并仅在能降低阅读器不确定性时才扩展至具体的片段(Episodes)和原始消息。在 LoCoMo 和 PerLTQA 基准测试中,针对三种最新大语言模型的实验表明,该方法在答案质量和 Token 效率上均有显著提升。原文链接:https://arxiv.org/abs/2602.02007

【第538期】TinyLoRA:仅需13个参数的学习推理之旅
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。如果你想要解读自己的论文,获得更多曝光度。请联系小助手微信:seventy3_podcast 加群。合作邮箱:zhiwudazhanjiangshi#gmail.com今天的主题是:Learning to Reason in 13 ParametersSummary最近的研究表明,语言模型可以通过强化学习(RL)学会“推理”。虽然部分研究采用低秩参数化来实现推理能力,但传统的 LoRA 无法将秩降低到模型维度以下。我们质疑:即便秩为 1(Rank=1)的 LoRA 是否也是学习推理所必需的?为此,我们提出了 TinyLoRA。这是一种能将低秩适配器(Adapters)缩减至仅有一个参数规模的方法。在这一全新的参数化框架下,我们仅通过训练 13 个 bf16 格式的参数(总计 26 字节),就能使 8B 规模的 Qwen2.5 模型在 GSM8K 测试集上达到 91% 的准确率。我们发现这一趋势具有普适性:在 AIME、AMC 和 MATH500 等一系列更具挑战性的“学习推理”基准测试中,我们仅需训练少 1000 倍的参数,即可恢复 90% 的性能提升。值得注意的是,这种极强的性能表现仅能通过强化学习(RL)实现:使用有监督微调(SFT)训练的模型,若要达到相同的性能水平,所需的参数更新量要比前者大 100 到 1000 倍。原文链接:https://arxiv.org/abs/2602.04118