
The Gradient: Perspectives on AI
149 episodes — Page 3 of 3

Nathan Benaich: The State of AI Report
* Have suggestions for future podcast guests (or other feedback)? Let us know here!* Want to write with us? Send a pitch using this form :)In episode 48 of The Gradient Podcast, Daniel Bashir speaks to Nathan Benaich.Nathan is Founder and General Partner at Air Street Capital, a venture capital (VC) firm focused on investing in AI-first technology and life sciences companies. Nathan runs a number of communities focused on AI including the Research and Applied AI Summit and leads Spinout.fyi to improve the creation of university spinouts. Together with investor Ian Hogarth, Nathan co-authors the State of AI Report.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterOutline:* (00:00) Intro* (02:40) Nathan’s interests in AI, life sciences, investing* (04:10) Biotech and tech-bio companies* (08:00) Why Nathan went into VC* (10:15) Air Street Capital’s focus, investing in AI at an early stage* (14:30) Why Nathan believes in specialism over generalism in AI, balancing consumer-focused ML with serious technical work* (17:30) The European startup ecosystem* (19:30) Spinouts and inventions born in academia* (23:35) Spinout.fyi and issues with the European model* (27:50) In the UK, only 4% of private AI companies are spinouts* (30:00) Solutions* (32:55) Origins of the State of AI Report* (35:00) Looking back on Nathan’s 2021 predictions: Anthropic and JAX* (39:00) AI semiconductors and the difficult reality* (42:45) Nathan’s perspectives on AI safety/alignment* (46:00) Long-termism and debates, safety research as an input into improving capabilities* (49:50) Decentralization and the commercialization of open-source AI (Stability AI, Eleuther AI, etc.)* (53:00) Second-order applications of diffusion models—chemistry, small molecule design, genome editors* (59:00) Semiconductor restrictions and geopolitics* (1:03:45) This year’s State of AI predictions* (1:04:30) Trouble in semiconductor startup land* (1:08:40) Predictions for AGI startups* (1:14:20) How regulation of AGI startups might look* (1:16:40) Nathan’s advice for founders, investors, and researchers* (1:19:00) OutroLinks:* State of AI Report* Air Street Capital* Spinout.fyi* Rewriting the European spinout playbook* Other sources mentioned* Bridging the Gap: the case for an Incompletely Theorized Agreement on AI policy* Choking Off China’s Access to the Future of AI* China's New AI Governance Initiatives Shouldn't Be Ignored Get full access to The Gradient at thegradientpub.substack.com/subscribe

Matt Sheehan: China's AI Strategy and Governance
* Have suggestions for future podcast guests (or other feedback)? Let us know here!* Want to write with us? Send a pitch using this form :)In episode 47 of The Gradient Podcast, Daniel Bashir speaks to Matt Sheehan.Matt is a fellow at the Carnegie Endowment for International Peace, where he researches global technology with a focus on China. His writing and research explores China’s AI ecosystem, the future of China’s technology policy, and technology’s role in China’s political economy. Matt has also written for Foreign Affairs andThe Huffington Post, among other venues.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterOutline:* (00:00) Intro* (02:28) Matt’s path to analyzing China’s AI governance* (06:50) Matt’s experience understanding daily life in China and developing a bottom-up perspective* (09:40) The development of government constraints in technology/AI in the US and China* (12:40) Matt’s take on China’s priorities and motivations* (17:00) How recent history influences China’s technology ambitions* (17:30) Matt gives an overview of the Century of Humiliation* (22:07) Adversarial perceptions, Xi Jinping’s brashness and its effect on discourse about International Relations, how this intersects with AI* (24:40) Self-reliance and semiconductors. Was the recent chip ban the right move?* (36:15) Matt’s question: could foundation models be trained on trailing edge chips if necessary? Limitations* (38:30) Silicon Valley and China, The Transpacific Experiment and stories* (46:17) 躺平 and how trends among youth in China interact with tech development, parallel trends in the US, work culture* (51:05) China’s recent AI governance initiatives* (56:25) Squaring China’s AI ethics stance with its use of AI* (59:53) The US can learn from both Chinese and European regulators* (1:02:03) How technologists should think about geopolitics and national tensions* (1:05:43) OutroLinks:* Matt’s Twitter* China’s influences/ambitions* Beijing’s Industrial Internet Ambitions* Beijing’s Tech Ambitions: What Exactly Does It Want?* US-China exchange and US responses* Who benefits from American AI research in China?* Two New Tech Bills Could Transform US Innovation* Fear of Chinese Competition Won’t Preserve US Tech Leadership* China’s tech standards, government initiatives and regulation in AI* How US businesses view China’s growing influence in tech standards* Three takeaways from China’s new standards strategy* China’s new AI governance initiatives shouldn’t be ignored* Semiconductors* Biden’s Unprecedented Semiconductor Bet (a new piece from Matt!)* Choking Off China’s Access to the Future of AI Get full access to The Gradient at thegradientpub.substack.com/subscribe

Luis Voloch: AI and Biology
* Have suggestions for future podcast guests (or other feedback)? Let us know here!* Want to write with us? Send a pitch using this form :)In episode 46 of The Gradient Podcast, Daniel Bashir speaks to Luis Voloch.Luis is co-founder of Immunai, a leading AI-led drug discovery company with over 140 employees and over one billion dollar valuation based out of NYC & Tel Aviv. Before Immunai, Luis was Head of Data Science and Machine Learning at ITC and worked at Palantir, where he worked on a variety of ML efforts. He did his studies and research in Math and CS in MIT. He has also led AI, genomics, and software efforts at a number of other companies.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterOutline:* (00:00) Intro* (02:25) Luis’s math background and getting into AI* (06:35) Luis’s PhD experience, proving theoretical guarantees for recommendation systems* (09:45) Why Luis left his PhD* (15:45) Why Luis is excited about intersection of ML and biology* (18:28) Challenges of applying AI to biology* (22:55) Immunai* (27:03) Challenges in building a biotech (or “tech-bio”) company* (30:30) Research at Immunai, Neural Design for Genetic Perturbation Experiments* (34:43) Interpretability in ML + biology* (36:00) What Luis plans to do next* (37:55) Luis’s advice for grad students / ML people interested in biology* (40:00) Luis’s perspective on the future of AI + biology* (43:10) OutroLinks:* Luis on LinkedIn, Crunchbase* Luis’s article on The convergence of deep neural networks and immunotherapy* Papers* Luis’s thesis* Neural Design for Genetic Perturbation Experiments* SystemMatch: optimizing preclinical drug models to human clinical outcomes via generative latent-space matching Get full access to The Gradient at thegradientpub.substack.com/subscribe

Zachary Lipton: Where Machine Learning Falls Short
* Have suggestions for future podcast guests (or other feedback)? Let us know here!* Want to write with us? Send a pitch using this form :)In episode 45 of The Gradient Podcast, Daniel Bashir speaks to Zachary Lipton. Zachary is an Assistant Professor of Machine Learning and Operations Research at Carnegie Mellon University, where he directs the Approximately Correct Machine Intelligence Lab. He holds a joint appointment between CMU’s ML Department and Tepper School of Business, and holds courtesy appointments at the Heinz School of Public Policy and the Software and Societal Systems Department. His research spans core ML methods and theory, applications in healthcare and natural language processing, and critical concerns about algorithms and their impacts.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterOutline:* (00:00) Intro* (2:30) From jazz music to AI* (4:40) “fix it in post” we had some technical issues :)* (4:50) spicy takes, music and tech* (7:30) Zack’s plan to get into grad school* (9:45) selection bias in who gets faculty positions* (12:20) The slow development of Zack’s wide range of research interests, Zack’s strengths coming into ML research* (22:00) How Zack got attention early in his PhD* (27:00) Should PhD students meander?* (30:30) Faults in the QA model literature* (35:00) Troubling Trends, antecedents in other fields* (39:40) Pretraining LMs on nonsense words, new paper!* The new paper (9/29)* (47:25) what “BERT learns linguistic structure” misses* (56:00) making causal claims in ML* (1:05:40) domain-adversarial networks don’t solve distribution shift, underspecified problems* (1:09:10) the benefits of floating between communities* (1:14:30) advice on finding inspiration and learning* (1:16:00) “fairness” and ML solutionism* (1:21:10) epistemic questions, how we make determinations of fairness* (1:29:00) Zack’s drives and motivationsLinks:* Zachary’s Homepage* Papers* DL Foundations, Distribution Shift, Generalization* Does Pretraining for Summarization Require Knowledge Transfer?* How Much Reading Does Reading Comprehension Require?* Learning Robust Global Representations by Penalizing Local Predictive Power* Detecting and Correcting for Label Shift with Black Box Predictors* RATT* Explanation/Interpretability/Fairness* The Mythos of Model Interpretability* Evaluating Explanations* Does mitigating ML’s impact disparity require treatment disparity?* Algorithmic Fairness from a Non-ideal Perspective* Broader perspectives/critiques* Troubling Trends in Machine Learning Scholarship* When Curation Becomes Creation Get full access to The Gradient at thegradientpub.substack.com/subscribe

Stuart Russell: The Foundations of Artificial Intelligence
Have suggestions for future podcast guests (or other feedback)? Let us know here!In episode 44 of The Gradient Podcast, Daniel Bashir speaks to Professor Stuart Russell. Stuart Russell is a Professor of Computer Science and the Smith-Zadeh Professor in Engineering at UC Berkeley, as well as an Honorary Fellow at Wadham College, Oxford. Professor Russell is the co-author with Peter Norvig of Artificial Intelligence: A Modern Approach, probably the most popular AI textbook in history. He is the founder and head of Berkeley’s Center for Human-Compatible Artificial Intelligence and recently authored the book Human Compatible: Artificial Intelligence and the Problem of Control. He has also served as co-chair on the World Economic Forum’s Council on AI and Robotics.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterOutline:* (00:00) Intro* (02:45) Stuart’s introduction to AI* (05:50) The two most important questions* (07:25) Historical perspectives during Stuart’s PhD, agents and learning* (14:30) Rationality and Intelligence, Bounded Optimality* (20:30) Stuart’s work on Metareasoning* (29:45) How does Metareasoning fit with Bounded Optimality?* (37:39) “Civilization advances by reducing complex operations to be trivial”* (39:20) Reactions to the rise of Deep Learning, connectionist/symbolic debates, probabilistic modeling* (51:00) The Deep Learning and traditional AI communities will adopt each other’s ideas* (51:55) Why Stuart finds the self-driving car arena interesting, Waymo’s old-fashioned AI approach* (57:30) Effective generalization without the full expressive power of first-order logic—deep learning is a “weird way to go about it”* (1:03:00) A very short shrift of Human Compatible and its ideas* (1:10:42) OutroLinks:* Stuart’s webpage* Human Compatible page with reviews and interviews* Papers mentioned* Rationality and Intelligence* Principles of Metareasoning Get full access to The Gradient at thegradientpub.substack.com/subscribe

Varun Ganapathi: AKASA, AI and Healthcare
Have suggestions for future podcast guests (or other feedback)? Let us know here!In episode 43 of The Gradient Podcast, Daniel Bashir speaks to Varun Ganapathi.Varun is co-founder and CTO at AKASA, a company developing AI systems for healthcare operations. Varun’s previous entrepreneurial experience includes co-founding Numovis, a company focused on motion tracking and computer vision for user interaction that was acquired by Google, and Terminal.com, a browser-based IDE acquired by Udacity. Varun received his PhD from Stanford in 2014.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterOutline:* (00:00) Intro* (1:50) Varun’s intro to AI* (3:25) Working with Andrew Ng* (7:37) Varun’s road to a PhD* (13:20) Numovis, Google acquisition* (15:00) Vacillating between research and entrepreneurship, Terminal.com* (17:10) Roots of Varun’s interest in AI + healthcare* (22:30) Research at AKASA, Deep Claim* (25:45) Causality in claim denial, expert knowledge* (25:52) we need to trademark the word “gradient”* (28:20) AKASA’s Unified Automation, expert-in-the-loop* (34:15) Varun’s near-term and long-term visions for AKASA* (39:50) Towards “deploying a new version of healthcare”* (42:25) Varun’s perspective on the role of AI in healthcare, the need for humans in the loop* (47:02) Varun’s advice for aspiring AI researchers and practitioners* (51:00) OutroLinks:* AKASA’s Homepage* Varun’s research* AKASA is hiring! Get full access to The Gradient at thegradientpub.substack.com/subscribe

Joel Lehman: Open-Endedness and Evolution through Large Models
Have suggestions for future podcast guests (or other feedback)? Let us know here!In episode 42 of The Gradient Podcast, Daniel Bashir speaks to Joel Lehman.Joel is a machine learning scientist interested in AI safety, reinforcement learning, and creative open-ended search algorithms. Joel has spent time at Uber AI Labs and OpenAI and is the co-author of the book Why Greatness Cannot be Planned: The Myth of the Objective. Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterOutline:* (00:00) Intro* (01:40) From game development to AI* (03:20) Why evolutionary algorithms* (10:00) Abandoning Objectives: Evolution Through the Search for Novelty Alone* (24:10) Measuring a desired behavior post-hoc vs optimizing for that behavior* (27:30) Neuroevolution through Augmenting Topologies (NEAT), Evolving a Diversity of Virtual Creatures* (35:00) Humans are an inefficient solution to evolution’s objectives* (47:30) Is embodiment required for understanding? Today’s LLMs as practical thought experiments in disembodied understanding* (51:15) Evolution through Large Models (ELM)* (1:01:07) ELM: Quality Diversity Algorithms, MAP-Elites, bootstrapping training data* (1:05:25) Dimensions of Diversity in MAP-Elites, what is “interesting”?* (1:12:30) ELM: Fine-tuning the language model* (1:18:00) Results of invention in ELM, complexity in creatures* (1:20:20) Future work building on ELM, key challenges in open-endedness* (1:24:30) How Joel’s research affects his approach to life and work* (1:28:30) Balancing novelty and exploitation in work* (1:34:10) Intense competition in AI, Joel’s advice for people considering ML research* (1:38:45) Daniel isn’t the worst interviewer ever* (1:38:50) OutroLinks:* Joel’s webpage* Evolution through Large Models: The Tweet* Papers:* Abandoning Objectives: Evolution through the search for novelty alone* Evolving a diversity of virtual creatures through novelty search and local competition* Designing neural networks through neuroevolution* Evolution through Large Models* Resources for (aspiring) ML researchers!* Cohere for AI* ML Collective Get full access to The Gradient at thegradientpub.substack.com/subscribe

Andrew Feldman: Cerebras and AI Hardware
Have suggestions for future podcast guests (or other feedback)? Let us know here!In episode 42 of The Gradient Podcast, Daniel Bashir speaks to Andrew Feldman.Andrew is the co-founder and CEO of Cerebras Systems, an AI accelerator company that has built the largest processor in the industry. Before Cerebras, Andrew co-founded and served as CEO of SeaMicro, which was acquired by AMD in 2012. He has also served in executive positions at Force10 Networks and RiverStone Networks.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterOutline:* (00:00) Intro* (02:05) Andrew’s trajectory, from business school to Cerebras* (10:00) The large model problem and Cerebras’ approach* (19:50) Cerebras’s GPT-J announcement* (22:20) Andrew explains weight streaming to Daniel* (32:30) Andrew’s thoughts on the MLPerf benchmark* (38:20) The venture landscape for AI accelerator companies* (42:50) The hardware lottery, hardware support for sparsity* (45:40) The CHIPS Act, NVIDIA China ban and the accelerator industry* (48:00) Politics and Chips, US and China* (52:20) Andrew’s perspective on tackling difficult problems* (56:42) OutroLinks:* Cerebras’ Homepage* GPT-J Announcement* TotalEnergies* GlaxoSmithKline (GSK)* Sources mentioned* “Political Chips” by Ben Thompson (because Daniel’s a fanboy)* Daniel’s conversation with Sara Hooker* The Hardware Lottery Get full access to The Gradient at thegradientpub.substack.com/subscribe

Christopher Manning: Linguistics and the Development of NLP
Have suggestions for future podcast guests (or other feedback)? Let us know here!In episode 41 of The Gradient Podcast, Daniel Bashir speaks to Christopher Manning.Chris is the Director of the Stanford AI Lab and an Associate Director of the Stanford Human-Centered Artificial Intelligence Institute. He is an ACM Fellow, an AAAI Fellow, and past President of ACL. His work currently focuses on applying deep learning to natural language processing; it has included tree recursive neural networks, GloVe, neural machine translation, and computational linguistic approaches to parsing, among other topics. Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterOutline:* (00:00) Intro* (02:40) Chris’s path to AI through computational linguistics* (06:10) Human language acquisition vs. ML systems* (09:20) Grounding language in the physical world, multimodality and DALL-E 2 vs. Imagen* (26:15) Chris’s Linguistics PhD, splitting time between Stanford and Xerox PARC, corpus-based empirical NLP* (34:45) Rationalist and Empiricist schools in linguistics, Chris’s work in 1990s* (45:30) GloVe and Attention-based Neural Machine Translation, global and local context in language* (50:30) Different Neural Architectures for Language, Chris’s work in the 2010s* (58:00) Large-scale Pretraining, learning to predict the next word helps you learn about the world* (1:00:00) mBERT’s Internal Representations vs. Universal Dependencies Taxonomy* (1:01:30) The Need for Inductive Priors for Language Systems* (1:05:55) Courage in Chris’s Research Career* (1:10:50) Outro (yes Daniel does have a new outro with ~ music ~)Links:* Chris’s webpage* Papers (1990s-2000s)* Distributional Phrase Structure Induction* Fast exact inference with a factored model for Natural Language Parsing* Accurate Unlexicalized Parsing* Corpus-based induction of syntactic structure* Foundations of Statistical Natural Language Processing* Papers (2010s):* Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank* GloVe* Effective Approaches to Attention-based Neural Machine Translation* Stanford’s Graph-based Neural dependency parser* Papers (2020s)* Electra: Pre-training text encoders as discriminators rather than generators* Finding Universal Grammatical Relations in Multilingual BERT* Emergent linguistic structure in artificial neural networks trained by self-supervision Get full access to The Gradient at thegradientpub.substack.com/subscribe

Jeff Clune: Genetic Algorithms, Quality-Diversity, Curiosity
In episode 41 of The Gradient Podcast, Andrey Kurenkov speaks to Professor Jeff Clune.Jeff is an Associate Professor of Computer Science at the University of British Columbia and a Faculty Member of the Vector Institute. Previously, he was a Research Team Leader at OpenAI and before that a Senior Research Manager and founding member of Uber AI Labs, and prior to that he was an Associate Professor in Computer Science at the University of Wyoming.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterThe Gradient is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.Outline:(00:00) Intro(01:05) Path into AI(08:05) Studying biology with simulations(10:30) Overview of genetic algorithms(14:00) Evolving gaits with genetic algorithms(20:00) Quality-Diversity Algorithms(27:00) Evolving Soft Robots(32:15) Genetic algorithms for studying Evolution(39:30) Modularity for Catastrophic Forgetting(45:15) Curiosity for Learning Diverse Skills(51:15) Evolving Environments (58:3) The Surprising Creativity of Digital Evolution(1:04:28) Hobbies Outside of Research(1:07:25) Outro Get full access to The Gradient at thegradientpub.substack.com/subscribe

Catherine Olsson and Nelson Elhage: Anthropic, Understanding Transformers
In episode 40 of The Gradient Podcast, Andrey Kurenkov speaks to Catherine Olsson and Nelson Elhage.Catherine and Nelson are both members of technical staff at Anthropic, which is an AI safety and research company that’s working to build reliable, interpretable, and steerable AI systems. Catherine and Nelson’s focus is on interpretability, and we will discuss several of their recent works in this interview. Follow The Gradient on TwitterOutline:(00:00) Intro(01:10) Catherine’s Path into AI(03:25) Nelson’s Path into AI(05:23) Overview of Anthropic(08:21) Mechanistic Interpretability(15:15) Transformer Circuits (21:30) Toy Transformer(27:25) Induction Heads(31:00) In-Context Learning(35:10) Evidence for Induction Heads Enabling In-Context Learning(39:30) What’s Next(43:10) Replicating Results(46:00) OutroLinks:AnthropicZoom In: An Introduction to CircuitsMechanistic Interpretability, Variables, and the Importance of Interpretable BasesA Mathematical Framework for Transformer CircuitsIn-context Learning and Induction Heads PySvelte Get full access to The Gradient at thegradientpub.substack.com/subscribe

Been Kim: Interpretable Machine Learning
In episode 38 of The Gradient Podcast, Daniel Bashir speaks to Been Kim.Been is a staff research scientist at Google Brain focused on interpretability–helping humans communicate with complex machine learning models by not only building tools but also studying how humans interact with these systems. She has served with a number of conferences including ICLR, NeurIPS, ICML, and AISTATS. She gave the keynotes at ICLR 2022, ECML 2020, and the G20 meeting in Argentina in 2018. Her work TCAV received the UNESCO Netexplo award, was featured at Google I/O 2019 and in Brian Christian’s book The Alignment Problem.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterOutline:(00:00) Intro(02:20) Path to AI/interpretability(06:10) The Progression of Been’s thinking / PhD thesis(11:30) Towards a Rigorous Science of Interpretable Machine Learning(24:52) Interpretability and Software Testing(27:00) Been’s ICLR Keynote and Human-Machine “Language”(37:30) TCAV(43:30) Mood Board Search and CAV Camera(48:00) TCAV’s Limitations and Follow-up Work(56:00) Acquisition of Chess Knowledge in AlphaZero(1:07:00) Daniel spends a very long time asking “what does it mean to you to be a researcher?”(1:09:00) The everyday drudgery, more lessons from Been(1:11:32) OutroLinks:* Been’s website* CAVcamera app Get full access to The Gradient at thegradientpub.substack.com/subscribe

Laura Weidinger: Ethical Risks, Harms, and Alignment of Large Language Models
In episode 37 of The Gradient Podcast, Andrey Kurenkov speaks to Laura WeidingerLaura is a senior research scientist at DeepMind, with her focus being AI ethics. Laura is also a PhD candidate at the University of Cambridge, studying philosophy of science and specifically approaches to measuring the ethics of AI systems. Previously Laura worked in technology policy at UK and EU levels, as a Policy executive at techUK. She then pivoted to cognitive science research and studied human learning at the Max Planck Institute for Human Development in Berlin, and was a Guest Lecturer at the Ada National College for Digital Skills. She received her Master's degree at the Humboldt University of Berlin, from the School of Mind and Brain, with her focus being Neuroscience/ Philosophy/ Cognitive science.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterOutline:(00:00) Intro(01:20) Path to AI(04:25) Research in Cognitive Science(06:40) Interest in AI Ethics(14:30) Ethics Considerations for Researchers(17:38) Ethical and social risks of harm from language models (25:30) Taxonomy of Risks posed by Language Models(27:33) Characteristics of Harmful Text: Towards Rigorous Benchmarking of Language Models(33:25) Main Insight for Measuring Harm(35:40) The EU AI Act(39:10) Alignment of language agents(46:10) GPT-4Chan(53:40) Interests outside of AI(55:30) OutroLinks:Ethical and social risks of harm from language models Taxonomy of Risks posed by Language ModelsCharacteristics of Harmful Text: Towards Rigorous Benchmarking of Language ModelsAlignment of language agents Get full access to The Gradient at thegradientpub.substack.com/subscribe

Sebastian Raschka: AI Education and Research
In episode 36 of The Gradient Podcast, Daniel Bashir speaks to Sebastian Raschka.Sebastian is an Assistant Professor of Statistics at the University of Wisconsin-Madison and Lead AI Educator at Lightning AI. He has written two bestselling books: Python Machine Learning and Machine Learning with PyTorch and Scikit-Learn.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterSections:(00:00) Intro(01:10) Sebastian’s intro to AI(05:15) Sebastian’s process for learning new things(12:15) Learning style varies with purpose(16:10) Ordinal Regression(31:00) Solving rank inconsistency with conditional probability(35:00) Semi-Adversarial Networks(44:15) Why Sebastian got into education(52:45) Lightning AI(1:00:00) Sebastian’s advice for educators(1:03:30) Be cool like Sebastian and follow the Gradient(1:03:40) OutroEpisode Links:* Sebastian’s Homepage* Sebastian’s Twitter* Sebastian’s Books Get full access to The Gradient at thegradientpub.substack.com/subscribe

Lt. General Jack Shanahan: AI in the DoD, Project Maven, and Bridging the Tech-DoD Gap
In episode 35 of The Gradient Podcast, guest host Sharon Zhou speaks to Jack Shanahan.John (Jack) Shanahan was a Lieutenant General in the United States Air Force, retired after a 36-year military career. He was the inaugural Director of the Joint Artificial Intelligence Center (JAIC) in the U.S. Department of Defense (DoD). He was also the Director of the Algorithmic Warfare Cross-Functional Team (Project Maven). Currently, he is a Special Government Employee supporting the National Security Commission on Artificial Intelligence; serves on the Board of Advisors for the Common Mission Project; is an advisor to The Changing Character of War Centre (Oxford University); is a member of the CACI Strategic Advisory Group; and serves as an Advisor to the Military Cyber Professionals Association.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterOutline:(00:00) Intro(01:20) Introduction to Jack and Sharon(07:30) Project Maven(09:45) Relationship of Tech Sector and DoD(16:40) Need for AI in DoD(20:10) Bringing the tech-DoD divide(30:00) ConclusionEpisode Links:* John N.T. Shanahan Wikipedia* AI To Revolutionize U.S. Intelligence Community With General Shanahan* Email: [email protected] Get full access to The Gradient at thegradientpub.substack.com/subscribe

Sara Hooker: Cohere For AI, the Hardware Lottery, and DL Tradeoffs
In episode 34 of The Gradient Podcast, Daniel Bashir speaks to Sara Hooker.Sara (@sarahookr) leads Cohere for AI and is a former Research Scientist at Google. Sara founded a Bay Area non-profit called Delta Analytics, which works with non-profits and communities to build technical capacity. She is also one of the co-founders of the Trustworthy ML Initiative, an active participant of the ML Collective research group, and a host of the underrated ML podcast.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterSections:(00:00) Intro(02:20) Podcasting gripe-fest(06:00) Sara’s journey: from economics to AI(09:15) Economics vs. AI research(12:45) The Hardware Lottery(19:15) Towards better hardware benchmarks(26:00) Getting away from the hardware lottery(32:30) The myth of compact, interpretable, robust, performant DNNs(35:15) Top-line metrics vs. disaggregated metrics(39:20) Solving memorization in the data pipeline, noisy examples(45:35) Cohere For AIEpisode Links:* Cohere for AI* Sara’s Homepage Get full access to The Gradient at thegradientpub.substack.com/subscribe

Lukas Biewald: Crowdsourcing at CrowdFlower and ML Tooling at Weights & Biases
In episode 33 of The Gradient Podcast, Andrey Kurenkov speaks to Lukas Biewald.Lukas Biewald is a co-founder of Weights and Biases, a company that creates developer tools for machine learning. Prior to that he was a co-founder and CEO of Figure Eight Inc. (formerly CrowdFlower) — an Internet company that collects training data for machine learning, which was sold for 300 million dollars.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterOutline:* (00:00) Intro* (01:18) Start in AI* (06:17) CrowdFlower / Crowdsourcing* (21:06) Discovering Deep Learning * (25:10) Learning Deep Learning* (32:50) Weights and Biases* (37:30) State of Tooling for ML * (41:20) Exciting AI Trends* (44:42) Interests outside of AI* (45:40) OutroLinks:* Lukas’s website* Lukas’s GitHub* Starting a Second Machine Learning Tools Company, Ten Years Later* Confession of a so-called AI expert* What I learned from looking at 200 machine learning tools* CS 329S: Machine Learning Systems Design* Designing Machine Learning SystemsOpportunity at Weights & Biases: Get full access to The Gradient at thegradientpub.substack.com/subscribe

Chip Huyen: Machine Learning Tools and Systems
In episode 32 of The Gradient Podcast, Andrey Kurenkov speaks to Chip Huyen.Chip Huyen is a co-founder of Claypot AI, a platform for real-time machine learning. Previously, she was with Snorkel AI and NVIDIA. She teaches CS 329S: Machine Learning Systems Design at Stanford. She has also written four bestselling Vietnamese books, and more recently her new O’Reilly book Designing Machine Learning Systems has just come out! Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterShe also maintains a Discord server with a focus on Machine Learning Systems.Outline:* (00:00) Intro* (01:30) 3-year trip through Asia, Africa, and South America* (04:00) Getting into AI at Stanford* (11:30) Confession of a so-called AI expert* (16:40) Academia vs Industry* (17:40) Focus on ML Systems* (20:00) ML in Academia vs Industry* (28:15) Maturity of AI in Industry* (31:45) ML Tools* (37:20) Real Time ML* (43:00) ML Systems Class and BookLinks:* Chip’s website* MLOps Discord server* Confession of a so-called AI expert* What I learned from looking at 200 machine learning tools* CS 329S: Machine Learning Systems Design* Designing Machine Learning Systems Get full access to The Gradient at thegradientpub.substack.com/subscribe

Preetum Nakkiran: An Empirical Theory of Deep Learning
In episode 31 of The Gradient Podcast, Daniel Bashir speaks to Preetum Nakkiran.Preetum is a Research Scientist at Apple, a Visiting Researcher at UCSD, and part of the NSF/Simons Collaboration on the Theoretical Foundations of Deep Learning. He completed his PhD at Harvard, where he co-founded the ML Foundations Group. Preetum’s research focuses on building conceptual tools for understanding learning systems.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterSections:(00:00) Intro(01:25) Getting into AI through Theoretical Computer Science (TCS)(09:08) Lack of Motivation in TCS and Learning What Research Is(12:12) Foundational vs Problem-Solving Research, Antipatterns in TCS(16:30) Theory and Empirics in Deep Learning(18:30) What is an Empirical Theory of Deep Learning(28:21) Deep Double Descent(40:00) Inductive Biases in SGD, epoch-wise double descent(45:25) Inductive Biases Stick Around(47:12) Deep Bootstrap(59:40) Distributional Generalization - Paper Rejections(1:02:30) Classical Generalization and Distributional Generalization(1:16:46) Future Work: Studying Structure in Data(1:20:51) The Tweets^TM(1:37:00) OutroEpisode Links:* Preetum’s Homepage* Preetum’s PhD Thesis Get full access to The Gradient at thegradientpub.substack.com/subscribe

Max Woolf: Data Science at BuzzFeed and AI Content Generation
In episode 30 of The Gradient Podcast, Daniel Bashir speaks to Max Woolf.Max Woolf (@minimaxir) is currently a Data Scientist at BuzzFeed in San Francisco. Some work he’s done for BuzzFeed includes using StyleGAN to create AI-generated fake boyfriends and AI-generated art quizzes. In his free time, Max creates open source Python and R software on his GitHub. More recently, Max has been developing tooling for AI content generation, such as aitextgen for easy AI text generation.Max’s projects are funded by his Patreon. If you have found anything on his website helpful, please help contribute!Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterSections:(00:00) Intro(01:20) Max’s Intro to Data Science and AI(07:00) Software Engineering in Data Science, Max’s Perspectives(09:00) Max’s Work at BuzzFeed(23:10) Scaling, Inference, Large Models(27:00) AI Content Generation(30:45) Discourse About GPT-3(34:30) AI Inventors(38:35) Fun Projects and One-Offs: AI-generated Pokémon(43:35) GPT-3-generated Discussion Topics(46:30) Advice for Data Scientists(48:10) BuzzFeed is Hiring :)(48:20) OutroEpisode Links:* Max’s Homepage* Real-World Data Science Get full access to The Gradient at thegradientpub.substack.com/subscribe

Rosanne Liu: Paths in AI Research and ML Collective
In episode 29 of The Gradient Podcast, we chat with Rosanne Liu. Rosanne is a research scientist in Google Brain, and co-founder and executive director of ML Collective, a nonprofit organization for open collaboration and accessible mentorship. Before that she was a founding member of Uber AI. Outside of research, she supports underrepresented communities, and organizes symposiums, workshops, and a weekly reading group “Deep Learning: Classics and Trends” since 2018. She is currently thinking deeply how to democratize AI research even further, and improve the diversity and fairness of the field, while working on multiple fronts of machine learning research including understanding training dynamics, rethinking model capacity and scaling. Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterOutline:* (01:30) How did you go into AI / research* (6:45) AI research: the unreasonably narrow path and how not to be miserable* (16:30) ML Collective Overview* (21:45) Deep Learning: Classics and Trends Reading Group* (26:25) More details about ML Collective* (39:35) ICLR 2022 Diversity, Equity & Inclusion* (48:00) Narrowness vs Variety in research* (57:20) Favorite Papers * (58:50) Measuring the Intrinsic Dimension of Objective Landscapes * (01:01:40) Natural Adversarial Objects * (01:03:00) Interests outside of AI - Writing* (01:08:05) Interests outside of AI - Narrating Travels with Charley* (01:13:22) Outro Get full access to The Gradient at thegradientpub.substack.com/subscribe

Ben Green: "Tech for Social Good" Needs to Do More
In episode 28 of The Gradient Podcast, Daniel Bashir speaks to Ben Green, postdoctoral scholar in the Michigan Society of Fellows and Assistant Professor at the Gerald R. Ford School of Public Policy. Ben’s work focuses on the social and political impacts of government algorithms.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterSections:(00:00) Intro(02:00) Getting Started(06:15) Soul Searching(11:55) Decentering Algorithms(19:50) The Future of the City(27:25) Ethical Lip Service(32:30) Ethics Research and Industry Incentives(36:30) Broadening our Vision of Tech Ethics(47:35) What Types of Research are Valued?(52:40) OutroEpisode Links:* Ben’s Homepage* Algorithmic Realism* Special Issue of the Journal of Social Computing Get full access to The Gradient at thegradientpub.substack.com/subscribe

Max Braun: Teaching Robots to Help People in their Everyday Lives
In episode 27 of The Gradient Podcast, Andrey Kurenkov speaks to Max Braun, who leads the AI and robotics software engineering team at Everyday Robots, a moonshot to create robots that can learn to help people in their everyday lives. Previously, he worked on building frontier technology products as an entrepreneur and later at Google and X. Max enjoys exploring the intersection of art, technology, and philosophy as a writer and designer. Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterOutline:* (00:00) Intro* (01:00) Start in AI* (5:45) Humanoid Research in Osaka* (8:45) Joining Google X* (12:15) Visual Search and Google Glass* (15:58) Academia Industry Connection* (18:45) Overview of Robotics Vision* (26:00) Machine Learning for Robotics* (32:00) Robot Platform* (38:00) Development Process and History* (43:35) QT-Opt* (49:05) Imitation Learning* (55:00) Simulation Platform* (59:45) Sim2Real* (1:07:00) SayCan* (1:14:30) Current Objectives* (1:17:00) Other Projects* (1:21:40) OutroEpisode Links:* Max Braun’s Website* Everyday Robots* Simulating Artificial Muscles for Controlling a Robotic Arm with Fluctuation* Introducing the Everyday Robot Project* Scalable Deep Reinforcement Learning from Robotic Manipulation (QT-Opt)* Alphabet is putting its prototype robots to work cleaning up around Google’s offices* Everyday robots are (slowly) leaving the lab* Can Robots Follow Instructions for New Tasks?* Efficiently Initializing Reinforcement Learning With Prior Policies* Combining RL + IL at Scale* Shortening the Sim to Real Gap* Action-Image: Teaching Grasping in Sim* SayCan* I Made an AI Read Wittgenstein, Then Told It to Play Philosopher Get full access to The Gradient at thegradientpub.substack.com/subscribe

Yejin Choi: Teaching Machines Common Sense and Morality
In episode 26 of The Gradient Podcast, Daniel Bashir speaks to Yejin Choi, professor of Computer Science at the University of Washington, and senior research manager at the Allen Institute for Artificial Intelligence.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterSections:(00:00) Intro(01:42) Getting Started in the Winter(09:17) Has NLP lost its way?(12:57) The Mosaic Project, Commonsense Intelligence(18:20) A Priori Intuitions and Common Sense in Machines(21:35) Abductive Reasoning(24:49) Benchmarking Common Sense(33:00) DeLorean and COMET - Algorithms for Commonsense Reasoning(43:30) Positive and Negative uses of Commonsense Models(49:40) Moral Reasoning(57:00) Descriptive Morality, Meta-Ethical Concerns(1:04:30) Potential Misuse(1:12:15) Future Work(1:16:23) OutroEpisode Links:* Yejin’s Homepage* The Curious Case of Commonsense Intelligence in Daedalus* Common Sense Comes Close to Computers in Quanta* Can Computers Learn Common Sense? in The New Yorker Get full access to The Gradient at thegradientpub.substack.com/subscribe

David Chalmers on AI and Consciousness
In episode 25 of The Gradient Podcast, Daniel Bashir speaks to David Chalmers, professor of philosophy and Philosophy and Neural Science at New York University, and co-director of NYU’s center for Mind, Brain, and Consciousness. Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterSections:(00:00) Intro(00:42) “Today’s neural networks may be slightly conscious”(03:55) Openness to Machine Consciousness(09:37) Integrated Information Theory(18:41) Epistemic Gaps, Verbal Reports(25:52) Vision Models and Consciousness(33:37) Reasoning about Consciousness(38:20) Illusionism(41:30) Best Approaches to the Hard Problem(44:21) Panpsychism(46:35) OutroEpisode Links:* Chalmers’ Homepage* Facing Up to the Hard Problem of Consciousness (1995)* Reality+: Virtual Worlds and the Problems of Philosophy* Amanda Askell on AI Consciousness Get full access to The Gradient at thegradientpub.substack.com/subscribe

Greg Yang on Communicating Research, Tensor Programs, and µTransfer
In episode 24 of The Gradient Podcast, Daniel Bashir talks to Greg Yang, senior researcher at Microsoft Research. Greg Yang’s Tensor Programs framework recently received attention for its role in the µTransfer paradigm for tuning the hyperparameters of large neural networks. Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterSections:(00:00) Intro(01:50) Start in AI / Research(05:55) Fear of Math in ML(08:00) Presentation of Research(17:35) Path to MSR(21:20) Origin of Tensor Programs(26:05) Refining TP’s Presentation(39:55) The Sea of Garbage (Initializations) and the Oasis(47:44) Scaling Up Further(55:53) On Theory and Practice in Deep Learning(01:05:28) OutroEpisode Links:* Greg’s Homepage* Greg’s Twitter* µP GitHub* Visual Intro to Gaussian Processes (Distill) Get full access to The Gradient at thegradientpub.substack.com/subscribe

Nick Walton on AI Dungeon and the Future of AI in Games
In the 23rd interview of The Gradient Podcast, we talk to Nick Walton, the CEO and Co-Founder of Latitude, the goal of which is to make AI a tool of freedom and creativity for everyone, and which is currently developing AI Dungeon and Voyage. Subscribe to The Gradient Podcast: * Apple Podcasts* Spotify * Pocket Casts * RSSOutline:(00:00) Intro(01:38) How did you go into AI / research(3:50) Origin of AI Dungeon(8:15) What is a Dungeon Master(12:!5) Brief history of AI Dungeon(17:30) AI in videogames, past and future(23:35) Early days of AI Dungeon(29:45) AI Dungeon as a Creative Tool(33:50) Technical Aspects of AI Dungeon(39:15) Voyage(48:27) Visuals in AI Dungeon(50:45) How to Control AI in Games(55:38) Future of AI in Games(57:50) Funny stories(59:45) Interests / Hobbies(01:01:45) Outro Get full access to The Gradient at thegradientpub.substack.com/subscribe

Connor Leahy on EleutherAI, Replicating GPT-2/GPT-3, AI Risk and Alignment
In episode 22 of The Gradient Podcast, we talk to Connor Leahy, an AI researcher focused on AI alignment and a co-founder of EleutherAI.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterConnor is an AI researcher working on understanding large ML models and aligning them to human values, and a cofounder of EleutherAI, a decentralized grassroots collective of volunteer researchers, engineers, and developers focused on AI alignment, scaling, and open source AI research. The organization's flagship project is the GPT-Neo family of models designed to match those developed by OpenAI as GPT-3.Sections:(00:00:00) Intro(00:01:20) Start in AI(00:08:00) Being excited about GPT-2 (00:18:00) Discovering AI safety and alignment(00:21:10) Replicating GPT-2 (00:27:30) Deciding whether to relese GPT-2 weights(00:36:15) Life after GPT-2 (00:40:05) GPT-3 and Start of Eleuther AI(00:44:40) Early days of Eleuther AI(00:47:30) Creating the Pile, GPT-Neo, Hacker Culture(00:55:10) Growth of Eleuther AI, Cultivating Community(01:02:22) Why release a large language model(01:08:50) AI Risk and Alignment(01:21:30) Worrying (or not) about Superhuman AI(01:25:20) AI alignment and releasing powerful models(01:32:08) AI risk and research norms(01:37:10) Work on GPT-3 replication, GPT-NeoX(01:38:48) Joining Eleuther AI(01:43:28) Personal interests / hobbies(01:47:20) OutroLinks to things discussed:* Replicating GPT2–1.5B , GPT2, Counting Consciousness and the Curious Hacker* The Hacker Learns to Trust* The Pile* GPT-Neo* GPT-J* Why Release a Large Language Model?* What A Long, Strange Trip It's Been: EleutherAI One Year Retrospective* GPT-NeoX Get full access to The Gradient at thegradientpub.substack.com/subscribe

Percy Liang on Machine Learning Robustness, Foundation Models, and Reproducibility
In interview 21 of The Gradient Podcast, we talk to Percy Liang, an Associate Professor of Computer Science at Stanford University and the director of the Center for Research on Foundation Models.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterPercy Liang’s research spans many topics in machine learning and natural language processing, including robustness, interpretability, semantics, and reasoning. He is also a strong proponent of reproducibility through the creation of CodaLab Worksheets. His awards include the Presidential Early Career Award for Scientists and Engineers (2019), IJCAI Computers and Thought Award (2016), an NSF CAREER Award (2016), a Sloan Research Fellowship (2015), a Microsoft Research Faculty Fellowship (2014), and multiple paper awards at ACL, EMNLP, ICML, and COLT.Sections:(00:00) Intro(01:21) Start in AI(06:52) Interest in Language(10:17) Start of PhD(12:22) Semantic Parsing(17:49) Focus on ML robustness(22:30) Foundation Models, model robustness(28:55) Foundation Model bias(34:48) Foundation Model research by academia(37:13) Current research interests(39:40) Surprising robustness results(44:24) Reproducibility and CodaLab(50:17) OutroPapers / Topics discussed:* On the Opportunities and Risks of Foundation Models* Reflections on Foundation Models* Removing spurious features can hurt accuracy and affect groups disproportionately.* Selective classification can magnify disparities across groups * Just train twice: improving group robustness without training group information * LILA: language-informed latent actions * CodaLab Get full access to The Gradient at thegradientpub.substack.com/subscribe

Eric Jang on Robots Learning at Google and Generalization via Language
In episode 20 of The Gradient Podcast, we talk to Eric Jang, a research scientist on the Robotics team at Google.Eric is a research scientist on the Robotics team at Google. His research focuses on answering whether big data and small algorithms can yield unprecedented capabilities in the domain of robotics, just like the computer vision, translation, and speech revolutions before it. Specifically, he focuses on robotic manipulation and self-supervised robotic learning.Sections:(00:00) Intro(00:50) Start in AI / Research(03:58) Joining Google Robotics(10:08) End to End Learning of Semantic Grasping(19:11) Off Policy RL for Robotic Grasping(29:33) Grasp2Vec(40:50) Watch, Try, Learn Meta-Learning from Demonstrations and Rewards(50:12) BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning(59:41) Just Ask for Generalization(01:09:02) Data for Robotics(01:22:10) To Understand Language is to Understand Generalization (01:32:38) OutroPapers discussed:* Grasp2Vec: Learning Object Representations from Self-Supervised Grasping* End-to-End Learning of Semantic Grasping* Deep reinforcement learning for vision-based robotic grasping: A simulated comparative evaluation of off-policy methods* Watch, Try, Learn Meta-Learning from Demonstrations and Rewards* BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning* Just Ask for Generalization* To Understand Language is to Understand Generalization* Robots Must Be Ephemeralized Get full access to The Gradient at thegradientpub.substack.com/subscribe

Rishi Bommasani on Foundation Models
In episode 19 of The Gradient Podcast, we talk to Rishi Bommasani, a Ph.D student at Stanford focused on Foundation Models. Rish is a second-year Ph.D. student in the CS Department at Stanford, where he is advised by Percy Liang and Dan Jurafsky. His research focuses on understanding AI systems and their social impact, as well as using NLP to further scientific inquiry. Over the past year, he helped build and organize the Stanford Center for Research on Foundation Models (CRFM).Sections:(00:00:00) Intro(00:01:05) How did you get into AI?(00:09:55) Towards Understanding Position Embeddings(00:14:23) Long-Distance Dependencies don’t have to be Long(00:18:55) Interpreting Pretrained Contextualized Representations via Reductions to Static Embeddings(00:30:25) Masters Thesis(00:34:05) Start of PhD and work on foundation models(00:42:14) Why were people intested in foundation models(00:46:45) Formation of CRFM(00:51:25) Writing report on foundation models(00:56:33) Challenges in writing report(01:05:45) Response to reception(01:15:35) Goals of CRFM(01:25:43) Current research focus(01:30:35) Interests outside of research(01:33:10) OutroPapers discussed:* Towards Understanding Position Embeddings* Long-Distance Dependencies don’t have to be Long: Simplifying through Provably (Approximately) Optimal Permutations* Interpreting Pretrained Contextualized Representations via Reductions to Static Embeddings* Generalized Optimal Linear Orders* On the Opportunities and Risks of Foundation Models* Reflections on Foundation Models Get full access to The Gradient at thegradientpub.substack.com/subscribe

Upol Ehsan on Human-Centered Explainable AI and Social Transparency
In episode 18 of The Gradient Podcast, we talked to Upol Ehsan, an Explainable AI (XAI) researcher who combines his background in Philosophy and Human-Computer Interaction to address problems in XAI beyond just opening the "black-box" of AI. You can find his Gradient article charting this vision here.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterPapers Discussed:* Rationalization: A Neural Machine Translation Approach to Generating Natural Language Explanations* Automated Rationale Generation: A Technique for Explainable AI and its Effects on Human Perceptions* Human-centered Explainable AI: Towards a Reflective Sociotechnical Approach* Expanding Explainability: Towards Social Transparency in AI systems* The Who in Explainable AI: How AI Background Shapes Perceptions of AI Explanations* Explainability Pitfalls: Beyond Dark Patterns in Explainable AIExciting update! In addition to listening to the audio recording, you can now experience the interview over at The Gradient’s main site, with live captions and the ability to jump to certain sections. In addition, you can experience it as follows: Interactive Transcript | Transcript PDF | Interview on YouTubeAbout Upol:Upol Ehsan cares about people first, technology second. He is a doctoral candidate in the School of Interactive Computing at Georgia Tech and an affiliate at the Data & Society Research Institute. Combining his expertise in AI and background in Philosophy, his work in Explainable AI (XAI) aims to foster a future where anyone, regardless of their background, can use AI-powered technology with dignity.Actively publishing in top peer-reviewed venues like CHI, his work has received multiple awards and been covered in major media outlets. Bridging industry and academia, he serves on multiple program committees in HCI and AI conferences (e.g., DIS, IUI, NeurIPS) and actively connects these communities (e.g, the widely attended HCXAI workshop at CHI). By promoting equity and ethics in AI, he wants to ensure stakeholders who aren’t at the table do not end up on the menu. Outside research, he is an advisor for Aalor Asha, an educational institute he started for underprivileged children subjected to child labor.Follow him on Twitter: @upolehsan Get full access to The Gradient at thegradientpub.substack.com/subscribe

Miles Brundage on AI Misuse and Trustworthy AI
In episode 17 of The Gradient Podcast, we talk to Miles Brundage, Head of Policy Research at OpenAI and a researcher passionate about the responsible governance of artificial intelligence. Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSLinks:* Will Technology Make Work Better for Everyone?* Economic Possibilities for Our Children: Artificial Intelligence and the Future of Work, Education, and Leisure* Taking Superintelligence Seriously* The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and Mitigation* Release Strategies and the Social Impact of Language Models* All the News that’s Fit to Fabricate: AI-Generated Text as a Tool of Media Misinformation* Toward Trustworthy AI Development: Mechanisms for Supporting Verifiable ClaimsTimeline:(00:00) Intro(01:05) How did you get started in AI(07:05) Writing about AI on Slate(09:20) Start of PhD(13:00) AI and the End of Scarcity(18:12) Malicious Uses of AI(28:00) GPT-2 and Publication Norms(33:30) AI-Generated Text for Misinformation(37:05) State of AI Misinformation(41:30) Trustworthy AI(48:50) OpenAI Policy Research Team(53:15) OutroMiles is a researcher and research manager, and is passionate about the responsible governance of artificial intelligence. In 2018, he joined OpenAI, where he began as a Research Scientist and recently became Head of Policy Research. Before that, he was a Research Fellow at the University of Oxford's Future of Humanity Institute, where he is still a Research Affiliate).He also serves as a member of Axon's AI and Policing Technology Ethics Board. He completed a PhD in Human and Social Dimensions of Science and Technology from Arizona State University in 2019.Podcast Theme: “MusicVAE: Trio 16-bar Sample #2” from "MusicVAE: A Hierarchical Latent Vector Model for Learning Long-Term Structure in Music"Hosted by Andrey Kurenkov (@andrey_kurenkov), a PhD student with the Stanford Vision and Learning Lab working on learning techniques for robotic manipulation and search. Get full access to The Gradient at thegradientpub.substack.com/subscribe

Jeffrey Ding on China's AI Dream, the AI 'Arms Race', and AI as a General Purpose Technology
In episode 16 of The Gradient Podcast, we talk to Jeffrey Ding, a postdoctoral fellow at Stanford's Center for International Security and Cooperation(01:35) Getting into AI research(04:20) Interest in studying China(06:50) Deciphering China’s AI Dream(23:25) Beyond the AI Arms Race(36:45) China's Current Capabilities in AI(46:45) AI as a General Purpose and Strategic Technology(57:38) ChinaAI Newsletter(01:04:20) Teaching AI to Policy People(01:06:30) Current Focus(01:09:10) Interests Outside of Work + OutroSubscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSJeffrey Ding (@jjding99) is a postdoctoral fellow at Stanford's Center for International Security and Cooperation, sponsored by Stanford's Institute for Human-Centered Artificial Intelligence, as well as a research affiliate with the Centre for the Governance of AI at the University of Oxford. His current research is centered on how technological change affects the rise and fall of great powers, with an eye toward the implications of advances in AI for a possible U.S.-China power transition. He also puts out the excellent ChinaAI newsletter, which has (sometimes) weekly translations of Chinese-language musings on AI and related topics. Podcast Theme: “MusicVAE: Trio 16-bar Sample #2” from "MusicVAE: A Hierarchical Latent Vector Model for Learning Long-Term Structure in Music"Hosted by Andrey Kurenkov (@andrey_kurenkov), a PhD student with the Stanford Vision and Learning Lab working on learning techniques for robotic manipulation and search. Get full access to The Gradient at thegradientpub.substack.com/subscribe

Alex Tamkin on Self-Supervised Learning and Large Language Models
In episode 15 of The Gradient Podcast, we talk to Stanford PhD Candidate Alex TamkinSubscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSAlex Tamkin is a fourth-year PhD student in Computer Science at Stanford, advised by Noah Goodman and part of the Stanford NLP Group. His research focuses on understanding, building, and controlling pretrained models, especially in domain-general or multimodal settings.We discuss:* Viewmaker Networks: Learning Views for Unsupervised Representation Learning* DABS: A Domain-Agnostic Benchmark for Self-Supervised Learning* On the Opportunities and Risks of Foundation Models* Understanding the Capabilities, Limitations, and Societal Impact of Large Language Models* Mentoring, teaching and fostering a healthy and inclusive research culture* Scientific communication and breaking down walls between fieldsPodcast Theme: “MusicVAE: Trio 16-bar Sample #2” from "MusicVAE: A Hierarchical Latent Vector Model for Learning Long-Term Structure in Music" Get full access to The Gradient at thegradientpub.substack.com/subscribe

Peter Henderson on RL Benchmarking, Climate Impacts of AI, and AI for Law
In episode 14 of The Gradient Podcast, we interview Stanford PhD Candidate Peter HendersonSubscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSPeter is a joint JD-PhD student at Stanford University advised by Dan Jurafsky. He is also an OpenPhilanthropy AI Fellow and a Graduate Student Fellow at the Regulation, Evaluation, and Governance Lab. His research focuses on creating robust decision-making systems, with three main goals: (1) use AI to make governments more efficient and fair; (2) ensure that AI isn’t deployed in ways that can harm people; (3) create new ML methods for applications that are beneficial to society.Links:* Reproducibility and Reusability in Deep Reinforcement Learning. * Benchmark Environments for Multitask Learning in Continuous Domains* Reproducibility of Bench-marked Deep Reinforcement Learning Tasks for Continuous Control.* Deep Reinforcement Learning that Matters* Reproducibility and Replicability in Deep Reinforcement Learning (and Other Deep Learning Methods)* Towards the Systematic Reporting of the Energy and Carbon Footprints of Machine Learning* How blockers can turn into a paper: A retrospective on 'Towards The Systematic Reporting of the Energy and Carbon Footprints of Machine Learning* When Does Pretraining Help? Assessing Self-Supervised Learning for Law and the CaseHOLD Dataset”* How US law will evaluate artificial intelligence for Covid-19Podcast Theme: “MusicVAE: Trio 16-bar Sample #2” from "MusicVAE: A Hierarchical Latent Vector Model for Learning Long-Term Structure in Music" Get full access to The Gradient at thegradientpub.substack.com/subscribe

Chelsea Finn on Meta Learning & Model Based Reinforcement Learning
In episode 13 of The Gradient Podcast, we interview Stanford Professor Chelsea FinnSubscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSChelsea is an Assistant Professor at Stanford University. Her lab, IRIS, studies intelligence through robotic interaction at scale, and is affiliated with SAIL and the Statistical ML Group. I also spend time at Google as a part of the Google Brain team. Her research deals with the capability of robots and other agents to develop broadly intelligent behavior through learning and interaction.Links:* Learning to Learn with Gradients* Visual Model-Based Reinforcement Learning as a Path towards Generalist Robots* RoboNet: A Dataset for Large-Scale Multi-Robot Learning* Greedy Hierarchical Variational Autoencoders for Large-Scale Video* Example-Driven Model-Based Reinforcement Learning for Solving Long-Horizon Visuomotor Tasks Podcast Theme: “MusicVAE: Trio 16-bar Sample #2” from "MusicVAE: A Hierarchical Latent Vector Model for Learning Long-Term Structure in Music". Get full access to The Gradient at thegradientpub.substack.com/subscribe

Devi Parikh on Generative Art & AI for Creativity
In episode 12 of The Gradient Podcast, we interview Devi Parikh, a professor at Georgia Tech whose research focuses on computer vision, natural language processing, embodied AI, human-AI collaboration, and AI for creativity.Devi Parikh is an Associate Professor in the School of Interactive Computing at Georgia Tech, and a Research Scientist at Facebook AI Research (FAIR). Her research interests are in computer vision, natural language processing, embodied AI, human-AI collaboration, and AI for creativity. In the past, she has also been an Assistant Professor at Virginia Tech and a Research Assistant Professor at Toyota Technological Institute at Chicago (TTIC). She received her M.S. and Ph.D. degrees from the Electrical and Computer Engineering department at Carnegie Mellon University in 2007 and 2009 respectively. Links:* Humans of AI Podcast* Feel The Music: Automatically Generating A Dance For An Input Song* Exploring Crowd Co-creation Scenarios for Sketches* Neuro-Symbolic Generative Art: A Preliminary Study* Creative Sketch GenerationSubscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSPodcast Theme: “MusicVAE: Trio 16-bar Sample #2” from "MusicVAE: A Hierarchical Latent Vector Model for Learning Long-Term Structure in Music". Get full access to The Gradient at thegradientpub.substack.com/subscribe

Sergey Levine on Robot Learning & Offline RL
In episode 11 of The Gradient Podcast, we interview Sergey Levine, a professor at Berkeley whose research focuses on machine learning for decision making and control, with an emphasis on deep learning and reinforcement learning algorithms for robotics.Sergey Levine received a BS and MS in Computer Science from Stanford University in 2009, and a Ph.D. in Computer Science from Stanford University in 2014. He joined the faculty of the Department of Electrical Engineering and Computer Sciences at UC Berkeley in fall 2016. His work focuses on machine learning for decision making and control, with an emphasis on deep learning and reinforcement learning algorithms, and includes developing algorithms for end-to-end training of deep neural network policies that combine perception and control, scalable algorithms for inverse reinforcement learning, deep reinforcement learning algorithms, and more.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSPodcast Theme: “MusicVAE: Trio 16-bar Sample #2” from "MusicVAE: A Hierarchical Latent Vector Model for Learning Long-Term Structure in Music". Get full access to The Gradient at thegradientpub.substack.com/subscribe

Jeremy Howard on Kaggle, Enlitic, and fast.ai
In episode 10 of The Gradient Podcast, we interview data scientist, researcher, developer, educator, and entrepreneur Jeremy Howard.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSJeremy Howard is a data scientist, researcher, developer, educator, and entrepreneur. Jeremy is a founding researcher at fast.ai, a research institute dedicated to making deep learning more accessible. He is also a Distinguished Research Scientist at the University of San Francisco, the chair of WAMRI, and is Chief Scientist at platform.ai. Previously, Jeremy was the founding CEO Enlitic, which was the first company to apply deep learning to medicine, was the President and Chief Scientist of the data science platform Kaggle, and was the founding CEO of two successful Australian startups.Podcast Theme: “MusicVAE: Trio 16-bar Sample #2” from "MusicVAE: A Hierarchical Latent Vector Model for Learning Long-Term Structure in Music". Get full access to The Gradient at thegradientpub.substack.com/subscribe

Evan Hubinger on Effective Altruism and AI Safety
In episode 9 of The Gradient Podcast, we interview Yannic Kilcher, an AI researcher and educator.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSEvan is an AI safety veteran who’s done research at leading AI labs like OpenAI, and whose experience also includes stints at Google, Ripple andYelp. He currently works at the Machine Intelligence Research Institute (MIRI) as a Research Fellow, and joined me to talk about his views on AI safety, the alignment problem, and whether humanity is likely to survive the advent of superintelligent AI.Podcast Theme: “MusicVAE: Trio 16-bar Sample #2” from "MusicVAE: A Hierarchical Latent Vector Model for Learning Long-Term Structure in Music". Get full access to The Gradient at thegradientpub.substack.com/subscribe

Yannic Kilcher on Being an AI Researcher and Educator
In episode 8 of The Gradient Podcast, we interview Yannic Kilcher, an AI researcher and educator.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSYannic graduated with his PhD from ETH Zurich’s data analytics lab and is now the Chief Technology Officer of DeepJudge, a company building the next-generation AI-powered context-sensitive legal document processing platform. He famously produces videos on his very popular Youtube channel, which cover machine learning research papers, programming, and issues of the AI community, and the broader impact of AI in society.Check out his Youtube channel here and follow him on Twitter herePodcast Theme: “MusicVAE: Trio 16-bar Sample #2” from "MusicVAE: A Hierarchical Latent Vector Model for Learning Long-Term Structure in Music". Get full access to The Gradient at thegradientpub.substack.com/subscribe
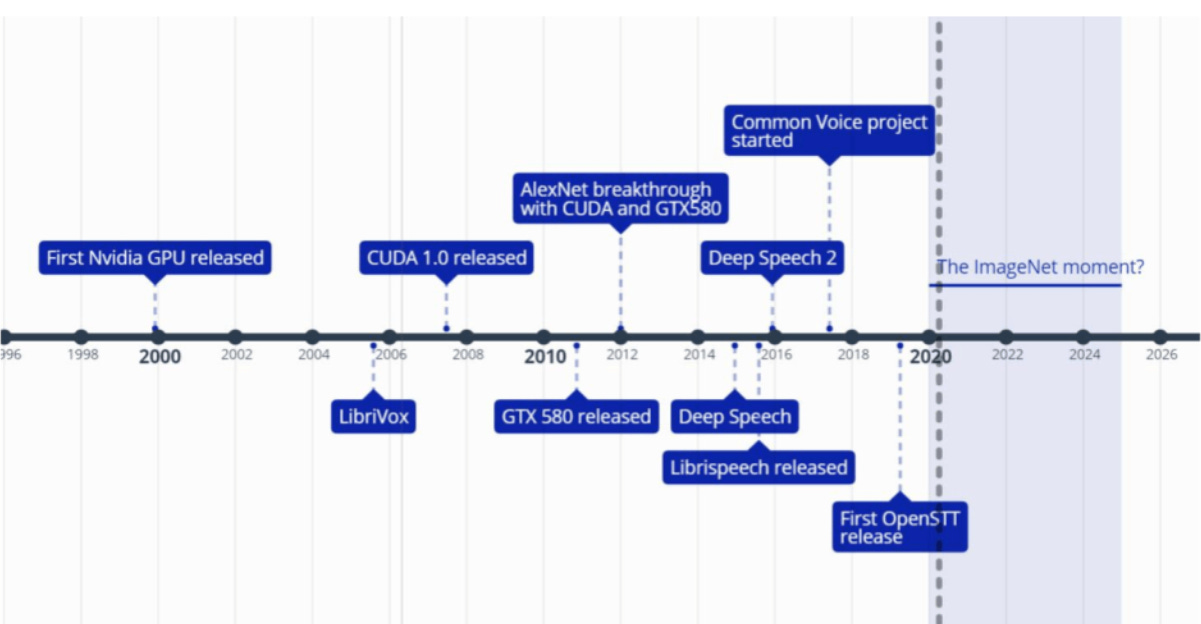
Alexander Veysov on Self-Teaching AI and Creating Open Speech-To-Text
In episode 7 of The Gradient Podcast, we interview founder and owner of Silero Alexander Veysov. You can find a transcript of our conversation here, and the repositories for Open Speech To Text and Silero Models here.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSAlexander Veysov is the founder / owner of Silero, a small company building Speech / NLP enabled products, and author of Open STT. Silero has recently shipped its own Russian STT engine. Previously he worked in a then Moscow-based VC firm and Ponominalu.ru, a ticketing startup acquired by MTS (major Russian TelCo). He received his BA and MA in Economics in Moscow State University for International Relations (MGIMO). You can follow his channel in telegram (@snakers41).Theme: “MusicVAE: Trio 16-bar Sample #2” from "MusicVAE: A Hierarchical Latent Vector Model for Learning Long-Term Structure in Music". Get full access to The Gradient at thegradientpub.substack.com/subscribe

Yann LeCun on his Start in Research and Self-Supervised Learning
In episode 6 of The Gradient Podcast, we interview Deep Learning pioneer Yann LeCun.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSFollow The Gradient on TwitterYann LeCun is the VP & Chief AI Scientist at Facebook and Silver Professor at NYU and he was also the founding Director of Facebook AI Research and of the NYU Center for Data Science. He famously pioneered the use of Convolutional Neural Nets for image processing in the 80s and 90s, and is generally regarded as one of the people whose work was pivotal to the Deep Learning revolution in AI. In fact he is the recipient of the 2018 ACM Turing Award (with Geoffrey Hinton and Yoshua Bengio) for "conceptual and engineering breakthroughs that have made deep neural networks a critical component of computing". Theme: “MusicVAE: Trio 16-bar Sample #2” from "MusicVAE: A Hierarchical Latent Vector Model for Learning Long-Term Structure in Music". Get full access to The Gradient at thegradientpub.substack.com/subscribe

Anna Rogers on the Flaws of Peer Review in AI
In episode 5 of The Gradient Podcast, we interview NLP researcher Anna Rogers.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSAnna Rogers is a post-doctoral associate at the University of Copenhagen, working with the research groups in the Center for Social Data Science and Machine Learning section. Her main research area is Natural Language Processing, with focus on interpretability and evaluation of deep learning models. She is also known for her work on improving peer review in NLP and as organizer of the workshop on Insights from Negative Results in NLP.Check out her article What Can We Do To Improve Peer Review in NLP and her tutorial Reviewing NLP Research. Get full access to The Gradient at thegradientpub.substack.com/subscribe

Joel Simon on AI art and Artbreeder
In episode 4 of The Gradient Podcast, we interview artist, engineer, and entrepreneur Joel Simon.Subscribe to The Gradient Podcast: Apple Podcasts | Spotify | Pocket Casts | RSSJoel Simon is a multidisciplinary artist, toolmaker, and researcher. He studied computer science and art at Carnegie Mellon University, worked on bioinformatics at Rockefeller University, and most recently is the founder and director of Morphogen, a generative design company developing Artbreeder, a massively collaborative creative tool and network. His interests lie in the intersection of computer science, biology and design as well as furniture-design, collaborative-creativity, sculpture and game-design.Theme: “MusicVAE: Trio 16-bar Sample #2” from "MusicVAE: A Hierarchical Latent Vector Model for Learning Long-Term Structure in Music". Get full access to The Gradient at thegradientpub.substack.com/subscribe

Abubakar Abid on AI for Genomics, Gradio, and the Fatima Fellowship
Subscribe to The Gradient Podcast: iTunes | RSS | SpotifyIn episode 3 of The Gradient Podcast, we interview researcher and entrepreneur Abubakar Abid. Follow him on Twitter and check out the websites of his company Gradio and his side project the Fatima Fellowship.Abubakar is an entrepreneur and researcher focused on AI and its applications to medicine. He is currently running the company Gradio, which is developing a product to generate an easy-to-use UI for any ML model, function, or API. He is also running the Fatima Al-Fihri Predoctoral Fellowship, which is a 9-month program for computer science students from around the world who are planning on applying to PhD programs in the United States. Theme: “MusicVAE: Trio 16-bar Sample #2” from "MusicVAE: A Hierarchical Latent Vector Model for Learning Long-Term Structure in Music". Get full access to The Gradient at thegradientpub.substack.com/subscribe

Helena Sarin on being an AI Artist
In episode 2 of The Gradient Podcast, we interview AI artist Helana Sarin. Check out her work and follow her over at her Twitter @NeuralBricolage.Helena Sarin is a visual artist and software engineer and is among the most prominent artists utilizing AI for their work. After she discovered GANs (Generative Adversarial Networks) several years ago and then made generative models her primary medium. She is a frequent speaker at ML/AI conferences, for the past year delivering invited talks at MIT, Library of Congress and Capitol One, and her artwork was exhibited at AI Art exhibitions in Zurich, Dubai, Oxford, Shanghai and Miami. Lastly, Helena was among the earliest authors to contribute a piece to The Gradient with 2018’s “Playing a game of GANstruction”, in which she described the process she follows to make her art.Image credit: Happy Nation - The Waterpark By Helena Sarin Theme: “MusicVAE: Trio 16-bar Sample #2” from "MusicVAE: A Hierarchical Latent Vector Model for Learning Long-Term Structure in Music". Get full access to The Gradient at thegradientpub.substack.com/subscribe

Hello World from The Gradient Podcast!
Hello world! After more than 3 years of publishing overviews and perspectives from the AI community on thegradient.pub, The Gradient now has a podcast. In this first episode our lead editors take a look back on how it all started, as well as a look ahead at where things are heading. Keep an eye out for our next episode, coming soon!Theme: “MusicVAE: Trio 16-bar Sample #2” from "MusicVAE: A Hierarchical Latent Vector Model for Learning Long-Term Structure in Music". Get full access to The Gradient at thegradientpub.substack.com/subscribe