
Learning Machines 101
85 episodes — Page 1 of 2

S2 Ep 86LM101-086: Ch8: How to Learn the Probability of Infinitely Many Outcomes
This 86th episode of Learning Machines 101 discusses the problem of assigning probabilities to a possibly infinite set of outcomes in a space-time continuum which characterizes our physical world. Such a set is called an "environmental event". The machine learning algorithm uses information about the frequency of environmental events to support learning. If we want to study statistical machine learning, then we must be able to discuss how to represent and compute the probability of an environmental event. It is essential that we have methods for communicating probability concepts to other researchers, methods for calculating probabilities, and methods for calculating the expectation of specific environmental events. This episode discusses the challenges of assigning probabilities to events when we allow for the case of events comprised of an infinite number of outcomes. Along the way we introduce essential concepts for representing and computing probabilities using measure theory mathematical tools such as sigma fields, and the Radon-Nikodym probability density function. Near the end we also briefly discuss the intriguing Banach-Tarski paradox and how it motivates the development of some of these special mathematical tools. Check out: www.learningmachines101.com and www.statisticalmachinelearning.com for more information!!!

S2 Ep 85LM101-085:Ch7:How to Guarantee your Batch Learning Algorithm Converges
This 85th episode of Learning Machines 101 discusses formal convergence guarantees for a broad class of machine learning algorithms designed to minimize smooth non-convex objective functions using batch learning methods. In particular, a broad class of unsupervised, supervised, and reinforcement machine learning algorithms which iteratively update their parameter vector by adding a perturbation based upon all of the training data. This process is repeated, making a perturbation of the parameter vector based upon all of the training data until a parameter vector is generated which exhibits improved predictive performance. The magnitude of the perturbation at each learning iteration is called the "stepsize" or "learning rate" and the identity of the perturbation vector is called the "search direction". Simple mathematical formulas are presented based upon research from the late 1960s by Philip Wolfe and G. Zoutendijk that ensure convergence of the generated sequence of parameter vectors. These formulas may be used as the basis for the design of artificially intelligent smart automatic learning rate selection algorithms. The material in this podcast is designed to provide an overview of Chapter 7 of my new book "Statistical Machine Learning" and is based upon material originally presented in Episode 68 of Learning Machines 101! Check out: www.learningmachines101.com for the show notes!!!

S2 Ep 84LM101-084: Ch6: How to Analyze the Behavior of Smart Dynamical Systems
In this episode of Learning Machines 101, we review Chapter 6 of my book "Statistical Machine Learning" which introduces methods for analyzing the behavior of machine inference algorithms and machine learning algorithms as dynamical systems. We show that when dynamical systems can be viewed as special types of optimization algorithms, the behavior of those systems even when they are highly nonlinear and high-dimensional can be analyzed. Learn more by visiting: www.learningmachines101.com and www.statisticalmachinelearning.com .

S2 Ep 83LM101-083: Ch5: How to Use Calculus to Design Learning Machines
This particular podcast covers the material from Chapter 5 of my new book "Statistical Machine Learning: A unified framework" which is now available! The book chapter shows how matrix calculus is very useful for the analysis and design of both linear and nonlinear learning machines with lots of examples. We discuss how to use the matrix chain rule for deriving deep learning descent algorithms and how it is relevant to software implementations of deep learning algorithms. We also discuss how matrix Taylor series expansions are relevant to machine learning algorithm design and the analysis of generalization performance!! For additional details check out: www.learningmachines101.com and www.statisticalmachinelearning.com

S2 Ep 82LM101-082: Ch4: How to Analyze and Design Linear Machines
The main focus of this particular episode covers the material in Chapter 4 of my new forthcoming book titled "Statistical Machine Learning: A unified framework." Chapter 4 is titled "Linear Algebra for Machine Learning. Many important and widely used machine learning algorithms may be interpreted as linear machines and this chapter shows how to use linear algebra to analyze and design such machines. In addition, these same techniques are fundamentally important for the development of techniques for the analysis and design of nonlinear machines. This podcast provides a brief overview of Linear Algebra for Machine Learning for the general public as well as information for students and instructors regarding the contents of Chapter 4 of Statistical Machine Learning. For more details, check out: www.statisticalmachinelearning.com

S2 Ep 81LM101-081: Ch3: How to Define Machine Learning (or at Least Try)
This particular podcast covers the material in Chapter 3 of my new book "Statistical Machine Learning: A unified framework" with expected publication date May 2020. In this episode we discuss Chapter 3 of my new book which discusses how to formally define machine learning algorithms. Briefly, a learning machine is viewed as a dynamical system that is minimizing an objective function. In addition, the knowledge structure of the learning machine is interpreted as a preference relation graph which is implicitly specified by the objective function. In addition, this week we include in our book review section a new book titled "The Practioner's Guide to Graph Data" by Denise Gosnell and Matthias Broecheler. To find out more information visit the website: www.learningmachines101.com .

S2 Ep 80LM101-080: Ch2: How to Represent Knowledge using Set Theory
This particular podcast covers the material in Chapter 2 of my new book "Statistical Machine Learning: A unified framework" with expected publication date May 2020. In this episode we discuss Chapter 2 of my new book, which discusses how to represent knowledge using set theory notation. Chapter 2 is titled "Set Theory for Concept Modeling".

S2 Ep 79LM101-079: Ch1: How to View Learning as Risk Minimization
This particular podcast covers the material in Chapter 1 of my new (unpublished) book "Statistical Machine Learning: A unified framework". In this episode we discuss Chapter 1 of my new book, which shows how supervised, unsupervised, and reinforcement learning algorithms can be viewed as special cases of a general empirical risk minimization framework. This is useful because it provides a framework for not only understanding existing algorithms but also for suggesting new algorithms for specific applications.

S2 Ep 78LM101-078: Ch0: How to Become a Machine Learning Expert
This particular podcast (Episode 78 of Learning Machines 101) is the initial episode in a new special series of episodes designed to provide commentary on a new book that I am in the process of writing. In this episode we discuss books, software, courses, and podcasts designed to help you become a machine learning expert! For more information, check out: www.learningmachines101.com

S1 Ep 77LM101-077: How to Choose the Best Model using BIC
In this 77th episode of www.learningmachines101.com , we explain the proper semantic interpretation of the Bayesian Information Criterion (BIC) and emphasize how this semantic interpretation is fundamentally different from AIC (Akaike Information Criterion) model selection methods. Briefly, BIC is used to estimate the probability of the training data given the probability model, while AIC is used to estimate out-of-sample prediction error. The probability of the training data given the model is called the "marginal likelihood". Using the marginal likelihood, one can calculate the probability of a model given the training data and then use this analysis to support selecting the most probable model, selecting a model that minimizes expected risk, and support Bayesian model averaging. The assumptions which are required for BIC to be a valid approximation for the probability of the training data given the probability model are also discussed.

S1 Ep 76LM101-076: How to Choose the Best Model using AIC and GAIC
In this episode, we explain the proper semantic interpretation of the Akaike Information Criterion (AIC) and the Generalized Akaike Information Criterion (GAIC) for the purpose of picking the best model for a given set of training data. The precise semantic interpretation of these model selection criteria is provided, explicit assumptions are provided for the AIC and GAIC to be valid, and explicit formulas are provided for the AIC and GAIC so they can be used in practice. Briefly, AIC and GAIC provide a way of estimating the average prediction error of your learning machine on test data without using test data or cross-validation methods. The GAIC is also called the Takeuchi Information Criterion (TIC).

S1 Ep 75LM101-075: Can computers think? A Mathematician's Response (remix)
In this episode, we explore the question of what can computers do as well as what computers can't do using the Turing Machine argument. Specifically, we discuss the computational limits of computers and raise the question of whether such limits pertain to biological brains and other non-standard computing machines. This episode is dedicated to the memory of my mom, Sandy Golden. To learn more about Turing Machines, SuperTuring Machines, Hypercomputation, and my Mom, check out: www.learningmachines101.com

S1 Ep 74LM101-074: How to Represent Knowledge using Logical Rules (remix)
In this episode we will learn how to use "rules" to represent knowledge. We discuss how this works in practice and we explain how these ideas are implemented in a special architecture called the production system. The challenges of representing knowledge using rules are also discussed. Specifically, these challenges include: issues of feature representation, having an adequate number of rules, obtaining rules that are not inconsistent, and having rules that handle special cases and situations. To learn more, visit: www.learningmachines101.com

S1 Ep 73LM101-073: How to Build a Machine that Learns to Play Checkers (remix)
This is a remix of the original second episode Learning Machines 101 which describes in a little more detail how the computer program that Arthur Samuel developed in 1959 learned to play checkers by itself without human intervention using a mixture of classical artificial intelligence search methods and artificial neural network learning algorithms. The podcast ends with a book review of Professor Nilsson's book: "The Quest for Artificial Intelligence: A History of Ideas and Achievements". For more information, check out: www.learningmachines101.com

S1 Ep 72LM101-072: Welcome to the Big Artificial Intelligence Magic Show! (Remix of LM101-001 and LM101-002)
This podcast is basically a remix of the first and second episodes of Learning Machines 101 and is intended to serve as the new introduction to the Learning Machines 101 podcast series. The search for common organizing principles which could support the foundations of machine learning and artificial intelligence is discussed and the concept of the Big Artificial Intelligence Magic Show is introduced. At the end of the podcast, the book After Digital: Computation as Done by Brains and Machines by Professor James A. Anderson is briefly reviewed. For more information, please visit: www.learningmachines101.com

S1 Ep 71LM101-071: How to Model Common Sense Knowledge using First-Order Logic and Markov Logic Nets
In this podcast, we provide some insights into the complexity of common sense. First, we discuss the importance of building common sense into learning machines. Second, we discuss how first-order logic can be used to represent common sense knowledge. Third, we describe a large database of common sense knowledge where the knowledge is represented using first-order logic which is free for researchers in machine learning. We provide a hyperlink to this free database of common sense knowledge. Fourth, we discuss some problems of first-order logic and explain how these problems can be resolved by transforming logical rules into probabilistic rules using Markov Logic Nets. And finally, we have another book review of the book "Markov Logic: An Interface Layer for Artificial Intelligence" by Pedro Domingos and Daniel Lowd which provides further discussion of the issues in this podcast. In this book review, we cover some additional important applications of Markov Logic Nets not covered in detail in this podcast such as: object labeling, social network link analysis, information extraction, and helping support robot navigation. Finally, at the end of the podcast we provide information about a free software program which you can use to build and evaluate your own Markov Logic Net! For more information check out: www.learningmachines101.com

S1 Ep 70LM101-070: How to Identify Facial Emotion Expressions in Images Using Stochastic Neighborhood Embedding
This 70th episode of Learning Machines 101 we discuss how to identify facial emotion expressions in images using an advanced clustering technique called Stochastic Neighborhood Embedding. We discuss the concept of recognizing facial emotions in images including applications to problems such as: improving online communication quality, identifying suspicious individuals such as terrorists using video cameras, improving lie detector tests, improving athletic performance by providing emotion feedback, and designing smart advertising which can look at the customer's face to determine if they are bored or interested and dynamically adapt the advertising accordingly. To address this problem we review clustering algorithm methods including K-means clustering, Linear Discriminant Analysis, Spectral Clustering, and the relatively new technique of Stochastic Neighborhood Embedding (SNE) clustering. At the end of this podcast we provide a brief review of the classic machine learning text by Christopher Bishop titled "Pattern Recognition and Machine Learning". Make sure to visit: www.learningmachines101.com to obtain free transcripts of this podcast and important supplemental reference materials!
S1 Ep 69LM101-069: What Happened at the 2017 Neural Information Processing Systems Conference?
This 69th episode of Learning Machines 101 provides a short overview of the 2017 Neural Information Processing Systems conference with a focus on the development of methods for teaching learning machines rather than simply training them on examples. In addition, a book review of the book "Deep Learning" is provided. #nips2017

S1 Ep 68LM101-068: How to Design Automatic Learning Rate Selection for Gradient Descent Type Machine Learning Algorithms
This 68th episode of Learning Machines 101 discusses a broad class of unsupervised, supervised, and reinforcement machine learning algorithms which iteratively update their parameter vector by adding a perturbation based upon all of the training data. This process is repeated, making a perturbation of the parameter vector based upon all of the training data until a parameter vector is generated which exhibits improved predictive performance. The magnitude of the perturbation at each learning iteration is called the "stepsize" or "learning rate" and the identity of the perturbation vector is called the "search direction". Simple mathematical formulas are presented based upon research from the late 1960s by Philip Wolfe and G. Zoutendijk that ensure convergence of the generated sequence of parameter vectors. These formulas may be used as the basis for the design of artificially intelligent smart automatic learning rate selection algorithms. For more information, please visit the official website: www.learningmachines101.com

S1 Ep 67LM101-067: How to use Expectation Maximization to Learn Constraint Satisfaction Solutions (Rerun)
In this episode we discuss how to learn to solve constraint satisfaction inference problems. The goal of the inference process is to infer the most probable values for unobservable variables. These constraints, however, can be learned from experience. Specifically, the important machine learning method for handling unobservable components of the data using Expectation Maximization is introduced. Check it out at: www.learningmachines101.com

S1 Ep 66LM101-066: How to Solve Constraint Satisfaction Problems using MCMC Methods (Rerun)
In this episode of Learning Machines 101 (www.learningmachines101.com) we discuss how to solve constraint satisfaction inference problems where knowledge is represented as a large unordered collection of complicated probabilistic constraints among a collection of variables. The goal of the inference process is to infer the most probable values of the unobservable variables given the observable variables. Specifically, Monte Carlo Markov Chain ( MCMC ) methods are discussed.

S1 Ep 65LM101-065: How to Design Gradient Descent Learning Machines (Rerun)
In this episode rerun we introduce the concept of gradient descent which is the fundamental principle underlying learning in the majority of deep learning and neural network learning algorithms. Check out the website: www.learningmachines101.com to obtain a transcript of this episode!

S1 Ep 64LM101-064: Stochastic Model Search and Selection with Genetic Algorithms (Rerun)
In this rerun of episode 24 we explore the concept of evolutionary learning machines. That is, learning machines that reproduce themselves in the hopes of evolving into more intelligent and smarter learning machines. This leads us to the topic of stochastic model search and evaluation. Check out the blog with additional technical references at: www.learningmachines101.com
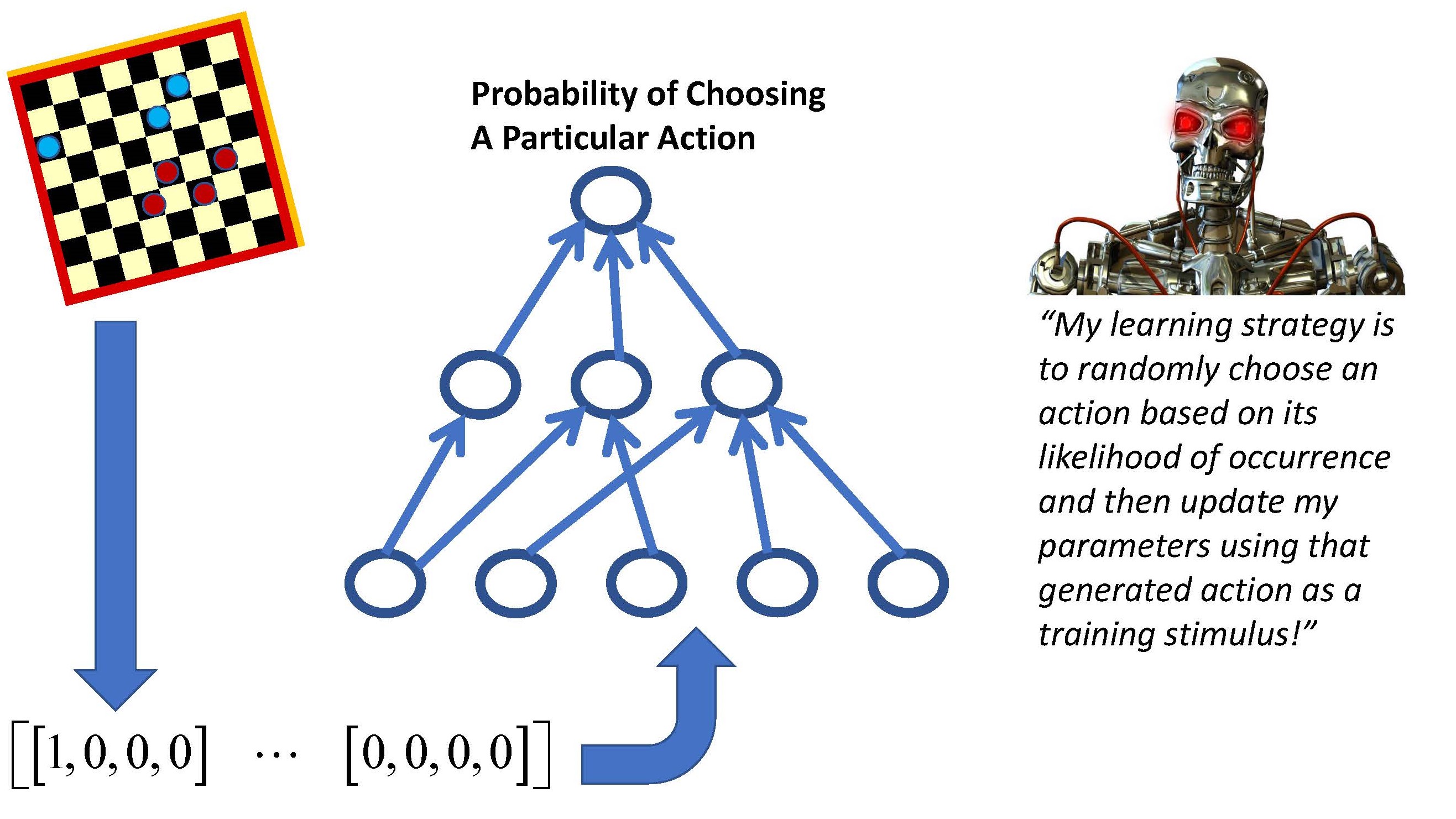
S1 Ep 63LM101-063: How to Transform a Supervised Learning Machine into a Policy Gradient Reinforcement Learning Machine
This 63rd episode of Learning Machines 101 discusses how to build reinforcement learning machines which become smarter with experience but do not use this acquired knowledge to modify their actions and behaviors. This episode explains how to build reinforcement learning machines whose behavior evolves as the learning machines become increasingly smarter. The essential idea for the construction of such reinforcement learning machines is based upon first developing a supervised learning machine. The supervised learning machine then "guesses" the desired response and updates its parameters using its guess for the desired response! Although the reasoning seems circular, this approach in fact is a variation of the important widely used machine learning method of Expectation-Maximization. Some applications to learning to play video games, control walking robots, and developing optimal trading strategies for the stock market are briefly mentioned as well. Check us out at: www.learningmachines101.com
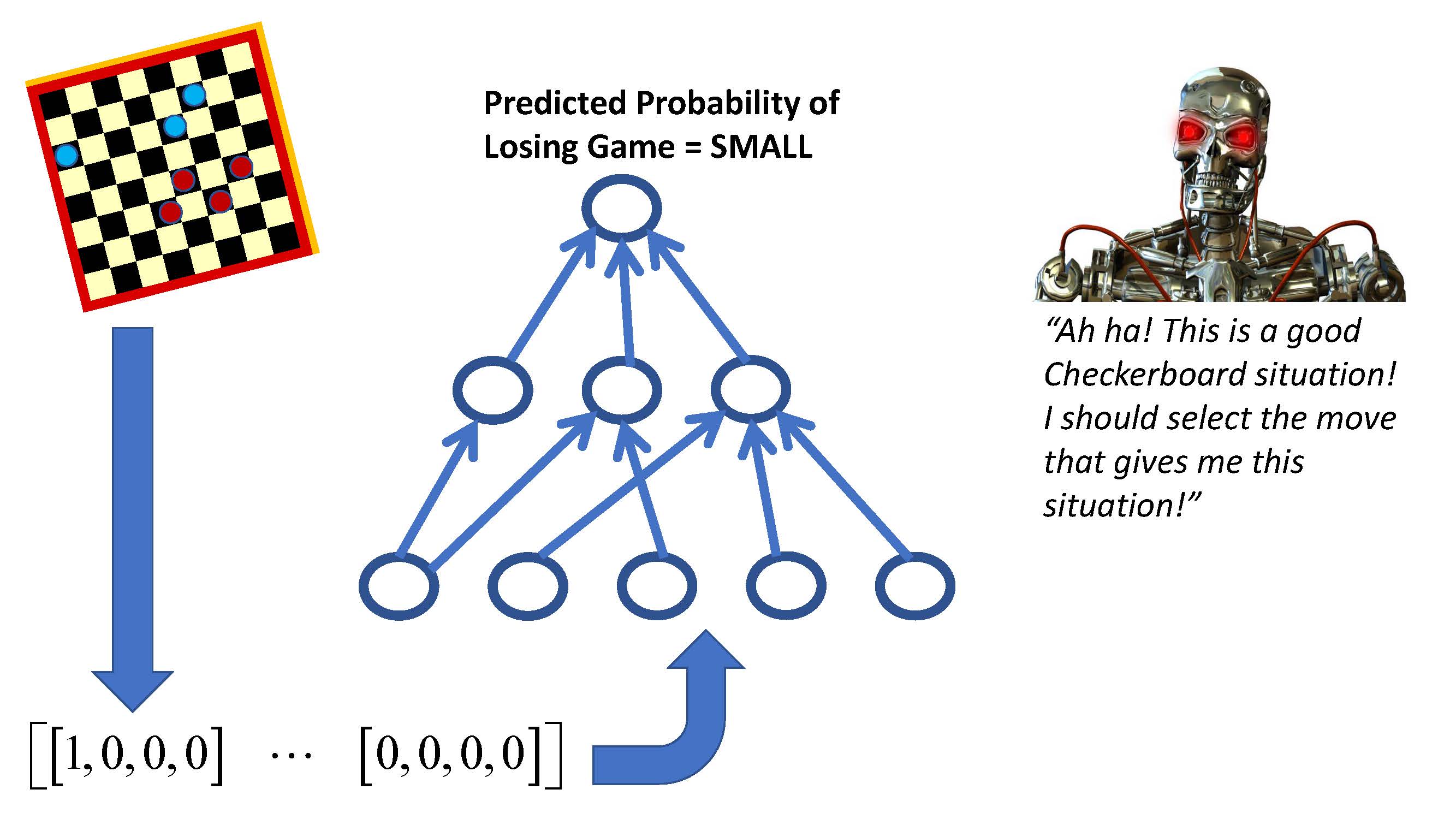
S1 Ep 62LM101-062: How to Transform a Supervised Learning Machine into a Value Function Reinforcement Learning Machine
This 62nd episode of Learning Machines 101 (www.learningmachines101.com) discusses how to design reinforcement learning machines using your knowledge of how to build supervised learning machines! Specifically, we focus on Value Function Reinforcement Learning Machines which estimate the unobservable total penalty associated with an episode when only the beginning of the episode is observable. This estimated Value Function can then be used by the learning machine to select a particular action in a given situation to minimize the total future penalties that will be received. Applications include: building your own robot, building your own automatic aircraft lander, building your own automated stock market trading system, and building your own self-driving car!!
S1 Ep 61LM101-061: What happened at the Reinforcement Learning Tutorial? (RERUN)
This is the third of a short subsequence of podcasts providing a summary of events associated with Dr. Golden's recent visit to the 2015 Neural Information Processing Systems Conference. This is one of the top conferences in the field of Machine Learning. This episode reviews and discusses topics associated with the Introduction to Reinforcement Learning with Function Approximation Tutorial presented by Professor Richard Sutton on the first day of the conference. This episode is a RERUN of an episode originally presented in January 2016 and lays the groundwork for future episodes on the topic of reinforcement learning! Check out: www.learningmachines101.com for more info!!

S1 Ep 60LM101-060: How to Monitor Machine Learning Algorithms using Anomaly Detection Machine Learning Algorithms
This 60th episode of Learning Machines 101 discusses how one can use novelty detection or anomaly detection machine learning algorithms to monitor the performance of other machine learning algorithms deployed in real world environments. The episode is based upon a review of a talk by Chief Data Scientist Ira Cohen of Anodot presented at the 2016 Berlin Buzzwords Data Science Conference. Check out: www.learningmachines101.com to hear the podcast or read a transcription of the podcast!

S1 Ep 59LM101-059: How to Properly Introduce a Neural Network
I discuss the concept of a "neural network" by providing some examples of recent successes in neural network machine learning algorithms and providing a historical perspective on the evolution of the neural network concept from its biological origins. For more details visit us at: www.learningmachines101.com

S1 Ep 58LM101-058: How to Identify Hallucinating Learning Machines using Specification Analysis
In this 58th episode of Learning Machines 101, I'll be discussing an important new scientific breakthrough published just last week for the first time in the journal Econometrics in the special issue on model misspecification titled "Generalized Information Matrix Tests for Detecting Model Misspecification". The article provides a unified theoretical framework for the development of a wide range of methods for determining if a learning machine is capable of learning its statistical environment. The article is co-authored by myself, Steven Henley, Halbert White, and Michael Kashner. It is an open-access article so the complete article can be downloaded for free! The download link can be found in the show notes of this episode at: www.learningmachines101.com . In 30 years everyone will be using these methods so you might as well start using them now!

S1 Ep 57LM101-057: How to Catch Spammers using Spectral Clustering
In this 57th episode, we explain how to use unsupervised machine learning algorithms to catch internet criminals who try to steal your money electronically! Check it out at: www.learningmachines101.com

S1 Ep 56LM101-056: How to Build Generative Latent Probabilistic Topic Models for Search Engine and Recommender System Applications
In this NEW episode we discuss Latent Semantic Indexing type machine learning algorithms which have a PROBABILISTIC interpretation. We explain why such a probabilistic interpretation is important and discuss how such algorithms can be used in the design of document retrieval systems, search engines, and recommender systems. Check us out at: www.learningmachines101.com and follow us on twitter at: @lm101talk

S1 Ep 55LM101-055: How to Learn Statistical Regularities using MAP and Maximum Likelihood Estimation (Rerun)
In this rerun of Episode 10, we discuss fundamental principles of learning in statistical environments including the design of learning machines that can use prior knowledge to facilitate and guide the learning of statistical regularities. In particular, the episode introduces fundamental machine learning concepts such as: probability models, model misspecification, maximum likelihood estimation, and MAP estimation. Check us out at: www.learningmachines101.com

S1 Ep 54LM101-054: How to Build Search Engine and Recommender Systems using Latent Semantic Analysis (RERUN)
Welcome to the 54th Episode of Learning Machines 101 titled "How to Build a Search Engine, Automatically Grade Essays, and Identify Synonyms using Latent Semantic Analysis" (rerun of Episode 40). The principles in this episode are also applicable to the problem of "Market Basket Analysis" and the design of Recommender Systems. Check it out at: www.learningmachines101.com and follow us on twitter: @lm101talk

S1 Ep 53LM101-053: How to Enhance Learning Machines with Swarm Intelligence (Particle Swarm Optimization)
In this 53rd episode of Learning Machines 101, we introduce the concept of a Swarm Intelligence with respect to Particle Swarm Optimization Algorithms. The essential idea of "Swarm Intelligence" is that you have a group of individual entities which behave in a coordinated manner yet there is no master control center providing directions to all of the individuals in the group. The global group behavior is an "emergent property" of local interactions among individuals in the group! We will analyze the concept of swarm intelligence as a Markov Random Field, discuss how it can be harnessed to enhance the performance of machine learning algorithms, and comment upon relevant mathematics for analyzing and designing "swarm intelligences" so they behave in an appropriate manner by viewing the Swarm as a nonlinear optimization algorithm. For more information check out: www.learningmachines101.com and also check us out on twitter (@lm101talk).

S1 Ep 52LM101-052: How to Use the Kernel Trick to Make Hidden Units Disappear
Today, we discuss a simple yet powerful idea which began popular in the machine learning literature in the 1990s which is called "The Kernel Trick". The basic idea of the "Kernel Trick" is that you specify similarity relationships among input patterns rather than a recoding transformation to solve a nonlinear problem with a linear learning machine. It's a great magic trick...check it out at: www.learningmachines101.com where you can obtain transcripts of this episode and download free machine learning software! Also check out the "Statistical Machine Learning Forum" on Linked In and follow us on Twitter using the twitter handle: @lm101talk
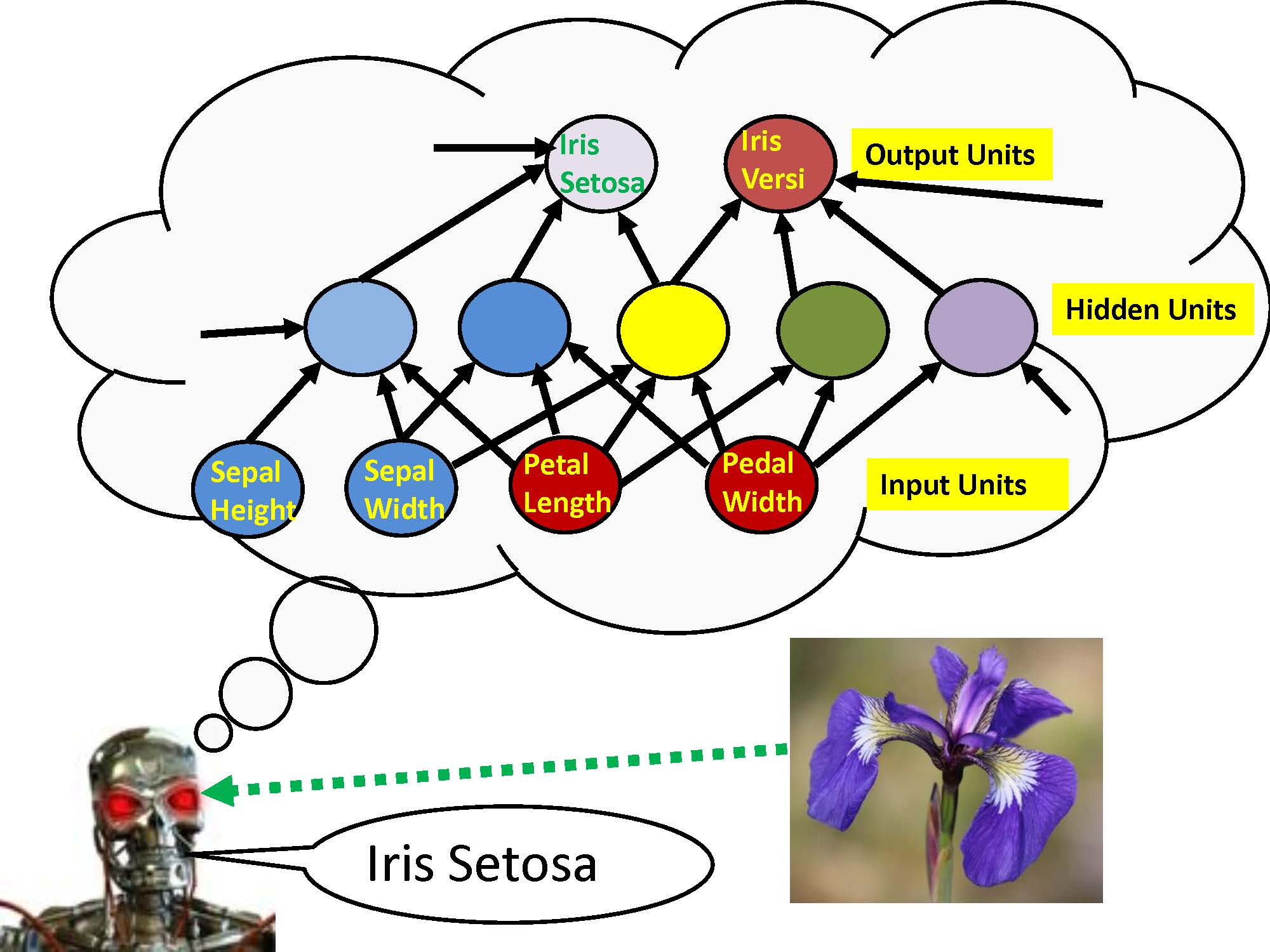
S1 Ep 51LM101-051: How to Use Radial Basis Function Perceptron Software for Supervised Learning[Rerun]
This particular podcast is a RERUN of Episode 20 and describes step by step how to download free software which can be used to make predictions using a feedforward artificial neural network whose hidden units are radial basis functions. This is essentially a nonlinear regression modeling problem. We show the performance of this nonlinear learning machine is substantially better on test data set than the linear learning machine software presented in Episode 13. Basically performance for the linear learning machine was about 13% because the data set was specifically designed to be unlearnable by a linear learning machine, while the performance for the nonlinear machine learning software in this episode is about 70%. Again, I'm a little disappointed that only a few people have downloaded the software and tried things out. You can download windows executable, mac executable, or the MATLAB source code. It's important to actually experiment with real machine learning software if you want to learn about machine learning! Check out: www.learningmachines101.com to obtain transcripts of this podcast and download free machine learning software! Or tweet us at: @lm101talk

S1 Ep 50LM101-050: How to Use Linear Machine Learning Software to Make Predictions (Linear Regression Software)[RERUN]
In this episode we will explain how to download and use free machine learning software from the website: www.learningmachines101.com. This podcast is concerned with the very practical issues associated with downloading and installing machine learning software on your computer. If you follow these instructions, by the end of this episode you will have installed one of the simplest (yet most widely used) machine learning algorithms on your computer. You can then use the software to make virtually any kind of prediction you like. Also follow us on twitter at: lm101talk
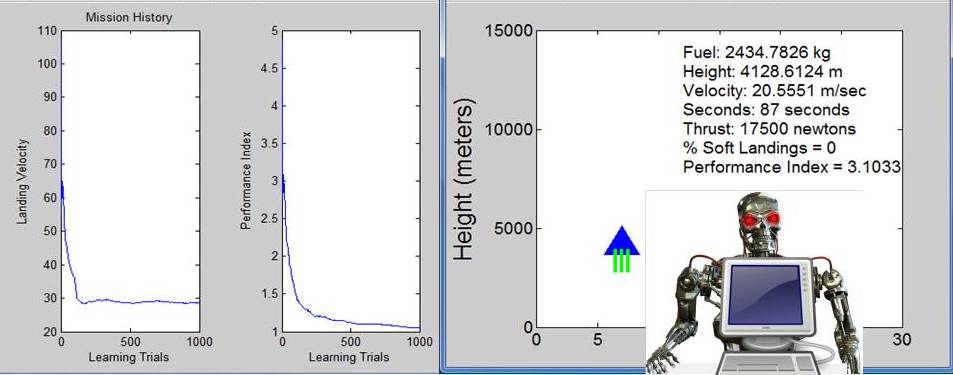
S1 Ep 49LM101-049: How to Experiment with Lunar Lander Software
In this episode we continue the discussion of learning when the actions of the learning machine can alter the characteristics of the learning machine’s statistical environment. We describe how to download free lunar lander software so you can experiment with an autopilot for a lunar lander module that learns from its experiences and describe the results of some simulation studies. To learn more, visit: www.learningmachines101.com to download the free lunar lander software which illustrates principles of temporal reinforcement learning and nonlinear control theory. You will also have the opportunity to download free software which illustrates how a simple deep learning neural network with one layer of radial basis functions works and a simple linear regression model learning machine. Check it out!!!

S1 Ep 48LM101-048: How to Build a Lunar Lander Autopilot Learning Machine (Rerun)
In this episode we consider the problem of learning when the actions of the learning machine can alter the characteristics of the learning machine’s statistical environment. We illustrate the solution to this problem by designing an autopilot for a lunar lander module that learns from its experiences. For more information, check out: www.learningmachines101.com and visit us a twitter: @lm101talk #machinelearning #statistics #artificialintelligence

S1 Ep 47LM101-047: How Build a Support Vector Machine to Classify Patterns (Rerun)
We explain how to estimate the parameters of such machines to classify a pattern vector as a member of one of two categories as well as identify special pattern vectors called “support vectors” which are important for characterizing the Support Vector Machine decision boundary. The relationship of Support Vector Machine parameter estimation and logistic regression parameter estimation is also discussed.For more information..check us out at: www.learningmachines101.com also check us out on twitter at: lm101talk

S1 Ep 46LM101-046: How to Optimize Student Learning using Recurrent Neural Networks (Educational Technology)
In this episode, we briefly review Item Response Theory and Bayesian Network Theory methods for the assessment and optimization of student learning and then describe a poster presented on the first day of the Neural Information Processing Systems conference in December 2015 in Montreal which describes a Recurrent Neural Network approach for the assessment and optimization of student learning called “Deep Knowledge Tracing”. For more details check out: www.learningmachines101.com and follow us on Twitter at: @lm101talk

S1 Ep 45LM101-045: How to Build a Deep Learning Machine for Answering Questions about Images
In this episode we discuss just one out of the 102 different posters which was presented on the first night of the 2015 Neural Information Processing Systems Conference. This presentation describes a system which can answer simple questions about images. Check out: www.learningmachines101.com for additional details!!

S1 Ep 44LM101-044: What happened at the Deep Reinforcement Learning Tutorial at the 2015 Neural Information Processing Systems Conference?
This is the third of a short subsequence of podcasts providing a summary of events associated with Dr. Golden’s recent visit to the 2015 Neural Information Processing Systems Conference. This is one of the top conferences in the field of Machine Learning. This episode reviews and discusses topics associated with the Introduction to Reinforcement Learning with Function Approximation Tutorial presented by Professor Richard Sutton on the first day of the conference. Check out: www.learningmachines101.com to learn more!! Also follow us at: "lm101talk" on twitter!
S1 Ep 43LM101-043: How to Learn a Monte Carlo Markov Chain to Solve Constraint Satisfaction Problems (Rerun of Episode 22)
Welcome to the 43rd Episode of Learning Machines 101!We are currently presenting a subsequence of episodes covering the events of the recent Neural Information Processing Systems Conference. However, this weekwill digress with a rerun of Episode 22 which nicely complements our previous discussion of the Monte Carlo Markov Chain Algorithm Tutorial. Specifically, today wediscuss the problem of approaches for learning or equivalently parameter estimation in Monte Carlo Markov Chain algorithms. The topics covered in this episode include: What is the pseudolikelihood method and what are its advantages and disadvantages?What is Monte Carlo Expectation Maximization? And...as a bonus prize...a mathematical theory of "dreaming"!!! The current plan is to returnto coverage of the Neural Information Processing Systems Conference in 2 weeks on January 25!! Check out: www.learningmachines101.com for more details!

S1 Ep 42LM101-042: What happened at the Monte Carlo Markov Chain (MCMC) Inference Methods Tutorial at the 2015 Neural Information Processing Systems Conference?
This is the second of a short subsequence of podcasts providing a summary of events associated with Dr. Golden’s recent visit to the 2015 Neural Information Processing Systems Conference. This is one of the top conferences in the field of Machine Learning. This episode reviews and discusses topics associated with the Monte Carlo Markov Chain (MCMC) Inference Methods Tutorial held on the first day of the conference. Check out: www.learningmachines101.com to listen or download this podcast episode or download the transcripts! Also visit us at LINKEDIN or TWITTER. The twitter handle is: LM101TALK

S1 Ep 41LM101-041: What happened at the 2015 Neural Information Processing Systems Deep Learning Tutorial?
This is the first of a short subsequence of podcasts which provides a summary of events associated with Dr. Golden’s recent visit to the 2015 Neural Information Processing Systems Conference. This is one of the top conferences in the field of Machine Learning. This episode introduces the Neural Information Processing Systems Conference and reviews the content of the Morning Deep Learning Tutorial which took place on the first day of the conference. Check out: www.learningmachines101.comfor additional supplementary hyperlinks to the conference and conference papers!!

S1 Ep 40LM101-040: How to Build a Search Engine, Automatically Grade Essays, and Identify Synonyms using Latent Semantic Analysis
In this episode we introduce a very powerful approach for computing semantic similarity between documents. Here, the terminology “document” could refer to a web-page, a word document, a paragraph of text, an essay, a sentence, or even just a single word. Two semantically similar documents, therefore, will discuss many of the same topics while two semantically different documents will not have many topics in common. Machine learning methods are described which can take as input large collections of documents and use those documents to automatically learn semantic similarity relations. This approach is called Latent Semantic Indexing (LSI) or Latent Semantic Analysis (LSA). Visit us at: www.learningmachines101.com to learn more!

S1 Ep 39LM101-039: How to Solve Large Complex Constraint Satisfaction Problems (Monte Carlo Markov Chain and Markov Fields)[Rerun]
In this episode we discuss how to solve constraint satisfaction inference problems where knowledge is represented as a large unordered collection of complicated probabilistic constraints among a collection of variables. The goal of the inference process is to infer the most probable values of the unobservable variables given the observable variables. Concepts of Markov Random Fields and Monte Carlo Markov Chain methods are discussed. For additional details and technical notes, please visit the website: www.learningmachines101.com Also feel free to visit us at twitter: @lm101talk
S1 Ep 38LM101-038: How to Model Knowledge Skill Growth Over Time using Bayesian Nets
In this episode, we examine the problem of developing an advanced artificially intelligent technology which is capable of tracking knowledge growth in students in real-time, representing the knowledge state of a student a skill profile, and automatically defining the concept of a skill without human intervention! The approach can be viewed as a sophisticated state-of-the-art extension of the Item Response Theory approach to Computerized Adaptive Testing Educational Technology described in Episode 37. Both tutorial notes and advanced implementational notes can be found in the show notes at: www.learningmachines101.com.
S1 Ep 37LM101-037: How to Build a Smart Computerized Adaptive Testing Machine using Item Response Theory
In this episode, we discuss the problem of how to build a smart computerized adaptive testing machine using Item Response Theory (IRT). Suppose that you are teaching a student a particular target set of knowledge. Examples of such situations obviously occur in nursery school, elementary school, junior high school, high school, and college. However, such situations also occur in industry when top professionals in a particular field attend an advanced training seminar. All of these situations would benefit from a smart adaptive assessment machine which attempts to estimate a student’s knowledge in real-time. Such a machine could then use that information to optimize the choice and order of questions to be presented to the student in order to develop a customized exam for efficiently assessing the student’s knowledge level and possibly guiding instructional strategies. Both tutorial notes and advanced implementational notes can be found in the show notes at: www.learningmachines101.com .